Apache Pig — Обзор
Apache Pig — это абстракция над MapReduce. Это инструмент / платформа, которая используется для анализа больших наборов данных, представляющих их как потоки данных. Свинья обычно используется с Hadoop ; мы можем выполнять все операции с данными в Hadoop, используя Apache Pig.
Для написания программ анализа данных Pig предоставляет язык высокого уровня, известный как Pig Latin . Этот язык предоставляет различные операторы, с помощью которых программисты могут разрабатывать свои собственные функции для чтения, записи и обработки данных.
Чтобы анализировать данные с помощью Apache Pig , программистам необходимо писать сценарии на языке Pig Latin. Все эти скрипты внутренне преобразованы в задачи Map и Reduce. Apache Pig имеет компонент, известный как Pig Engine, который принимает латинские сценарии Pig в качестве входных данных и преобразует эти сценарии в задания MapReduce.
Зачем нам Apache Pig?
Программисты, которые не очень хороши в Java, обычно борются с работой с Hadoop, особенно при выполнении любых задач MapReduce. Apache Pig — благо для всех таких программистов.
-
Используя Pig Latin , программисты могут легко выполнять задачи MapReduce, не вводя сложные коды в Java.
-
Apache Pig использует подход с несколькими запросами , тем самым сокращая длину кодов. Например, операцию, которая потребует от вас ввода 200 строк кода (LoC) в Java, можно легко выполнить, введя всего лишь 10 LoC в Apache Pig. В конечном итоге Apache Pig сокращает время разработки почти в 16 раз.
-
Pig Latin — это SQL-подобный язык, и Apache Pig легко освоить, если вы знакомы с SQL.
-
Apache Pig предоставляет множество встроенных операторов для поддержки операций с данными, таких как объединения, фильтры, упорядочение и т. Д. Кроме того, он также предоставляет вложенные типы данных, такие как кортежи, сумки и карты, которые отсутствуют в MapReduce.
Используя Pig Latin , программисты могут легко выполнять задачи MapReduce, не вводя сложные коды в Java.
Apache Pig использует подход с несколькими запросами , тем самым сокращая длину кодов. Например, операцию, которая потребует от вас ввода 200 строк кода (LoC) в Java, можно легко выполнить, введя всего лишь 10 LoC в Apache Pig. В конечном итоге Apache Pig сокращает время разработки почти в 16 раз.
Pig Latin — это SQL-подобный язык, и Apache Pig легко освоить, если вы знакомы с SQL.
Apache Pig предоставляет множество встроенных операторов для поддержки операций с данными, таких как объединения, фильтры, упорядочение и т. Д. Кроме того, он также предоставляет вложенные типы данных, такие как кортежи, сумки и карты, которые отсутствуют в MapReduce.
Особенности Свиньи
Apache Pig поставляется со следующими функциями —
-
Богатый набор операторов — предоставляет множество операторов для выполнения таких операций, как объединение, сортировка, фильтрация и т. Д.
-
Простота программирования — Pig Latin похож на SQL, и его легко написать, если вы хорошо разбираетесь в SQL.
-
Возможности оптимизации — задачи в Apache Pig автоматически оптимизируют их выполнение, поэтому программистам необходимо сосредоточиться только на семантике языка.
-
Расширяемость — Используя существующие операторы, пользователи могут разрабатывать свои собственные функции для чтения, обработки и записи данных.
-
UDF’s — Pig предоставляет возможность создавать пользовательские функции на других языках программирования, таких как Java, а также вызывать или встраивать их в сценарии Pig.
-
Обрабатывает все виды данных — Apache Pig анализирует все виды данных, как структурированных, так и неструктурированных. Он сохраняет результаты в HDFS.
Богатый набор операторов — предоставляет множество операторов для выполнения таких операций, как объединение, сортировка, фильтрация и т. Д.
Простота программирования — Pig Latin похож на SQL, и его легко написать, если вы хорошо разбираетесь в SQL.
Возможности оптимизации — задачи в Apache Pig автоматически оптимизируют их выполнение, поэтому программистам необходимо сосредоточиться только на семантике языка.
Расширяемость — Используя существующие операторы, пользователи могут разрабатывать свои собственные функции для чтения, обработки и записи данных.
UDF’s — Pig предоставляет возможность создавать пользовательские функции на других языках программирования, таких как Java, а также вызывать или встраивать их в сценарии Pig.
Обрабатывает все виды данных — Apache Pig анализирует все виды данных, как структурированных, так и неструктурированных. Он сохраняет результаты в HDFS.
Apache Pig Vs MapReduce
Ниже перечислены основные различия между Apache Pig и MapReduce.
| Apache Pig | Уменьшение карты |
|---|---|
| Apache Pig — это язык потоков данных. | MapReduce — это парадигма обработки данных. |
| Это язык высокого уровня. | MapReduce низкоуровневый и жесткий. |
| Выполнить операцию соединения в Apache Pig довольно просто. | В MapReduce довольно сложно выполнить операцию соединения между наборами данных. |
| Любой начинающий программист с базовыми знаниями SQL может удобно работать с Apache Pig. | Экспозиция на Java должна работать с MapReduce. |
| Apache Pig использует подход с несколькими запросами, тем самым значительно сокращая длину кодов. | MapReduce потребует почти в 20 раз больше количества строк для выполнения той же задачи. |
| Нет необходимости в компиляции. При выполнении каждый оператор Apache Pig внутренне преобразуется в задание MapReduce. | Задания MapReduce имеют длительный процесс компиляции. |
Apache Pig Vs SQL
Ниже перечислены основные различия между Apache Pig и SQL.
| свинья | SQL |
|---|---|
| Свинья латынь является процедурным языком. | SQL является декларативным языком. |
| В Apache Pig схема является необязательной. Мы можем хранить данные без разработки схемы (значения хранятся как $ 01, $ 02 и т. Д.) | Схема обязательна в SQL. |
| Модель данных в Apache Pig является вложенной реляционной . | Модель данных, используемая в SQL, является плоской реляционной . |
| Apache Pig предоставляет ограниченные возможности для оптимизации запросов . | Существует больше возможностей для оптимизации запросов в SQL. |
В дополнение к вышеуказанным различиям, Apache Pig Latin —
- Позволяет расколы в конвейере.
- Позволяет разработчикам хранить данные в любом месте конвейера.
- Объявляет планы выполнения.
- Предоставляет операторы для выполнения функций ETL (извлечение, преобразование и загрузка).
Apache Pig Vs Hive
Apache Pig и Hive используются для создания рабочих мест MapReduce. А в некоторых случаях Hive работает с HDFS аналогично Apache Pig. В следующей таблице мы перечислили несколько важных моментов, которые отличают Apache Pig от Hive.
| Apache Pig | улей |
|---|---|
| Apache Pig использует язык Pig Latin . Первоначально он был создан в Yahoo . | Hive использует язык HiveQL . Первоначально он был создан на Facebook . |
| Pig Latin — это язык потоков данных. | HiveQL — это язык обработки запросов. |
| Свинья латынь является процедурным языком, и она соответствует парадигме конвейера. | HiveQL — декларативный язык. |
| Apache Pig может обрабатывать структурированные, неструктурированные и полуструктурированные данные. | Улей в основном для структурированных данных. |
Приложения Apache Pig
Apache Pig обычно используется исследователями данных для выполнения задач, включающих специальную обработку и быстрое создание прототипов. Apache Pig используется —
- Для обработки огромных источников данных, таких как веб-журналы.
- Выполнить обработку данных для поисковых платформ.
- Для обработки чувствительных ко времени загрузок данных.
Apache Pig — История
В 2006 году Apache Pig был разработан в качестве исследовательского проекта в Yahoo, особенно для создания и выполнения заданий MapReduce для каждого набора данных. В 2007 году Apache Pig был открыт с помощью инкубатора Apache. В 2008 году вышел первый выпуск Apache Pig. В 2010 году Apache Pig получил высшее образование в качестве проекта Apache.
Apache Pig — Архитектура
Язык, используемый для анализа данных в Hadoop с использованием Pig, известен как Pig Latin . Это язык обработки данных высокого уровня, который предоставляет богатый набор типов данных и операторов для выполнения различных операций с данными.
Для выполнения конкретной задачи Программистам, использующим Pig, программистам необходимо написать сценарий Pig с использованием языка Pig Latin и выполнить их с использованием любого из механизмов выполнения (Grunt Shell, UDFs, Embedded). После выполнения эти сценарии пройдут серию преобразований, применяемых Pig Framework, для получения желаемого результата.
Внутренне Apache Pig преобразует эти сценарии в серию заданий MapReduce, что облегчает работу программиста. Архитектура Apache Pig показана ниже.
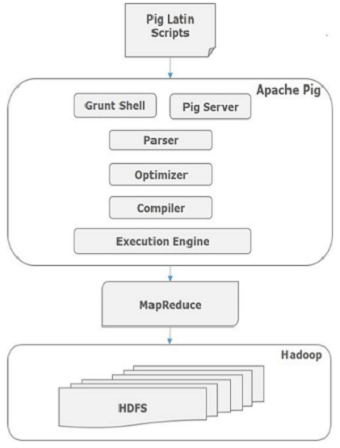
Apache Pig Компоненты
Как показано на рисунке, в платформе Apache Pig есть различные компоненты. Давайте посмотрим на основные компоненты.
синтаксический анализатор
Первоначально сценарии Pig обрабатываются парсером. Он проверяет синтаксис скрипта, выполняет проверку типов и другие разные проверки. Результатом парсера будет DAG (направленный ациклический граф), который представляет операторы Pig Latin и логические операторы.
В группе обеспечения доступности баз данных логические операторы сценария представлены в виде узлов, а потоки данных представлены в виде ребер.
оптимизатор
Логический план (DAG) передается логическому оптимизатору, который выполняет логические оптимизации, такие как проекция и опускание.
составитель
Компилятор компилирует оптимизированный логический план в серию заданий MapReduce.
Движок исполнения
Наконец, задания MapReduce передаются в Hadoop в отсортированном порядке. Наконец, эти задания MapReduce выполняются в Hadoop и дают желаемые результаты.
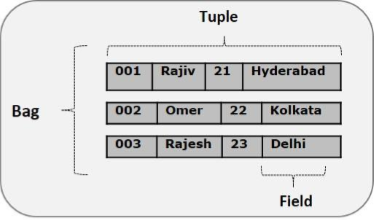
Модель данных Pig Latin
Модель данных Pig Latin полностью вложена, и она допускает сложные неатомарные типы данных, такие как map и tuple . Ниже приведено схематическое представление модели данных Pig Latin.
Атом
Любое отдельное значение в Pig Latin, независимо от типа данных, называется Atom . Он хранится как строка и может использоваться как строка и число. int, long, float, double, chararray и bytearray — это атомные значения Pig. Часть данных или простая атомарная величина называется полем .
Пример — «Раджа» или «30»
Кортеж
Запись, которая формируется упорядоченным набором полей, называется кортежем, поля могут быть любого типа. Кортеж похож на строку в таблице RDBMS.
Пример — (Раджа, 30)
Мешок
Сумка — это неупорядоченный набор кортежей. Другими словами, коллекция кортежей (неуникальная) называется сумкой. Каждый кортеж может иметь любое количество полей (гибкая схема). Сумка представлена как {{}. Она похожа на таблицу в RDBMS, но в отличие от таблицы в RDBMS, необязательно, чтобы каждый кортеж содержал одинаковое количество полей или чтобы поля в одной и той же позиции (столбце) имели одинаковый тип.
Пример — {(Раджа, 30), (Мухаммед, 45)}
Сумка может быть полем в отношениях; в этом контексте это известно как внутренняя сумка .
Пример — {Raja, 30, {9848022338, raja@gmail.com,} }
карта
Карта (или карта данных) представляет собой набор пар ключ-значение. Ключ должен быть типа chararray и должен быть уникальным. Значение может быть любого типа. Он представлен как ‘[]’
Пример — [имя # Раджа, возраст # 30]
Связь
Отношение — это мешок кортежей. Отношения в Pig Latin неупорядочены (нет никакой гарантии, что кортежи будут обработаны в каком-либо конкретном порядке).
Apache Pig — Установка
В этой главе объясняется, как загрузить, установить и настроить Apache Pig в вашей системе.
Предпосылки
Очень важно, чтобы в вашей системе были установлены Hadoop и Java, прежде чем переходить на Apache Pig. Поэтому перед установкой Apache Pig установите Hadoop и Java, выполнив действия, указанные в следующей ссылке:
http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Скачать Apache Pig
Прежде всего, загрузите последнюю версию Apache Pig со следующего веб-сайта — https://pig.apache.org/
Шаг 1
Откройте домашнюю страницу веб-сайта Apache Pig. Под разделом Новости нажмите на страницу выпуска ссылки, как показано на следующем снимке.
Шаг 2
При нажатии на указанную ссылку вы будете перенаправлены на страницу Apache Pig Releases . На этой странице в разделе « Загрузка » у вас будет две ссылки: Pig 0.8 и более поздние версии и Pig 0.7 и более ранние версии . Нажмите на ссылку Pig 0.8 и позже , после чего вы будете перенаправлены на страницу с набором зеркал.
Шаг 3
Выберите и нажмите любое из этих зеркал, как показано ниже.
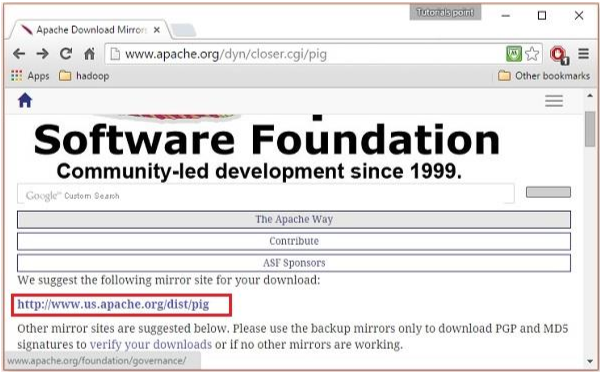
Шаг 4
Эти зеркала перенесут вас на страницу Pig Releases . Эта страница содержит различные версии Apache Pig. Нажмите на последнюю версию среди них.
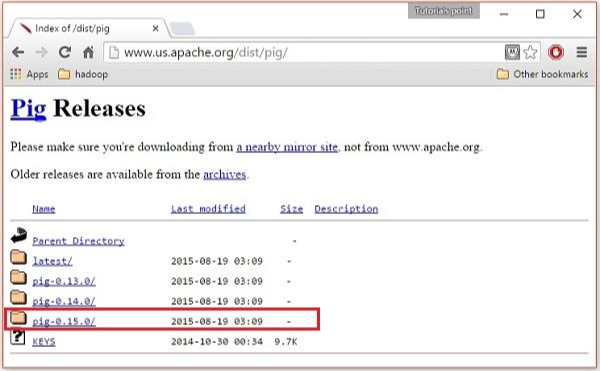
Шаг 5
В этих папках у вас будут исходные и двоичные файлы Apache Pig в различных дистрибутивах. Загрузите tar-файлы исходного кода и двоичные файлы Apache Pig 0.15, pig0.15.0-src.tar.gz и pig-0.15.0.tar.gz.
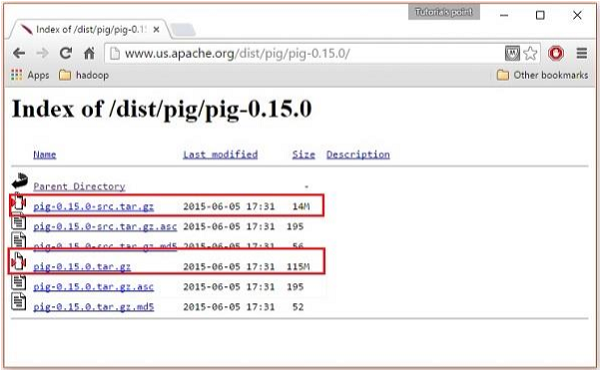
Установите Apache Pig
После загрузки программного обеспечения Apache Pig установите его в своей среде Linux, следуя инструкциям, приведенным ниже.
Шаг 1
Создайте каталог с именем Pig в том же каталоге, где были установлены каталоги установки Hadoop, Java и другого программного обеспечения. (В нашем уроке мы создали каталог Pig для пользователя с именем Hadoop).
$ mkdir Pig
Шаг 2
Извлеките загруженные файлы tar, как показано ниже.
$ cd Downloads/ $ tar zxvf pig-0.15.0-src.tar.gz $ tar zxvf pig-0.15.0.tar.gz
Шаг 3
Переместите содержимое файла pig-0.15.0-src.tar.gz в каталог Pig, созданный ранее, как показано ниже.
$ mv pig-0.15.0-src.tar.gz/* /home/Hadoop/Pig/
Настройте Apache Pig
После установки Apache Pig мы должны его настроить. Для настройки нам нужно отредактировать два файла — bashrc и pig.properties .
файл .bashrc
В файле .bashrc установите следующие переменные —
-
Папка PIG_HOME в папку установки Apache Pig,
-
Переменная среды PATH для папки bin и
-
Переменная среды PIG_CLASSPATH в папку etc (configuration) ваших установок Hadoop (каталог, содержащий файлы core-site.xml, hdfs-site.xml и mapred-site.xml).
Папка PIG_HOME в папку установки Apache Pig,
Переменная среды PATH для папки bin и
Переменная среды PIG_CLASSPATH в папку etc (configuration) ваших установок Hadoop (каталог, содержащий файлы core-site.xml, hdfs-site.xml и mapred-site.xml).
export PIG_HOME = /home/Hadoop/Pig export PATH = $PATH:/home/Hadoop/pig/bin export PIG_CLASSPATH = $HADOOP_HOME/conf
файл pig.properties
В папке conf Pig у нас есть файл с именем pig.properties . В файле pig.properties вы можете установить различные параметры, как указано ниже.
pig -h properties
Поддерживаются следующие свойства —
Logging: verbose = true|false; default is false. This property is the same as -v
switch brief=true|false; default is false. This property is the same
as -b switch debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO.
This property is the same as -d switch aggregate.warning = true|false; default is true.
If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=<mem fraction>; default is 0.2 (20% of all memory).
Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=<mem fraction>; default is 0.3 (30% of all memory).
Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false.
Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default.
Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default.
Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default.
Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip.
Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default.
Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false.
Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=<min aggregation factor>. Default is 10.
If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=<comma seperated list of jars>. Used in place of register command.
udf.import.list=<comma seperated list of imports>. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=<UTC time offset>. e.g. +08:00. Default is the default timezone of the host.
Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.
Проверка установки
Проверьте установку Apache Pig, введя команду version. Если установка прошла успешно, вы получите версию Apache Pig, как показано ниже.
$ pig –version Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35
Apache Pig — Казнь
В предыдущей главе мы объяснили, как установить Apache Pig. В этой главе мы обсудим, как выполнить Apache Pig.
Режимы выполнения Apache Pig
Вы можете запустить Apache Pig в двух режимах, а именно, в локальном режиме и в режиме HDFS .
Локальный режим
В этом режиме все файлы устанавливаются и запускаются с локального хоста и локальной файловой системы. Нет необходимости в Hadoop или HDFS. Этот режим обычно используется для целей тестирования.
Режим MapReduce
В режиме MapReduce мы загружаем или обрабатываем данные, которые существуют в файловой системе Hadoop (HDFS), с использованием Apache Pig. В этом режиме всякий раз, когда мы выполняем операторы Pig Latin для обработки данных, в серверной части вызывается задание MapReduce для выполнения определенной операции с данными, существующими в HDFS.
Apache Pig Механизмы исполнения
Сценарии Apache Pig могут быть выполнены тремя способами, а именно: интерактивный режим, пакетный режим и встроенный режим.
-
Интерактивный режим (оболочка Grunt) — вы можете запустить Apache Pig в интерактивном режиме с помощью оболочки Grunt. В этой оболочке вы можете ввести операторы Pig Latin и получить выходные данные (используя оператор Dump).
-
Пакетный режим (скрипт) — вы можете запустить Apache Pig в пакетном режиме, написав скрипт Pig Latin в одном файле с расширением .pig .
-
Встроенный режим (UDF) — Apache Pig предоставляет возможность определения наших собственных функций (определенных функций F ) в таких языках программирования, как Java, и их использования в нашем скрипте.
Интерактивный режим (оболочка Grunt) — вы можете запустить Apache Pig в интерактивном режиме с помощью оболочки Grunt. В этой оболочке вы можете ввести операторы Pig Latin и получить выходные данные (используя оператор Dump).
Пакетный режим (скрипт) — вы можете запустить Apache Pig в пакетном режиме, написав скрипт Pig Latin в одном файле с расширением .pig .
Встроенный режим (UDF) — Apache Pig предоставляет возможность определения наших собственных функций (определенных функций F ) в таких языках программирования, как Java, и их использования в нашем скрипте.
Вызов скорлупы
Вы можете вызвать оболочку Grunt в нужном режиме (local / MapReduce), используя параметр -x, как показано ниже.
| Локальный режим | Режим MapReduce |
|---|---|
|
Команда — $ ./pig –x local |
Команда — $ ./pig -x mapreduce |
|
Выход —
|
Выход —
|
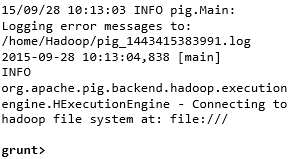
Команда —
$ ./pig –x local
Команда —
$ ./pig -x mapreduce
Выход —
Выход —
Любая из этих команд выдает приглашение оболочки Grunt, как показано ниже.
grunt>
Вы можете выйти из оболочки Grunt, используя ctrl + d.
После вызова оболочки Grunt вы можете выполнить скрипт Pig, непосредственно введя в него операторы Pig Latin.
grunt> customers = LOAD 'customers.txt' USING PigStorage(',');
Выполнение Apache Pig в пакетном режиме
Вы можете написать весь скрипт Pig Latin в файле и выполнить его с помощью команды –x . Предположим, у нас есть скрипт Pig в файле с именем sample_script.pig, как показано ниже.
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',') as (id:int,name:chararray,city:chararray); Dump student;
Теперь вы можете выполнить скрипт в вышеуказанном файле, как показано ниже.
| Локальный режим | Режим MapReduce |
|---|---|
| $ pig -x local Sample_script.pig | $ pig -x mapreduce Sample_script.pig |
Примечание. В последующих главах мы подробно обсудим, как запускать сценарий Pig в режиме Баха и во встроенном режиме .
Apache Pig — Grunt Shell
После вызова оболочки Grunt вы можете запустить свои сценарии Pig в оболочке. В дополнение к этому, есть некоторые полезные команды оболочки и утилиты, предоставляемые оболочкой Grunt. В этой главе описываются команды оболочки и утилиты, предоставляемые оболочкой Grunt.
Примечание. В некоторых частях этой главы используются такие команды, как Load и Store . Обратитесь к соответствующим главам, чтобы получить подробную информацию о них.
Команды оболочки
Оболочка Grunt Apache Pig в основном используется для написания латинских скриптов Pig. До этого мы можем вызывать любые команды оболочки, используя sh и fs .
Sh Command
Используя команду sh , мы можем вызывать любые команды оболочки из оболочки Grunt. Используя команду sh из оболочки Grunt, мы не можем выполнять команды, которые являются частью среды оболочки ( ex- cd).
Синтаксис
Ниже приведен синтаксис команды sh .
grunt> sh shell command parameters
пример
Мы можем вызвать команду ls оболочки Linux из оболочки Grunt, используя опцию sh, как показано ниже. В этом примере он перечисляет файлы в каталоге / pig / bin / .
grunt> sh ls pig pig_1444799121955.log pig.cmd pig.py
Команда FS
Используя команду fs , мы можем вызывать любые команды FsShell из оболочки Grunt.
Синтаксис
Ниже приведен синтаксис команды fs .
grunt> sh File System command parameters
пример
Мы можем вызвать команду ls HDFS из оболочки Grunt с помощью команды fs. В следующем примере перечислены файлы в корневом каталоге HDFS.
grunt> fs –ls Found 3 items drwxrwxrwx - Hadoop supergroup 0 2015-09-08 14:13 Hbase drwxr-xr-x - Hadoop supergroup 0 2015-09-09 14:52 seqgen_data drwxr-xr-x - Hadoop supergroup 0 2015-09-08 11:30 twitter_data
Таким же образом мы можем вызывать все другие команды оболочки файловой системы из оболочки Grunt с помощью команды fs .
Команды утилиты
Оболочка Grunt предоставляет набор служебных команд. К ним относятся служебные команды, такие как очистка, справка, история, выход и установка ; и такие команды, как exec, kill и run для управления Pig из оболочки Grunt. Ниже приведено описание служебных команд, предоставляемых оболочкой Grunt.
очистить команду
Команда очистки используется для очистки экрана оболочки Grunt.
Синтаксис
Вы можете очистить экран оболочки grunt с помощью команды очистки, как показано ниже.
grunt> clear
Команда помощи
Команда help выдает список команд Pig или свойств Pig.
использование
Вы можете получить список команд Pig, используя команду help, как показано ниже.
grunt> help
Commands: <pig latin statement>; - See the PigLatin manual for details:
http://hadoop.apache.org/pig
File system commands:fs <fs arguments> - Equivalent to Hadoop dfs command:
http://hadoop.apache.org/common/docs/current/hdfs_shell.html
Diagnostic Commands:describe <alias>[::<alias] - Show the schema for the alias.
Inner aliases can be described as A::B.
explain [-script <pigscript>] [-out <path>] [-brief] [-dot|-xml]
[-param <param_name>=<pCram_value>]
[-param_file <file_name>] [<alias>] -
Show the execution plan to compute the alias or for entire script.
-script - Explain the entire script.
-out - Store the output into directory rather than print to stdout.
-brief - Don't expand nested plans (presenting a smaller graph for overview).
-dot - Generate the output in .dot format. Default is text format.
-xml - Generate the output in .xml format. Default is text format.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
alias - Alias to explain.
dump <alias> - Compute the alias and writes the results to stdout.
Utility Commands: exec [-param <param_name>=param_value] [-param_file <file_name>] <script> -
Execute the script with access to grunt environment including aliases.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
script - Script to be executed.
run [-param <param_name>=param_value] [-param_file <file_name>] <script> -
Execute the script with access to grunt environment.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
script - Script to be executed.
sh <shell command> - Invoke a shell command.
kill <job_id> - Kill the hadoop job specified by the hadoop job id.
set <key> <value> - Provide execution parameters to Pig. Keys and values are case sensitive.
The following keys are supported:
default_parallel - Script-level reduce parallelism. Basic input size heuristics used
by default.
debug - Set debug on or off. Default is off.
job.name - Single-quoted name for jobs. Default is PigLatin:<script name>
job.priority - Priority for jobs. Values: very_low, low, normal, high, very_high.
Default is normal stream.skippath - String that contains the path.
This is used by streaming any hadoop property.
help - Display this message.
history [-n] - Display the list statements in cache.
-n Hide line numbers.
quit - Quit the grunt shell.
Команда истории
Эта команда отображает список операторов, выполненных / использованных до тех пор, пока вызывается Grunt sell.
использование
Предположим, мы выполнили три оператора с момента открытия оболочки Grunt.
grunt> customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(','); grunt> orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(','); grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',');
Затем, используя команду history, получим следующий вывод.
grunt> history
customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',');
orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(',');
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',');
установить команду
Команда set используется для отображения / назначения значений клавишам, используемым в Pig.
использование
Используя эту команду, вы можете установить значения для следующих клавиш.
| ключ | Описание и значения |
|---|---|
| default_parallel | Вы можете установить число редукторов для задания карты, передавая любое целое число в качестве значения для этого ключа. |
| отлаживать | Вы можете выключить или включить существо отладки в Pig, передавая / выключая эту клавишу. |
| название работы | Вы можете установить имя задания на требуемое задание, передав строковое значение этому ключу. |
| job.priority |
Вы можете установить приоритет задания для задания, передав этому ключу одно из следующих значений:
|
| stream.skippath | Для потоковой передачи вы можете установить путь, откуда данные не должны передаваться, передавая этот ключ в виде строки в виде строки. |
Вы можете установить приоритет задания для задания, передав этому ключу одно из следующих значений:
выйти из команды
Вы можете выйти из оболочки Grunt с помощью этой команды.
использование
Выйдите из оболочки Grunt, как показано ниже.
grunt> quit
Давайте теперь посмотрим на команды, с помощью которых вы можете управлять Apache Pig из оболочки Grunt.
Exec Command
Используя команду exec , мы можем выполнить сценарии Pig из оболочки Grunt.
Синтаксис
Ниже приведен синтаксис служебной команды exec .
grunt> exec [–param param_name = param_value] [–param_file file_name] [script]
пример
Предположим, что в каталоге / pig_data / HDFS есть файл student.txt со следующим содержимым.
Student.txt
001,Rajiv,Hyderabad 002,siddarth,Kolkata 003,Rajesh,Delhi
И, предположим, у нас есть файл сценария с именем sample_script.pig в каталоге / pig_data / HDFS со следующим содержимым.
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',') as (id:int,name:chararray,city:chararray); Dump student;
Теперь давайте выполним приведенный выше скрипт из оболочки Grunt с помощью команды exec, как показано ниже.
grunt> exec /sample_script.pig
Выход
Команда exec выполняет сценарий в файле sample_script.pig . Как указано в сценарии, он загружает файл student.txt в Pig и выдает результат оператора Dump, отображающий следующее содержимое.
(1,Rajiv,Hyderabad) (2,siddarth,Kolkata) (3,Rajesh,Delhi)
убить команду
Вы можете убить задание из оболочки Grunt с помощью этой команды.
Синтаксис
Ниже приведен синтаксис команды kill .
grunt> kill JobId
пример
Предположим, что есть запущенное задание Pig с идентификатором Id_0055 , вы можете уничтожить его из оболочки Grunt с помощью команды kill , как показано ниже.
grunt> kill Id_0055
Команда запуска
Вы можете запустить скрипт Pig из оболочки Grunt с помощью команды run
Синтаксис
Ниже приведен синтаксис команды run .
grunt> run [–param param_name = param_value] [–param_file file_name] script
пример
Предположим, что в каталоге / pig_data / HDFS есть файл student.txt со следующим содержимым.
Student.txt
001,Rajiv,Hyderabad 002,siddarth,Kolkata 003,Rajesh,Delhi
И, предположим, у нас есть файл сценария с именем sample_script.pig в локальной файловой системе со следующим содержимым.
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',') as (id:int,name:chararray,city:chararray);
Теперь давайте запустим приведенный выше скрипт из оболочки Grunt с помощью команды run, как показано ниже.
grunt> run /sample_script.pig
Вы можете увидеть вывод скрипта с помощью оператора Dump, как показано ниже.
grunt> Dump; (1,Rajiv,Hyderabad) (2,siddarth,Kolkata) (3,Rajesh,Delhi)
Примечание . Разница между exec и командой run заключается в том, что если мы используем run , операторы из сценария доступны в истории команд.
Свинья латынь — Основы
Pig Latin — это язык, используемый для анализа данных в Hadoop с использованием Apache Pig. В этой главе мы собираемся обсудить основы Pig Latin, такие как операторы Pig Latin, типы данных, общие и реляционные операторы и пользовательские функции Pig Latin.
Свинья латинская — модель данных
Как обсуждалось в предыдущих главах, модель данных Pig полностью вложена. Отношение является самой внешней структурой модели данных Pig Latin. И это сумка, где —
- Сумка — это коллекция кортежей.
- Кортеж — это упорядоченный набор полей.
- Поле — это часть данных.
Свинья латинская — Statemets
При обработке данных с использованием Pig Latin операторы являются основными конструкциями.
-
Эти заявления работают с отношениями . Они включают выражения и схемы .
-
Каждое утверждение заканчивается точкой с запятой (;).
-
Мы будем выполнять различные операции, используя операторы, предоставленные Pig Latin, через операторы.
-
За исключением LOAD и STORE, при выполнении всех других операций операторы Pig Latin принимают отношение в качестве входных данных и создают другое отношение в качестве выходных данных.
-
Как только вы введете оператор Load в оболочку Grunt, будет выполнена его семантическая проверка. Чтобы увидеть содержимое схемы, вам нужно использовать оператор Dump . Только после выполнения операции дампа будет выполнено задание MapReduce для загрузки данных в файловую систему.
Эти заявления работают с отношениями . Они включают выражения и схемы .
Каждое утверждение заканчивается точкой с запятой (;).
Мы будем выполнять различные операции, используя операторы, предоставленные Pig Latin, через операторы.
За исключением LOAD и STORE, при выполнении всех других операций операторы Pig Latin принимают отношение в качестве входных данных и создают другое отношение в качестве выходных данных.
Как только вы введете оператор Load в оболочку Grunt, будет выполнена его семантическая проверка. Чтобы увидеть содержимое схемы, вам нужно использовать оператор Dump . Только после выполнения операции дампа будет выполнено задание MapReduce для загрузки данных в файловую систему.
пример
Ниже приведен оператор Pig Latin, который загружает данные в Apache Pig.
grunt> Student_data = LOAD 'student_data.txt' USING PigStorage(',')as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Pig Latin — Типы данных
Приведенная ниже таблица описывает типы данных Pig Latin.
| SN | Тип данных | Описание и пример |
|---|---|---|
| 1 | ИНТ |
Представляет 32-разрядное целое число со знаком. Пример : 8 |
| 2 | долго |
Представляет 64-разрядное целое число со знаком. Пример : 5л |
| 3 | поплавок |
Представляет 32-битную с плавающей запятой со знаком. Пример : 5.5F |
| 4 | двойной |
Представляет 64-битную плавающую точку. Пример : 10,5 |
| 5 | chararray |
Представляет массив символов (строку) в формате Unicode UTF-8. Пример : «точка обучения» |
| 6 | ByteArray, |
Представляет массив байтов (BLOB-объектов). |
| 7 | логический |
Представляет логическое значение. Пример : правда / ложь. |
| 8 | Datetime |
Представляет дату-время. Пример : 1970-01-01T00: 00: 00.000 + 00: 00 |
| 9 | BigInteger |
Представляет Java BigInteger. Пример : 60708090709 |
| 10 | BigDecimal |
Представляет Java BigDecimal Пример : 185,98376256272893883 |
| Сложные типы | ||
| 11 | Кортеж |
Кортеж — это упорядоченный набор полей. Пример : (Раджа, 30) |
| 12 | Мешок |
Сумка — это коллекция кортежей. Пример : {(Раджу, 30), (Мухаммед, 45)} |
| 13 | карта |
Карта — это набор пар ключ-значение. Пример : [‘name’ # ‘Raju’, ‘age’ # 30] |
Представляет 32-разрядное целое число со знаком.
Пример : 8
Представляет 64-разрядное целое число со знаком.
Пример : 5л
Представляет 32-битную с плавающей запятой со знаком.
Пример : 5.5F
Представляет 64-битную плавающую точку.
Пример : 10,5
Представляет массив символов (строку) в формате Unicode UTF-8.
Пример : «точка обучения»
Представляет массив байтов (BLOB-объектов).
Представляет логическое значение.
Пример : правда / ложь.
Представляет дату-время.
Пример : 1970-01-01T00: 00: 00.000 + 00: 00
Представляет Java BigInteger.
Пример : 60708090709
Представляет Java BigDecimal
Пример : 185,98376256272893883
Кортеж — это упорядоченный набор полей.
Пример : (Раджа, 30)
Сумка — это коллекция кортежей.
Пример : {(Раджу, 30), (Мухаммед, 45)}
Карта — это набор пар ключ-значение.
Пример : [‘name’ # ‘Raju’, ‘age’ # 30]
Нулевые значения
Значения для всех вышеперечисленных типов данных могут быть NULL. Apache Pig обрабатывает нулевые значения таким же образом, как SQL.
Ноль может быть неизвестным значением или несуществующим значением. Он используется в качестве заполнителя для необязательных значений. Эти нули могут возникать естественным образом или быть результатом операции.
Pig Latin — Арифметические операторы
В следующей таблице описаны арифметические операторы Pig Latin. Предположим, что а = 10 и б = 20.
| оператор | Описание | пример |
|---|---|---|
| + |
Добавление — добавляет значения по обе стороны от оператора |
а + б даст 30 |
| — |
Вычитание — вычитает правый операнд из левого операнда |
а — б даст -10 |
| * |
Умножение — умножает значения по обе стороны от оператора |
а * б даст 200 |
| / |
Деление — делит левый операнд на правый операнд |
б / у даст 2 |
| % |
Модуль — Делит левый операнд на правый операнд и возвращает остаток |
б% а даст 0 |
| ? : |
Bincond — оценивает логические операторы. У него есть три операнда, как показано ниже. переменная х = (выражение)? value1, если true : значение2, если false . |
б = (а == 1)? 20:30; если a = 1, значение b равно 20. если a! = 1, значение b равно 30. |
|
ДЕЛО КОГДА ЗАТЕМ ELSE END |
Case — Оператор case эквивалентен вложенному оператору bincond. |
ДЕЛО f2% 2 КОГДА 0 ТОГДА КОГДА 1 ТОГДА «ЧУДА» КОНЕЦ |
Добавление — добавляет значения по обе стороны от оператора
Вычитание — вычитает правый операнд из левого операнда
Умножение — умножает значения по обе стороны от оператора
Деление — делит левый операнд на правый операнд
Модуль — Делит левый операнд на правый операнд и возвращает остаток
Bincond — оценивает логические операторы. У него есть три операнда, как показано ниже.
переменная х = (выражение)? value1, если true : значение2, если false .
б = (а == 1)? 20:30;
если a = 1, значение b равно 20.
если a! = 1, значение b равно 30.
ДЕЛО
КОГДА
ЗАТЕМ
ELSE END
Case — Оператор case эквивалентен вложенному оператору bincond.
ДЕЛО f2% 2
КОГДА 0 ТОГДА
КОГДА 1 ТОГДА «ЧУДА»
КОНЕЦ
Pig Latin — Операторы сравнения
В следующей таблице описаны операторы сравнения Pig Latin.
| оператор | Описание | пример |
|---|---|---|
| == |
Равно — Проверяет, равны ли значения двух операндов или нет; если да, то условие становится истинным. |
(а = б) не соответствует действительности |
| знак равно |
Не равно — Проверяет, равны ли значения двух операндов или нет. Если значения не равны, то условие становится истинным. |
(a! = b) верно. |
| > |
Больше чем — Проверяет, больше ли значение левого операнда, чем значение правого операнда. Если да, то условие становится истинным. |
(а> б) не соответствует действительности. |
| < |
Меньше — Проверяет, меньше ли значение левого операнда, чем значение правого операнда. Если да, то условие становится истинным. |
(а <б) верно. |
| > = |
Больше или равно — Проверяет, является ли значение левого операнда больше или равно значению правого операнда. Если да, то условие становится истинным. |
(a> = b) не соответствует действительности. |
| <= |
Меньше или равно — Проверяет, является ли значение левого операнда меньше или равно значению правого операнда. Если да, то условие становится истинным. |
(a <= b) верно. |
| Матчи |
Сопоставление с образцом — проверяет, совпадает ли строка в левой части с константой в правой части. |
f1 соответствует «. * tutorial. *» |
Равно — Проверяет, равны ли значения двух операндов или нет; если да, то условие становится истинным.
Не равно — Проверяет, равны ли значения двух операндов или нет. Если значения не равны, то условие становится истинным.
Больше чем — Проверяет, больше ли значение левого операнда, чем значение правого операнда. Если да, то условие становится истинным.
Меньше — Проверяет, меньше ли значение левого операнда, чем значение правого операнда. Если да, то условие становится истинным.
Больше или равно — Проверяет, является ли значение левого операнда больше или равно значению правого операнда. Если да, то условие становится истинным.
Меньше или равно — Проверяет, является ли значение левого операнда меньше или равно значению правого операнда. Если да, то условие становится истинным.
Сопоставление с образцом — проверяет, совпадает ли строка в левой части с константой в правой части.
Pig Latin — Тип строительных операторов
В следующей таблице описаны операторы конструирования типа Pig Latin.
| оператор | Описание | пример |
|---|---|---|
| () |
Оператор конструктора кортежа — этот оператор используется для создания кортежа. |
(Раджу, 30) |
| {} |
Оператор конструктора сумки — этот оператор используется для создания сумки. |
{(Раджу, 30), (Мухаммед, 45)} |
| [] |
Оператор конструктора карты — этот оператор используется для создания кортежа. |
[имя # Раджа, возраст # 30] |
Оператор конструктора кортежа — этот оператор используется для создания кортежа.
Оператор конструктора сумки — этот оператор используется для создания сумки.
Оператор конструктора карты — этот оператор используется для создания кортежа.
Свинья Латинская — Реляционные Операции
Следующая таблица описывает реляционные операторы Pig Latin.
| оператор | Описание |
|---|---|
| Загрузка и хранение | |
| НАГРУЗКИ | Загрузить данные из файловой системы (локальной / HDFS) в отношение. |
| ХРАНИТЬ | Сохранить отношение к файловой системе (локальной / HDFS). |
| фильтрация | |
| ФИЛЬТР | Чтобы удалить ненужные строки из отношения. |
| DISTINCT | Удалить дублирующиеся строки из отношения. |
| FOREACH, GENERATE | Для генерации преобразований данных на основе столбцов данных. |
| ПОТОК | Для преобразования отношения используется внешняя программа. |
| Группировка и объединение | |
| ПРИСОЕДИНИТЬСЯ | Чтобы объединить два или более отношений. |
| COGROUP | Группировать данные в два или более отношений. |
| GROUP | Для группировки данных в одном отношении. |
| ПЕРЕСЕКАТЬ | Для создания перекрестного произведения двух или более отношений. |
| Сортировка | |
| ПОРЯДОК | Упорядочить отношения в отсортированном порядке на основе одного или нескольких полей (по возрастанию или по убыванию). |
| ПРЕДЕЛ | Чтобы получить ограниченное количество кортежей из отношения. |
| Объединение и расщепление | |
| UNION | Объединить два или более отношений в одно отношение. |
| ТРЕЩИНА | Разделить одно отношение на два или более отношений. |
| Диагностические операторы | |
| DUMP | Распечатать содержимое отношения на консоли. |
| ОПИСАНИЯ | Для описания схемы отношения. |
| EXPLAIN | Чтобы просмотреть планы выполнения логического, физического или MapReduce для вычисления отношения. |
| иллюстрировать | Для просмотра пошагового выполнения серии заявлений. |
Apache Pig — чтение данных
В общем, Apache Pig работает поверх Hadoop. Это аналитический инструмент, который анализирует большие наборы данных, которые существуют в H adoop File System. Чтобы проанализировать данные с помощью Apache Pig, мы должны сначала загрузить данные в Apache Pig. В этой главе объясняется, как загрузить данные в Apache Pig из HDFS.
Подготовка HDFS
В режиме MapReduce Pig считывает (загружает) данные из HDFS и сохраняет результаты обратно в HDFS. Поэтому давайте запустим HDFS и создадим следующий пример данных в HDFS.
| Студенческий билет | Имя | Фамилия | Телефон | город |
|---|---|---|---|---|
| 001 | Раджив | Reddy | 9848022337 | Хайдарабад |
| 002 | Siddarth | Battacharya | 9848022338 | Kolkata |
| 003 | Раджеш | Кханна | 9848022339 | Дели |
| 004 | Preethi | Агарвал | 9848022330 | Пуна |
| 005 | Trupthi | Mohanthy | 9848022336 | Bhuwaneshwar |
| 006 | Archana | Мишра | 9848022335 | Chennai |
Приведенный выше набор данных содержит личные данные, такие как удостоверение личности, имя, фамилия, номер телефона и город для шести студентов.
Шаг 1: Проверка Hadoop
Прежде всего, проверьте установку с помощью команды версии Hadoop, как показано ниже.
$ hadoop version
Если ваша система содержит Hadoop, и вы установили переменную PATH, вы получите следующий вывод:
Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop common-2.6.0.jar
Шаг 2: Запуск HDFS
Просмотрите каталог sbin Hadoop и запустите yarn и Hadoop dfs (распределенную файловую систему), как показано ниже.
cd /$Hadoop_Home/sbin/ $ start-dfs.sh localhost: starting namenode, logging to /home/Hadoop/hadoop/logs/hadoopHadoop-namenode-localhost.localdomain.out localhost: starting datanode, logging to /home/Hadoop/hadoop/logs/hadoopHadoop-datanode-localhost.localdomain.out Starting secondary namenodes [0.0.0.0] starting secondarynamenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoopsecondarynamenode-localhost.localdomain.out $ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoopresourcemanager-localhost.localdomain.out localhost: starting nodemanager, logging to /home/Hadoop/hadoop/logs/yarnHadoop-nodemanager-localhost.localdomain.out
Шаг 3: Создайте каталог в HDFS
В Hadoop DFS вы можете создавать каталоги с помощью команды mkdir . Создайте новый каталог в HDFS с именем Pig_Data в требуемом пути, как показано ниже.
$cd /$Hadoop_Home/bin/ $ hdfs dfs -mkdir hdfs://localhost:9000/Pig_Data
Шаг 4: Размещение данных в HDFS
Входной файл Pig содержит каждый кортеж / запись в отдельных строках. А сущности записи разделяются разделителем (в нашем примере мы использовали «,» ).
В локальной файловой системе создайте входной файл student_data.txt, содержащий данные, как показано ниже.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
Теперь переместите файл из локальной файловой системы в HDFS, используя команду put, как показано ниже. (Вы также можете использовать команду copyFromLocal .)
$ cd $HADOOP_HOME/bin $ hdfs dfs -put /home/Hadoop/Pig/Pig_Data/student_data.txt dfs://localhost:9000/pig_data/
Проверка файла
Вы можете использовать команду cat, чтобы проверить, был ли файл перемещен в HDFS, как показано ниже.
$ cd $HADOOP_HOME/bin $ hdfs dfs -cat hdfs://localhost:9000/pig_data/student_data.txt
Выход
Вы можете увидеть содержимое файла, как показано ниже.
15/10/01 12:16:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai
Оператор загрузки
Вы можете загрузить данные в Apache Pig из файловой системы (HDFS / Local), используя оператор LOAD для Pig Latin .
Синтаксис
Оператор загрузки состоит из двух частей, разделенных оператором «=». С левой стороны нам нужно указать имя отношения, в котором мы хотим хранить данные, а с правой стороны мы должны определить, как мы храним данные. Ниже приведен синтаксис оператора Load .
Relation_name = LOAD 'Input file path' USING function as schema;
Куда,
-
имя_отношения — мы должны упомянуть отношение, в котором мы хотим хранить данные.
-
Путь к входному файлу — мы должны упомянуть каталог HDFS, в котором хранится файл. (В режиме MapReduce)
-
функция — мы должны выбрать функцию из набора функций загрузки, предоставляемых Apache Pig ( BinStorage, JsonLoader, PigStorage, TextLoader ).
-
Схема — мы должны определить схему данных. Мы можем определить требуемую схему следующим образом:
имя_отношения — мы должны упомянуть отношение, в котором мы хотим хранить данные.
Путь к входному файлу — мы должны упомянуть каталог HDFS, в котором хранится файл. (В режиме MapReduce)
функция — мы должны выбрать функцию из набора функций загрузки, предоставляемых Apache Pig ( BinStorage, JsonLoader, PigStorage, TextLoader ).
Схема — мы должны определить схему данных. Мы можем определить требуемую схему следующим образом:
(column1 : data type, column2 : data type, column3 : data type);
Примечание. Мы загружаем данные без указания схемы. В этом случае столбцы будут адресованы как $ 01, $ 02 и т. Д. (Отметьте).
пример
В качестве примера, давайте загрузим данные в student_data.txt в Pig по схеме с именем Student, используя команду LOAD .
Запустите Pig Grunt Shell
Прежде всего, откройте терминал Linux. Запустите оболочку Pig Grunt в режиме MapReduce, как показано ниже.
$ Pig –x mapreduce
Это запустит Pig Grunt, как показано ниже.
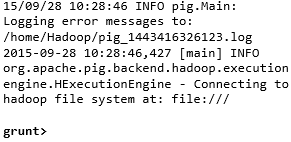
15/10/01 12:33:37 INFO pig.ExecTypeProvider: Trying ExecType : LOCAL 15/10/01 12:33:37 INFO pig.ExecTypeProvider: Trying ExecType : MAPREDUCE 15/10/01 12:33:37 INFO pig.ExecTypeProvider: Picked MAPREDUCE as the ExecType 2015-10-01 12:33:38,080 [main] INFO org.apache.pig.Main - Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35 2015-10-01 12:33:38,080 [main] INFO org.apache.pig.Main - Logging error messages to: /home/Hadoop/pig_1443683018078.log 2015-10-01 12:33:38,242 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/Hadoop/.pigbootup not found 2015-10-01 12:33:39,630 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://localhost:9000 grunt>
Выполнить оператор загрузки
Теперь загрузите данные из файла student_data.txt в Pig, выполнив следующую инструкцию Pig Latin в оболочке Grunt.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Ниже приведено описание вышеприведенного утверждения.
| Имя отношения | Мы сохранили данные в схеме студента . | ||||||||||||
| Путь к входному файлу | Мы читаем данные из файла student_data.txt, которая находится в каталоге / pig_data / HDFS. | ||||||||||||
| Функция хранения | Мы использовали функцию PigStorage () . Он загружает и хранит данные в виде структурированных текстовых файлов. В качестве параметра требуется разделитель, использующий каждую сущность кортежа. По умолчанию он принимает ‘\ t’ в качестве параметра. | ||||||||||||
| схема |
Мы сохранили данные, используя следующую схему.
|
Мы сохранили данные, используя следующую схему.
Примечание. Оператор load просто загружает данные в указанное отношение в Pig. Чтобы проверить выполнение оператора Load , вы должны использовать диагностические операторы, которые обсуждаются в следующих главах.
Apache Pig — Хранение данных
В предыдущей главе мы узнали, как загружать данные в Apache Pig. Вы можете сохранить загруженные данные в файловой системе, используя оператор хранилища . В этой главе объясняется, как хранить данные в Apache Pig с помощью оператора Store .
Синтаксис
Ниже приведен синтаксис оператора Store.
STORE Relation_name INTO ' required_directory_path ' [USING function];
пример
Предположим, у нас есть файл student_data.txt в HDFS со следующим содержимым.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
И мы прочитали это в студента отношений, используя оператор LOAD, как показано ниже.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Теперь давайте сохраним отношение в каталоге HDFS «/ pig_Output /», как показано ниже.
grunt> STORE student INTO ' hdfs://localhost:9000/pig_Output/ ' USING PigStorage (',');
Выход
После выполнения оператора store вы получите следующий вывод. Каталог создается с указанным именем, и в нем будут храниться данные.
2015-10-05 13:05:05,429 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.
MapReduceLau ncher - 100% complete
2015-10-05 13:05:05,429 [main] INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats -
Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.6.0 0.15.0 Hadoop 2015-10-0 13:03:03 2015-10-05 13:05:05 UNKNOWN
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTime AvgMapTime MedianMapTime
job_14459_06 1 0 n/a n/a n/a n/a
MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature
0 0 0 0 student MAP_ONLY
OutPut folder
hdfs://localhost:9000/pig_Output/
Input(s): Successfully read 0 records from: "hdfs://localhost:9000/pig_data/student_data.txt"
Output(s): Successfully stored 0 records in: "hdfs://localhost:9000/pig_Output"
Counters:
Total records written : 0
Total bytes written : 0
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG: job_1443519499159_0006
2015-10-05 13:06:06,192 [main] INFO org.apache.pig.backend.hadoop.executionengine
.mapReduceLayer.MapReduceLau ncher - Success!
верификация
Вы можете проверить сохраненные данные, как показано ниже.
Шаг 1
Прежде всего, перечислите файлы в каталоге с именем pig_output с помощью команды ls, как показано ниже.
hdfs dfs -ls 'hdfs://localhost:9000/pig_Output/' Found 2 items rw-r--r- 1 Hadoop supergroup 0 2015-10-05 13:03 hdfs://localhost:9000/pig_Output/_SUCCESS rw-r--r- 1 Hadoop supergroup 224 2015-10-05 13:03 hdfs://localhost:9000/pig_Output/part-m-00000
Вы можете заметить, что два файла были созданы после выполнения оператора store .
Шаг 2
Используя команду cat , перечислите содержимое файла с именем part-m-00000, как показано ниже.
$ hdfs dfs -cat 'hdfs://localhost:9000/pig_Output/part-m-00000' 1,Rajiv,Reddy,9848022337,Hyderabad 2,siddarth,Battacharya,9848022338,Kolkata 3,Rajesh,Khanna,9848022339,Delhi 4,Preethi,Agarwal,9848022330,Pune 5,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 6,Archana,Mishra,9848022335,Chennai
Apache Pig — диагностические операторы
Оператор load просто загрузит данные в указанное отношение в Apache Pig. Чтобы проверить выполнение оператора Load , вы должны использовать диагностические операторы . Pig Latin предоставляет четыре различных типа диагностических операторов —
- Оператор дампа
- Опишите оператора
- Объяснение оператора
- Оператор иллюстрации
В этой главе мы обсудим операторы дампа Pig Latin.
Оператор дампа
Оператор Dump используется для запуска операторов Pig Latin и отображения результатов на экране. Обычно используется для отладки.
Синтаксис
Ниже приведен синтаксис оператора дампа .
grunt> Dump Relation_Name
пример
Предположим, у нас есть файл student_data.txt в HDFS со следующим содержимым.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
И мы прочитали это в студента отношений, используя оператор LOAD, как показано ниже.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Теперь давайте распечатаем содержимое отношения, используя оператор Dump, как показано ниже.
grunt> Dump student
Как только вы выполните вышеупомянутый оператор Pig Latin , он запустит задание MapReduce для чтения данных из HDFS. Это даст следующий результат.
2015-10-01 15:05:27,642 [main]
INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher -
100% complete
2015-10-01 15:05:27,652 [main]
INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.6.0 0.15.0 Hadoop 2015-10-01 15:03:11 2015-10-01 05:27 UNKNOWN
Success!
Job Stats (time in seconds):
JobId job_14459_0004
Maps 1
Reduces 0
MaxMapTime n/a
MinMapTime n/a
AvgMapTime n/a
MedianMapTime n/a
MaxReduceTime 0
MinReduceTime 0
AvgReduceTime 0
MedianReducetime 0
Alias student
Feature MAP_ONLY
Outputs hdfs://localhost:9000/tmp/temp580182027/tmp757878456,
Input(s): Successfully read 0 records from: "hdfs://localhost:9000/pig_data/
student_data.txt"
Output(s): Successfully stored 0 records in: "hdfs://localhost:9000/tmp/temp580182027/
tmp757878456"
Counters: Total records written : 0 Total bytes written : 0 Spillable Memory Manager
spill count : 0Total bags proactively spilled: 0 Total records proactively spilled: 0
Job DAG: job_1443519499159_0004
2015-10-01 15:06:28,403 [main]
INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLau ncher - Success!
2015-10-01 15:06:28,441 [main] INFO org.apache.pig.data.SchemaTupleBackend -
Key [pig.schematuple] was not set... will not generate code.
2015-10-01 15:06:28,485 [main]
INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths
to process : 1
2015-10-01 15:06:28,485 [main]
INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths
to process : 1
(1,Rajiv,Reddy,9848022337,Hyderabad)
(2,siddarth,Battacharya,9848022338,Kolkata)
(3,Rajesh,Khanna,9848022339,Delhi)
(4,Preethi,Agarwal,9848022330,Pune)
(5,Trupthi,Mohanthy,9848022336,Bhuwaneshwar)
(6,Archana,Mishra,9848022335,Chennai)
Apache Pig — Опишите оператора
Оператор description используется для просмотра схемы отношения.
Синтаксис
Синтаксис оператора description выглядит следующим образом:
grunt> Describe Relation_name
пример
Предположим, у нас есть файл student_data.txt в HDFS со следующим содержимым.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
И мы прочитали это в студента отношений, используя оператор LOAD, как показано ниже.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Теперь давайте опишем отношение с именем student и проверим схему, как показано ниже.
grunt> describe student;
Выход
Как только вы выполните вышеупомянутое выражение Pig Latin , оно выдаст следующий результат.
grunt> student: { id: int,firstname: chararray,lastname: chararray,phone: chararray,city: chararray }
Apache Pig — оператор объяснения
Оператор объяснения используется для отображения логических, физических и планов выполнения MapReduce отношения.
Синтаксис
Ниже приведен синтаксис оператора объяснения .
grunt> explain Relation_name;
пример
Предположим, у нас есть файл student_data.txt в HDFS со следующим содержимым.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
И мы прочитали это в студента отношений, используя оператор LOAD, как показано ниже.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Теперь давайте объясним отношение с именем student с помощью оператора объяснения, как показано ниже.
grunt> explain student;
Выход
Это даст следующий результат.
$ explain student;
2015-10-05 11:32:43,660 [main]
2015-10-05 11:32:43,660 [main] INFO org.apache.pig.newplan.logical.optimizer
.LogicalPlanOptimizer -
{RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, ConstantCalculator,
GroupByConstParallelSetter, LimitOptimizer, LoadTypeCastInserter, MergeFilter,
MergeForEach, PartitionFilterOptimizer, PredicatePushdownOptimizer,
PushDownForEachFlatten, PushUpFilter, SplitFilter, StreamTypeCastInserter]}
#-----------------------------------------------
# New Logical Plan:
#-----------------------------------------------
student: (Name: LOStore Schema:
id#31:int,firstname#32:chararray,lastname#33:chararray,phone#34:chararray,city#
35:chararray)
|
|---student: (Name: LOForEach Schema:
id#31:int,firstname#32:chararray,lastname#33:chararray,phone#34:chararray,city#
35:chararray)
| |
| (Name: LOGenerate[false,false,false,false,false] Schema:
id#31:int,firstname#32:chararray,lastname#33:chararray,phone#34:chararray,city#
35:chararray)ColumnPrune:InputUids=[34, 35, 32, 33,
31]ColumnPrune:OutputUids=[34, 35, 32, 33, 31]
| | |
| | (Name: Cast Type: int Uid: 31)
| | | | | |---id:(Name: Project Type: bytearray Uid: 31 Input: 0 Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 32)
| | |
| | |---firstname:(Name: Project Type: bytearray Uid: 32 Input: 1
Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 33)
| | |
| | |---lastname:(Name: Project Type: bytearray Uid: 33 Input: 2
Column: (*))
| | |
| | (Name: Cast Type: chararray Uid: 34)
| | |
| | |---phone:(Name: Project Type: bytearray Uid: 34 Input: 3 Column:
(*))
| | |
| | (Name: Cast Type: chararray Uid: 35)
| | |
| | |---city:(Name: Project Type: bytearray Uid: 35 Input: 4 Column:
(*))
| |
| |---(Name: LOInnerLoad[0] Schema: id#31:bytearray)
| |
| |---(Name: LOInnerLoad[1] Schema: firstname#32:bytearray)
| |
| |---(Name: LOInnerLoad[2] Schema: lastname#33:bytearray)
| |
| |---(Name: LOInnerLoad[3] Schema: phone#34:bytearray)
| |
| |---(Name: LOInnerLoad[4] Schema: city#35:bytearray)
|
|---student: (Name: LOLoad Schema:
id#31:bytearray,firstname#32:bytearray,lastname#33:bytearray,phone#34:bytearray
,city#35:bytearray)RequiredFields:null
#-----------------------------------------------
# Physical Plan: #-----------------------------------------------
student: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-36
|
|---student: New For Each(false,false,false,false,false)[bag] - scope-35
| |
| Cast[int] - scope-21
| |
| |---Project[bytearray][0] - scope-20
| |
| Cast[chararray] - scope-24
| |
| |---Project[bytearray][1] - scope-23
| |
| Cast[chararray] - scope-27
| |
| |---Project[bytearray][2] - scope-26
| |
| Cast[chararray] - scope-30
| |
| |---Project[bytearray][3] - scope-29
| |
| Cast[chararray] - scope-33
| |
| |---Project[bytearray][4] - scope-32
|
|---student: Load(hdfs://localhost:9000/pig_data/student_data.txt:PigStorage(',')) - scope19
2015-10-05 11:32:43,682 [main]
INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler -
File concatenation threshold: 100 optimistic? false
2015-10-05 11:32:43,684 [main]
INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOp timizer -
MR plan size before optimization: 1 2015-10-05 11:32:43,685 [main]
INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.
MultiQueryOp timizer - MR plan size after optimization: 1
#--------------------------------------------------
# Map Reduce Plan
#--------------------------------------------------
MapReduce node scope-37
Map Plan
student: Store(fakefile:org.apache.pig.builtin.PigStorage) - scope-36
|
|---student: New For Each(false,false,false,false,false)[bag] - scope-35
| |
| Cast[int] - scope-21
| |
| |---Project[bytearray][0] - scope-20
| |
| Cast[chararray] - scope-24
| |
| |---Project[bytearray][1] - scope-23
| |
| Cast[chararray] - scope-27
| |
| |---Project[bytearray][2] - scope-26
| |
| Cast[chararray] - scope-30
| |
| |---Project[bytearray][3] - scope-29
| |
| Cast[chararray] - scope-33
| |
| |---Project[bytearray][4] - scope-32
|
|---student:
Load(hdfs://localhost:9000/pig_data/student_data.txt:PigStorage(',')) - scope
19-------- Global sort: false
----------------
Apache Pig — иллюстрированный оператор
Оператор illustrate предоставляет пошаговое выполнение последовательности операторов.
Синтаксис
Ниже приведен синтаксис оператора Illustrate.
grunt> illustrate Relation_name;
пример
Предположим, у нас есть файл student_data.txt в HDFS со следующим содержимым.
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
И мы прочитали это в студента отношений, используя оператор LOAD, как показано ниже.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt' USING PigStorage(',') as ( id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray );
Теперь давайте проиллюстрируем отношение с именем student, как показано ниже.
grunt> illustrate student;
Выход
Выполнив вышеприведенное утверждение, вы получите следующий вывод.
grunt> illustrate student; INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigMapOnly$M ap - Aliases being processed per job phase (AliasName[line,offset]): M: student[1,10] C: R: --------------------------------------------------------------------------------------------- |student | id:int | firstname:chararray | lastname:chararray | phone:chararray | city:chararray | --------------------------------------------------------------------------------------------- | | 002 | siddarth | Battacharya | 9848022338 | Kolkata | ---------------------------------------------------------------------------------------------
Apache Pig — оператор группы
Оператор GROUP используется для группировки данных в одно или несколько отношений. Он собирает данные, имеющие один и тот же ключ.
Синтаксис
Ниже приведен синтаксис группового оператора.
grunt> Group_data = GROUP Relation_name BY age;
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Apache Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
Теперь давайте сгруппируем записи / кортежи в зависимости от возраста, как показано ниже.
grunt> group_data = GROUP student_details by age;
верификация
Проверьте отношение group_data с помощью оператора DUMP, как показано ниже.
grunt> Dump group_data;
Выход
Затем вы получите вывод, отображающий содержимое отношения с именем group_data, как показано ниже. Здесь вы можете заметить, что полученная схема имеет два столбца:
-
Одним из них является возраст , по которому мы сгруппировали отношения.
-
Другой представляет собой сумку , которая содержит группу кортежей, студенческие записи с соответствующим возрастом.
Одним из них является возраст , по которому мы сгруппировали отношения.
Другой представляет собой сумку , которая содержит группу кортежей, студенческие записи с соответствующим возрастом.
(21,{(4,Preethi,Agarwal,21,9848022330,Pune),(1,Rajiv,Reddy,21,9848022337,Hydera bad)})
(22,{(3,Rajesh,Khanna,22,9848022339,Delhi),(2,siddarth,Battacharya,22,984802233 8,Kolkata)})
(23,{(6,Archana,Mishra,23,9848022335,Chennai),(5,Trupthi,Mohanthy,23,9848022336 ,Bhuwaneshwar)})
(24,{(8,Bharathi,Nambiayar,24,9848022333,Chennai),(7,Komal,Nayak,24,9848022334, trivendram)})
Вы можете увидеть схему таблицы после группировки данных с помощью команды описать, как показано ниже.
grunt> Describe group_data;
group_data: {group: int,student_details: {(id: int,firstname: chararray,
lastname: chararray,age: int,phone: chararray,city: chararray)}}
Таким же образом вы можете получить образец иллюстрации схемы, используя команду illustrate, как показано ниже.
$ Illustrate group_data;
Это даст следующий результат —
-------------------------------------------------------------------------------------------------
|group_data| group:int | student_details:bag{:tuple(id:int,firstname:chararray,lastname:chararray,age:int,phone:chararray,city:chararray)}|
-------------------------------------------------------------------------------------------------
| | 21 | { 4, Preethi, Agarwal, 21, 9848022330, Pune), (1, Rajiv, Reddy, 21, 9848022337, Hyderabad)}|
| | 2 | {(2,siddarth,Battacharya,22,9848022338,Kolkata),(003,Rajesh,Khanna,22,9848022339,Delhi)}|
-------------------------------------------------------------------------------------------------
Группировка по нескольким столбцам
Давайте сгруппируем соотношение по возрасту и городу, как показано ниже.
grunt> group_multiple = GROUP student_details by (age, city);
Вы можете проверить содержимое отношения с именем group_multiple, используя оператор Dump, как показано ниже.
grunt> Dump group_multiple;
((21,Pune),{(4,Preethi,Agarwal,21,9848022330,Pune)})
((21,Hyderabad),{(1,Rajiv,Reddy,21,9848022337,Hyderabad)})
((22,Delhi),{(3,Rajesh,Khanna,22,9848022339,Delhi)})
((22,Kolkata),{(2,siddarth,Battacharya,22,9848022338,Kolkata)})
((23,Chennai),{(6,Archana,Mishra,23,9848022335,Chennai)})
((23,Bhuwaneshwar),{(5,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar)})
((24,Chennai),{(8,Bharathi,Nambiayar,24,9848022333,Chennai)})
(24,trivendram),{(7,Komal,Nayak,24,9848022334,trivendram)})
Группа Все
Вы можете сгруппировать отношения по всем столбцам, как показано ниже.
grunt> group_all = GROUP student_details All;
Теперь проверьте содержимое отношения group_all, как показано ниже.
grunt> Dump group_all;
(all,{(8,Bharathi,Nambiayar,24,9848022333,Chennai),(7,Komal,Nayak,24,9848022334 ,trivendram),
(6,Archana,Mishra,23,9848022335,Chennai),(5,Trupthi,Mohanthy,23,9848022336,Bhuw aneshwar),
(4,Preethi,Agarwal,21,9848022330,Pune),(3,Rajesh,Khanna,22,9848022339,Delhi),
(2,siddarth,Battacharya,22,9848022338,Kolkata),(1,Rajiv,Reddy,21,9848022337,Hyd erabad)})
Apache Pig — оператор Cogroup
Оператор COGROUP работает более или менее так же, как оператор GROUP . Единственное различие между этими двумя операторами состоит в том, что оператор группы обычно используется с одним отношением, тогда как оператор cogroup используется в операторах, включающих два или более отношений.
Группировка двух отношений с использованием Cogroup
Предположим, что у нас есть два файла, а именно student_details.txt и employee_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
employee_details.txt
001,Robin,22,newyork 002,BOB,23,Kolkata 003,Maya,23,Tokyo 004,Sara,25,London 005,David,23,Bhuwaneshwar 006,Maggy,22,Chennai
И мы загрузили эти файлы в Pig с именами отношений student_details и employee_details соответственно, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray); grunt> employee_details = LOAD 'hdfs://localhost:9000/pig_data/employee_details.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, city:chararray);
Теперь давайте сгруппируем записи / кортежи отношений student_details и employee_details с ключевым возрастом, как показано ниже.
grunt> cogroup_data = COGROUP student_details by age, employee_details by age;
верификация
Проверьте отношение cogroup_data, используя оператор DUMP, как показано ниже.
grunt> Dump cogroup_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения с именем cogroup_data, как показано ниже.
(21,{(4,Preethi,Agarwal,21,9848022330,Pune), (1,Rajiv,Reddy,21,9848022337,Hyderabad)},
{ })
(22,{ (3,Rajesh,Khanna,22,9848022339,Delhi), (2,siddarth,Battacharya,22,9848022338,Kolkata) },
{ (6,Maggy,22,Chennai),(1,Robin,22,newyork) })
(23,{(6,Archana,Mishra,23,9848022335,Chennai),(5,Trupthi,Mohanthy,23,9848022336 ,Bhuwaneshwar)},
{(5,David,23,Bhuwaneshwar),(3,Maya,23,Tokyo),(2,BOB,23,Kolkata)})
(24,{(8,Bharathi,Nambiayar,24,9848022333,Chennai),(7,Komal,Nayak,24,9848022334, trivendram)},
{ })
(25,{ },
{(4,Sara,25,London)})
Оператор cogroup группирует кортежи из каждого отношения в соответствии с возрастом, где каждая группа отображает определенное значение возраста.
Например, если мы рассмотрим 1-й кортеж результата, он сгруппирован по возрасту 21. И он содержит две сумки —
-
первая сумка содержит все кортежи из первого отношения (в данном случае student_details ), имеющие возраст 21, и
-
второй пакет содержит все кортежи из второго отношения (в данном случае employee_details ), которым исполнился 21 год.
первая сумка содержит все кортежи из первого отношения (в данном случае student_details ), имеющие возраст 21, и
второй пакет содержит все кортежи из второго отношения (в данном случае employee_details ), которым исполнился 21 год.
Если отношение не имеет кортежей со значением возраста 21, оно возвращает пустой пакет.
Apache Pig — присоединиться к оператору
Оператор JOIN используется для объединения записей из двух или более отношений. При выполнении операции соединения мы объявляем один (или группу) кортежей из каждого отношения в качестве ключей. Когда эти ключи совпадают, два конкретных кортежа совпадают, иначе записи удаляются. Объединения могут быть следующих типов —
- Автообъединение
- Внутреннее соединение
- Внешнее соединение — левое соединение, правое соединение и полное соединение
В этой главе с примерами объясняется, как использовать оператор соединения в Pig Latin. Предположим, что у нас есть два файла, а именно customer.txt и orders.txt в каталоге / pig_data / HDFS, как показано ниже.
customers.txt
1,Ramesh,32,Ahmedabad,2000.00 2,Khilan,25,Delhi,1500.00 3,kaushik,23,Kota,2000.00 4,Chaitali,25,Mumbai,6500.00 5,Hardik,27,Bhopal,8500.00 6,Komal,22,MP,4500.00 7,Muffy,24,Indore,10000.00
orders.txt
102,2009-10-08 00:00:00,3,3000 100,2009-10-08 00:00:00,3,1500 101,2009-11-20 00:00:00,2,1560 103,2008-05-20 00:00:00,4,2060
И мы загрузили эти два файла в Pig с отношениями с клиентами и заказами, как показано ниже.
grunt> customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, address:chararray, salary:int); grunt> orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(',') as (oid:int, date:chararray, customer_id:int, amount:int);
Давайте теперь выполним различные операции соединения над этими двумя отношениями.
Самостоятельно присоединиться
Self-join используется для объединения таблицы с самим собой, как если бы в таблице было два отношения, временно переименовывающих хотя бы одно отношение.
Обычно в Apache Pig для самостоятельного объединения мы загружаем одни и те же данные несколько раз под разными псевдонимами (именами). Поэтому давайте загрузим содержимое файла customer.txt в виде двух таблиц, как показано ниже.
grunt> customers1 = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, address:chararray, salary:int); grunt> customers2 = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, address:chararray, salary:int);
Синтаксис
Ниже приведен синтаксис выполнения операции самостоятельного соединения с использованием оператора JOIN .
grunt> Relation3_name = JOIN Relation1_name BY key, Relation2_name BY key ;
пример
Давайте выполним операцию самосоединения над отношениями клиентов , объединив два отношения клиенты1 и клиенты2, как показано ниже.
grunt> customers3 = JOIN customers1 BY id, customers2 BY id;
верификация
Проверьте отношение клиентов3 с помощью оператора DUMP, как показано ниже.
grunt> Dump customers3;
Выход
Он выдаст следующий вывод, отображающий содержимое отношений с клиентами .
(1,Ramesh,32,Ahmedabad,2000,1,Ramesh,32,Ahmedabad,2000) (2,Khilan,25,Delhi,1500,2,Khilan,25,Delhi,1500) (3,kaushik,23,Kota,2000,3,kaushik,23,Kota,2000) (4,Chaitali,25,Mumbai,6500,4,Chaitali,25,Mumbai,6500) (5,Hardik,27,Bhopal,8500,5,Hardik,27,Bhopal,8500) (6,Komal,22,MP,4500,6,Komal,22,MP,4500) (7,Muffy,24,Indore,10000,7,Muffy,24,Indore,10000)
Внутреннее соединение
Inner Join используется довольно часто; это также упоминается как equijoin . Внутреннее соединение возвращает строки, когда в обеих таблицах есть совпадение.
Он создает новое отношение путем объединения значений столбцов двух отношений (скажем, A и B) на основе предиката соединения. Запрос сравнивает каждую строку A с каждой строкой B, чтобы найти все пары строк, которые удовлетворяют предикату соединения. Когда предикат соединения удовлетворяется, значения столбцов для каждой соответствующей пары строк A и B объединяются в результирующую строку.
Синтаксис
Вот синтаксис выполнения операции внутреннего соединения с использованием оператора JOIN .
grunt> result = JOIN relation1 BY columnname, relation2 BY columnname;
пример
Давайте выполним внутреннюю операцию соединения двух клиентов и заказов, как показано ниже.
grunt> coustomer_orders = JOIN customers BY id, orders BY customer_id;
верификация
Проверьте отношение coustomer_orders с помощью оператора DUMP, как показано ниже.
grunt> Dump coustomer_orders;
Выход
Вы получите следующий вывод, который будет содержать содержимое отношения с именем coustomer_orders .
(2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (3,kaushik,23,Kota,2000,100,2009-10-08 00:00:00,3,1500) (3,kaushik,23,Kota,2000,102,2009-10-08 00:00:00,3,3000) (4,Chaitali,25,Mumbai,6500,103,2008-05-20 00:00:00,4,2060)
Примечание —
Внешнее соединение : в отличие от внутреннего соединения, внешнее соединение возвращает все строки хотя бы из одного отношения. Операция внешнего соединения выполняется тремя способами:
- Левое внешнее соединение
- Правое внешнее соединение
- Полное внешнее соединение
Левое внешнее соединение
Левая внешняя операция Join возвращает все строки из левой таблицы, даже если в правом отношении нет совпадений.
Синтаксис
Ниже приведен синтаксис выполнения левой операции внешнего соединения с использованием оператора JOIN .
grunt> Relation3_name = JOIN Relation1_name BY id LEFT OUTER, Relation2_name BY customer_id;
пример
Давайте выполним операцию левого внешнего соединения для двух отношений с клиентами и заказами, как показано ниже.
grunt> outer_left = JOIN customers BY id LEFT OUTER, orders BY customer_id;
верификация
Проверьте отношение external_left с помощью оператора DUMP, как показано ниже.
grunt> Dump outer_left;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения external_left .
(1,Ramesh,32,Ahmedabad,2000,,,,) (2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (3,kaushik,23,Kota,2000,100,2009-10-08 00:00:00,3,1500) (3,kaushik,23,Kota,2000,102,2009-10-08 00:00:00,3,3000) (4,Chaitali,25,Mumbai,6500,103,2008-05-20 00:00:00,4,2060) (5,Hardik,27,Bhopal,8500,,,,) (6,Komal,22,MP,4500,,,,) (7,Muffy,24,Indore,10000,,,,)
Правое внешнее соединение
Правая операция внешнего соединения возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
Синтаксис
Ниже приведен синтаксис выполнения правой операции внешнего соединения с использованием оператора JOIN .
grunt> outer_right = JOIN customers BY id RIGHT, orders BY customer_id;
пример
Давайте выполним операцию правого внешнего соединения для двух отношений с клиентами и заказами, как показано ниже.
grunt> outer_right = JOIN customers BY id RIGHT, orders BY customer_id;
верификация
Проверьте отношение external_right, используя оператор DUMP, как показано ниже.
grunt> Dump outer_right
Выход
Он выдаст следующий вывод, отображающий содержимое отношения external_right .
(2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (3,kaushik,23,Kota,2000,100,2009-10-08 00:00:00,3,1500) (3,kaushik,23,Kota,2000,102,2009-10-08 00:00:00,3,3000) (4,Chaitali,25,Mumbai,6500,103,2008-05-20 00:00:00,4,2060)
Полное внешнее соединение
Операция полного внешнего соединения возвращает строки при совпадении в одном из отношений.
Синтаксис
Ниже приведен синтаксис выполнения полного внешнего соединения с использованием оператора JOIN .
grunt> outer_full = JOIN customers BY id FULL OUTER, orders BY customer_id;
пример
Давайте выполним полную внешнюю операцию соединения двух клиентов и заказов, как показано ниже.
grunt> outer_full = JOIN customers BY id FULL OUTER, orders BY customer_id;
верификация
Проверьте отношение external_full, используя оператор DUMP, как показано ниже.
grun> Dump outer_full;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения external_full .
(1,Ramesh,32,Ahmedabad,2000,,,,) (2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (3,kaushik,23,Kota,2000,100,2009-10-08 00:00:00,3,1500) (3,kaushik,23,Kota,2000,102,2009-10-08 00:00:00,3,3000) (4,Chaitali,25,Mumbai,6500,103,2008-05-20 00:00:00,4,2060) (5,Hardik,27,Bhopal,8500,,,,) (6,Komal,22,MP,4500,,,,) (7,Muffy,24,Indore,10000,,,,)
Использование нескольких ключей
Мы можем выполнить операцию JOIN, используя несколько ключей.
Синтаксис
Вот как вы можете выполнить операцию JOIN для двух таблиц, используя несколько ключей.
grunt> Relation3_name = JOIN Relation2_name BY (key1, key2), Relation3_name BY (key1, key2);
Предположим, что у нас есть два файла, а именно employee.txt и employee_contact.txt в каталоге / pig_data / HDFS, как показано ниже.
employee.txt
001,Rajiv,Reddy,21,programmer,003 002,siddarth,Battacharya,22,programmer,003 003,Rajesh,Khanna,22,programmer,003 004,Preethi,Agarwal,21,programmer,003 005,Trupthi,Mohanthy,23,programmer,003 006,Archana,Mishra,23,programmer,003 007,Komal,Nayak,24,teamlead,002 008,Bharathi,Nambiayar,24,manager,001
employee_contact.txt
001,9848022337,Rajiv@gmail.com,Hyderabad,003 002,9848022338,siddarth@gmail.com,Kolkata,003 003,9848022339,Rajesh@gmail.com,Delhi,003 004,9848022330,Preethi@gmail.com,Pune,003 005,9848022336,Trupthi@gmail.com,Bhuwaneshwar,003 006,9848022335,Archana@gmail.com,Chennai,003 007,9848022334,Komal@gmail.com,trivendram,002 008,9848022333,Bharathi@gmail.com,Chennai,001
И мы загрузили эти два файла в Pig с отношениями employee и employee_contact, как показано ниже.
grunt> employee = LOAD 'hdfs://localhost:9000/pig_data/employee.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, age:int, designation:chararray, jobid:int); grunt> employee_contact = LOAD 'hdfs://localhost:9000/pig_data/employee_contact.txt' USING PigStorage(',') as (id:int, phone:chararray, email:chararray, city:chararray, jobid:int);
Теперь давайте объединим содержимое этих двух отношений, используя оператор JOIN, как показано ниже.
grunt> emp = JOIN employee BY (id,jobid), employee_contact BY (id,jobid);
верификация
Проверьте отношение emp, используя оператор DUMP, как показано ниже.
grunt> Dump emp;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения с именем emp, как показано ниже.
(1,Rajiv,Reddy,21,programmer,113,1,9848022337,Rajiv@gmail.com,Hyderabad,113) (2,siddarth,Battacharya,22,programmer,113,2,9848022338,siddarth@gmail.com,Kolka ta,113) (3,Rajesh,Khanna,22,programmer,113,3,9848022339,Rajesh@gmail.com,Delhi,113) (4,Preethi,Agarwal,21,programmer,113,4,9848022330,Preethi@gmail.com,Pune,113) (5,Trupthi,Mohanthy,23,programmer,113,5,9848022336,Trupthi@gmail.com,Bhuwaneshw ar,113) (6,Archana,Mishra,23,programmer,113,6,9848022335,Archana@gmail.com,Chennai,113) (7,Komal,Nayak,24,teamlead,112,7,9848022334,Komal@gmail.com,trivendram,112) (8,Bharathi,Nambiayar,24,manager,111,8,9848022333,Bharathi@gmail.com,Chennai,111)
Apache Pig — кросс-оператор
Оператор CROSS вычисляет перекрестное произведение двух или более отношений. В этой главе на примере объясняется, как использовать кросс-оператор в Pig Latin.
Синтаксис
Ниже приведен синтаксис оператора CROSS .
grunt> Relation3_name = CROSS Relation1_name, Relation2_name;
пример
Предположим, что у нас есть два файла, а именно customer.txt и orders.txt в каталоге / pig_data / HDFS, как показано ниже.
customers.txt
1,Ramesh,32,Ahmedabad,2000.00 2,Khilan,25,Delhi,1500.00 3,kaushik,23,Kota,2000.00 4,Chaitali,25,Mumbai,6500.00 5,Hardik,27,Bhopal,8500.00 6,Komal,22,MP,4500.00 7,Muffy,24,Indore,10000.00
orders.txt
102,2009-10-08 00:00:00,3,3000 100,2009-10-08 00:00:00,3,1500 101,2009-11-20 00:00:00,2,1560 103,2008-05-20 00:00:00,4,2060
И мы загрузили эти два файла в Pig с отношениями с клиентами и заказами, как показано ниже.
grunt> customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',') as (id:int, name:chararray, age:int, address:chararray, salary:int); grunt> orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(',') as (oid:int, date:chararray, customer_id:int, amount:int);
Давайте теперь получим перекрестное произведение этих двух отношений, используя кросс- оператор этих двух отношений, как показано ниже.
grunt> cross_data = CROSS customers, orders;
верификация
Проверьте отношение cross_data, используя оператор DUMP, как показано ниже.
grunt> Dump cross_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения cross_data .
(7,Muffy,24,Indore,10000,103,2008-05-20 00:00:00,4,2060) (7,Muffy,24,Indore,10000,101,2009-11-20 00:00:00,2,1560) (7,Muffy,24,Indore,10000,100,2009-10-08 00:00:00,3,1500) (7,Muffy,24,Indore,10000,102,2009-10-08 00:00:00,3,3000) (6,Komal,22,MP,4500,103,2008-05-20 00:00:00,4,2060) (6,Komal,22,MP,4500,101,2009-11-20 00:00:00,2,1560) (6,Komal,22,MP,4500,100,2009-10-08 00:00:00,3,1500) (6,Komal,22,MP,4500,102,2009-10-08 00:00:00,3,3000) (5,Hardik,27,Bhopal,8500,103,2008-05-20 00:00:00,4,2060) (5,Hardik,27,Bhopal,8500,101,2009-11-20 00:00:00,2,1560) (5,Hardik,27,Bhopal,8500,100,2009-10-08 00:00:00,3,1500) (5,Hardik,27,Bhopal,8500,102,2009-10-08 00:00:00,3,3000) (4,Chaitali,25,Mumbai,6500,103,2008-05-20 00:00:00,4,2060) (4,Chaitali,25,Mumbai,6500,101,2009-20 00:00:00,4,2060) (2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (2,Khilan,25,Delhi,1500,100,2009-10-08 00:00:00,3,1500) (2,Khilan,25,Delhi,1500,102,2009-10-08 00:00:00,3,3000) (1,Ramesh,32,Ahmedabad,2000,103,2008-05-20 00:00:00,4,2060) (1,Ramesh,32,Ahmedabad,2000,101,2009-11-20 00:00:00,2,1560) (1,Ramesh,32,Ahmedabad,2000,100,2009-10-08 00:00:00,3,1500) (1,Ramesh,32,Ahmedabad,2000,102,2009-10-08 00:00:00,3,3000)-11-20 00:00:00,2,1560) (4,Chaitali,25,Mumbai,6500,100,2009-10-08 00:00:00,3,1500) (4,Chaitali,25,Mumbai,6500,102,2009-10-08 00:00:00,3,3000) (3,kaushik,23,Kota,2000,103,2008-05-20 00:00:00,4,2060) (3,kaushik,23,Kota,2000,101,2009-11-20 00:00:00,2,1560) (3,kaushik,23,Kota,2000,100,2009-10-08 00:00:00,3,1500) (3,kaushik,23,Kota,2000,102,2009-10-08 00:00:00,3,3000) (2,Khilan,25,Delhi,1500,103,2008-05-20 00:00:00,4,2060) (2,Khilan,25,Delhi,1500,101,2009-11-20 00:00:00,2,1560) (2,Khilan,25,Delhi,1500,100,2009-10-08 00:00:00,3,1500) (2,Khilan,25,Delhi,1500,102,2009-10-08 00:00:00,3,3000) (1,Ramesh,32,Ahmedabad,2000,103,2008-05-20 00:00:00,4,2060) (1,Ramesh,32,Ahmedabad,2000,101,2009-11-20 00:00:00,2,1560) (1,Ramesh,32,Ahmedabad,2000,100,2009-10-08 00:00:00,3,1500) (1,Ramesh,32,Ahmedabad,2000,102,2009-10-08 00:00:00,3,3000)
Apache Pig — Союз Оператор
Оператор СОЮЗА Pig Latin используется для объединения содержимого двух отношений. Для выполнения операции UNION над двумя отношениями их столбцы и домены должны быть идентичными.
Синтаксис
Ниже приведен синтаксис оператора UNION .
grunt> Relation_name3 = UNION Relation_name1, Relation_name2;
пример
Предположим, что у нас есть два файла, а именно student_data1.txt и student_data2.txt в каталоге / pig_data / HDFS, как показано ниже.
Student_data1.txt
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai.
Student_data2.txt
7,Komal,Nayak,9848022334,trivendram. 8,Bharathi,Nambiayar,9848022333,Chennai.
И мы загрузили эти два файла в Pig с отношениями student1 и student2, как показано ниже.
grunt> student1 = LOAD 'hdfs://localhost:9000/pig_data/student_data1.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray); grunt> student2 = LOAD 'hdfs://localhost:9000/pig_data/student_data2.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray);
Давайте теперь объединим содержимое этих двух отношений, используя оператор UNION, как показано ниже.
grunt> student = UNION student1, student2;
верификация
Проверьте отношения ученика с помощью оператора DUMP, как показано ниже.
grunt> Dump student;
Выход
Он отобразит следующий вывод, отображающий содержание отношения ученика .
(1,Rajiv,Reddy,9848022337,Hyderabad) (2,siddarth,Battacharya,9848022338,Kolkata) (3,Rajesh,Khanna,9848022339,Delhi) (4,Preethi,Agarwal,9848022330,Pune) (5,Trupthi,Mohanthy,9848022336,Bhuwaneshwar) (6,Archana,Mishra,9848022335,Chennai) (7,Komal,Nayak,9848022334,trivendram) (8,Bharathi,Nambiayar,9848022333,Chennai)
Apache Pig — Сплит Оператор
Оператор SPLIT используется для разделения отношения на два или более отношений.
Синтаксис
Ниже приведен синтаксис оператора SPLIT .
grunt> SPLIT Relation1_name INTO Relation2_name IF (condition1), Relation2_name (condition2),
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
Давайте теперь разделим отношение на две части: одну, в которой перечислены работники в возрасте до 23 лет, а в другой — работники в возрасте от 22 до 25 лет.
SPLIT student_details into student_details1 if age<23, student_details2 if (22<age and age>25);
верификация
Проверьте отношения student_details1 и student_details2, используя оператор DUMP, как показано ниже.
grunt> Dump student_details1; grunt> Dump student_details2;
Выход
Он выдаст следующий вывод, отображающий содержимое отношений student_details1 и student_details2 соответственно.
grunt> Dump student_details1; (1,Rajiv,Reddy,21,9848022337,Hyderabad) (2,siddarth,Battacharya,22,9848022338,Kolkata) (3,Rajesh,Khanna,22,9848022339,Delhi) (4,Preethi,Agarwal,21,9848022330,Pune) grunt> Dump student_details2; (5,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar) (6,Archana,Mishra,23,9848022335,Chennai) (7,Komal,Nayak,24,9848022334,trivendram) (8,Bharathi,Nambiayar,24,9848022333,Chennai)
Apache Pig — оператор фильтра
Оператор FILTER используется для выбора требуемых кортежей из отношения на основе условия.
Синтаксис
Ниже приведен синтаксис оператора FILTER .
grunt> Relation2_name = FILTER Relation1_name BY (condition);
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
Давайте теперь воспользуемся оператором «Фильтр», чтобы получить информацию о студентах, которые принадлежат городу Ченнаи.
filter_data = FILTER student_details BY city == 'Chennai';
верификация
Проверьте отношение filter_data, используя оператор DUMP, как показано ниже.
grunt> Dump filter_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения filter_data следующим образом.
(6,Archana,Mishra,23,9848022335,Chennai) (8,Bharathi,Nambiayar,24,9848022333,Chennai)
Apache Pig — Отличный Оператор
Оператор DISTINCT используется для удаления избыточных (дублирующих) кортежей из отношения.
Синтаксис
Ниже приведен синтаксис оператора DISTINCT .
grunt> Relation_name2 = DISTINCT Relatin_name1;
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,9848022337,Hyderabad 002,siddarth,Battacharya,9848022338,Kolkata 002,siddarth,Battacharya,9848022338,Kolkata 003,Rajesh,Khanna,9848022339,Delhi 003,Rajesh,Khanna,9848022339,Delhi 004,Preethi,Agarwal,9848022330,Pune 005,Trupthi,Mohanthy,9848022336,Bhuwaneshwar 006,Archana,Mishra,9848022335,Chennai 006,Archana,Mishra,9848022335,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray);
Теперь давайте удалим избыточные (дубликаты) кортежи из отношения с именем student_details, используя оператор DISTINCT , и сохраним их как другое отношение с именем diver_data, как показано ниже.
grunt> distinct_data = DISTINCT student_details;
верификация
Проверьте отношение Different_data, используя оператор DUMP, как показано ниже.
grunt> Dump distinct_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения Different_data следующим образом.
(1,Rajiv,Reddy,9848022337,Hyderabad) (2,siddarth,Battacharya,9848022338,Kolkata) (3,Rajesh,Khanna,9848022339,Delhi) (4,Preethi,Agarwal,9848022330,Pune) (5,Trupthi,Mohanthy,9848022336,Bhuwaneshwar) (6,Archana,Mishra,9848022335,Chennai)
Apache Pig — оператор Foreach
Оператор FOREACH используется для генерации определенных преобразований данных на основе данных столбца.
Синтаксис
Ниже приведен синтаксис оператора FOREACH .
grunt> Relation_name2 = FOREACH Relatin_name1 GENERATE (required data);
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,age:int, phone:chararray, city:chararray);
Давайте теперь получим значения id, age и city каждого студента из отношения student_details и сохраним их в другое отношение с именем foreach_data, используя оператор foreach, как показано ниже.
grunt> foreach_data = FOREACH student_details GENERATE id,age,city;
верификация
Проверьте отношение foreach_data, используя оператор DUMP, как показано ниже.
grunt> Dump foreach_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения foreach_data .
(1,21,Hyderabad) (2,22,Kolkata) (3,22,Delhi) (4,21,Pune) (5,23,Bhuwaneshwar) (6,23,Chennai) (7,24,trivendram) (8,24,Chennai)
Apache Pig — Заказать
Оператор ORDER BY используется для отображения содержимого отношения в отсортированном порядке на основе одного или нескольких полей.
Синтаксис
Ниже приведен синтаксис оператора ORDER BY .
grunt> Relation_name2 = ORDER Relatin_name1 BY (ASC|DESC);
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,age:int, phone:chararray, city:chararray);
Давайте теперь отсортируем отношение в порядке убывания на основе возраста учащегося и сохраним его в другом отношении с именем order_by_data, используя оператор ORDER BY, как показано ниже.
grunt> order_by_data = ORDER student_details BY age DESC;
верификация
Проверьте отношение order_by_data, используя оператор DUMP, как показано ниже.
grunt> Dump order_by_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения order_by_data .
(8,Bharathi,Nambiayar,24,9848022333,Chennai) (7,Komal,Nayak,24,9848022334,trivendram) (6,Archana,Mishra,23,9848022335,Chennai) (5,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar) (3,Rajesh,Khanna,22,9848022339,Delhi) (2,siddarth,Battacharya,22,9848022338,Kolkata) (4,Preethi,Agarwal,21,9848022330,Pune) (1,Rajiv,Reddy,21,9848022337,Hyderabad)
Apache Pig — оператор ограничения
Оператор LIMIT используется для получения ограниченного числа кортежей из отношения.
Синтаксис
Ниже приведен синтаксис оператора LIMIT .
grunt> Result = LIMIT Relation_name required number of tuples;
пример
Предположим, что у нас есть файл student_details.txt в каталоге HDFS / pig_data /, как показано ниже.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
И мы загрузили этот файл в Pig с именем отношения student_details, как показано ниже.
grunt> student_details = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,age:int, phone:chararray, city:chararray);
Теперь давайте отсортируем отношение в порядке убывания на основе возраста учащегося и сохраним его в другом отношении с именем limit_data, используя оператор ORDER BY, как показано ниже.
grunt> limit_data = LIMIT student_details 4;
верификация
Проверьте отношение limit_data, используя оператор DUMP, как показано ниже.
grunt> Dump limit_data;
Выход
Он выдаст следующий вывод, отображающий содержимое отношения limit_data следующим образом.
(1,Rajiv,Reddy,21,9848022337,Hyderabad) (2,siddarth,Battacharya,22,9848022338,Kolkata) (3,Rajesh,Khanna,22,9848022339,Delhi) (4,Preethi,Agarwal,21,9848022330,Pune)
Apache Pig — Eval Функции
Apache Pig предоставляет различные встроенные функции: функции eval, load, store, math, string, bag и tuple .
Eval Функции
Ниже приведен список функций eval, предоставляемых Apache Pig.
| SN | Описание функции |
|---|---|
| 1 | AVG ()
Вычислить средние числовые значения в сумке. |
| 2 | BagToString ()
Чтобы объединить элементы сумки в строку. При объединении мы можем поместить разделитель между этими значениями (необязательно). |
| 3 | CONCAT ()
Объединить два или более выражения одного типа. |
| 4 | COUNT ()
Чтобы получить количество элементов в сумке, при подсчете количества кортежей в сумке. |
| 5 | COUNT_STAR ()
Это похоже на функцию COUNT () . Используется для получения количества элементов в сумке. |
| 6 | Diff ()
Сравнить две сумки (поля) в кортеже. |
| 7 | Пустой()
Проверить, если сумка или карта пуста. |
| 8 | МАКСИМУМ()
Чтобы рассчитать максимальное значение для столбца (числовые значения или массивы) в сумке из одного столбца. |
| 9 | MIN ()
Получить минимальное (наименьшее) значение (числовое или chararray) для определенного столбца в сумке из одного столбца. |
| 10 | PluckTuple ()
Используя функцию Pig Latin PluckTuple () , мы можем определить префикс строки и отфильтровать столбцы в отношении, начинающемся с данного префикса. |
| 11 | РАЗМЕР()
Вычислить количество элементов на основе любого типа данных Pig. |
| 12 | SUBTRACT ()
Вычесть две сумки. Он принимает две сумки в качестве входных данных и возвращает сумку, которая содержит кортежи первой сумки, которых нет во второй сумке. |
| 13 | СУММА ()
Чтобы получить сумму числовых значений столбца в сумке с одним столбцом. |
| 14 | Токенизировать ()
Разделить строку (которая содержит группу слов) в один кортеж и вернуть пакет, содержащий выходные данные операции разделения. |
Вычислить средние числовые значения в сумке.
Чтобы объединить элементы сумки в строку. При объединении мы можем поместить разделитель между этими значениями (необязательно).
Объединить два или более выражения одного типа.
Чтобы получить количество элементов в сумке, при подсчете количества кортежей в сумке.
Это похоже на функцию COUNT () . Используется для получения количества элементов в сумке.
Сравнить две сумки (поля) в кортеже.
Проверить, если сумка или карта пуста.
Чтобы рассчитать максимальное значение для столбца (числовые значения или массивы) в сумке из одного столбца.
Получить минимальное (наименьшее) значение (числовое или chararray) для определенного столбца в сумке из одного столбца.
Используя функцию Pig Latin PluckTuple () , мы можем определить префикс строки и отфильтровать столбцы в отношении, начинающемся с данного префикса.
Вычислить количество элементов на основе любого типа данных Pig.
Вычесть две сумки. Он принимает две сумки в качестве входных данных и возвращает сумку, которая содержит кортежи первой сумки, которых нет во второй сумке.
Чтобы получить сумму числовых значений столбца в сумке с одним столбцом.
Разделить строку (которая содержит группу слов) в один кортеж и вернуть пакет, содержащий выходные данные операции разделения.
Apache Pig — Функции загрузки и хранения
Функции « Загрузить» и « Сохранить» в Apache Pig используются для определения того, как данные поступают, а информация поступает из Pig. Эти функции используются с операторами загрузки и хранения. Ниже приведен список функций загрузки и хранения, доступных в Pig.
| SN | Описание функции |
|---|---|
| 1 | PigStorage ()
Загружать и хранить структурированные файлы. |
| 2 | TextLoader ()
Для загрузки неструктурированных данных в Pig. |
| 3 | BinStorage ()
Для загрузки и сохранения данных в Pig используется машиночитаемый формат. |
| 4 | Обработка сжатия
В Pig Latin мы можем загружать и хранить сжатые данные. |
Загружать и хранить структурированные файлы.
Для загрузки неструктурированных данных в Pig.
Для загрузки и сохранения данных в Pig используется машиночитаемый формат.
В Pig Latin мы можем загружать и хранить сжатые данные.
Apache Pig — Bag & Tuple Функции
Ниже приведен список функций Bag и Tuple.
| SN | Описание функции |
|---|---|
| 1 | TOBAG ()
Для преобразования двух или более выражений в сумку. |
| 2 | ТОП()
Чтобы получить топ N кортежей отношения. |
| 3 | TOTUPLE ()
Чтобы преобразовать одно или несколько выражений в кортеж. |
| 4 | НА КАРТУ()
Чтобы преобразовать пары ключ-значение в карту. |
Для преобразования двух или более выражений в сумку.
Чтобы получить топ N кортежей отношения.
Чтобы преобразовать одно или несколько выражений в кортеж.
Чтобы преобразовать пары ключ-значение в карту.
Apache Pig — Строковые функции
У нас есть следующие функции String в Apache Pig.
| SN | Функции и описание |
|---|---|
| 1 | ENDSWITH (строка, testAgainst)
Чтобы проверить, заканчивается ли данная строка определенной подстрокой. |
| 2 | STARTSWITH (строка, подстрока)
Принимает два строковых параметра и проверяет, начинается ли первая строка со второй. |
| 3 | SUBSTRING (строка, startIndex, stopIndex)
Возвращает подстроку из заданной строки. |
| 4 | EqualsIgnoreCase (строка1, строка2)
Чтобы сравнить два укуса, игнорируя дела. |
| 5 | INDEXOF (строка, символ, startIndex)
Возвращает первое вхождение символа в строке с поиском вперед по стартовому индексу. |
| 6 | LAST_INDEX_OF (выражение)
Возвращает индекс последнего вхождения символа в строке с обратным поиском по начальному индексу. |
| 7 | LCFIRST (выражение)
Преобразует первый символ в строке в нижний регистр. |
| 8 | UCFIRST (выражение)
Возвращает строку с первым символом, преобразованным в верхний регистр. |
| 9 | ВЕРХНИЙ (выражение)
UPPER (выражение) Возвращает строку, преобразованную в верхний регистр. |
| 10 | НИЖНЯЯ (выражение)
Преобразует все символы в строке в нижний регистр. |
| 11 | REPLACE (строка, ‘oldChar’, ‘newChar’);
Заменить существующие символы в строке новыми символами. |
| 12 | STRSPLIT (строка, регулярное выражение, предел)
Разделить строку вокруг совпадений заданного регулярного выражения. |
| 13 | STRSPLITTOBAG (строка, регулярное выражение, предел)
Подобно функции STRSPLIT () , она разбивает строку по заданному разделителю и возвращает результат в сумке. |
| 14 | TRIM (выражение)
Возвращает копию строки с удаленными начальными и конечными пробелами. |
| 15 | LTRIM (выражение)
Возвращает копию строки с удаленными начальными пробелами. |
| 16 | RTRIM (выражение)
Возвращает копию строки с удаленными конечными пробелами. |
Чтобы проверить, заканчивается ли данная строка определенной подстрокой.
Принимает два строковых параметра и проверяет, начинается ли первая строка со второй.
Возвращает подстроку из заданной строки.
Чтобы сравнить два укуса, игнорируя дела.
Возвращает первое вхождение символа в строке с поиском вперед по стартовому индексу.
Возвращает индекс последнего вхождения символа в строке с обратным поиском по начальному индексу.
Преобразует первый символ в строке в нижний регистр.
Возвращает строку с первым символом, преобразованным в верхний регистр.
UPPER (выражение) Возвращает строку, преобразованную в верхний регистр.
Преобразует все символы в строке в нижний регистр.
Заменить существующие символы в строке новыми символами.
Разделить строку вокруг совпадений заданного регулярного выражения.
Подобно функции STRSPLIT () , она разбивает строку по заданному разделителю и возвращает результат в сумке.
Возвращает копию строки с удаленными начальными и конечными пробелами.
Возвращает копию строки с удаленными начальными пробелами.
Возвращает копию строки с удаленными конечными пробелами.
Apache Pig — функции даты и времени
Apache Pig предоставляет следующие функции даты и времени:
| SN | Функции и описание |
|---|---|
| 1 | Todate (миллисекунды)
Эта функция возвращает объект даты и времени в соответствии с заданными параметрами. Другой альтернативой для этой функции являются ToDate (iosstring), ToDate (userstring, format), ToDate (userstring, format, timezone) |
| 2 | Текущее время()
возвращает объект даты и времени текущего времени. |
| 3 | GetDay (DateTime)
Возвращает день месяца из объекта даты и времени. |
| 4 | GetHour (DateTime)
Возвращает час дня из объекта даты и времени. |
| 5 | GetMilliSecond (DateTime)
Возвращает миллисекунду секунды из объекта даты и времени. |
| 6 | GetMinute (DateTime)
Возвращает минуту часа из объекта даты и времени. |
| 7 | GetMonth (DateTime)
Возвращает месяц года из объекта даты и времени. |
| 8 | GetSecond (DateTime)
Возвращает секунду минуты из объекта даты и времени. |
| 9 | GetWeek (DateTime)
Возвращает неделю года из объекта даты и времени. |
| 10 | GetWeekYear (DateTime)
Возвращает год недели из объекта даты и времени. |
| 11 | GetYear (DateTime)
Возвращает год из объекта даты и времени. |
| 12 | AddDuration (дата, время, продолжительность)
Возвращает результат объекта даты и времени вместе с объектом продолжительности. |
| 13 | SubtractDuration (дата, время, продолжительность)
Вычитает объект Duration из объекта Date-Time и возвращает результат. |
| 14 | DaysBetween (datetime1, datetime2)
Возвращает количество дней между двумя объектами даты и времени. |
| 15 | HoursBetween (datetime1, datetime2)
Возвращает количество часов между двумя объектами даты и времени. |
| 16 | MilliSecondsBetween (datetime1, datetime2)
Возвращает количество миллисекунд между двумя объектами даты и времени. |
| 17 | MinutesBetween (datetime1, datetime2)
Возвращает количество минут между двумя объектами даты и времени. |
| 18 | MonthsBetween (datetime1, datetime2)
Возвращает количество месяцев между двумя объектами даты и времени. |
| 19 | SecondsBetween (datetime1, datetime2)
Возвращает количество секунд между двумя объектами даты и времени. |
| 20 | WeeksBetween (datetime1, datetime2)
Возвращает количество недель между двумя объектами даты и времени. |
| 21 | YearsBetween (datetime1, datetime2)
Возвращает количество лет между двумя объектами даты и времени. |
Эта функция возвращает объект даты и времени в соответствии с заданными параметрами. Другой альтернативой для этой функции являются ToDate (iosstring), ToDate (userstring, format), ToDate (userstring, format, timezone)
возвращает объект даты и времени текущего времени.
Возвращает день месяца из объекта даты и времени.
Возвращает час дня из объекта даты и времени.
Возвращает миллисекунду секунды из объекта даты и времени.
Возвращает минуту часа из объекта даты и времени.
Возвращает месяц года из объекта даты и времени.
Возвращает секунду минуты из объекта даты и времени.
Возвращает неделю года из объекта даты и времени.
Возвращает год недели из объекта даты и времени.
Возвращает год из объекта даты и времени.
Возвращает результат объекта даты и времени вместе с объектом продолжительности.
Вычитает объект Duration из объекта Date-Time и возвращает результат.
Возвращает количество дней между двумя объектами даты и времени.
Возвращает количество часов между двумя объектами даты и времени.
Возвращает количество миллисекунд между двумя объектами даты и времени.
Возвращает количество минут между двумя объектами даты и времени.
Возвращает количество месяцев между двумя объектами даты и времени.
Возвращает количество секунд между двумя объектами даты и времени.
Возвращает количество недель между двумя объектами даты и времени.
Возвращает количество лет между двумя объектами даты и времени.
Apache Pig — Математические функции
У нас есть следующие математические функции в Apache Pig —
| SN | Функции и описание |
|---|---|
| 1 | ABS (выражение)
Получить абсолютное значение выражения. |
| 2 | ACOS (выражение)
Чтобы получить арккосинус выражения. |
| 3 | ASIN (выражение)
Чтобы получить дугу синуса выражения. |
| 4 | ATAN (выражение)
Эта функция используется для получения арктангенса выражения. |
| 5 | CBRT (выражение)
Эта функция используется для получения кубического корня выражения. |
| 6 | CEIL (выражение)
Эта функция используется для получения значения выражения, округленного до ближайшего целого числа. |
| 7 | COS (выражение)
Эта функция используется для получения тригонометрического косинуса выражения. |
| 8 | COSH (выражение)
Эта функция используется для получения гиперболического косинуса выражения. |
| 9 | EXP (выражение)
Эта функция используется для получения числа Эйлера е, возведенного в степень х. |
| 10 | ПОЛ (выражение)
Чтобы получить значение выражения, округленное до ближайшего целого числа. |
| 11 | LOG (выражение)
Чтобы получить натуральный логарифм (основание е) выражения. |
| 12 | Log10 (выражение)
Чтобы получить основание 10 логарифм выражения. |
| 13 | СЛУЧАЙНО ()
Чтобы получить псевдослучайное число (тип double) больше или равно 0,0 и меньше 1,0. |
| 14 | ROUND (выражение)
Получить значение выражения, округленное до целого числа (если тип результата float) или округленное до длинного (если тип результата double). |
| 15 | SIN (выражение)
Чтобы получить синус выражения. |
| 16 | SINH (выражение)
Чтобы получить гиперболический синус выражения. |
| 17 | SQRT (выражение)
Чтобы получить положительный квадратный корень выражения. |
| 18 | ТАН (выражение)
Чтобы получить тригонометрическую касательную угла. |
| 19 | TANH (выражение)
Чтобы получить гиперболический тангенс выражения. |
Получить абсолютное значение выражения.
Чтобы получить арккосинус выражения.
Чтобы получить дугу синуса выражения.
Эта функция используется для получения арктангенса выражения.
Эта функция используется для получения кубического корня выражения.
Эта функция используется для получения значения выражения, округленного до ближайшего целого числа.
Эта функция используется для получения тригонометрического косинуса выражения.
Эта функция используется для получения гиперболического косинуса выражения.
Эта функция используется для получения числа Эйлера е, возведенного в степень х.
Чтобы получить значение выражения, округленное до ближайшего целого числа.
Чтобы получить натуральный логарифм (основание е) выражения.
Чтобы получить основание 10 логарифм выражения.
Чтобы получить псевдослучайное число (тип double) больше или равно 0,0 и меньше 1,0.
Получить значение выражения, округленное до целого числа (если тип результата float) или округленное до длинного (если тип результата double).
Чтобы получить синус выражения.
Чтобы получить гиперболический синус выражения.
Чтобы получить положительный квадратный корень выражения.
Чтобы получить тригонометрическую касательную угла.
Чтобы получить гиперболический тангенс выражения.
Apache Pig — пользовательские функции
В дополнение к встроенным функциям Apache Pig обеспечивает расширенную поддержку определенных функций (UDF). Используя эти UDF, мы можем определить свои собственные функции и использовать их. Поддержка UDF предоставляется на шести языках программирования, а именно на Java, Jython, Python, JavaScript, Ruby и Groovy.
Для написания UDF предоставляется полная поддержка на Java, а ограниченная поддержка предоставляется на всех остальных языках. Используя Java, вы можете писать UDF, включающие все части обработки, такие как загрузка / хранение данных, преобразование столбцов и агрегирование. Поскольку Apache Pig был написан на Java, UDF, написанный на языке Java, работает эффективно по сравнению с другими языками.
В Apache Pig у нас также есть хранилище Java для UDF с именем Piggybank . Используя Piggybank, мы можем получить доступ к Java UDF, написанным другими пользователями, и предоставить свои собственные UDF.
Типы UDF в Java
При написании UDF с использованием Java мы можем создавать и использовать следующие три типа функций:
-
Функции фильтра — Функции фильтра используются в качестве условий в операторах фильтра. Эти функции принимают значение Pig в качестве входных данных и возвращают логическое значение.
-
Функции Eval — Функции Eval используются в инструкциях FOREACH-GENERATE. Эти функции принимают значение Pig в качестве входных данных и возвращают результат Pig.
-
Алгебраические функции — Алгебраические функции действуют на внутренние пакеты в выражении FOREACHGENERATE. Эти функции используются для выполнения полных операций MapReduce на внутренней сумке.
Функции фильтра — Функции фильтра используются в качестве условий в операторах фильтра. Эти функции принимают значение Pig в качестве входных данных и возвращают логическое значение.
Функции Eval — Функции Eval используются в инструкциях FOREACH-GENERATE. Эти функции принимают значение Pig в качестве входных данных и возвращают результат Pig.
Алгебраические функции — Алгебраические функции действуют на внутренние пакеты в выражении FOREACHGENERATE. Эти функции используются для выполнения полных операций MapReduce на внутренней сумке.
Написание UDF с использованием Java
Чтобы написать UDF с использованием Java, мы должны интегрировать файл jar Pig-0.15.0.jar . В этом разделе мы обсудим, как написать пример UDF с использованием Eclipse. Прежде чем продолжить, убедитесь, что в вашей системе установлены Eclipse и Maven.
Следуйте инструкциям ниже, чтобы написать функцию UDF —
-
Откройте Eclipse и создайте новый проект (скажем, myproject ).
-
Преобразуйте недавно созданный проект в проект Maven.
-
Скопируйте следующий контент в pom.xml. Этот файл содержит зависимости Maven для jar-файлов Apache Pig и Hadoop-core.
Откройте Eclipse и создайте новый проект (скажем, myproject ).
Преобразуйте недавно созданный проект в проект Maven.
Скопируйте следующий контент в pom.xml. Этот файл содержит зависимости Maven для jar-файлов Apache Pig и Hadoop-core.
<project xmlns = "http://maven.apache.org/POM/4.0.0" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0http://maven.apache .org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>Pig_Udf</groupId> <artifactId>Pig_Udf</artifactId> <version>0.0.1-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.pig</groupId> <artifactId>pig</artifactId> <version>0.15.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-core</artifactId> <version>0.20.2</version> </dependency> </dependencies> </project>
-
Сохраните файл и обновите его. В разделе Maven Dependencies вы можете найти загруженные файлы JAR.
-
Создайте новый файл класса с именем Sample_Eval и скопируйте в него следующее содержимое.
Сохраните файл и обновите его. В разделе Maven Dependencies вы можете найти загруженные файлы JAR.
Создайте новый файл класса с именем Sample_Eval и скопируйте в него следующее содержимое.
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class Sample_Eval extends EvalFunc<String>{
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
String str = (String)input.get(0);
return str.toUpperCase();
}
}
При написании UDF обязательно наследовать класс EvalFunc и предоставлять реализацию функции exec () . Внутри этой функции написан код, необходимый для UDF. В приведенном выше примере мы возвращаем код для преобразования содержимого данного столбца в верхний регистр.
-
После компиляции класса без ошибок щелкните правой кнопкой мыши файл Sample_Eval.java. Это дает вам меню. Выберите экспорт, как показано на следующем снимке экрана.
После компиляции класса без ошибок щелкните правой кнопкой мыши файл Sample_Eval.java. Это дает вам меню. Выберите экспорт, как показано на следующем снимке экрана.
-
При нажатии кнопки экспорта вы получите следующее окно. Нажмите на файл JAR .
При нажатии кнопки экспорта вы получите следующее окно. Нажмите на файл JAR .
-
Продолжите, нажав кнопку Далее> . Вы получите другое окно, где вам нужно ввести путь в локальной файловой системе, где вам нужно сохранить файл JAR.
Продолжите, нажав кнопку Далее> . Вы получите другое окно, где вам нужно ввести путь в локальной файловой системе, где вам нужно сохранить файл JAR.
-
Наконец нажмите кнопку Готово . В указанной папке создается файл Jar sample_udf.jar . Этот файл jar содержит UDF, написанный на Java.
Наконец нажмите кнопку Готово . В указанной папке создается файл Jar sample_udf.jar . Этот файл jar содержит UDF, написанный на Java.
Использование UDF
После написания UDF и генерации файла Jar выполните следующие действия:
Шаг 1: Регистрация файла Jar
После написания UDF (на Java) мы должны зарегистрировать файл Jar, содержащий UDF, используя оператор Register. Зарегистрировав файл Jar, пользователи могут указать расположение UDF для Apache Pig.
Синтаксис
Ниже приведен синтаксис оператора Register.
REGISTER path;
пример
В качестве примера давайте зарегистрируем файл sample_udf.jar, созданный ранее в этой главе.
Запустите Apache Pig в локальном режиме и зарегистрируйте файл jar sample_udf.jar, как показано ниже.
$cd PIG_HOME/bin $./pig –x local REGISTER '/$PIG_HOME/sample_udf.jar'
Примечание. Предположим, файл Jar указан в пути — /$PIG_HOME/sample_udf.jar.
Шаг 2: Определение псевдонима
После регистрации UDF мы можем определить его псевдоним с помощью оператора Define .
Синтаксис
Ниже приведен синтаксис оператора Define.
DEFINE alias {function | [`command` [input] [output] [ship] [cache] [stderr] ] };
пример
Определите псевдоним для sample_eval, как показано ниже.
DEFINE sample_eval sample_eval();
Шаг 3: Использование UDF
После определения псевдонима вы можете использовать UDF так же, как встроенные функции. Предположим, что в каталоге HDFS / Pig_Data / есть файл emp_data со следующим содержимым.
001,Robin,22,newyork 002,BOB,23,Kolkata 003,Maya,23,Tokyo 004,Sara,25,London 005,David,23,Bhuwaneshwar 006,Maggy,22,Chennai 007,Robert,22,newyork 008,Syam,23,Kolkata 009,Mary,25,Tokyo 010,Saran,25,London 011,Stacy,25,Bhuwaneshwar 012,Kelly,22,Chennai
И предположим, что мы загрузили этот файл в Pig, как показано ниже.
grunt> emp_data = LOAD 'hdfs://localhost:9000/pig_data/emp1.txt' USING PigStorage(',')
as (id:int, name:chararray, age:int, city:chararray);
Теперь давайте преобразуем имена сотрудников в верхний регистр, используя UDF sample_eval .
grunt> Upper_case = FOREACH emp_data GENERATE sample_eval(name);
Проверьте содержимое отношения Upper_case, как показано ниже.
grunt> Dump Upper_case; (ROBIN) (BOB) (MAYA) (SARA) (DAVID) (MAGGY) (ROBERT) (SYAM) (MARY) (SARAN) (STACY) (KELLY)
Apache Pig — Бегущие скрипты
Здесь, в этой главе, мы увидим, как запускать скрипты Apache Pig в пакетном режиме.
Комментарии в Pig Script
При написании сценария в файле мы можем включить в него комментарии, как показано ниже.
Многострочные комментарии
Мы начинаем многострочные комментарии с ‘/ *’, заканчиваем их с ‘* /’.
/* These are the multi-line comments In the pig script */
Однострочные комментарии
Мы начнем однострочные комментарии с «-».
--we can write single line comments like this.
Выполнение Pig Script в пакетном режиме
При выполнении операторов Apache Pig в пакетном режиме выполните следующие действия.
Шаг 1
Запишите все необходимые выражения Pig Latin в одном файле. Мы можем записать все операторы и команды Pig Latin в одном файле и сохранить его как файл .pig .
Шаг 2
Выполните скрипт Apache Pig. Вы можете выполнить скрипт Pig из оболочки (Linux), как показано ниже.
| Локальный режим | Режим MapReduce |
|---|---|
| $ pig -x local Sample_script.pig | $ pig -x mapreduce Sample_script.pig |
Вы также можете выполнить его из оболочки Grunt, используя команду exec, как показано ниже.
grunt> exec /sample_script.pig
Выполнение сценария Pig из HDFS
Мы также можем выполнить сценарий Pig, который находится в HDFS. Предположим, что в каталоге HDFS с именем / pig_data / есть сценарий Pig с именем Sample_script.pig . Мы можем выполнить это, как показано ниже.
$ pig -x mapreduce hdfs://localhost:9000/pig_data/Sample_script.pig
пример
Предположим, у нас есть файл student_details.txt в HDFS со следующим содержимым.
student_details.txt
001,Rajiv,Reddy,21,9848022337,Hyderabad 002,siddarth,Battacharya,22,9848022338,Kolkata 003,Rajesh,Khanna,22,9848022339,Delhi 004,Preethi,Agarwal,21,9848022330,Pune 005,Trupthi,Mohanthy,23,9848022336,Bhuwaneshwar 006,Archana,Mishra,23,9848022335,Chennai 007,Komal,Nayak,24,9848022334,trivendram 008,Bharathi,Nambiayar,24,9848022333,Chennai
У нас также есть пример сценария с именем sample_script.pig в том же каталоге HDFS. Этот файл содержит операторы, выполняющие операции и преобразования в отношении студента , как показано ниже.
student = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, phone:chararray, city:chararray);
student_order = ORDER student BY age DESC;
student_limit = LIMIT student_order 4;
Dump student_limit;
-
Первая инструкция скрипта загрузит данные в файл student_details.txt в виде отношения с именем student .
-
Второе утверждение скрипта упорядочит кортежи отношения в порядке убывания в зависимости от возраста и сохранит его как student_order .
-
Третье утверждение скрипта будет хранить первые 4 кортежа student_order как student_limit .
-
Наконец, четвертое утверждение выведет содержимое отношения student_limit .
Первая инструкция скрипта загрузит данные в файл student_details.txt в виде отношения с именем student .
Второе утверждение скрипта упорядочит кортежи отношения в порядке убывания в зависимости от возраста и сохранит его как student_order .
Третье утверждение скрипта будет хранить первые 4 кортежа student_order как student_limit .
Наконец, четвертое утверждение выведет содержимое отношения student_limit .
Давайте теперь выполним пример sample_script.pig, как показано ниже.
$./pig -x mapreduce hdfs://localhost:9000/pig_data/sample_script.pig
Apache Pig исполняется и выдает результат со следующим содержимым.