Язык, используемый для анализа данных в Hadoop с использованием Pig, известен как Pig Latin . Это язык обработки данных высокого уровня, который предоставляет богатый набор типов данных и операторов для выполнения различных операций с данными.
Для выполнения конкретной задачи Программистам, использующим Pig, программистам необходимо написать сценарий Pig с использованием языка Pig Latin и выполнить их с использованием любого из механизмов выполнения (Grunt Shell, UDFs, Embedded). После выполнения эти сценарии пройдут серию преобразований, применяемых Pig Framework, для получения желаемого результата.
Внутренне Apache Pig преобразует эти сценарии в серию заданий MapReduce, что облегчает работу программиста. Архитектура Apache Pig показана ниже.
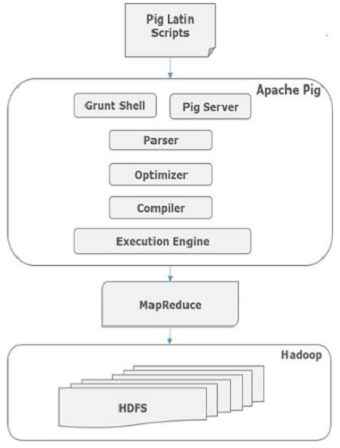
Apache Pig Компоненты
Как показано на рисунке, в платформе Apache Pig есть различные компоненты. Давайте посмотрим на основные компоненты.
синтаксический анализатор
Первоначально сценарии Pig обрабатываются парсером. Он проверяет синтаксис скрипта, выполняет проверку типов и другие разные проверки. Результатом парсера будет DAG (направленный ациклический граф), который представляет операторы Pig Latin и логические операторы.
В группе обеспечения доступности баз данных логические операторы сценария представлены в виде узлов, а потоки данных представлены в виде ребер.
оптимизатор
Логический план (DAG) передается логическому оптимизатору, который выполняет логические оптимизации, такие как проекция и опускание.
составитель
Компилятор компилирует оптимизированный логический план в серию заданий MapReduce.
Движок исполнения
Наконец, задания MapReduce передаются в Hadoop в отсортированном порядке. Наконец, эти задания MapReduce выполняются в Hadoop и дают желаемые результаты.
Модель данных Pig Latin
Модель данных Pig Latin полностью вложена, и она допускает сложные неатомарные типы данных, такие как map и tuple . Ниже приведено схематическое представление модели данных Pig Latin.
Атом
Любое отдельное значение в Pig Latin, независимо от типа данных, называется Atom . Он хранится как строка и может использоваться как строка и число. int, long, float, double, chararray и bytearray — это атомные значения Pig. Часть данных или простая атомарная величина называется полем .
Пример — «Раджа» или «30»
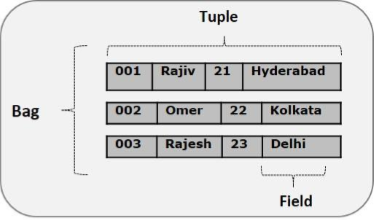
Кортеж
Запись, которая формируется упорядоченным набором полей, называется кортежем, поля могут быть любого типа. Кортеж похож на строку в таблице RDBMS.
Пример — (Раджа, 30)
Мешок
Сумка — это неупорядоченный набор кортежей. Другими словами, коллекция кортежей (неуникальная) называется сумкой. Каждый кортеж может иметь любое количество полей (гибкая схема). Сумка представлена как {{}. Она похожа на таблицу в RDBMS, но в отличие от таблицы в RDBMS, необязательно, чтобы каждый кортеж содержал одинаковое количество полей или чтобы поля в одной и той же позиции (столбце) имели одинаковый тип.
Пример — {(Раджа, 30), (Мухаммед, 45)}
Сумка может быть полем в отношениях; в этом контексте это известно как внутренняя сумка .
Пример — {Raja, 30, {9848022338, raja@gmail.com,} }
карта
Карта (или карта данных) представляет собой набор пар ключ-значение. Ключ должен быть типа chararray и должен быть уникальным. Значение может быть любого типа. Он представлен как ‘[]’
Пример — [имя # Раджа, возраст # 30]
Связь
Отношение — это мешок кортежей. Отношения в Pig Latin неупорядочены (нет никакой гарантии, что кортежи будут обработаны в каком-либо конкретном порядке).