Ниже приведена программа для извлечения контента и метаданных из текстового документа —
import java.io.File; import java.io.FileInputStream; import java.io.IOException; import org.apache.tika.exception.TikaException; import org.apache.tika.metadata.Metadata; import org.apache.tika.parser.ParseContext; import org.apache.tika.sax.BodyContentHandler; import org.apache.tika.parser.txt.TXTParser; import org.xml.sax.SAXException; public class TextParser { public static void main(final String[] args) throws IOException,SAXException, TikaException { //detecting the file type BodyContentHandler handler = new BodyContentHandler(); Metadata metadata = new Metadata(); FileInputStream inputstream = new FileInputStream(new File("example.txt")); ParseContext pcontext=new ParseContext(); //Text document parser TXTParser TexTParser = new TXTParser(); TexTParser.parse(inputstream, handler, metadata,pcontext); System.out.println("Contents of the document:" + handler.toString()); System.out.println("Metadata of the document:"); String[] metadataNames = metadata.names(); for(String name : metadataNames) { System.out.println(name + " : " + metadata.get(name)); } } }
Сохраните приведенный выше код как TextParser.java и скомпилируйте его из командной строки, используя следующие команды:
javac TextParser.java java TextParser
Ниже приведен снимок файла sample.txt —
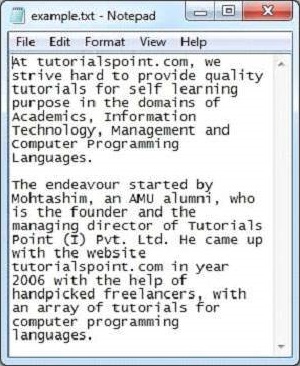
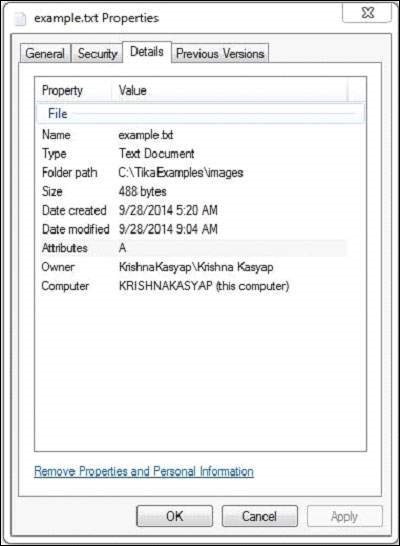
Текстовый документ имеет следующие свойства —
Если вы выполните вышеупомянутую программу, она даст вам следующий результат.
Выход —