IMS DB — Обзор
База данных представляет собой набор взаимосвязанных элементов данных. Эти элементы данных организованы и хранятся таким образом, чтобы обеспечить быстрый и легкий доступ. База данных IMS представляет собой иерархическую базу данных, в которой данные хранятся на разных уровнях, и каждый объект зависит от объектов более высокого уровня. Физические элементы в прикладной системе, использующей IMS, показаны на следующем рисунке.
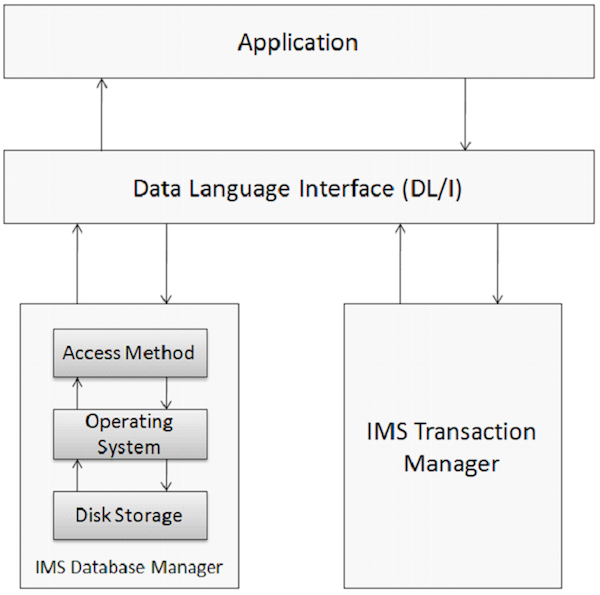
Управление базой данных
Система управления базами данных — это набор прикладных программ, используемых для хранения, доступа и управления данными в базе данных. Система управления базами данных IMS поддерживает целостность и позволяет быстро восстанавливать данные, организовывая их таким образом, чтобы их было легко извлечь. IMS хранит большой объем мировых корпоративных данных с помощью своей системы управления базами данных.
Менеджер транзакций
Функция диспетчера транзакций заключается в обеспечении коммуникационной платформы между базой данных и прикладными программами. IMS действует как менеджер транзакций. Менеджер транзакций имеет дело с конечным пользователем для хранения и извлечения данных из базы данных. IMS может использовать базу данных IMS или DB2 в качестве своей внутренней базы данных для хранения данных.
DL / I — интерфейс языка данных
DL / I состоит из прикладных программ, которые предоставляют доступ к данным, хранящимся в базе данных. IMS DB использует DL / I, который служит языком интерфейса, который программисты используют для доступа к базе данных в прикладной программе. Мы обсудим это более подробно в следующих главах.
Характеристики IMS
Обращает на себя внимание —
- IMS поддерживает приложения из разных языков, таких как Java и XML.
- Приложения и данные IMS доступны на любой платформе.
- IMS DB обрабатывает очень быстро по сравнению с DB2.
Ограничения IMS
Обращает на себя внимание —
- Реализация БД IMS очень сложна.
- Предопределенная древовидная структура IMS снижает гибкость.
- БД IMS сложна в управлении.
IMS DB — Структура
Иерархическая структура
База данных IMS представляет собой набор данных, содержащих физические файлы. В иерархической базе данных самый верхний уровень содержит общую информацию об объекте. По мере продвижения от верхнего уровня к нижним уровням в иерархии, мы получаем все больше и больше информации о сущности.
Каждый уровень в иерархии содержит сегменты. В стандартных файлах сложно реализовать иерархии, но DL / I поддерживает иерархии. На следующем рисунке показана структура БД IMS.
сегмент
Обращает на себя внимание —
-
Сегмент создается путем группировки похожих данных.
-
Это наименьшая единица информации, которую DL / I передает в прикладную программу и из нее во время любой операции ввода-вывода.
-
Сегмент может иметь одно или несколько полей данных, сгруппированных вместе.
Сегмент создается путем группировки похожих данных.
Это наименьшая единица информации, которую DL / I передает в прикладную программу и из нее во время любой операции ввода-вывода.
Сегмент может иметь одно или несколько полей данных, сгруппированных вместе.
В следующем примере сегмент Student имеет четыре поля данных.
| Ученик | |||
|---|---|---|---|
| Номер рулона | название | Курс | Мобильный номер |
поле
Указывает на примечание
-
Поле — это отдельный фрагмент данных в сегменте. Например, Номер ролла, Имя, Курс и Номер мобильного телефона — это отдельные поля в сегменте Студента.
-
Сегмент состоит из связанных полей для сбора информации об объекте.
-
Поля могут быть использованы в качестве ключа для упорядочения сегментов.
-
Поля могут быть использованы в качестве классификатора для поиска информации о конкретном сегменте.
Поле — это отдельный фрагмент данных в сегменте. Например, Номер ролла, Имя, Курс и Номер мобильного телефона — это отдельные поля в сегменте Студента.
Сегмент состоит из связанных полей для сбора информации об объекте.
Поля могут быть использованы в качестве ключа для упорядочения сегментов.
Поля могут быть использованы в качестве классификатора для поиска информации о конкретном сегменте.
Тип сегмента
Обращает на себя внимание —
-
Тип сегмента — это категория данных в сегменте.
-
База данных DL / I может иметь 255 различных типов сегментов и 15 уровней иерархии.
-
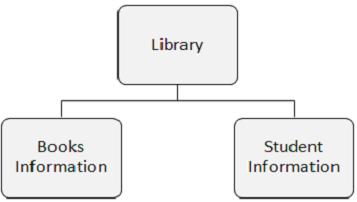
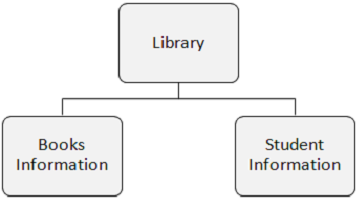
На следующем рисунке представлены три сегмента: библиотека, информация о книгах и информация о студентах.
Тип сегмента — это категория данных в сегменте.
База данных DL / I может иметь 255 различных типов сегментов и 15 уровней иерархии.
На следующем рисунке представлены три сегмента: библиотека, информация о книгах и информация о студентах.
Происхождение сегмента
Обращает на себя внимание —
-
Вхождение сегмента — это отдельный сегмент определенного типа, содержащий пользовательские данные. В приведенном выше примере «Информация о книгах» относится к одному типу сегмента и может иметь любое количество экземпляров, поскольку она может хранить информацию о любом количестве книг.
-
В базе данных IMS существует только одно вхождение каждого типа сегмента, но может быть неограниченное количество вхождений каждого типа сегмента.
Вхождение сегмента — это отдельный сегмент определенного типа, содержащий пользовательские данные. В приведенном выше примере «Информация о книгах» относится к одному типу сегмента и может иметь любое количество экземпляров, поскольку она может хранить информацию о любом количестве книг.
В базе данных IMS существует только одно вхождение каждого типа сегмента, но может быть неограниченное количество вхождений каждого типа сегмента.
IMS DB — DL / I Терминология
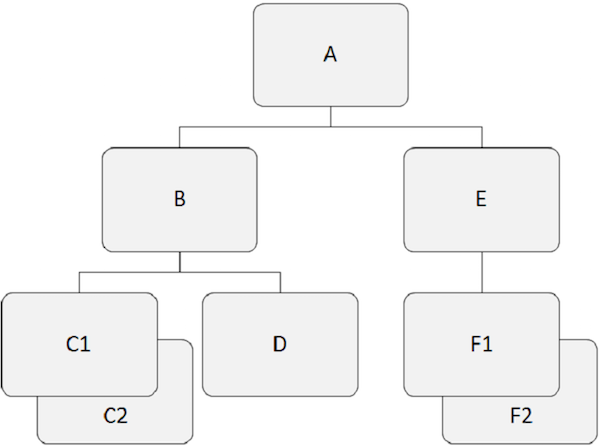
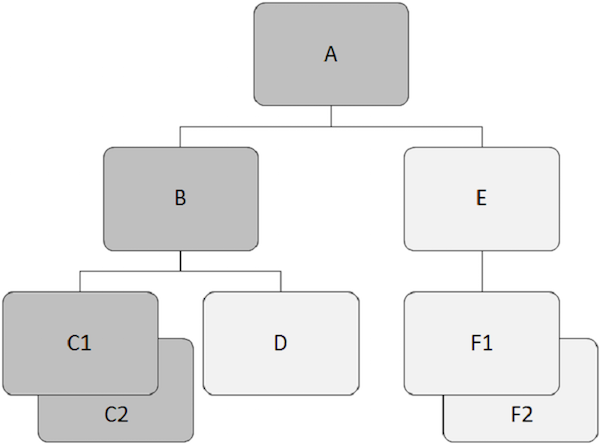
Иерархические базы данных работают над отношениями между двумя или более сегментами. В следующем примере показано, как сегменты связаны друг с другом в структуре базы данных IMS.
Корневой сегмент
Обращает на себя внимание —
-
Сегмент, который находится на вершине иерархии, называется корневым сегментом.
-
Корневой сегмент является единственным сегментом, через который осуществляется доступ ко всем зависимым сегментам.
-
Корневой сегмент является единственным сегментом в базе данных, который никогда не является дочерним сегментом.
-
В структуре базы данных IMS может быть только один корневой сегмент.
-
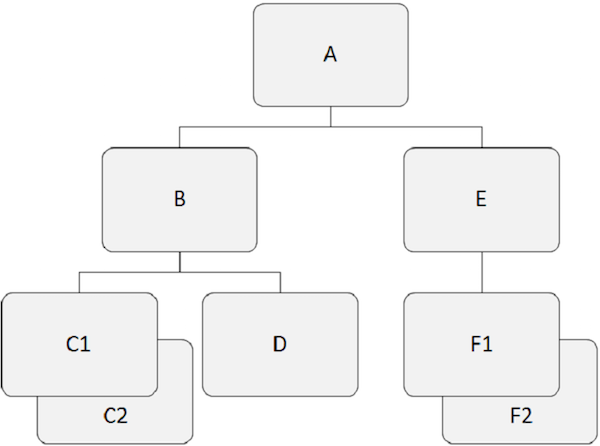
Например, «A» является корневым сегментом в приведенном выше примере.
Сегмент, который находится на вершине иерархии, называется корневым сегментом.
Корневой сегмент является единственным сегментом, через который осуществляется доступ ко всем зависимым сегментам.
Корневой сегмент является единственным сегментом в базе данных, который никогда не является дочерним сегментом.
В структуре базы данных IMS может быть только один корневой сегмент.
Например, «A» является корневым сегментом в приведенном выше примере.
Родительский сегмент
Обращает на себя внимание —
-
Родительский сегмент имеет один или несколько зависимых сегментов непосредственно под ним.
-
Например, «A» , «B» и «E» являются родительскими сегментами в вышеприведенном примере.
Родительский сегмент имеет один или несколько зависимых сегментов непосредственно под ним.
Например, «A» , «B» и «E» являются родительскими сегментами в вышеприведенном примере.
Зависимый сегмент
Обращает на себя внимание —
-
Все сегменты, кроме корневого сегмента, называются зависимыми сегментами.
-
Зависимые сегменты зависят от одного или нескольких сегментов для представления полного значения.
-
Например, «B», «C1», «C2», «D», «E», «F1» и «F2» являются зависимыми сегментами в нашем примере.
Все сегменты, кроме корневого сегмента, называются зависимыми сегментами.
Зависимые сегменты зависят от одного или нескольких сегментов для представления полного значения.
Например, «B», «C1», «C2», «D», «E», «F1» и «F2» являются зависимыми сегментами в нашем примере.
Детский сегмент
Обращает на себя внимание —
-
Любой сегмент, имеющий сегмент непосредственно над ним в иерархии, называется дочерним сегментом.
-
Каждый зависимый сегмент в структуре является дочерним сегментом.
-
Например, «B», «C1», «C2», «D», «E», «F1» и «F2» являются дочерними сегментами.
Любой сегмент, имеющий сегмент непосредственно над ним в иерархии, называется дочерним сегментом.
Каждый зависимый сегмент в структуре является дочерним сегментом.
Например, «B», «C1», «C2», «D», «E», «F1» и «F2» являются дочерними сегментами.
Двойные сегменты
Обращает на себя внимание —
-
Два или более вхождения сегмента определенного типа сегмента в одном родительском сегменте называются двойными сегментами.
-
Например, «C1» и «C2» — это двойные сегменты, также как «F1» и «F2» .
Два или более вхождения сегмента определенного типа сегмента в одном родительском сегменте называются двойными сегментами.
Например, «C1» и «C2» — это двойные сегменты, также как «F1» и «F2» .
Сегмент родного брата
Обращает на себя внимание —
-
Сегменты братьев и сестер — это сегменты разных типов и одного и того же родителя.
-
Например, «B» и «E» являются соседними сегментами. Точно так же «C1», «C2» и «D» являются соседними сегментами.
Сегменты братьев и сестер — это сегменты разных типов и одного и того же родителя.
Например, «B» и «E» являются соседними сегментами. Точно так же «C1», «C2» и «D» являются соседними сегментами.
Запись базы данных
Обращает на себя внимание —
-
Каждое вхождение корневого сегмента плюс все вхождения подчиненного сегмента составляют одну запись базы данных.
-
Каждая запись базы данных имеет только один корневой сегмент, но может иметь любое количество вхождений сегмента.
-
При стандартной обработке файлов запись — это единица данных, которую прикладная программа использует для определенных операций. В DL / I эта единица данных называется сегментом. Одна запись базы данных имеет много вхождений сегмента.
Каждое вхождение корневого сегмента плюс все вхождения подчиненного сегмента составляют одну запись базы данных.
Каждая запись базы данных имеет только один корневой сегмент, но может иметь любое количество вхождений сегмента.
При стандартной обработке файлов запись — это единица данных, которую прикладная программа использует для определенных операций. В DL / I эта единица данных называется сегментом. Одна запись базы данных имеет много вхождений сегмента.
Путь к базе данных
Обращает на себя внимание —
-
Путь — это серия сегментов, которая начинается от корневого сегмента записи базы данных до любого конкретного вхождения сегмента.
-
Путь в иерархической структуре не обязательно должен быть завершен до самого низкого уровня. Это зависит от того, сколько информации нам требуется о компании.
-
Путь должен быть непрерывным, и мы не можем пропустить промежуточные уровни в структуре.
-
На следующем рисунке дочерние записи темно-серого цвета показывают путь, который начинается с «A» и проходит через «C2» .
Путь — это серия сегментов, которая начинается от корневого сегмента записи базы данных до любого конкретного вхождения сегмента.
Путь в иерархической структуре не обязательно должен быть завершен до самого низкого уровня. Это зависит от того, сколько информации нам требуется о компании.
Путь должен быть непрерывным, и мы не можем пропустить промежуточные уровни в структуре.
На следующем рисунке дочерние записи темно-серого цвета показывают путь, который начинается с «A» и проходит через «C2» .
IMS DB — DL / I Обработка
БД IMS хранит данные на разных уровнях. Данные извлекаются и вставляются с помощью вызовов DL / I из прикладной программы. Мы подробно обсудим вызовы DL / I в следующих главах. Данные могут быть обработаны следующими двумя способами:
- Последовательная обработка
- Случайная обработка
Последовательная обработка
Когда сегменты извлекаются последовательно из базы данных, DL / I следует предварительно определенному шаблону. Давайте разберемся с последовательной обработкой БД IMS.
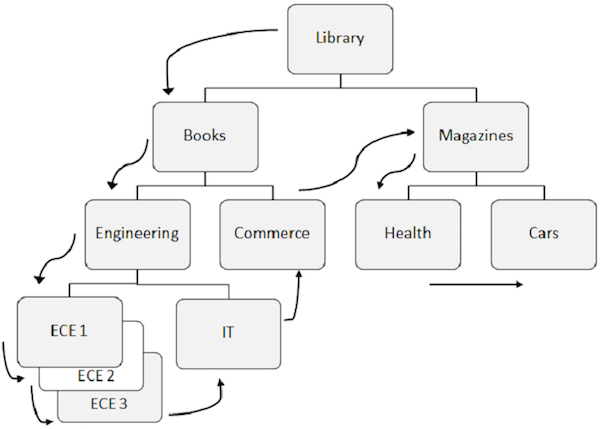
Ниже перечислены моменты, которые нужно отметить для последовательной обработки —
-
Предопределенный шаблон для доступа к данным в DL / I сначала идет вниз по иерархии, затем слева направо.
-
Сначала извлекается корневой сегмент, затем DL / I перемещается к первому левому потомку и опускается до самого низкого уровня. На самом низком уровне он извлекает все случаи двойных сегментов. Затем он идет в правый сегмент.
-
Для лучшего понимания просмотрите стрелки на приведенном выше рисунке, которые показывают порядок доступа к сегментам. Библиотека является корневым сегментом, и поток начинается оттуда и продолжается до автомобилей, чтобы получить доступ к одной записи. Тот же процесс повторяется для всех вхождений, чтобы получить все записи данных.
-
При доступе к данным программа использует позицию в базе данных, которая помогает извлекать и вставлять сегменты.
Предопределенный шаблон для доступа к данным в DL / I сначала идет вниз по иерархии, затем слева направо.
Сначала извлекается корневой сегмент, затем DL / I перемещается к первому левому потомку и опускается до самого низкого уровня. На самом низком уровне он извлекает все случаи двойных сегментов. Затем он идет в правый сегмент.
Для лучшего понимания просмотрите стрелки на приведенном выше рисунке, которые показывают порядок доступа к сегментам. Библиотека является корневым сегментом, и поток начинается оттуда и продолжается до автомобилей, чтобы получить доступ к одной записи. Тот же процесс повторяется для всех вхождений, чтобы получить все записи данных.
При доступе к данным программа использует позицию в базе данных, которая помогает извлекать и вставлять сегменты.
Случайная обработка
Случайная обработка также известна как прямая обработка данных в БД IMS. Давайте возьмем пример, чтобы понять случайную обработку в БД IMS —
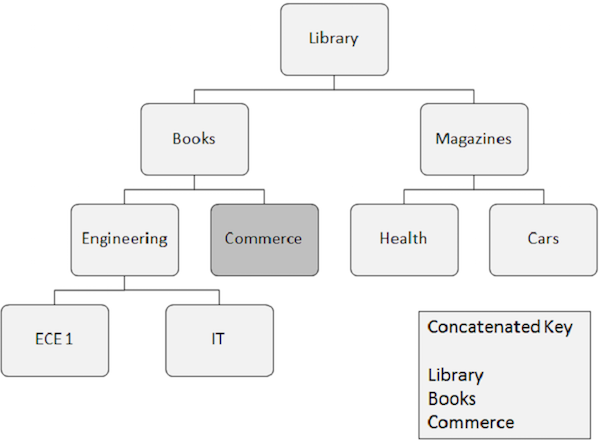
Ниже перечислены моменты, которые следует учитывать при случайной обработке.
-
Вхождение сегмента, которое необходимо получить случайным образом, требует наличия ключевых полей всех сегментов, от которых оно зависит. Эти ключевые поля предоставляются прикладной программой.
-
Связанный ключ полностью идентифицирует путь от корневого сегмента к сегменту, который вы хотите получить.
-
Предположим, что вы хотите получить экземпляр сегмента Commerce, а затем вам нужно указать значения сцепленных ключевых полей для сегментов, от которых он зависит, таких как Библиотека, Книги и Торговля.
-
Случайная обработка выполняется быстрее, чем последовательная. В реальном сценарии приложения объединяют как последовательные, так и случайные методы обработки для достижения наилучших результатов.
Вхождение сегмента, которое необходимо получить случайным образом, требует наличия ключевых полей всех сегментов, от которых оно зависит. Эти ключевые поля предоставляются прикладной программой.
Связанный ключ полностью идентифицирует путь от корневого сегмента к сегменту, который вы хотите получить.
Предположим, что вы хотите получить экземпляр сегмента Commerce, а затем вам нужно указать значения сцепленных ключевых полей для сегментов, от которых он зависит, таких как Библиотека, Книги и Торговля.
Случайная обработка выполняется быстрее, чем последовательная. В реальном сценарии приложения объединяют как последовательные, так и случайные методы обработки для достижения наилучших результатов.
Ключевое поле
Обращает на себя внимание —
-
Ключевое поле также называется полем последовательности.
-
Ключевое поле присутствует внутри сегмента и используется для получения вхождения сегмента.
-
Ключевое поле управляет появлением сегмента в порядке возрастания.
-
В каждом сегменте только одно поле может быть использовано в качестве ключевого поля или поля последовательности.
Ключевое поле также называется полем последовательности.
Ключевое поле присутствует внутри сегмента и используется для получения вхождения сегмента.
Ключевое поле управляет появлением сегмента в порядке возрастания.
В каждом сегменте только одно поле может быть использовано в качестве ключевого поля или поля последовательности.
Поле поиска
Как уже упоминалось, только одно поле может быть использовано в качестве ключевого поля. Если вы хотите искать содержимое других полей сегмента, которые не являются ключевыми, то поле, которое используется для извлечения данных, называется полем поиска.
IMS DB — блоки управления
Блоки управления IMS определяют структуру базы данных IMS и доступ к ним программы. Следующая диаграмма показывает структуру блоков управления IMS.
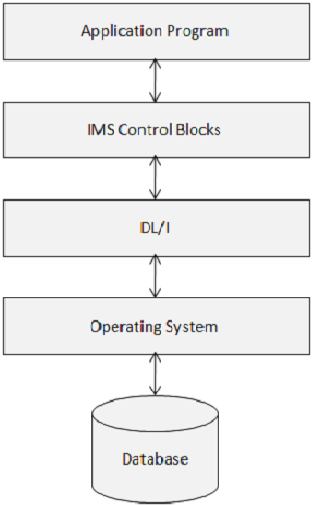
DL / I использует следующие три типа блоков управления —
- Дескриптор базы данных (DBD)
- Блок спецификации программы (PSB)
- Блок контроля доступа (ACB)
Дескриптор базы данных (DBD)
Обращает на себя внимание —
-
DBD описывает полную физическую структуру базы данных после определения всех сегментов.
-
При установке базы данных DL / I необходимо создать один DBD, поскольку он необходим для доступа к базе данных IMS.
-
Приложения могут использовать разные виды DBD. Они называются структурами данных приложений и указываются в блоке спецификации программы.
-
Администратор базы данных создает DBD путем кодирования управляющих операторов DBDGEN .
DBD описывает полную физическую структуру базы данных после определения всех сегментов.
При установке базы данных DL / I необходимо создать один DBD, поскольку он необходим для доступа к базе данных IMS.
Приложения могут использовать разные виды DBD. Они называются структурами данных приложений и указываются в блоке спецификации программы.
Администратор базы данных создает DBD путем кодирования управляющих операторов DBDGEN .
DBDGEN
DBDGEN — это генератор дескрипторов базы данных. Создание блоков управления является обязанностью администратора базы данных. Все загружаемые модули хранятся в библиотеке IMS. Операторы макроса языка ассемблера используются для создания блоков управления. Ниже приведен пример кода, который показывает, как создать DBD с помощью управляющих операторов DBDGEN —
PRINT NOGEN DBD NAME=LIBRARY,ACCESS=HIDAM DATASET DD1=LIB,DEVICE=3380 SEGM NAME=LIBSEG,PARENT=0,BYTES=10 FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5 FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9 FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C DBDGEN FINISH END
Позвольте нам понять термины, используемые в вышеупомянутом DBDGEN —
-
Когда вы выполняете вышеуказанные управляющие операторы в JCL , он создает физическую структуру, в которой LIBRARY является корневым сегментом, а BOOKS и MAGZINES — его дочерними сегментами.
-
Первый оператор макроса DBD идентифицирует базу данных. Здесь мы должны упомянуть ИМЯ и ДОСТУП, которые используются DL / I для доступа к этой базе данных.
-
Второй оператор макроса DATASET идентифицирует файл, содержащий базу данных.
-
Типы сегментов определяются с помощью макрокоманды SEGM. Нам нужно указать РОДИТЕЛЯ этого сегмента. Если это корневой сегмент, то упомяните PARENT = 0.
Когда вы выполняете вышеуказанные управляющие операторы в JCL , он создает физическую структуру, в которой LIBRARY является корневым сегментом, а BOOKS и MAGZINES — его дочерними сегментами.
Первый оператор макроса DBD идентифицирует базу данных. Здесь мы должны упомянуть ИМЯ и ДОСТУП, которые используются DL / I для доступа к этой базе данных.
Второй оператор макроса DATASET идентифицирует файл, содержащий базу данных.
Типы сегментов определяются с помощью макрокоманды SEGM. Нам нужно указать РОДИТЕЛЯ этого сегмента. Если это корневой сегмент, то упомяните PARENT = 0.
В следующей таблице приведены параметры, используемые в операторе макроса FIELD.
| S.No | Параметр и описание |
|---|---|
| 1 |
название Название поля, обычно от 1 до 8 символов |
| 2 |
Б Длина поля |
| 3 |
Начните Положение поля в сегменте |
| 4 |
Тип Тип данных поля |
| 5 |
Тип С Тип символьных данных |
| 6 |
Тип Р Упакованный десятичный тип данных |
| 7 |
Тип Z Зонный десятичный тип данных |
| 8 |
Тип Х Шестнадцатеричный тип данных |
| 9 |
Тип Н Полусловный двоичный тип данных |
| 10 |
Тип F Бинарный тип данных полного слова |
название
Название поля, обычно от 1 до 8 символов
Б
Длина поля
Начните
Положение поля в сегменте
Тип
Тип данных поля
Тип С
Тип символьных данных
Тип Р
Упакованный десятичный тип данных
Тип Z
Зонный десятичный тип данных
Тип Х
Шестнадцатеричный тип данных
Тип Н
Полусловный двоичный тип данных
Тип F
Бинарный тип данных полного слова
Блок спецификации программы (PSB)
Основные принципы общественного вещания приведены ниже.
-
База данных имеет единую физическую структуру, определяемую DBD, но прикладные программы, обрабатывающие ее, могут иметь разные представления базы данных. Эти представления называются структурой данных приложения и определяются в PSB.
-
Ни одна программа не может использовать более одного PSB в одном исполнении.
-
Прикладные программы имеют свой собственный PSB, и для прикладных программ, которые имеют схожие требования к обработке базы данных, обычно используется общий PSB.
-
PSB состоит из одного или нескольких блоков управления, называемых блоками программной связи (PCB). PSB содержит одну печатную плату для каждой базы данных DL / I, к которой будет обращаться прикладная программа. Мы обсудим больше о печатных платах в следующих модулях.
-
PSBGEN необходимо выполнить, чтобы создать PSB для программы.
База данных имеет единую физическую структуру, определяемую DBD, но прикладные программы, обрабатывающие ее, могут иметь разные представления базы данных. Эти представления называются структурой данных приложения и определяются в PSB.
Ни одна программа не может использовать более одного PSB в одном исполнении.
Прикладные программы имеют свой собственный PSB, и для прикладных программ, которые имеют схожие требования к обработке базы данных, обычно используется общий PSB.
PSB состоит из одного или нескольких блоков управления, называемых блоками программной связи (PCB). PSB содержит одну печатную плату для каждой базы данных DL / I, к которой будет обращаться прикладная программа. Мы обсудим больше о печатных платах в следующих модулях.
PSBGEN необходимо выполнить, чтобы создать PSB для программы.
PSBGEN
PSBGEN известен как генератор блоков спецификации программы. В следующем примере создается PSB с использованием PSBGEN —
PRINT NOGEN PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS SENSEG NAME=LIBSEG SENSEG NAME=BOOKSEG,PARENT=LIBSEG SENSEG NAME=MAGSEG,PARENT=LIBSEG PSBGEN PSBNAME=LIBPSB,LANG=COBOL END
Позвольте нам понять термины, используемые в вышеупомянутом DBDGEN —
-
Первый оператор макроса — это блок связи с программой (PCB), который описывает тип базы данных, имя, длину ключа и параметр обработки.
-
Параметр DBDNAME в макросе PCB указывает имя DBD. KEYLEN указывает длину самого длинного каскадного ключа. Программа может обрабатывать в базе данных. Параметр PROCOPT указывает параметры обработки программы. Например, LS означает только операции загрузки.
-
SENSEG известен как чувствительность уровня сегмента. Он определяет доступ программы к частям базы данных и определяется на уровне сегмента. Программа имеет доступ ко всем полям внутри сегментов, к которым она чувствительна. Программа также может иметь чувствительность на уровне поля. В этом мы определяем имя сегмента и родительское имя сегмента.
-
Последнее утверждение макроса — PCBGEN. PSBGEN — последнее утверждение, сообщающее, что больше нет операторов для обработки. PSBNAME определяет имя, данное выходному модулю PSB. Параметр LANG указывает язык, на котором написана прикладная программа, например, COBOL.
Первый оператор макроса — это блок связи с программой (PCB), который описывает тип базы данных, имя, длину ключа и параметр обработки.
Параметр DBDNAME в макросе PCB указывает имя DBD. KEYLEN указывает длину самого длинного каскадного ключа. Программа может обрабатывать в базе данных. Параметр PROCOPT указывает параметры обработки программы. Например, LS означает только операции загрузки.
SENSEG известен как чувствительность уровня сегмента. Он определяет доступ программы к частям базы данных и определяется на уровне сегмента. Программа имеет доступ ко всем полям внутри сегментов, к которым она чувствительна. Программа также может иметь чувствительность на уровне поля. В этом мы определяем имя сегмента и родительское имя сегмента.
Последнее утверждение макроса — PCBGEN. PSBGEN — последнее утверждение, сообщающее, что больше нет операторов для обработки. PSBNAME определяет имя, данное выходному модулю PSB. Параметр LANG указывает язык, на котором написана прикладная программа, например, COBOL.
Блок контроля доступа (ACB)
Ниже перечислены пункты, которые нужно отметить относительно блоков контроля доступа.
-
Блоки контроля доступа для прикладной программы объединяют дескриптор базы данных и блок спецификации программы в исполняемую форму.
-
ACBGEN известен как генератор блоков контроля доступа. Он используется для генерации ACB.
-
Для онлайн-программ нам нужно предварительно собрать ACB. Следовательно, утилита ACBGEN выполняется перед выполнением прикладной программы.
-
Для пакетных программ ACB могут быть сгенерированы также во время выполнения.
Блоки контроля доступа для прикладной программы объединяют дескриптор базы данных и блок спецификации программы в исполняемую форму.
ACBGEN известен как генератор блоков контроля доступа. Он используется для генерации ACB.
Для онлайн-программ нам нужно предварительно собрать ACB. Следовательно, утилита ACBGEN выполняется перед выполнением прикладной программы.
Для пакетных программ ACB могут быть сгенерированы также во время выполнения.
IMS DB — Программирование
Прикладная программа, включающая вызовы DL / I, не может выполняться напрямую. Вместо этого требуется JCL для запуска пакетного модуля IMS DL / I. Модуль пакетной инициализации в IMS — DFSRRC00. Прикладная программа и модуль DL / I выполняются вместе. На следующей диаграмме показана структура прикладной программы, которая включает вызовы DL / I для доступа к базе данных.
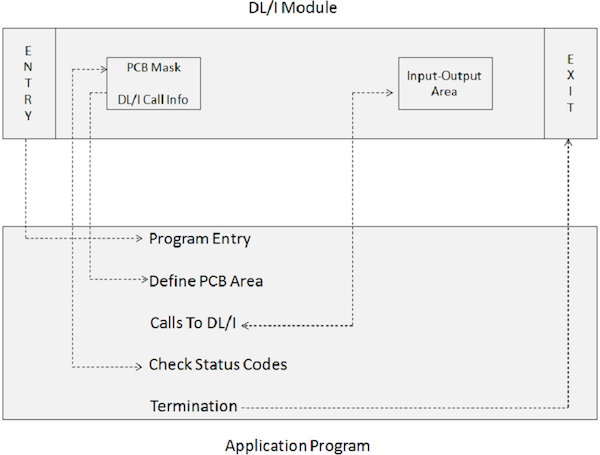
Прикладная программа взаимодействует с модулями IMS DL / I через следующие элементы программы:
-
Оператор ENTRY указывает, что печатные платы используются программой.
-
Маска печатной платы связана с информацией, сохраненной в предварительно сконструированной печатной плате, которая получает информацию возврата от IMS.
-
Область ввода-вывода используется для передачи сегментов данных в базу данных IMS и из нее.
-
В вызовах DL / I указываются такие функции обработки, как выборка, вставка, удаление, замена и т. Д.
-
Проверка кодов состояния используется для проверки кода возврата SQL указанного параметра обработки, чтобы сообщить, была ли операция успешной или нет.
-
Оператор Terminate используется для завершения обработки прикладной программы, которая включает DL / I.
Оператор ENTRY указывает, что печатные платы используются программой.
Маска печатной платы связана с информацией, сохраненной в предварительно сконструированной печатной плате, которая получает информацию возврата от IMS.
Область ввода-вывода используется для передачи сегментов данных в базу данных IMS и из нее.
В вызовах DL / I указываются такие функции обработки, как выборка, вставка, удаление, замена и т. Д.
Проверка кодов состояния используется для проверки кода возврата SQL указанного параметра обработки, чтобы сообщить, была ли операция успешной или нет.
Оператор Terminate используется для завершения обработки прикладной программы, которая включает DL / I.
Расположение сегментов
На данный момент мы узнали, что IMS состоит из сегментов, которые используются на языках программирования высокого уровня для доступа к данным. Рассмотрим следующую структуру базы данных IMS библиотеки, которую мы видели ранее, и здесь мы видим расположение ее сегментов в COBOL:
01 LIBRARY-SEGMENT. 05 BOOK-ID PIC X(5). 05 ISSUE-DATE PIC X(10). 05 RETURN-DATE PIC X(10). 05 STUDENT-ID PIC A(25). 01 BOOK-SEGMENT. 05 BOOK-ID PIC X(5). 05 BOOK-NAME PIC A(30). 05 AUTHOR PIC A(25). 01 STUDENT-SEGMENT. 05 STUDENT-ID PIC X(5). 05 STUDENT-NAME PIC A(25). 05 DIVISION PIC X(10).
Обзор прикладной программы
Структура прикладной программы IMS отличается от структуры прикладной программы не-IMS. Программа IMS не может быть выполнена напрямую; скорее это всегда называется подпрограммой. Прикладная программа IMS состоит из блоков спецификации программ, чтобы обеспечить просмотр базы данных IMS.
Прикладная программа и PSB, связанные с этой программой, загружаются, когда мы выполняем прикладную программу, которая включает модули IMS DL / I. Затем запросы CALL, запускаемые прикладными программами, выполняются модулем IMS.
IMS Services
Следующие службы IMS используются прикладной программой:
- Доступ к записям базы данных
- Выдача команд IMS
- Вызов сервисных вызовов IMS
- Звонки на контрольные точки
- Синхронизировать звонки
- Отправка или получение сообщений от онлайн-терминалов
IMS DB — основы кобола
Мы включаем вызовы DL / I в прикладную программу COBOL для связи с базой данных IMS. Мы используем следующие операторы DL / I в программе COBOL для доступа к базе данных —
- Заявление о въезде
- Заявление гобака
- Заявление о звонке
Заявление о въезде
Он используется для передачи управления из DL / I в программу COBOL. Вот синтаксис оператора ввода —
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]
Вышеупомянутое утверждение закодировано в Отделе процедур программы COBOL. Давайте углубимся в детали оператора ввода в программе COBOL —
-
Модуль пакетной инициализации запускает прикладную программу и выполняется под его контролем.
-
DL / I загружает необходимые блоки управления и модули, а также прикладную программу, и управление передается прикладной программе.
-
DLITCBL означает DL / I для COBOL . Оператор ввода используется для определения точки входа в программу.
-
Когда мы вызываем подпрограмму на языке COBOL, ее адрес также предоставляется. Аналогично, когда DL / I передает управление прикладной программе, он также предоставляет адрес каждой печатной платы, определенной в PSB программы.
-
Все печатные платы, используемые в прикладной программе, должны быть определены в разделе связывания программы COBOL, поскольку печатная плата находится за пределами прикладной программы.
-
Определение печатной платы внутри секции связывания называется маской печатной платы .
-
Связь между масками печатных плат и фактическими печатными платами в хранилище создается путем перечисления печатных плат в операторе ввода. Последовательность перечисления в операторе ввода должна быть такой же, как они появляются в PSBGEN.
Модуль пакетной инициализации запускает прикладную программу и выполняется под его контролем.
DL / I загружает необходимые блоки управления и модули, а также прикладную программу, и управление передается прикладной программе.
DLITCBL означает DL / I для COBOL . Оператор ввода используется для определения точки входа в программу.
Когда мы вызываем подпрограмму на языке COBOL, ее адрес также предоставляется. Аналогично, когда DL / I передает управление прикладной программе, он также предоставляет адрес каждой печатной платы, определенной в PSB программы.
Все печатные платы, используемые в прикладной программе, должны быть определены в разделе связывания программы COBOL, поскольку печатная плата находится за пределами прикладной программы.
Определение печатной платы внутри секции связывания называется маской печатной платы .
Связь между масками печатных плат и фактическими печатными платами в хранилище создается путем перечисления печатных плат в операторе ввода. Последовательность перечисления в операторе ввода должна быть такой же, как они появляются в PSBGEN.
Заявление гобака
Он используется для передачи управления обратно в программу управления IMS. Ниже приводится синтаксис оператора Goback —
GOBACK
Ниже перечислены основные моменты, которые следует отметить в отношении заявления Гобака:
-
GOBACK кодируется в конце прикладной программы. Возвращает управление DL / I из программы.
-
Мы не должны использовать STOP RUN, поскольку это возвращает управление операционной системе. Если мы используем STOP RUN, DL / I никогда не получит возможности выполнить свои завершающие функции. Вот почему в прикладных программах DL / I используется оператор Goback.
-
Перед выполнением оператора Goback все наборы данных не-DL / I, используемые в прикладной программе COBOL, должны быть закрыты, в противном случае программа будет аварийно завершена.
GOBACK кодируется в конце прикладной программы. Возвращает управление DL / I из программы.
Мы не должны использовать STOP RUN, поскольку это возвращает управление операционной системе. Если мы используем STOP RUN, DL / I никогда не получит возможности выполнить свои завершающие функции. Вот почему в прикладных программах DL / I используется оператор Goback.
Перед выполнением оператора Goback все наборы данных не-DL / I, используемые в прикладной программе COBOL, должны быть закрыты, в противном случае программа будет аварийно завершена.
Заявление о звонке
Оператор вызова используется для запроса услуг DL / I, таких как выполнение определенных операций с базой данных IMS. Вот синтаксис оператора вызова —
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Синтаксис выше показывает параметры, которые вы можете использовать с оператором вызова. Мы обсудим каждый из них в следующей таблице —
| S.No. | Параметр и описание |
|---|---|
| 1 |
Код функции DLI Определяет функцию DL / I для выполнения. Этот аргумент является именем четырехсимвольных полей, которые описывают операцию ввода / вывода. |
| 2 |
PCB Mask Определение печатной платы внутри секции связывания называется маской печатной платы. Они используются в заявлении на вход. Операторы SELECT, ASSIGN, OPEN или CLOSE не требуются. |
| 3 |
Область ввода / вывода сегмента Название рабочей области ввода / вывода. Это область прикладной программы, в которую DL / I помещает запрошенный сегмент. |
| 4 |
Сегмент поиска аргументов Это необязательные параметры в зависимости от типа звонка. Они используются для поиска сегментов данных в базе данных IMS. |
Код функции DLI
Определяет функцию DL / I для выполнения. Этот аргумент является именем четырехсимвольных полей, которые описывают операцию ввода / вывода.
PCB Mask
Определение печатной платы внутри секции связывания называется маской печатной платы. Они используются в заявлении на вход. Операторы SELECT, ASSIGN, OPEN или CLOSE не требуются.
Область ввода / вывода сегмента
Название рабочей области ввода / вывода. Это область прикладной программы, в которую DL / I помещает запрошенный сегмент.
Сегмент поиска аргументов
Это необязательные параметры в зависимости от типа звонка. Они используются для поиска сегментов данных в базе данных IMS.
Ниже приведены пункты, которые нужно отметить в отношении оператора Call.
-
CBLTDLI расшифровывается как COBOL для DL / I. Это имя интерфейсного модуля, ссылка на который редактируется с помощью объектного модуля вашей программы.
-
После каждого вызова DL / I DLI сохраняет код состояния на печатной плате. Программа может использовать этот код, чтобы определить, был ли вызов успешным или неудачным.
CBLTDLI расшифровывается как COBOL для DL / I. Это имя интерфейсного модуля, ссылка на который редактируется с помощью объектного модуля вашей программы.
После каждого вызова DL / I DLI сохраняет код состояния на печатной плате. Программа может использовать этот код, чтобы определить, был ли вызов успешным или неудачным.
пример
Для более глубокого понимания COBOL, вы можете пройти наш учебник COBOL здесь . В следующем примере показана структура программы на языке COBOL, которая использует базу данных IMS и вызовы DL / I. Мы подробно обсудим каждый из параметров, использованных в примере в следующих главах.
IDENTIFICATION DIVISION. PROGRAM-ID. TEST1. DATA DIVISION. WORKING-STORAGE SECTION. 01 DLI-FUNCTIONS. 05 DLI-GU PIC X(4) VALUE 'GU '. 05 DLI-GHU PIC X(4) VALUE 'GHU '. 05 DLI-GN PIC X(4) VALUE 'GN '. 05 DLI-GHN PIC X(4) VALUE 'GHN '. 05 DLI-GNP PIC X(4) VALUE 'GNP '. 05 DLI-GHNP PIC X(4) VALUE 'GHNP'. 05 DLI-ISRT PIC X(4) VALUE 'ISRT'. 05 DLI-DLET PIC X(4) VALUE 'DLET'. 05 DLI-REPL PIC X(4) VALUE 'REPL'. 05 DLI-CHKP PIC X(4) VALUE 'CHKP'. 05 DLI-XRST PIC X(4) VALUE 'XRST'. 05 DLI-PCB PIC X(4) VALUE 'PCB '. 01 SEGMENT-I-O-AREA PIC X(150). LINKAGE SECTION. 01 STUDENT-PCB-MASK. 05 STD-DBD-NAME PIC X(8). 05 STD-SEGMENT-LEVEL PIC XX. 05 STD-STATUS-CODE PIC XX. 05 STD-PROC-OPTIONS PIC X(4). 05 FILLER PIC S9(5) COMP. 05 STD-SEGMENT-NAME PIC X(8). 05 STD-KEY-LENGTH PIC S9(5) COMP. 05 STD-NUMB-SENS-SEGS PIC S9(5) COMP. 05 STD-KEY PIC X(11). PROCEDURE DIVISION. ENTRY 'DLITCBL' USING STUDENT-PCB-MASK. A000-READ-PARA. 110-GET-INVENTORY-SEGMENT. CALL ‘CBLTDLI’ USING DLI-GN STUDENT-PCB-MASK SEGMENT-I-O-AREA. GOBACK.
IMS DB — DL / I Функции
Функция DL / I — это первый параметр, который используется в вызове DL / I. Эта функция сообщает, какая операция будет выполняться в базе данных IMS с помощью вызова IMS DL / I. Синтаксис функции DL / I следующий:
01 DLI-FUNCTIONS. 05 DLI-GU PIC X(4) VALUE 'GU '. 05 DLI-GHU PIC X(4) VALUE 'GHU '. 05 DLI-GN PIC X(4) VALUE 'GN '. 05 DLI-GHN PIC X(4) VALUE 'GHN '. 05 DLI-GNP PIC X(4) VALUE 'GNP '. 05 DLI-GHNP PIC X(4) VALUE 'GHNP'. 05 DLI-ISRT PIC X(4) VALUE 'ISRT'. 05 DLI-DLET PIC X(4) VALUE 'DLET'. 05 DLI-REPL PIC X(4) VALUE 'REPL'. 05 DLI-CHKP PIC X(4) VALUE 'CHKP'. 05 DLI-XRST PIC X(4) VALUE 'XRST'. 05 DLI-PCB PIC X(4) VALUE 'PCB '.
Этот синтаксис представляет следующие ключевые моменты —
-
Для этого параметра мы можем предоставить любое четырехзначное имя в качестве поля хранения для хранения кода функции.
-
Функциональный параметр DL / I кодируется в разделе рабочего хранилища программы COBOL.
-
Для указания функции DL / I программисту необходимо кодировать одно из имен данных уровня 05, таких как DLI-GU, в вызове DL / I, поскольку COBOL не позволяет кодировать литералы в операторе CALL.
-
Функции DL / I разделены на три категории: функции «Получить», «Обновить» и «Другие». Давайте обсудим каждый из них подробно.
Для этого параметра мы можем предоставить любое четырехзначное имя в качестве поля хранения для хранения кода функции.
Функциональный параметр DL / I кодируется в разделе рабочего хранилища программы COBOL.
Для указания функции DL / I программисту необходимо кодировать одно из имен данных уровня 05, таких как DLI-GU, в вызове DL / I, поскольку COBOL не позволяет кодировать литералы в операторе CALL.
Функции DL / I разделены на три категории: функции «Получить», «Обновить» и «Другие». Давайте обсудим каждый из них подробно.
Получить функции
Функции Get аналогичны операции чтения, поддерживаемой любым языком программирования. Функция Get используется для извлечения сегментов из базы данных IMS DL / I. Следующие функции Get используются в IMS DB —
- Получить уникальный
- Получить следующий
- Получить следующий в рамках родительского
- Get Hold Unique
- Get Hold Next
- Держись рядом с родителем
Давайте рассмотрим следующую структуру базы данных IMS, чтобы понять вызовы функций DL / I:
Получить уникальный
Код GU используется для функции Get Unique. Он работает так же, как оператор случайного чтения в языке COBOL. Он используется для выборки конкретного вхождения сегмента на основе значений поля. Значения полей могут быть предоставлены с использованием аргументов поиска сегмента. Синтаксис вызова GU выглядит следующим образом:
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Если вы выполнили приведенный выше оператор вызова, предоставив соответствующие значения для всех параметров в программе COBOL, вы можете извлечь сегмент в области ввода / вывода сегмента из базы данных. В приведенном выше примере, если вы предоставите значения полей «Библиотека», «Журналы» и «Здоровье», вы получите желаемое вхождение сегмента «Здоровье».
Получить следующий
Код GN используется для функции Get Next. Он работает аналогично следующему утверждению в COBOL. Он используется для извлечения вхождений сегмента в последовательности. Предопределенный шаблон для доступа к вхождениям сегментов данных располагается вниз по иерархии, затем слева направо. Синтаксис вызова GN выглядит следующим образом:
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Если вы выполнили вышеуказанный оператор вызова, предоставив соответствующие значения для всех параметров в программе COBOL, вы можете извлечь вхождение сегмента в область ввода-вывода сегмента из базы данных в последовательном порядке. В приведенном выше примере он начинается с доступа к сегменту библиотеки, затем к сегменту книг и т. Д. Мы выполняем вызов GN снова и снова, пока не достигнем нужного вхождения сегмента.
Получить следующий в рамках родительского
Код GNP используется для Get Next в Parent. Эта функция используется для извлечения вхождений сегмента в последовательности, подчиненной установленному родительскому сегменту. Синтаксис вызова ВНП выглядит следующим образом:
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Get Hold Unique
Код «GHU» используется для Get Hold Unique. Функция Hold указывает, что мы собираемся обновить сегмент после извлечения. Функция Get Hold Unique соответствует вызову Get Unique. Ниже приведен синтаксис вызова GHU —
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Get Hold Next
Код «GHN» используется для Get Hold Next. Функция Hold указывает, что мы собираемся обновить сегмент после извлечения. Функция Get Hold Next соответствует вызову Get Next. Ниже приведен синтаксис вызова GHN —
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Держись рядом с родителем
Код «GHNP» используется для Get Hold Next в Parent. Функция Hold указывает, что мы собираемся обновить сегмент после извлечения. Функция Get Hold Next в Parent соответствует функции Get Next в Parent. Ниже приведен синтаксис вызова GHNP —
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Функции обновления
Функции обновления аналогичны операциям перезаписи или вставки на любом другом языке программирования. Функции обновления используются для обновления сегментов в базе данных IMS DL / I. Перед использованием функции обновления должен быть успешный вызов с предложением Hold для вхождения сегмента. В базе данных IMS используются следующие функции обновления:
- Вставить
- удалять
- замещать
Вставить
Код ISRT используется для функции вставки. Функция ISRT используется для добавления нового сегмента в базу данных. Он используется для изменения существующей базы данных или загрузки новой базы данных. Ниже приведен синтаксис вызова ISRT —
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]
удалять
Код «DLET» используется для функции «Удалить». Он используется для удаления сегмента из базы данных IMS DL / I. Ниже приведен синтаксис вызова DLET —
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]
замещать
Код «REPL» используется для Get Hold Next в Parent. Функция Replace используется для замены сегмента в базе данных IMS DL / I. Ниже приведен синтаксис вызова REPL —
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Другие функции
Следующие другие функции используются в вызовах IMS DL / I —
- Контрольно-пропускной пункт
- Запустить снова
- печатная плата
Контрольно-пропускной пункт
Код «CHKP» используется для функции Checkpoint. Он используется в функциях восстановления IMS. Ниже приведен синтаксис вызова CHKP —
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Запустить снова
Код XRST используется для функции перезапуска. Он используется в функциях перезапуска IMS. Ниже приведен синтаксис вызова XRST —
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]
печатная плата
Функция PCB используется в программах CICS в базе данных IMS DL / I. Ниже приведен синтаксис вызова PCB —
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]
Вы можете найти более подробную информацию об этих функциях в главе восстановления.
IMS DB — PCB Mask
PCB расшифровывается как Program Communication Block. PCB Mask — это второй параметр, используемый в вызове DL / I. Это объявлено в разделе ссылок. Ниже приведен синтаксис маски PCB —
01 PCB-NAME. 05 DBD-NAME PIC X(8). 05 SEG-LEVEL PIC XX. 05 STATUS-CODE PIC XX. 05 PROC-OPTIONS PIC X(4). 05 RESERVED-DLI PIC S9(5). 05 SEG-NAME PIC X(8). 05 LENGTH-FB-KEY PIC S9(5). 05 NUMB-SENS-SEGS PIC S9(5). 05 KEY-FB-AREA PIC X(n).
Вот ключевые моменты, чтобы отметить —
-
Для каждой базы данных DL / I поддерживает область хранения, которая называется блоком связи с программой. Он хранит информацию о базе данных, доступ к которой осуществляется внутри прикладных программ.
-
Оператор ENTRY создает соединение между масками печатных плат в секции Linkage и печатными платами в PSB программы. Маски PCB, используемые в вызове DL / I, указывают, какую базу данных использовать для работы.
-
Можно предположить, что это похоже на указание имени файла в операторе COBOL READ или имени записи в операторе записи COBOL. Операторы SELECT, ASSIGN, OPEN или CLOSE не требуются.
-
После каждого вызова DL / I DL / I сохраняет код состояния на печатной плате, и программа может использовать этот код, чтобы определить, был ли вызов успешным или неудачным.
Для каждой базы данных DL / I поддерживает область хранения, которая называется блоком связи с программой. Он хранит информацию о базе данных, доступ к которой осуществляется внутри прикладных программ.
Оператор ENTRY создает соединение между масками печатных плат в секции Linkage и печатными платами в PSB программы. Маски PCB, используемые в вызове DL / I, указывают, какую базу данных использовать для работы.
Можно предположить, что это похоже на указание имени файла в операторе COBOL READ или имени записи в операторе записи COBOL. Операторы SELECT, ASSIGN, OPEN или CLOSE не требуются.
После каждого вызова DL / I DL / I сохраняет код состояния на печатной плате, и программа может использовать этот код, чтобы определить, был ли вызов успешным или неудачным.
Название печатной платы
Обращает на себя внимание —
-
Имя печатной платы — это название области, которая относится ко всей структуре полей печатной платы.
-
Имя PCB используется в программных заявлениях.
-
Имя печатной платы не является полем в печатной плате.
Имя печатной платы — это название области, которая относится ко всей структуре полей печатной платы.
Имя PCB используется в программных заявлениях.
Имя печатной платы не является полем в печатной плате.
Имя DBD
Обращает на себя внимание —
-
Имя DBD содержит символьные данные. Это восемь байтов в длину.
-
Первое поле в PCB — это имя обрабатываемой базы данных, и оно содержит имя DBD из библиотеки описаний базы данных, связанной с конкретной базой данных.
Имя DBD содержит символьные данные. Это восемь байтов в длину.
Первое поле в PCB — это имя обрабатываемой базы данных, и оно содержит имя DBD из библиотеки описаний базы данных, связанной с конкретной базой данных.
Уровень сегмента
Обращает на себя внимание —
-
Уровень сегмента известен как Индикатор уровня иерархии сегментов. Он содержит символьные данные и имеет длину два байта.
-
Поле уровня сегмента хранит уровень сегмента, который был обработан. Когда сегмент извлекается успешно, номер уровня извлеченного сегмента сохраняется здесь.
-
Поле уровня сегмента никогда не имеет значения больше 15, поскольку это максимальное количество уровней, разрешенных в базе данных DL / I.
Уровень сегмента известен как Индикатор уровня иерархии сегментов. Он содержит символьные данные и имеет длину два байта.
Поле уровня сегмента хранит уровень сегмента, который был обработан. Когда сегмент извлекается успешно, номер уровня извлеченного сегмента сохраняется здесь.
Поле уровня сегмента никогда не имеет значения больше 15, поскольку это максимальное количество уровней, разрешенных в базе данных DL / I.
Код состояния
Обращает на себя внимание —
-
Поле кода состояния содержит два байта символьных данных.
-
Код состояния содержит код состояния DL / I.
-
Пробелы перемещаются в поле кода состояния, когда DL / I успешно завершает обработку вызовов.
-
Непустые значения указывают, что вызов не был успешным.
-
Код состояния GB указывает конец файла, а код состояния GE указывает, что запрошенный сегмент не найден.
Поле кода состояния содержит два байта символьных данных.
Код состояния содержит код состояния DL / I.
Пробелы перемещаются в поле кода состояния, когда DL / I успешно завершает обработку вызовов.
Непустые значения указывают, что вызов не был успешным.
Код состояния GB указывает конец файла, а код состояния GE указывает, что запрошенный сегмент не найден.
Параметры Proc
Обращает на себя внимание —
-
Параметры процесса известны как параметры обработки, которые содержат поля данных из четырех символов.
-
Поле «Параметр обработки» указывает, какую обработку программа может выполнять в базе данных.
Параметры процесса известны как параметры обработки, которые содержат поля данных из четырех символов.
Поле «Параметр обработки» указывает, какую обработку программа может выполнять в базе данных.
Зарезервированный DL / I
Обращает на себя внимание —
-
Зарезервированный DL / I известен как зарезервированная область IMS. Он хранит четырехбайтовые двоичные данные.
-
IMS использует эту область для собственной внутренней связи, связанной с прикладной программой.
Зарезервированный DL / I известен как зарезервированная область IMS. Он хранит четырехбайтовые двоичные данные.
IMS использует эту область для собственной внутренней связи, связанной с прикладной программой.
Имя сегмента
Обращает на себя внимание —
-
Имя SEG известно как область обратной связи имени сегмента. Содержит 8 байтов символьных данных.
-
Имя сегмента сохраняется в этом поле после каждого вызова DL / I.
Имя SEG известно как область обратной связи имени сегмента. Содержит 8 байтов символьных данных.
Имя сегмента сохраняется в этом поле после каждого вызова DL / I.
Длина ключа FB
Обращает на себя внимание —
-
Длина клавиши FB известна как длина области обратной связи ключа. Он хранит четыре байта двоичных данных.
-
Это поле используется для сообщения длины связанного ключа сегмента самого низкого уровня, обработанного во время предыдущего вызова.
-
Используется с ключевой областью обратной связи.
Длина клавиши FB известна как длина области обратной связи ключа. Он хранит четыре байта двоичных данных.
Это поле используется для сообщения длины связанного ключа сегмента самого низкого уровня, обработанного во время предыдущего вызова.
Используется с ключевой областью обратной связи.
Количество сегментов чувствительности
Обращает на себя внимание —
-
Количество сегментов чувствительности хранит четырехбайтовые двоичные данные.
-
Он определяет уровень чувствительности прикладной программы. Он представляет собой количество сегментов в логической структуре данных.
Количество сегментов чувствительности хранит четырехбайтовые двоичные данные.
Он определяет уровень чувствительности прикладной программы. Он представляет собой количество сегментов в логической структуре данных.
Ключевая область обратной связи
Обращает на себя внимание —
-
Основная область обратной связи варьируется по длине от одной печатной платы до другой.
-
Он содержит максимально длинный каскадный ключ, который можно использовать с программным представлением базы данных.
-
После операции с базой данных DL / I возвращает сцепленный ключ сегмента самого низкого уровня, обработанного в этом поле, и возвращает длину ключа в области обратной связи длины ключа.
Основная область обратной связи варьируется по длине от одной печатной платы до другой.
Он содержит максимально длинный каскадный ключ, который можно использовать с программным представлением базы данных.
После операции с базой данных DL / I возвращает сцепленный ключ сегмента самого низкого уровня, обработанного в этом поле, и возвращает длину ключа в области обратной связи длины ключа.
IMS DB — SSA
SSA означает «Аргументы поиска сегмента». SSA используется для идентификации вхождения сегмента, к которому осуществляется доступ. Это необязательный параметр. Мы можем включить любое количество SSA в зависимости от требования. Есть два типа SSA —
- Неквалифицированный SSA
- Квалифицированный SSA
Неквалифицированный SSA
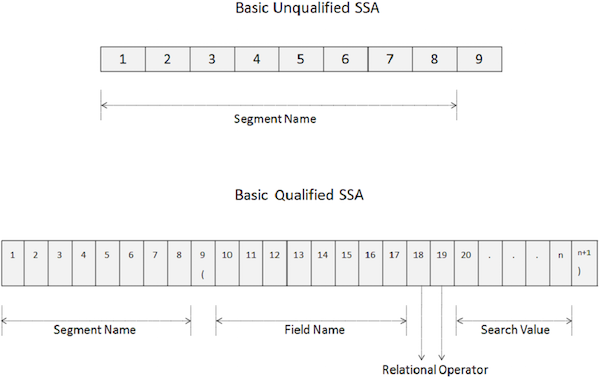
Неквалифицированный SSA предоставляет имя сегмента, используемого внутри вызова. Ниже приведен синтаксис неквалифицированного SSA —
01 UNQUALIFIED-SSA. 05 SEGMENT-NAME PIC X(8). 05 FILLER PIC X VALUE SPACE.
Ключевые пункты неквалифицированного SSA следующие:
-
Базовый неквалифицированный SSA имеет длину 9 байтов.
-
Первые 8 байтов содержат имя сегмента, которое используется для обработки.
-
Последний байт всегда содержит пробел.
-
DL / I использует последний байт для определения типа SSA.
-
Чтобы получить доступ к определенному сегменту, переместите имя сегмента в поле ИМЯ СЕГМЕНТА.
Базовый неквалифицированный SSA имеет длину 9 байтов.
Первые 8 байтов содержат имя сегмента, которое используется для обработки.
Последний байт всегда содержит пробел.
DL / I использует последний байт для определения типа SSA.
Чтобы получить доступ к определенному сегменту, переместите имя сегмента в поле ИМЯ СЕГМЕНТА.
Следующие изображения показывают структуры неквалифицированных и квалифицированных SSA —
Квалифицированный SSA
Квалифицированный SSA предоставляет типу сегмента конкретное вхождение базы данных в сегмент. Ниже приведен синтаксис квалифицированного SSA —
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.
Ключевые пункты квалифицированного SSA следующие:
-
Первые 8 байтов квалифицированного SSA содержат имя сегмента, используемое для обработки.
-
Девятый байт — это левая скобка ‘(‘.
-
Следующие 8 байтов, начиная с десятой позиции, указывают имя поля, которое мы хотим найти.
-
После имени поля в 18- й и 19- й позициях указывается двухсимвольный код реляционного оператора.
-
Затем мы указываем значение поля и в последнем байте есть правая скобка ‘)’.
Первые 8 байтов квалифицированного SSA содержат имя сегмента, используемое для обработки.
Девятый байт — это левая скобка ‘(‘.
Следующие 8 байтов, начиная с десятой позиции, указывают имя поля, которое мы хотим найти.
После имени поля в 18- й и 19- й позициях указывается двухсимвольный код реляционного оператора.
Затем мы указываем значение поля и в последнем байте есть правая скобка ‘)’.
В следующей таблице показаны реляционные операторы, используемые в квалифицированном SSA.
| Оператор связи | Условное обозначение | Описание |
|---|---|---|
| EQ | знак равно | равных |
| Небраска | ~ = ˜ | Не равный |
| GT | > | Лучше чем |
| GE | > = | Больше или равно |
| LT | << | Меньше, чем |
| LE | <= | Меньше или равно |
Командные коды
Коды команд используются для улучшения функциональности вызовов DL / I. Коды команд уменьшают количество вызовов DL / I, делая программы простыми. Кроме того, это повышает производительность, так как количество вызовов уменьшается. На следующем рисунке показано, как коды команд используются в неквалифицированных и квалифицированных SSA —
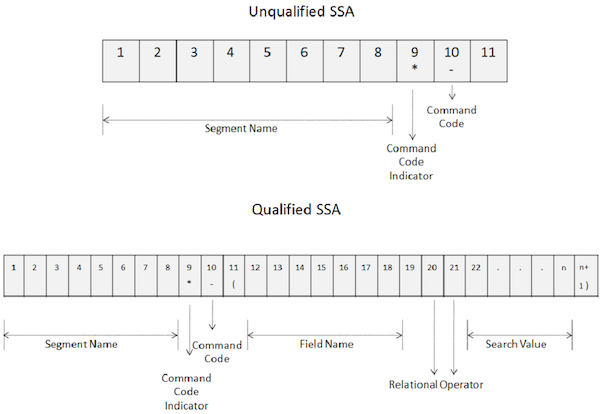
Ключевые пункты командных кодов следующие:
-
Чтобы использовать коды команд, укажите звездочку в 9- й позиции SSA, как показано на рисунке выше.
-
Код команды кодируется на десятой позиции.
-
Начиная с 10- й позиции, DL / I рассматривает все символы как коды команд, пока не встретит пробел для неквалифицированного SSA и левую скобку для квалифицированного SSA.
Чтобы использовать коды команд, укажите звездочку в 9- й позиции SSA, как показано на рисунке выше.
Код команды кодируется на десятой позиции.
Начиная с 10- й позиции, DL / I рассматривает все символы как коды команд, пока не встретит пробел для неквалифицированного SSA и левую скобку для квалифицированного SSA.
В следующей таблице приведен список кодов команд, используемых в SSA —
| Код команды | Описание |
|---|---|
| С | Сцепленный ключ |
| D | Путь вызова |
| F | Первое появление |
| L | Последнее вхождение |
| N | Путь вызова игнорируется |
| п | Установить Происхождение |
| Q | Сегмент Enqueue |
| U | Поддерживать позицию на этом уровне |
| В | Поддерживать позицию на этом и всех вышеперечисленных уровнях |
| — | Нулевой код команды |
Несколько квалификаций
Основные пункты нескольких квалификаций следующие:
-
Многократные квалификации требуются, когда нам нужно использовать две или более квалификации или поля для сравнения.
-
Мы используем логические операторы, такие как AND и OR, чтобы соединить две или более квалификаций.
-
Можно использовать несколько квалификаций, когда мы хотим обработать сегмент на основе диапазона возможных значений для одного поля.
Многократные квалификации требуются, когда нам нужно использовать две или более квалификации или поля для сравнения.
Мы используем логические операторы, такие как AND и OR, чтобы соединить две или более квалификаций.
Можно использовать несколько квалификаций, когда мы хотим обработать сегмент на основе диапазона возможных значений для одного поля.
Ниже приведен синтаксис множественных квалификаций —
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.
MUL-QUAL — это краткий термин для MULtiple QUALIification, в котором мы можем предоставить логические операторы, такие как AND или OR.
IMS DB — извлечение данных
Различные методы извлечения данных, используемые в вызовах IMS DL / I, следующие:
- GU Call
- GN Call
- Использование командных кодов
- Многократная Обработка
Давайте рассмотрим следующую структуру базы данных IMS, чтобы понять вызовы функций поиска данных:
GU Call
Основы вызова ГУ следующие:
-
Вызов ГУ известен как Получить уникальный вызов. Используется для случайной обработки.
-
Если приложение не обновляет базу данных регулярно или количество обновлений базы данных меньше, мы используем случайную обработку.
-
Вызов GU используется для размещения указателя в определенной позиции для дальнейшего последовательного поиска.
-
Вызовы GU не зависят от позиции указателя, установленной предыдущими вызовами.
-
Обработка вызовов ГУ основана на уникальных ключевых полях, указанных в операторе вызова.
-
Если мы предоставляем ключевое поле, которое не является уникальным, то DL / I возвращает вхождение первого сегмента ключевого поля.
Вызов ГУ известен как Получить уникальный вызов. Используется для случайной обработки.
Если приложение не обновляет базу данных регулярно или количество обновлений базы данных меньше, мы используем случайную обработку.
Вызов GU используется для размещения указателя в определенной позиции для дальнейшего последовательного поиска.
Вызовы GU не зависят от позиции указателя, установленной предыдущими вызовами.
Обработка вызовов ГУ основана на уникальных ключевых полях, указанных в операторе вызова.
Если мы предоставляем ключевое поле, которое не является уникальным, то DL / I возвращает вхождение первого сегмента ключевого поля.
CALL 'CBLTDLI' USING DLI-GU PCB-NAME IO-AREA LIBRARY-SSA BOOKS-SSA ENGINEERING-SSA IT-SSA
Приведенный выше пример показывает, что мы выполняем вызов GU, предоставляя полный набор квалифицированных SSA. Он включает в себя все ключевые поля, начиная с корневого уровня до вхождения сегмента, который мы хотим получить.
GU Call Соображения
Если мы не предоставляем полный набор квалифицированных SSA в вызове, то DL / I работает следующим образом —
-
Когда мы используем неквалифицированный SSA в вызове GU, DL / I получает доступ к первому вхождению сегмента в базе данных, которое соответствует указанным вами критериям.
-
Когда мы выполняем вызов GU без каких-либо SSA, DL / I возвращает первое вхождение корневого сегмента в базу данных.
-
Если некоторые SSA на промежуточных уровнях не упоминаются в вызове, то DL / I использует либо установленную позицию, либо значение по умолчанию неквалифицированного SSA для сегмента.
Когда мы используем неквалифицированный SSA в вызове GU, DL / I получает доступ к первому вхождению сегмента в базе данных, которое соответствует указанным вами критериям.
Когда мы выполняем вызов GU без каких-либо SSA, DL / I возвращает первое вхождение корневого сегмента в базу данных.
Если некоторые SSA на промежуточных уровнях не упоминаются в вызове, то DL / I использует либо установленную позицию, либо значение по умолчанию неквалифицированного SSA для сегмента.
Коды состояния
В следующей таблице показаны соответствующие коды состояния после вызова ГУ —
| S.No | Код состояния и описание |
|---|---|
| 1 |
пространства Успешный звонок |
| 2 |
GE DL / Я не смог найти сегмент, отвечающий критериям, указанным в звонке |
пространства
Успешный звонок
GE
DL / Я не смог найти сегмент, отвечающий критериям, указанным в звонке
GN Call
Основы GN call следующие:
-
Звонок GN называется вызовом Get Next. Используется для базовой последовательной обработки.
-
Начальная позиция указателя в базе данных находится перед корневым сегментом первой записи базы данных.
-
Положение указателя базы данных находится перед следующим появлением сегмента в последовательности после успешного вызова GN.
-
Вызов GN начинается через базу данных с позиции, установленной предыдущим вызовом.
-
Если вызов GN неквалифицирован, он возвращает следующее вхождение сегмента в базу данных независимо от его типа в иерархической последовательности.
-
Если вызов GN включает SSA, то DL / I извлекает только те сегменты, которые соответствуют требованиям всех указанных SSA.
Звонок GN называется вызовом Get Next. Используется для базовой последовательной обработки.
Начальная позиция указателя в базе данных находится перед корневым сегментом первой записи базы данных.
Положение указателя базы данных находится перед следующим появлением сегмента в последовательности после успешного вызова GN.
Вызов GN начинается через базу данных с позиции, установленной предыдущим вызовом.
Если вызов GN неквалифицирован, он возвращает следующее вхождение сегмента в базу данных независимо от его типа в иерархической последовательности.
Если вызов GN включает SSA, то DL / I извлекает только те сегменты, которые соответствуют требованиям всех указанных SSA.
CALL 'CBLTDLI' USING DLI-GN PCB-NAME IO-AREA BOOKS-SSA
Приведенный выше пример показывает, что мы выполняем вызов GN, обеспечивающий начальную позицию для последовательного чтения записей. Он получает первое вхождение сегмента BOOKS.
Коды состояния
В следующей таблице приведены соответствующие коды состояния после вызова GN —
| S.No | Код состояния и описание |
|---|---|
| 1 |
пространства Успешный звонок |
| 2 |
GE DL / Я не смог найти сегмент, отвечающий критериям, указанным в вызове. |
| 3 |
Джорджия Неквалифицированный вызов GN перемещается на один уровень вверх по иерархии базы данных для извлечения сегмента. |
| 4 |
гигабайт Конец базы данных достигнут, а сегмент не найден. |
|
Г.К. Неквалифицированный вызов GN пытается извлечь сегмент определенного типа, отличный от только что извлеченного, но остается на том же уровне иерархии. |
пространства
Успешный звонок
GE
DL / Я не смог найти сегмент, отвечающий критериям, указанным в вызове.
Джорджия
Неквалифицированный вызов GN перемещается на один уровень вверх по иерархии базы данных для извлечения сегмента.
гигабайт
Конец базы данных достигнут, а сегмент не найден.
Г.К.
Неквалифицированный вызов GN пытается извлечь сегмент определенного типа, отличный от только что извлеченного, но остается на том же уровне иерархии.
Командные коды
Коды команд используются с вызовами для получения вхождения сегмента. Различные коды команд, используемые с вызовами, обсуждаются ниже.
Код команды F
Обращает на себя внимание —
-
Когда в команде указан код команды F, этот вызов обрабатывает первое вхождение сегмента.
-
Коды F-команд можно использовать, когда мы хотим обрабатывать последовательно, и их можно использовать с вызовами GN и вызовами GNP.
-
Если мы указываем код команды F с помощью вызова GU, это не имеет никакого значения, поскольку вызовы GU по умолчанию извлекают вхождение первого сегмента.
Когда в команде указан код команды F, этот вызов обрабатывает первое вхождение сегмента.
Коды F-команд можно использовать, когда мы хотим обрабатывать последовательно, и их можно использовать с вызовами GN и вызовами GNP.
Если мы указываем код команды F с помощью вызова GU, это не имеет никакого значения, поскольку вызовы GU по умолчанию извлекают вхождение первого сегмента.
L Код команды
Обращает на себя внимание —
-
Когда в вызове указан код команды L, этот вызов обрабатывает последнее вхождение сегмента.
-
Коды команд L могут использоваться, когда мы хотим обрабатывать последовательно, и это может использоваться с вызовами GN и вызовами GNP.
Когда в вызове указан код команды L, этот вызов обрабатывает последнее вхождение сегмента.
Коды команд L могут использоваться, когда мы хотим обрабатывать последовательно, и это может использоваться с вызовами GN и вызовами GNP.
Код команды D
Обращает на себя внимание —
-
Код команды D используется для выборки более чем одного вхождения сегмента, используя всего один вызов.
-
Обычно DL / I работает с сегментом самого низкого уровня, указанным в SSA, но во многих случаях нам нужны данные и с других уровней. В этих случаях мы можем использовать код команды D.
-
Код команды D облегчает поиск по всему пути сегментов.
Код команды D используется для выборки более чем одного вхождения сегмента, используя всего один вызов.
Обычно DL / I работает с сегментом самого низкого уровня, указанным в SSA, но во многих случаях нам нужны данные и с других уровней. В этих случаях мы можем использовать код команды D.
Код команды D облегчает поиск по всему пути сегментов.
Код команды С
Обращает на себя внимание —
-
Код команды C используется для объединения ключей.
-
Использование реляционных операторов немного сложнее, так как нам нужно указать имя поля, реляционный оператор и значение поиска. Вместо этого мы можем использовать код команды C для предоставления связанного ключа.
Код команды C используется для объединения ключей.
Использование реляционных операторов немного сложнее, так как нам нужно указать имя поля, реляционный оператор и значение поиска. Вместо этого мы можем использовать код команды C для предоставления связанного ключа.
В следующем примере показано использование кода команды C —
01 LOCATION-SSA. 05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘. 05 LIBRARY-SSA PIC X(5). 05 BOOKS-SSA PIC X(4). 05 ENGINEERING-SSA PIC X(6). 05 IT-SSA PIC X(3) 05 FILLER PIC X VALUE ‘)’. CALL 'CBLTDLI' USING DLI-GU PCB-NAME IO-AREA LOCATION-SSA
Код команды P
Обращает на себя внимание —
-
Когда мы выполняем вызов GU или GN, DL / I устанавливает свое происхождение в сегменте самого низкого уровня, который извлекается.
-
Если мы включим код команды P, то DL / I устанавливает свое происхождение в сегменте более высокого уровня в иерархическом пути.
Когда мы выполняем вызов GU или GN, DL / I устанавливает свое происхождение в сегменте самого низкого уровня, который извлекается.
Если мы включим код команды P, то DL / I устанавливает свое происхождение в сегменте более высокого уровня в иерархическом пути.
Код команды U
Обращает на себя внимание —
-
Когда в неквалифицированном SSA в вызове GN указан код команды U, DL / I ограничивает поиск сегмента.
-
Код команды U игнорируется, если он используется с квалифицированным SSA.
Когда в неквалифицированном SSA в вызове GN указан код команды U, DL / I ограничивает поиск сегмента.
Код команды U игнорируется, если он используется с квалифицированным SSA.
V Код команды
Обращает на себя внимание —
-
Код команды V работает аналогично коду команды U, но он ограничивает поиск сегмента на определенном уровне и всех уровнях выше иерархии.
-
Код команды V игнорируется при использовании с квалифицированным SSA.
Код команды V работает аналогично коду команды U, но он ограничивает поиск сегмента на определенном уровне и всех уровнях выше иерархии.
Код команды V игнорируется при использовании с квалифицированным SSA.
Код Q команды
Обращает на себя внимание —
-
Код команды Q используется для постановки в очередь или резервирования сегмента для эксклюзивного использования вашей прикладной программой.
-
Код команды Q используется в интерактивной среде, где другая программа может внести изменения в сегмент.
Код команды Q используется для постановки в очередь или резервирования сегмента для эксклюзивного использования вашей прикладной программой.
Код команды Q используется в интерактивной среде, где другая программа может внести изменения в сегмент.
Многократная Обработка
Программа может иметь несколько позиций в базе данных IMS, которая называется многократной обработкой. Многократную обработку можно выполнить двумя способами:
- Несколько печатных плат
- Многократное Позиционирование
Несколько печатных плат
Несколько плат могут быть определены для одной базы данных. Если имеется несколько печатных плат, то прикладная программа может иметь разные представления о ней. Этот метод для реализации множественной обработки неэффективен из-за накладных расходов, налагаемых дополнительными печатными платами.
Многократное Позиционирование
Программа может поддерживать несколько позиций в базе данных, используя одну печатную плату. Это достигается путем поддержания отдельной позиции для каждого иерархического пути. Множественное позиционирование используется для одновременного доступа к сегментам двух или более типов.
IMS DB — манипулирование данными
Ниже перечислены различные методы обработки данных, используемые в вызовах IMS DL / I.
- ISRT Call
- Получить удержание звонков
- REPL Call
- DLET Call
Давайте рассмотрим следующую структуру базы данных IMS для понимания вызовов функций манипулирования данными:
ISRT Call
Обращает на себя внимание —
-
Вызов ISRT известен как вызов вставки, который используется для добавления экземпляров сегментов в базу данных.
-
Звонки ISRT используются для загрузки новой базы данных.
-
Мы запускаем вызов ISRT, когда в поле описания сегмента загружаются данные.
-
Неквалифицированный или квалифицированный SSA должен быть указан в вызове, чтобы DL / I знал, где разместить вхождение сегмента.
-
Мы можем использовать комбинацию как неквалифицированного, так и квалифицированного SSA в вызове. Квалифицированный SSA может быть указан для всех вышеперечисленных уровней. Давайте рассмотрим следующий пример —
Вызов ISRT известен как вызов вставки, который используется для добавления экземпляров сегментов в базу данных.
Звонки ISRT используются для загрузки новой базы данных.
Мы запускаем вызов ISRT, когда в поле описания сегмента загружаются данные.
Неквалифицированный или квалифицированный SSA должен быть указан в вызове, чтобы DL / I знал, где разместить вхождение сегмента.
Мы можем использовать комбинацию как неквалифицированного, так и квалифицированного SSA в вызове. Квалифицированный SSA может быть указан для всех вышеперечисленных уровней. Давайте рассмотрим следующий пример —
CALL 'CBLTDLI' USING DLI-ISRT PCB-NAME IO-AREA LIBRARY-SSA BOOKS-SSA UNQUALIFIED-ENGINEERING-SSA
Приведенный выше пример показывает, что мы выполняем вызов ISRT, предоставляя комбинацию квалифицированных и неквалифицированных SSA.
Когда новый сегмент, который мы вставляем, имеет уникальное ключевое поле, он добавляется в правильную позицию. Если ключевое поле не уникально, оно добавляется по правилам, определенным администратором базы данных.
Когда мы выполняем вызов ISRT без указания ключевого поля, тогда правило вставки сообщает, где разместить сегменты относительно существующих двойных сегментов. Ниже приведены правила вставки —
-
Первый — если правило является первым, новый сегмент добавляется перед любыми существующими близнецами.
-
Последний — если правило является последним, новый сегмент добавляется после всех существующих двойников.
-
Здесь — если правило здесь, оно добавляется в текущей позиции относительно существующих близнецов, которые могут быть первыми, последними или где угодно.
Первый — если правило является первым, новый сегмент добавляется перед любыми существующими близнецами.
Последний — если правило является последним, новый сегмент добавляется после всех существующих двойников.
Здесь — если правило здесь, оно добавляется в текущей позиции относительно существующих близнецов, которые могут быть первыми, последними или где угодно.
Коды состояния
В следующей таблице показаны соответствующие коды состояния после вызова ISRT.
| S.No | Код состояния и описание |
|---|---|
| 1 |
пространства Успешный звонок |
| 2 |
GE Используются несколько SSA, и DL / I не может удовлетворить вызов с указанным путем. |
| 3 |
II Попробуйте добавить вхождение сегмента, которое уже присутствует в базе данных. |
| 4 |
LB / LC LD / LE Мы получаем эти коды состояния при обработке загрузки. В большинстве случаев они указывают, что вы не вставляете сегменты в точной иерархической последовательности. |
пространства
Успешный звонок
GE
Используются несколько SSA, и DL / I не может удовлетворить вызов с указанным путем.
II
Попробуйте добавить вхождение сегмента, которое уже присутствует в базе данных.
LB / LC LD / LE
Мы получаем эти коды состояния при обработке загрузки. В большинстве случаев они указывают, что вы не вставляете сегменты в точной иерархической последовательности.
Get Hold Call
Обращает на себя внимание —
-
Существует три типа вызовов Get Hold, которые мы указываем в вызове DL / I:
-
Get Hold Unique (GHU)
-
Get Hold Next (GHN)
-
Держись дальше внутри родителя (GHNP)
-
-
Функция Hold указывает, что мы собираемся обновить сегмент после извлечения. Поэтому перед вызовом REPL или DLET должен быть выполнен успешный вызов удержания, сообщающий DL / I о намерении обновить базу данных.
Существует три типа вызовов Get Hold, которые мы указываем в вызове DL / I:
Get Hold Unique (GHU)
Get Hold Next (GHN)
Держись дальше внутри родителя (GHNP)
Функция Hold указывает, что мы собираемся обновить сегмент после извлечения. Поэтому перед вызовом REPL или DLET должен быть выполнен успешный вызов удержания, сообщающий DL / I о намерении обновить базу данных.
REPL Call
Обращает на себя внимание —
-
После успешного вызова удержания мы выполняем вызов REPL, чтобы обновить вхождение сегмента.
-
Мы не можем изменить длину сегмента с помощью вызова REPL.
-
Мы не можем изменить значение ключевого поля с помощью вызова REPL.
-
Мы не можем использовать квалифицированный SSA с вызовом REPL. Если мы укажем квалифицированный SSA, вызов не будет выполнен.
После успешного вызова удержания мы выполняем вызов REPL, чтобы обновить вхождение сегмента.
Мы не можем изменить длину сегмента с помощью вызова REPL.
Мы не можем изменить значение ключевого поля с помощью вызова REPL.
Мы не можем использовать квалифицированный SSA с вызовом REPL. Если мы укажем квалифицированный SSA, вызов не будет выполнен.
CALL 'CBLTDLI' USING DLI-GHU PCB-NAME IO-AREA LIBRARY-SSA BOOKS-SSA ENGINEERING-SSA IT-SSA. *Move the values which you want to update in IT segment occurrence* CALL ‘CBLTDLI’ USING DLI-REPL PCB-NAME IO-AREA.
Приведенный выше пример обновляет вхождение сегмента IT с помощью вызова REPL. Сначала мы запускаем вызов GHU, чтобы получить вхождение сегмента, которое мы хотим обновить. Затем мы выполняем вызов REPL, чтобы обновить значения этого сегмента.
DLET Call
Обращает на себя внимание —
-
Вызов DLET работает так же, как и вызов REPL.
-
После успешного вызова get hold мы выполняем вызов DLET, чтобы удалить вхождение сегмента.
-
Мы не можем использовать квалифицированный SSA с вызовом DLET. Если мы укажем квалифицированный SSA, вызов не будет выполнен.
Вызов DLET работает так же, как и вызов REPL.
После успешного вызова get hold мы выполняем вызов DLET, чтобы удалить вхождение сегмента.
Мы не можем использовать квалифицированный SSA с вызовом DLET. Если мы укажем квалифицированный SSA, вызов не будет выполнен.
CALL 'CBLTDLI' USING DLI-GHU PCB-NAME IO-AREA LIBRARY-SSA BOOKS-SSA ENGINEERING-SSA IT-SSA. CALL ‘CBLTDLI’ USING DLI-DLET PCB-NAME IO-AREA.
Приведенный выше пример удаляет вхождение сегмента IT с помощью вызова DLET. Сначала мы вызываем вызов GHU, чтобы получить вхождение сегмента, которое мы хотим удалить. Затем мы запускаем вызов DLET для обновления значений этого сегмента.
Коды состояния
В следующей таблице показаны соответствующие коды состояния после вызова REPL или DLET.
| S.No | Код состояния и описание |
|---|---|
| 1 |
пространства Успешный звонок |
| 2 |
AJ Квалифицированный SSA, используемый для вызовов REPL или DLET. |
| 3 |
диджей Программа выдает вызов замены без непосредственного вызова удержания вызова. |
| 4 |
DA Программа вносит изменения в ключевое поле сегмента перед выполнением вызова REPL или DLET. |
пространства
Успешный звонок
AJ
Квалифицированный SSA, используемый для вызовов REPL или DLET.
диджей
Программа выдает вызов замены без непосредственного вызова удержания вызова.
DA
Программа вносит изменения в ключевое поле сегмента перед выполнением вызова REPL или DLET.
IMS DB — вторичная индексация
Вторичное индексирование используется, когда мы хотим получить доступ к базе данных без использования полного объединенного ключа или когда мы не хотим использовать первичные поля последовательности.
Сегмент указателя индекса
DL / I хранит указатель на сегменты индексированной базы данных в отдельной базе данных. Сегмент указателя индекса является единственным типом вторичного индекса. Он состоит из двух частей —
- Префикс Элемент
- Элемент данных
Префикс Элемент
Префиксная часть сегмента указателя индекса содержит указатель на целевой сегмент индекса. Целевой сегмент индекса — это сегмент, доступный с использованием вторичного индекса.
Элемент данных
Элемент данных содержит значение ключа из сегмента в индексированной базе данных, на которой построен индекс. Это также называется сегментом источника индекса.
Вот ключевые моменты, которые следует отметить о вторичной индексации:
-
Сегмент источника индекса и целевой сегмент источника не обязательно должны совпадать.
-
Когда мы устанавливаем вторичный индекс, он автоматически поддерживается DL / I.
-
DBA определяет много вторичных индексов в соответствии с путями множественного доступа. Эти вторичные индексы хранятся в отдельной базе данных индексов.
-
Мы не должны создавать больше вторичных индексов, поскольку они накладывают дополнительные накладные расходы на обработку DL / I.
Сегмент источника индекса и целевой сегмент источника не обязательно должны совпадать.
Когда мы устанавливаем вторичный индекс, он автоматически поддерживается DL / I.
DBA определяет много вторичных индексов в соответствии с путями множественного доступа. Эти вторичные индексы хранятся в отдельной базе данных индексов.
Мы не должны создавать больше вторичных индексов, поскольку они накладывают дополнительные накладные расходы на обработку DL / I.
Вторичные ключи
Обращает на себя внимание —
-
Поле в сегменте источника индекса, над которым построен вторичный индекс, называется вторичным ключом.
-
Любое поле может быть использовано в качестве вторичного ключа. Это не должно быть поле последовательности сегментов.
-
Вторичные ключи могут быть любой комбинацией отдельных полей в сегменте источника индекса.
-
Значения вторичного ключа не должны быть уникальными.
Поле в сегменте источника индекса, над которым построен вторичный индекс, называется вторичным ключом.
Любое поле может быть использовано в качестве вторичного ключа. Это не должно быть поле последовательности сегментов.
Вторичные ключи могут быть любой комбинацией отдельных полей в сегменте источника индекса.
Значения вторичного ключа не должны быть уникальными.
Вторичные структуры данных
Обращает на себя внимание —
-
Когда мы создаем вторичный индекс, видимая иерархическая структура базы данных также изменяется.
-
Целевой сегмент индекса становится видимым корневым сегментом. Как показано на следующем рисунке, инженерный сегмент становится корневым, даже если он не является корневым.
-
Перестройка структуры базы данных, вызванная вторичным индексом, называется вторичной структурой данных.
-
Вторичные структуры данных не вносят никаких изменений в основную физическую структуру базы данных, присутствующую на диске. Это просто способ изменить структуру базы данных перед прикладной программой.
Когда мы создаем вторичный индекс, видимая иерархическая структура базы данных также изменяется.
Целевой сегмент индекса становится видимым корневым сегментом. Как показано на следующем рисунке, инженерный сегмент становится корневым, даже если он не является корневым.
Перестройка структуры базы данных, вызванная вторичным индексом, называется вторичной структурой данных.
Вторичные структуры данных не вносят никаких изменений в основную физическую структуру базы данных, присутствующую на диске. Это просто способ изменить структуру базы данных перед прикладной программой.
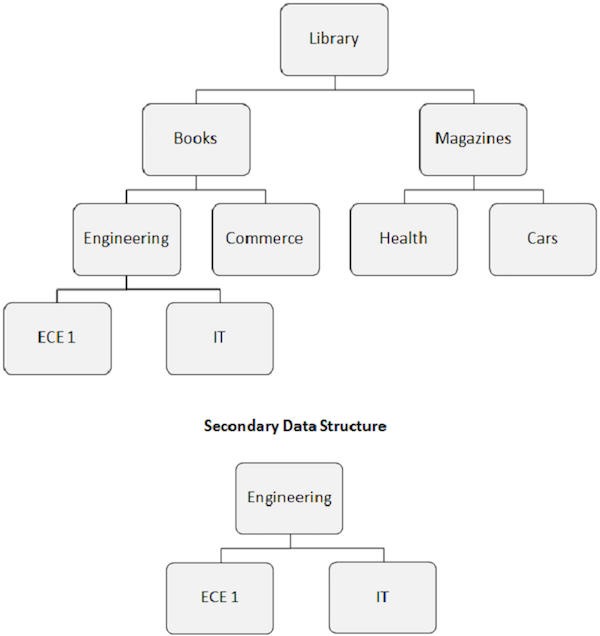
Независимый оператор
Обращает на себя внимание —
-
Когда оператор AND (* или &) используется со вторичными индексами, он называется зависимым оператором AND.
-
Независимое AND (#) позволяет нам определять квалификации, которые были бы невозможны с зависимым AND.
-
Этот оператор может использоваться только для вторичных индексов, где сегмент источника индекса зависит от целевого сегмента индекса.
-
Мы можем закодировать SSA с независимым AND, чтобы указать, что вхождение целевого сегмента будет обрабатываться на основе полей в двух или более зависимых исходных сегментах.
Когда оператор AND (* или &) используется со вторичными индексами, он называется зависимым оператором AND.
Независимое AND (#) позволяет нам определять квалификации, которые были бы невозможны с зависимым AND.
Этот оператор может использоваться только для вторичных индексов, где сегмент источника индекса зависит от целевого сегмента индекса.
Мы можем закодировать SSA с независимым AND, чтобы указать, что вхождение целевого сегмента будет обрабатываться на основе полей в двух или более зависимых исходных сегментах.
01 ITEM-SELECTION-SSA. 05 FILLER PIC X(8). 05 FILLER PIC X(1) VALUE '('. 05 FILLER PIC X(10). 05 SSA-KEY-1 PIC X(8). 05 FILLER PIC X VALUE '#'. 05 FILLER PIC X(10). 05 SSA-KEY-2 PIC X(8). 05 FILLER PIC X VALUE ')'.
Редкая последовательность
Обращает на себя внимание —
-
Разреженное секвенирование также известно как Разреженное индексирование. Мы можем удалить некоторые из исходных сегментов индекса из индекса, используя разреженную последовательность с базой данных вторичного индекса.
-
Разреженная последовательность используется для улучшения производительности. Когда некоторые вхождения исходного сегмента индекса не используются, мы можем удалить это.
-
DL / I использует значение подавления или подпрограмму подавления, или и то, и другое, чтобы определить, следует ли индексировать сегмент.
-
Если значение поля последовательности в сегменте источника индекса соответствует значению подавления, то связь с индексом не устанавливается.
-
Подпрограмма подавления — это написанная пользователем программа, которая оценивает сегмент и определяет, следует ли его индексировать.
-
Когда используется разреженная индексация, ее функции обрабатываются DL / I. Нам не нужно делать специальные условия для этого в прикладной программе.
Разреженное секвенирование также известно как Разреженное индексирование. Мы можем удалить некоторые из исходных сегментов индекса из индекса, используя разреженную последовательность с базой данных вторичного индекса.
Разреженная последовательность используется для улучшения производительности. Когда некоторые вхождения исходного сегмента индекса не используются, мы можем удалить это.
DL / I использует значение подавления или подпрограмму подавления, или и то, и другое, чтобы определить, следует ли индексировать сегмент.
Если значение поля последовательности в сегменте источника индекса соответствует значению подавления, то связь с индексом не устанавливается.
Подпрограмма подавления — это написанная пользователем программа, которая оценивает сегмент и определяет, следует ли его индексировать.
Когда используется разреженная индексация, ее функции обрабатываются DL / I. Нам не нужно делать специальные условия для этого в прикладной программе.
Требования DBDGEN
Как обсуждалось в предыдущих модулях, DBDGEN используется для создания DBD. Когда мы создаем вторичные индексы, участвуют две базы данных. Администратор баз данных должен создать два DBD, используя два DBDGEN для создания связи между индексированной базой данных и вторичной индексированной базой данных.
Требования PSBGEN
После создания вторичного индекса для базы данных администратор базы данных должен создать PSB. PSBGEN для программы указывает правильную последовательность обработки для базы данных в параметре PROCSEQ макроса PSB. Для параметра PROCSEQ DBA кодирует имя DBD для базы данных вторичного индекса.
IMS DB — логическая база данных
В базе данных IMS есть правило, согласно которому у каждого типа сегмента может быть только один родительский элемент. Это ограничивает сложность физической базы данных. Многие приложения DL / I требуют сложной структуры, которая позволяет сегменту иметь два родительских типа сегмента. Чтобы преодолеть это ограничение, DL / I позволяет администратору баз данных реализовывать логические отношения, в которых сегмент может иметь как физических, так и логических родителей. Мы можем создать дополнительные отношения в одной физической базе данных. Новая структура данных после реализации логических отношений называется логической базой данных.
Логическая связь
Логическое отношение имеет следующие свойства —
-
Логические отношения — это путь между двумя сегментами, которые связаны логически, а не физически.
-
Обычно между отдельными базами данных устанавливается логическая связь. Но возможно иметь связь между сегментами одной конкретной базы данных.
Логические отношения — это путь между двумя сегментами, которые связаны логически, а не физически.
Обычно между отдельными базами данных устанавливается логическая связь. Но возможно иметь связь между сегментами одной конкретной базы данных.
На следующем рисунке показаны две разные базы данных. Одна — это база данных студентов, а другая — база данных библиотеки. Мы создаем логическую связь между сегментом «Выпущенные книги» из базы данных «Студент» и сегментом «Книги» из базы данных «Библиотека».
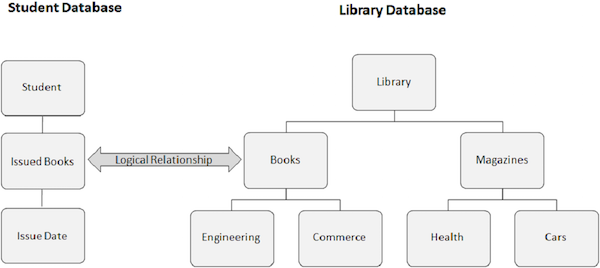
Вот как выглядит логическая база данных при создании логических отношений —
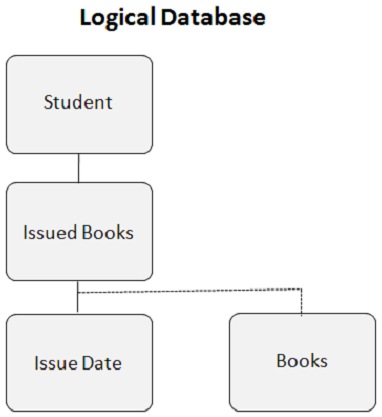
Логический дочерний сегмент
Логический дочерний сегмент является основой логических отношений. Это физический сегмент данных, но для DL / I кажется, что у него два родителя. Сегмент Книги в приведенном выше примере имеет два родительских сегмента. Сегмент выпущенных книг является логическим родителем, а сегмент библиотеки — физическим родителем. Одно вхождение логического дочернего сегмента имеет только одно вхождение логического родительского сегмента, и одно вхождение логического родительского сегмента может иметь много вхождений логического дочернего сегмента.
Логические близнецы
Логические двойники — это вхождения типа логического дочернего сегмента, все они подчинены одному вхождению типа логического родительского сегмента. DL / I делает логический дочерний сегмент похожим на фактический физический дочерний сегмент. Это также известно как виртуальный логический дочерний сегмент.
Типы логических отношений
DBA создает логические отношения между сегментами. Для реализации логической связи администратор базы данных должен указать ее в DBDGEN для задействованных физических баз данных. Есть три типа логических отношений —
- однонаправленный
- Двунаправленный Виртуальный
- Двунаправленный Физический
однонаправленный
Логическое соединение переходит от логического потомка к логическому родителю и не может быть наоборот.
Двунаправленный Виртуальный
Это позволяет получить доступ в обоих направлениях. Логический дочерний элемент в его физической структуре и соответствующий виртуальный логический дочерний элемент могут рассматриваться как парные сегменты.
Двунаправленный Физический
Логический ребенок является физически сохраненным подчиненным как своим физическим, так и логическим родителям. Для прикладных программ это выглядит так же, как двунаправленный виртуальный логический дочерний элемент.
Вопросы программирования
Программные соображения для использования логической базы данных следующие:
-
Звонки DL / I для доступа к базе данных остаются такими же с логической базой данных.
-
Блок спецификации программы указывает структуру, которую мы используем в наших вызовах. В некоторых случаях мы не можем определить, что мы используем логическую базу данных.
-
Логические отношения добавляют новое измерение программированию базы данных.
-
Вы должны быть осторожны при работе с логическими базами данных, так как две базы данных объединены вместе. Если вы изменяете одну базу данных, те же самые изменения должны быть отражены в другой базе данных.
-
Спецификации программы должны указывать, какая обработка разрешена в базе данных. Если правило обработки нарушено, вы получите непустой код состояния.
Звонки DL / I для доступа к базе данных остаются такими же с логической базой данных.
Блок спецификации программы указывает структуру, которую мы используем в наших вызовах. В некоторых случаях мы не можем определить, что мы используем логическую базу данных.
Логические отношения добавляют новое измерение программированию базы данных.
Вы должны быть осторожны при работе с логическими базами данных, так как две базы данных объединены вместе. Если вы изменяете одну базу данных, те же самые изменения должны быть отражены в другой базе данных.
Спецификации программы должны указывать, какая обработка разрешена в базе данных. Если правило обработки нарушено, вы получите непустой код состояния.
Каскадный сегмент
Логический дочерний сегмент всегда начинается с полного сцепленного ключа родительского целевого объекта. Это известно как сцепленный родительский ключ (DPCK). Вы должны всегда кодировать DPCK в начале области ввода / вывода вашего сегмента для логического дочернего элемента. В логической базе данных объединенный сегмент устанавливает связь между сегментами, которые определены в разных физических базах данных. Объединенный сегмент состоит из следующих двух частей:
- Логический дочерний сегмент
- Целевой родительский сегмент
Логический дочерний сегмент состоит из следующих двух частей:
- Родительский каскадный ключ (DPCK)
- Логические дочерние данные пользователя

Когда мы работаем со связанными сегментами во время обновления, может быть возможно добавить или изменить данные как в логическом дочернем элементе, так и в родительском получателе с помощью одного вызова. Это также зависит от правил администратора баз данных, указанных для базы данных. Для вставки поместите DPCK в правильное положение. Для замены или удаления не изменяйте данные DPCK или поля последовательности ни в одной части объединенного сегмента.
IMS DB — Восстановление
Администратор базы данных должен спланировать восстановление базы данных в случае сбоев системы. Сбои могут быть разных типов, таких как сбои приложений, аппаратные ошибки, сбои питания и т. Д.
Простой подход
Вот несколько простых подходов к восстановлению базы данных:
-
Периодически делайте резервные копии важных наборов данных, чтобы сохранить все транзакции, проведенные с наборами данных.
-
Если набор данных поврежден из-за сбоя системы, эта проблема устраняется путем восстановления резервной копии. Затем накопленные транзакции повторно публикуются в резервной копии, чтобы обновить их.
Периодически делайте резервные копии важных наборов данных, чтобы сохранить все транзакции, проведенные с наборами данных.
Если набор данных поврежден из-за сбоя системы, эта проблема устраняется путем восстановления резервной копии. Затем накопленные транзакции повторно публикуются в резервной копии, чтобы обновить их.
Недостатки простого подхода
Недостатки простого подхода к восстановлению базы данных следующие:
-
Повторная публикация накопленных транзакций занимает много времени.
-
Все остальные приложения должны ждать исполнения до завершения восстановления.
-
Восстановление базы данных занимает больше времени, чем восстановление файлов, если задействованы логические и вторичные отношения индекса.
Повторная публикация накопленных транзакций занимает много времени.
Все остальные приложения должны ждать исполнения до завершения восстановления.
Восстановление базы данных занимает больше времени, чем восстановление файлов, если задействованы логические и вторичные отношения индекса.
Процедуры аварийного завершения
Сбой программы DL / I отличается от способа сбоя стандартной программы, поскольку стандартная программа выполняется непосредственно операционной системой, а программа DL / I — нет. Используя процедуру аварийного завершения, система вмешивается, так что восстановление может быть выполнено после аварийного окончания (ABEND). Процедура аварийного завершения выполняет следующие действия:
- Закрывает все наборы данных
- Отменяет все ожидающие работы в очереди
- Создает дамп хранилища, чтобы выяснить первопричину ABEND.
Ограничением этой процедуры является то, что она не гарантирует, являются ли используемые данные точными или нет.
DL / I Log
Когда прикладная программа ABENDs, необходимо отменить изменения, внесенные прикладной программой, исправить ошибку и повторно запустить прикладную программу. Для этого необходимо иметь журнал DL / I. Вот ключевые моменты о регистрации DL / I —
-
DL / I записывает все изменения, сделанные прикладной программой, в файл, который называется файлом журнала.
-
Когда прикладная программа изменяет сегмент, DL / I создает его изображение до и после изображения.
-
Эти изображения сегментов можно использовать для восстановления сегментов в случае сбоя прикладной программы.
-
DL / I использует технику, называемую запись с опережением записи, для записи изменений в базе данных. При ведении журнала с предварительной записью изменение базы данных записывается в набор данных журнала, прежде чем оно записывается в фактический набор данных.
-
Поскольку журнал всегда опережает базу данных, утилиты восстановления могут определять состояние любого изменения базы данных.
-
Когда программа выполняет вызов для изменения сегмента базы данных, DL / I заботится о своей части ведения журнала.
DL / I записывает все изменения, сделанные прикладной программой, в файл, который называется файлом журнала.
Когда прикладная программа изменяет сегмент, DL / I создает его изображение до и после изображения.
Эти изображения сегментов можно использовать для восстановления сегментов в случае сбоя прикладной программы.
DL / I использует технику, называемую запись с опережением записи, для записи изменений в базе данных. При ведении журнала с предварительной записью изменение базы данных записывается в набор данных журнала, прежде чем оно записывается в фактический набор данных.
Поскольку журнал всегда опережает базу данных, утилиты восстановления могут определять состояние любого изменения базы данных.
Когда программа выполняет вызов для изменения сегмента базы данных, DL / I заботится о своей части ведения журнала.
Восстановление — вперед и назад
Два подхода к восстановлению базы данных:
-
Прямое восстановление — DL / I использует файл журнала для хранения данных изменений. Накопленные транзакции повторно публикуются с использованием этого файла журнала.
-
Обратное восстановление — Обратное восстановление также называется восстановлением с возвратом. Записи журнала для программы считываются в обратном направлении, а их эффекты обращаются в базу данных. После завершения возврата базы данных находятся в том же состоянии, в котором они находились до сбоя, при условии, что ни одна другая прикладная программа не изменила базу данных за это время.
Прямое восстановление — DL / I использует файл журнала для хранения данных изменений. Накопленные транзакции повторно публикуются с использованием этого файла журнала.
Обратное восстановление — Обратное восстановление также называется восстановлением с возвратом. Записи журнала для программы считываются в обратном направлении, а их эффекты обращаются в базу данных. После завершения возврата базы данных находятся в том же состоянии, в котором они находились до сбоя, при условии, что ни одна другая прикладная программа не изменила базу данных за это время.
Контрольно-пропускной пункт
Контрольная точка — это этап, на котором изменения базы данных, сделанные прикладной программой, считаются полными и точными. Ниже перечислены пункты, которые нужно отметить относительно контрольно-пропускного пункта —
-
Изменения базы данных, сделанные до самой последней контрольной точки, не отменяются при обратном восстановлении.
-
Изменения базы данных, зарегистрированные после последней контрольной точки, не применяются к копии базы данных во время прямого восстановления.
-
Используя метод контрольной точки, база данных восстанавливается до ее состояния на самой последней контрольной точке после завершения процесса восстановления.
-
По умолчанию для пакетных программ контрольная точка является началом программы.
-
Контрольная точка может быть установлена с помощью вызова контрольной точки (CHKP).
-
При вызове контрольной точки запись контрольной точки записывается в журнал DL / I.
Изменения базы данных, сделанные до самой последней контрольной точки, не отменяются при обратном восстановлении.
Изменения базы данных, зарегистрированные после последней контрольной точки, не применяются к копии базы данных во время прямого восстановления.
Используя метод контрольной точки, база данных восстанавливается до ее состояния на самой последней контрольной точке после завершения процесса восстановления.
По умолчанию для пакетных программ контрольная точка является началом программы.
Контрольная точка может быть установлена с помощью вызова контрольной точки (CHKP).
При вызове контрольной точки запись контрольной точки записывается в журнал DL / I.
Ниже показан синтаксис вызова CHKP —
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-ID
Есть два метода контрольных точек —
Основные контрольные точки — это позволяет программисту выполнять вызовы контрольных точек, которые утилиты восстановления DL / I используют во время обработки восстановления.
Символическая контрольная точка — это расширенная форма контрольной точки, которая используется в сочетании с расширенной функцией перезапуска. Символическая контрольная точка и расширенный перезапуск вместе позволяют программисту прикладных программ кодировать программы, чтобы они могли возобновить обработку в точке сразу после контрольной точки.