Sqoop — Введение
Традиционная система управления приложениями, то есть взаимодействие приложений с реляционной базой данных с использованием RDBMS, является одним из источников, генерирующих большие данные. Такие большие данные, генерируемые RDBMS, хранятся на серверах реляционных баз данных в структуре реляционных баз данных.
Когда появились хранилища и анализаторы больших данных, такие как MapReduce, Hive, HBase, Cassandra, Pig и т. Д. Экосистемы Hadoop, им потребовался инструмент для взаимодействия с серверами реляционных баз данных для импорта и экспорта находящихся в них больших данных. Здесь Sqoop занимает место в экосистеме Hadoop для обеспечения возможного взаимодействия между сервером реляционной базы данных и HDFS Hadoop.
Sqoop — «SQL для Hadoop и Hadoop для SQL»
Sqoop — это инструмент, предназначенный для передачи данных между Hadoop и серверами реляционных баз данных. Он используется для импорта данных из реляционных баз данных, таких как MySQL, Oracle, в Hadoop HDFS и экспорта из файловой системы Hadoop в реляционные базы данных. Это обеспечивается Apache Software Foundation.
Как работает Sqoop?
На следующем рисунке описан рабочий процесс Sqoop.
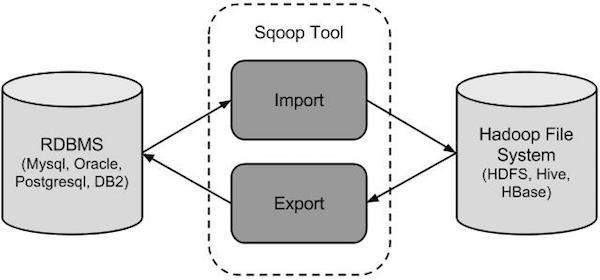
Sqoop Import
Инструмент импорта импортирует отдельные таблицы из RDBMS в HDFS. Каждая строка в таблице рассматривается как запись в HDFS. Все записи хранятся в виде текстовых данных в текстовых файлах или в виде двоичных данных в файлах Avro и Sequence.
Sqoop Export
Инструмент экспорта экспортирует набор файлов из HDFS обратно в RDBMS. Файлы, указанные в качестве входных данных для Sqoop, содержат записи, которые называются строками в таблице. Они читаются и разбираются в набор записей и разделяются указанным пользователем разделителем.
Sqoop — Установка
Поскольку Sqoop является подпроектом Hadoop, он может работать только в операционной системе Linux. Следуйте приведенным ниже инструкциям, чтобы установить Sqoop в своей системе.
Шаг 1: Проверка установки JAVA
Вам необходимо установить Java в вашей системе перед установкой Sqoop. Давайте проверим установку Java с помощью следующей команды —
$ java –version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если Java не установлена в вашей системе, выполните следующие действия.
Установка Java
Следуйте простым шагам, приведенным ниже, чтобы установить Java в вашей системе.
Шаг 1
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке .
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Как правило, вы можете найти загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/java # exitStep IV:
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java —
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте установку, используя команду java -version из терминала, как описано выше.
Шаг 2: Проверка установки Hadoop
Hadoop должен быть установлен в вашей системе перед установкой Sqoop. Давайте проверим установку Hadoop с помощью следующей команды —
$ hadoop version
Если Hadoop уже установлен в вашей системе, вы получите следующий ответ:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Если Hadoop не установлен в вашей системе, выполните следующие шаги:
Загрузка Hadoop
Загрузите и извлеките Hadoop 2.4.1 из Apache Software Foundation, используя следующие команды.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Установка Hadoop в псевдо-распределенном режиме
Выполните шаги, указанные ниже, чтобы установить Hadoop 2.4.1 в псевдораспределенном режиме.
Шаг 1: Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2: Конфигурация Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести соответствующие изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Чтобы разрабатывать программы Hadoop с использованием java, необходимо сбросить переменные среды java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением java в вашей системе.
export JAVA_HOME=/usr/local/java
Ниже приведен список файлов, которые необходимо отредактировать для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и путь datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего вам необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1: Настройка имени узла
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2: Проверка Hadoop dfs
Следующая команда используется для запуска dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3: Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующий:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
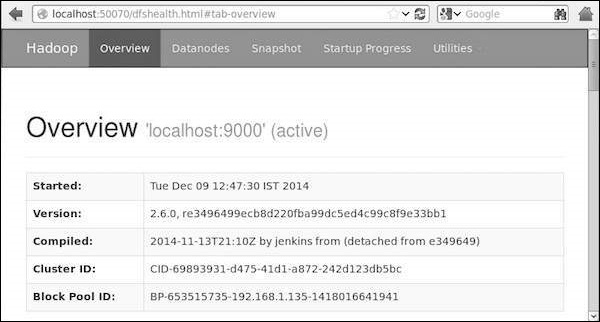
Шаг 4: Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в своем браузере.
http://localhost:50070/
На следующем изображении показан браузер Hadoop.
Шаг 5. Проверьте все приложения для кластера.
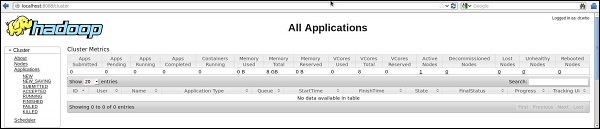
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для посещения этой службы.
http://localhost:8088/
На следующем изображении показан браузерный кластер Hadoop.
Шаг 3: Загрузка Sqoop
Мы можем загрузить последнюю версию Sqoop по следующей ссылке. Для этого урока мы используем версию 1.4.5, то есть sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz .
Шаг 4: Установка Sqoop
Следующие команды используются для извлечения tar-шара Sqoop и перемещения его в каталог «/ usr / lib / sqoop».
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz $ su password: # mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop #exit
Шаг 5: Настройка bashrc
Вы должны настроить среду Sqoop, добавив следующие строки в файл ~ / .bashrc —
#Sqoop export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/bin
Следующая команда используется для выполнения файла ~ / .bashrc .
$ source ~/.bashrc
Шаг 6: Настройка Sqoop
Чтобы настроить Sqoop с Hadoop, вам нужно отредактировать файл sqoop-env.sh , который находится в каталоге $ SQOOP_HOME / conf . Прежде всего, перенаправьте в каталог конфигурации Sqoop и скопируйте файл шаблона с помощью следующей команды —
$ cd $SQOOP_HOME/conf $ mv sqoop-env-template.sh sqoop-env.sh
Откройте sqoop-env.sh и отредактируйте следующие строки —
export HADOOP_COMMON_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=/usr/local/hadoop
Шаг 7: Загрузите и настройте mysql-connector-java
Мы можем скачать файл mysql-connector-java-5.1.30.tar.gz по следующей ссылке .
Следующие команды используются для извлечения архива mysql-connector-java и перемещения файла mysql-connector-java-5.1.30-bin.jar в каталог / usr / lib / sqoop / lib.
$ tar -zxf mysql-connector-java-5.1.30.tar.gz $ su password: # cd mysql-connector-java-5.1.30 # mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/lib
Шаг 8: Проверка Sqoop
Следующая команда используется для проверки версии Sqoop.
$ cd $SQOOP_HOME/bin $ sqoop-version
Ожидаемый результат —
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83 Compiled by abe on Fri Aug 1 11:19:26 PDT 2014
Установка Sqoop завершена.
Sqoop — Импорт
В этой главе описывается, как импортировать данные из базы данных MySQL в Hadoop HDFS. «Инструмент импорта» импортирует отдельные таблицы из РСУБД в HDFS. Каждая строка в таблице рассматривается как запись в HDFS. Все записи хранятся в виде текстовых данных в текстовых файлах или в виде двоичных данных в файлах Avro и Sequence.
Синтаксис
Следующий синтаксис используется для импорта данных в HDFS.
$ sqoop import (generic-args) (import-args) $ sqoop-import (generic-args) (import-args)
пример
Давайте рассмотрим пример трех таблиц с именами emp , emp_add и emp_contact , которые находятся в базе данных с именем userdb на сервере базы данных MySQL.
Три таблицы и их данные следующие.
эй:
| Я бы | название | градус | оплата труда | отдел |
|---|---|---|---|---|
| 1201 | Гопал | менеджер | 50000 | TP |
| 1202 | Маниша | Корректор | 50000 | TP |
| 1203 | Халил | php dev | 30000 | переменный ток |
| 1204 | Prasanth | php dev | 30000 | переменный ток |
| 1204 | kranthi | админ | 20000 | TP |
emp_add:
| Я бы | HNO | улица | город |
|---|---|---|---|
| 1201 | 288A | vgiri | jublee |
| 1202 | 108I | AOC | втор-плохо |
| 1203 | 144Z | pgutta | ГИД |
| 1204 | 78B | Старый город | втор-плохо |
| 1205 | 720x | Hitec | втор-плохо |
emp_contact:
| Я бы | phno | Эл. адрес |
|---|---|---|
| 1201 | 2356742 | gopal@tp.com |
| 1202 | 1661663 | manisha@tp.com |
| 1203 | 8887776 | khalil@ac.com |
| 1204 | 9988774 | prasanth@ac.com |
| 1205 | 1231231 | kranthi@tp.com |
Импорт таблицы
Инструмент Sqoop ‘import’ используется для импорта данных таблицы из таблицы в файловую систему Hadoop в виде текстового файла или двоичного файла.
Следующая команда используется для импорта таблицы emp с сервера базы данных MySQL в HDFS.
$ sqoop import \ --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp --m 1
Если оно выполнено успешно, вы получите следующий вывод.
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 14/12/22 15:24:56 INFO tool.CodeGenTool: Beginning code generation 14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 14/12/22 15:24:58 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop 14/12/22 15:25:11 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:25:40 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1419242001831_0001/ 14/12/22 15:26:45 INFO mapreduce.Job: Job job_1419242001831_0001 running in uber mode : false 14/12/22 15:26:45 INFO mapreduce.Job: map 0% reduce 0% 14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0% 14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds (0.8165 bytes/sec) 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records.
Чтобы проверить импортированные данные в HDFS, используйте следующую команду.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*
Он показывает данные таблицы emp и поля разделяются запятой (,).
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP
Импорт в целевой каталог
Мы можем указать целевой каталог при импорте табличных данных в HDFS с помощью инструмента импорта Sqoop.
Ниже приведен синтаксис для указания целевого каталога в качестве опции для команды импорта Sqoop.
--target-dir <new or exist directory in HDFS>
Следующая команда используется для импорта данных таблицы emp_add в каталог / queryresult.
$ sqoop import \ --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp_add \ --m 1 \ --target-dir /queryresult
Следующая команда используется для проверки импортированных данных в каталоге / queryresult в форме таблицы emp_add .
$ $HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-*
Он покажет вам данные таблицы emp_add с разделенными запятыми (,) полями.
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad
Импортировать подмножество табличных данных
Мы можем импортировать подмножество таблицы, используя предложение ‘where’ в инструменте импорта Sqoop. Он выполняет соответствующий запрос SQL на соответствующем сервере базы данных и сохраняет результат в целевом каталоге в HDFS.
Синтаксис предложения where следующий.
--where <condition>
Следующая команда используется для импорта подмножества данных таблицы emp_add . Подмножеством запроса является получение идентификатора и адреса сотрудника, который живет в городе Секундерабад.
$ sqoop import \ --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp_add \ --m 1 \ --where “city =’sec-bad’” \ --target-dir /wherequery
Следующая команда используется для проверки импортированных данных в каталоге / wherequery из таблицы emp_add .
$ $HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-*
Он покажет вам данные таблицы emp_add с разделенными запятыми (,) полями.
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad
Добавочный импорт
Инкрементальный импорт — это метод, который импортирует только недавно добавленные строки в таблицу. Для выполнения инкрементального импорта необходимо добавить опции «incremental», «check-column» и «last-value».
Следующий синтаксис используется для параметра приращения в команде импорта Sqoop.
--incremental <mode> --check-column <column name> --last value <last check column value>
Предположим, что новые данные добавлены в таблицу emp следующим образом:
1206, satish p, grp des, 20000, GR
Следующая команда используется для выполнения добавочного импорта в таблицу emp .
$ sqoop import \ --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp \ --m 1 \ --incremental append \ --check-column id \ -last value 1205
Следующая команда используется для проверки импортированных данных из таблицы emp в каталог emp / HDFS.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*
Он показывает вам данные таблицы emp с разделенными запятыми (,) полями.
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR
Следующая команда используется для просмотра измененных или вновь добавленных строк из таблицы emp .
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1
Он показывает новые добавленные строки в таблицу emp с разделенными запятыми (,) полями.
1206, satish p, grp des, 20000, GR
Sqoop — импортировать все таблицы
В этой главе описывается, как импортировать все таблицы с сервера базы данных RDBMS в HDFS. Данные каждой таблицы хранятся в отдельном каталоге, а имя каталога совпадает с именем таблицы.
Синтаксис
Следующий синтаксис используется для импорта всех таблиц.
$ sqoop import-all-tables (generic-args) (import-args) $ sqoop-import-all-tables (generic-args) (import-args)
пример
Давайте рассмотрим пример импорта всех таблиц из базы данных userdb . Список таблиц, которые содержит база данных userdb, выглядит следующим образом.
+--------------------+ | Tables | +--------------------+ | emp | | emp_add | | emp_contact | +--------------------+
Следующая команда используется для импорта всех таблиц из базы данных userdb .
$ sqoop import-all-tables \ --connect jdbc:mysql://localhost/userdb \ --username root
Примечание. Если вы используете таблицы импорта всех данных, обязательно, чтобы каждая таблица в этой базе данных имела поле первичного ключа.
Следующая команда используется для проверки всех данных таблицы в базе данных userdb в HDFS.
$ $HADOOP_HOME/bin/hadoop fs -ls
Он покажет вам список имен таблиц в базе данных userdb в виде каталогов.
Выход
drwxr-xr-x - hadoop supergroup 0 2014-12-22 22:50 _sqoop drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:46 emp drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:50 emp_add drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:52 emp_contact
Sqoop — Экспорт
В этой главе описывается, как экспортировать данные обратно из HDFS в базу данных RDBMS. Целевая таблица должна существовать в целевой базе данных. Файлы, которые передаются в качестве входных данных для Sqoop, содержат записи, которые называются строками в таблице. Они читаются и разбираются в набор записей и разделяются указанным пользователем разделителем.
Операцией по умолчанию является вставка всей записи из входных файлов в таблицу базы данных с помощью оператора INSERT. В режиме обновления Sqoop генерирует инструкцию UPDATE, которая заменяет существующую запись в базе данных.
Синтаксис
Ниже приведен синтаксис команды экспорта.
$ sqoop export (generic-args) (export-args) $ sqoop-export (generic-args) (export-args)
пример
Давайте рассмотрим пример данных о сотрудниках в файле в HDFS. Данные о сотрудниках доступны в файле emp_data в каталоге ’emp /’ в HDFS. Emp_data выглядит следующим образом.
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR
Обязательно, чтобы экспортируемая таблица создавалась вручную и присутствовала в базе данных, откуда она должна быть экспортирована.
Следующий запрос используется для создания таблицы ’employee’ в командной строке mysql.
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10));
Следующая команда используется для экспорта данных таблицы (которая находится в файле emp_data в HDFS) в таблицу employee в базе данных db сервера базы данных Mysql.
$ sqoop export \ --connect jdbc:mysql://localhost/db \ --username root \ --table employee \ --export-dir /emp/emp_data
Следующая команда используется для проверки таблицы в командной строке mysql.
mysql>select * from employee;
Если данные данные успешно сохранены, вы можете найти следующую таблицу данных о сотрудниках.
+------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+
Sqoop — Работа
В этой главе описывается, как создавать и поддерживать задания Sqoop. Задание Sqoop создает и сохраняет команды импорта и экспорта. Он определяет параметры для идентификации и вызова сохраненной работы. Этот повторный вызов или повторное выполнение используется в добавочном импорте, который может импортировать обновленные строки из таблицы RDBMS в HDFS.
Синтаксис
Ниже приведен синтаксис для создания задания Sqoop.
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)] $ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
Создать работу (—создать)
Здесь мы создаем задание с именем myjob , которое может импортировать данные таблицы из таблицы RDBMS в HDFS. Следующая команда используется для создания задания, которое импортирует данные из таблицы employee в базе данных db в файл HDFS.
$ sqoop job --create myjob \ -- import \ --connect jdbc:mysql://localhost/db \ --username root \ --table employee --m 1
Подтвердить работу (—list)
Аргумент —list используется для проверки сохраненных заданий. Следующая команда используется для проверки списка сохраненных заданий Sqoop.
$ sqoop job --list
Показывает список сохраненных заданий.
Available jobs: myjob
Осмотреть работу (—show)
Аргумент —show используется для проверки или проверки конкретных заданий и их данных. Следующая команда и пример выходных данных используются для проверки задания myjob .
$ sqoop job --show myjob
Он показывает инструменты и их параметры, которые используются в myjob .
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ...
Выполнить задание (—exec)
Параметр —exec используется для выполнения сохраненного задания. Следующая команда используется для выполнения сохраненного задания под названием myjob .
$ sqoop job --exec myjob
Он показывает вам следующий вывод.
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ...
Sqoop — Codegen
В этой главе описывается важность инструмента «codegen». С точки зрения объектно-ориентированного приложения каждая таблица базы данных имеет один класс DAO, который содержит методы ‘getter’ и ‘setter’ для инициализации объектов. Этот инструмент (-codegen) генерирует класс DAO автоматически.
Он генерирует класс DAO в Java на основе структуры схемы таблиц. Определение Java создается как часть процесса импорта. Основное использование этого инструмента — проверка того, потеряла ли Java код Java. Если это так, он создаст новую версию Java с разделителем по умолчанию между полями.
Синтаксис
Ниже приведен синтаксис команды Sqoop codegen.
$ sqoop codegen (generic-args) (codegen-args) $ sqoop-codegen (generic-args) (codegen-args)
пример
Давайте возьмем пример, который генерирует код Java для таблицы emp в базе данных userdb .
Следующая команда используется для выполнения данного примера.
$ sqoop codegen \ --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp
Если команда выполняется успешно, она выдаст следующий вывод на терминал.
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation ………………. 14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar
верификация
Давайте посмотрим на результат. Путь, выделенный жирным шрифтом, является местоположением, которое генерирует и сохраняет код Java таблицы emp . Давайте проверим файлы в этом месте, используя следующие команды.
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/ $ ls emp.class emp.jar emp.java
Если вы хотите подробно проверить, сравните таблицу emp в базе данных userdb и emp.java в следующем каталоге
/ TMP / sqoop-Hadoop / компиляции / 9a300a1f94899df4a9b10f9935ed9f91 /.
Sqoop — Eval
В этой главе описывается, как использовать инструмент eq Sqoop. Это позволяет пользователям выполнять пользовательские запросы к соответствующим серверам баз данных и просматривать результаты в консоли. Таким образом, пользователь может ожидать, что данные результирующей таблицы будут импортированы. Используя eval, мы можем оценить любой тип SQL-запроса, который может быть выражением DDL или DML.
Синтаксис
Следующий синтаксис используется для команды Sqoop eval.
$ sqoop eval (generic-args) (eval-args) $ sqoop-eval (generic-args) (eval-args)
Выберите оценку запроса
Используя инструмент eval, мы можем оценить любой тип SQL-запроса. Давайте рассмотрим пример выбора ограниченных строк в таблице сотрудников базы данных БД. Следующая команда используется для оценки данного примера с использованием SQL-запроса.
$ sqoop eval \ --connect jdbc:mysql://localhost/db \ --username root \ --query “SELECT * FROM employee LIMIT 3”
Если команда выполняется успешно, она выдаст следующий вывод на терминал.
+------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | khalil | php dev | 30000 | AC | +------+--------------+-------------+-------------------+--------+
Вставить оценку запроса
Средство Sqoop eval может применяться как для моделирования, так и для определения операторов SQL. Это означает, что мы также можем использовать eval для операторов вставки. Следующая команда используется для вставки новой строки в таблицу сотрудников базы данных базы данных.
$ sqoop eval \ --connect jdbc:mysql://localhost/db \ --username root \ -e “INSERT INTO employee VALUES(1207,‘Raju’,‘UI dev’,15000,‘TP’)”
Если команда выполняется успешно, она отобразит состояние обновленных строк на консоли.
Или вы можете проверить таблицу сотрудников на консоли MySQL. Следующая команда используется для проверки строк таблицы employee базы данных db с помощью запроса select ‘.
mysql> mysql> use db; mysql> SELECT * FROM employee; +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | khalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | | 1207 | Raju | UI dev | 15000 | TP | +------+--------------+-------------+-------------------+--------+
Sqoop — Список баз данных
В этой главе описывается, как вывести список баз данных с помощью Sqoop. Инструмент списка баз данных Sqoop анализирует и выполняет запрос SHOW DATABASES к серверу баз данных. После этого он перечисляет существующие базы данных на сервере.
Синтаксис
Следующий синтаксис используется для команды Sqoop list-database.
$ sqoop list-databases (generic-args) (list-databases-args) $ sqoop-list-databases (generic-args) (list-databases-args)
Образец запроса
Следующая команда используется для вывода списка всех баз данных на сервере баз данных MySQL.
$ sqoop list-databases \ --connect jdbc:mysql://localhost/ \ --username root
Если команда выполняется успешно, она отобразит список баз данных на вашем сервере баз данных MySQL следующим образом.
... 13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. mysql test userdb db
В этой главе описывается, как составить список таблиц конкретной базы данных на сервере базы данных MySQL, используя Sqoop. Инструмент Sqoop list-tables анализирует и выполняет запрос SHOW TABLES для определенной базы данных. После этого он перечисляет существующие таблицы в базе данных.
Синтаксис
Следующий синтаксис используется для команды Sqoop list-tables.
$ sqoop list-tables (generic-args) (list-tables-args) $ sqoop-list-tables (generic-args) (list-tables-args)
Образец запроса
Следующая команда используется для вывода списка всех таблиц в базе данных userdb сервера базы данных MySQL.
$ sqoop list-tables \ --connect jdbc:mysql://localhost/userdb \ --username root
Если команда выполнена успешно, она отобразит список таблиц в базе данных userdb следующим образом.
... 13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. emp emp_add emp_contact
Sqoop — Список таблиц
В этой главе описывается, как составить список таблиц конкретной базы данных на сервере базы данных MySQL, используя Sqoop. Инструмент Sqoop list-tables анализирует и выполняет запрос SHOW TABLES для определенной базы данных. После этого он перечисляет существующие таблицы в базе данных.
Синтаксис
Следующий синтаксис используется для команды Sqoop list-tables.
$ sqoop list-tables (generic-args) (list-tables-args) $ sqoop-list-tables (generic-args) (list-tables-args)
Образец запроса
Следующая команда используется для вывода списка всех таблиц в базе данных userdb сервера базы данных MySQL.
$ sqoop list-tables \ --connect jdbc:mysql://localhost/userdb \ --username root
Если команда выполнена успешно, она отобразит список таблиц в базе данных userdb следующим образом.