СУБД — Обзор
База данных представляет собой набор связанных данных, а данные представляют собой набор фактов и цифр, которые могут быть обработаны для получения информации.
В основном данные представляют собой записываемые факты. Данные помогают в получении информации, которая основана на фактах. Например, если у нас есть данные о оценках, полученных всеми учащимися, мы можем сделать вывод о баллах и средних оценках.
Система управления базами данных хранит данные таким образом, что становится легче получать, манипулировать и производить информацию.
Характеристики
Традиционно данные были организованы в файловых форматах. СУБД была новой концепцией, и все исследования были проведены для того, чтобы преодолеть недостатки традиционного стиля управления данными. Современная СУБД имеет следующие характеристики —
-
Реальная сущность — современная СУБД более реалистична и использует реальные сущности для проектирования своей архитектуры. Он использует поведение и атрибуты тоже. Например, школьная база данных может использовать учащихся как сущность, а их возраст — как атрибут.
-
Таблицы на основе отношений — СУБД позволяет сущностям и отношениям между ними формировать таблицы. Пользователь может понять архитектуру базы данных, просто взглянув на имена таблиц.
-
Изоляция данных и приложений. Система баз данных полностью отличается от своих данных. База данных является активной сущностью, тогда как данные называются пассивными, на которых база данных работает и организует. СУБД также хранит метаданные, которые представляют собой данные о данных, чтобы упростить собственный процесс.
-
Меньшая избыточность — СУБД следует правилам нормализации, которая разделяет отношение, когда любой из ее атрибутов имеет избыточность в значениях. Нормализация — это математически насыщенный и научный процесс, который уменьшает избыточность данных.
-
Согласованность. Согласованность — это состояние, при котором каждое отношение в базе данных остается согласованным. Существуют методы и приемы, которые могут обнаружить попытку перевода базы данных в несогласованное состояние. СУБД может обеспечить большую согласованность по сравнению с более ранними формами приложений для хранения данных, таких как системы обработки файлов.
-
Язык запросов — СУБД оснащена языком запросов, что делает его более эффективным для извлечения и обработки данных. Пользователь может применить столько разных вариантов фильтрации, сколько требуется для получения набора данных. Традиционно это было невозможно, когда использовалась система обработки файлов.
-
Свойства ACID — СУБД следует концепциям Tomicity, C- согласованности, I- солирования и устойчивости (обычно сокращается до ACID). Эти понятия применяются к транзакциям, которые манипулируют данными в базе данных. Свойства ACID помогают базе данных оставаться работоспособной в мультитранзакционных средах и в случае сбоя.
-
Многопользовательский и параллельный доступ — СУБД поддерживает многопользовательскую среду и позволяет им получать доступ к данным и управлять ими параллельно. Хотя существуют ограничения на транзакции, когда пользователи пытаются обрабатывать один и тот же элемент данных, но пользователи всегда не знают о них.
-
Несколько представлений — СУБД предлагает несколько представлений для разных пользователей. Пользователь, который находится в отделе продаж, будет иметь другое представление о базе данных, чем человек, работающий в отделе производства. Эта функция позволяет пользователям иметь общее представление о базе данных в соответствии с их требованиями.
-
Безопасность. Такие функции, как множественные представления, в некоторой степени обеспечивают безопасность, когда пользователи не могут получить доступ к данным других пользователей и отделов. СУБД предлагает методы наложения ограничений при вводе данных в базу данных и извлечении их на более позднем этапе. СУБД предлагает много разных уровней функций безопасности, что позволяет нескольким пользователям иметь разные представления с разными функциями. Например, пользователь в отделе продаж не может видеть данные, принадлежащие отделу закупок. Кроме того, также можно управлять тем, сколько данных отдела продаж должно быть отображено пользователю. Поскольку СУБД не сохраняется на диске как традиционные файловые системы, злоумышленникам очень сложно взломать код.
Реальная сущность — современная СУБД более реалистична и использует реальные сущности для проектирования своей архитектуры. Он использует поведение и атрибуты тоже. Например, школьная база данных может использовать учащихся как сущность, а их возраст — как атрибут.
Таблицы на основе отношений — СУБД позволяет сущностям и отношениям между ними формировать таблицы. Пользователь может понять архитектуру базы данных, просто взглянув на имена таблиц.
Изоляция данных и приложений. Система баз данных полностью отличается от своих данных. База данных является активной сущностью, тогда как данные называются пассивными, на которых база данных работает и организует. СУБД также хранит метаданные, которые представляют собой данные о данных, чтобы упростить собственный процесс.
Меньшая избыточность — СУБД следует правилам нормализации, которая разделяет отношение, когда любой из ее атрибутов имеет избыточность в значениях. Нормализация — это математически насыщенный и научный процесс, который уменьшает избыточность данных.
Согласованность. Согласованность — это состояние, при котором каждое отношение в базе данных остается согласованным. Существуют методы и приемы, которые могут обнаружить попытку перевода базы данных в несогласованное состояние. СУБД может обеспечить большую согласованность по сравнению с более ранними формами приложений для хранения данных, таких как системы обработки файлов.
Язык запросов — СУБД оснащена языком запросов, что делает его более эффективным для извлечения и обработки данных. Пользователь может применить столько разных вариантов фильтрации, сколько требуется для получения набора данных. Традиционно это было невозможно, когда использовалась система обработки файлов.
Свойства ACID — СУБД следует концепциям Tomicity, C- согласованности, I- солирования и устойчивости (обычно сокращается до ACID). Эти понятия применяются к транзакциям, которые манипулируют данными в базе данных. Свойства ACID помогают базе данных оставаться работоспособной в мультитранзакционных средах и в случае сбоя.
Многопользовательский и параллельный доступ — СУБД поддерживает многопользовательскую среду и позволяет им получать доступ к данным и управлять ими параллельно. Хотя существуют ограничения на транзакции, когда пользователи пытаются обрабатывать один и тот же элемент данных, но пользователи всегда не знают о них.
Несколько представлений — СУБД предлагает несколько представлений для разных пользователей. Пользователь, который находится в отделе продаж, будет иметь другое представление о базе данных, чем человек, работающий в отделе производства. Эта функция позволяет пользователям иметь общее представление о базе данных в соответствии с их требованиями.
Безопасность. Такие функции, как множественные представления, в некоторой степени обеспечивают безопасность, когда пользователи не могут получить доступ к данным других пользователей и отделов. СУБД предлагает методы наложения ограничений при вводе данных в базу данных и извлечении их на более позднем этапе. СУБД предлагает много разных уровней функций безопасности, что позволяет нескольким пользователям иметь разные представления с разными функциями. Например, пользователь в отделе продаж не может видеть данные, принадлежащие отделу закупок. Кроме того, также можно управлять тем, сколько данных отдела продаж должно быть отображено пользователю. Поскольку СУБД не сохраняется на диске как традиционные файловые системы, злоумышленникам очень сложно взломать код.
пользователей
Типичная СУБД имеет пользователей с разными правами и разрешениями, которые используют ее для разных целей. Некоторые пользователи получают данные, а некоторые их поддерживают. Пользователи СУБД можно в общих чертах классифицировать следующим образом:
-
Администраторы. Администраторы обслуживают СУБД и несут ответственность за администрирование базы данных. Они несут ответственность за его использование и кем оно должно быть использовано. Они создают профили доступа для пользователей и применяют ограничения для обеспечения изоляции и обеспечения безопасности. Администраторы также следят за ресурсами СУБД, такими как системная лицензия, необходимые инструменты и другое техническое обслуживание программного и аппаратного обеспечения.
-
Дизайнеры. Дизайнеры — это группа людей, которые фактически работают над частью проектирования базы данных. Они внимательно следят за тем, какие данные следует хранить и в каком формате. Они идентифицируют и проектируют весь набор объектов, отношений, ограничений и представлений.
-
Конечные пользователи. Конечные пользователи — это те, кто действительно получает выгоду от наличия СУБД. Конечные пользователи могут варьироваться от простых зрителей, которые обращают внимание на журналы или рыночные ставки, до искушенных пользователей, таких как бизнес-аналитики.
Администраторы. Администраторы обслуживают СУБД и несут ответственность за администрирование базы данных. Они несут ответственность за его использование и кем оно должно быть использовано. Они создают профили доступа для пользователей и применяют ограничения для обеспечения изоляции и обеспечения безопасности. Администраторы также следят за ресурсами СУБД, такими как системная лицензия, необходимые инструменты и другое техническое обслуживание программного и аппаратного обеспечения.
Дизайнеры. Дизайнеры — это группа людей, которые фактически работают над частью проектирования базы данных. Они внимательно следят за тем, какие данные следует хранить и в каком формате. Они идентифицируют и проектируют весь набор объектов, отношений, ограничений и представлений.
Конечные пользователи. Конечные пользователи — это те, кто действительно получает выгоду от наличия СУБД. Конечные пользователи могут варьироваться от простых зрителей, которые обращают внимание на журналы или рыночные ставки, до искушенных пользователей, таких как бизнес-аналитики.
СУБД — Архитектура
Дизайн СУБД зависит от ее архитектуры. Он может быть централизованным или децентрализованным или иерархическим. Архитектура СУБД может рассматриваться как одноуровневая или многоуровневая. N-уровневая архитектура делит всю систему на связанные, но независимые n модулей, которые могут быть независимо изменены, изменены, изменены или заменены.
В одноуровневой архитектуре СУБД является единственным объектом, где пользователь непосредственно сидит в СУБД и использует ее. Любые изменения, сделанные здесь, будут сделаны непосредственно в самой СУБД. Он не предоставляет удобных инструментов для конечных пользователей. Разработчики баз данных и программисты обычно предпочитают использовать одноуровневую архитектуру.
Если архитектура СУБД является двухуровневой, то у нее должно быть приложение, через которое можно получить доступ к СУБД. Программисты используют двухуровневую архитектуру, где они получают доступ к СУБД с помощью приложения. Здесь уровень приложения полностью независим от базы данных с точки зрения работы, дизайна и программирования.
3-х уровневая архитектура
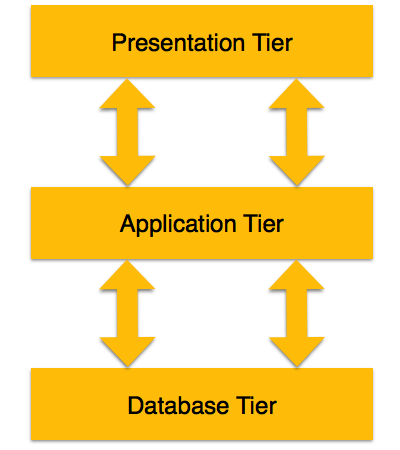
3-уровневая архитектура отделяет свои уровни друг от друга на основе сложности пользователей и того, как они используют данные, представленные в базе данных. Это наиболее широко используемая архитектура для проектирования СУБД.
-
Уровень базы данных (данных) — на этом уровне база данных находится вместе с ее языками обработки запросов. У нас также есть отношения, которые определяют данные и их ограничения на этом уровне.
-
Уровень приложений (средний) — на этом уровне находятся сервер приложений и программы, обращающиеся к базе данных. Для пользователя этот уровень приложения представляет собой абстрактное представление базы данных. Конечные пользователи не знают о существовании базы данных за пределами приложения. С другой стороны, уровень базы данных не знает ни о каком другом пользователе, кроме уровня приложения. Следовательно, прикладной уровень находится посередине и действует как посредник между конечным пользователем и базой данных.
-
Пользовательский (презентационный) уровень — конечные пользователи работают на этом уровне, и они ничего не знают о существовании базы данных за пределами этого уровня. На этом уровне приложение может предоставить несколько представлений базы данных. Все представления создаются приложениями, которые находятся на уровне приложений.
Уровень базы данных (данных) — на этом уровне база данных находится вместе с ее языками обработки запросов. У нас также есть отношения, которые определяют данные и их ограничения на этом уровне.
Уровень приложений (средний) — на этом уровне находятся сервер приложений и программы, обращающиеся к базе данных. Для пользователя этот уровень приложения представляет собой абстрактное представление базы данных. Конечные пользователи не знают о существовании базы данных за пределами приложения. С другой стороны, уровень базы данных не знает ни о каком другом пользователе, кроме уровня приложения. Следовательно, прикладной уровень находится посередине и действует как посредник между конечным пользователем и базой данных.
Пользовательский (презентационный) уровень — конечные пользователи работают на этом уровне, и они ничего не знают о существовании базы данных за пределами этого уровня. На этом уровне приложение может предоставить несколько представлений базы данных. Все представления создаются приложениями, которые находятся на уровне приложений.
Многоуровневая архитектура базы данных легко модифицируется, так как почти все ее компоненты независимы и могут быть изменены независимо.
СУБД — Модели данных
Модели данных определяют, как моделируется логическая структура базы данных. Модели данных являются фундаментальными объектами для введения абстракции в СУБД. Модели данных определяют, как данные связаны друг с другом и как они обрабатываются и хранятся в системе.
Самой первой моделью данных могут быть плоские модели данных, где все используемые данные должны храниться в одной плоскости. Более ранние модели данных не были настолько научными, поэтому они были склонны вводить много дублирования и обновлять аномалии.
Модель сущности-отношения
Модель Entity-Relationship (ER) основана на представлении о сущностях реального мира и отношениях между ними. При формулировании реального сценария в модель базы данных модель ER создает набор сущностей, набор отношений, общие атрибуты и ограничения.
Модель ER лучше всего использовать для концептуального проектирования базы данных.
Модель ER основана на:
-
Сущности и их атрибуты.
-
Отношения между сущностями.
Сущности и их атрибуты.
Отношения между сущностями.
Эти понятия объяснены ниже.
-
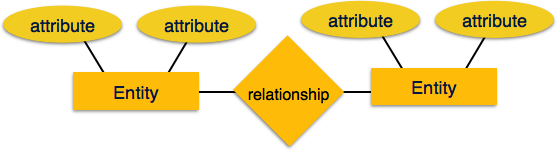
Сущность — Сущность в модели ER — это сущность реального мира, имеющая свойства, называемые атрибутами . Каждый атрибут определяется своим набором значений, называемых доменом . Например, в школьной базе данных ученик рассматривается как сущность. Студент имеет различные атрибуты, такие как имя, возраст, класс и т. Д.
-
Отношения — логическая связь между сущностями называется отношениями . Отношения отображаются с сущностями различными способами. Кардинальности отображения определяют количество ассоциаций между двумя объектами.
Отображение кардиналов —
- один к одному
- один ко многим
- много к одному
- много ко многим
Сущность — Сущность в модели ER — это сущность реального мира, имеющая свойства, называемые атрибутами . Каждый атрибут определяется своим набором значений, называемых доменом . Например, в школьной базе данных ученик рассматривается как сущность. Студент имеет различные атрибуты, такие как имя, возраст, класс и т. Д.
Отношения — логическая связь между сущностями называется отношениями . Отношения отображаются с сущностями различными способами. Кардинальности отображения определяют количество ассоциаций между двумя объектами.
Отображение кардиналов —
Реляционная модель
Наиболее популярной моделью данных в СУБД является реляционная модель. Это более научная модель, чем другие. Эта модель основана на логике предикатов первого порядка и определяет таблицу как n-арное отношение .
Основные моменты этой модели —
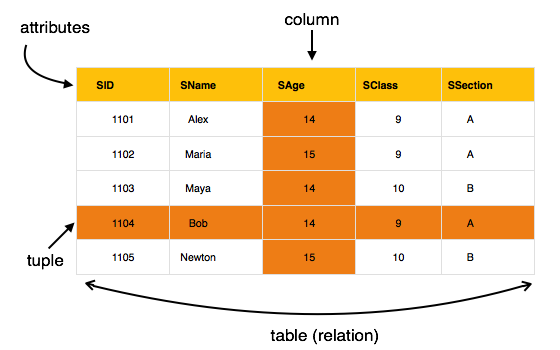
- Данные хранятся в таблицах, называемых отношениями .
- Отношения могут быть нормализованы.
- В нормализованных отношениях сохраненные значения являются атомарными.
- Каждая строка в отношении содержит уникальное значение.
- Каждый столбец в отношении содержит значения из одного домена.
СУБД — Схемы данных
Схема базы данных
Схема базы данных — это каркасная структура, которая представляет логическое представление всей базы данных. Он определяет, как организованы данные и как связаны между собой отношения. Он формулирует все ограничения, которые должны применяться к данным.
Схема базы данных определяет ее сущности и отношения между ними. Он содержит описательную деталь базы данных, которая может быть изображена с помощью схематических представлений. Именно дизайнеры базы данных разрабатывают схему, чтобы помочь программистам понять базу данных и сделать ее полезной.
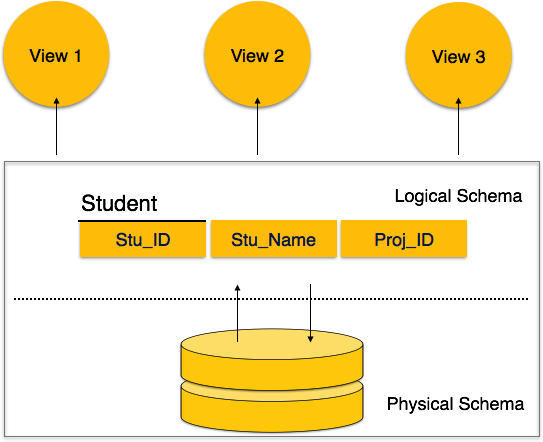
Схема базы данных может быть разделена на две категории:
-
Физическая схема базы данных — эта схема относится к фактическому хранилищу данных и его форме хранения, такой как файлы, индексы и т. Д. Она определяет, как данные будут храниться во вторичном хранилище.
-
Схема логической базы данных — эта схема определяет все логические ограничения, которые необходимо применить к хранимым данным. Он определяет таблицы, представления и ограничения целостности.
Физическая схема базы данных — эта схема относится к фактическому хранилищу данных и его форме хранения, такой как файлы, индексы и т. Д. Она определяет, как данные будут храниться во вторичном хранилище.
Схема логической базы данных — эта схема определяет все логические ограничения, которые необходимо применить к хранимым данным. Он определяет таблицы, представления и ограничения целостности.
Экземпляр базы данных
Важно, чтобы мы различали эти два термина по отдельности. Схема базы данных является каркасом базы данных. Он разработан, когда база данных не существует вообще. После того, как база данных заработает, в нее очень сложно внести какие-либо изменения. Схема базы данных не содержит никаких данных или информации.
Экземпляр базы данных — это состояние оперативной базы данных с данными в любой момент времени. Он содержит снимок базы данных. Экземпляры базы данных имеют тенденцию меняться со временем. СУБД гарантирует, что каждый ее экземпляр (состояние) находится в допустимом состоянии, старательно следуя всем валидациям, ограничениям и условиям, наложенным разработчиками базы данных.
СУБД — Независимость данных
Если система базы данных не является многоуровневой, то становится трудно вносить какие-либо изменения в систему базы данных. Системы баз данных спроектированы в несколько слоев, как мы узнали ранее.
Независимость данных
Система баз данных обычно содержит много данных в дополнение к данным пользователей. Например, он хранит данные о данных, известные как метаданные, чтобы легко находить и получать данные. Довольно сложно изменить или обновить набор метаданных после их сохранения в базе данных. Но по мере расширения СУБД она должна со временем меняться, чтобы удовлетворить требования пользователей. Если все данные зависят, это станет утомительной и очень сложной задачей.
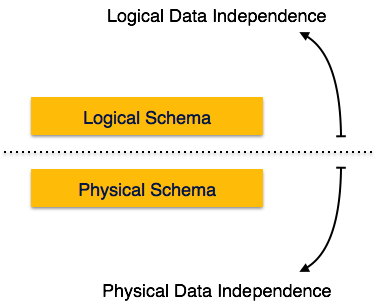
Метаданные сами по себе следуют многоуровневой архитектуре, поэтому при изменении данных на одном уровне они не влияют на данные на другом уровне. Эти данные независимы, но сопоставлены друг с другом.
Независимость логических данных
Логические данные — это данные о базе данных, то есть они хранят информацию об управлении данными внутри. Например, таблица (отношение), хранящаяся в базе данных, и все ее ограничения, примененные к этому отношению.
Независимость логических данных — это своего рода механизм, который освобождает себя от фактических данных, хранящихся на диске. Если мы внесем некоторые изменения в формат таблицы, это не должно изменить данные, хранящиеся на диске.
Независимость физических данных
Все схемы являются логическими, а фактические данные хранятся в битовом формате на диске. Независимость от физических данных — это возможность изменять физические данные без влияния на схему или логические данные.
Например, в случае, если мы хотим изменить или обновить саму систему хранения — предположим, что мы хотим заменить жесткие диски на SSD — это не должно оказывать никакого влияния на логические данные или схемы.
Модель ER — Основные понятия
Модель ER определяет концептуальное представление базы данных. Он работает вокруг сущностей реального мира и их ассоциаций. На уровне представления модель ER считается хорошим вариантом для проектирования баз данных.
сущность
Сущность может быть объектом реального мира, одушевленным или неодушевленным, который можно легко идентифицировать. Например, в школьной базе данных учащиеся, учителя, классы и предлагаемые курсы могут рассматриваться как объекты. Все эти объекты имеют некоторые атрибуты или свойства, которые придают им идентичность.
Набор сущностей — это совокупность сущностей схожего типа. Набор сущностей может содержать сущности с атрибутами, имеющими сходные значения. Например, набор учеников может содержать всех учеников школы; аналогичным образом, в набор учителей могут входить все учителя школы со всех факультетов. Наборы сущностей не должны быть непересекающимися.
Атрибуты
Объекты представлены с помощью их свойств, называемых атрибутами . Все атрибуты имеют значения. Например, учащийся может иметь имя, класс и возраст в качестве атрибутов.
Существует домен или диапазон значений, которые могут быть назначены атрибутам. Например, имя студента не может быть числовым значением. Это должно быть буквенным. Возраст ученика не может быть отрицательным и т. Д.
Типы атрибутов
-
Простой атрибут. Простые атрибуты представляют собой атомарные значения, которые не могут быть разделены далее. Например, телефонный номер учащегося является атомным значением из 10 цифр.
-
Составной атрибут — Составные атрибуты состоят из нескольких простых атрибутов. Например, полное имя учащегося может иметь имя_имя и фамилия.
-
Производный атрибут — Производные атрибуты — это атрибуты, которые не существуют в физической базе данных, но их значения получены из других атрибутов, присутствующих в базе данных. Например, Average_salary в отделе не следует сохранять непосредственно в базе данных, вместо этого его можно получить. Для другого примера, возраст может быть получен из data_of_birth.
-
Атрибут с одним значением — Атрибуты с одним значением содержат одно значение. Например — Social_Security_Number.
-
Многозначный атрибут — многозначные атрибуты могут содержать более одного значения. Например, человек может иметь более одного номера телефона, адрес электронной почты и т. Д.
Простой атрибут. Простые атрибуты представляют собой атомарные значения, которые не могут быть разделены далее. Например, телефонный номер учащегося является атомным значением из 10 цифр.
Составной атрибут — Составные атрибуты состоят из нескольких простых атрибутов. Например, полное имя учащегося может иметь имя_имя и фамилия.
Производный атрибут — Производные атрибуты — это атрибуты, которые не существуют в физической базе данных, но их значения получены из других атрибутов, присутствующих в базе данных. Например, Average_salary в отделе не следует сохранять непосредственно в базе данных, вместо этого его можно получить. Для другого примера, возраст может быть получен из data_of_birth.
Атрибут с одним значением — Атрибуты с одним значением содержат одно значение. Например — Social_Security_Number.
Многозначный атрибут — многозначные атрибуты могут содержать более одного значения. Например, человек может иметь более одного номера телефона, адрес электронной почты и т. Д.
Эти типы атрибутов могут объединяться таким образом, как —
- простые однозначные атрибуты
- простые многозначные атрибуты
- составные однозначные атрибуты
- составные многозначные атрибуты
Набор сущностей и ключи
Ключ — это атрибут или набор атрибутов, который однозначно идентифицирует сущность среди множества сущностей.
Например, номер студента делает его идентифицируемым среди студентов.
-
Super Key — Набор атрибутов (один или несколько), которые совместно идентифицируют объект в наборе объектов.
-
Ключ-кандидат — минимальный супер-ключ называется ключом-кандидатом. Набор объектов может иметь более одного ключа-кандидата.
-
Первичный ключ — первичный ключ — это один из ключей-кандидатов, выбранных разработчиком базы данных для однозначной идентификации набора сущностей.
Super Key — Набор атрибутов (один или несколько), которые совместно идентифицируют объект в наборе объектов.
Ключ-кандидат — минимальный супер-ключ называется ключом-кандидатом. Набор объектов может иметь более одного ключа-кандидата.
Первичный ключ — первичный ключ — это один из ключей-кандидатов, выбранных разработчиком базы данных для однозначной идентификации набора сущностей.
отношения
Ассоциация между сущностями называется отношениями. Например, сотрудник работает на кафедре, студент записывается на курс. Здесь Works_at и Enrolls называются отношениями.
Набор отношений
Набор отношений подобного типа называется набором отношений. Как и сущности, отношения тоже могут иметь атрибуты. Эти атрибуты называются описательными атрибутами .
Степень Отношения
Количество участвующих субъектов в отношениях определяет степень отношений.
- Двоичный = степень 2
- Троичный = степень 3
- n-ary = степень
Отображение мощности
Количество элементов определяет количество объектов в одном наборе объектов, которое может быть связано с количеством объектов другого набора через набор отношений.
-
Один-к-одному. Один объект из набора объектов A может быть связан не более чем с одним объектом из набора объектов B и наоборот.
-
Один-ко-многим. Один объект из набора объектов A может быть связан с более чем одним объектом из набора B объектов, однако объект из набора B объектов может быть связан не более чем с одним объектом.
-
Много-к-одному — более одного объекта из набора объектов A могут быть связаны не более чем с одним объектом набора объектов B, однако объект из набора объектов B может быть связан с несколькими объектами из набора объектов A.
-
Многие ко многим — Один объект из A может быть связан с несколькими объектами из B и наоборот.
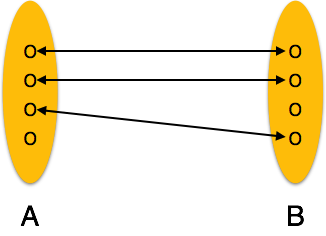
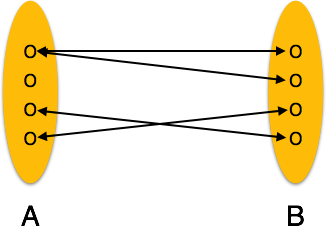
Один-к-одному. Один объект из набора объектов A может быть связан не более чем с одним объектом из набора объектов B и наоборот.
Один-ко-многим. Один объект из набора объектов A может быть связан с более чем одним объектом из набора B объектов, однако объект из набора B объектов может быть связан не более чем с одним объектом.
Много-к-одному — более одного объекта из набора объектов A могут быть связаны не более чем с одним объектом набора объектов B, однако объект из набора объектов B может быть связан с несколькими объектами из набора объектов A.
Многие ко многим — Один объект из A может быть связан с несколькими объектами из B и наоборот.
Представление ER-диаграммы
Давайте теперь узнаем, как модель ER представлена с помощью диаграммы ER. Любой объект, например, объекты, атрибуты объекта, наборы отношений и атрибуты наборов отношений, могут быть представлены с помощью диаграммы ER.
сущность
Сущности представлены с помощью прямоугольников. Прямоугольники именуются набором сущностей, который они представляют.

Атрибуты
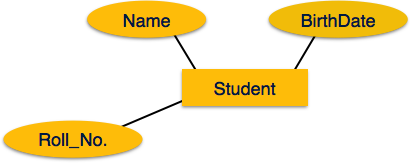
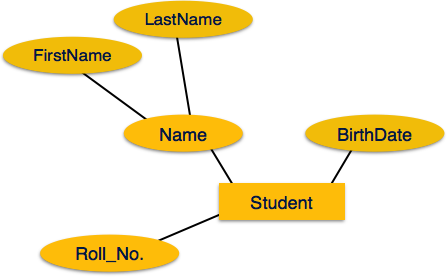
Атрибуты являются свойствами сущностей. Атрибуты представлены с помощью эллипсов. Каждый эллипс представляет один атрибут и напрямую связан с его сущностью (прямоугольником).
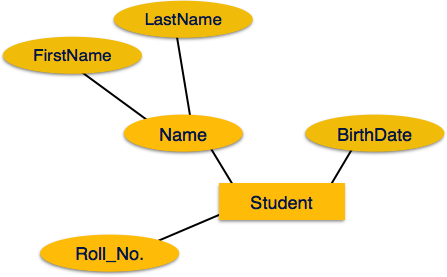
Если атрибуты составные , они далее делятся на древовидную структуру. Каждый узел затем подключается к своему атрибуту. То есть составные атрибуты представлены эллипсами, которые связаны с эллипсом.
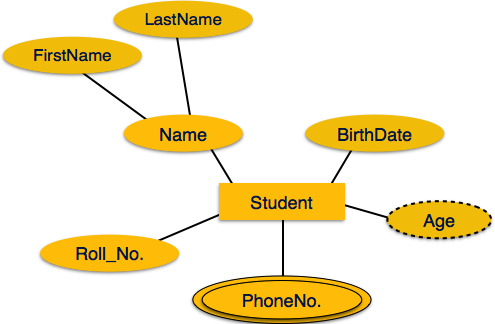
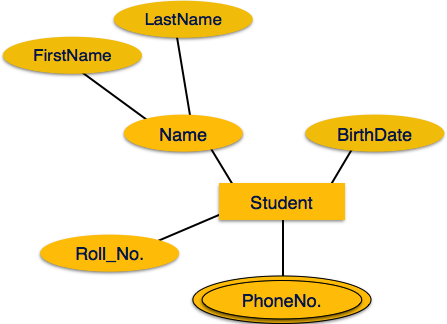
Многозначные атрибуты изображены двойным эллипсом.
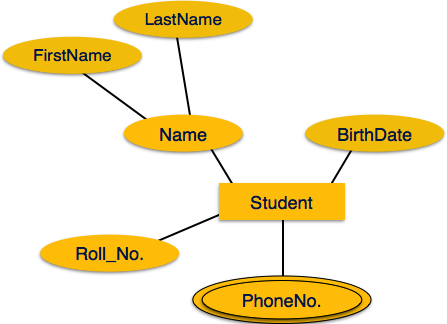
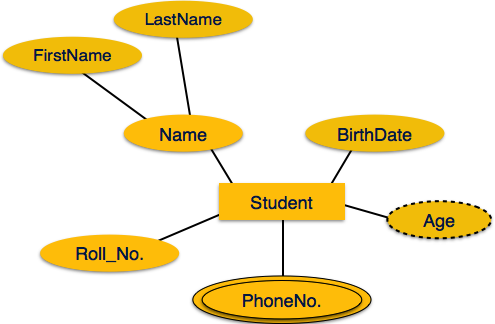
Производные атрибуты изображены пунктирным эллипсом.
отношения
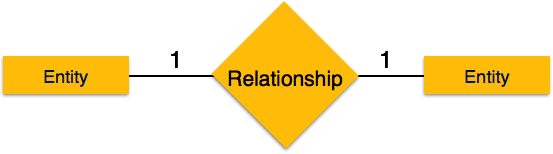
Отношения представлены ромбовидной коробкой. Название отношений написано внутри алмазной коробки. Все сущности (прямоугольники), участвующие в отношениях, связаны с ней линией.
Бинарные отношения и мощность
Отношение, в котором участвуют два объекта, называется бинарным отношением . Количество элементов — это число экземпляров объекта из отношения, которое может быть связано с отношением.
-
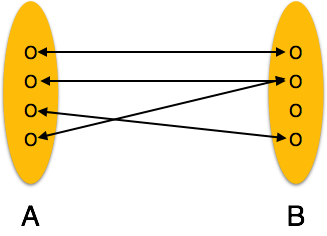
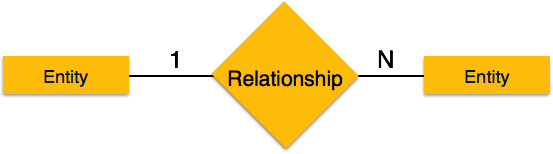
Один-к-одному — когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
-
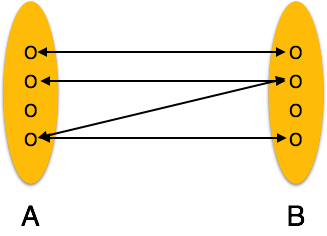
Один-ко-многим — когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
-
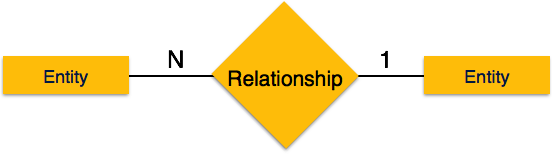
Много-к-одному — когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
-
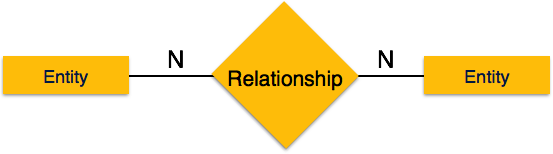
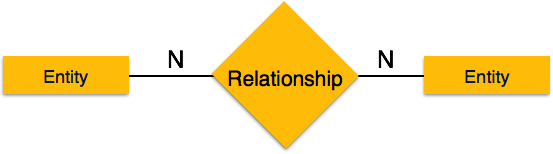
Многие ко многим — следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
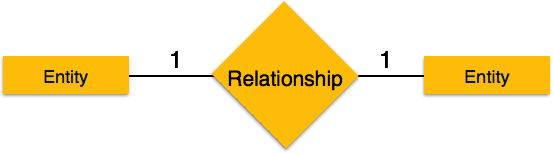
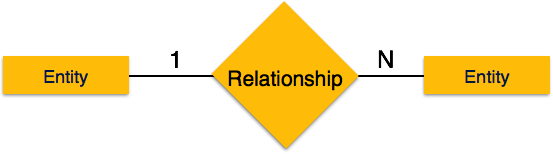
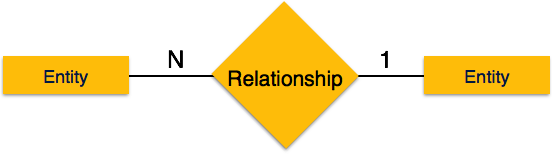
Один-к-одному — когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
Один-ко-многим — когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
Много-к-одному — когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
Многие ко многим — следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Ограничения участия
-
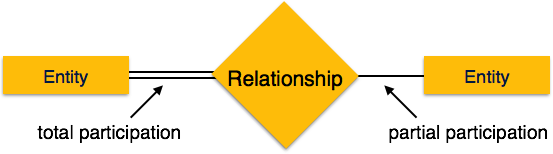
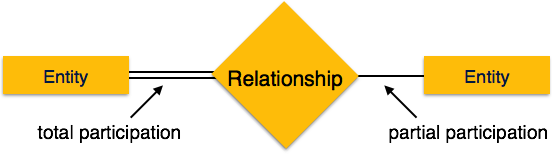
Общее участие — каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
-
Частичное участие — не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Общее участие — каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
Частичное участие — не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Генерализация Агрегация
Давайте теперь узнаем, как модель ER представлена с помощью диаграммы ER. Любой объект, например, объекты, атрибуты объекта, наборы отношений и атрибуты наборов отношений, могут быть представлены с помощью диаграммы ER.
сущность
Сущности представлены с помощью прямоугольников. Прямоугольники именуются набором сущностей, который они представляют.

Атрибуты
Атрибуты являются свойствами сущностей. Атрибуты представлены с помощью эллипсов. Каждый эллипс представляет один атрибут и напрямую связан с его сущностью (прямоугольником).
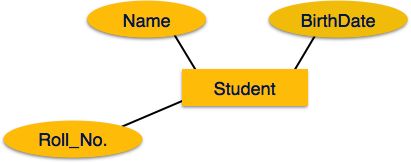
Если атрибуты составные , они далее делятся на древовидную структуру. Каждый узел затем подключается к своему атрибуту. То есть составные атрибуты представлены эллипсами, которые связаны с эллипсом.
Многозначные атрибуты изображены двойным эллипсом.
Производные атрибуты изображены пунктирным эллипсом.
отношения
Отношения представлены ромбовидной коробкой. Название отношений написано внутри алмазной коробки. Все сущности (прямоугольники), участвующие в отношениях, связаны с ней линией.
Бинарные отношения и мощность
Отношение, в котором участвуют два объекта, называется бинарным отношением . Количество элементов — это число экземпляров объекта из отношения, которое может быть связано с отношением.
-
Один-к-одному — когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
-
Один-ко-многим — когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
-
Много-к-одному — когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
-
Многие ко многим — следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Один-к-одному — когда только один экземпляр объекта связан с отношением, он помечается как «1: 1». На следующем рисунке показано, что только один экземпляр каждого объекта должен быть связан с отношением. Он изображает отношения один-к-одному.
Один-ко-многим — когда более чем один экземпляр объекта связан с отношением, он помечается как «1: N». На следующем рисунке показано, что только один экземпляр объекта слева и более одного экземпляра объекта справа могут быть связаны с отношением. Он изображает отношения один ко многим.
Много-к-одному — когда с отношением связано более одного экземпляра объекта, оно помечается как «N: 1». На следующем рисунке показано, что более одного экземпляра объекта слева и только один экземпляр объекта справа могут быть связаны с отношением. Он изображает отношения многие-к-одному.
Многие ко многим — следующее изображение отражает то, что с этим отношением может быть связано более одного экземпляра объекта слева и более одного экземпляра объекта справа. Он изображает отношения многих ко многим.
Ограничения участия
-
Общее участие — каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
-
Частичное участие — не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Общее участие — каждая организация участвует в отношениях. Общее участие представлено двойными линиями.
Частичное участие — не все лица вовлечены в отношения. Частичное участие представлено отдельными строчками.
Генерализация Агрегация
Модель ER обладает способностью выражать сущности базы данных в концептуальной иерархической манере. Когда иерархия повышается, она обобщает представление о сущностях, а когда мы углубляемся в иерархию, она дает нам детали каждой включенной сущности.
Подъем в эту структуру называется обобщением , когда сущности объединяются, чтобы представить более обобщенное представление. Например, конкретного ученика по имени Мира можно обобщить вместе со всеми учениками. Субъект должен быть студентом, и далее студент является человеком. Обратное называется специализацией, где человек — студент, а этот студент — Мира.
Обобщение
Как упомянуто выше, процесс обобщения сущностей, где обобщенные сущности содержат свойства всех обобщенных сущностей, называется обобщением. В общем, несколько объектов объединяются в один обобщенный объект на основе их сходных характеристик. Например, голубь, воробей, ворона и голубь могут быть обобщены как птицы.

специализация
Специализация противоположна обобщению. По специализации группа субъектов делится на подгруппы в зависимости от их характеристик. Возьмем, к примеру, группу «Персона». У человека есть имя, дата рождения, пол и т. Д. Эти свойства являются общими для всех людей, людей. Но в компании люди могут быть определены как работник, работодатель, клиент или продавец, в зависимости от того, какую роль они играют в компании.
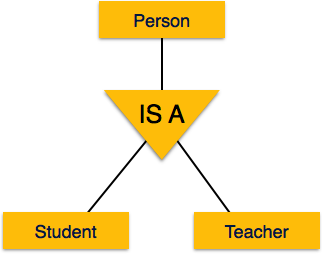
Аналогичным образом, в базе данных школы люди могут быть специализированы как учитель, ученик или персонал, в зависимости от того, какую роль они играют в школе как субъекты.
наследование
Мы используем все вышеперечисленные возможности ER-модели для создания классов объектов в объектно-ориентированном программировании. Детали сущностей обычно скрыты от пользователя; этот процесс известен как абстракция .
Наследование является важной особенностью обобщения и специализации. Это позволяет объектам более низкого уровня наследовать атрибуты объектов более высокого уровня.
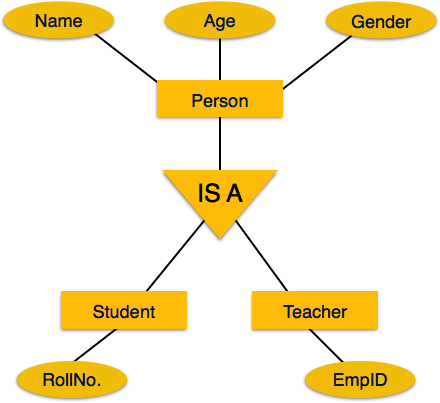
Например, атрибуты класса Person, такие как имя, возраст и пол, могут наследоваться объектами более низкого уровня, такими как ученик или учитель.
12 правил Кодда
Д-р Эдгар Ф. Кодд, после своего обширного исследования реляционной модели систем баз данных, разработал двенадцать собственных правил, которые, по его мнению, должны подчиняться базе данных, чтобы считаться истинной реляционной базой данных.
Эти правила могут применяться в любой системе баз данных, которая управляет сохраненными данными, используя только свои реляционные возможности. Это базовое правило, которое служит основой для всех остальных правил.
Правило 1: Информационное Правило
Данные, хранящиеся в базе данных, могут быть пользовательские данные или метаданные, должны быть значением некоторой ячейки таблицы. Все в базе данных должно храниться в табличном формате.
Правило 2: Правило гарантированного доступа
Каждый отдельный элемент данных (значение) гарантированно доступен логически с комбинацией имени таблицы, первичного ключа (значение строки) и имени атрибута (значение столбца). Никакие другие средства, такие как указатели, не могут быть использованы для доступа к данным.
Правило 3: Систематическое лечение значений NULL
Значения NULL в базе данных должны обрабатываться систематически и единообразно. Это очень важное правило, потому что NULL может интерпретироваться как одно из следующих: данные отсутствуют, данные неизвестны или данные неприменимы.
Правило 4: Активный онлайн-каталог
Описание структуры всей базы данных должно храниться в онлайн-каталоге, известном как словарь данных , к которому могут обращаться авторизованные пользователи. Пользователи могут использовать один и тот же язык запросов для доступа к каталогу, который они используют для доступа к самой базе данных.
Правило 5: Правило всеобъемлющего подъязыка данных
Доступ к базе данных возможен только с использованием языка, имеющего линейный синтаксис, который поддерживает определение данных, манипулирование данными и операции управления транзакциями. Этот язык можно использовать напрямую или с помощью какого-либо приложения. Если база данных разрешает доступ к данным без помощи этого языка, то это считается нарушением.
Правило 6: просмотр правила обновления
Все представления базы данных, которые теоретически могут быть обновлены, также должны обновляться системой.
Правило 7: правило высокого уровня для вставки, обновления и удаления
База данных должна поддерживать высокоуровневую вставку, обновление и удаление. Это не должно быть ограничено одной строкой, то есть оно также должно поддерживать операции объединения, пересечения и минуса для получения наборов записей данных.
Правило 8: физическая независимость данных
Данные, хранящиеся в базе данных, должны быть независимыми от приложений, которые обращаются к базе данных. Любые изменения в физической структуре базы данных не должны влиять на доступ к данным со стороны внешних приложений.
Правило 9: логическая независимость данных
Логические данные в базе данных должны быть независимы от представления пользователя (приложения). Любые изменения в логических данных не должны влиять на приложения, использующие их. Например, если две таблицы объединены или одна разбита на две разные таблицы, это не должно повлиять или изменить пользовательское приложение. Это одно из самых сложных правил для применения.
Правило 10: Честность Независимость
База данных должна быть независимой от приложения, которое ее использует. Все ограничения целостности могут быть независимо изменены без каких-либо изменений в приложении. Это правило делает базу данных независимой от интерфейсного приложения и его интерфейса.
Правило 11: Независимость распределения
Конечный пользователь не должен видеть, что данные распределены по разным местам. У пользователей всегда должно быть впечатление, что данные расположены только на одном сайте. Это правило считается основой распределенных систем баз данных.
Правило 12: Правило без подрывной деятельности
Если в системе имеется интерфейс, обеспечивающий доступ к записям низкого уровня, то интерфейс не должен быть способен подорвать систему и обойти ограничения безопасности и целостности.
Модель данных отношений
Реляционная модель данных является основной моделью данных, которая широко используется во всем мире для хранения и обработки данных. Эта модель проста и обладает всеми свойствами и возможностями, необходимыми для обработки данных с эффективностью хранения.
Концепции
Таблицы. В реляционной модели данных отношения сохраняются в формате таблиц. Этот формат хранит отношения между сущностями. В таблице есть строки и столбцы, где строки представляют записи, а столбцы представляют атрибуты.
Кортеж — одна строка таблицы, которая содержит одну запись для этого отношения, называется кортежем.
Экземпляр отношения — конечный набор кортежей в системе реляционной базы данных представляет экземпляр отношения. Экземпляры отношений не имеют повторяющихся кортежей.
Схема отношений — схема отношений описывает имя отношения (имя таблицы), атрибуты и их имена.
Ключ отношения — каждая строка имеет один или несколько атрибутов, известных как ключ отношения, которые могут однозначно идентифицировать строку в отношении (таблице).
Домен атрибута — каждый атрибут имеет некоторую предопределенную область значений, известную как домен атрибута.
Ограничения
Каждое отношение имеет некоторые условия, которые должны выполняться, чтобы оно было действительным. Эти условия называются ограничениями реляционной целостности . Есть три основных ограничения целостности —
- Ключевые ограничения
- Доменные ограничения
- Ограничения ссылочной целостности
Ключевые ограничения
В отношении должно быть хотя бы одно минимальное подмножество атрибутов, которое может однозначно идентифицировать кортеж. Это минимальное подмножество атрибутов называется ключом для этого отношения. Если существует более одного такого минимального подмножества, они называются ключами-кандидатами .
Ключевые ограничения заставляют это —
-
в отношении с ключевым атрибутом никакие два кортежа не могут иметь одинаковые значения для ключевых атрибутов.
-
ключевой атрибут не может иметь значения NULL.
в отношении с ключевым атрибутом никакие два кортежа не могут иметь одинаковые значения для ключевых атрибутов.
ключевой атрибут не может иметь значения NULL.
Ключевые ограничения также называются сущностными ограничениями.
Ограничения домена
Атрибуты имеют конкретные значения в реальном сценарии. Например, возраст может быть только положительным целым числом. Те же ограничения пытались использовать для атрибутов отношения. Каждый атрибут должен иметь определенный диапазон значений. Например, возраст не может быть меньше нуля, а телефонные номера не могут содержать цифры за пределами 0-9.
Ограничения ссылочной целостности
Ограничения ссылочной целостности работают над концепцией внешних ключей. Внешний ключ — это ключевой атрибут отношения, на который можно ссылаться в другом отношении.
Ограничение ссылочной целостности гласит, что если отношение ссылается на ключевой атрибут другого или того же отношения, то этот ключевой элемент должен существовать.
Реляционная алгебра
Предполагается, что реляционные системы баз данных будут оснащены языком запросов, который поможет пользователям запрашивать экземпляры базы данных. Существует два вида языков запросов — реляционная алгебра и реляционное исчисление.
Реляционная алгебра
Реляционная алгебра — это процедурный язык запросов, который принимает экземпляры отношений в качестве входных данных и выдает экземпляры отношений в качестве выходных. Он использует операторы для выполнения запросов. Оператор может быть как унарным, так и двоичным . Они принимают отношения как свой вклад и дают отношения как свой выход. Реляционная алгебра выполняется рекурсивно в отношении, и промежуточные результаты также считаются отношениями.
Основные операции реляционной алгебры следующие:
- Выбрать
- проект
- союз
- Установить разные
- Декартово произведение
- переименовывать
Мы обсудим все эти операции в следующих разделах.
Выберите операцию (σ)
Он выбирает кортежи, которые удовлетворяют данному предикату из отношения.
Обозначение — σ p (r)
Где σ обозначает предикат выбора, а r обозначает отношение. p — логическая формула предложения, которая может использовать соединители, такие как и, или, и нет . В этих терминах могут использоваться реляционные операторы, такие как — =, ≠, ≥, <,>, ≤.
Например —
σ subject="database" (Books)
σ subject=»database» (Books)
Вывод — выбирает кортежи из книг, предметом которых является «база данных».
σ subject="database" and price="450" (Books)
σ subject=»database» and price=»450″ (Books)
Вывод — выбирает кортежи из книг, где предметом является «база данных», а «цена» — 450.
σ subject="database" and price < "450" or year > "2010" (Books)
σ subject=»database» and price < «450» or year > «2010» (Books)
Выходные данные — выбирает кортежи из книг, где предметом является «база данных», а «цена» составляет 450, или тех книг, которые были опубликованы после 2010 года.
Операция проекта (∏)
Он проецирует столбцы, которые удовлетворяют данному предикату.
Обозначения — ∏ A 1 , A 2 , A n (r)
Где A 1 , A 2 , A n являются именами атрибутов отношения r .
Дублирующиеся строки автоматически удаляются, так как отношение является множеством.
Например —
∏ subject, author (Books)
∏ subject, author (Books)
Выбирает и проецирует столбцы, названные как субъект и автор из книги отношений.
Союз Операция (∪)
Он выполняет двоичное соединение между двумя данными отношениями и определяется как —
r ∪ s = { t | t ∈ r or t ∈ s}
r ∪ s = { t | t ∈ r or t ∈ s}
Обозначения — r U s
Где r и s — это либо отношения базы данных, либо набор результатов отношений (временное отношение).
Чтобы операция объединения была действительной, должны выполняться следующие условия:
- r и s должны иметь одинаковое количество атрибутов.
- Домены атрибутов должны быть совместимы.
- Дублирующиеся кортежи автоматически удаляются.
∏ author (Books) ∪ ∏ author (Articles)
∏ author (Books) ∪ ∏ author (Articles)
Вывод — проецирует имена авторов, написавших книгу, статью или обоих.
Установить разницу (-)
Результатом операции установки разности являются кортежи, которые присутствуют в одном отношении, но не во втором.
Обозначения — r — s
Находит все кортежи, которые присутствуют в r, но не в s .
∏ author (Books) − ∏ author (Articles)
∏ author (Books) − ∏ author (Articles)
Вывод — содержит имена авторов, которые написали книги, но не статьи.
Декартово произведение (Χ)
Объединяет информацию двух разных отношений в одно.
Обозначение — r Χ s
Где r и s — отношения, и их выходные данные будут определены как —
r Χ s = {qt | q ∈ r и t ∈ s}
∏ author = 'tutorialspoint' (Books Χ Articles)
∏ author = ‘tutorialspoint’ (Books Χ Articles)
Выходные данные — возвращает отношение, которое показывает все книги и статьи, написанные tutorialspoint.
Переименовать операцию (ρ)
Результаты реляционной алгебры также являются отношениями, но без какого-либо имени. Операция переименования позволяет нам переименовать выходное отношение. Операция переименования обозначается маленькой греческой буквой rho .
Обозначение — ρ x (E)
Где результат выражения E сохраняется с именем x .
Дополнительные операции —
- Установить пересечение
- присваивание
- Естественное соединение
Реляционное исчисление
В отличие от реляционной алгебры, реляционное исчисление — это непроцедурный язык запросов, то есть он говорит, что делать, но никогда не объясняет, как это сделать.
Реляционное исчисление существует в двух формах —
Реляционное исчисление кортежей (TRC)
Фильтрация диапазонов переменных по кортежам
Обозначение — {T | Состояние}
Возвращает все кортежи T, которые удовлетворяют условию.
Например —
{ T.name | Author(T) AND T.article = 'database' }
Выходные данные — возвращает кортежи с именем name от автора, который написал статью о «базе данных».
TRC может быть определена количественно. Мы можем использовать Existential (∃) и Universal Quantifiers (∀).
Например —
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}
Вывод. Приведенный выше запрос даст тот же результат, что и предыдущий.
Доменное реляционное исчисление (DRC)
В DRC фильтрующая переменная использует область атрибутов вместо целых значений кортежа (как сделано в TRC, упомянутом выше).
Запись —
{a 1 , a 2 , a 3 , …, a n | P (a 1 , a 2 , a 3 , …, a n )}
Где a1, a2 — атрибуты, а P — формулы, построенные из внутренних атрибутов.
Например —
{< article, page, subject > |
∈ TutorialsPoint ∧ subject = 'database'}
{< article, page, subject > |
Выходные данные — возвращает статью, страницу и тему из отношения TutorialsPoint, где тема — это база данных.
Как и TRC, DRC также может быть записан с использованием экзистенциальных и универсальных квантификаторов. В DRC также участвуют реляционные операторы.
Выражение силы Tuple Relation Calculus и Domain Relation Calculus эквивалентно реляционной алгебре.
ER модель для реляционной модели
Модель ER, представленная в виде диаграмм, дает хороший обзор взаимоотношений сущностей, который легче понять. ER-диаграммы могут быть сопоставлены с реляционной схемой, то есть можно создать реляционную схему, используя ER-диаграмму. Мы не можем импортировать все ограничения ER в реляционную модель, но можно создать приблизительную схему.
Есть несколько процессов и алгоритмов, доступных для преобразования ER-диаграмм в реляционную схему. Некоторые из них автоматизированы, а некоторые — ручные. Мы можем сосредоточиться здесь на отображении содержимого схемы на реляционные основы.
Диаграммы ER в основном состоят из —
- Сущность и ее атрибуты
- Отношения, которые являются ассоциацией между сущностями.
Картографическая сущность
Сущность — это объект реального мира с некоторыми атрибутами.
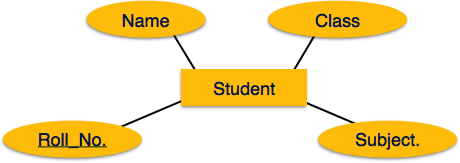
Процесс картирования (алгоритм)
- Создать таблицу для каждой сущности.
- Атрибуты объекта должны стать полями таблиц с соответствующими типами данных.
- Объявите первичный ключ.
Картографическая связь
Отношения — это ассоциация между сущностями.
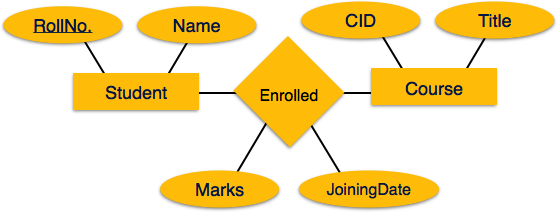
Процесс картирования
- Создать таблицу для отношений.
- Добавьте первичные ключи всех участвующих сущностей в виде полей таблицы с соответствующими им типами данных.
- Если отношение имеет какой-либо атрибут, добавьте каждый атрибут в качестве поля таблицы.
- Объявите первичный ключ, составляющий все первичные ключи участвующих субъектов.
- Объявите все ограничения внешнего ключа.
Отображение слабых наборов сущностей
Слабым набором сущностей является тот, который не имеет никакого первичного ключа, связанного с ним.
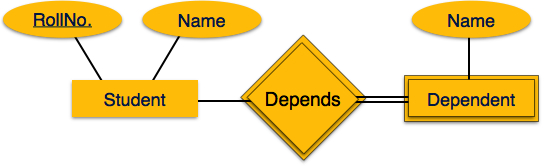
Процесс картирования
- Создать таблицу для набора слабых сущностей.
- Добавьте все его атрибуты в таблицу как поле.
- Добавьте первичный ключ идентифицирующего набора сущностей.
- Объявите все ограничения внешнего ключа.
Отображение иерархических объектов
ER специализация или обобщение происходит в форме иерархических наборов сущностей.
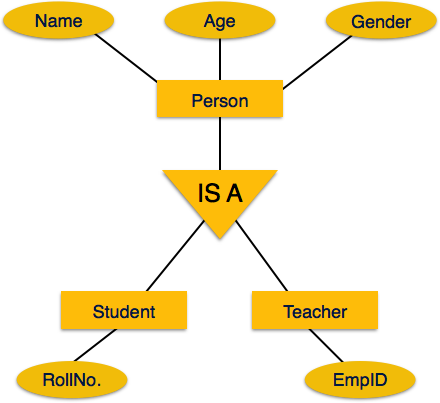
Процесс картирования
-
Создать таблицы для всех объектов более высокого уровня.
-
Создайте таблицы для объектов более низкого уровня.
-
Добавьте первичные ключи объектов более высокого уровня в таблицу объектов более низкого уровня.
-
В таблицах нижнего уровня добавьте все остальные атрибуты сущностей нижнего уровня.
-
Объявите первичный ключ таблицы более высокого уровня и первичный ключ таблицы более низкого уровня.
-
Объявите ограничения внешнего ключа.
Создать таблицы для всех объектов более высокого уровня.
Создайте таблицы для объектов более низкого уровня.
Добавьте первичные ключи объектов более высокого уровня в таблицу объектов более низкого уровня.
В таблицах нижнего уровня добавьте все остальные атрибуты сущностей нижнего уровня.
Объявите первичный ключ таблицы более высокого уровня и первичный ключ таблицы более низкого уровня.
Объявите ограничения внешнего ключа.
Обзор SQL
SQL — это язык программирования для реляционных баз данных. Он разработан на основе реляционной алгебры и кортежного реляционного исчисления. SQL поставляется в виде пакета со всеми основными дистрибутивами RDBMS.
SQL включает в себя как определения данных, так и языки манипулирования данными. Используя свойства определения данных SQL, можно проектировать и модифицировать схему базы данных, тогда как свойства манипулирования данными позволяют SQL хранить и извлекать данные из базы данных.
Язык определения данных
SQL использует следующий набор команд для определения схемы базы данных —
СОЗДАЙТЕ
Создает новые базы данных, таблицы и представления из RDBMS.
Например —
Create database tutorialspoint; Create table article; Create view for_students;
DROP
Удаляет команды, представления, таблицы и базы данных из RDBMS.
Например —
Drop object_type object_name; Drop database tutorialspoint; Drop table article; Drop view for_students;
ALTER
Изменяет схему базы данных.
Alter object_type object_name parameters;
Например —
Alter table article add subject varchar;
Эта команда добавляет атрибут в статью отношений с именем субъекта строкового типа.
Язык манипулирования данными
SQL оснащен языком манипулирования данными (DML). DML изменяет экземпляр базы данных, вставляя, обновляя и удаляя ее данные. DML отвечает за изменение данных всех форм в базе данных. SQL содержит следующий набор команд в своем разделе DML —
- SELECT / FROM / WHERE
- INSERT INTO / VALUES
- UPDATE / SET / WHERE
- УДАЛИТЬ ИЗ / ГДЕ
Эти базовые конструкции позволяют программистам и пользователям баз данных вводить данные и информацию в базу данных и эффективно извлекать их с использованием ряда параметров фильтра.
SELECT / FROM / WHERE
-
SELECT — это одна из основных команд запроса SQL. Это похоже на операцию проекции реляционной алгебры. Он выбирает атрибуты на основе условия, описанного предложением WHERE.
-
FROM — это предложение принимает имя отношения в качестве аргумента, из которого должны быть выбраны / спроектированы атрибуты. Если дано более одного имени отношения, этот пункт соответствует декартовому произведению.
-
WHERE — этот пункт определяет предикат или условия, которые должны совпадать, чтобы квалифицировать атрибуты, которые должны быть спроецированы.
SELECT — это одна из основных команд запроса SQL. Это похоже на операцию проекции реляционной алгебры. Он выбирает атрибуты на основе условия, описанного предложением WHERE.
FROM — это предложение принимает имя отношения в качестве аргумента, из которого должны быть выбраны / спроектированы атрибуты. Если дано более одного имени отношения, этот пункт соответствует декартовому произведению.
WHERE — этот пункт определяет предикат или условия, которые должны совпадать, чтобы квалифицировать атрибуты, которые должны быть спроецированы.
Например —
Select author_name From book_author Where age > 50;
Эта команда выдаст имена авторов из отношения book_author, чей возраст превышает 50.
INSERT INTO / VALUES
Эта команда используется для вставки значений в строки таблицы (отношения).
Синтаксис —
INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value3 ... ])
Или же
INSERT INTO table VALUES (value1, [value2, ... ])
Например —
INSERT INTO tutorialspoint (Author, Subject) VALUES ("anonymous", "computers");
UPDATE / SET / WHERE
Эта команда используется для обновления или изменения значений столбцов в таблице (отношение).
Синтаксис —
UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]
Например —
UPDATE tutorialspoint SET Author="webmaster" WHERE Author="anonymous";
DELETE / ОТ / ГДЕ
Эта команда используется для удаления одной или нескольких строк из таблицы (отношения).
Синтаксис —
DELETE FROM table_name [WHERE condition];
Например —
DELETE FROM tutorialspoints WHERE Author="unknown";
СУБД — нормализация
Функциональная зависимость
Функциональная зависимость (FD) — это набор ограничений между двумя атрибутами в отношении. Функциональная зависимость говорит, что если два кортежа имеют одинаковые значения для атрибутов A1, A2, …, An, то эти два кортежа должны иметь одинаковые значения для атрибутов B1, B2, …, Bn.
Функциональная зависимость представлена знаком стрелки (→), то есть X → Y, где X функционально определяет Y. Атрибуты левой стороны определяют значения атрибутов с правой стороны.
Аксиомы Армстронга
Если F представляет собой набор функциональных зависимостей, то замыкание F, обозначаемое как F + , представляет собой набор всех функциональных зависимостей, логически подразумеваемых F. Аксиомы Армстронга представляют собой набор правил, которые при многократном применении генерируют замыкание функциональных зависимостей. ,
-
Правило рефлексии — если альфа является набором атрибутов и бета-версией is_subset_of альфа, то альфа содержит бета-версию.
-
Правило аугментации — если a → b выполнено, а y является установленным атрибутом, то также выполняется ay → by. То есть добавление атрибутов в зависимости не меняет основных зависимостей.
-
Правило транзитивности — То же самое, что и транзитивное правило в алгебре, если выполняется a → b и b → c, то также выполняется a → c. a → b называется функционально определяющим b.
Правило рефлексии — если альфа является набором атрибутов и бета-версией is_subset_of альфа, то альфа содержит бета-версию.
Правило аугментации — если a → b выполнено, а y является установленным атрибутом, то также выполняется ay → by. То есть добавление атрибутов в зависимости не меняет основных зависимостей.
Правило транзитивности — То же самое, что и транзитивное правило в алгебре, если выполняется a → b и b → c, то также выполняется a → c. a → b называется функционально определяющим b.
Тривиальная функциональная зависимость
-
Trivial — если выполняется функциональная зависимость (FD) X → Y, где Y — подмножество X, то она называется тривиальной FD. Тривиальные ФД всегда держатся.
-
Нетривиальный. Если выполняется FD X → Y, где Y не является подмножеством X, то он называется нетривиальным FD.
-
Полностью нетривиальный — если выполняется FD X → Y, где x пересекается с Y = Φ, он называется совершенно нетривиальным FD.
Trivial — если выполняется функциональная зависимость (FD) X → Y, где Y — подмножество X, то она называется тривиальной FD. Тривиальные ФД всегда держатся.
Нетривиальный. Если выполняется FD X → Y, где Y не является подмножеством X, то он называется нетривиальным FD.
Полностью нетривиальный — если выполняется FD X → Y, где x пересекается с Y = Φ, он называется совершенно нетривиальным FD.
нормализация
Если дизайн базы данных не идеален, он может содержать аномалии, которые кажутся плохим сном для любого администратора базы данных. Управление базой данных с аномалиями практически невозможно.
-
Обновление аномалий — если элементы данных разбросаны и не связаны должным образом друг с другом, это может привести к странным ситуациям. Например, когда мы пытаемся обновить один элемент данных, копии которого разбросаны по нескольким местам, несколько экземпляров обновляются должным образом, а несколько других остаются со старыми значениями. Такие экземпляры оставляют базу данных в несогласованном состоянии.
-
Аномалии удаления — мы пытались удалить запись, но ее части остались неосознанными из-за неосведомленности, данные также сохраняются в другом месте.
-
Вставить аномалии — мы попытались вставить данные в запись, которая вообще не существует.
Обновление аномалий — если элементы данных разбросаны и не связаны должным образом друг с другом, это может привести к странным ситуациям. Например, когда мы пытаемся обновить один элемент данных, копии которого разбросаны по нескольким местам, несколько экземпляров обновляются должным образом, а несколько других остаются со старыми значениями. Такие экземпляры оставляют базу данных в несогласованном состоянии.
Аномалии удаления — мы пытались удалить запись, но ее части остались неосознанными из-за неосведомленности, данные также сохраняются в другом месте.
Вставить аномалии — мы попытались вставить данные в запись, которая вообще не существует.
Нормализация — это метод устранения всех этих аномалий и приведения базы данных в согласованное состояние.
Первая нормальная форма
Первая нормальная форма определяется в определении самих отношений (таблиц). Это правило определяет, что все атрибуты в отношении должны иметь атомарные домены. Значения в атомной области являются неделимыми единицами.
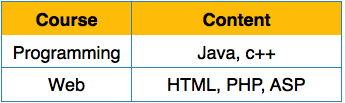
Мы переупорядочиваем отношение (таблицу), как показано ниже, чтобы преобразовать его в первую нормальную форму.
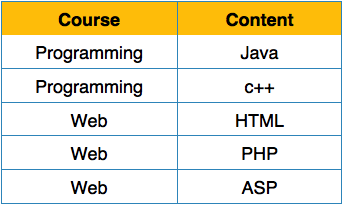
Каждый атрибут должен содержать только одно значение из своего предварительно определенного домена.
Вторая нормальная форма
Прежде чем мы узнаем о второй нормальной форме, мы должны понять следующее —
-
Основной атрибут . Атрибут, являющийся частью ключа-кандидата, называется основным атрибутом.
-
Непростой атрибут . Атрибут, который не является частью простого ключа, называется непростым атрибутом.
Основной атрибут . Атрибут, являющийся частью ключа-кандидата, называется основным атрибутом.
Непростой атрибут . Атрибут, который не является частью простого ключа, называется непростым атрибутом.
Если мы следуем второй нормальной форме, то каждый непростой атрибут должен полностью функционально зависеть от атрибута первичного ключа. То есть, если X → A выполнено, то не должно быть никакого собственного подмножества Y в X, для которого Y → A также верно.
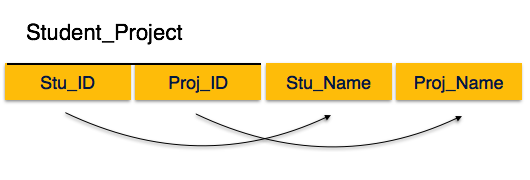
Здесь мы видим в отношении Student_Project, что атрибутами простого ключа являются Stu_ID и Proj_ID. В соответствии с правилом неключевые атрибуты, то есть Stu_Name и Proj_Name, должны зависеть от обоих, а не от какого-либо отдельного атрибута первичного ключа. Но мы обнаруживаем, что Stu_Name может быть идентифицировано Stu_ID, а Proj_Name может быть идентифицировано Proj_ID независимо. Это называется частичной зависимостью , которая не допускается во второй нормальной форме.
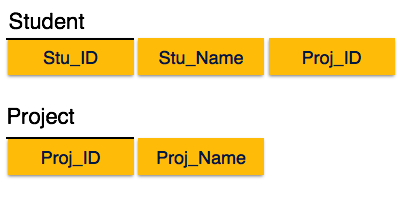
Мы разорвали отношения на две части, как показано на картинке выше. Таким образом, не существует частичной зависимости.
Третья нормальная форма
Чтобы отношение было в третьей нормальной форме, оно должно быть во второй нормальной форме, а следующее должно удовлетворять:
- Ни один не простой атрибут не является транзитивно зависимым от атрибута простого ключа.
- Для любой нетривиальной функциональной зависимости X → A, тогда либо —
- Х это суперключ или,
- А является основным атрибутом.

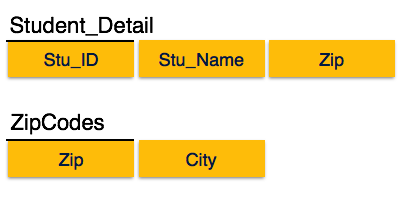
Мы обнаруживаем, что в приведенном выше отношении Student_detail Stu_ID является ключевым и единственным атрибутом простого ключа. Мы находим, что Город может быть идентифицирован как Stu_ID, так и самим Zip. Ни Zip не является суперключем, ни City не является главным атрибутом. Кроме того, Stu_ID → Zip → City, поэтому существует транзитивная зависимость .
Чтобы привести это отношение в третью нормальную форму, мы разбиваем отношение на два отношения следующим образом:
Бойс-Кодд Нормальная форма
Нормальная форма Бойса-Кодда (BCNF) является продолжением третьей нормальной формы на строгих условиях. BCNF заявляет, что —
- Для любой нетривиальной функциональной зависимости X → A, X должен быть суперключом.
На изображении выше Stu_ID — это супер-ключ в отношении Student_Detail, а Zip — это супер-ключ в отношении ZipCodes. Так,
Stu_ID → Stu_Name, Zip
а также
Zip → Город
Что подтверждает, что оба отношения находятся в BCNF.
СУБД — Объединения
Мы понимаем преимущества взятия декартова произведения двух отношений, что дает нам все возможные кортежи, соединенные вместе. Но в некоторых случаях для нас может оказаться невозможным взять декартово произведение, где мы сталкиваемся с огромными отношениями с тысячами кортежей, имеющих значительное количество атрибутов.
Join — это комбинация декартового произведения, за которым следует процесс выбора. Операция Join объединяет два кортежа из разных отношений, если и только если удовлетворяется заданное условие соединения.
Мы кратко опишем различные типы соединений в следующих разделах.
Тета (θ) Присоединиться
Тета-соединение объединяет кортежи из разных отношений при условии, что они удовлетворяют условию тета. Условие соединения обозначается символом θ .
нотация
R1 ⋈ θ R2
R1 и R2 являются отношениями, имеющими атрибуты (A1, A2, .., An) и (B1, B2, .., Bn), так что атрибуты не имеют ничего общего, то есть R1 ∩ R2 = Φ.
Тета-соединение может использовать все виды операторов сравнения.
| Ученик | ||
|---|---|---|
| SID | название | Std |
| 101 | Alex | 10 |
| 102 | Мария | 11 |
| Предметы | |
|---|---|
| Учебный класс | Предмет |
| 10 | математический |
| 10 | английский |
| 11 | Музыка |
| 11 | Спортивный |
Student_Detail =
STUDENT ⋈ Student.Std = Subject.Class SUBJECT
| Student_detail | ||||
|---|---|---|---|---|
| SID | название | Std | Учебный класс | Предмет |
| 101 | Alex | 10 | 10 | математический |
| 101 | Alex | 10 | 10 | английский |
| 102 | Мария | 11 | 11 | Музыка |
| 102 | Мария | 11 | 11 | Спортивный |
эквисоединения
Когда соединение Theta использует только оператор сравнения на равенство , оно называется equijoin. Приведенный выше пример соответствует equijoin.
Естественное соединение ( ⋈ )
Естественное объединение не использует оператор сравнения. Он не объединяет способ декартовых произведений. Мы можем выполнить естественное соединение, только если между двумя отношениями существует хотя бы один общий атрибут. Кроме того, атрибуты должны иметь одинаковые имя и домен.
Естественное объединение действует для тех совпадающих атрибутов, где значения атрибутов в обоих отношениях одинаковы.
| Курсы | ||
|---|---|---|
| ИДС | Курс | Отдел |
| CS01 | База данных | CS |
| ME01 | механика | МНЕ |
| EE01 | электроника | EE |
| HoD | |
|---|---|
| Отдел | Голова |
| CS | Alex |
| МНЕ | майя |
| EE | Мир |
| Курсы ⋈ HoD | |||
|---|---|---|---|
| Отдел | ИДС | Курс | Голова |
| CS | CS01 | База данных | Alex |
| МНЕ | ME01 | механика | майя |
| EE | EE01 | электроника | Мир |
Внешние соединения
Theta Join, Equijoin и Natural Join называются внутренними объединениями. Внутреннее объединение включает только те кортежи с соответствующими атрибутами, а остальные отбрасываются в результирующем отношении. Поэтому нам нужно использовать внешние объединения, чтобы включить все кортежи из участвующих отношений в результирующее отношение. Существует три вида внешних объединений — левое внешнее соединение, правое внешнее соединение и полное внешнее соединение.
Левое внешнее соединение (R  S)
S)
Все кортежи из отношения Left, R, включены в результирующее отношение. Если в R есть кортежи без соответствующих кортежей в правом отношении S, то S-атрибуты результирующего отношения становятся равными NULL.
| Оставил | |
|---|---|
| В | |
| 100 | База данных |
| 101 | механика |
| 102 | электроника |
| Правильно | |
|---|---|
| В | |
| 100 | Alex |
| 102 | майя |
| 104 | Мир |
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 101 | механика | — | — |
| 102 | электроника | 102 | майя |
Правое внешнее соединение: (R  S)
S)
Все кортежи из отношения Right, S, включены в результирующее отношение. Если в S есть кортежи без соответствующих кортежей в R, то R-атрибуты результирующего отношения становятся равными NULL.
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 102 | электроника | 102 | майя |
| — | — | 104 | Мир |
Полное внешнее соединение: (R  S)
S)
Все кортежи из обоих участвующих отношений включены в результирующее отношение. Если для обоих отношений нет соответствующих кортежей, их соответствующие несопоставленные атрибуты становятся равными NULL.
| Курсы |
|||
|---|---|---|---|
| В | С | D | |
| 100 | База данных | 100 | Alex |
| 101 | механика | — | — |
| 102 | электроника | 102 | майя |
| — | — | 104 | Мир |
СУБД — Система хранения
Базы данных хранятся в файловых форматах, которые содержат записи. На физическом уровне фактические данные хранятся в электромагнитном формате на каком-либо устройстве. Эти запоминающие устройства можно разделить на три типа:

-
Основное хранилище — хранилище памяти, которое напрямую доступно ЦПУ, относится к этой категории. Внутренняя память ЦП (регистры), быстрая память (кэш) и основная память (ОЗУ) напрямую доступны для ЦП, поскольку все они размещены на материнской плате или чипсете ЦП. Это хранилище обычно очень маленькое, сверхбыстрое и нестабильное. Первичное хранилище требует постоянного источника питания, чтобы поддерживать его состояние. В случае сбоя питания все его данные теряются.
-
Вторичное хранилище — Вторичные устройства хранения используются для хранения данных для будущего использования или в качестве резервной копии. Вторичное хранилище включает в себя устройства памяти, которые не являются частью набора микросхем ЦП или материнской платы, например магнитные диски, оптические диски (DVD, CD и т. Д.), Жесткие диски, флэш-накопители и магнитные ленты.
-
Третичное хранилище — Третичное хранилище используется для хранения огромных объемов данных. Поскольку такие запоминающие устройства являются внешними по отношению к компьютерной системе, они являются самыми медленными по скорости. Эти устройства хранения в основном используются для резервного копирования всей системы. Оптические диски и магнитные ленты широко используются в качестве третичного хранилища.
Основное хранилище — хранилище памяти, которое напрямую доступно ЦПУ, относится к этой категории. Внутренняя память ЦП (регистры), быстрая память (кэш) и основная память (ОЗУ) напрямую доступны для ЦП, поскольку все они размещены на материнской плате или чипсете ЦП. Это хранилище обычно очень маленькое, сверхбыстрое и нестабильное. Первичное хранилище требует постоянного источника питания, чтобы поддерживать его состояние. В случае сбоя питания все его данные теряются.
Вторичное хранилище — Вторичные устройства хранения используются для хранения данных для будущего использования или в качестве резервной копии. Вторичное хранилище включает в себя устройства памяти, которые не являются частью набора микросхем ЦП или материнской платы, например магнитные диски, оптические диски (DVD, CD и т. Д.), Жесткие диски, флэш-накопители и магнитные ленты.
Третичное хранилище — Третичное хранилище используется для хранения огромных объемов данных. Поскольку такие запоминающие устройства являются внешними по отношению к компьютерной системе, они являются самыми медленными по скорости. Эти устройства хранения в основном используются для резервного копирования всей системы. Оптические диски и магнитные ленты широко используются в качестве третичного хранилища.
Иерархия памяти
Компьютерная система имеет четко определенную иерархию памяти. Процессор имеет прямой доступ к основной памяти, а также к встроенным регистрам. Время доступа к основной памяти явно меньше скорости процессора. Чтобы минимизировать это несоответствие скорости, введена кэш-память. Кэш-память обеспечивает самое быстрое время доступа и содержит данные, к которым центральный процессор чаще всего обращается.
Память с самым быстрым доступом является самой дорогой. Большие устройства хранения данных предлагают низкую скорость и дешевле, однако они могут хранить огромные объемы данных по сравнению с регистрами ЦП или кэш-памятью.
Магнитные Диски
Жесткие диски являются наиболее распространенными вторичными устройствами хранения данных в современных компьютерных системах. Они называются магнитными дисками, потому что они используют концепцию намагничивания для хранения информации. Жесткие диски состоят из металлических дисков, покрытых намагничиваемым материалом. Эти диски расположены вертикально на шпинделе. Головка чтения / записи перемещается между дисками и используется для намагничивания или размагничивания пятна под ней. Намагниченное пятно может быть распознано как 0 (ноль) или 1 (один).
Жесткие диски отформатированы в четко определенном порядке для эффективного хранения данных. На пластине жесткого диска много концентрических кругов, называемых дорожками . Каждый трек далее делится на сектора . Сектор на жестком диске обычно хранит 512 байт данных.
RAID
RAID означает « R edundant» — « Множество независимых дисков», представляющих собой технологию подключения нескольких вторичных устройств хранения и использования их в качестве единого носителя.
RAID состоит из массива дисков, в которых несколько дисков соединены вместе для достижения разных целей. Уровни RAID определяют использование дисковых массивов.
-
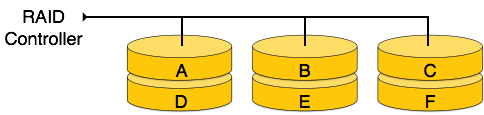
RAID 0 — на этом уровне реализован чередующийся массив дисков. Данные разбиваются на блоки и блоки распределяются по дискам. Каждый диск получает блок данных для записи / чтения параллельно. Это увеличивает скорость и производительность устройства хранения. На уровне 0 нет четности и резервного копирования.
RAID 0 — на этом уровне реализован чередующийся массив дисков. Данные разбиваются на блоки и блоки распределяются по дискам. Каждый диск получает блок данных для записи / чтения параллельно. Это увеличивает скорость и производительность устройства хранения. На уровне 0 нет четности и резервного копирования.
-
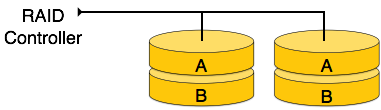
RAID 1 — RAID 1 использует методы зеркалирования. Когда данные отправляются на контроллер RAID, он отправляет копию данных на все диски в массиве. Уровень RAID 1 также называется зеркалированием и обеспечивает 100% резервирование в случае сбоя.
RAID 1 — RAID 1 использует методы зеркалирования. Когда данные отправляются на контроллер RAID, он отправляет копию данных на все диски в массиве. Уровень RAID 1 также называется зеркалированием и обеспечивает 100% резервирование в случае сбоя.
-
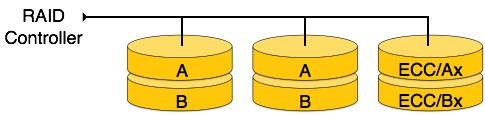
RAID 2 — RAID 2 записывает код исправления ошибок, используя расстояние Хемминга для своих данных, размеченных на разных дисках. Как и уровень 0, каждый бит данных в слове записывается на отдельный диск, а коды ECC слов данных хранятся на разных дисках. Из-за его сложной структуры и высокой стоимости, RAID 2 не доступен в продаже.
RAID 2 — RAID 2 записывает код исправления ошибок, используя расстояние Хемминга для своих данных, размеченных на разных дисках. Как и уровень 0, каждый бит данных в слове записывается на отдельный диск, а коды ECC слов данных хранятся на разных дисках. Из-за его сложной структуры и высокой стоимости, RAID 2 не доступен в продаже.
-
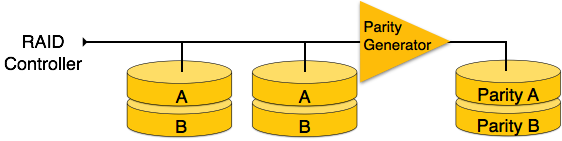
RAID 3 — RAID 3 чередует данные на нескольких дисках. Бит четности, сгенерированный для слова данных, хранится на другом диске. Этот метод позволяет преодолеть сбои в работе одного диска.
RAID 3 — RAID 3 чередует данные на нескольких дисках. Бит четности, сгенерированный для слова данных, хранится на другом диске. Этот метод позволяет преодолеть сбои в работе одного диска.
-
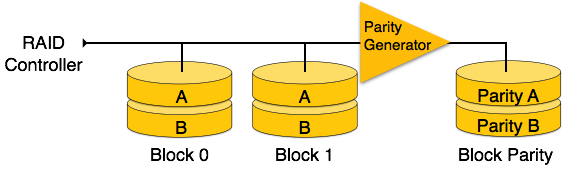
RAID 4 — на этом уровне весь блок данных записывается на диски данных, а затем генерируется четность и сохраняется на другом диске. Обратите внимание, что уровень 3 использует чередование на уровне байтов, тогда как уровень 4 использует чередование на уровне блоков. Как для уровня 3, так и для уровня 4 требуется как минимум три диска для реализации RAID.
RAID 4 — на этом уровне весь блок данных записывается на диски данных, а затем генерируется четность и сохраняется на другом диске. Обратите внимание, что уровень 3 использует чередование на уровне байтов, тогда как уровень 4 использует чередование на уровне блоков. Как для уровня 3, так и для уровня 4 требуется как минимум три диска для реализации RAID.
-
RAID 5 — RAID 5 записывает целые блоки данных на разные диски, но биты четности, генерируемые для полосы блоков данных, распределяются между всеми дисками данных, а не хранятся на другом выделенном диске.
RAID 5 — RAID 5 записывает целые блоки данных на разные диски, но биты четности, генерируемые для полосы блоков данных, распределяются между всеми дисками данных, а не хранятся на другом выделенном диске.
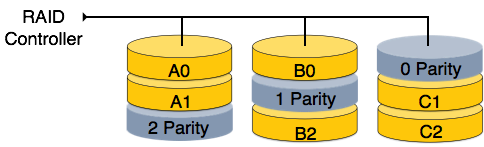
-
RAID 6 — RAID 6 является расширением уровня 5. На этом уровне два независимых контроля четности генерируются и хранятся распределенным образом среди нескольких дисков. Два соотношения обеспечивают дополнительную отказоустойчивость. Для этого уровня требуется как минимум четыре диска для реализации RAID.
RAID 6 — RAID 6 является расширением уровня 5. На этом уровне два независимых контроля четности генерируются и хранятся распределенным образом среди нескольких дисков. Два соотношения обеспечивают дополнительную отказоустойчивость. Для этого уровня требуется как минимум четыре диска для реализации RAID.
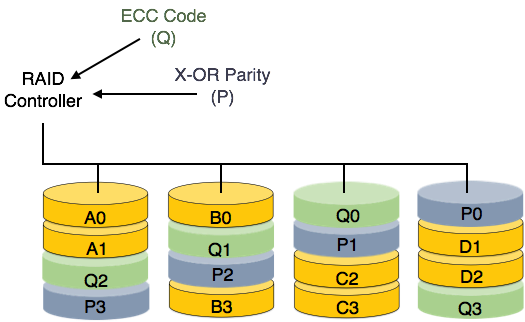
СУБД — Файловая структура
Относительные данные и информация хранятся вместе в форматах файлов. Файл представляет собой последовательность записей, хранящихся в двоичном формате. Диск отформатирован в несколько блоков, которые могут хранить записи. Файловые записи отображаются на эти блоки диска.
Организация файлов
Организация файлов определяет, как файловые записи отображаются на дисковые блоки. У нас есть четыре типа организации файлов для организации записей файлов —
Организация файлов кучи
Когда файл создается с помощью организации файлов кучи, операционная система выделяет область памяти для этого файла без каких-либо дополнительных учетных данных. Файловые записи могут быть размещены в любом месте этой области памяти. Ответственность за управление записями лежит на программном обеспечении. Heap File не поддерживает само упорядочение, последовательность или индексацию.
Последовательная организация файлов
Каждая запись файла содержит поле данных (атрибут), чтобы однозначно идентифицировать эту запись. При последовательной организации файлов записи помещаются в файл в некотором последовательном порядке на основе поля уникального ключа или ключа поиска. Практически невозможно хранить все записи последовательно в физической форме.
Организация хэш-файлов
Организация хеш-файлов использует вычисления хеш-функции в некоторых полях записей. Выходные данные хеш-функции определяют местоположение дискового блока, в который должны быть помещены записи.
Организация кластерных файлов
Организация кластерных файлов не считается хорошей для больших баз данных. В этом механизме связанные записи из одного или нескольких отношений хранятся в одном и том же блоке диска, то есть порядок записей не основан на первичном ключе или ключе поиска.
Файловые операции
Операции над файлами базы данных можно в целом разделить на две категории:
-
Операции обновления
-
Операции поиска
Операции обновления
Операции поиска
Операции обновления изменяют значения данных путем вставки, удаления или обновления. Операции извлечения, с другой стороны, не изменяют данные, а извлекают их после необязательной условной фильтрации. В обоих типах операций выбор играет значительную роль. Помимо создания и удаления файла, может быть несколько операций над файлами.
-
Открыть — файл можно открыть в одном из двух режимов : режиме чтения или записи . В режиме чтения операционная система не позволяет никому изменять данные. Другими словами, данные только для чтения. Файлы, открытые в режиме чтения, могут быть разделены между несколькими объектами. Режим записи позволяет изменять данные. Файлы, открытые в режиме записи, могут быть прочитаны, но не могут использоваться совместно.
-
Locate — каждый файл имеет указатель файла, который сообщает текущую позицию, где данные должны быть прочитаны или записаны. Этот указатель можно настроить соответствующим образом. Используя операцию поиска (поиска), ее можно перемещать вперед или назад.
-
Чтение — по умолчанию, когда файлы открываются в режиме чтения, указатель файла указывает на начало файла. Существуют варианты, в которых пользователь может указать операционной системе, где находится указатель файла во время открытия файла. Самые следующие данные к указателю файла читаются.
-
Запись — Пользователь может выбрать, чтобы открыть файл в режиме записи, что позволяет им редактировать его содержимое. Это может быть удаление, вставка или изменение. Указатель файла может находиться во время открытия или может быть динамически изменен, если операционная система позволяет это сделать.
-
Закрыть — это самая важная операция с точки зрения операционной системы. Когда генерируется запрос на закрытие файла, операционная система
- удаляет все блокировки (если в режиме совместного использования),
- сохраняет данные (если они были изменены) на вторичном носителе и
- освобождает все буферы и обработчики файлов, связанные с файлом.
Открыть — файл можно открыть в одном из двух режимов : режиме чтения или записи . В режиме чтения операционная система не позволяет никому изменять данные. Другими словами, данные только для чтения. Файлы, открытые в режиме чтения, могут быть разделены между несколькими объектами. Режим записи позволяет изменять данные. Файлы, открытые в режиме записи, могут быть прочитаны, но не могут использоваться совместно.
Locate — каждый файл имеет указатель файла, который сообщает текущую позицию, где данные должны быть прочитаны или записаны. Этот указатель можно настроить соответствующим образом. Используя операцию поиска (поиска), ее можно перемещать вперед или назад.
Чтение — по умолчанию, когда файлы открываются в режиме чтения, указатель файла указывает на начало файла. Существуют варианты, в которых пользователь может указать операционной системе, где находится указатель файла во время открытия файла. Самые следующие данные к указателю файла читаются.
Запись — Пользователь может выбрать, чтобы открыть файл в режиме записи, что позволяет им редактировать его содержимое. Это может быть удаление, вставка или изменение. Указатель файла может находиться во время открытия или может быть динамически изменен, если операционная система позволяет это сделать.
Закрыть — это самая важная операция с точки зрения операционной системы. Когда генерируется запрос на закрытие файла, операционная система
Организация данных внутри файла играет здесь важную роль. Процесс поиска указателя файла на нужную запись внутри файла зависит от того, расположены ли записи последовательно или кластеризовано.
СУБД — Индексирование
Мы знаем, что данные хранятся в виде записей. Каждая запись имеет ключевое поле, которое помогает ее узнавать однозначно.
Индексирование — это метод структуры данных, позволяющий эффективно извлекать записи из файлов базы данных на основе некоторых атрибутов, по которым была выполнена индексация. Индексирование в системах баз данных похоже на то, что мы видим в книгах.
Индексирование определяется на основе его атрибутов индексации. Индексирование может быть следующих типов —
-
Первичный индекс — первичный индекс определяется в упорядоченном файле данных. Файл данных упорядочен по ключевому полю . Поле ключа, как правило, является первичным ключом отношения.
-
Вторичный индекс — Вторичный индекс может быть создан из поля, которое является ключом-кандидатом и имеет уникальное значение в каждой записи, или неключевой ключ с дублирующимися значениями.
-
Индекс кластеризации. Индекс кластеризации определяется в упорядоченном файле данных. Файл данных упорядочен в неключевом поле.
Первичный индекс — первичный индекс определяется в упорядоченном файле данных. Файл данных упорядочен по ключевому полю . Поле ключа, как правило, является первичным ключом отношения.
Вторичный индекс — Вторичный индекс может быть создан из поля, которое является ключом-кандидатом и имеет уникальное значение в каждой записи, или неключевой ключ с дублирующимися значениями.
Индекс кластеризации. Индекс кластеризации определяется в упорядоченном файле данных. Файл данных упорядочен в неключевом поле.
Упорядоченное индексирование бывает двух типов:
- Плотный индекс
- Разреженный индекс
Плотный индекс
В плотном индексе есть индексная запись для каждого значения ключа поиска в базе данных. Это ускоряет поиск, но требует больше места для хранения записей индекса. Индексные записи содержат значение ключа поиска и указатель на фактическую запись на диске.
Разреженный индекс
В разреженном индексе записи индекса создаются не для каждого ключа поиска. Индексная запись здесь содержит ключ поиска и фактический указатель на данные на диске. Для поиска записи мы сначала переходим к индексной записи и достигаем фактическое местоположение данных. Если данные, которые мы ищем, находятся не там, где мы непосредственно достигаем, следуя индексу, то система начинает последовательный поиск, пока не будут найдены нужные данные.
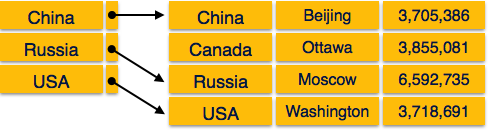
Многоуровневый индекс
Индексные записи содержат значения ключей поиска и указатели данных. Многоуровневый индекс хранится на диске вместе с актуальными файлами базы данных. По мере увеличения размера базы данных увеличивается и размер индексов. Существует огромная необходимость хранить записи индекса в основной памяти, чтобы ускорить операции поиска. Если используется одноуровневый индекс, индекс большого размера не может быть сохранен в памяти, что приводит к нескольким обращениям к диску.
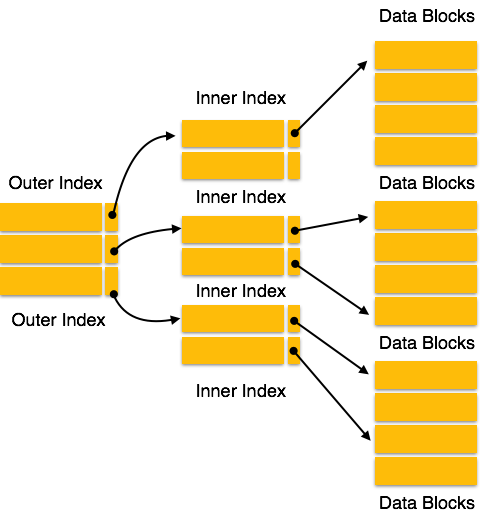
Многоуровневый индекс помогает разбить индекс на несколько меньших индексов, чтобы сделать внешний уровень настолько маленьким, чтобы его можно было сохранить в одном блоке диска, который можно легко разместить в любом месте основной памяти.
B + Дерево
AB + дерево — это сбалансированное двоичное дерево поиска, которое соответствует многоуровневому формату индекса. Листовые узлы дерева B + обозначают фактические указатели данных. B + дерево гарантирует, что все листовые узлы остаются на одной высоте, таким образом, сбалансированы. Кроме того, конечные узлы связаны с использованием списка ссылок; следовательно, дерево B + может поддерживать произвольный доступ, а также последовательный доступ.
Структура дерева B +
Каждый листовой узел находится на одинаковом расстоянии от корневого узла. Дерево AB + имеет порядок n, где n фиксировано для каждого дерева B + .
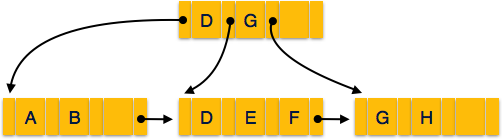
Внутренние узлы —
- Внутренние (неконечные) узлы содержат как минимум ⌈n / 2⌉ указателей, кроме корневого узла.
- Максимум, внутренний узел может содержать n указателей.
Листовые узлы —
- Конечные узлы содержат как минимум ⌈n / 2⌉ указатели записи и ⌈n / 2⌉ ключевые значения.
- Самое большее, листовой узел может содержать n указателей записи и n значений ключа.
- Каждый листовой узел содержит один блок-указатель P для указания на следующий листовой узел и формирует связанный список.
B + Tree Вставка
-
B + деревья заполняются снизу, и каждая запись выполняется на листовом узле.
- Если листовой узел переполняется —
-
Разделите узел на две части.
-
Разбиение при i = ⌊ (m + 1) / 2 ⌋.
-
Сначала i записи хранятся в одном узле.
-
Остальные записи (i + 1 и далее) перемещаются в новый узел.
-
i- й ключ продублирован у родителя листа.
-
-
Если неконечный узел переполняется —
-
Разделите узел на две части.
-
Разбейте узел на i = ⌈ (m + 1) / 2 ⌉ .
-
Записи до i хранятся в одном узле.
-
Остальные записи перемещаются на новый узел.
-
B + деревья заполняются снизу, и каждая запись выполняется на листовом узле.
Разделите узел на две части.
Разбиение при i = ⌊ (m + 1) / 2 ⌋.
Сначала i записи хранятся в одном узле.
Остальные записи (i + 1 и далее) перемещаются в новый узел.
i- й ключ продублирован у родителя листа.
Если неконечный узел переполняется —
Разделите узел на две части.
Разбейте узел на i = ⌈ (m + 1) / 2 ⌉ .
Записи до i хранятся в одном узле.
Остальные записи перемещаются на новый узел.
Удаление дерева B +
-
Записи дерева B + удаляются в конечных узлах.
-
Целевая запись ищется и удаляется.
-
Если это внутренний узел, удалите и замените запись с левой позиции.
-
-
После удаления проверяется недостаточное количество
-
Если происходит переполнение, распределите записи от оставленных ему узлов.
-
-
Если распределение слева невозможно, то
-
Распределите от узлов прямо к нему.
-
-
Если распределение не возможно слева или справа, то
-
Объедините узел с левой и правой стороны.
-
Записи дерева B + удаляются в конечных узлах.
Целевая запись ищется и удаляется.
Если это внутренний узел, удалите и замените запись с левой позиции.
После удаления проверяется недостаточное количество
Если происходит переполнение, распределите записи от оставленных ему узлов.
Если распределение слева невозможно, то
Распределите от узлов прямо к нему.
Если распределение не возможно слева или справа, то
Объедините узел с левой и правой стороны.
СУБД — Хеширование
Для огромной структуры базы данных может быть практически невозможно выполнить поиск по всем значениям индекса по всему его уровню, а затем достичь целевого блока данных, чтобы получить нужные данные. Хеширование — это эффективный метод расчета прямого расположения записи данных на диске без использования структуры индекса.
Хеширование использует хеш-функции с ключами поиска в качестве параметров для генерации адреса записи данных.
Хэш-организация
-
Bucket — Хэш-файл хранит данные в формате Bucket . Ведро считается единицей хранения. В корзине обычно хранится один полный блок диска, который, в свою очередь, может хранить одну или несколько записей.
-
Хеш-функция — хеш-функция h является функцией отображения, которая отображает весь набор ключей K поиска на адрес, на котором размещены фактические записи. Это функция от ключей поиска до адресов корзины.
Bucket — Хэш-файл хранит данные в формате Bucket . Ведро считается единицей хранения. В корзине обычно хранится один полный блок диска, который, в свою очередь, может хранить одну или несколько записей.
Хеш-функция — хеш-функция h является функцией отображения, которая отображает весь набор ключей K поиска на адрес, на котором размещены фактические записи. Это функция от ключей поиска до адресов корзины.
Статическое хеширование
В статическом хешировании, когда предоставляется значение ключа поиска, хеш-функция всегда вычисляет один и тот же адрес. Например, если используется хеш-функция mod-4, то она должна генерировать только 5 значений. Выходной адрес всегда должен быть одинаковым для этой функции. Количество предоставляемых ковшей остается неизменным во все времена.
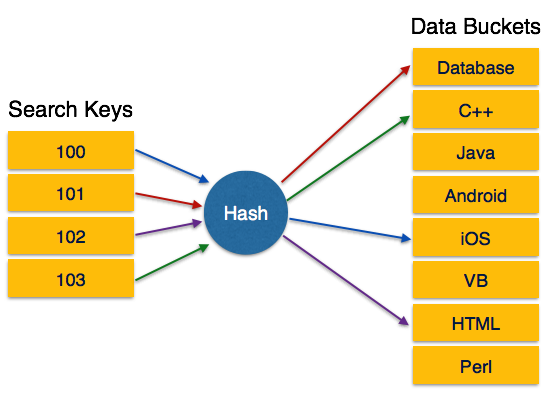
операция
-
Вставка — Когда запись должна быть введена с использованием статического хэша, хэш-функция h вычисляет адрес сегмента для ключа поиска K , где запись будет сохранена.
Адрес корзины = h (K)
-
Поиск — когда требуется извлечь запись, та же хеш-функция может использоваться для получения адреса группы, в которой хранятся данные.
-
Удалить — это просто поиск с последующей операцией удаления.
Вставка — Когда запись должна быть введена с использованием статического хэша, хэш-функция h вычисляет адрес сегмента для ключа поиска K , где запись будет сохранена.
Адрес корзины = h (K)
Поиск — когда требуется извлечь запись, та же хеш-функция может использоваться для получения адреса группы, в которой хранятся данные.
Удалить — это просто поиск с последующей операцией удаления.
Переполнение ковша
Условие переполнения ковша известно как столкновение . Это смертельное состояние для любой статической хэш-функции. В этом случае можно использовать цепочку переполнения.
-
Переполнение цепочки — когда сегменты заполнены, новый сегмент выделяется для того же результата хеширования и связывается после предыдущего. Этот механизм называется закрытым хешированием .
Переполнение цепочки — когда сегменты заполнены, новый сегмент выделяется для того же результата хеширования и связывается после предыдущего. Этот механизм называется закрытым хешированием .
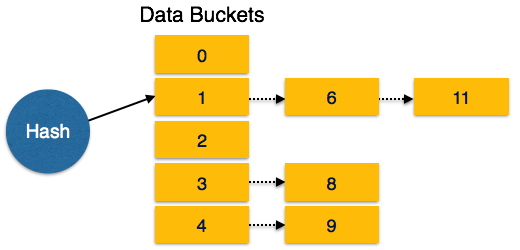
-
Линейное зондирование — когда хеш-функция генерирует адрес, по которому данные уже сохранены, ему выделяется следующий свободный сегмент. Этот механизм называется Open Hashing .
Линейное зондирование — когда хеш-функция генерирует адрес, по которому данные уже сохранены, ему выделяется следующий свободный сегмент. Этот механизм называется Open Hashing .
Динамическое хеширование
Проблема статического хэширования заключается в том, что он не расширяется и не сжимается динамически при увеличении или уменьшении размера базы данных. Динамическое хеширование обеспечивает механизм, в котором корзины данных добавляются и удаляются динамически и по требованию. Динамическое хеширование также известно как расширенное хеширование .
Функция хеширования в динамическом хешировании предназначена для получения большого числа значений, и только несколько из них используются изначально.
организация
Префикс всего хэш-значения принимается как хеш-индекс. Только часть значения хэша используется для вычисления адресов сегмента. Каждый хеш-индекс имеет значение глубины, чтобы указать, сколько битов используется для вычисления хеш-функции. Эти биты могут адресовать 2n сегментов. Когда все эти биты используются — то есть, когда все сегменты заполнены, — значение глубины увеличивается линейно и выделяется в два раза больше сегментов.
операция
-
Запросы — посмотрите на значение глубины хеш-индекса и используйте эти биты для вычисления адреса сегмента.
-
Обновить — выполнить запрос, как указано выше, и обновить данные.
-
Удаление — выполните запрос, чтобы найти нужные данные и удалить их.
-
Вставка — Вычислить адрес корзины
- Если ведро уже заполнено.
- Добавьте больше ведер.
- Добавьте дополнительные биты к значению хеша.
- Пересчитать хеш-функцию.
- еще
- Добавить данные в корзину,
- Если все ведра заполнены, выполните действия статического хеширования.
- Если ведро уже заполнено.
Запросы — посмотрите на значение глубины хеш-индекса и используйте эти биты для вычисления адреса сегмента.
Обновить — выполнить запрос, как указано выше, и обновить данные.
Удаление — выполните запрос, чтобы найти нужные данные и удалить их.
Вставка — Вычислить адрес корзины
Хеширование не выгодно, когда данные организованы в некотором порядке, а запросы требуют диапазона данных. Когда данные дискретны и случайны, хеш работает лучше всего.
Алгоритмы хеширования имеют большую сложность, чем индексация. Все хеш-операции выполняются в постоянное время.
СУБД — Транзакция
Транзакция может быть определена как группа задач. Единственная задача — это минимальная единица обработки, которую нельзя разделить дальше.
Давайте рассмотрим пример простой транзакции. Предположим, сотрудник банка переводит 500 рупий со счета А на счет Б. Эта очень простая и небольшая транзакция включает в себя несколько задач низкого уровня.
Счет А
Open_Account(A) Old_Balance = A.balance New_Balance = Old_Balance - 500 A.balance = New_Balance Close_Account(A)
B счет
Open_Account(B) Old_Balance = B.balance New_Balance = Old_Balance + 500 B.balance = New_Balance Close_Account(B)
ACID Свойства
Транзакция — это очень маленькая единица программы, и она может содержать несколько низкоуровневых задач. Для обеспечения точности, полноты и целостности данных транзакция в системе базы данных должна поддерживать единообразие, согласованность, согласованность и устойчивость, обычно известные как свойства ACID.
-
Атомарность. Это свойство указывает, что транзакция должна рассматриваться как атомарная единица, то есть либо все ее операции выполняются, либо их нет. В базе данных не должно быть состояния, в котором транзакция оставлена частично завершенной. Состояния должны быть определены либо до выполнения транзакции, либо после выполнения / прерывания / сбоя транзакции.
-
Согласованность — база данных должна оставаться в согласованном состоянии после любой транзакции. Ни одна транзакция не должна оказывать неблагоприятного воздействия на данные, находящиеся в базе данных. Если база данных находилась в согласованном состоянии до выполнения транзакции, она должна оставаться согласованной и после выполнения транзакции.
-
Долговечность. База данных должна быть достаточно надежной, чтобы в ней можно было хранить все последние обновления, даже если система выходит из строя или перезагружается. Если транзакция обновляет порцию данных в базе данных и фиксирует, то база данных будет содержать измененные данные. Если транзакция завершается, но система завершается неудачей, прежде чем данные могут быть записаны на диск, эти данные будут обновлены, как только система вернется в действие.
-
Изоляция. В системе баз данных, в которой одновременно и параллельно выполняется более одной транзакции, свойство изоляции указывает, что все транзакции будут выполняться и выполняться так, как если бы это была единственная транзакция в системе. Никакая транзакция не повлияет на существование любой другой транзакции.
Атомарность. Это свойство указывает, что транзакция должна рассматриваться как атомарная единица, то есть либо все ее операции выполняются, либо их нет. В базе данных не должно быть состояния, в котором транзакция оставлена частично завершенной. Состояния должны быть определены либо до выполнения транзакции, либо после выполнения / прерывания / сбоя транзакции.
Согласованность — база данных должна оставаться в согласованном состоянии после любой транзакции. Ни одна транзакция не должна оказывать неблагоприятного воздействия на данные, находящиеся в базе данных. Если база данных находилась в согласованном состоянии до выполнения транзакции, она должна оставаться согласованной и после выполнения транзакции.
Долговечность. База данных должна быть достаточно надежной, чтобы в ней можно было хранить все последние обновления, даже если система выходит из строя или перезагружается. Если транзакция обновляет порцию данных в базе данных и фиксирует, то база данных будет содержать измененные данные. Если транзакция завершается, но система завершается неудачей, прежде чем данные могут быть записаны на диск, эти данные будут обновлены, как только система вернется в действие.
Изоляция. В системе баз данных, в которой одновременно и параллельно выполняется более одной транзакции, свойство изоляции указывает, что все транзакции будут выполняться и выполняться так, как если бы это была единственная транзакция в системе. Никакая транзакция не повлияет на существование любой другой транзакции.
Сериализуемость
Когда операционная система выполняет несколько транзакций в многопрограммной среде, есть вероятность, что инструкции одной транзакции чередуются с какой-либо другой транзакцией.
-
Расписание — хронологическая последовательность выполнения транзакции называется расписанием. В расписании может быть много транзакций, каждая из которых состоит из ряда инструкций / задач.
-
Последовательное расписание — это расписание, в котором транзакции выровнены таким образом, что одна транзакция выполняется первой. Когда первая транзакция завершает свой цикл, выполняется следующая транзакция. Транзакции заказываются одна за другой. Этот тип расписания называется последовательным расписанием, поскольку транзакции выполняются последовательным образом.
Расписание — хронологическая последовательность выполнения транзакции называется расписанием. В расписании может быть много транзакций, каждая из которых состоит из ряда инструкций / задач.
Последовательное расписание — это расписание, в котором транзакции выровнены таким образом, что одна транзакция выполняется первой. Когда первая транзакция завершает свой цикл, выполняется следующая транзакция. Транзакции заказываются одна за другой. Этот тип расписания называется последовательным расписанием, поскольку транзакции выполняются последовательным образом.
В среде с несколькими транзакциями последовательные расписания считаются эталоном. Последовательность выполнения инструкции в транзакции не может быть изменена, но две транзакции могут иметь свои инструкции, выполненные случайным образом. Это выполнение не вредит, если две транзакции независимы друг от друга и работают с разными сегментами данных; но если эти две транзакции работают с одними и теми же данными, результаты могут отличаться. Этот постоянно меняющийся результат может привести базу данных в несогласованное состояние.
Чтобы решить эту проблему, мы разрешаем параллельное выполнение расписания транзакций, если его транзакции либо сериализуемы, либо имеют некоторое отношение эквивалентности между ними.
Графики эквивалентности
График эквивалентности может быть следующих типов:
Результат Эквивалентность
Если два графика дают один и тот же результат после выполнения, они называются эквивалентными. Они могут давать один и тот же результат для некоторого значения и разные результаты для другого набора значений. Вот почему эта эквивалентность обычно не считается значимой.
Посмотреть эквивалентность
Два расписания были бы эквивалентны представлению, если транзакции в обоих расписаниях выполняют аналогичные действия одинаковым образом.
Например —
-
Если T читает начальные данные в S1, то он также читает начальные данные в S2.
-
Если T читает значение, записанное J в S1, то оно также читает значение, записанное J в S2.
-
Если T выполняет окончательную запись значения данных в S1, то он также выполняет окончательную запись значения данных в S2.
Если T читает начальные данные в S1, то он также читает начальные данные в S2.
Если T читает значение, записанное J в S1, то оно также читает значение, записанное J в S2.
Если T выполняет окончательную запись значения данных в S1, то он также выполняет окончательную запись значения данных в S2.
Эквивалентность конфликта
Два расписания будут конфликтовать, если они имеют следующие свойства —
- Оба относятся к отдельным транзакциям.
- Оба получают доступ к одному и тому же элементу данных.
- По крайней мере, один из них — операция записи.
Два расписания с несколькими транзакциями с конфликтующими операциями называются конфликтно-эквивалентными, если и только если —
- Оба графика содержат одинаковый набор транзакций.
- Порядок конфликтующих пар операций поддерживается в обоих расписаниях.
Примечание. Просмотр эквивалентных расписаний можно просматривать сериализуемо, а конфликтно-эквивалентные расписания можно сериализировать конфликтом. Все конфликтные сериализуемые графики также доступны для просмотра.
Состояния транзакций
Транзакция в базе данных может находиться в одном из следующих состояний:
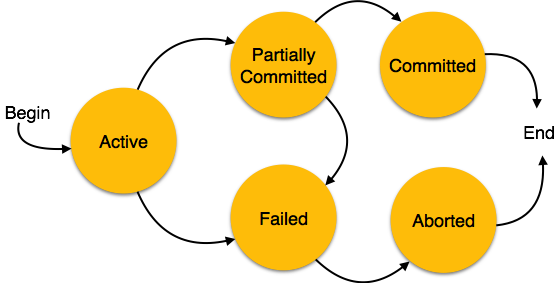
-
Активно — в этом состоянии транзакция выполняется. Это начальное состояние каждой транзакции.
-
Частично зафиксировано — когда транзакция выполняет свою последнюю операцию, говорят, что она находится в частично зафиксированном состоянии.
-
Failed (Сбой) — считается, что транзакция находится в состоянии сбоя, если какая-либо из проверок, выполненных системой восстановления базы данных, дает сбой. Неудачная транзакция больше не может продолжаться дальше.
-
Прервано — если какая-либо из проверок завершилась неудачно и транзакция достигла состояния отказа, менеджер восстановления откатывает все свои операции записи в базе данных, чтобы вернуть базу данных в исходное состояние, в котором она находилась до выполнения транзакции. Транзакции в этом состоянии называются прерванными. Модуль восстановления базы данных может выбрать одну из двух операций после завершения транзакции —
- Перезапустить транзакцию
- Убить сделку
-
Подтверждено — если транзакция успешно выполняет все свои операции, она считается подтвержденной. Все его эффекты теперь постоянно установлены в системе баз данных.
Активно — в этом состоянии транзакция выполняется. Это начальное состояние каждой транзакции.
Частично зафиксировано — когда транзакция выполняет свою последнюю операцию, говорят, что она находится в частично зафиксированном состоянии.
Failed (Сбой) — считается, что транзакция находится в состоянии сбоя, если какая-либо из проверок, выполненных системой восстановления базы данных, дает сбой. Неудачная транзакция больше не может продолжаться дальше.
Прервано — если какая-либо из проверок завершилась неудачно и транзакция достигла состояния отказа, менеджер восстановления откатывает все свои операции записи в базе данных, чтобы вернуть базу данных в исходное состояние, в котором она находилась до выполнения транзакции. Транзакции в этом состоянии называются прерванными. Модуль восстановления базы данных может выбрать одну из двух операций после завершения транзакции —
Подтверждено — если транзакция успешно выполняет все свои операции, она считается подтвержденной. Все его эффекты теперь постоянно установлены в системе баз данных.
СУБД — контроль параллелизма
В многопрограммной среде, где несколько транзакций могут выполняться одновременно, очень важно контролировать параллельность транзакций. У нас есть протоколы контроля параллелизма для обеспечения атомарности, изоляции и сериализуемости параллельных транзакций. Протоколы управления параллелизмом можно разделить на две категории:
- Протоколы на основе блокировки
- Протоколы на основе меток времени
Протоколы на основе блокировки
Системы баз данных, оснащенные протоколами на основе блокировок, используют механизм, с помощью которого любая транзакция не может читать или записывать данные, пока не получит соответствующую блокировку. Замки бывают двух видов —
-
Двоичные блокировки — блокировка элемента данных может находиться в двух состояниях; он либо заблокирован, либо разблокирован.
-
Разделяемый / эксклюзивный — этот тип механизма блокировки различает замки в зависимости от их использования. Если для элемента данных установлена блокировка для выполнения операции записи, это исключительная блокировка. Разрешение на запись более чем одной транзакции в один и тот же элемент данных приведет базу данных в несогласованное состояние. Блокировки чтения являются общими, поскольку значение данных не изменяется.
Двоичные блокировки — блокировка элемента данных может находиться в двух состояниях; он либо заблокирован, либо разблокирован.
Разделяемый / эксклюзивный — этот тип механизма блокировки различает замки в зависимости от их использования. Если для элемента данных установлена блокировка для выполнения операции записи, это исключительная блокировка. Разрешение на запись более чем одной транзакции в один и тот же элемент данных приведет базу данных в несогласованное состояние. Блокировки чтения являются общими, поскольку значение данных не изменяется.
Доступны четыре типа протоколов блокировки —
Упрощенный протокол блокировки
Упрощенные протоколы на основе блокировок позволяют транзакциям получать блокировку для каждого объекта перед выполнением операции записи. Транзакции могут разблокировать элемент данных после завершения операции записи.
Предварительный запрос протокола блокировки
Протоколы предварительной заявки оценивают их операции и создают список элементов данных, для которых они нуждаются в блокировках. Перед началом выполнения транзакция запрашивает у системы все блокировки, в которых она нуждается заранее. Если все блокировки предоставлены, транзакция выполняется и освобождает все блокировки, когда все ее операции завершены. Если все блокировки не предоставлены, транзакция откатывается и ждет, пока все блокировки не будут предоставлены.
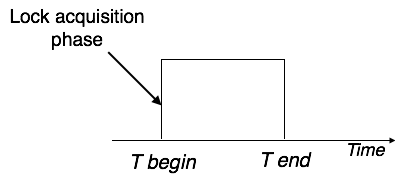
Двухфазная блокировка 2PL
Этот протокол блокировки разделяет этап выполнения транзакции на три части. В первой части, когда транзакция начинает выполняться, она ищет разрешения для требуемых блокировок. Вторая часть, где транзакция получает все блокировки. Как только транзакция освобождает свою первую блокировку, начинается третья фаза. На этом этапе транзакция не может требовать каких-либо новых блокировок; это только освобождает приобретенные замки.
Двухфазная блокировка имеет две фазы, одна растет , где все блокировки приобретаются транзакцией; и вторая фаза сокращается, когда освобождаются блокировки, удерживаемые транзакцией.
Чтобы запросить исключительную блокировку (запись), транзакция должна сначала получить общую (чтение) блокировку, а затем обновить ее до эксклюзивной блокировки.
Строгая двухфазная блокировка
Первая фаза Strict-2PL такая же, как 2PL. После получения всех блокировок на первом этапе транзакция продолжает выполняться в обычном режиме. Но в отличие от 2PL, Strict-2PL не снимает блокировку после его использования. Strict-2PL удерживает все блокировки до момента фиксации и снимает все блокировки одновременно.
Strict-2PL не имеет каскадного прерывания, как 2PL.
Протоколы на основе меток времени
Наиболее часто используемый протокол параллелизма — это протокол, основанный на метках времени. Этот протокол использует системное время или логический счетчик в качестве метки времени.
Протоколы на основе блокировок управляют порядком между конфликтующими парами между транзакциями во время выполнения, тогда как протоколы на основе временных меток начинают работать, как только создается транзакция.
С каждой транзакцией связана временная метка, а порядок определяется возрастом транзакции. Транзакция, созданная в 0002 тактового времени, будет старше всех других транзакций, следующих за ней. Например, любая транзакция ‘y’, входящая в систему на 0004, на две секунды моложе, и приоритет будет отдан более старой.
Кроме того, каждому элементу данных присваивается последняя отметка времени чтения и записи. Это позволяет системе узнать, когда была выполнена последняя операция чтения и записи для элемента данных.
Протокол заказа метки времени
Протокол упорядочения меток времени обеспечивает сериализуемость между транзакциями в их конфликтующих операциях чтения и записи. Система протокола отвечает за то, что конфликтующая пара задач должна выполняться в соответствии со значениями временных меток транзакций.
- Временная метка транзакции T i обозначается как TS (T i ).
- Отметка времени чтения элемента данных X обозначается как R-отметка времени (X).
- Отметка времени записи элемента данных X обозначается W-отметкой времени (X).
Протокол заказа метки времени работает следующим образом:
-
Если транзакция Ti выполняет операцию чтения (X) —
- Если TS (Ti) <W-метка времени (X)
- Операция отклонена.
- Если TS (Ti)> = W-метка времени (X)
- Операция выполнена.
- Все метки времени элемента данных обновлены.
-
Если транзакция Ti выполняет операцию записи (X) —
- Если TS (Ti) <R-отметка времени (X)
- Операция отклонена.
- Если TS (Ti) <W-метка времени (X)
- Операция отклонена и Ti откатился назад.
- В противном случае операция выполнена.
Если транзакция Ti выполняет операцию чтения (X) —
Если транзакция Ti выполняет операцию записи (X) —
Писать правило Томаса
Это правило гласит, что если TS (Ti) <W-timestamp (X), то операция отклоняется и T i откатывается.
Правила упорядочения меток времени можно изменить, чтобы сделать сериализованным представление расписания.
Вместо того, чтобы откатить T i , сама операция записи игнорируется.
СУБД — тупик
В многопроцессорной системе тупиковая ситуация — это нежелательная ситуация, которая возникает в среде общих ресурсов, где процесс бесконечно ожидает ресурс, который удерживается другим процессом.
Например, предположим набор транзакций {T 0 , T 1 , T 2 , …, T n }. T 0 нужен ресурс X, чтобы завершить свою задачу. Ресурс X удерживается T 1 , а T 1 ожидает ресурс Y, который удерживается T 2 . T 2 ожидает ресурс Z, который удерживается T 0 . Таким образом, все процессы ждут друг друга, чтобы освободить ресурсы. В этой ситуации ни один из процессов не может завершить свою задачу. Эта ситуация известна как тупик.
Тупики не полезны для системы. В случае, если система застревает в тупике, транзакции, вовлеченные в тупик, либо откатываются, либо перезапускаются.
Предотвращение тупиковой ситуации
Чтобы предотвратить любую тупиковую ситуацию в системе, СУБД настойчиво проверяет все операции, в которых собираются выполнить транзакции. СУБД проверяет операции и анализирует, могут ли они создать тупиковую ситуацию. Если он обнаруживает, что может возникнуть ситуация взаимоблокировки, эта транзакция никогда не будет разрешена для выполнения.
Существуют схемы предотвращения взаимоблокировок, в которых используется механизм упорядочения временных меток транзакций для предопределения ситуации взаимоблокировки.
Схема ожидания
В этой схеме, если транзакция запрашивает блокировку ресурса (элемента данных), который уже удерживается с конфликтующей блокировкой другой транзакцией, то может возникнуть одна из двух возможностей:
-
Если TS (T i ) <TS (T j ) — то есть T i , который запрашивает конфликтующую блокировку, старше, чем T j — тогда T i разрешается ждать, пока элемент данных станет доступным.
-
Если TS (T i )> TS (t j ) — то есть T i моложе, чем T j — тогда T i умирает. T i перезапускается позже со случайной задержкой, но с той же отметкой времени.
Если TS (T i ) <TS (T j ) — то есть T i , который запрашивает конфликтующую блокировку, старше, чем T j — тогда T i разрешается ждать, пока элемент данных станет доступным.
Если TS (T i )> TS (t j ) — то есть T i моложе, чем T j — тогда T i умирает. T i перезапускается позже со случайной задержкой, но с той же отметкой времени.
Эта схема позволяет старшей транзакции ждать, но убивает младшую.
Схема ожидания
В этой схеме, если транзакция запрашивает блокировку ресурса (элемента данных), который уже удерживается с конфликтующей блокировкой какой-либо другой транзакцией, может возникнуть одна из двух возможностей:
-
Если TS (T i ) <TS (T j ), то T i заставляет T j откатываться — то есть T i ранит T j . T j перезапускается позже со случайной задержкой, но с той же временной меткой.
-
Если TS (T i )> TS (T j ), то T i вынужден ждать, пока ресурс не станет доступен.
Если TS (T i ) <TS (T j ), то T i заставляет T j откатываться — то есть T i ранит T j . T j перезапускается позже со случайной задержкой, но с той же временной меткой.
Если TS (T i )> TS (T j ), то T i вынужден ждать, пока ресурс не станет доступен.
Эта схема позволяет младшей транзакции ждать; но когда более старая транзакция запрашивает элемент, принадлежащий более молодой, более старая транзакция вынуждает более молодую транзакцию прервать и отпустить элемент.
В обоих случаях транзакция, поступающая в систему на более позднем этапе, прерывается.
Предотвращение тупиков
Отмена транзакции не всегда практический подход. Вместо этого можно заранее использовать механизмы предотвращения тупиковой ситуации для обнаружения любой тупиковой ситуации. Такие методы, как «график ожидания», доступны, но они подходят только для тех систем, где транзакции имеют малый вес и имеют меньшее количество экземпляров ресурса. В громоздкой системе методы предотвращения тупиковых ситуаций могут хорошо работать.
График ожидания
Это простой метод, доступный для отслеживания возможных ситуаций тупика. Для каждой транзакции, входящей в систему, создается узел. Когда транзакция T i запрашивает блокировку элемента, скажем, X, которая удерживается какой-либо другой транзакцией T j , создается направленный край от T i до T j . Если T j освобождает элемент X, грань между ними отбрасывается, и T i блокирует элемент данных.
Система поддерживает этот график ожидания для каждой транзакции, ожидающей некоторые элементы данных, удерживаемые другими. Система постоянно проверяет, есть ли цикл на графике.
Здесь мы можем использовать любой из следующих двух подходов:
-
Во-первых, не допускайте никаких запросов на элемент, который уже заблокирован другой транзакцией. Это не всегда выполнимо и может вызвать голод, когда транзакция бесконечно ожидает элемент данных и никогда не сможет его получить.
-
Второй вариант — откатить одну из транзакций. Не всегда выполнимо откатить младшую транзакцию, поскольку она может быть важнее старой. С помощью некоторого относительного алгоритма выбирается транзакция, которая должна быть прервана. Эта транзакция называется жертвой, а процесс — выбором жертвы .
Во-первых, не допускайте никаких запросов на элемент, который уже заблокирован другой транзакцией. Это не всегда выполнимо и может вызвать голод, когда транзакция бесконечно ожидает элемент данных и никогда не сможет его получить.
Второй вариант — откатить одну из транзакций. Не всегда выполнимо откатить младшую транзакцию, поскольку она может быть важнее старой. С помощью некоторого относительного алгоритма выбирается транзакция, которая должна быть прервана. Эта транзакция называется жертвой, а процесс — выбором жертвы .
СУБД — Резервное копирование данных
Потеря Летучего Хранения
В энергозависимом хранилище, таком как ОЗУ, хранятся все активные журналы, дисковые буферы и связанные данные. Кроме того, он хранит все транзакции, которые выполняются в данный момент. Что произойдет, если такое энергозависимое хранилище внезапно выйдет из строя? Очевидно, он забрал бы все журналы и активные копии базы данных. Это делает восстановление практически невозможным, так как все, что требуется для восстановления данных, потеряно.
Следующие методы могут быть приняты в случае потери энергозависимого хранения —
-
Мы можем иметь контрольные точки на нескольких этапах, чтобы периодически сохранять содержимое базы данных.
-
Состояние активной базы данных в энергозависимой памяти может периодически выгружаться в стабильное хранилище, которое также может содержать журналы и активные транзакции и буферные блоки.
-
<dump> может быть отмечен в файле журнала всякий раз, когда содержимое базы данных выгружается из энергонезависимой памяти в стабильную.
Мы можем иметь контрольные точки на нескольких этапах, чтобы периодически сохранять содержимое базы данных.
Состояние активной базы данных в энергозависимой памяти может периодически выгружаться в стабильное хранилище, которое также может содержать журналы и активные транзакции и буферные блоки.
<dump> может быть отмечен в файле журнала всякий раз, когда содержимое базы данных выгружается из энергонезависимой памяти в стабильную.
восстановление
-
Когда система восстанавливается после сбоя, она может восстановить последний дамп.
-
Он может поддерживать повторный список и список отмен как контрольные точки.
-
Он может восстановить систему, просмотрев списки отмен и повторов, чтобы восстановить состояние всех транзакций до последней контрольной точки.
Когда система восстанавливается после сбоя, она может восстановить последний дамп.
Он может поддерживать повторный список и список отмен как контрольные точки.
Он может восстановить систему, просмотрев списки отмен и повторов, чтобы восстановить состояние всех транзакций до последней контрольной точки.
Резервное копирование и восстановление базы данных после катастрофического сбоя
Катастрофический сбой — это тот случай, когда стабильное вторичное запоминающее устройство повреждено. При использовании устройства хранения все ценные данные, которые хранятся внутри, теряются. У нас есть две разные стратегии для восстановления данных после такого катастрофического сбоя —
-
Удаленное резервное копирование & minu; Здесь резервная копия базы данных хранится в удаленном месте, откуда она может быть восстановлена в случае катастрофы.
-
Кроме того, резервные копии базы данных могут быть сделаны на магнитных лентах и храниться в более безопасном месте. Впоследствии эта резервная копия может быть перенесена в недавно установленную базу данных, чтобы привести ее к точке резервного копирования.
Удаленное резервное копирование & minu; Здесь резервная копия базы данных хранится в удаленном месте, откуда она может быть восстановлена в случае катастрофы.
Кроме того, резервные копии базы данных могут быть сделаны на магнитных лентах и храниться в более безопасном месте. Впоследствии эта резервная копия может быть перенесена в недавно установленную базу данных, чтобы привести ее к точке резервного копирования.
Взрослые базы данных слишком громоздки, чтобы их можно было часто копировать. В таких случаях у нас есть методы, при которых мы можем восстановить базу данных, просто взглянув на ее логи. Итак, все, что нам нужно сделать здесь, это сделать резервную копию всех журналов с частыми интервалами времени. Резервное копирование базы данных может производиться один раз в неделю, а журналы очень малого размера могут создаваться ежедневно или как можно чаще.
Удаленное резервное копирование
Удаленное резервное копирование обеспечивает чувство безопасности на случай, если основное местоположение, где расположена база данных, разрушено. Удаленное резервное копирование может быть в автономном режиме или в режиме реального времени или онлайн. В случае, если он не в сети, он поддерживается вручную.
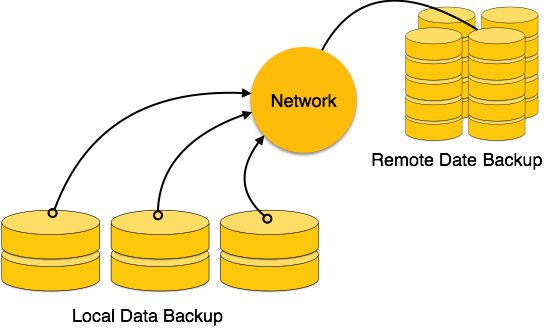
Системы резервного копирования в режиме онлайн являются в реальном времени и спасают для администраторов баз данных и инвесторов. Система оперативного резервного копирования — это механизм, в котором каждый бит данных в реальном времени резервируется одновременно в двух удаленных местах. Один из них напрямую подключен к системе, а другой хранится в удаленном месте в качестве резервной копии.
Как только происходит сбой основного хранилища базы данных, система резервного копирования обнаруживает сбой и переключает пользовательскую систему на удаленное хранилище. Иногда это происходит настолько мгновенно, что пользователи даже не осознают неудачу.
СУБД — Восстановление данных
Восстановление после сбоя
СУБД — очень сложная система с сотнями транзакций, выполняемых каждую секунду. Долговечность и надежность СУБД зависят от ее сложной архитектуры и лежащего в ее основе аппаратного и системного программного обеспечения. Если в результате транзакции происходит сбой или происходит сбой, ожидается, что система будет использовать какой-то алгоритм или методы для восстановления потерянных данных.
Классификация отказов
Чтобы увидеть, где возникла проблема, мы обобщаем отказ на различные категории, а именно:
Сбой транзакции
Транзакция должна быть прервана, если она не выполняется или когда она достигает точки, из которой она не может идти дальше. Это называется сбой транзакции, когда повреждены только несколько транзакций или процессов.
Причины сбоя транзакции могут быть:
-
Логические ошибки — когда транзакция не может быть завершена из-за ошибки в коде или из-за внутренней ошибки.
-
Системные ошибки — когда система базы данных сама завершает активную транзакцию, потому что СУБД не может выполнить ее, или она должна остановиться из-за какого-либо состояния системы. Например, в случае тупика или недоступности ресурса система прерывает активную транзакцию.
Логические ошибки — когда транзакция не может быть завершена из-за ошибки в коде или из-за внутренней ошибки.
Системные ошибки — когда система базы данных сама завершает активную транзакцию, потому что СУБД не может выполнить ее, или она должна остановиться из-за какого-либо состояния системы. Например, в случае тупика или недоступности ресурса система прерывает активную транзакцию.
Системный сбой
Существуют проблемы, внешние по отношению к системе, которые могут привести к внезапной остановке системы и ее аварийному завершению. Например, перебои в электроснабжении могут вызвать сбой основного аппаратного или программного сбоя.
Примеры могут включать ошибки операционной системы.
Ошибка диска
На заре развития технологии это была распространенная проблема, когда жесткие диски или накопители часто выходили из строя.
Отказы диска включают в себя образование поврежденных секторов, недоступность диска, поломку головки диска или любой другой сбой, который разрушает все или часть дискового хранилища.
Структура хранения
Мы уже описали систему хранения. Вкратце, структуру хранения можно разделить на две категории —
-
Энергозависимое хранилище. Как следует из названия, энергозависимое хранилище не может выдержать сбои системы. Энергозависимые запоминающие устройства расположены очень близко к процессору; обычно они встроены в сам чипсет. Например, основная память и кэш-память являются примерами энергозависимой памяти. Они быстрые, но могут хранить только небольшое количество информации.
-
Энергонезависимое хранилище — эти воспоминания созданы для того, чтобы выдерживать сбои системы. Они огромны по объему хранения данных, но медленнее по доступу. Примерами могут быть жесткие диски, магнитные ленты, флэш-память и энергонезависимое ОЗУ (с резервным питанием от батареи).
Энергозависимое хранилище. Как следует из названия, энергозависимое хранилище не может выдержать сбои системы. Энергозависимые запоминающие устройства расположены очень близко к процессору; обычно они встроены в сам чипсет. Например, основная память и кэш-память являются примерами энергозависимой памяти. Они быстрые, но могут хранить только небольшое количество информации.
Энергонезависимое хранилище — эти воспоминания созданы для того, чтобы выдерживать сбои системы. Они огромны по объему хранения данных, но медленнее по доступу. Примерами могут быть жесткие диски, магнитные ленты, флэш-память и энергонезависимое ОЗУ (с резервным питанием от батареи).
Восстановление и атомарность
В случае сбоя системы может быть выполнено несколько транзакций и открыты различные файлы для изменения элементов данных. Сделки состоят из различных операций, которые по своей природе являются атомарными. Но согласно ACID-свойствам СУБД, атомарность транзакций в целом должна поддерживаться, то есть либо все операции выполняются, либо их нет.
Когда СУБД восстанавливается после сбоя, она должна поддерживать следующее:
-
Он должен проверять состояния всех транзакций, которые выполнялись.
-
Транзакция может быть в середине некоторой операции; СУБД должна обеспечивать атомарность транзакции в этом случае.
-
Он должен проверить, может ли транзакция быть завершена сейчас или ее необходимо откатить.
-
Никакие транзакции не позволят оставить СУБД в несогласованном состоянии.
Он должен проверять состояния всех транзакций, которые выполнялись.
Транзакция может быть в середине некоторой операции; СУБД должна обеспечивать атомарность транзакции в этом случае.
Он должен проверить, может ли транзакция быть завершена сейчас или ее необходимо откатить.
Никакие транзакции не позволят оставить СУБД в несогласованном состоянии.
Существует два типа методов, которые могут помочь СУБД в восстановлении, а также в поддержании атомарности транзакции.
-
Ведение журналов каждой транзакции и запись их в некоторое стабильное хранилище перед тем, как вносить изменения в базу данных.
-
Ведение теневой подкачки, когда изменения выполняются в энергозависимой памяти, а затем актуальная база данных обновляется.
Ведение журналов каждой транзакции и запись их в некоторое стабильное хранилище перед тем, как вносить изменения в базу данных.
Ведение теневой подкачки, когда изменения выполняются в энергозависимой памяти, а затем актуальная база данных обновляется.
Восстановление на основе журнала
Журнал — это последовательность записей, которая ведет записи действий, выполненных транзакцией. Важно, чтобы журналы записывались до фактического изменения и сохранялись на стабильном носителе, который является отказоустойчивым.
Восстановление на основе журнала работает следующим образом:
-
Файл журнала хранится на стабильном носителе.
-
Когда транзакция входит в систему и начинает выполнение, она записывает в нее журнал.
Файл журнала хранится на стабильном носителе.
Когда транзакция входит в систему и начинает выполнение, она записывает в нее журнал.
<T n , Start>
-
Когда транзакция изменяет элемент X, она записывает журналы следующим образом:
Когда транзакция изменяет элемент X, она записывает журналы следующим образом:
<T n , X, V 1 , V 2 >
В нем говорится, что T n изменило значение X с V 1 до V 2 .
- Когда транзакция заканчивается, она регистрирует —
<T n , commit>
База данных может быть изменена с использованием двух подходов —
-
Отложенная модификация базы данных — все журналы записываются в стабильное хранилище, а база данных обновляется при фиксации транзакции.
-
Немедленное изменение базы данных — каждый журнал следует за фактическим изменением базы данных. То есть база данных модифицируется сразу после каждой операции.
Отложенная модификация базы данных — все журналы записываются в стабильное хранилище, а база данных обновляется при фиксации транзакции.
Немедленное изменение базы данных — каждый журнал следует за фактическим изменением базы данных. То есть база данных модифицируется сразу после каждой операции.
Восстановление с параллельными транзакциями
Когда несколько транзакций выполняются параллельно, журналы чередуются. Во время восстановления системе восстановления будет трудно отследить все журналы, а затем начать восстановление. Чтобы облегчить эту ситуацию, большинство современных СУБД используют концепцию «контрольных точек».
Контрольно-пропускной пункт
Хранение и ведение журналов в реальном времени и в реальной среде может заполнить все пространство памяти, доступное в системе. Со временем файл журнала может стать слишком большим, чтобы его можно было обрабатывать вообще. Контрольная точка — это механизм, при котором все предыдущие журналы удаляются из системы и постоянно хранятся на диске. Контрольная точка объявляет точку, до которой СУБД находилась в согласованном состоянии, и все транзакции были зафиксированы.
восстановление
Когда происходит сбой и восстановление системы с одновременными транзакциями, она ведет себя следующим образом:

-
Система восстановления считывает журналы в обратном направлении от конца до последней контрольной точки.
-
Он поддерживает два списка: список отмены и список повторов.
-
Если система восстановления видит журнал с <T n , Start> и <T n , Commit> или просто <T n , Commit>, она помещает транзакцию в повторный список.
-
Если система восстановления видит журнал с <T n , Start>, но журнал фиксации или отмены не найден, она помещает транзакцию в список отмены.
Система восстановления считывает журналы в обратном направлении от конца до последней контрольной точки.
Он поддерживает два списка: список отмены и список повторов.
Если система восстановления видит журнал с <T n , Start> и <T n , Commit> или просто <T n , Commit>, она помещает транзакцию в повторный список.
Если система восстановления видит журнал с <T n , Start>, но журнал фиксации или отмены не найден, она помещает транзакцию в список отмены.
Все транзакции в списке отмены затем отменяются и их журналы удаляются. Все транзакции в повторном списке и их предыдущие журналы удаляются и затем переделываются перед сохранением их журналов.