AVRO — Обзор
Для передачи данных по сети или для ее постоянного хранения необходимо сериализовать данные. До API-интерфейсов сериализации, предоставляемых Java и Hadoop, у нас есть специальная утилита, называемая Avro , метод сериализации на основе схемы.
Из этого туториала вы узнаете, как сериализовать и десериализовать данные с помощью Avro. Avro предоставляет библиотеки для различных языков программирования. В этом уроке мы продемонстрируем примеры использования библиотеки Java.
Что такое Авро?
Apache Avro является независимой от языка системой сериализации данных. Он был разработан Дагом Каттингом, отцом Hadoop. Поскольку доступным для записи классам Hadoop не хватает переносимости языка, Avro становится весьма полезным, поскольку имеет дело с форматами данных, которые могут обрабатываться несколькими языками. Avro — это предпочтительный инструмент для сериализации данных в Hadoop.
Avro имеет систему, основанную на схемах. Независимая от языка схема связана с операциями чтения и записи. Avro сериализует данные, которые имеют встроенную схему. Avro сериализует данные в компактный двоичный формат, который может быть десериализован любым приложением.
Avro использует формат JSON для объявления структур данных. В настоящее время он поддерживает такие языки, как Java, C, C ++, C #, Python и Ruby.
Авро Схемы
Авро сильно зависит от его схемы . Это позволяет записывать все данные без предварительного знания схемы. Он сериализуется быстро, и получающиеся в результате сериализованные данные имеют меньший размер. Схема хранится вместе с данными Avro в файле для дальнейшей обработки.
В RPC клиент и сервер обмениваются схемами во время соединения. Этот обмен помогает в общении между одноименными полями, пропущенными полями, дополнительными полями и т. Д.
Схемы Avro определяются с помощью JSON, что упрощает его реализацию на языках с библиотеками JSON.
Как и в Avro, в Hadoop есть и другие механизмы сериализации, такие как Sequence Files, Protocol Buffers и Thrift .
Сравнение с экономичными и протокольными буферами
Thrift и Protocol Buffers — самые компетентные библиотеки с Avro. Avro отличается от этих рамок следующими способами —
-
Avro поддерживает как динамические, так и статические типы в соответствии с требованиями. Буферы протокола и Thrift используют языки определения интерфейса (IDL) для определения схем и их типов. Эти IDL используются для генерации кода для сериализации и десериализации.
-
Avro встроен в экосистему Hadoop. Экономичные и протокольные буферы не встроены в экосистему Hadoop.
Avro поддерживает как динамические, так и статические типы в соответствии с требованиями. Буферы протокола и Thrift используют языки определения интерфейса (IDL) для определения схем и их типов. Эти IDL используются для генерации кода для сериализации и десериализации.
Avro встроен в экосистему Hadoop. Экономичные и протокольные буферы не встроены в экосистему Hadoop.
В отличие от Thrift и Protocol Buffer, определение схемы Avro дано в формате JSON, а не в любом проприетарном IDL.
| Имущество | Avro | Экономия и протокол буфера |
|---|---|---|
| Динамическая схема | да | нет |
| Встроенный в Hadoop | да | нет |
| Схема в JSON | да | нет |
| Нет необходимости компилировать | да | нет |
| Не нужно объявлять идентификаторы | да | нет |
| Кровоточащий край | да | нет |
Особенности Avro
Ниже перечислены некоторые из выдающихся особенностей Avro —
-
Avro — это независимая от языка система сериализации данных.
-
Он может обрабатываться многими языками (в настоящее время C, C ++, C #, Java, Python и Ruby).
-
Avro создает двоичный структурированный формат, который является сжимаемым и разделяемым . Следовательно, его можно эффективно использовать в качестве входных данных для заданий Hadoop MapReduce.
-
Avro предоставляет богатые структуры данных . Например, вы можете создать запись, которая содержит массив, перечислимый тип и вложенную запись. Эти типы данных могут быть созданы на любом языке, могут быть обработаны в Hadoop, а результаты могут быть переданы на третий язык.
-
Схемы Avro, определенные в JSON , облегчают реализацию на языках, которые уже имеют библиотеки JSON.
-
Avro создает файл с самоописанием Avro Data File, в котором он хранит данные вместе со своей схемой в разделе метаданных.
-
Avro также используется в удаленных вызовах процедур (RPC). Во время RPC клиент и сервер обмениваются схемами при установлении соединения.
Avro — это независимая от языка система сериализации данных.
Он может обрабатываться многими языками (в настоящее время C, C ++, C #, Java, Python и Ruby).
Avro создает двоичный структурированный формат, который является сжимаемым и разделяемым . Следовательно, его можно эффективно использовать в качестве входных данных для заданий Hadoop MapReduce.
Avro предоставляет богатые структуры данных . Например, вы можете создать запись, которая содержит массив, перечислимый тип и вложенную запись. Эти типы данных могут быть созданы на любом языке, могут быть обработаны в Hadoop, а результаты могут быть переданы на третий язык.
Схемы Avro, определенные в JSON , облегчают реализацию на языках, которые уже имеют библиотеки JSON.
Avro создает файл с самоописанием Avro Data File, в котором он хранит данные вместе со своей схемой в разделе метаданных.
Avro также используется в удаленных вызовах процедур (RPC). Во время RPC клиент и сервер обмениваются схемами при установлении соединения.
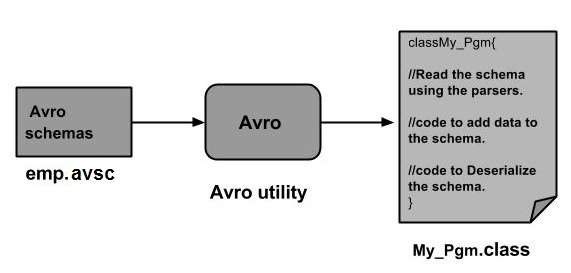
Генеральный рабочий Авро
Чтобы использовать Avro, вам нужно следовать заданному рабочему процессу —
-
Шаг 1 — Создание схем. Здесь вам нужно спроектировать схему Avro согласно вашим данным.
-
Шаг 2 — Прочитайте схемы в вашей программе. Это делается двумя способами —
-
Создав класс, соответствующий схеме — скомпилируйте схему с помощью Avro. Это создает файл класса, соответствующий схеме
-
Используя библиотеку парсеров — Вы можете напрямую читать схему, используя библиотеку парсеров.
-
-
Шаг 3 — Сериализация данных с использованием API сериализации, предоставленного для Avro, который находится в пакете org.apache.avro.specific .
-
Шаг 4 — Десериализация данных с использованием API десериализации, предоставленного для Avro, который находится в пакете org.apache.avro.specific.
Шаг 1 — Создание схем. Здесь вам нужно спроектировать схему Avro согласно вашим данным.
Шаг 2 — Прочитайте схемы в вашей программе. Это делается двумя способами —
Создав класс, соответствующий схеме — скомпилируйте схему с помощью Avro. Это создает файл класса, соответствующий схеме
Используя библиотеку парсеров — Вы можете напрямую читать схему, используя библиотеку парсеров.
Шаг 3 — Сериализация данных с использованием API сериализации, предоставленного для Avro, который находится в пакете org.apache.avro.specific .
Шаг 4 — Десериализация данных с использованием API десериализации, предоставленного для Avro, который находится в пакете org.apache.avro.specific.
AVRO — Сериализация
Данные сериализуются для двух целей —
-
Для постоянного хранения
-
Для транспортировки данных по сети
Для постоянного хранения
Для транспортировки данных по сети
Что такое сериализация?
Сериализация — это процесс перевода структур данных или состояния объектов в двоичную или текстовую форму для передачи данных по сети или для хранения в каком-либо постоянном хранилище. Как только данные передаются по сети или извлекаются из постоянного хранилища, их необходимо снова десериализовать. Сериализация называется маршаллингом, а десериализация — не маршалингом .
Сериализация в Java
Java предоставляет механизм, называемый сериализацией объекта, где объект может быть представлен в виде последовательности байтов, которая включает в себя данные объекта, а также информацию о типе объекта и типах данных, хранящихся в объекте.
После записи в файл сериализованного объекта его можно прочитать из файла и десериализовать. То есть информация о типе и байты, которые представляют объект и его данные, могут использоваться для воссоздания объекта в памяти.
Классы ObjectInputStream и ObjectOutputStream используются для сериализации и десериализации объекта соответственно в Java.
Сериализация в Hadoop
Обычно в распределенных системах, таких как Hadoop, концепция сериализации используется для межпроцессного взаимодействия и постоянного хранения .
Межпроцессного взаимодействия
-
Для установления межпроцессного взаимодействия между узлами, подключенными к сети, использовалась технология RPC.
-
RPC использовал внутреннюю сериализацию для преобразования сообщения в двоичный формат перед отправкой его на удаленный узел по сети. На другом конце удаленная система десериализует двоичный поток в исходное сообщение.
-
Формат сериализации RPC должен быть следующим:
-
Компактность — для наилучшего использования пропускной способности сети, которая является наиболее дефицитным ресурсом в центре обработки данных.
-
Быстро — поскольку связь между узлами имеет решающее значение в распределенных системах, процесс сериализации и десериализации должен быть быстрым, производя меньше накладных расходов.
-
Расширяемость — протоколы меняются с течением времени, чтобы соответствовать новым требованиям, поэтому должно быть просто и понятно развивать протокол контролируемым образом для клиентов и серверов.
-
Совместимость — формат сообщения должен поддерживать узлы, которые написаны на разных языках.
-
Для установления межпроцессного взаимодействия между узлами, подключенными к сети, использовалась технология RPC.
RPC использовал внутреннюю сериализацию для преобразования сообщения в двоичный формат перед отправкой его на удаленный узел по сети. На другом конце удаленная система десериализует двоичный поток в исходное сообщение.
Формат сериализации RPC должен быть следующим:
Компактность — для наилучшего использования пропускной способности сети, которая является наиболее дефицитным ресурсом в центре обработки данных.
Быстро — поскольку связь между узлами имеет решающее значение в распределенных системах, процесс сериализации и десериализации должен быть быстрым, производя меньше накладных расходов.
Расширяемость — протоколы меняются с течением времени, чтобы соответствовать новым требованиям, поэтому должно быть просто и понятно развивать протокол контролируемым образом для клиентов и серверов.
Совместимость — формат сообщения должен поддерживать узлы, которые написаны на разных языках.
Постоянное хранение
Постоянное хранилище — это цифровое хранилище, которое не теряет свои данные при потере электропитания. Файлы, папки, базы данных являются примерами постоянного хранения.
Интерфейс для записи
Это интерфейс в Hadoop, который предоставляет методы для сериализации и десериализации. В следующей таблице описаны методы —
| S.No. | Методы и описание |
|---|---|
| 1 |
void readFields (DataInput in) Этот метод используется для десериализации полей данного объекта. |
| 2 |
пустая запись (DataOutput out) Этот метод используется для сериализации полей данного объекта. |
void readFields (DataInput in)
Этот метод используется для десериализации полей данного объекта.
пустая запись (DataOutput out)
Этот метод используется для сериализации полей данного объекта.
Записываемый сопоставимый интерфейс
Это комбинация записываемого и сопоставимого интерфейсов. Этот интерфейс наследует интерфейс записи Hadoop, а также сопоставимый интерфейс Java. Поэтому он предоставляет методы для сериализации данных, десериализации и сравнения.
| S.No. | Методы и описание |
|---|---|
| 1 |
int CompareTo (класс obj) Этот метод сравнивает текущий объект с заданным объектом obj. |
int CompareTo (класс obj)
Этот метод сравнивает текущий объект с заданным объектом obj.
В дополнение к этим классам Hadoop поддерживает ряд классов-оболочек, которые реализуют интерфейс WritableComparable. Каждый класс содержит Java-примитивный тип. Иерархия классов сериализации Hadoop приведена ниже —
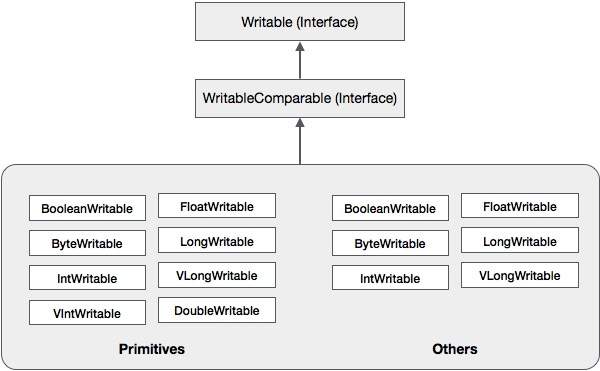
Эти классы полезны для сериализации различных типов данных в Hadoop. Например, давайте рассмотрим класс IntWritable . Давайте посмотрим, как этот класс используется для сериализации и десериализации данных в Hadoop.
IntWritable Class
Этот класс реализует интерфейсы Writable, Comparable и WritableComparable . Он заключает в себе целочисленный тип данных. Этот класс предоставляет методы, используемые для сериализации и десериализации целочисленного типа данных.
Конструкторы
| S.No. | Резюме |
|---|---|
| 1 | IntWritable () |
| 2 | IntWritable (значение типа int) |
методы
| S.No. | Резюме |
|---|---|
| 1 |
int get () Используя этот метод, вы можете получить целочисленное значение, присутствующее в текущем объекте. |
| 2 |
void readFields (DataInput in) Этот метод используется для десериализации данных в данном объекте DataInput . |
| 3 |
void set (int value) Этот метод используется для установки значения текущего объекта IntWritable . |
| 4 |
пустая запись (DataOutput out) Этот метод используется для сериализации данных в текущем объекте в заданный объект DataOutput . |
int get ()
Используя этот метод, вы можете получить целочисленное значение, присутствующее в текущем объекте.
void readFields (DataInput in)
Этот метод используется для десериализации данных в данном объекте DataInput .
void set (int value)
Этот метод используется для установки значения текущего объекта IntWritable .
пустая запись (DataOutput out)
Этот метод используется для сериализации данных в текущем объекте в заданный объект DataOutput .
Сериализация данных в Hadoop
Процедура сериализации целочисленного типа данных обсуждается ниже.
-
Создайте класс IntWritable, поместив в него целочисленное значение.
-
Создайте класс ByteArrayOutputStream .
-
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
-
Сериализуйте целочисленное значение в объекте IntWritable, используя метод write () . Этот метод нуждается в объекте класса DataOutputStream.
-
Сериализованные данные будут храниться в объекте байтового массива, который передается в качестве параметра классу DataOutputStream во время создания экземпляра. Преобразуйте данные в объекте в байтовый массив.
Создайте класс IntWritable, поместив в него целочисленное значение.
Создайте класс ByteArrayOutputStream .
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
Сериализуйте целочисленное значение в объекте IntWritable, используя метод write () . Этот метод нуждается в объекте класса DataOutputStream.
Сериализованные данные будут храниться в объекте байтового массива, который передается в качестве параметра классу DataOutputStream во время создания экземпляра. Преобразуйте данные в объекте в байтовый массив.
пример
В следующем примере показано, как сериализовать данные целочисленного типа в Hadoop —
import java.io.ByteArrayOutputStream; import java.io.DataOutputStream; import java.io.IOException; import org.apache.hadoop.io.IntWritable; public class Serialization { public byte[] serialize() throws IOException{ //Instantiating the IntWritable object IntWritable intwritable = new IntWritable(12); //Instantiating ByteArrayOutputStream object ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream(); //Instantiating DataOutputStream object DataOutputStream dataOutputStream = new DataOutputStream(byteoutputStream); //Serializing the data intwritable.write(dataOutputStream); //storing the serialized object in bytearray byte[] byteArray = byteoutputStream.toByteArray(); //Closing the OutputStream dataOutputStream.close(); return(byteArray); } public static void main(String args[]) throws IOException{ Serialization serialization= new Serialization(); serialization.serialize(); System.out.println(); } }
Десериализация данных в Hadoop
Процедура десериализации целочисленного типа данных обсуждается ниже —
-
Создайте класс IntWritable, поместив в него целочисленное значение.
-
Создайте класс ByteArrayOutputStream .
-
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
-
Десериализовать данные в объекте DataInputStream с помощью метода readFields () класса IntWritable.
-
Десериализованные данные будут храниться в объекте класса IntWritable. Вы можете получить эти данные, используя метод get () этого класса.
Создайте класс IntWritable, поместив в него целочисленное значение.
Создайте класс ByteArrayOutputStream .
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
Десериализовать данные в объекте DataInputStream с помощью метода readFields () класса IntWritable.
Десериализованные данные будут храниться в объекте класса IntWritable. Вы можете получить эти данные, используя метод get () этого класса.
пример
В следующем примере показано, как десериализовать данные целочисленного типа в Hadoop —
import java.io.ByteArrayInputStream; import java.io.DataInputStream; import org.apache.hadoop.io.IntWritable; public class Deserialization { public void deserialize(byte[]byteArray) throws Exception{ //Instantiating the IntWritable class IntWritable intwritable =new IntWritable(); //Instantiating ByteArrayInputStream object ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray); //Instantiating DataInputStream object DataInputStream datainputstream=new DataInputStream(InputStream); //deserializing the data in DataInputStream intwritable.readFields(datainputstream); //printing the serialized data System.out.println((intwritable).get()); } public static void main(String args[]) throws Exception { Deserialization dese = new Deserialization(); dese.deserialize(new Serialization().serialize()); } }
Преимущество Hadoop над сериализацией Java
Сериализация, основанная на записи, в Hadoop способна снизить накладные расходы на создание объектов путем повторного использования объектов, доступных для записи, что невозможно с помощью встроенной в Java инфраструктуры сериализации.
Недостатки сериализации Hadoop
Для сериализации данных Hadoop существует два способа:
-
Вы можете использовать классы Writable , предоставляемые нативной библиотекой Hadoop.
-
Вы также можете использовать Sequence Files, которые хранят данные в двоичном формате.
Вы можете использовать классы Writable , предоставляемые нативной библиотекой Hadoop.
Вы также можете использовать Sequence Files, которые хранят данные в двоичном формате.
Основным недостатком этих двух механизмов является то, что Writables и SequenceFiles имеют только API Java, и их нельзя писать или читать на любом другом языке.
Поэтому ни один из файлов, созданных в Hadoop с двумя вышеупомянутыми механизмами, не может быть прочитан никаким другим третьим языком, что делает Hadoop ограниченной рамкой. Чтобы устранить этот недостаток, Дуг Каттинг создал Avro, которая является независимой от языка структурой данных .
AVRO — Настройка среды
Apache Software Foundation предоставляет Avro различные версии. Вы можете скачать необходимый выпуск с Apache зеркал. Давайте посмотрим, как настроить среду для работы с Avro —
Скачивание Авро
Чтобы загрузить Apache Avro, выполните следующие действия:
-
Откройте веб-страницу Apache.org . Вы увидите домашнюю страницу Apache Avro, как показано ниже —
Откройте веб-страницу Apache.org . Вы увидите домашнюю страницу Apache Avro, как показано ниже —
-
Нажмите на проект → релизы. Вы получите список выпусков.
-
Выберите последний выпуск, который приведет вас к ссылке для скачивания.
-
mirror.nexcess — это одна из ссылок, где вы можете найти список всех библиотек разных языков, которые поддерживает Avro, как показано ниже —
Нажмите на проект → релизы. Вы получите список выпусков.
Выберите последний выпуск, который приведет вас к ссылке для скачивания.
mirror.nexcess — это одна из ссылок, где вы можете найти список всех библиотек разных языков, которые поддерживает Avro, как показано ниже —
Вы можете выбрать и загрузить библиотеку для любого из предоставленных языков. В этом уроке мы используем Java. Следовательно, скачайте файлы jar avro-1.7.7.jar и avro-tools-1.7.7.jar .
Авро с Затмением
Чтобы использовать Avro в среде Eclipse, вам необходимо выполнить следующие шаги:
-
Шаг 1. Откройте затмение.
-
Шаг 2. Создайте проект.
-
Шаг 3. Щелкните правой кнопкой мыши по названию проекта. Вы получите контекстное меню.
-
Шаг 4. Нажмите на Путь сборки . Это приводит вас к другому контекстному меню.
-
Шаг 5. Нажмите Configure Build Path … Вы можете увидеть окно Properties вашего проекта, как показано ниже —
Шаг 1. Откройте затмение.
Шаг 2. Создайте проект.
Шаг 3. Щелкните правой кнопкой мыши по названию проекта. Вы получите контекстное меню.
Шаг 4. Нажмите на Путь сборки . Это приводит вас к другому контекстному меню.
Шаг 5. Нажмите Configure Build Path … Вы можете увидеть окно Properties вашего проекта, как показано ниже —
-
Шаг 6. На вкладке библиотеки нажмите кнопку ДОБАВИТЬ ВНЕШНИЕ JAR …
-
Шаг 7. Выберите файл jar avro-1.77.jar, который вы скачали.
-
Шаг 8. Нажмите ОК .
Шаг 6. На вкладке библиотеки нажмите кнопку ДОБАВИТЬ ВНЕШНИЕ JAR …
Шаг 7. Выберите файл jar avro-1.77.jar, который вы скачали.
Шаг 8. Нажмите ОК .
Авро с мавеном
Вы также можете добавить библиотеку Avro в свой проект, используя Maven. Ниже приведен файл pom.xml для Avro.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>Test</groupId> <artifactId>Test</artifactId> <version>0.0.1-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.7.7</version> </dependency> <dependency> <groupId>org.apache.avro</groupId> <artifactId>avro-tools</artifactId> <version>1.7.7</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>2.0-beta9</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.0-beta9</version> </dependency> </dependencies> </project>
Настройка пути к классам
Для работы с Avro в среде Linux загрузите следующие файлы jar —
- Авро-1.77.jar
- Avro-инструменты-1.77.jar
- log4j-апи-2,0-beta9.jar
- og4j-ядро-2.0.beta9.jar.
Скопируйте эти файлы в папку и установите путь к классу в папке, в. Файл / bashrc, как показано ниже.
#class path for Avro export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
AVRO — Схемы
Avro, являющаяся утилитой сериализации на основе схем, принимает схемы в качестве входных данных. Несмотря на доступность различных схем, Avro придерживается своих собственных стандартов определения схем. Эти схемы описывают следующие детали —
- тип файла (запись по умолчанию)
- место записи
- название записи
- поля в записи с соответствующими им типами данных
Используя эти схемы, вы можете хранить сериализованные значения в двоичном формате, используя меньше места. Эти значения хранятся без метаданных.
Создание Авро Схем
Схема Avro создается в формате документа JavaScript Object Notation (JSON), который представляет собой легкий текстовый формат обмена данными. Он создан одним из следующих способов —
- Строка JSON
- Объект JSON
- Массив JSON
Пример. В следующем примере показана схема, определяющая документ в пространстве имен Tutorialspoint с именем Employee, имеющим поля name и age.
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}
В этом примере вы можете заметить, что для каждой записи есть четыре поля:
-
тип — это поле относится как к документу, так и к полю с именем fields.
-
В случае документа, он показывает тип документа, как правило, запись, потому что есть несколько полей.
-
Когда это поле, тип описывает тип данных.
-
тип — это поле относится как к документу, так и к полю с именем fields.
В случае документа, он показывает тип документа, как правило, запись, потому что есть несколько полей.
Когда это поле, тип описывает тип данных.
-
namespace — это поле описывает имя пространства имен, в котором находится объект.
-
name — это поле относится как к документу, так и к полю с именем fields.
-
В случае документа, это описывает имя схемы. Это имя схемы вместе с пространством имен однозначно идентифицирует схему в хранилище ( имя Namespace.schema ). В приведенном выше примере полное имя схемы будет Tutorialspoint.Employee.
-
В случае полей, это описывает имя поля.
-
namespace — это поле описывает имя пространства имен, в котором находится объект.
name — это поле относится как к документу, так и к полю с именем fields.
В случае документа, это описывает имя схемы. Это имя схемы вместе с пространством имен однозначно идентифицирует схему в хранилище ( имя Namespace.schema ). В приведенном выше примере полное имя схемы будет Tutorialspoint.Employee.
В случае полей, это описывает имя поля.
Примитивные типы данных Avro
Схема Avro имеет примитивные типы данных, а также сложные типы данных. В следующей таблице описаны примитивные типы данных Avro —
| Тип данных | Описание |
|---|---|
| ноль | Нуль — это тип, не имеющий значения. |
| ИНТ | 32-разрядное целое число со знаком. |
| долго | 64-разрядное целое число со знаком. |
| поплавок | 32-разрядное число IEEE 754 одинарной точности с плавающей запятой. |
| двойной | 64-разрядное число IEEE 754 с двойной точностью. |
| байтов | последовательность 8-битных байтов без знака. |
| строка | Последовательность символов Юникода. |
Сложные типы данных Avro
Наряду с примитивными типами данных Avro предоставляет шесть сложных типов данных, а именно: записи, перечисления, массивы, карты, объединения и фиксированные данные.
запись
Тип данных записи в Avro представляет собой набор из нескольких атрибутов. Он поддерживает следующие атрибуты —
-
name — значение этого поля содержит название записи.
-
namespace — значение этого поля содержит имя пространства имен, в котором хранится объект.
-
type — значение этого атрибута содержит либо тип документа (записи), либо тип данных поля в схеме.
-
fields — это поле содержит массив JSON, в котором есть список всех полей в схеме, каждое из которых имеет имя и атрибуты типа.
name — значение этого поля содержит название записи.
namespace — значение этого поля содержит имя пространства имен, в котором хранится объект.
type — значение этого атрибута содержит либо тип документа (записи), либо тип данных поля в схеме.
fields — это поле содержит массив JSON, в котором есть список всех полей в схеме, каждое из которых имеет имя и атрибуты типа.
пример
Ниже приведен пример записи.
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}
Enum
Перечисление — это список элементов в коллекции, перечисление Avro поддерживает следующие атрибуты:
-
name — значение этого поля содержит имя перечисления.
-
namespace — значение этого поля содержит строку, которая квалифицирует имя перечисления.
-
символы — значение этого поля содержит символы перечисления в виде массива имен.
name — значение этого поля содержит имя перечисления.
namespace — значение этого поля содержит строку, которая квалифицирует имя перечисления.
символы — значение этого поля содержит символы перечисления в виде массива имен.
пример
Ниже приведен пример перечисления.
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}
Массивы
Этот тип данных определяет поле массива, имеющее один атрибут элементов. Этот атрибут items указывает тип элементов в массиве.
пример
{ " type " : " array ", " items " : " int " }
Карты
Тип данных карты представляет собой массив пар ключ-значение, он организует данные в виде пар ключ-значение. Ключ для карты Avro должен быть строкой. Значения карты содержат тип данных содержимого карты.
пример
{"type" : "map", "values" : "int"}
Союзы
Тип данных объединения используется всякий раз, когда поле имеет один или несколько типов данных. Они представлены в виде массивов JSON. Например, если поле может быть как int, так и null, объединение представляется как [«int», «null»].
пример
Ниже приведен пример документа с использованием союзов —
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}
Исправлена
Этот тип данных используется для объявления поля фиксированного размера, которое можно использовать для хранения двоичных данных. Он имеет имя поля и данные в качестве атрибутов. Имя содержит имя поля, а размер — размер поля.
пример
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}
AVRO — Справочный API
В предыдущей главе мы описали тип ввода Avro, то есть схемы Avro. В этой главе мы объясним классы и методы, используемые при сериализации и десериализации схем Avro.
SpecificDatumWriter Class
Этот класс принадлежит пакету org.apache.avro.specific . Он реализует интерфейс DatumWriter, который преобразует объекты Java в сериализованный формат в памяти.
Конструктор
| S.No. | Описание |
|---|---|
| 1 | SpecificDatumWriter (схема схемы) |
метод
| S.No. | Описание |
|---|---|
| 1 |
SpecificData getSpecificData () Возвращает реализацию SpecificData, используемую этим автором. |
SpecificData getSpecificData ()
Возвращает реализацию SpecificData, используемую этим автором.
SpecificDatumReader Class
Этот класс принадлежит пакету org.apache.avro.specific . Он реализует интерфейс DatumReader, который считывает данные схемы и определяет представление данных в памяти. SpecificDatumReader — это класс, который поддерживает сгенерированные классы Java.
Конструктор
| S.No. | Описание |
|---|---|
| 1 |
SpecificDatumReader (схема схемы) Построить, где схемы писателя и читателя совпадают. |
SpecificDatumReader (схема схемы)
Построить, где схемы писателя и читателя совпадают.
методы
| S.No. | Описание |
|---|---|
| 1 |
SpecificData getSpecificData () Возвращает содержащиеся SpecificData. |
| 2 |
void setSchema (актуальная схема) Этот метод используется для установки схемы автора. |
SpecificData getSpecificData ()
Возвращает содержащиеся SpecificData.
void setSchema (актуальная схема)
Этот метод используется для установки схемы автора.
DataFileWriter
Создает экземпляр DataFileWrite для класса emp . Этот класс записывает последовательно сериализованные записи данных, соответствующие схеме, вместе со схемой в файле.
Конструктор
| S.No. | Описание |
|---|---|
| 1 | DataFileWriter (DatumWriter <D> dout) |
методы
| S.No | Описание |
|---|---|
| 1 |
void append (D datum) Добавляет данные в файл. |
| 2 |
DataFileWriter <D> appendTo (файл файла) Этот метод используется для открытия модуля записи, добавляющего к существующему файлу. |
void append (D datum)
Добавляет данные в файл.
DataFileWriter <D> appendTo (файл файла)
Этот метод используется для открытия модуля записи, добавляющего к существующему файлу.
Data FileReader
Этот класс обеспечивает произвольный доступ к файлам, написанным с помощью DataFileWriter . Он наследует класс DataFileStream .
Конструктор
| S.No. | Описание |
|---|---|
| 1 | DataFileReader (Файловый файл, DatumReader <D> reader)) |
методы
| S.No. | Описание |
|---|---|
| 1 |
следующий() Читает следующую информацию в файле. |
| 2 |
Boolean hasNext () Возвращает true, если в этом файле осталось больше записей. |
следующий()
Читает следующую информацию в файле.
Boolean hasNext ()
Возвращает true, если в этом файле осталось больше записей.
Класс Schema.parser
Этот класс является синтаксическим анализатором для схем в формате JSON. Он содержит методы для разбора схемы. Он принадлежит пакету org.apache.avro .
Конструктор
| S.No. | Описание |
|---|---|
| 1 | Schema.Parser () |
методы
| S.No. | Описание |
|---|---|
| 1 |
анализ (файл файла) Разбирает схему, предоставленную в данном файле . |
| 2 |
parse (InputStream in) Анализирует схему, предоставленную в данном InputStream . |
| 3 |
parse (String s) Анализирует схему, предоставленную в данной строке . |
анализ (файл файла)
Разбирает схему, предоставленную в данном файле .
parse (InputStream in)
Анализирует схему, предоставленную в данном InputStream .
parse (String s)
Анализирует схему, предоставленную в данной строке .
Интерфейс GenricRecord
Этот интерфейс предоставляет методы для доступа к полям по имени, а также по индексу.
методы
| S.No. | Описание |
|---|---|
| 1 |
Объект get (Строковый ключ) Возвращает значение заданного поля. |
| 2 |
void put (Строковый ключ, Объект v) Устанавливает значение поля по имени. |
Объект get (Строковый ключ)
Возвращает значение заданного поля.
void put (Строковый ключ, Объект v)
Устанавливает значение поля по имени.
Класс GenericData.Record
Конструктор
| S.No. | Описание |
|---|---|
| 1 | GenericData.Record (схема схемы) |
методы
| S.No. | Описание |
|---|---|
| 1 |
Объект get (Строковый ключ) Возвращает значение поля с указанным именем. |
| 2 |
Схема getSchema () Возвращает схему этого экземпляра. |
| 3 |
void put (int i, Object v) Устанавливает значение поля с учетом его положения в схеме. |
| 4 |
void put (Строковый ключ, Значение объекта) Устанавливает значение поля по имени. |
Объект get (Строковый ключ)
Возвращает значение поля с указанным именем.
Схема getSchema ()
Возвращает схему этого экземпляра.
void put (int i, Object v)
Устанавливает значение поля с учетом его положения в схеме.
void put (Строковый ключ, Значение объекта)
Устанавливает значение поля по имени.
AVRO — Сериализация созданием класса
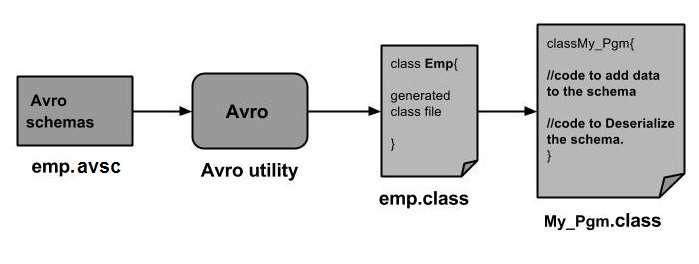
Можно прочитать схему Avro в программу, либо сгенерировав класс, соответствующий схеме, либо с помощью библиотеки анализаторов. В этой главе описывается, как читать схему , генерируя класс и сериализуя данные с помощью Avr.
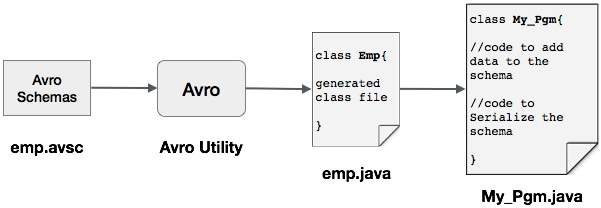
Сериализация путем создания класса
Для сериализации данных с помощью Avro выполните следующие действия:
-
Напишите схему Avro.
-
Скомпилируйте схему с помощью утилиты Avro. Вы получаете код Java, соответствующий этой схеме.
-
Заполните схему данными.
-
Сериализуйте его, используя библиотеку Avro.
Напишите схему Avro.
Скомпилируйте схему с помощью утилиты Avro. Вы получаете код Java, соответствующий этой схеме.
Заполните схему данными.
Сериализуйте его, используя библиотеку Avro.
Определение схемы
Предположим, вы хотите схему со следующими деталями —
| поле | название | Я бы | возраст | оплата труда | адрес |
| тип | строка | ИНТ | ИНТ | ИНТ | строка |
Создайте схему Avro, как показано ниже.
Сохраните его как emp.avsc .
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}
Составление схемы
После создания схемы Avro вам необходимо скомпилировать созданную схему с помощью инструментов Avro. avro-tools-1.7.7.jar — это банка, содержащая инструменты.
Синтаксис для компиляции схемы Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>
Откройте терминал в домашней папке.
Создайте новый каталог для работы с Avro, как показано ниже —
$ mkdir Avro_Work
Во вновь созданном каталоге создайте три подкаталога —
-
Имя схемы, чтобы разместить схему.
-
Второй с именем with_code_gen, чтобы разместить сгенерированный код.
-
Третий по имени банок, чтобы разместить файлы банок .
Имя схемы, чтобы разместить схему.
Второй с именем with_code_gen, чтобы разместить сгенерированный код.
Третий по имени банок, чтобы разместить файлы банок .
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
На следующем снимке экрана показано, как должна выглядеть папка Avro_work после создания всех каталогов.
-
Теперь /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar — это путь к каталогу, в который вы скачали файл avro-tools-1.7.7.jar.
-
/ home / Hadoop / Avro_work / schema / — это путь к каталогу, в котором хранится ваш файл схемы emp.avsc.
-
/ home / Hadoop / Avro_work / with_code_gen — это каталог, в котором вы хотите сохранить сгенерированные файлы классов.
Теперь /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar — это путь к каталогу, в который вы скачали файл avro-tools-1.7.7.jar.
/ home / Hadoop / Avro_work / schema / — это путь к каталогу, в котором хранится ваш файл схемы emp.avsc.
/ home / Hadoop / Avro_work / with_code_gen — это каталог, в котором вы хотите сохранить сгенерированные файлы классов.
Теперь скомпилируйте схему, как показано ниже —
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
После компиляции пакет в соответствии с пространством имен схемы создается в каталоге назначения. В этом пакете создается исходный код Java с именем схемы. Этот сгенерированный исходный код является Java-кодом данной схемы, который может использоваться непосредственно в приложениях.
Например, в этом случае создается пакет / папка с именем tutorialspoint, которая содержит другую папку с именем com (поскольку пространство имен — tutorialspoint.com), и внутри нее вы можете наблюдать сгенерированный файл emp.java . Следующий снимок показывает emp.java —
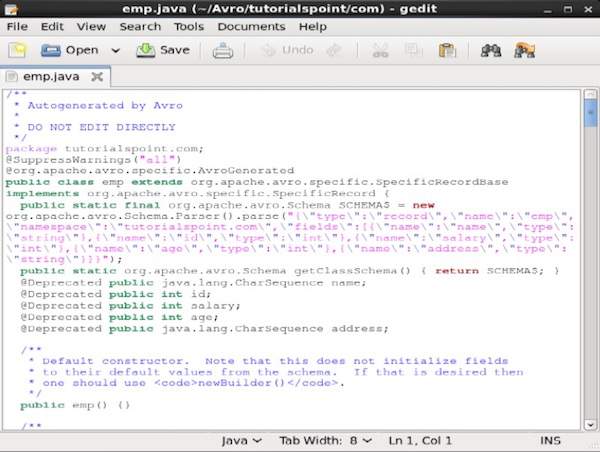
Этот класс полезен для создания данных в соответствии со схемой.
Сгенерированный класс содержит —
- Конструктор по умолчанию и параметризованный конструктор, который принимает все переменные схемы.
- Методы установки и получения для всех переменных в схеме.
- Метод Get (), который возвращает схему.
- Методы построения.
Создание и сериализация данных
Прежде всего, скопируйте сгенерированный файл Java, используемый в этом проекте, в текущий каталог или импортируйте его из того места, где он находится.
Теперь мы можем написать новый файл Java и создать экземпляр класса в сгенерированном файле ( emp ), чтобы добавить данные сотрудника в схему.
Давайте посмотрим процедуру создания данных по схеме с использованием apache Avro.
Шаг 1
Создайте сгенерированный класс emp .
emp e1=new emp( );
Шаг 2
Используя методы установки, вставьте данные первого сотрудника. Например, мы создали детали сотрудника по имени Омар.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
Точно так же заполните все данные о сотруднике, используя методы установки.
Шаг 3
Создайте объект интерфейса DatumWriter, используя класс SpecificDatumWriter . Это преобразует объекты Java в сериализованный формат в памяти. В следующем примере создается экземпляр объекта класса SpecificDatumWriter для класса emp .
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
Шаг 4
Создание экземпляра DataFileWriter для класса emp . Этот класс записывает в файл последовательную сериализованную запись данных, соответствующую схеме, вместе с самой схемой. Этот класс требует объекта DatumWriter в качестве параметра для конструктора.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
Шаг 5
Откройте новый файл, чтобы сохранить данные, соответствующие данной схеме, используя метод create () . Этот метод требует схему и путь к файлу, в котором должны храниться данные, в качестве параметров.
В следующем примере схема передается с использованием метода getSchema () , а файл данных сохраняется по пути — /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));
Шаг 6
Добавьте все созданные записи в файл, используя метод append (), как показано ниже —
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
Пример — Сериализация путем генерации класса
Следующая полная программа показывает, как сериализовать данные в файл с помощью Apache Avro.
import java.io.File; import java.io.IOException; import org.apache.avro.file.DataFileWriter; import org.apache.avro.io.DatumWriter; import org.apache.avro.specific.SpecificDatumWriter; public class Serialize { public static void main(String args[]) throws IOException{ //Instantiating generated emp class emp e1=new emp(); //Creating values according the schema e1.setName("omar"); e1.setAge(21); e1.setSalary(30000); e1.setAddress("Hyderabad"); e1.setId(001); emp e2=new emp(); e2.setName("ram"); e2.setAge(30); e2.setSalary(40000); e2.setAddress("Hyderabad"); e2.setId(002); emp e3=new emp(); e3.setName("robbin"); e3.setAge(25); e3.setSalary(35000); e3.setAddress("Hyderabad"); e3.setId(003); //Instantiate DatumWriter class DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class); DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter); empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro")); empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3); empFileWriter.close(); System.out.println("data successfully serialized"); } }
Просмотрите каталог, в котором находится сгенерированный код. В этом случае дома / Hadoop / Avro_work / with_code_gen .
В терминале —
$ cd home/Hadoop/Avro_work/with_code_gen/
В графическом интерфейсе
Теперь скопируйте и сохраните вышеуказанную программу в файл с именем Serialize.java.
Скомпилируйте и выполните его, как показано ниже —
$ javac Serialize.java $ java Serialize
Выход
data successfully serialized
Если вы проверите путь, указанный в программе, вы можете найти сгенерированный сериализованный файл, как показано ниже.
AVRO — Десериализация путем создания класса
Как описано ранее, можно прочитать схему Avro в программу, создав класс, соответствующий этой схеме, или используя библиотеку синтаксических анализаторов. В этой главе описывается, как читать схему путем создания класса и десериализации данных с помощью Avro.
Десериализация путем генерации класса
Сериализованные данные хранятся в файле emp.avro . Вы можете десериализовать и прочитать его с помощью Avro.
Следуйте процедуре, приведенной ниже, для десериализации сериализованных данных из файла.
Шаг 1
Создайте объект интерфейса DatumReader, используя класс SpecificDatumReader .
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
Шаг 2
Создание экземпляра DataFileReader для класса emp . Этот класс читает сериализованные данные из файла. В качестве параметров для конструктора требуется объект Dataumeader и путь к файлу, в котором существуют сериализованные данные.
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/ emp.avro "), empDatumReader);
Шаг 3
Распечатайте десериализованные данные, используя методы DataFileReader .
-
Метод hasNext () вернет логическое значение, если в Reader есть какие-либо элементы.
-
Метод next () объекта DataFileReader возвращает данные в Reader.
Метод hasNext () вернет логическое значение, если в Reader есть какие-либо элементы.
Метод next () объекта DataFileReader возвращает данные в Reader.
while(dataFileReader.hasNext()){ em=dataFileReader.next(em); System.out.println(em); }
Пример — десериализация путем генерации класса
Следующая полная программа показывает, как десериализовать данные в файле с помощью Avro.
import java.io.File; import java.io.IOException; import org.apache.avro.file.DataFileReader; import org.apache.avro.io.DatumReader; import org.apache.avro.specific.SpecificDatumReader; public class Deserialize { public static void main(String args[]) throws IOException{ //DeSerializing the objects DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class); //Instantiating DataFileReader DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader); emp em=null; while(dataFileReader.hasNext()){ em=dataFileReader.next(em); System.out.println(em); } } }
Перейдите в каталог, где находится сгенерированный код. В этом случае дома / Hadoop / Avro_work / with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/
Теперь скопируйте и сохраните вышеуказанную программу в файл с именем DeSerialize.java . Скомпилируйте и выполните его, как показано ниже —
$ javac Deserialize.java $ java Deserialize
Выход
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}
AVRO — Сериализация с использованием парсеров
Можно прочитать схему Avro в программу, создав класс, соответствующий схеме, или используя библиотеку синтаксических анализаторов. В Avro данные всегда хранятся с соответствующей схемой. Поэтому мы всегда можем прочитать схему без генерации кода.
В этой главе описывается, как прочитать схему с помощью библиотеки синтаксических анализаторов и сериализовать данные с помощью Avro.
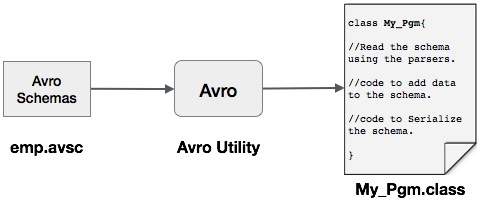
Сериализация с использованием библиотеки парсеров
Чтобы сериализовать данные, нам нужно прочитать схему, создать данные в соответствии со схемой и сериализовать схему с помощью API Avro. Следующая процедура сериализует данные без генерации кода —
Шаг 1
Прежде всего, прочитайте схему из файла. Для этого используйте класс Schema.Parser . Этот класс предоставляет методы для анализа схемы в разных форматах.
Создайте экземпляр класса Schema.Parser , передав путь к файлу, в котором хранится схема.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
Шаг 2
Создайте объект интерфейса GenericRecord , создав экземпляр класса GenericData.Record, как показано ниже. Передайте созданный выше объект схемы его конструктору.
GenericRecord e1 = new GenericData.Record(schema);
Шаг 3
Вставьте значения в схему, используя метод put () класса GenericData .
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");
Шаг 4
Создайте объект интерфейса DatumWriter, используя класс SpecificDatumWriter . Он преобразует объекты Java в сериализованный формат в памяти. В следующем примере создается экземпляр объекта класса SpecificDatumWriter для класса emp —
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
Шаг 5
Создание экземпляра DataFileWriter для класса emp . Этот класс записывает в файл сериализованные записи данных, соответствующих схеме, вместе с самой схемой. Этот класс требует объекта DatumWriter в качестве параметра для конструктора.
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);
Шаг 6
Откройте новый файл, чтобы сохранить данные, соответствующие данной схеме, используя метод create () . Этот метод требует схему и путь к файлу, в котором должны храниться данные, в качестве параметров.
В приведенном ниже примере схема передается с использованием метода getSchema (), а файл данных сохраняется в пути
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));
Шаг 7
Добавьте все созданные записи в файл, используя метод append (), как показано ниже.
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
Пример — Сериализация с использованием парсеров
Следующая полная программа показывает, как сериализовать данные с использованием анализаторов:
import java.io.File; import java.io.IOException; import org.apache.avro.Schema; import org.apache.avro.file.DataFileWriter; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.DatumWriter; public class Seriali { public static void main(String args[]) throws IOException{ //Instantiating the Schema.Parser class. Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc")); //Instantiating the GenericRecord class. GenericRecord e1 = new GenericData.Record(schema); //Insert data according to schema e1.put("name", "ramu"); e1.put("id", 001); e1.put("salary",30000); e1.put("age", 25); e1.put("address", "chenni"); GenericRecord e2 = new GenericData.Record(schema); e2.put("name", "rahman"); e2.put("id", 002); e2.put("salary", 35000); e2.put("age", 30); e2.put("address", "Delhi"); DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema); DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter); dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt")); dataFileWriter.append(e1); dataFileWriter.append(e2); dataFileWriter.close(); System.out.println(“data successfully serialized”); } }
Перейдите в каталог, где находится сгенерированный код. В этом случае дома / Hadoop / Avro_work / без_кода_ген .
$ cd home/Hadoop/Avro_work/without_code_gen/
Теперь скопируйте и сохраните вышеуказанную программу в файл с именем Serialize.java . Скомпилируйте и выполните его, как показано ниже —
$ javac Serialize.java $ java Serialize
Выход
data successfully serialized
Если вы проверите путь, указанный в программе, вы можете найти сгенерированный сериализованный файл, как показано ниже.
AVRO — десериализация с использованием парсеров
Как упоминалось ранее, можно прочитать схему Avro в программу, создав класс, соответствующий схеме, или используя библиотеку синтаксических анализаторов. В Avro данные всегда хранятся с соответствующей схемой. Поэтому мы всегда можем прочитать сериализованный элемент без генерации кода.
В этой главе описывается, как читать схему с использованием библиотеки синтаксических анализаторов и десериализацию данных с помощью Avro.
Десериализация с использованием библиотеки парсеров
Сериализованные данные хранятся в файле mydata.txt . Вы можете десериализовать и прочитать его с помощью Avro.
Следуйте процедуре, приведенной ниже, для десериализации сериализованных данных из файла.
Шаг 1
Прежде всего, прочитайте схему из файла. Для этого используйте класс Schema.Parser . Этот класс предоставляет методы для анализа схемы в разных форматах.
Создайте экземпляр класса Schema.Parser , передав путь к файлу, в котором хранится схема.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));
Шаг 2
Создайте объект интерфейса DatumReader, используя класс SpecificDatumReader .
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);
Шаг 3
Создание экземпляра класса DataFileReader . Этот класс читает сериализованные данные из файла. В качестве параметров для конструктора требуется объект DatumReader и путь к файлу, в котором существуют сериализованные данные.
DataFileReader <GenericRecord> dataFileReader = new DataFileReader <GenericRecord> (новый файл ("/ path / to / mydata.txt"), datumReader);
Шаг 4
Распечатайте десериализованные данные, используя методы DataFileReader .
-
Метод hasNext () возвращает логическое значение, если в Reader есть какие-либо элементы.
-
Метод next () объекта DataFileReader возвращает данные в Reader.
Метод hasNext () возвращает логическое значение, если в Reader есть какие-либо элементы.
Метод next () объекта DataFileReader возвращает данные в Reader.
while(dataFileReader.hasNext()){ em=dataFileReader.next(em); System.out.println(em); }
Пример — десериализация с использованием библиотеки парсеров
Следующая полная программа показывает, как десериализовать сериализованные данные с использованием библиотеки Parsers.
public class Deserialize { public static void main(String args[]) throws Exception{ //Instantiating the Schema.Parser class. Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc")); DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema); DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader); GenericRecord emp = null; while (dataFileReader.hasNext()) { emp = dataFileReader.next(emp); System.out.println(emp); } System.out.println("hello"); } }
Перейдите в каталог, где находится сгенерированный код. В этом случае он находится дома / Hadoop / Avro_work / без_кода_ген .
$ cd home/Hadoop/Avro_work/without_code_gen/
Теперь скопируйте и сохраните вышеуказанную программу в файл с именем DeSerialize.java . Скомпилируйте и выполните его, как показано ниже —