Генетические алгоритмы — Введение
Генетический алгоритм (GA) — это поисковая оптимизация, основанная на принципах генетики и естественного отбора . Он часто используется для поиска оптимальных или почти оптимальных решений сложных проблем, которые в противном случае потребовались бы для решения целой жизни. Он часто используется для решения задач оптимизации, в исследованиях и в машинном обучении.
Введение в оптимизацию
Оптимизация — это процесс создания чего-то лучшего . В любом процессе у нас есть набор входов и набор выходов, как показано на следующем рисунке.
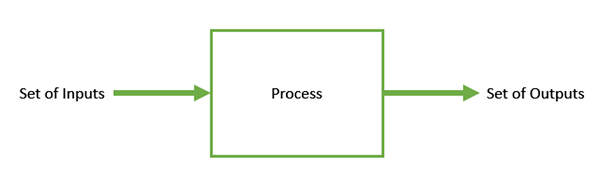
Оптимизация относится к нахождению значений входных данных таким образом, что мы получаем «наилучшие» выходные значения. Определение «наилучшего» варьируется от проблемы к проблеме, но в математических терминах оно относится к максимизации или минимизации одной или нескольких целевых функций путем изменения входных параметров.
Множество всех возможных решений или значений, которые могут принимать входные данные, составляют пространство поиска. В этом пространстве поиска лежит точка или набор точек, которые дают оптимальное решение. Цель оптимизации — найти эту точку или набор точек в пространстве поиска.
Что такое генетические алгоритмы?
Природа всегда была источником вдохновения для всего человечества. Генетические алгоритмы (GA) — это алгоритмы поиска, основанные на понятиях естественного отбора и генетики. GA — это подмножество гораздо большей ветви вычислений, известной как эволюционные вычисления .
GA были разработаны Джоном Холландом и его студентами и коллегами из Мичиганского университета, прежде всего Дэвидом Э. Голдбергом, и с тех пор пробовали решать различные задачи оптимизации с высокой степенью успеха.
В ГА у нас есть пул или совокупность возможных решений данной проблемы. Эти решения затем подвергаются рекомбинации и мутации (как в естественной генетике), порождая новых детей, и процесс повторяется на протяжении разных поколений. Каждому индивидууму (или подходящему решению) присваивается значение пригодности (в зависимости от значения его целевой функции), и более подходящие индивидуумы получают более высокий шанс на спаривание и получают больше «более подходящих» индивидуумов. Это соответствует дарвиновской теории выживания наиболее приспособленных.
Таким образом, мы продолжаем «развивать» лучших людей или решения из поколения в поколение, пока не достигнем критерия остановки.
Генетические алгоритмы по своей природе достаточно рандомизированы, но они выполняют намного лучше, чем случайный локальный поиск (в котором мы просто пробуем различные случайные решения, отслеживая лучшие на данный момент), поскольку они также используют историческую информацию.
Преимущества ГА
У GA есть различные преимущества, которые сделали их чрезвычайно популярными. К ним относятся —
-
Не требует никакой производной информации (которая может быть недоступна для многих реальных проблем).
-
Это быстрее и эффективнее по сравнению с традиционными методами.
-
Имеет очень хорошие параллельные возможности.
-
Оптимизирует как непрерывные, так и дискретные функции, а также многоцелевые задачи.
-
Предоставляет список «хороших» решений, а не просто одно решение.
-
Всегда получает ответ на проблему, которая со временем становится лучше.
-
Полезно, когда пространство поиска очень велико и задействовано большое количество параметров.
Не требует никакой производной информации (которая может быть недоступна для многих реальных проблем).
Это быстрее и эффективнее по сравнению с традиционными методами.
Имеет очень хорошие параллельные возможности.
Оптимизирует как непрерывные, так и дискретные функции, а также многоцелевые задачи.
Предоставляет список «хороших» решений, а не просто одно решение.
Всегда получает ответ на проблему, которая со временем становится лучше.
Полезно, когда пространство поиска очень велико и задействовано большое количество параметров.
Ограничения ГА
Как и любая техника, ГА также страдают от нескольких ограничений. К ним относятся —
-
GA не подходят для всех проблем, особенно для задач, которые просты и для которых доступна производная информация.
-
Значение пригодности рассчитывается многократно, что может быть вычислительно дорогостоящим для некоторых задач.
-
Будучи стохастическим, нет никаких гарантий относительно оптимальности или качества решения.
-
Если не реализовано должным образом, GA может не сходиться к оптимальному решению.
GA не подходят для всех проблем, особенно для задач, которые просты и для которых доступна производная информация.
Значение пригодности рассчитывается многократно, что может быть вычислительно дорогостоящим для некоторых задач.
Будучи стохастическим, нет никаких гарантий относительно оптимальности или качества решения.
Если не реализовано должным образом, GA может не сходиться к оптимальному решению.
GA — Мотивация
Генетические алгоритмы обладают способностью предоставлять «достаточно хорошее» решение «достаточно быстро». Это делает генетические алгоритмы привлекательными для использования при решении задач оптимизации. Причины, по которым нужны ГА, следующие:
Решение сложных проблем
В информатике существует большой набор проблем, которые NP-Hard . По сути это означает, что даже самым мощным вычислительным системам требуется очень много времени (даже лет!) Для решения этой проблемы. В таком сценарии ГА оказываются эффективным инструментом для предоставления практически оптимальных решений за короткое время.
Отказ градиентных методов
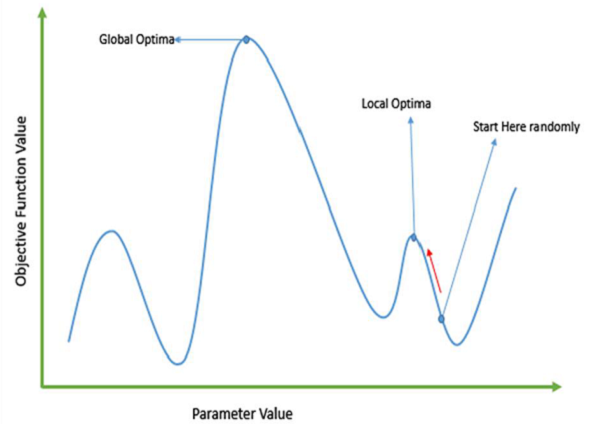
Традиционные методы, основанные на исчислении, работают, начиная со случайной точки и двигаясь в направлении градиента, пока мы не достигнем вершины холма. Этот метод эффективен и очень хорошо работает для однопиковых целевых функций, таких как функция стоимости в линейной регрессии. Но в большинстве реальных ситуаций у нас есть очень сложная проблема, называемая ландшафтами, которые состоят из множества вершин и долин, что приводит к сбою таких методов, поскольку они страдают от присущей им тенденции застревания в локальных оптимальных условиях. как показано на следующем рисунке.
Быстрое получение хорошего решения
У некоторых сложных проблем, таких как Задача коммивояжера (TSP), есть реальные приложения, такие как поиск пути и VLSI Design. Теперь представьте, что вы используете свою систему GPS-навигации, и для расчета «оптимального» пути от источника до пункта назначения требуется несколько минут (или даже нескольких часов). Задержка в таких реальных приложениях неприемлема, и поэтому требуется «достаточно хорошее» решение, которое доставляется «быстро».
Генетические алгоритмы — основы
В этом разделе представлена основная терминология, необходимая для понимания ГА. Кроме того, общая структура GA представлена как в псевдокоде, так и в графической форме . Читателю рекомендуется правильно понимать все концепции, представленные в этом разделе, и помнить о них при чтении других разделов этого учебника.
Основная терминология
Прежде чем начать обсуждение генетических алгоритмов, важно ознакомиться с некоторой базовой терминологией, которая будет использоваться в этом учебном пособии.
-
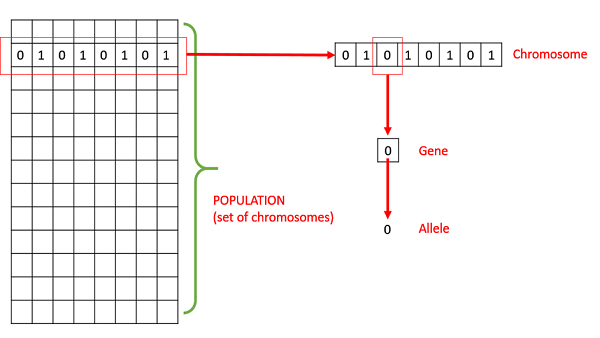
Население — это подмножество всех возможных (закодированных) решений данной проблемы. Население для ГА аналогично населению для людей, за исключением того, что вместо людей у нас есть кандидатские решения, представляющие людей.
-
Хромосомы . Хромосома — одно из таких решений данной проблемы.
-
Ген — ген является одним из элементов хромосомы.
-
Аллель — это значение, которое ген принимает для конкретной хромосомы.
Население — это подмножество всех возможных (закодированных) решений данной проблемы. Население для ГА аналогично населению для людей, за исключением того, что вместо людей у нас есть кандидатские решения, представляющие людей.
Хромосомы . Хромосома — одно из таких решений данной проблемы.
Ген — ген является одним из элементов хромосомы.
Аллель — это значение, которое ген принимает для конкретной хромосомы.
-
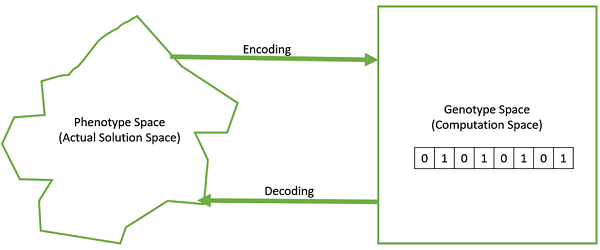
Генотип — генотип — популяция в вычислительном пространстве. В вычислительном пространстве решения представлены таким способом, который можно легко понять и манипулировать с помощью вычислительной системы.
-
Фенотип. Фенотип — это совокупность в реальном пространстве решений реального мира, в которой решения представлены так, как они представлены в ситуациях реального мира.
-
Декодирование и кодирование — Для простых задач фенотип и пространство генотипа одинаковы. Однако в большинстве случаев пространства фенотипа и генотипа различны. Декодирование — это процесс преобразования решения из генотипа в пространство фенотипа, в то время как кодирование — это процесс преобразования из фенотипа в пространство генотипа. Декодирование должно быть быстрым, поскольку оно выполняется многократно в GA во время вычисления значения пригодности.
Например, рассмотрим проблему ранца 0/1. Пространство фенотипа состоит из решений, которые просто содержат номера предметов для выбора.
Однако в пространстве генотипа его можно представить в виде двоичной строки длиной n (где n — количество элементов). 0 в позиции x означает, что x- й элемент выбран, а 1 — наоборот. Это тот случай, когда генотип и фенотип пространства различаются.
Генотип — генотип — популяция в вычислительном пространстве. В вычислительном пространстве решения представлены таким способом, который можно легко понять и манипулировать с помощью вычислительной системы.
Фенотип. Фенотип — это совокупность в реальном пространстве решений реального мира, в которой решения представлены так, как они представлены в ситуациях реального мира.
Декодирование и кодирование — Для простых задач фенотип и пространство генотипа одинаковы. Однако в большинстве случаев пространства фенотипа и генотипа различны. Декодирование — это процесс преобразования решения из генотипа в пространство фенотипа, в то время как кодирование — это процесс преобразования из фенотипа в пространство генотипа. Декодирование должно быть быстрым, поскольку оно выполняется многократно в GA во время вычисления значения пригодности.
Например, рассмотрим проблему ранца 0/1. Пространство фенотипа состоит из решений, которые просто содержат номера предметов для выбора.
Однако в пространстве генотипа его можно представить в виде двоичной строки длиной n (где n — количество элементов). 0 в позиции x означает, что x- й элемент выбран, а 1 — наоборот. Это тот случай, когда генотип и фенотип пространства различаются.
-
Функция пригодности — просто определенная функция пригодности — это функция, которая принимает решение в качестве входных данных и выдает пригодность решения в качестве выходных данных. В некоторых случаях фитнес-функция и целевая функция могут быть одинаковыми, в то время как в других они могут различаться в зависимости от проблемы.
-
Генетические операторы — Они изменяют генетический состав потомства. К ним относятся кроссовер, мутация, отбор и т. Д.
Функция пригодности — просто определенная функция пригодности — это функция, которая принимает решение в качестве входных данных и выдает пригодность решения в качестве выходных данных. В некоторых случаях фитнес-функция и целевая функция могут быть одинаковыми, в то время как в других они могут различаться в зависимости от проблемы.
Генетические операторы — Они изменяют генетический состав потомства. К ним относятся кроссовер, мутация, отбор и т. Д.
Базовая структура
Основная структура ГА выглядит следующим образом —
Мы начнем с начальной популяции (которая может быть сгенерирована случайным образом или посеяна другими эвристиками), выбираем родителей из этой популяции для спаривания. Примените кроссовер и операторы мутации на родителях, чтобы произвести новых потомков. И, наконец, эти потомки заменяют существующих людей в популяции, и процесс повторяется. Таким образом, генетические алгоритмы в некоторой степени пытаются имитировать эволюцию человека.
Каждый из следующих шагов рассматривается в отдельной главе далее в этом руководстве.
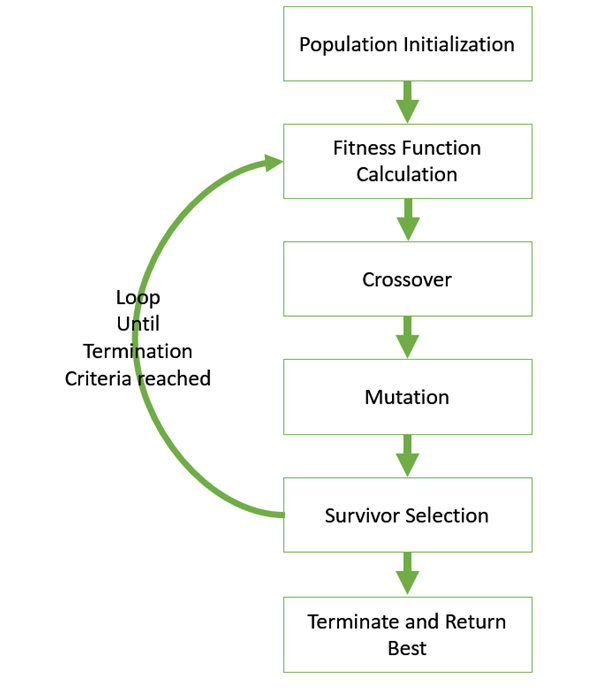
Обобщенный псевдокод для GA объясняется в следующей программе:
GA()
initialize population
find fitness of population
while (termination criteria is reached) do
parent selection
crossover with probability pc
mutation with probability pm
decode and fitness calculation
survivor selection
find best
return best
Представление генотипа
Одним из наиболее важных решений, которые необходимо принять при реализации генетического алгоритма, является определение представления, которое мы будем использовать для представления наших решений. Было отмечено, что неправильное представление может привести к плохой производительности ГА.
Следовательно, выбор правильного представления, правильное определение отображений между фенотипом и пространством генотипа имеет важное значение для успеха ГА.
В этом разделе мы представляем некоторые из наиболее часто используемых представлений для генетических алгоритмов. Тем не менее, представление в значительной степени зависит от проблемы, и читатель может обнаружить, что другое представление или сочетание представлений, упомянутых здесь, могут лучше удовлетворить его / ее проблему.
Бинарное Представление
Это одно из самых простых и широко используемых представлений в ГА. В этом типе представления генотип состоит из битовых строк.
Для некоторых задач, когда пространство решений состоит из логических переменных решения — да или нет, двоичное представление является естественным. Возьмем, к примеру, проблему ранца 0/1. Если есть n элементов, мы можем представить решение в виде двоичной строки из n элементов, где x- й элемент сообщает, выбран ли элемент x (1) или нет (0).

Для других задач, в частности тех, которые касаются чисел, мы можем представить числа с их двоичным представлением. Проблема с этим типом кодирования состоит в том, что разные биты имеют разное значение, и поэтому операторы мутации и кроссовера могут иметь нежелательные последствия. Эту проблему можно решить в некоторой степени, используя кодирование Грея, поскольку изменение в один бит не оказывает существенного влияния на решение.
Реальное представление
Для задач, где мы хотим определить гены, используя непрерывные, а не дискретные переменные, реальное представление является наиболее естественным. Точность этих вещественных чисел или чисел с плавающей точкой, однако, ограничена компьютером.

Целочисленное представление
Для дискретных генов мы не всегда можем ограничить пространство решения бинарным «да» или «нет». Например, если мы хотим кодировать четыре расстояния — север, юг, восток и запад, мы можем кодировать их как {0,1,2,3} . В таких случаях желательно целочисленное представление.

Представление перестановки
Во многих задачах решение представлено порядком элементов. В таких случаях представление перестановки является наиболее подходящим.
Классическим примером этого представления является проблема коммивояжера (TSP). При этом продавец должен совершить экскурсию по всем городам, посетить каждый город ровно один раз и вернуться в стартовый город. Общая дистанция тура должна быть минимизирована. Решением этого TSP является, естественно, упорядочение или перестановка всех городов, и поэтому использование перестановочного представления имеет смысл для этой проблемы.

Генетические Алгоритмы — Население
Население является подмножеством решений в нынешнем поколении. Он также может быть определен как набор хромосом. Есть несколько вещей, которые следует иметь в виду при работе с населением ГА —
-
Разнообразие населения должно быть сохранено, иначе это может привести к преждевременной конвергенции.
-
Размер популяции не должен быть очень большим, так как это может привести к замедлению ГА, в то время как меньшая популяция может оказаться недостаточной для хорошего спаривания. Следовательно, оптимальный размер популяции должен решаться методом проб и ошибок.
Разнообразие населения должно быть сохранено, иначе это может привести к преждевременной конвергенции.
Размер популяции не должен быть очень большим, так как это может привести к замедлению ГА, в то время как меньшая популяция может оказаться недостаточной для хорошего спаривания. Следовательно, оптимальный размер популяции должен решаться методом проб и ошибок.
Популяция обычно определяется как двумерный массив: размер населения, размер х, размер хромосомы .
Инициализация населения
Существует два основных метода инициализации населения в GA. Они —
-
Случайная инициализация — заполнить начальную популяцию совершенно случайными решениями.
-
Эвристическая инициализация — Заполните начальную популяцию, используя известную эвристику для задачи.
Случайная инициализация — заполнить начальную популяцию совершенно случайными решениями.
Эвристическая инициализация — Заполните начальную популяцию, используя известную эвристику для задачи.
Наблюдалось, что вся популяция не должна быть инициализирована с использованием эвристики, поскольку это может привести к тому, что популяция будет иметь схожие решения и очень небольшое разнообразие. Экспериментально наблюдалось, что случайные решения — те, которые приводят население к оптимальности. Следовательно, с помощью эвристической инициализации мы просто заполняем популяцию парой хороших решений, заполняя остальные случайными решениями, а не заполняем все население эвристическими решениями.
Также было отмечено, что эвристическая инициализация в некоторых случаях влияет только на начальную приспособленность населения, но, в конце концов, именно разнообразие решений приводит к оптимальности.
Модели народонаселения
Есть две широко используемые модели населения —
Устойчивое состояние
В стационарном GA мы генерируем одного или двух потомков в каждой итерации, и они заменяют одного или двух особей из совокупности. ГА в устойчивом состоянии также известен как Инкрементальный ГА .
Generational
В модели поколений мы генерируем «n» потомков, где n — это размер популяции, а вся популяция заменяется новой в конце итерации.
Генетические алгоритмы — Фитнес-функция
Просто определенная фитнес-функция — это функция, которая принимает в качестве входных данных возможное решение проблемы и выдает в качестве выходных данных то, насколько «соответствует» нашему, насколько «хорошим» является решение по отношению к рассматриваемой проблеме.
Расчет значения пригодности проводится повторно в GA, и поэтому он должен быть достаточно быстрым. Медленное вычисление значения пригодности может отрицательно повлиять на GA и сделать его исключительно медленным.
В большинстве случаев фитнес-функция и целевая функция совпадают с целью — максимизировать или минимизировать данную целевую функцию. Однако для более сложных задач с несколькими целями и ограничениями конструктор алгоритмов может выбрать другую пригодную функцию.
Фитнес-функция должна обладать следующими характеристиками —
-
Фитнес-функция должна быть достаточно быстрой для вычисления.
-
Он должен количественно измерить, насколько подходит данное решение или как индивидуумы могут быть получены из данного решения.
Фитнес-функция должна быть достаточно быстрой для вычисления.
Он должен количественно измерить, насколько подходит данное решение или как индивидуумы могут быть получены из данного решения.
В некоторых случаях непосредственный расчет фитнес-функции может оказаться невозможным из-за сложностей, присущих данной проблеме. В таких случаях мы выполняем фитнес-аппроксимацию в соответствии с нашими потребностями.
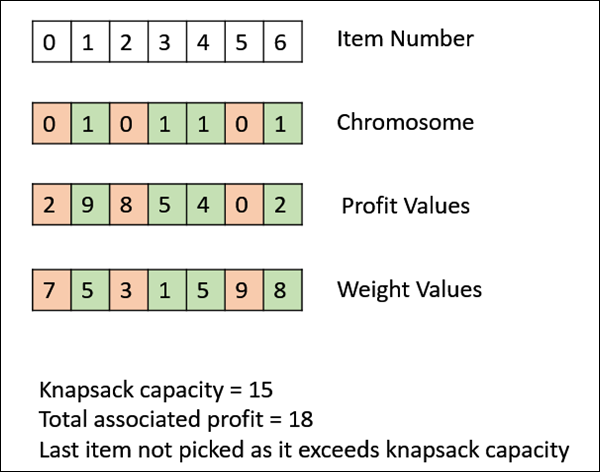
На следующем рисунке показан расчет пригодности для решения рюкзака 0/1. Это простая фитнес-функция, которая просто суммирует значения прибыли выбранных предметов (которые имеют 1), сканируя элементы слева направо, пока рюкзак не заполнится.
Генетические алгоритмы — выбор родителей
Выбор родителей — это процесс выбора родителей, которые спариваются и рекомбинируют, чтобы создать потомство для следующего поколения. Выбор родителей очень важен для скорости конвергенции ГА, поскольку хорошие родители подталкивают людей к лучшим и более подходящим решениям.
Однако следует позаботиться о том, чтобы одно чрезвычайно подходящее решение не охватило всю совокупность в течение нескольких поколений, поскольку это приводит к тому, что решения в пространстве решений находятся близко друг к другу, что приводит к потере разнообразия. Поддержание хорошего разнообразия в популяции чрезвычайно важно для успеха ГА. Это поглощение всей совокупности одним чрезвычайно подходящим решением известно как преждевременная конвергенция и является нежелательным условием в GA.
Фитнес пропорциональный выбор
Фитнес пропорциональный отбор является одним из самых популярных способов родительского отбора. В этом каждый человек может стать родителем с вероятностью, которая пропорциональна его пригодности. Таким образом, у людей, имеющих более крепкие шансы, больше шансов на спаривание и распространение своих возможностей для следующего поколения. Таким образом, такая стратегия отбора оказывает давление отбора на более подходящих людей в популяции, развивая лучших людей с течением времени.
Рассмотрим круговое колесо. Колесо делится на n пирогов , где n — количество особей в популяции. Каждый человек получает часть круга, которая пропорциональна его значению пригодности.
Возможны две реализации пропорционального выбора фитнеса —
Выбор колеса рулетки
При выборе колеса рулетки круговое колесо делится, как описано выше. Фиксированная точка выбирается на окружности колеса, как показано, и колесо вращается. Область колеса, которая находится перед фиксированной точкой, выбирается в качестве родительской. Для второго родителя тот же процесс повторяется.
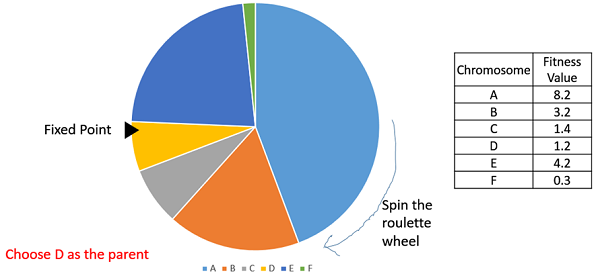
Понятно, что у человека-сборщика больший круг на колесе и, следовательно, больше шансов приземлиться перед неподвижной точкой при вращении колеса. Поэтому вероятность выбора человека напрямую зависит от его пригодности.
Для реализации мы используем следующие шаги:
-
Рассчитать S = сумма дел.
-
Генерация случайного числа от 0 до S.
-
Начиная с верхней части населения, продолжайте добавлять сферы к частичной сумме P, пока P <S.
-
Индивидуум, для которого P превышает S, является выбранным индивидуумом.
Рассчитать S = сумма дел.
Генерация случайного числа от 0 до S.
Начиная с верхней части населения, продолжайте добавлять сферы к частичной сумме P, пока P <S.
Индивидуум, для которого P превышает S, является выбранным индивидуумом.
Стохастическая универсальная выборка (SUS)
Стохастическая универсальная выборка очень похожа на выбор колеса рулетки, однако вместо одной фиксированной точки мы имеем несколько фиксированных точек, как показано на следующем рисунке. Поэтому все родители выбираются всего за один оборот колеса. Кроме того, такая схема поощряет выбор подходящих людей хотя бы один раз.
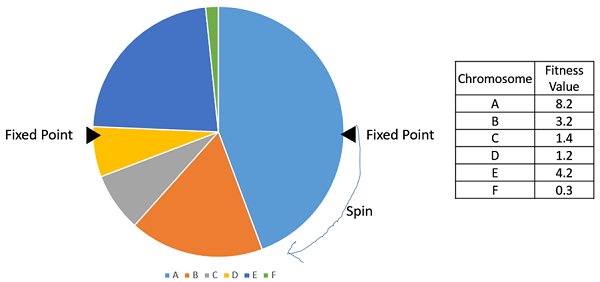
Следует отметить, что методы пропорционального выбора пригодности не работают в тех случаях, когда пригодность может принимать отрицательное значение.
Выбор турнира
В отборе турниров K-Way мы выбираем K человек из популяции случайно и выбираем лучших из них, чтобы стать родителями. Тот же процесс повторяется для выбора следующего родителя. Турнирный отбор также чрезвычайно популярен в литературе, поскольку он может работать даже с отрицательными значениями пригодности.
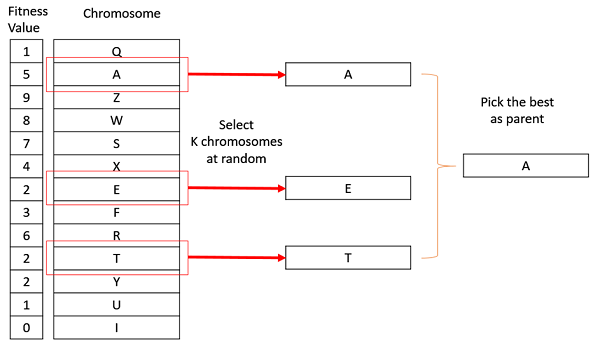
Выбор ранга
Выбор ранга также работает с отрицательными значениями пригодности и в основном используется, когда люди в популяции имеют очень близкие значения пригодности (это обычно происходит в конце цикла). Это приводит к тому, что каждый человек имеет почти равную долю пирога (как в случае соразмерного выбора пригодности), как показано на следующем изображении, и, следовательно, каждый человек, независимо от его соответствия относительно друг друга, имеет приблизительно одинаковую вероятность выбора в качестве родитель. Это, в свою очередь, приводит к потере давления отбора по отношению к более приспособленным людям, что делает ГА плохим выбором родителей в таких ситуациях.
![]()
В этом мы удалим понятие пригодности при выборе родителя. Тем не менее, каждый человек в популяции ранжируется в зависимости от их пригодности. Выбор родителей зависит от ранга каждого человека, а не от его пригодности. Люди с более высоким рейтингом предпочтительнее, чем люди с более низким рейтингом.
| хромосома | Фитнес-ценность | Ранг |
|---|---|---|
| 8,1 | 1 | |
| В | 8,0 | 4 |
| С | 8,05 | 2 |
| D | 7,95 | 6 |
| Е | 8,02 | 3 |
| F | 7,99 | 5 |
Случайный выбор
В этой стратегии мы случайным образом выбираем родителей из существующего населения. Не существует давления отбора в отношении более приспособленных людей, и поэтому этой стратегии обычно избегают.
Генетические алгоритмы — кроссовер
В этой главе мы обсудим, что такое оператор кроссовера, а также другие его модули, их использование и преимущества.
Введение в кроссовер
Оператор кроссовера аналогичен воспроизведению и биологическому кроссоверу. При этом выбирается более одного родителя, и один или несколько потомков производятся с использованием генетического материала родителей. Кроссовер обычно применяется в GA с высокой вероятностью — p c .
Операторы кроссовера
В этом разделе мы обсудим некоторые из наиболее популярных операторов кроссовера. Следует отметить, что эти операторы кроссовера являются очень общими, и GA Designer может также решить реализовать оператор кроссовера для конкретной задачи.
One Point Crossover
В этом одноточечном пересечении выбирается случайная точка пересечения, и хвосты двух ее родителей меняются местами, чтобы получить новые исходные элементы.
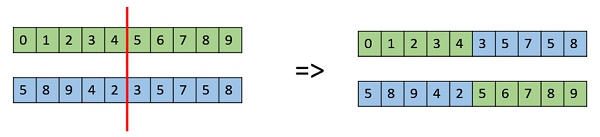
Многоточечный кроссовер
Многоточечный кроссовер — это обобщение одноточечного кроссовера, в котором чередующиеся сегменты меняются местами для получения новых выходных пружин.
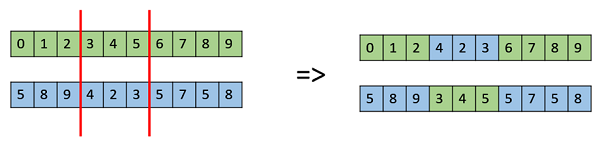
Единый кроссовер
В равномерном кроссовере мы не делим хромосому на сегменты, мы рассматриваем каждый ген отдельно. В этом мы по существу подбрасываем монету для каждой хромосомы, чтобы решить, будет ли она включена в потомство. Мы также можем привязать монету к одному из родителей, чтобы у ребенка было больше генетического материала от этого родителя.
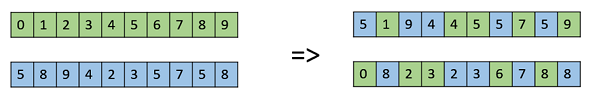
Целая арифметическая рекомбинация
Это обычно используется для целочисленных представлений и работает, взяв средневзвешенное значение двух родителей, используя следующие формулы:
- Child1 = α.x + (1-α) .y
- Child2 = α.x + (1-α) .y
Очевидно, что если α = 0,5, то оба потомка будут идентичны, как показано на следующем рисунке.

Кроссовер Ордена Дэвиса (OX1)
OX1 используется для кроссоверов на основе перестановок с целью передачи информации об относительном упорядочении выходным источникам. Это работает следующим образом —
-
Создайте две случайные точки пересечения в родительском элементе и скопируйте сегмент между ними от первого родительского элемента к первому потомству.
-
Теперь, начиная со второй точки пересечения во втором родительском элементе, скопируйте оставшиеся неиспользуемые числа от второго родительского элемента к первому дочернему элементу, оборачивая список.
-
Повторите эти действия для второго ребенка с перевернутой ролью родителя.
Создайте две случайные точки пересечения в родительском элементе и скопируйте сегмент между ними от первого родительского элемента к первому потомству.
Теперь, начиная со второй точки пересечения во втором родительском элементе, скопируйте оставшиеся неиспользуемые числа от второго родительского элемента к первому дочернему элементу, оборачивая список.
Повторите эти действия для второго ребенка с перевернутой ролью родителя.
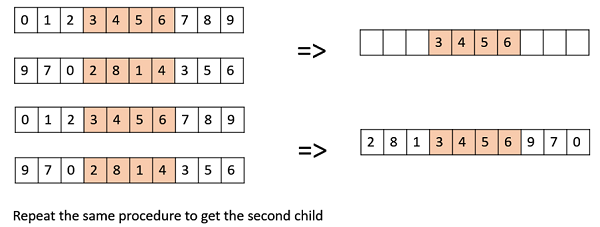
Существует множество других кроссоверов, таких как кроссинговер с частичным отображением (PMX), кроссовер на основе заказов (OX2), кроссовер с перемешиванием, кольцевой кроссовер и т. Д.
Генетические алгоритмы — мутация
Введение в мутацию
Проще говоря, мутация может быть определена как небольшая случайная подстройка в хромосоме, чтобы получить новое решение. Он используется для поддержания и внесения разнообразия в генетическую популяцию и обычно применяется с низкой вероятностью — p m . Если вероятность очень высока, GA уменьшается до случайного поиска.
Мутация — это часть ГА, которая связана с «исследованием» пространства поиска. Наблюдалось, что мутация необходима для конвергенции ГА, а кроссовер — нет.
Операторы мутации
В этом разделе мы опишем некоторые из наиболее часто используемых операторов мутации. Как и операторы кроссовера, это не исчерпывающий список, и разработчик GA может найти сочетание этих подходов или оператора мутации для конкретной задачи более полезным.
Бит-флип-мутация
В этой битовой мутации мы выбираем один или несколько случайных битов и переворачиваем их. Это используется для двоичных кодированных GA.
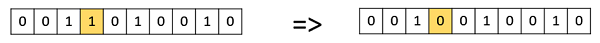
Случайный сброс
Случайный сброс — это расширение переворота битов для целочисленного представления. При этом случайное значение из набора допустимых значений присваивается случайно выбранному гену.
Поменять местами мутацию
В мутации обмена мы выбираем две позиции в хромосоме случайным образом и меняем значения. Это часто встречается в кодировках на основе перестановок.
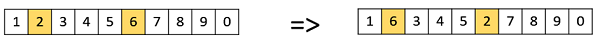
Мутация Scramble
Мутация скремблирования также популярна в представлениях перестановок. При этом из всей хромосомы выбирается подмножество генов, и их значения случайным образом перемешиваются или перемешиваются.
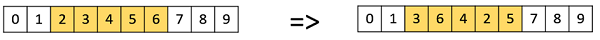
Инверсионная мутация
В инверсионной мутации мы выбираем подмножество генов, как в мутации скремблирования, но вместо того, чтобы перетасовывать подмножество, мы просто инвертируем всю строку в подмножестве.
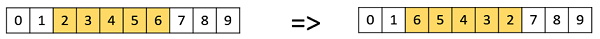
Генетические алгоритмы — выбор выживших
Политика отбора оставшихся в живых определяет, какие лица должны быть выгнаны, а какие должны быть сохранены в следующем поколении. Это очень важно, так как это должно гарантировать, что более подходящие люди не будут выгнаны из популяции, и в то же время разнообразие должно сохраняться в популяции.
Некоторые ГА используют элитарность . Проще говоря, это означает, что текущий наиболее подходящий член населения всегда передается следующему поколению. Таким образом, ни при каких обстоятельствах нельзя заменить наиболее подходящего члена нынешнего населения.
Самая простая политика состоит в том, чтобы выгнать случайных членов из населения, но такой подход часто имеет проблемы сходимости, поэтому следующие стратегии широко используются.
Возрастной отбор
В Возрастном отборе у нас нет понятия пригодности. Это основано на предпосылке, что каждый индивид разрешен в популяции для конечного поколения, где ему разрешено размножаться, после чего его выгоняют из популяции независимо от того, насколько хороша его физическая форма.
Например, в следующем примере возраст — это число поколений, для которых человек был в популяции. Самые старые члены населения, то есть P4 и P7, выбрасываются из населения, а возраст остальных членов увеличивается на единицу.
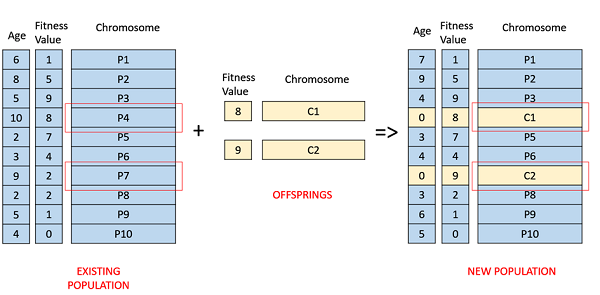
Фитнес на основе выбора
В этом выборе на основе фитнеса дети, как правило, заменяют наименее приспособленных людей в популяции. Отбор наименее подходящих лиц может быть сделан с использованием варианта любой из политик отбора, описанных ранее — выбор турнира, пропорциональный отбор по пригодности и т. Д.
Например, на следующем изображении дети заменяют наименее приспособленных лиц P1 и P10 населения. Следует отметить, что, поскольку P1 и P9 имеют одинаковое значение пригодности, решение об исключении того или иного индивида из популяции является произвольным.
Генетические алгоритмы — условие прекращения
Условие завершения Генетического Алгоритма важно при определении, когда закончится работа GA. Было отмечено, что первоначально GA прогрессирует очень быстро, и лучшие решения приходят через каждые несколько итераций, но это имеет тенденцию насыщаться на более поздних этапах, когда улучшения очень малы. Обычно мы хотим, чтобы условие завершения было таким, чтобы наше решение было близко к оптимальному в конце цикла.
Обычно мы соблюдаем одно из следующих условий расторжения —
- Когда не было никакого улучшения в населении для X итераций.
- Когда мы достигнем абсолютного числа поколений.
- Когда значение целевой функции достигло определенного заранее заданного значения.
Например, в генетическом алгоритме мы ведем счетчик, который отслеживает поколения, для которых не было улучшения в популяции. Первоначально мы устанавливаем этот счетчик на ноль. Каждый раз, когда мы не генерируем потомство, которое лучше, чем отдельные люди в популяции, мы увеличиваем счетчик.
Однако, если пригодность любого из источников лучше, тогда мы сбрасываем счетчик на ноль. Алгоритм завершается, когда счетчик достигает заданного значения.
Как и другие параметры GA, условие завершения также сильно зависит от проблемы, и разработчик GA должен попробовать различные варианты, чтобы увидеть, что лучше всего подходит для его конкретной задачи.
Модели пожизненной адаптации
До сих пор в этом уроке все, что мы обсуждали, соответствует дарвиновской модели эволюции — естественному отбору и генетическому изменению посредством рекомбинации и мутации. В природе только информация, содержащаяся в генотипе человека, может быть передана следующему поколению. Это подход, которому мы следовали в этом уроке до сих пор.
Тем не менее, существуют и другие модели адаптации на протяжении всей жизни — модель Ламарка и модель Болдуина . Следует отметить, что какая бы модель ни была лучшей, она открыта для дискуссий, и результаты, полученные исследователями, показывают, что выбор адаптации на протяжении всей жизни зависит от конкретной проблемы.
Часто мы гибридизуем GA с локальным поиском — как в Memetic Algorithms. В таких случаях можно выбрать, использовать лимарковскую или балдвиновскую модель, чтобы решить, что делать с людьми, сгенерированными после локального поиска.
Ламаркская модель
Ламаркская модель, по сути, говорит, что черты, которые человек приобретает за свою жизнь, могут быть переданы его потомству. Он назван в честь французского биолога Жана-Батиста Ламарка.
Несмотря на то, что естественная биология полностью игнорирует ламаркизм, поскольку все мы знаем, что только информация в генотипе может быть передана. Однако с точки зрения вычислений было показано, что принятие модели Ламарка позволяет получить хорошие результаты для некоторых проблем.
В модели Ламарка, оператор локального поиска исследует окрестности (приобретая новые признаки), и, если обнаруживается лучшая хромосома, она становится потомком.
Балдвинская модель
Болдвиновская модель — это промежуточная идея, названная в честь Джеймса Марка Болдуина (1896). В модели Болдуина, хромосомы могут кодировать тенденцию изучения полезного поведения. Это означает, что в отличие от модели Ламарка, мы не передаем приобретенные черты следующему поколению и не полностью игнорируем приобретенные черты, как в дарвиновской модели.
Модель Болдуина находится в середине этих двух крайностей, где тенденция индивида приобретать определенные черты закодирована, а не сами черты.
В этой балдвиновской модели местный оператор поиска исследует окрестности (приобретая новые признаки), и, если обнаруживается лучшая хромосома, он только назначает улучшенную приспособленность хромосоме и не модифицирует саму хромосому. Изменение пригодности означает способность хромосом «приобретать черту», даже если она не передается непосредственно будущим поколениям.
Эффективная реализация
ГА имеют очень общий характер, и простое применение их к любой проблеме оптимизации не даст хороших результатов. В этом разделе мы опишем несколько моментов, которые могут помочь и помочь конструктору GA или исполнителю GA в их работе.
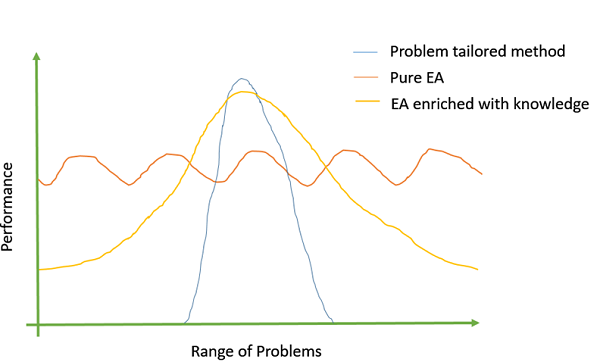
Внедрить знание предметной области
Было замечено, что более специфические знания предметной области мы включаем в ГА; лучшие объективные ценности мы получаем. Добавление информации, специфичной для проблемы, может быть выполнено либо с помощью специфического для проблемы кроссовера, либо операторов мутации, пользовательских представлений и т. Д.
На следующем рисунке показан вид советника Михалевича (1990 г.).
Уменьшить скученность
Переполнение происходит, когда хромосома с высокой посадкой начинает много размножаться, и через несколько поколений все население заполняется аналогичными решениями, имеющими сходную пригодность. Это уменьшает разнообразие, что является очень важным элементом для обеспечения успеха ГА. Есть множество способов ограничить скученность. Некоторые из них —
-
Мутация для внесения разнообразия.
-
Переключение на отбор рангов и отбор турниров, которые оказывают большее отборочное давление, чем пропорциональный отбор по пригодности для людей с подобной подготовкой.
-
Совместное использование фитнеса — при этом физическое состояние человека снижается, если население уже содержит похожих людей.
Мутация для внесения разнообразия.
Переключение на отбор рангов и отбор турниров, которые оказывают большее отборочное давление, чем пропорциональный отбор по пригодности для людей с подобной подготовкой.
Совместное использование фитнеса — при этом физическое состояние человека снижается, если население уже содержит похожих людей.
Помогает рандомизация!
Экспериментально установлено, что лучшие решения определяются рандомизированными хромосомами, поскольку они придают разнообразие населению. Исполнитель ГА должен быть осторожен, чтобы сохранить достаточное количество рандомизации и разнообразия в популяции для достижения наилучших результатов.
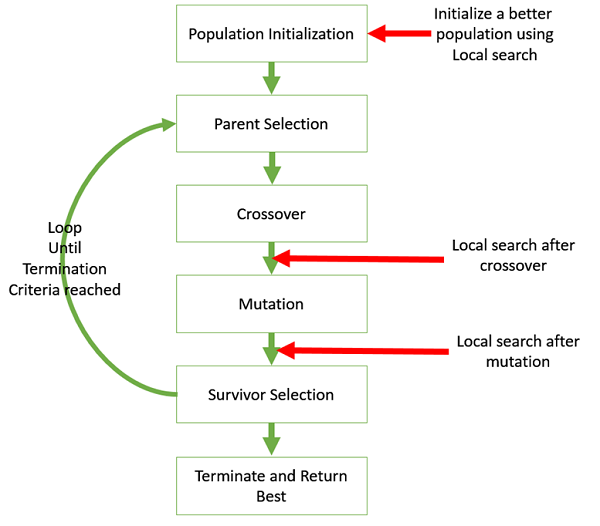
Гибридизировать GA с локальным поиском
Локальный поиск относится к проверке решений в окрестности данного решения для поиска лучших объективных значений.
Иногда может быть полезно смешать GA с локальным поиском. На следующем рисунке показаны различные места, в которых локальный поиск может быть введен в GA.
Вариация параметров и методов
В генетических алгоритмах не существует «одного размера для всех» или волшебной формулы, которая работает для всех задач. Даже после того, как начальный GA будет готов, потребуется много времени и усилий, чтобы поиграть с такими параметрами, как размер популяции, вероятность мутации и кроссовера и т. Д., Чтобы найти те, которые удовлетворяют конкретной проблеме.
Генетические алгоритмы — продвинутые темы
В этом разделе мы представляем некоторые продвинутые темы по генетическим алгоритмам. Читатель, ищущий просто введение в ГА, может пропустить этот раздел.
Ограниченные проблемы оптимизации
Ограниченные проблемы оптимизации — это те проблемы оптимизации, в которых мы должны максимизировать или минимизировать заданное значение целевой функции, на которое распространяются определенные ограничения. Следовательно, не все результаты в пространстве решений достижимы, и пространство решений содержит допустимые области, как показано на следующем рисунке.
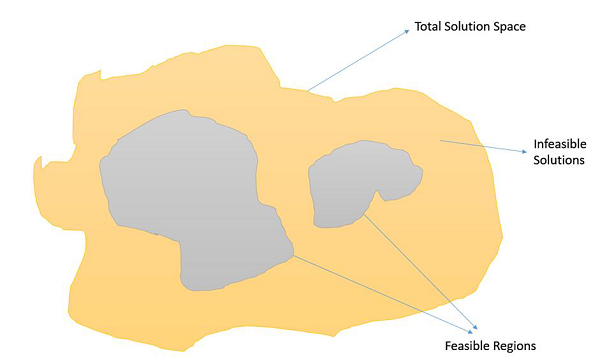
В таком случае операторы кроссовера и мутации могут дать нам решения, которые неосуществимы. Поэтому при работе с ограниченными задачами оптимизации необходимо использовать дополнительные механизмы в GA.
Некоторые из наиболее распространенных методов —
-
Использование штрафных функций, которые уменьшают пригодность невыполнимых решений, предпочтительно, чтобы пригодность уменьшалась пропорционально количеству нарушенных ограничений или расстоянию от допустимой области.
-
Использование функций восстановления, которые принимают недопустимое решение и модифицируют его так, чтобы нарушенные ограничения были удовлетворены.
-
Не допускать попадания неосуществимых решений в население.
-
Используйте специальные функции представления или декодирования, которые обеспечивают выполнимость решений.
Использование штрафных функций, которые уменьшают пригодность невыполнимых решений, предпочтительно, чтобы пригодность уменьшалась пропорционально количеству нарушенных ограничений или расстоянию от допустимой области.
Использование функций восстановления, которые принимают недопустимое решение и модифицируют его так, чтобы нарушенные ограничения были удовлетворены.
Не допускать попадания неосуществимых решений в население.
Используйте специальные функции представления или декодирования, которые обеспечивают выполнимость решений.
Основные теоретические основы
В этом разделе мы обсудим теорему Схемы и НФЛ вместе с гипотезой строительного блока.
Схема Теорема
Исследователи пытаются выяснить математику, лежащую в основе работы генетических алгоритмов, и теорема о схеме Голландии является шагом в этом направлении. В течение года были внесены различные улучшения и предложения в теорему схемы, чтобы сделать ее более общей.
В этом разделе мы не углубляемся в математику теоремы схемы, а скорее пытаемся развить базовое понимание того, что такое теорема схемы. Основная терминология, которую нужно знать, такова:
-
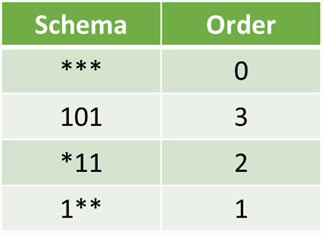
Схема — это «шаблон». Формально это строка над алфавитом = {0,1, *},
где * не волнует и может принимать любое значение.
Следовательно, * 10 * 1 может означать 01001, 01011, 11001 или 11011.
Геометрически схема является гиперплоскостью в пространстве поиска решения.
-
Порядок схемы — это количество указанных фиксированных позиций в гене.
Схема — это «шаблон». Формально это строка над алфавитом = {0,1, *},
где * не волнует и может принимать любое значение.
Следовательно, * 10 * 1 может означать 01001, 01011, 11001 или 11011.
Геометрически схема является гиперплоскостью в пространстве поиска решения.
Порядок схемы — это количество указанных фиксированных позиций в гене.
-
Определение длины — это расстояние между двумя самыми дальними фиксированными символами в гене.
Определение длины — это расстояние между двумя самыми дальними фиксированными символами в гене.
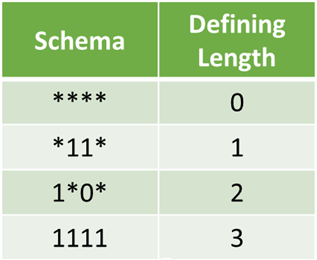
Теорема о схеме гласит, что эта схема с пригодностью выше среднего, короткой определяющей длиной и более низким порядком, скорее всего, переживет кроссовер и мутацию.
Гипотеза строительного блока
Строительные блоки представляют собой схемы низкого порядка с низкой определяемой длиной с учетом приведенной выше средней пригодности. Гипотеза о строительном блоке говорит, что такие строительные блоки служат основой для успеха и адаптации ГА в ГА, поскольку она прогрессирует путем последовательной идентификации и рекомбинации таких «строительных блоков».
Нет свободного обеда (НФЛ) Теорема
Wolpert и Macready в 1997 году опубликовали статью под названием «Теоремы об отсутствии бесплатного обеда для оптимизации». По сути, это говорит о том, что если мы усредним по пространству всех возможных проблем, то все не повторяющиеся алгоритмы черного ящика будут демонстрировать одинаковую производительность.
Это означает, что чем больше мы понимаем проблему, наш GA становится более специфичным для проблемы и дает лучшую производительность, но это компенсирует это, выполняя плохо для других проблем.
GA на основе машинного обучения
Генетические алгоритмы также находят применение в машинном обучении. Системы классификаторов — это форма системы машинного обучения на основе генетики (GBML), которая часто используется в области машинного обучения. Методы GBML являются нишевым подходом к машинному обучению.
Есть две категории систем GBML —
-
Подход Питтсбурга — В этом подходе одна хромосома кодировала одно решение, и таким образом пригодность была назначена решениям.
-
Мичиганский подход — одно решение, как правило, представлено многими хромосомами, и поэтому пригодность определяется частичными решениями.
Подход Питтсбурга — В этом подходе одна хромосома кодировала одно решение, и таким образом пригодность была назначена решениям.
Мичиганский подход — одно решение, как правило, представлено многими хромосомами, и поэтому пригодность определяется частичными решениями.
Следует иметь в виду, что стандартные проблемы, такие как кроссовер, мутация, ламарковская или дарвиновская и т. Д., Также присутствуют в системах GBML.
Генетические алгоритмы — Области применения
Генетические алгоритмы в основном используются в задачах оптимизации различного рода, но они часто используются и в других областях применения.
В этом разделе мы перечислим некоторые области, в которых часто используются генетические алгоритмы. Это —
-
Оптимизация — Генетические алгоритмы чаще всего используются в задачах оптимизации, где мы должны максимизировать или минимизировать заданное значение целевой функции при данном наборе ограничений. Подход к решению проблем оптимизации был выделен в учебнике.
-
Экономика — GA также используются для характеристики различных экономических моделей, таких как модель паутины, разрешение равновесия в теории игр, ценообразование активов и т. Д.
-
Нейронные сети — ГА также используются для обучения нейронных сетей, особенно рекуррентных нейронных сетей.
-
Распараллеливание — GA также обладают очень хорошими возможностями параллелизма и являются очень эффективным средством решения определенных проблем, а также предоставляют хорошую область для исследований.
-
Обработка изображений — GA используются для различных задач цифровой обработки изображений (DIP), а также для плотного сопоставления пикселей.
-
Проблемы с маршрутизацией транспортных средств — с несколькими мягкими временными окнами, несколькими складами и разнородным парком.
-
Приложения для планирования — GA также используются для решения различных задач планирования, в частности, для определения времени.
-
Машинное обучение — как уже говорилось, машинное обучение на основе генетики (GBML) — это нишевая область машинного обучения.
-
Генерация траектории робота — GA использовались для планирования пути, по которому движется рука робота при перемещении из одной точки в другую.
-
Параметрическое проектирование самолетов — ГА использовались для проектирования самолетов, изменяя параметры и разрабатывая лучшие решения.
-
Анализ ДНК — ГА были использованы для определения структуры ДНК с использованием спектрометрических данных об образце.
-
Мультимодальная оптимизация — GA, безусловно, являются очень хорошими подходами для мультимодальной оптимизации, в которой мы должны найти несколько оптимальных решений.
-
Задача коммивояжера и ее применение — GA использовались для решения TSP, которая является хорошо известной комбинаторной проблемой, использующей новые стратегии кроссовера и упаковки.
Оптимизация — Генетические алгоритмы чаще всего используются в задачах оптимизации, где мы должны максимизировать или минимизировать заданное значение целевой функции при данном наборе ограничений. Подход к решению проблем оптимизации был выделен в учебнике.
Экономика — GA также используются для характеристики различных экономических моделей, таких как модель паутины, разрешение равновесия в теории игр, ценообразование активов и т. Д.
Нейронные сети — ГА также используются для обучения нейронных сетей, особенно рекуррентных нейронных сетей.
Распараллеливание — GA также обладают очень хорошими возможностями параллелизма и являются очень эффективным средством решения определенных проблем, а также предоставляют хорошую область для исследований.
Обработка изображений — GA используются для различных задач цифровой обработки изображений (DIP), а также для плотного сопоставления пикселей.
Проблемы с маршрутизацией транспортных средств — с несколькими мягкими временными окнами, несколькими складами и разнородным парком.
Приложения для планирования — GA также используются для решения различных задач планирования, в частности, для определения времени.
Машинное обучение — как уже говорилось, машинное обучение на основе генетики (GBML) — это нишевая область машинного обучения.
Генерация траектории робота — GA использовались для планирования пути, по которому движется рука робота при перемещении из одной точки в другую.
Параметрическое проектирование самолетов — ГА использовались для проектирования самолетов, изменяя параметры и разрабатывая лучшие решения.
Анализ ДНК — ГА были использованы для определения структуры ДНК с использованием спектрометрических данных об образце.
Мультимодальная оптимизация — GA, безусловно, являются очень хорошими подходами для мультимодальной оптимизации, в которой мы должны найти несколько оптимальных решений.
Задача коммивояжера и ее применение — GA использовались для решения TSP, которая является хорошо известной комбинаторной проблемой, использующей новые стратегии кроссовера и упаковки.
Генетические алгоритмы — дальнейшие чтения
Следующие книги могут быть использованы для дальнейшего расширения знаний читателя о генетических алгоритмах и эволюционных вычислениях в целом —
Генетические алгоритмы в поиске, оптимизации и машинном обучении Дэвид Э. Голдберг .
Генетические алгоритмы + структуры данных = эволюционные программы Збигнева Михалевича .
Практические генетические алгоритмы Рэнди Л. Хаупта и Сью Эллен Хаупт .
Многоцелевая оптимизация с использованием эволюционных алгоритмов. Автор: Kalyanmoy Deb .