ТИКА — Обзор
Apache Tika — это библиотека, которая используется для обнаружения типов документов и извлечения контента из различных форматов файлов.
Внутренне, Tika использует существующие различные анализаторы документов и методы обнаружения типов документов для обнаружения и извлечения данных.
Используя Tika, можно разработать универсальный детектор типов и экстрактор контента для извлечения как структурированного текста, так и метаданных из различных типов документов, таких как электронные таблицы, текстовые документы, изображения, PDF-файлы и даже мультимедийные форматы ввода в определенной степени.
Тика предоставляет единый универсальный API для анализа файлов разных форматов. Он использует существующие специализированные библиотеки синтаксического анализатора для каждого типа документа.
Все эти библиотеки синтаксического анализатора инкапсулированы в единый интерфейс, называемый интерфейсом Parser .
Согласно filext.com, существует от 15 до 51 тысяч типов контента, и это число растет день ото дня. Данные хранятся в различных форматах, таких как текстовые документы, электронные таблицы Excel, PDF-файлы, изображения и мультимедийные файлы. Поэтому приложения, такие как поисковые системы и системы управления контентом, нуждаются в дополнительной поддержке для простого извлечения данных из этих типов документов. Apache Tika служит этой цели, предоставляя универсальный API для поиска и извлечения данных из нескольких форматов файлов.
Приложения Apache Tika
Существуют различные приложения, которые используют Apache Tika. Здесь мы обсудим несколько важных приложений, которые сильно зависят от Apache Tika.
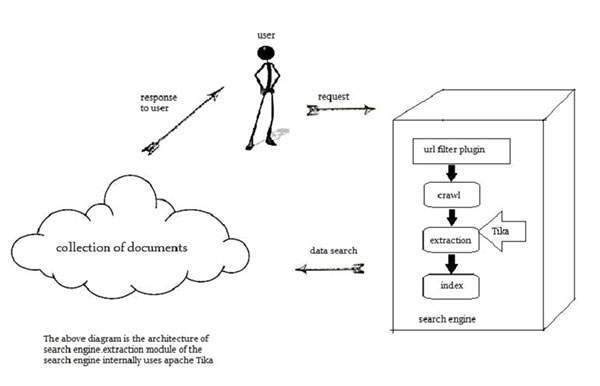
Поисковые системы
Тика широко используется при разработке поисковых систем для индексирования текстового содержимого цифровых документов.
-
Поисковые системы — это системы обработки информации, предназначенные для поиска информации и индексированных документов из Интернета.
-
Crawler является важным компонентом поисковой системы, которая сканирует через Интернет для извлечения документов, которые должны быть проиндексированы с использованием некоторой техники индексации. После этого искатель передает эти проиндексированные документы в компонент извлечения.
-
Обязанность компонента извлечения заключается в извлечении текста и метаданных из документа. Такой извлеченный контент и метаданные очень полезны для поисковой системы. Этот компонент извлечения содержит Tika.
-
Извлеченный контент затем передается в индексатор поисковой системы, которая использует его для создания поискового индекса. Помимо этого, поисковая система использует извлеченный контент и во многих других отношениях.
Поисковые системы — это системы обработки информации, предназначенные для поиска информации и индексированных документов из Интернета.
Crawler является важным компонентом поисковой системы, которая сканирует через Интернет для извлечения документов, которые должны быть проиндексированы с использованием некоторой техники индексации. После этого искатель передает эти проиндексированные документы в компонент извлечения.
Обязанность компонента извлечения заключается в извлечении текста и метаданных из документа. Такой извлеченный контент и метаданные очень полезны для поисковой системы. Этот компонент извлечения содержит Tika.
Извлеченный контент затем передается в индексатор поисковой системы, которая использует его для создания поискового индекса. Помимо этого, поисковая система использует извлеченный контент и во многих других отношениях.
Анализ документов
-
В области искусственного интеллекта существуют определенные инструменты для автоматического анализа документов на семантическом уровне и извлечения из них всех видов данных.
-
В таких приложениях документы классифицируются на основе видных терминов в извлеченном содержании документа.
-
Эти инструменты используют Tika для извлечения контента для анализа документов от простого текста до цифровых документов.
В области искусственного интеллекта существуют определенные инструменты для автоматического анализа документов на семантическом уровне и извлечения из них всех видов данных.
В таких приложениях документы классифицируются на основе видных терминов в извлеченном содержании документа.
Эти инструменты используют Tika для извлечения контента для анализа документов от простого текста до цифровых документов.
Управление цифровыми активами
-
Некоторые организации управляют своими цифровыми активами, такими как фотографии, электронные книги, рисунки, музыка и видео, используя специальное приложение, известное как управление цифровыми активами (DAM).
-
Такие приложения используют детекторы типов документов и экстрактор метаданных для классификации различных документов.
Некоторые организации управляют своими цифровыми активами, такими как фотографии, электронные книги, рисунки, музыка и видео, используя специальное приложение, известное как управление цифровыми активами (DAM).
Такие приложения используют детекторы типов документов и экстрактор метаданных для классификации различных документов.
Анализ содержания
-
Такие сайты, как Amazon, рекомендуют только что опубликованное содержимое своего сайта отдельным пользователям в соответствии с их интересами. Для этого эти веб-сайты следуют методам машинного обучения или используют веб-сайты социальных сетей, такие как Facebook, для получения необходимой информации, такой как лайки и интересы пользователей. Эта собранная информация будет в форме HTML-тегов или других форматов, которые требуют дальнейшего обнаружения и извлечения типов контента.
-
Для анализа содержимого документа у нас есть технологии, которые реализуют методы машинного обучения, такие как UIMA и Mahout . Эти технологии полезны при кластеризации и анализе данных в документах.
-
Apache Mahout — это фреймворк, который предоставляет алгоритмы ML на Apache Hadoop — платформе облачных вычислений. Mahout предоставляет архитектуру, следуя определенным методам кластеризации и фильтрации. Следуя этой архитектуре, программисты могут писать свои собственные алгоритмы ML для выработки рекомендаций, используя различные комбинации текста и метаданных. Чтобы предоставить входные данные для этих алгоритмов, последние версии Mahout используют Tika для извлечения текста и метаданных из двоичного содержимого.
-
Apache UIMA анализирует и обрабатывает различные языки программирования и создает аннотации UIMA. Внутренне он использует Tika Annotator для извлечения текста и метаданных документа.
Такие сайты, как Amazon, рекомендуют только что опубликованное содержимое своего сайта отдельным пользователям в соответствии с их интересами. Для этого эти веб-сайты следуют методам машинного обучения или используют веб-сайты социальных сетей, такие как Facebook, для получения необходимой информации, такой как лайки и интересы пользователей. Эта собранная информация будет в форме HTML-тегов или других форматов, которые требуют дальнейшего обнаружения и извлечения типов контента.
Для анализа содержимого документа у нас есть технологии, которые реализуют методы машинного обучения, такие как UIMA и Mahout . Эти технологии полезны при кластеризации и анализе данных в документах.
Apache Mahout — это фреймворк, который предоставляет алгоритмы ML на Apache Hadoop — платформе облачных вычислений. Mahout предоставляет архитектуру, следуя определенным методам кластеризации и фильтрации. Следуя этой архитектуре, программисты могут писать свои собственные алгоритмы ML для выработки рекомендаций, используя различные комбинации текста и метаданных. Чтобы предоставить входные данные для этих алгоритмов, последние версии Mahout используют Tika для извлечения текста и метаданных из двоичного содержимого.
Apache UIMA анализирует и обрабатывает различные языки программирования и создает аннотации UIMA. Внутренне он использует Tika Annotator для извлечения текста и метаданных документа.
история
| Год | развитие |
|---|---|
| 2006 | Идея Тики была представлена в комитете по управлению проектами Lucene. |
| 2006 | Была обсуждена концепция Tika и ее полезность в проекте Jackrabbit. |
| 2007 | Тика вошла в апачский инкубатор. |
| 2008 | Были выпущены версии 0.1 и 0.2, и Тика вышла из инкубатора в подпроект Lucene. |
| 2009 | Версии 0.3, 0.4 и 0.5 были выпущены. |
| 2010 | Были выпущены версии 0.6 и 0.7, и Тика перешла в проект Apache верхнего уровня. |
| 2011 | Тика 1.0 была выпущена, и книга о Тике «Тика в действии» также была выпущена в том же году. |
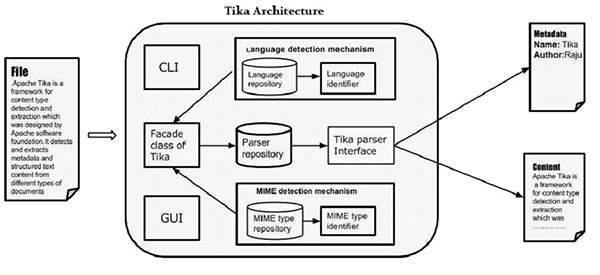
ТИКА — Архитектура
Архитектура уровня приложения Тика
Прикладные программисты могут легко интегрировать Tika в свои приложения. Тика предоставляет интерфейс командной строки и графический интерфейс, чтобы сделать его удобным для пользователя.
В этой главе мы обсудим четыре важных модуля, составляющих архитектуру Tika. На следующем рисунке показана архитектура Tika с четырьмя модулями:
- Механизм определения языка.
- Механизм обнаружения MIME.
- Интерфейс парсера.
- Тика Фасадный класс.
Механизм обнаружения языка
Всякий раз, когда текстовый документ передается в Tika, он определяет язык, на котором он был написан. Он принимает документы без языковой аннотации и добавляет эту информацию в метаданные документа, определяя язык.
Для поддержки идентификации языка в пакете org.apache.tika.language у Tika есть класс с именем Language Identifier , а внутри — хранилище идентификации языка, содержащее алгоритмы определения языка по заданному тексту. Тика внутренне использует алгоритм N-граммы для определения языка.
Механизм обнаружения MIME
Тика может определить тип документа в соответствии со стандартами MIME. Обнаружение типа MIME по умолчанию в Tika выполняется с использованием org.apache.tika.mime.mimeTypes . Он использует интерфейс org.apache.tika.detect.Detector для определения большинства типов контента.
Внутренне Tika использует несколько техник, таких как глобусы файлов, подсказки типа контента, магические байты, кодировки символов и несколько других техник.
Интерфейс парсера
Интерфейс парсера org.apache.tika.parser является ключевым интерфейсом для анализа документов в Tika. Этот интерфейс извлекает текст и метаданные из документа и суммирует их для внешних пользователей, которые готовы писать плагины анализатора.
Используя различные конкретные классы анализаторов, специфичные для отдельных типов документов, Tika поддерживает множество форматов документов. Эти классы, специфичные для формата, обеспечивают поддержку различных форматов документов, либо непосредственно реализуя логику синтаксического анализатора, либо используя внешние библиотеки синтаксического анализатора.
Тика Фасад Класс
Использование класса фасадов Tika — это самый простой и прямой способ вызова Tika из Java, который следует шаблону дизайна фасада. Вы можете найти класс фасадов Tika в пакете org.apache.tika API Tika.
Реализуя базовые сценарии использования, Tika выступает в роли посредника в ландшафте. Он абстрагирует основную сложность библиотеки Tika, такую как механизм обнаружения MIME, интерфейс синтаксического анализатора и механизм обнаружения языка, и предоставляет пользователям простой в использовании интерфейс.
Особенности Тика
-
Унифицированный интерфейс синтаксического анализатора — Tika инкапсулирует все сторонние библиотеки синтаксического анализатора в единый интерфейс синтаксического анализатора. Благодаря этой функции пользователь избавляется от необходимости выбирать подходящую библиотеку синтаксического анализатора и использовать ее в соответствии с типом найденного файла.
-
Низкое использование памяти — Tika потребляет меньше ресурсов памяти, поэтому ее легко встраивать в приложения Java. Мы также можем использовать Tika в приложении, которое работает на платформах с меньшими ресурсами, таких как мобильный КПК.
-
Быстрая обработка — можно ожидать быстрого обнаружения контента и извлечения из приложений.
-
Гибкие метаданные — Tika понимает все модели метаданных, которые используются для описания файлов.
-
Интеграция парсера — Tika может использовать различные библиотеки парсеров, доступные для каждого типа документа в одном приложении.
-
Обнаружение типов MIME — Tika может обнаруживать и извлекать контент из всех типов носителей, включенных в стандарты MIME.
-
Определение языка — Tika включает функцию идентификации языка, поэтому может использоваться в документах, основанных на типе языка, на многоязычных веб-сайтах.
Унифицированный интерфейс синтаксического анализатора — Tika инкапсулирует все сторонние библиотеки синтаксического анализатора в единый интерфейс синтаксического анализатора. Благодаря этой функции пользователь избавляется от необходимости выбирать подходящую библиотеку синтаксического анализатора и использовать ее в соответствии с типом найденного файла.
Низкое использование памяти — Tika потребляет меньше ресурсов памяти, поэтому ее легко встраивать в приложения Java. Мы также можем использовать Tika в приложении, которое работает на платформах с меньшими ресурсами, таких как мобильный КПК.
Быстрая обработка — можно ожидать быстрого обнаружения контента и извлечения из приложений.
Гибкие метаданные — Tika понимает все модели метаданных, которые используются для описания файлов.
Интеграция парсера — Tika может использовать различные библиотеки парсеров, доступные для каждого типа документа в одном приложении.
Обнаружение типов MIME — Tika может обнаруживать и извлекать контент из всех типов носителей, включенных в стандарты MIME.
Определение языка — Tika включает функцию идентификации языка, поэтому может использоваться в документах, основанных на типе языка, на многоязычных веб-сайтах.
Функциональные возможности Тика
Тика поддерживает различные функции —
- Определение типа документа
- Извлечение контента
- Извлечение метаданных
- Определение языка
Определение типа документа
Тика использует различные методы обнаружения и определяет тип документа, переданного ей.

Извлечение контента
Тика имеет библиотеку синтаксического анализатора, которая может анализировать содержимое документов различных форматов и извлекать их. После определения типа документа он выбирает соответствующий анализатор из хранилища анализатора и передает документ. Различные классы Tika имеют методы для анализа различных форматов документов.

Извлечение метаданных
Наряду с контентом, Tika извлекает метаданные документа с помощью той же процедуры, что и при извлечении контента. Для некоторых типов документов в Tika есть классы для извлечения метаданных.

Обнаружение языка
Внутренне Tika использует алгоритмы, такие как n-грамм, для определения языка содержимого в данном документе. Тика зависит от классов, таких как Languageidentifier и Profiler для идентификации языка.
ТИКА — Окружающая среда
В этой главе рассказывается, как настроить Apache Tika для Windows и Linux. Администрация пользователя необходима при установке Apache Tika.
Системные Требования
| JDK | Java SE 2 JDK 1.6 или выше |
| объем памяти | 1 ГБ ОЗУ (рекомендуется) |
| Дисковое пространство | Нет минимальных требований |
| Версия операционной системы | Windows XP или выше, Linux |
Шаг 1. Проверка установки Java
Чтобы проверить установку Java, откройте консоль и выполните следующую команду Java .
| Операционные системы | задача | команда |
|---|---|---|
| Windows | Открыть командную консоль | \> Java-версия |
| Linux | Открыть командный терминал | $ java – версия |
Если Java правильно установлена в вашей системе, вы должны получить один из следующих выводов, в зависимости от платформы, на которой вы работаете.
| Операционные системы | Выход |
|---|---|
| Windows |
Java версия «1.7.0_60» Среда выполнения Java (TM) SE (сборка 1.7.0_60-b19) 64-разрядная серверная виртуальная машина Java Hotspot (TM) (сборка 24.60-b09, смешанный режим) |
| Lunix |
Java-версия «1.7.0_25» Открытая среда выполнения JDK (rhel-2.3.10.4.el6_4-x86_64) Откройте виртуальную машину 64-разрядного сервера JDK (сборка 23.7-b01, смешанный режим) |
Java версия «1.7.0_60»
Среда выполнения Java (TM) SE (сборка 1.7.0_60-b19)
64-разрядная серверная виртуальная машина Java Hotspot (TM) (сборка 24.60-b09, смешанный режим)
Java-версия «1.7.0_25»
Открытая среда выполнения JDK (rhel-2.3.10.4.el6_4-x86_64)
Откройте виртуальную машину 64-разрядного сервера JDK (сборка 23.7-b01, смешанный режим)
-
Мы предполагаем, что читатели этого учебного пособия установили Java 1.7.0_60 в своей системе, прежде чем приступить к этому учебному пособию.
-
Если у вас нет Java SDK, загрузите его текущую версию с https://www.oracle.com/technetwork/java/javase/downloads/index.html и установите его .
Мы предполагаем, что читатели этого учебного пособия установили Java 1.7.0_60 в своей системе, прежде чем приступить к этому учебному пособию.
Если у вас нет Java SDK, загрузите его текущую версию с https://www.oracle.com/technetwork/java/javase/downloads/index.html и установите его .
Шаг 2: настройка среды Java
Установите переменную среды JAVA_HOME, чтобы она указывала на местоположение базовой директории, где установлена Java на вашем компьютере. Например,
| Операционные системы | Выход |
|---|---|
| Windows | Установите переменную среды JAVA_HOME в C: \ ProgramFiles \ java \ jdk1.7.0_60 |
| Linux | экспорт JAVA_HOME = / usr / local / java-current |
Добавьте полный путь расположения компилятора Java к системному пути.
| Операционные системы | Выход |
|---|---|
| Windows | Добавить строку; C: \ Program Files \ Java \ jdk1.7.0_60 \ bin до конца системной переменной PATH. |
| Linux | экспорт PATH = $ PATH: $ JAVA_HOME / bin / |
Проверьте команду java-version из командной строки, как описано выше.
Шаг 3: Настройка среды Apache Tika
Программисты могут интегрировать Apache Tika в свою среду, используя
- Командная строка,
- Тика API,
- Интерфейс командной строки (CLI) Тика,
- Графический интерфейс пользователя (GUI) Tika, или
- исходный код.
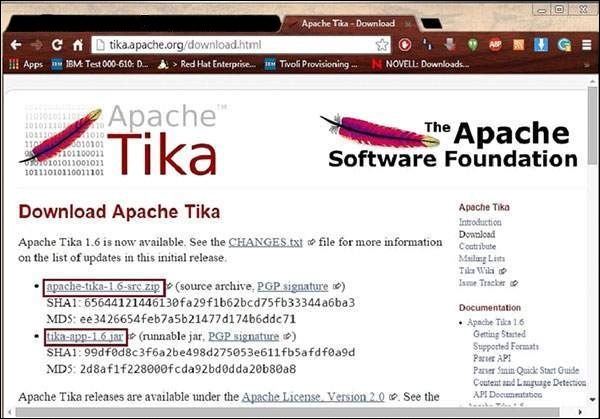
Для любого из этих подходов, прежде всего, вам необходимо скачать исходный код Tika.
Вы найдете исходный код Tika по адресу https://Tika.apache.org/download.html, где вы найдете две ссылки:
-
apache-tika-1.6-src.zip — содержит исходный код Тики и
-
Tika -app-1.6.jar — это файл jar, содержащий приложение Tika.
apache-tika-1.6-src.zip — содержит исходный код Тики и
Tika -app-1.6.jar — это файл jar, содержащий приложение Tika.
Загрузите эти два файла. Снимок официального сайта Tika показан ниже.
После загрузки файлов установите classpath для файла jar tika-app-1.6.jar . Добавьте полный путь к файлу JAR, как показано в таблице ниже.
| Операционные системы | Выход |
|---|---|
| Windows | Добавьте строку «C: \ jars \ Tika-app-1.6.jar» к пользовательской переменной среды CLASSPATH. |
| Linux |
Экспортировать CLASSPATH = $ CLASSPATH — /usr/share/jars/Tika-app-1.6.tar — |
Экспортировать CLASSPATH = $ CLASSPATH —
/usr/share/jars/Tika-app-1.6.tar —
Apache предоставляет приложение Tika, приложение с графическим интерфейсом пользователя (GUI), использующее Eclipse.
Tika-Maven Build с использованием Eclipse
-
Откройте затмение и создайте новый проект.
-
Если у вас нет Maven в Eclipse, настройте его, следуя приведенным ниже инструкциям.
-
Откройте ссылку https://wiki.eclipse.org/M2E_updatesite_and_gittags . Там вы найдете релизы плагинов m2e в табличном формате
-
Откройте затмение и создайте новый проект.
Если у вас нет Maven в Eclipse, настройте его, следуя приведенным ниже инструкциям.
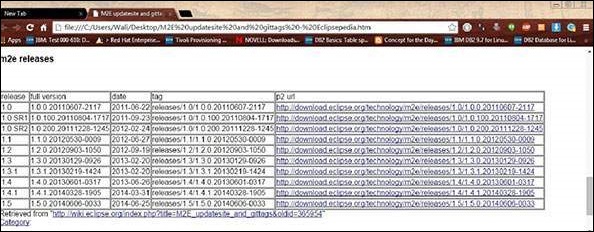
Откройте ссылку https://wiki.eclipse.org/M2E_updatesite_and_gittags . Там вы найдете релизы плагинов m2e в табличном формате
-
Выберите последнюю версию и сохраните путь URL в столбце p2 url.
-
Теперь вернитесь к eclipse, в строке меню нажмите « Справка» и выберите « Установить новое программное обеспечение» в раскрывающемся меню.
Выберите последнюю версию и сохраните путь URL в столбце p2 url.
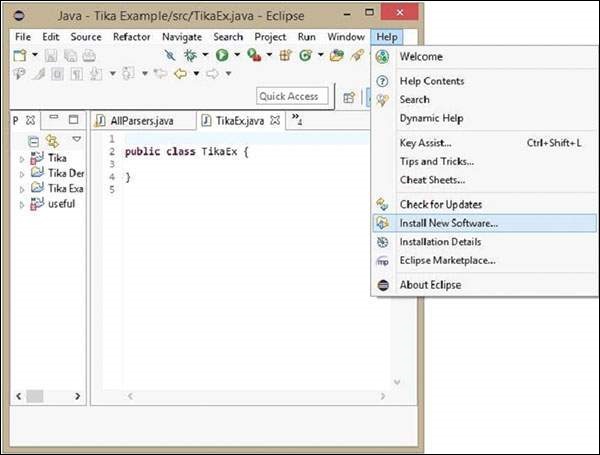
Теперь вернитесь к eclipse, в строке меню нажмите « Справка» и выберите « Установить новое программное обеспечение» в раскрывающемся меню.
-
Нажмите кнопку Добавить , введите любое желаемое имя, так как оно необязательно. Теперь вставьте сохраненный URL в поле Location .
-
Будет добавлен новый плагин с именем, выбранным на предыдущем шаге, установите флажок перед ним и нажмите « Далее» .
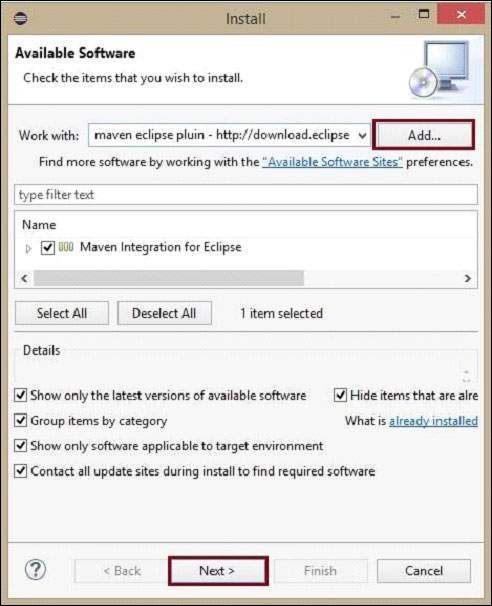
Нажмите кнопку Добавить , введите любое желаемое имя, так как оно необязательно. Теперь вставьте сохраненный URL в поле Location .
Будет добавлен новый плагин с именем, выбранным на предыдущем шаге, установите флажок перед ним и нажмите « Далее» .
-
Продолжить установку. После завершения перезапустите Eclipse.
-
Теперь щелкните правой кнопкой мыши по проекту и в параметре конфигурации выберите « Преобразовать в проект Maven» .
-
Появится новый мастер для создания нового пом. Введите идентификатор группы как org.apache.tika, введите последнюю версию Tika, выберите упаковку в виде банки и нажмите « Готово» .
Продолжить установку. После завершения перезапустите Eclipse.
Теперь щелкните правой кнопкой мыши по проекту и в параметре конфигурации выберите « Преобразовать в проект Maven» .
Появится новый мастер для создания нового пом. Введите идентификатор группы как org.apache.tika, введите последнюю версию Tika, выберите упаковку в виде банки и нажмите « Готово» .
Проект Maven успешно установлен, а ваш проект преобразован в Maven. Теперь вам нужно настроить файл pom.xml.
Настройте файл XML
Получите зависимость Tika Maven от https://mvnrepository.com/artifact/org.apache.tika
Ниже показана полная зависимость Apache Tika от Maven.
<dependency> <groupId>org.apache.Tika</groupId> <artifactId>Tika-core</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> <artifactId> Tika-parsers</artifactId> <version> 1.6</version> <groupId> org.apache.Tika</groupId> <artifactId>Tika</artifactId> <version>1.6</version> <groupId>org.apache.Tika</groupId> < artifactId>Tika-serialization</artifactId> < version>1.6< /version> < groupId>org.apache.Tika< /groupId> < artifactId>Tika-app< /artifactId> < version>1.6< /version> <groupId>org.apache.Tika</groupId> <artifactId>Tika-bundle</artifactId> <version>1.6</version> </dependency>
TIKA — ссылочный API
Пользователи могут встраивать Tika в свои приложения, используя класс фасадов Tika. У этого есть методы, чтобы исследовать все функциональные возможности Тики. Поскольку это класс фасадов, Tika раскрывает сложность своих функций. В дополнение к этому пользователи могут также использовать различные классы Tika в своих приложениях.
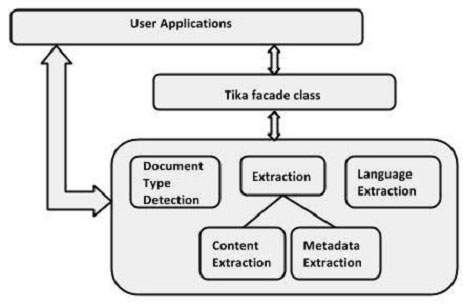
Тика Класс (фасад)
Это самый выдающийся класс библиотеки Тика, который следует шаблону оформления фасада. Поэтому он абстрагирует все внутренние реализации и предоставляет простые методы для доступа к функциям Tika. В следующей таблице перечислены конструкторы этого класса вместе с их описаниями.
пакет — org.apache.tika
класс — тика
| Sr.No. | Конструктор и описание |
|---|---|
| 1 |
Тика () Использует конфигурацию по умолчанию и создает класс Tika. |
| 2 |
Тика (детектор детектор) Создает фасад Tika, принимая экземпляр детектора в качестве параметра |
| 3 |
Тика (детектор детектор, парсер парсер) Создает фасад Tika, принимая экземпляры детектора и анализатора в качестве параметров. |
| 4 |
Тика (Детектор детектор, Парсер парсер, Переводчик переводчик) Создает фасад Tika, принимая в качестве параметров детектор, анализатор и экземпляр транслятора. |
| 5 |
Тика (конфиг TikaConfig) Создает фасад Tika, принимая объект класса TikaConfig в качестве параметра. |
Тика ()
Использует конфигурацию по умолчанию и создает класс Tika.
Тика (детектор детектор)
Создает фасад Tika, принимая экземпляр детектора в качестве параметра
Тика (детектор детектор, парсер парсер)
Создает фасад Tika, принимая экземпляры детектора и анализатора в качестве параметров.
Тика (Детектор детектор, Парсер парсер, Переводчик переводчик)
Создает фасад Tika, принимая в качестве параметров детектор, анализатор и экземпляр транслятора.
Тика (конфиг TikaConfig)
Создает фасад Tika, принимая объект класса TikaConfig в качестве параметра.
Методы и описание
Ниже приведены важные методы класса фасадов Тика —
| Sr.No. | Методы и описание |
|---|---|
| 1 |
анализ ToString ( файл файла) Этот метод и все его варианты анализируют файл, переданный в качестве параметра, и возвращают извлеченное текстовое содержимое в формате String. По умолчанию длина этого строкового параметра ограничена. |
| 2 |
int getMaxStringLength () Возвращает максимальную длину строк, возвращаемых методами parseToString. |
| 3 |
void setMaxStringLength (int maxStringLength) Устанавливает максимальную длину строк, возвращаемых методами parseToString. |
| 4 |
Считывание читателя ( файл файла) Этот метод и все его варианты анализируют файл, переданный в качестве параметра, и возвращают извлеченное текстовое содержимое в виде объекта java.io.reader. |
| 5 |
Обнаружение строки (поток InputStream , метаданные метаданных) Этот метод и все его варианты принимают объект InputStream и объект Metadata в качестве параметров, определяют тип данного документа и возвращают имя типа документа как объект String. Этот метод абстрагирует механизмы обнаружения, используемые Tika. |
| 6 |
Строковый перевод ( InputStream text, String targetLanguage) Этот метод и все его варианты принимают объект InputStream и строку, представляющую язык, на который мы хотим, чтобы наш текст был переведен, и переводит данный текст на нужный язык, пытаясь автоматически определить исходный язык. |
анализ ToString ( файл файла)
Этот метод и все его варианты анализируют файл, переданный в качестве параметра, и возвращают извлеченное текстовое содержимое в формате String. По умолчанию длина этого строкового параметра ограничена.
int getMaxStringLength ()
Возвращает максимальную длину строк, возвращаемых методами parseToString.
void setMaxStringLength (int maxStringLength)
Устанавливает максимальную длину строк, возвращаемых методами parseToString.
Считывание читателя ( файл файла)
Этот метод и все его варианты анализируют файл, переданный в качестве параметра, и возвращают извлеченное текстовое содержимое в виде объекта java.io.reader.
Обнаружение строки (поток InputStream , метаданные метаданных)
Этот метод и все его варианты принимают объект InputStream и объект Metadata в качестве параметров, определяют тип данного документа и возвращают имя типа документа как объект String. Этот метод абстрагирует механизмы обнаружения, используемые Tika.
Строковый перевод ( InputStream text, String targetLanguage)
Этот метод и все его варианты принимают объект InputStream и строку, представляющую язык, на который мы хотим, чтобы наш текст был переведен, и переводит данный текст на нужный язык, пытаясь автоматически определить исходный язык.
Интерфейс парсера
Это интерфейс, который реализован всеми классами анализатора пакета Tika.
пакет — org.apache.tika.parser
Интерфейс — Парсер
Методы и описание
Ниже приводится важный метод интерфейса Tika Parser.
| Sr.No. | Методы и описание |
|---|---|
| 1 |
анализ (поток InputStream, обработчик ContentHandler, метаданные метаданных, контекст ParseContext) Этот метод анализирует данный документ в последовательность событий XHTML и SAX. После анализа он помещает извлеченное содержимое документа в объект класса ContentHandler, а метаданные — в объект класса Metadata. |
анализ (поток InputStream, обработчик ContentHandler, метаданные метаданных, контекст ParseContext)
Этот метод анализирует данный документ в последовательность событий XHTML и SAX. После анализа он помещает извлеченное содержимое документа в объект класса ContentHandler, а метаданные — в объект класса Metadata.
Класс метаданных
Этот класс реализует различные интерфейсы, такие как CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys, Serializable для поддержки различных моделей данных. В следующих таблицах перечислены конструкторы и методы этого класса вместе с их описаниями.
пакет — org.apache.tika.metadata
класс — Метаданные
| Sr.No. | Конструктор и описание |
|---|---|
| 1 |
Метаданные () Создает новые пустые метаданные. |
Метаданные ()
Создает новые пустые метаданные.
| Sr.No. | Методы и описание |
|---|---|
| 1 |
add (свойство property, строковое значение) Добавляет отображение свойства / значения метаданных в данный документ. Используя эту функцию, мы можем установить значение для свойства. |
| 2 |
добавить (имя строки, значение строки) Добавляет отображение свойства / значения метаданных в данный документ. Используя этот метод, мы можем установить новое значение имени для существующих метаданных документа. |
| 3 |
Строка get (Собственность) Возвращает значение (если есть) указанного свойства метаданных. |
| 4 |
Строка получить (имя строки) Возвращает значение (если есть) заданного имени метаданных. |
| 5 |
Дата getDate (Свойство собственности) Возвращает значение свойства метаданных Date. |
| 6 |
String [] getValues (Свойство собственности) Возвращает все значения свойства метаданных. |
| 7 |
String [] getValues (имя строки) Возвращает все значения заданного имени метаданных. |
| 8 |
Строка [] names () Возвращает все имена элементов метаданных в объекте метаданных. |
| 9 |
set (свойство собственности, дата дата) Устанавливает значение даты для данного свойства метаданных |
| 10 |
set (свойство property, значения String []) Устанавливает несколько значений для свойства метаданных. |
add (свойство property, строковое значение)
Добавляет отображение свойства / значения метаданных в данный документ. Используя эту функцию, мы можем установить значение для свойства.
добавить (имя строки, значение строки)
Добавляет отображение свойства / значения метаданных в данный документ. Используя этот метод, мы можем установить новое значение имени для существующих метаданных документа.
Строка get (Собственность)
Возвращает значение (если есть) указанного свойства метаданных.
Строка получить (имя строки)
Возвращает значение (если есть) заданного имени метаданных.
Дата getDate (Свойство собственности)
Возвращает значение свойства метаданных Date.
String [] getValues (Свойство собственности)
Возвращает все значения свойства метаданных.
String [] getValues (имя строки)
Возвращает все значения заданного имени метаданных.
Строка [] names ()
Возвращает все имена элементов метаданных в объекте метаданных.
set (свойство собственности, дата дата)
Устанавливает значение даты для данного свойства метаданных
set (свойство property, значения String [])
Устанавливает несколько значений для свойства метаданных.
Класс идентификатора языка
Этот класс определяет язык данного контента. В следующих таблицах перечислены конструкторы этого класса вместе с их описаниями.
пакет — org.apache.tika.language
класс — Идентификатор языка
| Sr.No. | Конструктор и описание |
|---|---|
| 1 |
LanguageIdentifier (профиль LanguageProfile) Создает идентификатор языка. Здесь вы должны передать объект LanguageProfile в качестве параметра. |
| 2 |
LanguageIdentifier (Строковый контент) Этот конструктор может создавать идентификатор языка, передавая строку из текстового содержимого. |
LanguageIdentifier (профиль LanguageProfile)
Создает идентификатор языка. Здесь вы должны передать объект LanguageProfile в качестве параметра.
LanguageIdentifier (Строковый контент)
Этот конструктор может создавать идентификатор языка, передавая строку из текстового содержимого.
| Sr.No. | Методы и описание |
|---|---|
| 1 |
Строка getLanguage () Возвращает язык, данный текущему объекту LanguageIdentifier. |
Строка getLanguage ()
Возвращает язык, данный текущему объекту LanguageIdentifier.
TIKA — Форматы файлов
Форматы файлов, поддерживаемые Tika
В следующей таблице приведены форматы файлов, которые поддерживает Tika.
| Формат файла | Библиотека пакетов | Класс в тике |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html и использует библиотеку Tagsoup | HTMLparser |
| Составной документ MS-Office Ole2 до 2007 ooxml 2007 года и далее |
org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml и использует библиотеку Apache Poi |
OfficeParser (OLE2) OOXMLParser (ooxml) |
| OpenDocument Формат openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| формат переносимого документа (PDF) | org.apache.tika.parser.pdf, и этот пакет использует библиотеку Apache PdfBox | PDFParser |
| Электронный формат публикации (цифровые книги) | org.apache.tika.parser.epub | EpubParser |
| Формат Rich Text | org.apache.tika.parser.rtf | RTFParser |
| Форматы сжатия и упаковки | org.apache.tika.parser.pkg, и этот пакет использует общую библиотеку сжатия | PackageParser и CompressorParser и его подклассы |
| Текстовый формат | org.apache.tika.parser.txt | TXTParser |
| Форматы каналов и синдикации | org.apache.tika.parser.feed | FeedParser |
| Аудио форматы | org.apache.tika.parser.audio и org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- для mp3parser |
| Imageparsers | org.apache.tika.parser.jpeg | JpegParser-для изображений JPEG |
| Videoformats | org.apache.tika.parser.mp4 и org.apache.tika.parser.video этот синтаксический анализатор внутренне использует простой алгоритм для анализа форматов флэш-видео | Mp4parser FlvParser |
| файлы классов Java и файлы JAR | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (сообщения электронной почты) | org.apache.tika.parser.mbox | MobXParser |
| Cad форматы | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| исполняемые программы и библиотеки | org.apache.tika.parser.executable | ExecutableParser |
org.apache.tika.parser.microsoft
org.apache.tika.parser.microsoft.ooxml и использует библиотеку Apache Poi
OfficeParser (OLE2)
OOXMLParser (ooxml)
TIKA — определение типа документа
Стандарты MIME
Стандарты многоцелевого интернет-почтового расширения (MIME) являются лучшими доступными стандартами для идентификации типов документов. Знание этих стандартов помогает браузеру во внутренних взаимодействиях.
Всякий раз, когда браузер обнаруживает мультимедийный файл, он выбирает совместимое программное обеспечение, доступное с ним, для отображения его содержимого. В случае, если у него нет подходящего приложения для запуска определенного медиа-файла, он рекомендует пользователю получить подходящее программное обеспечение для плагина.
Тип обнаружения в Тика
Тика поддерживает все типы документов в Интернете, представленные в MIME. Всякий раз, когда файл проходит через Tika, он обнаруживает файл и его тип документа. Для определения типов носителей Tika использует следующие механизмы.
Расширения файлов
Проверка расширений файлов — это самый простой и наиболее распространенный метод определения формата файла. Многие приложения и операционные системы обеспечивают поддержку этих расширений. Ниже показано расширение нескольких известных типов файлов.
| Имя файла | Удлинитель |
|---|---|
| образ | .jpg |
| аудио | .mp3 |
| файл архива Java | .jar |
| файл классов Java | .учебный класс |
Тип контента Подсказки
Когда вы извлекаете файл из базы данных или присоединяете его к другому документу, вы можете потерять имя или расширение файла. В таких случаях метаданные, поставляемые с файлом, используются для определения расширения файла.
Волшебный байт
Наблюдая за необработанными байтами файла, вы можете найти несколько уникальных шаблонов символов для каждого файла. Некоторые файлы имеют специальные байтовые префиксы, называемые магическими байтами , которые специально созданы и включены в файл с целью определения типа файла.
Например, вы можете найти CA FE BA BE (шестнадцатеричный формат) в java-файле и% PDF (формат ASCII) в pdf-файле. Тика использует эту информацию для определения типа носителя файла.
Кодировки символов
Файлы с простым текстом кодируются с использованием различных типов кодировки символов. Основная задача здесь — определить тип кодировки символов, используемый в файлах. Тика использует методы кодирования символов, такие как Bom-маркеры и байтовые частоты, чтобы идентифицировать систему кодирования, используемую в текстовом контенте.
Корневые символы XML
Чтобы обнаружить XML-документы, Tika анализирует XML-документы и извлекает информацию, такую как корневые элементы, пространства имен и ссылочные схемы, из которой можно найти истинный медиа-тип файлов.
Обнаружение типов с использованием класса фасадов
Метод detect () класса фасадов используется для определения типа документа. Этот метод принимает файл в качестве ввода. Ниже показан пример программы для определения типа документа с классом фасадов Tika.
import java.io.File; import org.apache.tika.Tika; public class Typedetection { public static void main(String[] args) throws Exception { //assume example.mp3 is in your current directory File file = new File("example.mp3");// //Instantiating tika facade class Tika tika = new Tika(); //detecting the file type using detect method String filetype = tika.detect(file); System.out.println(filetype); } }
Сохраните приведенный выше код как TypeDetection.java и запустите его из командной строки, используя следующие команды:
javac TypeDetection.java java TypeDetection audio/mpeg
ТИКА — Извлечение контента
Тика использует различные библиотеки парсеров для извлечения контента из заданных парсеров. Он выбирает правильный парсер для извлечения данного типа документа.
Для анализа документов обычно используется метод parseToString () класса фасада Tika. Ниже показаны этапы процесса синтаксического анализа, которые абстрагируются методом Tika ParsertoString ().
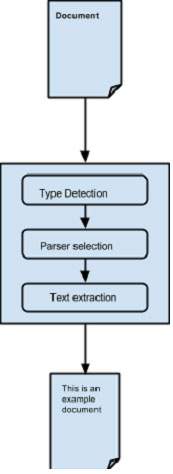
Абстрагирование процесса разбора —
-
Первоначально, когда мы передаем документ в Tika, он использует подходящий механизм обнаружения типов и обнаруживает тип документа.
-
Как только тип документа известен, он выбирает подходящий анализатор из своего хранилища анализатора. Репозиторий парсера содержит классы, которые используют внешние библиотеки.
-
Затем документ передается для выбора парсера, который будет анализировать содержимое, извлекать текст, а также выбрасывать исключения для нечитаемых форматов.
Первоначально, когда мы передаем документ в Tika, он использует подходящий механизм обнаружения типов и обнаруживает тип документа.
Как только тип документа известен, он выбирает подходящий анализатор из своего хранилища анализатора. Репозиторий парсера содержит классы, которые используют внешние библиотеки.
Затем документ передается для выбора парсера, который будет анализировать содержимое, извлекать текст, а также выбрасывать исключения для нечитаемых форматов.
Извлечение контента с использованием Tika
Ниже приведена программа для извлечения текста из файла с использованием класса фасадов Tika —
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}
Сохраните приведенный выше код как TikaExtraction.java и запустите его из командной строки —
javac TikaExtraction.java java TikaExtraction
Ниже приведено содержание sample.txt.
Hi students welcome to tutorialspoint
Это дает вам следующий вывод —
Extracted Content: Hi students welcome to tutorialspoint
Извлечение контента с использованием интерфейса Parser
Пакет анализатора Tika предоставляет несколько интерфейсов и классов, с помощью которых мы можем анализировать текстовый документ. Ниже приведена блок-схема пакета org.apache.tika.parser .
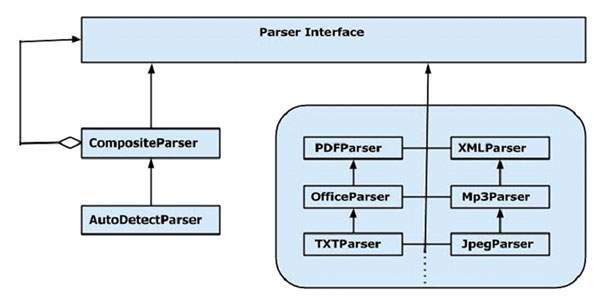
Существует несколько доступных классов синтаксического анализатора, например, pdf parser, Mp3Passer, OfficeParser и т. Д., Для индивидуального анализа соответствующих документов. Все эти классы реализуют интерфейс парсера.
CompositeParser
На данной диаграмме показаны классы синтаксического анализатора Tika общего назначения: CompositeParser и AutoDetectParser . Поскольку класс CompositeParser следует шаблону составного проекта, вы можете использовать группу экземпляров синтаксического анализатора в качестве одного анализатора. Класс CompositeParser также обеспечивает доступ ко всем классам, которые реализуют интерфейс синтаксического анализатора.
AutoDetectParser
Это подкласс CompositeParser, который обеспечивает автоматическое определение типа. Используя эту функцию, AutoDetectParser автоматически отправляет входящие документы в соответствующие классы синтаксического анализатора, используя составную методологию.
метод parse ()
Наряду с parseToString (), вы также можете использовать метод parse () интерфейса синтаксического анализатора. Прототип этого способа показан ниже.
parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)
В следующей таблице перечислены четыре объекта, которые он принимает в качестве параметров.
| Sr.No. | Объект и описание |
|---|---|
| 1 |
InputStream stream Любой объект Inputstream, который содержит содержимое файла |
| 2 |
Обработчик ContentHandler Тика передает документ в виде содержимого XHTML этому обработчику, после чего документ обрабатывается с использованием SAX API. Это обеспечивает эффективную постобработку содержимого в документе. |
| 3 |
Метаданные метаданные Объект метаданных используется как источник и цель метаданных документа. |
| 4 |
ParseContext context Этот объект используется в тех случаях, когда клиентское приложение хочет настроить процесс синтаксического анализа. |
InputStream stream
Любой объект Inputstream, который содержит содержимое файла
Обработчик ContentHandler
Тика передает документ в виде содержимого XHTML этому обработчику, после чего документ обрабатывается с использованием SAX API. Это обеспечивает эффективную постобработку содержимого в документе.
Метаданные метаданные
Объект метаданных используется как источник и цель метаданных документа.
ParseContext context
Этот объект используется в тех случаях, когда клиентское приложение хочет настроить процесс синтаксического анализа.
пример
Ниже приведен пример, который показывает, как используется метод parse ().
Шаг 1 —
Чтобы использовать метод parse () интерфейса анализатора, создайте экземпляр любого из классов, обеспечивающих реализацию для этого интерфейса.
Существуют отдельные классы анализатора, такие как PDFParser, OfficeParser, XMLParser и т. Д. Вы можете использовать любой из этих отдельных анализаторов документов. В качестве альтернативы вы можете использовать либо CompositeParser, либо AutoDetectParser, который использует все классы анализатора внутренне и извлекает содержимое документа с использованием подходящего анализатора.
Parser parser = new AutoDetectParser(); (or) Parser parser = new CompositeParser(); (or) object of any individual parsers given in Tika Library
Шаг 2 —
Создайте объект класса обработчика. Ниже приведены три обработчика контента —
| Sr.No. | Класс и описание |
|---|---|
| 1 |
BodyContentHandler Этот класс выбирает часть тела вывода XHTML и записывает это содержимое в выходной модуль записи или выходной поток. Затем он перенаправляет содержимое XHTML в другой экземпляр обработчика содержимого. |
| 2 |
LinkContentHandler Этот класс обнаруживает и выбирает все теги H-Ref документа XHTML и перенаправляет их для использования такими инструментами, как веб-сканеры. |
| 3 |
TeeContentHandler Этот класс помогает использовать несколько инструментов одновременно. |
BodyContentHandler
Этот класс выбирает часть тела вывода XHTML и записывает это содержимое в выходной модуль записи или выходной поток. Затем он перенаправляет содержимое XHTML в другой экземпляр обработчика содержимого.
LinkContentHandler
Этот класс обнаруживает и выбирает все теги H-Ref документа XHTML и перенаправляет их для использования такими инструментами, как веб-сканеры.
TeeContentHandler
Этот класс помогает использовать несколько инструментов одновременно.
Поскольку нашей целью является извлечение текстового содержимого из документа, создайте экземпляр BodyContentHandler, как показано ниже —
BodyContentHandler handler = new BodyContentHandler( );
Шаг 3 —
Создайте объект метаданных, как показано ниже —
Metadata metadata = new Metadata();
Шаг 4 —
Создайте любой из объектов входного потока и передайте в него файл, который следует извлечь.
FileInputStream
Создайте объект файла, передав путь к файлу в качестве параметра, и передайте этот объект конструктору класса FileInputStream.
Примечание . Путь к объекту файла не должен содержать пробелов.
Проблема с этими классами входного потока заключается в том, что они не поддерживают чтение с произвольным доступом, что необходимо для эффективной обработки некоторых форматов файлов. Чтобы решить эту проблему, Tika предоставляет TikaInputStream.
File file = new File(filepath) FileInputStream inputstream = new FileInputStream(file); (or) InputStream stream = TikaInputStream.get(new File(filename));
Шаг 5 —
Создайте объект контекста разбора, как показано ниже —
ParseContext context =new ParseContext();
Шаг 6 —
Создайте экземпляр объекта анализатора, вызовите метод parse и передайте все необходимые объекты, как показано в прототипе ниже:
parser.parse(inputstream, handler, metadata, context);
Ниже приведена программа для извлечения контента с использованием интерфейса парсера —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}
Сохраните приведенный выше код как ParserExtraction.java и запустите его из командной строки —
javac ParserExtraction.java java ParserExtraction
Ниже приведено содержание sample.txt
Hi students welcome to tutorialspoint
Если вы выполните вышеупомянутую программу, она выдаст следующий вывод:
File content : Hi students welcome to tutorialspoint
ТИКА — Извлечение метаданных
Помимо контента, Тика также извлекает метаданные из файла. Метаданные — это не что иное, как дополнительная информация, поставляемая с файлом. Если мы рассмотрим аудиофайл, имя исполнителя, название альбома, название попадают под метаданные.
Стандарты XMP
Платформа расширяемых метаданных (XMP) — это стандарт для обработки и хранения информации, относящейся к содержимому файла. Он был создан компанией Adobe Systems Inc. XMP предоставляет стандарты для определения, создания и обработки метаданных . Вы можете встроить этот стандарт в несколько форматов файлов, таких как PDF , JPEG , JPEG , GIF , jpg , HTML и т. Д.
Класс недвижимости
Тика использует класс Property, чтобы следовать определению свойства XMP. Он предоставляет перечисления PropertyType и ValueType для захвата имени и значения метаданных.
Класс метаданных
Этот класс реализует различные интерфейсы, такие как ClimateForcast, CativeCommons, Geographic , TIFF и т. Д., Чтобы обеспечить поддержку различных моделей метаданных. Кроме того, этот класс предоставляет различные методы для извлечения содержимого из файла.
Имена метаданных
Мы можем извлечь список всех имен метаданных файла из его объекта метаданных, используя метод names () . Возвращает все имена в виде строкового массива. Используя имя метаданных, мы можем получить значение с помощью метода get () . Он принимает имя метаданных и возвращает значение, связанное с ним.
String[] metadaNames = metadata.names(); String value = metadata.get(name);
Извлечение метаданных с использованием метода разбора
Всякий раз, когда мы анализируем файл с помощью parse (), мы передаем пустой объект метаданных в качестве одного из параметров. Этот метод извлекает метаданные данного файла (если этот файл содержит их) и помещает их в объект метаданных. Поэтому после анализа файла с помощью parse () мы можем извлечь метаданные из этого объекта.
Parser parser = new AutoDetectParser(); BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); //empty metadata object FileInputStream inputstream = new FileInputStream(file); ParseContext context = new ParseContext(); parser.parse(inputstream, handler, metadata, context); // now this metadata object contains the extracted metadata of the given file. metadata.metadata.names();
Ниже приведена полная программа для извлечения метаданных из текстового файла.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как GetMetadata.java и запустите его из командной строки, используя следующие команды:
javac GetMetadata .java java GetMetadata
Ниже приведен снимок boy.jpg
Если вы выполните вышеупомянутую программу, она выдаст следующий вывод:
X-Parsed-By: org.apache.tika.parser.DefaultParser Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 3000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert Image Height: 3000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1 Image Width: 4000 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 4000 Content-Type: image/jpeg Y Resolution: 300 dots
Мы также можем получить желаемые значения метаданных.
Добавление новых значений метаданных
Мы можем добавить новые значения метаданных, используя метод add () класса метаданных. Ниже приведен синтаксис этого метода. Здесь мы добавляем имя автора.
metadata.add(“author”,”Tutorials point”);
Класс Metadata имеет предопределенные свойства, включая свойства, унаследованные от таких классов, как ClimateForcast, CativeCommons, Geographic и т. Д., Для поддержки различных моделей данных. Ниже показано использование типа данных ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ, унаследованного от интерфейса TIFF, реализованного Tika для соответствия стандартам метаданных XMP для форматов изображений TIFF.
metadata.add(Metadata.SOFTWARE,"ms paint");
Ниже приведена полная программа, которая демонстрирует, как добавить значения метаданных в данный файл. Здесь список элементов метаданных отображается в выходных данных, так что вы можете наблюдать за изменениями в списке после добавления новых значений.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}
Сохраните приведенный выше код как класс AddMetadata.java и запустите его из командной строки —
javac AddMetadata .java java AddMetadata
Ниже приведено содержание Example.txt
Hi students welcome to tutorialspoint
Если вы выполните вышеупомянутую программу, она выдаст следующий вывод:
metadata elements of the given file : [Content-Encoding, Content-Type] enter the number of metadata name value pairs to be added 1 enter metadata1name: Author enter metadata1value: Tutorials point metadata name value pair is successfully added Here is the list of all the metadata elements after adding new elements [Content-Encoding, Author, Content-Type]
Установка значений для существующих элементов метаданных
Вы можете установить значения для существующих элементов метаданных, используя метод set (). Синтаксис установки свойства даты с помощью метода set () следующий:
metadata.set(Metadata.DATE, new Date());
Вы также можете установить несколько значений свойств, используя метод set (). Синтаксис установки нескольких значений для свойства Author с помощью метода set () следующий:
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
Ниже приведена полная программа, демонстрирующая метод set ().
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как SetMetadata.java и запустите его из командной строки —
javac SetMetadata.java java SetMetadata
Ниже приведено содержание example.txt.
Hi students welcome to tutorialspoint
Если вы выполните вышеупомянутую программу, она даст вам следующий результат. На выходе вы можете наблюдать недавно добавленные элементы метаданных.
metadata elements and values of the given file : Content-Encoding: ISO-8859-1 Content-Type: text/plain; charset = ISO-8859-1 Here is the list of all the metadata elements after adding new elements date: 2014-09-24T07:01:32Z Content-Encoding: ISO-8859-1 Author: ram, raheem, robin Content-Type: text/plain; charset = ISO-8859-1
TIKA — Определение языка
Необходимость определения языка
Для классификации документов на основе языка, на котором они написаны на многоязычном веб-сайте, необходим инструмент определения языка. Этот инструмент должен принимать документы без языковой аннотации (метаданные) и добавлять эту информацию в метаданные документа, обнаруживая язык.
Алгоритмы для профилирования корпуса
Что такое корпус?
Чтобы определить язык документа, создается языковой профиль и сравнивается с профилем известных языков. Набор текстов этих известных языков известен как корпус .
Корпус — это набор текстов письменного языка, который объясняет, как язык используется в реальных ситуациях.
Корпус разработан из книг, стенограмм и других источников данных, таких как Интернет. Точность корпуса зависит от алгоритма профилирования, который мы используем для формирования корпуса.
Что такое алгоритмы профилирования?
Распространенным способом обнаружения языков является использование словарей. Слова, используемые в данном фрагменте текста, будут сопоставляться с теми, которые есть в словарях.
Список общих слов, используемых в языке, будет наиболее простым и эффективным набором для определения конкретного языка, например статей a , an , the на английском языке.
Использование наборов слов в качестве корпуса
Используя наборы слов, простой алгоритм создается, чтобы найти расстояние между двумя корпусами, которое будет равно сумме разностей между частотами совпадающих слов.
Такие алгоритмы страдают от следующих проблем —
-
Поскольку частота совпадения слов очень мала, алгоритм не может эффективно работать с небольшими текстами, имеющими несколько предложений. Для точного соответствия нужно много текста.
-
Он не может определить границы слов для языков, имеющих составные предложения, и для языков, не имеющих разделителей слов, таких как пробелы или знаки препинания.
Поскольку частота совпадения слов очень мала, алгоритм не может эффективно работать с небольшими текстами, имеющими несколько предложений. Для точного соответствия нужно много текста.
Он не может определить границы слов для языков, имеющих составные предложения, и для языков, не имеющих разделителей слов, таких как пробелы или знаки препинания.
Из-за этих трудностей в использовании наборов слов в качестве корпуса рассматриваются отдельные символы или группы символов.
Использование наборов символов в качестве корпуса
Поскольку символы, которые обычно используются в языке, имеют конечное число, легко применить алгоритм, основанный на частотах слов, а не на символах. Этот алгоритм работает даже лучше в случае определенных наборов символов, используемых в одном или очень немногих языках.
Этот алгоритм имеет следующие недостатки:
-
Трудно различить два языка с одинаковыми частотами символов.
-
Не существует специального инструмента или алгоритма для конкретной идентификации языка с помощью (как корпус) набора символов, используемого несколькими языками.
Трудно различить два языка с одинаковыми частотами символов.
Не существует специального инструмента или алгоритма для конкретной идентификации языка с помощью (как корпус) набора символов, используемого несколькими языками.
Алгоритм N-граммы
Указанные выше недостатки привели к новому подходу использования последовательностей символов заданной длины для составления корпуса. Такая последовательность символов обычно называется N-граммами, где N представляет длину последовательности символов.
-
Алгоритм N-граммы является эффективным подходом для определения языка, особенно в случае европейских языков, таких как английский.
-
Этот алгоритм отлично работает с короткими текстами.
-
Хотя существуют усовершенствованные алгоритмы профилирования языков для обнаружения нескольких языков в многоязычном документе, имеющем более привлекательные функции, Tika использует алгоритм 3 грамма, который подходит в большинстве практических ситуаций.
Алгоритм N-граммы является эффективным подходом для определения языка, особенно в случае европейских языков, таких как английский.
Этот алгоритм отлично работает с короткими текстами.
Хотя существуют усовершенствованные алгоритмы профилирования языков для обнаружения нескольких языков в многоязычном документе, имеющем более привлекательные функции, Tika использует алгоритм 3 грамма, который подходит в большинстве практических ситуаций.
Обнаружение языка в Тике
Среди всех 184 стандартных языков, стандартизированных по ISO 639-1, Tika может распознавать 18 языков. Определение языка в Tika осуществляется с помощью метода getLanguage () класса LanguageIdentifier . Этот метод возвращает кодовое имя языка в формате String. Ниже приведен список из 18 пар кодов языков, обнаруженных Тикой.
| да-датский | де-немецкий | е-эстонский | эль-греческий |
| ан-английски | эс-испанский | фи-фински | FR-французский |
| Hu-венгерский | это-исландский | он-итальянский | п-нидерландский |
| нет-норвежский | пл-Польский | пт-Portuguese | ру-русский |
| св-Swedish | го-тайская |
При создании экземпляра класса LanguageIdentifier вы должны передать формат String содержимого, которое нужно извлечь, или объект класса LanguageProfile .
LanguageIdentifier object = new LanguageIdentifier(“this is english”);
Ниже приведен пример программы для определения языка в Tika.
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}
Сохраните приведенный выше код как LanguageDetection.java и запустите его из командной строки, используя следующие команды:
javac LanguageDetection.java java LanguageDetection
Если вы выполните вышеупомянутую программу, это даст следующую результат-
Language of the given content is : en
Определение языка документа
Чтобы определить язык данного документа, вы должны проанализировать его с помощью метода parse (). Метод parse () анализирует содержимое и сохраняет его в объекте-обработчике, который был передан ему в качестве одного из аргументов. Передайте формат String объекта-обработчика в конструктор класса LanguageIdentifier, как показано ниже —
parser.parse(inputstream, handler, metadata, context); LanguageIdentifier object = new LanguageIdentifier(handler.toString());
Ниже приведена полная программа, которая демонстрирует, как определить язык данного документа —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}
Сохраните приведенный выше код как SetMetadata.java и запустите его из командной строки —
javac SetMetadata.java java SetMetadata
Ниже приведено содержание Example.txt.
Hi students welcome to tutorialspoint
Если вы выполните вышеупомянутую программу, она выдаст следующий вывод:
Language name :en
Наряду с банкой Tika, Tika предоставляет приложение графического интерфейса пользователя (GUI) и интерфейс командной строки (CLI). Вы также можете запустить приложение Tika из командной строки, как и другие приложения Java.
ТИКА — GUI
Графический интерфейс пользователя (GUI)
-
Тика предоставляет файл jar вместе с исходным кодом по следующей ссылке https://tika.apache.org/download.html.
-
Загрузите оба файла, установите classpath для файла jar.
-
Извлеките zip-папку с исходным кодом, откройте папку tika-app.
-
В извлеченной папке «tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui» вы увидите два файла классов: ParsingTransferHandler.java и TikaGUI.java .
-
Скомпилируйте оба файла класса и выполните файл класса TikaGUI.java, он откроет следующее окно.
Тика предоставляет файл jar вместе с исходным кодом по следующей ссылке https://tika.apache.org/download.html.
Загрузите оба файла, установите classpath для файла jar.
Извлеките zip-папку с исходным кодом, откройте папку tika-app.
В извлеченной папке «tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui» вы увидите два файла классов: ParsingTransferHandler.java и TikaGUI.java .
Скомпилируйте оба файла класса и выполните файл класса TikaGUI.java, он откроет следующее окно.
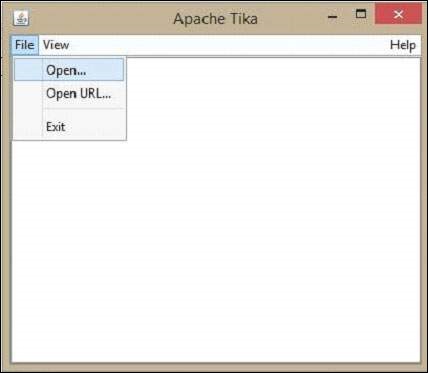
Давайте теперь посмотрим, как использовать графический интерфейс Tika.
В графическом интерфейсе нажмите кнопку «Открыть», найдите и выберите файл, который нужно извлечь, или перетащите его в пробел окна.
Тика извлекает содержимое файлов и отображает его в пяти различных форматах, а именно. метаданные, форматированный текст, простой текст, основное содержание и структурированный текст. Вы можете выбрать любой формат, который вы хотите.
Таким же образом вы также найдете класс CLI в папке «tika-1.6 \ tikaapp \ src \ main \ java \ org \ apache \ tika \ cli».
На следующем рисунке показано, что может сделать Тика. Когда мы опускаем изображение в графический интерфейс, Тика извлекает и отображает его метаданные.
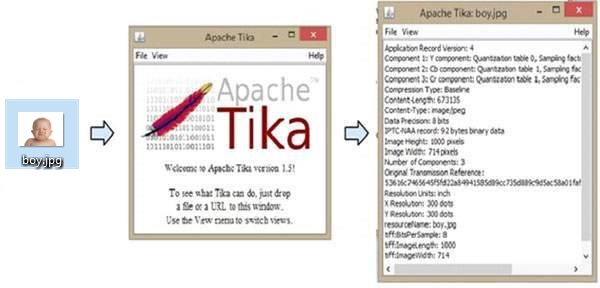
ТИКА — Извлечение PDF
Ниже приведена программа для извлечения контента и метаданных из PDF.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как PdfParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac PdfParse.java java PdfParse
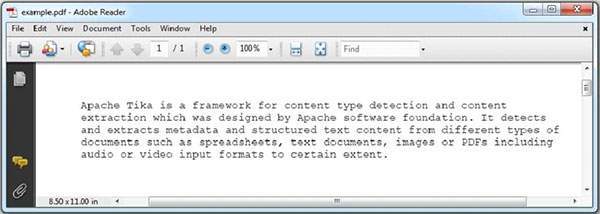
Ниже приведен снимок примера .pdf
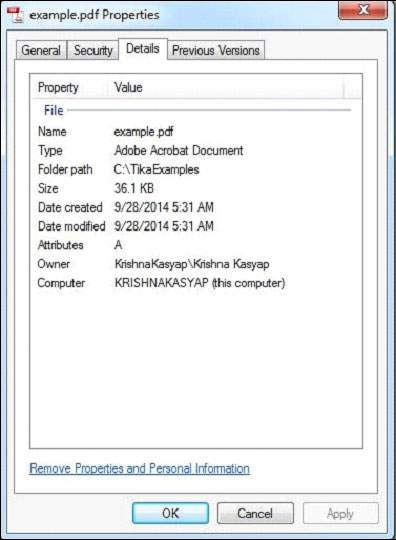
PDF, который мы передаем, имеет следующие свойства —
После компиляции программы вы получите вывод, как показано ниже.
Выход —
Contents of the PDF: Apache Tika is a framework for content type detection and content extraction which was designed by Apache software foundation. It detects and extracts metadata and structured text content from different types of documents such as spreadsheets, text documents, images or PDFs including audio or video input formats to certain extent. Metadata of the PDF: dcterms:modified : 2014-09-28T12:31:16Z meta:creation-date : 2014-09-28T12:31:16Z meta:save-date : 2014-09-28T12:31:16Z dc:creator : Krishna Kasyap pdf:PDFVersion : 1.5 Last-Modified : 2014-09-28T12:31:16Z Author : Krishna Kasyap dcterms:created : 2014-09-28T12:31:16Z date : 2014-09-28T12:31:16Z modified : 2014-09-28T12:31:16Z creator : Krishna Kasyap xmpTPg:NPages : 1 Creation-Date : 2014-09-28T12:31:16Z pdf:encrypted : false meta:author : Krishna Kasyap created : Sun Sep 28 05:31:16 PDT 2014 dc:format : application/pdf; version = 1.5 producer : Microsoft® Word 2013 Content-Type : application/pdf xmp:CreatorTool : Microsoft® Word 2013 Last-Save-Date : 2014-09-28T12:31:16Z
ТИКА — Извлечение ODF
Ниже приведена программа для извлечения контента и метаданных из Open Office Document Format (ODF).
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как OpenDocumentParse.java и скомпилируйте его в командной строке с помощью следующих команд:
javac OpenDocumentParse.java java OpenDocumentParse
Ниже приведен снимок файла example_open_document_presentation.odp.

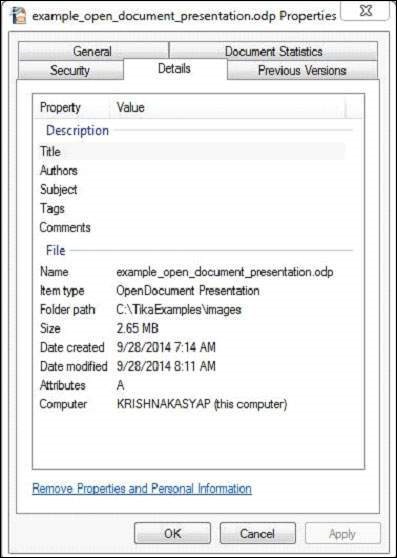
Этот документ имеет следующие свойства —
После компиляции программы вы получите следующий вывод.
Выход —
Contents of the document: Apache Tika Apache Tika is a framework for content type detection and content extraction which was designed by Apache software foundation. It detects and extracts metadata and structured text content from different types of documents such as spreadsheets, text documents, images or PDFs including audio or video input formats to certain extent. Metadata of the document: editing-cycles: 4 meta:creation-date: 2009-04-16T11:32:32.86 dcterms:modified: 2014-09-28T07:46:13.03 meta:save-date: 2014-09-28T07:46:13.03 Last-Modified: 2014-09-28T07:46:13.03 dcterms:created: 2009-04-16T11:32:32.86 date: 2014-09-28T07:46:13.03 modified: 2014-09-28T07:46:13.03 nbObject: 36 Edit-Time: PT32M6S Creation-Date: 2009-04-16T11:32:32.86 Object-Count: 36 meta:object-count: 36 generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764 Content-Type: application/vnd.oasis.opendocument.presentation Last-Save-Date: 2014-09-28T07:46:13.03
TIKA — Извлечение файлов MS-Office
Ниже приведена программа для извлечения содержимого и метаданных из документа Microsoft Office.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как MSExelParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac MSExcelParse.java java MSExcelParse
Здесь мы передаем следующий образец файла Excel.
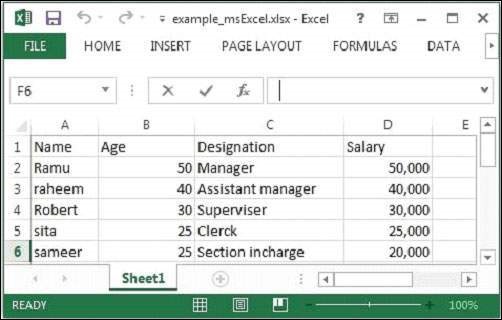
Данный файл Excel имеет следующие свойства —
После выполнения вышеуказанной программы вы получите следующий вывод.
Выход —
Contents of the document: Sheet1 Name Age Designation Salary Ramu 50 Manager 50,000 Raheem 40 Assistant manager 40,000 Robert 30 Superviser 30,000 sita 25 Clerk 25,000 sameer 25 Section in-charge 20,000 Metadata of the document: meta:creation-date: 2006-09-16T00:00:00Z dcterms:modified: 2014-09-28T15:18:41Z meta:save-date: 2014-09-28T15:18:41Z Application-Name: Microsoft Excel extended-properties:Company: dcterms:created: 2006-09-16T00:00:00Z Last-Modified: 2014-09-28T15:18:41Z Application-Version: 15.0300 date: 2014-09-28T15:18:41Z publisher: modified: 2014-09-28T15:18:41Z Creation-Date: 2006-09-16T00:00:00Z extended-properties:AppVersion: 15.0300 protected: false dc:publisher: extended-properties:Application: Microsoft Excel Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet Last-Save-Date: 2014-09-28T15:18:41Z
ТИКА — Извлечение текстового документа
Ниже приведена программа для извлечения контента и метаданных из текстового документа —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как TextParser.java и скомпилируйте его из командной строки, используя следующие команды:
javac TextParser.java java TextParser
Ниже приведен снимок файла sample.txt —
Текстовый документ имеет следующие свойства —
Если вы выполните вышеупомянутую программу, она даст вам следующий результат.
Выход —
Contents of the document: At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning purpose in the domains of Academics, Information Technology, Management and Computer Programming Languages. The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com in year 2006 with the help of handpicked freelancers, with an array of tutorials for computer programming languages. Metadata of the document: Content-Encoding: windows-1252 Content-Type: text/plain; charset = windows-1252
TIKA — Извлечение HTML-документа
Ниже приведена программа для извлечения контента и метаданных из HTML-документа.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как HtmlParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac HtmlParse.java java HtmlParse
Ниже приведен снимок файла example.txt.
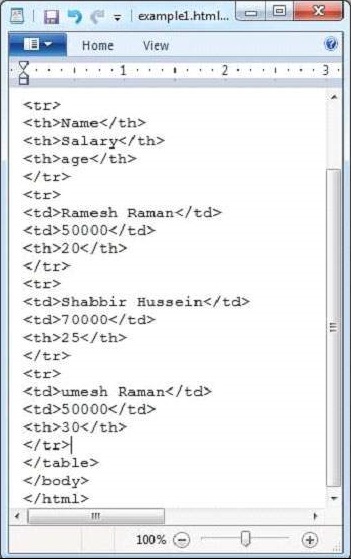
HTML-документ имеет следующие свойства:
Если вы выполните вышеупомянутую программу, она даст вам следующий результат.
Выход —
Contents of the document: Name Salary age Ramesh Raman 50000 20 Shabbir Hussein 70000 25 Umesh Raman 50000 30 Somesh 50000 35 Metadata of the document: title: HTML Table Header Content-Encoding: windows-1252 Content-Type: text/html; charset = windows-1252 dc:title: HTML Table Header
TIKA — Извлечение XML-документа
Ниже приведена программа для извлечения контента и метаданных из XML-документа —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как XmlParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac XmlParse.java java XmlParse
Ниже приведен снимок файла example.xml
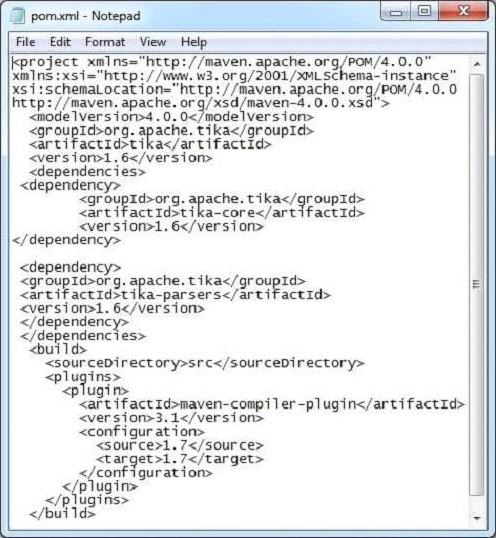
Этот документ имеет следующие свойства —
Если вы выполните вышеупомянутую программу, она даст вам следующий вывод —
Выход —
Contents of the document: 4.0.0 org.apache.tika tika 1.6 org.apache.tika tika-core 1.6 org.apache.tika tika-parsers 1.6 src maven-compiler-plugin 3.1 1.7 1.7 Metadata of the document: Content-Type: application/xml
TIKA — Извлечение .class файла
Ниже приведена программа для извлечения контента и метаданных из файла .class.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как JavaClassParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac JavaClassParse.java java JavaClassParse
Ниже приведен снимок файла Example.java, который сгенерирует Example.class после компиляции.
Файл Example.class имеет следующие свойства —
После выполнения вышеуказанной программы вы получите следующий вывод.
Выход —
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: Example
TIKA — Извлечение файла JAR
Ниже приведена программа для извлечения содержимого и метаданных из файла Java-архива (jar) —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как PackageParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac PackageParse.java java PackageParse
Ниже приведен снимок файла Example.java, который находится внутри пакета.
JAR-файл имеет следующие свойства —
После выполнения вышеуказанной программы она выдаст следующий вывод:
Выход —
Contents of the document: META-INF/MANIFEST.MF tutorialspoint/tika/examples/Example.class Metadata of the document: Content-Type: application/zip
TIKA — Извлечение файла изображения
Ниже приведена программа для извлечения контента и метаданных из изображения JPEG.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как JpegParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac JpegParse.java java JpegParse
Ниже приведен снимок файла Example.jpeg —
Файл JPEG имеет следующие свойства —
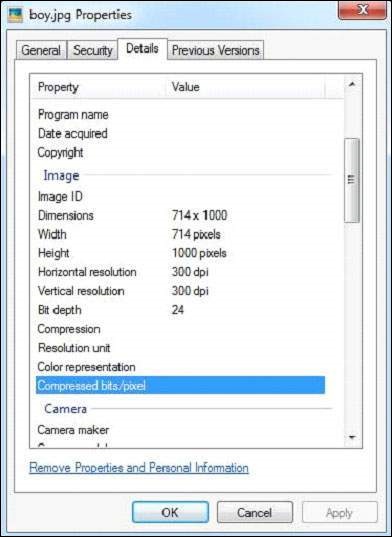
После выполнения программы вы получите следующий вывод.
Выход —
Contents of the document: Meta data of the document: Resolution Units: inch Compression Type: Baseline Data Precision: 8 bits Number of Components: 3 tiff:ImageLength: 3000 Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert Image Height: 3000 pixels X Resolution: 300 dots Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1 Image Width: 4000 pixels IPTC-NAA record: 92 bytes binary data Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert tiff:BitsPerSample: 8 Application Record Version: 4 tiff:ImageWidth: 4000 Y Resolution: 300 dots
TIKA — Извлечение файлов mp4
Ниже приведена программа для извлечения контента и метаданных из файлов mp4 —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как JpegParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac Mp4Parse.java java Mp4Parse
Ниже приведен снимок свойств файла Example.mp4.
После выполнения вышеуказанной программы вы получите следующий вывод:
Выход —
Contents of the document: Metadata of the document: dcterms:modified: 2014-01-06T12:10:27Z meta:creation-date: 1904-01-01T00:00:00Z meta:save-date: 2014-01-06T12:10:27Z Last-Modified: 2014-01-06T12:10:27Z dcterms:created: 1904-01-01T00:00:00Z date: 2014-01-06T12:10:27Z tiff:ImageLength: 360 modified: 2014-01-06T12:10:27Z Creation-Date: 1904-01-01T00:00:00Z tiff:ImageWidth: 640 Content-Type: video/mp4 Last-Save-Date: 2014-01-06T12:10:27Z
TIKA — Извлечение mp3 файлов
Ниже приведена программа для извлечения контента и метаданных из mp3 файлов —
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
Сохраните приведенный выше код как JpegParse.java и скомпилируйте его из командной строки, используя следующие команды:
javac Mp3Parse.java java Mp3Parse
Файл Example.mp3 имеет следующие свойства —
Вы получите следующий вывод после выполнения программы. Если в данном файле есть какие-либо тексты, наше приложение запишет и отобразит их вместе с выводом.
Выход —