Машинное обучение — Введение
Сегодняшний искусственный интеллект (ИИ) намного превзошел шумиху в блокчейне и квантовых вычислениях. Это связано с тем, что огромные вычислительные ресурсы легко доступны обычному человеку. Разработчики теперь используют это при создании новых моделей машинного обучения и переподготовке существующих моделей для повышения производительности и результатов. Легкая доступность высокопроизводительных вычислений (HPC) привела к внезапному увеличению спроса на ИТ-специалистов, обладающих навыками машинного обучения.
В этом уроке вы подробно узнаете о —
В чем суть машинного обучения?
-
Какие существуют виды машинного обучения?
-
Какие существуют алгоритмы для разработки моделей машинного обучения?
-
Какие инструменты доступны для разработки этих моделей?
-
Каковы варианты выбора языка программирования?
-
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
-
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
-
Как быстро улучшить свои навыки в этой важной области?
Какие существуют виды машинного обучения?
Какие существуют алгоритмы для разработки моделей машинного обучения?
Какие инструменты доступны для разработки этих моделей?
Каковы варианты выбора языка программирования?
Какие платформы поддерживают разработку и развертывание приложений машинного обучения?
Какие интегрированные среды разработки (интегрированная среда разработки) доступны?
Как быстро улучшить свои навыки в этой важной области?
Машинное обучение — что умеет сегодня ИИ?
Когда вы отмечаете лицо на фотографии в Facebook, это искусственный интеллект, который работает за кулисами и идентифицирует лица на фотографии. В некоторых приложениях тегирование лиц теперь вездесуще, и в нем отображаются изображения с человеческими лицами. Почему только человеческие лица? Существует несколько приложений, которые обнаруживают такие объекты, как кошки, собаки, бутылки, автомобили и т. Д. На наших дорогах работают автономные автомобили, которые в режиме реального времени обнаруживают объекты для управления автомобилем. Когда вы путешествуете, вы используете Google Directions, чтобы изучать ситуации с трафиком в режиме реального времени и следовать лучшему пути, предложенному Google на тот момент. Это еще одна реализация метода обнаружения объектов в реальном времени.
Давайте рассмотрим пример приложения Google Translate, которое мы обычно используем при посещении зарубежных стран. Приложение Google для онлайн-перевода на вашем мобильном телефоне поможет вам общаться с местными людьми, которые говорят на иностранном для вас языке.
Есть несколько приложений ИИ, которые мы используем практически сегодня. Фактически, каждый из нас использует ИИ во многих частях нашей жизни, даже без нашего ведома. Сегодняшний ИИ может выполнять чрезвычайно сложные задания с большой точностью и скоростью. Давайте обсудим пример сложной задачи, чтобы понять, какие возможности ожидаются в приложении для искусственного интеллекта, которое вы разрабатываете сегодня для своих клиентов.
пример
Мы все используем Google Directions во время нашей поездки в любую точку города для ежедневных поездок на работу или даже для поездок по городу. Приложение Google Directions предлагает самый быстрый путь к месту назначения в данный момент. Следуя этому пути, мы заметили, что Google почти на 100% прав в своих предложениях, и мы экономим наше драгоценное время в поездке.
Вы можете вообразить сложность, связанную с разработкой такого рода приложений, учитывая, что существует множество путей к пункту назначения, и приложение должно оценивать ситуацию с дорожным движением на каждом возможном пути, чтобы дать вам оценку времени в пути для каждого такого пути. Кроме того, учтите тот факт, что Google Directions охватывает весь земной шар. Несомненно, под капотами таких приложений используется множество методов искусственного интеллекта и машинного обучения.
Учитывая постоянную потребность в разработке таких приложений, вы теперь поймете, почему внезапно возникает потребность в ИТ-специалистах с навыками искусственного интеллекта.
В нашей следующей главе мы узнаем, что нужно для разработки программ ИИ.
Машинное обучение — традиционный ИИ
Путешествие ИИ началось в 1950-х годах, когда вычислительная мощность была незначительной по сравнению с сегодняшней. ИИ начал с прогнозов, сделанных машиной так, как статистик делает прогнозы, используя свой калькулятор. Таким образом, начальная разработка ИИ была основана главным образом на статистических методах.
В этой главе давайте обсудим подробно, что это за статистические методы.
Статистические методы
Разработка современных приложений ИИ началась с использования вековых традиционных статистических методов. Вы, должно быть, использовали прямую интерполяцию в школах, чтобы предсказать будущее значение. Существует несколько других подобных статистических методов, которые успешно применяются при разработке так называемых программ ИИ. Мы говорим «так называемые», потому что программы ИИ, которые мы имеем сегодня, намного более сложны и используют методы, намного превосходящие статистические методы, используемые в ранних программах ИИ.
Некоторые из примеров статистических методов, которые использовались для разработки приложений ИИ в те дни и все еще применяются на практике, перечислены здесь —
- регрессия
- классификация
- Кластеризация
- Теории вероятностей
- Деревья решений
Здесь мы перечислили только некоторые основные методы, которых достаточно, чтобы вы начали изучать ИИ, не пугая вас обширностью, которую требует ИИ. Если вы разрабатываете приложения ИИ на основе ограниченных данных, вы будете использовать эти статистические методы.
Однако сегодня данных в изобилии. Анализ огромных данных, которыми мы располагаем, не очень помогает, поскольку у них есть свои собственные ограничения. Поэтому для решения многих сложных проблем разрабатываются более продвинутые методы, такие как глубокое обучение.
Продвигаясь вперед в этом руководстве, мы поймем, что такое машинное обучение и как оно используется для разработки таких сложных приложений ИИ.
Машинное обучение — Что такое машинное обучение?
Рассмотрим следующий рисунок, который показывает график цен на жилье в зависимости от его размера в кв. Футах.
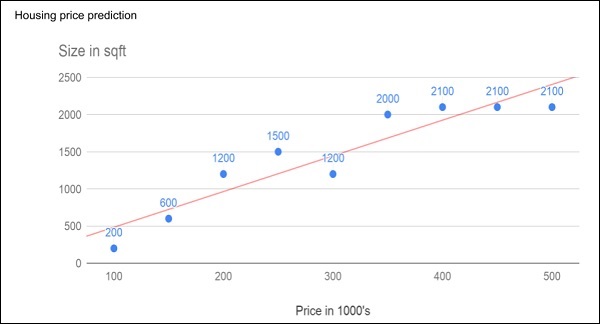
После построения различных точек данных на графике XY мы рисуем наиболее подходящую линию, чтобы сделать наши прогнозы для любого другого дома с учетом его размера. Вы передадите известные данные на машину и попросите найти линию наилучшего соответствия. Как только машина найдет наилучшую линию подгонки, вы проверите ее пригодность, введя известный размер дома, то есть значение Y на приведенной выше кривой. Теперь машина вернет приблизительное значение Х, то есть ожидаемую цену дома. Диаграмма может быть экстраполирована, чтобы узнать цену дома, который составляет 3000 кв. Футов или даже больше. Это называется регрессией в статистике. В частности, этот вид регрессии называется линейной регрессией, поскольку отношения между точками данных X & Y являются линейными.
Во многих случаях отношения между точками данных X & Y могут не быть прямой линией, и это может быть кривая со сложным уравнением. Ваша задача теперь состоит в том, чтобы найти наиболее подходящую кривую, которая может быть экстраполирована для прогнозирования будущих значений. Один такой сюжет приложения показан на рисунке ниже.
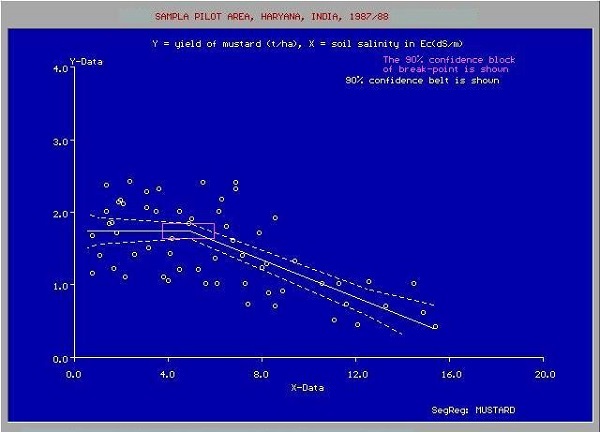
Источник:
https://upload.wikimedia.org/wikipedia/commons/c/c9/
Вы будете использовать методы статистической оптимизации, чтобы найти здесь уравнение для наилучшей кривой соответствия. И это именно то, что такое машинное обучение. Вы используете известные методы оптимизации, чтобы найти лучшее решение вашей проблемы.
Далее давайте рассмотрим различные категории машинного обучения.
Машинное обучение — Категории
Машинное обучение широко классифицируется под следующими заголовками —
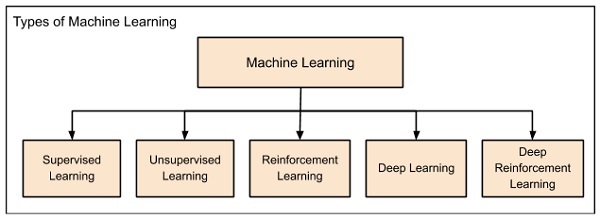
Машинное обучение развивалось слева направо, как показано на схеме выше.
-
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
-
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
-
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
-
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
-
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
-
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
-
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
-
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Первоначально исследователи начали с контролируемого обучения. Это случай прогноза цен на жилье, который обсуждался ранее.
За этим последовало неконтролируемое обучение, когда машина обучалась самостоятельно без какого-либо надзора.
Ученые также обнаружили, что это может быть хорошей идеей, чтобы вознаградить машину, когда она выполняет работу ожидаемым образом, и наступило обучение по усилению.
Очень скоро данные, доступные в наши дни, стали настолько огромными, что разработанные до сих пор традиционные методы не смогли проанализировать большие данные и дать нам прогнозы.
Таким образом, пришло глубокое понимание, где человеческий мозг моделируется в искусственных нейронных сетях (ANN), созданных в наших двоичных компьютерах.
Теперь машина учится самостоятельно, используя высокую вычислительную мощность и огромные ресурсы памяти, доступные сегодня.
В настоящее время наблюдается, что глубокое обучение решило многие из ранее неразрешимых проблем.
В настоящее время эта техника получила дальнейшее развитие, поощряя сети Deep Learning в качестве наград, и, наконец, приходит Deep Reinforcement Learning.
Давайте теперь изучим каждую из этих категорий более подробно.
Контролируемое обучение
Обучение под присмотром аналогично обучению ребенка ходить. Вы будете держать ребенка за руку, показывать ему, как сделать шаг вперед, ходить на демонстрацию и так далее, пока ребенок не научится ходить самостоятельно.
регрессия
Аналогично, в случае контролируемого обучения вы даете конкретные известные примеры компьютеру. Вы говорите, что для данного значения признака x1 выход равен y1, для x2 это y2, для x3 это y3 и так далее. Основываясь на этих данных, вы позволяете компьютеру определить эмпирические отношения между x и y.
После того, как машина обучена таким образом с достаточным количеством точек данных, теперь вы бы попросили машину предсказать Y для данного X. Предполагая, что вы знаете реальное значение Y для данного X, вы сможете вывести правильный ли прогноз машины?
Таким образом, вы будете проверять, узнал ли машина, используя известные тестовые данные. Как только вы убедитесь, что машина может делать прогнозы с желаемым уровнем точности (скажем, от 80 до 90%), вы можете прекратить дальнейшую подготовку машины.
Теперь вы можете безопасно использовать машину для прогнозирования неизвестных точек данных или попросить машину прогнозировать Y для заданного X, для которого вы не знаете действительного значения Y. Это обучение относится к регрессии, о которой мы говорили ранее.
классификация
Вы также можете использовать методы машинного обучения для задач классификации. В задачах классификации вы классифицируете объекты сходной природы в одну группу. Например, в наборе из 100 студентов вы можете сгруппировать их в три группы в зависимости от их роста — короткая, средняя и длинная. Измеряя рост каждого ученика, вы поместите их в соответствующую группу.
Теперь, когда приходит новый студент, вы поместите его в соответствующую группу, измерив его рост. Следуя принципам регрессионного обучения, вы научите машину классифицировать ученика на основе его характеристики — роста. Когда машина узнает, как формируются группы, она сможет правильно классифицировать любого неизвестного нового ученика. Еще раз, вы должны использовать данные испытаний, чтобы убедиться, что машина изучила вашу технику классификации, прежде чем запускать разработанную модель в производство.
Обучение под наблюдением — это место, где ИИ действительно начал свое путешествие. Эта методика была успешно применена в нескольких случаях. Вы использовали эту модель во время распознавания рукописного текста на своем компьютере. Для контролируемого обучения было разработано несколько алгоритмов. Вы узнаете о них в следующих главах.
Обучение без учителя
При неконтролируемом обучении мы не указываем целевую переменную для машины, а спрашиваем машину: «Что вы можете рассказать мне о X?». В частности, мы можем задавать вопросы, такие как огромный набор данных X: «Какие пять лучших групп мы можем сделать из X?» Или «Какие функции чаще всего встречаются вместе в X?». Чтобы получить ответы на такие вопросы, вы можете понять, что число точек данных, которые потребуются машине для определения стратегии, будет очень большим. В случае контролируемого обучения, машина может быть обучена даже с несколькими тысячами точек данных. Однако в случае неконтролируемого обучения количество точек данных, приемлемо приемлемых для обучения, начинается с нескольких миллионов. В наши дни данные, как правило, в изобилии доступны. Данные в идеале требуют кураторства. Тем не менее, объем данных, который непрерывно течет в социальной сети, в большинстве случаев курирование данных является невыполнимой задачей.
На следующем рисунке показана граница между желтыми и красными точками, как это определено автоматическим обучением без присмотра. Вы можете ясно видеть, что машина будет в состоянии определить класс каждой из черных точек с довольно хорошей точностью.
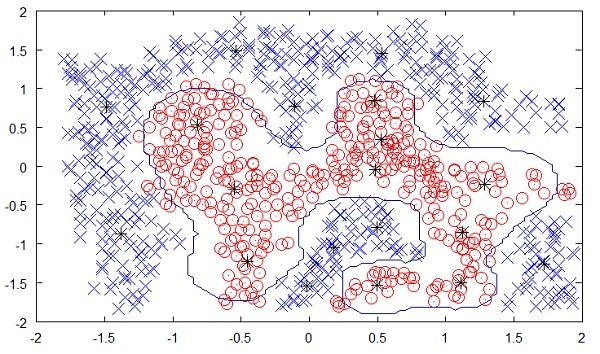
Источник:
https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Обучение без присмотра показало большой успех во многих современных приложениях ИИ, таких как обнаружение лиц, обнаружение объектов и так далее.
Усиление обучения
Подумайте над тем, чтобы дрессировать собаку, мы дрессируем ее, чтобы он приносил нам мяч. Мы бросаем мяч на определенное расстояние и просим собаку вернуть его нам. Каждый раз, когда собака делает это правильно, мы награждаем собаку. Медленно, собака узнает, что правильное выполнение работы дает ему вознаграждение, и затем собака начинает выполнять работу правильно каждый раз в будущем. Именно эта концепция применяется в обучении типа «Укрепление». Техника изначально была разработана для машин, чтобы играть в игры. У машины есть алгоритм для анализа всех возможных ходов на каждом этапе игры. Машина может выбрать один из ходов наугад. Если ход правильный, машина вознаграждена, в противном случае она может быть оштрафована. Постепенно машина начнет различать правильные и неправильные ходы и после нескольких итераций научится решать головоломку с большей точностью. Точность выигрыша в игре улучшится, когда машина будет играть все больше и больше игр.
Весь процесс может быть изображен на следующей диаграмме —
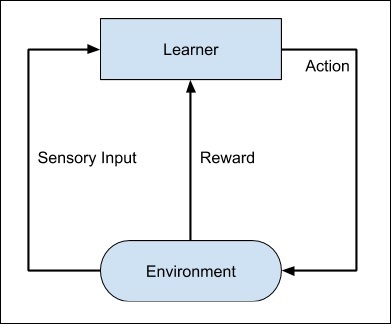
Этот метод машинного обучения отличается от контролируемого обучения тем, что вам не нужно снабжать помеченные пары ввода / вывода. Основное внимание уделяется поиску баланса между изучением новых решений и использованием изученных решений.
Глубокое обучение
Глубокое обучение — это модель, основанная на искусственных нейронных сетях (ANN), более конкретно, на сверточных нейронных сетях (CNN). Есть несколько архитектур, используемых в глубоком обучении, таких как глубокие нейронные сети, сети глубокого убеждения, рекуррентные нейронные сети и сверточные нейронные сети.
Эти сети успешно применяются для решения проблем компьютерного зрения, распознавания речи, обработки естественного языка, биоинформатики, разработки лекарств, анализа медицинских изображений и игр. Есть несколько других областей, в которых глубокое обучение активно применяется. Глубокое обучение требует огромной вычислительной мощности и огромных данных, которые обычно легко доступны в наши дни.
Мы поговорим о глубоком изучении более подробно в следующих главах.
Глубокое обучение
Глубокое обучение с подкреплением (DRL) сочетает в себе методы глубокого и подкрепляющего обучения. Алгоритмы обучения с подкреплением, такие как Q-learning, теперь сочетаются с глубоким обучением для создания мощной модели DRL. Техника была с большим успехом в области робототехники, видеоигр, финансов и здравоохранения. Многие ранее неразрешимые проблемы теперь решаются путем создания моделей DRL. В этой области ведется множество исследований, и отрасль очень активно этим занимается.
Пока у вас есть краткое введение в различные модели машинного обучения, а теперь давайте немного углубимся в различные алгоритмы, доступные в этих моделях.
Машинное обучение — под наблюдением
Контролируемое обучение является одной из важных моделей обучения, связанных с обучением машин. В этой главе подробно говорится о том же.
Алгоритмы для контролируемого обучения
Есть несколько алгоритмов, доступных для контролируемого обучения. Некоторые из широко используемых алгоритмов контролируемого обучения, как показано ниже —
- k-Ближайшие соседи
- Деревья решений
- Наивный байесовский
- Логистическая регрессия
- Опорные векторные машины
По мере продвижения в этой главе давайте поговорим подробно о каждом из алгоритмов.
k-Ближайшие соседи
K-Ближайшие соседи, которые просто называются kNN, — это статистический метод, который можно использовать для решения задач классификации и регрессии. Давайте обсудим случай классификации неизвестного объекта с использованием kNN. Рассмотрим распределение объектов, как показано на рисунке ниже —
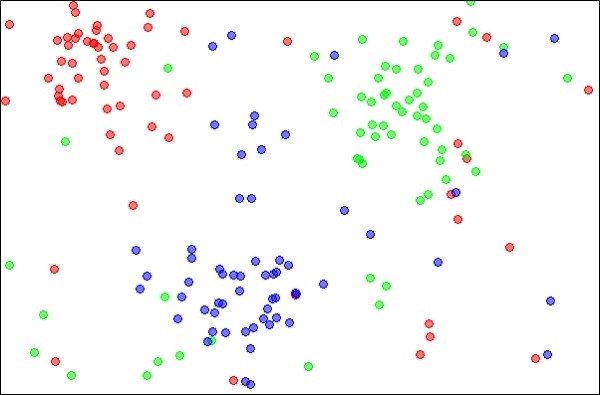
Источник:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Диаграмма показывает три типа объектов, отмеченных красным, синим и зеленым цветами. Когда вы запустите классификатор kNN в указанном наборе данных, границы для каждого типа объекта будут отмечены, как показано ниже —
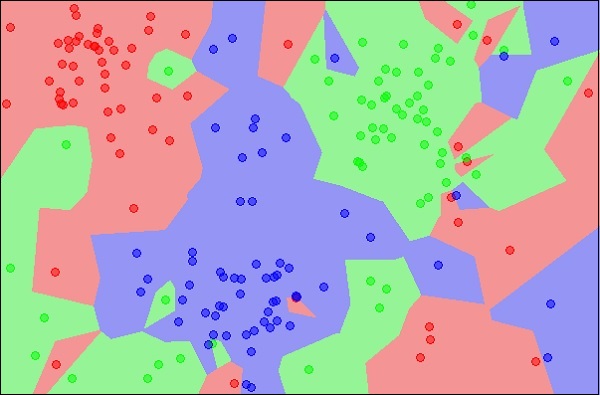
Источник:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Теперь рассмотрим новый неизвестный объект, который вы хотите классифицировать как красный, зеленый или синий. Это изображено на рисунке ниже.
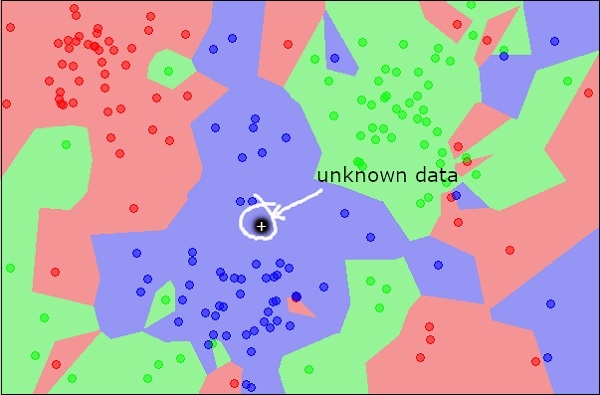
Как вы видите, неизвестная точка данных принадлежит классу синих объектов. Математически это можно сделать путем измерения расстояния этой неизвестной точки до каждой другой точки в наборе данных. Когда вы сделаете это, вы узнаете, что большинство его соседей имеют синий цвет. Среднее расстояние до красных и зеленых объектов будет определенно больше, чем среднее расстояние до синих объектов. Таким образом, этот неизвестный объект может быть классифицирован как принадлежащий к синему классу.
Алгоритм kNN также может использоваться для задач регрессии. Алгоритм kNN доступен как готовый к использованию в большинстве библиотек ML.
Деревья решений
Простое дерево решений в формате блок-схемы показано ниже —
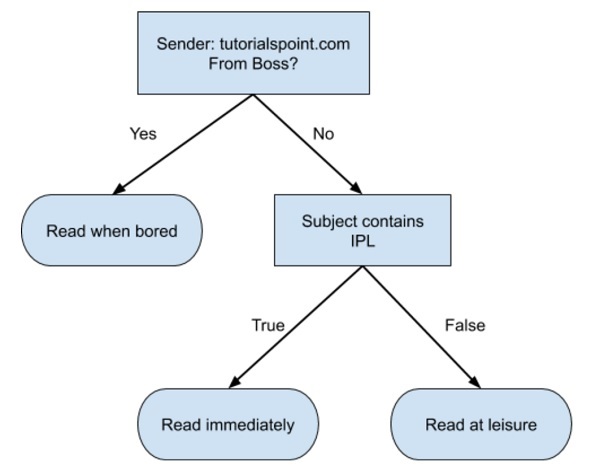
Вы бы написали код для классификации ваших входных данных на основе этой блок-схемы. Блок-схема не требует пояснений и тривиальна. В этом сценарии вы пытаетесь классифицировать входящее письмо, чтобы решить, когда его читать.
В действительности деревья решений могут быть большими и сложными. Есть несколько алгоритмов, доступных для создания и обхода этих деревьев. Как энтузиаст машинного обучения, вы должны понять и освоить эти методы создания и обхода деревьев решений.
Наивный байесовский
Наивный Байес используется для создания классификаторов. Предположим, вы хотите отсортировать (классифицировать) фрукты разных видов из корзины с фруктами. Вы можете использовать такие функции, как цвет, размер и форма фрукта. Например, любой фрукт красного цвета, круглой формы и диаметром около 10 см может рассматриваться как яблоко. Таким образом, для обучения модели вы должны использовать эти функции и проверить вероятность того, что данный объект соответствует желаемым ограничениям. Вероятности различных функций затем объединяются, чтобы получить вероятность того, что данный фрукт является яблоком. Наивный байесовский метод обычно требует небольшого количества обучающих данных для классификации.
Логистическая регрессия
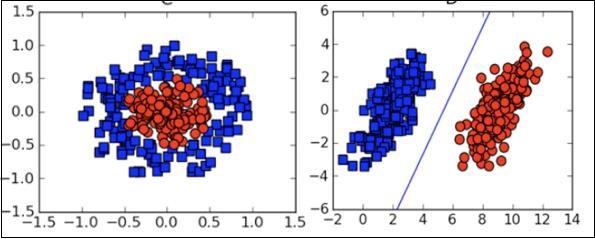
Посмотрите на следующую диаграмму. Показывает распределение точек данных в плоскости XY.
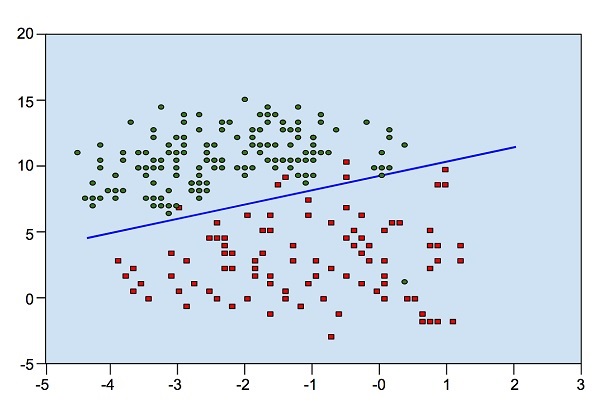
Из диаграммы мы можем визуально осмотреть отделение красных точек от зеленых точек. Вы можете нарисовать границу, чтобы отделить эти точки. Теперь, чтобы классифицировать новую точку данных, вам просто нужно определить, на какой стороне линии находится точка.
Опорные векторные машины
Посмотрите на следующее распределение данных. Здесь три класса данных не могут быть линейно разделены. Граничные кривые являются нелинейными. В таком случае поиск уравнения кривой становится сложной задачей.
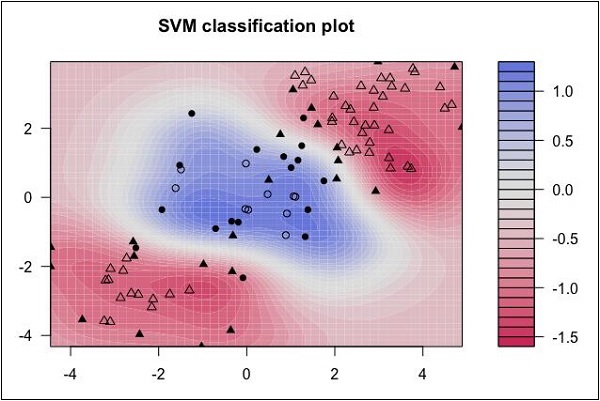
Источник: http://uc-r.github.io/svm
Машины опорных векторов (SVM) пригодятся для определения границ разделения в таких ситуациях.
Машинное обучение — алгоритм Scikit-learn
К счастью, в большинстве случаев вам не нужно кодировать алгоритмы, упомянутые в предыдущем уроке. Существует много стандартных библиотек, которые обеспечивают готовую реализацию этих алгоритмов. Одним из таких инструментов, который обычно используется, является scikit-learn. На рисунке ниже показаны алгоритмы, доступные для использования в этой библиотеке.
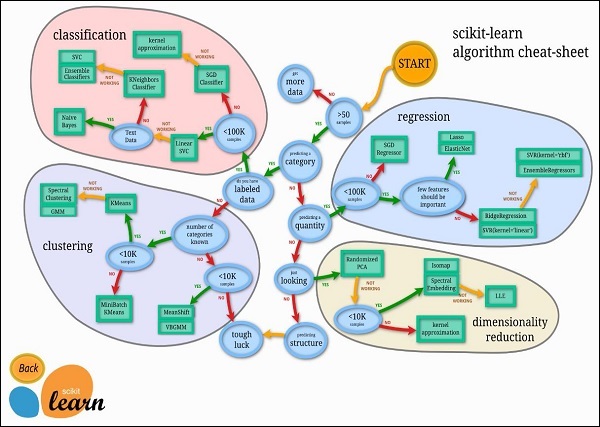
Источник: https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Использование этих алгоритмов тривиально, и, поскольку они хорошо протестированы на практике, вы можете безопасно использовать их в своих приложениях ИИ. Большинство из этих библиотек могут свободно использовать даже в коммерческих целях.
Машинное обучение — без присмотра
Пока что вы видели, как заставить машину научиться находить решение для нашей цели. В регрессии мы обучаем машину предсказывать будущее значение. При классификации мы обучаем машину классифицировать неизвестный объект в одной из определенных нами категорий. Короче говоря, мы обучали машины так, чтобы они могли прогнозировать Y для наших данных X. Учитывая огромный набор данных и не оценивая категории, нам было бы трудно обучить машину, используя контролируемое обучение. Что если машина может искать и анализировать большие данные, занимающие несколько гигабайт и терабайт, и сообщать нам, что эти данные содержат так много разных категорий?
В качестве примера рассмотрим данные избирателя. Рассматривая некоторые входные данные от каждого избирателя (это называется особенностями в терминологии ИИ), позвольте машине предсказать, что есть так много избирателей, которые проголосовали бы за X политическую партию, и так много проголосовало бы за Y, и так далее. Таким образом, в общем, мы запрашиваем у машины огромный набор точек данных X: «Что вы можете рассказать мне о X?». Или это может быть вопрос типа «Какие пять лучших групп мы можем сделать из X?». Или это может быть даже похоже на «Какие три функции чаще всего встречаются вместе в X?».
Это как раз и есть самообучаемое обучение.
Алгоритмы для обучения без учителя
Давайте теперь обсудим один из широко используемых алгоритмов классификации в неконтролируемом машинном обучении.
К-среднее кластеризация
Президентские выборы 2000 и 2004 годов в Соединенных Штатах были близкими — очень близкими. Самый большой процент голосов избирателей, полученных любым кандидатом, составлял 50,7%, а самый низкий — 47,9%. Если бы процент избирателей перешел на другую сторону, исход выборов был бы другим. Есть небольшие группы избирателей, которые при правильном обращении перейдут на другую сторону. Эти группы могут быть не очень большими, но с такими близкими расами они могут быть достаточно большими, чтобы изменить исход выборов. Как вы находите эти группы людей? Как вы обращаетесь к ним с ограниченным бюджетом? Ответ кластеризация.
Давайте разберемся, как это делается.
-
Во-первых, вы собираете информацию о людях как с их согласия, так и без него: любую информацию, которая может дать некоторое представление о том, что для них важно и что повлияет на их голосование.
-
Затем вы помещаете эту информацию в какой-то алгоритм кластеризации.
-
Далее, для каждого кластера (было бы разумно сначала выбрать самый большой), вы создаете сообщение, которое понравится этим избирателям.
-
Наконец, вы проводите кампанию и измеряете, работает ли она.
Во-первых, вы собираете информацию о людях как с их согласия, так и без него: любую информацию, которая может дать некоторое представление о том, что для них важно и что повлияет на их голосование.
Затем вы помещаете эту информацию в какой-то алгоритм кластеризации.
Далее, для каждого кластера (было бы разумно сначала выбрать самый большой), вы создаете сообщение, которое понравится этим избирателям.
Наконец, вы проводите кампанию и измеряете, работает ли она.
Кластеризация — это разновидность обучения без присмотра, которое автоматически формирует кластеры похожих вещей. Это как автоматическая классификация. Вы можете кластеризовать практически все, и чем больше элементов в кластере схожи, тем лучше кластеры. В этой главе мы собираемся изучить один тип алгоритма кластеризации, который называется k-means. Он называется k-means, поскольку он находит «k» уникальных кластеров, а центр каждого кластера является средним значением в этом кластере.
Идентификация кластера
Идентификация кластера говорит алгоритму: «Вот некоторые данные. Теперь сгруппируйте похожие вещи и расскажите мне об этих группах ». Ключевое отличие от классификации в том, что в классификации вы знаете, что ищете. Пока дело не в кластеризации.
Кластеризацию иногда называют неконтролируемой классификацией, потому что она дает тот же результат, что и классификация, но без наличия предопределенных классов.
Теперь мы довольны как контролируемым, так и неконтролируемым обучением. Чтобы понять остальные категории машинного обучения, мы должны сначала понять Искусственные нейронные сети (ANN), которые мы изучим в следующей главе.
Машинное обучение — искусственные нейронные сети
Идея искусственных нейронных сетей была получена из нейронных сетей в человеческом мозге. Человеческий мозг действительно сложен. Тщательно изучая мозг, ученые и инженеры придумали архитектуру, которая могла бы вписаться в наш цифровой мир бинарных компьютеров. Одна такая типичная архитектура показана на диаграмме ниже —
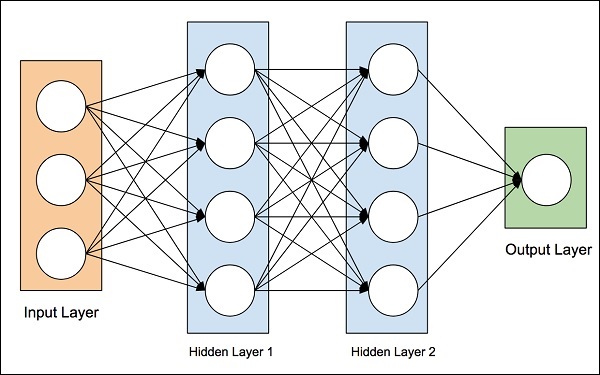
Существует входной слой, который имеет много датчиков для сбора данных из внешнего мира. Справа у нас есть выходной слой, который дает нам прогнозируемый сетью результат. Между этими двумя скрыты несколько слоев. Каждый дополнительный уровень добавляет дополнительную сложность в обучении сети, но обеспечит лучшие результаты в большинстве ситуаций. Существует несколько типов архитектур, которые мы сейчас обсудим.
АНН Архитектур
Диаграмма ниже показывает несколько архитектур ANN, разработанных за определенный период времени и применяемых сегодня.
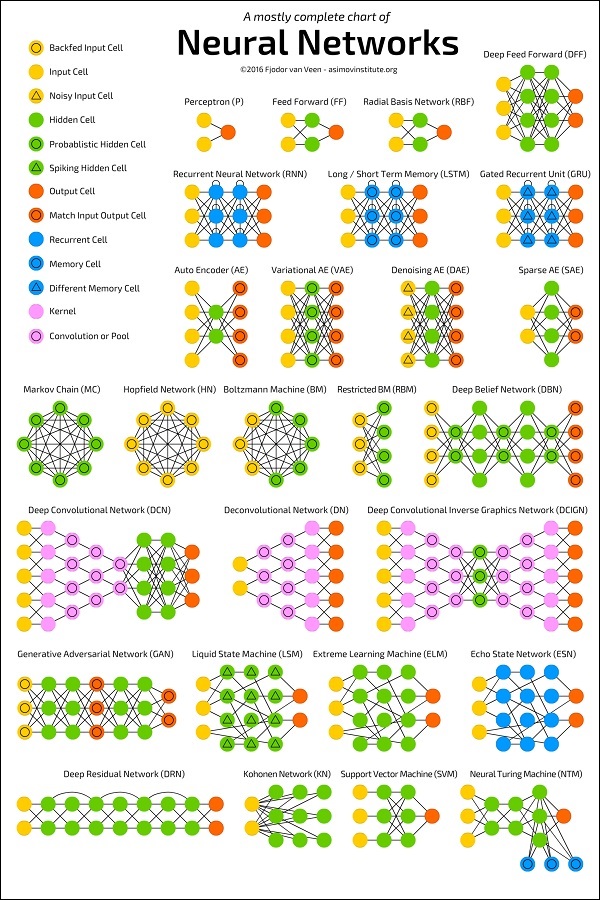
Источник:
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
Каждая архитектура разработана для конкретного типа приложения. Таким образом, когда вы используете нейронную сеть для своего приложения машинного обучения, вам придется использовать либо одну из существующих архитектур, либо разрабатывать свою собственную. Тип приложения, с которым вы окончательно определитесь, зависит от потребностей вашего приложения. Не существует единого руководства, которое бы указывало на использование конкретной сетевой архитектуры.
Машинное обучение — глубокое обучение
Глубокое обучение использует ANN. Сначала мы рассмотрим несколько приложений глубокого обучения, которые дадут вам представление о его силе.
Приложения
Глубокое обучение показало большой успех в нескольких областях применения машинного обучения.
Автомобили с самостоятельным вождением — в автономных автомобилях с автономным управлением используются методы глубокого обучения Как правило, они адаптируются к постоянно меняющимся дорожным ситуациям и становятся все лучше и лучше за время вождения.
Распознавание речи — еще одно интересное приложение Deep Learning — распознавание речи. Сегодня мы все используем несколько мобильных приложений, способных распознавать нашу речь. Siri от Apple, Alexa от Amazon, Microsoft Cortena и Google Assistant — все они используют методы глубокого обучения.
Мобильные приложения. Мы используем несколько веб-приложений и мобильных приложений для организации наших фотографий. Обнаружение лица, идентификация лица, маркировка лица, идентификация объектов на изображении — все это требует глубокого изучения.
Неиспользованные возможности глубокого обучения
Взглянув на огромный успех, достигнутый приложениями глубокого обучения во многих областях, люди начали изучать другие области, где машинное обучение пока не применялось. Есть несколько областей, в которых методы глубокого обучения успешно применяются, и есть много других областей, которые могут быть использованы. Некоторые из них обсуждаются здесь.
-
Сельское хозяйство является одной из таких отраслей, где люди могут применять методы глубокого обучения для повышения урожайности.
-
Потребительское финансирование является еще одной областью, где машинное обучение может в значительной степени помочь в раннем обнаружении мошенничества и анализе платежеспособности клиента.
-
Методы глубокого обучения также применяются в области медицины для создания новых лекарств и предоставления индивидуального рецепта пациенту.
Сельское хозяйство является одной из таких отраслей, где люди могут применять методы глубокого обучения для повышения урожайности.
Потребительское финансирование является еще одной областью, где машинное обучение может в значительной степени помочь в раннем обнаружении мошенничества и анализе платежеспособности клиента.
Методы глубокого обучения также применяются в области медицины для создания новых лекарств и предоставления индивидуального рецепта пациенту.
Возможности бесконечны, и нужно постоянно наблюдать, как часто появляются новые идеи и разработки.
Что требуется для достижения большего с помощью глубокого обучения
Чтобы использовать глубокое обучение, суперкомпьютерная мощность является обязательным требованием. Вам нужны как память, так и процессор для разработки моделей глубокого обучения. К счастью, сегодня у нас есть легкая доступность высокопроизводительных вычислений. Благодаря этому разработка приложений для глубокого обучения, о которых мы упоминали выше, стала реальностью сегодня, и в будущем мы также сможем увидеть приложения в тех неиспользованных областях, которые мы обсуждали ранее.
Теперь мы рассмотрим некоторые ограничения глубокого обучения, которые мы должны рассмотреть, прежде чем использовать его в нашем приложении для машинного обучения.
Недостатки глубокого обучения
Некоторые из важных моментов, которые вы должны рассмотреть, прежде чем использовать глубокое обучение, перечислены ниже —
- Подход черного ящика
- Продолжительность разработки
- Количество данных
- Вычислительно дорого
Теперь мы подробно изучим каждое из этих ограничений.
Подход черного ящика
ANN похож на черный ящик. Вы даете ему определенный вклад, и он предоставит вам конкретный вывод. На следующей диаграмме показано одно из таких приложений, в котором вы передаете изображение животного в нейронную сеть, и оно говорит о том, что это изображение собаки.
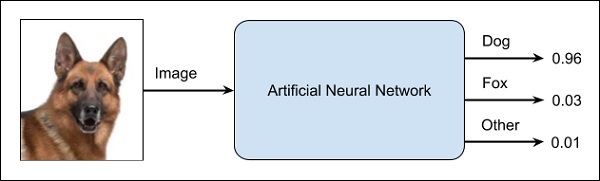
Почему этот подход называется «черным ящиком», вы не знаете, почему сеть дала определенный результат. Вы не знаете, как в сети пришли к выводу, что это собака? Теперь рассмотрим банковское приложение, в котором банк хочет решить вопрос кредитоспособности клиента. Сеть обязательно даст вам ответ на этот вопрос. Однако сможете ли вы оправдать это для клиента? Банки должны объяснить своим клиентам, почему кредит не санкционирован?
Продолжительность разработки
Процесс обучения нейронной сети изображен на диаграмме ниже —
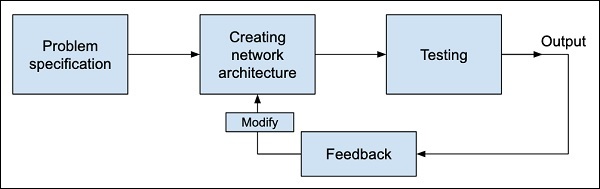
Сначала вы определяете проблему, которую хотите решить, создаете для нее спецификацию, выбираете входные функции, проектируете сеть, разворачиваете ее и тестируете выходные данные. Если результат не соответствует ожиданиям, примите это как обратную связь для реструктуризации сети. Это итеративный процесс, и может потребоваться несколько итераций, пока сеть времени не будет полностью обучена для получения желаемых результатов.
Количество данных
Сети глубокого обучения обычно требуют огромного количества данных для обучения, в то время как традиционные алгоритмы машинного обучения могут быть с большим успехом использованы даже с несколькими тысячами точек данных. К счастью, обилие данных растет на 40% в год, а мощность процессора увеличивается на 20% в год, как показано на диаграмме, приведенной ниже —
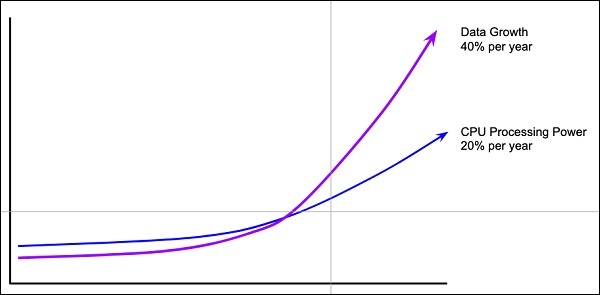
Вычислительно дорого
Обучение нейронной сети требует в несколько раз большей вычислительной мощности, чем требуется для запуска традиционных алгоритмов. Для успешного обучения глубоких нейронных сетей может потребоваться несколько недель тренировочного времени.
В отличие от этого, традиционные алгоритмы машинного обучения занимают всего несколько минут / часов. Кроме того, объем вычислительной мощности, необходимой для обучения глубокой нейронной сети, сильно зависит от размера ваших данных, а также от того, насколько глубока и сложна сеть?
После обзора того, что такое машинное обучение, его возможностей, ограничений и приложений, давайте теперь углубимся в изучение «машинного обучения».
Машинное обучение — навыки
Машинное обучение имеет очень большую ширину и требует навыков в нескольких областях. Навыки, которые вам необходимо приобрести, чтобы стать экспертом в области машинного обучения, перечислены ниже —
- Статистика
- Теории вероятностей
- Исчисление
- Методы оптимизации
- Визуализация
Необходимость различных навыков машинного обучения
Чтобы дать вам краткое представление о том, какие навыки вам необходимо приобрести, давайте обсудим несколько примеров:
Математическая запись
Большинство алгоритмов машинного обучения в значительной степени основаны на математике. Уровень математики, который вам нужно знать, вероятно, только начальный уровень. Важно то, что вы должны быть в состоянии прочитать обозначения, которые математики используют в своих уравнениях. Например — если вы можете прочитать нотацию и понять, что это значит, вы готовы к обучению машинному обучению. Если нет, возможно, вам придется освежить свои знания по математике.
f_ {AN} (net- \ theta) = \ begin {case} \ gamma & if \: net- \ theta \ geq \ epsilon \\ net- \ theta & if — \ epsilon <net- \ theta <\ epsilon \\ — \ gamma & if \: net- \ theta \ leq- \ epsilon \ end {case}
displaystyle max limit alpha beginbmatrix displaystyle sum limitmi=1 alpha− frac12 displaystyle sum limitmi,j=1метка left( beginarrayci endarray right) cdotметка left( beginarraycj endarray right) cdotai cdotaj langlex left( beginarrayci endarray справа),x left( beginarraycj endarray right) rangle endbmatrix
fAN(net− тета)= влево( гидроразрывае Lambda(net− тета)−е− Lambda(net− тета)е лямбда(net− тета)+е− Lambda(net− тета) справа)
Теория вероятности
Вот пример, чтобы проверить ваши текущие знания теории вероятностей: Классификация с условными вероятностями.
р(Cя|х,у) = гидроразрывар(х,у|Cг)р(Cя)р(х,у)
С помощью этих определений мы можем определить правило байесовской классификации —
- Если P (c1 | x, y)> P (c2 | x, y), класс c1.
- Если P (c1 | x, y) <P (c2 | x, y), класс c2.
Задача оптимизации
Вот функция оптимизации
displaystyle max limit alpha beginbmatrix displaystyle sum limitmi=1 alpha− frac12 displaystyle sum limitmi,j=1метка left( beginarrayci endarray right) cdotметка left( beginarraycj endarray right) cdotai cdotaj langlex left( beginarrayci endarray справа),x left( beginarraycj endarray right) rangle endbmatrix
С учетом следующих ограничений —
alpha geq0и displaystyle sum limitmi−1 alphai cdotметка left( beginarrayci endмассив справа)=0
Если вы можете прочитать и понять вышеизложенное, у вас все настроено.
Визуализация
Во многих случаях вам нужно будет понимать различные типы графиков визуализации, чтобы понять распределение ваших данных и интерпретировать результаты вывода алгоритма.
Помимо вышеупомянутых теоретических аспектов машинного обучения, вам нужны хорошие навыки программирования для написания этих алгоритмов.
Так что же нужно для реализации ML? Давайте посмотрим на это в следующей главе.
Машинное обучение — внедрение
Для разработки ML-приложений вам нужно будет выбрать платформу, IDE и язык разработки. Есть несколько вариантов. Большинство из них легко удовлетворят ваши требования, поскольку все они обеспечивают реализацию алгоритмов ИИ, которые обсуждались до сих пор.
Если вы разрабатываете алгоритм ML самостоятельно, необходимо внимательно изучить следующие аспекты:
Язык по вашему выбору — это, по сути, ваше знание одного из языков, поддерживаемых в разработке ML.
IDE, которую вы используете — это будет зависеть от вашего знакомства с существующими IDE и вашего уровня комфорта.
Платформа разработки. Существует несколько платформ для разработки и развертывания. Большинство из них бесплатны для использования. В некоторых случаях вам может потребоваться оплатить лицензионный сбор сверх определенного объема использования. Вот краткий список выбора языков, IDE и платформ для вашего удобства.
Выбор языка
Вот список языков, которые поддерживают разработку ML —
- питон
- р
- Matlab
- октава
- Юля
- C ++
- С
Этот список не является по сути полным; тем не менее, он охватывает многие популярные языки, используемые в разработке машинного обучения. В зависимости от вашего уровня комфорта выберите язык для разработки, разработайте свои модели и протестируйте.
Иды
Вот список IDE, которые поддерживают разработку ML —
- R Studio
- PyCharm
- iPython / Jupyter Notebook
- Юля
- Spyder
- анаконда
- Родео
- Google -Colab
Приведенный выше список не является исчерпывающим. У каждого есть свои достоинства и недостатки. Читателю рекомендуется опробовать эти различные IDE, прежде чем сужаться до одной.
платформы
Вот список платформ, на которых могут быть развернуты ML-приложения:
- IBM
- Microsoft Azure
- Google Cloud
- Амазонка
- Mlflow
Еще раз этот список не является исчерпывающим. Читателю рекомендуется подписаться на вышеупомянутые услуги и попробовать их самостоятельно.
Машинное обучение — Заключение
Этот учебник познакомил вас с машинным обучением. Теперь вы знаете, что машинное обучение — это техника обучения машин для выполнения действий, которые может выполнять человеческий мозг, хотя и немного быстрее и лучше, чем обычный человек. Сегодня мы увидели, что машины могут побеждать чемпионов-людей в таких играх, как Шахматы, AlphaGO, которые считаются очень сложными. Вы видели, что машины могут быть обучены выполнять деятельность человека в нескольких областях и могут помочь людям жить лучше.
Машинное обучение может быть контролируемым или неконтролируемым. Если у вас есть меньше данных и четко обозначенные данные для обучения, выберите «Обучение под наблюдением». Обучение без учителя обычно дает лучшую производительность и результаты для больших наборов данных. Если у вас есть огромный набор данных, легко доступных, используйте методы глубокого обучения. Вы также изучили обучение по усилению и глубокому обучению. Теперь вы знаете, что такое нейронные сети, их приложения и ограничения.
Наконец, когда речь заходит о разработке собственных моделей машинного обучения, вы рассматриваете выбор различных языков разработки, IDE и платформ. Следующее, что вам нужно сделать, это начать изучать и практиковать каждую технику машинного обучения. Тема обширна, это означает, что есть ширина, но если учесть глубину, каждая тема может быть изучена в течение нескольких часов. Каждая тема не зависит друг от друга. Вы должны принимать во внимание одну тему за раз, изучать ее, практиковать ее и реализовывать алгоритмы в ней, используя выбранный вами язык. Это лучший способ начать изучение машинного обучения. Практикуя одну тему за раз, очень скоро вы приобретете ширину, которая в конечном итоге требуется специалисту по машинному обучению.
Удачи!