Данные сериализуются для двух целей —
-
Для постоянного хранения
-
Для транспортировки данных по сети
Для постоянного хранения
Для транспортировки данных по сети
Что такое сериализация?
Сериализация — это процесс перевода структур данных или состояния объектов в двоичную или текстовую форму для передачи данных по сети или для хранения в каком-либо постоянном хранилище. Как только данные передаются по сети или извлекаются из постоянного хранилища, их необходимо снова десериализовать. Сериализация называется маршаллингом, а десериализация — не маршалингом .
Сериализация в Java
Java предоставляет механизм, называемый сериализацией объекта, где объект может быть представлен в виде последовательности байтов, которая включает в себя данные объекта, а также информацию о типе объекта и типах данных, хранящихся в объекте.
После записи в файл сериализованного объекта его можно прочитать из файла и десериализовать. То есть информация о типе и байты, которые представляют объект и его данные, могут использоваться для воссоздания объекта в памяти.
Классы ObjectInputStream и ObjectOutputStream используются для сериализации и десериализации объекта соответственно в Java.
Сериализация в Hadoop
Обычно в распределенных системах, таких как Hadoop, концепция сериализации используется для межпроцессного взаимодействия и постоянного хранения .
Межпроцессного взаимодействия
-
Для установления межпроцессного взаимодействия между узлами, подключенными к сети, использовалась технология RPC.
-
RPC использовал внутреннюю сериализацию для преобразования сообщения в двоичный формат перед отправкой его на удаленный узел по сети. На другом конце удаленная система десериализует двоичный поток в исходное сообщение.
-
Формат сериализации RPC должен быть следующим:
-
Компактность — для наилучшего использования пропускной способности сети, которая является наиболее дефицитным ресурсом в центре обработки данных.
-
Быстро — поскольку связь между узлами имеет решающее значение в распределенных системах, процесс сериализации и десериализации должен быть быстрым, производя меньше накладных расходов.
-
Расширяемость — протоколы меняются с течением времени, чтобы соответствовать новым требованиям, поэтому должно быть просто и понятно развивать протокол контролируемым образом для клиентов и серверов.
-
Совместимость — формат сообщения должен поддерживать узлы, которые написаны на разных языках.
-
Для установления межпроцессного взаимодействия между узлами, подключенными к сети, использовалась технология RPC.
RPC использовал внутреннюю сериализацию для преобразования сообщения в двоичный формат перед отправкой его на удаленный узел по сети. На другом конце удаленная система десериализует двоичный поток в исходное сообщение.
Формат сериализации RPC должен быть следующим:
Компактность — для наилучшего использования пропускной способности сети, которая является наиболее дефицитным ресурсом в центре обработки данных.
Быстро — поскольку связь между узлами имеет решающее значение в распределенных системах, процесс сериализации и десериализации должен быть быстрым, производя меньше накладных расходов.
Расширяемость — протоколы меняются с течением времени, чтобы соответствовать новым требованиям, поэтому должно быть просто и понятно развивать протокол контролируемым образом для клиентов и серверов.
Совместимость — формат сообщения должен поддерживать узлы, которые написаны на разных языках.
Постоянное хранение
Постоянное хранилище — это цифровое хранилище, которое не теряет свои данные при потере электропитания. Файлы, папки, базы данных являются примерами постоянного хранения.
Интерфейс для записи
Это интерфейс в Hadoop, который предоставляет методы для сериализации и десериализации. В следующей таблице описаны методы —
| S.No. | Методы и описание |
|---|---|
| 1 |
void readFields (DataInput in) Этот метод используется для десериализации полей данного объекта. |
| 2 |
пустая запись (DataOutput out) Этот метод используется для сериализации полей данного объекта. |
void readFields (DataInput in)
Этот метод используется для десериализации полей данного объекта.
пустая запись (DataOutput out)
Этот метод используется для сериализации полей данного объекта.
Записываемый сопоставимый интерфейс
Это комбинация записываемого и сопоставимого интерфейсов. Этот интерфейс наследует интерфейс записи Hadoop, а также сопоставимый интерфейс Java. Поэтому он предоставляет методы для сериализации данных, десериализации и сравнения.
| S.No. | Методы и описание |
|---|---|
| 1 |
int CompareTo (класс obj) Этот метод сравнивает текущий объект с заданным объектом obj. |
int CompareTo (класс obj)
Этот метод сравнивает текущий объект с заданным объектом obj.
В дополнение к этим классам Hadoop поддерживает ряд классов-оболочек, которые реализуют интерфейс WritableComparable. Каждый класс содержит Java-примитивный тип. Иерархия классов сериализации Hadoop приведена ниже —
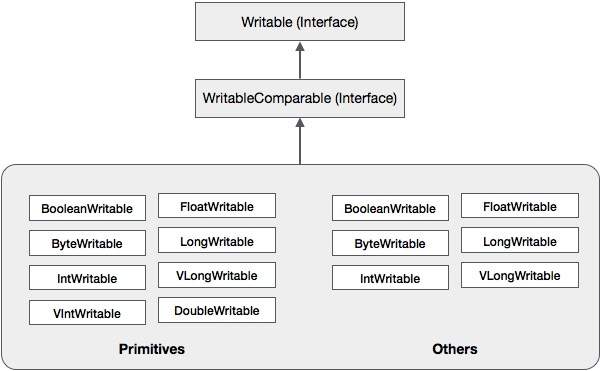
Эти классы полезны для сериализации различных типов данных в Hadoop. Например, давайте рассмотрим класс IntWritable . Давайте посмотрим, как этот класс используется для сериализации и десериализации данных в Hadoop.
IntWritable Class
Этот класс реализует интерфейсы Writable, Comparable и WritableComparable . Он заключает в себе целочисленный тип данных. Этот класс предоставляет методы, используемые для сериализации и десериализации целочисленного типа данных.
Конструкторы
| S.No. | Резюме |
|---|---|
| 1 | IntWritable () |
| 2 | IntWritable (значение типа int) |
методы
| S.No. | Резюме |
|---|---|
| 1 |
int get () Используя этот метод, вы можете получить целочисленное значение, присутствующее в текущем объекте. |
| 2 |
void readFields (DataInput in) Этот метод используется для десериализации данных в данном объекте DataInput . |
| 3 |
void set (int value) Этот метод используется для установки значения текущего объекта IntWritable . |
| 4 |
пустая запись (DataOutput out) Этот метод используется для сериализации данных в текущем объекте в заданный объект DataOutput . |
int get ()
Используя этот метод, вы можете получить целочисленное значение, присутствующее в текущем объекте.
void readFields (DataInput in)
Этот метод используется для десериализации данных в данном объекте DataInput .
void set (int value)
Этот метод используется для установки значения текущего объекта IntWritable .
пустая запись (DataOutput out)
Этот метод используется для сериализации данных в текущем объекте в заданный объект DataOutput .
Сериализация данных в Hadoop
Процедура сериализации целочисленного типа данных обсуждается ниже.
-
Создайте класс IntWritable, поместив в него целочисленное значение.
-
Создайте класс ByteArrayOutputStream .
-
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
-
Сериализуйте целочисленное значение в объекте IntWritable, используя метод write () . Этот метод нуждается в объекте класса DataOutputStream.
-
Сериализованные данные будут храниться в объекте байтового массива, который передается в качестве параметра классу DataOutputStream во время создания экземпляра. Преобразуйте данные в объекте в байтовый массив.
Создайте класс IntWritable, поместив в него целочисленное значение.
Создайте класс ByteArrayOutputStream .
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
Сериализуйте целочисленное значение в объекте IntWritable, используя метод write () . Этот метод нуждается в объекте класса DataOutputStream.
Сериализованные данные будут храниться в объекте байтового массива, который передается в качестве параметра классу DataOutputStream во время создания экземпляра. Преобразуйте данные в объекте в байтовый массив.
пример
В следующем примере показано, как сериализовать данные целочисленного типа в Hadoop —
import java.io.ByteArrayOutputStream; import java.io.DataOutputStream; import java.io.IOException; import org.apache.hadoop.io.IntWritable; public class Serialization { public byte[] serialize() throws IOException{ //Instantiating the IntWritable object IntWritable intwritable = new IntWritable(12); //Instantiating ByteArrayOutputStream object ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream(); //Instantiating DataOutputStream object DataOutputStream dataOutputStream = new DataOutputStream(byteoutputStream); //Serializing the data intwritable.write(dataOutputStream); //storing the serialized object in bytearray byte[] byteArray = byteoutputStream.toByteArray(); //Closing the OutputStream dataOutputStream.close(); return(byteArray); } public static void main(String args[]) throws IOException{ Serialization serialization= new Serialization(); serialization.serialize(); System.out.println(); } }
Десериализация данных в Hadoop
Процедура десериализации целочисленного типа данных обсуждается ниже —
-
Создайте класс IntWritable, поместив в него целочисленное значение.
-
Создайте класс ByteArrayOutputStream .
-
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
-
Десериализовать данные в объекте DataInputStream с помощью метода readFields () класса IntWritable.
-
Десериализованные данные будут храниться в объекте класса IntWritable. Вы можете получить эти данные, используя метод get () этого класса.
Создайте класс IntWritable, поместив в него целочисленное значение.
Создайте класс ByteArrayOutputStream .
Создайте экземпляр класса DataOutputStream и передайте ему объект класса ByteArrayOutputStream .
Десериализовать данные в объекте DataInputStream с помощью метода readFields () класса IntWritable.
Десериализованные данные будут храниться в объекте класса IntWritable. Вы можете получить эти данные, используя метод get () этого класса.
пример
В следующем примере показано, как десериализовать данные целочисленного типа в Hadoop —
import java.io.ByteArrayInputStream; import java.io.DataInputStream; import org.apache.hadoop.io.IntWritable; public class Deserialization { public void deserialize(byte[]byteArray) throws Exception{ //Instantiating the IntWritable class IntWritable intwritable =new IntWritable(); //Instantiating ByteArrayInputStream object ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray); //Instantiating DataInputStream object DataInputStream datainputstream=new DataInputStream(InputStream); //deserializing the data in DataInputStream intwritable.readFields(datainputstream); //printing the serialized data System.out.println((intwritable).get()); } public static void main(String args[]) throws Exception { Deserialization dese = new Deserialization(); dese.deserialize(new Serialization().serialize()); } }
Преимущество Hadoop над сериализацией Java
Сериализация, основанная на записи, в Hadoop способна снизить накладные расходы на создание объектов путем повторного использования объектов, доступных для записи, что невозможно с помощью встроенной в Java инфраструктуры сериализации.
Недостатки сериализации Hadoop
Для сериализации данных Hadoop существует два способа:
-
Вы можете использовать классы Writable , предоставляемые нативной библиотекой Hadoop.
-
Вы также можете использовать Sequence Files, которые хранят данные в двоичном формате.
Вы можете использовать классы Writable , предоставляемые нативной библиотекой Hadoop.
Вы также можете использовать Sequence Files, которые хранят данные в двоичном формате.
Основным недостатком этих двух механизмов является то, что Writables и SequenceFiles имеют только API Java, и их нельзя писать или читать на любом другом языке.
Поэтому ни один из файлов, созданных в Hadoop с двумя вышеупомянутыми механизмами, не может быть прочитан никаким другим третьим языком, что делает Hadoop ограниченной рамкой. Чтобы устранить этот недостаток, Дуг Каттинг создал Avro, которая является независимой от языка структурой данных .