AWS Data Pipeline — это веб-сервис, который облегчает пользователям интеграцию данных, распределенных по нескольким сервисам AWS, и анализирует их из одного места.
Используя AWS Data Pipeline, данные могут быть доступны из источника, обработаны, а затем результаты могут быть эффективно переданы в соответствующие сервисы AWS.
Как настроить конвейер данных?
Ниже приведены шаги для настройки конвейера данных.
Шаг 1 — Создайте конвейер, используя следующие шаги.
-
Войдите в аккаунт AWS.
-
Используйте эту ссылку для открытия консоли AWS Data Pipeline — https://console.aws.amazon.com/datapipeline/
-
Выберите регион на панели навигации.
-
Нажмите кнопку Создать новый конвейер.
-
Заполните необходимые данные в соответствующих полях.
-
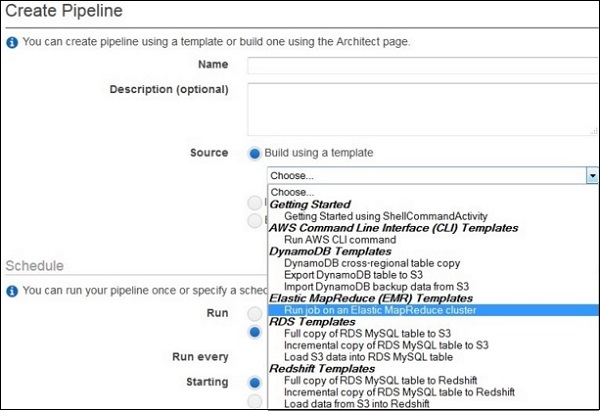
В поле «Источник» выберите «Построить с использованием шаблона», а затем выберите этот шаблон — «Начало работы с использованием ShellCommandActivity».
-
Войдите в аккаунт AWS.
Используйте эту ссылку для открытия консоли AWS Data Pipeline — https://console.aws.amazon.com/datapipeline/
Выберите регион на панели навигации.
Нажмите кнопку Создать новый конвейер.
Заполните необходимые данные в соответствующих полях.
В поле «Источник» выберите «Построить с использованием шаблона», а затем выберите этот шаблон — «Начало работы с использованием ShellCommandActivity».
-
Раздел «Параметры» открывается только при выборе шаблона. Оставьте входную папку S3 и команду Shell для запуска с их значениями по умолчанию. Щелкните значок папки рядом с выходной папкой S3 и выберите сегменты.
-
В расписании оставьте значения по умолчанию.
-
В Конфигурации конвейера оставьте ведение журнала включенным. Нажмите значок папки под S3 местоположением для журналов и выберите сегменты.
-
В Security / Access оставьте значения ролей IAM по умолчанию.
-
Нажмите кнопку Активировать.
Раздел «Параметры» открывается только при выборе шаблона. Оставьте входную папку S3 и команду Shell для запуска с их значениями по умолчанию. Щелкните значок папки рядом с выходной папкой S3 и выберите сегменты.
В расписании оставьте значения по умолчанию.
В Конфигурации конвейера оставьте ведение журнала включенным. Нажмите значок папки под S3 местоположением для журналов и выберите сегменты.
В Security / Access оставьте значения ролей IAM по умолчанию.
Нажмите кнопку Активировать.
Как удалить конвейер?
Удаление конвейера также удалит все связанные объекты.
Шаг 1 — Выберите конвейер из списка конвейеров.
Шаг 2 — Нажмите кнопку «Действия» и выберите «Удалить».
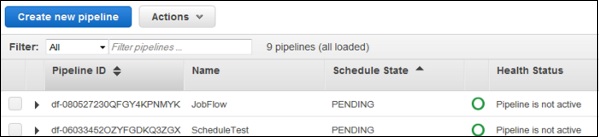
Шаг 3 — Откроется окно с запросом подтверждения. Нажмите Удалить.
Особенности AWS Data Pipeline
Простой и экономичный — его функции перетаскивания позволяют легко создавать конвейер на консоли. Его создатель визуальных конвейеров предоставляет библиотеку шаблонов конвейеров. Эти шаблоны упрощают создание конвейеров для таких задач, как обработка файлов журналов, архивирование данных в Amazon S3 и т. Д.
Надежный — его инфраструктура предназначена для отказоустойчивых исполнительных действий. Если в логике действия или источниках данных возникают сбои, AWS Data Pipeline автоматически повторяет действие. Если сбой продолжается, он отправит уведомление о сбое. Мы даже можем настроить эти уведомления для таких ситуаций, как успешные запуски, сбой, задержки в работе и т. Д.
Гибкость — AWS Data Pipeline предоставляет различные функции, такие как планирование, отслеживание, обработка ошибок и т. Д. Его можно настроить на такие действия, как запуск заданий Amazon EMR, выполнение запросов SQL непосредственно к базам данных, выполнение пользовательских приложений, работающих на Amazon EC2 и т. Д.