Можно прочитать схему Avro в программу, либо сгенерировав класс, соответствующий схеме, либо с помощью библиотеки анализаторов. В этой главе описывается, как читать схему , генерируя класс и сериализуя данные с помощью Avr.
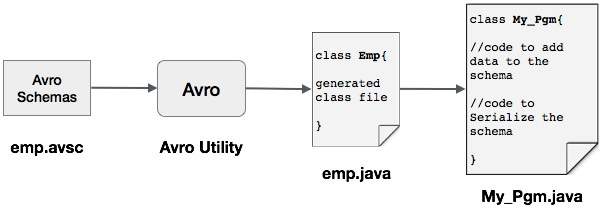
Сериализация путем создания класса
Для сериализации данных с помощью Avro выполните следующие действия:
-
Напишите схему Avro.
-
Скомпилируйте схему с помощью утилиты Avro. Вы получаете код Java, соответствующий этой схеме.
-
Заполните схему данными.
-
Сериализуйте его, используя библиотеку Avro.
Напишите схему Avro.
Скомпилируйте схему с помощью утилиты Avro. Вы получаете код Java, соответствующий этой схеме.
Заполните схему данными.
Сериализуйте его, используя библиотеку Avro.
Определение схемы
Предположим, вы хотите схему со следующими деталями —
| поле | название | Я бы | возраст | оплата труда | адрес |
| тип | строка | ИНТ | ИНТ | ИНТ | строка |
Создайте схему Avro, как показано ниже.
Сохраните его как emp.avsc .
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
Составление схемы
После создания схемы Avro вам необходимо скомпилировать созданную схему с помощью инструментов Avro. avro-tools-1.7.7.jar — это банка, содержащая инструменты.
Синтаксис для компиляции схемы Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>
Откройте терминал в домашней папке.
Создайте новый каталог для работы с Avro, как показано ниже —
$ mkdir Avro_Work
Во вновь созданном каталоге создайте три подкаталога —
-
Имя схемы, чтобы разместить схему.
-
Второй с именем with_code_gen, чтобы разместить сгенерированный код.
-
Третий по имени банок, чтобы разместить файлы банок .
Имя схемы, чтобы разместить схему.
Второй с именем with_code_gen, чтобы разместить сгенерированный код.
Третий по имени банок, чтобы разместить файлы банок .
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
На следующем снимке экрана показано, как должна выглядеть папка Avro_work после создания всех каталогов.
-
Теперь /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar — это путь к каталогу, в который вы скачали файл avro-tools-1.7.7.jar.
-
/ home / Hadoop / Avro_work / schema / — это путь к каталогу, в котором хранится ваш файл схемы emp.avsc.
-
/ home / Hadoop / Avro_work / with_code_gen — это каталог, в котором вы хотите сохранить сгенерированные файлы классов.
Теперь /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar — это путь к каталогу, в который вы скачали файл avro-tools-1.7.7.jar.
/ home / Hadoop / Avro_work / schema / — это путь к каталогу, в котором хранится ваш файл схемы emp.avsc.
/ home / Hadoop / Avro_work / with_code_gen — это каталог, в котором вы хотите сохранить сгенерированные файлы классов.
Теперь скомпилируйте схему, как показано ниже —
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
После компиляции пакет в соответствии с пространством имен схемы создается в каталоге назначения. В этом пакете создается исходный код Java с именем схемы. Этот сгенерированный исходный код является Java-кодом данной схемы, который может использоваться непосредственно в приложениях.
Например, в этом случае создается пакет / папка с именем tutorialspoint, которая содержит другую папку с именем com (поскольку пространство имен — tutorialspoint.com), и внутри нее вы можете наблюдать сгенерированный файл emp.java . Следующий снимок показывает emp.java —
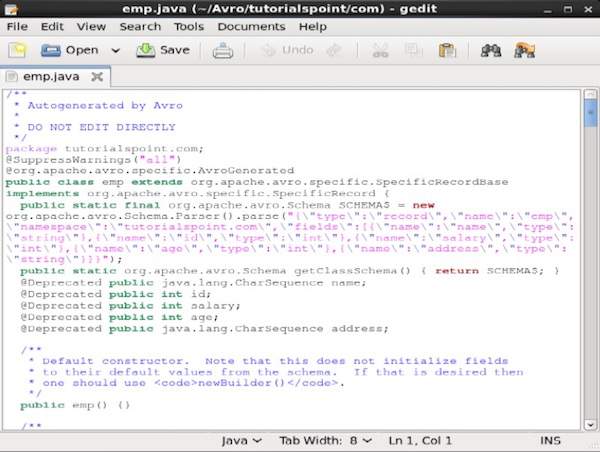
Этот класс полезен для создания данных в соответствии со схемой.
Сгенерированный класс содержит —
- Конструктор по умолчанию и параметризованный конструктор, который принимает все переменные схемы.
- Методы установки и получения для всех переменных в схеме.
- Метод Get (), который возвращает схему.
- Методы построения.
Создание и сериализация данных
Прежде всего, скопируйте сгенерированный файл Java, используемый в этом проекте, в текущий каталог или импортируйте его из того места, где он находится.
Теперь мы можем написать новый файл Java и создать экземпляр класса в сгенерированном файле ( emp ), чтобы добавить данные сотрудника в схему.
Давайте посмотрим процедуру создания данных по схеме с использованием apache Avro.
Шаг 1
Создайте сгенерированный класс emp .
emp e1=new emp( );
Шаг 2
Используя методы установки, вставьте данные первого сотрудника. Например, мы создали детали сотрудника по имени Омар.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
Точно так же заполните все данные о сотруднике, используя методы установки.
Шаг 3
Создайте объект интерфейса DatumWriter, используя класс SpecificDatumWriter . Это преобразует объекты Java в сериализованный формат в памяти. В следующем примере создается экземпляр объекта класса SpecificDatumWriter для класса emp .
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
Шаг 4
Создание экземпляра DataFileWriter для класса emp . Этот класс записывает в файл последовательную сериализованную запись данных, соответствующую схеме, вместе с самой схемой. Этот класс требует объекта DatumWriter в качестве параметра для конструктора.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
Шаг 5
Откройте новый файл, чтобы сохранить данные, соответствующие данной схеме, используя метод create () . Этот метод требует схему и путь к файлу, в котором должны храниться данные, в качестве параметров.
В следующем примере схема передается с использованием метода getSchema () , а файл данных сохраняется по пути — /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));
Шаг 6
Добавьте все созданные записи в файл, используя метод append (), как показано ниже —
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
Пример — Сериализация путем генерации класса
Следующая полная программа показывает, как сериализовать данные в файл с помощью Apache Avro.
import java.io.File; import java.io.IOException; import org.apache.avro.file.DataFileWriter; import org.apache.avro.io.DatumWriter; import org.apache.avro.specific.SpecificDatumWriter; public class Serialize { public static void main(String args[]) throws IOException{ //Instantiating generated emp class emp e1=new emp(); //Creating values according the schema e1.setName("omar"); e1.setAge(21); e1.setSalary(30000); e1.setAddress("Hyderabad"); e1.setId(001); emp e2=new emp(); e2.setName("ram"); e2.setAge(30); e2.setSalary(40000); e2.setAddress("Hyderabad"); e2.setId(002); emp e3=new emp(); e3.setName("robbin"); e3.setAge(25); e3.setSalary(35000); e3.setAddress("Hyderabad"); e3.setId(003); //Instantiate DatumWriter class DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class); DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter); empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro")); empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3); empFileWriter.close(); System.out.println("data successfully serialized"); } }
Просмотрите каталог, в котором находится сгенерированный код. В этом случае дома / Hadoop / Avro_work / with_code_gen .
В терминале —
$ cd home/Hadoop/Avro_work/with_code_gen/
В графическом интерфейсе
Теперь скопируйте и сохраните вышеуказанную программу в файл с именем Serialize.java.
Скомпилируйте и выполните его, как показано ниже —
$ javac Serialize.java $ java Serialize
Выход
data successfully serialized
Если вы проверите путь, указанный в программе, вы можете найти сгенерированный сериализованный файл, как показано ниже.