Дизайн компилятора — Обзор
Компьютеры представляют собой сбалансированное сочетание программного и аппаратного обеспечения. Аппаратное обеспечение — это всего лишь механическое устройство, а его функции контролируются совместимым программным обеспечением. Аппаратное обеспечение понимает инструкции в форме электронного заряда, который является аналогом двоичного языка в программировании программного обеспечения. Двоичный язык имеет только два алфавита, 0 и 1. Для инструктажа аппаратные коды должны быть записаны в двоичном формате, который представляет собой просто последовательность из 1 и 0. Написание таких кодов для программистов было бы сложной и обременительной, поэтому у нас есть компиляторы для написания таких кодов.
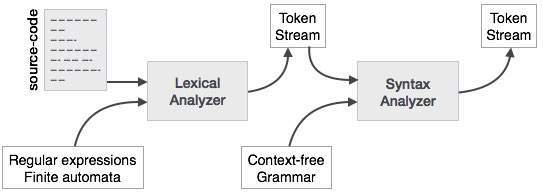
Система языковой обработки
Мы узнали, что любая компьютерная система состоит из аппаратного и программного обеспечения. Аппаратное обеспечение понимает язык, который люди не могут понять. Поэтому мы пишем программы на языке высокого уровня, который нам легче понять и запомнить. Эти программы затем подаются в набор инструментов и компонентов ОС для получения желаемого кода, который может использоваться машиной. Это известно как система языковой обработки.
Язык высокого уровня преобразуется в бинарный язык на разных этапах. Компилятор — это программа, которая преобразует язык высокого уровня в язык ассемблера. Аналогично, ассемблер — это программа, которая конвертирует язык ассемблера в язык машинного уровня.
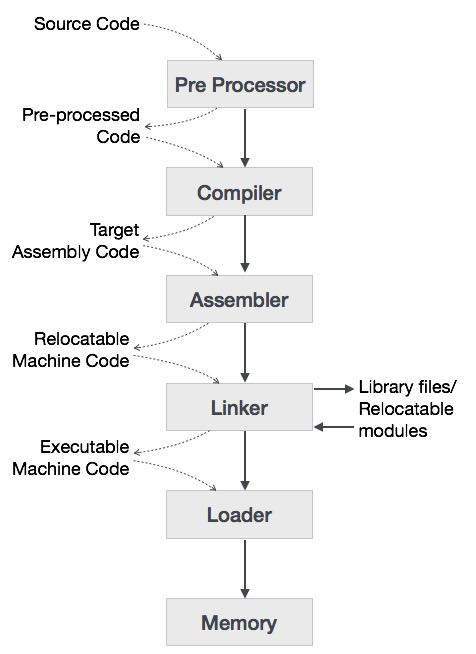
Давайте сначала разберемся, как программа, использующая компилятор C, выполняется на хост-машине.
-
Пользователь пишет программу на языке Си (язык высокого уровня).
-
Компилятор C компилирует программу и переводит ее в программу ассемблера (язык низкого уровня).
-
Затем ассемблер переводит программу сборки в машинный код (объект).
-
Инструмент компоновщика используется для связывания всех частей программы для выполнения (исполняемый машинный код).
-
Загрузчик загружает их все в память, а затем программа выполняется.
Пользователь пишет программу на языке Си (язык высокого уровня).
Компилятор C компилирует программу и переводит ее в программу ассемблера (язык низкого уровня).
Затем ассемблер переводит программу сборки в машинный код (объект).
Инструмент компоновщика используется для связывания всех частей программы для выполнения (исполняемый машинный код).
Загрузчик загружает их все в память, а затем программа выполняется.
Прежде чем углубиться в концепцию компиляторов, мы должны понять несколько других инструментов, которые тесно работают с компиляторами.
препроцессор
Препроцессор, обычно рассматриваемый как часть компилятора, является инструментом, который производит ввод для компиляторов. Он занимается обработкой макросов, расширением, включением файлов, расширением языка и т. Д.
переводчик
Интерпретатор, как и компилятор, переводит язык высокого уровня на машинный язык низкого уровня. Разница заключается в том, как они читают исходный код или ввод. Компилятор считывает весь исходный код сразу, создает токены, проверяет семантику, генерирует промежуточный код, выполняет всю программу и может включать много проходов. Напротив, интерпретатор считывает оператор из входных данных, преобразует его в промежуточный код, выполняет его, а затем принимает следующий оператор в последовательности. Если возникает ошибка, интерпретатор останавливает выполнение и сообщает об этом. тогда как компилятор читает всю программу, даже если он сталкивается с несколькими ошибками.
ассемблер
Ассемблер переводит программы на языке ассемблера в машинный код. Выходные данные ассемблера называются объектным файлом, который содержит комбинацию машинных инструкций, а также данные, необходимые для помещения этих инструкций в память.
Linker
Linker — это компьютерная программа, которая связывает и объединяет различные объектные файлы для создания исполняемого файла. Все эти файлы могли быть скомпилированы отдельными ассемблерами. Основная задача компоновщика состоит в том, чтобы искать и находить ссылочный модуль / подпрограммы в программе и определять область памяти, куда будут загружаться эти коды, что делает указание программы иметь абсолютные ссылки.
погрузчик
Загрузчик является частью операционной системы и отвечает за загрузку исполняемых файлов в память и их выполнение. Он рассчитывает размер программы (инструкции и данные) и создает для нее место в памяти. Он инициализирует различные регистры, чтобы инициировать выполнение.
Кросс-компилятор
Компилятор, работающий на платформе (A) и способный генерировать исполняемый код для платформы (B), называется кросс-компилятором.
Компилятор исходного кода
Компилятор, который берет исходный код одного языка программирования и переводит его в исходный код другого языка программирования, называется компилятором исходного кода.
Архитектура компилятора
Компилятор можно разделить на две фазы в зависимости от способа компиляции.
Этап анализа
Известный как внешний интерфейс компилятора, фаза анализа компилятора считывает исходную программу, делит ее на основные части и затем проверяет на наличие лексических, грамматических и синтаксических ошибок. На этапе анализа создается промежуточное представление исходной программы и символа таблица, которая должна быть введена в фазу синтеза в качестве входных данных.
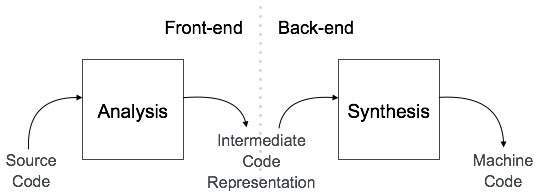
Фаза синтеза
Эта фаза синтеза, известная как серверная часть компилятора, генерирует целевую программу с помощью промежуточного представления исходного кода и таблицы символов.
Компилятор может иметь много фаз и проходов.
-
Pass : Pass относится к обходу компилятора через всю программу.
-
Фаза . Фаза компилятора — это различимая стадия, которая принимает входные данные с предыдущего этапа, обрабатывает и выдает выходные данные, которые можно использовать в качестве входных данных для следующего этапа. Пропуск может иметь более одной фазы.
Pass : Pass относится к обходу компилятора через всю программу.
Фаза . Фаза компилятора — это различимая стадия, которая принимает входные данные с предыдущего этапа, обрабатывает и выдает выходные данные, которые можно использовать в качестве входных данных для следующего этапа. Пропуск может иметь более одной фазы.
Фазы компилятора
Процесс компиляции представляет собой последовательность различных этапов. Каждая фаза принимает входные данные от предыдущего этапа, имеет свое собственное представление исходной программы и направляет свои выходные данные на следующую фазу компилятора. Давайте разберемся с фазами компилятора.
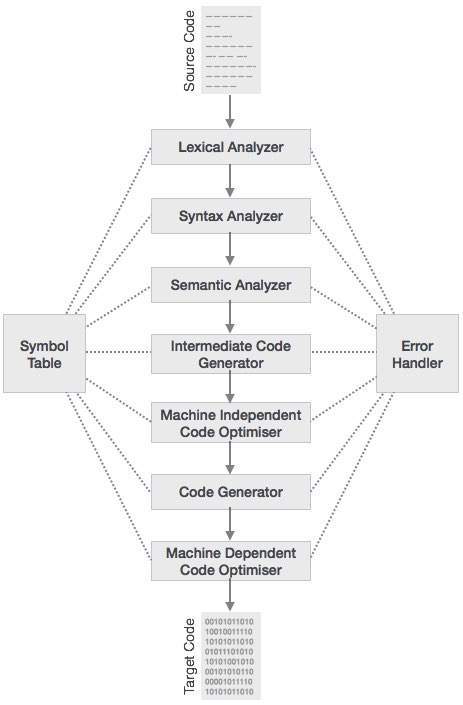
Лексический анализ
Первая фаза сканера работает как текстовый сканер. Эта фаза сканирует исходный код как поток символов и преобразует его в значимые лексемы. Лексический анализатор представляет эти лексемы в виде токенов как:
<token-name, attribute-value>
Синтаксический анализ
Следующий этап называется синтаксическим анализом или анализом. Он принимает токен, созданный лексическим анализом, в качестве входных данных и генерирует дерево разбора (или дерево синтаксиса). На этом этапе расположение токенов проверяется по грамматике исходного кода, то есть анализатор проверяет, является ли выражение, сделанное токенами, синтаксически правильным.
Семантический анализ
Семантический анализ проверяет, соответствует ли построенное дерево разбора правилам языка. Например, присвоение значений происходит между совместимыми типами данных и добавлением строки к целому числу. Кроме того, семантический анализатор отслеживает идентификаторы, их типы и выражения; объявляются ли идентификаторы перед использованием или нет и т. д. Семантический анализатор создает аннотированное синтаксическое дерево в качестве выходных данных.
Промежуточная генерация кода
После семантического анализа компилятор генерирует промежуточный код исходного кода для целевой машины. Он представляет собой программу для некоторой абстрактной машины. Он находится между языком высокого уровня и машинным языком. Этот промежуточный код должен быть сгенерирован таким образом, чтобы его было легче преобразовать в целевой машинный код.
Оптимизация кода
На следующем этапе выполняется оптимизация кода промежуточного кода. Оптимизацию можно предположить как нечто, удаляющее ненужные строки кода и упорядочивающее последовательность операторов, чтобы ускорить выполнение программы, не тратя ресурсы (процессор, память).
Генерация кода
На этом этапе генератор кода принимает оптимизированное представление промежуточного кода и отображает его на целевой машинный язык. Генератор кода преобразует промежуточный код в последовательность (обычно) перемещаемого машинного кода. Последовательность инструкций машинного кода выполняет задачу как промежуточный код.
Таблица символов
Это структура данных, поддерживаемая на всех этапах компилятора. Все имена идентификаторов вместе с их типами хранятся здесь. Таблица символов облегчает компилятору быстрый поиск записи идентификатора и ее извлечение. Таблица символов также используется для управления областью.
Дизайн компилятора — Лексический анализ
Лексический анализ — это первая фаза компилятора. Он принимает модифицированный исходный код от языковых препроцессоров, которые написаны в форме предложений. Лексический анализатор разбивает эти синтаксисы на серию токенов, удаляя любые пробелы или комментарии в исходном коде.
Если лексический анализатор находит токен недействительным, он генерирует ошибку. Лексический анализатор тесно сотрудничает с синтаксическим анализатором. Он считывает символьные потоки из исходного кода, проверяет допустимые токены и передает данные в синтаксический анализатор, когда это требуется.
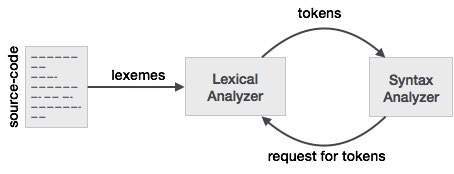
Лексемы
Лексемы называются последовательностью символов (буквенно-цифровых) в токене. Есть несколько предопределенных правил для каждой лексемы, которая будет определена как действительный токен. Эти правила определяются грамматическими правилами посредством шаблона. Шаблон объясняет, что может быть токеном, и эти шаблоны определяются с помощью регулярных выражений.
В языке программирования ключевые слова, константы, идентификаторы, строки, числа, операторы и символы пунктуации могут рассматриваться как токены.
Например, в языке C строка объявления переменной
int value = 100;
содержит токены:
int (keyword), value (identifier), = (operator), 100 (constant) and ; (symbol).
Характеристики токенов
Давайте разберемся, как теория языка принимает следующие термины:
алфавиты
Любой конечный набор символов {0,1} является набором двоичных алфавитов, {0,1,2,3,4,5,6,7,8,9, A, B, C, D, E, F} представляет собой набор шестнадцатеричных алфавитов, {az, AZ} представляет собой набор алфавитов английского языка.
Струны
Любая конечная последовательность алфавитов называется строкой. Длина строки — это общее количество вхождений алфавитов, например, длина строки tutorialspoint равна 14 и обозначается как | tutorialspoint | = 14. Строка, не имеющая алфавитов, то есть строка нулевой длины, называется пустой строкой и обозначается как ε (эпсилон).
Специальные символы
Типичный язык высокого уровня содержит следующие символы:
| Арифметические символы | Сложение (+), Вычитание (-), Модуль (%), Умножение (*), Деление (/) |
| пунктуация | Запятая (,), точка с запятой (;), точка (.), Стрелка (->) |
| присваивание | знак равно |
| Специальное Назначение | + =, / =, * =, — = |
| сравнение | ==,! =, <, <=,>,> = |
| препроцессор | # |
| Спецификатор местоположения | & |
| логический | &, &&, |, ||,! |
| Оператор смены | >>, >>>, <<, <<< |
язык
Язык рассматривается как конечный набор строк над некоторым конечным набором алфавитов. Компьютерные языки рассматриваются как конечные множества, и над ними могут выполняться математически заданные операции. Конечные языки могут быть описаны с помощью регулярных выражений.
Регулярные выражения
Лексический анализатор должен сканировать и идентифицировать только конечный набор допустимых строк / токенов / лексем, которые принадлежат используемому языку. Он ищет шаблон, определенный правилами языка.
Регулярные выражения имеют возможность выражать конечные языки, определяя шаблон для конечных строк символов. Грамматика, определяемая регулярными выражениями, называется регулярной грамматикой . Язык, определяемый регулярной грамматикой, известен как обычный язык .
Регулярное выражение является важной нотацией для определения шаблонов. Каждый шаблон соответствует набору строк, поэтому регулярные выражения служат именами для набора строк. Языковые токены программирования могут быть описаны обычными языками. Спецификация регулярных выражений является примером рекурсивного определения. Обычные языки просты для понимания и имеют эффективную реализацию.
Существует ряд алгебраических законов, которым подчиняются регулярные выражения, которые можно использовать для манипулирования регулярными выражениями в эквивалентных формах.
операции
Различные операции над языками:
-
Союз двух языков L и M записывается как
LUM = {s | s находится в L или s находится в M}
-
Объединение двух языков L и M записывается как
LM = {st | s находится в L и t находится в M}
-
Закрытие клини языка L записывается как
L * = ноль или более вхождение языка L.
Союз двух языков L и M записывается как
LUM = {s | s находится в L или s находится в M}
Объединение двух языков L и M записывается как
LM = {st | s находится в L и t находится в M}
Закрытие клини языка L записывается как
L * = ноль или более вхождение языка L.
нотации
Если r и s являются регулярными выражениями, обозначающими языки L (r) и L (s), то
-
Союз : (r) | (s) — регулярное выражение, обозначающее L (r) UL (s)
-
Объединение : (r) (s) — это регулярное выражение, обозначающее L (r) L (s)
-
Закрытие Клини : (r) * — регулярное выражение, обозначающее (L (r)) *
-
(r) регулярное выражение, обозначающее L (r)
Союз : (r) | (s) — регулярное выражение, обозначающее L (r) UL (s)
Объединение : (r) (s) — это регулярное выражение, обозначающее L (r) L (s)
Закрытие Клини : (r) * — регулярное выражение, обозначающее (L (r)) *
(r) регулярное выражение, обозначающее L (r)
Приоритетность и ассоциативность
- *, конкатенация (.) и | (знак трубы) остаются ассоциативными
- * имеет высший приоритет
- Конкатенация (.) Имеет второй по значимости приоритет.
- | (знак трубы) имеет самый низкий приоритет из всех.
Представление действительных токенов языка в регулярном выражении
Если x является регулярным выражением, то:
-
х * означает ноль или более вхождения х.
то есть он может генерировать {e, x, xx, xxx, xxxx,…}
-
х + означает одно или несколько вхождений х.
то есть он может генерировать {x, xx, xxx, xxxx…} или xx *
-
Икс? означает не более одного вхождения х
т.е. он может генерировать либо {x}, либо {e}.
[az] — все строчные буквы английского языка.
[AZ] это все прописные буквы английского языка.
[0-9] — все натуральные цифры, используемые в математике.
х * означает ноль или более вхождения х.
то есть он может генерировать {e, x, xx, xxx, xxxx,…}
х + означает одно или несколько вхождений х.
то есть он может генерировать {x, xx, xxx, xxxx…} или xx *
Икс? означает не более одного вхождения х
т.е. он может генерировать либо {x}, либо {e}.
[az] — все строчные буквы английского языка.
[AZ] это все прописные буквы английского языка.
[0-9] — все натуральные цифры, используемые в математике.
Представление вхождения символов с помощью регулярных выражений
буква = [a — z] или [A — Z]
цифра = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 или [0-9]
знак = [+ | -]
Представление языковых токенов с помощью регулярных выражений
Десятичный = (знак) ? (цифра) +
Идентификатор = (буква) (буква | цифра) *
Единственная проблема, которая осталась с лексическим анализатором, заключается в том, как проверить правильность регулярного выражения, используемого при определении шаблонов ключевых слов языка. Хорошо принятым решением является использование конечных автоматов для проверки.
Конечные Автоматы
Конечные автоматы — это конечный автомат, который принимает на вход строку символов и соответственно изменяет свое состояние. Конечные автоматы — это распознаватель регулярных выражений. Когда строка регулярного выражения подается в конечные автоматы, она меняет свое состояние для каждого литерала. Если входная строка успешно обработана и автоматы достигают своего конечного состояния, она принимается, т. Е. Только что переданная строка считается допустимым токеном языка в руке.
Математическая модель конечных автоматов состоит из:
- Конечный набор состояний (Q)
- Конечный набор входных символов (Σ)
- Одно стартовое состояние (q0)
- Набор конечных состояний (qf)
- Функция перехода (δ)
Функция перехода (δ) отображает конечный набор состояний (Q) в конечный набор входных символов (Σ), Q × Σ ➔ Q
Конечные Автоматы Констракшн
Пусть L (r) регулярный язык, распознаваемый некоторыми конечными автоматами (FA).
-
Состояния : государства ФА представлены кружками. Названия штатов пишутся внутри кружков.
-
Начальное состояние : состояние, с которого начинается автомат, называется начальным состоянием. Стартовое состояние имеет стрелку, направленную на него.
-
Промежуточные состояния : все промежуточные состояния имеют как минимум две стрелки; один указывает на другого, а другой указывает на них.
-
Конечное состояние : если входная строка успешно проанализирована, ожидается, что автоматы находятся в этом состоянии. Конечное состояние представлено двойными кружками. У него может быть любое нечетное количество стрелок, указывающих на него, и четное количество стрелок, указывающих на него. Количество нечетных стрелок на единицу больше четного, то есть нечетное = четное + 1 .
-
Переход : переход из одного состояния в другое происходит, когда на входе найден нужный символ. После перехода автоматы могут либо перейти в следующее состояние, либо остаться в том же состоянии. Перемещение из одного состояния в другое показано в виде направленной стрелки, где стрелки указывают на состояние назначения. Если автоматы остаются в том же состоянии, рисуется стрелка, указывающая из состояния в себя.
Состояния : государства ФА представлены кружками. Названия штатов пишутся внутри кружков.
Начальное состояние : состояние, с которого начинается автомат, называется начальным состоянием. Стартовое состояние имеет стрелку, направленную на него.
Промежуточные состояния : все промежуточные состояния имеют как минимум две стрелки; один указывает на другого, а другой указывает на них.
Конечное состояние : если входная строка успешно проанализирована, ожидается, что автоматы находятся в этом состоянии. Конечное состояние представлено двойными кружками. У него может быть любое нечетное количество стрелок, указывающих на него, и четное количество стрелок, указывающих на него. Количество нечетных стрелок на единицу больше четного, то есть нечетное = четное + 1 .
Переход : переход из одного состояния в другое происходит, когда на входе найден нужный символ. После перехода автоматы могут либо перейти в следующее состояние, либо остаться в том же состоянии. Перемещение из одного состояния в другое показано в виде направленной стрелки, где стрелки указывают на состояние назначения. Если автоматы остаются в том же состоянии, рисуется стрелка, указывающая из состояния в себя.
Пример : мы предполагаем, что FA принимает любые трехзначные двоичные значения, заканчивающиеся цифрой 1. FA = {Q (q 0 , q f ), Σ (0,1), q 0 , q f , δ}
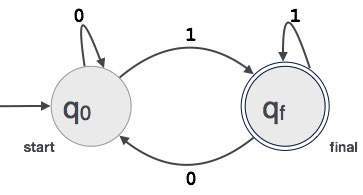
Правило самого длинного матча
Когда лексический анализатор считывает исходный код, он сканирует код по буквам; и когда он встречает пробел, символ оператора или специальные символы, он решает, что слово завершено.
Например:
int intvalue;
При сканировании обеих лексем до ‘int’ лексический анализатор не может определить, является ли это ключевое слово int или инициалы значения идентификатора int.
Правило самого длинного совпадения гласит, что отсканированная лексема должна определяться на основе самого длинного совпадения среди всех доступных токенов.
Лексический анализатор также следует приоритету правила, когда зарезервированное слово, например ключевое слово, языка имеет приоритет над пользовательским вводом. То есть, если лексический анализатор находит лексему, которая соответствует любому существующему зарезервированному слову, он должен генерировать ошибку.
Дизайн компилятора — синтаксический анализ
Синтаксический анализ или синтаксический анализ — это вторая фаза компилятора. В этой главе мы изучим основные понятия, используемые при построении парсера.
Мы видели, что лексический анализатор может идентифицировать токены с помощью регулярных выражений и шаблонных правил. Но лексический анализатор не может проверить синтаксис данного предложения из-за ограничений регулярных выражений. Регулярные выражения не могут проверять балансировочные токены, такие как скобки. Таким образом, на этом этапе используется грамматика без контекста (CFG), которая распознается автоматами.
CFG, с другой стороны, является надмножеством регулярной грамматики, как показано ниже:

Это означает, что каждая регулярная грамматика также не зависит от контекста, но существуют некоторые проблемы, которые выходят за рамки обычной грамматики. CFG — полезный инструмент для описания синтаксиса языков программирования.
Контекстная грамматика
В этом разделе мы сначала увидим определение контекстно-свободной грамматики и введем терминологию, используемую в технологии синтаксического анализа.
Контекстная грамматика состоит из четырех компонентов:
-
Набор нетерминалов (V). Нетерминалы являются синтаксическими переменными, которые обозначают наборы строк. Нетерминалы определяют наборы строк, которые помогают определить язык, генерируемый грамматикой.
-
Набор токенов, известный как терминальные символы (Σ). Терминалы являются основными символами, из которых формируются строки.
-
Набор производств (П). Продукция грамматики определяет способ, которым терминалы и нетерминалы могут быть объединены, чтобы сформировать строки. Каждое производство состоит из нетерминала, называемого левой стороной производства, стрелки и последовательности токенов и / или терминалов , называемых правой стороной производства.
-
Один из нетерминалов обозначен как начальный символ (S); откуда начинается производство.
Набор нетерминалов (V). Нетерминалы являются синтаксическими переменными, которые обозначают наборы строк. Нетерминалы определяют наборы строк, которые помогают определить язык, генерируемый грамматикой.
Набор токенов, известный как терминальные символы (Σ). Терминалы являются основными символами, из которых формируются строки.
Набор производств (П). Продукция грамматики определяет способ, которым терминалы и нетерминалы могут быть объединены, чтобы сформировать строки. Каждое производство состоит из нетерминала, называемого левой стороной производства, стрелки и последовательности токенов и / или терминалов , называемых правой стороной производства.
Один из нетерминалов обозначен как начальный символ (S); откуда начинается производство.
Строки извлекаются из начального символа путем многократной замены нетерминала (первоначально начального символа) правой стороной производства для этого нетерминала.
пример
Мы берем проблему языка палиндрома, который нельзя описать с помощью регулярных выражений. То есть L = {w | w = w R } не является обычным языком. Но это можно описать с помощью CFG, как показано ниже:
G = ( V, Σ, P, S )
Куда:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }
Эта грамматика описывает язык палиндрома, такой как: 1001, 11100111, 00100, 1010101, 11111 и т. Д.
Синтаксические анализаторы
Синтаксический анализатор или анализатор принимает входные данные от лексического анализатора в виде потоков токенов. Анализатор анализирует исходный код (поток токенов) на соответствие производственным правилам, чтобы обнаружить любые ошибки в коде. Результатом этой фазы является дерево разбора .
Таким образом, синтаксический анализатор выполняет две задачи: синтаксический анализ кода, поиск ошибок и генерирование дерева синтаксического анализа в качестве вывода фазы.
Предполагается, что парсеры будут анализировать весь код, даже если в программе есть ошибки. Парсеры используют стратегии восстановления после ошибок, о которых мы узнаем позже в этой главе.
отвлечение
Деривация — это в основном последовательность производственных правил, чтобы получить входную строку. Во время синтаксического анализа мы принимаем два решения для некоторой предложенной формы ввода:
- Решение нетерминала, который должен быть заменен.
- Принятие решения о производственном правиле, по которому будет заменен нетерминал.
Чтобы решить, какой нетерминал заменить производственным правилом, у нас может быть два варианта.
Самый левый вывод
Если форма предложения ввода сканируется и заменяется слева направо, это называется крайним левым выводом. Форма предложения, полученная самым левым выводом, называется формой слева.
Самый правый вывод
Если мы сканируем и заменяем входные данные производственными правилами справа налево, это называется самой правой производной. Форма предложения, полученная из самого правого вывода, называется формой предложения справа.
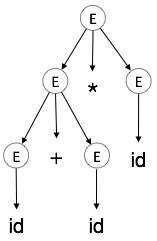
пример
Правила производства:
E → E + E E → E * E E → id
Входная строка: идентификатор + идентификатор * идентификатор
Самый левый вывод:
E → E * E E → E + E * E E → id + E * E E → id + id * E E → id + id * id
Обратите внимание, что крайний левый нетерминал всегда обрабатывается первым.
Самый правый вывод:
E → E + E E → E + E * E E → E + E * id E → E + id * id E → id + id * id
Parse Tree
Дерево разбора — это графическое изображение деривации. Удобно видеть, как строки получаются из начального символа. Начальный символ деривации становится корнем дерева разбора. Давайте посмотрим на это на примере из последней темы.
Мы берем самый левый вывод a + b * c
Самый левый вывод:
E → E * E E → E + E * E E → id + E * E E → id + id * E E → id + id * id
Шаг 1:
| E → E * E | 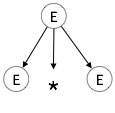 |
Шаг 2:
| E → E + E * E | 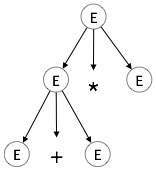 |
Шаг 3:
| E → id + E * E | 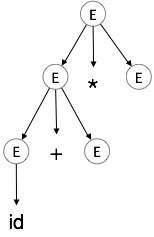 |
Шаг 4:
| E → id + id * E | 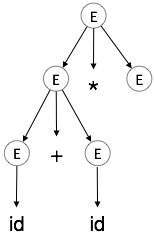 |
Шаг 5:
| E → id + id * id | 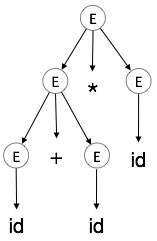 |
В дереве разбора:
- Все конечные узлы являются терминалами.
- Все внутренние узлы не являются терминалами.
- Упорядоченный обход дает исходную строку ввода.
Дерево разбора отображает ассоциативность и приоритет операторов. Сначала перебирается самое глубокое поддерево, поэтому оператор в этом поддереве получает приоритет над оператором, который находится в родительских узлах.
Типы разбора
Синтаксические анализаторы следуют производственным правилам, определенным посредством контекстно-свободной грамматики. Способ реализации правил производства (деривация) разделяет разбор на два типа: разбор сверху вниз и разбор снизу вверх.
Разбор сверху вниз
Когда синтаксический анализатор начинает конструировать дерево анализа из начального символа, а затем пытается преобразовать начальный символ во входные данные, это называется синтаксическим анализом сверху вниз.
-
Разбор рекурсивного спуска : это распространенная форма синтаксического анализа сверху вниз. Он называется рекурсивным, поскольку он использует рекурсивные процедуры для обработки ввода. При рекурсивном разборе страдает откат назад.
-
Возврат . Это означает, что в случае сбоя одного производного процесса анализатор синтаксиса перезапускает процесс, используя разные правила одного и того же производства. Этот метод может обрабатывать входную строку более одного раза, чтобы определить правильную продукцию.
Разбор рекурсивного спуска : это распространенная форма синтаксического анализа сверху вниз. Он называется рекурсивным, поскольку он использует рекурсивные процедуры для обработки ввода. При рекурсивном разборе страдает откат назад.
Возврат . Это означает, что в случае сбоя одного производного процесса анализатор синтаксиса перезапускает процесс, используя разные правила одного и того же производства. Этот метод может обрабатывать входную строку более одного раза, чтобы определить правильную продукцию.
Анализ снизу вверх
Как следует из названия, анализ снизу вверх начинается с входных символов и пытается построить дерево разбора до начального символа.
Пример:
Входная строка: a + b * c
Правила производства:
S → E E → E + T E → E * T E → T T → id
Давайте начнем анализ снизу вверх
a + b * c
Прочитайте ввод и проверьте, совпадает ли какая-либо продукция с вводом:
a + b * c T + b * c E + b * c E + T * c E * c E * T E S
неоднозначность
Грамматика G называется неоднозначной, если она имеет более одного дерева синтаксического анализа (производное слева или справа) хотя бы для одной строки.
пример
E → E + E E → E – E E → id
Для строки id + id — id вышеприведенная грамматика генерирует два дерева разбора:
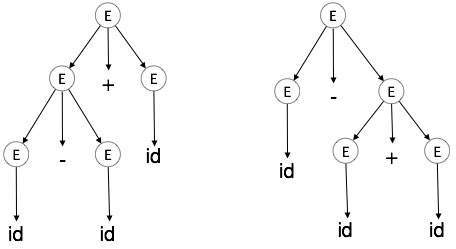
Говорят, что язык, порожденный неоднозначной грамматикой, по своей сути неоднозначен . Неоднозначность в грамматике не годится для компиляции. Ни один метод не может обнаружить и устранить неоднозначность автоматически, но его можно удалить либо переписав всю грамматику без неоднозначности, либо установив и следуя ограничениям ассоциативности и приоритетов.
Ассоциативность
Если операнд имеет операторы с обеих сторон, то сторона, на которой оператор берет этот операнд, определяется ассоциативностью этих операторов. Если операция левоассоциативна, то операнд будет взят левым оператором или, если операция ассоциативно справа, правый оператор примет операнд.
пример
Такие операции, как сложение, умножение, вычитание и деление, остаются ассоциативными. Если выражение содержит:
id op id op id
это будет оценено как:
(id op id) op id
Например, (id + id) + id
Такие операции, как Exponentiation, являются ассоциативными справа, т. Е. Порядок вычисления в том же выражении будет:
id op (id op id)
Например, id ^ (id ^ id)
старшинство
Если два разных оператора совместно используют общий операнд, приоритет отдается оператору, который будет принимать операнд. То есть 2 + 3 * 4 может иметь два разных дерева разбора, одно из которых соответствует (2 + 3) * 4, а другое соответствует 2+ (3 * 4). Установив приоритет среди операторов, эта проблема может быть легко устранена. Как и в предыдущем примере, математически * (умножение) имеет приоритет над + (сложение), поэтому выражение 2 + 3 * 4 всегда будет интерпретироваться как:
2 + (3 * 4)
Эти методы уменьшают вероятность неоднозначности в языке или его грамматике.
Левая рекурсия
Грамматика становится леворекурсивной, если в ней есть какой-либо нетерминальный «A», чье происхождение содержит «A» в качестве самого левого символа. Леворекурсивная грамматика считается проблемной ситуацией для анализаторов сверху вниз. Нисходящие парсеры начинают разбор с символа Start, который сам по себе не является терминальным. Таким образом, когда синтаксический анализатор встречает тот же нетерминал в своем выводе, ему становится трудно судить, когда прекратить синтаксический анализ левого нетерминала, и он входит в бесконечный цикл.
Пример:
(1) A => Aα | β
(2) S => Aα | β
A => Sd
(1) является примером немедленной левой рекурсии, где A — любой нетерминальный символ, а α — строка нетерминалов.
(2) является примером косвенной левой рекурсии.
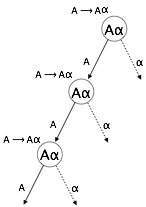
Нисходящий синтаксический анализатор сначала анализирует A, что, в свою очередь, приведет к строке, состоящей из самой A, и анализатор может навсегда зацикливаться.
Удаление левой рекурсии
Один из способов удалить левую рекурсию — использовать следующую технику:
Производство
A => Aα | β
превращается в следующие производства
A => βA’ A => αA’ | ε
Это не влияет на строки, полученные из грамматики, но устраняет непосредственную левую рекурсию.
Второй метод заключается в использовании следующего алгоритма, который должен исключить все прямые и косвенные левые рекурсии.
Algorithm
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai⟹Aj?
with Ai ⟹ δ1? | δ2? | δ3? |…| ?
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
END
пример
Производственный набор
S => Aα | β A => Sd
после применения вышеуказанного алгоритма, должно стать
S => Aα | β A => Aαd | βd
а затем удалите немедленную левую рекурсию, используя первую технику.
A => βdA’ A => αdA’ | ε
Теперь ни у одного производства нет ни прямой, ни косвенной левой рекурсии.
Левый Факторинг
Если более одного правила создания грамматики имеют общую строку префикса, то анализатор, работающий сверху вниз, не может сделать выбор относительно того, какой из производств следует предпринять, чтобы проанализировать строку в руке.
пример
Если нисходящий синтаксический анализатор встречает производство как
A ⟹ αβ | α? | …
Затем он не может определить, какое производство следует выполнить для анализа строки, поскольку оба производства начинаются с одного и того же терминала (или нетерминала). Чтобы устранить эту путаницу, мы используем технику, называемую левым факторингом.
Левый факторинг преобразует грамматику, чтобы сделать ее полезной для анализаторов сверху вниз. В этом методе мы создаем одну продукцию для каждого общего префикса, а остальная часть деривации добавляется новой продукцией.
пример
Вышеуказанные произведения могут быть записаны как
A => αA’ A’=> β | ? | …
Теперь у парсера есть только одна продукция на префикс, что облегчает принятие решений.
Первый и последующие сеты
Важной частью построения таблицы анализатора является создание первого и последующих наборов. Эти наборы могут предоставить фактическую позицию любого терминала в деривации. Это делается для создания таблицы синтаксического анализа, где принимается решение о замене T [A, t] = α на некоторое производственное правило.
Первый сет
Этот набор создан, чтобы знать, какой символ терминала выводится в первой позиции нетерминалом. Например,
α → t β
То есть α выводит t (терминал) в самой первой позиции. Итак, t ∈ FIRST (α).
Алгоритм расчета первого набора
Посмотрите на определение первого набора (α):
- если α терминал, то ПЕРВЫЙ (α) = {α}.
- если α нетерминально и α → ℇ — произведение, то FIRST (α) = {ℇ}.
- если α нетерминально и α → ?1 ?2 ?3… ?n и любой FIRST (?) содержит t, то t находится в FIRST (α).
Первый набор можно рассматривать как: FIRST (α) = {t | α → * t β} ∪ {ℇ | α → * ε}
Следовать сет
Аналогично, мы вычисляем, какой конечный символ следует непосредственно за нетерминальным α в правилах производства. Мы не рассматриваем то, что может генерировать нетерминал, но вместо этого мы видим, каким будет следующий символ терминала, который следует за продукцией нетерминала.
Алгоритм расчета следующий набор:
-
если α является начальным символом, то FOLLOW () = $
-
если α нетерминален и имеет произведение α → AB, то FIRST (B) находится в следующем (A), кроме ℇ.
-
если α нетерминален и имеет произведение α → AB, где B ℇ, то FOLLOW (A) находится в FOLLOW (α).
если α является начальным символом, то FOLLOW () = $
если α нетерминален и имеет произведение α → AB, то FIRST (B) находится в следующем (A), кроме ℇ.
если α нетерминален и имеет произведение α → AB, где B ℇ, то FOLLOW (A) находится в FOLLOW (α).
Следующий набор можно увидеть как: FOLLOW (α) = {t | S * αt *}
Стратегии восстановления после ошибок
Парсер должен уметь обнаруживать и сообщать о любых ошибках в программе. Ожидается, что при возникновении ошибки синтаксический анализатор сможет ее обработать и продолжить анализ остальной части входных данных. В основном от парсера ожидается проверка на наличие ошибок, но ошибки могут встречаться на разных этапах процесса компиляции. Программа может иметь следующие виды ошибок на разных этапах:
-
Лексический : имя некоторого идентификатора набрано неправильно
-
Синтаксический : отсутствует точка с запятой или несбалансированная скобка
-
Семантический : несовместимое присвоение значения
-
Логично : код недоступен, бесконечный цикл
Лексический : имя некоторого идентификатора набрано неправильно
Синтаксический : отсутствует точка с запятой или несбалансированная скобка
Семантический : несовместимое присвоение значения
Логично : код недоступен, бесконечный цикл
Существует четыре распространенных стратегии восстановления после ошибок, которые можно реализовать в синтаксическом анализаторе для устранения ошибок в коде.
Режим паники
Когда синтаксический анализатор обнаруживает ошибку в любом месте оператора, он игнорирует остальную часть оператора, не обрабатывая ввод от ошибочного ввода до разделителя, такого как точка с запятой. Это самый простой способ восстановления после ошибок, а также он предотвращает развитие бесконечных циклов анализатором.
Режим выписки
Когда синтаксический анализатор обнаруживает ошибку, он пытается принять корректирующие меры, чтобы остальные входы оператора позволили синтаксическому анализатору выполнить анализ вперед. Например, вставка пропущенной точки с запятой, замена запятой точкой с запятой и т. Д. Разработчики парсера должны быть здесь осторожны, потому что одно неправильное исправление может привести к бесконечному циклу.
Ошибка производства
Разработчикам компилятора известны некоторые распространенные ошибки, которые могут возникнуть в коде. Кроме того, разработчики могут создавать расширенную грамматику для использования в качестве производств, которые генерируют ошибочные конструкции при обнаружении этих ошибок.
Глобальная коррекция
Синтаксический анализатор рассматривает программу в целом и пытается выяснить, для чего предназначена программа, и пытается найти для нее наиболее близкое соответствие, которое не содержит ошибок. Когда вводится ошибочный ввод (оператор) X, он создает дерево разбора для некоторого ближайшего безошибочного оператора Y. Это может позволить синтаксическому анализатору внести минимальные изменения в исходный код, но из-за сложности (времени и пространства) эта стратегия, она еще не реализована на практике.
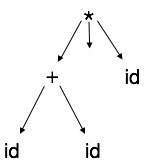
Абстрактные синтаксические деревья
Представления дерева разбора не легко анализируются компилятором, так как они содержат больше деталей, чем фактически необходимо. Возьмите в качестве примера следующее дерево разбора:
Если присмотреться, мы обнаружим, что большинство конечных узлов являются дочерними по отношению к их родительским узлам. Эта информация может быть устранена перед передачей ее на следующий этап. Скрывая дополнительную информацию, мы можем получить дерево, как показано ниже:
Абстрактное дерево может быть представлено как:
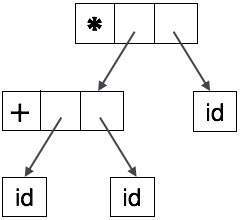
AST — это важные структуры данных в компиляторе с наименьшим количеством ненужной информации. AST более компактны, чем дерево разбора, и могут быть легко использованы компилятором.
Ограничения синтаксических анализаторов
Синтаксические анализаторы получают свои входные данные в виде токенов от лексических анализаторов. Лексические анализаторы несут ответственность за достоверность токена, предоставленного синтаксическим анализатором. Синтаксические анализаторы имеют следующие недостатки:
- он не может определить, является ли токен действительным,
- он не может определить, объявлен ли токен перед его использованием,
- он не может определить, инициализирован ли токен перед его использованием,
- он не может определить, действительна ли операция над типом токена или нет.
Эти задачи выполняются семантическим анализатором, который мы будем изучать в семантическом анализе.
Дизайн компилятора — семантический анализ
Мы узнали, как синтаксический анализатор создает деревья разбора на этапе синтаксического анализа. Простое дерево синтаксического анализа, построенное на этом этапе, как правило, бесполезно для компилятора, поскольку оно не несет никакой информации о том, как оценивать дерево. Производство контекстно-свободной грамматики, которая составляет правила языка, не учитывает, как их интерпретировать.
Например
E → E + T
Вышеупомянутое производство CFG не имеет семантического правила, связанного с ним, и оно не может помочь понять смысл производства.
Семантика
Семантика языка придает смысл его конструкциям, таким как токены и синтаксическая структура. Семантика помогает интерпретировать символы, их типы и их отношения друг с другом. Семантический анализ определяет, имеет ли синтаксическая структура, созданная в исходной программе, какое-либо значение или нет.
CFG + semantic rules = Syntax Directed Definitions
Например:
int a = “value”;
не должен выдавать ошибку на этапе лексического и синтаксического анализа, поскольку он является лексическим и структурно правильным, но он должен генерировать семантическую ошибку, поскольку тип назначения различается. Эти правила устанавливаются грамматикой языка и оцениваются в семантическом анализе. В семантическом анализе должны быть выполнены следующие задачи:
- Разрешение области
- Проверка типа
- Проверка массива
Семантические ошибки
Мы упомянули некоторые из ошибок семантики, которые, как ожидается, распознает семантический анализатор:
- Несоответствие типов
- Необъявленная переменная
- Использование зарезервированного идентификатора.
- Многократное объявление переменной в области видимости.
- Доступ к переменной вне области.
- Фактическое и формальное несоответствие параметров.
Атрибут Грамматика
Грамматика атрибута — это особая форма контекстно-свободной грамматики, в которой некоторая дополнительная информация (атрибуты) добавляется к одному или нескольким ее нетерминалам для предоставления контекстно-зависимой информации. Каждый атрибут имеет четко определенный домен значений, таких как целое число, число с плавающей запятой, символ, строка и выражения.
Грамматика атрибутов — это среда, обеспечивающая семантику для контекстно-свободной грамматики, и она может помочь определить синтаксис и семантику языка программирования. Грамматика атрибута (при просмотре в виде дерева разбора) может передавать значения или информацию между узлами дерева.
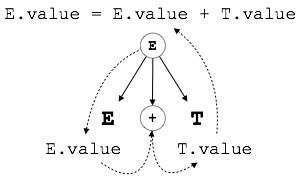
Пример:
E → E + T { E.value = E.value + T.value }
Правая часть CFG содержит семантические правила, которые определяют, как следует интерпретировать грамматику. Здесь значения нетерминалов E и T складываются вместе, и результат копируется в нетерминал E.
Семантические атрибуты могут быть назначены их значениям из их домена во время синтаксического анализа и оценены во время назначения или условий. В зависимости от того, как атрибуты получают свои значения, их можно разделить на две категории: синтезированные атрибуты и унаследованные атрибуты.
Синтезированные атрибуты
Эти атрибуты получают значения из значений атрибутов своих дочерних узлов. Для иллюстрации предположим следующую продукцию:
S → ABC
Если S принимает значения из своих дочерних узлов (A, B, C), то он называется синтезированным атрибутом, поскольку значения ABC синтезируются в S.
Как и в нашем предыдущем примере (E → E + T), родительский узел E получает свое значение от своего дочернего узла. Синтезированные атрибуты никогда не принимают значения из своих родительских узлов или любых дочерних узлов.
Унаследованные атрибуты
В отличие от синтезированных атрибутов, унаследованные атрибуты могут принимать значения от родителя и / или братьев и сестер. Как и в следующем производстве,
S → ABC
A может получать значения из S, B и C. B может принимать значения из S, A и C. Аналогично, C может принимать значения из S, A и B.
Расширение : когда нетерминал расширяется до терминалов согласно грамматическому правилу
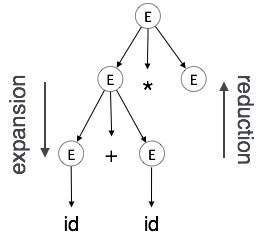
Сокращение : когда терминал сокращен до соответствующего ему нетерминала согласно грамматическим правилам. Синтаксические деревья анализируются сверху вниз и слева направо. Всякий раз, когда происходит сокращение, мы применяем соответствующие ему семантические правила (действия).
Семантический анализ использует синтаксически направленные переводы для выполнения вышеуказанных задач.
Семантический анализатор получает AST (Абстрактное синтаксическое дерево) с предыдущего этапа (синтаксический анализ).
Семантический анализатор присоединяет информацию об атрибутах с помощью AST, которые называются Attributed AST.
Атрибутами являются два значения кортежа, <имя атрибута, значение атрибута>
Например:
int value = 5; <type, “integer”> <presentvalue, “5”>
Для каждого производства мы прилагаем семантическое правило.
S-атрибут SDT
Если SDT использует только синтезированные атрибуты, он называется S-атрибутным SDT. Эти атрибуты оцениваются с использованием S-атрибутов SDT, семантические действия которых записаны после производства (справа).
Как показано выше, атрибуты в S-атрибутных SDT оцениваются при анализе снизу вверх, поскольку значения родительских узлов зависят от значений дочерних узлов.
L-атрибут SDT
Эта форма SDT использует как синтезированные, так и унаследованные атрибуты с ограничением не принимать значения от правильных братьев и сестер.
В LT-атрибутных SDT нетерминалы могут получать значения из родительских, дочерних и дочерних узлов. Как в следующем производстве
S → ABC
S может принимать значения из A, B и C (синтезировано). A может принимать значения только из S. B может принимать значения от S и A. C может получать значения от S, A и B. Ни один нетерминал не может получить значения от родного брата справа от него.
Атрибуты в L-атрибутных SDT оцениваются методом разбора по глубине и слева направо.
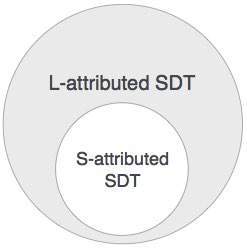
Мы можем заключить, что если определение S-атрибутировано, то оно также L-атрибутировано, так как L-атрибутированное определение включает S-атрибутированные определения.
Дизайн компилятора — Парсер
В предыдущей главе мы поняли основные понятия, связанные с анализом. В этой главе мы изучим различные типы доступных методов построения синтаксического анализатора.
Синтаксический анализ может быть определен как нисходящий или восходящий в зависимости от того, как построено дерево разбора.
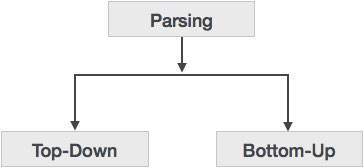
Разбор сверху вниз
В предыдущей главе мы узнали, что метод синтаксического анализа сверху вниз анализирует входные данные и начинает создавать дерево синтаксического анализа от корневого узла, постепенно перемещаясь вниз к конечным узлам. Типы синтаксического анализа сверху вниз показаны ниже:
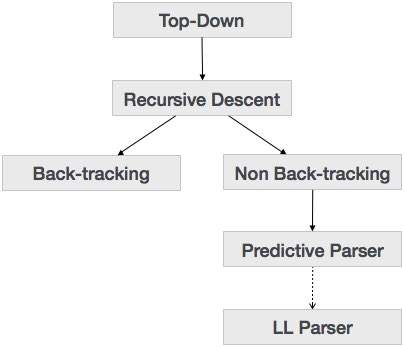
Разбор рекурсивного спуска
Рекурсивный спуск — это метод синтаксического анализа сверху вниз, который создает дерево разбора сверху, а входные данные читаются слева направо. Он использует процедуры для каждого терминала и нетерминального объекта. Этот метод синтаксического анализа рекурсивно анализирует входные данные для создания дерева разбора, которое может требовать или не требовать обратного отслеживания. Но грамматика, связанная с ней (если не оставить факторизованной), не может избежать обратного отслеживания. Форма синтаксического анализа с рекурсивным спуском, которая не требует обратного отслеживания, называется предиктивным анализом .
Этот метод синтаксического анализа считается рекурсивным, так как он использует грамматику без контекста, которая по своей природе является рекурсивной.
Back-трекинга
Сверху вниз парсеры начинаются с корневого узла (начальный символ) и сопоставляют входную строку с производственными правилами, чтобы заменить их (если они совпадают). Чтобы понять это, возьмите следующий пример CFG:
S → rXd | rZd X → oa | ea Z → ai
Для входной строки: read, анализатор сверху вниз, будет вести себя так:
Он будет начинаться с S из правил производства и будет сопоставлять его выход с самой левой буквой ввода, т. Е. ‘R’. Само производство S (S → rXd) совпадает с этим. Таким образом, нисходящий синтаксический анализатор переходит к следующей вводимой букве (то есть ‘e’). Парсер пытается развернуть нетерминал ‘X’ и проверяет его производство слева (X → oa). Он не совпадает со следующим символом ввода. Поэтому нисходящий синтаксический анализатор возвращает назад, чтобы получить следующее производственное правило X, (X → ea).
Теперь парсер сопоставляет все введенные буквы упорядоченным образом. Строка принята.
Прогнозирующий парсер
Predictive parser — это синтаксический анализатор с рекурсивным спуском, который может предсказать, какую продукцию использовать для замены входной строки. Прогностический парсер не страдает от возврата.
Для выполнения своих задач синтаксический анализатор использует упреждающий указатель, который указывает на следующие входные символы. Чтобы сделать анализатор обратным отслеживанием свободным, прогнозирующий синтаксический анализатор накладывает некоторые ограничения на грамматику и принимает только класс грамматики, известный как LL (k) грамматика.
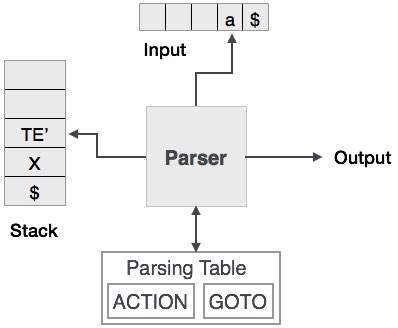
Прогнозирующий синтаксический анализ использует стек и таблицу синтаксического анализа для анализа входных данных и создания дерева синтаксического анализа. И стек, и вход содержит конечный символ $, обозначающий, что стек пуст и вход используется. Синтаксический анализатор обращается к таблице синтаксического анализа, чтобы принять любое решение относительно комбинации элементов ввода и стека.
При анализе с рекурсивным спуском у синтаксического анализатора может быть несколько вариантов выбора для одного экземпляра входных данных, тогда как в прогнозирующем синтаксическом анализаторе у каждого шага есть не более одного производства. Могут быть случаи, когда нет никакой продукции, соответствующей входной строке, что приводит к сбою процедуры синтаксического анализа.
LL Parser
LL Parser принимает грамматику LL. LL грамматика — это подмножество контекстно-свободной грамматики, но с некоторыми ограничениями, чтобы получить упрощенную версию, чтобы добиться легкой реализации. LL грамматика может быть реализована с помощью обоих алгоритмов, а именно рекурсивного спуска или табличного управления.
LL-парсер обозначается как LL (k). Первый L в LL (k) анализирует входные данные слева направо, второй L в LL (k) обозначает самый левый вывод, а само k представляет количество заблаговременных просмотров. Обычно k = 1, поэтому LL (k) также можно записать как LL (1).
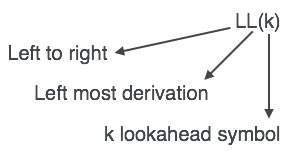
Алгоритм синтаксического анализа LL
Мы можем придерживаться детерминированного LL (1) для объяснения синтаксического анализатора, так как размер таблицы растет экспоненциально со значением k. Во-вторых, если данная грамматика не является LL (1), то обычно это не LL (k) для любого заданного k.
Ниже приведен алгоритм синтаксического анализа LL (1):
Input: string ω parsing table M for grammar G Output: If ω is in L(G) then left-most derivation of ω, error otherwise. Initial State : $S on stack (with S being start symbol) ω$ in the input buffer SET ip to point the first symbol of ω$. repeat let X be the top stack symbol and a the symbol pointed by ip. if X∈ V t or $ if X = a POP X and advance ip. else error() endif else /* X is non-terminal */ if M[X,a] = X → Y1, Y2,... Yk POP X PUSH Yk, Yk-1,... Y1 /* Y1 on top */ Output the production X → Y1, Y2,... Yk else error() endif endif until X = $ /* empty stack */
Грамматика G — это LL (1), если A-> alpha | б два разных производства G:
-
для терминалов нет, и альфа, и бета получают строки, начинающиеся с.
-
не более одного из альфа и бета может получить пустую строку.
-
если бета => t, то альфа не выводит строку, начинающуюся с терминала в FOLLOW (A).
для терминалов нет, и альфа, и бета получают строки, начинающиеся с.
не более одного из альфа и бета может получить пустую строку.
если бета => t, то альфа не выводит строку, начинающуюся с терминала в FOLLOW (A).
Анализ снизу вверх
Анализ снизу вверх начинается с листовых узлов дерева и работает в направлении вверх, пока не достигнет корневого узла. Здесь мы начинаем с предложения, а затем применяем правила производства в обратном порядке, чтобы достичь начального символа. На приведенном ниже изображении показаны доступные парсеры снизу вверх.
Shift-Reduce Parsing
Разбор Shift-Reduce использует два уникальных шага для анализа снизу вверх. Эти шаги известны как шаг сдвига и шаг понижения.
-
Шаг сдвига: шаг сдвига относится к продвижению входного указателя к следующему входному символу, который называется смещенным символом. Этот символ помещается в стек. Смещенный символ обрабатывается как один узел дерева разбора.
-
Шаг сокращения : когда анализатор находит полное правило грамматики (RHS) и заменяет его на (LHS), это называется сокращением шага. Это происходит, когда вершина стека содержит дескриптор. Чтобы уменьшить, функция POP выполняется в стеке, который выскакивает из дескриптора и заменяет его нетерминальным символом LHS.
Шаг сдвига: шаг сдвига относится к продвижению входного указателя к следующему входному символу, который называется смещенным символом. Этот символ помещается в стек. Смещенный символ обрабатывается как один узел дерева разбора.
Шаг сокращения : когда анализатор находит полное правило грамматики (RHS) и заменяет его на (LHS), это называется сокращением шага. Это происходит, когда вершина стека содержит дескриптор. Чтобы уменьшить, функция POP выполняется в стеке, который выскакивает из дескриптора и заменяет его нетерминальным символом LHS.
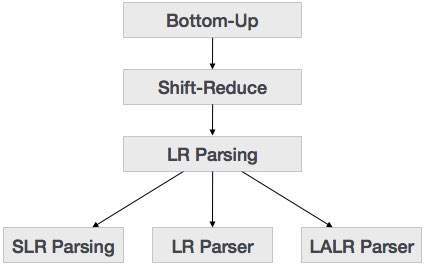
LR Parser
Парсер LR — это нерекурсивный парсер снизу вверх. Он использует широкий класс контекстно-свободной грамматики, что делает его наиболее эффективным методом синтаксического анализа. Парсеры LR также известны как парсеры LR (k), где L обозначает сканирование входного потока слева направо; R обозначает построение крайнего правого вывода в обратном направлении, а k обозначает количество символов предпросмотра для принятия решений.
Существует три широко используемых алгоритма для создания парсера LR:
- SLR (1) — простой анализатор LR:
- Работает на наименьшем классе грамматики
- Несколько штатов, следовательно, очень маленькая таблица
- Простая и быстрая конструкция
- LR (1) — LR Parser:
- Работы по комплектации грамматики LR (1)
- Создает большую таблицу и большое количество состояний
- Медленное строительство
- LALR (1) — синтаксический анализатор LR:
- Работает на среднем уровне грамматики
- Количество состояний такое же, как в SLR (1)
Алгоритм синтаксического анализа LR
Здесь мы опишем скелетный алгоритм парсера LR:
token = next_token() repeat forever s = top of stack if action[s, token] = “shift si” then PUSH token PUSH si token = next_token() else if action[s, tpken] = “reduce A::= β“ then POP 2 * |β| symbols s = top of stack PUSH A PUSH goto[s,A] else if action[s, token] = “accept” then return else error()
LL vs. LR
| LL | LR |
|---|---|
| Делает самый левый вывод. | Делает самый правый вывод в обратном порядке. |
| Начинается с корневого нетерминала в стеке. | Заканчивается корневым нетерминалом в стеке. |
| Заканчивается, когда стек пуст. | Начинается с пустого стека. |
| Использует стек для обозначения того, что еще ожидается. | Использует стек для обозначения того, что уже увидено. |
| Строит дерево разбора сверху вниз. | Строит дерево разбора снизу вверх. |
| Непрерывно выталкивает нетерминал из стека и выталкивает соответствующую правую часть. | Пытается распознать правую часть стека, вытолкнуть его и вытолкнуть соответствующий нетерминал. |
| Расширяет нетерминалы. | Уменьшает нетерминалы. |
| Читает терминалы, когда он выталкивает один из стека. | Читает терминалы, пока он толкает их в стек. |
| Предварительный порядок обхода дерева разбора. | Последовательный обход дерева разбора. |
Проектирование компилятора — среда выполнения
Программа в качестве исходного кода — это просто набор текста (код, операторы и т. Д.), И для того, чтобы сделать его живым, необходимо выполнить действия на целевой машине. Для выполнения инструкций программе необходимы ресурсы памяти. Программа содержит имена для процедур, идентификаторов и т. Д., Которые требуют сопоставления с фактическим расположением памяти во время выполнения.
Под временем выполнения мы подразумеваем программу в процессе выполнения. Среда выполнения — это состояние целевого компьютера, которое может включать библиотеки программного обеспечения, переменные среды и т. Д., Чтобы предоставлять услуги процессам, работающим в системе.
Система поддержки времени выполнения — это пакет, который в основном генерируется самой исполняемой программой и облегчает взаимодействие процесса между процессом и средой выполнения. Он заботится о выделении и удалении памяти во время выполнения программы.
Деревья активации
Программа — это последовательность инструкций, объединенных в несколько процедур. Инструкции в процедуре выполняются последовательно. Процедура имеет начальный и конечный разделители, и все, что внутри нее, называется телом процедуры. Идентификатор процедуры и последовательность конечных инструкций внутри нее составляют тело процедуры.
Выполнение процедуры называется ее активацией. Запись активации содержит всю необходимую информацию, необходимую для вызова процедуры. Запись активации может содержать следующие единицы (в зависимости от используемого исходного языка).
| временных | Хранит временные и промежуточные значения выражения. |
| Локальные данные | Хранит локальные данные вызванной процедуры. |
| Статус машины | Сохраняет состояние машины, такое как регистры, счетчик программ и т. Д., До вызова процедуры. |
| Контрольная ссылка | Хранит адрес активации записи вызывающей процедуры. |
| Ссылка доступа | Хранит информацию о данных, которые находятся за пределами локальной области. |
| Фактические параметры | Сохраняет фактические параметры, то есть параметры, которые используются для отправки ввода в вызываемую процедуру. |
| Возвращаемое значение | Магазины возвращают значения. |
Всякий раз, когда процедура выполняется, ее запись активации сохраняется в стеке, также известном как стек управления. Когда процедура вызывает другую процедуру, выполнение вызывающей стороны приостанавливается до тех пор, пока вызываемая процедура не завершит выполнение. В это время запись активации вызванной процедуры сохраняется в стеке.
Мы предполагаем, что управление программой выполняется последовательно, и когда процедура вызывается, ее управление передается вызываемой процедуре. Когда вызванная процедура выполняется, она возвращает элемент управления вызывающей стороне. Этот тип потока управления упрощает представление серии активаций в форме дерева, известного как дерево активации .
Чтобы понять эту концепцию, мы возьмем кусок кода в качестве примера:
. . .
printf(“Enter Your Name: “);
scanf(“%s”, username);
show_data(username);
printf(“Press any key to continue…”);
. . .
int show_data(char *user)
{
printf(“Your name is %s”, username);
return 0;
}
. . .
Ниже приведено дерево активации приведенного кода.
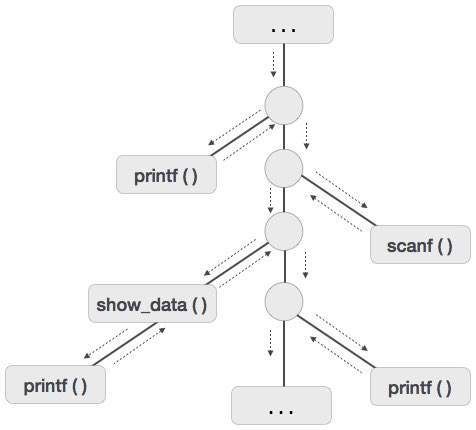
Теперь мы понимаем, что процедуры выполняются в глубину, поэтому распределение стеков является наиболее подходящей формой хранения для активаций процедур.
Распределение памяти
Среда выполнения управляет требованиями к памяти во время выполнения для следующих объектов:
-
Код : Он известен как текстовая часть программы, которая не изменяется во время выполнения. Требования к памяти известны во время компиляции.
-
Процедуры : их текстовая часть статична, но они вызываются случайным образом. Вот почему стековое хранилище используется для управления вызовами и активациями процедур.
-
Переменные . Переменные известны только во время выполнения, если они не являются глобальными или постоянными. Схема выделения памяти кучи используется для управления распределением и выделением памяти для переменных во время выполнения.
Код : Он известен как текстовая часть программы, которая не изменяется во время выполнения. Требования к памяти известны во время компиляции.
Процедуры : их текстовая часть статична, но они вызываются случайным образом. Вот почему стековое хранилище используется для управления вызовами и активациями процедур.
Переменные . Переменные известны только во время выполнения, если они не являются глобальными или постоянными. Схема выделения памяти кучи используется для управления распределением и выделением памяти для переменных во время выполнения.
Статическое Распределение
В этой схеме размещения данные компиляции привязаны к фиксированному месту в памяти и не изменяются при выполнении программы. Поскольку требования к памяти и места хранения известны заранее, пакет поддержки времени выполнения для выделения и перераспределения памяти не требуется.
Распределение стека
Вызовы процедур и их активации управляются посредством выделения стековой памяти. Он работает в методе «последний пришел первым» (LIFO), и эта стратегия распределения очень полезна для рекурсивных вызовов процедур.
Распределение кучи
Переменные, локальные для процедуры, выделяются и удаляются только во время выполнения. Распределение кучи используется для динамического выделения памяти для переменных и получения ее обратно, когда переменные больше не требуются.
За исключением статически выделенной области памяти, память стека и кучи может увеличиваться и уменьшаться динамически и неожиданно. Следовательно, они не могут быть обеспечены фиксированным объемом памяти в системе.
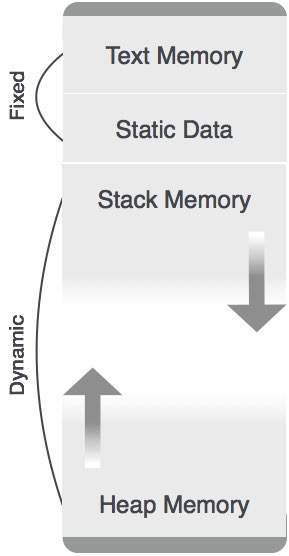
Как показано на рисунке выше, текстовой части кода выделяется фиксированный объем памяти. Память стека и кучи располагаются в пределах общего объема памяти, выделенной программе. Оба уменьшаются и растут друг против друга.
Передача параметров
Среда связи между процедурами называется передачей параметров. Значения переменных из вызывающей процедуры передаются в вызываемую процедуру некоторым механизмом. Прежде чем двигаться вперед, сначала пройдемся по некоторым основным терминологиям, относящимся к значениям в программе.
г-значение
Значение выражения называется его r-значением. Значение, содержащееся в одной переменной, также становится r-значением, если оно появляется в правой части оператора присваивания. Значения r всегда можно присвоить некоторой другой переменной.
л-значение
Местоположение памяти (адрес), где хранится выражение, называется l-значением этого выражения. Он всегда отображается слева от оператора присваивания.
Например:
day = 1; week = day * 7; month = 1; year = month * 12;
Из этого примера мы понимаем, что постоянные значения, такие как 1, 7, 12, и переменные, такие как день, неделя, месяц и год, все имеют r-значения. Только переменные имеют l-значения, так как они также представляют ячейку памяти, назначенную им.
Например:
7 = x + y;
является ошибкой l-значения, поскольку константа 7 не представляет какую-либо ячейку памяти.
Формальные параметры
Переменные, которые принимают информацию, переданную процедурой вызывающей стороны, называются формальными параметрами. Эти переменные объявляются в определении вызываемой функции.
Фактические параметры
Переменные, значения или адреса которых передаются в вызываемую процедуру, называются фактическими параметрами. Эти переменные указываются в вызове функции в качестве аргументов.
Пример:
fun_one()
{
int actual_parameter = 10;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}
Формальные параметры содержат информацию о фактическом параметре, в зависимости от используемого метода передачи параметров. Это может быть значение или адрес.
Передать по значению
В механизме передачи по значению вызывающая процедура передает r-значение фактических параметров, и компилятор помещает это в запись активации вызываемой процедуры. Затем формальные параметры содержат значения, переданные вызывающей процедурой. Если значения, содержащиеся в формальных параметрах, изменяются, это не должно влиять на фактические параметры.
Передача по ссылке
При передаче по эталонному механизму значение l фактического параметра копируется в запись активации вызванной процедуры. Таким образом, вызываемая процедура теперь имеет адрес (ячейку памяти) фактического параметра, а формальный параметр ссылается на ту же ячейку памяти. Поэтому, если значение, указанное формальным параметром, изменяется, влияние должно быть видно на фактический параметр, поскольку они также должны указывать на одно и то же значение.
Пройти копировать-восстановить
Этот механизм передачи параметров работает аналогично «передаче по ссылке» за исключением того, что изменения в фактических параметрах делаются, когда завершается вызываемая процедура. При вызове функции значения фактических параметров копируются в запись активации вызванной процедуры. Формальные параметры, если ими манипулируют, не влияют в реальном времени на фактические параметры (поскольку передаются l-значения), но когда завершается вызванная процедура, l-значения формальных параметров копируются в l-значения фактических параметров.
Пример:
int y;
calling_procedure()
{
y = 10;
copy_restore(y); //l-value of y is passed
printf y; //prints 99
}
copy_restore(int x)
{
x = 99; // y still has value 10 (unaffected)
y = 0; // y is now 0
}
Когда эта функция заканчивается, значение l формального параметра x копируется в фактический параметр y. Даже если значение y изменяется до завершения процедуры, l-значение x копируется в l-значение y, что ведет себя как вызов по ссылке.
Передать по имени
Такие языки, как Algol, предоставляют новый тип механизма передачи параметров, который работает как препроцессор в языке Си. В механизме передачи по имени имя вызываемой процедуры заменяется ее фактическим телом. Передача по имени заменяет выражения аргумента в вызове процедуры на соответствующие параметры в теле процедуры, чтобы теперь она могла работать с фактическими параметрами, подобно передаче по ссылке.
Дизайн компилятора — таблица символов
Таблица символов — это важная структура данных, созданная и поддерживаемая компиляторами для хранения информации о появлении различных объектов, таких как имена переменных, имена функций, объекты, классы, интерфейсы и т. Д. Таблица символов используется как для анализа, так и для синтеза. части компилятора.
Таблица символов может служить следующим целям в зависимости от используемого языка:
-
Хранить имена всех сущностей в структурированной форме в одном месте.
-
Чтобы проверить, была ли объявлена переменная.
-
Чтобы реализовать проверку типов, путем проверки присваиваний и выражений в исходном коде семантически правильно.
-
Чтобы определить область имени (разрешение области).
Хранить имена всех сущностей в структурированной форме в одном месте.
Чтобы проверить, была ли объявлена переменная.
Чтобы реализовать проверку типов, путем проверки присваиваний и выражений в исходном коде семантически правильно.
Чтобы определить область имени (разрешение области).
Таблица символов — это просто таблица, которая может быть линейной или хеш-таблицей. Он поддерживает запись для каждого имени в следующем формате:
<symbol name, type, attribute>
Например, если таблица символов должна хранить информацию о следующем объявлении переменной:
static int interest;
тогда он должен хранить запись, такую как:
<interest, int, static>
Предложение атрибута содержит записи, связанные с именем.
Реализация
Если компилятор должен обрабатывать небольшой объем данных, тогда таблица символов может быть реализована в виде неупорядоченного списка, который легко кодировать, но он подходит только для небольших таблиц. Таблица символов может быть реализована одним из следующих способов:
- Линейный (отсортированный или несортированный) список
- Двоичное дерево поиска
- Хеш-таблица
Среди всех таблиц символов в основном реализованы в виде хеш-таблиц, где сам символ исходного кода рассматривается как ключ для хэш-функции, а возвращаемое значение является информацией о символе.
операции
Таблица символов, как линейная, так и хэш, должна обеспечивать следующие операции.
вставить ()
Эта операция чаще используется на этапе анализа, т. Е. В первой половине компилятора, где идентифицируются токены и имена хранятся в таблице. Эта операция используется для добавления в таблицу символов информации об уникальных именах, встречающихся в исходном коде. Формат или структура, в которой хранятся имена, зависит от используемого компилятора.
Атрибутом символа в исходном коде является информация, связанная с этим символом. Эта информация содержит значение, состояние, область и тип символа. Функция insert () принимает символ и его атрибуты в качестве аргументов и сохраняет информацию в таблице символов.
Например:
int a;
должен быть обработан компилятором как:
insert(a, int);
уважать()
Операция lookup () используется для поиска имени в таблице символов для определения:
- если символ существует в таблице.
- если он объявлен до его использования.
- если имя используется в области.
- если символ инициализирован.
- если символ объявлен несколько раз.
Формат функции lookup () зависит от языка программирования. Базовый формат должен соответствовать следующему:
lookup(symbol)
Этот метод возвращает 0 (ноль), если символ не существует в таблице символов. Если символ существует в таблице символов, он возвращает свои атрибуты, хранящиеся в таблице.
Управление областью
Компилятор поддерживает два типа таблиц символов: глобальную таблицу символов, к которой могут обращаться все процедуры, и таблицы символов области , которые создаются для каждой области в программе.
Чтобы определить область имени, таблицы символов расположены в иерархической структуре, как показано в примере ниже:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .
Вышеуказанная программа может быть представлена в иерархической структуре таблиц символов:
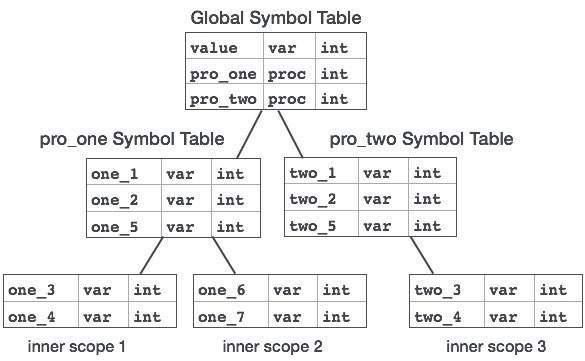
Глобальная таблица символов содержит имена для одной глобальной переменной (значение int) и двух имен процедур, которые должны быть доступны для всех дочерних узлов, показанных выше. Имена, упомянутые в таблице символов pro_one (и всех ее дочерних таблицах), недоступны для символов pro_two и его дочерних таблиц.
Эта иерархия структуры данных таблицы символов хранится в семантическом анализаторе, и всякий раз, когда нужно искать имя в таблице символов, он ищется с использованием следующего алгоритма:
-
сначала будет выполнен поиск символа в текущей области видимости, то есть в текущей таблице символов.
-
если имя найдено, то поиск завершен, иначе оно будет искать в таблице родительских символов до тех пор, пока
-
либо имя найдено, либо имя таблицы было найдено в глобальной таблице символов.
сначала будет выполнен поиск символа в текущей области видимости, то есть в текущей таблице символов.
если имя найдено, то поиск завершен, иначе оно будет искать в таблице родительских символов до тех пор, пока
либо имя найдено, либо имя таблицы было найдено в глобальной таблице символов.
Компилятор — промежуточная генерация кода
Исходный код может быть непосредственно переведен в его целевой машинный код, тогда зачем вообще нужно переводить исходный код в промежуточный код, который затем транслируется в его целевой код? Давайте посмотрим причины, по которым нам нужен промежуточный код.
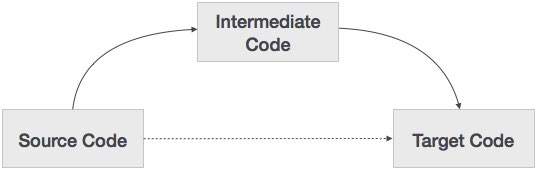
-
Если компилятор переводит исходный язык на свой целевой машинный язык, не имея возможности генерировать промежуточный код, то для каждой новой машины требуется полный собственный компилятор.
-
Промежуточный код устраняет необходимость в новом полном компиляторе для каждой уникальной машины, сохраняя часть анализа одинаковой для всех компиляторов.
-
Вторая часть компилятора, синтез, изменяется в зависимости от целевой машины.
-
Становится легче применять модификации исходного кода для повышения производительности кода, применяя методы оптимизации кода к промежуточному коду.
Если компилятор переводит исходный язык на свой целевой машинный язык, не имея возможности генерировать промежуточный код, то для каждой новой машины требуется полный собственный компилятор.
Промежуточный код устраняет необходимость в новом полном компиляторе для каждой уникальной машины, сохраняя часть анализа одинаковой для всех компиляторов.
Вторая часть компилятора, синтез, изменяется в зависимости от целевой машины.
Становится легче применять модификации исходного кода для повышения производительности кода, применяя методы оптимизации кода к промежуточному коду.
Промежуточное Представительство
Промежуточные коды могут быть представлены различными способами, и они имеют свои преимущества.
-
High Level IR — высокоуровневое представление промежуточного кода очень близко к самому исходному языку. Они могут быть легко сгенерированы из исходного кода, и мы можем легко применить модификации кода для повышения производительности. Но для оптимизации целевой машины это менее предпочтительно.
-
Низкоуровневое ИК — Это устройство близко к целевой машине, что делает его пригодным для распределения регистров и памяти, выбора набора команд и т. Д. Это хорошо для машинно-зависимых оптимизаций.
High Level IR — высокоуровневое представление промежуточного кода очень близко к самому исходному языку. Они могут быть легко сгенерированы из исходного кода, и мы можем легко применить модификации кода для повышения производительности. Но для оптимизации целевой машины это менее предпочтительно.
Низкоуровневое ИК — Это устройство близко к целевой машине, что делает его пригодным для распределения регистров и памяти, выбора набора команд и т. Д. Это хорошо для машинно-зависимых оптимизаций.
Промежуточный код может быть либо специфичным для языка (например, Байт-код для Java), либо независимым от языка (трехадресный код).
Трехадресный код
Генератор промежуточного кода получает входные данные от своего предшественника, семантического анализатора, в форме аннотированного синтаксического дерева. Затем это синтаксическое дерево может быть преобразовано в линейное представление, например постфиксную запись. Промежуточный код, как правило, является машинно-независимым кодом. Следовательно, генератор кода предполагает наличие неограниченного количества памяти (регистра) для генерации кода.
Например:
a = b + c * d;
Генератор промежуточного кода попытается разделить это выражение на подвыражения, а затем сгенерирует соответствующий код.
r1 = c * d; r2 = b + r1; a = r2
используется в качестве регистров в целевой программе.
Трехадресный код имеет не более трех адресных местоположений для вычисления выражения. Трехадресный код может быть представлен в двух формах: четверки и тройки.
четверок
Каждая инструкция в четырехкратном представлении разделена на четыре поля: оператор, arg1, arg2 и результат. Приведенный выше пример представлен ниже в формате четверок:
| Op | аргумент 1 | аргумент 2 | результат |
| * | с | d | r1 |
| + | б | r1 | r2 |
| + | r2 | r1 | r3 |
| знак равно | r3 |
троек
Каждая инструкция в представлении триплета имеет три поля: op, arg1 и arg2.Результаты соответствующих подвыражений обозначаются позицией выражения. Тройки представляют сходство с DAG и синтаксическим деревом. Они эквивалентны DAG при представлении выражений.
| Op | аргумент 1 | аргумент 2 |
| * | с | d |
| + | б | (0) |
| + | (1) | (0) |
| знак равно | (2) |
Тройки сталкиваются с проблемой неподвижности кода при оптимизации, поскольку результаты являются позиционными, и изменение порядка или позиции выражения может вызвать проблемы.
Косвенные тройки
Это представление является улучшением по сравнению с представлением троек. Он использует указатели вместо позиции для хранения результатов. Это позволяет оптимизаторам свободно перемещать подвыражение для получения оптимизированного кода.
Объявления
Переменная или процедура должна быть объявлена, прежде чем ее можно будет использовать. Декларация включает в себя выделение места в памяти и запись типа и имени в таблице символов. Программа может быть закодирована и разработана с учетом структуры целевой машины, но не всегда возможно точно преобразовать исходный код в целевой язык.
Принимая всю программу как набор процедур и подпроцедур, становится возможным объявить все имена, локальные для процедуры. Выделение памяти производится последовательно, а имена выделяются памяти в той последовательности, в которой они объявлены в программе. Мы используем переменную смещения и устанавливаем ее в ноль {offset = 0}, которая обозначает базовый адрес.
Исходный язык программирования и архитектура целевого компьютера могут варьироваться в зависимости от способа хранения имен, поэтому используется относительная адресация. В то время как первое имя выделяется памяти, начиная с ячейки памяти 0 {offset = 0}, следующее имя, объявленное позже, должно быть выделено памяти рядом с первым.
Пример:
Мы возьмем пример языка программирования Си, где целочисленной переменной назначается 2 байта памяти, а переменной с плавающей запятой назначается 4 байта памяти.
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}
Для ввода этой детали в таблицу символов можно использовать процедуру ввода . Этот метод может иметь следующую структуру:
enter(name, type, offset)
Эта процедура должна создать запись в таблице символов для имени переменной с типом, установленным на тип, и относительным смещением адреса в ее области данных.
Дизайн компилятора — генерация кода
Генерация кода может рассматриваться как финальная фаза компиляции. Посредством генерации почтового кода процесс оптимизации может быть применен к коду, но это может рассматриваться как часть самой фазы генерации кода. Код, сгенерированный компилятором, является объектным кодом некоторого языка программирования более низкого уровня, например, языка ассемблера. Мы видели, что исходный код, написанный на языке более высокого уровня, преобразуется в язык более низкого уровня, что приводит к объектному коду более низкого уровня, который должен иметь следующие минимальные свойства:
- Он должен нести точное значение исходного кода.
- Он должен быть эффективным с точки зрения использования процессора и управления памятью.
Теперь мы увидим, как промежуточный код преобразуется в код целевого объекта (в данном случае ассемблерный код).
Направленный ациклический граф
Направленный ациклический граф (DAG) — это инструмент, который отображает структуру базовых блоков, помогает видеть поток значений, проходящих между базовыми блоками, а также предлагает оптимизацию. DAG обеспечивает легкое преобразование на основных блоках. DAG можно понять здесь:
-
Конечные узлы представляют идентификаторы, имена или константы.
-
Внутренние узлы представляют операторов.
-
Внутренние узлы также представляют результаты выражений или идентификаторов / имен, где значения должны быть сохранены или назначены.
Конечные узлы представляют идентификаторы, имена или константы.
Внутренние узлы представляют операторов.
Внутренние узлы также представляют результаты выражений или идентификаторов / имен, где значения должны быть сохранены или назначены.
Пример:
t 0 = a + b t 1 = t 0 + c d = t 0 + t 1
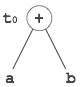
[t 0 = a + b] |
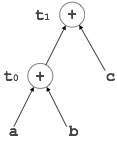
[t 1 = t 0 + c] |
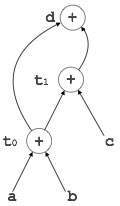
[d = t 0 + t 1 ] |
[t 0 = a + b]
[t 1 = t 0 + c]
[d = t 0 + t 1 ]
Оптимизация глазка
Этот метод оптимизации работает локально над исходным кодом, чтобы преобразовать его в оптимизированный код. Под локально мы подразумеваем небольшую часть блока кода под рукой. Эти методы могут применяться к промежуточным кодам, а также к целевым кодам. Группа утверждений анализируется и проверяется на следующую возможную оптимизацию:
Избыточное удаление инструкций
На уровне исходного кода пользователь может сделать следующее:
int add_ten(int x)
{
int y, z;
y = 10;
z = x + y;
return z;
}
|
int add_ten(int x)
{
int y;
y = 10;
y = x + y;
return y;
}
|
int add_ten(int x)
{
int y = 10;
return x + y;
}
|
int add_ten(int x)
{
return x + 10;
}
|
На уровне компиляции компилятор ищет инструкции, избыточные по своей природе. Многократная загрузка и хранение инструкций может иметь одинаковое значение, даже если некоторые из них удалены. Например:
- MOV x, R0
- MOV R0, R1
Мы можем удалить первую инструкцию и переписать предложение так:
MOV x, R1
Недостижимый код
Недоступный код является частью программного кода, к которому никогда не обращаются из-за программных конструкций. Программисты, возможно, случайно написали кусок кода, который никогда не будет достигнут.
Пример:
void add_ten(int x)
{
return x + 10;
printf(“value of x is %d”, x);
}
В этом сегменте кода оператор printf никогда не будет выполнен, так как программный элемент управления вернется назад, прежде чем он сможет выполнить, следовательно, printf может быть удален.
Поток оптимизации управления
В коде есть примеры, когда программный элемент управления перемещается назад и вперед без выполнения каких-либо значительных задач. Эти прыжки могут быть удалены. Рассмотрим следующий фрагмент кода:
... MOV R1, R2 GOTO L1 ... L1 : GOTO L2 L2 : INC R1
В этом коде метка L1 может быть удалена, поскольку она передает управление L2. Таким образом, вместо перехода к L1, а затем к L2, элемент управления может напрямую достигать L2, как показано ниже:
... MOV R1, R2 GOTO L2 ... L2 : INC R1
Упрощение алгебраических выражений
Есть случаи, когда алгебраические выражения могут быть сделаны простыми. Например, выражение a = a + 0 можно заменить самим a , а выражение a = a + 1 можно просто заменить на INC a.
Снижение силы
Есть операции, которые занимают больше времени и места. Их «сила» может быть уменьшена путем замены их другими операциями, которые занимают меньше времени и места, но дают тот же результат.
Например, x * 2 может быть заменено на x << 1 , что предполагает только один сдвиг влево. Хотя выходные данные a * a и a 2 одинаковы, a 2 гораздо эффективнее реализовать.
Доступ к инструкциям машины
На целевом компьютере могут быть развернуты более сложные инструкции, которые могут иметь возможность эффективно выполнять определенные операции. Если целевой код может содержать эти инструкции напрямую, это не только улучшит качество кода, но и даст более эффективные результаты.
Генератор кода
Ожидается, что генератор кода будет иметь представление о среде выполнения целевой машины и ее наборе команд. Генератор кода должен принимать во внимание следующие вещи для генерации кода:
-
Целевой язык : генератор кода должен знать природу целевого языка, для которого код должен быть преобразован. Этот язык может облегчить некоторые машинно-ориентированные инструкции, чтобы помочь компилятору генерировать код более удобным способом. Целевая машина может иметь архитектуру процессора CISC или RISC.
-
Тип IR : Промежуточное представление имеет различные формы. Это может быть структура абстрактного синтаксического дерева (AST), обратная польская запись или трехадресный код.
-
Выбор команды : генератор кода принимает в качестве входных данных промежуточное представление и преобразует (отображает) его в набор команд целевой машины. Одно представление может иметь много способов (инструкций) для его преобразования, поэтому на генератор кода ложится ответственность за правильный выбор соответствующих инструкций.
-
Распределение регистров : программа имеет ряд значений, которые должны поддерживаться во время выполнения. Архитектура целевой машины не позволяет хранить все значения в памяти или регистрах ЦП. Генератор кода решает, какие значения хранить в регистрах. Кроме того, он решает, какие регистры будут использоваться для хранения этих значений.
-
Порядок следования инструкций : наконец, генератор кода определяет порядок выполнения инструкции. Он создает графики для инструкций по их выполнению.
Целевой язык : генератор кода должен знать природу целевого языка, для которого код должен быть преобразован. Этот язык может облегчить некоторые машинно-ориентированные инструкции, чтобы помочь компилятору генерировать код более удобным способом. Целевая машина может иметь архитектуру процессора CISC или RISC.
Тип IR : Промежуточное представление имеет различные формы. Это может быть структура абстрактного синтаксического дерева (AST), обратная польская запись или трехадресный код.
Выбор команды : генератор кода принимает в качестве входных данных промежуточное представление и преобразует (отображает) его в набор команд целевой машины. Одно представление может иметь много способов (инструкций) для его преобразования, поэтому на генератор кода ложится ответственность за правильный выбор соответствующих инструкций.
Распределение регистров : программа имеет ряд значений, которые должны поддерживаться во время выполнения. Архитектура целевой машины не позволяет хранить все значения в памяти или регистрах ЦП. Генератор кода решает, какие значения хранить в регистрах. Кроме того, он решает, какие регистры будут использоваться для хранения этих значений.
Порядок следования инструкций : наконец, генератор кода определяет порядок выполнения инструкции. Он создает графики для инструкций по их выполнению.
Дескрипторы
Генератор кода должен отслеживать как регистры (для доступности), так и адреса (расположение значений) при генерации кода. Для них обоих используются следующие два дескриптора:
-
Дескриптор регистра : дескриптор регистра используется для информирования генератора кода о доступности регистров. Дескриптор регистра отслеживает значения, хранящиеся в каждом регистре. Всякий раз, когда новый регистр требуется во время генерации кода, этот дескриптор консультируется для доступности регистра.
-
Дескриптор адреса : Значения имен (идентификаторов), используемых в программе, могут храниться в разных местах во время выполнения. Дескрипторы адресов используются для отслеживания областей памяти, где хранятся значения идентификаторов. Эти местоположения могут включать в себя регистры ЦП, кучи, стеки, память или комбинацию упомянутых местоположений.
Дескриптор регистра : дескриптор регистра используется для информирования генератора кода о доступности регистров. Дескриптор регистра отслеживает значения, хранящиеся в каждом регистре. Всякий раз, когда новый регистр требуется во время генерации кода, этот дескриптор консультируется для доступности регистра.
Дескриптор адреса : Значения имен (идентификаторов), используемых в программе, могут храниться в разных местах во время выполнения. Дескрипторы адресов используются для отслеживания областей памяти, где хранятся значения идентификаторов. Эти местоположения могут включать в себя регистры ЦП, кучи, стеки, память или комбинацию упомянутых местоположений.
Генератор кода обновляет дескриптор в режиме реального времени. Для оператора загрузки LD R1, x, генератор кода:
- updates the Register Descriptor R1 that has value of x and
- updates the Address Descriptor (x) to show that one instance of x is in R1.
Генерация кода
Базовые блоки состоят из последовательности трехадресных инструкций. Генератор кода принимает эту последовательность команд в качестве входных данных.
Примечание . Если значение имени найдено более чем в одном месте (регистр, кэш или память), значение регистра будет предпочтительнее, чем кэш и основная память. Аналогично значение кэша будет предпочтительнее, чем основная память. Основная память едва ли дает какие-либо предпочтения.
getReg : генератор кода использует функцию getReg для определения состояния доступных регистров и расположения значений имен. getReg работает следующим образом:
-
Если переменная Y уже находится в регистре R, она использует этот регистр.
-
Иначе, если какой-то регистр R доступен, он использует этот регистр.
-
Иначе, если оба вышеупомянутых варианта невозможны, он выбирает регистр, который требует минимального количества инструкций загрузки и сохранения.
Если переменная Y уже находится в регистре R, она использует этот регистр.
Иначе, если какой-то регистр R доступен, он использует этот регистр.
Иначе, если оба вышеупомянутых варианта невозможны, он выбирает регистр, который требует минимального количества инструкций загрузки и сохранения.
Для инструкции x = y OP z генератор кода может выполнять следующие действия. Предположим, что L — это место (предпочтительно регистр), в котором следует сохранить выходные данные y OP z:
-
Вызвать функцию getReg, чтобы определить местоположение L.
-
Определите текущее местоположение (регистр или память) y , обратившись к дескриптору адреса y . Если y в настоящее время нет в регистре L , то сгенерируйте следующую инструкцию, чтобы скопировать значение y в L :
MOV y ‘, L
где у ‘ представляет скопированное значение у .
-
Определите текущее местоположение z, используя тот же метод, который использовался в шаге 2 для y, и сгенерируйте следующую инструкцию:
OP z ‘, L
где z ‘ представляет скопированное значение z .
-
Теперь L содержит значение y OP z, которое предназначено для присвоения x . Итак, если L является регистром, обновите его дескриптор, чтобы указать, что он содержит значение x . Обновите дескриптор x, чтобы указать, что он хранится в местоположении L.
-
Если y и z больше не используются, они могут быть возвращены в систему.
Вызвать функцию getReg, чтобы определить местоположение L.
Определите текущее местоположение (регистр или память) y , обратившись к дескриптору адреса y . Если y в настоящее время нет в регистре L , то сгенерируйте следующую инструкцию, чтобы скопировать значение y в L :
MOV y ‘, L
где у ‘ представляет скопированное значение у .
Определите текущее местоположение z, используя тот же метод, который использовался в шаге 2 для y, и сгенерируйте следующую инструкцию:
OP z ‘, L
где z ‘ представляет скопированное значение z .
Теперь L содержит значение y OP z, которое предназначено для присвоения x . Итак, если L является регистром, обновите его дескриптор, чтобы указать, что он содержит значение x . Обновите дескриптор x, чтобы указать, что он хранится в местоположении L.
Если y и z больше не используются, они могут быть возвращены в систему.
Другие конструкции кода, такие как циклы и условные операторы, в общем случае преобразуются в язык ассемблера.
Дизайн компилятора — оптимизация кода
Оптимизация — это метод преобразования программы, который пытается улучшить код, заставляя его потреблять меньше ресурсов (т. Е. ЦП, память) и обеспечивать высокую скорость.
При оптимизации общие программные конструкции высокого уровня заменяются очень эффективными низкоуровневыми программными кодами. Процесс оптимизации кода должен следовать трем правилам, приведенным ниже:
-
Выходной код никоим образом не должен изменять значение программы.
-
Оптимизация должна увеличить скорость программы и, если возможно, программа должна потреблять меньше ресурсов.
-
Оптимизация должна быть быстрой и не должна задерживать весь процесс компиляции.
Выходной код никоим образом не должен изменять значение программы.
Оптимизация должна увеличить скорость программы и, если возможно, программа должна потреблять меньше ресурсов.
Оптимизация должна быть быстрой и не должна задерживать весь процесс компиляции.
Усилия по оптимизации кода могут быть предприняты на разных уровнях компиляции процесса.
-
В начале пользователи могут изменять / переставлять код или использовать лучшие алгоритмы для написания кода.
-
После генерации промежуточного кода компилятор может модифицировать промежуточный код путем вычисления адресов и улучшения циклов.
-
При создании целевого машинного кода компилятор может использовать иерархию памяти и регистры процессора.
В начале пользователи могут изменять / переставлять код или использовать лучшие алгоритмы для написания кода.
После генерации промежуточного кода компилятор может модифицировать промежуточный код путем вычисления адресов и улучшения циклов.
При создании целевого машинного кода компилятор может использовать иерархию памяти и регистры процессора.
Оптимизацию можно разделить на два типа: машинно-независимый и машинно-зависимый.
Машинно-независимая оптимизация
При этой оптимизации компилятор принимает промежуточный код и преобразует часть кода, которая не включает какие-либо регистры ЦП и / или абсолютные ячейки памяти. Например:
do
{
item = 10;
value = value + item;
}while(value<100);
Этот код включает в себя повторное присвоение идентификатора элемента, который, если мы скажем так:
Item = 10;
do
{
value = value + item;
} while(value<100);
Следует не только сохранять циклы процессора, но и использовать его на любом процессоре.
Машинно-зависимая оптимизация
Машинно-зависимая оптимизация выполняется после того, как целевой код был сгенерирован, и когда код преобразуется в соответствии с архитектурой целевой машины. Он включает регистры ЦП и может иметь абсолютные ссылки на память, а не относительные ссылки. Машинно-зависимые оптимизаторы прилагают усилия, чтобы максимально использовать иерархию памяти.
Основные блоки
Исходные коды обычно имеют ряд инструкций, которые всегда выполняются последовательно и рассматриваются как основные блоки кода. В этих базовых блоках нет операторов перехода, т. Е. Когда выполняется первая инструкция, все инструкции в одном и том же базовом блоке будут выполняться в их последовательности появления без потери управления потоком программы.
Программа может иметь различные конструкции в качестве базовых блоков, таких как условные операторы IF-THEN-ELSE, SWITCH-CASE и циклы, такие как DO-WHILE, FOR и REPEAT-UNTIL и т. Д.
Идентификация основного блока
Мы можем использовать следующий алгоритм, чтобы найти основные блоки в программе:
-
Искать в заголовках всех базовых блоков, с которых начинается базовый блок:
- Первое утверждение программы.
- Утверждения, которые являются целью любой ветви (условные / безусловные).
- Заявления, которые следуют за любым оператором ветви.
-
Операторы заголовка и операторы, следующие за ними, образуют основной блок.
-
Базовый блок не включает в себя какой-либо оператор заголовка любого другого базового блока.
Искать в заголовках всех базовых блоков, с которых начинается базовый блок:
Операторы заголовка и операторы, следующие за ними, образуют основной блок.
Базовый блок не включает в себя какой-либо оператор заголовка любого другого базового блока.
Базовые блоки являются важными понятиями как с точки зрения генерации кода, так и с точки зрения оптимизации.
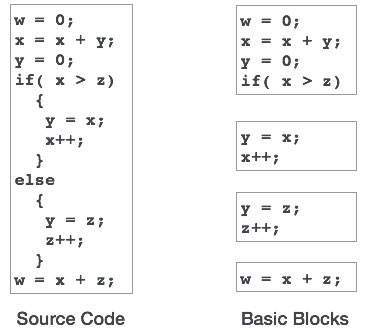
Базовые блоки играют важную роль в определении переменных, которые используются более одного раза в одном базовом блоке. Если какая-либо переменная используется более одного раза, память регистра, выделенную для этой переменной, не должна быть освобождена, пока блок не завершит выполнение.
График потока управления
Основные блоки в программе могут быть представлены с помощью управляющих графов. График потока управления показывает, как управление программой передается между блоками. Это полезный инструмент, который помогает в оптимизации, помогая найти любые нежелательные циклы в программе.
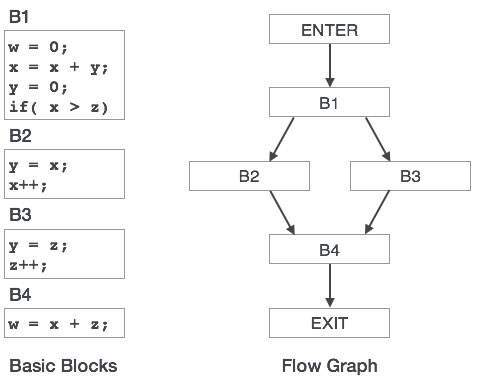
Loop Optimization
Большинство программ работают в системе как цикл. Становится необходимым оптимизировать циклы, чтобы сэкономить циклы процессора и память. Циклы могут быть оптимизированы следующими методами:
-
Инвариантный код : фрагмент кода, который находится в цикле и вычисляет одно и то же значение на каждой итерации, называется циклически инвариантным кодом. Этот код можно вывести из цикла, сохранив его для вычисления только один раз, а не с каждой итерацией.
-
Индукционный анализ : переменная называется индукционной переменной, если ее значение в цикле изменяется инвариантным значением цикла.
-
Снижение прочности : есть выражения, которые потребляют больше циклов ЦП, времени и памяти. Эти выражения должны быть заменены на более дешевые выражения без ущерба для вывода выражения. Например, умножение (x * 2) дороже с точки зрения циклов ЦП, чем (x << 1) и дает тот же результат.
Инвариантный код : фрагмент кода, который находится в цикле и вычисляет одно и то же значение на каждой итерации, называется циклически инвариантным кодом. Этот код можно вывести из цикла, сохранив его для вычисления только один раз, а не с каждой итерацией.
Индукционный анализ : переменная называется индукционной переменной, если ее значение в цикле изменяется инвариантным значением цикла.
Снижение прочности : есть выражения, которые потребляют больше циклов ЦП, времени и памяти. Эти выражения должны быть заменены на более дешевые выражения без ущерба для вывода выражения. Например, умножение (x * 2) дороже с точки зрения циклов ЦП, чем (x << 1) и дает тот же результат.
Устранение мертвого кода
Мертвый код — это один или несколько операторов кода, которые:
- Либо никогда не выполняется, либо недоступен,
- Или, если выполняется, их вывод никогда не используется.
Таким образом, мертвый код не играет никакой роли в любой операции программы, и поэтому его можно просто устранить.
Частично мертвый код
Существуют некоторые операторы кода, вычисленные значения которых используются только при определенных обстоятельствах, то есть иногда используются значения, а иногда нет. Такие коды известны как частично мертвый код.
На приведенном выше графике потока управления изображен фрагмент программы, в котором переменная «a» используется для назначения вывода выражения «x * y». Предположим, что значение, присвоенное ‘a’, никогда не используется внутри цикла. Сразу после того, как элемент управления покидает цикл, ‘a’ присваивается значение переменной ‘z’, которое будет использоваться позже в программе. Здесь мы заключаем, что код присваивания «а» нигде не используется, поэтому он может быть исключен.
Аналогично, на рисунке выше показано, что условный оператор всегда ложен, подразумевая, что код, написанный в истинном регистре, никогда не будет выполнен, следовательно, его можно удалить.
Частичное резервирование
Избыточные выражения вычисляются более одного раза в параллельном пути, без каких-либо изменений в операндах, тогда как частично-избыточные выражения вычисляются более одного раза в пути, без каких-либо изменений в операндах. Например,
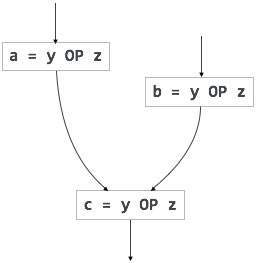
[избыточное выражение] |
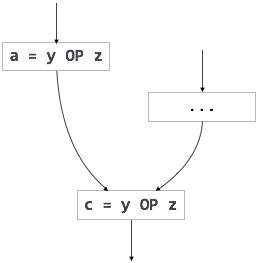
[частично избыточное выражение] |
[избыточное выражение]
[частично избыточное выражение]
Код, инвариантный к циклам, частично избыточен и может быть устранен с помощью техники перемещения кода.
Другим примером частично избыточного кода может быть:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;
Мы предполагаем, что значения операндов ( y и z ) не изменяются от присвоения переменной a переменной c . Здесь, если выражение условия истинно, тогда y OP z вычисляется дважды, в противном случае — один раз. Кодовое движение может использоваться для устранения этой избыточности, как показано ниже:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;
Здесь, является ли условие истинным или ложным; y OP z следует вычислять только один раз.