БД IMS хранит данные на разных уровнях. Данные извлекаются и вставляются с помощью вызовов DL / I из прикладной программы. Мы подробно обсудим вызовы DL / I в следующих главах. Данные могут быть обработаны следующими двумя способами:
- Последовательная обработка
- Случайная обработка
Последовательная обработка
Когда сегменты извлекаются последовательно из базы данных, DL / I следует предварительно определенному шаблону. Давайте разберемся с последовательной обработкой БД IMS.
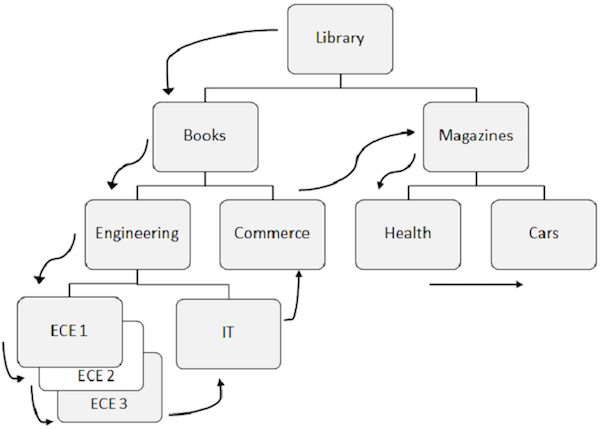
Ниже перечислены моменты, которые нужно отметить для последовательной обработки —
-
Предопределенный шаблон для доступа к данным в DL / I сначала идет вниз по иерархии, затем слева направо.
-
Сначала извлекается корневой сегмент, затем DL / I перемещается к первому левому потомку и опускается до самого низкого уровня. На самом низком уровне он извлекает все случаи двойных сегментов. Затем он идет в правый сегмент.
-
Для лучшего понимания просмотрите стрелки на приведенном выше рисунке, которые показывают порядок доступа к сегментам. Библиотека является корневым сегментом, и поток начинается оттуда и продолжается до автомобилей, чтобы получить доступ к одной записи. Тот же процесс повторяется для всех вхождений, чтобы получить все записи данных.
-
При доступе к данным программа использует позицию в базе данных, которая помогает извлекать и вставлять сегменты.
Предопределенный шаблон для доступа к данным в DL / I сначала идет вниз по иерархии, затем слева направо.
Сначала извлекается корневой сегмент, затем DL / I перемещается к первому левому потомку и опускается до самого низкого уровня. На самом низком уровне он извлекает все случаи двойных сегментов. Затем он идет в правый сегмент.
Для лучшего понимания просмотрите стрелки на приведенном выше рисунке, которые показывают порядок доступа к сегментам. Библиотека является корневым сегментом, и поток начинается оттуда и продолжается до автомобилей, чтобы получить доступ к одной записи. Тот же процесс повторяется для всех вхождений, чтобы получить все записи данных.
При доступе к данным программа использует позицию в базе данных, которая помогает извлекать и вставлять сегменты.
Случайная обработка
Случайная обработка также известна как прямая обработка данных в БД IMS. Давайте возьмем пример, чтобы понять случайную обработку в БД IMS —
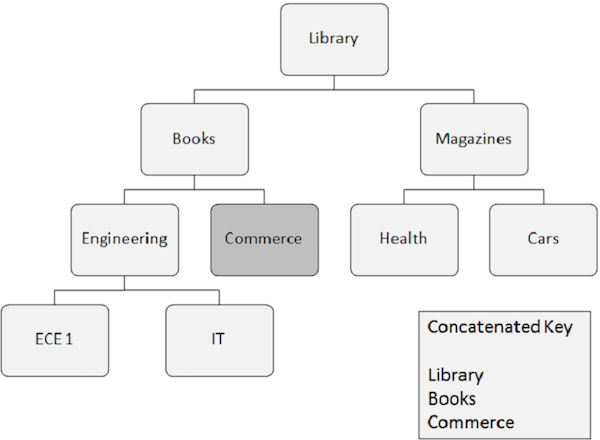
Ниже перечислены моменты, которые следует учитывать при случайной обработке.
-
Вхождение сегмента, которое необходимо получить случайным образом, требует наличия ключевых полей всех сегментов, от которых оно зависит. Эти ключевые поля предоставляются прикладной программой.
-
Связанный ключ полностью идентифицирует путь от корневого сегмента к сегменту, который вы хотите получить.
-
Предположим, что вы хотите получить экземпляр сегмента Commerce, а затем вам нужно указать значения сцепленных ключевых полей для сегментов, от которых он зависит, таких как Библиотека, Книги и Торговля.
-
Случайная обработка выполняется быстрее, чем последовательная. В реальном сценарии приложения объединяют как последовательные, так и случайные методы обработки для достижения наилучших результатов.
Вхождение сегмента, которое необходимо получить случайным образом, требует наличия ключевых полей всех сегментов, от которых оно зависит. Эти ключевые поля предоставляются прикладной программой.
Связанный ключ полностью идентифицирует путь от корневого сегмента к сегменту, который вы хотите получить.
Предположим, что вы хотите получить экземпляр сегмента Commerce, а затем вам нужно указать значения сцепленных ключевых полей для сегментов, от которых он зависит, таких как Библиотека, Книги и Торговля.
Случайная обработка выполняется быстрее, чем последовательная. В реальном сценарии приложения объединяют как последовательные, так и случайные методы обработки для достижения наилучших результатов.
Ключевое поле
Обращает на себя внимание —
-
Ключевое поле также называется полем последовательности.
-
Ключевое поле присутствует внутри сегмента и используется для получения вхождения сегмента.
-
Ключевое поле управляет появлением сегмента в порядке возрастания.
-
В каждом сегменте только одно поле может быть использовано в качестве ключевого поля или поля последовательности.
Ключевое поле также называется полем последовательности.
Ключевое поле присутствует внутри сегмента и используется для получения вхождения сегмента.
Ключевое поле управляет появлением сегмента в порядке возрастания.
В каждом сегменте только одно поле может быть использовано в качестве ключевого поля или поля последовательности.
Поле поиска
Как уже упоминалось, только одно поле может быть использовано в качестве ключевого поля. Если вы хотите искать содержимое других полей сегмента, которые не являются ключевыми, то поле, которое используется для извлечения данных, называется полем поиска.