Когда запрос размещен, он сначала сканируется, анализируется и проверяется. Затем создается внутреннее представление запроса, такое как дерево запросов или граф запросов. Затем разрабатываются альтернативные стратегии выполнения для извлечения результатов из таблиц базы данных. Процесс выбора наиболее подходящей стратегии выполнения для обработки запросов называется оптимизацией запросов.
Проблемы оптимизации запросов в DDBMS
В DDBMS оптимизация запросов является критически важной задачей. Сложность высока, поскольку число альтернативных стратегий может возрастать в геометрической прогрессии из-за следующих факторов:
- Наличие ряда фрагментов.
- Распределение фрагментов или таблиц по различным сайтам.
- Скорость связи.
- Несоответствие в возможностях локальной обработки.
Следовательно, в распределенной системе целью часто является найти хорошую стратегию выполнения для обработки запросов, а не лучшую. Время выполнения запроса является суммой следующего:
- Время передавать запросы в базы данных.
- Время выполнять фрагменты локальных запросов.
- Время собирать данные с разных сайтов.
- Время для отображения результатов в приложении.
Обработка запросов
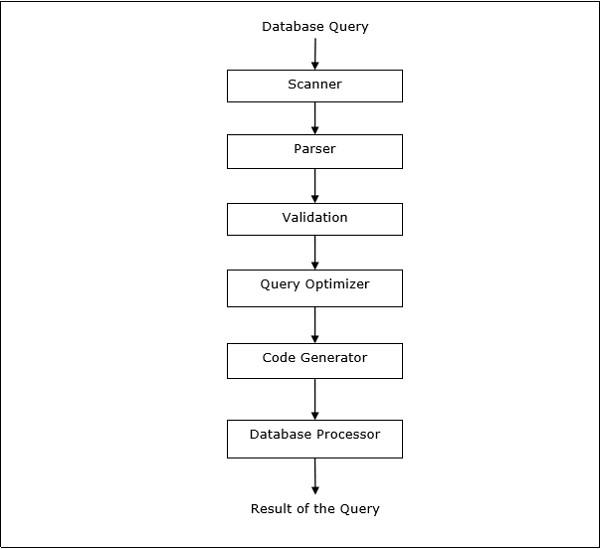
Обработка запросов — это набор всех действий, начиная с размещения запроса и заканчивая отображением результатов запроса. Шаги, как показано на следующей диаграмме —
Реляционная алгебра
Реляционная алгебра определяет базовый набор операций модели реляционной базы данных. Последовательность операций реляционной алгебры образует выражение реляционной алгебры. Результат этого выражения представляет собой результат запроса к базе данных.
Основные операции —
- проекция
- выбор
- союз
- пересечение
- Минус
- Присоединиться
проекция
Операция проецирования отображает подмножество полей таблицы. Это дает вертикальное разделение таблицы.
Синтаксис в реляционной алгебре
pi<AttributeList>(<Имятаблицы>)
Например, давайте рассмотрим следующую базу данных студентов —
| Roll_No | название | Курс | Семестр | Пол |
| 2 | Амит Прасад | BCA | 1 | мужчина |
| 4 | Варша Тивари | BCA | 1 | женский |
| 5 | Асиф Али | MCA | 2 | мужчина |
| 6 | Джо Уоллес | MCA | 1 | мужчина |
| 8 | Шивани Айенгар | BCA | 1 | женский |
Если мы хотим отобразить имена и курсы всех студентов, мы будем использовать следующее выражение реляционной алгебры:
piName,курс(СТУДЕНТ)
выбор
Операция выбора отображает подмножество кортежей таблицы, которое удовлетворяет определенным условиям. Это дает горизонтальный раздел стола.
Синтаксис в реляционной алгебре
sigma<Условия>(<Имятаблицы>)
Например, в таблице «Студент», если мы хотим отобразить сведения обо всех студентах, которые выбрали курс MCA, мы будем использовать следующее выражение реляционной алгебры:
sigmaCourse= small«BCA«(STUDENT)
Сочетание операций проекции и выбора
Для большинства запросов нам нужна комбинация операций проекции и выбора. Есть два способа написания этих выражений:
- Использование последовательности операций проецирования и выбора.
- Использование операции переименования для генерации промежуточных результатов.
Например, чтобы отобразить имена всех учениц курса BCA —
- Выражение реляционной алгебры с использованием последовательности операций проекции и выбора
piName( sigmaGender= small«Female«ANDCourse= small«BCA«(STUDENT))
- Выражение реляционной алгебры с использованием операции переименования для получения промежуточных результатов
FemaleBCAStudent leftarrow sigmaGender= small«Female«ANDCourse= small«BCA«(STUDENT)
Result leftarrow piName(FemaleBCAStudent)
союз
Если P является результатом операции, а Q является результатом другой операции, объединение P и Q (p cupQ) является множеством всех кортежей, находящихся либо в P, либо в Q, либо в обоих без дубликатов. ,
Например, для отображения всех студентов, которые находятся либо в 1 семестре, либо в курсе BCA —
Sem1Student leftarrow sigmaSemester=1(СТУДЕНТ)
BCAStudent leftarrow sigmaCourse= small«BCA«(STUDENT)
Результат leftarrowSem1Student cupBCAStudent
пересечение
Если P является результатом операции, а Q является результатом другой операции, пересечение P и Q (p capQ) является множеством всех кортежей, которые находятся в P и Q, и то и другое.
Например, с учетом следующих двух схем —
РАБОТНИК
| EmpID | название | город | отдел | Оплата труда |
ПРОЕКТ
| PId | город | отдел | Статус |
Чтобы отобразить названия всех городов, в которых находится проект, а также сотрудник, —
CityEmp leftarrow piCity(СОТРУДНИК)
CityProject leftarrow piCity(PROJECT)
Результат leftarrowCityEmp capCityProject
Минус
Если P — результат операции, а Q — результат другой операции, P — Q — это множество всех кортежей, которые находятся в P, а не в Q.
Например, перечислить все отделы, у которых нет текущего проекта (проекты со статусом = текущий) —
AllDept leftarrow piDepartment(СОТРУДНИК)
ProjectDept leftarrow piDepartment( sigmaStatus= small«продолжается«(PROJECT))
Результат leftarrowAllDept−ProjectDept
Присоединиться
Операция объединения объединяет связанные кортежи двух разных таблиц (результаты запросов) в одну таблицу.
Например, рассмотрим две схемы, Клиент и Филиал в базе данных Банка следующим образом:
ПОКУПАТЕЛЬ
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
ВЕТКА
| BranchID | BranchName | IFSCcode | Адрес |
Чтобы вывести список сотрудников вместе с информацией о филиале —
Результат leftarrowCUSTOMER bowtieCustomer.BranchID=Branch.BranchIDBRANCH
Перевод SQL-запросов в реляционную алгебру
SQL-запросы перед оптимизацией переводятся в эквивалентные выражения реляционной алгебры. Запрос сначала разбивается на меньшие блоки запроса. Эти блоки переводятся в эквивалентные выражения реляционной алгебры. Оптимизация включает в себя оптимизацию каждого блока, а затем оптимизацию запроса в целом.
Примеры
Давайте рассмотрим следующие схемы —
РАБОТНИК
| EmpID | название | город | отдел | Оплата труда |
ПРОЕКТ
| PId | город | отдел | Статус |
РАБОТАЕТ
| EmpID | PID | часов |
Пример 1
Чтобы отобразить сведения обо всех сотрудниках, которые получают зарплату МЕНЬШЕ, чем средняя зарплата, мы пишем запрос SQL —
SELECT * FROM EMPLOYEE WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;
Этот запрос содержит один вложенный подзапрос. Итак, это можно разбить на два блока.
Внутренний блок —
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;
Если результатом этого запроса является AvgSal, то внешний блок —
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;
Выражение реляционной алгебры для внутреннего блока —
AvgSal leftarrow ImAVERAGE(Зарплата)СОТРУДНИК
Выражение реляционной алгебры для внешнего блока —
\ sigma_ {Salary <{AvgSal}>> {СОТРУДНИК}
Пример 2
Чтобы отобразить идентификатор проекта и статус всех проектов сотрудника «Арун Кумар», мы пишем SQL-запрос —
SELECT PID, STATUS FROM PROJECT WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR'));
Этот запрос содержит два вложенных подзапроса. Таким образом, можно разбить на три блока, а именно:
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR'; SELECT PID FROM WORKS WHERE EMPID = ArunEmpID; SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;
(Здесь ArunEmpID и ArunPID являются результатами внутренних запросов)
Выражения реляционной алгебры для трех блоков:
ArunEmpID leftarrow piEmpID( sigmaName= small«ArunKumar«(EMPLOYEE))
ArunPID leftarrow piPID( sigmaEmpID= small«ArunEmpID«(WORKS))
Result leftarrow piPID,Status( sigmaPID= small«ArunPID«(PROJECT))
Вычисление операторов реляционной алгебры
Вычисление операторов реляционной алгебры может быть выполнено многими различными способами, и каждая альтернатива называется путем доступа .
Альтернатива вычислений зависит от трех основных факторов:
- Тип оператора
- Доступная память
- Дисковые структуры
Время выполнения операции реляционной алгебры является суммой:
- Время обрабатывать кортежи.
- Время извлекать кортежи таблицы с диска в память.
Поскольку время обработки кортежа намного меньше, чем время извлечения кортежа из хранилища, особенно в распределенной системе, доступ к диску очень часто рассматривается как показатель для расчета стоимости реляционного выражения.
Вычисление выбора
Вычисление операции выбора зависит от сложности условия выбора и наличия индексов для атрибутов таблицы.
Ниже приведены альтернативы вычислений в зависимости от индексов.
-
Без индекса — если таблица не отсортирована и не имеет индексов, тогда процесс выбора включает сканирование всех дисковых блоков таблицы. Каждый блок заносится в память, и каждый кортеж в блоке проверяется, чтобы убедиться, что он удовлетворяет условию выбора. Если условие выполнено, оно отображается как вывод. Это наиболее затратный подход, поскольку каждый кортеж заносится в память, а каждый кортеж обрабатывается.
-
Индекс B + Tree — Большинство систем баз данных построены на основе индекса B + Tree. Если условие выбора основано на поле, которое является ключом этого индекса B + Tree, то этот индекс используется для получения результатов. Однако обработка операторов выбора со сложными условиями может включать в себя большее количество обращений к дисковым блокам и в некоторых случаях полное сканирование таблицы.
-
Хеш-индекс — если используются хеш-индексы и его ключевое поле используется в условии выбора, то получение кортежей с использованием хеш-индекса становится простым процессом. Хеш-индекс использует хеш-функцию для поиска адреса сегмента, в котором хранится значение ключа, соответствующее хеш-значению. Чтобы найти значение ключа в индексе, выполняется хэш-функция и определяется адрес сегмента. Ключевые значения в корзине ищутся. Если совпадение найдено, фактический кортеж извлекается из блока диска в память.
Без индекса — если таблица не отсортирована и не имеет индексов, тогда процесс выбора включает сканирование всех дисковых блоков таблицы. Каждый блок заносится в память, и каждый кортеж в блоке проверяется, чтобы убедиться, что он удовлетворяет условию выбора. Если условие выполнено, оно отображается как вывод. Это наиболее затратный подход, поскольку каждый кортеж заносится в память, а каждый кортеж обрабатывается.
Индекс B + Tree — Большинство систем баз данных построены на основе индекса B + Tree. Если условие выбора основано на поле, которое является ключом этого индекса B + Tree, то этот индекс используется для получения результатов. Однако обработка операторов выбора со сложными условиями может включать в себя большее количество обращений к дисковым блокам и в некоторых случаях полное сканирование таблицы.
Хеш-индекс — если используются хеш-индексы и его ключевое поле используется в условии выбора, то получение кортежей с использованием хеш-индекса становится простым процессом. Хеш-индекс использует хеш-функцию для поиска адреса сегмента, в котором хранится значение ключа, соответствующее хеш-значению. Чтобы найти значение ключа в индексе, выполняется хэш-функция и определяется адрес сегмента. Ключевые значения в корзине ищутся. Если совпадение найдено, фактический кортеж извлекается из блока диска в память.
Расчет соединений
Когда мы хотим объединить две таблицы, скажем, P и Q, каждый кортеж в P нужно сравнивать с каждым кортежем в Q, чтобы проверить, выполняется ли условие соединения. Если условие выполнено, соответствующие кортежи объединяются, удаляя дубликаты полей и добавляя их в отношение результата. Следовательно, это самая дорогая операция.
Общие подходы к вычислительным объединениям —
Подход с вложенным циклом
Это обычный подход соединения. Это можно проиллюстрировать с помощью следующего псевдокода (таблицы P и Q, с кортежами tuple_p и tuple_q и присоединяющим атрибутом a) —
For each tuple_p in P For each tuple_q in Q If tuple_p.a = tuple_q.a Then Concatenate tuple_p and tuple_q and append to Result End If Next tuple_q Next tuple-p
Подход сортировки-слияния
В этом подходе две таблицы сортируются по отдельности на основе атрибута соединения, а затем отсортированные таблицы объединяются. Применяются методы внешней сортировки, поскольку число записей очень велико и не может быть помещено в память. Как только отдельные таблицы отсортированы, одна страница каждой из отсортированных таблиц заносится в память, объединяется на основе атрибута объединения, и объединенные кортежи записываются.
Подход хэш-соединения
Этот подход состоит из двух фаз: фазы разделения и фазы зондирования. На этапе разбиения таблицы P и Q разбиваются на два набора непересекающихся разбиений. Общей хэш-функции решено. Эта хеш-функция используется для назначения кортежей разделам. На этапе проверки кортежи в разделе P сравниваются с кортежами соответствующего раздела Q. Если они совпадают, то они записываются.