В дополнение к встроенным функциям Apache Pig обеспечивает расширенную поддержку определенных функций (UDF). Используя эти UDF, мы можем определить свои собственные функции и использовать их. Поддержка UDF предоставляется на шести языках программирования, а именно на Java, Jython, Python, JavaScript, Ruby и Groovy.
Для написания UDF предоставляется полная поддержка на Java, а ограниченная поддержка предоставляется на всех остальных языках. Используя Java, вы можете писать UDF, включающие все части обработки, такие как загрузка / хранение данных, преобразование столбцов и агрегирование. Поскольку Apache Pig был написан на Java, UDF, написанный на языке Java, работает эффективно по сравнению с другими языками.
В Apache Pig у нас также есть хранилище Java для UDF с именем Piggybank . Используя Piggybank, мы можем получить доступ к Java UDF, написанным другими пользователями, и предоставить свои собственные UDF.
Типы UDF в Java
При написании UDF с использованием Java мы можем создавать и использовать следующие три типа функций:
-
Функции фильтра — Функции фильтра используются в качестве условий в операторах фильтра. Эти функции принимают значение Pig в качестве входных данных и возвращают логическое значение.
-
Функции Eval — Функции Eval используются в инструкциях FOREACH-GENERATE. Эти функции принимают значение Pig в качестве входных данных и возвращают результат Pig.
-
Алгебраические функции — Алгебраические функции действуют на внутренние пакеты в выражении FOREACHGENERATE. Эти функции используются для выполнения полных операций MapReduce на внутренней сумке.
Функции фильтра — Функции фильтра используются в качестве условий в операторах фильтра. Эти функции принимают значение Pig в качестве входных данных и возвращают логическое значение.
Функции Eval — Функции Eval используются в инструкциях FOREACH-GENERATE. Эти функции принимают значение Pig в качестве входных данных и возвращают результат Pig.
Алгебраические функции — Алгебраические функции действуют на внутренние пакеты в выражении FOREACHGENERATE. Эти функции используются для выполнения полных операций MapReduce на внутренней сумке.
Написание UDF с использованием Java
Чтобы написать UDF с использованием Java, мы должны интегрировать файл jar Pig-0.15.0.jar . В этом разделе мы обсудим, как написать пример UDF с использованием Eclipse. Прежде чем продолжить, убедитесь, что в вашей системе установлены Eclipse и Maven.
Следуйте инструкциям ниже, чтобы написать функцию UDF —
-
Откройте Eclipse и создайте новый проект (скажем, myproject ).
-
Преобразуйте недавно созданный проект в проект Maven.
-
Скопируйте следующий контент в pom.xml. Этот файл содержит зависимости Maven для jar-файлов Apache Pig и Hadoop-core.
Откройте Eclipse и создайте новый проект (скажем, myproject ).
Преобразуйте недавно созданный проект в проект Maven.
Скопируйте следующий контент в pom.xml. Этот файл содержит зависимости Maven для jar-файлов Apache Pig и Hadoop-core.
<project xmlns = "http://maven.apache.org/POM/4.0.0" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0http://maven.apache .org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>Pig_Udf</groupId> <artifactId>Pig_Udf</artifactId> <version>0.0.1-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.pig</groupId> <artifactId>pig</artifactId> <version>0.15.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>0.20.2</version> </dependency> </dependencies> </project>
-
Сохраните файл и обновите его. В разделе Maven Dependencies вы можете найти загруженные файлы JAR.
-
Создайте новый файл класса с именем Sample_Eval и скопируйте в него следующее содержимое.
Сохраните файл и обновите его. В разделе Maven Dependencies вы можете найти загруженные файлы JAR.
Создайте новый файл класса с именем Sample_Eval и скопируйте в него следующее содержимое.
import java.io.IOException; import org.apache.pig.EvalFunc; import org.apache.pig.data.Tuple; import java.io.IOException; import org.apache.pig.EvalFunc; import org.apache.pig.data.Tuple; public class Sample_Eval extends EvalFunc<String>{ public String exec(Tuple input) throws IOException { if (input == null || input.size() == 0) return null; String str = (String)input.get(0); return str.toUpperCase(); } }
При написании UDF обязательно наследовать класс EvalFunc и предоставлять реализацию функции exec () . Внутри этой функции написан код, необходимый для UDF. В приведенном выше примере мы возвращаем код для преобразования содержимого данного столбца в верхний регистр.
-
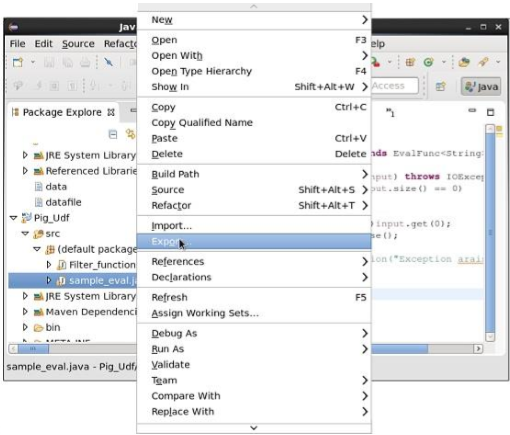
После компиляции класса без ошибок щелкните правой кнопкой мыши файл Sample_Eval.java. Это дает вам меню. Выберите экспорт, как показано на следующем снимке экрана.
После компиляции класса без ошибок щелкните правой кнопкой мыши файл Sample_Eval.java. Это дает вам меню. Выберите экспорт, как показано на следующем снимке экрана.
-
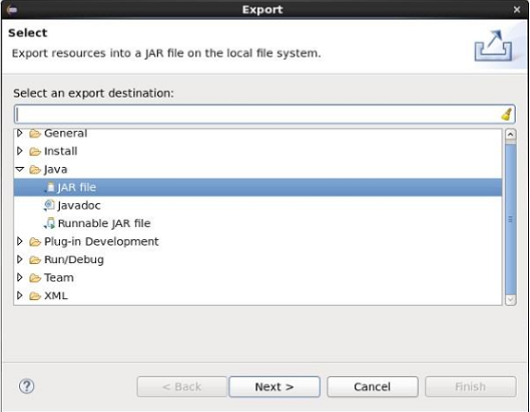
При нажатии кнопки экспорта вы получите следующее окно. Нажмите на файл JAR .
При нажатии кнопки экспорта вы получите следующее окно. Нажмите на файл JAR .
-
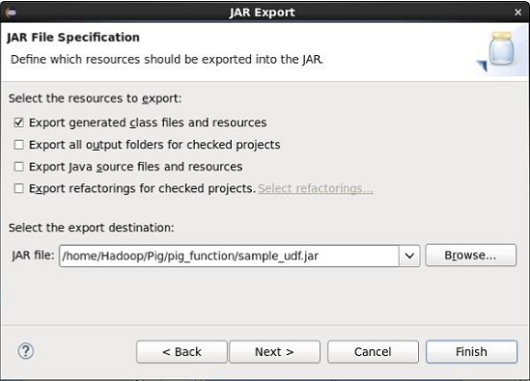
Продолжите, нажав кнопку Далее> . Вы получите другое окно, где вам нужно ввести путь в локальной файловой системе, где вам нужно сохранить файл JAR.
Продолжите, нажав кнопку Далее> . Вы получите другое окно, где вам нужно ввести путь в локальной файловой системе, где вам нужно сохранить файл JAR.
-
Наконец нажмите кнопку Готово . В указанной папке создается файл Jar sample_udf.jar . Этот файл jar содержит UDF, написанный на Java.
Наконец нажмите кнопку Готово . В указанной папке создается файл Jar sample_udf.jar . Этот файл jar содержит UDF, написанный на Java.
Использование UDF
После написания UDF и генерации файла Jar выполните следующие действия:
Шаг 1: Регистрация файла Jar
После написания UDF (на Java) мы должны зарегистрировать файл Jar, содержащий UDF, используя оператор Register. Зарегистрировав файл Jar, пользователи могут указать расположение UDF для Apache Pig.
Синтаксис
Ниже приведен синтаксис оператора Register.
REGISTER path;
пример
В качестве примера давайте зарегистрируем файл sample_udf.jar, созданный ранее в этой главе.
Запустите Apache Pig в локальном режиме и зарегистрируйте файл jar sample_udf.jar, как показано ниже.
$cd PIG_HOME/bin $./pig –x local REGISTER '/$PIG_HOME/sample_udf.jar'
Примечание. Предположим, файл Jar указан в пути — /$PIG_HOME/sample_udf.jar.
Шаг 2: Определение псевдонима
После регистрации UDF мы можем определить его псевдоним с помощью оператора Define .
Синтаксис
Ниже приведен синтаксис оператора Define.
DEFINE alias {function | [`command` [input] [output] [ship] [cache] [stderr] ] };
пример
Определите псевдоним для sample_eval, как показано ниже.
DEFINE sample_eval sample_eval();
Шаг 3: Использование UDF
После определения псевдонима вы можете использовать UDF так же, как встроенные функции. Предположим, что в каталоге HDFS / Pig_Data / есть файл emp_data со следующим содержимым.
001,Robin,22,newyork 002,BOB,23,Kolkata 003,Maya,23,Tokyo 004,Sara,25,London 005,David,23,Bhuwaneshwar 006,Maggy,22,Chennai 007,Robert,22,newyork 008,Syam,23,Kolkata 009,Mary,25,Tokyo 010,Saran,25,London 011,Stacy,25,Bhuwaneshwar 012,Kelly,22,Chennai
И предположим, что мы загрузили этот файл в Pig, как показано ниже.
grunt> emp_data = LOAD 'hdfs://localhost:9000/pig_data/emp1.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, city:chararray);
Теперь давайте преобразуем имена сотрудников в верхний регистр, используя UDF sample_eval .
grunt> Upper_case = FOREACH emp_data GENERATE sample_eval(name);
Проверьте содержимое отношения Upper_case, как показано ниже.