Поскольку Sqoop является подпроектом Hadoop, он может работать только в операционной системе Linux. Следуйте приведенным ниже инструкциям, чтобы установить Sqoop в своей системе.
Шаг 1: Проверка установки JAVA
Вам необходимо установить Java в вашей системе перед установкой Sqoop. Давайте проверим установку Java с помощью следующей команды —
$ java –version
Если Java уже установлена в вашей системе, вы увидите следующий ответ:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если Java не установлена в вашей системе, выполните следующие действия.
Установка Java
Следуйте простым шагам, приведенным ниже, чтобы установить Java в вашей системе.
Шаг 1
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке .
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Как правило, вы можете найти загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/java # exitStep IV:
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME=/usr/local/java export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java —
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте установку, используя команду java -version из терминала, как описано выше.
Шаг 2: Проверка установки Hadoop
Hadoop должен быть установлен в вашей системе перед установкой Sqoop. Давайте проверим установку Hadoop с помощью следующей команды —
$ hadoop version
Если Hadoop уже установлен в вашей системе, вы получите следующий ответ:
Hadoop 2.4.1 -- Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Если Hadoop не установлен в вашей системе, выполните следующие шаги:
Загрузка Hadoop
Загрузите и извлеките Hadoop 2.4.1 из Apache Software Foundation, используя следующие команды.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Установка Hadoop в псевдо-распределенном режиме
Выполните шаги, указанные ниже, чтобы установить Hadoop 2.4.1 в псевдораспределенном режиме.
Шаг 1: Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2: Конфигурация Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Вам необходимо внести соответствующие изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Чтобы разрабатывать программы Hadoop с использованием java, необходимо сбросить переменные среды java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением java в вашей системе.
export JAVA_HOME=/usr/local/java
Ниже приведен список файлов, которые необходимо отредактировать для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration> и </ configuration>.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000 </value> </property> </configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и путь datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the following path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value> </property> </configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего вам необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1: Настройка имени узла
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2: Проверка Hadoop dfs
Следующая команда используется для запуска dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3: Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующий:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting node manager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Шаг 4: Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в своем браузере.
http://localhost:50070/
На следующем изображении показан браузер Hadoop.
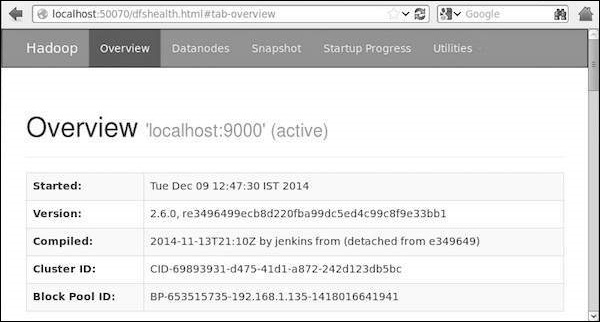
Шаг 5. Проверьте все приложения для кластера.
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для посещения этой службы.
http://localhost:8088/
На следующем изображении показан браузерный кластер Hadoop.
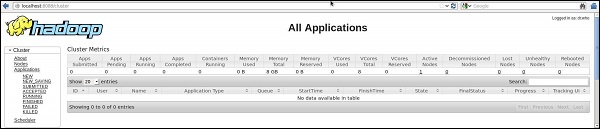
Шаг 3: Загрузка Sqoop
Мы можем загрузить последнюю версию Sqoop по следующей ссылке. Для этого урока мы используем версию 1.4.5, то есть sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz .
Шаг 4: Установка Sqoop
Следующие команды используются для извлечения tar-шара Sqoop и перемещения его в каталог «/ usr / lib / sqoop».
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz $ su password: # mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop #exit
Шаг 5: Настройка bashrc
Вы должны настроить среду Sqoop, добавив следующие строки в файл ~ / .bashrc —
#Sqoop export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/bin
Следующая команда используется для выполнения файла ~ / .bashrc .
$ source ~/.bashrc
Шаг 6: Настройка Sqoop
Чтобы настроить Sqoop с Hadoop, вам нужно отредактировать файл sqoop-env.sh , который находится в каталоге $ SQOOP_HOME / conf . Прежде всего, перенаправьте в каталог конфигурации Sqoop и скопируйте файл шаблона с помощью следующей команды —
$ cd $SQOOP_HOME/conf $ mv sqoop-env-template.sh sqoop-env.sh
Откройте sqoop-env.sh и отредактируйте следующие строки —
export HADOOP_COMMON_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=/usr/local/hadoop
Шаг 7: Загрузите и настройте mysql-connector-java
Мы можем скачать файл mysql-connector-java-5.1.30.tar.gz по следующей ссылке .
Следующие команды используются для извлечения архива mysql-connector-java и перемещения файла mysql-connector-java-5.1.30-bin.jar в каталог / usr / lib / sqoop / lib.
$ tar -zxf mysql-connector-java-5.1.30.tar.gz $ su password: # cd mysql-connector-java-5.1.30 # mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/lib
Шаг 8: Проверка Sqoop
Следующая команда используется для проверки версии Sqoop.
$ cd $SQOOP_HOME/bin $ sqoop-version
Ожидаемый результат —
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83 Compiled by abe on Fri Aug 1 11:19:26 PDT 2014
Установка Sqoop завершена.