Традиционная система управления приложениями, то есть взаимодействие приложений с реляционной базой данных с использованием RDBMS, является одним из источников, генерирующих большие данные. Такие большие данные, генерируемые RDBMS, хранятся на серверах реляционных баз данных в структуре реляционных баз данных.
Когда появились хранилища и анализаторы больших данных, такие как MapReduce, Hive, HBase, Cassandra, Pig и т. Д. Экосистемы Hadoop, им потребовался инструмент для взаимодействия с серверами реляционных баз данных для импорта и экспорта находящихся в них больших данных. Здесь Sqoop занимает место в экосистеме Hadoop для обеспечения возможного взаимодействия между сервером реляционной базы данных и HDFS Hadoop.
Sqoop — «SQL для Hadoop и Hadoop для SQL»
Sqoop — это инструмент, предназначенный для передачи данных между Hadoop и серверами реляционных баз данных. Он используется для импорта данных из реляционных баз данных, таких как MySQL, Oracle, в Hadoop HDFS и экспорта из файловой системы Hadoop в реляционные базы данных. Это обеспечивается Apache Software Foundation.
Как работает Sqoop?
На следующем рисунке описан рабочий процесс Sqoop.
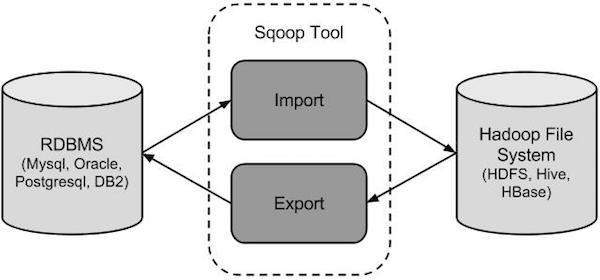
Sqoop Import
Инструмент импорта импортирует отдельные таблицы из RDBMS в HDFS. Каждая строка в таблице рассматривается как запись в HDFS. Все записи хранятся в виде текстовых данных в текстовых файлах или в виде двоичных данных в файлах Avro и Sequence.
Sqoop Export
Инструмент экспорта экспортирует набор файлов из HDFS обратно в RDBMS. Файлы, указанные в качестве входных данных для Sqoop, содержат записи, которые называются строками в таблице. Они читаются и разбираются в набор записей и разделяются указанным пользователем разделителем.