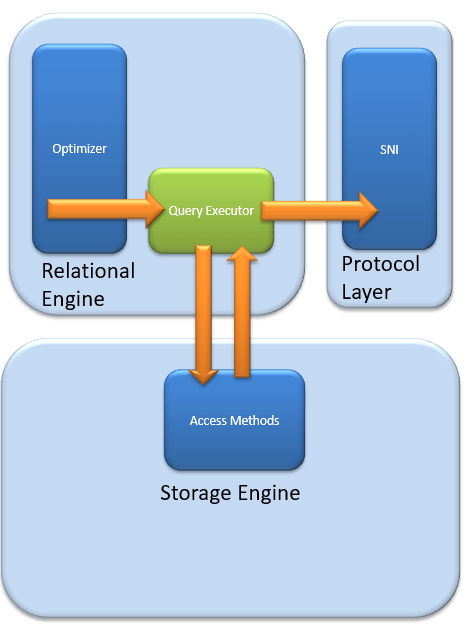
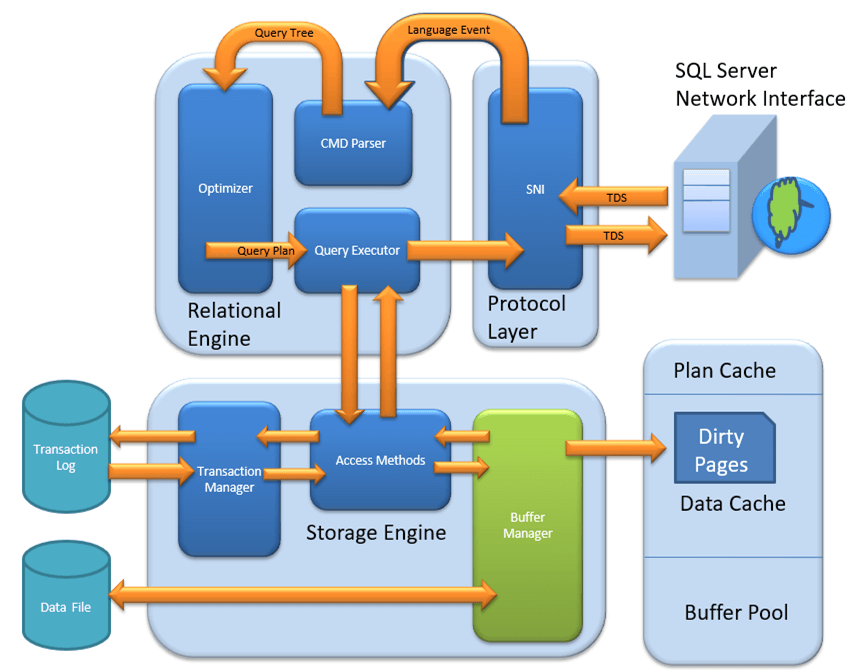
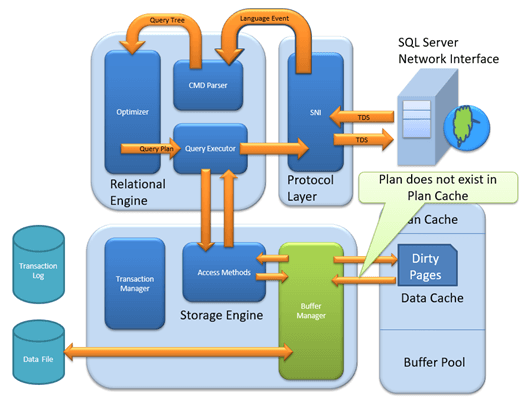
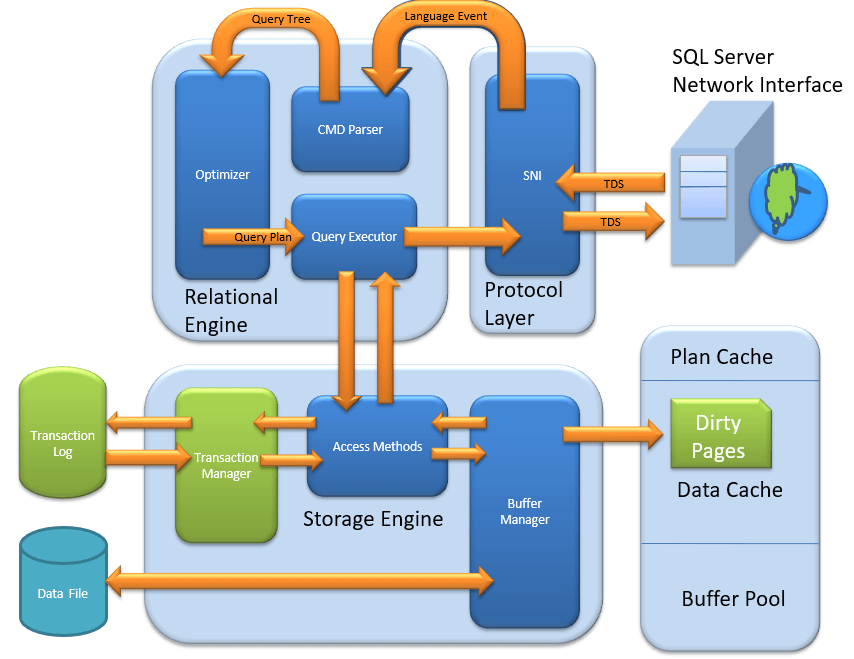
MS SQL Server — это клиент-серверная архитектура. Процесс MS SQL Server начинается с того, что клиентское приложение отправляет запрос. SQL Server принимает, обрабатывает и отвечает на запрос обработанными данными. Давайте подробно обсудим всю архитектуру, показанную ниже:
Как показано на диаграмме ниже, в архитектуре SQL Server есть три основных компонента:
- Уровень протокола
- Реляционный двигатель
- Двигатель хранения
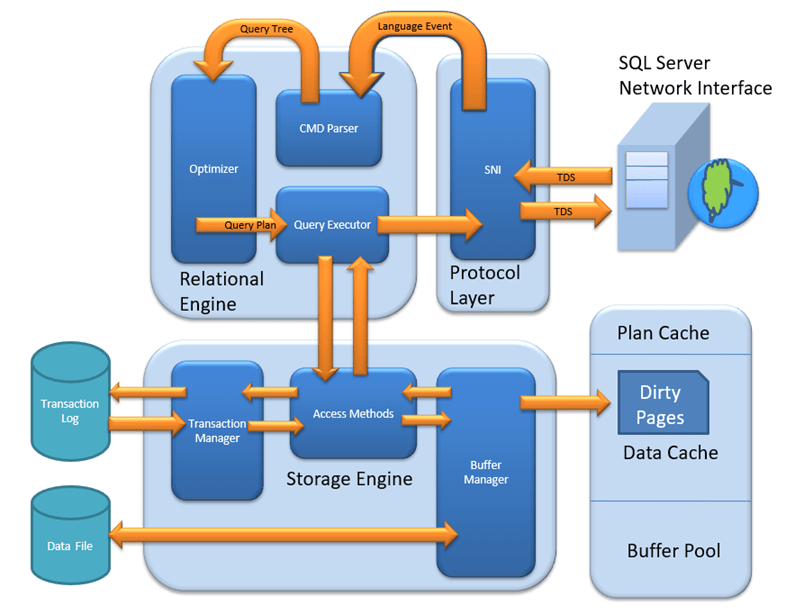
Давайте подробно обсудим все три вышеупомянутых основных модуля. В этом уроке вы узнаете.
Уровень протокола — SNI
MS SQL SERVER PROTOCOL LAYER поддерживает 3 типа клиент-серверной архитектуры. Мы начнем с « Три типа в архитектуре клиент — сервер» , который поддерживает MS SQL Server.
Общая память
Давайте пересмотрим сценарий разговора ранним утром.
Мама и Том — Здесь Том и его мама, были в одном логическом месте, то есть в их доме. Том мог попросить кофе, а мама — подавать горячим.
СЕРВЕР MS SQL — Здесь сервер MS SQL предоставляет общий протокол памяти . Здесь CLIENT и сервер MS SQL работают на одной машине. Оба могут общаться через протокол общей памяти.
Аналогия: позволяет сопоставить сущности в двух вышеупомянутых сценариях. Мы можем легко сопоставить Tom с клиентом, Mom с SQL-сервером, Home to Machine и устную коммуникацию с протоколом общей памяти.
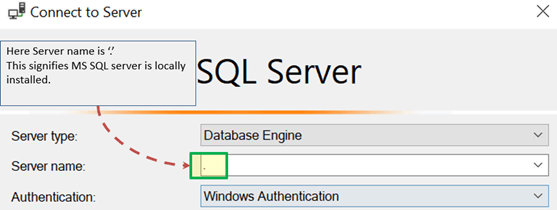
Со стола настройки и установки:
Для подключения к локальной базе данных — в SQL Management Studio параметр «Имя сервера» может быть
«»
«Локальный»
«127.0.0.1»
«Machine \ Instance»
TCP / IP
А теперь посмотрим вечером, у Тома праздничное настроение. Он хочет кофе, заказанный в известной кофейне. Кофейня находится в 10 км от его дома.

Здесь Том и Старбак находятся в разных физических местах. Том дома и Старбакс на оживленной торговой площадке. Они общаются через сотовую сеть. Аналогично, MS SQL SERVER обеспечивает возможность взаимодействия по протоколу TCP / IP, где CLIENT и MS SQL Server являются удаленными друг от друга и установлены на отдельной машине.
Аналогия: позволяет сопоставить сущности в двух вышеупомянутых сценариях. Мы можем легко сопоставить Tom с клиентом, Starbuck с SQL-сервером, Home / Market place с удаленным местоположением и, наконец, с сотовой сети по протоколу TCP / IP.
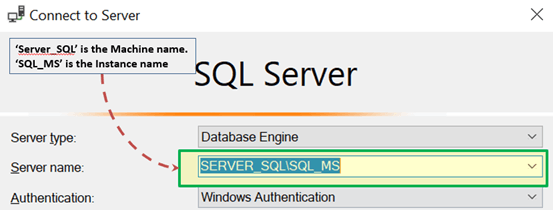
Заметки с пульта Конфигурации / установки:
- В SQL Management Studio — для подключения через TCP \ IP параметр «Имя сервера» должен быть «Компьютер \ Экземпляр сервера».
- SQL-сервер использует порт 1433 в TCP / IP.
Именованные трубы
Теперь, наконец, ночью, Том хотел выпить светло-зеленый чай, который очень хорошо готовила ее соседка Сьерра.

Здесь Том и его сосед Сьерра находятся в одном физическом месте, будучи соседом друг друга. Они общаются через сеть Intra. Точно так же MS SQL SERVER предоставляет возможность взаимодействия через протокол Named Pipe . Здесь КЛИЕНТ и MS SQL SERVER подключены через локальную сеть .
Analogy: Lets map entities in the above two scenarios. We can easily map Tom to Client, Sierra to SQL server, Neighbor to LAN and finally Intra network to Named Pipe Protocol.
Notes from the desk of Configuration/installation:
- For Connection via Named Pipe. This option is disabled by default and needs to be enabled by the SQL Configuration Manager.
What is TDS?
Now that we know that there are three types of Client-Server Architecture, lets us have a glance at TDS:
- TDS stands for Tabular Data Stream.
- All 3 protocols use TDS packets. TDS is encapsulated in Network packets. This enables data transfer from the client machine to the server machine.
- TDS was first developed by Sybase and is now Owned by Microsoft
Relational Engine
The Relational Engine is also known as the Query Processor. It has the SQL Server components that determine what exactly a query needs to do and how it can be done best. It is responsible for the execution of user queries by requesting data from the storage engine and processing the results that are returned.
As depicted in the Architectural Diagram there are 3 major components of the Relational Engine. Let’s study the components in detail:
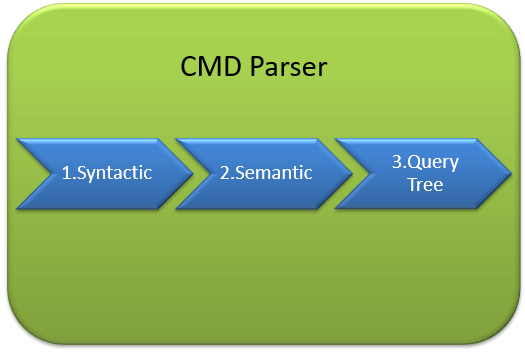
CMD Parser
Data once received from Protocol Layer is then passed to Relational Engine. «CMD Parser» is the first component of Relational Engine to receive the Query data. The principal job of CMD Parser is to check the query for Syntactic and Semantic error. Finally, it generates a Query Tree. Let’s discuss in detail.
Syntactic check:
- Like every other Programming language, MS SQL also has the predefined set of Keywords. Also, SQL Server has its own grammar which SQL server understands.
- SELECT, INSERT, UPDATE, and many others belong to MS SQL predefined Keyword lists.
- CMD Parser does syntactic check. If users’ input does not follow these language syntax or grammar rules, it returns an error.
Example: Let’s say a Russian went to a Japanese restaurant. He orders fast food in the Russian language. Unfortunately, the waiter only understands Japanese. What would be the most obvious result?
The Answer is – the waiter is unable to process the order further.
There should not be any deviation in Grammar or language which SQL server accepts. If there are, SQL server cannot process it and hence will return an error message.
We will learn about MS SQL query more in upcoming tutorials. Yet, consider below most basic Query Syntax as
SELECT * from <TABLE_NAME>;
Now, to get the perception of what syntactic does, say if the user runs the basic query as below:
SELECR * from <TABLE_NAME>
Note that instead of ‘SELECT’ user typed «SELECR.»
Результат: анализатор CMD проанализирует этот оператор и выдаст сообщение об ошибке. Так как «SELECR» не соответствует заранее заданному ключевому слову и грамматике. Здесь CMD Parser ожидал «SELECT».
Семантическая проверка:
- Это выполняется нормализатором .
- В простейшем виде он проверяет, существуют ли в схеме имя столбца и запрашиваемое имя таблицы. И если он существует, свяжите его с Query. Это также известно как Binding .
- Сложность возрастает, когда пользовательские запросы содержат VIEW. Нормализатор выполняет замену с сохраненным внутри определением представления и многим другим.
Давайте разберемся с помощью приведенного ниже примера —
SELECT * from USER_ID
Результат: синтаксический анализатор CMD проанализирует этот оператор для семантической проверки. Парсер выдаст сообщение об ошибке, так как Normalizer не найдет запрошенную таблицу (USER_ID), так как она не существует.
Создать дерево запросов:
- На этом этапе создается другое дерево выполнения, в котором можно выполнить запрос.
- Обратите внимание, что все разные деревья имеют одинаковый желаемый результат.
оптимизатор
Работа оптимизатора заключается в создании плана выполнения запроса пользователя. Это план, который будет определять, как будет выполняться пользовательский запрос.
Обратите внимание, что не все запросы оптимизированы. Оптимизация выполняется для таких команд DML (язык изменения данных), как SELECT, INSERT, DELETE и UPDATE. Такие запросы сначала помечаются, а затем отправляются оптимизатору. Команды DDL, такие как CREATE и ALTER, не оптимизированы, но вместо этого они скомпилированы во внутреннюю форму. Стоимость запроса рассчитывается на основе таких факторов, как загрузка процессора, использование памяти и потребности ввода / вывода.
Роль оптимизатора состоит в том, чтобы найти самый дешевый, не самый лучший и экономически эффективный план выполнения.
Прежде чем перейти к более техническим деталям Оптимизатора, рассмотрим пример из реальной жизни:
Пример:
Допустим, вы хотите открыть онлайн-счет в банке. Вы уже знаете об одном банке, который занимает максимум 2 дня, чтобы открыть счет. Но у вас также есть список из 20 других банков, что может занять или не занять менее 2 дней. Вы можете начать взаимодействие с этими банками, чтобы определить, какие банки занимают менее 2 дней. Теперь вы можете не найти банк, который занимает менее 2 дней, и из-за самой поисковой активности теряется дополнительное время. Было бы лучше открыть счет в самом первом банке.
Вывод: важнее выбирать с умом. Чтобы быть точным, выберите, какой вариант лучше, а не самый дешевый.
Аналогично, MS SQL Optimizer работает на встроенных исчерпывающих / эвристических алгоритмах. Цель состоит в том, чтобы минимизировать время выполнения запроса. Все алгоритмы оптимизатора являются собственностью Microsoft и являются секретом. Несмотря на то , ниже приведены шаги высокого уровня , выполняемые MS SQL Optimizer. Поиски оптимизации выполняются в три этапа, как показано на диаграмме ниже:
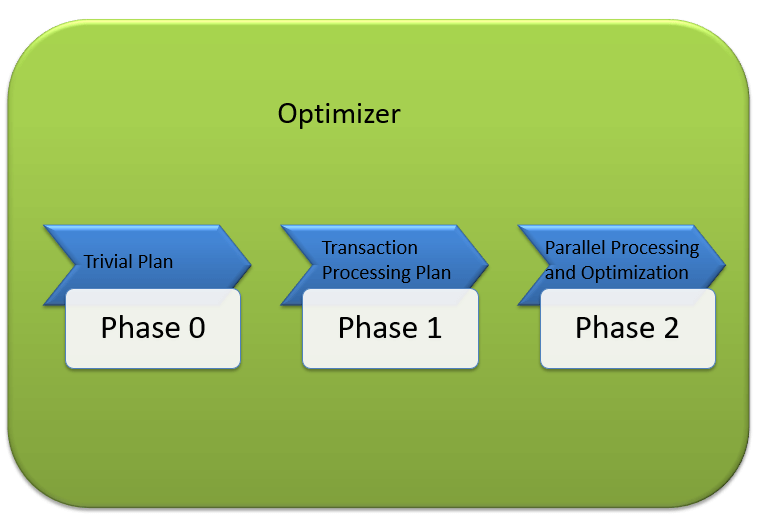
Этап 0: поиск тривиального плана:
- Это также называется этапом предварительной оптимизации .
- В некоторых случаях может существовать только один практичный, выполнимый план, известный как тривиальный план. Нет необходимости создавать оптимизированный план. Причина в том, что поиск большего числа приведет к нахождению того же плана выполнения во время выполнения. Это также связано с дополнительными затратами на поиск оптимизированного плана, который вообще не требовался.
- Если тривиальный план не найден, начинается 1- я фаза.
Этап 1: поиск планов обработки транзакций
- Это включает в себя поиск простого и сложного плана .
- Простой поиск по плану: прошлые данные столбца и индекса, участвующего в запросе, будут использоваться для статистического анализа. Это обычно состоит, но не ограничивается одним индексом на таблицу.
- Тем не менее, если простой план не найден, то ищется более сложный план. Он включает в себя несколько индексов на таблицу.
Этап 2: параллельная обработка и оптимизация.
- Если ни одна из вышеуказанных стратегий не работает, Оптимизатор ищет возможности параллельной обработки. Это зависит от возможностей и конфигурации машины.
- Если это все еще невозможно, начинается финальная фаза оптимизации. Теперь конечной целью оптимизации является поиск всех других возможных вариантов наилучшего выполнения запроса. Финальная фаза оптимизации Алгоритмы являются собственностью Microsoft.
Query Executor
Исполнитель запроса вызывает метод доступа. Он предоставляет план выполнения для логики выборки данных, необходимой для выполнения. Как только данные получены от Storage Engine, результат публикуется на уровне протокола. Наконец, данные отправляются конечному пользователю.
Двигатель хранения
Работа механизма хранения заключается в хранении данных в системе хранения, такой как диск или SAN, и извлечении данных при необходимости. Прежде чем мы углубимся в механизм хранения, давайте посмотрим, как данные хранятся в базе данных, и типы доступных файлов.
Файл данных и экстент:
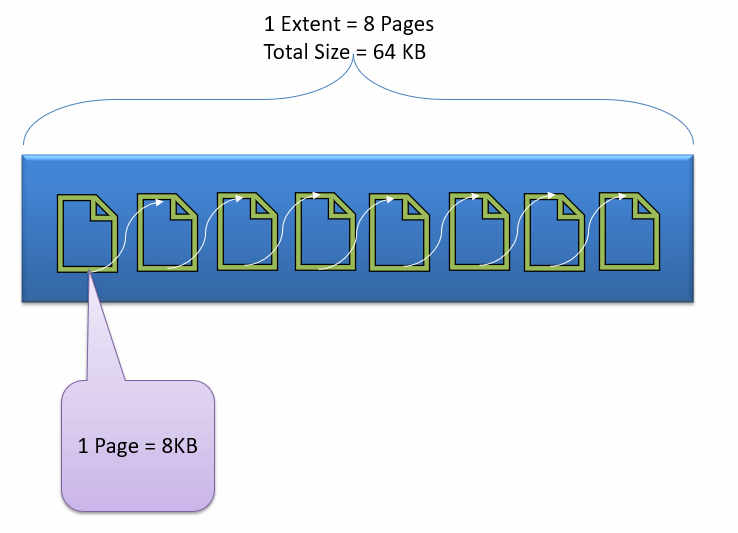
Файл данных, физически хранящий данные в форме страниц данных, причем каждая страница данных имеет размер 8 КБ, образуя наименьшую единицу хранения в SQL Server. Эти страницы данных логически сгруппированы для формирования экстентов. Ни одному объекту не назначена страница в SQL Server.
Содержание объекта осуществляется через экстенты. На странице есть раздел под названием «Верхний колонтитул страницы» размером 96 байт, содержащий метаданные информации о странице, такие как тип страницы, номер страницы, размер используемого пространства, размер свободного пространства и указатель на следующую страницу и предыдущую страницу. , так далее.
Типы файлов
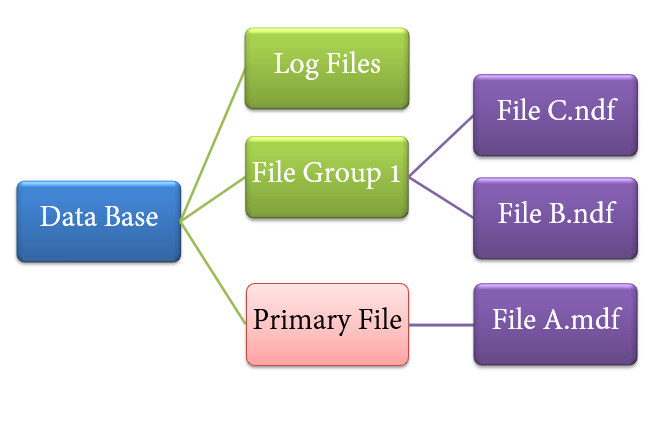
- Основной файл
- Каждая база данных содержит один основной файл.
- Здесь хранятся все важные данные, связанные с таблицами, представлениями, триггерами и т. Д.
- Расширение есть. мдф обычно но может быть любого расширения.
- Вторичный файл
- База данных может содержать или не содержать несколько вторичных файлов.
- Это необязательно и содержит данные, специфичные для пользователя.
- Расширение есть. ndf обычно, но может быть любого расширения.
- Лог-файл
- Также известен как Запись впереди журналов.
- Расширение есть. LDF
- Используется для управления транзакциями.
- Это используется для восстановления от любых нежелательных экземпляров. Выполните важную задачу отката к незафиксированным транзакциям.
Storage Engine имеет 3 компонента; давайте рассмотрим их подробно.
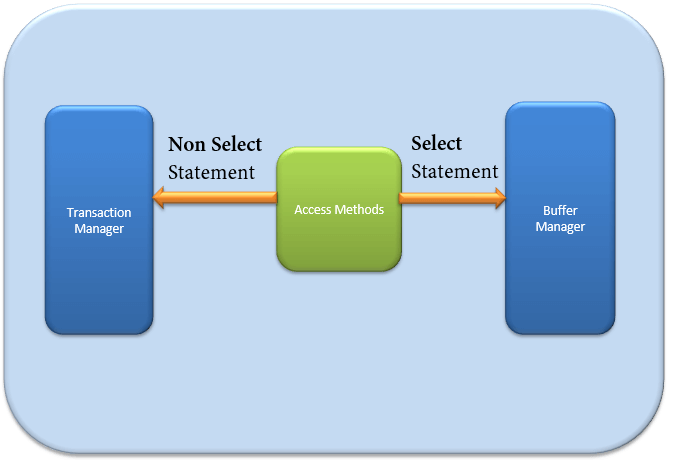
Метод доступа
Он действует как интерфейс между исполнителем запросов и Buffer Manager / Transaction Logs.
Сам метод доступа не выполняет никаких действий.
Первое действие — определить, является ли запрос:
- Выберите заявление (DDL)
- Оператор без выбора (DDL и DML)
В зависимости от результата метод доступа выполняет следующие шаги:
- Если запрос DDL , оператор SELECT, запрос передается в Buffer Manager для дальнейшей обработки.
- И если запрос DDL, оператор NON-SELECT , запрос передается в Transaction Manager. Это в основном включает в себя оператор UPDATE.
Буферный менеджер
Диспетчер буфера управляет основными функциями модулей ниже:
- План кэш
- Разбор данных: буферный кеш и хранение данных
- Грязная страница
В этом разделе мы узнаем, что такое Plan, Buffer и Data cache. Мы рассмотрим грязные страницы в разделе Транзакции.
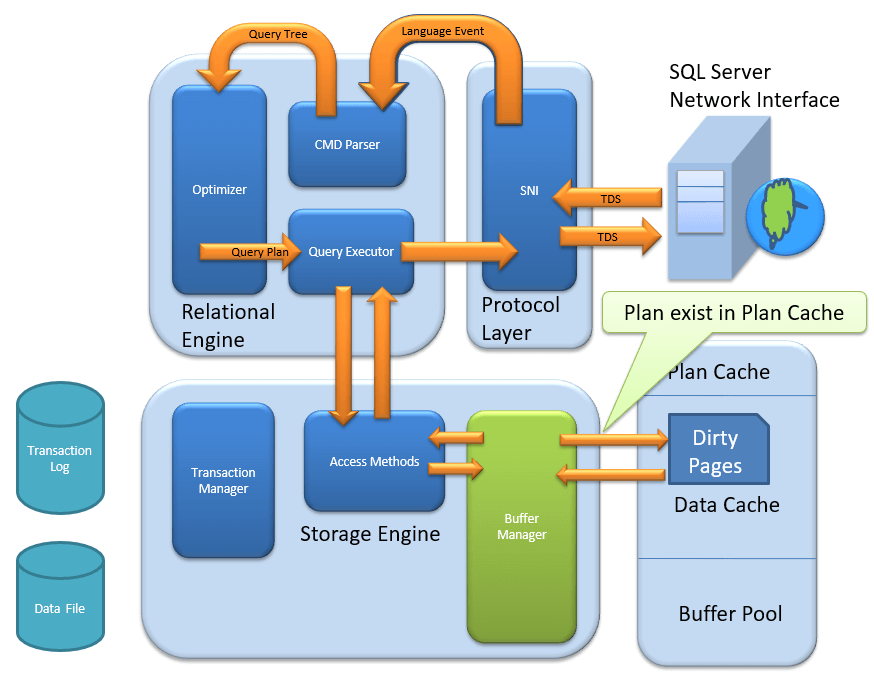
План кэш
- Существующий план запроса: менеджер буфера проверяет, есть ли план выполнения в сохраненном кэше плана. Если да, то используется кеш плана запросов и связанный с ним кеш данных.
- Первый план кэширования: откуда берется существующий план кэша?
Если первый план выполнения запроса выполняется и является сложным, имеет смысл сохранить его в кэше плоскости. Это обеспечит более высокую доступность, когда в следующий раз SQL-сервер получит тот же запрос. Таким образом, это не что иное, как запрос, который выполнение Plan сохраняется, если он выполняется в первый раз.
Синтаксический анализ данных: буферный кеш и хранение данных
Диспетчер буфера обеспечивает доступ к необходимым данным. Ниже возможны два подхода в зависимости от того, существуют данные в кэше данных или нет:
Буферный кеш — мягкий разбор:
Диспетчер буфера ищет данные в буфере в кеше данных. Если эти данные присутствуют, то эти данные используются Query Executor. Это повышает производительность, поскольку количество операций ввода-вывода уменьшается при извлечении данных из кэша по сравнению с извлечением данных из хранилища данных.
Хранение данных — жесткий анализ:
Если данные отсутствуют в Buffer Manager, необходимо выполнить поиск данных в хранилище данных. Если также хранит данные в кэше данных для дальнейшего использования.
Грязная страница
Он хранится как логика обработки менеджера транзакций. Подробнее об этом мы узнаем в разделе «Менеджер транзакций».
Менеджер транзакций
Диспетчер транзакций вызывается, когда метод доступа определяет, что запрос является оператором без выбора.
Менеджер журналов
- Диспетчер журналов отслеживает все обновления, сделанные в системе, через журналы в журналах транзакций.
- Журналы имеют порядковый номер журналов с идентификатором транзакции и записью изменения данных .
- Это используется для отслеживания совершенной транзакции и отката транзакции .
Менеджер блокировки
- Во время транзакции связанные данные в хранилище данных находятся в состоянии блокировки. Этот процесс обрабатывается менеджером блокировок.
- Этот процесс обеспечивает согласованность и изоляцию данных . Также известен как свойства ACID.
Процесс исполнения
- Менеджер журналов начинает регистрацию, а менеджер блокировок блокирует связанные данные.
- Копия данных сохраняется в кеше буфера.
- Копия данных, которые должны быть обновлены, сохраняется в буфере журнала, а все события обновляют данные в буфере данных.
- Страницы, на которых хранятся данные, также называются « грязными страницами» .
- Регистрация контрольных точек и запись в очередь: этот процесс запускается и помечает все страницы от грязных страниц до диска, но страница остается в кэше. Частота составляет приблизительно 1 прогон в минуту. Но страница сначала перемещается на страницу данных файла журнала из журнала буфера. Это известно как запись в журнал.
- Ленивый писатель: грязная страница может остаться в памяти. Когда сервер SQL обнаруживает огромную нагрузку и для новой транзакции требуется буферная память, он освобождает грязные страницы из кэша. Он работает на LRU — наименьший недавно использованный алгоритм очистки страницы от пула буферов до диска.
Резюме:
- Существует три типа клиент-серверной архитектуры: 1) Общая память 2) TCP / IP 3) Именованные каналы
- TDS, разработанный Sybase и в настоящее время принадлежащий Microsoft, представляет собой пакет, который инкапсулируется в сетевые пакеты для передачи данных с клиентского компьютера на серверный компьютер.
- Реляционный движок содержит три основных компонента:
CMD Parser: он отвечает за синтаксическую и семантическую ошибку и, наконец, генерирует дерево запросов.
Оптимизатор: роль Оптимизатора состоит в том, чтобы найти самый дешевый, не самый лучший и экономичный план выполнения.
Исполнитель запроса: Исполнитель запроса вызывает метод доступа и предоставляет план выполнения для логики выборки данных, необходимой для выполнения.
- Существует три типа файлов: Первичный файл, Вторичный файл и Файлы журнала.
- Механизм хранения: имеет следующие важные компоненты
Метод доступа: этот компонент Определяет, является ли запрос оператором «Выбор» или «Не выбран». Вызывает Buffer и Transfer Manager соответственно.
Buffer Manager: Buffer Manager управляет основными функциями для Plan Cache, Darsing & Dirty Page.
Менеджер транзакций: Это менеджер транзакций без выбора с помощью менеджеров журналов и блокировок. Кроме того, облегчает важную реализацию ведения журнала Write Ahead и Lazy Writers.