Генерация кода может рассматриваться как финальная фаза компиляции. Посредством генерации почтового кода процесс оптимизации может быть применен к коду, но это может рассматриваться как часть самой фазы генерации кода. Код, сгенерированный компилятором, является объектным кодом некоторого языка программирования более низкого уровня, например, языка ассемблера. Мы видели, что исходный код, написанный на языке более высокого уровня, преобразуется в язык более низкого уровня, что приводит к объектному коду более низкого уровня, который должен иметь следующие минимальные свойства:
- Он должен нести точное значение исходного кода.
- Он должен быть эффективным с точки зрения использования процессора и управления памятью.
Теперь мы увидим, как промежуточный код преобразуется в код целевого объекта (в данном случае ассемблерный код).
Направленный ациклический граф
Направленный ациклический граф (DAG) — это инструмент, который отображает структуру базовых блоков, помогает видеть поток значений, проходящих между базовыми блоками, а также предлагает оптимизацию. DAG обеспечивает легкое преобразование на основных блоках. DAG можно понять здесь:
-
Конечные узлы представляют идентификаторы, имена или константы.
-
Внутренние узлы представляют операторов.
-
Внутренние узлы также представляют результаты выражений или идентификаторов / имен, где значения должны быть сохранены или назначены.
Конечные узлы представляют идентификаторы, имена или константы.
Внутренние узлы представляют операторов.
Внутренние узлы также представляют результаты выражений или идентификаторов / имен, где значения должны быть сохранены или назначены.
Пример:
t 0 = a + b t 1 = t 0 + c d = t 0 + t 1
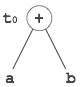
[t 0 = a + b] |
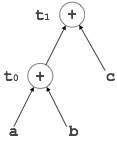
[t 1 = t 0 + c] |
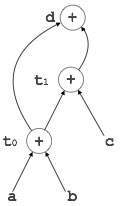
[d = t 0 + t 1 ] |
[t 0 = a + b]
[t 1 = t 0 + c]
[d = t 0 + t 1 ]
Оптимизация глазка
Этот метод оптимизации работает локально над исходным кодом, чтобы преобразовать его в оптимизированный код. Под локально мы подразумеваем небольшую часть блока кода под рукой. Эти методы могут применяться к промежуточным кодам, а также к целевым кодам. Группа утверждений анализируется и проверяется на следующую возможную оптимизацию:
Избыточное удаление инструкций
На уровне исходного кода пользователь может сделать следующее:
int add_ten(int x) { int y, z; y = 10; z = x + y; return z; } |
int add_ten(int x) { int y; y = 10; y = x + y; return y; } |
int add_ten(int x) { int y = 10; return x + y; } |
int add_ten(int x) { return x + 10; } |
На уровне компиляции компилятор ищет инструкции, избыточные по своей природе. Многократная загрузка и хранение инструкций может иметь одинаковое значение, даже если некоторые из них удалены. Например:
- MOV x, R0
- MOV R0, R1
Мы можем удалить первую инструкцию и переписать предложение так:
MOV x, R1
Недостижимый код
Недоступный код является частью программного кода, к которому никогда не обращаются из-за программных конструкций. Программисты, возможно, случайно написали кусок кода, который никогда не будет достигнут.
Пример:
void add_ten(int x) { return x + 10; printf(“value of x is %d”, x); }
В этом сегменте кода оператор printf никогда не будет выполнен, так как программный элемент управления вернется назад, прежде чем он сможет выполнить, следовательно, printf может быть удален.
Поток оптимизации управления
В коде есть примеры, когда программный элемент управления перемещается назад и вперед без выполнения каких-либо значительных задач. Эти прыжки могут быть удалены. Рассмотрим следующий фрагмент кода:
... MOV R1, R2 GOTO L1 ... L1 : GOTO L2 L2 : INC R1
В этом коде метка L1 может быть удалена, поскольку она передает управление L2. Таким образом, вместо перехода к L1, а затем к L2, элемент управления может напрямую достигать L2, как показано ниже:
... MOV R1, R2 GOTO L2 ... L2 : INC R1
Упрощение алгебраических выражений
Есть случаи, когда алгебраические выражения могут быть сделаны простыми. Например, выражение a = a + 0 можно заменить самим a , а выражение a = a + 1 можно просто заменить на INC a.
Снижение силы
Есть операции, которые занимают больше времени и места. Их «сила» может быть уменьшена путем замены их другими операциями, которые занимают меньше времени и места, но дают тот же результат.
Например, x * 2 может быть заменено на x << 1 , что предполагает только один сдвиг влево. Хотя выходные данные a * a и a 2 одинаковы, a 2 гораздо эффективнее реализовать.
Доступ к инструкциям машины
На целевом компьютере могут быть развернуты более сложные инструкции, которые могут иметь возможность эффективно выполнять определенные операции. Если целевой код может содержать эти инструкции напрямую, это не только улучшит качество кода, но и даст более эффективные результаты.
Генератор кода
Ожидается, что генератор кода будет иметь представление о среде выполнения целевой машины и ее наборе команд. Генератор кода должен принимать во внимание следующие вещи для генерации кода:
-
Целевой язык : генератор кода должен знать природу целевого языка, для которого код должен быть преобразован. Этот язык может облегчить некоторые машинно-ориентированные инструкции, чтобы помочь компилятору генерировать код более удобным способом. Целевая машина может иметь архитектуру процессора CISC или RISC.
-
Тип IR : Промежуточное представление имеет различные формы. Это может быть структура абстрактного синтаксического дерева (AST), обратная польская запись или трехадресный код.
-
Выбор команды : генератор кода принимает в качестве входных данных промежуточное представление и преобразует (отображает) его в набор команд целевой машины. Одно представление может иметь много способов (инструкций) для его преобразования, поэтому на генератор кода ложится ответственность за правильный выбор соответствующих инструкций.
-
Распределение регистров : программа имеет ряд значений, которые должны поддерживаться во время выполнения. Архитектура целевой машины не позволяет хранить все значения в памяти или регистрах ЦП. Генератор кода решает, какие значения хранить в регистрах. Кроме того, он решает, какие регистры будут использоваться для хранения этих значений.
-
Порядок следования инструкций : наконец, генератор кода определяет порядок выполнения инструкции. Он создает графики для инструкций по их выполнению.
Целевой язык : генератор кода должен знать природу целевого языка, для которого код должен быть преобразован. Этот язык может облегчить некоторые машинно-ориентированные инструкции, чтобы помочь компилятору генерировать код более удобным способом. Целевая машина может иметь архитектуру процессора CISC или RISC.
Тип IR : Промежуточное представление имеет различные формы. Это может быть структура абстрактного синтаксического дерева (AST), обратная польская запись или трехадресный код.
Выбор команды : генератор кода принимает в качестве входных данных промежуточное представление и преобразует (отображает) его в набор команд целевой машины. Одно представление может иметь много способов (инструкций) для его преобразования, поэтому на генератор кода ложится ответственность за правильный выбор соответствующих инструкций.
Распределение регистров : программа имеет ряд значений, которые должны поддерживаться во время выполнения. Архитектура целевой машины не позволяет хранить все значения в памяти или регистрах ЦП. Генератор кода решает, какие значения хранить в регистрах. Кроме того, он решает, какие регистры будут использоваться для хранения этих значений.
Порядок следования инструкций : наконец, генератор кода определяет порядок выполнения инструкции. Он создает графики для инструкций по их выполнению.
Дескрипторы
Генератор кода должен отслеживать как регистры (для доступности), так и адреса (расположение значений) при генерации кода. Для них обоих используются следующие два дескриптора:
-
Дескриптор регистра : дескриптор регистра используется для информирования генератора кода о доступности регистров. Дескриптор регистра отслеживает значения, хранящиеся в каждом регистре. Всякий раз, когда новый регистр требуется во время генерации кода, этот дескриптор консультируется для доступности регистра.
-
Дескриптор адреса : Значения имен (идентификаторов), используемых в программе, могут храниться в разных местах во время выполнения. Дескрипторы адресов используются для отслеживания областей памяти, где хранятся значения идентификаторов. Эти местоположения могут включать в себя регистры ЦП, кучи, стеки, память или комбинацию упомянутых местоположений.
Дескриптор регистра : дескриптор регистра используется для информирования генератора кода о доступности регистров. Дескриптор регистра отслеживает значения, хранящиеся в каждом регистре. Всякий раз, когда новый регистр требуется во время генерации кода, этот дескриптор консультируется для доступности регистра.
Дескриптор адреса : Значения имен (идентификаторов), используемых в программе, могут храниться в разных местах во время выполнения. Дескрипторы адресов используются для отслеживания областей памяти, где хранятся значения идентификаторов. Эти местоположения могут включать в себя регистры ЦП, кучи, стеки, память или комбинацию упомянутых местоположений.
Генератор кода обновляет дескриптор в режиме реального времени. Для оператора загрузки LD R1, x, генератор кода:
- updates the Register Descriptor R1 that has value of x and
- updates the Address Descriptor (x) to show that one instance of x is in R1.
Генерация кода
Базовые блоки состоят из последовательности трехадресных инструкций. Генератор кода принимает эту последовательность команд в качестве входных данных.
Примечание . Если значение имени найдено более чем в одном месте (регистр, кэш или память), значение регистра будет предпочтительнее, чем кэш и основная память. Аналогично значение кэша будет предпочтительнее, чем основная память. Основная память едва ли дает какие-либо предпочтения.
getReg : генератор кода использует функцию getReg для определения состояния доступных регистров и расположения значений имен. getReg работает следующим образом:
-
Если переменная Y уже находится в регистре R, она использует этот регистр.
-
Иначе, если какой-то регистр R доступен, он использует этот регистр.
-
Иначе, если оба вышеупомянутых варианта невозможны, он выбирает регистр, который требует минимального количества инструкций загрузки и сохранения.
Если переменная Y уже находится в регистре R, она использует этот регистр.
Иначе, если какой-то регистр R доступен, он использует этот регистр.
Иначе, если оба вышеупомянутых варианта невозможны, он выбирает регистр, который требует минимального количества инструкций загрузки и сохранения.
Для инструкции x = y OP z генератор кода может выполнять следующие действия. Предположим, что L — это место (предпочтительно регистр), в котором следует сохранить выходные данные y OP z:
-
Вызвать функцию getReg, чтобы определить местоположение L.
-
Определите текущее местоположение (регистр или память) y , обратившись к дескриптору адреса y . Если y в настоящее время нет в регистре L , то сгенерируйте следующую инструкцию, чтобы скопировать значение y в L :
MOV y ‘, L
где у ‘ представляет скопированное значение у .
-
Определите текущее местоположение z, используя тот же метод, который использовался в шаге 2 для y, и сгенерируйте следующую инструкцию:
OP z ‘, L
где z ‘ представляет скопированное значение z .
-
Теперь L содержит значение y OP z, которое предназначено для присвоения x . Итак, если L является регистром, обновите его дескриптор, чтобы указать, что он содержит значение x . Обновите дескриптор x, чтобы указать, что он хранится в местоположении L.
-
Если y и z больше не используются, они могут быть возвращены в систему.
Вызвать функцию getReg, чтобы определить местоположение L.
Определите текущее местоположение (регистр или память) y , обратившись к дескриптору адреса y . Если y в настоящее время нет в регистре L , то сгенерируйте следующую инструкцию, чтобы скопировать значение y в L :
MOV y ‘, L
где у ‘ представляет скопированное значение у .
Определите текущее местоположение z, используя тот же метод, который использовался в шаге 2 для y, и сгенерируйте следующую инструкцию:
OP z ‘, L
где z ‘ представляет скопированное значение z .
Теперь L содержит значение y OP z, которое предназначено для присвоения x . Итак, если L является регистром, обновите его дескриптор, чтобы указать, что он содержит значение x . Обновите дескриптор x, чтобы указать, что он хранится в местоположении L.
Если y и z больше не используются, они могут быть возвращены в систему.
Другие конструкции кода, такие как циклы и условные операторы, в общем случае преобразуются в язык ассемблера.