Прикладные программисты могут легко интегрировать Tika в свои приложения. Тика предоставляет интерфейс командной строки и графический интерфейс, чтобы сделать его удобным для пользователя.
В этой главе мы обсудим четыре важных модуля, составляющих архитектуру Tika. На следующем рисунке показана архитектура Tika с четырьмя модулями:
- Механизм определения языка.
- Механизм обнаружения MIME.
- Интерфейс парсера.
- Тика Фасадный класс.
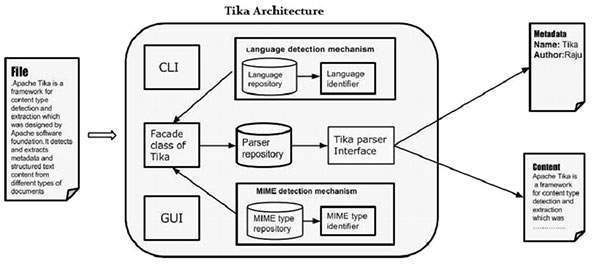
Механизм обнаружения языка
Всякий раз, когда текстовый документ передается в Tika, он определяет язык, на котором он был написан. Он принимает документы без языковой аннотации и добавляет эту информацию в метаданные документа, определяя язык.
Для поддержки идентификации языка в пакете org.apache.tika.language у Tika есть класс с именем Language Identifier , а внутри — хранилище идентификации языка, содержащее алгоритмы определения языка по заданному тексту. Тика внутренне использует алгоритм N-граммы для определения языка.
Механизм обнаружения MIME
Тика может определить тип документа в соответствии со стандартами MIME. Обнаружение типа MIME по умолчанию в Tika выполняется с использованием org.apache.tika.mime.mimeTypes . Он использует интерфейс org.apache.tika.detect.Detector для определения большинства типов контента.
Внутренне Tika использует несколько техник, таких как глобусы файлов, подсказки типа контента, магические байты, кодировки символов и несколько других техник.
Интерфейс парсера
Интерфейс парсера org.apache.tika.parser является ключевым интерфейсом для анализа документов в Tika. Этот интерфейс извлекает текст и метаданные из документа и суммирует их для внешних пользователей, которые готовы писать плагины анализатора.
Используя различные конкретные классы анализаторов, специфичные для отдельных типов документов, Tika поддерживает множество форматов документов. Эти классы, специфичные для формата, обеспечивают поддержку различных форматов документов, либо непосредственно реализуя логику синтаксического анализатора, либо используя внешние библиотеки синтаксического анализатора.
Тика Фасад Класс
Использование класса фасадов Tika — это самый простой и прямой способ вызова Tika из Java, который следует шаблону дизайна фасада. Вы можете найти класс фасадов Tika в пакете org.apache.tika API Tika.
Реализуя базовые сценарии использования, Tika выступает в роли посредника в ландшафте. Он абстрагирует основную сложность библиотеки Tika, такую как механизм обнаружения MIME, интерфейс синтаксического анализатора и механизм обнаружения языка, и предоставляет пользователям простой в использовании интерфейс.
Особенности Тика
-
Унифицированный интерфейс синтаксического анализатора — Tika инкапсулирует все сторонние библиотеки синтаксического анализатора в единый интерфейс синтаксического анализатора. Благодаря этой функции пользователь избавляется от необходимости выбирать подходящую библиотеку синтаксического анализатора и использовать ее в соответствии с типом найденного файла.
-
Низкое использование памяти — Tika потребляет меньше ресурсов памяти, поэтому ее легко встраивать в приложения Java. Мы также можем использовать Tika в приложении, которое работает на платформах с меньшими ресурсами, таких как мобильный КПК.
-
Быстрая обработка — можно ожидать быстрого обнаружения контента и извлечения из приложений.
-
Гибкие метаданные — Tika понимает все модели метаданных, которые используются для описания файлов.
-
Интеграция парсера — Tika может использовать различные библиотеки парсеров, доступные для каждого типа документа в одном приложении.
-
Обнаружение типов MIME — Tika может обнаруживать и извлекать контент из всех типов носителей, включенных в стандарты MIME.
-
Определение языка — Tika включает функцию идентификации языка, поэтому может использоваться в документах, основанных на типе языка, на многоязычных веб-сайтах.
Унифицированный интерфейс синтаксического анализатора — Tika инкапсулирует все сторонние библиотеки синтаксического анализатора в единый интерфейс синтаксического анализатора. Благодаря этой функции пользователь избавляется от необходимости выбирать подходящую библиотеку синтаксического анализатора и использовать ее в соответствии с типом найденного файла.
Низкое использование памяти — Tika потребляет меньше ресурсов памяти, поэтому ее легко встраивать в приложения Java. Мы также можем использовать Tika в приложении, которое работает на платформах с меньшими ресурсами, таких как мобильный КПК.
Быстрая обработка — можно ожидать быстрого обнаружения контента и извлечения из приложений.
Гибкие метаданные — Tika понимает все модели метаданных, которые используются для описания файлов.
Интеграция парсера — Tika может использовать различные библиотеки парсеров, доступные для каждого типа документа в одном приложении.
Обнаружение типов MIME — Tika может обнаруживать и извлекать контент из всех типов носителей, включенных в стандарты MIME.
Определение языка — Tika включает функцию идентификации языка, поэтому может использоваться в документах, основанных на типе языка, на многоязычных веб-сайтах.
Функциональные возможности Тика
Тика поддерживает различные функции —
- Определение типа документа
- Извлечение контента
- Извлечение метаданных
- Определение языка
Определение типа документа
Тика использует различные методы обнаружения и определяет тип документа, переданного ей.

Извлечение контента
Тика имеет библиотеку синтаксического анализатора, которая может анализировать содержимое документов различных форматов и извлекать их. После определения типа документа он выбирает соответствующий анализатор из хранилища анализатора и передает документ. Различные классы Tika имеют методы для анализа различных форматов документов.

Извлечение метаданных
Наряду с контентом, Tika извлекает метаданные документа с помощью той же процедуры, что и при извлечении контента. Для некоторых типов документов в Tika есть классы для извлечения метаданных.

Обнаружение языка
Внутренне Tika использует алгоритмы, такие как n-грамм, для определения языка содержимого в данном документе. Тика зависит от классов, таких как Languageidentifier и Profiler для идентификации языка.