Вторичное индексирование используется, когда мы хотим получить доступ к базе данных без использования полного объединенного ключа или когда мы не хотим использовать первичные поля последовательности.
Сегмент указателя индекса
DL / I хранит указатель на сегменты индексированной базы данных в отдельной базе данных. Сегмент указателя индекса является единственным типом вторичного индекса. Он состоит из двух частей —
- Префикс Элемент
- Элемент данных
Префикс Элемент
Префиксная часть сегмента указателя индекса содержит указатель на целевой сегмент индекса. Целевой сегмент индекса — это сегмент, доступный с использованием вторичного индекса.
Элемент данных
Элемент данных содержит значение ключа из сегмента в индексированной базе данных, на которой построен индекс. Это также называется сегментом источника индекса.
Вот ключевые моменты, которые следует отметить о вторичной индексации:
-
Сегмент источника индекса и целевой сегмент источника не обязательно должны совпадать.
-
Когда мы устанавливаем вторичный индекс, он автоматически поддерживается DL / I.
-
DBA определяет много вторичных индексов в соответствии с путями множественного доступа. Эти вторичные индексы хранятся в отдельной базе данных индексов.
-
Мы не должны создавать больше вторичных индексов, поскольку они накладывают дополнительные накладные расходы на обработку DL / I.
Сегмент источника индекса и целевой сегмент источника не обязательно должны совпадать.
Когда мы устанавливаем вторичный индекс, он автоматически поддерживается DL / I.
DBA определяет много вторичных индексов в соответствии с путями множественного доступа. Эти вторичные индексы хранятся в отдельной базе данных индексов.
Мы не должны создавать больше вторичных индексов, поскольку они накладывают дополнительные накладные расходы на обработку DL / I.
Вторичные ключи
Обращает на себя внимание —
-
Поле в сегменте источника индекса, над которым построен вторичный индекс, называется вторичным ключом.
-
Любое поле может быть использовано в качестве вторичного ключа. Это не должно быть поле последовательности сегментов.
-
Вторичные ключи могут быть любой комбинацией отдельных полей в сегменте источника индекса.
-
Значения вторичного ключа не должны быть уникальными.
Поле в сегменте источника индекса, над которым построен вторичный индекс, называется вторичным ключом.
Любое поле может быть использовано в качестве вторичного ключа. Это не должно быть поле последовательности сегментов.
Вторичные ключи могут быть любой комбинацией отдельных полей в сегменте источника индекса.
Значения вторичного ключа не должны быть уникальными.
Вторичные структуры данных
Обращает на себя внимание —
-
Когда мы создаем вторичный индекс, видимая иерархическая структура базы данных также изменяется.
-
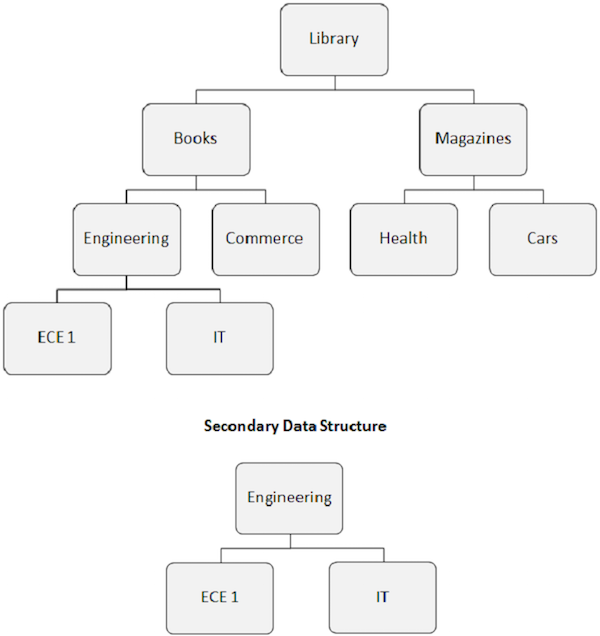
Целевой сегмент индекса становится видимым корневым сегментом. Как показано на следующем рисунке, инженерный сегмент становится корневым, даже если он не является корневым.
-
Перестройка структуры базы данных, вызванная вторичным индексом, называется вторичной структурой данных.
-
Вторичные структуры данных не вносят никаких изменений в основную физическую структуру базы данных, присутствующую на диске. Это просто способ изменить структуру базы данных перед прикладной программой.
Когда мы создаем вторичный индекс, видимая иерархическая структура базы данных также изменяется.
Целевой сегмент индекса становится видимым корневым сегментом. Как показано на следующем рисунке, инженерный сегмент становится корневым, даже если он не является корневым.
Перестройка структуры базы данных, вызванная вторичным индексом, называется вторичной структурой данных.
Вторичные структуры данных не вносят никаких изменений в основную физическую структуру базы данных, присутствующую на диске. Это просто способ изменить структуру базы данных перед прикладной программой.
Независимый оператор
Обращает на себя внимание —
-
Когда оператор AND (* или &) используется со вторичными индексами, он называется зависимым оператором AND.
-
Независимое AND (#) позволяет нам определять квалификации, которые были бы невозможны с зависимым AND.
-
Этот оператор может использоваться только для вторичных индексов, где сегмент источника индекса зависит от целевого сегмента индекса.
-
Мы можем закодировать SSA с независимым AND, чтобы указать, что вхождение целевого сегмента будет обрабатываться на основе полей в двух или более зависимых исходных сегментах.
Когда оператор AND (* или &) используется со вторичными индексами, он называется зависимым оператором AND.
Независимое AND (#) позволяет нам определять квалификации, которые были бы невозможны с зависимым AND.
Этот оператор может использоваться только для вторичных индексов, где сегмент источника индекса зависит от целевого сегмента индекса.
Мы можем закодировать SSA с независимым AND, чтобы указать, что вхождение целевого сегмента будет обрабатываться на основе полей в двух или более зависимых исходных сегментах.
01 ITEM-SELECTION-SSA. 05 FILLER PIC X(8). 05 FILLER PIC X(1) VALUE '('. 05 FILLER PIC X(10). 05 SSA-KEY-1 PIC X(8). 05 FILLER PIC X VALUE '#'. 05 FILLER PIC X(10). 05 SSA-KEY-2 PIC X(8). 05 FILLER PIC X VALUE ')'.
Редкая последовательность
Обращает на себя внимание —
-
Разреженное секвенирование также известно как Разреженное индексирование. Мы можем удалить некоторые из исходных сегментов индекса из индекса, используя разреженную последовательность с базой данных вторичного индекса.
-
Разреженная последовательность используется для улучшения производительности. Когда некоторые вхождения исходного сегмента индекса не используются, мы можем удалить это.
-
DL / I использует значение подавления или подпрограмму подавления, или и то, и другое, чтобы определить, следует ли индексировать сегмент.
-
Если значение поля последовательности в сегменте источника индекса соответствует значению подавления, то связь с индексом не устанавливается.
-
Подпрограмма подавления — это написанная пользователем программа, которая оценивает сегмент и определяет, следует ли его индексировать.
-
Когда используется разреженная индексация, ее функции обрабатываются DL / I. Нам не нужно делать специальные условия для этого в прикладной программе.
Разреженное секвенирование также известно как Разреженное индексирование. Мы можем удалить некоторые из исходных сегментов индекса из индекса, используя разреженную последовательность с базой данных вторичного индекса.
Разреженная последовательность используется для улучшения производительности. Когда некоторые вхождения исходного сегмента индекса не используются, мы можем удалить это.
DL / I использует значение подавления или подпрограмму подавления, или и то, и другое, чтобы определить, следует ли индексировать сегмент.
Если значение поля последовательности в сегменте источника индекса соответствует значению подавления, то связь с индексом не устанавливается.
Подпрограмма подавления — это написанная пользователем программа, которая оценивает сегмент и определяет, следует ли его индексировать.
Когда используется разреженная индексация, ее функции обрабатываются DL / I. Нам не нужно делать специальные условия для этого в прикладной программе.
Требования DBDGEN
Как обсуждалось в предыдущих модулях, DBDGEN используется для создания DBD. Когда мы создаем вторичные индексы, участвуют две базы данных. Администратор баз данных должен создать два DBD, используя два DBDGEN для создания связи между индексированной базой данных и вторичной индексированной базой данных.
Требования PSBGEN
После создания вторичного индекса для базы данных администратор базы данных должен создать PSB. PSBGEN для программы указывает правильную последовательность обработки для базы данных в параметре PROCSEQ макроса PSB. Для параметра PROCSEQ DBA кодирует имя DBD для базы данных вторичного индекса.