Процесс компиляции представляет собой последовательность различных этапов. Каждая фаза принимает входные данные от предыдущего этапа, имеет свое собственное представление исходной программы и направляет свои выходные данные на следующую фазу компилятора. Давайте разберемся с фазами компилятора.
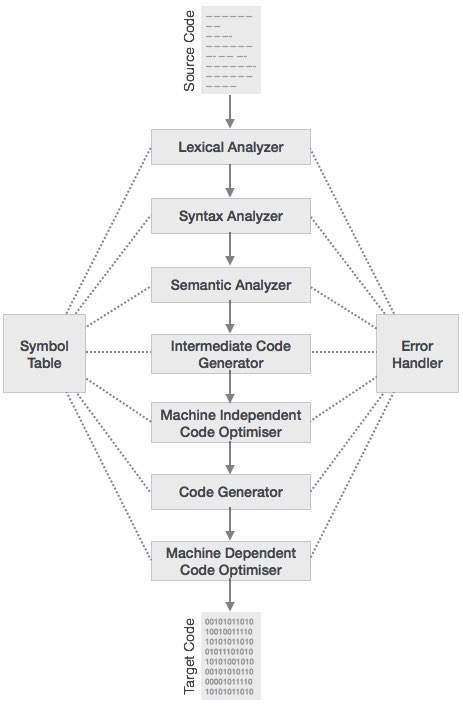
Лексический анализ
Первая фаза сканера работает как текстовый сканер. Эта фаза сканирует исходный код как поток символов и преобразует его в значимые лексемы. Лексический анализатор представляет эти лексемы в виде токенов как:
<token-name, attribute-value>
Синтаксический анализ
Следующий этап называется синтаксическим анализом или анализом. Он принимает токен, созданный лексическим анализом, в качестве входных данных и генерирует дерево разбора (или дерево синтаксиса). На этом этапе расположение токенов проверяется по грамматике исходного кода, то есть анализатор проверяет, является ли выражение, сделанное токенами, синтаксически правильным.
Семантический анализ
Семантический анализ проверяет, соответствует ли построенное дерево разбора правилам языка. Например, присвоение значений происходит между совместимыми типами данных и добавлением строки к целому числу. Кроме того, семантический анализатор отслеживает идентификаторы, их типы и выражения; объявляются ли идентификаторы перед использованием или нет и т. д. Семантический анализатор создает аннотированное синтаксическое дерево в качестве выходных данных.
Промежуточная генерация кода
После семантического анализа компилятор генерирует промежуточный код исходного кода для целевой машины. Он представляет собой программу для некоторой абстрактной машины. Он находится между языком высокого уровня и машинным языком. Этот промежуточный код должен быть сгенерирован таким образом, чтобы его было легче преобразовать в целевой машинный код.
Оптимизация кода
На следующем этапе выполняется оптимизация кода промежуточного кода. Оптимизацию можно предположить как нечто, удаляющее ненужные строки кода и упорядочивающее последовательность операторов, чтобы ускорить выполнение программы, не тратя ресурсы (процессор, память).
Генерация кода
На этом этапе генератор кода принимает оптимизированное представление промежуточного кода и отображает его на целевой машинный язык. Генератор кода преобразует промежуточный код в последовательность (обычно) перемещаемого машинного кода. Последовательность инструкций машинного кода выполняет задачу как промежуточный код.
Таблица символов
Это структура данных, поддерживаемая на всех этапах компилятора. Все имена идентификаторов вместе с их типами хранятся здесь. Таблица символов облегчает компилятору быстрый поиск записи идентификатора и ее извлечение. Таблица символов также используется для управления областью.