Файловая система Hadoop была разработана с использованием распределенной файловой системы. Он запускается на товарном оборудовании. В отличие от других распределенных систем, HDFS обладает высокой отказоустойчивостью и разработана с использованием недорогого оборудования.
HDFS хранит очень большой объем данных и обеспечивает более легкий доступ. Для хранения таких огромных данных файлы хранятся на нескольких машинах. Эти файлы хранятся в избыточном виде, чтобы спасти систему от возможных потерь данных в случае сбоя. HDFS также делает приложения доступными для параллельной обработки.
Особенности HDFS
- Подходит для распределенного хранения и обработки.
- Hadoop предоставляет командный интерфейс для взаимодействия с HDFS.
- Встроенные серверы namenode и datanode помогают пользователям легко проверить состояние кластера.
- Потоковый доступ к данным файловой системы.
- HDFS обеспечивает права доступа к файлам и аутентификацию.
Архитектура HDFS
Ниже приведена архитектура файловой системы Hadoop.
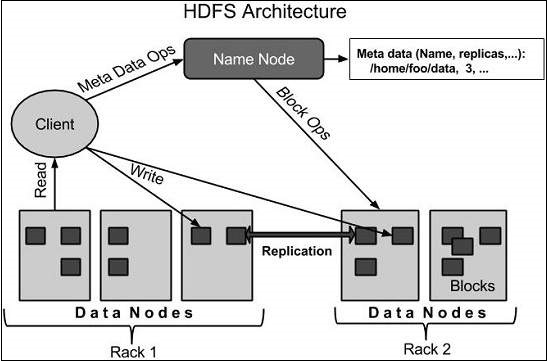
HDFS следует архитектуре «ведущий-ведомый» и имеет следующие элементы.
NameNode
Namenode — это стандартное аппаратное обеспечение, которое содержит операционную систему GNU / Linux и программное обеспечение namenode. Это программное обеспечение, которое может работать на обычном оборудовании. Система, имеющая наменоде, действует как главный сервер и выполняет следующие задачи:
-
Управляет пространством имен файловой системы.
-
Регулирует доступ клиента к файлам.
-
Он также выполняет операции с файловой системой, такие как переименование, закрытие и открытие файлов и каталогов.
Управляет пространством имен файловой системы.
Регулирует доступ клиента к файлам.
Он также выполняет операции с файловой системой, такие как переименование, закрытие и открытие файлов и каталогов.
DataNode
Датодода — это стандартное аппаратное обеспечение с операционной системой GNU / Linux и программным обеспечением датоде. Для каждого узла (Commodity hardware / System) в кластере будет указана дата данных. Эти узлы управляют хранением данных своей системы.
-
Датододы выполняют операции чтения-записи в файловых системах в соответствии с запросом клиента.
-
Они также выполняют такие операции, как создание, удаление и репликация блоков в соответствии с инструкциями namenode.
Датододы выполняют операции чтения-записи в файловых системах в соответствии с запросом клиента.
Они также выполняют такие операции, как создание, удаление и репликация блоков в соответствии с инструкциями namenode.
блок
Обычно пользовательские данные хранятся в файлах HDFS. Файл в файловой системе будет разделен на один или несколько сегментов и / или сохранен в отдельных узлах данных. Эти файловые сегменты называются блоками. Другими словами, минимальный объем данных, которые HDFS может читать или записывать, называется блоком. Размер блока по умолчанию составляет 64 МБ, но его можно увеличить в соответствии с необходимостью изменения конфигурации HDFS.
Цели HDFS
Обнаружение и устранение неисправностей — поскольку HDFS включает в себя большое количество стандартного оборудования, часто происходят сбои компонентов. Поэтому HDFS должна иметь механизмы для быстрого и автоматического обнаружения и устранения неисправностей.
Огромные наборы данных — HDFS должна иметь сотни узлов на кластер для управления приложениями, имеющими огромные наборы данных.
Аппаратное обеспечение данных . Запрошенная задача может быть выполнена эффективно, когда вычисления выполняются рядом с данными. Особенно там, где задействованы огромные наборы данных, это уменьшает сетевой трафик и увеличивает пропускную способность.