Логистическая регрессия в Python — Введение
Логистическая регрессия — это статистический метод классификации объектов. В этой главе будет дано введение в логистическую регрессию с помощью нескольких примеров.
классификация
Чтобы понять логистическую регрессию, вы должны знать, что означает классификация. Давайте рассмотрим следующие примеры, чтобы понять это лучше —
- Врач классифицирует опухоль как злокачественную или доброкачественную.
- Банковская операция может быть мошеннической или подлинной.
В течение многих лет люди выполняли такие задачи — хотя они подвержены ошибкам. Вопрос в том, можем ли мы обучить машины выполнять эти задачи с большей точностью?
Одним из примеров того, как машина выполняет классификацию, является почтовый клиент на вашем компьютере, который классифицирует каждое входящее письмо как «спам» или «не спам» и делает это с довольно большой точностью. Статистический метод логистической регрессии был успешно применен в почтовом клиенте. В этом случае мы обучили нашу машину решать проблему классификации.
Логистическая регрессия — это только одна часть машинного обучения, используемая для решения этой проблемы бинарной классификации. Существует несколько других методов машинного обучения, которые уже разработаны и применяются для решения других видов проблем.
Если вы заметили, что во всех приведенных выше примерах результат предикации имеет только два значения — Да или Нет. Мы называем их классами — так сказать, мы говорим, что наш классификатор классифицирует объекты по двум классам. С технической точки зрения, мы можем сказать, что результат или целевая переменная имеет дихотомический характер.
Существуют и другие проблемы классификации, в которых выходные данные могут быть классифицированы более чем на два класса. Например, при наличии корзины с фруктами вас просят разделить фрукты разных видов. Теперь корзина может содержать апельсины, яблоки, манго и так далее. Поэтому, когда вы отделяете фрукты, вы разделяете их более чем на два класса. Это проблема многомерной классификации.
Логистическая регрессия в Python — тематическое исследование
Учтите, что банк обращается к вам с просьбой разработать приложение для машинного обучения, которое поможет им идентифицировать потенциальных клиентов, которые открывают им срочный депозит (также называемый срочным депозитом некоторыми банками). Банк регулярно проводит опрос с помощью телефонных звонков или веб-форм для сбора информации о потенциальных клиентах. Опрос носит общий характер и проводится для очень большой аудитории, из которой многие могут быть не заинтересованы в работе с этим банком. Из остальных только немногие могут быть заинтересованы в открытии Срочного депозита. Другие могут быть заинтересованы в других услугах, предлагаемых банком. Таким образом, опрос не обязательно проводится для выявления клиентов, открывающих ТД. Ваша задача — выявить всех тех клиентов, которые с высокой вероятностью открывают TD, по огромным данным опроса, которыми банк собирается поделиться с вами.
К счастью, один из таких данных общедоступен для тех, кто стремится разработать модели машинного обучения. Эти данные были подготовлены некоторыми студентами UC Irvine при внешнем финансировании. База данных доступна как часть UCI Machine Learning Repository и широко используется студентами, преподавателями и исследователями во всем мире. Данные можно скачать здесь .
В следующих главах давайте теперь выполним разработку приложения с использованием тех же данных.
Настройка проекта
В этой главе мы подробно разберем процесс настройки проекта для выполнения логистической регрессии в Python.
Установка Jupyter
Мы будем использовать Jupyter — одну из наиболее широко используемых платформ для машинного обучения. Если на вашем компьютере не установлен Jupyter, загрузите его отсюда . Для установки вы можете следовать инструкциям на их сайте для установки платформы. Как предполагает сайт, вы можете предпочесть использовать Anaconda Distribution, который поставляется вместе с Python, и многие обычно используемые пакеты Python для научных вычислений и обработки данных. Это избавит от необходимости устанавливать эти пакеты индивидуально.
После успешной установки Jupyter, запустите новый проект, ваш экран на этом этапе будет выглядеть следующим образом, готовым принять ваш код.
Теперь измените имя проекта с Untitled1 на «Logistic Regression» , щелкнув название заголовка и отредактировав его.
Сначала мы импортируем несколько пакетов Python, которые нам понадобятся в нашем коде.
Импорт пакетов Python
Для этого введите или вырезайте и вставляйте следующий код в редактор кода —
In [1]: # import statements import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split
Ваш Блокнот должен выглядеть следующим образом на этом этапе —
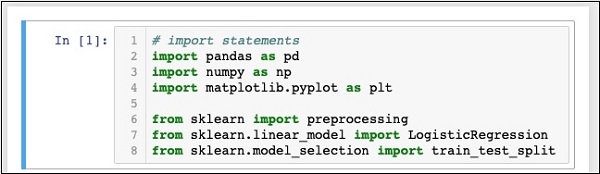
Запустите код, нажав на кнопку « Выполнить» . Если ошибки не генерируются, вы успешно установили Jupyter и теперь готовы к остальной части разработки.
Первые три оператора import импортируют пакеты pandas, numpy и matplotlib.pyplot в нашем проекте. Следующие три оператора импортируют указанные модули из sklearn.
Наша следующая задача — загрузить данные, необходимые для нашего проекта. Мы узнаем об этом в следующей главе.
Логистическая регрессия в Python — Получение данных
Этапы получения данных для выполнения логистической регрессии в Python подробно обсуждаются в этой главе.
Загрузка набора данных
Если вы еще не загрузили упомянутый ранее набор данных UCI, загрузите его сейчас отсюда . Нажмите на папку данных. Вы увидите следующий экран —

Загрузите файл bank.zip, нажав на данную ссылку. ZIP-файл содержит следующие файлы:

Мы будем использовать файл bank.csv для разработки нашей модели. Файл bank-names.txt содержит описание базы данных, которая понадобится вам позже. В файле bank-full.csv содержится гораздо больший набор данных, который вы можете использовать для более сложных разработок.
Здесь мы включили файл bank.csv в загружаемый исходный zip-архив. Этот файл содержит поля, разделенные запятыми. Мы также внесли несколько изменений в файл. Для обучения рекомендуется использовать файл, включенный в исходный zip-файл проекта.
Загрузка данных
Чтобы загрузить данные из файла CSV, который вы только что скопировали, введите следующую инструкцию и запустите код.
In [2]: df = pd.read_csv('bank.csv', header=0)
Вы также сможете проверить загруженные данные, выполнив следующую инструкцию кода:
IN [3]: df.head()
Как только команда будет запущена, вы увидите следующий вывод:
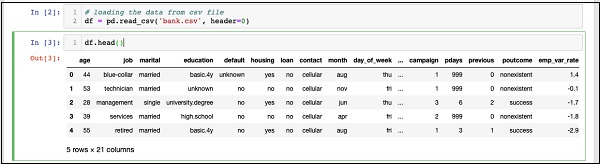
По сути, он напечатал первые пять строк загруженных данных. Изучите 21 присутствующих столбцов. Мы будем использовать только несколько столбцов из них для разработки нашей модели.
Далее нам нужно очистить данные. Данные могут содержать несколько строк с NaN . Чтобы устранить такие строки, используйте следующую команду —
IN [4]: df = df.dropna()
К счастью, bank.csv не содержит строк с NaN, поэтому в нашем случае этот шаг действительно не требуется. Тем не менее, в целом трудно обнаружить такие строки в огромной базе данных. Поэтому всегда безопаснее запускать приведенный выше оператор для очистки данных.
Примечание. Вы можете легко проверить размер данных в любой момент времени, используя следующую инструкцию:
IN [5]: print (df.shape) (41188, 21)
Количество строк и столбцов будет напечатано в выходных данных, как показано во второй строке выше.
Следующее, что нужно сделать, это изучить пригодность каждого столбца для модели, которую мы пытаемся построить.
Логистическая регрессия в Python — Реструктуризация данных
Всякий раз, когда какая-либо организация проводит опрос, она старается собрать как можно больше информации от клиента, полагая, что эта информация будет полезна для организации тем или иным способом в более поздний момент времени. Чтобы решить текущую проблему, мы должны подобрать информацию, которая имеет непосредственное отношение к нашей проблеме.
Отображение всех полей
Теперь давайте посмотрим, как выбрать полезные для нас поля данных. Запустите следующую инструкцию в редакторе кода.
In [6]: print(list(df.columns))
Вы увидите следующий вывод —
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays', 'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx', 'euribor3m', 'nr_employed', 'y']
Вывод показывает имена всех столбцов в базе данных. Последний столбец «y» представляет собой логическое значение, указывающее, имеет ли данный клиент срочный депозит в банке. Значения этого поля: «y» или «n». Вы можете прочитать описание и назначение каждого столбца в файле banks-name.txt, который был загружен как часть данных.
Устранение нежелательных полей
Изучив имена столбцов, вы узнаете, что некоторые поля не имеют значения для рассматриваемой проблемы. Например, такие поля, как месяц, day_of_week , кампания и т. Д. Нам не нужны . Мы удалим эти поля из нашей базы данных. Чтобы удалить столбец, мы используем команду сброса, как показано ниже —
In [8]: #drop columns which are not needed. df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]], axis = 1, inplace = True)
Команда говорит, что выпадающий столбец номер 0, 3, 7, 8 и т. Д. Чтобы убедиться, что индекс выбран правильно, используйте следующий оператор —
In [7]: df.columns[9] Out[7]: 'day_of_week'
Это печатает имя столбца для данного индекса.
После удаления ненужных столбцов проверьте данные с помощью оператора head. Вывод экрана показан здесь —
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1
Теперь у нас есть только те поля, которые мы считаем важными для анализа и прогнозирования данных. Важность Data Scientist проявляется на этом этапе. Специалист по данным должен выбрать соответствующие столбцы для построения модели.
Например, тип работы, хотя, на первый взгляд, может не всех убедить для включения в базу данных, это будет очень полезное поле. Не все типы клиентов будут открывать ТД. Люди с более низким доходом могут не открывать ТД, тогда как люди с более высоким доходом обычно размещают свои избыточные деньги в ТД. Таким образом, тип работы становится значимым в этом сценарии. Точно так же тщательно выберите столбцы, которые, по вашему мнению, будут иметь отношение к вашему анализу.
В следующей главе мы подготовим наши данные для построения модели.
Логистическая регрессия в Python — подготовка данных
Для создания классификатора мы должны подготовить данные в формате, который запрашивается модулем построения классификатора. Мы готовим данные, выполняя One Hot Encoding .
Кодирование данных
Мы кратко обсудим, что мы подразумеваем под кодированием данных. Во-первых, давайте запустим код. Выполните следующую команду в окне кода.
In [10]: # creating one hot encoding of the categorical columns. data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])
Как говорится в комментарии, приведенное выше утверждение создаст единственное горячее кодирование данных. Давайте посмотрим, что он создал? Изучите созданные данные, называемые «данными» , распечатав записи голов в базе данных.
In [11]: data.head()
Вы увидите следующий вывод —
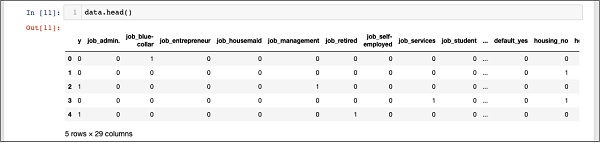
Чтобы понять вышеприведенные данные, мы перечислим имена столбцов, выполнив команду data.columns, как показано ниже —
In [12]: data.columns Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married', 'marital_single', 'marital_unknown', 'default_no', 'default_unknown', 'default_yes', 'housing_no', 'housing_unknown', 'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
Теперь мы объясним, как выполняется горячая кодировка командой get_dummies . Первый столбец во вновь сгенерированной базе данных — это поле «y», которое указывает, подписан ли этот клиент на TD или нет. Теперь давайте посмотрим на столбцы, которые закодированы. Первый закодированный столбец — «работа» . В базе данных вы обнаружите, что в столбце «работа» есть много возможных значений, таких как «администратор», «синие воротнички», «предприниматель» и т. Д. Для каждого возможного значения у нас есть новый столбец, созданный в базе данных, с именем столбца, добавленным в качестве префикса.
Таким образом, у нас есть столбцы с именами «job_admin», «job_blue-collar» и так далее. Для каждого закодированного поля в нашей исходной базе данных вы найдете список столбцов, добавленных в созданную базу данных, со всеми возможными значениями, которые столбец принимает в исходной базе данных. Внимательно изучите список столбцов, чтобы понять, как данные отображаются в новую базу данных.
Понимание сопоставления данных
Чтобы понять сгенерированные данные, давайте распечатаем все данные с помощью команды data. Частичный вывод после выполнения команды показан ниже.
In [13]: data
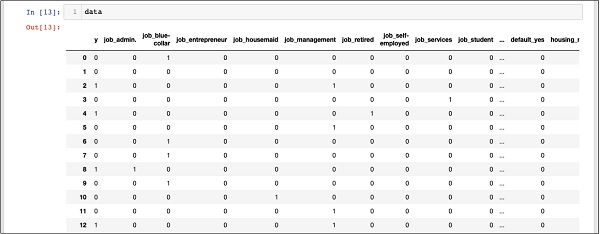
На приведенном выше экране показаны первые двенадцать строк. Если вы прокрутите вниз дальше, вы увидите, что сопоставление выполнено для всех строк.
Частичный вывод на экран ниже базы данных показан здесь для быстрого ознакомления.
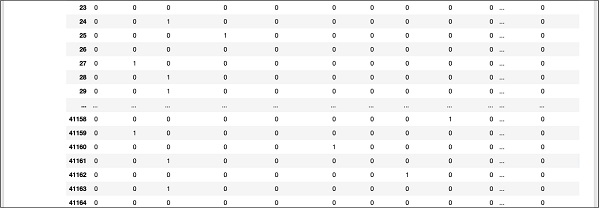
Чтобы понять сопоставленные данные, давайте рассмотрим первую строку.

Это говорит о том, что этот клиент не подписан на TD, как указано значением в поле «y». Это также указывает на то, что этот клиент является «синим воротничком». Прокручивая по горизонтали, он скажет вам, что у него есть «жилье» и он не взял «кредит».
После этого горячего кодирования нам нужно еще немного обработать данные, прежде чем мы сможем начать строить нашу модель.
Отбрасывание «неизвестного»
Если мы рассмотрим столбцы в сопоставленной базе данных, вы обнаружите наличие нескольких столбцов, оканчивающихся на «неизвестно». Например, проверьте столбец с индексом 12 с помощью следующей команды, показанной на снимке экрана:
In [14]: data.columns[12] Out[14]: 'job_unknown'
Это означает, что задание для указанного клиента неизвестно. Очевидно, что нет смысла включать такие столбцы в наш анализ и построение модели. Таким образом, все столбцы с «неизвестным» значением должны быть удалены. Это делается с помощью следующей команды —
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)
Убедитесь, что вы указали правильные номера столбцов. В случае сомнений вы можете в любое время проверить имя столбца, указав его индекс в команде столбцов, как описано ранее.
После удаления нежелательных столбцов, вы можете просмотреть окончательный список столбцов, как показано в выходных данных ниже —
In [16]: data.columns Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired', 'job_self-employed', 'job_services', 'job_student', 'job_technician', 'job_unemployed', 'marital_divorced', 'marital_married', 'marital_single', 'default_no', 'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'], dtype='object')
На данный момент наши данные готовы для построения модели.
Логистическая регрессия в Python — расщепление данных
У нас около сорока одной тысячи с лишним записей. Если мы будем использовать все данные для построения модели, у нас не останется никаких данных для тестирования. Поэтому, как правило, мы разбиваем весь набор данных на две части, скажем, 70/30 процентов. Мы используем 70% данных для построения модели, а остальные — для проверки точности прогноза нашей созданной модели. Вы можете использовать другой коэффициент разделения согласно вашему требованию.
Создание массива объектов
Перед тем, как разделить данные, мы разделяем данные на два массива X и Y. Массив X содержит все объекты (столбцы данных), которые мы хотим проанализировать, а массив Y представляет собой одномерный массив булевых значений, который является выходом прогноз. Чтобы понять это, давайте запустим некоторый код.
Во-первых, выполните следующую инструкцию Python для создания массива X —
In [17]: X = data.iloc[:,1:]
Чтобы проверить содержимое X, используйте head для печати нескольких начальных записей. На следующем экране показано содержимое массива X.
In [18]: X.head ()
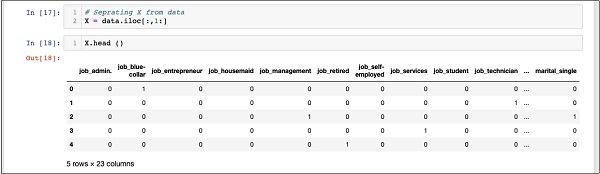
Массив имеет несколько строк и 23 столбца.
Далее мы создадим выходной массив, содержащий значения « y ».
Создание выходного массива
Чтобы создать массив для столбца с прогнозируемым значением, используйте следующую инструкцию Python —
In [19]: Y = data.iloc[:,0]
Изучите его содержимое, позвонив главе . На экране ниже показан результат —
In [20]: Y.head() Out[20]: 0 0 1 0 2 1 3 0 4 1 Name: y, dtype: int64
Теперь разделите данные с помощью следующей команды —
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
Это создаст четыре массива с именами X_train, Y_train, X_test и Y_test . Как и раньше, вы можете проверить содержимое этих массивов с помощью команды head. Мы будем использовать массивы X_train и Y_train для обучения нашей модели, а массивы X_test и Y_test — для тестирования и валидации.
Теперь мы готовы построить наш классификатор. Мы рассмотрим это в следующей главе.
Логистическая регрессия в Python — классификатор зданий
Не требуется, чтобы вы строили классификатор с нуля. Построение классификаторов является сложным и требует знания нескольких областей, таких как статистика, теории вероятностей, методы оптимизации и так далее. На рынке имеется несколько готовых библиотек, которые имеют полностью протестированную и очень эффективную реализацию этих классификаторов. Мы будем использовать одну из таких готовых моделей от sklearn .
Склеарн Классификатор
Создание классификатора логистической регрессии из набора инструментов sklearn тривиально и выполняется одним оператором программы, как показано здесь:
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)
После того, как классификатор создан, вы будете подавать свои тренировочные данные в классификатор, чтобы он мог настраивать свои внутренние параметры и быть готовым к предсказаниям ваших будущих данных. Чтобы настроить классификатор, мы запускаем следующий оператор —
In [23]: classifier.fit(X_train, Y_train)
Классификатор теперь готов к тестированию. Следующий код является результатом выполнения двух вышеприведенных операторов:
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))
Теперь мы готовы протестировать созданный классификатор. Мы рассмотрим это в следующей главе.
Логистическая регрессия в Python — Тестирование
Нам нужно протестировать созданный выше классификатор, прежде чем мы используем его в производстве. Если тестирование показывает, что модель не соответствует требуемой точности, нам придется вернуться в вышеописанном процессе, выбрать другой набор функций (поля данных), построить модель снова и протестировать ее. Это будет итеративный шаг до тех пор, пока классификатор не удовлетворит ваше требование желаемой точности. Итак, давайте проверим наш классификатор.
Прогнозирование данных испытаний
Чтобы проверить классификатор, мы используем тестовые данные, сгенерированные на более ранней стадии. Мы вызываем метод прогнозирования для созданного объекта и передаем массив X тестовых данных, как показано в следующей команде:
In [24]: predicted_y = classifier.predict(X_test)
Это создает одномерный массив для всего набора обучающих данных, дающий прогноз для каждой строки в массиве X. Вы можете проверить этот массив с помощью следующей команды —
In [25]: predicted_y
Ниже приведен результат выполнения двух вышеуказанных команд:
Out[25]: array([0, 0, 0, ..., 0, 0, 0])
Вывод показывает, что первые и последние три клиента не являются потенциальными кандидатами на срочный депозит . Вы можете изучить весь массив, чтобы отсортировать потенциальных клиентов. Для этого используйте следующий фрагмент кода Python —
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")
Результат выполнения вышеуказанного кода показан ниже —

Выходные данные показывают индексы всех строк, которые являются вероятными кандидатами для подписки на TD. Теперь вы можете передать этот вывод команде маркетинга банка, которая выберет контактную информацию для каждого клиента в выбранной строке и приступит к выполнению своей работы.
Прежде чем мы запустим эту модель в производство, нам нужно проверить точность прогноза.
Проверка точности
Чтобы проверить точность модели, используйте метод оценки на классификаторе, как показано ниже —
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))
Вывод на экран выполнения этой команды показан ниже —
Accuracy: 0.90
Это показывает, что точность нашей модели составляет 90%, что считается очень хорошим в большинстве приложений. Таким образом, дальнейшая настройка не требуется. Теперь наш клиент готов запустить следующую кампанию, получить список потенциальных клиентов и преследовать их за открытие ТД с вероятным высоким уровнем успеха.
Логистическая регрессия в Python — ограничения
Как вы видели из приведенного выше примера, применение логистической регрессии для машинного обучения не является сложной задачей. Однако это имеет свои ограничения. Логистическая регрессия не сможет обрабатывать большое количество категориальных функций. В примере, который мы обсуждали до сих пор, мы значительно сократили количество функций.
Однако, если бы эти особенности были важны в нашем прогнозе, мы были бы вынуждены включить их, но тогда логистическая регрессия не дала бы нам хорошую точность. Логистическая регрессия также уязвима для переоснащения. Это не может быть применено к нелинейной задаче. Он будет плохо работать с независимыми переменными, которые не связаны с целью и связаны друг с другом. Таким образом, вам придется тщательно оценить пригодность логистической регрессии к проблеме, которую вы пытаетесь решить.
Существует много областей машинного обучения, в которых определены другие методы. Чтобы назвать несколько, у нас есть алгоритмы, такие как k-ближайшие соседи (kNN), линейная регрессия, машины опорных векторов (SVM), деревья решений, наивный байесовский метод и так далее. Прежде чем завершить работу над конкретной моделью, вам необходимо оценить применимость этих различных методов к проблеме, которую мы пытаемся решить.
Логистическая регрессия в Python — Резюме
Логистическая регрессия — это статистический метод бинарной классификации. В этом уроке вы узнали, как обучить машину использовать логистическую регрессию. При создании моделей машинного обучения наиболее важным требованием является доступность данных. Без адекватных и релевантных данных вы не сможете просто заставить машину учиться.
Когда у вас есть данные, вашей следующей главной задачей будет очистка данных, удаление ненужных строк, полей и выбор соответствующих полей для разработки вашей модели. После того, как это сделано, вам нужно отобразить данные в формат, требуемый классификатором для его обучения. Таким образом, подготовка данных является основной задачей в любом приложении машинного обучения. Когда вы будете готовы с данными, вы можете выбрать определенный тип классификатора.
В этом руководстве вы узнали, как использовать классификатор логистической регрессии, представленный в библиотеке sklearn . Для обучения классификатора мы используем около 70% данных для обучения модели. Мы используем остальные данные для тестирования. Мы проверяем точность модели. Если это не в приемлемых пределах, мы вернемся к выбору нового набора функций.
Еще раз проследите весь процесс подготовки данных, обучите модель и протестируйте ее, пока вы не будете удовлетворены ее точностью. Прежде чем приступить к любому проекту машинного обучения, вы должны изучить и ознакомиться с широким спектром методов, которые были разработаны до настоящего времени и которые успешно применялись в отрасли.