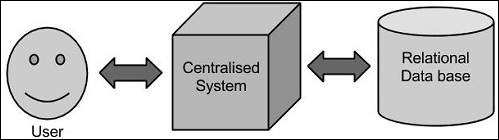
При таком подходе у предприятия будет компьютер для хранения и обработки больших данных. Для целей хранения программисты воспользуются выбором поставщиков баз данных, таких как Oracle, IBM и т. Д. При таком подходе пользователь взаимодействует с приложением, которое, в свою очередь, выполняет часть хранения и анализа данных.
ограничение
Этот подход прекрасно работает с теми приложениями, которые обрабатывают менее объемные данные, которые могут быть размещены на стандартных серверах баз данных, или вплоть до предела процессора, который обрабатывает данные. Но когда дело доходит до работы с огромными объемами масштабируемых данных, это сложная задача — обрабатывать такие данные через единственное узкое место в базе данных.
Решение Google
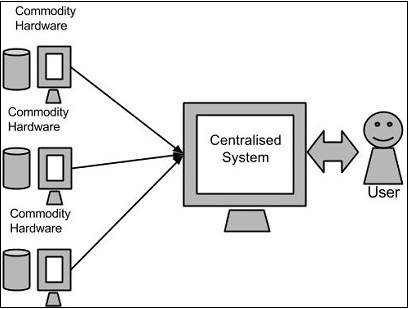
Google решил эту проблему, используя алгоритм MapReduce. Этот алгоритм разделяет задачу на небольшие части и назначает их многим компьютерам, а также собирает результаты с них, которые при интеграции образуют набор данных результатов.
Hadoop
Используя решение, предоставленное Google, Дуг Каттинг и его команда разработали проект с открытым исходным кодом под названием HADOOP .
Hadoop запускает приложения, используя алгоритм MapReduce, где данные обрабатываются параллельно с другими. Короче говоря, Hadoop используется для разработки приложений, которые могут выполнять полный статистический анализ огромных объемов данных.