В предыдущей главе мы узнали, что метод синтаксического анализа сверху вниз анализирует входные данные и начинает создавать дерево синтаксического анализа от корневого узла, постепенно перемещаясь вниз к конечным узлам. Типы синтаксического анализа сверху вниз показаны ниже:
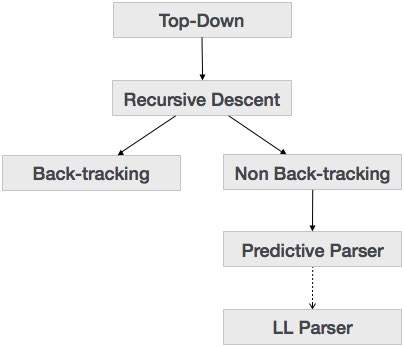
Разбор рекурсивного спуска
Рекурсивный спуск — это метод синтаксического анализа сверху вниз, который создает дерево разбора сверху, а входные данные читаются слева направо. Он использует процедуры для каждого терминала и нетерминального объекта. Этот метод синтаксического анализа рекурсивно анализирует входные данные для создания дерева разбора, которое может требовать или не требовать обратного отслеживания. Но грамматика, связанная с ней (если не оставить факторизованной), не может избежать обратного отслеживания. Форма синтаксического анализа с рекурсивным спуском, которая не требует обратного отслеживания, называется предиктивным анализом .
Этот метод синтаксического анализа считается рекурсивным, так как он использует грамматику без контекста, которая по своей природе является рекурсивной.
Back-трекинга
Сверху вниз парсеры начинаются с корневого узла (начальный символ) и сопоставляют входную строку с производственными правилами, чтобы заменить их (если они совпадают). Чтобы понять это, возьмите следующий пример CFG:
S → rXd | rZd X → oa | ea Z → ai
Для входной строки: read, анализатор сверху вниз, будет вести себя так:
Он будет начинаться с S из правил производства и будет сопоставлять его выход с самой левой буквой ввода, т. Е. ‘R’. Само производство S (S → rXd) совпадает с этим. Таким образом, нисходящий синтаксический анализатор переходит к следующей вводимой букве (то есть ‘e’). Парсер пытается развернуть нетерминал ‘X’ и проверяет его производство слева (X → oa). Он не совпадает со следующим символом ввода. Поэтому нисходящий синтаксический анализатор возвращает назад, чтобы получить следующее производственное правило X, (X → ea).
Теперь парсер сопоставляет все введенные буквы упорядоченным образом. Строка принята.
Прогнозирующий парсер
Predictive parser — это синтаксический анализатор с рекурсивным спуском, который может предсказать, какую продукцию использовать для замены входной строки. Прогностический парсер не страдает от возврата.
Для выполнения своих задач синтаксический анализатор использует упреждающий указатель, который указывает на следующие входные символы. Чтобы сделать анализатор обратным отслеживанием свободным, прогнозирующий синтаксический анализатор накладывает некоторые ограничения на грамматику и принимает только класс грамматики, известный как LL (k) грамматика.
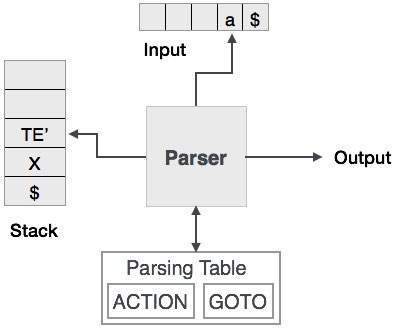
Прогнозирующий синтаксический анализ использует стек и таблицу синтаксического анализа для анализа входных данных и создания дерева синтаксического анализа. И стек, и вход содержит конечный символ $, обозначающий, что стек пуст и вход используется. Синтаксический анализатор обращается к таблице синтаксического анализа, чтобы принять любое решение относительно комбинации элементов ввода и стека.
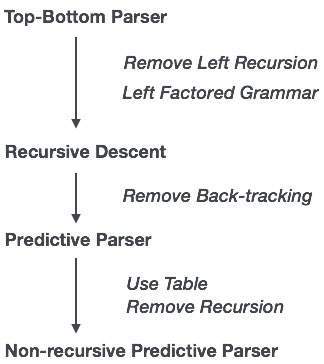
При анализе с рекурсивным спуском у синтаксического анализатора может быть несколько вариантов выбора для одного экземпляра входных данных, тогда как в прогнозирующем синтаксическом анализаторе у каждого шага есть не более одного производства. Могут быть случаи, когда нет никакой продукции, соответствующей входной строке, что приводит к сбою процедуры синтаксического анализа.
LL Parser
LL Parser принимает грамматику LL. LL грамматика — это подмножество контекстно-свободной грамматики, но с некоторыми ограничениями, чтобы получить упрощенную версию, чтобы добиться легкой реализации. LL грамматика может быть реализована с помощью обоих алгоритмов, а именно рекурсивного спуска или табличного управления.
LL-парсер обозначается как LL (k). Первый L в LL (k) анализирует входные данные слева направо, второй L в LL (k) обозначает самый левый вывод, а само k представляет количество заблаговременных просмотров. Обычно k = 1, поэтому LL (k) также можно записать как LL (1).
Алгоритм синтаксического анализа LL
Мы можем придерживаться детерминированного LL (1) для объяснения синтаксического анализатора, так как размер таблицы растет экспоненциально со значением k. Во-вторых, если данная грамматика не является LL (1), то обычно это не LL (k) для любого заданного k.
Ниже приведен алгоритм синтаксического анализа LL (1):
Input: string ω parsing table M for grammar G Output: If ω is in L(G) then left-most derivation of ω, error otherwise. Initial State : $S on stack (with S being start symbol) ω$ in the input buffer SET ip to point the first symbol of ω$. repeat let X be the top stack symbol and a the symbol pointed by ip. if X∈ V t or $ if X = a POP X and advance ip. else error() endif else /* X is non-terminal */ if M[X,a] = X → Y1, Y2,... Yk POP X PUSH Yk, Yk-1,... Y1 /* Y1 on top */ Output the production X → Y1, Y2,... Yk else error() endif endif until X = $ /* empty stack */
Грамматика G есть LL (1), если A → α | β — это две разные продукции G:
для терминалов нет, и α, и β выводят строки, начинающиеся с a.
не более одного из α и β может выводить пустую строку.
если β → t, то α не выводит никакой строки, начинающейся с терминала в FOLLOW (A).