В этой главе мы подробно разберем процесс настройки проекта для выполнения логистической регрессии в Python.
Установка Jupyter
Мы будем использовать Jupyter — одну из наиболее широко используемых платформ для машинного обучения. Если на вашем компьютере не установлен Jupyter, загрузите его отсюда . Для установки вы можете следовать инструкциям на их сайте для установки платформы. Как предполагает сайт, вы можете предпочесть использовать Anaconda Distribution, который поставляется вместе с Python, и многие обычно используемые пакеты Python для научных вычислений и обработки данных. Это избавит от необходимости устанавливать эти пакеты индивидуально.
После успешной установки Jupyter, запустите новый проект, ваш экран на этом этапе будет выглядеть следующим образом, готовым принять ваш код.
Теперь измените имя проекта с Untitled1 на «Logistic Regression» , щелкнув название заголовка и отредактировав его.
Сначала мы импортируем несколько пакетов Python, которые нам понадобятся в нашем коде.
Импорт пакетов Python
Для этого введите или вырезайте и вставляйте следующий код в редактор кода —
In [1]: # import statements import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
Ваш Блокнот должен выглядеть следующим образом на этом этапе —
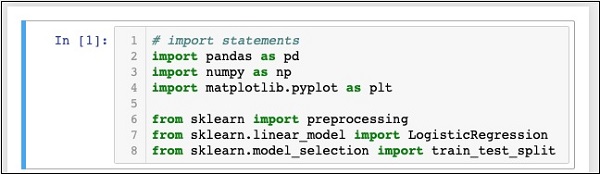
Запустите код, нажав на кнопку « Выполнить» . Если ошибки не генерируются, вы успешно установили Jupyter и теперь готовы к остальной части разработки.
Первые три оператора import импортируют пакеты pandas, numpy и matplotlib.pyplot в нашем проекте. Следующие три оператора импортируют указанные модули из sklearn.
Наша следующая задача — загрузить данные, необходимые для нашего проекта. Мы узнаем об этом в следующей главе.