SQL — Обзор
SQL — это язык для работы с базами данных; он включает в себя создание базы данных, удаление, выборку строк, изменение строк и т. д. SQL является стандартным языком ANSI (Американский национальный институт стандартов), но существует множество различных версий языка SQL.
Что такое SQL?
SQL — это язык структурированных запросов, который является компьютерным языком для хранения, обработки и извлечения данных, хранящихся в реляционной базе данных.
SQL является стандартным языком для реляционной системы баз данных. Все системы управления реляционными базами данных (RDMS), такие как MySQL, MS Access, Oracle, Sybase, Informix, Postgres и SQL Server, используют SQL в качестве стандартного языка баз данных.
Кроме того, они используют разные диалекты, такие как —
- MS SQL Server с использованием T-SQL,
- Oracle использует PL / SQL,
- MS Access версия SQL называется JET SQL (собственный формат) и т. Д.
Почему SQL?
SQL широко популярен, потому что предлагает следующие преимущества —
-
Позволяет пользователям получать доступ к данным в системах управления реляционными базами данных.
-
Позволяет пользователям описывать данные.
-
Позволяет пользователям определять данные в базе данных и манипулировать этими данными.
-
Позволяет встраивать в другие языки, используя модули SQL, библиотеки и прекомпиляторы.
-
Позволяет пользователям создавать и удалять базы данных и таблицы.
-
Позволяет пользователям создавать представления, хранимые процедуры, функции в базе данных.
-
Позволяет пользователям устанавливать разрешения для таблиц, процедур и представлений.
Позволяет пользователям получать доступ к данным в системах управления реляционными базами данных.
Позволяет пользователям описывать данные.
Позволяет пользователям определять данные в базе данных и манипулировать этими данными.
Позволяет встраивать в другие языки, используя модули SQL, библиотеки и прекомпиляторы.
Позволяет пользователям создавать и удалять базы данных и таблицы.
Позволяет пользователям создавать представления, хранимые процедуры, функции в базе данных.
Позволяет пользователям устанавливать разрешения для таблиц, процедур и представлений.
Краткая история SQL
-
1970 — Доктор Эдгар Ф. «Тед» Кодд из IBM известен как отец реляционных баз данных. Он описал реляционную модель для баз данных.
-
1974 — появился язык структурированных запросов.
-
1978 — IBM работала над развитием идей Кодда и выпустила продукт под названием System / R.
-
1986 — IBM разработала первый прототип реляционной базы данных и стандартизировала ANSI. Первая реляционная база данных была выпущена Relational Software, которая позже стала известна как Oracle.
1970 — Доктор Эдгар Ф. «Тед» Кодд из IBM известен как отец реляционных баз данных. Он описал реляционную модель для баз данных.
1974 — появился язык структурированных запросов.
1978 — IBM работала над развитием идей Кодда и выпустила продукт под названием System / R.
1986 — IBM разработала первый прототип реляционной базы данных и стандартизировала ANSI. Первая реляционная база данных была выпущена Relational Software, которая позже стала известна как Oracle.
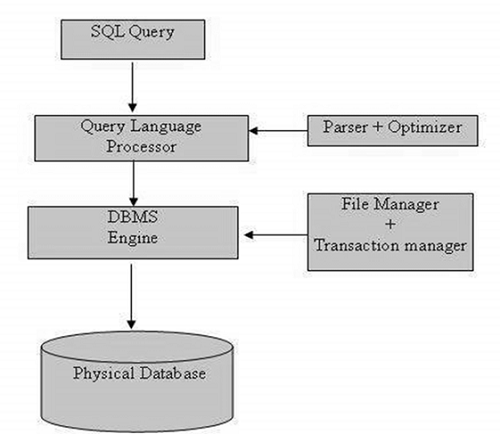
Процесс SQL
Когда вы выполняете команду SQL для любой СУБД, система определяет лучший способ выполнить ваш запрос, а механизм SQL выясняет, как интерпретировать задачу.
В этот процесс включены различные компоненты.
Эти компоненты —
- Диспетчер запросов
- Двигатели оптимизации
- Классический Query Engine
- SQL Query Engine и т. Д.
Классический механизм запросов обрабатывает все запросы, отличные от SQL, но механизм запросов SQL не будет обрабатывать логические файлы.
Ниже приведена простая диаграмма, показывающая архитектуру SQL:
Команды SQL
Стандартными командами SQL для взаимодействия с реляционными базами данных являются CREATE, SELECT, INSERT, UPDATE, DELETE и DROP. Эти команды могут быть классифицированы в следующие группы в зависимости от их характера —
DDL — язык определения данных
| Sr.No. | Команда и описание |
|---|---|
| 1 |
СОЗДАЙТЕ Создает новую таблицу, представление таблицы или другой объект в базе данных. |
| 2 |
ALTER Изменяет существующий объект базы данных, например таблицу. |
| 3 |
DROP Удаляет всю таблицу, представление таблицы или других объектов в базе данных. |
СОЗДАЙТЕ
Создает новую таблицу, представление таблицы или другой объект в базе данных.
ALTER
Изменяет существующий объект базы данных, например таблицу.
DROP
Удаляет всю таблицу, представление таблицы или других объектов в базе данных.
DML — язык манипулирования данными
| Sr.No. | Команда и описание |
|---|---|
| 1 |
ВЫБРАТЬ Извлекает определенные записи из одной или нескольких таблиц. |
| 2 |
ВСТАВИТЬ Создает запись. |
| 3 |
ОБНОВИТЬ Изменяет записи. |
| 4 |
УДАЛЯТЬ Удаляет записи. |
ВЫБРАТЬ
Извлекает определенные записи из одной или нескольких таблиц.
ВСТАВИТЬ
Создает запись.
ОБНОВИТЬ
Изменяет записи.
УДАЛЯТЬ
Удаляет записи.
DCL — язык управления данными
| Sr.No. | Команда и описание |
|---|---|
| 1 |
ГРАНТ Предоставляет привилегию пользователю. |
| 2 |
КЕУОКЕ Возвращает привилегии, предоставленные пользователем. |
ГРАНТ
Предоставляет привилегию пользователю.
КЕУОКЕ
Возвращает привилегии, предоставленные пользователем.
Концепции СУБД SQL
Что такое СУБД?
RDBMS расшифровывается как Реляционная система базы данных. СУБД является основой для SQL и для всех современных систем баз данных, таких как MS SQL Server, IBM DB2, Oracle, MySQL и Microsoft Access.
Система управления реляционными базами данных (RDBMS) — это система управления базами данных (СУБД), основанная на реляционной модели, представленной EF Codd.
Что такое стол?
Данные в СУБД хранятся в объектах базы данных, которые называются таблицами . Эта таблица в основном представляет собой набор связанных записей данных и состоит из множества столбцов и строк.
Помните, что таблица является наиболее распространенной и простой формой хранения данных в реляционной базе данных. Следующая программа является примером таблицы CUSTOMERS —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Что такое поле?
Каждая таблица разбита на более мелкие объекты, называемые полями. Поля в таблице CUSTOMERS состоят из ID, NAME, AGE, ADDRESS и SALARY.
Поле — это столбец в таблице, предназначенный для хранения конкретной информации о каждой записи в таблице.
Что такое запись или строка?
Запись также называется строкой данных — это каждая отдельная запись в таблице. Например, в приведенной выше таблице CUSTOMERS есть 7 записей. Ниже приводится одна строка данных или записи в таблице CUSTOMERS —
+----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | +----+----------+-----+-----------+----------+
Запись — это горизонтальная сущность в таблице.
Что такое столбец?
Столбец — это вертикальная сущность в таблице, которая содержит всю информацию, связанную с конкретным полем в таблице.
Например, столбец в таблице CUSTOMERS — это ADDRESS, который представляет описание местоположения и будет таким, как показано ниже:
+-----------+ | ADDRESS | +-----------+ | Ahmedabad | | Delhi | | Kota | | Mumbai | | Bhopal | | MP | | Indore | +----+------+
Что такое значение NULL?
Значение NULL в таблице — это значение в поле, которое кажется пустым, что означает, что поле со значением NULL является полем без значения.
Очень важно понимать, что значение NULL отличается от нулевого значения или поля, которое содержит пробелы. Поле со значением NULL — это поле, которое было оставлено пустым при создании записи.
Ограничения SQL
Ограничения — это правила, применяемые к столбцам данных в таблице. Они используются для ограничения типа данных, которые могут попадать в таблицу. Это обеспечивает точность и достоверность данных в базе данных.
Ограничения могут быть либо на уровне столбца, либо на уровне таблицы. Ограничения уровня столбца применяются только к одному столбцу, тогда как ограничения уровня таблицы применяются ко всей таблице.
Ниже приведены некоторые из наиболее часто используемых ограничений, доступных в SQL.
-
Ограничение NOT NULL — Гарантирует, что столбец не может иметь значение NULL.
-
DEFAULT Constraint — Предоставляет значение по умолчанию для столбца, когда ни один не указан.
-
УНИКАЛЬНОЕ Ограничение — Гарантирует, что все значения в столбце различны.
-
PRIMARY Key — уникально идентифицирует каждую строку / запись в таблице базы данных.
-
Ключ FOREIGN — уникально идентифицирует строку / запись в любой другой таблице базы данных.
-
Ограничение CHECK — ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
-
INDEX — Используется для очень быстрого создания и извлечения данных из базы данных.
Ограничение NOT NULL — Гарантирует, что столбец не может иметь значение NULL.
DEFAULT Constraint — Предоставляет значение по умолчанию для столбца, когда ни один не указан.
УНИКАЛЬНОЕ Ограничение — Гарантирует, что все значения в столбце различны.
PRIMARY Key — уникально идентифицирует каждую строку / запись в таблице базы данных.
Ключ FOREIGN — уникально идентифицирует строку / запись в любой другой таблице базы данных.
Ограничение CHECK — ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
INDEX — Используется для очень быстрого создания и извлечения данных из базы данных.
Целостность данных
В каждой СУБД существуют следующие категории целостности данных:
-
Целостность сущности — в таблице нет повторяющихся строк.
-
Целостность домена — обеспечивает допустимые записи для данного столбца, ограничивая тип, формат или диапазон значений.
-
Ссылочная целостность — Строки не могут быть удалены, которые используются другими записями.
-
Определяемая пользователем целостность — обеспечивает соблюдение некоторых конкретных бизнес-правил, которые не попадают в целостность объекта, домена или ссылки.
Целостность сущности — в таблице нет повторяющихся строк.
Целостность домена — обеспечивает допустимые записи для данного столбца, ограничивая тип, формат или диапазон значений.
Ссылочная целостность — Строки не могут быть удалены, которые используются другими записями.
Определяемая пользователем целостность — обеспечивает соблюдение некоторых конкретных бизнес-правил, которые не попадают в целостность объекта, домена или ссылки.
Нормализация базы данных
Нормализация базы данных — это процесс эффективной организации данных в базе данных. Есть две причины этого процесса нормализации —
-
Устранение избыточных данных, например, сохранение одних и тех же данных в нескольких таблицах.
-
Обеспечение зависимости данных имеет смысл.
Устранение избыточных данных, например, сохранение одних и тех же данных в нескольких таблицах.
Обеспечение зависимости данных имеет смысл.
Обе эти причины являются достойными целями, поскольку они уменьшают объем пространства, потребляемого базой данных, и обеспечивают логическое хранение данных. Нормализация состоит из ряда рекомендаций, которые помогут вам создать хорошую структуру базы данных.
Рекомендации по нормализации делятся на нормальные формы; думать о форме как о формате или о том, как выстроена структура базы данных. Цель нормальных форм — организовать структуру базы данных так, чтобы она соответствовала правилам первой нормальной формы, затем второй нормальной формы и, наконец, третьей нормальной формы.
Вы можете пойти дальше и перейти к четвертой нормальной форме, пятой нормальной форме и т. Д., Но в целом третьей нормальной формы более чем достаточно.
SQL — базы данных RDBMS
Есть много популярных РСУБД, с которыми можно работать. Этот учебник дает краткий обзор некоторых из самых популярных РСУБД. Это поможет вам сравнить их основные функции.
MySQL
MySQL — это база данных SQL с открытым исходным кодом, разработанная шведской компанией MySQL AB. MySQL произносится как «мой ess-que-ell», в отличие от SQL, произносится как «продолжение».
MySQL поддерживает множество различных платформ, включая Microsoft Windows, основные дистрибутивы Linux, UNIX и Mac OS X.
MySQL имеет бесплатные и платные версии, в зависимости от его использования (некоммерческого / коммерческого) и функций. MySQL поставляется с очень быстрым, многопоточным, многопользовательским и надежным сервером баз данных SQL.
история
-
Разработка MySQL Майклом Видениусом и Дэвидом Аксмарком началась в 1994 году.
-
Первый внутренний релиз 23 мая 1995 г.
-
Версия для Windows была выпущена 8 января 1998 года для Windows 95 и NT.
-
Версия 3.23: бета-версия с июня 2000 года, промышленный выпуск январь 2001 года.
-
Версия 4.0: бета-версия с августа 2002 г., промышленный выпуск, март 2003 г. (союзы).
-
Версия 4.1: бета-версия с июня 2004 г., промышленный выпуск, октябрь 2004 г.
-
Версия 5.0: бета-версия с марта 2005 г., промышленный выпуск, октябрь 2005 г.
-
Sun Microsystems приобрела MySQL AB 26 февраля 2008 года.
-
Версия 5.1: производственный выпуск 27 ноября 2008 г.
Разработка MySQL Майклом Видениусом и Дэвидом Аксмарком началась в 1994 году.
Первый внутренний релиз 23 мая 1995 г.
Версия для Windows была выпущена 8 января 1998 года для Windows 95 и NT.
Версия 3.23: бета-версия с июня 2000 года, промышленный выпуск январь 2001 года.
Версия 4.0: бета-версия с августа 2002 г., промышленный выпуск, март 2003 г. (союзы).
Версия 4.1: бета-версия с июня 2004 г., промышленный выпуск, октябрь 2004 г.
Версия 5.0: бета-версия с марта 2005 г., промышленный выпуск, октябрь 2005 г.
Sun Microsystems приобрела MySQL AB 26 февраля 2008 года.
Версия 5.1: производственный выпуск 27 ноября 2008 г.
Характеристики
- Высокая производительность.
- Высокая доступность.
- Масштабируемость и гибкость Запускайте все что угодно.
- Надежная поддержка транзакций.
- Сильные стороны сети и хранилища данных.
- Сильная защита данных.
- Комплексная разработка приложений.
- Легкость управления.
- Свобода с открытым исходным кодом и поддержка 24 х 7.
- Самая низкая общая стоимость владения.
MS SQL Server
MS SQL Server — это система управления реляционными базами данных, разработанная корпорацией Microsoft. Основные языки запросов —
- T-SQL
- ANSI SQL
история
-
1987 — Sybase выпускает SQL Server для UNIX.
-
1988 — Microsoft, Sybase и Aston-Tate переносят SQL Server на OS / 2.
-
1989 — Microsoft, Sybase и Aston-Tate выпустили SQL Server 1.0 для OS / 2.
-
1990 — выпущен SQL Server 1.1 с поддержкой клиентов Windows 3.0.
-
Астон — Тейт уходит из разработки SQL Server.
-
2000 — Microsoft выпускает SQL Server 2000.
-
2001 — Microsoft выпускает XML для SQL Server Web Release 1 (скачать).
-
2002 — Microsoft выпускает SQLXML 2.0 (переименован из XML для SQL Server).
-
2002 — Microsoft выпускает SQLXML 3.0.
-
2005 — Microsoft выпускает SQL Server 2005 7 ноября 2005 г.
1987 — Sybase выпускает SQL Server для UNIX.
1988 — Microsoft, Sybase и Aston-Tate переносят SQL Server на OS / 2.
1989 — Microsoft, Sybase и Aston-Tate выпустили SQL Server 1.0 для OS / 2.
1990 — выпущен SQL Server 1.1 с поддержкой клиентов Windows 3.0.
Астон — Тейт уходит из разработки SQL Server.
2000 — Microsoft выпускает SQL Server 2000.
2001 — Microsoft выпускает XML для SQL Server Web Release 1 (скачать).
2002 — Microsoft выпускает SQLXML 2.0 (переименован из XML для SQL Server).
2002 — Microsoft выпускает SQLXML 3.0.
2005 — Microsoft выпускает SQL Server 2005 7 ноября 2005 г.
Характеристики
- Высокая производительность
- Высокая доступность
- Зеркальное отображение базы данных
- Снимки базы данных
- Интеграция CLR
- Сервисный Брокер
- DDL запускает
- Функции ранжирования
- Уровни изоляции на основе версий строк
- Интеграция XML
- ПОПРОБУЙ ПОЙМАТЬ
- База данных Почта
ORACLE
Это очень большая многопользовательская система управления базами данных. Oracle — это система управления реляционными базами данных, разработанная Oracle Corporation.
Oracle работает для эффективного управления своими ресурсами, базой данных информации среди множества клиентов, запрашивающих и отправляющих данные в сети.
Это отличный выбор сервера баз данных для клиент-серверных вычислений. Oracle поддерживает все основные операционные системы для клиентов и серверов, включая MSDOS, NetWare, UnixWare, OS / 2 и большинство версий UNIX.
история
Oracle начал свою деятельность в 1977 году и отметил 32 замечательных года в своей отрасли (с 1977 по 2009 год).
-
1977 — Ларри Эллисон, Боб Майнер и Эд Оутс основали лаборатории разработки программного обеспечения для разработки.
-
1979 — Выпущена версия 2.0 Oracle, ставшая первой коммерческой реляционной базой данных и первой базой данных SQL. Компания изменила свое название на Relational Software Inc. (RSI).
-
1981 — RSI начала разработку инструментов для Oracle.
-
1982 — RSI был переименован в Oracle Corporation.
-
1983 — Oracle выпустила версию 3.0, переписанную на языке C и работающую на нескольких платформах.
-
1984 — выпущена версия Oracle 4.0. Он содержал такие функции, как управление параллелизмом — согласованность чтения нескольких версий и т. Д.
-
1985 — выпущена версия Oracle 4.0. Он содержал такие функции, как управление параллелизмом — согласованность чтения нескольких версий и т. Д.
-
2007 — Oracle выпустила Oracle11g. Новая версия ориентирована на лучшее разбиение, легкую миграцию и т. Д.
1977 — Ларри Эллисон, Боб Майнер и Эд Оутс основали лаборатории разработки программного обеспечения для разработки.
1979 — Выпущена версия 2.0 Oracle, ставшая первой коммерческой реляционной базой данных и первой базой данных SQL. Компания изменила свое название на Relational Software Inc. (RSI).
1981 — RSI начала разработку инструментов для Oracle.
1982 — RSI был переименован в Oracle Corporation.
1983 — Oracle выпустила версию 3.0, переписанную на языке C и работающую на нескольких платформах.
1984 — выпущена версия Oracle 4.0. Он содержал такие функции, как управление параллелизмом — согласованность чтения нескольких версий и т. Д.
1985 — выпущена версия Oracle 4.0. Он содержал такие функции, как управление параллелизмом — согласованность чтения нескольких версий и т. Д.
2007 — Oracle выпустила Oracle11g. Новая версия ориентирована на лучшее разбиение, легкую миграцию и т. Д.
Характеристики
- совпадение
- Последовательность чтения
- Механизмы блокировки
- База данных Quiesce
- портативность
- Самоуправляющаяся база данных
- SQL * Plus
- КАК М
- планировщик
- Менеджер ресурсов
- Хранилище данных
- Материализованные взгляды
- Растровые индексы
- Сжатие таблицы
- Параллельное выполнение
- Аналитический SQL
- Сбор данных
- Разметка
MS ACCESS
Это один из самых популярных продуктов Microsoft. Microsoft Access — это программное обеспечение для управления базами данных начального уровня. База данных MS Access — это не только недорогая, но и мощная база данных для небольших проектов.
MS Access использует ядро базы данных Jet, которое использует определенный диалект языка SQL (иногда его называют Jet SQL).
MS Access поставляется с профессиональной версией пакета MS Office. MS Access имеет простой в использовании интуитивно понятный графический интерфейс.
-
1992 — Доступ версии 1.0 был выпущен.
-
1993 — выпущен Access 1.1 для улучшения совместимости с включением языка программирования Access Basic.
-
Наиболее значительный переход произошел с Access 97 на Access 2000.
-
2007 — Access 2007, был представлен новый формат базы данных ACCDB, который поддерживает сложные типы данных, такие как многозначные поля и поля вложений.
1992 — Доступ версии 1.0 был выпущен.
1993 — выпущен Access 1.1 для улучшения совместимости с включением языка программирования Access Basic.
Наиболее значительный переход произошел с Access 97 на Access 2000.
2007 — Access 2007, был представлен новый формат базы данных ACCDB, который поддерживает сложные типы данных, такие как многозначные поля и поля вложений.
Характеристики
-
Пользователи могут создавать таблицы, запросы, формы и отчеты и связывать их вместе с макросами.
-
Возможность импорта и экспорта данных во многие форматы, включая Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server, Oracle, ODBC и т. Д.
-
Существует также формат базы данных Jet (MDB или ACCDB в Access 2007), который может содержать приложение и данные в одном файле. Это делает очень удобным распространение всего приложения другому пользователю, который может запускать его в автономных средах.
-
Microsoft Access предлагает параметризованные запросы. На эти запросы и таблицы доступа можно ссылаться из других программ, таких как VB6 и .NET, через DAO или ADO.
-
Настольные выпуски Microsoft SQL Server могут использоваться с Access в качестве альтернативы Jet Database Engine.
-
Microsoft Access — это база данных на основе файлового сервера. В отличие от клиент-серверных систем управления реляционными базами данных (RDBMS), Microsoft Access не реализует триггеры базы данных, хранимые процедуры или ведение журнала транзакций.
Пользователи могут создавать таблицы, запросы, формы и отчеты и связывать их вместе с макросами.
Возможность импорта и экспорта данных во многие форматы, включая Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server, Oracle, ODBC и т. Д.
Существует также формат базы данных Jet (MDB или ACCDB в Access 2007), который может содержать приложение и данные в одном файле. Это делает очень удобным распространение всего приложения другому пользователю, который может запускать его в автономных средах.
Microsoft Access предлагает параметризованные запросы. На эти запросы и таблицы доступа можно ссылаться из других программ, таких как VB6 и .NET, через DAO или ADO.
Настольные выпуски Microsoft SQL Server могут использоваться с Access в качестве альтернативы Jet Database Engine.
Microsoft Access — это база данных на основе файлового сервера. В отличие от клиент-серверных систем управления реляционными базами данных (RDBMS), Microsoft Access не реализует триггеры базы данных, хранимые процедуры или ведение журнала транзакций.
SQL — синтаксис
За SQL следует уникальный набор правил и рекомендаций, называемых синтаксисом. Этот учебник дает вам быстрый старт с SQL, перечисляя все основные синтаксис SQL.
Все операторы SQL начинаются с любого из ключевых слов, таких как SELECT, INSERT, UPDATE, DELETE, ALTER, DROP, CREATE, USE, SHOW, и все операторы заканчиваются точкой с запятой (;).
Наиболее важный момент, который следует здесь отметить, заключается в том, что SQL нечувствителен к регистру, что означает, что SELECT и select имеют одинаковое значение в инструкциях SQL. Принимая во внимание, что MySQL имеет значение в именах таблиц. Итак, если вы работаете с MySQL, вам нужно дать имена таблиц, которые существуют в базе данных.
Различный синтаксис в SQL
Все примеры, приведенные в этом руководстве, были протестированы на сервере MySQL.
Оператор SQL SELECT
SELECT column1, column2....columnN FROM table_name;
SQL DISTINCT предложение
SELECT DISTINCT column1, column2....columnN FROM table_name;
SQL WHERE предложение
SELECT column1, column2....columnN FROM table_name WHERE CONDITION;
Предложение SQL AND / OR
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION-1 {AND|OR} CONDITION-2;
Предложение SQL IN
SELECT column1, column2....columnN FROM table_name WHERE column_name IN (val-1, val-2,...val-N);
SQL между предложением
SELECT column1, column2....columnN FROM table_name WHERE column_name BETWEEN val-1 AND val-2;
Предложение SQL LIKE
SELECT column1, column2....columnN
FROM table_name
WHERE column_name LIKE { PATTERN };
Предложение SQL ORDER BY
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION
ORDER BY column_name {ASC|DESC};
Предложение SQL GROUP BY
SELECT SUM(column_name) FROM table_name WHERE CONDITION GROUP BY column_name;
Предложение SQL COUNT
SELECT COUNT(column_name) FROM table_name WHERE CONDITION;
SQL HAVING пункт
SELECT SUM(column_name) FROM table_name WHERE CONDITION GROUP BY column_name HAVING (arithematic function condition);
Инструкция SQL CREATE TABLE
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
Оператор SQL DROP TABLE
DROP TABLE table_name;
Инструкция SQL CREATE INDEX
CREATE UNIQUE INDEX index_name ON table_name ( column1, column2,...columnN);
Оператор SQL DROP INDEX
ALTER TABLE table_name DROP INDEX index_name;
SQL DESC оператор
DESC table_name;
SQL TRUNCATE TABLE
TRUNCATE TABLE table_name;
SQL ALTER TABLE Инструкция
ALTER TABLE table_name {ADD|DROP|MODIFY} column_name {data_ype};
Оператор SQL ALTER TABLE (переименование)
ALTER TABLE table_name RENAME TO new_table_name;
SQL INSERT INTO Заявление
INSERT INTO table_name( column1, column2....columnN) VALUES ( value1, value2....valueN);
Оператор SQL UPDATE
UPDATE table_name SET column1 = value1, column2 = value2....columnN=valueN [ WHERE CONDITION ];
SQL-оператор DELETE
DELETE FROM table_name
WHERE {CONDITION};
Оператор SQL CREATE DATABASE
CREATE DATABASE database_name;
Оператор SQL DROP DATABASE
DROP DATABASE database_name;
SQL USE Statement
USE database_name;
Оператор SQL COMMIT
COMMIT;
SQL-оператор ROLLBACK
ROLLBACK;
SQL — типы данных
Тип данных SQL — это атрибут, который определяет тип данных любого объекта. Каждый столбец, переменная и выражение имеют связанный тип данных в SQL. Вы можете использовать эти типы данных при создании таблиц. Вы можете выбрать тип данных для столбца таблицы на основе ваших требований.
SQL Server предлагает шесть категорий типов данных для вашего использования, которые перечислены ниже —
Точные числовые типы данных
| ТИП ДАННЫХ | ОТ | К |
|---|---|---|
| BIGINT | -9.223.372.036.854.775.808 | 9.223.372.036.854.775.807 |
| ИНТ | -2147483648 | 2147483647 |
| SMALLINT | -32768 | 32767 |
| TINYINT | 0 | 255 |
| немного | 0 | 1 |
| десятичный | -10 ^ 38 +1 | 10 ^ 38 -1 |
| числовой | -10 ^ 38 +1 | 10 ^ 38 -1 |
| Деньги | -922,337,203,685,477.5808 | +922,337,203,685,477.5807 |
| smallmoney | -214,748.3648 | +214,748.3647 |
Приблизительные числовые типы данных
| ТИП ДАННЫХ | ОТ | К |
|---|---|---|
| поплавок | -1,79E + 308 | 1,79E + 308 |
| реальный | -3.40E + 38 | 3.40E + 38 |
Типы данных даты и времени
| ТИП ДАННЫХ | ОТ | К |
|---|---|---|
| Дата и время | 1 января 1753 г. | 31 декабря 9999 г. |
| smalldatetime | 1 января 1900 г. | 6 июня 2079 г. |
| Дата | Хранит дату как 30 июня 1991 | |
| время | Хранит время суток, как 12:30 вечера | |
Примечание. Здесь datetime имеет точность 3,33 миллисекунды, тогда как smalldatetime имеет точность 1 минуту.
Типы данных Строки символов
| Sr.No. | Тип данных и описание |
|---|---|
| 1 |
голец Максимальная длина 8000 символов. (Фиксированная длина символов, отличных от Unicode) |
| 2 |
VARCHAR Максимум 8000 символов. (Данные не переменной Юникода). |
| 3 |
VARCHAR (макс) Максимальная длина 2E + 31 символ, переменная длина не в Юникоде (только для SQL Server 2005). |
| 4 |
текст Данные переменной длины, отличные от Unicode, с максимальной длиной 2 147 483 647 символов. |
голец
Максимальная длина 8000 символов. (Фиксированная длина символов, отличных от Unicode)
VARCHAR
Максимум 8000 символов. (Данные не переменной Юникода).
VARCHAR (макс)
Максимальная длина 2E + 31 символ, переменная длина не в Юникоде (только для SQL Server 2005).
текст
Данные переменной длины, отличные от Unicode, с максимальной длиной 2 147 483 647 символов.
Unicode Символьные строки Типы данных
| Sr.No. | Тип данных и описание |
|---|---|
| 1 |
NCHAR Максимальная длина 4000 символов. (Фиксированная длина Unicode) |
| 2 |
NVARCHAR Максимальная длина 4000 символов. (Переменная длина Unicode) |
| 3 |
NVARCHAR (макс) Максимальная длина 2E + 31 символов (только для SQL Server 2005). (Unicode с переменной длиной) |
| 4 |
NTEXT Максимальная длина 1 073 741 823 символа. (Переменная длина Unicode) |
NCHAR
Максимальная длина 4000 символов. (Фиксированная длина Unicode)
NVARCHAR
Максимальная длина 4000 символов. (Переменная длина Unicode)
NVARCHAR (макс)
Максимальная длина 2E + 31 символов (только для SQL Server 2005). (Unicode с переменной длиной)
NTEXT
Максимальная длина 1 073 741 823 символа. (Переменная длина Unicode)
Двоичные типы данных
| Sr.No. | Тип данных и описание |
|---|---|
| 1 |
двоичный Максимальная длина 8000 байт (двоичные данные фиксированной длины) |
| 2 |
VARBINARY Максимальная длина 8000 байт. (Двоичные данные переменной длины) |
| 3 |
VARBINARY (макс) Максимальная длина 2E + 31 байт (только для SQL Server 2005). (Двоичные данные переменной длины) |
| 4 |
образ Максимальная длина 2 147 483 647 байт. (Двоичные данные переменной длины) |
двоичный
Максимальная длина 8000 байт (двоичные данные фиксированной длины)
VARBINARY
Максимальная длина 8000 байт. (Двоичные данные переменной длины)
VARBINARY (макс)
Максимальная длина 2E + 31 байт (только для SQL Server 2005). (Двоичные данные переменной длины)
образ
Максимальная длина 2 147 483 647 байт. (Двоичные данные переменной длины)
Разные типы данных
| Sr.No. | Тип данных и описание |
|---|---|
| 1 |
sql_variant Хранит значения различных типов данных, поддерживаемых SQL Server, кроме text, ntext и timestamp. |
| 2 |
отметка времени Хранит уникальный для всей базы данных номер, который обновляется каждый раз при обновлении строки |
| 3 |
уникальный идентификатор Хранит глобальный уникальный идентификатор (GUID) |
| 4 |
XML Хранит данные XML. Вы можете хранить экземпляры XML в столбце или переменной (только для SQL Server 2005). |
| 5 |
курсор Ссылка на объект курсора |
| 6 |
Таблица Сохраняет набор результатов для последующей обработки |
sql_variant
Хранит значения различных типов данных, поддерживаемых SQL Server, кроме text, ntext и timestamp.
отметка времени
Хранит уникальный для всей базы данных номер, который обновляется каждый раз при обновлении строки
уникальный идентификатор
Хранит глобальный уникальный идентификатор (GUID)
XML
Хранит данные XML. Вы можете хранить экземпляры XML в столбце или переменной (только для SQL Server 2005).
курсор
Ссылка на объект курсора
Таблица
Сохраняет набор результатов для последующей обработки
SQL — операторы
Что такое оператор в SQL?
Оператор — это зарезервированное слово или символ, используемый в основном в предложении WHERE оператора SQL для выполнения операций, таких как сравнения и арифметические операции. Эти операторы используются для указания условий в операторе SQL и в качестве союзов для нескольких условий в операторе.
- Арифметические операторы
- Операторы сравнения
- Логические операторы
- Операторы, используемые для отрицания условий
SQL арифметические операторы
Предположим, что «переменная a» содержит 10, а «переменная b» содержит 20, тогда —
| оператор | Описание | пример |
|---|---|---|
| + (Дополнение) | Добавляет значения по обе стороны от оператора. | а + б даст 30 |
| — (вычитание) | Вычитает правый операнд из левого операнда. | а — б даст -10 |
| * (Умножение) | Умножает значения по обе стороны от оператора. | а * б даст 200 |
| / (Отдел) | Делит левый операнд на правый операнд. | б / у даст 2 |
| % (Модуль) | Делит левый операнд на правый и возвращает остаток. | б% а даст 0 |
Операторы сравнения SQL
Предположим, что «переменная a» содержит 10, а «переменная b» содержит 20, тогда —
| оператор | Описание | пример |
|---|---|---|
| знак равно | Проверяет, равны ли значения двух операндов или нет, если да, тогда условие становится истинным. | (а = б) не соответствует действительности. |
| знак равно | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. | (a! = b) верно. |
| <> | Проверяет, равны ли значения двух операндов или нет, если значения не равны, тогда условие становится истинным. | (а <> б) верно. |
| > | Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (а> б) не соответствует действительности. |
| < | Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, тогда условие становится истинным. | (а <б) верно. |
| > = | Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (a> = b) не соответствует действительности. |
| <= | Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, тогда условие становится истинным. | (a <= b) верно. |
| <! | Проверяет, является ли значение левого операнда не меньше, чем значение правого операнда, если да, тогда условие становится истинным. | (a! <b) ложно. |
| !> | Проверяет, не превышает ли значение левого операнда значение правого операнда, если да, тогда условие становится истинным. | (а!> б) это правда. |
Логические операторы SQL
Вот список всех логических операторов, доступных в SQL.
| Sr.No. | Оператор и описание |
|---|---|
| 1 |
ВСЕ Оператор ALL используется для сравнения значения со всеми значениями в другом наборе значений. |
| 2 |
А ТАКЖЕ Оператор AND допускает существование нескольких условий в предложении WHERE оператора SQL. |
| 3 |
ЛЮБОЙ ЛЮБОЙ оператор используется для сравнения значения с любым применимым значением в списке согласно условию. |
| 4 |
МЕЖДУ Оператор BETWEEN используется для поиска значений, которые находятся в пределах набора значений, учитывая минимальное значение и максимальное значение. |
| 5 |
СУЩЕСТВУЕТ Оператор EXISTS используется для поиска наличия строки в указанной таблице, которая соответствует определенному критерию. |
| 6 |
В Оператор IN используется для сравнения значения со списком литеральных значений, которые были указаны. |
| 7 |
ЛАЙК Оператор LIKE используется для сравнения значения с аналогичными значениями с использованием подстановочных операторов. |
| 8 |
НЕ Оператор NOT меняет значение логического оператора, с которым он используется. Например: НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ В и т. Д. Это оператор отрицания. |
| 9 |
ИЛИ ЖЕ Оператор OR используется для объединения нескольких условий в предложении WHERE оператора SQL. |
| 10 |
НУЛЕВОЙ Оператор NULL используется для сравнения значения со значением NULL. |
| 11 |
УНИКАЛЬНАЯ Оператор UNIQUE ищет в каждой строке указанной таблицы уникальность (без дубликатов). |
ВСЕ
Оператор ALL используется для сравнения значения со всеми значениями в другом наборе значений.
А ТАКЖЕ
Оператор AND допускает существование нескольких условий в предложении WHERE оператора SQL.
ЛЮБОЙ
ЛЮБОЙ оператор используется для сравнения значения с любым применимым значением в списке согласно условию.
МЕЖДУ
Оператор BETWEEN используется для поиска значений, которые находятся в пределах набора значений, учитывая минимальное значение и максимальное значение.
СУЩЕСТВУЕТ
Оператор EXISTS используется для поиска наличия строки в указанной таблице, которая соответствует определенному критерию.
В
Оператор IN используется для сравнения значения со списком литеральных значений, которые были указаны.
ЛАЙК
Оператор LIKE используется для сравнения значения с аналогичными значениями с использованием подстановочных операторов.
НЕ
Оператор NOT меняет значение логического оператора, с которым он используется. Например: НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ В и т. Д. Это оператор отрицания.
ИЛИ ЖЕ
Оператор OR используется для объединения нескольких условий в предложении WHERE оператора SQL.
НУЛЕВОЙ
Оператор NULL используется для сравнения значения со значением NULL.
УНИКАЛЬНАЯ
Оператор UNIQUE ищет в каждой строке указанной таблицы уникальность (без дубликатов).
SQL — выражения
Выражение представляет собой комбинацию одного или нескольких значений, операторов и функций SQL, которые оценивают значение. Эти выражения SQL похожи на формулы и написаны на языке запросов. Вы также можете использовать их для запроса базы данных для определенного набора данных.
Синтаксис
Рассмотрим основной синтаксис оператора SELECT следующим образом:
SELECT column1, column2, columnN FROM table_name WHERE [CONDITION|EXPRESSION];
Существуют различные типы выражений SQL, которые упомянуты ниже:
- логический
- числовой
- Дата
Давайте теперь обсудим каждый из них в деталях.
Логические выражения
Булевы выражения SQL извлекают данные на основе сопоставления одного значения. Ниже приводится синтаксис —
SELECT column1, column2, columnN FROM table_name WHERE SINGLE VALUE MATCHING EXPRESSION;
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
SQL> SELECT * FROM CUSTOMERS; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ 7 rows in set (0.00 sec)
Следующая таблица представляет собой простой пример, показывающий использование различных логических выражений SQL:
SQL> SELECT * FROM CUSTOMERS WHERE SALARY = 10000; +----+-------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+-------+-----+---------+----------+ | 7 | Muffy | 24 | Indore | 10000.00 | +----+-------+-----+---------+----------+ 1 row in set (0.00 sec)
Числовое выражение
Эти выражения используются для выполнения любой математической операции в любом запросе. Ниже приводится синтаксис —
SELECT numerical_expression as OPERATION_NAME [FROM table_name WHERE CONDITION] ;
Здесь числовое выражение используется для математического выражения или любой формулы. Ниже приведен простой пример использования числовых выражений SQL:
SQL> SELECT (15 + 6) AS ADDITION +----------+ | ADDITION | +----------+ | 21 | +----------+ 1 row in set (0.00 sec)
Существует несколько встроенных функций, таких как avg (), sum (), count () и т. Д., Которые выполняют так называемые вычисления совокупных данных для таблицы или определенного столбца таблицы.
SQL> SELECT COUNT(*) AS "RECORDS" FROM CUSTOMERS; +---------+ | RECORDS | +---------+ | 7 | +---------+ 1 row in set (0.00 sec)
Выражения даты
Выражения даты возвращают текущие системные значения даты и времени —
SQL> SELECT CURRENT_TIMESTAMP; +---------------------+ | Current_Timestamp | +---------------------+ | 2009-11-12 06:40:23 | +---------------------+ 1 row in set (0.00 sec)
Другое выражение даты показано ниже:
SQL> SELECT GETDATE();; +-------------------------+ | GETDATE | +-------------------------+ | 2009-10-22 12:07:18.140 | +-------------------------+ 1 row in set (0.00 sec)
SQL — создание базы данных
Оператор SQL CREATE DATABASE используется для создания новой базы данных SQL.
Синтаксис
Основной синтаксис этого оператора CREATE DATABASE следующий:
CREATE DATABASE DatabaseName;
Всегда имя базы данных должно быть уникальным в СУБД.
пример
Если вы хотите создать новую базу данных <testDB>, оператор CREATE DATABASE будет выглядеть так, как показано ниже:
SQL> CREATE DATABASE testDB;
Убедитесь, что у вас есть права администратора, прежде чем создавать любую базу данных. После создания базы данных вы можете проверить ее в списке баз данных следующим образом:
SQL> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | AMROOD | | TUTORIALSPOINT | | mysql | | orig | | test | | testDB | +--------------------+ 7 rows in set (0.00 sec)
SQL — DROP или DELETE Database
Оператор SQL DROP DATABASE используется для удаления существующей базы данных в схеме SQL.
Синтаксис
Основной синтаксис оператора DROP DATABASE следующий:
DROP DATABASE DatabaseName;
Всегда имя базы данных должно быть уникальным в СУБД.
пример
Если вы хотите удалить существующую базу данных <testDB>, оператор DROP DATABASE будет выглядеть так, как показано ниже:
SQL> DROP DATABASE testDB;
ПРИМЕЧАНИЕ. — Будьте внимательны перед использованием этой операции, поскольку удаление существующей базы данных приведет к потере полной информации, хранящейся в базе данных.
Убедитесь, что у вас есть права администратора, прежде чем удалять любую базу данных. Как только база данных удалена, вы можете проверить ее в списке баз данных, как показано ниже —
SQL> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | AMROOD | | TUTORIALSPOINT | | mysql | | orig | | test | +--------------------+ 6 rows in set (0.00 sec)
SQL — база данных SELECT, оператор USE
Если в вашей схеме SQL есть несколько баз данных, то перед началом работы вам нужно будет выбрать базу данных, в которой будут выполняться все операции.
Оператор SQL USE используется для выбора любой существующей базы данных в схеме SQL.
Синтаксис
Основной синтаксис оператора USE показан ниже:
USE DatabaseName;
Всегда имя базы данных должно быть уникальным в СУБД.
пример
Вы можете проверить доступные базы данных, как показано ниже —
SQL> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | AMROOD | | TUTORIALSPOINT | | mysql | | orig | | test | +--------------------+ 6 rows in set (0.00 sec)
Теперь, если вы хотите работать с базой данных AMROOD, вы можете выполнить следующую команду SQL и начать работать с базой данных AMROOD.
SQL> USE AMROOD;
SQL — CREATE Table
Создание базовой таблицы включает в себя наименование таблицы и определение ее столбцов и типа данных каждого столбца.
Оператор SQL CREATE TABLE используется для создания новой таблицы.
Синтаксис
Основной синтаксис оператора CREATE TABLE следующий:
CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
CREATE TABLE — это ключевое слово, сообщающее системе баз данных, что вы хотите сделать. В этом случае вы хотите создать новую таблицу. Уникальное имя или идентификатор таблицы следует за оператором CREATE TABLE.
Затем в скобках указывается список, определяющий каждый столбец таблицы и тип данных. Синтаксис становится понятнее в следующем примере.
Копия существующей таблицы может быть создана с использованием комбинации оператора CREATE TABLE и оператора SELECT. Вы можете проверить полную информацию в Создать таблицу с помощью другой таблицы.
пример
Следующий блок кода является примером, который создает таблицу CUSTOMERS с идентификатором в качестве первичного ключа, а NOT NULL являются ограничениями, показывающими, что эти поля не могут быть равны NULL при создании записей в этой таблице.
SQL> CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Вы можете проверить, была ли ваша таблица создана успешно, просмотрев сообщение, отображаемое сервером SQL, в противном случае вы можете использовать команду DESC следующим образом:
SQL> DESC CUSTOMERS; +---------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+---------------+------+-----+---------+-------+ | ID | int(11) | NO | PRI | | | | NAME | varchar(20) | NO | | | | | AGE | int(11) | NO | | | | | ADDRESS | char(25) | YES | | NULL | | | SALARY | decimal(18,2) | YES | | NULL | | +---------+---------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)
Теперь в вашей базе данных есть таблица CUSTOMERS, которую вы можете использовать для хранения необходимой информации о клиентах.
SQL — DROP или DELETE Table
Оператор SQL DROP TABLE используется для удаления определения таблицы и всех данных, индексов, триггеров, ограничений и спецификаций разрешений для этой таблицы.
ПРИМЕЧАНИЕ. — При использовании этой команды вы должны быть очень осторожны, поскольку после удаления таблицы вся информация, имеющаяся в этой таблице, также будет потеряна навсегда.
Синтаксис
Основной синтаксис этого оператора DROP TABLE следующий:
DROP TABLE table_name;
пример
Давайте сначала проверим таблицу CUSTOMERS, а затем удалим ее из базы данных, как показано ниже —
SQL> DESC CUSTOMERS; +---------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+---------------+------+-----+---------+-------+ | ID | int(11) | NO | PRI | | | | NAME | varchar(20) | NO | | | | | AGE | int(11) | NO | | | | | ADDRESS | char(25) | YES | | NULL | | | SALARY | decimal(18,2) | YES | | NULL | | +---------+---------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)
Это означает, что таблица CUSTOMERS доступна в базе данных, поэтому давайте теперь отбросим ее, как показано ниже.
SQL> DROP TABLE CUSTOMERS; Query OK, 0 rows affected (0.01 sec)
Теперь, если вы попробуете команду DESC, вы получите следующую ошибку:
SQL> DESC CUSTOMERS; ERROR 1146 (42S02): Table 'TEST.CUSTOMERS' doesn't exist
Здесь TEST — это имя базы данных, которое мы используем для наших примеров.
SQL — INSERT Query
Оператор SQL INSERT INTO используется для добавления новых строк данных в таблицу в базе данных.
Синтаксис
Существует два основных синтаксиса оператора INSERT INTO, которые показаны ниже.
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN);
Здесь column1, column2, column3, … columnN — это имена столбцов в таблице, в которую вы хотите вставить данные.
Вам может не потребоваться указывать имя столбца (-ов) в запросе SQL, если вы добавляете значения для всех столбцов таблицы. Но убедитесь, что порядок значений в том же порядке, что и столбцы в таблице.
Синтаксис SQL INSERT INTO будет следующим:
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
пример
Следующие операторы создадут шесть записей в таблице CUSTOMERS.
INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh', 32, 'Ahmedabad', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (2, 'Khilan', 25, 'Delhi', 1500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (3, 'kaushik', 23, 'Kota', 2000.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (4, 'Chaitali', 25, 'Mumbai', 6500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (5, 'Hardik', 27, 'Bhopal', 8500.00 ); INSERT INTO CUSTOMERS (ID,NAME,AGE,ADDRESS,SALARY) VALUES (6, 'Komal', 22, 'MP', 4500.00 );
Вы можете создать запись в таблице CUSTOMERS, используя второй синтаксис, как показано ниже.
INSERT INTO CUSTOMERS VALUES (7, 'Muffy', 24, 'Indore', 10000.00 );
Все приведенные выше операторы приведут к следующим записям в таблице CUSTOMERS, как показано ниже.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Заполните одну таблицу, используя другую таблицу
Вы можете заполнить данные в таблицу с помощью оператора выбора поверх другой таблицы; при условии, что другая таблица имеет набор полей, которые необходимы для заполнения первой таблицы.
Вот синтаксис —
INSERT INTO first_table_name [(column1, column2, ... columnN)] SELECT column1, column2, ...columnN FROM second_table_name [WHERE condition];
SQL — SELECT Query
Оператор SQL SELECT используется для извлечения данных из таблицы базы данных, которая возвращает эти данные в форме таблицы результатов. Эти таблицы результатов называются наборами результатов.
Синтаксис
Основной синтаксис оператора SELECT следующий:
SELECT column1, column2, columnN FROM table_name;
Здесь column1, column2 … — это поля таблицы, значения которых вы хотите получить. Если вы хотите получить все поля, доступные в поле, вы можете использовать следующий синтаксис.
SELECT * FROM table_name;
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий код является примером, который извлекает поля ID, Имя и Зарплата клиентов, доступных в таблице CUSTOMERS.
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS;
Это даст следующий результат —
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 1 | Ramesh | 2000.00 | | 2 | Khilan | 1500.00 | | 3 | kaushik | 2000.00 | | 4 | Chaitali | 6500.00 | | 5 | Hardik | 8500.00 | | 6 | Komal | 4500.00 | | 7 | Muffy | 10000.00 | +----+----------+----------+
Если вы хотите получить все поля таблицы CUSTOMERS, используйте следующий запрос.
SQL> SELECT * FROM CUSTOMERS;
Это даст результат, как показано ниже.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
SQL — предложение WHERE
Предложение SQL WHERE используется для указания условия при извлечении данных из одной таблицы или путем объединения с несколькими таблицами. Если данное условие выполняется, то только оно возвращает конкретное значение из таблицы. Вы должны использовать предложение WHERE для фильтрации записей и выборки только необходимых записей.
Предложение WHERE используется не только в операторе SELECT, но также в операторе UPDATE, DELETE и т. Д., Который мы рассмотрим в следующих главах.
Синтаксис
Основной синтаксис оператора SELECT с предложением WHERE показан ниже.
SELECT column1, column2, columnN FROM table_name WHERE [condition]
Вы можете указать условие, используя сравнение или логические операторы, такие как>, <, =, LIKE, NOT и т. Д. Следующие примеры прояснят эту концепцию.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий код является примером, который извлекает поля ID, Name и Salary из таблицы CUSTOMERS, где заработная плата больше 2000 —
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS WHERE SALARY > 2000;
Это даст следующий результат —
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 4 | Chaitali | 6500.00 | | 5 | Hardik | 8500.00 | | 6 | Komal | 4500.00 | | 7 | Muffy | 10000.00 | +----+----------+----------+
Следующий запрос является примером, который извлекает поля ID, Имя и Зарплата из таблицы CUSTOMERS для клиента с именем Hardik .
Здесь важно отметить, что все строки должны быть указаны в одинарных кавычках (»). Принимая во внимание, что числовые значения должны быть указаны без кавычек, как в приведенном выше примере.
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS WHERE NAME = 'Hardik';
Это даст следующий результат —
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 5 | Hardik | 8500.00 | +----+----------+----------+
SQL — И ИЛИ ИЛИ СОЕДИНИТЕЛЬНЫЕ ОПЕРАТОРЫ
Операторы SQL AND & OR используются для объединения нескольких условий для сужения данных в операторе SQL. Эти два оператора называются конъюнктивными операторами.
Эти операторы предоставляют возможность сделать несколько сравнений с разными операторами в одном и том же операторе SQL.
Оператор AND
Оператор AND допускает существование нескольких условий в предложении WHERE оператора SQL.
Синтаксис
Основной синтаксис оператора AND с предложением WHERE следующий:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
Вы можете объединить N условий с помощью оператора AND. Чтобы действие, выполняемое оператором SQL, будь то транзакция или запрос, все условия, разделенные AND, должны быть ИСТИНА.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который извлекает поля ID, Имя и Зарплата из таблицы CUSTOMERS, где оклад больше 2000, а возраст меньше 25 лет.
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS WHERE SALARY > 2000 AND age < 25;
Это даст следующий результат —
+----+-------+----------+ | ID | NAME | SALARY | +----+-------+----------+ | 6 | Komal | 4500.00 | | 7 | Muffy | 10000.00 | +----+-------+----------+
Оператор ИЛИ
Оператор OR используется для объединения нескольких условий в предложении WHERE оператора SQL.
Синтаксис
Основной синтаксис оператора OR с предложением WHERE следующий:
SELECT column1, column2, columnN FROM table_name WHERE [condition1] OR [condition2]...OR [conditionN]
Вы можете объединить N условий с помощью оператора ИЛИ. Для действия, выполняемого оператором SQL, будь то транзакция или запрос, единственным ОДНЫМ из условий, разделенных ИЛИ, должно быть ИСТИНА.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
В следующем блоке кода есть запрос, который извлекает поля ID, Имя и Зарплата из таблицы CUSTOMERS, где оклад больше 2000, ИЛИ возраст меньше 25 лет.
SQL> SELECT ID, NAME, SALARY FROM CUSTOMERS WHERE SALARY > 2000 OR age < 25;
Это даст следующий результат —
+----+----------+----------+ | ID | NAME | SALARY | +----+----------+----------+ | 3 | kaushik | 2000.00 | | 4 | Chaitali | 6500.00 | | 5 | Hardik | 8500.00 | | 6 | Komal | 4500.00 | | 7 | Muffy | 10000.00 | +----+----------+----------+
SQL — запрос ОБНОВЛЕНИЯ
Запрос SQL UPDATE используется для изменения существующих записей в таблице. Вы можете использовать предложение WHERE с запросом UPDATE, чтобы обновить выбранные строки, иначе это затронет все строки.
Синтаксис
Основной синтаксис запроса UPDATE с предложением WHERE выглядит следующим образом:
UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition];
Вы можете объединить N условий с помощью операторов И или ИЛИ.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий запрос обновит АДРЕС для клиента, чей идентификационный номер 6 в таблице.
SQL> UPDATE CUSTOMERS SET ADDRESS = 'Pune' WHERE ID = 6;
Теперь таблица CUSTOMERS будет иметь следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | Pune | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Если вы хотите изменить все значения столбца ADDRESS и SALARY в таблице CUSTOMERS, вам не нужно использовать предложение WHERE, так как запроса UPDATE будет достаточно, как показано в следующем блоке кода.
SQL> UPDATE CUSTOMERS SET ADDRESS = 'Pune', SALARY = 1000.00;
Теперь таблица CUSTOMERS будет иметь следующие записи:
+----+----------+-----+---------+---------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+---------+ | 1 | Ramesh | 32 | Pune | 1000.00 | | 2 | Khilan | 25 | Pune | 1000.00 | | 3 | kaushik | 23 | Pune | 1000.00 | | 4 | Chaitali | 25 | Pune | 1000.00 | | 5 | Hardik | 27 | Pune | 1000.00 | | 6 | Komal | 22 | Pune | 1000.00 | | 7 | Muffy | 24 | Pune | 1000.00 | +----+----------+-----+---------+---------+
SQL — УДАЛИТЬ запрос
Запрос SQL DELETE используется для удаления существующих записей из таблицы.
Вы можете использовать предложение WHERE с запросом DELETE, чтобы удалить выбранные строки, иначе все записи будут удалены.
Синтаксис
Основной синтаксис запроса DELETE с предложением WHERE следующий:
DELETE FROM table_name WHERE [condition];
Вы можете объединить N условий с помощью операторов И или ИЛИ.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
В следующем коде есть запрос, который удалит клиента с идентификатором 6.
SQL> DELETE FROM CUSTOMERS WHERE ID = 6;
Теперь таблица CUSTOMERS будет иметь следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Если вы хотите УДАЛИТЬ все записи из таблицы CUSTOMERS, вам не нужно использовать предложение WHERE, а запрос DELETE будет выглядеть следующим образом:
SQL> DELETE FROM CUSTOMERS;
Теперь в таблице CUSTOMERS не будет записей.
SQL — как предложение
Предложение SQL LIKE используется для сравнения значения с аналогичными значениями с использованием подстановочных операторов. В сочетании с оператором LIKE используются два подстановочных знака.
- Знак процента (%)
- Подчеркивание (_)
Знак процента представляет собой ноль, один или несколько символов. Подчеркивание представляет собой одно число или символ. Эти символы могут использоваться в комбинациях.
Синтаксис
Основной синтаксис% и _ следующий:
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
Вы можете объединить N условий с помощью операторов И или ИЛИ. Здесь XXXX может быть любым числовым или строковым значением.
пример
В следующей таблице приведено несколько примеров, показывающих, что часть WHERE имеет другое предложение LIKE с операторами «%» и «_» —
| Sr.No. | Заявление и описание |
|---|---|
| 1 |
Где заработная плата, как «200%» Находит любые значения, которые начинаются с 200. |
| 2 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ «% 200%» Находит любые значения, которые имеют 200 в любой позиции. |
| 3 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_00%’ Находит любые значения, которые имеют 00 во второй и третьей позиции. |
| 4 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘2 _% _%’ Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов. |
| 5 |
ГДЕ НАГРАДНАЯ НРАВИТСЯ ‘% 2’ Находит любые значения, которые заканчиваются на 2. |
| 6 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_2% 3’ Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3. |
| 7 |
Где заработная плата, как «2___3» Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3. |
Где заработная плата, как «200%»
Находит любые значения, которые начинаются с 200.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ «% 200%»
Находит любые значения, которые имеют 200 в любой позиции.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_00%’
Находит любые значения, которые имеют 00 во второй и третьей позиции.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘2 _% _%’
Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов.
ГДЕ НАГРАДНАЯ НРАВИТСЯ ‘% 2’
Находит любые значения, которые заканчиваются на 2.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_2% 3’
Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3.
Где заработная плата, как «2___3»
Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3.
Давайте возьмем реальный пример, рассмотрим таблицу CUSTOMERS с записями, как показано ниже.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который будет отображать все записи из таблицы CUSTOMERS, где SALARY начинается с 200.
SQL> SELECT * FROM CUSTOMERS WHERE SALARY LIKE '200%';
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+----------+-----+-----------+----------+
SQL — предложение TOP, LIMIT или ROWNUM
Предложение SQL TOP используется для извлечения числа TOP N или X процентов записей из таблицы.
Примечание. Все базы данных не поддерживают предложение TOP. Например, MySQL поддерживает предложение LIMIT для получения ограниченного числа записей, в то время как Oracle использует команду ROWNUM для получения ограниченного количества записей.
Синтаксис
Основной синтаксис предложения TOP с оператором SELECT будет следующим.
SELECT TOP number|percent column_name(s) FROM table_name WHERE [condition]
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий запрос является примером на сервере SQL, который извлекает 3 верхние записи из таблицы CUSTOMERS.
SQL> SELECT TOP 3 * FROM CUSTOMERS;
Это даст следующий результат —
+----+---------+-----+-----------+---------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+---------+-----+-----------+---------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+---------+-----+-----------+---------+
Если вы используете сервер MySQL, то вот эквивалентный пример —
SQL> SELECT * FROM CUSTOMERS LIMIT 3;
Это даст следующий результат —
+----+---------+-----+-----------+---------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+---------+-----+-----------+---------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+---------+-----+-----------+---------+
Если вы используете сервер Oracle, то следующий блок кода имеет эквивалентный пример.
SQL> SELECT * FROM CUSTOMERS WHERE ROWNUM <= 3;
Это даст следующий результат —
+----+---------+-----+-----------+---------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+---------+-----+-----------+---------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+---------+-----+-----------+---------+
SQL — предложение ORDER BY
Предложение SQL ORDER BY используется для сортировки данных в порядке возрастания или убывания на основе одного или нескольких столбцов. Некоторые базы данных по умолчанию сортируют результаты запроса в порядке возрастания.
Синтаксис
Основной синтаксис предложения ORDER BY следующий:
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
Вы можете использовать более одного столбца в предложении ORDER BY. Убедитесь, что любой столбец, который вы используете для сортировки этого столбца, должен быть в списке столбцов.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
В следующем блоке кода есть пример, который сортирует результат в возрастающем порядке по ИМЕНИ и ЗАПИСИ —
SQL> SELECT * FROM CUSTOMERS ORDER BY NAME, SALARY;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | +----+----------+-----+-----------+----------+
В следующем блоке кода есть пример, который сортирует результат в порядке убывания по ИМЯ.
SQL> SELECT * FROM CUSTOMERS ORDER BY NAME DESC;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 6 | Komal | 22 | MP | 4500.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | +----+----------+-----+-----------+----------+
SQL — Group By
Предложение SQL GROUP BY используется в сотрудничестве с оператором SELECT для объединения идентичных данных в группы. Это предложение GROUP BY следует за предложением WHERE в инструкции SELECT и предшествует предложению ORDER BY.
Синтаксис
Основной синтаксис предложения GROUP BY показан в следующем блоке кода. Предложение GROUP BY должно соответствовать условиям в предложении WHERE и должно предшествовать предложению ORDER BY, если оно используется.
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2 ORDER BY column1, column2
пример
Предположим, что таблица CUSTOMERS содержит следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Если вы хотите узнать общую сумму заработной платы по каждому клиенту, запрос GROUP BY будет выглядеть следующим образом.
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это даст следующий результат —
+----------+-------------+ | NAME | SUM(SALARY) | +----------+-------------+ | Chaitali | 6500.00 | | Hardik | 8500.00 | | kaushik | 2000.00 | | Khilan | 1500.00 | | Komal | 4500.00 | | Muffy | 10000.00 | | Ramesh | 2000.00 | +----------+-------------+
Теперь давайте посмотрим на таблицу, в которой таблица CUSTOMERS содержит следующие записи с повторяющимися именами:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Ramesh | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | kaushik | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Опять же, если вы хотите узнать общую сумму заработной платы по каждому клиенту, запрос GROUP BY будет выглядеть следующим образом:
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS GROUP BY NAME;
Это даст следующий результат —
+---------+-------------+ | NAME | SUM(SALARY) | +---------+-------------+ | Hardik | 8500.00 | | kaushik | 8500.00 | | Komal | 4500.00 | | Muffy | 10000.00 | | Ramesh | 3500.00 | +---------+-------------+
SQL — отличное ключевое слово
Ключевое слово SQL DISTINCT используется вместе с оператором SELECT, чтобы исключить все дублирующиеся записи и извлечь только уникальные записи.
Может возникнуть ситуация, когда в таблице несколько повторяющихся записей. При получении таких записей имеет смысл выбирать только эти уникальные записи, а не дублировать записи.
Синтаксис
Основной синтаксис ключевого слова DISTINCT для устранения повторяющихся записей заключается в следующем:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Сначала давайте посмотрим, как следующий запрос SELECT возвращает дубликаты записей зарплат.
SQL> SELECT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это привело бы к следующему результату, когда зарплата (2000) наступает дважды, что является дубликатом записи из исходной таблицы.
+----------+ | SALARY | +----------+ | 1500.00 | | 2000.00 | | 2000.00 | | 4500.00 | | 6500.00 | | 8500.00 | | 10000.00 | +----------+
Теперь давайте воспользуемся ключевым словом DISTINCT с вышеупомянутым запросом SELECT, а затем посмотрим на результат.
SQL> SELECT DISTINCT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это приведет к следующему результату, где у нас нет дублирующихся записей.
+----------+ | SALARY | +----------+ | 1500.00 | | 2000.00 | | 4500.00 | | 6500.00 | | 8500.00 | | 10000.00 | +----------+
SQL — сортировка результатов
Предложение SQL ORDER BY используется для сортировки данных в порядке возрастания или убывания на основе одного или нескольких столбцов. Некоторые базы данных по умолчанию сортируют результаты запроса в порядке возрастания.
Синтаксис
Основной синтаксис предложения ORDER BY, который будет использоваться для сортировки результата в порядке возрастания или убывания, выглядит следующим образом:
SELECT column-list FROM table_name [WHERE condition] [ORDER BY column1, column2, .. columnN] [ASC | DESC];
Вы можете использовать более одного столбца в предложении ORDER BY. Убедитесь, что любой столбец, который вы используете для сортировки, должен быть в списке столбцов.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который сортирует результат в порядке возрастания по NAME и SALARY.
SQL> SELECT * FROM CUSTOMERS ORDER BY NAME, SALARY;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | +----+----------+-----+-----------+----------+
В следующем блоке кода есть пример, который сортирует результат в порядке убывания по ИМЯ.
SQL> SELECT * FROM CUSTOMERS ORDER BY NAME DESC;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 6 | Komal | 22 | MP | 4500.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | +----+----------+-----+-----------+----------+
Чтобы получить строки с их собственным предпочтительным порядком, запрос SELECT будет выглядеть следующим образом:
SQL> SELECT * FROM CUSTOMERS ORDER BY (CASE ADDRESS WHEN 'DELHI' THEN 1 WHEN 'BHOPAL' THEN 2 WHEN 'KOTA' THEN 3 WHEN 'AHMADABAD' THEN 4 WHEN 'MP' THEN 5 ELSE 100 END) ASC, ADDRESS DESC;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 2 | Khilan | 25 | Delhi | 1500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 6 | Komal | 22 | MP | 4500.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | +----+----------+-----+-----------+----------+
Это отсортирует клиентов по АДРЕСУ в вашем предпочтении в первую очередь и в естественном порядке для остальных адресов. Кроме того, оставшиеся адреса будут отсортированы в обратном алфавитном порядке.
SQL — ограничения
Ограничения — это правила, применяемые к столбцам данных таблицы. Они используются для ограничения типа данных, которые могут попадать в таблицу. Это обеспечивает точность и достоверность данных в базе данных.
Ограничения могут быть либо на уровне столбца, либо на уровне таблицы. Ограничения уровня столбца применяются только к одному столбцу, тогда как ограничения уровня таблицы применяются ко всей таблице.
Ниже приведены некоторые из наиболее часто используемых ограничений, доступных в SQL. Эти ограничения уже обсуждались в главе « Основные понятия SQL — RDBMS» , но стоит их пересмотреть на этом этапе.
-
NOT NULL Ограничение — Гарантирует, что столбец не может иметь значение NULL.
-
DEFAULT Constraint — Предоставляет значение по умолчанию для столбца, когда ни один не указан.
-
UNIQUE Constraint — гарантирует, что все значения в столбце разные.
-
PRIMARY Key — уникально идентифицирует каждую строку / запись в таблице базы данных.
-
Ключ FOREIGN — уникально идентифицирует строку / запись в любой из данных таблиц базы данных.
-
Ограничение CHECK — ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
-
INDEX — Используется для очень быстрого создания и извлечения данных из базы данных.
NOT NULL Ограничение — Гарантирует, что столбец не может иметь значение NULL.
DEFAULT Constraint — Предоставляет значение по умолчанию для столбца, когда ни один не указан.
UNIQUE Constraint — гарантирует, что все значения в столбце разные.
PRIMARY Key — уникально идентифицирует каждую строку / запись в таблице базы данных.
Ключ FOREIGN — уникально идентифицирует строку / запись в любой из данных таблиц базы данных.
Ограничение CHECK — ограничение CHECK гарантирует, что все значения в столбце удовлетворяют определенным условиям.
INDEX — Используется для очень быстрого создания и извлечения данных из базы данных.
Ограничения могут быть указаны, когда таблица создается с помощью оператора CREATE TABLE, или вы можете использовать инструкцию ALTER TABLE для создания ограничений даже после создания таблицы.
Отбрасывание ограничений
Любое определенное вами ограничение можно удалить с помощью команды ALTER TABLE с параметром DROP CONSTRAINT.
Например, чтобы удалить ограничение первичного ключа в таблице EMPLOYEES, вы можете использовать следующую команду.
ALTER TABLE EMPLOYEES DROP CONSTRAINT EMPLOYEES_PK;
Некоторые реализации могут предоставлять ярлыки для удаления определенных ограничений. Например, чтобы удалить ограничение первичного ключа для таблицы в Oracle, вы можете использовать следующую команду.
ALTER TABLE EMPLOYEES DROP PRIMARY KEY;
Некоторые реализации позволяют отключить ограничения. Вместо того, чтобы навсегда удалить ограничение из базы данных, вы можете временно отключить ограничение, а затем включить его позже.
Ограничения целостности
Ограничения целостности используются для обеспечения точности и согласованности данных в реляционной базе данных. Целостность данных обрабатывается в реляционной базе данных посредством концепции ссылочной целостности.
Существует много типов ограничений целостности, которые играют роль в ссылочной целостности (RI) . Эти ограничения включают в себя первичный ключ, внешний ключ, уникальные ограничения и другие ограничения, которые упомянуты выше.
SQL — Использование объединений
Предложение SQL Joins используется для объединения записей из двух или более таблиц в базе данных. JOIN — это средство для объединения полей из двух таблиц с использованием значений, общих для каждой.
Рассмотрим следующие две таблицы:
Таблица 1 — Таблица клиентов
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Таблица 2 — Таблица заказов
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
Теперь давайте объединим эти две таблицы в нашем операторе SELECT, как показано ниже.
SQL> SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
Это дало бы следующий результат.
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
Здесь заметно, что соединение выполняется в предложении WHERE. Для объединения таблиц можно использовать несколько операторов, например =, <,>, <>, <=,> =,! =, BETWEEN, LIKE и NOT; все они могут быть использованы для объединения таблиц. Тем не менее, наиболее распространенный оператор равен символу.
В SQL доступны разные типы соединений:
-
INNER JOIN — возвращает строки при совпадении в обеих таблицах.
-
LEFT JOIN — возвращает все строки из левой таблицы, даже если в правой таблице нет совпадений.
-
RIGHT JOIN — возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
-
FULL JOIN — возвращает строки при совпадении в одной из таблиц.
-
SELF JOIN — используется для соединения таблицы с самим собой, как если бы эта таблица была двумя таблицами, временно переименовывая хотя бы одну таблицу в операторе SQL.
-
CARTESIAN JOIN — возвращает декартово произведение наборов записей из двух или более объединенных таблиц.
INNER JOIN — возвращает строки при совпадении в обеих таблицах.
LEFT JOIN — возвращает все строки из левой таблицы, даже если в правой таблице нет совпадений.
RIGHT JOIN — возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
FULL JOIN — возвращает строки при совпадении в одной из таблиц.
SELF JOIN — используется для соединения таблицы с самим собой, как если бы эта таблица была двумя таблицами, временно переименовывая хотя бы одну таблицу в операторе SQL.
CARTESIAN JOIN — возвращает декартово произведение наборов записей из двух или более объединенных таблиц.
Давайте теперь обсудим каждое из этих объединений подробно.
SQL — СОЮЗ
Предложение / оператор SQL UNION используется для объединения результатов двух или более операторов SELECT без возврата повторяющихся строк.
Чтобы использовать это предложение UNION, каждый оператор SELECT должен иметь
- Выбрано такое же количество столбцов
- Одинаковое количество выражений столбцов
- Тот же тип данных и
- У них в том же порядке
Но они не должны быть одинаковой длины.
Синтаксис
Основной синтаксис предложения UNION следующий:
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Здесь данное условие может быть любым выражением, основанным на вашем требовании.
пример
Рассмотрим следующие две таблицы.
Таблица 1 — Таблица клиентов выглядит следующим образом.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Таблица 2 — ЗАКАЗЫ Таблица выглядит следующим образом.
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
Теперь давайте объединим эти две таблицы в нашем операторе SELECT следующим образом:
SQL> SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS LEFT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID UNION SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS RIGHT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
Это даст следующий результат —
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | +------+----------+--------+---------------------+
СОЮЗ ВСЕ Статья
Оператор UNION ALL используется для объединения результатов двух операторов SELECT, включая повторяющиеся строки.
Те же правила, которые применяются к предложению UNION, будут применяться к оператору UNION ALL.
Синтаксис
Основной синтаксис UNION ALL заключается в следующем.
SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition] UNION ALL SELECT column1 [, column2 ] FROM table1 [, table2 ] [WHERE condition]
Здесь данное условие может быть любым выражением, основанным на вашем требовании.
пример
Рассмотрим следующие две таблицы:
Таблица 1 — Таблица клиентов выглядит следующим образом.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Таблица 2 — Таблица заказов выглядит следующим образом.
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
Теперь давайте объединим эти две таблицы в нашем операторе SELECT следующим образом:
SQL> SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS LEFT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID UNION ALL SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS RIGHT JOIN ORDERS ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
Это даст следующий результат —
+------+----------+--------+---------------------+ | ID | NAME | AMOUNT | DATE | +------+----------+--------+---------------------+ | 1 | Ramesh | NULL | NULL | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | | 5 | Hardik | NULL | NULL | | 6 | Komal | NULL | NULL | | 7 | Muffy | NULL | NULL | | 3 | kaushik | 3000 | 2009-10-08 00:00:00 | | 3 | kaushik | 1500 | 2009-10-08 00:00:00 | | 2 | Khilan | 1560 | 2009-11-20 00:00:00 | | 4 | Chaitali | 2060 | 2008-05-20 00:00:00 | +------+----------+--------+---------------------+
Есть два других предложения (т. Е. Операторы), которые похожи на предложение UNION.
-
Предложение SQL INTERSECT — используется для объединения двух операторов SELECT, но возвращает строки только из первого оператора SELECT, которые идентичны строке во втором операторе SELECT.
-
Предложение SQL EXCEPT — объединяет два оператора SELECT и возвращает строки из первого оператора SELECT, которые не возвращаются вторым оператором SELECT.
Предложение SQL INTERSECT — используется для объединения двух операторов SELECT, но возвращает строки только из первого оператора SELECT, которые идентичны строке во втором операторе SELECT.
Предложение SQL EXCEPT — объединяет два оператора SELECT и возвращает строки из первого оператора SELECT, которые не возвращаются вторым оператором SELECT.
SQL — значения NULL
SQL NULL — это термин, используемый для обозначения пропущенного значения. Значение NULL в таблице — это значение в поле, которое кажется пустым.
Поле со значением NULL является полем без значения. Очень важно понимать, что значение NULL отличается от нулевого значения или поля, которое содержит пробелы.
Синтаксис
Основной синтаксис NULL при создании таблицы.
SQL> CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Здесь NOT NULL означает, что столбец всегда должен принимать явное значение данного типа данных. Есть два столбца, в которых мы не использовали NOT NULL, что означает, что эти столбцы могут быть NULL.
Поле со значением NULL — это поле, которое было оставлено пустым при создании записи.
пример
Значение NULL может вызвать проблемы при выборе данных. Однако, поскольку при сравнении неизвестного значения с любым другим значением результат всегда неизвестен и не включается в результаты. Вы должны использовать операторы IS NULL или IS NOT NULL, чтобы проверить значение NULL.
Рассмотрим следующую таблицу CUSTOMERS, имеющую записи, как показано ниже.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | | | 7 | Muffy | 24 | Indore | | +----+----------+-----+-----------+----------+
Далее следует использование оператора IS NOT NULL .
SQL> SELECT ID, NAME, AGE, ADDRESS, SALARY FROM CUSTOMERS WHERE SALARY IS NOT NULL;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | +----+----------+-----+-----------+----------+
Далее следует использование оператора IS NULL .
SQL> SELECT ID, NAME, AGE, ADDRESS, SALARY FROM CUSTOMERS WHERE SALARY IS NULL;
Это даст следующий результат —
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 6 | Komal | 22 | MP | | | 7 | Muffy | 24 | Indore | | +----+----------+-----+-----------+----------+
SQL — псевдоним синтаксиса
Вы можете временно переименовать таблицу или столбец, дав другое имя, известное как Псевдоним . Псевдонимы таблиц используются для переименования таблицы в конкретном операторе SQL. Переименование является временным изменением, и фактическое имя таблицы не изменяется в базе данных. Псевдонимы столбцов используются для переименования столбцов таблицы с целью конкретного запроса SQL.
Синтаксис
Основной синтаксис псевдонима таблицы заключается в следующем.
SELECT column1, column2.... FROM table_name AS alias_name WHERE [condition];
Основной синтаксис псевдонима столбца заключается в следующем.
SELECT column_name AS alias_name FROM table_name WHERE [condition];
пример
Рассмотрим следующие две таблицы.
Таблица 1 — Таблица клиентов выглядит следующим образом.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Таблица 2 — ЗАКАЗЫ Таблица выглядит следующим образом.
+-----+---------------------+-------------+--------+ |OID | DATE | CUSTOMER_ID | AMOUNT | +-----+---------------------+-------------+--------+ | 102 | 2009-10-08 00:00:00 | 3 | 3000 | | 100 | 2009-10-08 00:00:00 | 3 | 1500 | | 101 | 2009-11-20 00:00:00 | 2 | 1560 | | 103 | 2008-05-20 00:00:00 | 4 | 2060 | +-----+---------------------+-------------+--------+
Теперь следующий блок кода показывает использование псевдонима таблицы .
SQL> SELECT C.ID, C.NAME, C.AGE, O.AMOUNT FROM CUSTOMERS AS C, ORDERS AS O WHERE C.ID = O.CUSTOMER_ID;
Это дало бы следующий результат.
+----+----------+-----+--------+ | ID | NAME | AGE | AMOUNT | +----+----------+-----+--------+ | 3 | kaushik | 23 | 3000 | | 3 | kaushik | 23 | 1500 | | 2 | Khilan | 25 | 1560 | | 4 | Chaitali | 25 | 2060 | +----+----------+-----+--------+
Ниже приведено использование псевдонима столбца .
SQL> SELECT ID AS CUSTOMER_ID, NAME AS CUSTOMER_NAME FROM CUSTOMERS WHERE SALARY IS NOT NULL;
Это дало бы следующий результат.
+-------------+---------------+ | CUSTOMER_ID | CUSTOMER_NAME | +-------------+---------------+ | 1 | Ramesh | | 2 | Khilan | | 3 | kaushik | | 4 | Chaitali | | 5 | Hardik | | 6 | Komal | | 7 | Muffy | +-------------+---------------+
SQL — индексы
Индексы — это специальные таблицы поиска, которые поисковая система базы данных может использовать для ускорения поиска данных. Проще говоря, индекс — это указатель на данные в таблице. Индекс в базе данных очень похож на индекс в конце книги.
Например, если вы хотите сослаться на все страницы в книге, где обсуждается определенная тема, вы сначала обращаетесь к индексу, который перечисляет все темы в алфавитном порядке, а затем ссылается на один или несколько конкретных номеров страниц.
Индекс помогает ускорить запросы SELECT и предложения WHERE , но замедляет ввод данных с помощью операторов UPDATE и INSERT . Индексы могут быть созданы или удалены без влияния на данные.
Создание индекса включает в себя инструкцию CREATE INDEX , которая позволяет указать имя индекса, указать таблицу и столбцы или столбцы для индексации, а также указать, находится ли индекс в порядке возрастания или убывания.
Индексы также могут быть уникальными, как ограничение UNIQUE , в том смысле , что индекс предотвращает дублирование записей в столбце или комбинации столбцов, для которых существует индекс.
Команда CREATE INDEX
Основной синтаксис CREATE INDEX заключается в следующем.
CREATE INDEX index_name ON table_name;
Одноколонные индексы
Индекс из одного столбца создается на основе только одного столбца таблицы. Основной синтаксис выглядит следующим образом.
CREATE INDEX index_name ON table_name (column_name);
Уникальные индексы
Уникальные индексы используются не только для производительности, но и для целостности данных. Уникальный индекс не позволяет вставлять повторяющиеся значения в таблицу. Основной синтаксис выглядит следующим образом.
CREATE UNIQUE INDEX index_name on table_name (column_name);
Композитные индексы
Составной индекс — это индекс двух или более столбцов таблицы. Его основной синтаксис выглядит следующим образом.
CREATE INDEX index_name on table_name (column1, column2);
Независимо от того, хотите ли вы создать индекс из одного столбца или составной индекс, примите во внимание столбцы, которые вы можете использовать очень часто в предложении WHERE запроса в качестве условий фильтра.
Если используется только один столбец, то должен быть выбран индекс из одного столбца. Если в предложении WHERE в качестве фильтров часто используются два или более столбца, наилучшим выбором будет составной индекс.
Неявные индексы
Неявные индексы — это индексы, которые автоматически создаются сервером базы данных при создании объекта. Индексы автоматически создаются для ограничений первичного ключа и уникальных ограничений.
Команда DROP INDEX
Индекс можно удалить с помощью команды SQL DROP . При отбрасывании индекса следует соблюдать осторожность, поскольку производительность может либо замедлиться, либо улучшиться.
Основной синтаксис выглядит следующим образом —
DROP INDEX index_name;
Вы можете проверить главу INDEX Constraint, чтобы увидеть некоторые реальные примеры по индексам.
Когда следует избегать индексов?
Хотя индексы предназначены для повышения производительности базы данных, бывают случаи, когда их следует избегать.
Следующие рекомендации указывают, когда следует пересмотреть использование индекса.
-
Индексы не должны использоваться на маленьких столах.
-
Таблицы с частыми, большими пакетными обновлениями или операциями вставки.
-
Индексы не должны использоваться для столбцов, которые содержат большое количество значений NULL.
-
Столбцы, которыми часто манипулируют, не должны индексироваться.
Индексы не должны использоваться на маленьких столах.
Таблицы с частыми, большими пакетными обновлениями или операциями вставки.
Индексы не должны использоваться для столбцов, которые содержат большое количество значений NULL.
Столбцы, которыми часто манипулируют, не должны индексироваться.
SQL — команда ALTER TABLE
Команда SQL ALTER TABLE используется для добавления, удаления или изменения столбцов в существующей таблице. Вам также следует использовать команду ALTER TABLE для добавления и удаления различных ограничений в существующей таблице.
Синтаксис
Основной синтаксис команды ALTER TABLE для добавления нового столбца в существующую таблицу заключается в следующем.
ALTER TABLE table_name ADD column_name datatype;
Основной синтаксис команды ALTER TABLE для DROP COLUMN в существующей таблице заключается в следующем.
ALTER TABLE table_name DROP COLUMN column_name;
Основной синтаксис команды ALTER TABLE для изменения ТИПА ДАННЫХ столбца в таблице заключается в следующем.
ALTER TABLE table_name MODIFY COLUMN column_name datatype;
Основной синтаксис команды ALTER TABLE для добавления ограничения NOT NULL к столбцу в таблице заключается в следующем.
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
Основной синтаксис ALTER TABLE для ДОБАВЛЕНИЯ УНИКАЛЬНОГО ОГРАНИЧЕНИЯ в таблицу состоит в следующем.
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
Основной синтаксис команды ALTER TABLE для ADD CHECK CONSTRAINT к таблице следующий.
ALTER TABLE table_name ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
Основной синтаксис команды ALTER TABLE для добавления ограничения PRIMARY KEY к таблице заключается в следующем.
ALTER TABLE table_name ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
Основной синтаксис команды ALTER TABLE для DROP CONSTRAINT из таблицы следующий.
ALTER TABLE table_name DROP CONSTRAINT MyUniqueConstraint;
Если вы используете MySQL, код выглядит следующим образом —
ALTER TABLE table_name DROP INDEX MyUniqueConstraint;
Основной синтаксис команды ALTER TABLE для ограничения DROP PRIMARY KEY из таблицы заключается в следующем.
ALTER TABLE table_name DROP CONSTRAINT MyPrimaryKey;
Если вы используете MySQL, код выглядит следующим образом —
ALTER TABLE table_name DROP PRIMARY KEY;
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример добавления нового столбца в существующую таблицу:
ALTER TABLE CUSTOMERS ADD SEX char(1);
Теперь таблица CUSTOMERS изменена, и из оператора SELECT будет выведено следующее.
+----+---------+-----+-----------+----------+------+ | ID | NAME | AGE | ADDRESS | SALARY | SEX | +----+---------+-----+-----------+----------+------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | NULL | | 2 | Ramesh | 25 | Delhi | 1500.00 | NULL | | 3 | kaushik | 23 | Kota | 2000.00 | NULL | | 4 | kaushik | 25 | Mumbai | 6500.00 | NULL | | 5 | Hardik | 27 | Bhopal | 8500.00 | NULL | | 6 | Komal | 22 | MP | 4500.00 | NULL | | 7 | Muffy | 24 | Indore | 10000.00 | NULL | +----+---------+-----+-----------+----------+------+
Ниже приведен пример удаления столбца пола из существующей таблицы.
ALTER TABLE CUSTOMERS DROP SEX;
Теперь таблица CUSTOMERS изменена, и последующим будет вывод из оператора SELECT.
+----+---------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+---------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Ramesh | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | kaushik | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+---------+-----+-----------+----------+
SQL — команда TRUNCATE TABLE
Команда SQL TRUNCATE TABLE используется для удаления полных данных из существующей таблицы.
Вы также можете использовать команду DROP TABLE для удаления полной таблицы, но это приведет к удалению полной структуры таблицы из базы данных, и вам потребуется заново создать эту таблицу, если вы хотите сохранить некоторые данные.
Синтаксис
Основной синтаксис команды TRUNCATE TABLE следующий.
TRUNCATE TABLE table_name;
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример команды Truncate.
SQL > TRUNCATE TABLE CUSTOMERS;
Теперь таблица CUSTOMERS усекается, и результат выполнения инструкции SELECT будет таким, как показано в блоке кода ниже —
SQL> SELECT * FROM CUSTOMERS; Empty set (0.00 sec)
SQL — Использование представлений
Представление — это не что иное, как оператор SQL, который хранится в базе данных со связанным именем. Представление на самом деле представляет собой композицию таблицы в форме предопределенного запроса SQL.
Представление может содержать все строки таблицы или выбирать строки из таблицы. Представление может быть создано из одной или нескольких таблиц, которые зависят от написанного SQL-запроса для создания представления.
Представления, которые являются типом виртуальных таблиц, позволяют пользователям делать следующее:
-
Структурируйте данные так, чтобы пользователи или классы пользователей находили естественные или интуитивно понятные.
-
Ограничьте доступ к данным таким образом, чтобы пользователь мог видеть и (иногда) изменять именно то, что ему нужно, и не более.
-
Суммируйте данные из различных таблиц, которые можно использовать для создания отчетов.
Структурируйте данные так, чтобы пользователи или классы пользователей находили естественные или интуитивно понятные.
Ограничьте доступ к данным таким образом, чтобы пользователь мог видеть и (иногда) изменять именно то, что ему нужно, и не более.
Суммируйте данные из различных таблиц, которые можно использовать для создания отчетов.
Создание видов
Представления базы данных создаются с помощью оператора CREATE VIEW . Представления могут быть созданы из одной таблицы, нескольких таблиц или другого представления.
Чтобы создать представление, пользователь должен иметь соответствующие системные привилегии в соответствии с конкретной реализацией.
Основной синтаксис CREATE VIEW следующий:
CREATE VIEW view_name AS SELECT column1, column2..... FROM table_name WHERE [condition];
Вы можете включить несколько таблиц в свой оператор SELECT таким же образом, как вы используете их в обычном запросе SQL SELECT.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример создания представления из таблицы CUSTOMERS. Это представление будет использоваться для указания имени и возраста клиента из таблицы CUSTOMERS.
SQL > CREATE VIEW CUSTOMERS_VIEW AS SELECT name, age FROM CUSTOMERS;
Теперь вы можете запросить CUSTOMERS_VIEW аналогично запросу реальной таблицы. Ниже приведен пример для того же.
SQL > SELECT * FROM CUSTOMERS_VIEW;
Это дало бы следующий результат.
+----------+-----+ | name | age | +----------+-----+ | Ramesh | 32 | | Khilan | 25 | | kaushik | 23 | | Chaitali | 25 | | Hardik | 27 | | Komal | 22 | | Muffy | 24 | +----------+-----+
С опцией проверки
Параметр WITH CHECK является параметром оператора CREATE VIEW. Целью ВАРИАНТА WITH CHECK является обеспечение того, чтобы все UPDATE и INSERT удовлетворяли условию (ам) в определении представления.
Если они не удовлетворяют условию (ам), UPDATE или INSERT возвращает ошибку.
В следующем блоке кода приведен пример создания того же представления CUSTOMERS_VIEW с опцией WITH CHECK.
CREATE VIEW CUSTOMERS_VIEW AS SELECT name, age FROM CUSTOMERS WHERE age IS NOT NULL WITH CHECK OPTION;
В этом случае опция WITH CHECK должна запрещать ввод любых значений NULL в столбце AGE представления, поскольку представление определяется данными, которые не имеют значения NULL в столбце AGE.
Обновление представления
Представление может быть обновлено при определенных условиях, которые приведены ниже —
-
Предложение SELECT не может содержать ключевое слово DISTINCT.
-
Предложение SELECT может не содержать итоговых функций.
-
Предложение SELECT может не содержать набор функций.
-
Предложение SELECT не может содержать операторы множеств.
-
Предложение SELECT не может содержать предложение ORDER BY.
-
Предложение FROM не может содержать несколько таблиц.
-
Предложение WHERE может не содержать подзапросов.
-
Запрос не может содержать GROUP BY или HAVING.
-
Рассчитанные столбцы могут не обновляться.
-
Все столбцы NOT NULL из базовой таблицы должны быть включены в представление, чтобы выполнялся запрос INSERT.
Предложение SELECT не может содержать ключевое слово DISTINCT.
Предложение SELECT может не содержать итоговых функций.
Предложение SELECT может не содержать набор функций.
Предложение SELECT не может содержать операторы множеств.
Предложение SELECT не может содержать предложение ORDER BY.
Предложение FROM не может содержать несколько таблиц.
Предложение WHERE может не содержать подзапросов.
Запрос не может содержать GROUP BY или HAVING.
Рассчитанные столбцы могут не обновляться.
Все столбцы NOT NULL из базовой таблицы должны быть включены в представление, чтобы выполнялся запрос INSERT.
Таким образом, если представление удовлетворяет всем вышеупомянутым правилам, вы можете обновить это представление. В следующем блоке кода есть пример обновления возраста Рамеша.
SQL > UPDATE CUSTOMERS_VIEW SET AGE = 35 WHERE name = 'Ramesh';
Это в конечном итоге обновит базовую таблицу CUSTOMERS и то же самое отразится на самом представлении. Теперь попробуйте выполнить запрос к базовой таблице, и инструкция SELECT выдаст следующий результат.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 35 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Вставка строк в представление
Ряды данных могут быть вставлены в представление. Те же правила, которые применяются к команде UPDATE, также применимы к команде INSERT.
Здесь мы не можем вставить строки в CUSTOMERS_VIEW, потому что мы не включили все столбцы NOT NULL в это представление, иначе вы можете вставить строки в представление аналогично тому, как вы вставляете их в таблицу.
Удаление строк в виде
Ряды данных могут быть удалены из представления. Те же правила, которые применяются к командам UPDATE и INSERT, применяются к команде DELETE.
Ниже приведен пример удаления записи, имеющей AGE = 22.
SQL > DELETE FROM CUSTOMERS_VIEW WHERE age = 22;
В конечном итоге это приведет к удалению строки из базовой таблицы CUSTOMERS, и это будет отражено в самом представлении. Теперь попробуйте выполнить запрос к базовой таблице, и инструкция SELECT выдаст следующий результат.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 35 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Отбрасывание просмотров
Очевидно, что там, где у вас есть представление, вам нужен способ отбросить представление, если оно больше не требуется. Синтаксис очень прост и приведен ниже —
DROP VIEW view_name;
Ниже приведен пример удаления CUSTOMERS_VIEW из таблицы CUSTOMERS.
DROP VIEW CUSTOMERS_VIEW;
SQL — предложение
Предложение HAVING позволяет вам указать условия, которые фильтруют, какие групповые результаты появляются в результатах.
Предложение WHERE помещает условия в выбранные столбцы, тогда как предложение HAVING помещает условия в группы, созданные предложением GROUP BY.
Синтаксис
Следующий блок кода показывает положение предложения HAVING в запросе.
SELECT FROM WHERE GROUP BY HAVING ORDER BY
Предложение HAVING должно следовать за предложением GROUP BY в запросе и также должно предшествовать предложению ORDER BY, если оно используется. Следующий блок кода имеет синтаксис оператора SELECT, включая предложение HAVING —
SELECT column1, column2 FROM table1, table2 WHERE [ conditions ] GROUP BY column1, column2 HAVING [ conditions ] ORDER BY column1, column2
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который будет отображать запись для аналогичного числа возрастов, которое будет больше или равно 2.
SQL > SELECT ID, NAME, AGE, ADDRESS, SALARY FROM CUSTOMERS GROUP BY age HAVING COUNT(age) >= 2;
Это даст следующий результат —
+ ---- + -------- + ----- + --------- + --------- + | ID | ИМЯ | ВОЗРАСТ | АДРЕС | Заработная плата | + ---- + -------- + ----- + --------- + --------- + | 2 | Хилан | 25 | Дели | 1500,00 | + ---- + -------- + ----- + --------- + --------- +
SQL — транзакции
Транзакция — это единица работы, выполняемая с базой данных. Транзакции — это единицы или последовательности работы, выполняемые в логическом порядке, либо вручную пользователем, либо автоматически какой-либо программой базы данных.
Транзакция — это распространение одного или нескольких изменений в базе данных. Например, если вы создаете или обновляете запись, или удаляете запись из таблицы, вы выполняете транзакцию для этой таблицы. Важно контролировать эти транзакции, чтобы гарантировать целостность данных и обрабатывать ошибки базы данных.
Практически вы объедините множество SQL-запросов в группу и выполните все их вместе как часть транзакции.
Свойства сделок
Транзакции имеют следующие четыре стандартных свойства, на которые обычно ссылается аббревиатура ACID .
-
Атомарность — гарантирует, что все операции внутри рабочего блока успешно завершены. В противном случае транзакция прерывается в точке сбоя, и все предыдущие операции возвращаются в прежнее состояние.
-
Согласованность — гарантирует, что база данных должным образом изменит состояния при успешно совершенной транзакции.
-
Изоляция — позволяет транзакциям работать независимо друг от друга и быть прозрачными друг для друга.
-
Долговечность — обеспечивает сохранение результата или эффекта совершенной транзакции в случае сбоя системы.
Атомарность — гарантирует, что все операции внутри рабочего блока успешно завершены. В противном случае транзакция прерывается в точке сбоя, и все предыдущие операции возвращаются в прежнее состояние.
Согласованность — гарантирует, что база данных должным образом изменит состояния при успешно совершенной транзакции.
Изоляция — позволяет транзакциям работать независимо друг от друга и быть прозрачными друг для друга.
Долговечность — обеспечивает сохранение результата или эффекта совершенной транзакции в случае сбоя системы.
Контроль транзакций
Следующие команды используются для управления транзакциями.
-
COMMIT — сохранить изменения.
-
ROLLBACK — откат изменений.
-
SAVEPOINT — создает точки внутри групп транзакций, в которых выполняется ROLLBACK.
-
SET TRANSACTION — помещает имя в транзакцию.
COMMIT — сохранить изменения.
ROLLBACK — откат изменений.
SAVEPOINT — создает точки внутри групп транзакций, в которых выполняется ROLLBACK.
SET TRANSACTION — помещает имя в транзакцию.
Команды управления транзакциями
Команды управления транзакциями используются только с такими командами DML , как — INSERT, UPDATE и DELETE. Их нельзя использовать при создании таблиц или их удалении, поскольку эти операции автоматически фиксируются в базе данных.
Команда COMMIT
Команда COMMIT — это команда транзакций, используемая для сохранения изменений, вызванных транзакцией, в базу данных.
Команда COMMIT — это команда транзакций, используемая для сохранения изменений, вызванных транзакцией, в базу данных. Команда COMMIT сохраняет все транзакции в базе данных с момента последней команды COMMIT или ROLLBACK.
Синтаксис команды COMMIT следующий.
COMMIT;
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который удаляет те записи из таблицы, которые имеют возраст = 25, а затем фиксирует изменения в базе данных.
SQL> DELETE FROM CUSTOMERS WHERE AGE = 25; SQL> COMMIT;
Таким образом, две строки из таблицы будут удалены, и инструкция SELECT выдаст следующий результат.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Команда ROLLBACK
Команда ROLLBACK — это команда транзакций, используемая для отмены транзакций, которые еще не были сохранены в базе данных. Эта команда может использоваться только для отмены транзакций с момента выполнения последней команды COMMIT или ROLLBACK.
Синтаксис команды ROLLBACK следующий:
ROLLBACK;
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Ниже приведен пример, который удаляет те записи из таблицы, которые имеют возраст = 25, а затем откатывает изменения в базе данных.
SQL> DELETE FROM CUSTOMERS WHERE AGE = 25; SQL> ROLLBACK;
Таким образом, операция удаления не повлияет на таблицу, а оператор SELECT даст следующий результат.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Команда SAVEPOINT
SAVEPOINT — это точка в транзакции, когда вы можете откатить транзакцию до определенной точки без отката всей транзакции.
Синтаксис команды SAVEPOINT показан ниже.
SAVEPOINT SAVEPOINT_NAME;
Эта команда служит только для создания SAVEPOINT среди всех операторов транзакций. Команда ROLLBACK используется для отмены группы транзакций.
Синтаксис для отката к SAVEPOINT показан ниже.
ROLLBACK TO SAVEPOINT_NAME;
Ниже приведен пример, в котором вы планируете удалить три разные записи из таблицы CUSTOMERS. Вы хотите создать SAVEPOINT перед каждым удалением, чтобы вы могли в любой момент выполнить ROLLBACK для любого SAVEPOINT, чтобы вернуть соответствующие данные в исходное состояние.
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий блок кода содержит последовательность операций.
SQL> SAVEPOINT SP1; Savepoint created. SQL> DELETE FROM CUSTOMERS WHERE ID=1; 1 row deleted. SQL> SAVEPOINT SP2; Savepoint created. SQL> DELETE FROM CUSTOMERS WHERE ID=2; 1 row deleted. SQL> SAVEPOINT SP3; Savepoint created. SQL> DELETE FROM CUSTOMERS WHERE ID=3; 1 row deleted.
Теперь, когда три удаления были выполнены, давайте предположим, что вы передумали и решили откатиться к SAVEPOINT, которую вы определили как SP2. Поскольку SP2 был создан после первого удаления, последние два удаления отменены —
SQL> ROLLBACK TO SP2; Rollback complete.
Обратите внимание, что с момента отката до SP2 произошло только первое удаление.
SQL> SELECT * FROM CUSTOMERS; +----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+ 6 rows selected.
Команда RELEASE SAVEPOINT
Команда RELEASE SAVEPOINT используется для удаления созданной вами SAVEPOINT.
Синтаксис команды RELEASE SAVEPOINT выглядит следующим образом.
RELEASE SAVEPOINT SAVEPOINT_NAME;
После освобождения SAVEPOINT вы больше не можете использовать команду ROLLBACK для отмены транзакций, выполненных с момента последнего SAVEPOINT.
Команда SET TRANSACTION
Команда SET TRANSACTION может использоваться для инициирования транзакции базы данных. Эта команда используется для указания признаков для следующей транзакции. Например, вы можете указать транзакцию только для чтения или для чтения и записи.
Синтаксис для команды SET TRANSACTION следующий.
SET TRANSACTION [ READ WRITE | READ ONLY ];
SQL — подстановочные операторы
Мы уже обсуждали оператор SQL LIKE, который используется для сравнения значения с аналогичными значениями с использованием подстановочных операторов.
SQL поддерживает два подстановочных оператора в сочетании с оператором LIKE, которые подробно описаны в следующей таблице.
| Sr.No. | Подстановочный знак и описание |
|---|---|
| 1 |
Знак процента (%) Соответствует одному или нескольким символам. Примечание. MS Access использует подстановочный знак звездочки (*) вместо подстановочного знака процента (%). |
| 2 |
Подчеркивание (_) Соответствует одному символу. Примечание. MS Access использует знак вопроса (?) Вместо подчеркивания (_) для соответствия любому одному символу. |
Знак процента (%)
Соответствует одному или нескольким символам.
Примечание. MS Access использует подстановочный знак звездочки (*) вместо подстановочного знака процента (%).
Подчеркивание (_)
Соответствует одному символу.
Примечание. MS Access использует знак вопроса (?) Вместо подчеркивания (_) для соответствия любому одному символу.
Знак процента представляет собой ноль, один или несколько символов. Подчеркивание представляет собой одно число или символ. Эти символы могут использоваться в комбинациях.
Синтаксис
Основной синтаксис операторов «%» и «_» следующий.
SELECT FROM table_name WHERE column LIKE 'XXXX%' or SELECT FROM table_name WHERE column LIKE '%XXXX%' or SELECT FROM table_name WHERE column LIKE 'XXXX_' or SELECT FROM table_name WHERE column LIKE '_XXXX' or SELECT FROM table_name WHERE column LIKE '_XXXX_'
Вы можете объединить N условий с помощью операторов И или ИЛИ. Здесь XXXX может быть любым числовым или строковым значением.
пример
В следующей таблице приведено несколько примеров, показывающих, что часть WHERE имеет различные предложения LIKE с операторами «%» и «_».
| Sr.No. | Заявление и описание |
|---|---|
| 1 |
Где заработная плата, как «200%» Находит любые значения, которые начинаются с 200. |
| 2 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ «% 200%» Находит любые значения, которые имеют 200 в любой позиции. |
| 3 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_00%’ Находит любые значения, которые имеют 00 во второй и третьей позиции. |
| 4 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘2 _% _%’ Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов. |
| 5 |
ГДЕ НАГРАДНАЯ НРАВИТСЯ ‘% 2’ Находит любые значения, которые заканчиваются на 2. |
| 6 |
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_2% 3’ Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3. |
| 7 |
Где заработная плата, как «2___3» Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3. |
Где заработная плата, как «200%»
Находит любые значения, которые начинаются с 200.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ «% 200%»
Находит любые значения, которые имеют 200 в любой позиции.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_00%’
Находит любые значения, которые имеют 00 во второй и третьей позиции.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘2 _% _%’
Находит любые значения, которые начинаются с 2 и имеют длину не менее 3 символов.
ГДЕ НАГРАДНАЯ НРАВИТСЯ ‘% 2’
Находит любые значения, которые заканчиваются на 2.
ГДЕ НАЛОГОВАЯ НРАВИТСЯ ‘_2% 3’
Находит любые значения, которые имеют 2 во второй позиции и заканчиваются на 3.
Где заработная плата, как «2___3»
Находит любые значения в пятизначном числе, которые начинаются с 2 и заканчиваются на 3.
Давайте возьмем реальный пример, рассмотрим таблицу CUSTOMERS, имеющую следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Следующий блок кода является примером, который будет отображать все записи из таблицы CUSTOMERS, где SALARY начинается с 200.
SQL> SELECT * FROM CUSTOMERS WHERE SALARY LIKE '200%';
Это дало бы следующий результат.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 3 | kaushik | 23 | Kota | 2000.00 | +----+----------+-----+-----------+----------+
SQL — функции даты
В следующей таблице приведен список всех важных функций, связанных с датой и временем, доступных через SQL. Существуют различные другие функции, поддерживаемые вашей СУБД. Данный список основан на СУБД MySQL.
| Sr.No. | Описание функции |
|---|---|
| 1 | ADDDATE ()
Добавляет даты |
| 2 | AddTime ()
Добавляет время |
| 3 | CONVERT_TZ ()
Преобразование из одного часового пояса в другой |
| 4 | CURDATE ()
Возвращает текущую дату |
| 5 | CURRENT_DATE (), CURRENT_DATE
Синонимов для CURDATE () |
| 6 | CURRENT_TIME (), CURRENT_TIME
Синонимов для CURTIME () |
| 7 | CURRENT_TIMESTAMP (), CURRENT_TIMESTAMP
Синонимов для NOW () |
| 8 | CURTIME ()
Возвращает текущее время |
| 9 | DATE_ADD ()
Добавляет две даты |
| 10 | ФОРМАТ ДАТЫ()
Форматирует дату как указано |
| 11 | DATE_SUB ()
Вычитает две даты |
| 12 | ДАТА()
Извлекает часть даты из выражения даты или даты и времени |
| 13 | DATEDIFF ()
Вычитает две даты |
| 14 | ДЕНЬ()
Синоним для DAYOFMONTH () |
| 15 | DAYNAME ()
Возвращает название дня недели |
| 16 | DAYOFMONTH ()
Возвращает день месяца (1-31) |
| 17 | ДЕНЬ НЕДЕЛИ()
Возвращает индекс дня недели для аргумента. |
| 18 | DAYOFYEAR ()
Возвращает день года (1-366) |
| 19 | ВЫПИСКА
Извлекает часть даты |
| 20 | FROM_DAYS ()
Преобразует номер дня в дату |
| 21 | FROM_UNIXTIME ()
Форматирует дату как метку времени UNIX |
| 22 | ЧАС()
Извлекает час |
| 23 | ПОСЛЕДНИЙ ДЕНЬ
Возвращает последний день месяца для аргумента |
| 24 | МЕСТНОЕ ВРЕМЯ (), МЕСТНОЕ ВРЕМЯ
Синоним для СЕЙЧАС () |
| 25 | LOCALTIMESTAMP, LOCALTIMESTAMP ()
Синоним для СЕЙЧАС () |
| 26 | MAKEDATE ()
Создает дату из года и дня года |
| 27 | MAKETIME
MAKETIME () |
| 28 | Микросекунды ()
Возвращает микросекунды от аргумента |
| 29 | МИНУТНЫЙ ()
Возвращает минуту от аргумента |
| 30 | МЕСЯЦ()
Вернуть месяц с даты |
| 31 | MONTHNAME ()
Возвращает название месяца |
| 32 | СЕЙЧАС()
Возвращает текущую дату и время |
| 33 | PERIOD_ADD ()
Добавляет период к году-месяцу |
| 34 | PERIOD_DIFF ()
Возвращает количество месяцев между периодами |
| 35 | КВАРТАЛ ()
Возвращает квартал из аргумента даты |
| 36 | SEC_TO_TIME ()
Преобразует секунды в формат «ЧЧ: ММ: СС». |
| 37 | ВТОРОЙ ()
Возвращает второе (0-59) |
| 38 | STR_TO_DATE ()
Преобразует строку в дату |
| 39 | SUBDATE ()
Когда вызывается с тремя аргументами, синоним DATE_SUB () |
| 40 | SUBTIME ()
Вычитает раз |
| 41 | SYSDATE ()
Возвращает время выполнения функции |
| 42 | TIME_FORMAT ()
Форматы как время |
| 43 | TIME_TO_SEC ()
Возвращает аргумент, преобразованный в секунды |
| 44 | ВРЕМЯ()
Извлекает временную часть переданного выражения |
| 45 | TimeDiff ()
Вычитает время |
| 46 | ТШЕЗТАМР ()
С одним аргументом эта функция возвращает выражение даты или даты и времени. С двумя аргументами, сумма аргументов |
| 47 | TIMESTAMPADD ()
Добавляет интервал к выражению даты и времени |
| 48 | TIMESTAMPDIFF ()
Вычитает интервал из выражения даты и времени |
| 49 | TO_DAYS ()
Возвращает аргумент даты, преобразованный в дни |
| 50 | UNIX_TIMESTAMP ()
Возвращает метку времени UNIX |
| 51 | UTC_DATE ()
Возвращает текущую дату UTC |
| 52 | UTC_TIME ()
Возвращает текущее время UTC |
| 53 | UTC_TIMESTAMP ()
Возвращает текущую дату и время UTC |
| 54 | НЕДЕЛЮ()
Возвращает номер недели |
| 55 | ДЕНЬНЕД ()
Возвращает индекс дня недели |
| 56 | WEEKOFYEAR ()
Возвращает календарную неделю даты (1-53) |
| 57 | ГОД()
Возвращает год |
| 58 | YEARWEEK ()
Возвращает год и неделю |
Добавляет даты
Добавляет время
Преобразование из одного часового пояса в другой
Возвращает текущую дату
Синонимов для CURDATE ()
Синонимов для CURTIME ()
Синонимов для NOW ()
Возвращает текущее время
Добавляет две даты
Форматирует дату как указано
Вычитает две даты
Извлекает часть даты из выражения даты или даты и времени
Вычитает две даты
Синоним для DAYOFMONTH ()
Возвращает название дня недели
Возвращает день месяца (1-31)
Возвращает индекс дня недели для аргумента.
Возвращает день года (1-366)
Извлекает часть даты
Преобразует номер дня в дату
Форматирует дату как метку времени UNIX
Извлекает час
Возвращает последний день месяца для аргумента
Синоним для СЕЙЧАС ()
Синоним для СЕЙЧАС ()
Создает дату из года и дня года
MAKETIME ()
Возвращает микросекунды от аргумента
Возвращает минуту от аргумента
Вернуть месяц с даты
Возвращает название месяца
Возвращает текущую дату и время
Добавляет период к году-месяцу
Возвращает количество месяцев между периодами
Возвращает квартал из аргумента даты
Преобразует секунды в формат «ЧЧ: ММ: СС».
Возвращает второе (0-59)
Преобразует строку в дату
Когда вызывается с тремя аргументами, синоним DATE_SUB ()
Вычитает раз
Возвращает время выполнения функции
Форматы как время
Возвращает аргумент, преобразованный в секунды
Извлекает временную часть переданного выражения
Вычитает время
С одним аргументом эта функция возвращает выражение даты или даты и времени. С двумя аргументами, сумма аргументов
Добавляет интервал к выражению даты и времени
Вычитает интервал из выражения даты и времени
Возвращает аргумент даты, преобразованный в дни
Возвращает метку времени UNIX
Возвращает текущую дату UTC
Возвращает текущее время UTC
Возвращает текущую дату и время UTC
Возвращает номер недели
Возвращает индекс дня недели
Возвращает календарную неделю даты (1-53)
Возвращает год
Возвращает год и неделю
ADDDATE (дата, интервал expr единица измерения), ADDDATE (expr, дни)
Когда вызывается с формой INTERVAL второго аргумента, ADDDATE () является синонимом DATE_ADD (). Связанная функция SUBDATE () является синонимом DATE_SUB (). Для получения информации об аргументе модуля INTERVAL см. Обсуждение DATE_ADD ().
mysql> SELECT DATE_ADD('1998-01-02', INTERVAL 31 DAY); +---------------------------------------------------------+ | DATE_ADD('1998-01-02', INTERVAL 31 DAY) | +---------------------------------------------------------+ | 1998-02-02 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT ADDDATE('1998-01-02', INTERVAL 31 DAY); +---------------------------------------------------------+ | ADDDATE('1998-01-02', INTERVAL 31 DAY) | +---------------------------------------------------------+ | 1998-02-02 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
При вызове с формой days второго аргумента MySQL рассматривает его как целое число дней, которое будет добавлено к expr.
mysql> SELECT ADDDATE('1998-01-02', 31); +---------------------------------------------------------+ | DATE_ADD('1998-01-02', INTERVAL 31 DAY) | +---------------------------------------------------------+ | 1998-02-02 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
AddTime (выражение1, выражение2)
ADDTIME () добавляет expr2 к expr1 и возвращает результат. Expr1 — это выражение времени или даты и времени, а expr2 — выражение времени.
mysql> SELECT ADDTIME('1997-12-31 23:59:59.999999','1 1:1:1.000002'); +---------------------------------------------------------+ | DATE_ADD('1997-12-31 23:59:59.999999','1 1:1:1.000002') | +---------------------------------------------------------+ | 1998-01-02 01:01:01.000001 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
CONVERT_TZ (дт, from_tz, to_tz)
Это преобразует значение datetime dt из часового пояса, заданного from_tz, во часовой пояс, заданный to_tz, и возвращает результирующее значение. Эта функция возвращает NULL, если аргументы неверны.
mysql> SELECT CONVERT_TZ('2004-01-01 12:00:00','GMT','MET'); +---------------------------------------------------------+ | CONVERT_TZ('2004-01-01 12:00:00','GMT','MET') | +---------------------------------------------------------+ | 2004-01-01 13:00:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT CONVERT_TZ('2004-01-01 12:00:00','+00:00','+10:00'); +---------------------------------------------------------+ | CONVERT_TZ('2004-01-01 12:00:00','+00:00','+10:00') | +---------------------------------------------------------+ | 2004-01-01 22:00:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
CURDATE ()
Возвращает текущую дату в виде значения в формате «ГГГГ-ММ-ДД» или ГГГГММДД в зависимости от того, используется ли функция в строке или в числовом контексте.
mysql> SELECT CURDATE(); +---------------------------------------------------------+ | CURDATE() | +---------------------------------------------------------+ | 1997-12-15 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT CURDATE() + 0; +---------------------------------------------------------+ | CURDATE() + 0 | +---------------------------------------------------------+ | 19971215 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
CURRENT_DATE и CURRENT_DATE ()
CURRENT_DATE и CURRENT_DATE () являются синонимами для CURDATE ()
CURTIME ()
Возвращает текущее время в виде значения в формате «ЧЧ: ММ: СС» или ЧЧММСС в зависимости от того, используется ли функция в строке или в числовом контексте. Значение выражается в текущем часовом поясе.
mysql> SELECT CURTIME(); +---------------------------------------------------------+ | CURTIME() | +---------------------------------------------------------+ | 23:50:26 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT CURTIME() + 0; +---------------------------------------------------------+ | CURTIME() + 0 | +---------------------------------------------------------+ | 235026 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
CURRENT_TIME и CURRENT_TIME ()
CURRENT_TIME и CURRENT_TIME () являются синонимами для CURTIME ().
CURRENT_TIMESTAMP и CURRENT_TIMESTAMP ()
CURRENT_TIMESTAMP и CURRENT_TIMESTAMP () являются синонимами для NOW ().
ДАТА (выражение)
Извлекает часть даты из выражения даты или даты и времени.
mysql> SELECT DATE('2003-12-31 01:02:03'); +---------------------------------------------------------+ | DATE('2003-12-31 01:02:03') | +---------------------------------------------------------+ | 2003-12-31 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DATEDIFF (выражение1, выражение2)
DATEDIFF () возвращает expr1. expr2 выражается в виде значений в днях от одной даты к другой. И expr1, и expr2 являются выражениями даты или даты и времени. В расчете используются только части даты значений.
mysql> SELECT DATEDIFF('1997-12-31 23:59:59','1997-12-30'); +---------------------------------------------------------+ | DATEDIFF('1997-12-31 23:59:59','1997-12-30') | +---------------------------------------------------------+ | 1 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DATE_ADD (дата, единица измерения INTERVAL), DATE_SUB (дата, единица измерения INTERVAL)
Эти функции выполняют арифметику даты. Дата является значением DATETIME или DATE, указывающим начальную дату. Expr — это выражение, определяющее значение интервала, которое будет добавлено или вычтено из начальной даты. Expr является строкой; может начинаться с «-» для отрицательных интервалов.
Единица — это ключевое слово, обозначающее единицы, в которых следует интерпретировать выражение.
Ключевое слово INTERVAL и спецификатор единицы не чувствительны к регистру.
В следующей таблице показана ожидаемая форма аргумента expr для каждого значения единицы.
| стоимость единицы | Ожидаемый exprFormat |
|---|---|
| микросекунда | микросекунд |
| ВТОРОЙ | СЕКУНД |
| МИНУТЫ | ПРОТОКОЛ |
| ЧАС | ЧАСЫ |
| ДЕНЬ | ДНИ |
| НЕДЕЛЮ | НЕДЕЛИ |
| МЕСЯЦ | МЕСЯЦЫ |
| КВАРТАЛ | QUARTERS |
| ГОД | ЛЕТ |
| SECOND_MICROSECOND | ‘SECONDS.MICROSECONDS’ |
| MINUTE_MICROSECOND | ‘MINUTES.MICROSECONDS’ |
| MINUTE_SECOND | ‘ПРОТОКОЛ: SECONDS’ |
| HOUR_MICROSECOND | ‘HOURS.MICROSECONDS’ |
| HOUR_SECOND | «ЧАСЫ: Минуты: Секунды» |
| HOUR_MINUTE | «ЧАСЫ: МИНУТЫ» |
| DAY_MICROSECOND | ‘DAYS.MICROSECONDS’ |
| DAY_SECOND | «Дни, часы, минуты, секунды» |
| DAY_MINUTE | «ДНИ ЧАСЫ: МИНУТЫ» |
| DAY_HOUR | «ДЕНЬ ЧАСОВ» |
| ГОД МЕСЯЦ | «лет- МЕСЯЦЕВ» |
Значения QUARTER и WEEK доступны в MySQL 5.0.0. версия.
mysql> SELECT DATE_ADD('1997-12-31 23:59:59', -> INTERVAL '1:1' MINUTE_SECOND); +---------------------------------------------------------+ | DATE_ADD('1997-12-31 23:59:59', INTERVAL... | +---------------------------------------------------------+ | 1998-01-01 00:01:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT DATE_ADD('1999-01-01', INTERVAL 1 HOUR); +---------------------------------------------------------+ | DATE_ADD('1999-01-01', INTERVAL 1 HOUR) | +---------------------------------------------------------+ | 1999-01-01 01:00:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DATE_FORMAT (дата, формат)
Эта команда форматирует значение даты в соответствии со строкой форматирования.
Следующие спецификаторы могут использоваться в строке формата. Символ «%» требуется перед символами спецификатора формата.
| Sr.No. | Спецификатор и описание |
|---|---|
| 1 |
% в Сокращенное название дня недели (вс ..сат) |
| 2 |
% б Сокращенное название месяца (янв .. декабрь) |
| 3 |
% с Месяц, числовой (0..12) |
| 4 |
% D День месяца с английским суффиксом (0, 1, 2, 3,.) |
| 5 |
% d День месяца, числовой (00..31) |
| 6 |
% е День месяца, числовой (0..31) |
| 7 |
% е Микросекунды (000000..999999) |
| 8 |
%ЧАС Час (00..23) |
| 9 |
%час Час (01.12.12) |
| 10 |
%Я Час (01.12.12) |
| 11 |
%я Минуты, числовые (00..59) |
| 12 |
% J День года (001..366) |
| 13 |
% к Час (0..23) |
| 14 |
% л Час (1..12) |
| 15 |
% M Название месяца (январь .. декабрь) |
| 16 |
% м Месяц, числовой (00..12) |
| 17 |
%п До или после полудня |
| 18 |
%р Время, 12 часов (чч: мм: сс, затем AM или PM) |
| 19 |
% S Секунды (00..59) |
| 20 |
% s Секунды (00..59) |
| 21 |
% Т Время, 24 часа (чч: мм: сс) |
| 22 |
% U Неделя (00..53), где воскресенье — первый день недели |
| 23 |
% U Неделя (00..53), где понедельник — первый день недели |
| 24 |
% V Неделя (01..53), где воскресенье — первый день недели; используется с% X |
| 25 |
% v Неделя (01..53), где понедельник — первый день недели; используется с% x |
| 26 |
% W Название дня недели (воскресенье .. суббота) |
| 27 |
% мас День недели (0 = воскресенье. 6 = суббота) |
| 28 |
%ИКС Год недели, где воскресенье — первый день недели, цифра, четыре цифры; используется с% V |
| 29 |
%Икс Год недели, где понедельник — первый день недели, цифра, четыре цифры; используется с% v |
| 30 |
% Y Год, цифра, четыре цифры |
| 31 |
% г Год, числовой (две цифры) |
| 32 |
%% Буквально.%. персонаж |
| 33 |
%Икс х, для любого х. не указано выше |
% в
Сокращенное название дня недели (вс ..сат)
% б
Сокращенное название месяца (янв .. декабрь)
% с
Месяц, числовой (0..12)
% D
День месяца с английским суффиксом (0, 1, 2, 3,.)
% d
День месяца, числовой (00..31)
% е
День месяца, числовой (0..31)
% е
Микросекунды (000000..999999)
%ЧАС
Час (00..23)
%час
Час (01.12.12)
%Я
Час (01.12.12)
%я
Минуты, числовые (00..59)
% J
День года (001..366)
% к
Час (0..23)
% л
Час (1..12)
% M
Название месяца (январь .. декабрь)
% м
Месяц, числовой (00..12)
%п
До или после полудня
%р
Время, 12 часов (чч: мм: сс, затем AM или PM)
% S
Секунды (00..59)
% s
Секунды (00..59)
% Т
Время, 24 часа (чч: мм: сс)
% U
Неделя (00..53), где воскресенье — первый день недели
% U
Неделя (00..53), где понедельник — первый день недели
% V
Неделя (01..53), где воскресенье — первый день недели; используется с% X
% v
Неделя (01..53), где понедельник — первый день недели; используется с% x
% W
Название дня недели (воскресенье .. суббота)
% мас
День недели (0 = воскресенье. 6 = суббота)
%ИКС
Год недели, где воскресенье — первый день недели, цифра, четыре цифры; используется с% V
%Икс
Год недели, где понедельник — первый день недели, цифра, четыре цифры; используется с% v
% Y
Год, цифра, четыре цифры
% г
Год, числовой (две цифры)
%%
Буквально.%. персонаж
%Икс
х, для любого х. не указано выше
mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y'); +---------------------------------------------------------+ | DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y') | +---------------------------------------------------------+ | Saturday October 1997 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00' -> '%H %k %I %r %T %S %w'); +---------------------------------------------------------+ | DATE_FORMAT('1997-10-04 22:23:00....... | +---------------------------------------------------------+ | 22 22 10 10:23:00 PM 22:23:00 00 6 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DATE_SUB (дата, единица измерения INTERVAL)
Это похоже на функцию DATE_ADD ().
ДЕНЬ (дата)
DAY () является синонимом функции DAYOFMONTH ().
DAYNAME (дата)
Возвращает название дня недели для даты.
mysql> SELECT DAYNAME('1998-02-05'); +---------------------------------------------------------+ | DAYNAME('1998-02-05') | +---------------------------------------------------------+ | Thursday | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DAYOFMONTH (дата)
Возвращает день месяца для даты в диапазоне от 0 до 31.
mysql> SELECT DAYOFMONTH('1998-02-03'); +---------------------------------------------------------+ | DAYOFMONTH('1998-02-03') | +---------------------------------------------------------+ | 3 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DAYOFWEEK (дата)
Возвращает индекс дня недели для даты (1 = воскресенье, 2 = понедельник, 7 = суббота). Эти значения индекса соответствуют стандарту ODBC.
mysql> SELECT DAYOFWEEK('1998-02-03'); +---------------------------------------------------------+ |DAYOFWEEK('1998-02-03') | +---------------------------------------------------------+ | 3 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
DAYOFYEAR (дата)
Возвращает день года для даты в диапазоне от 1 до 366.
mysql> SELECT DAYOFYEAR('1998-02-03'); +---------------------------------------------------------+ | DAYOFYEAR('1998-02-03') | +---------------------------------------------------------+ | 34 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
ВЫПИСКА (единица ИЗ ДАТЫ)
Функция EXTRACT () использует те же типы спецификаторов единиц, что и DATE_ADD () или DATE_SUB (), но извлекает части из даты, а не выполняет арифметику даты.
mysql> SELECT EXTRACT(YEAR FROM '1999-07-02'); +---------------------------------------------------------+ | EXTRACT(YEAR FROM '1999-07-02') | +---------------------------------------------------------+ | 1999 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT EXTRACT(YEAR_MONTH FROM '1999-07-02 01:02:03'); +---------------------------------------------------------+ | EXTRACT(YEAR_MONTH FROM '1999-07-02 01:02:03') | +---------------------------------------------------------+ | 199907 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
FROM_DAYS (N)
Учитывая номер дня N, возвращает значение DATE.
mysql> SELECT FROM_DAYS(729669); +---------------------------------------------------------+ | FROM_DAYS(729669) | +---------------------------------------------------------+ | 1997-10-07 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Примечание. Используйте FROM_DAYS () с осторожностью в отношении старых дат. Он не предназначен для использования со значениями, которые предшествуют появлению григорианского календаря (1582).
FROM_UNIXTIME (UNIX_TIMESTAMP)
FROM_UNIXTIME (UNIX_TIMESTAMP, формат)
Возвращает представление аргумента unix_timestamp в виде значения в формате ‘ГГГГ-ММ-ДД ЧЧ: ММ: СС или ГГГГММДДЧЧММСС, в зависимости от того, используется ли функция в строке или в числовом контексте. Значение выражается в текущем часовом поясе. Аргумент unix_timestamp является внутренним значением метки времени, которое создается функцией UNIX_TIMESTAMP () .
Если указан формат, результат форматируется в соответствии со строкой формата, которая используется так же, как указано в записи для функции DATE_FORMAT () .
mysql> SELECT FROM_UNIXTIME(875996580); +---------------------------------------------------------+ | FROM_UNIXTIME(875996580) | +---------------------------------------------------------+ | 1997-10-04 22:23:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
ЧАС (время)
Возвращает час времени. Диапазон возвращаемого значения от 0 до 23 для значений времени дня. Однако диапазон значений TIME на самом деле намного больше, поэтому HOUR может возвращать значения больше 23.
mysql> SELECT HOUR('10:05:03'); +---------------------------------------------------------+ | HOUR('10:05:03') | +---------------------------------------------------------+ | 10 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
LAST_DAY (дата)
Принимает значение даты или даты и времени и возвращает соответствующее значение для последнего дня месяца. Возвращает NULL, если аргумент неверен.
mysql> SELECT LAST_DAY('2003-02-05'); +---------------------------------------------------------+ | LAST_DAY('2003-02-05') | +---------------------------------------------------------+ | 2003-02-28 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
МЕСТНОЕ ВРЕМЯ и МЕСТНОЕ ВРЕМЯ ()
LOCALTIME и LOCALTIME () являются синонимами для NOW ().
LOCALTIMESTAMP и LOCALTIMESTAMP ()
LOCALTIMESTAMP и LOCALTIMESTAMP () являются синонимами для NOW ().
MAKEDATE (год, DayOfYear)
Возвращает дату, данные года и значения дня в году. Значение dayofyear должно быть больше 0, иначе результат будет NULL.
mysql> SELECT MAKEDATE(2001,31), MAKEDATE(2001,32); +---------------------------------------------------------+ | MAKEDATE(2001,31), MAKEDATE(2001,32) | +---------------------------------------------------------+ | '2001-01-31', '2001-02-01' | +---------------------------------------------------------+ 1 row in set (0.00 sec)
MAKETIME (час, минута, секунда)
Возвращает значение времени, вычисленное из аргументов часа, минуты и секунды.
mysql> SELECT MAKETIME(12,15,30); +---------------------------------------------------------+ | MAKETIME(12,15,30) | +---------------------------------------------------------+ | '12:15:30' | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Микросекунды (выражение)
Возвращает микросекунды из выражения времени или даты и времени (expr) в виде числа в диапазоне от 0 до 999999.
mysql> SELECT MICROSECOND('12:00:00.123456'); +---------------------------------------------------------+ | MICROSECOND('12:00:00.123456') | +---------------------------------------------------------+ | 123456 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
МИНУТЫ (время)
Возвращает минуты для времени в диапазоне от 0 до 59.
mysql> SELECT MINUTE('98-02-03 10:05:03'); +---------------------------------------------------------+ | MINUTE('98-02-03 10:05:03') | +---------------------------------------------------------+ | 5 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
МЕСЯЦ (дата)
Возвращает месяц для даты в диапазоне от 0 до 12.
mysql> SELECT MONTH('1998-02-03') +---------------------------------------------------------+ | MONTH('1998-02-03') | +---------------------------------------------------------+ | 2 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
MONTHNAME (дата)
Возвращает полное название месяца для даты.
mysql> SELECT MONTHNAME('1998-02-05'); +---------------------------------------------------------+ | MONTHNAME('1998-02-05') | +---------------------------------------------------------+ | February | +---------------------------------------------------------+ 1 row in set (0.00 sec)
СЕЙЧАС()
Возвращает текущую дату и время в виде значения в формате «ГГГГ-ММ-ДД ЧЧ: ММ: СС» или ГГГГММДДЧЧММСС в зависимости от того, используется ли функция в строковом или числовом контексте. Это значение выражено в текущем часовом поясе.
mysql> SELECT NOW(); +---------------------------------------------------------+ | NOW() | +---------------------------------------------------------+ | 1997-12-15 23:50:26 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
PERIOD_ADD (P, N)
Добавляет N месяцев к периоду P (в формате ГГММ или ГГГГММ). Возвращает значение в формате ГГГГММ. Обратите внимание, что аргумент периода P не является значением даты.
mysql> SELECT PERIOD_ADD(9801,2); +---------------------------------------------------------+ | PERIOD_ADD(9801,2) | +---------------------------------------------------------+ | 199803 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
PERIOD_DIFF (Р1, Р2)
Возвращает количество месяцев между периодами P1 и P2. Эти периоды P1 и P2 должны быть в формате ГГММ или ГГГГММ. Обратите внимание, что аргументы периода P1 и P2 не являются значениями даты.
mysql> SELECT PERIOD_DIFF(9802,199703); +---------------------------------------------------------+ | PERIOD_DIFF(9802,199703) | +---------------------------------------------------------+ | 11 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
КВАРТАЛ (дата)
Возвращает квартал года для даты в диапазоне от 1 до 4.
mysql> SELECT QUARTER('98-04-01'); +---------------------------------------------------------+ | QUARTER('98-04-01') | +---------------------------------------------------------+ | 2 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Второй раз)
Возвращает секунду для времени в диапазоне от 0 до 59.
mysql> SELECT SECOND('10:05:03'); +---------------------------------------------------------+ | SECOND('10:05:03') | +---------------------------------------------------------+ | 3 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
SEC_TO_TIME (в секундах)
Возвращает аргумент секунд, преобразованный в часы, минуты и секунды, в виде значения в формате «ЧЧ: ММ: СС» или ЧЧММСС в зависимости от того, используется ли функция в строковом или числовом контексте.
mysql> SELECT SEC_TO_TIME(2378); +---------------------------------------------------------+ | SEC_TO_TIME(2378) | +---------------------------------------------------------+ | 00:39:38 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
STR_TO_DATE (ул, формат)
Это обратная функция DATE_FORMAT (). Требуется строка str и формат строки формата. Функция STR_TO_DATE () возвращает значение DATETIME, если строка формата содержит части даты и времени. Иначе, он возвращает значение DATE или TIME, если строка содержит только части даты или времени.
mysql> SELECT STR_TO_DATE('04/31/2004', '%m/%d/%Y'); +---------------------------------------------------------+ | STR_TO_DATE('04/31/2004', '%m/%d/%Y') | +---------------------------------------------------------+ | 2004-04-31 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
SUBDATE (дата, интервал expr) и SUBDATE (expr, дни)
Когда вызывается с формой INTERVAL второго аргумента, SUBDATE () является синонимом DATE_SUB (). Для получения информации об аргументе модуля INTERVAL см. Обсуждение DATE_ADD ().
mysql> SELECT DATE_SUB('1998-01-02', INTERVAL 31 DAY); +---------------------------------------------------------+ | DATE_SUB('1998-01-02', INTERVAL 31 DAY) | +---------------------------------------------------------+ | 1997-12-02 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT SUBDATE('1998-01-02', INTERVAL 31 DAY); +---------------------------------------------------------+ | SUBDATE('1998-01-02', INTERVAL 31 DAY) | +---------------------------------------------------------+ | 1997-12-02 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
SUBTIME (выражение1, выражение2)
Функция SUBTIME () возвращает expr1. expr2 выражается как значение в том же формате, что и expr1. Значение expr1 является выражением времени или даты и времени, а значение expr2 является выражением времени.
mysql> SELECT SUBTIME('1997-12-31 23:59:59.999999', -> '1 1:1:1.000002'); +---------------------------------------------------------+ | SUBTIME('1997-12-31 23:59:59.999999'... | +---------------------------------------------------------+ | 1997-12-30 22:58:58.999997 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
SYSDATE ()
Возвращает текущую дату и время в виде значения в формате «ГГГГ-ММ-ДД ЧЧ: ММ: СС» или ГГГГММДДЧЧММСС в зависимости от того, используется ли функция в строке или в числовом контексте.
mysql> SELECT SYSDATE(); +---------------------------------------------------------+ | SYSDATE() | +---------------------------------------------------------+ | 2006-04-12 13:47:44 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIME (выражение)
Извлекает часть времени из выражения времени или даты и времени и возвращает его в виде строки.
mysql> SELECT TIME('2003-12-31 01:02:03'); +---------------------------------------------------------+ | TIME('2003-12-31 01:02:03') | +---------------------------------------------------------+ | 01:02:03 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TimeDiff (выражение1, выражение2)
Функция TIMEDIFF () возвращает expr1. expr2 выражается как значение времени. Эти значения expr1 и expr2 являются выражениями времени или даты и времени, но оба должны быть одного типа.
mysql> SELECT TIMEDIFF('1997-12-31 23:59:59.000001', -> '1997-12-30 01:01:01.000002'); +---------------------------------------------------------+ | TIMEDIFF('1997-12-31 23:59:59.000001'..... | +---------------------------------------------------------+ | 46:58:57.999999 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIMESTAMP (expr), TIMESTAMP (expr1, expr2)
С одним аргументом эта функция возвращает выражение даты или выражения даты и времени в качестве значения даты и времени. С двумя аргументами он добавляет выражение времени expr2 к выражению даты или даты и времени expr1 и возвращает результат в виде значения даты и времени.
mysql> SELECT TIMESTAMP('2003-12-31'); +---------------------------------------------------------+ | TIMESTAMP('2003-12-31') | +---------------------------------------------------------+ | 2003-12-31 00:00:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIMESTAMPADD (единица измерения, интервал, datetime_expr)
Эта функция добавляет интервал целочисленного выражения к выражению даты или даты и времени datetime_expr . Единица для интервала задается аргументом unit, который должен принимать одно из следующих значений:
- FRAC_SECOND
- ВТОРАЯ, МИНУТА
- ЧАС, ДЕНЬ
- НЕДЕЛЮ
- МЕСЯЦ
- КВАРТАЛ или
- ГОД
Значение единицы может быть указано с использованием одного из ключевых слов, как показано, или с префиксом SQL_TSI_.
Например, DAY и SQL_TSI_DAY допустимы.
mysql> SELECT TIMESTAMPADD(MINUTE,1,'2003-01-02'); +---------------------------------------------------------+ | TIMESTAMPADD(MINUTE,1,'2003-01-02') | +---------------------------------------------------------+ | 2003-01-02 00:01:00 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIMESTAMPDIFF (единица измерения, datetime_expr1, datetime_expr2)
Возвращает целочисленную разницу между выражениями date или datetime datetime_expr1 и datetime_expr2. Единица для результата задается аргументом единицы. Допустимые значения для единицы те же, что указаны в описании функции TIMESTAMPADD ().
mysql> SELECT TIMESTAMPDIFF(MONTH,'2003-02-01','2003-05-01'); +---------------------------------------------------------+ | TIMESTAMPDIFF(MONTH,'2003-02-01','2003-05-01') | +---------------------------------------------------------+ | 3 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIME_FORMAT (время, формат)
Эта функция используется как функция DATE_FORMAT (), но строка формата может содержать спецификаторы формата только для часов, минут и секунд.
Если значение времени содержит часть часа, которая больше 23, спецификаторы формата% H и% k часа выдают значение, превышающее обычный диапазон от 0 до 23. Другие спецификаторы формата часа создают значение часа по модулю 12.
mysql> SELECT TIME_FORMAT('100:00:00', '%H %k %h %I %l'); +---------------------------------------------------------+ | TIME_FORMAT('100:00:00', '%H %k %h %I %l') | +---------------------------------------------------------+ | 100 100 04 04 4 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
TIME_TO_SEC (время)
Возвращает аргумент времени, преобразованный в секунды.
mysql> SELECT TIME_TO_SEC('22:23:00'); +---------------------------------------------------------+ | TIME_TO_SEC('22:23:00') | +---------------------------------------------------------+ | 80580 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Сегодняшняя дата)
При заданной дате возвращает номер дня (количество дней с года 0).
mysql> SELECT TO_DAYS(950501); +---------------------------------------------------------+ | TO_DAYS(950501) | +---------------------------------------------------------+ | 728779 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
UNIX_TIMESTAMP (), UNIX_TIMESTAMP (дата)
Если вызывается без аргумента, эта функция возвращает метку времени Unix (секунды с UTC 1970-01-01 00:00:00) в виде целого числа без знака. Если UNIX_TIMESTAMP () вызывается с аргументом даты, он возвращает значение аргумента в секундах с UTC 1970-01-01 00:00:00. date может быть строкой DATE, строкой DATETIME, TIMESTAMP или числом в формате YYMMDD или YYYYMMDD.
mysql> SELECT UNIX_TIMESTAMP(); +---------------------------------------------------------+ | UNIX_TIMESTAMP() | +---------------------------------------------------------+ | 882226357 | +---------------------------------------------------------+ 1 row in set (0.00 sec) mysql> SELECT UNIX_TIMESTAMP('1997-10-04 22:23:00'); +---------------------------------------------------------+ | UNIX_TIMESTAMP('1997-10-04 22:23:00') | +---------------------------------------------------------+ | 875996580 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
UTC_DATE, UTC_DATE ()
Возвращает текущую дату UTC в виде значения в формате «ГГГГ-ММ-ДД» или ГГГГММДД в зависимости от того, используется ли функция в строковом или числовом контексте.
mysql> SELECT UTC_DATE(), UTC_DATE() + 0; +---------------------------------------------------------+ | UTC_DATE(), UTC_DATE() + 0 | +---------------------------------------------------------+ | 2003-08-14, 20030814 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
UTC_TIME, UTC_TIME ()
Возвращает текущее время UTC в виде значения в формате «ЧЧ: ММ: СС» или ЧЧММСС в зависимости от того, используется ли функция в строковом или числовом контексте.
mysql> SELECT UTC_TIME(), UTC_TIME() + 0; +---------------------------------------------------------+ | UTC_TIME(), UTC_TIME() + 0 | +---------------------------------------------------------+ | 18:07:53, 180753 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
UTC_TIMESTAMP, UTC_TIMESTAMP ()
Возвращает текущую дату и время UTC в виде значения в формате «ГГГГ-ММ-ДД ЧЧ: ММ: СС» или в формате ГГГГММДДЧЧММСС в зависимости от того, используется ли функция в строке или в числовом контексте.
mysql> SELECT UTC_TIMESTAMP(), UTC_TIMESTAMP() + 0; +---------------------------------------------------------+ | UTC_TIMESTAMP(), UTC_TIMESTAMP() + 0 | +---------------------------------------------------------+ | 2003-08-14 18:08:04, 20030814180804 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Неделя (дата [, режим])
Эта функция возвращает номер недели для даты. Форма WEEK () с двумя аргументами позволяет вам указать, начинается ли неделя в воскресенье или в понедельник и должно ли возвращаемое значение находиться в диапазоне от 0 до 53 или от 1 до 53. Если аргумент mode пропущен, используется значение системной переменной default_week_format
| Режим | Первый день недели | Спектр | 1-я неделя первая неделя. |
|---|---|---|---|
| 0 | Воскресенье | 0-53 | с воскресеньем в этом году |
| 1 | понедельник | 0-53 | с более чем 3 днями в этом году |
| 2 | Воскресенье | 1-53 | с воскресеньем в этом году |
| 3 | понедельник | 1-53 | с более чем 3 днями в этом году |
| 4 | Воскресенье | 0-53 | с более чем 3 днями в этом году |
| 5 | понедельник | 0-53 | с понедельника в этом году |
| 6 | Воскресенье | 1-53 | с более чем 3 днями в этом году |
| 7 | понедельник | 1-53 | с понедельника в этом году |
mysql> SELECT WEEK('1998-02-20'); +---------------------------------------------------------+ | WEEK('1998-02-20') | +---------------------------------------------------------+ | 7 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
WEEKDAY (дата)
Возвращает индекс дня недели для даты (0 = понедельник, 1 = вторник, 6 = воскресенье).
mysql> SELECT WEEKDAY('1998-02-03 22:23:00'); +---------------------------------------------------------+ | WEEKDAY('1998-02-03 22:23:00') | +---------------------------------------------------------+ | 1 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
WEEKOFYEAR (дата)
Возвращает календарную неделю даты в виде числа в диапазоне от 1 до 53. WEEKOFYEAR () — это функция совместимости, эквивалентная WEEK (дата, 3).
mysql> SELECT WEEKOFYEAR('1998-02-20'); +---------------------------------------------------------+ | WEEKOFYEAR('1998-02-20') | +---------------------------------------------------------+ | 8 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
YEAR (дата)
Возвращает год для даты в диапазоне от 1000 до 9999 или 0 для нуля. Дата.
mysql> SELECT YEAR('98-02-03'); +---------------------------------------------------------+ | YEAR('98-02-03') | +---------------------------------------------------------+ | 1998 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
YEARWEEK (дата), YEARWEEK (дата, режим)
Возвращает год и неделю для даты. Аргумент mode работает точно так же, как аргумент mode функции WEEK (). Год в результате может отличаться от года в аргументе даты для первой и последней недели года.
mysql> SELECT YEARWEEK('1987-01-01'); +---------------------------------------------------------+ | YEAR('98-02-03')YEARWEEK('1987-01-01') | +---------------------------------------------------------+ | 198653 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
Примечание. Номер недели отличается от того, что функция WEEK () будет возвращать (0) для необязательных аргументов 0 или 1, поскольку WEEK () затем возвращает неделю в контексте заданного года.
SQL — временные таблицы
Что такое временные таблицы?
Есть RDBMS, которые поддерживают временные таблицы. Временные таблицы — это отличная функция, которая позволяет хранить и обрабатывать промежуточные результаты , используя те же возможности выбора, обновления и объединения, которые можно использовать с типичными таблицами SQL Server.
Временные таблицы могут быть очень полезны в некоторых случаях для хранения временных данных. Самая важная вещь, которая должна быть известна для временных таблиц, — то, что они будут удалены, когда текущий сеанс клиента завершается.
Временные таблицы доступны в версии MySQL 3.23 и далее. Если вы используете более старую версию MySQL, чем 3.23, вы не можете использовать временные таблицы, но вы можете использовать таблицы кучи .
Как указывалось ранее, временные таблицы будут длиться только до тех пор, пока сеанс жив. Если вы запустите код в сценарии PHP, временная таблица будет автоматически уничтожена, когда сценарий завершит выполнение. Если вы подключены к серверу базы данных MySQL через клиентскую программу MySQL, временная таблица будет существовать до тех пор, пока вы не закроете клиент или не уничтожите таблицу вручную.
пример
Вот пример, показывающий использование временной таблицы.
mysql> CREATE TEMPORARY TABLE SALESSUMMARY ( -> product_name VARCHAR(50) NOT NULL -> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00 -> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00 -> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0 ); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO SALESSUMMARY -> (product_name, total_sales, avg_unit_price, total_units_sold) -> VALUES -> ('cucumber', 100.25, 90, 2); mysql> SELECT * FROM SALESSUMMARY; +--------------+-------------+----------------+------------------+ | product_name | total_sales | avg_unit_price | total_units_sold | +--------------+-------------+----------------+------------------+ | cucumber | 100.25 | 90.00 | 2 | +--------------+-------------+----------------+------------------+ 1 row in set (0.00 sec)
Когда вы вводите команду SHOW TABLES, ваша временная таблица не будет указана в списке. Теперь, если вы выйдете из сеанса MySQL, а затем введете команду SELECT, в базе данных не будет доступных данных. Даже ваша временная таблица не будет существовать.
Удаление временных таблиц
По умолчанию все временные таблицы удаляются MySQL при разрыве соединения с базой данных. Тем не менее, если вы хотите удалить их между ними, вы можете сделать это, введя команду DROP TABLE .
Ниже приведен пример удаления временной таблицы.
mysql> CREATE TEMPORARY TABLE SALESSUMMARY ( -> product_name VARCHAR(50) NOT NULL -> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00 -> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00 -> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0 ); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO SALESSUMMARY -> (product_name, total_sales, avg_unit_price, total_units_sold) -> VALUES -> ('cucumber', 100.25, 90, 2); mysql> SELECT * FROM SALESSUMMARY; +--------------+-------------+----------------+------------------+ | product_name | total_sales | avg_unit_price | total_units_sold | +--------------+-------------+----------------+------------------+ | cucumber | 100.25 | 90.00 | 2 | +--------------+-------------+----------------+------------------+ 1 row in set (0.00 sec) mysql> DROP TABLE SALESSUMMARY; mysql> SELECT * FROM SALESSUMMARY; ERROR 1146: Table 'TUTORIALS.SALESSUMMARY' doesn't exist
SQL — таблицы клонов
Может возникнуть ситуация, когда вам нужна точная копия таблицы, а команды CREATE TABLE … или SELECT … не соответствуют вашим целям, поскольку копия должна содержать те же индексы, значения по умолчанию и т. Д.
Если вы используете СУБД MySQL, вы можете справиться с этой ситуацией, следуя приведенным ниже шагам —
-
Используйте команду SHOW CREATE TABLE, чтобы получить инструкцию CREATE TABLE, которая определяет структуру исходной таблицы, индексы и все.
-
Измените оператор, чтобы изменить имя таблицы на имя таблицы клонов, и выполните оператор. Таким образом, у вас будет точная таблица клонов.
-
По желанию, если вам также необходимо скопировать содержимое таблицы, введите оператор INSERT INTO или SELECT.
Используйте команду SHOW CREATE TABLE, чтобы получить инструкцию CREATE TABLE, которая определяет структуру исходной таблицы, индексы и все.
Измените оператор, чтобы изменить имя таблицы на имя таблицы клонов, и выполните оператор. Таким образом, у вас будет точная таблица клонов.
По желанию, если вам также необходимо скопировать содержимое таблицы, введите оператор INSERT INTO или SELECT.
пример
Попробуйте следующий пример, чтобы создать таблицу клонов для TUTORIALS_TBL , структура которой выглядит следующим образом:
Шаг 1 — Получить полную структуру таблицы.
SQL> SHOW CREATE TABLE TUTORIALS_TBL \G; *************************** 1. row *************************** Table: TUTORIALS_TBL Create Table: CREATE TABLE 'TUTORIALS_TBL' ( 'tutorial_id' int(11) NOT NULL auto_increment, 'tutorial_title' varchar(100) NOT NULL default '', 'tutorial_author' varchar(40) NOT NULL default '', 'submission_date' date default NULL, PRIMARY KEY ('tutorial_id'), UNIQUE KEY 'AUTHOR_INDEX' ('tutorial_author') ) TYPE = MyISAM 1 row in set (0.00 sec)
Шаг 2 — Переименуйте эту таблицу и создайте другую таблицу.
SQL> CREATE TABLE `CLONE_TBL` ( -> 'tutorial_id' int(11) NOT NULL auto_increment, -> 'tutorial_title' varchar(100) NOT NULL default '', -> 'tutorial_author' varchar(40) NOT NULL default '', -> 'submission_date' date default NULL, -> PRIMARY KEY (`tutorial_id'), -> UNIQUE KEY 'AUTHOR_INDEX' ('tutorial_author') -> ) TYPE = MyISAM; Query OK, 0 rows affected (1.80 sec)
Шаг 3 — После выполнения шага 2 вы будете клонировать таблицу в своей базе данных. Если вы хотите скопировать данные из старой таблицы, вы можете сделать это с помощью оператора INSERT INTO … SELECT.
SQL> INSERT INTO CLONE_TBL (tutorial_id, -> tutorial_title, -> tutorial_author, -> submission_date) -> SELECT tutorial_id,tutorial_title, -> tutorial_author,submission_date, -> FROM TUTORIALS_TBL; Query OK, 3 rows affected (0.07 sec) Records: 3 Duplicates: 0 Warnings: 0
Наконец, у вас будет точная таблица клонов, как вы и хотели.
SQL — подзапросы
Подзапрос, Внутренний запрос или Вложенный запрос — это запрос в другом запросе SQL, который встроен в предложение WHERE.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе в качестве условия для дальнейшего ограничения данных, подлежащих извлечению.
Подзапросы могут использоваться с операторами SELECT, INSERT, UPDATE и DELETE вместе с такими операторами, как =, <,>,> =, <=, IN, BETWEEN и т. Д.
Есть несколько правил, которым должны следовать подзапросы —
-
Подзапросы должны быть заключены в круглые скобки.
-
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
-
Команда ORDER BY не может использоваться в подзапросе, хотя основной запрос может использовать ORDER BY. Команда GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
-
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
-
Список SELECT не может содержать ссылки на значения, которые оцениваются как BLOB, ARRAY, CLOB или NCLOB.
-
Подзапрос не может быть сразу заключен в функцию набора.
-
Оператор BETWEEN нельзя использовать с подзапросом. Тем не менее, оператор BETWEEN может использоваться внутри подзапроса.
Подзапросы должны быть заключены в круглые скобки.
У подзапроса может быть только один столбец в предложении SELECT, если в основном запросе нет нескольких столбцов для подзапроса для сравнения его выбранных столбцов.
Команда ORDER BY не может использоваться в подзапросе, хотя основной запрос может использовать ORDER BY. Команда GROUP BY может использоваться для выполнения той же функции, что и ORDER BY в подзапросе.
Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
Список SELECT не может содержать ссылки на значения, которые оцениваются как BLOB, ARRAY, CLOB или NCLOB.
Подзапрос не может быть сразу заключен в функцию набора.
Оператор BETWEEN нельзя использовать с подзапросом. Тем не менее, оператор BETWEEN может использоваться внутри подзапроса.
Подзапросы с оператором SELECT
Подзапросы чаще всего используются с оператором SELECT. Основной синтаксис выглядит следующим образом —
SELECT column_name [, column_name ] FROM table1 [, table2 ] WHERE column_name OPERATOR (SELECT column_name [, column_name ] FROM table1 [, table2 ] [WHERE])
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи:
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 35 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Теперь давайте проверим следующий подзапрос с помощью инструкции SELECT.
SQL> SELECT * FROM CUSTOMERS WHERE ID IN (SELECT ID FROM CUSTOMERS WHERE SALARY > 4500) ;
Это дало бы следующий результат.
+----+----------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+----------+ | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+---------+----------+
Подзапросы с оператором INSERT
Подзапросы также могут использоваться с операторами INSERT. Оператор INSERT использует данные, возвращенные из подзапроса, для вставки в другую таблицу. Выбранные данные в подзапросе могут быть изменены с помощью любой символьной, даты или числовой функции.
Основной синтаксис выглядит следующим образом.
INSERT INTO table_name [ (column1 [, column2 ]) ] SELECT [ *|column1 [, column2 ] FROM table1 [, table2 ] [ WHERE VALUE OPERATOR ]
пример
Рассмотрим таблицу CUSTOMERS_BKP с такой же структурой, что и таблица CUSTOMERS. Теперь, чтобы скопировать полную таблицу CUSTOMERS в таблицу CUSTOMERS_BKP, вы можете использовать следующий синтаксис.
SQL> INSERT INTO CUSTOMERS_BKP SELECT * FROM CUSTOMERS WHERE ID IN (SELECT ID FROM CUSTOMERS) ;
Подзапросы с оператором UPDATE
Подзапрос может использоваться вместе с оператором UPDATE. Можно использовать один или несколько столбцов в таблице при использовании подзапроса с оператором UPDATE.
Основной синтаксис выглядит следующим образом.
UPDATE table SET column_name = new_value [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
пример
Предполагая, что у нас есть таблица CUSTOMERS_BKP, которая является резервной копией таблицы CUSTOMERS. В следующем примере значение SALARY обновляется в таблице CUSTOMERS в 0,25 раза для всех клиентов, возраст которых больше или равен 27.
SQL> UPDATE CUSTOMERS SET SALARY = SALARY * 0.25 WHERE AGE IN (SELECT AGE FROM CUSTOMERS_BKP WHERE AGE >= 27 );
Это повлияет на две строки, и, наконец, таблица CUSTOMERS будет иметь следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 35 | Ahmedabad | 125.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 2125.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Подзапросы с оператором DELETE
Подзапрос может использоваться вместе с оператором DELETE, как и любые другие операторы, упомянутые выше.
Основной синтаксис выглядит следующим образом.
DELETE FROM TABLE_NAME [ WHERE OPERATOR [ VALUE ] (SELECT COLUMN_NAME FROM TABLE_NAME) [ WHERE) ]
пример
Предполагая, что у нас есть таблица CUSTOMERS_BKP, которая является резервной копией таблицы CUSTOMERS. В следующем примере удаляются записи из таблицы CUSTOMERS для всех клиентов, возраст которых больше или равен 27.
SQL> DELETE FROM CUSTOMERS WHERE AGE IN (SELECT AGE FROM CUSTOMERS_BKP WHERE AGE >= 27 );
Это повлияет на две строки, и, наконец, таблица CUSTOMERS будет иметь следующие записи.
+----+----------+-----+---------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+---------+----------+ | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+---------+----------+
SQL — Использование последовательностей
Последовательность — это набор целых чисел 1, 2, 3, …, которые генерируются в порядке по требованию. Последовательности часто используются в базах данных, поскольку многие приложения требуют, чтобы каждая строка в таблице содержала уникальное значение, а последовательности обеспечивают простой способ их создания.
Эта глава описывает, как использовать последовательности в MySQL.
Использование столбца AUTO_INCREMENT
Самый простой способ использования последовательностей в MySQL — это определить столбец как AUTO_INCREMENT, а остальное оставить для MySQL.
пример
Попробуйте следующий пример. Это создаст таблицу, и после этого он вставит несколько строк в эту таблицу, где не требуется указывать идентификатор записи, поскольку она автоматически увеличивается с помощью MySQL.
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected ); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO INSECT (id,name,date,origin) VALUES -> (NULL,'housefly','2001-09-10','kitchen'), -> (NULL,'millipede','2001-09-10','driveway'), -> (NULL,'grasshopper','2001-09-10','front yard'); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM INSECT ORDER BY id; +----+-------------+------------+------------+ | id | name | date | origin | +----+-------------+------------+------------+ | 1 | housefly | 2001-09-10 | kitchen | | 2 | millipede | 2001-09-10 | driveway | | 3 | grasshopper | 2001-09-10 | front yard | +----+-------------+------------+------------+ 3 rows in set (0.00 sec)
Получить значения AUTO_INCREMENT
LAST_INSERT_ID () — это функция SQL, поэтому вы можете использовать ее из любого клиента, который понимает, как выдавать операторы SQL. В противном случае сценарии PERL и PHP предоставляют эксклюзивные функции для извлечения автоматически увеличенного значения последней записи.
Пример PERL
Используйте атрибут mysql_insertid для получения значения AUTO_INCREMENT, сгенерированного запросом. Этот атрибут доступен через дескриптор базы данных или дескриптор оператора, в зависимости от того, как вы выполняете запрос. Следующий пример ссылается на него через дескриптор базы данных.
$dbh->do ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')"); my $seq = $dbh->{mysql_insertid};
Пример PHP
После выдачи запроса, который генерирует значение AUTO_INCREMENT, получите это значение, вызвав функцию mysql_insert_id () .
mysql_query ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')", $conn_id); $seq = mysql_insert_id ($conn_id);
Изменение нумерации существующей последовательности
Возможен случай, когда вы удалили много записей из таблицы и хотите повторно упорядочить все записи. Это можно сделать с помощью простого трюка, но вы должны быть очень осторожны, чтобы проверить, есть ли у вашей таблицы соединение с другой таблицей или нет.
Если вы решите, что повторное упорядочение столбца AUTO_INCREMENT является неизбежным, способ сделать это — удалить столбец из таблицы, а затем добавить его снова.
В следующем примере показано, как изменить нумерацию значений идентификатора в таблице насекомых с помощью этого метода.
mysql> ALTER TABLE INSECT DROP id; mysql> ALTER TABLE insect -> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST, -> ADD PRIMARY KEY (id);
Начало последовательности по определенному значению
По умолчанию MySQL запускает последовательность с 1, но вы также можете указать любой другой номер во время создания таблицы.
В следующем блоке кода есть пример, где MySQL начнет последовательность с 100.
mysql> CREATE TABLE INSECT -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected );
Кроме того, вы можете создать таблицу, а затем установить начальное значение последовательности с помощью ALTER TABLE.
mysql> ALTER TABLE t AUTO_INCREMENT = 100;
SQL — обработка дубликатов
Может возникнуть ситуация, когда в таблице несколько повторяющихся записей. При получении таких записей имеет смысл выбирать только уникальные записи, а не дублировать записи.
Ключевое слово SQL DISTINCT , которое мы уже обсуждали, используется вместе с оператором SELECT, чтобы исключить все дублирующиеся записи и извлечь только уникальные записи.
Синтаксис
Основной синтаксис ключевого слова DISTINCT для устранения повторяющихся записей заключается в следующем.
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
пример
Рассмотрим таблицу CUSTOMERS, имеющую следующие записи.
+----+----------+-----+-----------+----------+ | ID | NAME | AGE | ADDRESS | SALARY | +----+----------+-----+-----------+----------+ | 1 | Ramesh | 32 | Ahmedabad | 2000.00 | | 2 | Khilan | 25 | Delhi | 1500.00 | | 3 | kaushik | 23 | Kota | 2000.00 | | 4 | Chaitali | 25 | Mumbai | 6500.00 | | 5 | Hardik | 27 | Bhopal | 8500.00 | | 6 | Komal | 22 | MP | 4500.00 | | 7 | Muffy | 24 | Indore | 10000.00 | +----+----------+-----+-----------+----------+
Во-первых, давайте посмотрим, как следующий запрос SELECT возвращает дубликаты записей заработной платы.
SQL> SELECT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это привело бы к следующему результату, когда зарплата 2000 года прибывает дважды, что является дубликатом записи из исходной таблицы.
+----------+ | SALARY | +----------+ | 1500.00 | | 2000.00 | | 2000.00 | | 4500.00 | | 6500.00 | | 8500.00 | | 10000.00 | +----------+
Теперь давайте воспользуемся ключевым словом DISTINCT с вышеупомянутым запросом SELECT и увидим результат.
SQL> SELECT DISTINCT SALARY FROM CUSTOMERS ORDER BY SALARY;
Это приведет к следующему результату, где у нас нет дублирующихся записей.
+----------+ | SALARY | +----------+ | 1500.00 | | 2000.00 | | 4500.00 | | 6500.00 | | 8500.00 | | 10000.00 | +----------+
SQL — инъекция
Если вы берете пользовательский ввод через веб-страницу и вставляете его в базу данных SQL, есть вероятность, что вы оставите себя широко открытым для проблемы безопасности, известной как SQL-инъекция . Эта глава научит вас, как предотвратить это, и поможет защитить ваши сценарии и операторы SQL в сценариях на стороне сервера, таких как сценарий PERL.
Инъекция обычно происходит, когда вы запрашиваете ввод данных у пользователя, например, его имя, и вместо имени они дают вам оператор SQL, который вы будете бессознательно выполнять в своей базе данных. Никогда не доверяйте предоставленным пользователем данным, обрабатывайте эти данные только после проверки; как правило, это делается с помощью Pattern Matching .
В приведенном ниже примере имя ограничено буквенно-цифровыми символами и подчеркиванием и длиной от 8 до 20 символов (при необходимости измените эти правила).
if (preg_match("/^\w{8,20}$/", $_GET['username'], $matches)) { $result = mysql_query("SELECT * FROM CUSTOMERS WHERE name = $matches[0]"); } else { echo "user name not accepted"; }
Чтобы продемонстрировать проблему, рассмотрим этот отрывок —
// supposed input $name = "Qadir'; DELETE FROM CUSTOMERS;"; mysql_query("SELECT * FROM CUSTOMSRS WHERE name='{$name}'");
Предполагается, что вызов функции извлекает запись из таблицы CUSTOMERS, где столбец имени совпадает с именем, указанным пользователем. В обычных условиях $ name будет содержать только буквенно-цифровые символы и, возможно, пробелы, такие как строка ilia. Но здесь, добавив совершенно новый запрос к $ name, обращение к базе данных превращается в катастрофу; введенный запрос DELETE удаляет все записи из таблицы CUSTOMERS.
К счастью, если вы используете MySQL, функция mysql_query () не разрешает составлять запросы или выполнять несколько запросов SQL за один вызов функции. Если вы попытаетесь сложить запросы, вызов не удастся.
Однако другие расширения базы данных PHP, такие как SQLite и PostgreSQL, успешно выполняют суммированные запросы, выполняя все запросы, представленные в одной строке, и создают серьезную проблему безопасности.
Предотвращение SQL-инъекций
Вы можете грамотно обрабатывать все escape-символы на языках сценариев, таких как PERL и PHP. Расширение MySQL для PHP предоставляет функцию mysql_real_escape_string () для экранирования входных символов, которые являются специальными для MySQL.
if (get_magic_quotes_gpc()) { $name = stripslashes($name); } $name = mysql_real_escape_string($name); mysql_query("SELECT * FROM CUSTOMERS WHERE name='{$name}'");
Как затруднительное положение
Чтобы решить проблему LIKE, пользовательский механизм экранирования должен преобразовывать предоставленные пользователем символы «%» и «_» в литералы. Используйте addcslashes () , функцию, которая позволяет вам указать диапазон символов для экранирования.
$sub = addcslashes(mysql_real_escape_string("%str"), "%_"); // $sub == \%str\_ mysql_query("SELECT * FROM messages WHERE subject LIKE '{$sub}%'");
SQL — настройка базы данных
Требуется время, чтобы стать экспертом по базам данных или опытным администратором баз данных. Все это имеет большой опыт в разработке различных баз данных и хороших тренингах.
Но следующий список может быть полезен для начинающих, чтобы иметь хорошую производительность базы данных —
-
Используйте структуру базы данных 3BNF, описанную в этом руководстве в главе «Основные понятия СУБД».
-
Избегайте преобразования цифр в символы, поскольку цифры и символы сравниваются по-разному и приводят к снижению производительности.
-
При использовании оператора SELECT извлекайте только ту информацию, которая вам требуется, и избегайте использования * в запросах SELECT, поскольку это приведет к ненужной загрузке системы.
-
Тщательно создавайте свои индексы на всех таблицах, где вы часто выполняете операции поиска. Избегайте индексации таблиц, где у вас меньше операций поиска и больше операций вставки и обновления.
-
Полное сканирование таблицы происходит, когда столбцы в предложении WHERE не имеют индекс, связанный с ними. Вы можете избежать сканирования полной таблицы, создав индекс для столбцов, которые используются в качестве условий в предложении WHERE оператора SQL.
-
Будьте очень осторожны с операторами равенства с действительными числами и значениями даты / времени. У обоих из них могут быть небольшие различия, которые не очевидны для глаз, но делают невозможным точное совпадение, таким образом предотвращая когда-либо ваши запросы возвращать строки.
-
Используйте сопоставление с образцом разумно. LIKE COL% является допустимым условием WHERE, возвращая возвращаемый набор только к тем записям, данные которых начинаются со строки COL. Однако COL% Y не уменьшает количество возвращаемых результатов, так как% Y не может быть эффективно оценено. Усилия по проведению оценки слишком велики, чтобы их можно было рассмотреть. В этом случае используется COL%, но% Y выбрасывается. По той же причине ведущий подстановочный знак% COL эффективно предотвращает использование всего фильтра.
-
Точно настройте свои запросы SQL, изучив структуру запросов (и подзапросов), синтаксис SQL, чтобы выяснить, разработали ли вы таблицы для поддержки быстрой обработки данных и написали ли запрос оптимальным образом, позволяя вашей СУБД эффективно управлять данными ,
-
Для запросов, которые выполняются на регулярной основе, попробуйте использовать процедуры. Процедура — это потенциально большая группа операторов SQL. Процедуры компилируются ядром базы данных и затем выполняются. В отличие от оператора SQL, ядру базы данных не нужно оптимизировать процедуру перед ее выполнением.
-
Избегайте использования логического оператора ИЛИ в запросе, если это возможно. ИЛИ неизбежно замедляет практически любой запрос к таблице существенного размера.
-
Вы можете оптимизировать массовую загрузку данных, удалив индексы. Представьте себе таблицу истории со многими тысячами строк. Эта таблица истории также может иметь один или несколько индексов. Когда вы думаете об индексе, вы обычно думаете о более быстром доступе к таблице, но в случае пакетной загрузки вы можете извлечь выгоду, отбросив индекс (ы).
-
Выполняя пакетные транзакции, выполняйте COMMIT после создания достаточного количества записей вместо их создания после каждого создания записи.
-
Запланируйте регулярную дефрагментацию базы данных, даже если это означает разработку еженедельной программы.
Используйте структуру базы данных 3BNF, описанную в этом руководстве в главе «Основные понятия СУБД».
Избегайте преобразования цифр в символы, поскольку цифры и символы сравниваются по-разному и приводят к снижению производительности.
При использовании оператора SELECT извлекайте только ту информацию, которая вам требуется, и избегайте использования * в запросах SELECT, поскольку это приведет к ненужной загрузке системы.
Тщательно создавайте свои индексы на всех таблицах, где вы часто выполняете операции поиска. Избегайте индексации таблиц, где у вас меньше операций поиска и больше операций вставки и обновления.
Полное сканирование таблицы происходит, когда столбцы в предложении WHERE не имеют индекс, связанный с ними. Вы можете избежать сканирования полной таблицы, создав индекс для столбцов, которые используются в качестве условий в предложении WHERE оператора SQL.
Будьте очень осторожны с операторами равенства с действительными числами и значениями даты / времени. У обоих из них могут быть небольшие различия, которые не очевидны для глаз, но делают невозможным точное совпадение, таким образом предотвращая когда-либо ваши запросы возвращать строки.
Используйте сопоставление с образцом разумно. LIKE COL% является допустимым условием WHERE, возвращая возвращаемый набор только к тем записям, данные которых начинаются со строки COL. Однако COL% Y не уменьшает количество возвращаемых результатов, так как% Y не может быть эффективно оценено. Усилия по проведению оценки слишком велики, чтобы их можно было рассмотреть. В этом случае используется COL%, но% Y выбрасывается. По той же причине ведущий подстановочный знак% COL эффективно предотвращает использование всего фильтра.
Точно настройте свои запросы SQL, изучив структуру запросов (и подзапросов), синтаксис SQL, чтобы выяснить, разработали ли вы таблицы для поддержки быстрой обработки данных и написали ли запрос оптимальным образом, позволяя вашей СУБД эффективно управлять данными ,
Для запросов, которые выполняются на регулярной основе, попробуйте использовать процедуры. Процедура — это потенциально большая группа операторов SQL. Процедуры компилируются ядром базы данных и затем выполняются. В отличие от оператора SQL, ядру базы данных не нужно оптимизировать процедуру перед ее выполнением.
Избегайте использования логического оператора ИЛИ в запросе, если это возможно. ИЛИ неизбежно замедляет практически любой запрос к таблице существенного размера.
Вы можете оптимизировать массовую загрузку данных, удалив индексы. Представьте себе таблицу истории со многими тысячами строк. Эта таблица истории также может иметь один или несколько индексов. Когда вы думаете об индексе, вы обычно думаете о более быстром доступе к таблице, но в случае пакетной загрузки вы можете извлечь выгоду, отбросив индекс (ы).
Выполняя пакетные транзакции, выполняйте COMMIT после создания достаточного количества записей вместо их создания после каждого создания записи.
Запланируйте регулярную дефрагментацию базы данных, даже если это означает разработку еженедельной программы.
Встроенные инструменты настройки
У Oracle есть много инструментов для управления производительностью операторов SQL, но среди них два очень популярны. Эти два инструмента —
-
План объяснения — инструмент определяет путь доступа, который будет выбран при выполнении оператора SQL.
-
tkprof — измеряет производительность по времени, прошедшему во время каждой фазы обработки оператора SQL.
План объяснения — инструмент определяет путь доступа, который будет выбран при выполнении оператора SQL.
tkprof — измеряет производительность по времени, прошедшему во время каждой фазы обработки оператора SQL.
Если вы хотите просто измерить истекшее время запроса в Oracle, вы можете использовать команду SQL * Plus SET TIMING ON.
Обратитесь к документации СУБД для получения более подробной информации о вышеупомянутых инструментах и дефрагментации базы данных.