Распределенная СУБД — Основные понятия
Для правильного функционирования любой организации требуется хорошо поддерживаемая база данных. В недавнем прошлом базы данных были централизованными. Однако с ростом глобализации организации имеют тенденцию к диверсификации по всему миру. Они могут распределить данные по локальным серверам вместо центральной базы данных. Таким образом, появилась концепция распределенных баз данных .
В этой главе дается обзор баз данных и систем управления базами данных (СУБД). База данных — это упорядоченная коллекция связанных данных. СУБД — это программный пакет для работы с базой данных. Детальное изучение СУБД доступно в нашем учебном пособии под названием «Изучение СУБД». В этой главе мы пересматриваем основные концепции, чтобы можно было легко изучить DDBMS. Обсуждаются три темы: схемы баз данных, типы баз данных и операции с базами данных.
База данных и система управления базами данных
База данных — это упорядоченная коллекция связанных данных, созданная для определенной цели. База данных может быть организована как коллекция из нескольких таблиц, где таблица представляет элемент или сущность реального мира. Каждая таблица имеет несколько различных полей, которые представляют характерные признаки объекта.
Например, база данных компании может включать таблицы для проектов, сотрудников, отделов, продуктов и финансовых отчетов. Полями в таблице Employee могут быть Имя, Company_Id, Date_of_Joining и т. Д.
Система управления базой данных — это набор программ, которые позволяют создавать и поддерживать базу данных. СУБД доступна в виде программного пакета, который облегчает определение, создание, манипулирование и обмен данными в базе данных. Определение базы данных включает описание структуры базы данных. Построение базы данных предполагает фактическое хранение данных на любом носителе. Манипуляция относится к извлечению информации из базы данных, обновлению базы данных и формированию отчетов. Обмен данными облегчает доступ к данным для различных пользователей или программ.
Примеры областей применения СУБД
- Банкоматы
- Система бронирования поездов
- Система управления сотрудниками
- Студенческая информационная система
Примеры пакетов СУБД
- MySQL
- оракул
- SQL Server
- Dbase
- FoxPro
- PostgreSQL и др.
Схемы базы данных
Схема базы данных — это описание базы данных, которое указывается при разработке базы данных и подвержено редким изменениям. Он определяет организацию данных, отношения между ними и связанные с ними ограничения.
Базы данных часто представлены с помощью архитектуры с тремя схемами или архитектуры ANSISPARC . Цель этой архитектуры — отделить пользовательское приложение от физической базы данных. Три уровня —
-
Внутренний уровень с внутренней схемой — описывает физическую структуру, детали внутреннего хранилища и пути доступа к базе данных.
-
Концептуальный уровень с концептуальной схемой — описывает структуру всей базы данных, скрывая детали физического хранения данных. Это иллюстрирует сущности, атрибуты с их типами данных и ограничениями, пользовательскими операциями и отношениями.
-
Внешний уровень или уровень представления с внешними схемами или представлениями — описывает часть базы данных, относящуюся к конкретному пользователю или группе пользователей, при этом скрывая остальную часть базы данных.
Внутренний уровень с внутренней схемой — описывает физическую структуру, детали внутреннего хранилища и пути доступа к базе данных.
Концептуальный уровень с концептуальной схемой — описывает структуру всей базы данных, скрывая детали физического хранения данных. Это иллюстрирует сущности, атрибуты с их типами данных и ограничениями, пользовательскими операциями и отношениями.
Внешний уровень или уровень представления с внешними схемами или представлениями — описывает часть базы данных, относящуюся к конкретному пользователю или группе пользователей, при этом скрывая остальную часть базы данных.
Типы СУБД
Существует четыре типа СУБД.
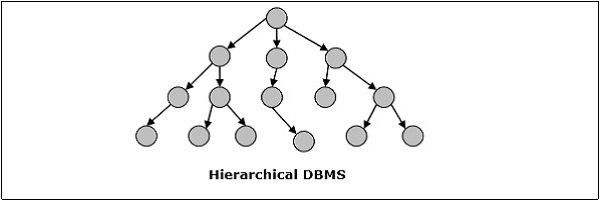
Иерархическая СУБД
В иерархической СУБД отношения между данными в базе данных устанавливаются так, что один элемент данных существует как подчиненный другому. Элементы данных имеют родительско-дочерние отношения и моделируются с использованием «древовидной» структуры данных. Это очень быстро и просто.
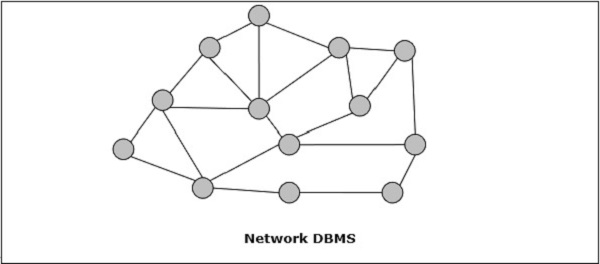
Сетевая СУБД
Сетевая СУБД в той, где отношения между данными в базе данных имеют тип многие-ко-многим в форме сети. Структура, как правило, сложна из-за существования многочисленных отношений «многие ко многим». Сетевая СУБД моделируется с использованием «графической» структуры данных.
Реляционная СУБД
В реляционных базах данных база данных представлена в виде отношений. Каждое отношение моделирует сущность и представляется в виде таблицы значений. В отношении или таблице строка называется кортежем и обозначает одну запись. Столбец называется полем или атрибутом и обозначает характеристическое свойство объекта. СУБД является самой популярной системой управления базами данных.
Например — Отношения со студентами —

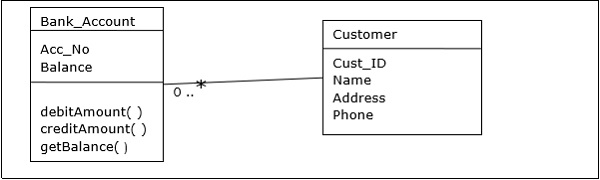
Объектно-ориентированная СУБД
Объектно-ориентированная СУБД получена из модели парадигмы объектно-ориентированного программирования. Они полезны для представления как согласованных данных, хранящихся в базах данных, так и временных данных, которые можно найти в исполняемых программах. Они используют небольшие, многократно используемые элементы, называемые объектами. Каждый объект содержит часть данных и набор операций, которые работают с данными. Доступ к объекту и его атрибутам осуществляется через указатели, а не хранится в моделях реляционных таблиц.
Например — Упрощенная объектно-ориентированная база данных банковского счета —
Распределенная СУБД
Распределенная база данных — это набор взаимосвязанных баз данных, которые распространяются по компьютерной сети или Интернету. Распределенная система управления базами данных (DDBMS) управляет распределенной базой данных и предоставляет механизмы для обеспечения прозрачности баз данных для пользователей. В этих системах данные преднамеренно распределяются между несколькими узлами, так что все вычислительные ресурсы организации могут быть оптимально использованы.
Операции на СУБД
Четыре основных операции с базой данных: создание, получение, обновление и удаление.
-
СОЗДАЙТЕ структуру базы данных и заполняйте ее данными. Создание отношения к базе данных включает в себя указание структур данных, типов данных и ограничений данных, которые будут сохранены.
Пример — команда SQL для создания таблицы ученика —
СОЗДАЙТЕ структуру базы данных и заполняйте ее данными. Создание отношения к базе данных включает в себя указание структур данных, типов данных и ограничений данных, которые будут сохранены.
Пример — команда SQL для создания таблицы ученика —
CREATE TABLE STUDENT ( ROLL INTEGER PRIMARY KEY, NAME VARCHAR2(25), YEAR INTEGER, STREAM VARCHAR2(10) );
-
Как только формат данных определен, фактические данные сохраняются в соответствии с форматом на некотором носителе данных.
Пример команды SQL для вставки одного кортежа в таблицу ученика —
Как только формат данных определен, фактические данные сохраняются в соответствии с форматом на некотором носителе данных.
Пример команды SQL для вставки одного кортежа в таблицу ученика —
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM) VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');
-
ПОЛУЧЕНИЕ информации из базы данных. Как правило, получение информации включает в себя выбор подмножества таблицы или отображение данных из таблицы после выполнения некоторых вычислений. Это делается путем запроса на стол.
Пример. Чтобы получить имена всех учащихся потока Computer Science, необходимо выполнить следующий запрос SQL:
ПОЛУЧЕНИЕ информации из базы данных. Как правило, получение информации включает в себя выбор подмножества таблицы или отображение данных из таблицы после выполнения некоторых вычислений. Это делается путем запроса на стол.
Пример. Чтобы получить имена всех учащихся потока Computer Science, необходимо выполнить следующий запрос SQL:
SELECT NAME FROM STUDENT WHERE STREAM = 'COMPUTER SCIENCE';
-
Информация ОБНОВЛЕНИЯ сохраняется и изменяет структуру базы данных. Обновление таблицы включает изменение старых значений в строках существующей таблицы новыми значениями.
Пример — команда SQL для изменения потока с электроники на электронику и связь —
Информация ОБНОВЛЕНИЯ сохраняется и изменяет структуру базы данных. Обновление таблицы включает изменение старых значений в строках существующей таблицы новыми значениями.
Пример — команда SQL для изменения потока с электроники на электронику и связь —
UPDATE STUDENT SET STREAM = 'ELECTRONICS AND COMMUNICATIONS' WHERE STREAM = 'ELECTRONICS';
-
Модификация базы данных означает изменение структуры таблицы. Тем не менее, изменение таблицы подлежит ряду ограничений.
Пример. Чтобы добавить новое поле или столбец, скажем, адрес в таблицу Student, мы используем следующую команду SQL:
Модификация базы данных означает изменение структуры таблицы. Тем не менее, изменение таблицы подлежит ряду ограничений.
Пример. Чтобы добавить новое поле или столбец, скажем, адрес в таблицу Student, мы используем следующую команду SQL:
ALTER TABLE STUDENT ADD ( ADDRESS VARCHAR2(50) );
-
УДАЛЕНИЕ сохраненной информации или удаление таблицы в целом. Удаление конкретной информации включает удаление выбранных строк из таблицы, удовлетворяющих определенным условиям.
Пример — чтобы удалить всех студентов, которые в настоящее время находятся на 4- м курсе, когда они заканчивают, мы используем команду SQL —
УДАЛЕНИЕ сохраненной информации или удаление таблицы в целом. Удаление конкретной информации включает удаление выбранных строк из таблицы, удовлетворяющих определенным условиям.
Пример — чтобы удалить всех студентов, которые в настоящее время находятся на 4- м курсе, когда они заканчивают, мы используем команду SQL —
DELETE FROM STUDENT WHERE YEAR = 4;
-
Кроме того, вся таблица может быть удалена из базы данных.
Пример. Чтобы полностью удалить таблицу ученика, используется команда SQL:
Кроме того, вся таблица может быть удалена из базы данных.
Пример. Чтобы полностью удалить таблицу ученика, используется команда SQL:
DROP TABLE STUDENT;
Распределенная СУБД — Распределенные базы данных
В этой главе вводится понятие DDBMS. В распределенной базе данных есть несколько баз данных, которые могут быть географически распределены по всему миру. Распределенная СУБД управляет распределенной базой данных таким образом, что она представляется пользователям как одна единая база данных. В последней части главы мы продолжим изучение факторов, которые приводят к распределенным базам данных, их преимуществам и недостаткам.
Распределенная база данных — это совокупность нескольких взаимосвязанных баз данных, которые физически распределены по различным местам, которые обмениваются данными через компьютерную сеть.
Характеристики
-
Базы данных в коллекции логически взаимосвязаны друг с другом. Часто они представляют собой единую логическую базу данных.
-
Данные физически хранятся на нескольких сайтах. Данные на каждом сайте могут управляться СУБД независимо от других сайтов.
-
Процессоры на сайтах подключены через сеть. Они не имеют многопроцессорной конфигурации.
-
Распределенная база данных не является слабо связанной файловой системой.
-
Распределенная база данных включает обработку транзакций, но она не является синонимом системы обработки транзакций.
Базы данных в коллекции логически взаимосвязаны друг с другом. Часто они представляют собой единую логическую базу данных.
Данные физически хранятся на нескольких сайтах. Данные на каждом сайте могут управляться СУБД независимо от других сайтов.
Процессоры на сайтах подключены через сеть. Они не имеют многопроцессорной конфигурации.
Распределенная база данных не является слабо связанной файловой системой.
Распределенная база данных включает обработку транзакций, но она не является синонимом системы обработки транзакций.
Система управления распределенной базой данных
Распределенная система управления базами данных (DDBMS) — это централизованная программная система, которая управляет распределенной базой данных таким образом, как если бы она все хранилась в одном месте.
Характеристики
-
Он используется для создания, поиска, обновления и удаления распределенных баз данных.
-
Он периодически синхронизирует базу данных и предоставляет механизмы доступа, благодаря которым распределение становится прозрачным для пользователей.
-
Это гарантирует, что данные, измененные на любом сайте, будут постоянно обновляться.
-
Он используется в прикладных областях, где большие объемы данных обрабатываются и доступны множеству пользователей одновременно.
-
Он предназначен для гетерогенных платформ баз данных.
-
Он поддерживает конфиденциальность и целостность данных баз данных.
Он используется для создания, поиска, обновления и удаления распределенных баз данных.
Он периодически синхронизирует базу данных и предоставляет механизмы доступа, благодаря которым распределение становится прозрачным для пользователей.
Это гарантирует, что данные, измененные на любом сайте, будут постоянно обновляться.
Он используется в прикладных областях, где большие объемы данных обрабатываются и доступны множеству пользователей одновременно.
Он предназначен для гетерогенных платформ баз данных.
Он поддерживает конфиденциальность и целостность данных баз данных.
Факторы, поощряющие DDBMS
Следующие факторы способствуют переходу на DDBMS:
-
Распределенная природа организационных единиц — Большинство организаций в настоящее время подразделяются на несколько единиц, которые физически распределены по всему миру. Каждому устройству требуется собственный набор локальных данных. Таким образом, общая база данных организации становится распределенной.
-
Необходимость обмена данными . Многим организационным подразделениям часто приходится общаться друг с другом и делиться своими данными и ресурсами. Это требует общих баз данных или реплицированных баз данных, которые должны использоваться синхронизированным образом.
-
Поддержка OLTP и OLAP — оперативная обработка транзакций (OLTP) и оперативная аналитическая обработка (OLAP) работают на разнородных системах, которые могут иметь общие данные. Распределенные базы данных помогают обеим этим обработкам, предоставляя синхронизированные данные.
-
Восстановление базы данных. Одним из распространенных методов, используемых в DDBMS, является репликация данных на разных сайтах. Репликация данных автоматически помогает в восстановлении данных, если база данных на любом сайте повреждена. Пользователи могут получать доступ к данным с других сайтов во время восстановления поврежденного сайта. Таким образом, сбой базы данных может стать почти незаметным для пользователей.
-
Поддержка нескольких прикладных программ. Большинство организаций используют разнообразные прикладные программы, каждая из которых поддерживает свою конкретную базу данных. DDBMS обеспечивает единую функциональность для использования одних и тех же данных на разных платформах.
Распределенная природа организационных единиц — Большинство организаций в настоящее время подразделяются на несколько единиц, которые физически распределены по всему миру. Каждому устройству требуется собственный набор локальных данных. Таким образом, общая база данных организации становится распределенной.
Необходимость обмена данными . Многим организационным подразделениям часто приходится общаться друг с другом и делиться своими данными и ресурсами. Это требует общих баз данных или реплицированных баз данных, которые должны использоваться синхронизированным образом.
Поддержка OLTP и OLAP — оперативная обработка транзакций (OLTP) и оперативная аналитическая обработка (OLAP) работают на разнородных системах, которые могут иметь общие данные. Распределенные базы данных помогают обеим этим обработкам, предоставляя синхронизированные данные.
Восстановление базы данных. Одним из распространенных методов, используемых в DDBMS, является репликация данных на разных сайтах. Репликация данных автоматически помогает в восстановлении данных, если база данных на любом сайте повреждена. Пользователи могут получать доступ к данным с других сайтов во время восстановления поврежденного сайта. Таким образом, сбой базы данных может стать почти незаметным для пользователей.
Поддержка нескольких прикладных программ. Большинство организаций используют разнообразные прикладные программы, каждая из которых поддерживает свою конкретную базу данных. DDBMS обеспечивает единую функциональность для использования одних и тех же данных на разных платформах.
Преимущества распределенных баз данных
Ниже приведены преимущества распределенных баз данных по сравнению с централизованными базами данных.
Модульная разработка — если система должна быть расширена до новых мест или новых единиц, в централизованных системах баз данных, действие требует существенных усилий и нарушения в существующем функционировании. Однако в распределенных базах данных работа просто требует добавления новых компьютеров и локальных данных на новый сайт и, наконец, подключения их к распределенной системе без прерывания текущих функций.
Более надежный — в случае сбоев баз данных вся система централизованных баз данных останавливается. Однако в распределенных системах при отказе компонента функционирование системы может продолжаться с пониженной производительностью. Следовательно, DDBMS более надежен.
Лучший ответ — если данные распределяются эффективным образом, то пользовательские запросы могут быть удовлетворены из самих локальных данных, что обеспечивает более быстрый ответ. С другой стороны, в централизованных системах все запросы должны проходить через центральный компьютер для обработки, что увеличивает время отклика.
Низкая стоимость связи — В распределенных системах баз данных, если данные находятся на месте , где он в основном используется, то расходы на связь для манипулирования данных могут быть сведены к минимуму. Это невозможно в централизованных системах.
Бедствия распределенных баз данных
Ниже приведены некоторые неприятности, связанные с распределенными базами данных.
-
Потребность в сложном и дорогом программном обеспечении — DDBMS требует сложного и часто дорогостоящего программного обеспечения для обеспечения прозрачности данных и координации на нескольких сайтах.
-
Затраты на обработку — даже простые операции могут потребовать большого количества сообщений и дополнительных вычислений для обеспечения единообразия данных на всех площадках.
-
Целостность данных . Необходимость обновления данных на нескольких сайтах создает проблемы целостности данных.
-
Затраты на неправильное распределение данных. Отзывчивость запросов во многом зависит от правильного распределения данных. Неправильное распределение данных часто приводит к очень медленному ответу на пользовательские запросы.
Потребность в сложном и дорогом программном обеспечении — DDBMS требует сложного и часто дорогостоящего программного обеспечения для обеспечения прозрачности данных и координации на нескольких сайтах.
Затраты на обработку — даже простые операции могут потребовать большого количества сообщений и дополнительных вычислений для обеспечения единообразия данных на всех площадках.
Целостность данных . Необходимость обновления данных на нескольких сайтах создает проблемы целостности данных.
Затраты на неправильное распределение данных. Отзывчивость запросов во многом зависит от правильного распределения данных. Неправильное распределение данных часто приводит к очень медленному ответу на пользовательские запросы.
Распределенная СУБД — Среды баз данных
В этой части руководства мы рассмотрим различные аспекты, которые помогают в разработке распределенных сред баз данных. Эта глава начинается с типов распределенных баз данных. Распределенные базы данных можно классифицировать на однородные и гетерогенные базы данных, имеющие дополнительные подразделения. В следующем разделе этой главы рассматриваются распределенные архитектуры, а именно клиент-серверная, одноранговая и мульти-СУБД. Наконец, представлены различные варианты дизайна, такие как репликация и фрагментация.
Типы распределенных баз данных
Распределенные базы данных можно широко классифицировать на однородные и гетерогенные среды распределенных баз данных, каждая из которых имеет дополнительные подразделения, как показано на следующем рисунке.
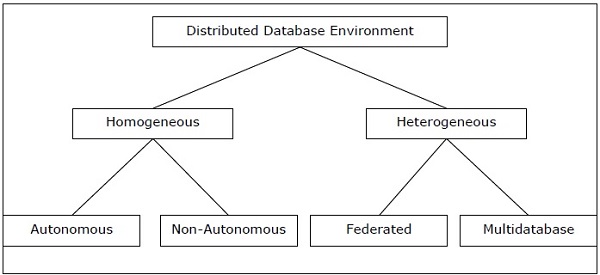
Однородные распределенные базы данных
В однородной распределенной базе данных все сайты используют идентичные СУБД и операционные системы. Его свойства —
-
На сайтах используется очень похожее программное обеспечение.
-
Сайты используют идентичные СУБД или СУБД одного и того же производителя.
-
Каждый сайт знает обо всех других сайтах и взаимодействует с другими сайтами для обработки пользовательских запросов.
-
Доступ к базе данных осуществляется через единый интерфейс, как если бы это была одна база данных.
На сайтах используется очень похожее программное обеспечение.
Сайты используют идентичные СУБД или СУБД одного и того же производителя.
Каждый сайт знает обо всех других сайтах и взаимодействует с другими сайтами для обработки пользовательских запросов.
Доступ к базе данных осуществляется через единый интерфейс, как если бы это была одна база данных.
Типы однородной распределенной базы данных
Существует два типа однородной распределенной базы данных —
-
Автономный — каждая база данных независима и функционирует самостоятельно. Они интегрированы управляющим приложением и используют передачу сообщений для обмена обновлениями данных.
-
Неавтономный — данные распределяются по однородным узлам, а центральная или главная СУБД координирует обновления данных по сайтам.
Автономный — каждая база данных независима и функционирует самостоятельно. Они интегрированы управляющим приложением и используют передачу сообщений для обмена обновлениями данных.
Неавтономный — данные распределяются по однородным узлам, а центральная или главная СУБД координирует обновления данных по сайтам.
Гетерогенные распределенные базы данных
В гетерогенной распределенной базе данных разные сайты имеют разные операционные системы, продукты СУБД и модели данных. Его свойства —
-
Различные сайты используют разные схемы и программное обеспечение.
-
Система может состоять из множества СУБД, таких как реляционная, сетевая, иерархическая или объектно-ориентированная.
-
Обработка запросов является сложной из-за разнородных схем.
-
Обработка транзакций является сложной из-за различий в программном обеспечении.
-
Сайт может не знать о других сайтах, поэтому сотрудничество при обработке пользовательских запросов ограничено.
Различные сайты используют разные схемы и программное обеспечение.
Система может состоять из множества СУБД, таких как реляционная, сетевая, иерархическая или объектно-ориентированная.
Обработка запросов является сложной из-за разнородных схем.
Обработка транзакций является сложной из-за различий в программном обеспечении.
Сайт может не знать о других сайтах, поэтому сотрудничество при обработке пользовательских запросов ограничено.
Типы гетерогенных распределенных баз данных
-
Федеративные — гетерогенные системы баз данных независимы по своей природе и объединены вместе, так что они функционируют как единая система баз данных.
-
Без федерации — в системах баз данных используется центральный координационный модуль, через который осуществляется доступ к базам данных.
Федеративные — гетерогенные системы баз данных независимы по своей природе и объединены вместе, так что они функционируют как единая система баз данных.
Без федерации — в системах баз данных используется центральный координационный модуль, через который осуществляется доступ к базам данных.
Архитектура распределенной СУБД
Архитектуры DDBMS обычно разрабатываются в зависимости от трех параметров:
-
Распределение. В нем указывается физическое распределение данных между различными сайтами.
-
Автономность — указывает распределение управления системой базы данных и степень, в которой каждая составляющая СУБД может работать независимо.
-
Гетерогенность — это относится к однородности или разнородности моделей данных, компонентов системы и баз данных.
Распределение. В нем указывается физическое распределение данных между различными сайтами.
Автономность — указывает распределение управления системой базы данных и степень, в которой каждая составляющая СУБД может работать независимо.
Гетерогенность — это относится к однородности или разнородности моделей данных, компонентов системы и баз данных.
Архитектурные Модели
Некоторые из общих архитектурных моделей —
- Клиент-серверная архитектура для DDBMS
- Одноранговая архитектура для DDBMS
- Архитектура нескольких СУБД
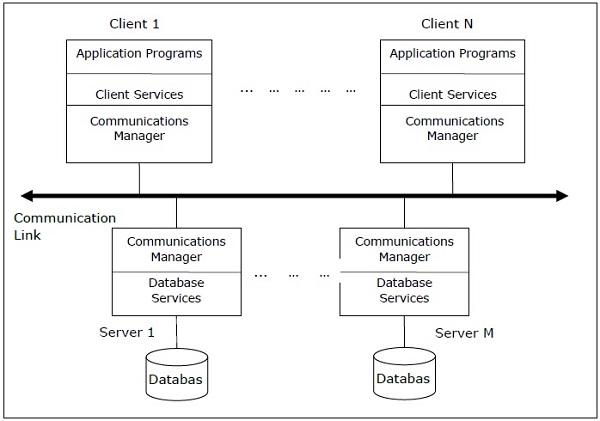
Клиент-серверная архитектура для DDBMS
Это двухуровневая архитектура, в которой функциональность разделена на серверы и клиенты. Функции сервера в основном охватывают управление данными, обработку запросов, оптимизацию и управление транзакциями. Клиентские функции включают в основном пользовательский интерфейс. Однако у них есть некоторые функции, такие как проверка согласованности и управление транзакциями.
Две разные клиент-серверные архитектуры —
- Один сервер, несколько клиентов
- Multiple Server Multiple Client (показано на следующей диаграмме)
Одноранговая архитектура для DDBMS
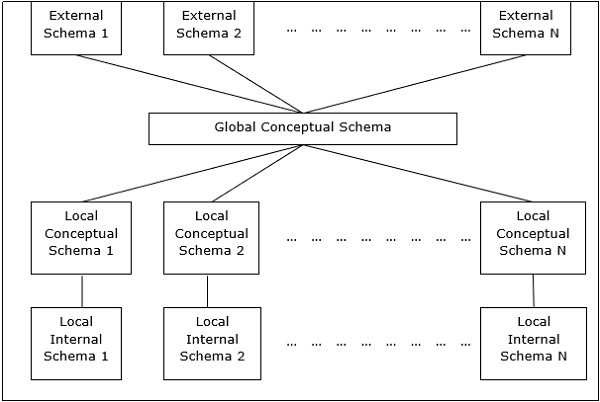
В этих системах каждый узел выступает как клиент и сервер для передачи услуг базы данных. Сверстники делятся своим ресурсом с другими сверстниками и координируют свою деятельность.
Эта архитектура обычно имеет четыре уровня схем:
-
Глобальная концептуальная схема — отображает глобальное логическое представление данных.
-
Локальная концептуальная схема — показывает логическую организацию данных на каждом сайте.
-
Локальная внутренняя схема — показывает физическую организацию данных на каждом сайте.
-
Внешняя схема — отображает представление данных пользователем.
Глобальная концептуальная схема — отображает глобальное логическое представление данных.
Локальная концептуальная схема — показывает логическую организацию данных на каждом сайте.
Локальная внутренняя схема — показывает физическую организацию данных на каждом сайте.
Внешняя схема — отображает представление данных пользователем.
Архитектура нескольких СУБД
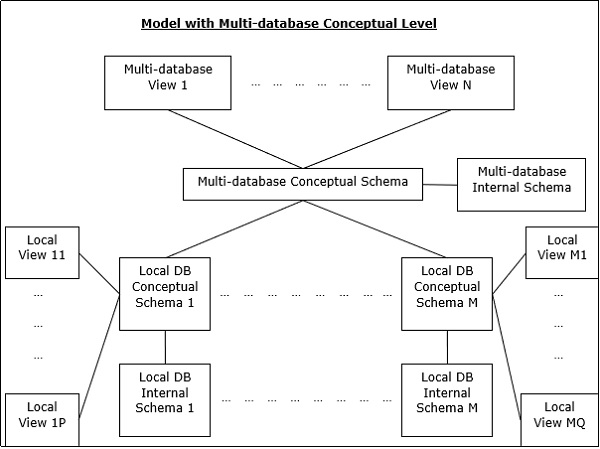
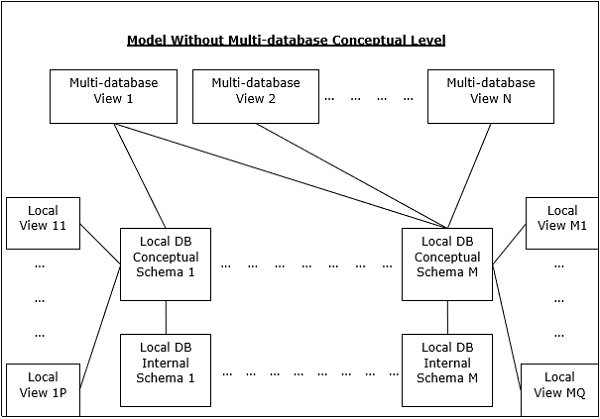
Это интегрированная система баз данных, образованная набором из двух или более автономных систем баз данных.
Мульти-СУБД может быть выражена через шесть уровней схем —
-
Уровень просмотра нескольких баз данных — показывает несколько пользовательских представлений, состоящих из подмножеств интегрированной распределенной базы данных.
-
Концептуальный уровень для нескольких баз данных — описывает интегрированную базу данных, состоящую из глобальных логических определений структуры нескольких баз данных.
-
Внутренний уровень для нескольких баз данных. Описывает распределение данных между различными сайтами и сопоставление нескольких баз данных с локальными данными.
-
Уровень просмотра локальной базы данных — отображает публичное представление локальных данных.
-
Концептуальный уровень локальной базы данных — показывает локальную организацию данных на каждом сайте.
-
Локальная база данных Внутренний уровень — показывает физическую организацию данных на каждом сайте.
Уровень просмотра нескольких баз данных — показывает несколько пользовательских представлений, состоящих из подмножеств интегрированной распределенной базы данных.
Концептуальный уровень для нескольких баз данных — описывает интегрированную базу данных, состоящую из глобальных логических определений структуры нескольких баз данных.
Внутренний уровень для нескольких баз данных. Описывает распределение данных между различными сайтами и сопоставление нескольких баз данных с локальными данными.
Уровень просмотра локальной базы данных — отображает публичное представление локальных данных.
Концептуальный уровень локальной базы данных — показывает локальную организацию данных на каждом сайте.
Локальная база данных Внутренний уровень — показывает физическую организацию данных на каждом сайте.
Существует две альтернативы проектирования для нескольких СУБД:
- Модель с несколькими базами данных концептуального уровня.
- Модель без мультибазы данных концептуального уровня.
Альтернативы дизайна
Варианты дизайна распределения для таблиц в СУБД следующие:
- Не реплицированные и не фрагментированные
- Полностью воспроизведен
- Частично воспроизведен
- Раздробленность
- смешанный
Не реплицированные и не фрагментированные
В этой альтернативе дизайна разные таблицы размещаются на разных сайтах. Данные размещаются таким образом, чтобы они находились в непосредственной близости от сайта, где они используются чаще всего. Он наиболее подходит для систем баз данных, где процент запросов, необходимых для объединения информации в таблицах, размещенных на разных сайтах, невелик. Если будет принята соответствующая стратегия распределения, то эта альтернатива разработки помогает снизить стоимость связи во время обработки данных.
Полностью тиражируется
В этой альтернативе разработки на каждом сайте хранится одна копия всех таблиц базы данных. Поскольку каждый сайт имеет свою собственную копию всей базы данных, запросы выполняются очень быстро и требуют незначительных затрат на связь. Напротив, массовая избыточность данных требует огромных затрат при операциях обновления. Следовательно, это подходит для систем, где требуется обрабатывать большое количество запросов, тогда как количество обновлений базы данных мало.
Частично реплицировано
Копии таблиц или части таблиц хранятся на разных сайтах. Распределение таблиц осуществляется в соответствии с частотой доступа. Это принимает во внимание тот факт, что частота доступа к таблицам значительно варьируется от сайта к сайту. Количество копий таблиц (или частей) зависит от того, как часто выполняются запросы доступа и сайт, который генерирует запросы доступа.
Раздробленность
В этом варианте таблица разделена на две или более частей, называемых фрагментами или разделами, и каждый фрагмент может храниться на разных сайтах. Это учитывает тот факт, что редко случается, что все данные, хранящиеся в таблице, требуются на данном сайте. Более того, фрагментация увеличивает параллелизм и обеспечивает лучшее аварийное восстановление. Здесь есть только одна копия каждого фрагмента в системе, т.е. нет избыточных данных.
Три метода фрагментации —
- Вертикальная фрагментация
- Горизонтальная фрагментация
- Гибридная фрагментация
Смешанное Распределение
Это сочетание фрагментации и частичной репликации. Здесь таблицы изначально фрагментированы в любой форме (горизонтальной или вертикальной), а затем эти фрагменты частично реплицируются на разные сайты в соответствии с частотой доступа к фрагментам.
Распределенная СУБД — Стратегии проектирования
В последней главе мы представили различные варианты дизайна. В этой главе мы рассмотрим стратегии, которые помогают в принятии дизайнов. Стратегии можно широко разделить на репликацию и фрагментацию. Однако в большинстве случаев используется комбинация этих двух.
Репликация данных
Репликация данных — это процесс хранения отдельных копий базы данных на двух или более сайтах. Это популярный отказоустойчивый метод распределенных баз данных.
Преимущества репликации данных
-
Надежность — в случае сбоя какого-либо сайта система базы данных продолжает работать, поскольку копия доступна на другом сайте (ах).
-
Снижение нагрузки на сеть — поскольку локальные копии данных доступны, обработка запросов может быть выполнена с меньшим использованием сети, особенно в пиковые часы. Обновление данных может быть сделано в нерабочее время.
-
Быстрый отклик — доступность локальных копий данных обеспечивает быструю обработку запросов и, следовательно, быстрое время отклика.
-
Упрощенные транзакции — Транзакции требуют меньшего количества объединений таблиц, расположенных на разных сайтах, и минимальной координации по сети. Таким образом, они становятся проще по своей природе.
Надежность — в случае сбоя какого-либо сайта система базы данных продолжает работать, поскольку копия доступна на другом сайте (ах).
Снижение нагрузки на сеть — поскольку локальные копии данных доступны, обработка запросов может быть выполнена с меньшим использованием сети, особенно в пиковые часы. Обновление данных может быть сделано в нерабочее время.
Быстрый отклик — доступность локальных копий данных обеспечивает быструю обработку запросов и, следовательно, быстрое время отклика.
Упрощенные транзакции — Транзакции требуют меньшего количества объединений таблиц, расположенных на разных сайтах, и минимальной координации по сети. Таким образом, они становятся проще по своей природе.
Недостатки репликации данных
-
Повышенные требования к хранилищу. Поддержание нескольких копий данных связано с увеличением затрат на хранение. Требуемое пространство для хранения кратно объему хранилища, необходимому для централизованной системы.
-
Повышенная стоимость и сложность обновления данных — каждый раз, когда элемент данных обновляется, обновление должно отражаться во всех копиях данных на разных сайтах. Это требует сложных методов синхронизации и протоколов.
-
Нежелательное приложение — соединение базы данных — если не используются сложные механизмы обновления, устранение несоответствия данных требует сложной координации на уровне приложения. Это приводит к нежелательному применению — соединению базы данных.
Повышенные требования к хранилищу. Поддержание нескольких копий данных связано с увеличением затрат на хранение. Требуемое пространство для хранения кратно объему хранилища, необходимому для централизованной системы.
Повышенная стоимость и сложность обновления данных — каждый раз, когда элемент данных обновляется, обновление должно отражаться во всех копиях данных на разных сайтах. Это требует сложных методов синхронизации и протоколов.
Нежелательное приложение — соединение базы данных — если не используются сложные механизмы обновления, устранение несоответствия данных требует сложной координации на уровне приложения. Это приводит к нежелательному применению — соединению базы данных.
Некоторые часто используемые методы репликации —
- Репликация снимков
- Репликация почти в реальном времени
- Тянуть репликацию
фрагментация
Фрагментация — это задача разделения таблицы на набор меньших таблиц. Подмножества таблицы называются фрагментами . Фрагментация может быть трех типов: горизонтальная, вертикальная и гибридная (комбинация горизонтальной и вертикальной). Горизонтальная фрагментация может быть далее классифицирована на два метода: первичная горизонтальная фрагментация и производная горизонтальная фрагментация.
Фрагментация должна быть выполнена таким образом, чтобы исходная таблица могла быть восстановлена из фрагментов. Это необходимо для того, чтобы исходная таблица могла быть восстановлена из фрагментов при необходимости. Это требование называется «реконструктивность».
Преимущества фрагментации
-
Поскольку данные хранятся рядом с местом использования, эффективность системы баз данных повышается.
-
Методы оптимизации локальных запросов достаточны для большинства запросов, поскольку данные доступны локально.
-
Поскольку нерелевантные данные не доступны на сайтах, безопасность и конфиденциальность системы базы данных могут быть сохранены.
Поскольку данные хранятся рядом с местом использования, эффективность системы баз данных повышается.
Методы оптимизации локальных запросов достаточны для большинства запросов, поскольку данные доступны локально.
Поскольку нерелевантные данные не доступны на сайтах, безопасность и конфиденциальность системы базы данных могут быть сохранены.
Недостатки фрагментации
-
Когда требуются данные из разных фрагментов, скорости доступа могут быть очень высокими.
-
В случае рекурсивных фрагментов для реконструкции потребуются дорогостоящие методы.
-
Отсутствие резервных копий данных на разных сайтах может сделать базу данных неэффективной в случае сбоя сайта.
Когда требуются данные из разных фрагментов, скорости доступа могут быть очень высокими.
В случае рекурсивных фрагментов для реконструкции потребуются дорогостоящие методы.
Отсутствие резервных копий данных на разных сайтах может сделать базу данных неэффективной в случае сбоя сайта.
Вертикальная фрагментация
При вертикальной фрагментации поля или столбцы таблицы группируются в фрагменты. Чтобы сохранить реконструктивность, каждый фрагмент должен содержать поле (я) первичного ключа таблицы. Вертикальная фрагментация может использоваться для обеспечения конфиденциальности данных.
Например, давайте предположим, что база данных университета хранит записи всех зарегистрированных студентов в таблице Student, имеющей следующую схему.
УЧЕНИК
| Regd_No | название | Курс | Адрес | Семестр | сборы | Метки |
Теперь детали сборов сохраняются в разделе счетов. В этом случае дизайнер фрагментирует базу данных следующим образом:
CREATE TABLE STD_FEES AS SELECT Regd_No, Fees FROM STUDENT;
Горизонтальная фрагментация
Горизонтальная фрагментация группирует кортежи таблицы в соответствии со значениями одного или нескольких полей. Горизонтальная фрагментация также должна подтверждать правило реконструктивности. Каждый горизонтальный фрагмент должен иметь все столбцы исходной базовой таблицы.
Например, в схеме учащегося, если в Школе информатики необходимо хранить сведения обо всех слушателях курса информатики, разработчик будет горизонтально фрагментировать базу данных следующим образом:
CREATE COMP_STD AS SELECT * FROM STUDENT WHERE COURSE = "Computer Science";
Гибридная фрагментация
В гибридной фрагментации используется комбинация горизонтальной и вертикальной методик фрагментации. Это наиболее гибкий метод фрагментации, поскольку он генерирует фрагменты с минимальной посторонней информацией. Однако реконструкция исходного стола часто является дорогостоящей задачей.
Гибридная фрагментация может быть сделана двумя альтернативными способами —
-
Сначала сгенерируйте набор горизонтальных фрагментов; затем генерировать вертикальные фрагменты из одного или нескольких горизонтальных фрагментов.
-
Сначала сгенерируйте набор вертикальных фрагментов; затем генерировать горизонтальные фрагменты из одного или нескольких вертикальных фрагментов.
Сначала сгенерируйте набор горизонтальных фрагментов; затем генерировать вертикальные фрагменты из одного или нескольких горизонтальных фрагментов.
Сначала сгенерируйте набор вертикальных фрагментов; затем генерировать горизонтальные фрагменты из одного или нескольких вертикальных фрагментов.
DDBMS — прозрачность распределения
Прозрачность распространения — это свойство распределенных баз данных, благодаря которому внутренние детали распределения скрыты от пользователей. Дизайнер DDBMS может выбрать фрагментацию таблиц, реплицировать фрагменты и хранить их на разных сайтах. Однако, поскольку пользователи не обращают внимания на эти детали, они считают, что распределенная база данных проста в использовании, как любая централизованная база данных.
Три аспекта прозрачности распределения:
- Прозрачность местоположения
- Фрагментарная прозрачность
- Прозрачность репликации
Прозрачность местоположения
Прозрачность расположения гарантирует, что пользователь может запросить любую таблицу (ы) или фрагмент (ы) таблицы, как если бы они хранились локально на сайте пользователя. Тот факт, что таблица или ее фрагменты хранятся на удаленном сайте в распределенной системе баз данных, должен быть полностью забыт конечным пользователем. Адрес удаленного сайта (ов) и механизмы доступа полностью скрыты.
Чтобы включить прозрачность местоположения, DDBMS должен иметь доступ к обновленному и точному словарю данных и каталогу DDBMS, который содержит детали местоположений данных.
Фрагментарная прозрачность
Прозрачность фрагментации позволяет пользователям запрашивать любую таблицу, как если бы она была нефрагментированной. Таким образом, он скрывает тот факт, что таблица, к которой обращается пользователь, на самом деле является фрагментом или объединением некоторых фрагментов. Это также скрывает тот факт, что фрагменты расположены в разных местах.
Это несколько похоже на пользователей представлений SQL, где пользователь может не знать, что он использует представление таблицы вместо самой таблицы.
Прозрачность репликации
Прозрачность репликации гарантирует, что репликация баз данных скрыта от пользователей. Это позволяет пользователям выполнять запросы к таблице, как будто существует только одна копия таблицы.
Прозрачность репликации связана с прозрачностью параллелизма и прозрачностью отказов. Всякий раз, когда пользователь обновляет элемент данных, обновление отражается во всех копиях таблицы. Однако эта операция не должна быть известна пользователю. Это прозрачность параллелизма. Кроме того, в случае сбоя сайта пользователь может продолжить выполнение своих запросов с использованием реплицированных копий без каких-либо сведений о сбое. Это провал прозрачности.
Сочетание прозрачных пленок
В любой распределенной системе баз данных проектировщик должен обеспечить, чтобы все заявленные прозрачности сохранялись в значительной степени. Дизайнер может выбирать фрагментировать таблицы, копировать их и хранить их на разных сайтах; все не обращая внимания на конечного пользователя. Однако полная прозрачность распространения — сложная задача, требующая значительных усилий по проектированию.
Распределенная СУБД — Управление базой данных
Управление базой данных относится к задаче обеспечения соблюдения правил с целью предоставления правильных данных аутентичным пользователям и приложениям базы данных. Для того чтобы правильные данные были доступны пользователям, все данные должны соответствовать ограничениям целостности, определенным в базе данных. Кроме того, данные должны быть защищены от несанкционированного доступа, чтобы обеспечить безопасность и конфиденциальность базы данных. Управление базой данных является одной из основных задач администратора базы данных (DBA).
Три измерения управления базой данных:
- Аутентификация
- Права доступа
- Ограничения целостности
Аутентификация
В распределенной системе баз данных аутентификация — это процесс, посредством которого только законные пользователи могут получить доступ к ресурсам данных.
Аутентификация может осуществляться на двух уровнях:
-
Управление доступом к клиентскому компьютеру — на этом уровне доступ пользователя ограничен при входе в систему на клиентском компьютере, который обеспечивает пользовательский интерфейс для сервера базы данных. Наиболее распространенный метод — это сочетание имени пользователя и пароля. Однако более сложные методы, такие как биометрическая аутентификация, могут использоваться для данных с высокой степенью защиты.
-
Управление доступом к программному обеспечению базы данных. На этом уровне программное обеспечение / администратор базы данных присваивает пользователю некоторые учетные данные. Пользователь получает доступ к базе данных, используя эти учетные данные. Один из методов — создать учетную запись на сервере базы данных.
Управление доступом к клиентскому компьютеру — на этом уровне доступ пользователя ограничен при входе в систему на клиентском компьютере, который обеспечивает пользовательский интерфейс для сервера базы данных. Наиболее распространенный метод — это сочетание имени пользователя и пароля. Однако более сложные методы, такие как биометрическая аутентификация, могут использоваться для данных с высокой степенью защиты.
Управление доступом к программному обеспечению базы данных. На этом уровне программное обеспечение / администратор базы данных присваивает пользователю некоторые учетные данные. Пользователь получает доступ к базе данных, используя эти учетные данные. Один из методов — создать учетную запись на сервере базы данных.
Права доступа
Права доступа пользователя относятся к привилегиям, которые ему предоставляются в отношении операций СУБД, таких как права на создание таблицы, удаление таблицы, добавление / удаление / обновление кортежей в таблице или запрос к таблице.
В распределенных средах, поскольку имеется большое количество таблиц и все же большее количество пользователей, невозможно назначить индивидуальные права доступа пользователям. Итак, DDBMS определяет определенные роли. Роль — это конструкция с определенными привилегиями в системе баз данных. Как только разные роли определены, отдельным пользователям назначается одна из этих ролей. Часто иерархия ролей определяется в соответствии с иерархией полномочий и ответственности организации.
Например, следующие операторы SQL создают роль «Бухгалтер», а затем назначают эту роль пользователю «ABC».
CREATE ROLE ACCOUNTANT; GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT; GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT; GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT; COMMIT; GRANT ACCOUNTANT TO ABC; COMMIT;
Контроль семантической целостности
Контроль семантической целостности определяет и обеспечивает ограничения целостности системы базы данных.
Ограничения целостности следующие:
- Ограничение целостности типа данных
- Ограничение целостности объекта
- Ограничение ссылочной целостности
Ограничение целостности типа данных
Ограничение типа данных ограничивает диапазон значений и тип операций, которые могут быть применены к полю с указанным типом данных.
Например, давайте предположим, что таблица «HOSTEL» имеет три поля — номер хостела, название хостела и его вместимость. Номер хостела должен начинаться с заглавной буквы «H» и не может быть НЕДЕЙСТВИТЕЛЕН; емкость не должна превышать 150. Следующая команда SQL может использоваться для определения данных:
CREATE TABLE HOSTEL ( H_NO VARCHAR2(5) NOT NULL, H_NAME VARCHAR2(15), CAPACITY INTEGER, CHECK ( H_NO LIKE 'H%'), CHECK ( CAPACITY <= 150) );
Контроль целостности объекта
Контроль целостности объекта обеспечивает соблюдение правил, так что каждый кортеж может быть однозначно идентифицирован из других кортежей. Для этого определяется первичный ключ. Первичный ключ — это набор минимальных полей, которые могут однозначно идентифицировать кортеж. Ограничение целостности объекта гласит, что никакие два кортежа в таблице не могут иметь одинаковые значения для первичных ключей и что никакое поле, которое является частью первичного ключа, не может иметь значение NULL.
Например, в приведенной выше таблице хостелов номер хостела можно назначить в качестве первичного ключа с помощью следующего оператора SQL (игнорируя проверки) —
CREATE TABLE HOSTEL ( H_NO VARCHAR2(5) PRIMARY KEY, H_NAME VARCHAR2(15), CAPACITY INTEGER );
Ограничение ссылочной целостности
Ограничение ссылочной целостности устанавливает правила внешних ключей. Внешний ключ — это поле в таблице данных, которое является первичным ключом связанной таблицы. Ограничение ссылочной целостности устанавливает правило, согласно которому значение поля внешнего ключа должно быть либо среди значений первичного ключа ссылочной таблицы, либо быть полностью NULL.
Например, давайте рассмотрим студенческий стол, где студент может выбрать проживание в общежитии. Чтобы включить это, первичный ключ таблицы общежития должен быть включен как внешний ключ в таблицу ученика. Следующий оператор SQL включает это —
CREATE TABLE STUDENT ( S_ROLL INTEGER PRIMARY KEY, S_NAME VARCHAR2(25) NOT NULL, S_COURSE VARCHAR2(10), S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL );
Реляционная алгебра для оптимизации запросов
Когда запрос размещен, он сначала сканируется, анализируется и проверяется. Затем создается внутреннее представление запроса, такое как дерево запросов или граф запросов. Затем разрабатываются альтернативные стратегии выполнения для извлечения результатов из таблиц базы данных. Процесс выбора наиболее подходящей стратегии выполнения для обработки запросов называется оптимизацией запросов.
Проблемы оптимизации запросов в DDBMS
В DDBMS оптимизация запросов является критически важной задачей. Сложность высока, поскольку число альтернативных стратегий может возрастать в геометрической прогрессии из-за следующих факторов:
- Наличие ряда фрагментов.
- Распределение фрагментов или таблиц по различным сайтам.
- Скорость связи.
- Несоответствие в возможностях локальной обработки.
Следовательно, в распределенной системе целью часто является найти хорошую стратегию выполнения для обработки запросов, а не лучшую. Время выполнения запроса является суммой следующего:
- Время передавать запросы в базы данных.
- Время выполнять фрагменты локальных запросов.
- Время собирать данные с разных сайтов.
- Время для отображения результатов в приложении.
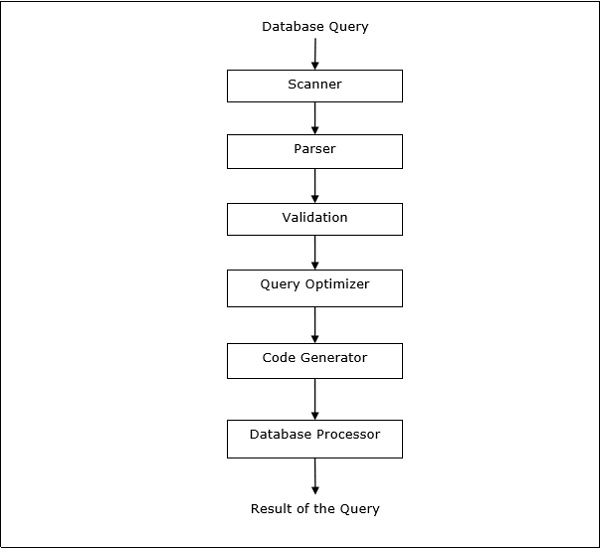
Обработка запросов
Обработка запросов — это набор всех действий, начиная с размещения запроса и заканчивая отображением результатов запроса. Шаги, как показано на следующей диаграмме —
Реляционная алгебра
Реляционная алгебра определяет базовый набор операций модели реляционной базы данных. Последовательность операций реляционной алгебры образует выражение реляционной алгебры. Результат этого выражения представляет собой результат запроса к базе данных.
Основные операции —
- проекция
- выбор
- союз
- пересечение
- Минус
- Присоединиться
проекция
Операция проецирования отображает подмножество полей таблицы. Это дает вертикальное разделение таблицы.
Синтаксис в реляционной алгебре
pi<AttributeList>(<Имятаблицы>)
Например, давайте рассмотрим следующую базу данных студентов —
| Roll_No | название | Курс | Семестр | Пол |
| 2 | Амит Прасад | BCA | 1 | мужчина |
| 4 | Варша Тивари | BCA | 1 | женский |
| 5 | Асиф Али | MCA | 2 | мужчина |
| 6 | Джо Уоллес | MCA | 1 | мужчина |
| 8 | Шивани Айенгар | BCA | 1 | женский |
Если мы хотим отобразить имена и курсы всех студентов, мы будем использовать следующее выражение реляционной алгебры:
piName,курс(СТУДЕНТ)
выбор
Операция выбора отображает подмножество кортежей таблицы, которое удовлетворяет определенным условиям. Это дает горизонтальный раздел стола.
Синтаксис в реляционной алгебре
sigma<Условия>(<Имятаблицы>)
Например, в таблице «Студент», если мы хотим отобразить сведения обо всех студентах, которые выбрали курс MCA, мы будем использовать следующее выражение реляционной алгебры:
sigmaCourse= small«BCA«(STUDENT)
Сочетание операций проекции и выбора
Для большинства запросов нам нужна комбинация операций проекции и выбора. Есть два способа написания этих выражений:
- Использование последовательности операций проецирования и выбора.
- Использование операции переименования для генерации промежуточных результатов.
Например, чтобы отобразить имена всех учениц курса BCA —
- Выражение реляционной алгебры с использованием последовательности операций проекции и выбора
piName( sigmaGender= small«Female«ANDCourse= small«BCA«(STUDENT))
- Выражение реляционной алгебры с использованием операции переименования для получения промежуточных результатов
FemaleBCAStudent leftarrow sigmaGender= small«Female«ANDCourse= small«BCA«(STUDENT)
Result leftarrow piName(FemaleBCAStudent)
союз
Если P является результатом операции, а Q является результатом другой операции, объединение P и Q (p cupQ) является множеством всех кортежей, находящихся либо в P, либо в Q, либо в обоих без дубликатов. ,
Например, для отображения всех студентов, которые находятся либо в 1 семестре, либо в курсе BCA —
Sem1Student leftarrow sigmaSemester=1(СТУДЕНТ)
BCAStudent leftarrow sigmaCourse= small«BCA«(STUDENT)
Результат leftarrowSem1Student cupBCAStudent
пересечение
Если P является результатом операции, а Q является результатом другой операции, пересечение P и Q (p capQ) является множеством всех кортежей, которые находятся в P и Q, и то и другое.
Например, с учетом следующих двух схем —
РАБОТНИК
| EmpID | название | город | отдел | Оплата труда |
ПРОЕКТ
| PId | город | отдел | Статус |
Чтобы отобразить названия всех городов, в которых находится проект, а также сотрудник, —
CityEmp leftarrow piCity(СОТРУДНИК)
CityProject leftarrow piCity(PROJECT)
Результат leftarrowCityEmp capCityProject
Минус
Если P — результат операции, а Q — результат другой операции, P — Q — это множество всех кортежей, которые находятся в P, а не в Q.
Например, перечислить все отделы, у которых нет текущего проекта (проекты со статусом = текущий) —
AllDept leftarrow piDepartment(СОТРУДНИК)
ProjectDept leftarrow piDepartment( sigmaStatus= small«продолжается«(PROJECT))
Результат leftarrowAllDept−ProjectDept
Присоединиться
Операция объединения объединяет связанные кортежи двух разных таблиц (результаты запросов) в одну таблицу.
Например, рассмотрим две схемы, Клиент и Филиал в базе данных Банка следующим образом:
ПОКУПАТЕЛЬ
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
ВЕТКА
| BranchID | BranchName | IFSCcode | Адрес |
Чтобы вывести список сотрудников вместе с информацией о филиале —
Результат leftarrowCUSTOMER bowtieCustomer.BranchID=Branch.BranchIDBRANCH
Перевод SQL-запросов в реляционную алгебру
SQL-запросы перед оптимизацией переводятся в эквивалентные выражения реляционной алгебры. Запрос сначала разбивается на меньшие блоки запроса. Эти блоки переводятся в эквивалентные выражения реляционной алгебры. Оптимизация включает в себя оптимизацию каждого блока, а затем оптимизацию запроса в целом.
Примеры
Давайте рассмотрим следующие схемы —
РАБОТНИК
| EmpID | название | город | отдел | Оплата труда |
ПРОЕКТ
| PId | город | отдел | Статус |
РАБОТАЕТ
| EmpID | PID | часов |
Пример 1
Чтобы отобразить сведения обо всех сотрудниках, которые получают зарплату МЕНЬШЕ, чем средняя зарплата, мы пишем запрос SQL —
SELECT * FROM EMPLOYEE WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;
Этот запрос содержит один вложенный подзапрос. Итак, это можно разбить на два блока.
Внутренний блок —
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;
Если результатом этого запроса является AvgSal, то внешний блок —
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;
Выражение реляционной алгебры для внутреннего блока —
AvgSal leftarrow ImAVERAGE(Зарплата)СОТРУДНИК
Выражение реляционной алгебры для внешнего блока —
\ sigma_ {Salary <{AvgSal}>> {СОТРУДНИК}
Пример 2
Чтобы отобразить идентификатор проекта и статус всех проектов сотрудника «Арун Кумар», мы пишем SQL-запрос —
SELECT PID, STATUS FROM PROJECT WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR'));
Этот запрос содержит два вложенных подзапроса. Таким образом, можно разбить на три блока, а именно:
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR'; SELECT PID FROM WORKS WHERE EMPID = ArunEmpID; SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;
(Здесь ArunEmpID и ArunPID являются результатами внутренних запросов)
Выражения реляционной алгебры для трех блоков:
ArunEmpID leftarrow piEmpID( sigmaName= small«ArunKumar«(EMPLOYEE))
ArunPID leftarrow piPID( sigmaEmpID= small«ArunEmpID«(WORKS))
Result leftarrow piPID,Status( sigmaPID= small«ArunPID«(PROJECT))
Вычисление операторов реляционной алгебры
Вычисление операторов реляционной алгебры может быть выполнено многими различными способами, и каждая альтернатива называется путем доступа .
Альтернатива вычислений зависит от трех основных факторов:
- Тип оператора
- Доступная память
- Дисковые структуры
Время выполнения операции реляционной алгебры является суммой:
- Время обрабатывать кортежи.
- Время извлекать кортежи таблицы с диска в память.
Поскольку время обработки кортежа намного меньше, чем время извлечения кортежа из хранилища, особенно в распределенной системе, доступ к диску очень часто рассматривается как показатель для расчета стоимости реляционного выражения.
Вычисление выбора
Вычисление операции выбора зависит от сложности условия выбора и наличия индексов для атрибутов таблицы.
Ниже приведены альтернативы вычислений в зависимости от индексов.
-
Без индекса — если таблица не отсортирована и не имеет индексов, тогда процесс выбора включает сканирование всех дисковых блоков таблицы. Каждый блок заносится в память, и каждый кортеж в блоке проверяется, чтобы убедиться, что он удовлетворяет условию выбора. Если условие выполнено, оно отображается как вывод. Это наиболее затратный подход, поскольку каждый кортеж заносится в память, а каждый кортеж обрабатывается.
-
Индекс B + Tree — Большинство систем баз данных построены на основе индекса B + Tree. Если условие выбора основано на поле, которое является ключом этого индекса B + Tree, то этот индекс используется для получения результатов. Однако обработка операторов выбора со сложными условиями может включать в себя большее количество обращений к дисковым блокам и в некоторых случаях полное сканирование таблицы.
-
Хеш-индекс — если используются хеш-индексы и его ключевое поле используется в условии выбора, то получение кортежей с использованием хеш-индекса становится простым процессом. Хеш-индекс использует хеш-функцию для поиска адреса сегмента, в котором хранится значение ключа, соответствующее хеш-значению. Чтобы найти значение ключа в индексе, выполняется хэш-функция и определяется адрес сегмента. Ключевые значения в корзине ищутся. Если совпадение найдено, фактический кортеж извлекается из блока диска в память.
Без индекса — если таблица не отсортирована и не имеет индексов, тогда процесс выбора включает сканирование всех дисковых блоков таблицы. Каждый блок заносится в память, и каждый кортеж в блоке проверяется, чтобы убедиться, что он удовлетворяет условию выбора. Если условие выполнено, оно отображается как вывод. Это наиболее затратный подход, поскольку каждый кортеж заносится в память, а каждый кортеж обрабатывается.
Индекс B + Tree — Большинство систем баз данных построены на основе индекса B + Tree. Если условие выбора основано на поле, которое является ключом этого индекса B + Tree, то этот индекс используется для получения результатов. Однако обработка операторов выбора со сложными условиями может включать в себя большее количество обращений к дисковым блокам и в некоторых случаях полное сканирование таблицы.
Хеш-индекс — если используются хеш-индексы и его ключевое поле используется в условии выбора, то получение кортежей с использованием хеш-индекса становится простым процессом. Хеш-индекс использует хеш-функцию для поиска адреса сегмента, в котором хранится значение ключа, соответствующее хеш-значению. Чтобы найти значение ключа в индексе, выполняется хэш-функция и определяется адрес сегмента. Ключевые значения в корзине ищутся. Если совпадение найдено, фактический кортеж извлекается из блока диска в память.
Расчет соединений
Когда мы хотим объединить две таблицы, скажем, P и Q, каждый кортеж в P нужно сравнивать с каждым кортежем в Q, чтобы проверить, выполняется ли условие соединения. Если условие выполнено, соответствующие кортежи объединяются, удаляя дубликаты полей и добавляя их в отношение результата. Следовательно, это самая дорогая операция.
Общие подходы к вычислительным объединениям —
Подход с вложенным циклом
Это обычный подход соединения. Это можно проиллюстрировать с помощью следующего псевдокода (таблицы P и Q, с кортежами tuple_p и tuple_q и присоединяющим атрибутом a) —
For each tuple_p in P For each tuple_q in Q If tuple_p.a = tuple_q.a Then Concatenate tuple_p and tuple_q and append to Result End If Next tuple_q Next tuple-p
Подход сортировки-слияния
В этом подходе две таблицы сортируются по отдельности на основе атрибута соединения, а затем отсортированные таблицы объединяются. Применяются методы внешней сортировки, поскольку число записей очень велико и не может быть помещено в память. Как только отдельные таблицы отсортированы, одна страница каждой из отсортированных таблиц заносится в память, объединяется на основе атрибута объединения, и объединенные кортежи записываются.
Подход хэш-соединения
Этот подход состоит из двух фаз: фазы разделения и фазы зондирования. На этапе разбиения таблицы P и Q разбиваются на два набора непересекающихся разбиений. Общей хэш-функции решено. Эта хеш-функция используется для назначения кортежей разделам. На этапе проверки кортежи в разделе P сравниваются с кортежами соответствующего раздела Q. Если они совпадают, то они записываются.
Оптимизация запросов в централизованных системах
Как только альтернативные пути доступа для вычисления выражения реляционной алгебры получены, определяется оптимальный путь доступа. В этой главе мы рассмотрим оптимизацию запросов в централизованной системе, а в следующей главе мы изучим оптимизацию запросов в распределенной системе.
В централизованной системе обработка запросов выполняется с целью:
-
Минимизация времени отклика на запрос (время, затраченное на получение результатов по запросу пользователя).
-
Максимизируйте пропускную способность системы (количество запросов, которые обрабатываются за определенный промежуток времени).
-
Уменьшите объем памяти и памяти, необходимых для обработки.
-
Увеличить параллелизм.
Минимизация времени отклика на запрос (время, затраченное на получение результатов по запросу пользователя).
Максимизируйте пропускную способность системы (количество запросов, которые обрабатываются за определенный промежуток времени).
Уменьшите объем памяти и памяти, необходимых для обработки.
Увеличить параллелизм.
Анализ запросов и перевод
Изначально SQL-запрос сканируется. Затем он анализируется на предмет синтаксических ошибок и правильности типов данных. Если запрос проходит этот шаг, запрос разбивается на меньшие блоки запроса. Каждый блок затем переводится в эквивалентное выражение реляционной алгебры.
Шаги для оптимизации запросов
Оптимизация запросов включает в себя три этапа, а именно: создание дерева запросов, создание плана и создание кода плана запроса.
Шаг 1 — Генерация дерева запросов
Дерево запросов — это древовидная структура данных, представляющая выражение реляционной алгебры. Таблицы запроса представлены в виде листовых узлов. Операции реляционной алгебры представлены как внутренние узлы. Корень представляет запрос в целом.
Во время выполнения внутренний узел выполняется всякий раз, когда доступны его таблицы операндов. Затем узел заменяется таблицей результатов. Этот процесс продолжается для всех внутренних узлов, пока корневой узел не будет выполнен и заменен таблицей результатов.
Например, давайте рассмотрим следующие схемы —
РАБОТНИК
| EmpID | Ename | Оплата труда | DeptNo | Дата присоединения |
ОТДЕЛ
| Дно | Dname | Место нахождения |
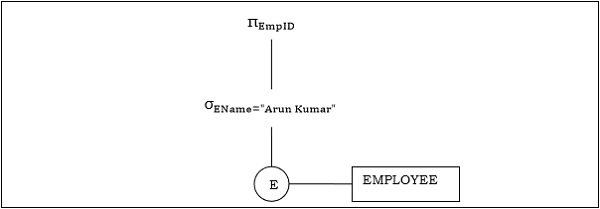
Пример 1
Давайте рассмотрим запрос следующим образом.
piEmpID( sigmaEName= small«ArunKumar«(EMPLOYEE))
Соответствующее дерево запросов будет —
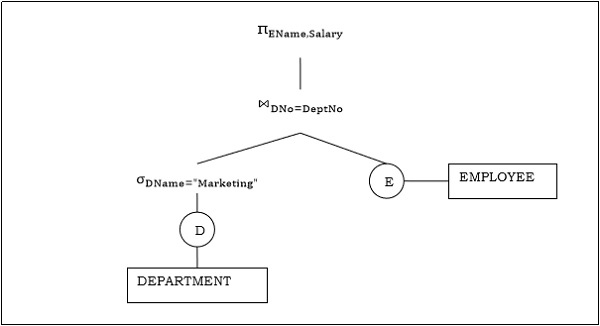
Пример 2
Давайте рассмотрим другой запрос, включающий соединение.
piEName,Salary( sigmaDName= small«Marketing«(DEPARTMENT)) bowtieDNo=DeptNo(EMPLOYEE)
Ниже приведено дерево запросов для вышеуказанного запроса.
Шаг 2 — Генерация плана запроса
После создания дерева запросов составляется план запроса. План запроса — это расширенное дерево запросов, которое включает пути доступа для всех операций в дереве запросов. Пути доступа определяют, как должны выполняться реляционные операции в дереве. Например, операция выбора может иметь путь доступа, который дает подробную информацию об использовании индекса дерева B + для выбора.
Кроме того, в плане запроса также указывается, как промежуточные таблицы должны передаваться от одного оператора к другому, как должны использоваться временные таблицы и как должны выполняться операции конвейеризации / объединения.
Шаг 3 — Генерация кода
Генерация кода — это последний шаг в оптимизации запросов. Это исполняемая форма запроса, форма которой зависит от типа базовой операционной системы. После того, как код запроса сгенерирован, диспетчер выполнения запускает его и выдает результаты.
Подходы к оптимизации запросов
Среди подходов к оптимизации запросов чаще всего используются алгоритмы исчерпывающего поиска и эвристики.
Исчерпывающая поисковая оптимизация
В этих методах для запроса сначала создаются все возможные планы запроса, а затем выбирается лучший план. Хотя эти методы обеспечивают лучшее решение, они имеют экспоненциальную временную и пространственную сложность из-за большого пространства решений. Например, техника динамического программирования.
Эвристическая оптимизация
Эвристическая оптимизация использует оптимизацию на основе правил для оптимизации запросов. Эти алгоритмы имеют полиномиальную временную и пространственную сложность, которая ниже, чем экспоненциальная сложность алгоритмов исчерпывающего поиска. Однако эти алгоритмы не обязательно дают лучший план запроса.
Некоторые из общих эвристических правил —
-
Выполните операции выбора и проецирования перед операциями объединения. Это делается путем перемещения операций select и project вниз по дереву запросов. Это уменьшает количество кортежей, доступных для объединения.
-
Сначала выполняйте самые строгие операции выбора / проекта перед другими операциями.
-
Избегайте операций с несколькими продуктами, поскольку они приводят к промежуточным таблицам очень большого размера.
Выполните операции выбора и проецирования перед операциями объединения. Это делается путем перемещения операций select и project вниз по дереву запросов. Это уменьшает количество кортежей, доступных для объединения.
Сначала выполняйте самые строгие операции выбора / проекта перед другими операциями.
Избегайте операций с несколькими продуктами, поскольку они приводят к промежуточным таблицам очень большого размера.
Оптимизация запросов в распределенных системах
В этой главе обсуждается оптимизация запросов в распределенной системе баз данных.
Архитектура распределенной обработки запросов
В распределенной системе баз данных обработка запроса включает в себя оптимизацию как на глобальном, так и на локальном уровне. Запрос поступает в систему базы данных на клиентском или управляющем сайте. Здесь пользователь проверяется, запрос проверяется, переводится и оптимизируется на глобальном уровне.
Архитектура может быть представлена как —
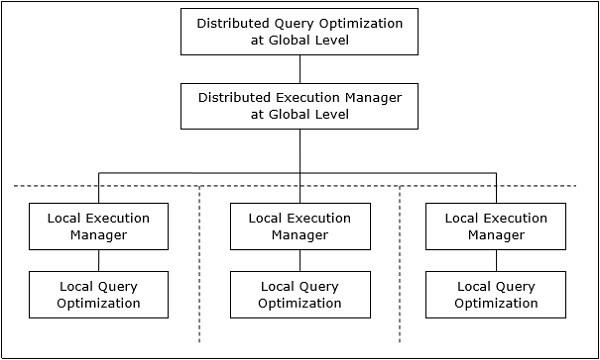
Отображение глобальных запросов в локальные запросы
Процесс отображения глобальных запросов на локальные может быть реализован следующим образом:
-
Таблицы, необходимые для глобального запроса, имеют фрагменты, распределенные по нескольким сайтам. Локальные базы данных имеют информацию только о локальных данных. Контролирующий сайт использует словарь глобальных данных для сбора информации о распределении и восстанавливает глобальное представление по фрагментам.
-
Если репликация отсутствует, глобальный оптимизатор запускает локальные запросы на сайтах, где хранятся фрагменты. При наличии репликации глобальный оптимизатор выбирает сайт на основе стоимости связи, рабочей нагрузки и скорости сервера.
-
Глобальный оптимизатор генерирует распределенный план выполнения, чтобы на сайтах происходил наименьший объем передачи данных. В плане указывается расположение фрагментов, порядок, в котором необходимо выполнить шаги запроса, и процессы, связанные с передачей промежуточных результатов.
-
Локальные запросы оптимизируются локальными серверами баз данных. Наконец, результаты локального запроса объединяются посредством операции объединения в случае горизонтальных фрагментов и операции объединения для вертикальных фрагментов.
Таблицы, необходимые для глобального запроса, имеют фрагменты, распределенные по нескольким сайтам. Локальные базы данных имеют информацию только о локальных данных. Контролирующий сайт использует словарь глобальных данных для сбора информации о распределении и восстанавливает глобальное представление по фрагментам.
Если репликация отсутствует, глобальный оптимизатор запускает локальные запросы на сайтах, где хранятся фрагменты. При наличии репликации глобальный оптимизатор выбирает сайт на основе стоимости связи, рабочей нагрузки и скорости сервера.
Глобальный оптимизатор генерирует распределенный план выполнения, чтобы на сайтах происходил наименьший объем передачи данных. В плане указывается расположение фрагментов, порядок, в котором необходимо выполнить шаги запроса, и процессы, связанные с передачей промежуточных результатов.
Локальные запросы оптимизируются локальными серверами баз данных. Наконец, результаты локального запроса объединяются посредством операции объединения в случае горизонтальных фрагментов и операции объединения для вертикальных фрагментов.
Например, давайте рассмотрим, что следующая схема проекта горизонтально фрагментирована в соответствии с городом, причем городами являются Нью-Дели, Калькутта и Хайдарабад.
ПРОЕКТ
| PId | город | отдел | Статус |
Предположим, существует запрос для получения сведений обо всех проектах, статус которых «Текущий».
Глобальный запрос будет & inus;
sigmastatus= small«продолжается«(PROJECT)
Запрос на сервер в Нью-Дели будет —
sigmastatus= small«продолжается«(NewD−PROJECT)
Запрос на сервере Калькутты будет —
sigmastatus= small«продолжается«(Kol−PROJECT)
Запрос на сервере Хайдарабада будет —
sigmastatus= small«продолжается«(Hyd−PROJECT)
Чтобы получить общий результат, нам нужно объединить результаты трех запросов следующим образом:
sigmastatus= small«продолжается«(NewD−PROJECT) cup sigmastatus= small«продолжается«(kol−PROJECT) cup sigmastatus= small«впроцессе«(Hyd−PROJECT)
Оптимизация распределенных запросов
Оптимизация распределенных запросов требует оценки большого количества деревьев запросов, каждое из которых дает требуемые результаты запроса. Это связано прежде всего с наличием большого количества реплицированных и фрагментированных данных. Следовательно, цель состоит в том, чтобы найти оптимальное решение вместо лучшего.
Основные проблемы для оптимизации распределенных запросов:
- Оптимальное использование ресурсов в распределенной системе.
- Запрос торгов.
- Сокращение пространства решения запроса.
Оптимальное использование ресурсов в распределенной системе
Распределенная система имеет несколько серверов баз данных на различных сайтах для выполнения операций, относящихся к запросу. Ниже приведены подходы для оптимального использования ресурсов —
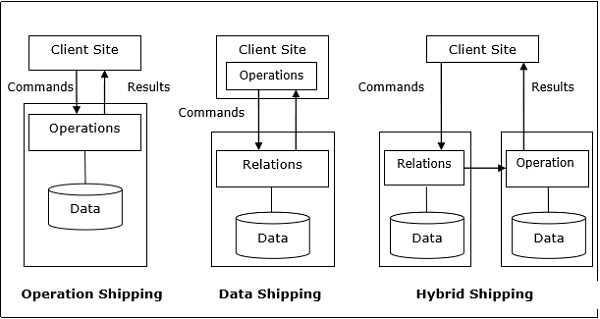
Операция «Доставка». Операция «Операция доставки» выполняется на сайте, где хранятся данные, а не на сайте клиента. Затем результаты передаются на сайт клиента. Это подходит для операций, где операнды доступны на том же сайте. Пример: операции выбора и проекта.
Доставка данных — при доставке данных фрагменты данных передаются на сервер базы данных, где выполняются операции. Это используется в операциях, где операнды распространяются на разных сайтах. Это также подходит для систем, где затраты на связь низкие, а локальные процессоры работают намного медленнее, чем клиентский сервер.
Гибридная доставка — это комбинация данных и операций доставки. Здесь фрагменты данных передаются на высокоскоростные процессоры, где выполняется операция. Результаты затем отправляются на сайт клиента.
Query Trading
В алгоритме торговли запросами для систем распределенных баз данных управляющий / клиентский сайт для распределенного запроса называется покупателем, а сайты, на которых выполняются локальные запросы, называются продавцами. Покупатель формулирует ряд альтернатив для выбора продавцов и для восстановления глобальных результатов. Целью покупателя является достижение оптимальной стоимости.
Алгоритм начинается с назначения покупателем подзапросов сайтам продавца. Оптимальный план создается из локальных оптимизированных планов запросов, предложенных продавцами, в сочетании со стоимостью связи для восстановления конечного результата. Как только глобальный оптимальный план сформулирован, запрос выполняется.
Сокращение пространства решений запроса
Оптимальное решение обычно включает в себя уменьшение пространства решения, так что стоимость запросов и передачи данных снижается. Этого можно достичь с помощью набора эвристических правил, так же как эвристика в централизованных системах.
Ниже приведены некоторые правила —
-
Выполните операции выбора и проецирования как можно раньше. Это уменьшает поток данных по сети связи.
-
Упростите операции с горизонтальными фрагментами, исключив условия выбора, которые не относятся к конкретному сайту.
-
В случае операций объединения и объединения, состоящих из фрагментов, расположенных на нескольких сайтах, передайте фрагментированные данные на сайт, где присутствует большая часть данных, и выполните там операцию.
-
Используйте операцию semi-join для определения кортежей, которые должны быть объединены. Это уменьшает объем передачи данных, что, в свою очередь, снижает стоимость связи.
-
Объедините общие листья и поддеревья в дереве распределенных запросов.
Выполните операции выбора и проецирования как можно раньше. Это уменьшает поток данных по сети связи.
Упростите операции с горизонтальными фрагментами, исключив условия выбора, которые не относятся к конкретному сайту.
В случае операций объединения и объединения, состоящих из фрагментов, расположенных на нескольких сайтах, передайте фрагментированные данные на сайт, где присутствует большая часть данных, и выполните там операцию.
Используйте операцию semi-join для определения кортежей, которые должны быть объединены. Это уменьшает объем передачи данных, что, в свою очередь, снижает стоимость связи.
Объедините общие листья и поддеревья в дереве распределенных запросов.
DDBMS — Системы обработки транзакций
В этой главе рассматриваются различные аспекты обработки транзакций. Мы также изучим задачи низкого уровня, включенные в транзакцию, состояния транзакции и свойства транзакции. В последней части мы рассмотрим графики и сериализуемость графиков.
операции
Транзакция — это программа, включающая в себя набор операций базы данных, выполняемых как логическая единица обработки данных. Операции, выполняемые в транзакции, включают в себя одну или несколько операций с базой данных, таких как вставка, удаление, обновление или получение данных. Это атомарный процесс, который либо выполняется полностью, либо не выполняется вообще. Транзакция, включающая только получение данных без какого-либо обновления данных, называется транзакцией только для чтения.
Каждую операцию высокого уровня можно разделить на ряд задач или операций низкого уровня. Например, операцию обновления данных можно разделить на три задачи:
-
read_item () — читает элемент данных из хранилища в основную память.
-
modify_item () — изменить значение элемента в основной памяти.
-
write_item () — записывает измененное значение из основной памяти в хранилище.
read_item () — читает элемент данных из хранилища в основную память.
modify_item () — изменить значение элемента в основной памяти.
write_item () — записывает измененное значение из основной памяти в хранилище.
Доступ к базе данных ограничен операциями read_item () и write_item (). Аналогично, для всех транзакций чтение и запись образуют основные операции базы данных.
Операционные операции
Операции низкого уровня, выполняемые в транзакции:
-
begin_transaction — Маркер, который указывает начало выполнения транзакции.
-
read_item или write_item — Операции с базой данных, которые могут чередоваться с операциями с основной памятью как часть транзакции.
-
end_transaction — маркер, который указывает конец транзакции.
-
commit — сигнал, указывающий, что транзакция была успешно завершена полностью и не будет отменена.
-
откат — сигнал, указывающий, что транзакция была неудачной, и поэтому все временные изменения в базе данных отменяются. Подтвержденная транзакция не может быть отменена.
begin_transaction — Маркер, который указывает начало выполнения транзакции.
read_item или write_item — Операции с базой данных, которые могут чередоваться с операциями с основной памятью как часть транзакции.
end_transaction — маркер, который указывает конец транзакции.
commit — сигнал, указывающий, что транзакция была успешно завершена полностью и не будет отменена.
откат — сигнал, указывающий, что транзакция была неудачной, и поэтому все временные изменения в базе данных отменяются. Подтвержденная транзакция не может быть отменена.
Состояния транзакции
Транзакция может проходить через подмножество из пяти состояний: активное, частично зафиксированное, зафиксированное, неудачное и прерванное.
-
Активный — начальное состояние, в которое входит транзакция, является активным состоянием. Транзакция остается в этом состоянии во время выполнения операций чтения, записи или других операций.
-
Частично зафиксировано — транзакция переходит в это состояние после выполнения последнего оператора транзакции.
-
Подтверждено — транзакция переходит в это состояние после успешного завершения транзакции и проверки системы подали сигнал подтверждения.
-
Failed (Сбой) — транзакция переходит из частично зафиксированного состояния или активного состояния в состояние сбоя, когда обнаруживается, что нормальное выполнение больше не может продолжаться или системные проверки не пройдены.
-
Прервано — это состояние после отката транзакции после сбоя и восстановления базы данных в состояние, которое было до ее начала.
Активный — начальное состояние, в которое входит транзакция, является активным состоянием. Транзакция остается в этом состоянии во время выполнения операций чтения, записи или других операций.
Частично зафиксировано — транзакция переходит в это состояние после выполнения последнего оператора транзакции.
Подтверждено — транзакция переходит в это состояние после успешного завершения транзакции и проверки системы подали сигнал подтверждения.
Failed (Сбой) — транзакция переходит из частично зафиксированного состояния или активного состояния в состояние сбоя, когда обнаруживается, что нормальное выполнение больше не может продолжаться или системные проверки не пройдены.
Прервано — это состояние после отката транзакции после сбоя и восстановления базы данных в состояние, которое было до ее начала.
Следующая диаграмма перехода состояний отображает состояния в транзакции и операции транзакции низкого уровня, которые вызывают изменение состояний.
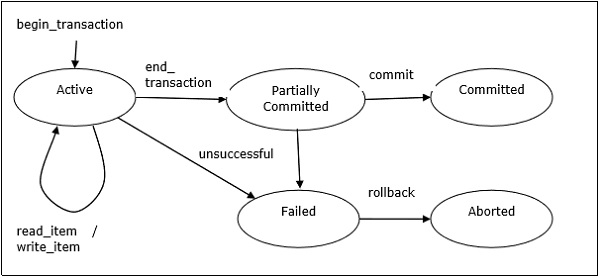
Желательные свойства сделок
Любая транзакция должна поддерживать свойства ACID, а именно. Атомность, последовательность, изоляция и долговечность.
-
Атомарность — это свойство указывает, что транзакция является атомарной единицей обработки, то есть либо выполняется полностью, либо не выполняется вообще. Частичное обновление не должно существовать.
-
Согласованность — транзакция должна перевести базу данных из одного согласованного состояния в другое согласованное состояние. Это не должно отрицательно влиять на любой элемент данных в базе данных.
-
Изоляция — транзакция должна выполняться так, как если бы она была единственной в системе. Не должно быть никаких помех от других одновременных транзакций, которые выполняются одновременно.
-
Долговечность — если совершенная транзакция приводит к изменению, это изменение должно быть долговременным в базе данных и не теряться в случае какого-либо сбоя.
Атомарность — это свойство указывает, что транзакция является атомарной единицей обработки, то есть либо выполняется полностью, либо не выполняется вообще. Частичное обновление не должно существовать.
Согласованность — транзакция должна перевести базу данных из одного согласованного состояния в другое согласованное состояние. Это не должно отрицательно влиять на любой элемент данных в базе данных.
Изоляция — транзакция должна выполняться так, как если бы она была единственной в системе. Не должно быть никаких помех от других одновременных транзакций, которые выполняются одновременно.
Долговечность — если совершенная транзакция приводит к изменению, это изменение должно быть долговременным в базе данных и не теряться в случае какого-либо сбоя.
Расписания и конфликты
В системе с несколькими одновременными транзакциями расписание — это общий порядок выполнения операций. При заданном расписании S, состоящем из n транзакций, скажем, T1, T2, T3 ……… ..Tn; для любой транзакции Ti операции в Ti должны выполняться в соответствии с графиком S.
Типы расписаний
Есть два типа графиков —
-
Последовательные расписания — в последовательном расписании в любой момент времени активна только одна транзакция, т.е. нет перекрытия транзакций. Это изображено на следующем графике —
Последовательные расписания — в последовательном расписании в любой момент времени активна только одна транзакция, т.е. нет перекрытия транзакций. Это изображено на следующем графике —
-
Параллельные расписания. В параллельных расписаниях одновременно активны несколько транзакций, то есть транзакции содержат операции, которые перекрываются во времени. Это изображено на следующем графике —
Параллельные расписания. В параллельных расписаниях одновременно активны несколько транзакций, то есть транзакции содержат операции, которые перекрываются во времени. Это изображено на следующем графике —
Конфликты в расписании
В расписании, состоящем из нескольких транзакций, возникает конфликт, когда две активные транзакции выполняют несовместимые операции. Говорят, что две операции находятся в конфликте, когда одновременно выполняются все три следующих условия:
-
Эти две операции являются частями разных транзакций.
-
Обе операции обращаются к одному и тому же элементу данных.
-
По крайней мере, одна из операций является операцией write_item (), то есть она пытается изменить элемент данных.
Эти две операции являются частями разных транзакций.
Обе операции обращаются к одному и тому же элементу данных.
По крайней мере, одна из операций является операцией write_item (), то есть она пытается изменить элемент данных.
Сериализуемость
Сериализуемое расписание «n» транзакций — это параллельное расписание, которое эквивалентно последовательному расписанию, состоящему из тех же «n» транзакций. Сериализуемое расписание содержит правильность последовательного расписания, одновременно обеспечивая лучшее использование ЦП параллельного расписания.
Эквивалентность графиков
Эквивалентность двух графиков может быть следующих типов —
-
Эквивалентность результатов — два графика, выдающих идентичные результаты, называются эквивалентными.
-
Эквивалентность представления — два расписания, которые выполняют подобное действие подобным образом, называются эквивалентными представления.
-
Эквивалентность конфликта — два расписания называются конфликтно-эквивалентными, если оба содержат одинаковый набор транзакций и имеют одинаковый порядок конфликтующих пар операций.
Эквивалентность результатов — два графика, выдающих идентичные результаты, называются эквивалентными.
Эквивалентность представления — два расписания, которые выполняют подобное действие подобным образом, называются эквивалентными представления.
Эквивалентность конфликта — два расписания называются конфликтно-эквивалентными, если оба содержат одинаковый набор транзакций и имеют одинаковый порядок конфликтующих пар операций.
Распределенная СУБД — Контроль параллелизма
Методы контроля параллелизма обеспечивают одновременное выполнение нескольких транзакций, сохраняя свойства ACID транзакций и сериализуемость в расписаниях.
В этой главе мы рассмотрим различные подходы к управлению параллелизмом.
Протоколы управления параллелизмом на основе блокировки
В протоколах управления параллелизмом на основе блокировки используется концепция блокировки элементов данных. Блокировка — это переменная, связанная с элементом данных, которая определяет, могут ли операции чтения / записи выполняться над этим элементом данных. Обычно используется матрица совместимости блокировок, в которой указывается, может ли элемент данных быть заблокирован двумя транзакциями одновременно.
Системы управления параллелизмом на основе блокировки могут использовать однофазные или двухфазные протоколы блокировки.
Протокол однофазной блокировки
В этом методе каждая транзакция блокирует элемент перед использованием и снимает блокировку, как только завершает его использование. Этот метод блокировки обеспечивает максимальный параллелизм, но не всегда обеспечивает сериализуемость.
Протокол двухфазной блокировки
В этом методе все операции блокировки предшествуют первой операции разблокировки или разблокировки блокировки. Сделка состоит из двух этапов. На первом этапе транзакция получает только все необходимые блокировки и не снимает блокировки. Это называется расширяющейся или растущей фазой . На втором этапе транзакция снимает блокировки и не может запрашивать новые блокировки. Это называется фазой сжатия .
Каждая транзакция, которая следует протоколу двухфазной блокировки, гарантированно сериализуется. Однако такой подход обеспечивает низкий параллелизм между двумя конфликтующими транзакциями.
Временная метка Параллельные алгоритмы управления
Алгоритмы управления параллелизмом на основе временной метки используют временную метку транзакции для координации одновременного доступа к элементу данных для обеспечения сериализуемости. Отметка времени — это уникальный идентификатор, назначаемый СУБД для транзакции, который представляет время начала транзакции.
Эти алгоритмы гарантируют, что транзакции фиксируются в порядке, определяемом их временными метками. Более старая транзакция должна быть зафиксирована до более молодой транзакции, так как более старая транзакция поступает в систему раньше, чем младшая.
Методы управления параллелизмом на основе временных меток генерируют сериализуемые расписания так, чтобы эквивалентное последовательное расписание располагалось в порядке возраста участвующих транзакций.
Некоторые из алгоритмов управления параллелизмом на основе временных меток:
- Основной алгоритм упорядочения временных меток.
- Консервативный алгоритм упорядочения временных меток.
- Мультиверсионный алгоритм, основанный на упорядочении временных меток.
Порядок на основе меток времени следует трем правилам для обеспечения сериализуемости —
-
Правило доступа — когда две транзакции пытаются получить доступ к одному и тому же элементу данных одновременно, для конфликтующих операций приоритет отдается более старой транзакции. Это приводит к тому, что младшая транзакция ожидает первой транзакции.
-
Правило поздней транзакции — если младшая транзакция записала элемент данных, то более старой транзакции не разрешается читать или записывать этот элемент данных. Это правило предотвращает фиксацию более старой транзакции после того, как более ранняя транзакция уже зафиксирована.
-
Младшее правило транзакции — младшая транзакция может считывать или записывать элемент данных, который уже был записан более старой транзакцией.
Правило доступа — когда две транзакции пытаются получить доступ к одному и тому же элементу данных одновременно, для конфликтующих операций приоритет отдается более старой транзакции. Это приводит к тому, что младшая транзакция ожидает первой транзакции.
Правило поздней транзакции — если младшая транзакция записала элемент данных, то более старой транзакции не разрешается читать или записывать этот элемент данных. Это правило предотвращает фиксацию более старой транзакции после того, как более ранняя транзакция уже зафиксирована.
Младшее правило транзакции — младшая транзакция может считывать или записывать элемент данных, который уже был записан более старой транзакцией.
Алгоритм управления оптимистичным параллелизмом
В системах с низкой частотой конфликтов задача проверки каждой транзакции на сериализуемость может снизить производительность. В этих случаях тест на сериализуемость откладывается непосредственно перед фиксацией. Поскольку частота конфликтов низкая, вероятность прерывания транзакций, которые не сериализуются, также низка. Этот подход называется оптимистичным методом управления параллелизмом.
При таком подходе жизненный цикл транзакции делится на следующие три фазы:
-
Этап выполнения — транзакция извлекает элементы данных в память и выполняет над ними операции.
-
Этап проверки — транзакция выполняет проверки, чтобы убедиться, что фиксация изменений в базе данных прошла тест на сериализуемость.
-
Фаза фиксации — транзакция записывает измененный элемент данных в памяти на диск.
Этап выполнения — транзакция извлекает элементы данных в память и выполняет над ними операции.
Этап проверки — транзакция выполняет проверки, чтобы убедиться, что фиксация изменений в базе данных прошла тест на сериализуемость.
Фаза фиксации — транзакция записывает измененный элемент данных в памяти на диск.
Этот алгоритм использует три правила для обеспечения сериализуемости на этапе проверки —
Правило 1 — Если для двух транзакций T i и T j , если T i читает элемент данных, который пишет T j , фаза выполнения T i не может перекрываться с фазой фиксации T j . T j может зафиксировать только после того, как T i закончил выполнение.
Правило 2 — Если для двух транзакций T i и T j , если T i записывает элемент данных, который читает T j , фаза фиксации T i не может перекрываться с фазой выполнения T j . T j может начать выполняться только после того, как T i уже зафиксировано.
Правило 3. Если для двух транзакций T i и T j записывается элемент данных, который также записывает T j , то фаза фиксации T i не может перекрываться с фазой фиксации T j . T j может начать фиксироваться только после того, как T i уже зафиксировал.
Управление параллелизмом в распределенных системах
В этом разделе мы увидим, как описанные выше методы реализованы в распределенной системе баз данных.
Распределенный двухфазный алгоритм блокировки
Основной принцип распределенной двухфазной блокировки такой же, как и основной протокол двухфазной блокировки. Однако в распределенной системе есть сайты, обозначенные как менеджеры блокировок. Менеджер блокировок контролирует запросы на получение блокировки от мониторов транзакций. Для обеспечения координации между менеджерами блокировок на разных сайтах, по крайней мере, одному сайту предоставлены полномочия просматривать все транзакции и обнаруживать конфликты блокировок.
В зависимости от количества сайтов, которые могут обнаружить конфликты блокировок, подходы распределенной двухфазной блокировки могут быть трех типов:
-
Централизованная двухфазная блокировка. При таком подходе один сайт назначается диспетчером центральной блокировки. Все сайты в среде знают местонахождение диспетчера центральной блокировки и получают блокировку от него во время транзакций.
-
Первичная копия двухфазной блокировки — при этом подходе ряд сайтов обозначаются как центры управления блокировками. Каждый из этих сайтов отвечает за управление определенным набором блокировок. Все сайты знают, какой центр управления блокировкой отвечает за управление блокировкой какой таблицы данных / элемента фрагмента.
-
Распределенная двухфазная блокировка. При таком подходе существует несколько менеджеров блокировок, где каждый диспетчер блокировок контролирует блокировки элементов данных, хранящихся на его локальном сайте. Расположение диспетчера блокировки основано на распределении и репликации данных.
Централизованная двухфазная блокировка. При таком подходе один сайт назначается диспетчером центральной блокировки. Все сайты в среде знают местонахождение диспетчера центральной блокировки и получают блокировку от него во время транзакций.
Первичная копия двухфазной блокировки — при этом подходе ряд сайтов обозначаются как центры управления блокировками. Каждый из этих сайтов отвечает за управление определенным набором блокировок. Все сайты знают, какой центр управления блокировкой отвечает за управление блокировкой какой таблицы данных / элемента фрагмента.
Распределенная двухфазная блокировка. При таком подходе существует несколько менеджеров блокировок, где каждый диспетчер блокировок контролирует блокировки элементов данных, хранящихся на его локальном сайте. Расположение диспетчера блокировки основано на распределении и репликации данных.
Управление параллельным распределением меток времени
В централизованной системе временная метка любой транзакции определяется показанием физических часов. Но в распределенной системе показания локальных физических / логических часов любого сайта не могут использоваться в качестве глобальных временных меток, поскольку они не являются глобально уникальными. Таким образом, временная метка содержит комбинацию идентификатора сайта и времени чтения этого сайта.
Для реализации алгоритмов упорядочения меток времени каждый сайт имеет планировщик, который поддерживает отдельную очередь для каждого менеджера транзакций. Во время транзакции менеджер транзакций отправляет запрос на блокировку в планировщик сайта. Планировщик помещает запрос в соответствующую очередь в порядке возрастания отметки времени. Запросы обрабатываются с начала очередей в порядке их меток времени, т. Е. Самые старые сначала.
Конфликт Графики
Другой метод — создание графиков конфликтов. Для этой транзакции определены классы. Класс транзакции содержит два набора элементов данных, называемых набором чтения и набором записи. Транзакция принадлежит определенному классу, если набор чтения транзакции является подмножеством набора чтения класса, а набор записи транзакции является подмножеством набора записи класса. На этапе чтения каждая транзакция выдает свои запросы на чтение для элементов данных в своем наборе чтения. На этапе записи каждая транзакция выдает свои запросы на запись.
Граф конфликтов создается для классов, к которым относятся активные транзакции. Он содержит набор вертикальных, горизонтальных и диагональных ребер. Вертикальное ребро соединяет два узла внутри класса и обозначает конфликты внутри класса. Горизонтальное ребро соединяет два узла между двумя классами и обозначает конфликт записи-записи между различными классами. Диагональное ребро соединяет два узла в двух классах и обозначает конфликт между двумя классами: запись-чтение или чтение-запись.
Графики конфликтов анализируются, чтобы определить, можно ли параллельно выполнять две транзакции в одном и том же классе или в двух разных классах.
Алгоритм распределенного оптимистического параллелизма
Алгоритм распределенного оптимистического параллелизма расширяет алгоритм оптимистичного параллелизма. Для этого расширения применяются два правила:
Правило 1. Согласно этому правилу транзакция должна быть проверена локально на всех сайтах при ее выполнении. Если транзакция признана недействительной на каком-либо сайте, она прерывается. Локальная проверка гарантирует, что транзакция поддерживает сериализуемость на сайтах, где она была выполнена. После того, как транзакция проходит локальный проверочный тест, она проверяется на глобальном уровне.
Правило 2 — Согласно этому правилу, после того, как транзакция прошла локальный проверочный тест, она должна быть проверена на глобальном уровне. Глобальная проверка гарантирует, что если две конфликтующие транзакции выполняются вместе на более чем одном сайте, они должны фиксироваться в одинаковом относительном порядке на всех сайтах, которые они запускают вместе. Для этого может потребоваться, чтобы транзакция ожидала другую конфликтующую транзакцию после проверки перед фиксацией. Это требование делает алгоритм менее оптимистичным, поскольку транзакция не сможет быть зафиксирована, как только она будет проверена на сайте.
Распределенная СУБД — обработка тупиковых ситуаций
В этой главе рассматриваются механизмы обработки тупиковых ситуаций в системах баз данных. Мы изучим механизмы обработки тупиковых ситуаций как в централизованной, так и в распределенной системе баз данных.
Что такое тупики?
Deadlock — это состояние системы базы данных, имеющей две или более транзакций, когда каждая транзакция ожидает элемент данных, который блокируется какой-либо другой транзакцией. О тупике можно указать циклом в графике ожидания. Это ориентированный граф, в котором вершины обозначают транзакции, а ребра — ожидания элементов данных.
Например, в следующем графике ожидания транзакция T1 ожидает элемент данных X, который заблокирован T3. T3 ожидает Y, который заблокирован T2, и T2 ждет Z, который заблокирован T1. Следовательно, формируется цикл ожидания, и ни одна из транзакций не может продолжаться.
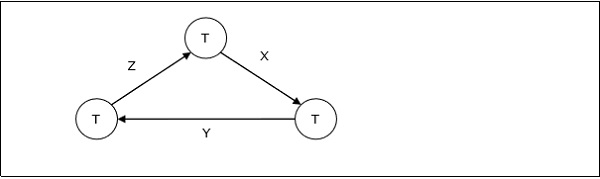
Обработка тупиковых ситуаций в централизованных системах
Существует три классических подхода к обработке тупиков, а именно:
- Предотвращение тупиковой ситуации.
- Предотвращение тупиковой ситуации.
- Обнаружение и устранение тупиковых ситуаций.
Все три подхода могут быть включены как в централизованную, так и в распределенную систему баз данных.
Предотвращение тупиковой ситуации
Подход предотвращения взаимных блокировок не позволяет какой-либо транзакции получить блокировки, которые приведут к взаимным блокировкам. Соглашение состоит в том, что, когда более одной транзакции запрашивают блокировку одного и того же элемента данных, только одной из них предоставляется блокировка.
Одним из самых популярных методов предотвращения тупиковых ситуаций является предварительное приобретение всех замков. В этом методе транзакция получает все блокировки перед началом выполнения и сохраняет блокировки в течение всей транзакции. Если другой транзакции требуется какая-либо из уже полученных блокировок, она должна подождать, пока все требуемые блокировки будут доступны. Используя этот подход, система не может быть заблокирована, поскольку ни одна из ожидающих транзакций не удерживает блокировку.
Предотвращение тупиков
Подход с предотвращением взаимоблокировок обрабатывает взаимоблокировки до их возникновения. Он анализирует транзакции и блокировки, чтобы определить, приводит ли ожидание к тупику.
Способ можно кратко изложить следующим образом. Транзакции начинают выполняться и запрашивают элементы данных, которые им необходимо заблокировать. Менеджер блокировок проверяет, доступна ли блокировка. Если он доступен, менеджер блокировок выделяет элемент данных, и транзакция получает блокировку. Однако, если элемент заблокирован какой-либо другой транзакцией в несовместимом режиме, менеджер блокировок запускает алгоритм, чтобы проверить, приведет ли удержание транзакции в состоянии ожидания к тупику или нет. Соответственно, алгоритм решает, может ли транзакция ждать или одна из транзакций должна быть прервана.
Для этого есть два алгоритма, а именно wait-die и wound-wait . Предположим, что есть две транзакции, T1 и T2, где T1 пытается заблокировать элемент данных, который уже заблокирован T2. Алгоритмы следующие:
-
Wait-Die — если T1 старше T2, T1 может ждать. В противном случае, если T1 моложе, чем T2, T1 прерывается и позже перезапускается.
-
Wound-Wait — если T1 старше T2, T2 прерывается и позже перезапускается. В противном случае, если T1 младше, чем T2, T1 может ждать.
Wait-Die — если T1 старше T2, T1 может ждать. В противном случае, если T1 моложе, чем T2, T1 прерывается и позже перезапускается.
Wound-Wait — если T1 старше T2, T2 прерывается и позже перезапускается. В противном случае, если T1 младше, чем T2, T1 может ждать.
Обнаружение и устранение тупиковых ситуаций
Подход обнаружения и удаления взаимоблокировки периодически запускает алгоритм обнаружения взаимоблокировки и устраняет взаимоблокировку, если она есть. Он не проверяет тупик, когда транзакция размещает запрос на блокировку. Когда транзакция запрашивает блокировку, менеджер блокировок проверяет, доступна ли она. Если он доступен, транзакция может заблокировать элемент данных; в противном случае транзакции разрешено ждать.
Поскольку при предоставлении запросов на блокировку нет мер предосторожности, некоторые транзакции могут быть заблокированы. Для обнаружения взаимоблокировок диспетчер блокировок периодически проверяет наличие циклов ожидания форграфа. Если система заблокирована, менеджер блокировок выбирает транзакцию жертвы из каждого цикла. Жертва прерывается и откатывается; а потом перезапустил позже. Некоторые методы, используемые для выбора жертвы:
- Выберите самую молодую транзакцию.
- Выберите транзакцию с наименьшим количеством элементов данных.
- Выберите транзакцию, которая выполнила наименьшее количество обновлений.
- Выберите транзакцию с минимальными издержками на перезапуск.
- Выберите транзакцию, которая является общей для двух или более циклов.
Этот подход в первую очередь подходит для систем с низким уровнем транзакций, где требуется быстрый ответ на запросы блокировки.
Обработка тупиковых ситуаций в распределенных системах
Обработка транзакций в распределенной системе баз данных также распределена, то есть одна и та же транзакция может обрабатываться более чем на одном сайте. Двумя основными проблемами обработки взаимоблокировок в системе распределенных баз данных, которых нет в централизованной системе, являются местоположение транзакции и управление транзакцией . Как только эти проблемы решаются, взаимоблокировки обрабатываются с помощью любого из предотвращения взаимоблокировок, предотвращения взаимоблокировок или обнаружения и удаления тупиков.
Местоположение транзакции
Транзакции в распределенной системе баз данных обрабатываются на нескольких сайтах и используют элементы данных на нескольких сайтах. Объем обработки данных неравномерно распределен между этими сайтами. Период времени обработки также варьируется. Таким образом, одна и та же транзакция может быть активной на некоторых сайтах и неактивной на других. Когда две конфликтующие транзакции находятся на сайте, может случиться, что одна из них находится в неактивном состоянии. Это условие не возникает в централизованной системе. Эта проблема называется проблемой местоположения транзакции.
Эта проблема может быть решена с помощью модели Daisy Chain. В этой модели транзакция несет определенные детали при перемещении с одного сайта на другой. Некоторые детали — это список необходимых таблиц, список требуемых сайтов, список посещенных таблиц и сайтов, список таблиц и сайтов, которые еще предстоит посетить, и список полученных блокировок с типами. После того, как транзакция завершается либо фиксацией, либо прерыванием, информация должна быть отправлена всем заинтересованным сайтам.
Контроль транзакций
Управление транзакциями связано с назначением и контролем сайтов, необходимых для обработки транзакции в распределенной системе баз данных. Существует много вариантов выбора места обработки транзакции и назначения центра управления, например:
- Один сервер может быть выбран в качестве центра управления.
- Центр контроля может перемещаться с одного сервера на другой.
- Ответственность за управление может быть разделена между несколькими серверами.
Распределенное предотвращение тупиковой ситуации
Так же, как в централизованном предотвращении взаимоблокировок, в подходе предотвращения распределенных взаимоблокировок транзакция должна получить все блокировки перед началом выполнения. Это предотвращает тупики.
Сайт, на который входит транзакция, обозначен как контролирующий. Контролирующий сайт отправляет сообщения на сайты, на которых расположены элементы данных, для блокировки элементов. Затем он ждет подтверждения. Когда все сайты подтвердят, что они заблокировали элементы данных, начинается транзакция. В случае сбоя какого-либо сайта или канала связи транзакция должна ждать, пока они не будут восстановлены.
Хотя реализация проста, у этого подхода есть некоторые недостатки —
-
Предварительное приобретение замков требует длительного времени для задержек связи. Это увеличивает время, необходимое для транзакции.
-
В случае сбоя сайта или ссылки транзакция должна долго ждать, чтобы сайты восстановились. Между тем на запущенных сайтах элементы заблокированы. Это может помешать выполнению других транзакций.
-
Если контролирующий сайт не работает, он не может связаться с другими сайтами. Эти сайты продолжают сохранять заблокированные элементы данных в заблокированном состоянии, что приводит к блокировке.
Предварительное приобретение замков требует длительного времени для задержек связи. Это увеличивает время, необходимое для транзакции.
В случае сбоя сайта или ссылки транзакция должна долго ждать, чтобы сайты восстановились. Между тем на запущенных сайтах элементы заблокированы. Это может помешать выполнению других транзакций.
Если контролирующий сайт не работает, он не может связаться с другими сайтами. Эти сайты продолжают сохранять заблокированные элементы данных в заблокированном состоянии, что приводит к блокировке.
Распределенное предотвращение тупиковой ситуации
Как и в централизованной системе, распределенное предотвращение взаимоблокировок обрабатывает взаимоблокировку до возникновения. Кроме того, в распределенных системах необходимо решить проблемы с расположением транзакций и управлением транзакциями. Из-за распределенного характера транзакции могут возникнуть следующие конфликты:
- Конфликт между двумя транзакциями на одном сайте.
- Конфликт между двумя транзакциями на разных сайтах.
В случае конфликта одна из транзакций может быть прервана или разрешена на ожидание в соответствии с распределенным алгоритмом ожидания или распределенным алгоритмом ожидания.
Предположим, что есть две транзакции, T1 и T2. T1 прибывает на сайт P и пытается заблокировать элемент данных, который уже заблокирован T2 на этом сайте. Следовательно, существует конфликт на сайте P. Алгоритмы следующие:
-
Распределенная рана
-
Если T1 старше, чем T2, T1 может ждать. T1 может возобновить выполнение после того, как Сайт P получит сообщение о том, что T2 либо зафиксировал, либо успешно прервал на всех сайтах.
-
Если T1 моложе, чем T2, T1 отменяется. Управление параллелизмом на сайте P отправляет сообщение всем сайтам, которые посетили T1, чтобы прервать T1. Контролирующий сайт уведомляет пользователя, когда T1 был успешно прерван на всех сайтах.
-
-
Распределенный Wait-Wait
-
Если T1 старше, чем T2, T2 необходимо прервать. Если T2 активен на сайте P, сайт P прерывает и откатывает T2, а затем передает это сообщение на другие соответствующие сайты. Если T2 покинул сайт P, но активен на сайте Q, сайт P сообщает, что T2 был прерван; Затем сайт L прерывает и откатывает T2 и отправляет это сообщение всем сайтам.
-
Если T1 младше, чем T1, T1 может ждать. T1 может возобновить выполнение после того, как узел P получит сообщение о том, что T2 завершил обработку.
-
Распределенная рана
Если T1 старше, чем T2, T1 может ждать. T1 может возобновить выполнение после того, как Сайт P получит сообщение о том, что T2 либо зафиксировал, либо успешно прервал на всех сайтах.
Если T1 моложе, чем T2, T1 отменяется. Управление параллелизмом на сайте P отправляет сообщение всем сайтам, которые посетили T1, чтобы прервать T1. Контролирующий сайт уведомляет пользователя, когда T1 был успешно прерван на всех сайтах.
Распределенный Wait-Wait
Если T1 старше, чем T2, T2 необходимо прервать. Если T2 активен на сайте P, сайт P прерывает и откатывает T2, а затем передает это сообщение на другие соответствующие сайты. Если T2 покинул сайт P, но активен на сайте Q, сайт P сообщает, что T2 был прерван; Затем сайт L прерывает и откатывает T2 и отправляет это сообщение всем сайтам.
Если T1 младше, чем T1, T1 может ждать. T1 может возобновить выполнение после того, как узел P получит сообщение о том, что T2 завершил обработку.
Распределенное обнаружение тупиковой ситуации
Точно так же, как и при централизованном обнаружении взаимоблокировок, взаимоблокировки могут возникать и удаляются при обнаружении. Система не выполняет никаких проверок, когда транзакция размещает запрос на блокировку. Для реализации созданы глобальные графы ожидания. Наличие цикла в глобальном графике ожидания указывает на взаимные блокировки. Однако трудно обнаружить взаимоблокировки, так как транзакция ожидает ресурсы по сети.
Альтернативно, алгоритмы обнаружения тупиков могут использовать таймеры. Каждая транзакция связана с таймером, который установлен на период времени, в течение которого ожидается завершение транзакции. Если транзакция не завершается в течение этого периода времени, таймер отключается, указывая на возможную тупиковую ситуацию.
Другим инструментом, используемым для обработки тупиков, является детектор тупиков. В централизованной системе есть один тупиковый детектор. В распределенной системе может быть более одного детектора тупиковой ситуации. Детектор взаимоблокировки может находить взаимоблокировки для сайтов, находящихся под его контролем. Существует три варианта обнаружения взаимоблокировок в распределенной системе, а именно:
-
Централизованный детектор тупиков — один сайт обозначен как центральный тупиковый детектор.
-
Иерархический детектор взаимоблокировки — ряд детекторов взаимоблокировки расположен в иерархии.
-
Распределенный детектор тупиков — Все сайты участвуют в обнаружении тупиков и их устранении.
Централизованный детектор тупиков — один сайт обозначен как центральный тупиковый детектор.
Иерархический детектор взаимоблокировки — ряд детекторов взаимоблокировки расположен в иерархии.
Распределенный детектор тупиков — Все сайты участвуют в обнаружении тупиков и их устранении.
Распределенная СУБД — Контроль репликации
В этой главе рассматривается контроль репликации, который необходим для обеспечения согласованности данных на всех сайтах. Мы изучим методы контроля репликации и алгоритмы, необходимые для контроля репликации.
Как обсуждалось ранее, репликация — это метод, используемый в распределенных базах данных для хранения нескольких копий таблицы данных на разных сайтах. Проблема с наличием нескольких копий на нескольких сайтах связана с поддержанием согласованности данных, особенно во время операций обновления.
Чтобы поддерживать взаимосогласованные данные на всех сайтах, необходимо принять методы контроля репликации. Существует два подхода к управлению репликацией, а именно:
- Управление синхронной репликацией
- Управление асинхронной репликацией
Управление синхронной репликацией
При подходе с синхронной репликацией база данных синхронизируется, поэтому все репликации всегда имеют одинаковое значение. Транзакция, запрашивающая элемент данных, будет иметь доступ к одному значению на всех сайтах. Чтобы обеспечить это единообразие, транзакция, которая обновляет элемент данных, расширяется, так что она выполняет обновление во всех копиях элемента данных. Обычно для этой цели используется протокол двухфазной фиксации.
Например, давайте рассмотрим таблицу данных PROJECT (PId, PName, PLocation). Нам нужно запустить транзакцию T1, которая обновляет PLocation на «Мумбаи», если PLocation — «Бомбей». Если репликации нет, операции в транзакции T1 будут:
Begin T1: Update PROJECT Set PLocation = 'Mumbai' Where PLocation = 'Bombay'; End T1;
Если таблица данных имеет две реплики на сайте A и сайте B, T1 должен порождать двух дочерних T1A и T1B, соответствующих двум сайтам. Расширенная транзакция T1 будет —
Begin T1: Begin T1A : Update PROJECT Set PLocation = 'Mumbai' Where PLocation = 'Bombay'; End T1A; Begin T2A : Update PROJECT Set PLocation = 'Mumbai' Where PLocation = 'Bombay'; End T2A; End T1;
Управление асинхронной репликацией
В подходе асинхронной репликации реплики не всегда поддерживают одно и то же значение. Одна или несколько реплик могут хранить устаревшее значение, а транзакция может видеть разные значения. Процесс приведения всех реплик к текущему значению называется синхронизацией .
Популярный метод синхронизации — это метод хранения и пересылки. В этом методе один сайт обозначается как основной сайт, а другие сайты являются вторичными сайтами. Основной сайт всегда содержит обновленные значения. Все транзакции сначала попадают на основной сайт. Эти транзакции затем ставятся в очередь для применения на вторичных сайтах. Вторичные сайты обновляются с использованием метода развертывания только в том случае, если на нем запланировано выполнение транзакции.
Алгоритмы управления репликацией
Некоторые из алгоритмов управления репликацией —
- Алгоритм управления репликацией ведущий-ведомый.
- Алгоритм распределенного голосования.
- Алгоритм консенсуса большинства.
- Алгоритм циркуляционного токена.
Главный-подчиненный алгоритм управления репликацией
Существует один главный сайт и N ведомых сайтов. Главный алгоритм запускается на главном сайте для обнаружения конфликтов. Копия подчиненного алгоритма выполняется на каждом подчиненном сайте. Общий алгоритм выполняется в следующие два этапа —
-
Фаза принятия / отклонения транзакции — когда транзакция входит в монитор транзакций подчиненного сайта, подчиненный сайт отправляет запрос на главный сайт. Главный сайт проверяет наличие конфликтов. Если нет никаких конфликтов, мастер отправляет сообщение «ACK +» на ведомый сайт, который затем начинает фазу приложения транзакции. В противном случае ведущее устройство отправляет ведомому сообщение «ACK-», которое затем отклоняет транзакцию.
-
Фаза применения транзакции. После входа в эту фазу подчиненный узел, на котором была введена транзакция, передает всем подчиненным запрос на выполнение транзакции. Получив запросы, равноправные ведомые выполняют транзакцию и отправляют «ACK» запрашивающему ведомому по завершении. После того, как запрашивающее ведомое устройство получило сообщения «ACK» от всех своих одноранговых узлов, оно отправляет сообщение «DONE» на главный сайт. Мастер понимает, что транзакция завершена, и удаляет ее из очереди ожидания.
Фаза принятия / отклонения транзакции — когда транзакция входит в монитор транзакций подчиненного сайта, подчиненный сайт отправляет запрос на главный сайт. Главный сайт проверяет наличие конфликтов. Если нет никаких конфликтов, мастер отправляет сообщение «ACK +» на ведомый сайт, который затем начинает фазу приложения транзакции. В противном случае ведущее устройство отправляет ведомому сообщение «ACK-», которое затем отклоняет транзакцию.
Фаза применения транзакции. После входа в эту фазу подчиненный узел, на котором была введена транзакция, передает всем подчиненным запрос на выполнение транзакции. Получив запросы, равноправные ведомые выполняют транзакцию и отправляют «ACK» запрашивающему ведомому по завершении. После того, как запрашивающее ведомое устройство получило сообщения «ACK» от всех своих одноранговых узлов, оно отправляет сообщение «DONE» на главный сайт. Мастер понимает, что транзакция завершена, и удаляет ее из очереди ожидания.
Алгоритм распределенного голосования
Он состоит из «N» одноранговых сайтов, каждый из которых должен «ок» подтвердить транзакцию, прежде чем она начнет выполняться. Ниже приведены две фазы этого алгоритма —
-
Фаза принятия распределенной транзакции. Когда транзакция входит в диспетчер транзакций сайта, она отправляет запрос транзакции всем остальным сайтам. При получении запроса одноранговый сайт разрешает конфликты, используя правила голосования на основе приоритетов. Если все одноранговые сайты в порядке с транзакцией, запрашивающий сайт начинает фазу приложения. Если какой-либо одноранговый сайт не «одобряет» транзакцию, запрашивающий сайт отклоняет транзакцию.
-
Этап применения распределенной транзакции. После входа в эту фазу сайт, на котором была выполнена транзакция, передает запрос всем подчиненным для выполнения транзакции. Получив запросы, равноправные ведомые выполняют транзакцию и отправляют сообщение «ACK» запрашивающему ведомому по завершении. После того, как запрашивающее ведомое устройство получило сообщения «ACK» от всех своих одноранговых узлов, оно сообщает менеджеру транзакций, что транзакция завершена.
Фаза принятия распределенной транзакции. Когда транзакция входит в диспетчер транзакций сайта, она отправляет запрос транзакции всем остальным сайтам. При получении запроса одноранговый сайт разрешает конфликты, используя правила голосования на основе приоритетов. Если все одноранговые сайты в порядке с транзакцией, запрашивающий сайт начинает фазу приложения. Если какой-либо одноранговый сайт не «одобряет» транзакцию, запрашивающий сайт отклоняет транзакцию.
Этап применения распределенной транзакции. После входа в эту фазу сайт, на котором была выполнена транзакция, передает запрос всем подчиненным для выполнения транзакции. Получив запросы, равноправные ведомые выполняют транзакцию и отправляют сообщение «ACK» запрашивающему ведомому по завершении. После того, как запрашивающее ведомое устройство получило сообщения «ACK» от всех своих одноранговых узлов, оно сообщает менеджеру транзакций, что транзакция завершена.
Алгоритм большинства консенсуса
Это отличие от алгоритма распределенного голосования, в котором транзакция может выполняться, когда большинство партнеров «ок» одобрили транзакцию. Это разделено на три этапа —
-
Фаза голосования. Когда транзакция входит в диспетчер транзакций сайта, она отправляет запрос транзакции всем остальным сайтам. При получении запроса одноранговый сайт проверяет наличие конфликтов с использованием правил голосования и сохраняет конфликтующие транзакции, если таковые имеются, в очереди ожидания. Затем он отправляет сообщение «ОК» или «НЕ ОК».
-
Фаза принятия / отклонения транзакции — если запрашивающий сайт получает большинство «ОК» по транзакции, он принимает транзакцию и передает «ПРИНЯТЬ» всем сайтам. В противном случае он передает «ОТКАЗ» на все сайты и отклоняет транзакцию.
-
Этап применения транзакции — когда одноранговый сайт получает сообщение «ОТКАЗ», он удаляет эту транзакцию из списка ожидания и пересматривает все отложенные транзакции. Когда одноранговый сайт получает сообщение «ПРИНЯТЬ», он применяет транзакцию и отклоняет все отложенные транзакции в очереди ожидания, которые находятся в конфликте с этой транзакцией. По завершении он отправляет «ACK» запрашивающему ведомому.
Фаза голосования. Когда транзакция входит в диспетчер транзакций сайта, она отправляет запрос транзакции всем остальным сайтам. При получении запроса одноранговый сайт проверяет наличие конфликтов с использованием правил голосования и сохраняет конфликтующие транзакции, если таковые имеются, в очереди ожидания. Затем он отправляет сообщение «ОК» или «НЕ ОК».
Фаза принятия / отклонения транзакции — если запрашивающий сайт получает большинство «ОК» по транзакции, он принимает транзакцию и передает «ПРИНЯТЬ» всем сайтам. В противном случае он передает «ОТКАЗ» на все сайты и отклоняет транзакцию.
Этап применения транзакции — когда одноранговый сайт получает сообщение «ОТКАЗ», он удаляет эту транзакцию из списка ожидания и пересматривает все отложенные транзакции. Когда одноранговый сайт получает сообщение «ПРИНЯТЬ», он применяет транзакцию и отклоняет все отложенные транзакции в очереди ожидания, которые находятся в конфликте с этой транзакцией. По завершении он отправляет «ACK» запрашивающему ведомому.
Алгоритм обращения токена
При таком подходе транзакции в системе сериализуются с использованием циркулирующего токена и выполняются соответствующим образом для каждой реплики базы данных. Таким образом, все транзакции принимаются, т.е. ни одна не отклоняется. Это имеет две фазы —
-
Этап сериализации транзакций — на этом этапе все транзакции запланированы для выполнения в порядке сериализации. Каждой транзакции на каждом сайте присваивается уникальный тикет из последовательной серии, указывающий порядок транзакции. После того, как транзакции был присвоен билет, она транслируется на все сайты.
-
Этап применения транзакции. Когда сайт получает транзакцию вместе со своим билетом, он помещает транзакцию для выполнения в соответствии со своим билетом. После завершения транзакции этот сайт передает соответствующее сообщение. Транзакция заканчивается, когда она завершила выполнение на всех сайтах.
Этап сериализации транзакций — на этом этапе все транзакции запланированы для выполнения в порядке сериализации. Каждой транзакции на каждом сайте присваивается уникальный тикет из последовательной серии, указывающий порядок транзакции. После того, как транзакции был присвоен билет, она транслируется на все сайты.
Этап применения транзакции. Когда сайт получает транзакцию вместе со своим билетом, он помещает транзакцию для выполнения в соответствии со своим билетом. После завершения транзакции этот сайт передает соответствующее сообщение. Транзакция заканчивается, когда она завершила выполнение на всех сайтах.
Распределенная СУБД — Failure & Commit
Система управления базами данных подвержена ряду сбоев. В этой главе мы изучим типы ошибок и протоколы фиксации. В распределенной системе баз данных сбои можно в широком смысле разделить на программные сбои, сбои и сетевые сбои.
Мягкая Отказ
Мягкий сбой — это тип сбоя, который приводит к потере энергозависимой памяти компьютера, а не постоянного хранилища. Здесь информация, хранящаяся в непостоянном хранилище, таком как основная память, буферы, кэши или регистры, теряется. Они также известны как сбой системы. Различные типы мягких отказов следующие:
- Сбой операционной системы.
- Сбой основной памяти.
- Сбой транзакции или аборт.
- Сгенерированная системой ошибка, такая как переполнение целого числа или ошибка деления на ноль.
- Отказ поддержки программного обеспечения.
- Отказ питания.
Тяжелая неудача
Тяжелый сбой — это тип сбоя, который приводит к потере данных в постоянном или энергонезависимом хранилище, например на диске. Отказ диска может привести к повреждению данных в некоторых дисковых блоках или к отказу всего диска. Причины серьезного отказа —
- Отказ питания.
- Неисправности в СМИ.
- Чтение-запись неисправности.
- Повреждение информации на диске.
- Сбой чтения / записи головки диска.
Восстановление после сбоев диска может быть коротким, если в резерве есть новый, отформатированный и готовый к использованию диск. В противном случае продолжительность включает время, необходимое для получения заказа на покупку, покупки диска и его подготовки.
Сбой в работе сети
Сбои в сети распространены в распределенных или сетевых базах данных. Они включают в себя ошибки, вызванные в системе базы данных из-за распределенного характера данных и передачи данных по сети. Причины сбоя сети следующие:
- Ошибка связи.
- Перегрузка сети.
- Повреждение информации при передаче.
- Сбои сайта.
- Сетевое разбиение.
Принять протоколы
Любая система баз данных должна гарантировать, что требуемые свойства транзакции сохраняются даже после сбоев. Если во время выполнения транзакции происходит сбой, может случиться так, что все изменения, вызванные транзакцией, не будут зафиксированы. Это делает базу данных несовместимой. Протоколы фиксации предотвращают этот сценарий, используя либо отмену транзакции (откат), либо повтор транзакции (откат).
Точка фиксации
Момент времени, когда принимается решение о принятии или прекращении транзакции, называется точкой фиксации. Ниже приведены свойства точки фиксации.
-
Это момент времени, когда база данных согласована.
-
На этом этапе изменения, внесенные базой данных, могут быть замечены другими транзакциями. Все транзакции могут иметь согласованное представление базы данных.
-
На этом этапе все операции транзакции были успешно выполнены, и их результаты были записаны в журнал транзакций.
-
На этом этапе транзакция может быть безопасно отменена, если требуется.
-
На этом этапе транзакция освобождает все удерживаемые ею блокировки.
Это момент времени, когда база данных согласована.
На этом этапе изменения, внесенные базой данных, могут быть замечены другими транзакциями. Все транзакции могут иметь согласованное представление базы данных.
На этом этапе все операции транзакции были успешно выполнены, и их результаты были записаны в журнал транзакций.
На этом этапе транзакция может быть безопасно отменена, если требуется.
На этом этапе транзакция освобождает все удерживаемые ею блокировки.
Отмена транзакции
Процесс отмены всех изменений, внесенных в базу данных транзакцией, называется отменой транзакции или откатом транзакции. Это в основном применяется в случае мягкого отказа.
Транзакция Redo
Процесс повторного применения изменений, внесенных в базу данных посредством транзакции, называется транзакцией повтора или повторной транзакции. Это в основном применяется для восстановления после серьезного сбоя.
Журнал транзакций
Журнал транзакций — это последовательный файл, который отслеживает операции транзакций над элементами базы данных. Поскольку журнал является последовательным по своей природе, он обрабатывается последовательно либо с начала, либо с конца.
Цели журнала транзакций —
- Поддерживать протоколы фиксации для фиксации или поддержки транзакций.
- Чтобы помочь восстановлению базы данных после сбоя.
Журнал транзакций обычно хранится на диске, поэтому на него не влияют программные сбои. Кроме того, журнал периодически копируется в архивное хранилище, такое как магнитная лента, чтобы защитить его от сбоев диска.
Списки в журналах транзакций
Журнал транзакций поддерживает пять типов списков в зависимости от статуса транзакции. Этот список помогает менеджеру восстановления выяснить состояние транзакции. Статус и соответствующие списки следующие:
-
Транзакция, имеющая запись начала транзакции и запись фиксации транзакции, является подтвержденной транзакцией и поддерживается в списке фиксации.
-
Транзакция, имеющая запись начала транзакции и запись неудачной транзакции, но не запись отмены транзакции, является неудачной транзакцией и поддерживается в списке неудачных транзакций.
-
Транзакция, имеющая запись начала транзакции и запись об отмене транзакции, является прерванной транзакцией и поддерживается в списке прерываний.
-
Транзакция, которая имеет запись начала транзакции и запись транзакции перед фиксацией, является транзакцией перед фиксацией, то есть транзакцией, в которой все операции были выполнены, но не зафиксированы — сохранены в списке перед фиксацией.
-
Транзакция, в которой есть начальная запись транзакции, но нет записей перед фиксацией, фиксацией, отменой или неудачей, является активной транзакцией и поддерживается в активном списке.
Транзакция, имеющая запись начала транзакции и запись фиксации транзакции, является подтвержденной транзакцией и поддерживается в списке фиксации.
Транзакция, имеющая запись начала транзакции и запись неудачной транзакции, но не запись отмены транзакции, является неудачной транзакцией и поддерживается в списке неудачных транзакций.
Транзакция, имеющая запись начала транзакции и запись об отмене транзакции, является прерванной транзакцией и поддерживается в списке прерываний.
Транзакция, которая имеет запись начала транзакции и запись транзакции перед фиксацией, является транзакцией перед фиксацией, то есть транзакцией, в которой все операции были выполнены, но не зафиксированы — сохранены в списке перед фиксацией.
Транзакция, в которой есть начальная запись транзакции, но нет записей перед фиксацией, фиксацией, отменой или неудачей, является активной транзакцией и поддерживается в активном списке.
Немедленное обновление и отложенное обновление
Немедленное обновление и отложенное обновление — два метода для ведения журналов транзакций.
В режиме немедленного обновления , когда транзакция выполняется, обновления, сделанные транзакцией, записываются непосредственно на диск. Старые значения и значения обновлений записываются в журнал перед записью в базу данных на диске. При фиксации изменения, сделанные на диске, становятся постоянными. При откате изменения, сделанные транзакцией в базе данных, отбрасываются, а старые значения восстанавливаются в базе данных из старых значений, хранящихся в журнале.
В режиме отложенного обновления , когда транзакция выполняется, обновления, сделанные транзакцией в базу данных, записываются в файл журнала. При фиксации изменения в журнале записываются на диск. При откате изменения в журнале отбрасываются, и к базе данных изменения не применяются.
Распределенная СУБД — Восстановление базы данных
Для восстановления после сбоя базы данных системы управления базами данных используют ряд методов управления восстановлением. В этой главе мы рассмотрим различные подходы к восстановлению базы данных.
Типичные стратегии восстановления базы данных:
-
В случае мягких сбоев, которые приводят к несогласованности базы данных, стратегия восстановления включает в себя отмену транзакции или откат. Однако иногда повторное выполнение транзакции также может быть принято для восстановления согласованного состояния транзакции.
-
В случае серьезных сбоев, приводящих к серьезному повреждению базы данных, стратегии восстановления включают восстановление предыдущей копии базы данных из архивной резервной копии. Более актуальное состояние базы данных достигается путем повторного выполнения операций зафиксированных транзакций из журнала транзакций.
В случае мягких сбоев, которые приводят к несогласованности базы данных, стратегия восстановления включает в себя отмену транзакции или откат. Однако иногда повторное выполнение транзакции также может быть принято для восстановления согласованного состояния транзакции.
В случае серьезных сбоев, приводящих к серьезному повреждению базы данных, стратегии восстановления включают восстановление предыдущей копии базы данных из архивной резервной копии. Более актуальное состояние базы данных достигается путем повторного выполнения операций зафиксированных транзакций из журнала транзакций.
Восстановление после сбоя питания
Сбой питания приводит к потере информации в непостоянной памяти. После восстановления питания операционная система и система управления базами данных перезагружаются. Менеджер восстановления инициирует восстановление из журналов транзакций.
В случае режима немедленного обновления менеджер восстановления выполняет следующие действия:
-
Транзакции, которые находятся в активном и неудачном списке, отменяются и записываются в список отмены.
-
Транзакции, находящиеся в списке перед фиксацией, переделываются.
-
Никаких действий не предпринимается для транзакций в списках фиксации или отмены.
Транзакции, которые находятся в активном и неудачном списке, отменяются и записываются в список отмены.
Транзакции, находящиеся в списке перед фиксацией, переделываются.
Никаких действий не предпринимается для транзакций в списках фиксации или отмены.
В случае отложенного режима обновления менеджер восстановления выполняет следующие действия:
-
Транзакции, которые находятся в активном списке и в списке с ошибками, записываются в список отмены. Операции отмены не требуются, поскольку изменения еще не записаны на диск.
-
Транзакции, находящиеся в списке перед фиксацией, переделываются.
-
Никаких действий не предпринимается для транзакций в списках фиксации или отмены.
Транзакции, которые находятся в активном списке и в списке с ошибками, записываются в список отмены. Операции отмены не требуются, поскольку изменения еще не записаны на диск.
Транзакции, находящиеся в списке перед фиксацией, переделываются.
Никаких действий не предпринимается для транзакций в списках фиксации или отмены.
Восстановление после сбоя диска
Сбой диска или жесткий сбой приводят к полной потере базы данных. Для восстановления после этого аварийного сбоя подготовлен новый диск, затем восстановлена операционная система и, наконец, база данных восстановлена с использованием резервного копирования базы данных и журнала транзакций. Метод восстановления одинаков для режимов немедленного и отложенного обновления.
Менеджер восстановления выполняет следующие действия:
-
Транзакции в списке фиксации и перед фиксацией переделываются и записываются в список фиксации в журнале транзакций.
-
Транзакции в активном и неудачном списках отменяются и записываются в список прерываний в журнале транзакций.
Транзакции в списке фиксации и перед фиксацией переделываются и записываются в список фиксации в журнале транзакций.
Транзакции в активном и неудачном списках отменяются и записываются в список прерываний в журнале транзакций.
Checkpointing
Контрольная точка — это момент времени, когда запись записывается в базу данных из буферов. Как следствие, в случае сбоя системы диспетчеру восстановления не нужно повторять транзакции, которые были зафиксированы до контрольной точки. Периодическая проверка сокращает процесс восстановления.
Два типа техники контрольных точек —
- Последовательная проверка
- Нечеткая контрольная точка
Последовательная проверка
Последовательная контрольная точка создает непротиворечивое изображение базы данных в контрольной точке. Во время восстановления отменяются или переделываются только те транзакции, которые находятся справа от последней контрольной точки. Транзакции с левой стороны последней непротиворечивой контрольной точки уже зафиксированы и не нуждаются в повторной обработке. Действия, предпринятые для контрольно-пропускного пункта:
- Активные транзакции временно приостановлены.
- Все изменения в буферах основной памяти записываются на диск.
- Запись «контрольная точка» записывается в журнал транзакций.
- Журнал транзакций записывается на диск.
- Приостановленные транзакции возобновляются.
Если на шаге 4 журнал транзакций также архивируется, то эта контрольная точка помогает восстановлению после сбоев диска и сбоев питания, в противном случае это помогает восстановлению только после сбоев питания.
Нечеткая проверка
В нечеткой контрольной точке во время контрольной точки все активные транзакции записываются в журнал. В случае сбоя питания менеджер восстановления обрабатывает только те транзакции, которые были активны во время контрольной точки и позже. Транзакции, которые были зафиксированы до контрольной точки, записываются на диск и, следовательно, не требуют повторного выполнения.
Пример контрольной точки
Давайте рассмотрим, что в системе время контрольной точки tcheck, а время сбоя системы — tfail. Пусть будет четыре транзакции T a , T b , T c и T d, такие что —
-
T a совершает перед контрольной точкой.
-
T b запускается до контрольной точки и фиксируется до сбоя системы.
-
T c запускается после контрольной точки и фиксируется до сбоя системы.
-
T d запускается после контрольной точки и был активен во время сбоя системы.
T a совершает перед контрольной точкой.
T b запускается до контрольной точки и фиксируется до сбоя системы.
T c запускается после контрольной точки и фиксируется до сбоя системы.
T d запускается после контрольной точки и был активен во время сбоя системы.
Ситуация изображена на следующей диаграмме —
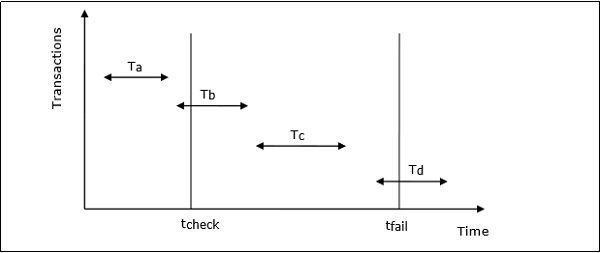
Действия, которые выполняет менеджер восстановления, —
- С Т а ничего не делается.
- Повтор транзакции выполняется для T b и T c .
- Отмена транзакции выполняется для T d .
Восстановление транзакции с использованием UNDO / REDO
Восстановление транзакции выполняется для устранения неблагоприятных последствий ошибочных транзакций, а не для восстановления после сбоя. К ошибочным транзакциям относятся все транзакции, которые изменили базу данных в нежелательное состояние, и транзакции, которые использовали значения, записанные ошибочными транзакциями.
Восстановление транзакции в этих случаях является двухэтапным процессом —
-
Отмените все ошибочные транзакции и транзакции, на которые могут повлиять ошибочные транзакции.
-
Удалите все транзакции, которые не являются неисправными, но были отменены из-за ошибочных транзакций.
Отмените все ошибочные транзакции и транзакции, на которые могут повлиять ошибочные транзакции.
Удалите все транзакции, которые не являются неисправными, но были отменены из-за ошибочных транзакций.
Шаги для операции UNDO —
-
Если ошибочная транзакция выполнила INSERT, менеджер восстановления удаляет вставленные элементы данных.
-
Если ошибочная транзакция выполнила DELETE, менеджер восстановления вставляет удаленные элементы данных из журнала.
-
Если ошибочная транзакция выполнила ОБНОВЛЕНИЕ, диспетчер восстановления удаляет это значение, записывая значение перед обновлением из журнала.
Если ошибочная транзакция выполнила INSERT, менеджер восстановления удаляет вставленные элементы данных.
Если ошибочная транзакция выполнила DELETE, менеджер восстановления вставляет удаленные элементы данных из журнала.
Если ошибочная транзакция выполнила ОБНОВЛЕНИЕ, диспетчер восстановления удаляет это значение, записывая значение перед обновлением из журнала.
Шаги для операции REDO —
-
Если транзакция выполнила INSERT, менеджер восстановления создает вставку из журнала.
-
Если транзакция выполнила DELETE, менеджер восстановления создает удаление из журнала.
-
Если транзакция выполнила ОБНОВЛЕНИЕ, менеджер восстановления создает обновление из журнала.
Если транзакция выполнила INSERT, менеджер восстановления создает вставку из журнала.
Если транзакция выполнила DELETE, менеджер восстановления создает удаление из журнала.
Если транзакция выполнила ОБНОВЛЕНИЕ, менеджер восстановления создает обновление из журнала.
Распределенная СУБД — протоколы коммитов
В локальной системе базы данных для принятия транзакции диспетчер транзакций должен только передать решение о фиксации диспетчеру восстановления. Однако в распределенной системе диспетчер транзакций должен передать решение о фиксации всем серверам в различных сайтах, где выполняется транзакция, и обеспечить единообразное выполнение решения. Когда обработка завершается на каждом сайте, она достигает состояния частично подтвержденной транзакции и ожидает, пока все другие транзакции достигнут их частично подтвержденных состояний. Когда он получает сообщение о том, что все сайты готовы к фиксации, он начинает фиксировать. В распределенной системе либо все сайты фиксируют, либо ни один из них не делает.
Различные протоколы распределенной фиксации:
- Однофазный коммит
- Двухфазный коммит
- Трехфазный коммит
Распределенная однофазная фиксация
Распределенная однофазная фиксация — это самый простой протокол фиксации. Давайте рассмотрим, что есть контролирующий сайт и несколько подчиненных сайтов, где выполняется транзакция. Шаги в распределенном коммите:
-
После того, как каждое ведомое устройство локально завершило свою транзакцию, оно отправляет сообщение «ГОТОВО» на контролирующий сайт.
-
Подчиненные ожидают сообщения «Подтвердить» или «Прервать» с контролирующего сайта. Это время ожидания называется окном уязвимости .
-
Когда контролирующий сайт получает сообщение «СДЕЛАНО» от каждого ведомого, он принимает решение о фиксации или отмене. Это называется точкой фиксации. Затем он отправляет это сообщение всем рабам.
-
При получении этого сообщения ведомое устройство либо фиксирует, либо прерывает работу, а затем отправляет подтверждающее сообщение на контролирующий сайт.
После того, как каждое ведомое устройство локально завершило свою транзакцию, оно отправляет сообщение «ГОТОВО» на контролирующий сайт.
Подчиненные ожидают сообщения «Подтвердить» или «Прервать» с контролирующего сайта. Это время ожидания называется окном уязвимости .
Когда контролирующий сайт получает сообщение «СДЕЛАНО» от каждого ведомого, он принимает решение о фиксации или отмене. Это называется точкой фиксации. Затем он отправляет это сообщение всем рабам.
При получении этого сообщения ведомое устройство либо фиксирует, либо прерывает работу, а затем отправляет подтверждающее сообщение на контролирующий сайт.
Распределенная двухфазная фиксация
Распределенная двухфазная фиксация снижает уязвимость однофазных протоколов фиксации. Шаги, выполняемые на двух этапах:
Этап 1: подготовить этап
-
После того, как каждое ведомое устройство локально завершило свою транзакцию, оно отправляет сообщение «ГОТОВО» на контролирующий сайт. Когда контролирующий сайт получил сообщение «ГОТОВО» от всех подчиненных, он отправляет сообщение «Подготовить» подчиненным.
-
Рабы голосуют за то, хотят ли они по-прежнему совершать или нет. Если ведомый хочет зафиксировать, он отправляет сообщение «Готово».
-
Раб, который не хочет коммитить, отправляет сообщение «Не готов». Это может произойти, если ведомое устройство имеет конфликтующие параллельные транзакции или истекло время ожидания.
После того, как каждое ведомое устройство локально завершило свою транзакцию, оно отправляет сообщение «ГОТОВО» на контролирующий сайт. Когда контролирующий сайт получил сообщение «ГОТОВО» от всех подчиненных, он отправляет сообщение «Подготовить» подчиненным.
Рабы голосуют за то, хотят ли они по-прежнему совершать или нет. Если ведомый хочет зафиксировать, он отправляет сообщение «Готово».
Раб, который не хочет коммитить, отправляет сообщение «Не готов». Это может произойти, если ведомое устройство имеет конфликтующие параллельные транзакции или истекло время ожидания.
Этап 2: Фиксация / Отмена
-
После того, как контролирующий сайт получил сообщение «Готово» от всех ведомых —
-
Контролирующий сайт отправляет сообщение «Global Commit» подчиненным.
-
Подчиненные устройства применяют транзакцию и отправляют сообщение «Подтвердить ACK» на контролирующий сайт.
-
Когда контролирующий сайт получает сообщение «Подтвердить ACK» от всех ведомых устройств, он считает транзакцию подтвержденной.
-
-
После того, как контролирующий сайт получил первое сообщение «Не готов» от любого ведомого —
-
Контролирующий сайт отправляет сообщение «Global Abort» подчиненным.
-
Слэйвы отменяют транзакцию и отправляют сообщение «Abort ACK» на контролирующий сайт.
-
Когда контролирующий сайт получает сообщение «Abort ACK» от всех ведомых устройств, он считает транзакцию отмененной.
-
После того, как контролирующий сайт получил сообщение «Готово» от всех ведомых —
Контролирующий сайт отправляет сообщение «Global Commit» подчиненным.
Подчиненные устройства применяют транзакцию и отправляют сообщение «Подтвердить ACK» на контролирующий сайт.
Когда контролирующий сайт получает сообщение «Подтвердить ACK» от всех ведомых устройств, он считает транзакцию подтвержденной.
После того, как контролирующий сайт получил первое сообщение «Не готов» от любого ведомого —
Контролирующий сайт отправляет сообщение «Global Abort» подчиненным.
Слэйвы отменяют транзакцию и отправляют сообщение «Abort ACK» на контролирующий сайт.
Когда контролирующий сайт получает сообщение «Abort ACK» от всех ведомых устройств, он считает транзакцию отмененной.
Распределенная трехфазная фиксация
Шаги в распределенной трехфазной фиксации следующие:
Этап 1: подготовить этап
Шаги такие же, как при распределенной двухфазной фиксации.
Фаза 2: Подготовьтесь к Фиксации Фазы
- Контролирующий сайт выдает широковещательное сообщение «Ввод подготовленного состояния».
- Ведомые сайты голосуют «ОК» в ответ.
Этап 3: Фиксация / Отмена
Этапы аналогичны двухфазной фиксации, за исключением того, что сообщение «Подтвердить ACK» / «Прервать ACK» не требуется.
DDBMS — безопасность баз данных и криптография
В этой главе мы рассмотрим угрозы, с которыми сталкивается система баз данных, и меры контроля. Мы также будем изучать криптографию как инструмент безопасности.
Безопасность базы данных и угрозы
Безопасность данных является обязательным аспектом любой системы баз данных. Это имеет особое значение в распределенных системах из-за большого количества пользователей, фрагментированных и реплицированных данных, множества сайтов и распределенного контроля.
Угрозы в базе данных
-
Потеря доступности — потеря доступности относится к недоступности объектов базы данных законными пользователями.
-
Потеря целостности — Потеря целостности происходит, когда недопустимые операции выполняются с базой данных случайно или злонамеренно. Это может произойти при создании, вставке, обновлении или удалении данных. Это приводит к повреждению данных, что приводит к неправильным решениям.
-
Потеря конфиденциальности. Потеря конфиденциальности происходит из-за несанкционированного или непреднамеренного разглашения конфиденциальной информации. Это может привести к незаконным действиям, угрозам безопасности и потере доверия общественности.
Потеря доступности — потеря доступности относится к недоступности объектов базы данных законными пользователями.
Потеря целостности — Потеря целостности происходит, когда недопустимые операции выполняются с базой данных случайно или злонамеренно. Это может произойти при создании, вставке, обновлении или удалении данных. Это приводит к повреждению данных, что приводит к неправильным решениям.
Потеря конфиденциальности. Потеря конфиденциальности происходит из-за несанкционированного или непреднамеренного разглашения конфиденциальной информации. Это может привести к незаконным действиям, угрозам безопасности и потере доверия общественности.
Меры контроля
Меры контроля можно широко разделить на следующие категории —
-
Контроль доступа — Контроль доступа включает механизмы безопасности в системе управления базами данных для защиты от несанкционированного доступа. Пользователь может получить доступ к базе данных после очистки процесса входа в систему только через действительные учетные записи пользователей. Каждая учетная запись пользователя защищена паролем.
-
Управление потоком — Распределенные системы охватывают большой поток данных с одного сайта на другой, а также внутри сайта. Управление потоком предотвращает передачу данных таким образом, чтобы к ним могли получить доступ неавторизованные агенты. Политика потока перечисляет каналы, по которым может передаваться информация. Он также определяет классы безопасности для данных и транзакций.
-
Шифрование данных — Шифрование данных относится к кодированию данных, когда конфиденциальные данные должны передаваться по общедоступным каналам. Даже если неавторизованный агент получает доступ к данным, он не может их понять, поскольку они представлены в непонятном формате.
Контроль доступа — Контроль доступа включает механизмы безопасности в системе управления базами данных для защиты от несанкционированного доступа. Пользователь может получить доступ к базе данных после очистки процесса входа в систему только через действительные учетные записи пользователей. Каждая учетная запись пользователя защищена паролем.
Управление потоком — Распределенные системы охватывают большой поток данных с одного сайта на другой, а также внутри сайта. Управление потоком предотвращает передачу данных таким образом, чтобы к ним могли получить доступ неавторизованные агенты. Политика потока перечисляет каналы, по которым может передаваться информация. Он также определяет классы безопасности для данных и транзакций.
Шифрование данных — Шифрование данных относится к кодированию данных, когда конфиденциальные данные должны передаваться по общедоступным каналам. Даже если неавторизованный агент получает доступ к данным, он не может их понять, поскольку они представлены в непонятном формате.
Что такое криптография?
Криптография — это наука кодирования информации перед ее отправкой по ненадежным каналам связи, так что только авторизованный получатель может ее декодировать и использовать.
Кодированное сообщение называется зашифрованным текстом, а исходное сообщение называется простым текстом . Процесс преобразования отправителем простого текста в зашифрованный текст называется кодированием или шифрованием . Процесс преобразования получателем зашифрованного текста в обычный текст называется расшифровкой или дешифрованием .
Вся процедура общения с использованием криптографии может быть проиллюстрирована с помощью следующей диаграммы:
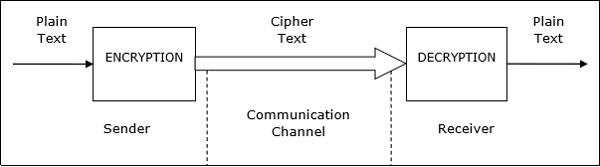
Обычные методы шифрования
В обычной криптографии шифрование и дешифрование выполняется с использованием одного и того же секретного ключа. Здесь отправитель шифрует сообщение с помощью алгоритма шифрования, используя копию секретного ключа. Зашифрованное сообщение затем отправляется по общедоступным каналам связи. Получив зашифрованное сообщение, получатель расшифровывает его с помощью соответствующего алгоритма дешифрования с использованием того же секретного ключа.
Безопасность в обычной криптографии зависит от двух факторов:
-
Звуковой алгоритм, который известен всем.
-
Сгенерированный случайным образом, предпочтительно длинный секретный ключ, известный только отправителю и получателю.
Звуковой алгоритм, который известен всем.
Сгенерированный случайным образом, предпочтительно длинный секретный ключ, известный только отправителю и получателю.
Самый известный алгоритм криптографии — это стандарт шифрования данных или DES .
Преимущество этого метода заключается в его легкой применимости. Однако самой большой проблемой обычной криптографии является совместное использование секретного ключа между связывающимися сторонами. Способы отправки ключа громоздки и очень восприимчивы к прослушиванию.
Криптография с открытым ключом
В отличие от обычной криптографии, криптография с открытым ключом использует два разных ключа, называемых открытым ключом и закрытым ключом. Каждый пользователь генерирует пару открытый ключ и закрытый ключ. Затем пользователь помещает открытый ключ в доступное место. Когда отправитель хочет отправить сообщение, он шифрует его, используя открытый ключ получателя. Получив зашифрованное сообщение, получатель расшифровывает его, используя свой закрытый ключ. Поскольку закрытый ключ не известен никому, кроме получателя, никто другой, получивший сообщение, не сможет его расшифровать.
Наиболее популярными алгоритмами шифрования с открытым ключом являются алгоритм RSA и алгоритм Диффи-Хеллмана . Этот метод очень безопасен для отправки личных сообщений. Однако проблема в том, что он требует большого количества вычислений и поэтому оказывается неэффективным для длинных сообщений.
Решение состоит в том, чтобы использовать комбинацию обычной криптографии и шифрования с открытым ключом. Секретный ключ зашифровывается с использованием криптографии с открытым ключом перед передачей между связывающимися сторонами. Затем сообщение отправляется с использованием обычной криптографии с помощью общего секретного ключа.
Цифровые подписи
Цифровая подпись (DS) — это метод аутентификации, основанный на криптографии с открытым ключом, используемой в приложениях электронной коммерции. Он связывает уникальный знак с человеком в теле его сообщения. Это помогает другим проверять подлинность отправителей сообщений.
Как правило, цифровая подпись пользователя изменяется от сообщения к сообщению, чтобы обеспечить защиту от подделок. Метод заключается в следующем —
-
Отправитель принимает сообщение, вычисляет дайджест сообщения и подписывает его с помощью закрытого ключа.
-
Затем отправитель добавляет подписанный дайджест вместе с открытым текстом.
-
Сообщение отправляется по каналу связи.
-
Получатель удаляет добавленный подписанный дайджест и проверяет дайджест, используя соответствующий открытый ключ.
-
Затем получатель принимает текстовое сообщение и запускает его по тому же алгоритму дайджеста сообщения.
-
Если результаты шага 4 и шага 5 совпадают, то получатель знает, что сообщение имеет целостность и является подлинным.
Отправитель принимает сообщение, вычисляет дайджест сообщения и подписывает его с помощью закрытого ключа.
Затем отправитель добавляет подписанный дайджест вместе с открытым текстом.
Сообщение отправляется по каналу связи.
Получатель удаляет добавленный подписанный дайджест и проверяет дайджест, используя соответствующий открытый ключ.
Затем получатель принимает текстовое сообщение и запускает его по тому же алгоритму дайджеста сообщения.
Если результаты шага 4 и шага 5 совпадают, то получатель знает, что сообщение имеет целостность и является подлинным.
DDBMS — безопасность в распределенных базах данных
Распределенная система нуждается в дополнительных мерах безопасности, чем централизованная система, поскольку в ней много пользователей, разнообразных данных, нескольких сайтов и распределенного управления. В этой главе мы рассмотрим различные аспекты безопасности распределенных баз данных.
В распределенных системах связи существует два типа злоумышленников —
-
Пассивные перехватчики — они отслеживают сообщения и получают конфиденциальную информацию.
-
Активные злоумышленники — они не только отслеживают сообщения, но и повреждают данные, вставляя новые данные или изменяя существующие данные.
Пассивные перехватчики — они отслеживают сообщения и получают конфиденциальную информацию.
Активные злоумышленники — они не только отслеживают сообщения, но и повреждают данные, вставляя новые данные или изменяя существующие данные.
Меры безопасности охватывают безопасность связи, безопасность данных и аудит данных.
Безопасность связи
В распределенной базе данных происходит много обмена данными благодаря разнообразному расположению данных, пользователей и транзакций. Таким образом, это требует безопасного взаимодействия между пользователями и базами данных, а также между различными средами баз данных.
Безопасность в общении включает следующее:
-
Данные не должны быть повреждены во время передачи.
-
Канал связи должен быть защищен как от пассивных перехватчиков, так и от активных атакующих.
-
Для достижения вышеуказанных требований должны быть приняты четко определенные алгоритмы и протоколы безопасности.
Данные не должны быть повреждены во время передачи.
Канал связи должен быть защищен как от пассивных перехватчиков, так и от активных атакующих.
Для достижения вышеуказанных требований должны быть приняты четко определенные алгоритмы и протоколы безопасности.
Две популярные, последовательные технологии для обеспечения сквозной безопасной связи:
- Протокол защищенного сокета или протокол безопасности транспортного уровня.
- Виртуальные частные сети (VPN).
Безопасность данных
В распределенных системах крайне важно принять меры для защиты данных помимо связи. Меры безопасности данных —
-
Аутентификация и авторизация — это меры контроля доступа, принятые, чтобы гарантировать, что только аутентичные пользователи могут использовать базу данных. Для обеспечения аутентификации используются цифровые сертификаты. Кроме того, вход в систему ограничен комбинацией имени пользователя и пароля.
-
Шифрование данных . Два подхода к шифрованию данных в распределенных системах:
-
Подход с внутренней к распределенной базе данных: пользовательские приложения шифруют данные и затем сохраняют зашифрованные данные в базе данных. Для использования сохраненных данных приложения извлекают зашифрованные данные из базы данных и затем дешифруют их.
-
Внешняя по отношению к распределенной базе данных. Система распределенных баз данных имеет свои собственные возможности шифрования. Пользовательские приложения хранят данные и извлекают их, не осознавая, что данные хранятся в зашифрованном виде в базе данных.
-
-
Подтвержденный ввод — в этой мере безопасности пользовательское приложение проверяет каждый ввод, прежде чем его можно будет использовать для обновления базы данных. Не подтвержденный ввод может вызвать широкий спектр эксплойтов, таких как переполнение буфера, внедрение команд, межсайтовый скриптинг и повреждение данных.
Аутентификация и авторизация — это меры контроля доступа, принятые, чтобы гарантировать, что только аутентичные пользователи могут использовать базу данных. Для обеспечения аутентификации используются цифровые сертификаты. Кроме того, вход в систему ограничен комбинацией имени пользователя и пароля.
Шифрование данных . Два подхода к шифрованию данных в распределенных системах:
Подход с внутренней к распределенной базе данных: пользовательские приложения шифруют данные и затем сохраняют зашифрованные данные в базе данных. Для использования сохраненных данных приложения извлекают зашифрованные данные из базы данных и затем дешифруют их.
Внешняя по отношению к распределенной базе данных. Система распределенных баз данных имеет свои собственные возможности шифрования. Пользовательские приложения хранят данные и извлекают их, не осознавая, что данные хранятся в зашифрованном виде в базе данных.
Подтвержденный ввод — в этой мере безопасности пользовательское приложение проверяет каждый ввод, прежде чем его можно будет использовать для обновления базы данных. Не подтвержденный ввод может вызвать широкий спектр эксплойтов, таких как переполнение буфера, внедрение команд, межсайтовый скриптинг и повреждение данных.
Аудит данных
Система безопасности базы данных должна обнаруживать и отслеживать нарушения безопасности, чтобы определить меры безопасности, которые она должна принять. Часто очень трудно обнаружить нарушение безопасности во время происшествия. Одним из способов выявления нарушений безопасности является проверка журналов аудита. Журналы аудита содержат такую информацию, как —
- Дата, время и место неудачных попыток доступа.
- Детали успешных попыток доступа.
- Жизненно важные изменения в системе баз данных.
- Доступ к огромным объемам данных, особенно из баз данных на нескольких сайтах.
Вся вышеуказанная информация дает представление о деятельности в базе данных. Периодический анализ журнала помогает выявить любую неестественную активность наряду с ее местом и временем возникновения. Этот журнал идеально хранится на отдельном сервере, чтобы он был недоступен для злоумышленников.