SciPy — Введение
SciPy, произносится как Sigh Pi, является открытым исходным кодом для Python, распространяемым в рамках лицензированной библиотеки BSD для выполнения математических, научных и инженерных вычислений.
Библиотека SciPy зависит от NumPy, который обеспечивает удобную и быструю манипуляцию с N-мерным массивом. Библиотека SciPy создана для работы с массивами NumPy и предоставляет множество удобных и эффективных численных методов, таких как процедуры численной интеграции и оптимизации. Вместе они работают на всех популярных операционных системах, быстро устанавливаются и бесплатны. NumPy и SciPy просты в использовании, но достаточно мощны, чтобы зависеть от ведущих мировых ученых и инженеров.
SciPy Sub-пакеты
SciPy состоит из подпакетов, охватывающих различные области научных вычислений. Они обобщены в следующей таблице —
| scipy.cluster | Векторное квантование / Kmeans |
| scipy.constants | Физико-математические константы |
| scipy.fftpack | преобразование Фурье |
| scipy.integrate | Процедуры интеграции |
| scipy.interpolate | интерполирование |
| scipy.io | Ввод и вывод данных |
| scipy.linalg | Процедуры линейной алгебры |
| scipy.ndimage | пакет n-мерных изображений |
| scipy.odr | Ортогональная регрессия расстояния |
| scipy.optimize | оптимизация |
| scipy.signal | Обработка сигнала |
| scipy.sparse | Разреженные матрицы |
| scipy.spatial | Пространственные структуры данных и алгоритмы |
| scipy.special | Любые специальные математические функции |
| scipy.stats | Статистика |
Структура данных
Базовая структура данных, используемая SciPy, представляет собой многомерный массив, предоставляемый модулем NumPy. NumPy предоставляет некоторые функции для линейной алгебры, преобразований Фурье и генерации случайных чисел, но не с общностью эквивалентных функций в SciPy.
SciPy — Настройка среды
Стандартный дистрибутив Python не поставляется в комплекте с любым модулем SciPy. Облегченной альтернативой является установка SciPy с использованием популярного установщика пакетов Python,
pip install pandas
Если мы установим пакет Anaconda Python , Pandas будет установлен по умолчанию. Ниже приведены пакеты и ссылки для их установки в разных операционных системах.
Windows
Anaconda (из https://www.continuum.io ) — это бесплатный дистрибутив Python для стека SciPy. Он также доступен для Linux и Mac.
Canopy ( https://www.enthought.com/products/canopy/ ) доступен бесплатно, а также для коммерческого распространения с полным стеком SciPy для Windows, Linux и Mac.
Python (x, y) — это бесплатный дистрибутив Python со стеком SciPy и Spyder IDE для ОС Windows. (Загружается с https://python-xy.github.io/ )
Linux
Менеджеры пакетов соответствующих дистрибутивов Linux используются для установки одного или нескольких пакетов в стек SciPy.
Ubuntu
Мы можем использовать следующий путь для установки Python в Ubuntu.
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipython-notebook python-pandas python-sympy python-nose
мягкая фетровая шляпа
Мы можем использовать следующий путь для установки Python в Fedora.
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy python-nose atlas-devel
SciPy — основная функциональность
По умолчанию все функции NumPy были доступны через пространство имен SciPy. При импорте SciPy не требуется явно импортировать функции NumPy. Основным объектом NumPy является однородный многомерный массив. Это таблица элементов (обычно чисел) одного типа, проиндексированных набором натуральных чисел. В NumPy размеры называются осями. Количество осей называется рангом .
Теперь давайте пересмотрим основные функциональные возможности векторов и матриц в NumPy. Поскольку SciPy построен поверх массивов NumPy, необходимо понимание основ NumPy. Поскольку большинство частей линейной алгебры имеет дело только с матрицами.
NumPy Vector
Вектор может быть создан несколькими способами. Некоторые из них описаны ниже.
Преобразование массивоподобных объектов Python в NumPy
Давайте рассмотрим следующий пример.
import numpy as np list = [1,2,3,4] arr = np.array(list) print arr
Вывод вышеуказанной программы будет следующим.
[1 2 3 4]
Внутреннее создание массива NumPy
NumPy имеет встроенные функции для создания массивов с нуля. Некоторые из этих функций описаны ниже.
Использование нулей ()
Функция нулей (форма) создаст массив, заполненный 0 значениями с указанной формой. По умолчанию dtype — это float64. Давайте рассмотрим следующий пример.
import numpy as np print np.zeros((2, 3))
Вывод вышеуказанной программы будет следующим.
array([[ 0., 0., 0.], [ 0., 0., 0.]])
Используя те ()
Функция ones (shape) создаст массив, заполненный 1 значением. Он идентичен нулям во всех остальных отношениях. Давайте рассмотрим следующий пример.
import numpy as np print np.ones((2, 3))
Вывод вышеуказанной программы будет следующим.
array([[ 1., 1., 1.], [ 1., 1., 1.]])
Использование arange ()
Функция arange () будет создавать массивы с регулярно увеличивающимися значениями. Давайте рассмотрим следующий пример.
import numpy as np print np.arange(7)
Вышеуказанная программа сгенерирует следующий вывод.
array([0, 1, 2, 3, 4, 5, 6])
Определение типа данных значений
Давайте рассмотрим следующий пример.
import numpy as np arr = np.arange(2, 10, dtype = np.float) print arr print "Array Data Type :",arr.dtype
Вышеуказанная программа сгенерирует следующий вывод.
[ 2. 3. 4. 5. 6. 7. 8. 9.] Array Data Type : float64
Использование linspace ()
Функция linspace () создаст массивы с указанным количеством элементов, которые будут равномерно распределены между указанными начальными и конечными значениями. Давайте рассмотрим следующий пример.
import numpy as np print np.linspace(1., 4., 6)
Вышеуказанная программа сгенерирует следующий вывод.
array([ 1. , 1.6, 2.2, 2.8, 3.4, 4. ])
матрица
Матрица — это специализированный двумерный массив, который сохраняет свою двумерную природу посредством операций. Он имеет определенные специальные операторы, такие как * (матричное умножение) и ** (матричная степень). Давайте рассмотрим следующий пример.
import numpy as np print np.matrix('1 2; 3 4')
Вышеуказанная программа сгенерирует следующий вывод.
matrix([[1, 2], [3, 4]])
Конъюгат транспонирования матрицы
Эта функция возвращает (сложную) сопряженную транспозицию себя . Давайте рассмотрим следующий пример.
import numpy as np mat = np.matrix('1 2; 3 4') print mat.H
Вышеуказанная программа сгенерирует следующий вывод.
matrix([[1, 3],
[2, 4]])
Транспонирование матрицы
Эта функция возвращает транспонирование себя. Давайте рассмотрим следующий пример.
import numpy as np mat = np.matrix('1 2; 3 4') mat.T
Вышеуказанная программа сгенерирует следующий вывод.
matrix([[1, 3],
[2, 4]])
Когда мы транспонируем матрицу, мы создаем новую матрицу, строки которой являются столбцами оригинала. Сопряженное преобразование, с другой стороны, чередует строку и индекс столбца для каждого элемента матрицы. Инверсия матрицы — это матрица, которая при умножении на исходную матрицу приводит к тождественной матрице.
SciPy — Кластер
Кластеризация K-средних — это метод поиска кластеров и центров кластеров в наборе немаркированных данных. Интуитивно, мы можем думать о кластере как о — состоящем из группы точек данных, чьи расстояния между точками малы по сравнению с расстояниями до точек вне кластера. Учитывая начальный набор K центров, алгоритм K-средних повторяет следующие два шага:
-
Для каждого центра идентифицируется подмножество точек обучения (его кластер), которое находится ближе к нему, чем любой другой центр.
-
Среднее значение каждого признака для точек данных в каждом кластере вычисляется, и этот средний вектор становится новым центром для этого кластера.
Для каждого центра идентифицируется подмножество точек обучения (его кластер), которое находится ближе к нему, чем любой другой центр.
Среднее значение каждого признака для точек данных в каждом кластере вычисляется, и этот средний вектор становится новым центром для этого кластера.
Эти два шага повторяются до тех пор, пока центры больше не перемещаются или назначения больше не меняются. Затем новая точка x может быть назначена кластеру ближайшего прототипа. Библиотека SciPy обеспечивает хорошую реализацию алгоритма K-Means через кластерный пакет. Дайте нам понять, как его использовать.
Внедрение K-Means в SciPy
Мы поймем, как реализовать K-Means в SciPy.
Импорт K-Средств
Мы увидим реализацию и использование каждой импортированной функции.
from SciPy.cluster.vq import kmeans,vq,whiten
Генерация данных
Мы должны смоделировать некоторые данные, чтобы исследовать кластеризацию.
from numpy import vstack,array from numpy.random import rand # data generation with three features data = vstack((rand(100,3) + array([.5,.5,.5]),rand(100,3)))
Теперь мы должны проверить данные. Вышеуказанная программа сгенерирует следующий вывод.
array([[ 1.48598868e+00, 8.17445796e-01, 1.00834051e+00],
[ 8.45299768e-01, 1.35450732e+00, 8.66323621e-01],
[ 1.27725864e+00, 1.00622682e+00, 8.43735610e-01],
…………….
Нормализуйте группу наблюдений на основе признаков. Перед запуском K-Means полезно изменить масштаб каждого измерения элемента набора наблюдений с отбеливанием. Каждая особенность делится на стандартное отклонение по всем наблюдениям, чтобы получить единичную дисперсию.
Отбелить данные
Мы должны использовать следующий код для отбеливания данных.
# whitening of data data = whiten(data)
Вычислить K-средние с тремя кластерами
Давайте теперь вычислим K-средние с тремя кластерами, используя следующий код.
# computing K-Means with K = 3 (2 clusters) centroids,_ = kmeans(data,3)
Приведенный выше код выполняет K-средние для набора векторов наблюдения, образующих K кластеров. Алгоритм K-средних корректирует центроиды до тех пор, пока не будет достигнут достаточный прогресс, то есть изменение искажения, поскольку последняя итерация меньше некоторого порогового значения. Здесь мы можем наблюдать центроид кластера, печатая переменную centroids, используя код, приведенный ниже.
print(centroids)
Приведенный выше код сгенерирует следующий вывод.
print(centroids)[ [ 2.26034702 1.43924335 1.3697022 ]
[ 2.63788572 2.81446462 2.85163854]
[ 0.73507256 1.30801855 1.44477558] ]
Присвойте каждое значение кластеру, используя приведенный ниже код.
# assign each sample to a cluster clx,_ = vq(data,centroids)
Функция vq сравнивает каждый вектор наблюдений в массиве «M» по «N» obs с центроидами и назначает наблюдение ближайшему кластеру. Он возвращает кластер каждого наблюдения и искажения. Мы также можем проверить искажение. Давайте проверим кластер каждого наблюдения, используя следующий код.
# check clusters of observation print clx
Приведенный выше код сгенерирует следующий вывод.
array([1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 2, 0, 2, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 0, 0, 2, 2, 2, 1, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2], dtype=int32)
Различные значения 0, 1, 2 из вышеуказанного массива указывают кластеры.
SciPy — Константы
Пакет констант SciPy предоставляет широкий спектр констант, которые используются в общей научной области.
SciPy Constants Package
Пакет scipy.constants предоставляет различные константы. Мы должны импортировать необходимую константу и использовать их согласно требованию. Давайте посмотрим, как эти постоянные переменные импортируются и используются.
Для начала давайте сравним значение «пи», рассмотрев следующий пример.
#Import pi constant from both the packages from scipy.constants import pi from math import pi print("sciPy - pi = %.16f"%scipy.constants.pi) print("math - pi = %.16f"%math.pi)
Вышеуказанная программа сгенерирует следующий вывод.
sciPy - pi = 3.1415926535897931 math - pi = 3.1415926535897931
Список доступных констант
В следующих таблицах кратко описаны различные константы.
Математические константы
| Старший | постоянная | Описание |
|---|---|---|
| 1 | число Пи | число Пи |
| 2 | золотой | Золотое сечение |
Физические константы
В следующей таблице перечислены наиболее часто используемые физические константы.
| Старший | Константа и описание |
|---|---|
| 1 |
с Скорость света в вакууме |
| 2 |
скорость света Скорость света в вакууме |
| 3 |
час Постоянная Планка |
| 4 |
Планка Постоянная Планка h |
| 5 |
г Гравитационная постоянная Ньютона |
| 6 |
е Элементарный заряд |
| 7 |
р Молярная газовая постоянная |
| 8 |
Авогадро Постоянная Авогадро |
| 9 |
К Постоянная Больцмана |
| 10 |
Electron_mass (OR) m_e Электронная масса |
| 11 |
proton_mass (OR) m_p Масса протона |
| 12 |
neutron_mass (ИЛИ) m_n Нейтронная масса |
с
Скорость света в вакууме
скорость света
Скорость света в вакууме
час
Постоянная Планка
Планка
Постоянная Планка h
г
Гравитационная постоянная Ньютона
е
Элементарный заряд
р
Молярная газовая постоянная
Авогадро
Постоянная Авогадро
К
Постоянная Больцмана
Electron_mass (OR) m_e
Электронная масса
proton_mass (OR) m_p
Масса протона
neutron_mass (ИЛИ) m_n
Нейтронная масса
Единицы
В следующей таблице приведен список единиц СИ.
| Старший | Единица измерения | Значение |
|---|---|---|
| 1 | Милли | 0,001 |
| 2 | микро | 1e-06 |
| 3 | кило | 1000 |
Эти единицы измерения варьируются от йотта, зетта, экза, пета, тера …… кило, гектор,… нано, пико,… до зепто.
Другие важные константы
В следующей таблице перечислены другие важные константы, используемые в SciPy.
| Старший | Единица измерения | Значение |
|---|---|---|
| 1 | грамм | 0,001 кг |
| 2 | атомная масса | Постоянная атомной массы |
| 3 | степень | Степень в радианах |
| 4 | минут | Одна минута в секундах |
| 5 | день | Один день в секундах |
| 6 | дюймовый | Один дюйм в метрах |
| 7 | микрон | Один микрон в метрах |
| 8 | световой год | Один световой год в метрах |
| 9 | Банкомат | Стандартная атмосфера в паскалях |
| 10 | акр | Один акр в квадратных метрах |
| 11 | литровый | Один литр в кубических метрах |
| 12 | галлон | Один галлон в кубических метрах |
| 13 | км / ч | Километров в час в метрах в секунду |
| 14 | degree_Fahrenheit | Один Фаренгейт в Кельвинах |
| 15 | эВ | Один электрон-вольт в джоулях |
| 16 | л.с. | Одна мощность в ваттах |
| 17 | динам | Одна дина в ньютонах |
| 18 | lambda2nu | Преобразовать длину волны в оптическую частоту |
Вспомнить все это немного сложно. Самый простой способ узнать, какая клавиша для какой функции — это метод scipy.constants.find () . Давайте рассмотрим следующий пример.
import scipy.constants res = scipy.constants.physical_constants["alpha particle mass"] print res
Вышеуказанная программа сгенерирует следующий вывод.
[ 'alpha particle mass', 'alpha particle mass energy equivalent', 'alpha particle mass energy equivalent in MeV', 'alpha particle mass in u', 'electron to alpha particle mass ratio' ]
Этот метод возвращает список ключей, иначе ничего, если ключевое слово не совпадает.
SciPy — FFTpack
Преобразование Фурье вычисляется на сигнале временной области, чтобы проверить его поведение в частотной области. Преобразование Фурье находит свое применение в таких дисциплинах, как обработка сигналов и шумов, обработка изображений, обработка аудиосигналов и т. Д. SciPy предлагает модуль fftpack, который позволяет пользователю быстро вычислять преобразования Фурье.
Ниже приведен пример функции синуса, которая будет использоваться для вычисления преобразования Фурье с использованием модуля fftpack.
Быстрое преобразование Фурье
Давайте разберемся, что такое быстрое преобразование Фурье.
Одномерное дискретное преобразование Фурье
БПФ y [k] длины N последовательности длина-N x [n] вычисляется с помощью функции fft (), а обратное преобразование вычисляется с использованием ifft (). Давайте рассмотрим следующий пример
#Importing the fft and inverse fft functions from fftpackage from scipy.fftpack import fft #create an array with random n numbers x = np.array([1.0, 2.0, 1.0, -1.0, 1.5]) #Applying the fft function y = fft(x) print y
Вышеуказанная программа сгенерирует следующий вывод.
[ 4.50000000+0.j 2.08155948-1.65109876j -1.83155948+1.60822041j -1.83155948-1.60822041j 2.08155948+1.65109876j ]
Давайте посмотрим на другой пример
#FFT is already in the workspace, using the same workspace to for inverse transform yinv = ifft(y) print yinv
Вышеуказанная программа сгенерирует следующий вывод.
[ 1.0+0.j 2.0+0.j 1.0+0.j -1.0+0.j 1.5+0.j ]
Модуль scipy.fftpack позволяет вычислять быстрые преобразования Фурье. В качестве иллюстрации (шумный) входной сигнал может выглядеть следующим образом:
import numpy as np time_step = 0.02 period = 5. time_vec = np.arange(0, 20, time_step) sig = np.sin(2 * np.pi / period * time_vec) + 0.5 *np.random.randn(time_vec.size) print sig.size
Мы создаем сигнал с шагом по времени 0,02 секунды. Последний оператор печатает размер сигнала sig. Вывод будет следующим:
1000
Мы не знаем частоту сигнала; мы знаем только шаг времени выборки сигнала sig. Предполагается, что сигнал исходит от реальной функции, поэтому преобразование Фурье будет симметричным. Функция scipy.fftpack.fftfreq () сгенерирует частоты дискретизации, а scipy.fftpack.fft () вычислит быстрое преобразование Фурье.
Позвольте нам понять это с помощью примера.
from scipy import fftpack sample_freq = fftpack.fftfreq(sig.size, d = time_step) sig_fft = fftpack.fft(sig) print sig_fft
Вышеуказанная программа сгенерирует следующий вывод.
array([ 25.45122234 +0.00000000e+00j, 6.29800973 +2.20269471e+00j, 11.52137858 -2.00515732e+01j, 1.08111300 +1.35488579e+01j, …….])
Дискретное косинусное преобразование
Дискретное косинусное преобразование (DCT) выражает конечную последовательность точек данных в виде суммы косинусных функций, колеблющихся на разных частотах. SciPy предоставляет DCT с функцией dct и соответствующий IDCT с функцией idct . Давайте рассмотрим следующий пример.
from scipy.fftpack import dct print dct(np.array([4., 3., 5., 10., 5., 3.]))
Вышеуказанная программа сгенерирует следующий вывод.
array([ 60., -3.48476592, -13.85640646, 11.3137085, 6., -6.31319305])
Обратное дискретное косинусное преобразование восстанавливает последовательность из ее коэффициентов дискретного косинусного преобразования (DCT). Функция idct является обратной функцией dct. Давайте поймем это на следующем примере.
from scipy.fftpack import dct print idct(np.array([4., 3., 5., 10., 5., 3.]))
Вышеуказанная программа сгенерирует следующий вывод.
array([ 39.15085889, -20.14213562, -6.45392043, 7.13341236, 8.14213562, -3.83035081])
SciPy — Интеграция
Когда функция не может быть интегрирована аналитически или очень трудно интегрироваться аналитически, обычно обращаются к методам численного интегрирования. SciPy имеет ряд процедур для выполнения числовой интеграции. Большинство из них находятся в одной библиотеке scipy.integrate . В следующей таблице перечислены некоторые часто используемые функции.
| Ср № | Описание функции |
|---|---|
| 1 |
квад Одиночная интеграция |
| 2 |
dblquad Двойная интеграция |
| 3 |
tplquad Тройная интеграция |
| 4 |
nquad n- кратная множественная интеграция |
| 5 |
fixed_quad Гауссовская квадратура, порядок n |
| 6 |
квадратура Гауссовская квадратура к толерантности |
| 7 |
Ромберга Интеграция Ромберга |
| 8 |
trapz Трапециевидное правило |
| 9 |
cumtrapz Трапециевидное правило для кумулятивного вычисления интеграла |
| 10 |
импсон Правило Симпсона |
| 11 |
ROMB Интеграция Ромберга |
| 12 |
polyint Аналитическая полиномиальная интеграция (NumPy) |
| 13 |
poly1d Вспомогательная функция для полиинт (NumPy) |
квад
Одиночная интеграция
dblquad
Двойная интеграция
tplquad
Тройная интеграция
nquad
n- кратная множественная интеграция
fixed_quad
Гауссовская квадратура, порядок n
квадратура
Гауссовская квадратура к толерантности
Ромберга
Интеграция Ромберга
trapz
Трапециевидное правило
cumtrapz
Трапециевидное правило для кумулятивного вычисления интеграла
импсон
Правило Симпсона
ROMB
Интеграция Ромберга
polyint
Аналитическая полиномиальная интеграция (NumPy)
poly1d
Вспомогательная функция для полиинт (NumPy)
Единственные Интегралы
Функция Quad является рабочей лошадкой интеграционных функций SciPy. Численное интегрирование иногда называют квадратурным , отсюда и название. Обычно это выбор по умолчанию для выполнения одиночных интегралов функции f (x) в заданном фиксированном диапазоне от a до b.
intbaf(x)dx
Общая форма quad — это scipy.integrate.quad (f, a, b) , где «f» — это имя интегрируемой функции. Принимая во внимание, что «a» и «b» являются нижним и верхним пределами соответственно. Давайте рассмотрим пример функции Гаусса, интегрированной в диапазоне от 0 до 1.
Сначала нам нужно определить функцию → f(x)=e−x2, это можно сделать с помощью лямбда-выражения, а затем вызвать метод quad для этой функции.
import scipy.integrate from numpy import exp f= lambda x:exp(-x**2) i = scipy.integrate.quad(f, 0, 1) print i
Вышеуказанная программа сгенерирует следующий вывод.
(0.7468241328124271, 8.291413475940725e-15)
Функция quad возвращает два значения, в которых первое число является значением интеграла, а второе значение является оценкой абсолютной ошибки в значении интеграла.
Примечание. Поскольку quad требует функции в качестве первого аргумента, мы не можем напрямую передать exp в качестве аргумента. Функция Quad принимает положительную и отрицательную бесконечность в качестве пределов. Функция Quad может интегрировать стандартные предопределенные функции NumPy одной переменной, такой как exp, sin и cos.
Множественные интегралы
Механика двойной и тройной интеграции была включена в функции dblquad, tplquad и nquad . Эти функции объединяют четыре или шесть аргументов соответственно. Пределы всех внутренних интегралов должны быть определены как функции.
Двойные интегралы
Общая форма dblquad — это scipy.integrate.dblquad (func, a, b, gfun, hfun). Где func — это имя интегрируемой функции, a и b — это нижний и верхний пределы переменной x соответственно, а gfun и hfun — это имена функций, которые определяют нижний и верхний пределы. переменной у.
В качестве примера приведем метод двойного интеграла.
int1/20dy int sqrt1−4y2016xydx
Мы определяем функции f, g и h, используя лямбда-выражения. Обратите внимание, что даже если g и h являются константами, как они могут быть во многих случаях, они должны быть определены как функции, как мы сделали здесь для нижнего предела.
import scipy.integrate from numpy import exp from math import sqrt f = lambda x, y : 16*x*y g = lambda x : 0 h = lambda y : sqrt(1-4*y**2) i = scipy.integrate.dblquad(f, 0, 0.5, g, h) print i
Вышеуказанная программа сгенерирует следующий вывод.
(0.5, 1.7092350012594845e-14)
В дополнение к подпрограммам, описанным выше, scipy.integrate имеет ряд других подпрограмм интеграции, включая nquad, который выполняет n-кратную множественную интеграцию, а также другие подпрограммы, которые реализуют различные алгоритмы интеграции. Тем не менее, quad и dblquad удовлетворят большинство наших потребностей в числовой интеграции.
SciPy — Интерполировать
В этой главе мы обсудим, как интерполяция помогает в SciPy.
Что такое интерполяция?
Интерполяция — это процесс нахождения значения между двумя точками на линии или кривой. Чтобы помочь нам вспомнить, что это значит, мы должны думать о первой части слова «inter» как о значении «enter», что напоминает нам о том, чтобы заглянуть «внутрь» данных, которые у нас были изначально. Этот инструмент, интерполяция, полезен не только в статистике, но и в науке, бизнесе или при необходимости прогнозирования значений, попадающих в две существующие точки данных.
Давайте создадим некоторые данные и посмотрим, как можно выполнить эту интерполяцию с помощью пакета scipy.interpolate .
import numpy as np from scipy import interpolate import matplotlib.pyplot as plt x = np.linspace(0, 4, 12) y = np.cos(x**2/3+4) print x,y
Вышеуказанная программа сгенерирует следующий вывод.
(
array([0., 0.36363636, 0.72727273, 1.09090909, 1.45454545, 1.81818182,
2.18181818, 2.54545455, 2.90909091, 3.27272727, 3.63636364, 4.]),
array([-0.65364362, -0.61966189, -0.51077021, -0.31047698, -0.00715476,
0.37976236, 0.76715099, 0.99239518, 0.85886263, 0.27994201,
-0.52586509, -0.99582185])
)
Теперь у нас есть два массива. Предполагая, что эти два массива являются двумя измерениями точек в пространстве, давайте построим график, используя следующую программу, и посмотрим, как они выглядят.
plt.plot(x, y,’o’) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
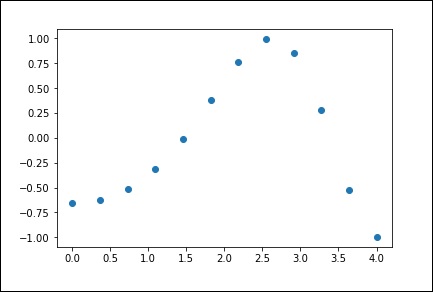
1-D Интерполяция
Класс interp1d в scipy.interpolate — это удобный метод для создания функции на основе фиксированных точек данных, которая может быть оценена в любом месте области, определенной данными, с использованием линейной интерполяции.
Используя приведенные выше данные, давайте создадим интерполяционную функцию и нарисуем новый интерполированный граф.
f1 = interp1d(x, y,kind = 'linear') f2 = interp1d(x, y, kind = 'cubic')
Используя функцию interp1d, мы создали две функции f1 и f2. Эти функции для данного входа x возвращают y. Третий тип переменных представляет тип метода интерполяции. «Линейный», «Ближайший», «Ноль», «Линейный», «Квадратичный», «Кубический» — это несколько методов интерполяции.
Теперь давайте создадим новый вход большей длины, чтобы увидеть явную разницу интерполяции. Мы будем использовать ту же функцию старых данных на новых данных.
xnew = np.linspace(0, 4,30) plt.plot(x, y, 'o', xnew, f(xnew), '-', xnew, f2(xnew), '--') plt.legend(['data', 'linear', 'cubic','nearest'], loc = 'best') plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
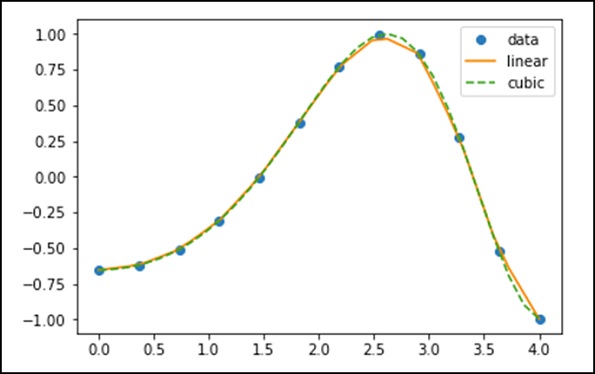
Сплайны
Чтобы нарисовать плавные кривые через точки данных, разработчики когда-то использовали тонкие гибкие полоски из дерева, твердой резины, металла или пластика, называемые механическими сплайнами. Чтобы использовать механический сплайн, штыри помещались в разумный выбор точек вдоль кривой в проекте, а затем сплайн сгибался так, чтобы он касался каждого из этих штифтов.
Понятно, что при такой конструкции сплайн интерполирует кривую на этих выводах. Может использоваться для воспроизведения кривой на других чертежах. Точки, где расположены штифты, называются узлами. Мы можем изменить форму кривой, определяемой сплайном, отрегулировав расположение узлов.
Одномерный сплайн
Одномерный сглаживающий сплайн соответствует заданному набору точек данных. Класс UnivariateSpline в scipy.interpolate — это удобный метод для создания функции на основе класса фиксированных точек данных — scipy.interpolate.UnivariateSpline (x, y, w = None, bbox = [None, None], k = 3, s). = Нет, ext = 0, check_finite = False).
Параметры — Ниже приведены параметры одномерного сплайна.
-
Это соответствует сплайну y = spl (x) степени k для предоставленных данных x, y.
-
‘w’ — указывает вес для подгонки сплайна. Должен быть позитивным. Если нет (по умолчанию), все веса равны.
-
‘s’ — определяет количество узлов, указывая условие сглаживания.
-
‘k’ — степень сглаживающего сплайна. Должно быть <= 5. По умолчанию k = 3, кубический сплайн.
-
Ext — управляет режимом экстраполяции для элементов, не входящих в интервал, определенный последовательностью узлов.
-
если ext = 0 или «extrapolate», возвращает экстраполированное значение.
-
если ext = 1 или ‘ноль’, возвращает 0
-
если ext = 2 или ‘поднимать’, вызывает ошибку ValueError
-
если ext = 3 из ‘const’, возвращает граничное значение.
-
check_finite — проверять, содержат ли входные массивы только конечные числа.
Это соответствует сплайну y = spl (x) степени k для предоставленных данных x, y.
‘w’ — указывает вес для подгонки сплайна. Должен быть позитивным. Если нет (по умолчанию), все веса равны.
‘s’ — определяет количество узлов, указывая условие сглаживания.
‘k’ — степень сглаживающего сплайна. Должно быть <= 5. По умолчанию k = 3, кубический сплайн.
Ext — управляет режимом экстраполяции для элементов, не входящих в интервал, определенный последовательностью узлов.
если ext = 0 или «extrapolate», возвращает экстраполированное значение.
если ext = 1 или ‘ноль’, возвращает 0
если ext = 2 или ‘поднимать’, вызывает ошибку ValueError
если ext = 3 из ‘const’, возвращает граничное значение.
check_finite — проверять, содержат ли входные массивы только конечные числа.
Давайте рассмотрим следующий пример.
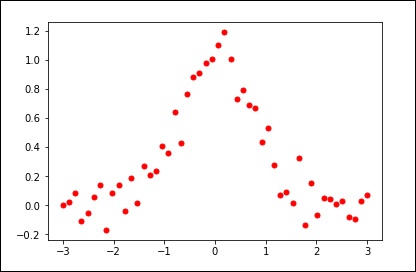
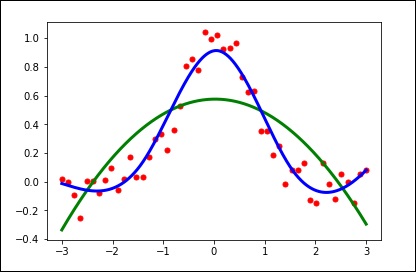
import matplotlib.pyplot as plt from scipy.interpolate import UnivariateSpline x = np.linspace(-3, 3, 50) y = np.exp(-x**2) + 0.1 * np.random.randn(50) plt.plot(x, y, 'ro', ms = 5) plt.show()
Используйте значение по умолчанию для параметра сглаживания.
spl = UnivariateSpline(x, y) xs = np.linspace(-3, 3, 1000) plt.plot(xs, spl(xs), 'g', lw = 3) plt.show()
Вручную измените величину сглаживания.
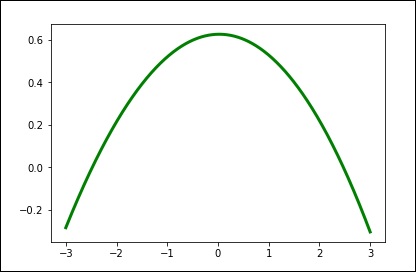
spl.set_smoothing_factor(0.5) plt.plot(xs, spl(xs), 'b', lw = 3) plt.show()
SciPy — вход и выход
Пакет Scipy.io (Input and Output) предоставляет широкий спектр функций для работы с различными форматами файлов. Некоторые из этих форматов —
- Matlab
- IDL
- Матрикс Маркет
- Волна
- ARFF
- Netcdf и др.
Давайте обсудим подробно о наиболее часто используемых форматах файлов —
MATLAB
Ниже приведены функции, используемые для загрузки и сохранения файла .mat.
| Старший | Описание функции |
|---|---|
| 1 |
loadmat Загружает файл MATLAB |
| 2 |
savemat Сохраняет файл MATLAB |
| 3 |
whosmat Перечисляет переменные внутри файла MATLAB |
loadmat
Загружает файл MATLAB
savemat
Сохраняет файл MATLAB
whosmat
Перечисляет переменные внутри файла MATLAB
Давайте рассмотрим следующий пример.
import scipy.io as sio import numpy as np #Save a mat file vect = np.arange(10) sio.savemat('array.mat', {'vect':vect}) #Now Load the File mat_file_content = sio.loadmat(‘array.mat’) Print mat_file_content
Вышеуказанная программа сгенерирует следующий вывод.
{
'vect': array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]), '__version__': '1.0',
'__header__': 'MATLAB 5.0 MAT-file Platform: posix, Created on: Sat Sep 30
09:49:32 2017', '__globals__': []
}
Мы можем увидеть массив вместе с мета-информацией. Если мы хотим проверить содержимое файла MATLAB без чтения данных в память, используйте команду whosmat, как показано ниже.
import scipy.io as sio mat_file_content = sio.whosmat(‘array.mat’) print mat_file_content
Вышеуказанная программа сгенерирует следующий вывод.
[('vect', (1, 10), 'int64')]
SciPy — Linalg
SciPy построен с использованием оптимизированных библиотек ATLAS LAPACK и BLAS . У этого есть очень быстрые возможности линейной алгебры. Все эти процедуры линейной алгебры ожидают объект, который может быть преобразован в двумерный массив. Результатом этих подпрограмм также является двумерный массив.
SciPy.linalg против NumPy.linalg
Scipy.linalg содержит все функции, которые есть в numpy.linalg. Кроме того, scipy.linalg также имеет некоторые другие расширенные функции, которых нет в numpy.linalg. Другое преимущество использования scipy.linalg перед numpy.linalg заключается в том, что он всегда компилируется с поддержкой BLAS / LAPACK, а для NumPy это необязательно. Поэтому версия SciPy может быть быстрее в зависимости от того, как был установлен NumPy.
Линейные уравнения
Функция scipy.linalg.solve решает линейное уравнение a * x + b * y = Z для неизвестных значений x, y.
В качестве примера предположим, что желательно решить следующие одновременные уравнения.
x + 3y + 5z = 10
2x + 5y + z = 8
2x + 3y + 8z = 3
Чтобы решить вышеприведенное уравнение для значений x, y, z, мы можем найти вектор решения, используя обратную матрицу, как показано ниже.
\ begin {bmatrix} x \\ y \\ z \ end {bmatrix} = \ begin {bmatrix} 1 & 3 & 5 \\ 2 & 5 & 1 \\ 2 & 3 & 8 \ end {bmatrix} ^ {-1} \ begin {bmatrix} 10 \\ 8 \\ 3 \ end {bmatrix} = \ frac {1} {25} \ begin {bmatrix} -232 \\ 129 \\ 19 \ end {bmatrix} = \ begin {bmatrix} -9.28 \\ 5.16 \\ 0.76 \ end {bmatrix}.
Однако лучше использовать команду linalg.solve , которая может быть быстрее и более численно устойчивой.
Функция решения принимает два входа «a» и «b», в которых «a» представляет коэффициенты, а «b» представляет соответствующее правое значение и возвращает массив решений.
Давайте рассмотрим следующий пример.
#importing the scipy and numpy packages from scipy import linalg import numpy as np #Declaring the numpy arrays a = np.array([[3, 2, 0], [1, -1, 0], [0, 5, 1]]) b = np.array([2, 4, -1]) #Passing the values to the solve function x = linalg.solve(a, b) #printing the result array print x
Вышеуказанная программа сгенерирует следующий вывод.
array([ 2., -2., 9.])
Нахождение детерминанта
Определитель квадратной матрицы A часто обозначается как | A | и является величиной, часто используемой в линейной алгебре. В SciPy это вычисляется с использованием функции det () . Он принимает матрицу в качестве входных данных и возвращает скалярное значение.
Давайте рассмотрим следующий пример.
#importing the scipy and numpy packages from scipy import linalg import numpy as np #Declaring the numpy array A = np.array([[1,2],[3,4]]) #Passing the values to the det function x = linalg.det(A) #printing the result print x
Вышеуказанная программа сгенерирует следующий вывод.
-2.0
Собственные значения и собственные векторы
Проблема собственных значений-собственных векторов является одной из наиболее часто используемых операций линейной алгебры. Мы можем найти собственные значения (λ) и соответствующие собственные векторы (v) квадратной матрицы (A), рассмотрев следующее соотношение:
Av = λv
scipy.linalg.eig вычисляет собственные значения из обычной или обобщенной задачи на собственные значения. Эта функция возвращает собственные значения и собственные векторы.
Давайте рассмотрим следующий пример.
#importing the scipy and numpy packages from scipy import linalg import numpy as np #Declaring the numpy array A = np.array([[1,2],[3,4]]) #Passing the values to the eig function l, v = linalg.eig(A) #printing the result for eigen values print l #printing the result for eigen vectors print v
Вышеуказанная программа сгенерирует следующий вывод.
array([-0.37228132+0.j, 5.37228132+0.j]) #--Eigen Values
array([[-0.82456484, -0.41597356], #--Eigen Vectors
[ 0.56576746, -0.90937671]])
Разложение по единственному значению
Разложение по сингулярным значениям (SVD) можно рассматривать как расширение задачи на собственные значения на матрицы, которые не являются квадратными.
Scipy.linalg.svd разлагает матрицу ‘a’ на две унитарные матрицы ‘U’ и ‘Vh’ и одномерный массив ‘s’ сингулярных значений (действительных, неотрицательных), таких что a == U * S * Vh, где ‘S’ — это матрица нулей подходящей формы с главной диагональю ‘s’.
Давайте рассмотрим следующий пример.
#importing the scipy and numpy packages from scipy import linalg import numpy as np #Declaring the numpy array a = np.random.randn(3, 2) + 1.j*np.random.randn(3, 2) #Passing the values to the eig function U, s, Vh = linalg.svd(a) # printing the result print U, Vh, s
Вышеуказанная программа сгенерирует следующий вывод.
(
array([
[ 0.54828424-0.23329795j, -0.38465728+0.01566714j,
-0.18764355+0.67936712j],
[-0.27123194-0.5327436j , -0.57080163-0.00266155j,
-0.39868941-0.39729416j],
[ 0.34443818+0.4110186j , -0.47972716+0.54390586j,
0.25028608-0.35186815j]
]),
array([ 3.25745379, 1.16150607]),
array([
[-0.35312444+0.j , 0.32400401+0.87768134j],
[-0.93557636+0.j , -0.12229224-0.33127251j]
])
)
SciPy — Ndimage
Подмодуль SciPy ndimage предназначен для обработки изображений. Здесь ndimage означает n-мерное изображение.
Вот некоторые из наиболее распространенных задач обработки изображений: & miuns;
- Ввод / вывод, отображение изображений
- Основные манипуляции — кадрирование, переворачивание, вращение и т. Д.
- Фильтрация изображений — устранение шумов, резкость и т. Д.
- Сегментация изображения — маркировка пикселей, соответствующих различным объектам
- классификация
- Извлечение функций
- Постановка на учет
Давайте обсудим, как некоторые из них могут быть достигнуты с помощью SciPy.
Открытие и запись в файлы изображений
Пакет misc в SciPy поставляется с некоторыми изображениями. Мы используем эти изображения для изучения манипуляций с изображениями. Давайте рассмотрим следующий пример.
from scipy import misc f = misc.face() misc.imsave('face.png', f) # uses the Image module (PIL) import matplotlib.pyplot as plt plt.imshow(f) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.

Любые изображения в необработанном формате представляют собой комбинацию цветов, представленных числами в матричном формате. Машина понимает и манипулирует изображениями только на основе этих чисел. RGB — это популярный способ представления.
Давайте посмотрим статистическую информацию на изображении выше.
from scipy import misc face = misc.face(gray = False) print face.mean(), face.max(), face.min()
Вышеуказанная программа сгенерирует следующий вывод.
110.16274388631184, 255, 0
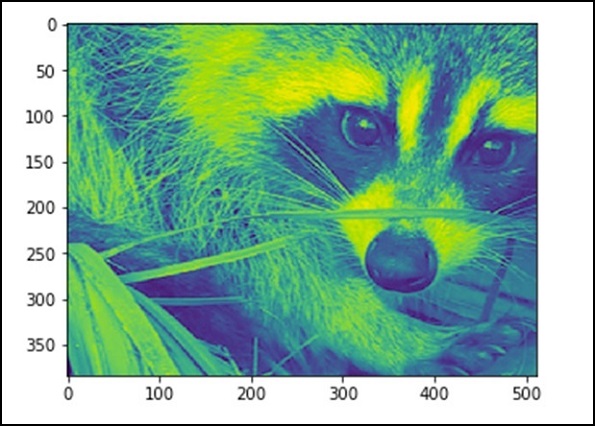
Теперь мы знаем, что изображение состоит из цифр, поэтому любое изменение значения числа приводит к изменению исходного изображения. Давайте выполним некоторые геометрические преобразования на изображении. Основная геометрическая операция — обрезка
from scipy import misc face = misc.face(gray = True) lx, ly = face.shape # Cropping crop_face = face[lx / 4: - lx / 4, ly / 4: - ly / 4] import matplotlib.pyplot as plt plt.imshow(crop_face) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
Мы также можем выполнить некоторые основные операции, например перевернуть изображение вверх ногами, как описано ниже.
# up <-> down flip from scipy import misc face = misc.face() flip_ud_face = np.flipud(face) import matplotlib.pyplot as plt plt.imshow(flip_ud_face) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.

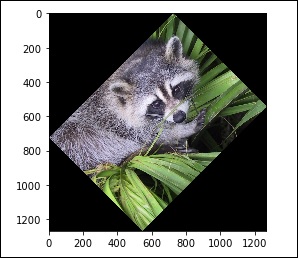
Кроме того, у нас есть функция rotate () , которая поворачивает изображение на заданный угол.
# rotation from scipy import misc,ndimage face = misc.face() rotate_face = ndimage.rotate(face, 45) import matplotlib.pyplot as plt plt.imshow(rotate_face) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
фильтры
Давайте обсудим, как фильтры помогают в обработке изображений.
Что такое фильтрация при обработке изображений?
Фильтрация — это метод модификации или улучшения изображения. Например, вы можете отфильтровать изображение, чтобы подчеркнуть определенные функции или удалить другие функции. Операции обработки изображений, реализованные с фильтрацией, включают сглаживание, повышение резкости и улучшение контуров.
Фильтрация — это операция окрестности, в которой значение любого данного пикселя в выходном изображении определяется путем применения некоторого алгоритма к значениям пикселей в окрестности соответствующего входного пикселя. Давайте теперь выполним несколько операций, используя SciPy ndimage.
нечеткость
Размытие широко используется для уменьшения шума на изображении. Мы можем выполнить операцию фильтра и увидеть изменения на изображении. Давайте рассмотрим следующий пример.
from scipy import misc face = misc.face() blurred_face = ndimage.gaussian_filter(face, sigma=3) import matplotlib.pyplot as plt plt.imshow(blurred_face) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.

Значение сигмы указывает уровень размытия по пятибалльной шкале. Мы можем увидеть изменение качества изображения, настроив значение сигмы. Для получения более подробной информации о размытии, нажмите на → Учебник по DIP (цифровая обработка изображений).
Обнаружение края
Давайте обсудим, как обнаружение краев помогает в обработке изображений.
Что такое Edge Detection?
Обнаружение краев — это метод обработки изображений для определения границ объектов в изображениях. Это работает, обнаруживая разрывы в яркости. Обнаружение края используется для сегментации изображения и извлечения данных в таких областях, как обработка изображений, компьютерное зрение и машинное зрение.
Наиболее часто используемые алгоритмы обнаружения краев включают
- Собела
- благоразумный
- Прюитт
- Робертс
- Методы нечеткой логики
Давайте рассмотрим следующий пример.
import scipy.ndimage as nd import numpy as np im = np.zeros((256, 256)) im[64:-64, 64:-64] = 1 im[90:-90,90:-90] = 2 im = ndimage.gaussian_filter(im, 8) import matplotlib.pyplot as plt plt.imshow(im) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
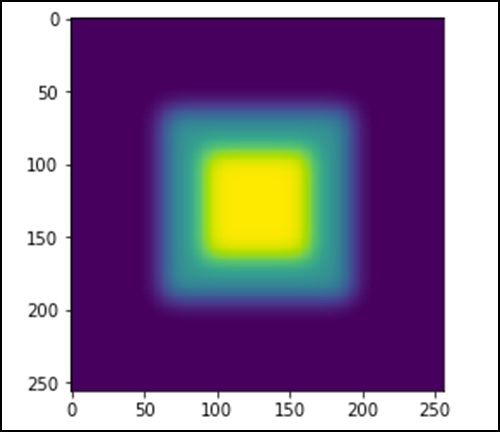
Изображение выглядит как квадратный блок цветов. Теперь мы обнаружим края этих цветных блоков. Здесь ndimage предоставляет функцию Sobel для выполнения этой операции. Принимая во внимание, что NumPy предоставляет функцию Hypot для объединения двух результирующих матриц в одну.
Давайте рассмотрим следующий пример.
import scipy.ndimage as nd import matplotlib.pyplot as plt im = np.zeros((256, 256)) im[64:-64, 64:-64] = 1 im[90:-90,90:-90] = 2 im = ndimage.gaussian_filter(im, 8) sx = ndimage.sobel(im, axis = 0, mode = 'constant') sy = ndimage.sobel(im, axis = 1, mode = 'constant') sob = np.hypot(sx, sy) plt.imshow(sob) plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
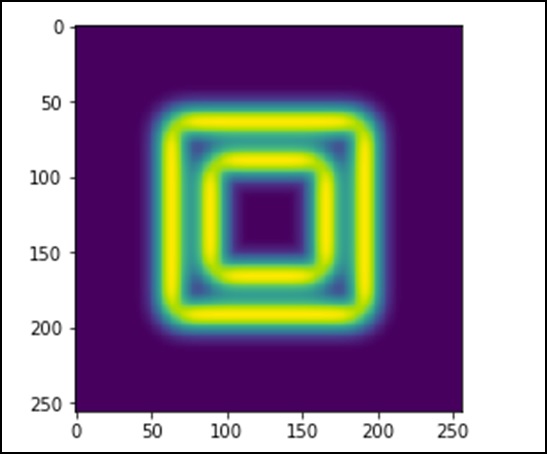
SciPy — Оптимизация
Пакет scipy.optimize предоставляет несколько часто используемых алгоритмов оптимизации. Этот модуль содержит следующие аспекты —
-
Неограниченная и ограниченная минимизация многомерных скалярных функций (минимизация ()) с использованием различных алгоритмов (например, BFGS, симплекс Нелдера-Мида, градиент сопряженного Ньютона, COBYLA или SLSQP)
-
Процедуры глобальной (грубой силы) оптимизации (например, отжиг (), тазобедренный отбор ())
-
Алгоритмы минимизации наименьших квадратов (leastsq ()) и аппроксимации кривой (curve_fit ())
-
Скалярные одномерные функции минимизаторы (minim_scalar ()) и корневые искатели (newton ())
-
Решатели системы многомерных уравнений (root ()) с использованием различных алгоритмов (например, гибридный метод Пауэлла, Левенберга-Марквардта или крупномасштабные методы, такие как Ньютон-Крылов)
Неограниченная и ограниченная минимизация многомерных скалярных функций (минимизация ()) с использованием различных алгоритмов (например, BFGS, симплекс Нелдера-Мида, градиент сопряженного Ньютона, COBYLA или SLSQP)
Процедуры глобальной (грубой силы) оптимизации (например, отжиг (), тазобедренный отбор ())
Алгоритмы минимизации наименьших квадратов (leastsq ()) и аппроксимации кривой (curve_fit ())
Скалярные одномерные функции минимизаторы (minim_scalar ()) и корневые искатели (newton ())
Решатели системы многомерных уравнений (root ()) с использованием различных алгоритмов (например, гибридный метод Пауэлла, Левенберга-Марквардта или крупномасштабные методы, такие как Ньютон-Крылов)
Неограниченная и ограниченная минимизация многомерных скалярных функций
Функция minimal () обеспечивает общий интерфейс с неограниченными и ограниченными алгоритмами минимизации для многомерных скалярных функций в scipy.optimize . Чтобы продемонстрировать функцию минимизации, рассмотрим задачу минимизации функции Розенброка NN-переменных:
f(x)= sumN−1i=1100(xi−x2i−1)
Минимальное значение этой функции равно 0, что достигается при xi = 1.
Симплексный алгоритм Нелдера – Мида
В следующем примере процедура minimal () используется с симплексным алгоритмом Nelder-Mead (method = ‘Nelder-Mead’) (выбирается через параметр метода). Давайте рассмотрим следующий пример.
import numpy as np from scipy.optimize import minimize def rosen(x): x0 = np.array([1.3, 0.7, 0.8, 1.9, 1.2]) res = minimize(rosen, x0, method='nelder-mead') print(res.x)
Вышеуказанная программа сгенерирует следующий вывод.
[7.93700741e+54 -5.41692163e+53 6.28769150e+53 1.38050484e+55 -4.14751333e+54]
Симплексный алгоритм — это, вероятно, самый простой способ минимизировать довольно корректную функцию. Он требует только оценки функций и является хорошим выбором для простых задач минимизации. Однако, поскольку он не использует какие-либо оценки градиента, может потребоваться больше времени, чтобы найти минимум.
Другим алгоритмом оптимизации, который требует только вызовов функций, чтобы найти минимум, является метод Пауэлла , который доступен путем установки method = ‘powell’ в функции minimal ().
Наименьших квадратов
Решить нелинейную задачу наименьших квадратов с оценками переменных. Учитывая невязки f (x) (m-мерная вещественная функция от n вещественных переменных) и функцию потерь rho (s) (скалярная функция), наименьшие квадраты находят локальный минимум функции стоимости F (x). Давайте рассмотрим следующий пример.
В этом примере мы находим минимум функции Розенброка без границ для независимых переменных.
#Rosenbrock Function def fun_rosenbrock(x): return np.array([10 * (x[1] - x[0]**2), (1 - x[0])]) from scipy.optimize import least_squares input = np.array([2, 2]) res = least_squares(fun_rosenbrock, input) print res
Обратите внимание, что мы предоставляем только вектор невязок. Алгоритм строит функцию стоимости как сумму квадратов невязок, которая дает функцию Розенброка. Точный минимум находится при х = [1,0,1,0].
Вышеуказанная программа сгенерирует следующий вывод.
active_mask: array([ 0., 0.])
cost: 9.8669242910846867e-30
fun: array([ 4.44089210e-15, 1.11022302e-16])
grad: array([ -8.89288649e-14, 4.44089210e-14])
jac: array([[-20.00000015,10.],[ -1.,0.]])
message: '`gtol` termination condition is satisfied.'
nfev: 3
njev: 3
optimality: 8.8928864934219529e-14
status: 1
success: True
x: array([ 1., 1.])
Поиск корней
Давайте разберемся, как поиск корней помогает в SciPy.
Скалярные функции
Если у одного есть уравнение с одной переменной, есть четыре различных алгоритма поиска корней, которые можно попробовать. Каждый из этих алгоритмов требует конечных точек интервала, в котором ожидается корень (потому что функция меняет знаки). В общем, brentq — лучший выбор, но другие методы могут быть полезны в определенных обстоятельствах или для академических целей.
Решение с фиксированной точкой
Проблема, тесно связанная с нахождением нулей функции, — это проблема нахождения неподвижной точки функции. Фиксированная точка функции — это точка, в которой оценка функции возвращает точку: g (x) = x. Ясно, что неподвижная точка gg является корнем f (x) = g (x) −x. Эквивалентно, корень ff — это точка с фиксированной точкой g (x) = f (x) + x. Процедура fixed_point предоставляет простой итеративный метод, использующий ускорение последовательности Айткенса для оценки фиксированной точки gg , если задана начальная точка.
Наборы уравнений
Найти корень системы нелинейных уравнений можно с помощью функции root () . Доступно несколько методов, среди которых hybr (по умолчанию) и lm, соответственно, используют гибридный метод Пауэлла и метод Левенберга-Марквардта из MINPACK.
В следующем примере рассматривается трансцендентное уравнение с одной переменной.
x 2 + 2cos (x) = 0
Корень которого можно найти следующим образом —
import numpy as np from scipy.optimize import root def func(x): return x*2 + 2 * np.cos(x) sol = root(func, 0.3) print sol
Вышеуказанная программа сгенерирует следующий вывод.
fjac: array([[-1.]])
fun: array([ 2.22044605e-16])
message: 'The solution converged.'
nfev: 10
qtf: array([ -2.77644574e-12])
r: array([-3.34722409])
status: 1
success: True
x: array([-0.73908513])
SciPy — Статистика
Все статистические функции находятся в подпакете scipy.stats, и довольно полный список этих функций можно получить с помощью функции info (stats) . Список доступных случайных величин также можно получить из строки документации для подпакета stats. Этот модуль содержит большое количество вероятностных распределений, а также растущую библиотеку статистических функций.
Каждый одномерный дистрибутив имеет свой собственный подкласс, как описано в следующей таблице:
| Старший | Класс и описание |
|---|---|
| 1 |
rv_continuous Универсальный непрерывный класс случайных величин, предназначенный для подклассов |
| 2 |
rv_discrete Общий класс дискретных случайных величин, предназначенный для подклассов |
| 3 |
rv_histogram Создает распределение, заданное гистограммой |
rv_continuous
Универсальный непрерывный класс случайных величин, предназначенный для подклассов
rv_discrete
Общий класс дискретных случайных величин, предназначенный для подклассов
rv_histogram
Создает распределение, заданное гистограммой
Нормальная непрерывная случайная величина
Распределение вероятностей, при котором случайная величина X может принимать любое значение, является непрерывной случайной величиной. Ключевое слово location (loc) указывает среднее. Ключевое слово scale (scale) определяет стандартное отклонение.
Как экземпляр класса rv_continuous , объект norm наследует от него коллекцию универсальных методов и дополняет их деталями, специфичными для данного конкретного распределения.
Чтобы вычислить CDF в нескольких точках, мы можем передать список или массив NumPy. Давайте рассмотрим следующий пример.
from scipy.stats import norm import numpy as np print norm.cdf(np.array([1,-1., 0, 1, 3, 4, -2, 6]))
Вышеуказанная программа сгенерирует следующий вывод.
array([ 0.84134475, 0.15865525, 0.5 , 0.84134475, 0.9986501 , 0.99996833, 0.02275013, 1. ])
Чтобы найти медиану распределения, мы можем использовать функцию процентной точки (PPF), которая является обратной к CDF. Давайте разберемся, используя следующий пример.
from scipy.stats import norm print norm.ppf(0.5)
Вышеуказанная программа сгенерирует следующий вывод.
0.0
Чтобы сгенерировать последовательность случайных переменных, мы должны использовать аргумент размера ключевого слова, который показан в следующем примере.
from scipy.stats import norm print norm.rvs(size = 5)
Вышеуказанная программа сгенерирует следующий вывод.
array([ 0.20929928, -1.91049255, 0.41264672, -0.7135557 , -0.03833048])
Вышеуказанный вывод не воспроизводим. Для генерации одинаковых случайных чисел используйте функцию seed.
Равномерное распределение
Равномерное распределение может быть сгенерировано с использованием равномерной функции. Давайте рассмотрим следующий пример.
from scipy.stats import uniform print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)
Вышеуказанная программа сгенерирует следующий вывод.
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
Построить дискретное распределение
Давайте сгенерируем случайную выборку и сравним наблюдаемые частоты с вероятностями.
Биномиальное распределение
Как экземпляр класса rv_discrete , объект binom наследует от него коллекцию универсальных методов и дополняет их деталями, специфичными для данного конкретного дистрибутива. Давайте рассмотрим следующий пример.
from scipy.stats import uniform print uniform.cdf([0, 1, 2, 3, 4, 5], loc = 1, scale = 4)
Вышеуказанная программа сгенерирует следующий вывод.
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
Описательная статистика
Базовая статистика, такая как Min, Max, Mean и Variance, принимает массив NumPy в качестве входных данных и возвращает соответствующие результаты. Несколько основных статистических функций, доступных в пакете scipy.stats , описаны в следующей таблице.
| Старший | Описание функции |
|---|---|
| 1 |
описывают () Вычисляет несколько описательной статистики переданного массива |
| 2 |
GMean () Вычисляет среднее геометрическое вдоль указанной оси |
| 3 |
hmean () Вычисляет среднее гармоническое вдоль указанной оси |
| 4 |
эксцесс () Вычисляет эксцесс |
| 5 |
Режим() Возвращает модальное значение |
| 6 |
перекос () Проверяет асимметрию данных |
| 7 |
f_oneway () Выполняет односторонний ANOVA |
| 8 |
IQR () Вычисляет межквартильный диапазон данных вдоль указанной оси |
| 9 |
zscore () Вычисляет z-оценку каждого значения в выборке относительно среднего значения по выборке и стандартного отклонения. |
| 10 |
СЭМ () Вычисляет стандартную ошибку среднего (или стандартную ошибку измерения) значений во входном массиве |
описывают ()
Вычисляет несколько описательной статистики переданного массива
GMean ()
Вычисляет среднее геометрическое вдоль указанной оси
hmean ()
Вычисляет среднее гармоническое вдоль указанной оси
эксцесс ()
Вычисляет эксцесс
Режим()
Возвращает модальное значение
перекос ()
Проверяет асимметрию данных
f_oneway ()
Выполняет односторонний ANOVA
IQR ()
Вычисляет межквартильный диапазон данных вдоль указанной оси
zscore ()
Вычисляет z-оценку каждого значения в выборке относительно среднего значения по выборке и стандартного отклонения.
СЭМ ()
Вычисляет стандартную ошибку среднего (или стандартную ошибку измерения) значений во входном массиве
Некоторые из этих функций имеют аналогичную версию в scipy.stats.mstats , которая работает для замаскированных массивов. Позвольте нам понять это на примере, приведенном ниже.
from scipy import stats import numpy as np x = np.array([1,2,3,4,5,6,7,8,9]) print x.max(),x.min(),x.mean(),x.var()
Вышеуказанная программа сгенерирует следующий вывод.
(9, 1, 5.0, 6.666666666666667)
Т-тест
Давайте поймем, как T-тест полезен в SciPy.
ttest_1samp
Вычисляет T-тест для среднего значения ОДНОЙ группы баллов. Это двусторонний тест для нулевой гипотезы о том, что ожидаемое значение (среднее) выборки независимых наблюдений «а» равно заданному среднему значению для популяции, среднему значению . Давайте рассмотрим следующий пример.
from scipy import stats rvs = stats.norm.rvs(loc = 5, scale = 10, size = (50,2)) print stats.ttest_1samp(rvs,5.0)
Вышеуказанная программа сгенерирует следующий вывод.
Ttest_1sampResult(statistic = array([-1.40184894, 2.70158009]), pvalue = array([ 0.16726344, 0.00945234]))
Сравнивая два образца
В следующих примерах есть две выборки, которые могут быть либо из одного, либо из другого распределения, и мы хотим проверить, имеют ли эти выборки одинаковые статистические свойства.
ttest_ind — вычисляет T-тест для средних двух независимых выборок баллов. Это двусторонний тест для нулевой гипотезы о том, что две независимые выборки имеют идентичные средние (ожидаемые) значения. Этот тест предполагает, что популяции имеют идентичные отклонения по умолчанию.
Мы можем использовать этот тест, если мы наблюдаем две независимые выборки из одной или разных популяций. Давайте рассмотрим следующий пример.
from scipy import stats rvs1 = stats.norm.rvs(loc = 5,scale = 10,size = 500) rvs2 = stats.norm.rvs(loc = 5,scale = 10,size = 500) print stats.ttest_ind(rvs1,rvs2)
Вышеуказанная программа сгенерирует следующий вывод.
Ttest_indResult(statistic = -0.67406312233650278, pvalue = 0.50042727502272966)
Вы можете проверить то же самое с новым массивом такой же длины, но с различным средним значением. Используйте другое значение в loc и тестируйте то же самое.
SciPy — CSGraph
CSGraph расшифровывается как Compressed Sparse Graph , который фокусируется на алгоритмах Fast графа, основанных на разреженных матричных представлениях.
Графические представления
Для начала давайте разберемся, что такое разреженный граф и как он помогает в представлении графов.
Что такое разреженный граф?
Граф — это просто набор узлов, между которыми есть связи. Графики могут представлять почти все — соединения в социальных сетях, где каждый узел является личностью и связан со знакомыми; изображения, где каждый узел является пикселем и связан с соседними пикселями; точки в многомерном распределении, где каждый узел связан со своими ближайшими соседями; и практически все, что вы можете себе представить.
Один очень эффективный способ представления данных графа — это разреженная матрица: назовем ее G. Матрица G имеет размер N x N, а G [i, j] дает значение связи между узлом «i» и узлом. ‘J’. Разреженный граф содержит в основном нули, то есть большинство узлов имеют только несколько соединений. Это свойство оказывается истинным в большинстве случаев, представляющих интерес.
Создание подмодуля разреженного графа было мотивировано несколькими алгоритмами, использованными в scikit-learn, которые включали следующее:
-
Isomap — алгоритм обучения многообразия, который требует нахождения кратчайших путей в графе.
-
Иерархическая кластеризация — алгоритм кластеризации, основанный на минимальном остовном дереве.
-
Спектральная декомпозиция — алгоритм проекции, основанный на лапласианах разреженных графов.
Isomap — алгоритм обучения многообразия, который требует нахождения кратчайших путей в графе.
Иерархическая кластеризация — алгоритм кластеризации, основанный на минимальном остовном дереве.
Спектральная декомпозиция — алгоритм проекции, основанный на лапласианах разреженных графов.
В качестве конкретного примера представьте, что мы хотели бы представить следующий неориентированный граф:
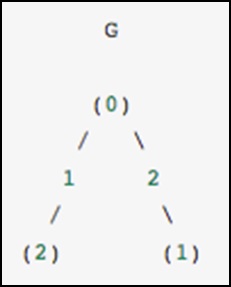
Этот граф имеет три узла, где узлы 0 и 1 соединены ребром веса 2, а узлы 0 и 2 соединены ребром веса 1. Мы можем построить плотные, замаскированные и разреженные представления, как показано в следующем примере. , имея в виду, что ненаправленный граф представлен симметричной матрицей.
G_dense = np.array([ [0, 2, 1], [2, 0, 0], [1, 0, 0] ]) G_masked = np.ma.masked_values(G_dense, 0) from scipy.sparse import csr_matrix G_sparse = csr_matrix(G_dense) print G_sparse.data
Вышеуказанная программа сгенерирует следующий вывод.
array([2, 1, 2, 1])
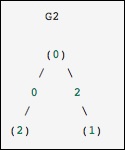
Это идентично предыдущему графику, за исключением того, что узлы 0 и 2 соединены ребром нулевого веса. В этом случае представленное выше плотное представление приводит к неоднозначности — как можно представить не-ребра, если ноль является значимым значением. В этом случае либо маскированное, либо разреженное представление должно использоваться для устранения неоднозначности.
Давайте рассмотрим следующий пример.
from scipy.sparse.csgraph import csgraph_from_dense G2_data = np.array ([ [np.inf, 2, 0 ], [2, np.inf, np.inf], [0, np.inf, np.inf] ]) G2_sparse = csgraph_from_dense(G2_data, null_value=np.inf) print G2_sparse.data
Вышеуказанная программа сгенерирует следующий вывод.
array([ 2., 0., 2., 0.])
Лестницы слов с использованием разреженных графов
Word ladders — это игра, изобретенная Льюисом Кэрроллом, в которой слова связаны между собой изменением одной буквы на каждом шаге. Например —
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
Здесь мы перешли от «APE» к «MAN» за семь шагов, каждый раз меняя одну букву. Вопрос в том, можем ли мы найти более короткий путь между этими словами, используя одно и то же правило? Эта проблема естественно выражается как проблема разреженных графов. Узлы будут соответствовать отдельным словам, и мы создадим связи между словами, которые различаются не более чем на одну букву.
Получение списка слов
Во-первых, конечно, мы должны получить список допустимых слов. Я использую Mac, и Mac имеет словарь слов в месте, указанном в следующем блоке кода. Если вы используете другую архитектуру, вам, возможно, придется немного поискать, чтобы найти системный словарь.
wordlist = open('/usr/share/dict/words').read().split() print len(wordlist)
Вышеуказанная программа сгенерирует следующий вывод.
235886
Теперь мы хотим взглянуть на слова длиной 3, поэтому давайте выберем только те слова правильной длины. Мы также исключим слова, которые начинаются с верхнего регистра (собственно существительные) или содержат не алфавитно-цифровые символы, такие как апострофы и дефисы. Наконец, мы убедимся, что все будет в нижнем регистре для сравнения позже.
word_list = [word for word in word_list if len(word) == 3] word_list = [word for word in word_list if word[0].islower()] word_list = [word for word in word_list if word.isalpha()] word_list = map(str.lower, word_list) print len(word_list)
Вышеуказанная программа сгенерирует следующий вывод.
1135
Теперь у нас есть список из 1135 правильных трехбуквенных слов (точное число может меняться в зависимости от конкретного используемого списка). Каждое из этих слов станет узлом в нашем графе, и мы создадим ребра, соединяющие узлы, связанные с каждой парой слов, которые отличаются только одной буквой.
import numpy as np word_list = np.asarray(word_list) word_list.dtype word_list.sort() word_bytes = np.ndarray((word_list.size, word_list.itemsize), dtype = 'int8', buffer = word_list.data) print word_bytes.shape
Вышеуказанная программа сгенерирует следующий вывод.
(1135, 3)
Мы будем использовать расстояние Хэмминга между каждой точкой, чтобы определить, какие пары слов связаны. Расстояние Хэмминга измеряет долю записей между двумя векторами, которые различаются: любые два слова с расстоянием Хэмминга, равным 1 / N1 / N, где NN — количество букв, которые связаны в словарной лестнице.
from scipy.spatial.distance import pdist, squareform from scipy.sparse import csr_matrix hamming_dist = pdist(word_bytes, metric = 'hamming') graph = csr_matrix(squareform(hamming_dist < 1.5 / word_list.itemsize))
При сравнении расстояний мы не используем равенство, потому что это может быть нестабильно для значений с плавающей запятой. Неравенство дает желаемый результат до тех пор, пока никакие две записи в списке слов не являются идентичными. Теперь, когда наш граф настроен, мы будем использовать поиск кратчайшего пути, чтобы найти путь между любыми двумя словами в графе.
i1 = word_list.searchsorted('ape') i2 = word_list.searchsorted('man') print word_list[i1],word_list[i2]
Вышеуказанная программа сгенерирует следующий вывод.
ape, man
Мы должны проверить, что они совпадают, потому что, если слова не находятся в списке, в выходных данных будет ошибка. Теперь все, что нам нужно, это найти кратчайший путь между этими двумя индексами в графе. Мы будем использовать алгоритм Дейкстры, потому что он позволяет нам найти путь только для одного узла.
from scipy.sparse.csgraph import dijkstra distances, predecessors = dijkstra(graph, indices = i1, return_predecessors = True) print distances[i2]
Вышеуказанная программа сгенерирует следующий вывод.
5.0
Таким образом, мы видим, что кратчайший путь между «обезьяной» и «человеком» содержит всего пять шагов. Мы можем использовать предшественников, возвращаемых алгоритмом, чтобы восстановить этот путь.
path = [] i = i2 while i != i1: path.append(word_list[i]) i = predecessors[i] path.append(word_list[i1]) print path[::-1]i2]
Вышеуказанная программа сгенерирует следующий вывод.
['ape', 'ope', 'opt', 'oat', 'mat', 'man']
SciPy — Пространственный
Пакет scipy.spatial может вычислять триангуляции, диаграммы Вороного и выпуклые оболочки из набора точек, используя библиотеку Qhull . Кроме того, он содержит реализации KDTree для запросов точек ближайших соседей и утилиты для вычислений расстояния в различных метриках.
Триангуляции Делоне
Давайте разберемся, что такое триангуляции Делоне и как они используются в SciPy.
Что такое триангуляции Делоне?
В математике и вычислительной геометрии триангуляция Делоне для заданного набора P дискретных точек на плоскости является триангуляцией DT (P), такой, что ни одна точка в P не находится внутри окружности любого треугольника в DT (P).
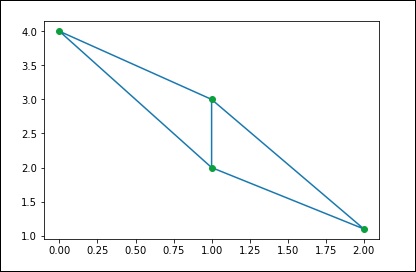
Мы можем вычислить то же самое через SciPy. Давайте рассмотрим следующий пример.
from scipy.spatial import Delaunay points = np.array([[0, 4], [2, 1.1], [1, 3], [1, 2]]) tri = Delaunay(points) import matplotlib.pyplot as plt plt.triplot(points[:,0], points[:,1], tri.simplices.copy()) plt.plot(points[:,0], points[:,1], 'o') plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
Копланарные точки
Давайте разберемся, что такое Копланарные Точки и как они используются в SciPy.
Что такое Копланарные Точки?
Копланарные точки — это три или более точек, которые лежат в одной плоскости. Напомним, что плоскость представляет собой плоскую поверхность, которая проходит без конца во всех направлениях. Обычно в учебниках по математике это изображено в виде четырехстороннего рисунка.
Давайте посмотрим, как мы можем найти это с помощью SciPy. Давайте рассмотрим следующий пример.
from scipy.spatial import Delaunay points = np.array([[0, 0], [0, 1], [1, 0], [1, 1], [1, 1]]) tri = Delaunay(points) print tri.coplanar
Вышеуказанная программа сгенерирует следующий вывод.
array([[4, 0, 3]], dtype = int32)
Это означает, что точка 4 находится вблизи треугольника 0 и вершины 3, но не включена в триангуляцию.
Выпуклые корпуса
Давайте разберемся, что такое выпуклые оболочки и как они используются в SciPy.
Что такое выпуклые оболочки?
В математике выпуклая оболочка или выпуклая оболочка множества точек X в евклидовой плоскости или в евклидовом пространстве (или, в более общем случае, в аффинном пространстве над реалами) является наименьшим выпуклым множеством , содержащим X.
Давайте рассмотрим следующий пример, чтобы понять его подробнее.
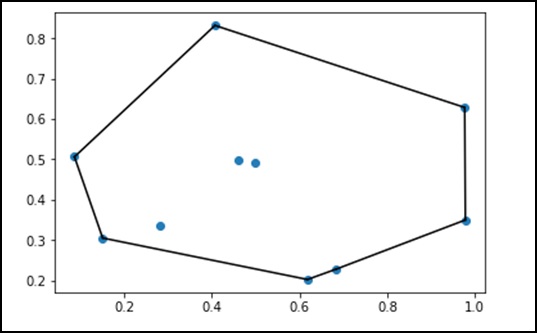
from scipy.spatial import ConvexHull points = np.random.rand(10, 2) # 30 random points in 2-D hull = ConvexHull(points) import matplotlib.pyplot as plt plt.plot(points[:,0], points[:,1], 'o') for simplex in hull.simplices: plt.plot(points[simplex,0], points[simplex,1], 'k-') plt.show()
Вышеуказанная программа сгенерирует следующий вывод.
SciPy — ODR
ODR обозначает регрессию ортогонального расстояния , которая используется в исследованиях регрессии. Базовая линейная регрессия часто используется для оценки взаимосвязи между двумя переменными y и x путем рисования линии наилучшего соответствия на графике.
Математический метод, который используется для этого, известен как наименьшие квадраты и направлен на минимизацию суммы квадратов ошибок для каждой точки. Ключевой вопрос здесь заключается в том, как рассчитать ошибку (также известную как остаток) для каждой точки?
В стандартной линейной регрессии цель состоит в том, чтобы предсказать значение Y по значению X, поэтому разумно будет рассчитать погрешность в значениях Y (показано серыми линиями на следующем изображении). Тем не менее, иногда разумнее учитывать ошибку как в X, так и в Y (как показано пунктирными красными линиями на следующем изображении).
Например — когда вы знаете, что ваши измерения X неопределенны или когда вы не хотите сосредоточиться на ошибках одной переменной над другой.
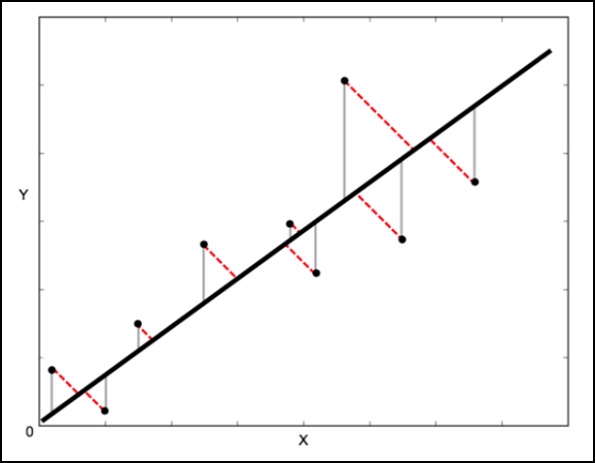
Ортогональная регрессия расстояния (ODR) — это метод, который может сделать это (ортогональный в данном контексте означает перпендикулярный — поэтому он вычисляет ошибки перпендикулярно линии, а не просто «вертикально»).
Реализация scipy.odr для одномерной регрессии
В следующем примере демонстрируется реализация scipy.odr для одномерной регрессии.
import numpy as np import matplotlib.pyplot as plt from scipy.odr import * import random # Initiate some data, giving some randomness using random.random(). x = np.array([0, 1, 2, 3, 4, 5]) y = np.array([i**2 + random.random() for i in x]) # Define a function (quadratic in our case) to fit the data with. def linear_func(p, x): m, c = p return m*x + c # Create a model for fitting. linear_model = Model(linear_func) # Create a RealData object using our initiated data from above. data = RealData(x, y) # Set up ODR with the model and data. odr = ODR(data, linear_model, beta0=[0., 1.]) # Run the regression. out = odr.run() # Use the in-built pprint method to give us results. out.pprint()
Вышеуказанная программа сгенерирует следующий вывод.
Beta: [ 5.51846098 -4.25744878] Beta Std Error: [ 0.7786442 2.33126407] Beta Covariance: [ [ 1.93150969 -4.82877433] [ -4.82877433 17.31417201 ]] Residual Variance: 0.313892697582 Inverse Condition #: 0.146618499389 Reason(s) for Halting: Sum of squares convergence
SciPy — Специальный пакет
Функции, доступные в специальном пакете, являются универсальными функциями, которые следуют за широковещательной передачей и автоматическим зацикливанием массива.
Давайте посмотрим на некоторые из наиболее часто используемых специальных функций —
- Кубическая корневая функция
- Экспоненциальная функция
- Экспоненциальная функция относительной погрешности
- Экспоненциальная функция логарифмической суммы
- Функция Ламберта
- Функция перестановок и комбинаций
- Гамма-функция
Давайте теперь поймем каждую из этих функций вкратце.
Кубическая корневая функция
Синтаксис этой кубической корневой функции — scipy.special.cbrt (x). Это извлечет поэлементный кубический корень из x .
Давайте рассмотрим следующий пример.
from scipy.special import cbrt res = cbrt([10, 9, 0.1254, 234]) print res
Вышеуказанная программа сгенерирует следующий вывод.
[ 2.15443469 2.08008382 0.50053277 6.16224015]
Экспоненциальная функция
Синтаксис экспоненциальной функции — scipy.special.exp10 (x). Это будет вычислять 10 ** х поэлементно.
Давайте рассмотрим следующий пример.
from scipy.special import exp10 res = exp10([2, 9]) print res
Вышеуказанная программа сгенерирует следующий вывод.
[1.00000000e+02 1.00000000e+09]
Экспоненциальная функция относительной погрешности
Синтаксис этой функции — scipy.special.exprel (x). Он генерирует экспоненциальную относительную ошибку (exp (x) — 1) / x.
Когда x близок к нулю, exp (x) близок к 1, поэтому численный расчет exp (x) — 1 может пострадать от катастрофической потери точности. Затем осуществляется exprel (x), чтобы избежать потери точности, которая возникает, когда x близок к нулю.
Давайте рассмотрим следующий пример.
from scipy.special import exprel res = exprel([-0.25, -0.1, 0, 0.1, 0.25]) print res
Вышеуказанная программа сгенерирует следующий вывод.
[0.88479687 0.95162582 1. 1.05170918 1.13610167]
Экспоненциальная функция логарифмической суммы
Синтаксис этой функции — scipy.special.logsumexp (x). Это помогает вычислить лог суммы экспонент входных элементов.
Давайте рассмотрим следующий пример.
from scipy.special import logsumexp import numpy as np a = np.arange(10) res = logsumexp(a) print res
Вышеуказанная программа сгенерирует следующий вывод.
9.45862974443
Функция Ламберта
Синтаксис этой функции — scipy.special.lambertw (x). Он также называется W-функцией Ламберта. Функция W Ламберта W (z) определяется как обратная функция от w * exp (w). Другими словами, значение W (z) таково, что z = W (z) * exp (W (z)) для любого комплексного числа z.
W-функция Ламберта — это многозначная функция с бесконечным числом ветвей. Каждая ветвь дает отдельное решение уравнения z = w exp (w). Здесь ветви индексируются целым числом k.
Давайте рассмотрим следующий пример. Здесь W-функция Ламберта является обратной к w exp (w).
from scipy.special import lambertw w = lambertw(1) print w print w * np.exp(w)
Вышеуказанная программа сгенерирует следующий вывод.
(0.56714329041+0j) (1+0j)
Перестановки и комбинации
Давайте обсудим перестановки и комбинации отдельно для их ясного понимания.
Комбинации . Синтаксис функции комбинаций — scipy.special.comb (N, k). Давайте рассмотрим следующий пример —
from scipy.special import comb res = comb(10, 3, exact = False,repetition=True) print res
Вышеуказанная программа сгенерирует следующий вывод.
220.0
Примечание. Аргументы массива принимаются только для точного = ложного случая. Если k> N, N <0 или k <0, то возвращается 0.
Перестановки . Синтаксис функции комбинаций — scipy.special.perm (N, k). Перестановки из N вещей, взятых k за раз, то есть, k-перестановок из N. Это также известно как «частичные перестановки».
Давайте рассмотрим следующий пример.
from scipy.special import perm res = perm(10, 3, exact = True) print res
Вышеуказанная программа сгенерирует следующий вывод.
720
Гамма-функция
Гамма-функцию часто называют обобщенным факториалом, поскольку z * gamma (z) = gamma (z + 1) и gamma (n + 1) = n !, для натурального числа ‘n’.
Синтаксис функции комбинаций — scipy.special.gamma (x). Перестановки из N вещей, взятых k за раз, то есть, k-перестановок из N. Это также известно как «частичные перестановки».
Синтаксис функции комбинаций — scipy.special.gamma (x). Перестановки из N вещей, взятых k за раз, то есть, k-перестановок из N. Это также известно как «частичные перестановки».
from scipy.special import gamma res = gamma([0, 0.5, 1, 5]) print res
Вышеуказанная программа сгенерирует следующий вывод.