XML DOM — Обзор
D Ocument O bject M odel (DOM) является стандартом W3C. Он определяет стандарт для доступа к таким документам, как HTML и XML.
Определение DOM в W3C —
Объектная модель документа (DOM) — это интерфейс прикладного программирования (API) для документов HTML и XML. Он определяет логическую структуру документов и способ доступа к документу и манипулирования им.
DOM определяет объекты, свойства и методы (интерфейс) для доступа ко всем элементам XML. Он разделен на 3 части / уровни —
-
Core DOM — стандартная модель для любого структурированного документа
-
XML DOM — стандартная модель для документов XML
-
HTML DOM — стандартная модель для документов HTML
Core DOM — стандартная модель для любого структурированного документа
XML DOM — стандартная модель для документов XML
HTML DOM — стандартная модель для документов HTML
XML DOM — это стандартная объектная модель для XML. XML-документы имеют иерархию информационных единиц, называемых узлами ; DOM — это стандартный программный интерфейс описания этих узлов и отношений между ними.
XML DOM также предоставляет API, который позволяет разработчику добавлять, редактировать, перемещать или удалять узлы в любой точке дерева для создания приложения.
Ниже приведена схема структуры DOM. Диаграмма показывает, что анализатор оценивает XML-документ как структуру DOM, проходя через каждый узел.
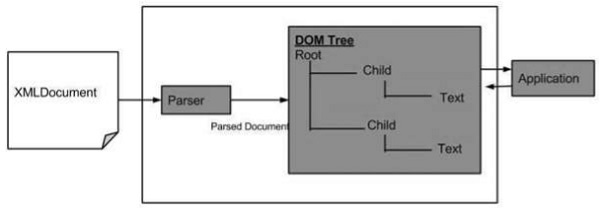
Преимущества XML DOM
Ниже приведены преимущества XML DOM.
-
XML DOM не зависит от языка и платформы.
-
XML DOM доступен для просмотра — информация в XML DOM организована в иерархию, которая позволяет разработчику перемещаться по иерархии в поисках конкретной информации.
-
XML DOM является изменяемым — он динамический по своей природе, предоставляя разработчику возможность добавлять, редактировать, перемещать или удалять узлы в любой точке дерева.
XML DOM не зависит от языка и платформы.
XML DOM доступен для просмотра — информация в XML DOM организована в иерархию, которая позволяет разработчику перемещаться по иерархии в поисках конкретной информации.
XML DOM является изменяемым — он динамический по своей природе, предоставляя разработчику возможность добавлять, редактировать, перемещать или удалять узлы в любой точке дерева.
Недостатки XML DOM
-
Он потребляет больше памяти (если структура XML велика), так как однажды написанная программа остается в памяти до тех пор, пока не будет удалена явно.
-
Из-за широкого использования памяти скорость ее работы по сравнению с SAX ниже.
Он потребляет больше памяти (если структура XML велика), так как однажды написанная программа остается в памяти до тех пор, пока не будет удалена явно.
Из-за широкого использования памяти скорость ее работы по сравнению с SAX ниже.
XML DOM — модель
Теперь, когда мы знаем, что означает DOM, давайте посмотрим, что такое структура DOM. Документ DOM представляет собой набор узлов или фрагментов информации, организованных в иерархию. Некоторые типы узлов могут иметь дочерние узлы различных типов, а другие являются конечными узлами, которые не могут иметь ничего под ними в структуре документа. Ниже приведен список типов узлов со списком типов узлов, которые они могут иметь в качестве дочерних элементов:
-
Документ — Элемент (максимум один), ProcessingInstruction, Comment, DocumentType (максимум один)
-
DocumentFragment — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
-
EntityReference — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
-
Элемент — Элемент, Текст, Комментарий, Обработка, Инструкция, CDATASection, EntityReference
-
Attr — Text, EntityReference
-
ProcessingInstruction — нет детей
-
Комментарий — детей нет
-
Текст — детей нет
-
CDATASection — нет детей
-
Entity — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
-
Запись — Нет детей
Документ — Элемент (максимум один), ProcessingInstruction, Comment, DocumentType (максимум один)
DocumentFragment — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
EntityReference — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
Элемент — Элемент, Текст, Комментарий, Обработка, Инструкция, CDATASection, EntityReference
Attr — Text, EntityReference
ProcessingInstruction — нет детей
Комментарий — детей нет
Текст — детей нет
CDATASection — нет детей
Entity — Элемент, ProcessingInstruction, Комментарий, Текст, CDATASection, EntityReference
Запись — Нет детей
пример
Рассмотрим представление DOM следующего XML-документа node.xml .
<?xml version = "1.0"?> <Company> <Employee category = "technical"> <FirstName>Tanmay</FirstName> <LastName>Patil</LastName> <ContactNo>1234567890</ContactNo> </Employee> <Employee category = "non-technical"> <FirstName>Taniya</FirstName> <LastName>Mishra</LastName> <ContactNo>1234667898</ContactNo> </Employee> </Company>
Объектная модель документа вышеуказанного XML-документа будет выглядеть следующим образом:
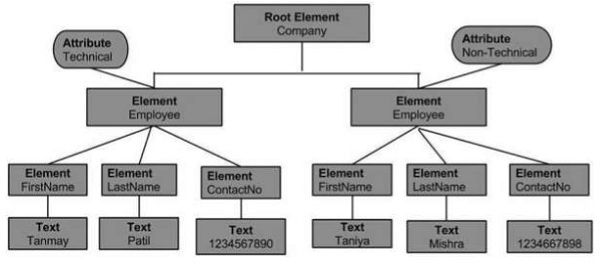
Из приведенной блок-схемы, мы можем сделать вывод —
-
Объект Node может иметь только один объект родительского узла . Это занимает положение над всеми узлами. Вот она компания .
-
Родительский узел может иметь несколько узлов, называемых дочерними узлами. Эти дочерние узлы могут иметь дополнительные узлы, называемые узлами атрибута . В приведенном выше примере у нас есть два узла атрибутов: технический и нетехнический . Узел атрибута на самом деле не является дочерним элементом узла элемента, но все еще связан с ним.
-
Эти дочерние узлы, в свою очередь, могут иметь несколько дочерних узлов. Текст внутри узлов называется текстовым узлом.
-
Узловые объекты на том же уровне называются братьями и сестрами.
-
DOM идентифицирует —
-
объекты для представления интерфейса и управления документом.
-
отношения между объектами и интерфейсами.
-
Объект Node может иметь только один объект родительского узла . Это занимает положение над всеми узлами. Вот она компания .
Родительский узел может иметь несколько узлов, называемых дочерними узлами. Эти дочерние узлы могут иметь дополнительные узлы, называемые узлами атрибута . В приведенном выше примере у нас есть два узла атрибутов: технический и нетехнический . Узел атрибута на самом деле не является дочерним элементом узла элемента, но все еще связан с ним.
Эти дочерние узлы, в свою очередь, могут иметь несколько дочерних узлов. Текст внутри узлов называется текстовым узлом.
Узловые объекты на том же уровне называются братьями и сестрами.
DOM идентифицирует —
объекты для представления интерфейса и управления документом.
отношения между объектами и интерфейсами.
XML DOM — узлы
В этой главе мы рассмотрим узлы XML DOM. Каждый XML DOM содержит информацию в иерархических единицах, называемых узлами, и DOM описывает эти узлы и отношения между ними.
Типы узлов
Следующая блок-схема показывает все типы узлов —
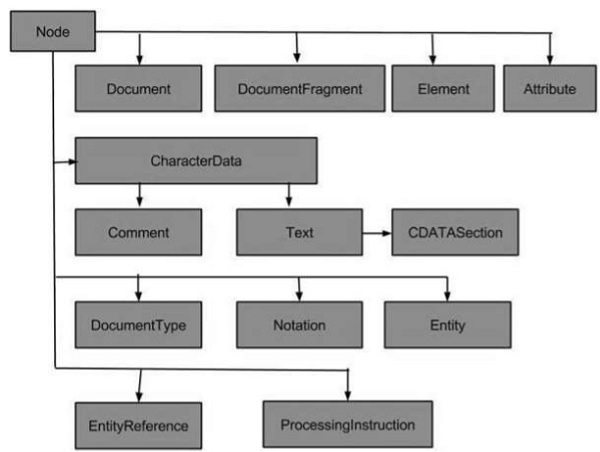
Наиболее распространенные типы узлов в XML:
-
Узел документа — полная структура документа XML является узлом документа .
-
Узел элемента — каждый элемент XML является узлом элемента . Это также единственный тип узла, который может иметь атрибуты.
-
Узел атрибута — каждый атрибут считается узлом атрибута . Он содержит информацию об узле элемента, но фактически не считается дочерним элементом этого элемента.
-
Текстовый узел — текст документа рассматривается как текстовый узел . Он может состоять из дополнительной информации или просто пустого пространства.
Узел документа — полная структура документа XML является узлом документа .
Узел элемента — каждый элемент XML является узлом элемента . Это также единственный тип узла, который может иметь атрибуты.
Узел атрибута — каждый атрибут считается узлом атрибута . Он содержит информацию об узле элемента, но фактически не считается дочерним элементом этого элемента.
Текстовый узел — текст документа рассматривается как текстовый узел . Он может состоять из дополнительной информации или просто пустого пространства.
Некоторые менее распространенные типы узлов:
-
Узел CData — этот узел содержит информацию, которая не должна анализироваться анализатором. Вместо этого он должен быть передан в виде простого текста.
-
Узел комментариев — этот узел содержит информацию о данных и обычно игнорируется приложением.
-
Узел инструкций по обработке — этот узел содержит информацию, специально предназначенную для приложения.
-
Узел фрагментов документа
-
Узел сущностей
-
Справочные узлы
-
Notations Node
Узел CData — этот узел содержит информацию, которая не должна анализироваться анализатором. Вместо этого он должен быть передан в виде простого текста.
Узел комментариев — этот узел содержит информацию о данных и обычно игнорируется приложением.
Узел инструкций по обработке — этот узел содержит информацию, специально предназначенную для приложения.
Узел фрагментов документа
Узел сущностей
Справочные узлы
Notations Node
XML DOM — дерево узлов
В этой главе мы рассмотрим дерево узлов XML DOM . В XML-документе информация хранится в иерархической структуре; эта иерархическая структура называется деревом узлов . Эта иерархия позволяет разработчику перемещаться по дереву в поисках конкретной информации, поэтому узлам разрешен доступ. Содержимое этих узлов может быть обновлено.
Структура дерева узлов начинается с корневого элемента и распространяется на дочерние элементы до самого нижнего уровня.
пример
В следующем примере демонстрируется простой XML-документ, структура узла которого показана на схеме ниже.
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>
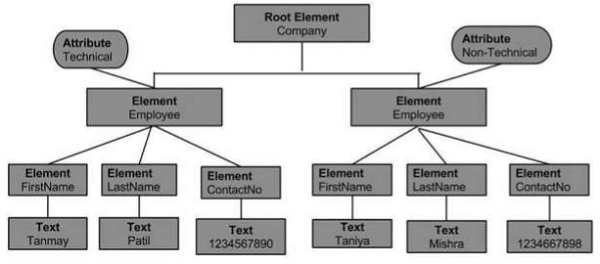
Как видно из приведенного выше примера, чье графическое представление (его DOM) показано ниже:
-
Самый верхний узел дерева называется корнем . Корневым узлом является <Company>, который, в свою очередь, содержит два узла <Employee>. Эти узлы называются дочерними узлами.
-
Дочерний узел <Employee> корневого узла <Company>, в свою очередь, состоит из собственного дочернего узла (<FirstName>, <LastName>, <ContactNo>).
-
Два дочерних узла, <Employee>, имеют значения атрибутов, Технические и Нетехнические, называются узлами атрибутов .
-
Текст в каждом узле называется текстовым узлом .
Самый верхний узел дерева называется корнем . Корневым узлом является <Company>, который, в свою очередь, содержит два узла <Employee>. Эти узлы называются дочерними узлами.
Дочерний узел <Employee> корневого узла <Company>, в свою очередь, состоит из собственного дочернего узла (<FirstName>, <LastName>, <ContactNo>).
Два дочерних узла, <Employee>, имеют значения атрибутов, Технические и Нетехнические, называются узлами атрибутов .
Текст в каждом узле называется текстовым узлом .
XML DOM — Методы
DOM как API содержит интерфейсы, которые представляют различные типы информации, которые можно найти в документе XML, такие как элементы и текст. Эти интерфейсы включают методы и свойства, необходимые для работы с этими объектами. Свойства определяют характеристику узла, тогда как методы дают возможность манипулировать узлами.
В следующей таблице перечислены классы и интерфейсы DOM.
| S.No. | Интерфейс и описание |
|---|---|
| 1 |
DOMImplementation Он предоставляет ряд методов для выполнения операций, которые не зависят от какого-либо конкретного экземпляра объектной модели документа. |
| 2 |
DocumentFragment Это «легкий» или «минимальный» объект документа, и он (как суперкласс Document) привязывает дерево XML / HTML к полноценному документу. |
| 3 |
Документ Он представляет собой узел верхнего уровня документа XML, который обеспечивает доступ ко всем узлам документа, включая корневой элемент. |
| 4 |
Узел Он представляет собой узел XML. |
| 5 |
NodeList Он представляет собой доступный только для чтения список объектов Node . |
| 6 |
NamedNodeMap Он представляет собой набор узлов, к которым можно получить доступ по имени. |
| 7 |
Данные Он расширяет Node набором атрибутов и методов для доступа к символьным данным в DOM. |
| 8 |
атрибут Он представляет атрибут в объекте Element. |
| 9 |
Элемент Он представляет узел элемента. Получается из узла. |
| 10 |
Текст Он представляет собой текстовый узел. Получается из CharacterData. |
| 11 |
Комментарий Он представляет узел комментария. Получается из CharacterData. |
| 12 |
ProcessingInstruction Он представляет собой «инструкцию по обработке». Он используется в XML как способ сохранить информацию о процессоре в тексте документа. |
| 13 |
Раздел CDATA Он представляет раздел CDATA. Получается из текста. |
| 14 |
сущность Он представляет собой сущность. Получается из узла. |
| 15 |
EntityReference Это представляет ссылку на сущность в дереве. Получается из узла. |
DOMImplementation
Он предоставляет ряд методов для выполнения операций, которые не зависят от какого-либо конкретного экземпляра объектной модели документа.
DocumentFragment
Это «легкий» или «минимальный» объект документа, и он (как суперкласс Document) привязывает дерево XML / HTML к полноценному документу.
Документ
Он представляет собой узел верхнего уровня документа XML, который обеспечивает доступ ко всем узлам документа, включая корневой элемент.
Узел
Он представляет собой узел XML.
NodeList
Он представляет собой доступный только для чтения список объектов Node .
NamedNodeMap
Он представляет собой набор узлов, к которым можно получить доступ по имени.
Данные
Он расширяет Node набором атрибутов и методов для доступа к символьным данным в DOM.
атрибут
Он представляет атрибут в объекте Element.
Элемент
Он представляет узел элемента. Получается из узла.
Текст
Он представляет собой текстовый узел. Получается из CharacterData.
Комментарий
Он представляет узел комментария. Получается из CharacterData.
ProcessingInstruction
Он представляет собой «инструкцию по обработке». Он используется в XML как способ сохранить информацию о процессоре в тексте документа.
Раздел CDATA
Он представляет раздел CDATA. Получается из текста.
сущность
Он представляет собой сущность. Получается из узла.
EntityReference
Это представляет ссылку на сущность в дереве. Получается из узла.
Мы будем обсуждать методы и свойства каждого из вышеуказанных интерфейсов в соответствующих главах.
XML DOM — Загрузка
В этой главе мы рассмотрим загрузку и анализ XML.
Для описания интерфейсов, предоставляемых API, W3C использует абстрактный язык, называемый языком определения интерфейса (IDL). Преимущество использования IDL заключается в том, что разработчик узнает, как использовать DOM со своим любимым языком, и может легко переключаться на другой язык.
Недостатком является то, что, поскольку он абстрактный, IDL не может использоваться непосредственно веб-разработчиками. Из-за различий между языками программирования они должны иметь отображение или связывание между абстрактными интерфейсами и их конкретными языками. DOM был сопоставлен с такими языками программирования, как Javascript, JScript, Java, C, C ++, PLSQL, Python и Perl.
В следующих разделах и главах мы будем использовать Javascript в качестве языка программирования для загрузки XML-файла.
синтаксический анализатор
Парсер — это программное приложение, которое предназначено для анализа документа, в нашем случае XML-документа, и выполнения каких-то конкретных действий с информацией. Некоторые парсеры на основе DOM перечислены в следующей таблице:
| S.No | Парсер и описание |
|---|---|
| 1 |
JAXP Java API Sun Microsystem для анализа XML (JAXP) |
| 2 |
XML4J XML-парсер IBM для Java (XML4J) |
| 3 |
MSXML XML-парсер Microsoft (msxml) версии 2.0 встроен в Internet Explorer 5.5 |
| 4 |
4DOM 4DOM — парсер для языка программирования Python |
| 5 |
XML :: DOM XML :: DOM — это модуль Perl для управления XML-документами с использованием Perl |
| 6 |
Xerces Apache Xerces Java Parser |
JAXP
Java API Sun Microsystem для анализа XML (JAXP)
XML4J
XML-парсер IBM для Java (XML4J)
MSXML
XML-парсер Microsoft (msxml) версии 2.0 встроен в Internet Explorer 5.5
4DOM
4DOM — парсер для языка программирования Python
XML :: DOM
XML :: DOM — это модуль Perl для управления XML-документами с использованием Perl
Xerces
Apache Xerces Java Parser
В древовидном API, таком как DOM, анализатор обходит XML-файл и создает соответствующие объекты DOM. Затем вы можете перемещаться по структуре DOM взад и вперед.
Загрузка и анализ XML
При загрузке XML-документа содержимое XML может иметь две формы:
- Прямо как файл XML
- Как строка XML
Содержимое в виде файла XML
В следующем примере демонстрируется загрузка данных XML ( node.xml ) с использованием Ajax и Javascript, когда содержимое XML принимается в виде файла XML. Здесь функция Ajax получает содержимое XML-файла и сохраняет его в XML DOM. Как только объект DOM создан, он затем анализируется.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>
node.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
Большинство деталей кода находится в коде скрипта.
-
Internet Explorer использует ActiveXObject («Microsoft.XMLHTTP») для создания экземпляра объекта XMLHttpRequest, другие браузеры используют метод XMLHttpRequest () .
-
responseXML преобразует содержимое XML непосредственно в XML DOM.
-
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue, и методы DOM, такие как getElementsById (ID), getElementsByTagName (tags_name).
Internet Explorer использует ActiveXObject («Microsoft.XMLHTTP») для создания экземпляра объекта XMLHttpRequest, другие браузеры используют метод XMLHttpRequest () .
responseXML преобразует содержимое XML непосредственно в XML DOM.
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue, и методы DOM, такие как getElementsById (ID), getElementsByTagName (tags_name).
выполнение
Сохраните этот файл как loadingexample.html и откройте его в своем браузере. Вы получите следующий вывод —

Содержимое как строка XML
В следующем примере показано, как загружать данные XML с помощью Ajax и Javascript, когда содержимое XML принимается в виде файла XML. Здесь функция Ajax получает содержимое XML-файла и сохраняет его в XML DOM. Как только объект DOM создан, он затем анализируется.
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>tanmaypatil@xyz.com</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
Большинство деталей кода находится в коде скрипта.
-
Internet Explorer использует ActiveXObject («Microsoft.XMLDOM») для загрузки данных XML в объект DOM, другие браузеры используют функцию DOMParser () и метод parseFromString (text, ‘text / xml’) .
-
Переменная text должна содержать строку с содержимым XML.
-
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue .
Internet Explorer использует ActiveXObject («Microsoft.XMLDOM») для загрузки данных XML в объект DOM, другие браузеры используют функцию DOMParser () и метод parseFromString (text, ‘text / xml’) .
Переменная text должна содержать строку с содержимым XML.
Как только содержимое XML преобразуется в JavaScript XML DOM, вы можете получить доступ к любому элементу XML с помощью методов и свойств JS DOM. Мы использовали свойства DOM, такие как childNodes , nodeValue .
выполнение
Сохраните этот файл как loadingexample.html и откройте его в своем браузере. Вы увидите следующий вывод —

Теперь, когда мы увидели, как содержимое XML преобразуется в JavaScript XML DOM, теперь вы можете получить доступ к любому элементу XML с помощью методов XML DOM.
XML DOM — обход
В этой главе мы обсудим XML DOM Traversing. В предыдущей главе мы изучали, как загружать XML-документ и анализировать полученный таким образом объект DOM. Этот проанализированный объект DOM может быть пройден. Обход — это процесс, в котором зацикливание выполняется систематическим образом, проходя каждый элемент поэтапно в дереве узлов.
пример
В следующем примере (traverse_example.htm) демонстрируется обход DOM. Здесь мы проходим через каждый дочерний узел элемента <Employee>.
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>
-
Этот код загружает node.xml .
-
Содержимое XML преобразуется в объект JavaScript XML DOM.
-
Получен массив элементов (с тегом Element) с использованием метода getElementsByTagName ().
-
Далее мы просматриваем этот массив и отображаем значения дочерних узлов в таблице.
Этот код загружает node.xml .
Содержимое XML преобразуется в объект JavaScript XML DOM.
Получен массив элементов (с тегом Element) с использованием метода getElementsByTagName ().
Далее мы просматриваем этот массив и отображаем значения дочерних узлов в таблице.
выполнение
Сохраните этот файл как traverse_example.html на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Вы получите следующий вывод —

XML DOM — навигация
До сих пор мы изучали структуру DOM, как загружать и анализировать XML-объект DOM и проходить через объекты DOM. Здесь мы увидим, как мы можем перемещаться между узлами в DOM-объекте. XML DOM состоит из различных свойств узлов, которые помогают нам перемещаться по узлам, таких как —
- ParentNode
- ChildNodes
- Первый ребенок
- последний ребенок
- NextSibling
- PreviousSibling
Ниже приведена схема дерева узлов, показывающая его связь с другими узлами.
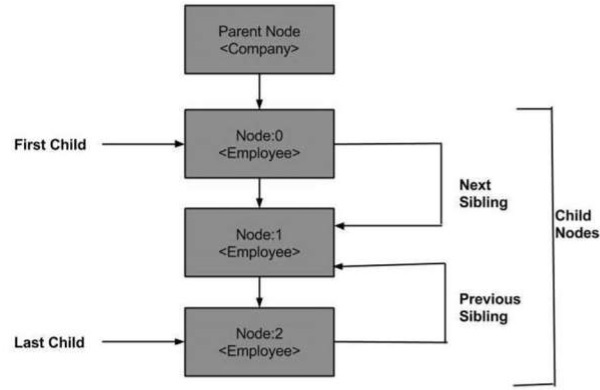
DOM — родительский узел
Это свойство определяет родительский узел как объект узла.
пример
В следующем примере (navigate_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM. Затем объект DOM перемещается к родительскому узлу через дочерний узел —
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>
Как видно из приведенного выше примера, дочерний узел Employee переходит к своему родительскому узлу.
выполнение
Сохраните этот файл как navigate_example.html на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем родительский узел Employee , т. Е. Company .
Первый ребенок
Это свойство имеет тип Node и представляет первое дочернее имя, присутствующее в NodeList.
пример
В следующем примере (first_node_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML, а затем выполняется переход к первому дочернему узлу, присутствующему в объекте DOM.
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>
-
Функция get_firstChild (p) используется для избежания пустых узлов. Это помогает получить элемент firstChild из списка узлов.
-
x = get_firstChild (xmlDoc.getElementsByTagName («Employee») [0]) извлекает первый дочерний узел для имени тега Employee .
Функция get_firstChild (p) используется для избежания пустых узлов. Это помогает получить элемент firstChild из списка узлов.
x = get_firstChild (xmlDoc.getElementsByTagName («Employee») [0]) извлекает первый дочерний узел для имени тега Employee .
выполнение
Сохраните этот файл как first_node_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем первый дочерний узел Employee, т.е. FirstName .
Последний ребенок
Это свойство имеет тип Node и представляет последнее дочернее имя, присутствующее в NodeList.
пример
В следующем примере (last_node_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM, а затем выполняется переход к последнему дочернему узлу, присутствующему в объекте xml DOM.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>
выполнение
Сохраните этот файл как last_node_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем последний дочерний узел Employee, т. Е. Email .
Следующий брат
Это свойство имеет тип Node и представляет следующий дочерний элемент, т. Е. Следующий элемент указанного дочернего элемента, присутствующего в NodeList.
пример
В следующем примере (nextSibling_example.htm) выполняется синтаксический анализ документа XML ( node.xml ) в объект XML DOM, который сразу переходит к следующему узлу, присутствующему в документе xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>
выполнение
Сохраните этот файл как nextSibling_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В выводе мы получаем следующий одноуровневый узел FirstName, т.е. LastName .
Предыдущий брат
Это свойство имеет тип Node и представляет предыдущий дочерний элемент, т. Е. Предыдущий элемент указанного дочернего элемента, присутствующий в NodeList.
пример
В следующем примере (previoussibling_example.htm) выполняется синтаксический анализ документа XML ( node.xml ) в объект DOM XML, а затем выполняется переход к узлу before последнего дочернего узла, присутствующего в документе xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>
выполнение
Сохраните этот файл как previoussibling_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В выводе мы получаем предыдущий одноуровневый узел электронной почты, т. Е. ContactNo .
XML DOM — Доступ
В этой главе мы изучим, как получить доступ к узлам XML DOM, которые рассматриваются как информационные единицы документа XML. Структура узла XML DOM позволяет разработчику перемещаться по дереву в поисках конкретной информации и одновременно получать к ней доступ.
Доступ к узлам
Ниже приведены три способа доступа к узлам:
-
Используя метод getElementsByTagName ()
-
Путем обхода или обхода дерева узлов
-
Перемещаясь по дереву узлов, используя связи узлов
Используя метод getElementsByTagName ()
Путем обхода или обхода дерева узлов
Перемещаясь по дереву узлов, используя связи узлов
getElementsByTagName ()
Этот метод позволяет получить доступ к информации об узле, указав имя узла. Это также позволяет получить доступ к информации списка узлов и длины списка узлов.
Синтаксис
Метод getElementByTagName () имеет следующий синтаксис:
node.getElementByTagName("tagname");
Куда,
-
узел — это узел документа.
-
tagname — содержит имя узла, значение которого вы хотите получить.
узел — это узел документа.
tagname — содержит имя узла, значение которого вы хотите получить.
пример
Ниже приведена простая программа, которая иллюстрирует использование метода getElementByTagName.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>
-
В приведенном выше примере мы обращаемся к информации узлов FirstName , LastName и Employee .
-
xmlDoc.getElementsByTagName ( «FirstName») [0] .childNodes [0] .nodeValue; Эта строка обращается к значению для дочернего узла FirstName с помощью метода getElementByTagName ().
-
xmlDoc.getElementsByTagName ( «Сотрудник») [0] .attributes [0] .nodeValue; Эта строка обращается к значению атрибута узла Employee getElementByTagName ().
В приведенном выше примере мы обращаемся к информации узлов FirstName , LastName и Employee .
xmlDoc.getElementsByTagName ( «FirstName») [0] .childNodes [0] .nodeValue; Эта строка обращается к значению для дочернего узла FirstName с помощью метода getElementByTagName ().
xmlDoc.getElementsByTagName ( «Сотрудник») [0] .attributes [0] .nodeValue; Эта строка обращается к значению атрибута узла Employee getElementByTagName ().
Пройдя через узлы
Это описано в главе DOM Traversing с примерами.
Навигация по узлам
Это описано в главе « Навигация по DOM» с примерами.
XML DOM — Get Node
В этой главе мы рассмотрим, как получить значение узла объекта DOM XML. XML-документы имеют иерархию информационных единиц, называемых узлами. Объект Node имеет свойство nodeValue , которое возвращает значение элемента.
В следующих разделах мы обсудим —
-
Получение значения узла элемента
-
Получение значения атрибута узла
Получение значения узла элемента
Получение значения атрибута узла
Файл node.xml, используемый во всех следующих примерах, показан ниже:
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
Получить значение узла
Метод getElementsByTagName () возвращает NodeList всех элементов в порядке документа с заданным именем тега.
пример
В следующем примере (getnode_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и извлекается значение узла дочернего узла Firstname (индекс в 0) —
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>
выполнение
Сохраните этот файл как getnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение узла как Tanmay .
Получить значение атрибута
Атрибуты являются частью элементов узла XML. Элемент узла может иметь несколько уникальных атрибутов. Атрибут дает больше информации об элементах узла XML. Чтобы быть более точным, они определяют свойства элементов узла. Атрибут XML всегда является парой имя-значение. Это значение атрибута называется узлом атрибута .
Метод getAttribute () извлекает значение атрибута по имени элемента.
пример
В следующем примере (get_attribute_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и извлекается значение атрибута категории Employee (индекс в 2) —
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>
выполнение
Сохраните этот файл как get_attribute_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута как Management .
XML DOM — Set Node
В этой главе мы рассмотрим, как изменить значения узлов в объекте XML DOM. Значение узла можно изменить следующим образом:
var value = node.nodeValue;
Если узел является Атрибутом, то значение переменной будет значением атрибута; если узел — это текстовый узел, это будет текстовое содержимое; если узел является Элементом, он будет нулевым .
В следующих разделах будет показана настройка значения узла для каждого типа узла (атрибута, текстового узла и элемента).
Файл node.xml, используемый во всех следующих примерах, показан ниже:
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
Изменить значение текстового узла
Когда мы, скажем, изменить значение элемента Node, мы имеем в виду редактировать текстовое содержимое элемента (которое также называется текстовым узлом ). Следующий пример демонстрирует, как изменить текстовый узел элемента.
пример
В следующем примере (set_text_node_example.htm) выполняется синтаксический анализ документа XML ( node.xml ) в объект XML DOM и изменение значения текстового узла элемента. В этом случае отправьте электронное письмо каждому сотруднику support@xyz.com и распечатайте значения.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "support@xyz.com";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
выполнение
Сохраните этот файл как set_text_node_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Вы получите следующий вывод —
0) support@xyz.com 1) support@xyz.com 2) support@xyz.com
Изменить значение узла атрибута
В следующем примере показано, как изменить узел атрибута элемента.
пример
В следующем примере (set_attribute_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и изменяется значение узла атрибута элемента. В этом случае Категория каждого Сотрудника равна admin-0, admin-1, admin-2 соответственно и распечатывает значения.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>
выполнение
Сохраните этот файл как set_node_attribute_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Результат будет следующим:
0) admin-0 1) admin-1 2) admin-2
XML DOM — Создать узел
В этой главе мы обсудим, как создавать новые узлы, используя несколько методов объекта документа. Эти методы обеспечивают область для создания нового узла элемента, текстового узла, узла комментария, узла раздела CDATA и узла атрибута . Если вновь созданный узел уже существует в объекте элемента, он заменяется новым. Следующие разделы демонстрируют это на примерах.
Создать новый элемент Элемент
Метод createElement () создает новый элементный узел. Если вновь созданный элементный узел существует в объекте элемента, он заменяется новым.
Синтаксис
Синтаксис для использования метода createElement () следующий:
var_name = xmldoc.createElement("tagname");
Куда,
-
var_name — это имя пользовательской переменной, которая содержит имя нового элемента.
-
(«tagname») — это имя нового элемента элемента, который будет создан.
var_name — это имя пользовательской переменной, которая содержит имя нового элемента.
(«tagname») — это имя нового элемента элемента, который будет создан.
пример
В следующем примере (createnewelement_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и создается новый узел элемента PhoneNo в документе XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
-
new_element = xmlDoc.createElement («PhoneNo»); создает новый узел элемента <PhoneNo>
-
x.appendChild (new_element); x содержит имя указанного дочернего узла <FirstName>, к которому добавляется новый элементный узел.
new_element = xmlDoc.createElement («PhoneNo»); создает новый узел элемента <PhoneNo>
x.appendChild (new_element); x содержит имя указанного дочернего узла <FirstName>, к которому добавляется новый элементный узел.
выполнение
Сохраните этот файл как createnewelement_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута как PhoneNo .
Создать новый текстовый узел
Метод createTextNode () создает новый текстовый узел.
Синтаксис
Синтаксис для использования createTextNode () выглядит следующим образом —
var_name = xmldoc.createTextNode("tagname");
Куда,
-
var_name — это имя пользовательской переменной, которая содержит имя нового текстового узла.
-
(«tagname») — в скобках указано имя нового текстового узла, который будет создан.
var_name — это имя пользовательской переменной, которая содержит имя нового текстового узла.
(«tagname») — в скобках указано имя нового текстового узла, который будет создан.
пример
В следующем примере (createtextnode_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и создается новый текстовый узел Im new text node в XML-документе.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>
Подробности вышеупомянутого кода как ниже —
-
create_e = xmlDoc.createElement («PhoneNo»); создает новый элемент < PhoneNo >.
-
create_t = xmlDoc.createTextNode («Я новый текстовый узел»); создает новый текстовый узел «Im new text node» .
-
x.appendChild (create_e); текстовый узел «Новый текстовый узел» добавляется к элементу < PhoneNo >.
-
document.write (x.getElementsByTagName ( «PhoneNo») [0] .childNodes [0] .nodeValue); записывает новое значение текстового узла в элемент <PhoneNo>.
create_e = xmlDoc.createElement («PhoneNo»); создает новый элемент < PhoneNo >.
create_t = xmlDoc.createTextNode («Я новый текстовый узел»); создает новый текстовый узел «Im new text node» .
x.appendChild (create_e); текстовый узел «Новый текстовый узел» добавляется к элементу < PhoneNo >.
document.write (x.getElementsByTagName ( «PhoneNo») [0] .childNodes [0] .nodeValue); записывает новое значение текстового узла в элемент <PhoneNo>.
выполнение
Сохраните этот файл как createtextnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В выводе мы получаем значение атрибута как, например, PhoneNO: Im новый текстовый узел .
Создать новый узел комментариев
Метод createComment () создает новый узел комментария. Узел комментариев включен в программу для легкого понимания функциональности кода.
Синтаксис
Синтаксис для использования createComment () выглядит следующим образом —
var_name = xmldoc.createComment("tagname");
Куда,
-
var_name — это имя пользовательской переменной, которая содержит имя нового узла комментария.
-
(«tagname») — это имя нового узла комментария, который будет создан.
var_name — это имя пользовательской переменной, которая содержит имя нового узла комментария.
(«tagname») — это имя нового узла комментария, который будет создан.
пример
В следующем примере (createcommentnode_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML и создается новый узел комментария «Компания является родительским узлом» в документе XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
В приведенном выше примере —
-
create_comment = xmlDoc.createComment («Компания является родительским узлом») создает указанную строку комментария .
-
x.appendChild (create_comment) В этой строке ‘x’ содержит имя элемента <Company>, к которому добавляется строка комментария.
create_comment = xmlDoc.createComment («Компания является родительским узлом») создает указанную строку комментария .
x.appendChild (create_comment) В этой строке ‘x’ содержит имя элемента <Company>, к которому добавляется строка комментария.
выполнение
Сохраните этот файл как createcommentnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута, так как Company является родительским узлом .
Создать новый узел раздела CDATA
Метод createCDATASection () создает новый узел раздела CDATA. Если в объекте элемента существует только что созданный узел раздела CDATA, он заменяется новым.
Синтаксис
Синтаксис для использования createCDATASection () выглядит следующим образом:
var_name = xmldoc.createCDATASection("tagname");
Куда,
-
var_name — это имя пользовательской переменной, которая содержит имя нового узла раздела CDATA.
-
(«tagname») — это имя нового узла раздела CDATA, который будет создан.
var_name — это имя пользовательской переменной, которая содержит имя нового узла раздела CDATA.
(«tagname») — это имя нового узла раздела CDATA, который будет создан.
пример
В следующем примере (createcdatanode_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и создается новый узел раздела CDATA «Создать пример CDATA» в документе XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>
В приведенном выше примере —
-
create_CDATA = xmlDoc.createCDATASection («Создать пример CDATA») создает новый узел раздела CDATA, «Создать пример CDATA»
-
Здесь x.appendChild (create_CDATA) , x содержит указанный элемент <Employee> с индексом 0, к которому добавляется значение узла CDATA.
create_CDATA = xmlDoc.createCDATASection («Создать пример CDATA») создает новый узел раздела CDATA, «Создать пример CDATA»
Здесь x.appendChild (create_CDATA) , x содержит указанный элемент <Employee> с индексом 0, к которому добавляется значение узла CDATA.
выполнение
Сохраните этот файл как createcdatanode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута как пример создания CDATA .
Создать новый Атрибут узла
Для создания нового узла атрибута используется метод setAttributeNode () . Если вновь созданный узел атрибута существует в объекте элемента, он заменяется новым.
Синтаксис
Синтаксис для использования метода createElement () следующий:
var_name = xmldoc.createAttribute("tagname");
Куда,
-
var_name — это имя пользовательской переменной, которая содержит имя нового атрибута узла.
-
(«tagname») — это имя нового атрибутивного узла, который будет создан.
var_name — это имя пользовательской переменной, которая содержит имя нового атрибута узла.
(«tagname») — это имя нового атрибутивного узла, который будет создан.
пример
В следующем примере (createattributenode_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML и создается новый раздел узла атрибута в документе XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>
В приведенном выше примере —
-
create_a = xmlDoc.createAttribute («Category») создает атрибут с именем <section>.
-
create_a.nodeValue = «Management» создает значение «A» для атрибута <section>.
-
x [0] .setAttributeNode (create_a) этому значению атрибута присваивается элемент узла <Employee> с индексом 0.
create_a = xmlDoc.createAttribute («Category») создает атрибут с именем <section>.
create_a.nodeValue = «Management» создает значение «A» для атрибута <section>.
x [0] .setAttributeNode (create_a) этому значению атрибута присваивается элемент узла <Employee> с индексом 0.
XML DOM — Добавить узел
В этой главе мы обсудим узлы существующего элемента. Это обеспечивает средства для —
-
добавить новые дочерние узлы до или после существующих дочерних узлов
-
вставить данные в текстовом узле
-
добавить узел атрибута
добавить новые дочерние узлы до или после существующих дочерних узлов
вставить данные в текстовом узле
добавить узел атрибута
Следующие методы могут быть использованы для добавления / добавления узлов к элементу в DOM —
- AppendChild ()
- InsertBefore ()
- insertData ()
AppendChild ()
Метод appendChild () добавляет новый дочерний узел после существующего дочернего узла.
Синтаксис
Синтаксис метода appendChild () выглядит следующим образом:
Node appendChild(Node newChild) throws DOMException
Куда,
-
newChild — это узел для добавления
-
Этот метод возвращает добавленный узел .
newChild — это узел для добавления
Этот метод возвращает добавленный узел .
пример
В следующем примере (appendchildnode_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и добавляется новый дочерний PhoneNo к элементу <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>
В приведенном выше примере —
-
используя метод createElement (), создается новый элемент PhoneNo .
-
Новый элемент PhoneNo добавляется в элемент FirstName с помощью метода appendChild ().
используя метод createElement (), создается новый элемент PhoneNo .
Новый элемент PhoneNo добавляется в элемент FirstName с помощью метода appendChild ().
выполнение
Сохраните этот файл как appendchildnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). В результате мы получаем значение атрибута как PhoneNo .
InsertBefore ()
Метод insertBefore () вставляет новые дочерние узлы перед указанными дочерними узлами.
Синтаксис
Синтаксис метода insertBefore () следующий:
Node insertBefore(Node newChild, Node refChild) throws DOMException
Куда,
-
newChild — это узел для вставки
-
refChild — Ссылочный узел, т. е. узел, перед которым должен быть вставлен новый узел.
-
Этот метод возвращает вставляемый узел .
newChild — это узел для вставки
refChild — Ссылочный узел, т. е. узел, перед которым должен быть вставлен новый узел.
Этот метод возвращает вставляемый узел .
пример
В следующем примере (insertnodebefore_example.htm) анализируется XML-документ ( node.xml ) в объект XML DOM и вставляется новый дочерний Email перед указанным элементом <Email>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("Email");
x = xmlDoc.documentElement;
y = xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements before inserting was: " + y.length);
document.write("<br>");
x.insertBefore(create_e,y[3]);
y=xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements after inserting is: " + y.length);
</script>
</body>
</html>
В приведенном выше примере —
-
используя метод createElement (), создается новый элемент Email .
-
Новый элемент Email добавляется перед элементом Email с помощью метода insertBefore ().
-
y.length дает общее количество элементов, добавленных до и после нового элемента.
используя метод createElement (), создается новый элемент Email .
Новый элемент Email добавляется перед элементом Email с помощью метода insertBefore ().
y.length дает общее количество элементов, добавленных до и после нового элемента.
выполнение
Сохраните этот файл как insertnodebefore_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим следующий вывод —
No of Email elements before inserting was: 3 No of Email elements after inserting is: 4
insertData ()
Метод insertData () вставляет строку с указанным 16-разрядным смещением.
Синтаксис
InsertData () имеет следующий синтаксис —
void insertData(int offset, java.lang.String arg) throws DOMException
Куда,
-
смещение — это смещение символа для вставки.
-
arg — это ключевое слово для вставки данных. Он включает в себя два параметра offset и string в скобках, разделенных запятой.
смещение — это смещение символа для вставки.
arg — это ключевое слово для вставки данных. Он включает в себя два параметра offset и string в скобках, разделенных запятой.
пример
В следующем примере (addtext_example.htm) выполняется синтаксический анализ XML-документа (» node.xml «) в объект XML DOM и вставка новых данных MiddleName в указанной позиции в элемент <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0];
document.write(x.nodeValue);
x.insertData(6,"MiddleName");
document.write("<br>");
document.write(x.nodeValue);
</script>
</body>
</html>
-
x.insertData (6, «MiddleName»); — Здесь x содержит имя указанного дочернего имени, то есть <FirstName>. Затем мы вставляем в этот текстовый узел данные «MiddleName», начиная с позиции 6.
x.insertData (6, «MiddleName»); — Здесь x содержит имя указанного дочернего имени, то есть <FirstName>. Затем мы вставляем в этот текстовый узел данные «MiddleName», начиная с позиции 6.
выполнение
Сохраните этот файл как addtext_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим следующее в выводе —
Tanmay TanmayMiddleName
XML DOM — заменить узел
В этой главе мы изучим операцию замены узла в объекте XML DOM. Как мы знаем, все в DOM поддерживается в иерархической информационной единице, известной как узел, и заменяющий узел предоставляет другой способ обновления этих указанных узлов или текстового узла.
Ниже приведены два метода замены узлов.
- replaceChild ()
- replaceData ()
replaceChild ()
Метод replaceChild () заменяет указанный узел новым узлом.
Синтаксис
InsertData () имеет следующий синтаксис —
Node replaceChild(Node newChild, Node oldChild) throws DOMException
Куда,
-
newChild — это новый узел для добавления в дочерний список.
-
oldChild — это заменяемый узел в списке.
-
Этот метод возвращает замененный узел.
newChild — это новый узел для добавления в дочерний список.
oldChild — это заменяемый узел в списке.
Этот метод возвращает замененный узел.
пример
В следующем примере (replacenode_example.htm) выполняется синтаксический анализ XML-документа ( node.xml ) в объект XML DOM и замена указанного узла <FirstName> новым узлом <Name>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.documentElement;
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element before replace operation</b><br>");
for (i=0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
//create a Employee element, FirstName element and a text node
newNode = xmlDoc.createElement("Employee");
newTitle = xmlDoc.createElement("Name");
newText = xmlDoc.createTextNode("MS Dhoni");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y = xmlDoc.getElementsByTagName("Employee")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element after replace operation</b><br>");
for (i = 0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
выполнение
Сохраните этот файл как replacenode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже —
Content of FirstName element before replace operation Tanmay Taniya Tanisha Content of FirstName element after replace operation Taniya Tanisha
replaceData ()
Метод replaceData () заменяет символы, начинающиеся с указанного 16-разрядного смещения, указанной строкой.
Синтаксис
ReplaceData () имеет следующий синтаксис —
void replaceData(int offset, int count, java.lang.String arg) throws DOMException
куда
-
смещение — это смещение, с которого начинается замена.
-
count — это количество 16-битных блоков для замены. Если сумма смещения и счетчика превышает длину, то все 16-битные единицы до конца данных заменяются.
-
arg — строка DOMString, с которой необходимо заменить диапазон.
смещение — это смещение, с которого начинается замена.
count — это количество 16-битных блоков для замены. Если сумма смещения и счетчика превышает длину, то все 16-битные единицы до конца данных заменяются.
arg — строка DOMString, с которой необходимо заменить диапазон.
пример
В следующем примере ( replaceata_example.htm ) анализируется документ XML ( node.xml ) в объект XML DOM и заменяется его.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0];
document.write("<b>ContactNo before replace operation:</b> "+x.nodeValue);
x.replaceData(1,5,"9999999");
document.write("<br>");
document.write("<b>ContactNo after replace operation:</b> "+x.nodeValue);
</script>
</body>
</html>
В приведенном выше примере —
-
x.replaceData (2,3, «999»); — Здесь x содержит текст указанного элемента <ContactNo>, текст которого заменяется новым текстом «9999999» , начиная с позиции 1 до длины 5 .
x.replaceData (2,3, «999»); — Здесь x содержит текст указанного элемента <ContactNo>, текст которого заменяется новым текстом «9999999» , начиная с позиции 1 до длины 5 .
выполнение
Сохраните этот файл как replaceata_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже —
ContactNo before replace operation: 1234567890 ContactNo after replace operation: 199999997890
XML DOM — Удалить узел
В этой главе мы изучим операцию удаления узла XML DOM. Операция удаления узла удаляет указанный узел из документа. Эта операция может быть реализована для удаления узлов, таких как текстовый узел, узел элемента или узел атрибута.
Ниже приведены методы, которые используются для операции удаления узла.
-
RemoveChild ()
-
removeAttribute ()
RemoveChild ()
removeAttribute ()
RemoveChild ()
Метод removeChild () удаляет дочерний узел, обозначенный oldChild, из списка дочерних и возвращает его. Удаление дочернего узла эквивалентно удалению текстового узла. Следовательно, удаление дочернего узла удаляет связанный с ним текстовый узел.
Синтаксис
Синтаксис для использования removeChild () следующий:
Node removeChild(Node oldChild) throws DOMException
Куда,
-
oldChild — это удаляемый узел.
-
Этот метод возвращает удаленный узел.
oldChild — это удаляемый узел.
Этот метод возвращает удаленный узел.
Пример — Удалить текущий узел
В следующем примере (removecurrentnode_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML и удаляется указанный узел <ContactNo> из родительского узла.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
document.write("<b>Before remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
document.write("<br>");
x = xmlDoc.getElementsByTagName("ContactNo")[0];
x.parentNode.removeChild(x);
document.write("<b>After remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
</script>
</body>
</html>
В приведенном выше примере —
-
x = xmlDoc.getElementsByTagName («ContactNo») [0] получает элемент <ContactNo>, проиндексированный в 0.
-
x.parentNode.removeChild (х); удаляет элемент <ContactNo>, проиндексированный в 0, из родительского узла.
x = xmlDoc.getElementsByTagName («ContactNo») [0] получает элемент <ContactNo>, проиндексированный в 0.
x.parentNode.removeChild (х); удаляет элемент <ContactNo>, проиндексированный в 0, из родительского узла.
выполнение
Сохраните этот файл как removecurrentnode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получаем следующий результат —
Before remove operation, total ContactNo elements: 3 After remove operation, total ContactNo elements: 2
Пример — удаление текстового узла
В следующем примере (removetextNode_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и удаляется указанный дочерний узел <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0];
document.write("<b>Text node of child node before removal is:</b> ");
document.write(x.childNodes.length);
document.write("<br>");
y = x.childNodes[0];
x.removeChild(y);
document.write("<b>Text node of child node after removal is:</b> ");
document.write(x.childNodes.length);
</script>
</body>
</html>
В приведенном выше примере —
-
x = xmlDoc.getElementsByTagName («FirstName») [0]; — получает первый элемент <FirstName> в x, проиндексированный в 0.
-
y = x.childNodes [0]; — в этой строке y содержит дочерний узел, который нужно удалить.
-
x.removeChild (у); — удаляет указанный дочерний узел.
x = xmlDoc.getElementsByTagName («FirstName») [0]; — получает первый элемент <FirstName> в x, проиндексированный в 0.
y = x.childNodes [0]; — в этой строке y содержит дочерний узел, который нужно удалить.
x.removeChild (у); — удаляет указанный дочерний узел.
выполнение
Сохраните этот файл как removetextNode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получаем следующий результат —
Text node of child node before removal is: 1 Text node of child node after removal is: 0
removeAttribute ()
Метод removeAttribute () удаляет атрибут элемента по имени.
Синтаксис
Синтаксис для использования removeAttribute () выглядит следующим образом —
void removeAttribute(java.lang.String name) throws DOMException
Куда,
-
name — это имя атрибута, который нужно удалить.
name — это имя атрибута, который нужно удалить.
пример
В следующем примере (removeelementattribute_example.htm) анализируется документ XML ( node.xml ) в объект DOM XML и удаляется указанный узел атрибута.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee');
document.write(x[1].getAttribute('category'));
document.write("<br>");
x[1].removeAttribute('category');
document.write(x[1].getAttribute('category'));
</script>
</body>
</html>
В приведенном выше примере —
-
document.write (х [1] .getAttribute ( ‘категория’)); — вызывается значение категории атрибута, проиндексированной на 1-й позиции.
-
х [1] .removeAttribute ( ‘категория’); — удаляет значение атрибута.
document.write (х [1] .getAttribute ( ‘категория’)); — вызывается значение категории атрибута, проиндексированной на 1-й позиции.
х [1] .removeAttribute ( ‘категория’); — удаляет значение атрибута.
выполнение
Сохраните этот файл как removeelementattribute_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получаем следующий результат —
Non-Technical null
XML DOM — узел клонирования
В этой главе мы обсудим операцию узла клонирования на объекте XML DOM. Операция клонирования узла используется для создания дубликата копии указанного узла. cloneNode () используется для этой операции.
cloneNode ()
Этот метод возвращает дубликат этого узла, то есть служит общим конструктором копирования для узлов. Дублированный узел не имеет родителя (parentNode имеет значение null) и пользовательских данных.
Синтаксис
Метод cloneNode () имеет следующий синтаксис —
Node cloneNode(boolean deep)
-
deep — если true, рекурсивно клонирует поддерево под указанным узлом; если ложь, клонировать только сам узел (и его атрибуты, если это элемент).
-
Этот метод возвращает дубликат узла.
deep — если true, рекурсивно клонирует поддерево под указанным узлом; если ложь, клонировать только сам узел (и его атрибуты, если это элемент).
Этот метод возвращает дубликат узла.
пример
В следующем примере (clonenode_example.htm) анализируется документ XML ( node.xml ) в объект XML DOM и создается глубокая копия первого элемента Employee .
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee')[0];
clone_node = x.cloneNode(true);
xmlDoc.documentElement.appendChild(clone_node);
firstname = xmlDoc.getElementsByTagName("FirstName");
lastname = xmlDoc.getElementsByTagName("LastName");
contact = xmlDoc.getElementsByTagName("ContactNo");
email = xmlDoc.getElementsByTagName("Email");
for (i = 0;i < firstname.length;i++) {
document.write(firstname[i].childNodes[0].nodeValue+'
'+lastname[i].childNodes[0].nodeValue+',
'+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
Как вы можете видеть в приведенном выше примере, мы установили для параметра cloneNode () значение true . Следовательно, каждый дочерний элемент в элементе Employee копируется или клонируется.
выполнение
Сохраните этот файл как clonenode_example.htm на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже —
Tanmay Patil, 1234567890, tanmaypatil@xyz.com Taniya Mishra, 1234667898, taniyamishra@xyz.com Tanisha Sharma, 1234562350, tanishasharma@xyz.com Tanmay Patil, 1234567890, tanmaypatil@xyz.com
Вы заметите, что первый элемент Employee полностью клонирован.
DOM — Node Object
Интерфейс узла является основным типом данных для всей объектной модели документа. Узел используется для представления одного элемента XML во всем дереве документа.
Узел может быть любого типа, который является узлом атрибута, текстовым узлом или любым другим узлом. Атрибуты nodeName, nodeValue и атрибуты включены в качестве механизма для получения информации об узле, не обращаясь к конкретному производному интерфейсу.
Атрибуты
В следующей таблице перечислены атрибуты объекта Node —
| атрибут | Тип | Описание |
|---|---|---|
| атрибуты | NamedNodeMap | Это тип NamedNodeMap, содержащий атрибуты этого узла (если это элемент) или ноль в противном случае. Это было удалено. См. Спецификации |
| BaseUri | DOMString | Он используется для указания абсолютного базового URI узла. |
| ChildNodes | NodeList | Это NodeList, который содержит все дочерние элементы этого узла. Если дочерних элементов нет, это NodeList, не содержащий узлов. |
| Первый ребенок | Узел | Указывает первого потомка узла. |
| последний ребенок | Узел | Указывает последнего потомка узла. |
| LocalName | DOMString | Он используется для указания имени локальной части узла. Это было удалено. См. Спецификации |
| NamespaceURI | DOMString | Он определяет URI пространства имен узла. Это было удалено. См. Спецификации |
| NextSibling | Узел | Он возвращает узел, следующий сразу за этим узлом. Если такого узла нет, возвращается ноль. |
| NODENAME | DOMString | Имя этого узла в зависимости от его типа. |
| NODETYPE | неподписанный короткий | Это код, представляющий тип базового объекта. |
| nodeValue | DOMString | Он используется для указания значения узла в зависимости от их типов. |
| ownerDocument | Документ | Он указывает объект Document, связанный с узлом. |
| ParentNode | Узел | Это свойство указывает родительский узел узла. |
| префикс | DOMString | Это свойство возвращает префикс пространства имен узла. Это было удалено. См. Спецификации |
| PreviousSibling | Узел | Это указывает узел, непосредственно предшествующий текущему узлу. |
| TextContent | DOMString | Это определяет текстовое содержимое узла. |
Типы узлов
Мы перечислили типы узлов, как показано ниже:
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
методы
Ниже в таблице перечислены различные методы объекта Node —
| S.No. | Метод и описание |
|---|---|
| 1 | appendChild (Узел newChild)
Этот метод добавляет узел после последнего дочернего узла указанного узла элемента. Возвращает добавленный узел. |
| 2 | cloneNode (логический глубокий)
Этот метод используется для создания дублирующего узла при переопределении в производном классе. Возвращает дублированный узел. |
| 3 | compareDocumentPosition (Узел другой)
Этот метод используется для сравнения положения текущего узла с указанным узлом в соответствии с порядком документов. Возвращает неподписанные короткий, как узел расположен относительно опорного узла. |
| 4 |
getFeature (функция DOMString, версия DOMString) Возвращает объект DOM, который реализует специализированные API указанной функции и версии, если таковые имеются, или null, если объекта нет. Это было удалено. См. Спецификации |
| 5 |
getUserData (ключ DOMString) Извлекает объект, связанный с ключом на этом узле. Сначала объект должен быть установлен на этот узел путем вызова setUserData с тем же ключом. Возвращает DOMUserData, связанный с данным ключом на этом узле, или ноль, если их не было. Это было удалено. См. Спецификации |
| 6 |
HasAttributes () Возвращает, имеет ли этот узел (если это элемент) какие-либо атрибуты или нет. Возвращает true, если какой-либо атрибут присутствует в указанном узле, иначе возвращает false . Это было удалено. См. Спецификации |
| 7 | hasChildNodes ()
Возвращает, есть ли у этого узла дочерние элементы. Этот метод возвращает true, если текущий узел имеет дочерние узлы, в противном случае — false . |
| 8 | insertBefore (Node newChild, Node refChild)
Этот метод используется для вставки нового узла в качестве дочернего элемента этого узла непосредственно перед существующим дочерним элементом этого узла. Возвращает вставляемый узел. |
| 9 | isDefaultNamespace (пространство имен DOMStringURI)
Этот метод принимает URI пространства имен в качестве аргумента и возвращает логическое значение со значением true, если пространство имен является пространством имен по умолчанию на данном узле, или false, если нет. |
| 10 | isEqualNode (Node arg)
Этот метод проверяет, равны ли два узла. Возвращает true, если узлы равны, иначе false . |
| 11 |
isSameNode (другой узел) Этот метод возвращает, является ли текущий узел тем же узлом, что и данный. Возвращает true, если узлы совпадают, иначе false . Это было удалено. См. Спецификации |
| 12 |
isSupported (функция DOMString, версия DOMString) Этот метод возвращает информацию о том, поддерживается ли указанный модуль DOM текущим узлом. Возвращает true, если указанная функция поддерживается на этом узле, иначе false . Это было удалено. См. Спецификации |
| 13 | lookupNamespaceURI (префикс DOMString)
Этот метод получает URI пространства имен, связанного с префиксом пространства имен. |
| 14 | lookupPrefix (пространство имен DOMStringURI)
Этот метод возвращает ближайший префикс, определенный в текущем пространстве имен для URI пространства имен. Возвращает связанный префикс пространства имен, если он найден, или ноль, если ничего не найдено. |
| 15 | нормализуют ()
Нормализация добавляет все текстовые узлы, включая узлы атрибутов, которые определяют нормальную форму, где структура узлов, которые содержат элементы, комментарии, инструкции по обработке, разделы CDATA и ссылки на сущности, разделяет текстовые узлы, т. Е. Ни смежные текстовые узлы, ни пустые текстовые узлы. |
| 16 | removeChild (Узел oldChild)
Этот метод используется для удаления указанного дочернего узла из текущего узла. Это возвращает удаленный узел. |
| 17 | replaceChild (Узел newChild, Узел oldChild)
Этот метод используется для замены старого дочернего узла новым узлом. Это возвращает замененный узел. |
| 18 |
setUserData (ключ DOMString, данные DOMUserData, обработчик UserDataHandler) Этот метод связывает объект с ключом на этом узле. Позже объект можно извлечь из этого узла, вызвав getUserData с тем же ключом. Это возвращает DOMUserData, ранее связанный с данным ключом на этом узле. Это было удалено. См. Спецификации |
Этот метод добавляет узел после последнего дочернего узла указанного узла элемента. Возвращает добавленный узел.
Этот метод используется для создания дублирующего узла при переопределении в производном классе. Возвращает дублированный узел.
Этот метод используется для сравнения положения текущего узла с указанным узлом в соответствии с порядком документов. Возвращает неподписанные короткий, как узел расположен относительно опорного узла.
getFeature (функция DOMString, версия DOMString)
Возвращает объект DOM, который реализует специализированные API указанной функции и версии, если таковые имеются, или null, если объекта нет. Это было удалено. См. Спецификации
getUserData (ключ DOMString)
Извлекает объект, связанный с ключом на этом узле. Сначала объект должен быть установлен на этот узел путем вызова setUserData с тем же ключом. Возвращает DOMUserData, связанный с данным ключом на этом узле, или ноль, если их не было. Это было удалено. См. Спецификации
HasAttributes ()
Возвращает, имеет ли этот узел (если это элемент) какие-либо атрибуты или нет. Возвращает true, если какой-либо атрибут присутствует в указанном узле, иначе возвращает false . Это было удалено. См. Спецификации
Возвращает, есть ли у этого узла дочерние элементы. Этот метод возвращает true, если текущий узел имеет дочерние узлы, в противном случае — false .
Этот метод используется для вставки нового узла в качестве дочернего элемента этого узла непосредственно перед существующим дочерним элементом этого узла. Возвращает вставляемый узел.
Этот метод принимает URI пространства имен в качестве аргумента и возвращает логическое значение со значением true, если пространство имен является пространством имен по умолчанию на данном узле, или false, если нет.
Этот метод проверяет, равны ли два узла. Возвращает true, если узлы равны, иначе false .
isSameNode (другой узел)
Этот метод возвращает, является ли текущий узел тем же узлом, что и данный. Возвращает true, если узлы совпадают, иначе false . Это было удалено. См. Спецификации
isSupported (функция DOMString, версия DOMString)
Этот метод возвращает информацию о том, поддерживается ли указанный модуль DOM текущим узлом. Возвращает true, если указанная функция поддерживается на этом узле, иначе false . Это было удалено. См. Спецификации
Этот метод получает URI пространства имен, связанного с префиксом пространства имен.
Этот метод возвращает ближайший префикс, определенный в текущем пространстве имен для URI пространства имен. Возвращает связанный префикс пространства имен, если он найден, или ноль, если ничего не найдено.
Нормализация добавляет все текстовые узлы, включая узлы атрибутов, которые определяют нормальную форму, где структура узлов, которые содержат элементы, комментарии, инструкции по обработке, разделы CDATA и ссылки на сущности, разделяет текстовые узлы, т. Е. Ни смежные текстовые узлы, ни пустые текстовые узлы.
Этот метод используется для удаления указанного дочернего узла из текущего узла. Это возвращает удаленный узел.
Этот метод используется для замены старого дочернего узла новым узлом. Это возвращает замененный узел.
setUserData (ключ DOMString, данные DOMUserData, обработчик UserDataHandler)
Этот метод связывает объект с ключом на этом узле. Позже объект можно извлечь из этого узла, вызвав getUserData с тем же ключом. Это возвращает DOMUserData, ранее связанный с данным ключом на этом узле. Это было удалено. См. Спецификации
DOM — объект NodeList
Объект NodeList определяет абстракцию упорядоченного набора узлов. Элементы в NodeList доступны через интегральный индекс, начиная с 0.
Атрибуты
В следующей таблице перечислены атрибуты объекта NodeList —
| атрибут | Тип | Описание |
|---|---|---|
| длина | без знака долго | Это дает количество узлов в списке узлов. |
методы
Следующее является единственным методом объекта NodeList.
| S.No. | Метод и описание |
|---|---|
| 1 | вещь()
Возвращает индексный элемент в коллекции. Если индекс больше или равен количеству узлов в списке, это возвращает нуль. |
Возвращает индексный элемент в коллекции. Если индекс больше или равен количеству узлов в списке, это возвращает нуль.
DOM — объект NamedNodeMap
Объект NamedNodeMap используется для представления коллекций узлов, к которым можно получить доступ по имени.
Атрибуты
В следующей таблице перечислены свойства объекта NamedNodeMap.
| атрибут | Тип | Описание |
|---|---|---|
| длина | без знака долго | Это дает количество узлов в этой карте. Диапазон допустимых индексов дочерних узлов составляет от 0 до длины-1 включительно. |
методы
В следующей таблице перечислены методы объекта NamedNodeMap .
| S.No. | Методы и описание |
|---|---|
| 1 | getNamedItem ()
Извлекает узел, указанный по имени. |
| 2 | getNamedItemNS ()
Извлекает узел, указанный локальным именем и URI пространства имен. |
| 3 | вещь ()
Возвращает индексный элемент на карте. Если индекс больше или равен количеству узлов в этой карте, это возвращает нуль. |
| 4 | removeNamedItem ()
Удаляет узел, указанный именем. |
| 5 | removeNamedItemNS ()
Удаляет узел, указанный локальным именем и URI пространства имен. |
| 6 | setNamedItem ()
Добавляет узел, используя его атрибут nodeName . Если узел с таким именем уже присутствует на этой карте, он заменяется новым. |
| 7 | setNamedItemNS ()
Добавляет узел, используя его namespaceURI и localName . Если узел с этим URI пространства имен и этим локальным именем уже присутствует в этой карте, он заменяется новым. Замена узла сама по себе не имеет никакого эффекта. |
Извлекает узел, указанный по имени.
Извлекает узел, указанный локальным именем и URI пространства имен.
Возвращает индексный элемент на карте. Если индекс больше или равен количеству узлов в этой карте, это возвращает нуль.
Удаляет узел, указанный именем.
Удаляет узел, указанный локальным именем и URI пространства имен.
Добавляет узел, используя его атрибут nodeName . Если узел с таким именем уже присутствует на этой карте, он заменяется новым.
Добавляет узел, используя его namespaceURI и localName . Если узел с этим URI пространства имен и этим локальным именем уже присутствует в этой карте, он заменяется новым. Замена узла сама по себе не имеет никакого эффекта.
DOM — Объект DOMImplementation
Объект DOMImplementation предоставляет ряд методов для выполнения операций, которые не зависят от какого-либо конкретного экземпляра объектной модели документа.
методы
В следующей таблице перечислены методы объекта DOMImplementation.
| S.No. | Метод и описание |
|---|---|
| 1 | createDocument (namespaceURI, qualName, doctype)
Он создает объект DOM Document указанного типа со своим элементом документа. |
| 2 | createDocumentType (qualName, publicId, systemId)
Создает пустой узел DocumentType . |
| 3 |
getFeature (функция, версия) Этот метод возвращает специализированный объект, который реализует специализированные API указанной функции и версии. Это было удалено. См. Спецификации |
| 4 | hasFeature (функция, версия)
Этот метод проверяет, реализует ли реализация DOM определенную функцию и версию. |
Он создает объект DOM Document указанного типа со своим элементом документа.
Создает пустой узел DocumentType .
getFeature (функция, версия)
Этот метод возвращает специализированный объект, который реализует специализированные API указанной функции и версии. Это было удалено. См. Спецификации
Этот метод проверяет, реализует ли реализация DOM определенную функцию и версию.
DOM — DocumentType Object
Объекты DocumentType являются ключом для доступа к данным документа, и в документе атрибут doctype может иметь либо нулевое значение, либо значение объекта DocumentType. Эти объекты DocumentType действуют как интерфейс для сущностей, описанных для документа XML.
Атрибуты
В следующей таблице перечислены атрибуты объекта DocumentType —
| атрибут | Тип | Описание |
|---|---|---|
| название | DOMString | Возвращает имя DTD, которое написано непосредственно рядом с ключевым словом! DOCTYPE. |
| юридические лица | NamedNodeMap | Он возвращает объект NamedNodeMap, содержащий общие сущности, как внешние, так и внутренние, объявленные в DTD. |
| условные обозначения | NamedNodeMap | Он возвращает NamedNodeMap, содержащий нотации, объявленные в DTD. |
| internalSubset | DOMString | Он возвращает внутреннее подмножество в виде строки или ноль, если его нет. Это было удалено. См. Спецификации |
| publicId | DOMString | Возвращает открытый идентификатор внешнего подмножества. |
| SYSTEMID | DOMString | Возвращает системный идентификатор внешнего подмножества. Это может быть абсолютный URI или нет. |
методы
DocumentType наследует методы от своего родителя Node и реализует интерфейс ChildNode .
DOM — объект ProcessingInstruction
ProcessingInstruction предоставляет ту специфическую для приложения информацию, которая обычно включена в раздел пролога XML-документа.
Инструкции по обработке (PI) могут использоваться для передачи информации приложениям. PI могут появляться в любом месте документа вне разметки. Они могут появляться в прологе, включая определение типа документа (DTD), в текстовом содержимом или после документа.
PI начинается со специального тега <? и заканчивается ?> . Обработка содержимого заканчивается сразу после появления строки ?> .
Атрибуты
В следующей таблице перечислены атрибуты объекта ProcessingInstruction —
| атрибут | Тип | Описание |
|---|---|---|
| данные | DOMString | Это символ, который описывает информацию, которую приложение должно обработать непосредственно перед символом?>. |
| цель | DOMString | Это идентифицирует приложение, к которому направлена инструкция или данные. |
DOM — Entity Object
Интерфейс сущности представляет известную сущность, анализируемую или не разбираемую, в документе XML. Атрибут nodeName , унаследованный от Node, содержит имя объекта.
Объект Entity не имеет родительского узла, и все его последующие узлы доступны только для чтения.
Атрибуты
В следующей таблице перечислены атрибуты объекта Entity —
| атрибут | Тип | Описание |
|---|---|---|
| КодировкаИсточника | DOMString | Это определяет кодировку, используемую внешним анализируемым объектом. Его значение равно нулю, если оно является сущностью из внутреннего подмножества или если оно неизвестно. |
| notationName | DOMString | Для неразобранных сущностей он дает имя нотации, а его значение для анализируемых сущностей равно нулю . |
| publicId | DOMString | Он дает имя общедоступного идентификатора, связанного с объектом. |
| SYSTEMID | DOMString | Он дает имя системного идентификатора, связанного с объектом. |
| xmlEncoding | DOMString | Он дает кодировку xml, включенную как часть текстового объявления для внешнего анализируемого объекта, в противном случае — ноль. |
| xmlVersion | DOMString | Он дает версию xml, включенную как часть текстового объявления для внешнего анализируемого объекта, в противном случае — ноль. |
DOM — Entity Reference Object
Объекты EntityReference — это общие ссылки на сущности, которые вставляются в документ XML, предоставляя область для замены текста. Объект EntityReference не работает для предопределенных объектов, поскольку считается, что они расширены процессором HTML или XML.
Этот интерфейс не имеет собственных свойств или методов, но наследуется от Node .
DOM — нотация объекта
В этой главе мы рассмотрим объект нотации XML DOM. Свойство объекта нотации обеспечивает область для распознавания формата элементов с атрибутом нотации, конкретной инструкцией обработки или данными, не относящимися к XML. Свойства объекта Node и методы могут быть выполнены на Объекте Обозначения, так как это также рассматривают как Узел.
Этот объект наследует методы и свойства от Node . Его nodeName — это имя нотации. Не имеет родителя.
Атрибуты
В следующей таблице перечислены атрибуты объекта Notation —
| атрибут | Тип | Описание |
|---|---|---|
| publicID | DOMString | Он дает имя общедоступного идентификатора, связанного с нотацией. |
| SYSTEMID | DOMString | Он дает имя системного идентификатора, связанного с нотацией. |
ДОМ — Элемент Объект
Элементы XML могут быть определены как строительные блоки XML. Элементы могут вести себя как контейнеры для хранения текста, элементов, атрибутов, объектов мультимедиа или всего этого. Всякий раз, когда синтаксический анализатор анализирует документ XML на предмет корректности, анализатор перемещается по узлу элемента. Узел элемента содержит текст внутри него, который называется текстовым узлом.
Объект элемента наследует свойства и методы объекта Node, так как объект элемента также рассматривается как Node. Помимо свойств и методов объекта узла, он имеет следующие свойства и методы.
свойства
В следующей таблице перечислены атрибуты объекта Element —
| атрибут | Тип | Описание |
|---|---|---|
| название тэга | DOMString | Он дает имя тега для указанного элемента. |
| schemaTypeInfo | TypeInfo | Он представляет информацию о типе, связанную с этим элементом. Это было удалено. См. Спецификации |
методы
Ниже в таблице перечислены методы Element Object —
| методы | Тип | Описание |
|---|---|---|
| GetAttribute () | DOMString | Извлекает значение атрибута, если существует для указанного элемента. |
| getAttributeNS () | DOMString | Получает значение атрибута по локальному имени и URI пространства имен. |
| getAttributeNode () | атр | Получает имя узла атрибута из текущего элемента. |
| getAttributeNodeNS () | атр | Извлекает узел Attr по локальному имени и URI пространства имен. |
| getElementsByTagName () | NodeList | Возвращает NodeList всех элементов-потомков с заданным именем тега в порядке документа. |
| getElementsByTagNameNS () | NodeList | Возвращает NodeList всех элементов-потомков с заданным локальным именем и URI пространства имен в порядке документа. |
| hasAttribute () | логический | Возвращает true, когда атрибут с данным именем указан для этого элемента или имеет значение по умолчанию, в противном случае — false. |
| hasAttributeNS () | логический | Возвращает true, если для этого элемента задан атрибут с заданным локальным именем и URI пространства имен или значение по умолчанию, в противном случае — false. |
| removeAttribute () | Нет возвращаемого значения | Удаляет атрибут по имени. |
| removeAttributeNS | Нет возвращаемого значения | Удаляет атрибут по локальному имени и URI пространства имен. |
| removeAttributeNode () | атр | Указанный атрибут узла удаляется из элемента. |
| SetAttribute () | Нет возвращаемого значения | Устанавливает новое значение атрибута для существующего элемента. |
| setAttributeNS () | Нет возвращаемого значения | Добавляет новый атрибут. Если атрибут с таким же локальным именем и URI пространства имен уже присутствует в элементе, его префикс изменяется на префиксную часть в поле qualName, а его значение изменяется на параметр-значение. |
| setAttributeNode () | атр | Устанавливает новый атрибутный узел для существующего элемента. |
| setAttributeNodeNS | атр | Добавляет новый атрибут. Если атрибут с этим локальным именем и URI этого пространства имен уже присутствует в элементе, он заменяется новым. |
| setIdAttribute | Нет возвращаемого значения | Если параметр isId равен true, этот метод объявляет указанный атрибут как определяемый пользователем атрибут ID. Это было удалено. См. Спецификации |
| setIdAttributeNS | Нет возвращаемого значения | Если параметр isId равен true, этот метод объявляет указанный атрибут как определяемый пользователем атрибут ID. Это было удалено. См. Спецификации |
DOM — Атрибут Объект
Интерфейс Attr представляет атрибут в объекте Element. Как правило, допустимые значения для атрибута определяются в схеме, связанной с документом. Объекты Attr не рассматриваются как часть дерева документа, поскольку они на самом деле не являются дочерними узлами элемента, который они описывают. Таким образом, для дочерних узлов parentNode , previousSibling и nextSibling значение атрибута равно нулю .
Атрибуты
В следующей таблице перечислены атрибуты объекта атрибутов —
| атрибут | Тип | Описание |
|---|---|---|
| название | DOMString | Это дает имя атрибута. |
| указанный | логический | Это логическое значение, которое возвращает true, если значение атрибута существует в документе. |
| значение | DOMString | Возвращает значение атрибута. |
| ownerElement | Элемент | Он дает узел, с которым связан атрибут, или ноль, если атрибут не используется. |
| ИРСС | логический | Он возвращает информацию о том, известен ли атрибут с идентификатором типа (т. Е. Содержит ли он идентификатор элемента-владельца) или нет. |
DOM — CDATASection Объект
В этой главе мы рассмотрим объект CDATASection XML DOM. Текст, представленный в документе XML, анализируется или не разбирается в зависимости от того, что он объявлен. Если текст объявлен как данные анализа символов (PCDATA), он анализируется синтаксическим анализатором для преобразования документа XML в объект DOM XML. С другой стороны, если текст объявлен как неразобранные символьные данные (CDATA), текст внутри не анализируется анализатором XML. Они не рассматриваются как разметка и не расширяют сущности.
Целью использования объекта CDATASection является экранирование блоков текста, содержащих символы, которые в противном случае считались бы разметкой. «]]>» , это единственный разделитель, распознаваемый в разделе CDATA, который заканчивается разделом CDATA.
Атрибут CharacterData.data содержит текст, содержащийся в разделе CDATA. Этот интерфейс наследует интерфейс CharatcterData через текстовый интерфейс.
Для объекта CDATASection не определены методы и атрибуты. Он только напрямую реализует текстовый интерфейс.
DOM — комментарий объекта
В этой главе мы будем изучать объект Comment . Комментарии добавляются в виде примечаний или строк для понимания цели XML-кода. Комментарии могут быть использованы для включения связанных ссылок, информации и терминов. Они могут появляться в любом месте XML-кода.
Интерфейс комментария наследует интерфейс CharacterData, представляющий содержание комментария.
Синтаксис
XML-комментарий имеет следующий синтаксис —
<!-------Your comment----->
Комментарий начинается с <! — и заканчивается ->. Вы можете добавить текстовые заметки в качестве комментариев между персонажами. Вы не должны вкладывать один комментарий в другой.
Для объекта Comment не определены методы и атрибуты. Он наследует те из своего родителя, CharacterData , и косвенно те из Node .
DOM — объект XMLHttpRequest
Объект XMLHttpRequest устанавливает посредник между клиентской и серверной сторонами веб-страницы, который может использоваться многими языками сценариев, такими как JavaScript, JScript, VBScript и другими веб-браузерами, для передачи и манипулирования данными XML.
С помощью объекта XMLHttpRequest можно обновлять часть веб-страницы без перезагрузки всей страницы, запрашивать и получать данные с сервера после загрузки страницы и отправлять данные на сервер.
Синтаксис
Объект XMLHttpRequest может быть установлен следующим образом:
xmlhttp = new XMLHttpRequest();
Для обработки всех браузеров, включая IE5 и IE6, проверьте, поддерживает ли браузер объект XMLHttpRequest, как показано ниже:
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
Примеры загрузки файла XML с использованием объекта XMLHttpRequest можно найти здесь.
методы
В следующей таблице перечислены методы объекта XMLHttpRequest.
| S.No. | Метод и описание |
|---|---|
| 1 |
прервать () Завершает текущий сделанный запрос. |
| 2 |
getAllResponseHeaders () Возвращает все заголовки ответа в виде строки или ноль, если ответ не получен. |
| 3 |
getResponseHeader () Возвращает строку, содержащую текст указанного заголовка, или ноль, если ответ еще не получен или заголовок не существует в ответе. |
| 4 |
открытый (метод, URL, асинхронный, uname, PSWD) Он используется в сочетании с методом Send для отправки запроса на сервер. Метод open указывает следующие параметры —
|
| 5 |
отправить (строка) Используется для отправки запроса, работающего в сопряжении с методом Open. |
| 6 |
setRequestHeader () Заголовок содержит пару метка / значение, к которой отправляется запрос. |
прервать ()
Завершает текущий сделанный запрос.
getAllResponseHeaders ()
Возвращает все заголовки ответа в виде строки или ноль, если ответ не получен.
getResponseHeader ()
Возвращает строку, содержащую текст указанного заголовка, или ноль, если ответ еще не получен или заголовок не существует в ответе.
открытый (метод, URL, асинхронный, uname, PSWD)
Он используется в сочетании с методом Send для отправки запроса на сервер. Метод open указывает следующие параметры —
Метод — указывает тип запроса, т. е. Get или Post.
url — это местоположение файла.
async — указывает, как должен обрабатываться запрос. Это логическое значение. где,
«true» означает, что запрос обрабатывается асинхронно, без ожидания ответа Http.
«ложь» означает, что запрос обрабатывается синхронно после получения ответа Http.
uname — это имя пользователя.
pswd — это пароль.
отправить (строка)
Используется для отправки запроса, работающего в сопряжении с методом Open.
setRequestHeader ()
Заголовок содержит пару метка / значение, к которой отправляется запрос.
Атрибуты
В следующей таблице перечислены атрибуты объекта XMLHttpRequest.
| S.No. | Атрибут и описание |
|---|---|
| 1 |
onreadystatechange Это свойство, основанное на событиях, которое устанавливается при каждом изменении состояния. |
| 2 |
readyState Это описывает текущее состояние объекта XMLHttpRequest. Существует пять возможных состояний свойства readyState —
|
| 3 |
responseText Это свойство используется, когда ответом от сервера является текстовый файл. |
| 4 |
responseXML Это свойство используется, когда ответом от сервера является файл XML. |
| 5 |
статус Предоставляет статус объекта запроса Http в виде числа. Например, «404» или «200». |
| 6 |
его статус Предоставляет статус объекта запроса Http в виде строки. Например, «Не найдено» или «ОК». |
onreadystatechange
Это свойство, основанное на событиях, которое устанавливается при каждом изменении состояния.
readyState
Это описывает текущее состояние объекта XMLHttpRequest. Существует пять возможных состояний свойства readyState —
readyState = 0 — означает, что запрос еще не инициализирован.
readyState = 1 — запрос установлен.
readyState = 2 — запрос отправлен.
readyState = 3 — запрос обрабатывается.
readyState = 4 — запрос завершен.
responseText
Это свойство используется, когда ответом от сервера является текстовый файл.
responseXML
Это свойство используется, когда ответом от сервера является файл XML.
статус
его статус
Предоставляет статус объекта запроса Http в виде строки. Например, «Не найдено» или «ОК».
Примеры
содержимое файла node.xml показано ниже:
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>taniyamishra@xyz.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>tanishasharma@xyz.com</Email>
</Employee>
</Company>
Получить конкретную информацию о файле ресурса
В следующем примере показано, как получить конкретную информацию о файле ресурса, используя метод getResponseHeader () и свойство readState .
<!DOCTYPE html>
<html>
<head>
<meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
}
else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length");
}
}
}
</script>
</head>
<body>
<button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button>
<div id = "ID">Specific header information is returned.</div>
</body>
</html>
выполнение
Сохраните этот файл как elementattribute_removeAttributeNS.htm на пути к серверу (этот файл и файл node_ns.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже —
Before removing the attributeNS: en After removing the attributeNS: null
Получить информацию заголовка файла ресурса
В следующем примере показано, как получить информацию заголовка файла ресурса, используя метод getAllResponseHeaders (), используя свойство readyState .
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders();
}
}
}
</script>
</head>
<body>
<button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')">
Click me to load the AllResponseHeaders</button>
<div id = "ID"></div>
</body>
</html>
выполнение
Сохраните этот файл как http_allheader.html на пути к серверу (этот файл и файл node.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже (зависит от браузера) —
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified:
Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip Content-Length: 256 Content-Type: text/xml
DOM — DOMException Object
DOMException представляет ненормальное событие, происходящее при использовании метода или свойства.
свойства
В приведенной ниже таблице перечислены свойства объекта DOMException
| S.No. | Описание недвижимости |
|---|---|
| 1 |
название Возвращает DOMString, которая содержит одну из строк, связанных с константой ошибки (как показано в таблице ниже). |
название
Возвращает DOMString, которая содержит одну из строк, связанных с константой ошибки (как показано в таблице ниже).
Типы ошибок
| S.No. | Тип и описание |
|---|---|
| 1 |
IndexSizeError Индекс не находится в допустимом диапазоне. Например, это может быть брошено объектом Range. (Значение старого кода: 1 и имя постоянной константы: INDEX_SIZE_ERR) |
| 2 |
HierarchyRequestError Неверная иерархия дерева узлов. (Значение старого кода: 3 и имя постоянной константы: HIERARCHY_REQUEST_ERR) |
| 3 |
WrongDocumentError Объект находится в неправильном документе. (Значение старого кода: 4 и имя постоянной константы: WRONG_DOCUMENT_ERR) |
| 4 |
InvalidCharacterError Строка содержит недопустимые символы. (Значение старого кода: 5 и имя постоянной константы: INVALID_CHARACTER_ERR) |
| 5 |
NoModificationAllowedError Объект не может быть изменен. (Значение старого кода: 7 и имя постоянной константы: NO_MODIFICATION_ALLOWED_ERR) |
| 6 |
NotFoundError Объект не может быть найден здесь. (Значение старого кода: 8 и имя постоянной константы: NOT_FOUND_ERR) |
| 7 |
NotSupportedError Операция не поддерживается. (Значение старого кода: 9 и имя постоянной константы: NOT_SUPPORTED_ERR) |
| 8 |
InvalidStateError Объект находится в недопустимом состоянии. (Значение старого кода: 11 и имя постоянной константы: INVALID_STATE_ERR) |
| 9 |
Ошибка синтаксиса Строка не соответствует ожидаемому шаблону. (Значение старого кода: 12 и имя постоянной константы: SYNTAX_ERR) |
| 10 |
InvalidModificationError Объект не может быть изменен таким образом. (Значение старого кода: 13 и имя постоянной константы: INVALID_MODIFICATION_ERR) |
| 11 |
NamespaceError Операция не разрешена пространствами имен в XML. (Значение старого кода: 14 и имя постоянной константы: NAMESPACE_ERR) |
| 12 |
InvalidAccessError Объект не поддерживает операцию или аргумент. (Значение старого кода: 15 и имя постоянной константы: INVALID_ACCESS_ERR) |
| 13 |
TypeMismatchError Тип объекта не соответствует ожидаемому типу. (Значение устаревшего кода: 17 и имя постоянной константы: TYPE_MISMATCH_ERR) Это значение устарело, исключение JavaScript TypeError теперь вызывается вместо исключения DOMException с этим значением. |
| 14 |
SecurityError Операция небезопасна. (Значение старого кода: 18 и имя постоянной константы: SECURITY_ERR) |
| 15 |
Ошибка сети Произошла ошибка сети. (Значение старого кода: 19 и имя постоянной константы: NETWORK_ERR) |
| 16 |
AbortError Операция была прервана. (Значение старого кода: 20 и имя постоянной константы: ABORT_ERR) |
| 17 |
URLMismatchError Данный URL не соответствует другому URL. (Значение старого кода: 21 и имя постоянной константы: URL_MISMATCH_ERR) |
| 18 |
QuotaExceededError Квота была превышена. (Значение старого кода: 22 и имя постоянной константы: QUOTA_EXCEEDED_ERR) |
| 19 |
TimeoutError Время операции вышло. (Значение старого кода: 23 и имя постоянной константы: TIMEOUT_ERR) |
| 20 |
InvalidNodeTypeError Узел неверен или имеет неверного предка для этой операции. (Значение старого кода: 24 и имя постоянной константы: INVALID_NODE_TYPE_ERR) |
| 21 |
DataCloneError Объект не может быть клонирован. (Значение старого кода: 25 и имя постоянной константы: DATA_CLONE_ERR) |
| 22 |
EncodingError Операция кодирования, будучи кодирующей или декодирующей, завершилась неудачно (без устаревшего значения кода и имени константы). |
| 23 |
NotReadableError Операция чтения ввода / вывода завершилась неудачно (без устаревшего значения кода и имени константы). |
IndexSizeError
Индекс не находится в допустимом диапазоне. Например, это может быть брошено объектом Range. (Значение старого кода: 1 и имя постоянной константы: INDEX_SIZE_ERR)
HierarchyRequestError
Неверная иерархия дерева узлов. (Значение старого кода: 3 и имя постоянной константы: HIERARCHY_REQUEST_ERR)
WrongDocumentError
Объект находится в неправильном документе. (Значение старого кода: 4 и имя постоянной константы: WRONG_DOCUMENT_ERR)
InvalidCharacterError
Строка содержит недопустимые символы. (Значение старого кода: 5 и имя постоянной константы: INVALID_CHARACTER_ERR)
NoModificationAllowedError
Объект не может быть изменен. (Значение старого кода: 7 и имя постоянной константы: NO_MODIFICATION_ALLOWED_ERR)
NotFoundError
Объект не может быть найден здесь. (Значение старого кода: 8 и имя постоянной константы: NOT_FOUND_ERR)
NotSupportedError
Операция не поддерживается. (Значение старого кода: 9 и имя постоянной константы: NOT_SUPPORTED_ERR)
InvalidStateError
Объект находится в недопустимом состоянии. (Значение старого кода: 11 и имя постоянной константы: INVALID_STATE_ERR)
Ошибка синтаксиса
Строка не соответствует ожидаемому шаблону. (Значение старого кода: 12 и имя постоянной константы: SYNTAX_ERR)
InvalidModificationError
Объект не может быть изменен таким образом. (Значение старого кода: 13 и имя постоянной константы: INVALID_MODIFICATION_ERR)
NamespaceError
Операция не разрешена пространствами имен в XML. (Значение старого кода: 14 и имя постоянной константы: NAMESPACE_ERR)
InvalidAccessError
Объект не поддерживает операцию или аргумент. (Значение старого кода: 15 и имя постоянной константы: INVALID_ACCESS_ERR)
TypeMismatchError
Тип объекта не соответствует ожидаемому типу. (Значение устаревшего кода: 17 и имя постоянной константы: TYPE_MISMATCH_ERR) Это значение устарело, исключение JavaScript TypeError теперь вызывается вместо исключения DOMException с этим значением.
SecurityError
Операция небезопасна. (Значение старого кода: 18 и имя постоянной константы: SECURITY_ERR)
Ошибка сети
Произошла ошибка сети. (Значение старого кода: 19 и имя постоянной константы: NETWORK_ERR)
AbortError
Операция была прервана. (Значение старого кода: 20 и имя постоянной константы: ABORT_ERR)
URLMismatchError
Данный URL не соответствует другому URL. (Значение старого кода: 21 и имя постоянной константы: URL_MISMATCH_ERR)
QuotaExceededError
Квота была превышена. (Значение старого кода: 22 и имя постоянной константы: QUOTA_EXCEEDED_ERR)
TimeoutError
Время операции вышло. (Значение старого кода: 23 и имя постоянной константы: TIMEOUT_ERR)
InvalidNodeTypeError
Узел неверен или имеет неверного предка для этой операции. (Значение старого кода: 24 и имя постоянной константы: INVALID_NODE_TYPE_ERR)
DataCloneError
Объект не может быть клонирован. (Значение старого кода: 25 и имя постоянной константы: DATA_CLONE_ERR)
EncodingError
Операция кодирования, будучи кодирующей или декодирующей, завершилась неудачно (без устаревшего значения кода и имени константы).
NotReadableError
Операция чтения ввода / вывода завершилась неудачно (без устаревшего значения кода и имени константы).
пример
Следующий пример демонстрирует, как использование неправильно сформированного XML-документа вызывает исключение DOMException.
Содержание error.xml приведено ниже:
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<Company id = "companyid">
<Employee category = "Technical" id = "firstelement" type = "text/html">
<FirstName>Tanmay</first>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
</Employee>
</Company>
Следующий пример демонстрирует использование атрибута name —
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
try {
xmlDoc = loadXMLDoc("/dom/error.xml");
var node = xmlDoc.getElementsByTagName("to").item(0);
var refnode = node.nextSibling;
var newnode = xmlDoc.createTextNode('That is why you fail.');
node.insertBefore(newnode, refnode);
} catch(err) {
document.write(err.name);
}
</script>
</body>
</html>
выполнение
Сохраните этот файл как Domexcption_name.html на пути к серверу (этот файл и error.xml должны находиться на одном и том же пути на вашем сервере). Мы получим вывод, как показано ниже —