Hadoop — Обзор больших данных
Из-за появления новых технологий, устройств и средств связи, таких как сайты социальных сетей, объем данных, производимых человечеством, быстро растет с каждым годом. Объем данных, произведенных нами с начала времен до 2003 года, составил 5 миллиардов гигабайт. Если вы накапливаете данные в виде дисков, они могут заполнить все футбольное поле. Одна и та же сумма создавалась каждые два дня в 2011 году и каждые десять минут в 2013 году . Этот показатель по-прежнему чрезвычайно растет. Хотя вся эта информация имеет смысл и может быть полезной при обработке, ею пренебрегают.
Что такое большие данные?
Большие данные — это набор больших наборов данных, которые не могут быть обработаны с использованием традиционных вычислительных технологий. Это не отдельная техника или инструмент, скорее, она стала полным предметом, который включает в себя различные инструменты, технологии и структуры.
Что входит в большие данные?
Большие данные включают в себя данные, произведенные различными устройствами и приложениями. Ниже приведены некоторые из полей, которые подпадают под зонтик больших данных.
-
Данные черного ящика — это компонент вертолета, самолетов, самолетов и т. Д. Он фиксирует голоса летного экипажа, записи микрофонов и наушников и информацию о характеристиках самолета.
-
Данные социальных сетей — социальные сети, такие как Facebook и Twitter, содержат информацию и мнения, опубликованные миллионами людей по всему миру.
-
Данные фондовой биржи — Данные фондовой биржи содержат информацию о решениях «купить» и «продать», принятых в отношении акций различных компаний, принятых клиентами.
-
Данные энергосистемы — данные энергосистемы содержат информацию, потребляемую конкретным узлом относительно базовой станции.
-
Транспортные данные — Транспортные данные включают модель, вместимость, расстояние и доступность транспортного средства.
-
Данные поисковой системы — поисковые системы извлекают много данных из разных баз данных.
Данные черного ящика — это компонент вертолета, самолетов, самолетов и т. Д. Он фиксирует голоса летного экипажа, записи микрофонов и наушников и информацию о характеристиках самолета.
Данные социальных сетей — социальные сети, такие как Facebook и Twitter, содержат информацию и мнения, опубликованные миллионами людей по всему миру.
Данные фондовой биржи — Данные фондовой биржи содержат информацию о решениях «купить» и «продать», принятых в отношении акций различных компаний, принятых клиентами.
Данные энергосистемы — данные энергосистемы содержат информацию, потребляемую конкретным узлом относительно базовой станции.
Транспортные данные — Транспортные данные включают модель, вместимость, расстояние и доступность транспортного средства.
Данные поисковой системы — поисковые системы извлекают много данных из разных баз данных.

Таким образом, большие данные включают в себя огромный объем, высокую скорость и расширяемое разнообразие данных. Данные в нем будут трех типов.
-
Структурированные данные — реляционные данные.
-
Полуструктурированные данные — данные XML.
-
Неструктурированные данные — Word, PDF, Text, Media Logs.
Структурированные данные — реляционные данные.
Полуструктурированные данные — данные XML.
Неструктурированные данные — Word, PDF, Text, Media Logs.
Преимущества больших данных
-
Используя информацию, хранящуюся в социальной сети, такой как Facebook, маркетинговые агентства узнают о реакции на свои кампании, рекламные акции и другие рекламные средства.
-
Используя информацию в социальных сетях, такую как предпочтения и восприятие продукта потребителями, производственные компании и розничные организации планируют их производство.
-
Используя данные, относящиеся к предыдущей истории болезни пациентов, больницы обеспечивают лучшее и быстрое обслуживание.
Используя информацию, хранящуюся в социальной сети, такой как Facebook, маркетинговые агентства узнают о реакции на свои кампании, рекламные акции и другие рекламные средства.
Используя информацию в социальных сетях, такую как предпочтения и восприятие продукта потребителями, производственные компании и розничные организации планируют их производство.
Используя данные, относящиеся к предыдущей истории болезни пациентов, больницы обеспечивают лучшее и быстрое обслуживание.
Технологии больших данных
Технологии больших данных важны для обеспечения более точного анализа, который может привести к более конкретному принятию решений, что приведет к повышению операционной эффективности, снижению затрат и снижению рисков для бизнеса.
Чтобы использовать возможности больших данных, вам потребуется инфраструктура, которая может управлять и обрабатывать огромные объемы структурированных и неструктурированных данных в режиме реального времени и защищать конфиденциальность и безопасность данных.
Для обработки больших данных на рынке существуют различные технологии от разных поставщиков, включая Amazon, IBM, Microsoft и т. Д. Изучая технологии обработки больших данных, мы рассмотрим следующие два класса технологий:
Оперативные большие данные
К ним относятся такие системы, как MongoDB, которые предоставляют оперативные возможности для интерактивных рабочих нагрузок в реальном времени, когда данные в основном собираются и хранятся.
Системы NoSQL Big Data предназначены для использования преимуществ новых архитектур облачных вычислений, появившихся за последнее десятилетие, которые позволяют выполнять массовые вычисления недорого и эффективно. Это делает управление большими рабочими нагрузками намного проще, дешевле и быстрее внедряется.
Некоторые системы NoSQL могут обеспечить понимание шаблонов и тенденций на основе данных в реальном времени с минимальным кодированием и без необходимости в специалистах по данным и дополнительной инфраструктуре.
Аналитические Большие Данные
К ним относятся такие системы, как системы баз данных Massively Parallel Processing (MPP) и MapReduce, которые предоставляют аналитические возможности для ретроспективного и комплексного анализа, который может касаться большей части или всех данных.
MapReduce предоставляет новый метод анализа данных, который дополняет возможности, предоставляемые SQL, и систему, основанную на MapReduce, которую можно масштабировать с одного сервера до тысяч компьютеров высокого и низкого уровня.
Эти два класса технологий дополняют друг друга и часто используются вместе.
Операционные и Аналитические Системы
| эксплуатационный | аналитический | |
|---|---|---|
| Задержка | 1 мс — 100 мс | 1 мин — 100 мин |
| совпадение | 1000 — 100 000 | 1 — 10 |
| Шаблон доступа | Пишет и читает | Читает |
| Запросы | выборочный | неселективных |
| Объем данных | эксплуатационный | ретроспективный |
| Конечный пользователь | Покупатель | Ученый данных |
| Технология | NoSQL | MapReduce, база данных MPP |
Проблемы с большими данными
Основные проблемы, связанные с большими данными, следующие:
- Сбор данных
- Курирование
- Место хранения
- поиск
- разделение
- Перечислить
- Анализ
- презентация
Для решения вышеперечисленных задач организации обычно пользуются помощью корпоративных серверов.
Hadoop — Решения для больших данных
Традиционный подход
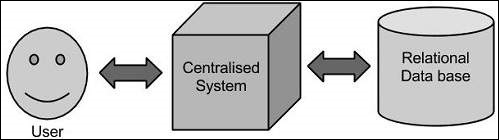
При таком подходе у предприятия будет компьютер для хранения и обработки больших данных. Для целей хранения программисты воспользуются выбором поставщиков баз данных, таких как Oracle, IBM и т. Д. При таком подходе пользователь взаимодействует с приложением, которое, в свою очередь, выполняет часть хранения и анализа данных.
ограничение
Этот подход прекрасно работает с теми приложениями, которые обрабатывают менее объемные данные, которые могут быть размещены на стандартных серверах баз данных, или вплоть до предела процессора, который обрабатывает данные. Но когда дело доходит до работы с огромными объемами масштабируемых данных, это сложная задача — обрабатывать такие данные через единственное узкое место в базе данных.
Решение Google
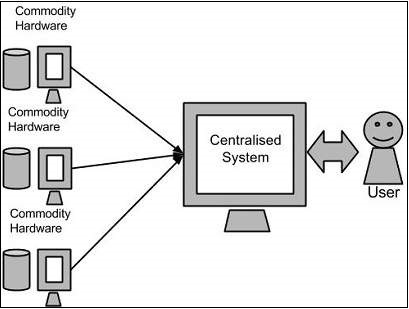
Google решил эту проблему, используя алгоритм MapReduce. Этот алгоритм разделяет задачу на небольшие части и назначает их многим компьютерам, а также собирает результаты с них, которые при интеграции образуют набор данных результатов.
Hadoop
Используя решение, предоставленное Google, Дуг Каттинг и его команда разработали проект с открытым исходным кодом под названием HADOOP .
Hadoop запускает приложения, используя алгоритм MapReduce, где данные обрабатываются параллельно с другими. Короче говоря, Hadoop используется для разработки приложений, которые могут выполнять полный статистический анализ огромных объемов данных.
Hadoop — Введение
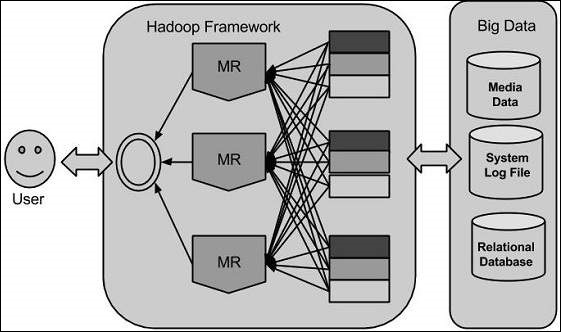
Hadoop — это платформа с открытым исходным кодом Apache, написанная на Java, которая позволяет распределенную обработку больших наборов данных по кластерам компьютеров с использованием простых моделей программирования. Приложение Hadoop Framework работает в среде, которая обеспечивает распределенное хранение и вычисления по кластерам компьютеров. Hadoop предназначен для масштабирования от одного сервера до тысяч машин, каждая из которых предлагает локальные вычисления и хранилище.
Hadoop Architecture
По своей сути Hadoop имеет два основных уровня, а именно —
- Уровень обработки / вычисления (MapReduce) и
- Уровень хранения (распределенная файловая система Hadoop).

Уменьшение карты
MapReduce — это модель параллельного программирования для написания распределенных приложений, разработанная в Google для эффективной обработки больших объемов данных (многотерабайтных наборов данных) на больших кластерах (тысячах узлов) стандартного оборудования надежным и отказоустойчивым способом. Программа MapReduce работает на Hadoop, который является фреймворком с открытым исходным кодом Apache.
Распределенная файловая система Hadoop
Распределенная файловая система Hadoop (HDFS) основана на файловой системе Google (GFS) и предоставляет распределенную файловую систему, предназначенную для работы на обычном оборудовании. Он имеет много общего с существующими распределенными файловыми системами. Однако отличия от других распределенных файловых систем значительны. Он обладает высокой отказоустойчивостью и предназначен для развертывания на недорогом оборудовании. Он обеспечивает высокопроизводительный доступ к данным приложения и подходит для приложений, имеющих большие наборы данных.
Помимо вышеупомянутых двух основных компонентов, инфраструктура Hadoop также включает в себя следующие два модуля:
-
Общее Hadoop — это библиотеки и утилиты Java, необходимые для других модулей Hadoop.
-
Hadoop YARN — это платформа для планирования заданий и управления ресурсами кластера.
Общее Hadoop — это библиотеки и утилиты Java, необходимые для других модулей Hadoop.
Hadoop YARN — это платформа для планирования заданий и управления ресурсами кластера.
Как работает Hadoop?
Довольно дорого строить большие серверы с тяжелыми конфигурациями, которые обрабатывают крупномасштабную обработку, но в качестве альтернативы вы можете связать множество обычных компьютеров с одним процессором в единую функциональную распределенную систему, и практически кластерные машины могут читать набор данных. параллельно и обеспечивают гораздо более высокую пропускную способность. Более того, это дешевле, чем один высокопроизводительный сервер. Так что это первый мотивационный фактор, стоящий за использованием Hadoop, который работает на кластерных и недорогих компьютерах.
Hadoop запускает код на кластере компьютеров. Этот процесс включает в себя следующие основные задачи, которые выполняет Hadoop:
-
Данные изначально делятся на каталоги и файлы. Файлы делятся на блоки одинакового размера 128M и 64M (предпочтительно 128M).
-
Эти файлы затем распределяются по различным узлам кластера для дальнейшей обработки.
-
HDFS, находясь поверх локальной файловой системы, контролирует обработку.
-
Блоки реплицируются для обработки аппаратного сбоя.
-
Проверка того, что код был успешно выполнен.
-
Выполнение сортировки между картами и этапами сокращения.
-
Отправка отсортированных данных на определенный компьютер.
-
Написание журналов отладки для каждого задания.
Данные изначально делятся на каталоги и файлы. Файлы делятся на блоки одинакового размера 128M и 64M (предпочтительно 128M).
Эти файлы затем распределяются по различным узлам кластера для дальнейшей обработки.
HDFS, находясь поверх локальной файловой системы, контролирует обработку.
Блоки реплицируются для обработки аппаратного сбоя.
Проверка того, что код был успешно выполнен.
Выполнение сортировки между картами и этапами сокращения.
Отправка отсортированных данных на определенный компьютер.
Написание журналов отладки для каждого задания.
Преимущества Hadoop
-
Hadoop Framework позволяет пользователю быстро писать и тестировать распределенные системы. Он эффективен и автоматически распределяет данные и работает между машинами и, в свою очередь, использует базовый параллелизм ядер ЦП.
-
Hadoop не полагается на аппаратное обеспечение для обеспечения отказоустойчивости и высокой доступности (FTHA), а сама библиотека Hadoop была разработана для обнаружения и обработки сбоев на уровне приложений.
-
Серверы могут быть добавлены или удалены из кластера динамически, и Hadoop продолжает работать без перерыва.
-
Еще одним большим преимуществом Hadoop является то, что он не только является открытым исходным кодом, но и совместим со всеми платформами, поскольку основан на Java.
Hadoop Framework позволяет пользователю быстро писать и тестировать распределенные системы. Он эффективен и автоматически распределяет данные и работает между машинами и, в свою очередь, использует базовый параллелизм ядер ЦП.
Hadoop не полагается на аппаратное обеспечение для обеспечения отказоустойчивости и высокой доступности (FTHA), а сама библиотека Hadoop была разработана для обнаружения и обработки сбоев на уровне приложений.
Серверы могут быть добавлены или удалены из кластера динамически, и Hadoop продолжает работать без перерыва.
Еще одним большим преимуществом Hadoop является то, что он не только является открытым исходным кодом, но и совместим со всеми платформами, поскольку основан на Java.
Hadoop — Настройка среды
Hadoop поддерживается платформой GNU / Linux и ее разновидностями. Поэтому нам нужно установить операционную систему Linux для настройки среды Hadoop. Если у вас есть ОС, отличная от Linux, вы можете установить в нее программное обеспечение Virtualbox и установить Linux внутри Virtualbox.
Настройка перед установкой
Перед установкой Hadoop в среду Linux нам нужно настроить Linux с помощью ssh (Secure Shell). Следуйте приведенным ниже инструкциям для настройки среды Linux.
Создание пользователя
Вначале рекомендуется создать отдельного пользователя для Hadoop, чтобы изолировать файловую систему Hadoop от файловой системы Unix. Следуйте инструкциям ниже, чтобы создать пользователя —
-
Откройте корень с помощью команды «su».
-
Создайте пользователя из учетной записи root с помощью команды «useradd username».
-
Теперь вы можете открыть существующую учетную запись пользователя с помощью команды «su username».
Откройте корень с помощью команды «su».
Создайте пользователя из учетной записи root с помощью команды «useradd username».
Теперь вы можете открыть существующую учетную запись пользователя с помощью команды «su username».
Откройте терминал Linux и введите следующие команды, чтобы создать пользователя.
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
Настройка SSH и генерация ключей
Настройка SSH требуется для выполнения различных операций в кластере, таких как запуск, остановка, операции распределенной оболочки демона. Для аутентификации разных пользователей Hadoop требуется предоставить пару открытого / закрытого ключа для пользователя Hadoop и поделиться ею с разными пользователями.
Следующие команды используются для генерации пары ключ-значение с использованием SSH. Скопируйте открытые ключи из формы id_rsa.pub в authorized_keys и предоставьте владельцу права на чтение и запись в файл authorized_keys соответственно.
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Установка Java
Java является основной предпосылкой для Hadoop. Прежде всего, вы должны проверить существование java в вашей системе, используя команду «java -version». Синтаксис команды версии Java приведен ниже.
$ java -version
Если все в порядке, это даст вам следующий вывод.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если java не установлен в вашей системе, следуйте приведенным ниже инструкциям для установки java.
Шаг 1
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке www.oracle.com
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Обычно вы найдете загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc .
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 5
Используйте следующие команды для настройки альтернатив Java —
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
Теперь проверьте команду java -version из терминала, как описано выше.
Загрузка Hadoop
Загрузите и извлеките Hadoop 2.4.1 из программного обеспечения Apache, используя следующие команды.
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Режимы работы Hadoop
Загрузив Hadoop, вы можете управлять кластером Hadoop в одном из трех поддерживаемых режимов:
-
Локальный / автономный режим — после загрузки Hadoop в вашу систему по умолчанию он настраивается в автономном режиме и может работать как отдельный процесс Java.
-
Псевдораспределенный режим — это распределенное моделирование на одной машине. Каждый демон Hadoop, такой как hdfs, yarn, MapReduce и т. Д., Будет работать как отдельный процесс Java. Этот режим полезен для разработки.
-
Полностью распределенный режим — этот режим полностью распределен с минимум двумя или более компьютерами в качестве кластера. Мы подробно познакомимся с этим режимом в следующих главах.
Локальный / автономный режим — после загрузки Hadoop в вашу систему по умолчанию он настраивается в автономном режиме и может работать как отдельный процесс Java.
Псевдораспределенный режим — это распределенное моделирование на одной машине. Каждый демон Hadoop, такой как hdfs, yarn, MapReduce и т. Д., Будет работать как отдельный процесс Java. Этот режим полезен для разработки.
Полностью распределенный режим — этот режим полностью распределен с минимум двумя или более компьютерами в качестве кластера. Мы подробно познакомимся с этим режимом в следующих главах.
Установка Hadoop в автономном режиме
Здесь мы обсудим установку Hadoop 2.4.1 в автономном режиме.
Демоны не запущены, и все работает в одной виртуальной машине Java. Автономный режим подходит для запуска программ MapReduce во время разработки, поскольку их легко тестировать и отлаживать.
Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME=/usr/local/hadoop
Прежде чем продолжить, вы должны убедиться, что Hadoop работает нормально. Просто введите следующую команду —
$ hadoop version
Если с вашими настройками все в порядке, вы должны увидеть следующий результат:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Это означает, что настройка автономного режима вашего Hadoop работает нормально. По умолчанию Hadoop настроен для работы в нераспределенном режиме на одной машине.
пример
Давайте проверим простой пример Hadoop. Установка Hadoop предоставляет следующий пример jar-файла MapReduce, который предоставляет базовые функциональные возможности MapReduce и может использоваться для вычисления, например, значения Pi, количества слов в заданном списке файлов и т. Д.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
Давайте создадим входной каталог, в который мы добавим несколько файлов, и наше требование — подсчитать общее количество слов в этих файлах. Чтобы вычислить общее количество слов, нам не нужно писать наш MapReduce, при условии, что файл .jar содержит реализацию для подсчета слов. Вы можете попробовать другие примеры, используя тот же файл .jar; просто выполните следующие команды, чтобы проверить поддерживаемые функциональные программы MapReduce с помощью файла hadoop-mapreduce-examples-2.2.0.jar.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
Шаг 1
Создайте временные файлы содержимого во входном каталоге. Вы можете создать этот входной каталог в любом месте, где бы вы хотели работать.
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input
Это даст следующие файлы в вашем входном каталоге —
total 24 -rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt -rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt -rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
Эти файлы были скопированы из домашнего каталога установки Hadoop. Для вашего эксперимента вы можете иметь разные и большие наборы файлов.
Шаг 2
Давайте запустим процесс Hadoop, чтобы подсчитать общее количество слов во всех файлах, доступных во входном каталоге, следующим образом:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input output
Шаг 3
Шаг 2 выполнит необходимую обработку и сохранит вывод в файле output / part-r00000, который можно проверить с помощью —
$cat output/*
Он перечислит все слова вместе с их общим количеством, доступным во всех файлах, доступных во входном каталоге.
"AS 4 "Contribution" 1 "Contributor" 1 "Derivative 1 "Legal 1 "License" 1 "License"); 1 "Licensor" 1 "NOTICE” 1 "Not 1 "Object" 1 "Source” 1 "Work” 1 "You" 1 "Your") 1 "[]" 1 "control" 1 "printed 1 "submitted" 1 (50%) 1 (BIS), 1 (C) 1 (Don't) 1 (ECCN) 1 (INCLUDING 2 (INCLUDING, 2 .............
Установка Hadoop в псевдо-распределенном режиме
Выполните шаги, указанные ниже, чтобы установить Hadoop 2.4.1 в псевдораспределенном режиме.
Шаг 1 — Настройка Hadoop
Вы можете установить переменные среды Hadoop, добавив следующие команды в файл ~ / .bashrc .
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 2 — Настройка Hadoop
Вы можете найти все файлы конфигурации Hadoop в папке «$ HADOOP_HOME / etc / hadoop». Необходимо внести изменения в эти файлы конфигурации в соответствии с вашей инфраструктурой Hadoop.
$ cd $HADOOP_HOME/etc/hadoop
Чтобы разрабатывать программы Hadoop на языке java, необходимо сбросить переменные среды java в файле hadoop-env.sh , заменив значение JAVA_HOME местоположением java в вашей системе.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Ниже приведен список файлов, которые вы должны отредактировать для настройки Hadoop.
ядро-site.xml
Файл core-site.xml содержит такую информацию, как номер порта, используемый для экземпляра Hadoop, память, выделенная для файловой системы, лимит памяти для хранения данных и размер буферов чтения / записи.
Откройте файл core-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
HDFS-site.xml
Файл hdfs-site.xml содержит такую информацию, как значение данных репликации, путь namenode и пути datanode вашей локальной файловой системы. Это место, где вы хотите хранить инфраструктуру Hadoop.
Допустим, следующие данные.
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Откройте этот файл и добавьте следующие свойства между тегами <configuration> </ configuration> в этом файле.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
Примечание. В приведенном выше файле все значения свойств определяются пользователем, и вы можете вносить изменения в соответствии с инфраструктурой Hadoop.
Пряжа-site.xml
Этот файл используется для настройки пряжи в Hadoop. Откройте файл yarn-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Этот файл используется, чтобы указать, какую платформу MapReduce мы используем. По умолчанию Hadoop содержит шаблон yarn-site.xml. Прежде всего, необходимо скопировать файл из mapred-site.xml.template в файл mapred-site.xml с помощью следующей команды.
$ cp mapred-site.xml.template mapred-site.xml
Откройте файл mapred-site.xml и добавьте следующие свойства между тегами <configuration>, </ configuration> в этом файле.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Проверка правильности установки Hadoop
Следующие шаги используются для проверки установки Hadoop.
Шаг 1 — Настройка узла имени
Настройте namenode с помощью команды «hdfs namenode -format» следующим образом.
$ cd ~ $ hdfs namenode -format
Ожидаемый результат заключается в следующем.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Шаг 2 — Проверка Hadoop dfs
Следующая команда используется для запуска dfs. Выполнение этой команды запустит вашу файловую систему Hadoop.
$ start-dfs.sh
Ожидаемый результат следующий:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Шаг 3 — Проверка скрипта пряжи
Следующая команда используется для запуска скрипта пряжи. Выполнение этой команды запустит ваши демоны пряжи.
$ start-yarn.sh
Ожидаемый результат следующим образом —
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Шаг 4 — Доступ к Hadoop в браузере
Номер порта по умолчанию для доступа к Hadoop — 50070. Используйте следующий URL-адрес, чтобы получить службы Hadoop в браузере.
http://localhost:50070/
Шаг 5 — Проверьте все приложения для кластера
Номер порта по умолчанию для доступа ко всем приложениям кластера — 8088. Используйте следующий URL для посещения этой службы.
http://localhost:8088/
Hadoop — HDFS Обзор
Файловая система Hadoop была разработана с использованием распределенной файловой системы. Он запускается на товарном оборудовании. В отличие от других распределенных систем, HDFS обладает высокой отказоустойчивостью и разработана с использованием недорогого оборудования.
HDFS хранит очень большой объем данных и обеспечивает более легкий доступ. Для хранения таких огромных данных файлы хранятся на нескольких машинах. Эти файлы хранятся в избыточном виде, чтобы спасти систему от возможных потерь данных в случае сбоя. HDFS также делает приложения доступными для параллельной обработки.
Особенности HDFS
- Подходит для распределенного хранения и обработки.
- Hadoop предоставляет командный интерфейс для взаимодействия с HDFS.
- Встроенные серверы namenode и datanode помогают пользователям легко проверить состояние кластера.
- Потоковый доступ к данным файловой системы.
- HDFS обеспечивает права доступа к файлам и аутентификацию.
Архитектура HDFS
Ниже приведена архитектура файловой системы Hadoop.
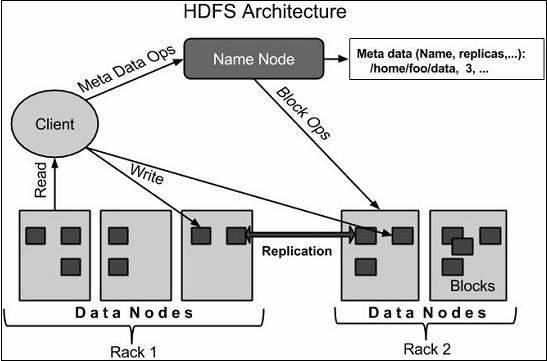
HDFS следует архитектуре «ведущий-ведомый» и имеет следующие элементы.
NameNode
Namenode — это стандартное аппаратное обеспечение, которое содержит операционную систему GNU / Linux и программное обеспечение namenode. Это программное обеспечение, которое может работать на обычном оборудовании. Система, имеющая наменоде, действует как главный сервер и выполняет следующие задачи:
-
Управляет пространством имен файловой системы.
-
Регулирует доступ клиента к файлам.
-
Он также выполняет операции с файловой системой, такие как переименование, закрытие и открытие файлов и каталогов.
Управляет пространством имен файловой системы.
Регулирует доступ клиента к файлам.
Он также выполняет операции с файловой системой, такие как переименование, закрытие и открытие файлов и каталогов.
DataNode
Датодода — это стандартное аппаратное обеспечение с операционной системой GNU / Linux и программным обеспечением датоде. Для каждого узла (Commodity hardware / System) в кластере будет указана дата данных. Эти узлы управляют хранением данных своей системы.
-
Датододы выполняют операции чтения-записи в файловых системах в соответствии с запросом клиента.
-
Они также выполняют такие операции, как создание, удаление и репликация блоков в соответствии с инструкциями namenode.
Датододы выполняют операции чтения-записи в файловых системах в соответствии с запросом клиента.
Они также выполняют такие операции, как создание, удаление и репликация блоков в соответствии с инструкциями namenode.
блок
Обычно пользовательские данные хранятся в файлах HDFS. Файл в файловой системе будет разделен на один или несколько сегментов и / или сохранен в отдельных узлах данных. Эти файловые сегменты называются блоками. Другими словами, минимальный объем данных, которые HDFS может читать или записывать, называется блоком. Размер блока по умолчанию составляет 64 МБ, но его можно увеличить в соответствии с необходимостью изменения конфигурации HDFS.
Цели HDFS
Обнаружение и устранение неисправностей — поскольку HDFS включает в себя большое количество стандартного оборудования, часто происходят сбои компонентов. Поэтому HDFS должна иметь механизмы для быстрого и автоматического обнаружения и устранения неисправностей.
Огромные наборы данных — HDFS должна иметь сотни узлов на кластер для управления приложениями, имеющими огромные наборы данных.
Аппаратное обеспечение данных . Запрошенная задача может быть выполнена эффективно, когда вычисления выполняются рядом с данными. Особенно там, где задействованы огромные наборы данных, это уменьшает сетевой трафик и увеличивает пропускную способность.
Hadoop — Операции HDFS
Запуск HDFS
Сначала необходимо отформатировать настроенную файловую систему HDFS, открыть namenode (сервер HDFS) и выполнить следующую команду.
$ hadoop namenode -format
После форматирования HDFS запустите распределенную файловую систему. Следующая команда запустит namenode, а также узлы данных как кластер.
$ start-dfs.sh
Перечисление файлов в HDFS
После загрузки информации на сервер, мы можем найти список файлов в каталоге, статус файла, используя ‘ls’ . Ниже приведен синтаксис ls, который вы можете передать в каталог или имя файла в качестве аргумента.
$ $HADOOP_HOME/bin/hadoop fs -ls <args>
Вставка данных в HDFS
Предположим, у нас есть данные в файле с именем file.txt в локальной системе, которые должны быть сохранены в файловой системе hdfs. Следуйте приведенным ниже инструкциям, чтобы вставить нужный файл в файловую систему Hadoop.
Шаг 1
Вы должны создать входной каталог.
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input
Шаг 2
Передайте и сохраните файл данных из локальных систем в файловую систему Hadoop с помощью команды put.
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input
Шаг 3
Вы можете проверить файл с помощью команды ls.
$ $HADOOP_HOME/bin/hadoop fs -ls /user/input
Извлечение данных из HDFS
Предположим, у нас есть файл в HDFS с именем outfile . Ниже приведена простая демонстрация получения необходимого файла из файловой системы Hadoop.
Шаг 1
Сначала просмотрите данные из HDFS с помощью команды cat .
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile
Шаг 2
Загрузите файл из HDFS в локальную файловую систему, используя команду get .
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/
Выключение HDFS
Вы можете выключить HDFS с помощью следующей команды.
$ stop-dfs.sh
Hadoop — Справочник по командам
В «$ HADOOP_HOME / bin / hadoop fs» есть намного больше команд, чем показано здесь, хотя эти основные операции помогут вам начать работу. При запуске ./bin/hadoop dfs без дополнительных аргументов будут перечислены все команды, которые можно запустить с системой FsShell. Кроме того, $ HADOOP_HOME / bin / hadoop fs -help commandName покажет краткую сводку об использовании рассматриваемой операции, если вы застряли.
Таблица всех операций показана ниже. Следующие соглашения используются для параметров —
"<path>" means any file or directory name. "<path>..." means one or more file or directory names. "<file>" means any filename. "<src>" and "<dest>" are path names in a directed operation. "<localSrc>" and "<localDest>" are paths as above, but on the local file system.
Все остальные файлы и пути к ним относятся к объектам внутри HDFS.
| Sr.No | Команда и описание |
|---|---|
| 1 |
-ls <путь> Содержит список содержимого каталога, указанного путем, с указанием имен, разрешений, владельца, размера и даты изменения для каждой записи. |
| 2 |
-lsr <путь> Ведет себя как -ls, но рекурсивно отображает записи во всех подкаталогах пути. |
| 3 |
-du <путь> Показывает использование диска в байтах для всех файлов, которые соответствуют пути; имена файлов сообщаются с полным префиксом протокола HDFS. |
| 4 |
-dus <путь> Аналогично -du, но выводит сводную информацию об использовании диска всеми файлами / каталогами в пути. |
| 5 |
-mv <src> <dest> Перемещает файл или каталог, указанный src, в dest в пределах HDFS. |
| 6 |
-cp <src> <dest> Копирует файл или каталог, указанный src в dest, в HDFS. |
| 7 |
-rm <путь> Удаляет файл или пустой каталог, указанный по пути. |
| 8 |
-rmr <путь> Удаляет файл или каталог, указанный по пути. Рекурсивно удаляет любые дочерние записи (например, файлы или подкаталоги пути). |
| 9 |
-put <localSrc> <dest> Копирует файл или каталог из локальной файловой системы, идентифицированной localSrc, в dest в DFS. |
| 10 |
-copyFromLocal <localSrc> <dest> Идентичный для |
| 11 |
-moveFromLocal <localSrc> <dest> Копирует файл или каталог из локальной файловой системы, идентифицированной localSrc, в dest в HDFS, а затем удаляет локальную копию в случае успеха. |
| 12 |
-get [-crc] <src> <localDest> Копирует файл или каталог в HDFS, идентифицированный src, в путь локальной файловой системы, идентифицированный localDest. |
| 13 |
-getmerge <src> <localDest> Извлекает все файлы, которые соответствуют пути src в HDFS, и копирует их в один объединенный файл в локальной файловой системе, идентифицируемый localDest. |
| 14 |
-cat <filen-ame> Отображает содержимое имени файла на стандартный вывод. |
| 15 |
-copyToLocal <src> <localDest> Идентичен для получения |
| 16 |
-moveToLocal <src> <localDest> Работает как -get, но удаляет копию HDFS в случае успеха. |
| 17 |
-mkdir <путь> Создает каталог с именем path в HDFS. Создает любые родительские каталоги в пути, которые отсутствуют (например, mkdir -p в Linux). |
| 18 |
-setrep [-R] [-w] rep <путь> Устанавливает целевой коэффициент репликации для файлов, идентифицированных путем к rep. (Фактический коэффициент репликации будет двигаться к цели с течением времени) |
| 19 |
-touchz <путь> Создает файл по пути, содержащий текущее время как метку времени. Сбой, если файл уже существует по пути, если размер файла уже не равен 0. |
| 20 |
-test — [ezd] <путь> Возвращает 1, если путь существует; имеет нулевую длину; или является каталогом или 0 в противном случае. |
| 21 |
-stat [формат] <путь> Печатает информацию о пути. Формат — это строка, которая принимает размер файла в блоках (% b), имя файла (% n), размер блока (% o), репликацию (% r) и дату изменения (% y,% Y). |
| 22 |
-tail [-f] <имя файла2> Показывает последний 1 КБ файла на стандартный вывод. |
| 23 |
-chmod [-R] mode, mode, … <путь> … Изменяет права доступа к файлу, связанные с одним или несколькими объектами, идентифицированными путем …. Выполняет изменения рекурсивно с R. Режим представляет собой восьмеричный режим из 3 цифр, или {augo} +/- {rwxX}. Предполагается, что область действия не указана, и не применяется umask. |
| 24 |
-chown [-R] [владелец] [: [группа]] <путь> … Устанавливает пользователя и / или группу-владельца для файлов или каталогов, идентифицированных путем …. Рекурсивно устанавливает владельца, если указан -R. |
| 25 |
-chgrp [-R] группа <путь> … Устанавливает группу-владельца для файлов или каталогов, идентифицированных путем …. Устанавливает группу рекурсивно, если указан -R. |
| 26 |
-help <cmd-name> Возвращает информацию об использовании для одной из команд, перечисленных выше. Вы должны опустить ведущий символ ‘-‘ в cmd. |
-ls <путь>
Содержит список содержимого каталога, указанного путем, с указанием имен, разрешений, владельца, размера и даты изменения для каждой записи.
-lsr <путь>
Ведет себя как -ls, но рекурсивно отображает записи во всех подкаталогах пути.
-du <путь>
Показывает использование диска в байтах для всех файлов, которые соответствуют пути; имена файлов сообщаются с полным префиксом протокола HDFS.
-dus <путь>
Аналогично -du, но выводит сводную информацию об использовании диска всеми файлами / каталогами в пути.
-mv <src> <dest>
Перемещает файл или каталог, указанный src, в dest в пределах HDFS.
-cp <src> <dest>
Копирует файл или каталог, указанный src в dest, в HDFS.
-rm <путь>
Удаляет файл или пустой каталог, указанный по пути.
-rmr <путь>
Удаляет файл или каталог, указанный по пути. Рекурсивно удаляет любые дочерние записи (например, файлы или подкаталоги пути).
-put <localSrc> <dest>
Копирует файл или каталог из локальной файловой системы, идентифицированной localSrc, в dest в DFS.
-copyFromLocal <localSrc> <dest>
Идентичный для
-moveFromLocal <localSrc> <dest>
Копирует файл или каталог из локальной файловой системы, идентифицированной localSrc, в dest в HDFS, а затем удаляет локальную копию в случае успеха.
-get [-crc] <src> <localDest>
Копирует файл или каталог в HDFS, идентифицированный src, в путь локальной файловой системы, идентифицированный localDest.
-getmerge <src> <localDest>
Извлекает все файлы, которые соответствуют пути src в HDFS, и копирует их в один объединенный файл в локальной файловой системе, идентифицируемый localDest.
-cat <filen-ame>
Отображает содержимое имени файла на стандартный вывод.
-copyToLocal <src> <localDest>
Идентичен для получения
-moveToLocal <src> <localDest>
Работает как -get, но удаляет копию HDFS в случае успеха.
-mkdir <путь>
Создает каталог с именем path в HDFS.
Создает любые родительские каталоги в пути, которые отсутствуют (например, mkdir -p в Linux).
-setrep [-R] [-w] rep <путь>
Устанавливает целевой коэффициент репликации для файлов, идентифицированных путем к rep. (Фактический коэффициент репликации будет двигаться к цели с течением времени)
-touchz <путь>
Создает файл по пути, содержащий текущее время как метку времени. Сбой, если файл уже существует по пути, если размер файла уже не равен 0.
-test — [ezd] <путь>
Возвращает 1, если путь существует; имеет нулевую длину; или является каталогом или 0 в противном случае.
-stat [формат] <путь>
Печатает информацию о пути. Формат — это строка, которая принимает размер файла в блоках (% b), имя файла (% n), размер блока (% o), репликацию (% r) и дату изменения (% y,% Y).
-tail [-f] <имя файла2>
Показывает последний 1 КБ файла на стандартный вывод.
-chmod [-R] mode, mode, … <путь> …
Изменяет права доступа к файлу, связанные с одним или несколькими объектами, идентифицированными путем …. Выполняет изменения рекурсивно с R. Режим представляет собой восьмеричный режим из 3 цифр, или {augo} +/- {rwxX}. Предполагается, что область действия не указана, и не применяется umask.
-chown [-R] [владелец] [: [группа]] <путь> …
Устанавливает пользователя и / или группу-владельца для файлов или каталогов, идентифицированных путем …. Рекурсивно устанавливает владельца, если указан -R.
-chgrp [-R] группа <путь> …
Устанавливает группу-владельца для файлов или каталогов, идентифицированных путем …. Устанавливает группу рекурсивно, если указан -R.
-help <cmd-name>
Возвращает информацию об использовании для одной из команд, перечисленных выше. Вы должны опустить ведущий символ ‘-‘ в cmd.
Hadoop — MapReduce
MapReduce — это фреймворк, с помощью которого мы можем писать приложения для параллельной обработки огромных объемов данных на больших кластерах стандартного оборудования.
Что такое MapReduce?
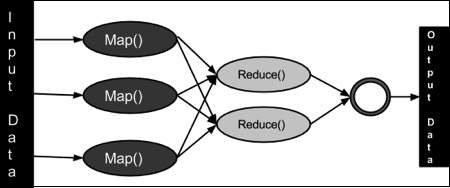
MapReduce — это технология обработки и программная модель для распределенных вычислений на основе Java. Алгоритм MapReduce содержит две важные задачи, а именно Map и Reduce. Карта берет набор данных и преобразует его в другой набор данных, где отдельные элементы разбиваются на кортежи (пары ключ / значение). Во-вторых, задача сокращения, которая принимает выходные данные карты в качестве входных данных и объединяет эти кортежи данных в меньший набор кортежей. Как следует из последовательности имени MapReduce, задача сокращения всегда выполняется после задания карты.
Основным преимуществом MapReduce является простота масштабирования обработки данных на нескольких вычислительных узлах. В модели MapReduce примитивы обработки данных называются преобразователями и преобразователями. Разложение приложения обработки данных на картографы и редукторы иногда бывает нетривиальным. Но как только мы напишем приложение в форме MapReduce, масштабирование приложения для запуска более сотни, тысяч или даже десятков тысяч машин в кластере — это просто изменение конфигурации. Эта простая масштабируемость привлекла многих программистов для использования модели MapReduce.
Алгоритм
-
Обычно парадигма MapReduce основана на отправке компьютера туда, где хранятся данные!
-
Программа MapReduce выполняется в три этапа, а именно: этап отображения, этап перемешивания и этап сокращения.
-
Этап карты — работа карты или картографа заключается в обработке входных данных. Обычно входные данные находятся в форме файла или каталога и хранятся в файловой системе Hadoop (HDFS). Входной файл передается в функцию картографа построчно. Картограф обрабатывает данные и создает несколько небольших порций данных.
-
Этап сокращения — этот этап является комбинацией этапа перемешивания и этапа уменьшения . Работа редуктора заключается в обработке данных, поступающих от картографа. После обработки он создает новый набор выходных данных, который будет храниться в HDFS.
-
-
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
-
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка завершения задач и копирование данных вокруг кластера между узлами.
-
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
-
После выполнения данных задач кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Обычно парадигма MapReduce основана на отправке компьютера туда, где хранятся данные!
Программа MapReduce выполняется в три этапа, а именно: этап отображения, этап перемешивания и этап сокращения.
Этап карты — работа карты или картографа заключается в обработке входных данных. Обычно входные данные находятся в форме файла или каталога и хранятся в файловой системе Hadoop (HDFS). Входной файл передается в функцию картографа построчно. Картограф обрабатывает данные и создает несколько небольших порций данных.
Этап сокращения — этот этап является комбинацией этапа перемешивания и этапа уменьшения . Работа редуктора заключается в обработке данных, поступающих от картографа. После обработки он создает новый набор выходных данных, который будет храниться в HDFS.
Во время задания MapReduce Hadoop отправляет задачи Map и Reduce на соответствующие серверы в кластере.
Каркас управляет всеми деталями передачи данных, такими как выдача задач, проверка завершения задач и копирование данных вокруг кластера между узлами.
Большая часть вычислений происходит на узлах с данными на локальных дисках, что снижает сетевой трафик.
После выполнения данных задач кластер собирает и сокращает данные, чтобы сформировать соответствующий результат, и отправляет их обратно на сервер Hadoop.
Входы и выходы (перспектива Java)
Каркас MapReduce работает с парами <ключ, значение>, то есть каркас просматривает входные данные для задания в виде набора пар <ключ, значение> и создает набор пар <ключ, значение> в качестве выходных данных задания. , возможно, разных типов.
Классы ключей и значений должны быть сериализованы способом и, следовательно, должны реализовывать интерфейс Writable. Кроме того, ключевые классы должны реализовывать интерфейс Writable-Comparable для облегчения сортировки в рамках. Типы ввода и вывода задания MapReduce — (Входные данные) <k1, v1> → карта → <k2, v2> → уменьшить → <k3, v3> (Выходные данные).
| вход | Выход | |
|---|---|---|
| карта | <k1, v1> | список (<k2, v2>) |
| уменьшить | <k2, список (v2)> | список (<k3, v3>) |
терминология
-
PayLoad — приложения реализуют функции Map и Reduce и составляют основу работы.
-
Mapper — Mapper отображает пары ключ / значение на набор промежуточных пар ключ / значение.
-
NamedNode — узел, управляющий распределенной файловой системой Hadoop (HDFS).
-
DataNode — Узел, в котором данные представляются заранее, до начала какой-либо обработки.
-
MasterNode — узел, где работает JobTracker и который принимает запросы на работу от клиентов.
-
SlaveNode — узел, в котором работает программа Map and Reduce.
-
JobTracker — Планирует задания и отслеживает назначения заданий для трекера задач.
-
Task Tracker — отслеживает задачу и сообщает о статусе в JobTracker.
-
Задание — программа — это выполнение картографа и редуктора в наборе данных.
-
Задача — выполнение Mapper или Reducer на срезе данных.
-
Попытка задачи — конкретный случай попытки выполнить задачу на подчиненном узле.
PayLoad — приложения реализуют функции Map и Reduce и составляют основу работы.
Mapper — Mapper отображает пары ключ / значение на набор промежуточных пар ключ / значение.
NamedNode — узел, управляющий распределенной файловой системой Hadoop (HDFS).
DataNode — Узел, в котором данные представляются заранее, до начала какой-либо обработки.
MasterNode — узел, где работает JobTracker и который принимает запросы на работу от клиентов.
SlaveNode — узел, в котором работает программа Map and Reduce.
JobTracker — Планирует задания и отслеживает назначения заданий для трекера задач.
Task Tracker — отслеживает задачу и сообщает о статусе в JobTracker.
Задание — программа — это выполнение картографа и редуктора в наборе данных.
Задача — выполнение Mapper или Reducer на срезе данных.
Попытка задачи — конкретный случай попытки выполнить задачу на подчиненном узле.
Пример сценария
Ниже приведены данные о потреблении электроэнергии в организации. Он содержит ежемесячное потребление электроэнергии и среднегодовое значение за разные годы.
| январь | февраль | март | апрель | май | июнь | июль | август | сентябрь | октябрь | ноябрь | декабрь | в среднем | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Если вышеуказанные данные приведены в качестве входных данных, мы должны написать приложения для их обработки и получения таких результатов, как определение года максимального использования, года минимального использования и так далее. Это прогулка для программистов с конечным числом записей. Они просто напишут логику для получения требуемого вывода и передадут данные в написанное приложение.
Но подумайте о данных, представляющих потребление электроэнергии всеми крупными отраслями определенного государства, с момента его образования.
Когда мы пишем приложения для обработки таких массовых данных,
-
Они займут много времени, чтобы выполнить.
-
Будет большой сетевой трафик, когда мы перемещаем данные с источника на сетевой сервер и так далее.
Они займут много времени, чтобы выполнить.
Будет большой сетевой трафик, когда мы перемещаем данные с источника на сетевой сервер и так далее.
Для решения этих проблем у нас есть инфраструктура MapReduce.
Входные данные
Приведенные выше данные сохраняются как sample.txt и передаются в качестве входных данных. Входной файл выглядит так, как показано ниже.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25 1980 26 27 28 28 28 30 31 31 31 30 30 30 29 1981 31 32 32 32 33 34 35 36 36 34 34 34 34 1984 39 38 39 39 39 41 42 43 40 39 38 38 40 1985 38 39 39 39 39 41 41 41 00 40 39 39 45
Пример программы
Ниже приведена программа для образца данных с использованием инфраструктуры MapReduce.
package hadoop; import java.util.*; import java.io.IOException; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.conf.*; import org.apache.hadoop.io.*; import org.apache.hadoop.mapred.*; import org.apache.hadoop.util.*; public class ProcessUnits { //Mapper class public static class E_EMapper extends MapReduceBase implements Mapper<LongWritable ,/*Input key Type */ Text, /*Input value Type*/ Text, /*Output key Type*/ IntWritable> /*Output value Type*/ { //Map function public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); String lasttoken = null; StringTokenizer s = new StringTokenizer(line,"\t"); String year = s.nextToken(); while(s.hasMoreTokens()) { lasttoken = s.nextToken(); } int avgprice = Integer.parseInt(lasttoken); output.collect(new Text(year), new IntWritable(avgprice)); } } //Reducer class public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > { //Reduce function public void reduce( Text key, Iterator <IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int maxavg = 30; int val = Integer.MIN_VALUE; while (values.hasNext()) { if((val = values.next().get())>maxavg) { output.collect(key, new IntWritable(val)); } } } } //Main function public static void main(String args[])throws Exception { JobConf conf = new JobConf(ProcessUnits.class); conf.setJobName("max_eletricityunits"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(E_EMapper.class); conf.setCombinerClass(E_EReduce.class); conf.setReducerClass(E_EReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } }
Сохраните вышеуказанную программу как ProcessUnits.java. Компиляция и выполнение программы объяснены ниже.
Компиляция и выполнение программы Process Units
Предположим, мы находимся в домашнем каталоге пользователя Hadoop (например, / home / hadoop).
Следуйте инструкциям ниже, чтобы скомпилировать и выполнить вышеуказанную программу.
Шаг 1
Следующая команда должна создать каталог для хранения скомпилированных классов Java.
$ mkdir units
Шаг 2
Загрузите Hadoop-core-1.2.1.jar, который используется для компиляции и запуска программы MapReduce. Посетите следующую ссылку mvnrepository.com, чтобы скачать банку. Давайте предположим, что загруженная папка — / home / hadoop /.
Шаг 3
Следующие команды используются для компиляции программы ProcessUnits.java и создания jar для программы.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
Шаг 4
Следующая команда используется для создания входного каталога в HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Шаг 5
Следующая команда используется для копирования входного файла с именем sample.txt во входной каталог HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
Шаг 6
Следующая команда используется для проверки файлов во входном каталоге.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Шаг 7
Следующая команда используется для запуска приложения Eleunit_max путем извлечения входных файлов из входного каталога.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Подождите некоторое время, пока файл не будет выполнен. После выполнения, как показано ниже, выходные данные будут содержать количество входных разбиений, количество задач Map, количество задач редуктора и т. Д.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40
Шаг 8
Следующая команда используется для проверки результирующих файлов в выходной папке.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Шаг 9
Следующая команда используется для просмотра выходных данных в файле Part-00000 . Этот файл создан HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Ниже вывод, сгенерированный программой MapReduce.
1981 34 1984 40 1985 45
Шаг 10
Следующая команда используется для копирования выходной папки из HDFS в локальную файловую систему для анализа.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop
Важные команды
Все команды Hadoop вызываются командой $ HADOOP_HOME / bin / hadoop . При запуске сценария Hadoop без каких-либо аргументов выводится описание всех команд.
Использование — hadoop [—config confdir] КОМАНДА
В следующей таблице перечислены доступные параметры и их описание.
| Sr.No. | Вариант и описание |
|---|---|
| 1 |
наменоде -формат Форматирует файловую систему DFS. |
| 2 |
secondarynamenode Запускает вторичный наменод DFS. |
| 3 |
NameNode Запускает DFS наменоде. |
| 4 |
DataNode Запускает данные DFS. |
| 5 |
dfsadmin Запускает клиент администратора DFS. |
| 6 |
mradmin Запускает клиент администрирования Map-Reduce. |
| 7 |
Fsck Запускает утилиту проверки файловой системы DFS. |
| 8 |
фс Запускает универсальный пользовательский клиент файловой системы. |
| 9 |
балансер Запускает утилиту балансировки кластера. |
| 10 |
OIV Применяет офлайн-просмотрщик fsimage к fsimage. |
| 11 |
fetchdt Извлекает токен делегирования из NameNode. |
| 12 |
JobTracker Запускает узел отслеживания заданий MapReduce. |
| 13 |
трубы Запускает работу Pipes. |
| 14 |
TaskTracker Запускает узел отслеживания задач MapReduce. |
| 15 |
historyserver Запускает серверы истории заданий как автономный демон. |
| 16 |
работа Управляет заданиями MapReduce. |
| 17 |
очередь Получает информацию о JobQueues. |
| 18 |
версия Печатает версию. |
| 19 |
баночка <баночка> Запускает файл JAR. |
| 20 |
distcp <srcurl> <desturl> Копирует файл или каталоги рекурсивно. |
| 21 |
distcp2 <srcurl> <desturl> DistCp версия 2. |
| 22 |
archive -archiveName NAME -p <родительский путь> <src> * <dest> Создает архив hadoop. |
| 23 |
Путь к классам Печатает путь к классу, необходимый для получения jar Hadoop и необходимых библиотек. |
| 24 |
daemonlog Получить / установить уровень журнала для каждого демона |
наменоде -формат
Форматирует файловую систему DFS.
secondarynamenode
Запускает вторичный наменод DFS.
NameNode
Запускает DFS наменоде.
DataNode
Запускает данные DFS.
dfsadmin
Запускает клиент администратора DFS.
mradmin
Запускает клиент администрирования Map-Reduce.
Fsck
Запускает утилиту проверки файловой системы DFS.
фс
Запускает универсальный пользовательский клиент файловой системы.
балансер
Запускает утилиту балансировки кластера.
OIV
Применяет офлайн-просмотрщик fsimage к fsimage.
fetchdt
Извлекает токен делегирования из NameNode.
JobTracker
Запускает узел отслеживания заданий MapReduce.
трубы
Запускает работу Pipes.
TaskTracker
Запускает узел отслеживания задач MapReduce.
historyserver
Запускает серверы истории заданий как автономный демон.
работа
Управляет заданиями MapReduce.
очередь
Получает информацию о JobQueues.
версия
Печатает версию.
баночка <баночка>
Запускает файл JAR.
distcp <srcurl> <desturl>
Копирует файл или каталоги рекурсивно.
distcp2 <srcurl> <desturl>
DistCp версия 2.
archive -archiveName NAME -p <родительский путь> <src> * <dest>
Создает архив hadoop.
Путь к классам
Печатает путь к классу, необходимый для получения jar Hadoop и необходимых библиотек.
daemonlog
Получить / установить уровень журнала для каждого демона
Как взаимодействовать с MapReduce Jobs
Использование — задание hadoop [GENERIC_OPTIONS]
Ниже приведены общие параметры, доступные в задании Hadoop.
| Sr.No. | GENERIC_OPTION & Описание |
|---|---|
| 1 |
-submit <файл-задания> Представляет работу. |
| 2 |
-status <идентификатор работы> Печатает карту и уменьшает процент выполнения и все счетчики заданий. |
| 3 |
-counter <идентификатор-задания> <имя-группы> <имя-счетчика> Печатает значение счетчика. |
| 4 |
-kill <идентификатор работы> Убивает работу. |
| 5 |
-events <идентификатор-задания> <fromevent — #> <# — of-events> Печатает детали событий, полученные трекером для заданного диапазона. |
| 6 |
-history [все] <jobOutputDir> — история <jobOutputDir> Печатает сведения о работе, ошибки и убитые подсказки Более подробную информацию о задании, например об успешных заданиях и попытках выполнения заданий для каждой задачи, можно просмотреть, указав параметр [все]. |
| 7 |
-лист [все] Отображает все вакансии. -list отображает только задания, которые еще не завершены. |
| 8 |
-kill-task <идентификатор задачи> Убивает задачу. Убитые задачи НЕ учитываются при неудачных попытках. |
| 9 |
-fail-task <идентификатор задачи> Сбой задачи Неудачные задачи учитываются как неудачные попытки. |
| 10 |
-set-priority <идентификатор-задания> <приоритет> Изменяет приоритет задания. Допустимые значения приоритета: VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW |
-submit <файл-задания>
Представляет работу.
-status <идентификатор работы>
Печатает карту и уменьшает процент выполнения и все счетчики заданий.
-counter <идентификатор-задания> <имя-группы> <имя-счетчика>
Печатает значение счетчика.
-kill <идентификатор работы>
Убивает работу.
-events <идентификатор-задания> <fromevent — #> <# — of-events>
Печатает детали событий, полученные трекером для заданного диапазона.
-history [все] <jobOutputDir> — история <jobOutputDir>
Печатает сведения о работе, ошибки и убитые подсказки Более подробную информацию о задании, например об успешных заданиях и попытках выполнения заданий для каждой задачи, можно просмотреть, указав параметр [все].
-лист [все]
Отображает все вакансии. -list отображает только задания, которые еще не завершены.
-kill-task <идентификатор задачи>
Убивает задачу. Убитые задачи НЕ учитываются при неудачных попытках.
-fail-task <идентификатор задачи>
Сбой задачи Неудачные задачи учитываются как неудачные попытки.
-set-priority <идентификатор-задания> <приоритет>
Изменяет приоритет задания. Допустимые значения приоритета: VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW
Чтобы увидеть статус работы
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004
Чтобы увидеть историю работы output-dir
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/output
Чтобы убить работу
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004
Hadoop — потоковое
Потоковая передача Hadoop — это утилита, поставляемая с дистрибутивом Hadoop. Эта утилита позволяет создавать и запускать задания Map / Reduce с любым исполняемым файлом или скриптом в качестве средства отображения и / или редуктора.
Пример использования Python
Для потоковой передачи Hadoop мы рассматриваем проблему подсчета слов. Любая работа в Hadoop должна иметь две фазы: маппер и редуктор. Мы написали коды для картографа и редуктора в скрипте Python для запуска его под Hadoop. То же самое можно написать на Perl и Ruby.
Код фазы картографирования
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)
Убедитесь, что у этого файла есть разрешение на выполнение (chmod + x / home / expert / hadoop-1.2.1 / mapper.py).
Код фазы редуктора
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
Сохраните коды мапперов и редукторов в mapper.py и reducer.py в домашнем каталоге Hadoop. Убедитесь, что эти файлы имеют разрешение на выполнение (chmod + x mapper.py и chmod + x reducer.py). Поскольку python чувствителен к отступам, такой же код можно скачать по ссылке ниже.
Выполнение программы WordCount
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1. 2.1.jar \ -input input_dirs \ -output output_dir \ -mapper <path/mapper.py \ -reducer <path/reducer.py
Где «\» используется для продолжения строки для четкого чтения.
Например,
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.py
Как работает потоковая передача
В приведенном выше примере и преобразователь, и преобразователь являются сценариями Python, которые считывают ввод из стандартного ввода и выводят вывод в стандартный вывод. Утилита создаст задание Map / Reduce, отправит задание в соответствующий кластер и будет отслеживать ход выполнения задания до его завершения.
Когда для мапперов указан скрипт, каждая задача маппера будет запускать скрипт как отдельный процесс при инициализации маппера. Когда задача mapper выполняется, она преобразует свои входные данные в строки и передает эти строки в стандартный ввод (STDIN) процесса. В то же время преобразователь собирает линейно-ориентированные выходные данные из стандартного вывода (STDOUT) процесса и преобразует каждую строку в пару ключ / значение, которая собирается в качестве выходных данных преобразователя. По умолчанию префикс строки до первого символа табуляции является ключом, а остальная часть строки (исключая символ табуляции) будет значением. Если в строке нет символа табуляции, тогда клавишей считается вся строка, а значение равно нулю. Однако, это может быть настроено, согласно одной потребности.
Если для редукторов указан сценарий, каждая задача редуктора запускает сценарий как отдельный процесс, а затем инициализируется редуктор. По мере выполнения задачи редуктора она преобразует свои пары ключ / значение ввода в строки и передает эти строки в стандартный ввод (STDIN) процесса. Между тем, редуктор собирает линейно-ориентированные выходы из стандартного выхода (STDOUT) процесса, преобразует каждую строку в пару ключ / значение, которая собирается как выход редуктора. По умолчанию префикс строки до первого символа табуляции является ключом, а остальная часть строки (исключая символ табуляции) является значением. Однако, это может быть настроено согласно определенным требованиям.
Важные команды
| параметры | Опции | Описание |
|---|---|---|
| -входной каталог / имя файла | необходимые | Входное местоположение для картографа. |
| -output имя-каталога | необходимые | Расположение выхода для редуктора. |
| исполняемый файл или скрипт или JavaClassName | необходимые | Mapper исполняемый. |
| исполняемый файл или скрипт или JavaClassName | необходимые | Редуктор исполняемый. |
| -file имя файла | Необязательный | Делает доступным исполняемый файл преобразователя, преобразователя или объединителя локально на вычислительных узлах. |
| -inputformat JavaClassName | Необязательный | Предоставляемый класс должен возвращать пары ключ / значение класса Text. Если не указано, TextInputFormat используется по умолчанию. |
| -outputformat JavaClassName | Необязательный | Класс, который вы предоставляете, должен принимать пары ключ / значение класса Text. Если не указано, TextOutputformat используется по умолчанию. |
| разделитель JavaClassName | Необязательный | Класс, который определяет, к какому ключу сокращения отправляется. |
| -combiner streamingCommand или JavaClassName | Необязательный | Исполняемый файл Combiner для вывода карты. |
| -cmdenv name = значение | Необязательный | Передает переменную среды в потоковые команды. |
| -inputreader | Необязательный | Для обратной совместимости: указывает класс считывателя записей (вместо класса входного формата). |
| -подробный | Необязательный | Подробный вывод. |
| -lazyOutput | Необязательный | Создает вывод лениво. Например, если формат вывода основан на FileOutputFormat, выходной файл создается только при первом вызове output.collect (или Context.write). |
| -numReduceTasks | Необязательный | Определяет количество редукторов. |
| -mapdebug | Необязательный | Скрипт для вызова при сбое задачи карты. |
| -reducedebug | Необязательный | Скрипт для вызова при сбое задачи уменьшения. |
Hadoop — многоузловой кластер
В этой главе описывается настройка многоузлового кластера Hadoop в распределенной среде.
Поскольку весь кластер не может быть продемонстрирован, мы объясняем кластерную среду Hadoop, используя три системы (одну ведущую и две подчиненные); ниже приведены их IP-адреса.
- Hadoop Master: 192.168.1.15 (hadoop-master)
- Hadoop Slave: 192.168.1.16 (hadoop-slave-1)
- Hadoop Slave: 192.168.1.17 (hadoop-slave-2)
Выполните шаги, указанные ниже, чтобы настроить кластер Hadoop Multi-Node.
Установка Java
Java является основной предпосылкой для Hadoop. Прежде всего, вы должны проверить существование java в вашей системе, используя «java -version». Синтаксис команды версии Java приведен ниже.
$ java -version
Если все работает нормально, вы получите следующий вывод.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Если Java не установлен в вашей системе, выполните следующие шаги для установки Java.
Шаг 1
Загрузите Java (JDK <последняя версия> — X64.tar.gz), перейдя по следующей ссылке www.oracle.com
Затем jdk-7u71-linux-x64.tar.gz будет загружен в вашу систему.
Шаг 2
Обычно вы найдете загруженный файл Java в папке Downloads. Проверьте его и извлеките файл jdk-7u71-linux-x64.gz, используя следующие команды.
$ cd Downloads/ $ ls jdk-7u71-Linux-x64.gz $ tar zxf jdk-7u71-Linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-Linux-x64.gz
Шаг 3
Чтобы сделать Java доступным для всех пользователей, вы должны переместить его в папку «/ usr / local /». Откройте корень и введите следующие команды.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Шаг 4
Для настройки переменных PATH и JAVA_HOME добавьте следующие команды в файл ~ / .bashrc .
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
Теперь проверьте команду java -version из терминала, как описано выше. Выполните описанный выше процесс и установите Java на всех узлах вашего кластера.
Создание учетной записи пользователя
Создайте системную учетную запись пользователя в главной и подчиненной системах, чтобы использовать установку Hadoop.
# useradd hadoop # passwd hadoop
Картирование узлов
Вы должны отредактировать файл hosts в папке / etc / на всех узлах, указать IP-адрес каждой системы, а затем их имена.
# vi /etc/hosts enter the following lines in the /etc/hosts file. 192.168.1.109 hadoop-master 192.168.1.145 hadoop-slave-1 192.168.56.1 hadoop-slave-2
Настройка входа на основе ключа
Настройте ssh на каждом узле так, чтобы они могли общаться друг с другом без запроса пароля.
# su hadoop $ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2 $ chmod 0600 ~/.ssh/authorized_keys $ exit
Установка Hadoop
На главном сервере загрузите и установите Hadoop, используя следующие команды.
# mkdir /opt/hadoop # cd /opt/hadoop/ # wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz # tar -xzf hadoop-1.2.0.tar.gz # mv hadoop-1.2.0 hadoop # chown -R hadoop /opt/hadoop # cd /opt/hadoop/hadoop/
Конфигурирование Hadoop
Вы должны настроить сервер Hadoop, внеся следующие изменения, как указано ниже.
ядро-site.xml
Откройте файл core-site.xml и отредактируйте его, как показано ниже.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
HDFS-site.xml
Откройте файл hdfs-site.xml и отредактируйте его, как показано ниже.
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
Откройте файл mapred-site.xml и отредактируйте его, как показано ниже.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
hadoop-env.sh
Откройте файл hadoop-env.sh и отредактируйте JAVA_HOME, HADOOP_CONF_DIR и HADOOP_OPTS, как показано ниже.
Примечание. Установите JAVA_HOME в соответствии с конфигурацией вашей системы.
export JAVA_HOME=/opt/jdk1.7.0_17 export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true export HADOOP_CONF_DIR=/opt/hadoop/hadoop/conf
Установка Hadoop на подчиненные серверы
Установите Hadoop на всех подчиненных серверах, следуя приведенным командам.
# su hadoop $ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop $ scp -r hadoop hadoop-slave-2:/opt/hadoop
Настройка Hadoop на главном сервере
Откройте главный сервер и настройте его, следуя приведенным командам.
# su hadoop $ cd /opt/hadoop/hadoop
Настройка главного узла
$ vi etc/hadoop/masters hadoop-master
Конфигурирование подчиненного узла
$ vi etc/hadoop/slaves hadoop-slave-1 hadoop-slave-2
Узел имени формата в Hadoop Master
# su hadoop $ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format 11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-master/192.168.1.109 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473; compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013 STARTUP_MSG: java = 1.7.0_71 ************************************************************/ 11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap editlog=/opt/hadoop/hadoop/dfs/name/current/edits …………………………………………………. …………………………………………………. …………………………………………………. 11/10/14 10:58:08 INFO common.Storage: Storage directory /opt/hadoop/hadoop/dfs/name has been successfully formatted. 11/10/14 10:58:08 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15 ************************************************************/
Запуск сервисов Hadoop
Следующая команда запускает все службы Hadoop на Hadoop-Master.
$ cd $HADOOP_HOME/sbin $ start-all.sh
Добавление нового узла данных в кластер Hadoop
Ниже приведены шаги, которые необходимо выполнить для добавления новых узлов в кластер Hadoop.
сетей
Добавьте новые узлы в существующий кластер Hadoop с соответствующей конфигурацией сети. Предположим следующую конфигурацию сети.
Для новой конфигурации узла —
IP address : 192.168.1.103 netmask : 255.255.255.0 hostname : slave3.in
Добавление пользователя и доступа по SSH
Добавить пользователя
На новом узле добавьте пользователя «hadoop» и установите пароль пользователя Hadoop на «hadoop123» или любой другой, используя следующие команды.
useradd hadoop passwd hadoop
Установить пароль меньше подключения от ведущего к новому ведомому.
Выполните следующее на мастере
mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory scp $HOME/.ssh/id_rsa.pub hadoop@192.168.1.103:/home/hadoop/
Выполните следующее на рабах
Войдите в hadoop. Если нет, войдите в систему пользователя hadoop.
su hadoop ssh -X hadoop@192.168.1.103
Скопируйте содержимое открытого ключа в файл «$ HOME / .ssh / authorized_keys», а затем измените разрешение на него, выполнив следующие команды.
cd $HOME mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys
Проверьте логин SSH с главного компьютера. Теперь проверьте, можете ли вы использовать ssh для нового узла без пароля от мастера.
ssh hadoop@192.168.1.103 or hadoop@slave3
Установить имя хоста нового узла
Вы можете установить имя хоста в файле / etc / sysconfig / network
On new slave3 machine NETWORKING = yes HOSTNAME = slave3.in
Чтобы изменения вступили в силу, либо перезапустите компьютер, либо выполните команду hostname на новом компьютере с соответствующим именем хоста (хороший вариант — перезагрузка).
На узле slave3 —
имя хоста slave3.in
Обновите / etc / hosts на всех машинах кластера следующими строками —
192.168.1.102 slave3.in slave3
Теперь попробуйте пропинговать компьютер с именами хостов, чтобы проверить, разрешается ли он по IP или нет.
На новом узле машины —
ping master.in
Запустите DataNode на новом узле
Запустите демон datanode вручную, используя скрипт $ HADOOP_HOME / bin / hadoop-daemon.sh . Он автоматически свяжется с мастером (NameNode) и присоединится к кластеру. Мы также должны добавить новый узел в файл conf / slaves на главном сервере. Команды на основе скриптов распознают новый узел.
Войти в новый узел
su hadoop or ssh -X hadoop@192.168.1.103
Запустите HDFS на вновь добавленном подчиненном узле, используя следующую команду
./bin/hadoop-daemon.sh start datanode
Проверьте вывод команды jps на новом узле. Это выглядит следующим образом.
$ jps 7141 DataNode 10312 Jps
Удаление DataNode из кластера Hadoop
Мы можем удалить узел из кластера на лету, пока он работает, без потери данных. HDFS предоставляет функцию вывода из эксплуатации, которая обеспечивает безопасное удаление узла. Чтобы использовать его, выполните следующие действия:
Шаг 1 — Войдите в мастер
Авторизуйтесь на главном компьютере пользователя, на котором установлен Hadoop.
$ su hadoop
Шаг 2 — Изменить конфигурацию кластера
Файл исключения должен быть настроен перед запуском кластера. Добавьте ключ с именем dfs.hosts.exclude в наш файл $ HADOOP_HOME / etc / hadoop / hdfs-site.xml . Значение, связанное с этим ключом, предоставляет полный путь к файлу в локальной файловой системе NameNode, который содержит список компьютеров, которым не разрешено подключаться к HDFS.
Например, добавьте эти строки в файл etc / hadoop / hdfs-site.xml .
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value> <description>DFS exclude</description> </property>
Шаг 3 — Определите хосты для вывода из эксплуатации
Каждая машина, подлежащая выводу из эксплуатации, должна быть добавлена в файл, идентифицируемый как hdfs_exclude.txt, по одному доменному имени на строку. Это предотвратит их подключение к NameNode. Содержимое файла «/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt» показано ниже, если вы хотите удалить DataNode2.
slave2.in
Шаг 4 — принудительная перезагрузка конфигурации
Запустите команду «$ HADOOP_HOME / bin / hadoop dfsadmin -refreshNodes» без кавычек.
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes
Это заставит NameNode перечитать свою конфигурацию, включая недавно обновленный файл «exclude». Он будет выводить из эксплуатации узлы в течение определенного периода времени, позволяя реплицировать блоки каждого узла на машины, которые по расписанию должны оставаться активными.
На slave2.in проверьте вывод команды jps. Через некоторое время вы увидите, что процесс DataNode автоматически отключается.
Шаг 5 — Отключение узлов
После завершения процесса вывода из эксплуатации выведенное из эксплуатации оборудование можно безопасно отключить для проведения технического обслуживания. Запустите команду report для dfsadmin, чтобы проверить состояние вывода из эксплуатации. Следующая команда опишет состояние узла вывода из эксплуатации и подключенных узлов к кластеру.
$ $HADOOP_HOME/bin/hadoop dfsadmin -report
Шаг 6 — Правка исключает файл снова
После списания машин их можно удалить из файла «исключает». Повторный запуск $ HADOOP_HOME / bin / hadoop dfsadmin -refreshNodes снова считывает исключаемый файл обратно в NameNode; предоставление возможности узлам данных присоединяться к кластеру после завершения обслуживания, или снова требуется дополнительная емкость в кластере и т. д.
Специальное примечание. Если вышеуказанный процесс выполняется, а процесс TaskTracker все еще выполняется на узле, его необходимо отключить. Один из способов — отключить машину, как мы делали на предыдущих этапах. Мастер распознает процесс автоматически и объявит его мертвым. Нет необходимости следовать одному и тому же процессу для удаления треккера задач, потому что это НЕ очень важно по сравнению с DataNode. DataNode содержит данные, которые вы хотите безопасно удалить без потери данных.
Tasktracker может быть запущен / выключен на лету с помощью следующей команды в любой момент времени.