DW — Обзор
Хранилище данных известно как центральное хранилище для хранения данных из одного или нескольких разнородных источников данных. Хранилище данных используется для составления отчетов и анализа информации и хранит как исторические, так и текущие данные. Данные в системе DW используются для аналитической отчетности, которая впоследствии используется бизнес-аналитиками, менеджерами по продажам или сотрудниками отдела знаний для принятия решений.
Данные в системе DW загружаются из операционной системы транзакций, такой как Sales, Marketing, HR, SCM и т. Д. Они могут проходить через хранилище операционных данных или другие преобразования, прежде чем загружаться в систему DW для обработки информации.
Хранилище данных — Ключевые особенности
Ключевые особенности системы DW:
-
Это центральное хранилище данных, где данные хранятся из одного или нескольких разнородных источников данных.
-
Система DW хранит как текущие, так и исторические данные. Обычно система DW хранит 5-10 лет исторических данных.
-
Система DW всегда хранится отдельно от операционной системы транзакций.
-
Данные в системе DW используются для различных типов аналитической отчетности в диапазоне от квартального до годового сравнения.
Это центральное хранилище данных, где данные хранятся из одного или нескольких разнородных источников данных.
Система DW хранит как текущие, так и исторические данные. Обычно система DW хранит 5-10 лет исторических данных.
Система DW всегда хранится отдельно от операционной системы транзакций.
Данные в системе DW используются для различных типов аналитической отчетности в диапазоне от квартального до годового сравнения.
Необходимость системы DW
Предположим, у вас есть агентство по жилищному кредитованию, в которое поступают данные из нескольких приложений, таких как: маркетинг, продажи, ERP, HRM, MM и т. Д. Эти данные извлекаются, преобразуются и загружаются в хранилище данных.
Например, если вам нужно сравнить квартальные / годовые продажи продукта, вы не можете использовать операционную транзакционную базу данных, так как это приведет к зависанию системы транзакций. Поэтому для этой цели используется хранилище данных.
Разница между DW и ODB
Различия между хранилищем данных и операционной базой данных (транзакционная база данных) заключаются в следующем:
-
Транзакционная система предназначена для известных рабочих нагрузок и транзакций, таких как обновление записи пользователя, поиск записи и т. Д. Однако транзакции хранилища данных являются более сложными и представляют общую форму данных.
-
Транзакционная система содержит текущие данные организации, а хранилище данных обычно содержит исторические данные.
-
Транзакционная система поддерживает параллельную обработку нескольких транзакций. Механизмы контроля и восстановления параллелизма необходимы для поддержания согласованности базы данных.
-
Запрос оперативной базы данных позволяет читать и изменять операции (удаление и обновление), в то время как для запроса OLAP требуется только доступ только для чтения к хранимым данным (оператор Select).
Транзакционная система предназначена для известных рабочих нагрузок и транзакций, таких как обновление записи пользователя, поиск записи и т. Д. Однако транзакции хранилища данных являются более сложными и представляют общую форму данных.
Транзакционная система содержит текущие данные организации, а хранилище данных обычно содержит исторические данные.
Транзакционная система поддерживает параллельную обработку нескольких транзакций. Механизмы контроля и восстановления параллелизма необходимы для поддержания согласованности базы данных.
Запрос оперативной базы данных позволяет читать и изменять операции (удаление и обновление), в то время как для запроса OLAP требуется только доступ только для чтения к хранимым данным (оператор Select).
DW Архитектура
Хранилище данных включает в себя очистку данных, интеграцию данных и консолидацию данных.
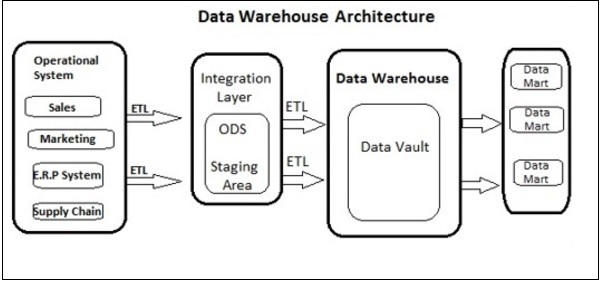
Хранилище данных имеет трехуровневую архитектуру — уровень источника данных, уровень интеграции и уровень представления . На приведенном выше рисунке показана общая архитектура системы хранилища данных.
DW — Типы
Существует четыре типа систем хранения данных.
- Data Mart
- Аналитическая обработка онлайн (OLAP)
- Оперативная обработка онлайн (OLTP)
- Прогнозный анализ (РА)
Data Mart
Data Mart известен как простейшая форма системы хранилища данных и обычно состоит из одной функциональной области в организации, такой как продажи, финансы или маркетинг и т. Д.
Data Mart в организации и создается и управляется одним отделом. Поскольку он принадлежит одному отделу, отдел обычно получает данные только из нескольких или одного типа источников / приложений. Этот источник может быть внутренней операционной системой, хранилищем данных или внешней системой.
Аналитическая обработка онлайн
В системе OLAP количество транзакций меньше, чем в транзакционной системе. Выполненные запросы имеют сложный характер и включают в себя агрегацию данных.
Что такое агрегация?
Мы сохраняем таблицы с агрегированными данными, такими как годовой (1 строка), квартальный (4 строки), ежемесячный (12 строк) или около того. Если кто-то должен делать сравнение из года в год, будет обрабатываться только одна строка. Однако в неагрегированной таблице будут сравниваться все строки.
SELECT SUM(salary) FROM employee WHERE title = 'Programmer';
Эффективные меры в системе OLAP
Время отклика известно как одна из наиболее эффективных и ключевых мер в системе OLAP . Агрегированные хранимые данные поддерживаются в многомерных схемах, таких как схемы типа «звезда» (когда данные сгруппированы в иерархические группы, часто называемые измерениями, в факты и агрегированные факты, это называется схемами).
Задержка системы OLAP составляет несколько часов по сравнению с витринами данных, где задержка ожидается ближе к дню.
Обработка транзакций онлайн
В системе OLTP существует большое количество коротких онлайн-транзакций, таких как INSERT, UPDATE и DELETE.
В системе OLTP эффективным показателем является время обработки коротких транзакций и оно очень мало. Он контролирует целостность данных в средах с множественным доступом. Для системы OLTP количество транзакций в секунду измеряет эффективность . Система хранилища данных OLTP содержит текущие и подробные данные и поддерживается в схемах в модели объекта (3NF).
пример
Система ежедневных транзакций в розничном магазине, где записи клиентов ежедневно вставляются, обновляются и удаляются. Это обеспечивает очень быструю обработку запросов. Базы данных OLTP содержат подробные и актуальные данные. Схема, используемая для хранения базы данных OLTP, является моделью сущностей.
Различия между OLTP и OLAP
На следующих рисунках показаны основные различия между OLTP и системой OLAP .
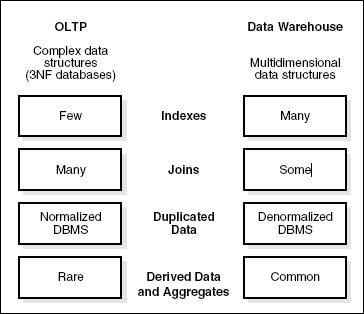
-
Индексы — в системе OLTP имеется всего несколько индексов, в то время как в системе OLAP есть много индексов для оптимизации производительности.
-
Объединения. В системе OLTP большое количество объединений и данных нормализуется. Однако в системе OLAP меньше соединений и они не нормализованы.
-
Агрегация. В системе OLTP данные не агрегируются, тогда как в базе данных OLAP используется больше агрегаций.
Индексы — в системе OLTP имеется всего несколько индексов, в то время как в системе OLAP есть много индексов для оптимизации производительности.
Объединения. В системе OLTP большое количество объединений и данных нормализуется. Однако в системе OLAP меньше соединений и они не нормализованы.
Агрегация. В системе OLTP данные не агрегируются, тогда как в базе данных OLAP используется больше агрегаций.
Прогнозный анализ
Прогнозный анализ известен как поиск скрытых закономерностей в данных, хранящихся в системе DW, с использованием различных математических функций для прогнозирования будущих результатов.
Система прогнозного анализа отличается от системы OLAP с точки зрения ее использования. Он используется, чтобы сосредоточиться на будущих результатах. Система OALP ориентирована на текущую и историческую обработку данных для аналитической отчетности.
DW — Продукты и поставщик
На рынке доступны различные системы хранилищ данных / баз данных, которые соответствуют возможностям системы DW. Наиболее распространенные поставщики систем хранения данных:
- Microsoft SQL Server
- Oracle Exadata
- IBM Netezza
- Teradata
- Sybase IQ
- SAP Business Warehouse (SAP BW)
SAP Business Warehouse
SAP Business Warehouse является частью платформы выпуска SAP NetWeaver. До NetWeaver 7.4 он назывался SAP NetWeaver Business Warehouse.
Хранилище данных в SAP BW означает интеграцию, преобразование, очистку, хранение и хранение данных. Процесс DW включает моделирование данных в системе BW, постановку и администрирование. Основным инструментом, который используется для управления заданиями DW в системе BW, является инструментальные средства администрирования.
Ключевая особенность
-
SAP BW предоставляет такие возможности, как Business Intelligence, которая включает в себя аналитические услуги и бизнес-планирование, аналитическую отчетность, обработку запросов и информации, а также хранилище данных предприятия.
-
Он предоставляет комбинацию баз данных и инструментов управления базами данных, которые помогают в принятии решений.
-
Другие ключевые функции системы BW включают интерфейс программирования бизнес-приложений (BAPI), который поддерживает подключение к приложениям, не относящимся к SAP R / 3, автоматическое извлечение и загрузку данных, встроенный процессор OLAP, хранилище метаданных, инструменты администрирования, многоязычную поддержку и веб-интерфейс.
-
SAP BW была впервые представлена в 1998 году немецкой компанией SAP. Система SAP BW была основана на модельном подходе, чтобы сделать Enterprise Data Warehouse простым, простым и более эффективным для данных SAP R3.
-
За последние 16 лет SAP BW превратилась в одну из ключевых систем для многих компаний для управления их потребностями в корпоративных хранилищах данных.
-
Business Explorer (BEx) предоставляет возможность гибкой отчетности, стратегического анализа и оперативной отчетности в компании.
-
Он используется для выполнения функций отчетности, выполнения запросов и анализа в системе BI. Вы также можете обрабатывать текущие и исторические данные с различной степенью детализации через Интернет и в формате Excel.
-
Используя трансляцию информации BEx , контент BI можно передавать по электронной почте в виде документа или в виде ссылок в виде оперативных данных, а также можно публиковать с использованием функций SAP EP.
SAP BW предоставляет такие возможности, как Business Intelligence, которая включает в себя аналитические услуги и бизнес-планирование, аналитическую отчетность, обработку запросов и информации, а также хранилище данных предприятия.
Он предоставляет комбинацию баз данных и инструментов управления базами данных, которые помогают в принятии решений.
Другие ключевые функции системы BW включают интерфейс программирования бизнес-приложений (BAPI), который поддерживает подключение к приложениям, не относящимся к SAP R / 3, автоматическое извлечение и загрузку данных, встроенный процессор OLAP, хранилище метаданных, инструменты администрирования, многоязычную поддержку и веб-интерфейс.
SAP BW была впервые представлена в 1998 году немецкой компанией SAP. Система SAP BW была основана на модельном подходе, чтобы сделать Enterprise Data Warehouse простым, простым и более эффективным для данных SAP R3.
За последние 16 лет SAP BW превратилась в одну из ключевых систем для многих компаний для управления их потребностями в корпоративных хранилищах данных.
Business Explorer (BEx) предоставляет возможность гибкой отчетности, стратегического анализа и оперативной отчетности в компании.
Он используется для выполнения функций отчетности, выполнения запросов и анализа в системе BI. Вы также можете обрабатывать текущие и исторические данные с различной степенью детализации через Интернет и в формате Excel.
Используя трансляцию информации BEx , контент BI можно передавать по электронной почте в виде документа или в виде ссылок в виде оперативных данных, а также можно публиковать с использованием функций SAP EP.
Бизнес-объекты и продукты
SAP Business Objects известен как наиболее распространенный инструмент бизнес-аналитики и используется для манипулирования данными, доступа пользователей, анализа, форматирования и публикации информации на разных платформах. Это интерфейсный набор инструментов, который позволяет бизнес-пользователям и лицам, принимающим решения, отображать, сортировать и анализировать текущие и исторические данные бизнес-аналитики.
Он состоит из следующих инструментов —
Веб-интеллект
Web Intelligence (WebI) называется наиболее распространенным инструментом подробных отчетов Business Objects, который поддерживает различные функции анализа данных, такие как детализация, иерархии, диаграммы, вычисляемые показатели и т. Д. Он позволяет конечным пользователям создавать специальные запросы в панели запросов и проводить анализ данных как онлайн, так и офлайн.
SAP Business Objects Xcelsius / Панели мониторинга
Панели мониторинга предоставляют конечным пользователям возможности визуализации данных и панели мониторинга, и вы можете создавать интерактивные панели мониторинга с помощью этого инструмента.
Вы также можете добавлять различные типы диаграмм и графиков и создавать динамические информационные панели для визуализации данных, которые в основном используются на финансовых совещаниях в организации.
Crystal Reports
Crystal Reports используются для создания отчетов с идеальной точностью пикселей. Это позволяет пользователям создавать и разрабатывать отчеты, а затем использовать их для печати.
исследователь
Проводник позволяет пользователю осуществлять поиск содержимого в репозитории BI, и наилучшие совпадения отображаются в виде диаграмм. Нет необходимости записывать запросы для выполнения поиска.
Различные другие компоненты и инструменты, представленные для подробных отчетов, визуализации данных и назначения панелей мониторинга, — это Design Studio, выпуск Analysis для платформы Microsoft Office, BI Repository и Business Objects Mobile.
ETL — Введение
ETL расшифровывается как Extract, Transform и Load. Инструмент ETL извлекает данные из различных исходных систем РСУБД, преобразует данные, например, применяет вычисления, объединяет и т. Д., А затем загружает данные в систему хранилища данных. Данные загружаются в систему DW в виде таблиц измерений и фактов.
экстракция
-
Зона подготовки требуется во время загрузки ETL. Существуют различные причины, по которым требуется место для постановки.
-
Исходные системы доступны только в течение определенного периода времени для извлечения данных. Этот период времени меньше, чем общее время загрузки данных. Следовательно, область подготовки позволяет извлекать данные из исходной системы и сохранять их в области подготовки до окончания временного интервала.
-
Промежуточная область необходима, когда вы хотите собрать данные из нескольких источников данных вместе или если вы хотите объединить две или более систем вместе. Например, вы не сможете выполнить SQL-запрос, объединяющий две таблицы из двух физически разных баз данных.
-
Временной интервал извлечения данных для разных систем варьируется в зависимости от часового пояса и часов работы.
-
Данные, извлеченные из исходных систем, могут использоваться в нескольких системах хранилищ данных, хранилищах рабочих данных и т. Д.
-
ETL позволяет выполнять сложные преобразования и требует дополнительной области для хранения данных.
Зона подготовки требуется во время загрузки ETL. Существуют различные причины, по которым требуется место для постановки.
Исходные системы доступны только в течение определенного периода времени для извлечения данных. Этот период времени меньше, чем общее время загрузки данных. Следовательно, область подготовки позволяет извлекать данные из исходной системы и сохранять их в области подготовки до окончания временного интервала.
Промежуточная область необходима, когда вы хотите собрать данные из нескольких источников данных вместе или если вы хотите объединить две или более систем вместе. Например, вы не сможете выполнить SQL-запрос, объединяющий две таблицы из двух физически разных баз данных.
Временной интервал извлечения данных для разных систем варьируется в зависимости от часового пояса и часов работы.
Данные, извлеченные из исходных систем, могут использоваться в нескольких системах хранилищ данных, хранилищах рабочих данных и т. Д.
ETL позволяет выполнять сложные преобразования и требует дополнительной области для хранения данных.
преобразование
При преобразовании данных вы применяете набор функций к извлеченным данным, чтобы загрузить их в целевую систему. Данные, которые не требуют какого-либо преобразования, называются прямым перемещением или передачей данных.
Вы можете применять различные преобразования к извлеченным данным из исходной системы. Например, вы можете выполнять индивидуальные расчеты. Если вам нужен доход от суммы продаж, которого нет в базе данных, вы можете применить формулу SUM во время преобразования и загрузить данные.
Например, если у вас есть имя и фамилия в таблице в разных столбцах, вы можете использовать сцепление перед загрузкой.
нагрузка
На этапе загрузки данные загружаются в конечную целевую систему, и это может быть простой файл или система хранилища данных.
SAP BODS — Обзор
SAP BO Data Services — это инструмент ETL, используемый для интеграции данных, качества данных, профилирования данных и обработки данных. Это позволяет интегрировать, трансформировать надежную систему хранилища данных в данные для аналитической отчетности.
BO Data Services состоит из интерфейса разработки пользовательского интерфейса, хранилища метаданных, подключения данных к исходной и целевой системе и консоли управления для планирования заданий.
Интеграция данных и управление данными
SAP BO Data Services — это инструмент интеграции и управления данными, состоящий из сервера заданий Data Integrator и Data Integrator Designer.
Ключевая особенность
-
Вы можете применять различные преобразования данных с помощью языка Data Integrator для применения сложных преобразований данных и создания пользовательских функций.
-
Data Integrator Designer используется для хранения в реальном времени и пакетных заданий и новых проектов в хранилище.
-
DI Designer также предоставляет возможность для групповой разработки ETL, предоставляя центральный репозиторий со всеми основными функциями.
-
Сервер заданий Data Integrator отвечает за обработку заданий, созданных с помощью DI Designer.
Вы можете применять различные преобразования данных с помощью языка Data Integrator для применения сложных преобразований данных и создания пользовательских функций.
Data Integrator Designer используется для хранения в реальном времени и пакетных заданий и новых проектов в хранилище.
DI Designer также предоставляет возможность для групповой разработки ETL, предоставляя центральный репозиторий со всеми основными функциями.
Сервер заданий Data Integrator отвечает за обработку заданий, созданных с помощью DI Designer.
Веб-администратор
Веб-администратор Data Integrator используется системными администраторами и администратором базы данных для поддержки репозиториев в службах данных. Службы данных включают в себя хранилище метаданных, центральное хранилище для групповой разработки, сервер заданий и веб-службы.
Ключевые функции DI Web Administrator
- Он используется для планирования, мониторинга и выполнения пакетных заданий.
- Он используется для настройки, запуска и остановки серверов реального времени.
- Он используется для настройки сервера заданий, сервера доступа и использования хранилища.
- Используется для настройки адаптеров.
- Он используется для настройки и управления всеми инструментами в BO Data Services.
Функция управления данными делает упор на качество данных. Это включает в себя очистку данных, улучшение и консолидацию данных для получения правильных данных в системе DW.
SAP BODS — Архитектура
В этой главе мы узнаем об архитектуре SAP BODS. На рисунке показана архитектура системы BODS с промежуточной областью.
Исходный слой
Уровень источника включает в себя различные источники данных, такие как приложения SAP и системы RDBMS, отличные от SAP, и интеграция данных происходит в промежуточной области.
Службы данных SAP Business Objects включают в себя различные компоненты, такие как Дизайнер служб данных, Консоль управления службами данных, Диспетчер репозитория, Диспетчер сервера служб данных, Рабочий стол и т. Д. Целевая система может быть системой DW, такой как SAP HANA, SAP BW или не-SAP. Система хранения данных.
На следующем снимке экрана показаны различные компоненты SAP BODS.
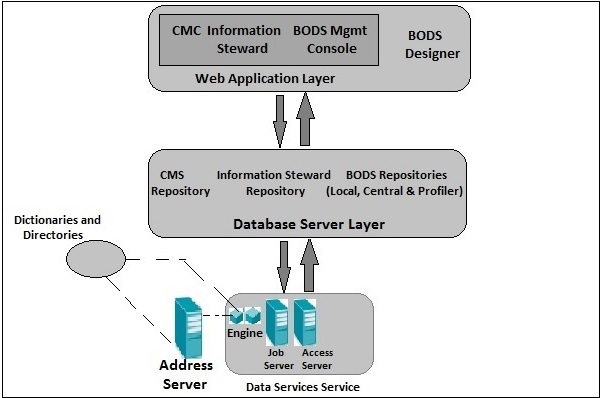
Вы также можете разделить архитектуру BODS на следующие уровни:
- Уровень веб-приложений
- Уровень сервера базы данных
- Сервисный уровень Data Services
На следующем рисунке показана архитектура BODS.
Эволюция продукта — ATL, DI & DQ
Acta Technology Inc. разработала службы данных SAP Business Objects, а затем приобрела компанию Business Objects. Acta Technology Inc. — американская компания, отвечающая за разработку первой платформы для интеграции данных. Двумя программными продуктами ETL, разработанными Acta Inc., были инструмент интеграции данных (DI) и инструмент управления данными или качества данных ( DQ ).
Французская компания Business Objects приобрела Acta Technology Inc. в 2002 году и позже, оба продукта были переименованы в инструмент интеграции данных бизнес-объектов (BODI) и инструмент качества данных бизнес-объектов (BODQ) .
SAP приобрела Business Objects в 2007 году, и оба продукта были переименованы в SAP BODI и SAP BODQ. В 2008 году SAP объединила оба продукта в единый программный продукт, названный SAP Business Objects Data Services (BODS).
SAP BODS предоставляет решение для интеграции данных и управления данными, а в более раннюю версию BODS было включено решение для обработки текстовых данных.
BODS — Объекты
Все объекты, которые используются в BO Data Services Designer, называются объектами . Все объекты, такие как проекты, задания, метаданные и системные функции, хранятся в локальной библиотеке объектов. Все объекты имеют иерархический характер.
Объекты в основном содержат следующее —
-
Свойства — они используются для описания объекта и не влияют на его работу. Пример — имя объекта, дата его создания и т. Д.
-
Опции — которые управляют работой объектов.
Свойства — они используются для описания объекта и не влияют на его работу. Пример — имя объекта, дата его создания и т. Д.
Опции — которые управляют работой объектов.
Типы объектов
В системе существует два типа объектов — объекты многократного использования и объекты одноразового использования. Тип объекта определяет, как этот объект используется и извлекается.
Многоразовые объекты
Большинство объектов, которые хранятся в хранилище, можно использовать повторно. Когда повторно используемый объект определен и сохранен в локальном хранилище, вы можете повторно использовать этот объект, создавая вызовы для определения. Каждый повторно используемый объект имеет только одно определение, и все вызовы этого объекта ссылаются на это определение. Теперь, если определение объекта изменяется в одном месте, вы меняете определение объекта во всех местах, где этот объект появляется.
Библиотека объектов используется для хранения определения объекта, и когда объект перетаскивается из библиотеки, создается новая ссылка на существующий объект.
Одноразовые объекты
Все объекты, которые определены специально для задания или потока данных, называются объектами одноразового использования. Например, конкретное преобразование используется при любой загрузке данных.
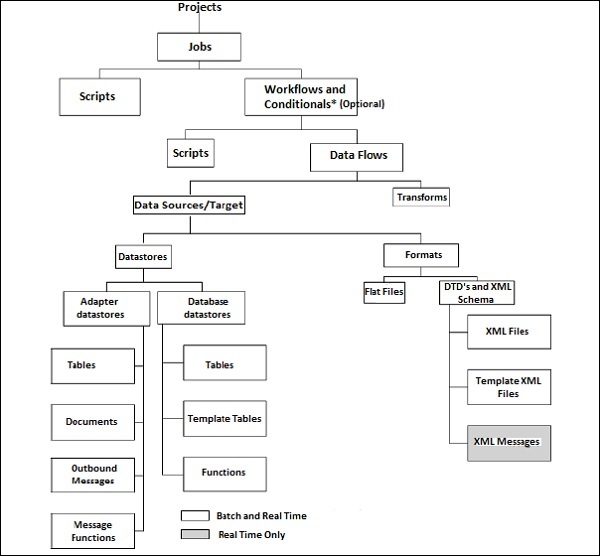
BODS — иерархия объектов
Все объекты имеют иерархический характер. На следующей диаграмме показана иерархия объектов в системе SAP BODS —
BODS — инструменты и функции
Основываясь на архитектуре, показанной ниже, у нас есть много инструментов, определенных в SAP Business Objects Data Services. Каждый инструмент имеет свою функцию в соответствии с системным ландшафтом.
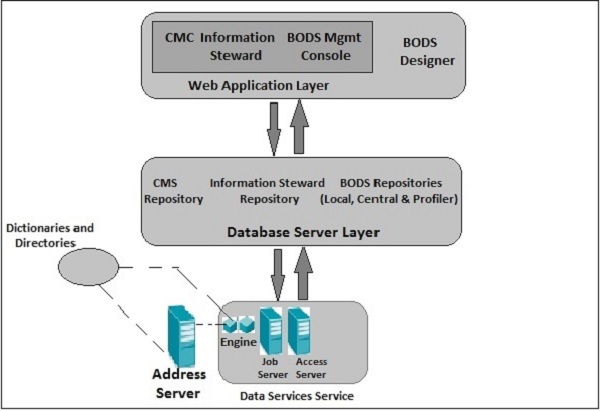
Вверху у вас установлены Службы информационной платформы для управления безопасностью пользователей и прав. BODS зависит от центральной консоли управления ( CMC ) для обеспечения доступа пользователей и обеспечения безопасности. Это применимо к версии 4.x. В предыдущей версии это было сделано в консоли управления.
SAP BODS — дизайнер служб данных
Data Services Designer — это инструмент разработчика, который используется для создания объектов, состоящих из отображения данных, преобразования и логики. Он основан на графическом интерфейсе и работает дизайнером для Data Services.
вместилище
Хранилище используется для хранения метаданных объектов, используемых в BO Data Services. Каждый репозиторий должен быть зарегистрирован в Central Management Console и связан с одним или несколькими серверами заданий, которые отвечают за выполнение заданий, созданных вами.
Типы хранилищ
Есть три типа хранилищ.
-
Локальный репозиторий — используется для хранения метаданных всех объектов, созданных в конструкторе служб данных, таких как проекты, задания, поток данных, поток операций и т. Д.
-
Центральный репозиторий — используется для управления управлением версиями объектов и используется для многоцелевой разработки. Центральный репозиторий хранит все версии объекта приложения. Следовательно, он позволяет вам перейти к предыдущим версиям.
-
Хранилище профилировщика — используется для управления всеми метаданными, связанными с задачами профилировщика, выполняемыми в конструкторе SAP BODS. Репозиторий CMS хранит метаданные всех задач, выполняемых в CMC на платформе BI. В репозитории информационного стюарда хранятся все метаданные профилирующих задач и объектов, созданных в информационном стюарде.
Локальный репозиторий — используется для хранения метаданных всех объектов, созданных в конструкторе служб данных, таких как проекты, задания, поток данных, поток операций и т. Д.
Центральный репозиторий — используется для управления управлением версиями объектов и используется для многоцелевой разработки. Центральный репозиторий хранит все версии объекта приложения. Следовательно, он позволяет вам перейти к предыдущим версиям.
Хранилище профилировщика — используется для управления всеми метаданными, связанными с задачами профилировщика, выполняемыми в конструкторе SAP BODS. Репозиторий CMS хранит метаданные всех задач, выполняемых в CMC на платформе BI. В репозитории информационного стюарда хранятся все метаданные профилирующих задач и объектов, созданных в информационном стюарде.
Работа сервера
Сервер заданий используется для выполнения созданных вами в режиме реального времени и пакетных заданий. Он получает информацию о задании из соответствующих репозиториев и запускает механизм данных для выполнения задания. Сервер заданий может выполнять задания в реальном времени или по расписанию и использует многопоточность в кэшировании памяти и параллельную обработку для обеспечения оптимизации производительности.
Сервер доступа
Сервер доступа в службах данных известен как система брокера сообщений в реальном времени, которая принимает запросы на сообщения, перемещается в службу реального времени и отображает сообщение в определенный период времени.
Консоль управления службами данных
Консоль управления службами данных используется для выполнения административных действий, таких как планирование заданий, создание отчетов о качестве в системе DS, проверка данных, документирование и т. Д.
BODS — Стандарты именования
Рекомендуется использовать стандартные соглашения об именах для всех объектов во всех системах, поскольку это позволяет легко идентифицировать объекты в репозиториях.
В таблице приведен список рекомендуемых соглашений об именах, которые следует использовать для всех заданий и других объектов.
| Префикс | Суффикс | объект |
|---|---|---|
| DF_ | н / | Поток данных |
| EDF_ | _INPUT | Встроенный поток данных |
| EDF_ | _Выход | Встроенный поток данных |
| RTJob_ | н / | Работа в реальном времени |
| WF_ | н / | Рабочий процесс |
| JOB_ | н / | работа |
| н / | _ds | Хранилище данных |
| ОКРУГ КОЛУМБИЯ_ | н / | Конфигурация данных |
| SC_ | н / | Конфигурация системы |
| н / | _Memory_DS | Хранилище данных памяти |
| PROC_ | н / | Хранимая процедура |
SAP BODS — Обзор репозитория
Основы BO Data Service включают в себя ключевые объекты при проектировании рабочего потока, такие как проект, работа, рабочий поток, поток данных, репозитории.
BODS — репозиторий и типы
Хранилище используется для хранения метаданных объектов, используемых в BO Data Services. Каждый репозиторий должен быть зарегистрирован в Central Management Console, CMC и связан с одним или несколькими серверами заданий, которые отвечают за выполнение заданий, созданных вами.
Типы хранилищ
Есть три типа хранилищ.
-
Локальный репозиторий — используется для хранения метаданных всех объектов, созданных в конструкторе служб данных, таких как проекты, задания, поток данных, поток операций и т. Д.
-
Центральный репозиторий — используется для управления управлением версиями объектов и используется для многоцелевой разработки. Центральный репозиторий хранит все версии объекта приложения. Следовательно, он позволяет вам перейти к предыдущим версиям.
-
Хранилище профилировщика — используется для управления всеми метаданными, связанными с задачами профилировщика, выполняемыми в конструкторе SAP BODS. Репозиторий CMS хранит метаданные всех задач, выполняемых в CMC на платформе BI. В репозитории информационного стюарда хранятся все метаданные профилирующих задач и объектов, созданных в информационном стюарде.
Локальный репозиторий — используется для хранения метаданных всех объектов, созданных в конструкторе служб данных, таких как проекты, задания, поток данных, поток операций и т. Д.
Центральный репозиторий — используется для управления управлением версиями объектов и используется для многоцелевой разработки. Центральный репозиторий хранит все версии объекта приложения. Следовательно, он позволяет вам перейти к предыдущим версиям.
Хранилище профилировщика — используется для управления всеми метаданными, связанными с задачами профилировщика, выполняемыми в конструкторе SAP BODS. Репозиторий CMS хранит метаданные всех задач, выполняемых в CMC на платформе BI. В репозитории информационного стюарда хранятся все метаданные профилирующих задач и объектов, созданных в информационном стюарде.
SAP BODS — Создание и обновление репозитория
Для создания BODS Repository вам необходимо установить базу данных. Вы можете использовать SQL Server, базу данных Oracle, My SQL, SAP HANA, Sybase и т. Д.
Создание репозитория
Вы должны создать следующих пользователей в базе данных при установке BODS и создать репозитории. Эти пользователи должны войти в систему на разных серверах, таких как CMS Server, Audit Server и т. Д.
Создание пользовательских BODS, идентифицированных Bodsserver1
- Грант Подключиться к BODS;
- Предоставить создание сеанса для BODS;
- Предоставление DBA для BODS;
- Предоставить создание любой таблицы для BODS;
- Предоставить создание любого вида для BODS;
- Grant Drop Любой стол для BODS;
- Грант Отбрасывать Любой Вид БОДАМ;
- Grant Вставить любую таблицу в BODS;
- Предоставить обновление любой таблицы до BODS;
- Предоставить удаление любой таблицы для BODS;
- Изменить квоту пользователей BODS без ограничений на пользователей;
Создать пользовательскую CMS, идентифицированную CMSserver1
- Грант Подключиться к CMS;
- Грант Создать сессию для CMS;
- Предоставление DBA для CMS;
- Предоставить создание любой таблицы в CMS;
- Грант Создать любое представление для CMS;
- Grant Drop Любой Стол в CMS;
- Grant Drop Any View для CMS;
- Грант Вставить любую таблицу в CMS;
- Предоставить обновление любой таблицы в CMS;
- Предоставить удаление любой таблицы в CMS;
- Измените USER CMS QUOTA НЕОГРАНИЧЕННО НА ПОЛЬЗОВАТЕЛЕЙ;
Создать пользователя CMSAUDIT, идентифицируемый CMSAUDITserver1
- Грант Подключиться к CMSAUDIT;
- Предоставить сеанс создания для CMSAUDIT;
- Предоставить DBA для CMSAUDIT;
- Грант Создать любую таблицу для CMSAUDIT;
- Грант Создать любое представление для CMSAUDIT;
- Grant Drop Любой Стол в CMSAUDIT;
- Предоставить любой вид CMSAUDIT;
- Грант Вставить любую таблицу в CMSAUDIT;
- Предоставить обновление любой таблицы в CMSAUDIT;
- Предоставить удаление любой таблицы в CMSAUDIT;
- Изменить цитату пользователя CMSAUDIT НЕОГРАНИЧЕННО НА ПОЛЬЗОВАТЕЛЕЙ;
Создать новый репозиторий после установки
Шаг 1 — Создайте базу данных Local_Repo и перейдите к Менеджеру репозитория служб данных. Настройте базу данных как локальный репозиторий.
Откроется новое окно.
Шаг 2 — Введите данные в следующие поля —
Тип репозитория, Тип базы данных, Имя сервера базы данных, Порт, Имя пользователя и пароль.
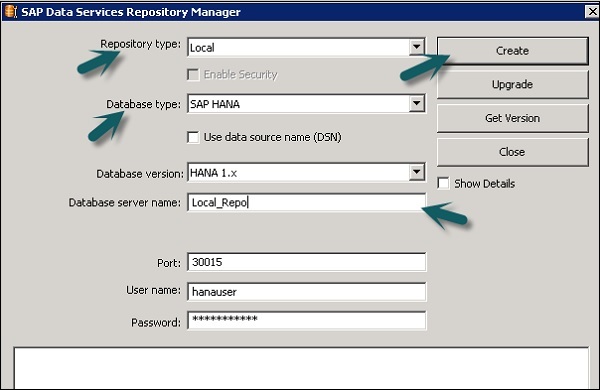
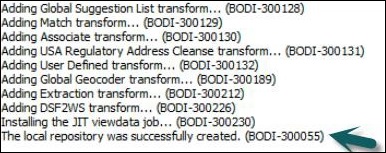
Шаг 3 — Нажмите кнопку Создать . Вы получите следующее сообщение —
Шаг 4 — Теперь войдите в CMC Central Management Console в SAP BI Platform с именем пользователя и паролем.
Шаг 5. На домашней странице CMC щелкните Службы данных .
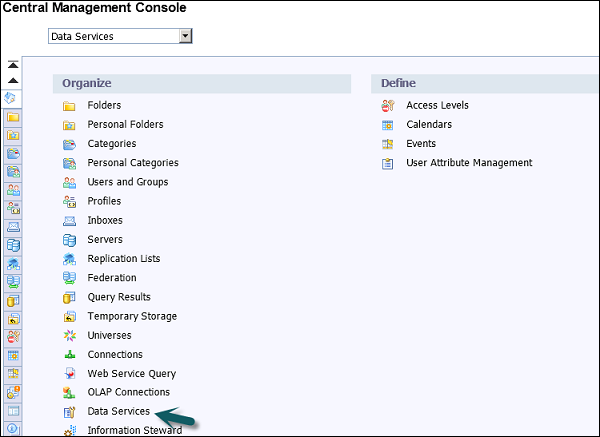
Шаг 6. В меню « Службы данных» выберите « Настроить новый репозиторий служб данных» .
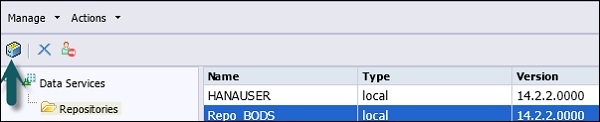
Шаг 7 — Введите данные, как указано в новом окне.
- Имя репозитория: Local_Repo
- Тип базы данных: SAP HANA
- Имя сервера базы данных: лучший
- Имя базы данных: LOCAL_REPO
- Имя пользователя:
- Пароль:*****
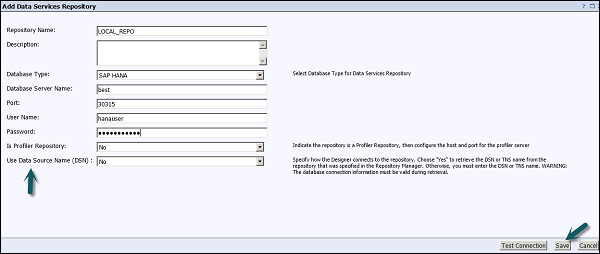
Шаг 8 — Нажмите кнопку « Проверить соединение» и, если она прошла успешно, нажмите « Сохранить» . После сохранения он перейдет на вкладку «Репозиторий» в CMC.
Шаг 9 — Применение прав доступа и безопасности в локальном хранилище в CMC → Пользователь и группы .
Шаг 10. Получив доступ, перейдите в Дизайнер служб данных → Выберите Репозиторий → Введите имя пользователя и пароль для входа.
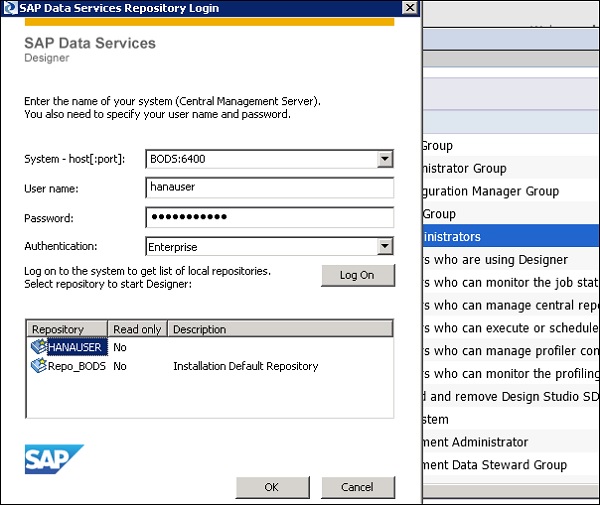
Обновление репозитория
Чтобы обновить репозиторий, выполните указанные шаги.
Шаг 1. Чтобы обновить репозиторий после установки, создайте базу данных Local_Repo и перейдите в Диспетчер репозитория служб данных.
Шаг 2 — Настройте базу данных как локальный репозиторий.
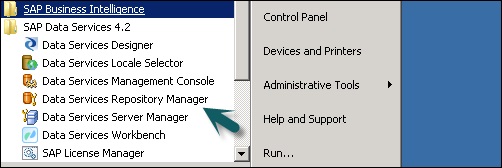
Откроется новое окно.
Шаг 3 — Введите данные для следующих полей.
Тип репозитория, Тип базы данных, Имя сервера базы данных, Порт, Имя пользователя и пароль.
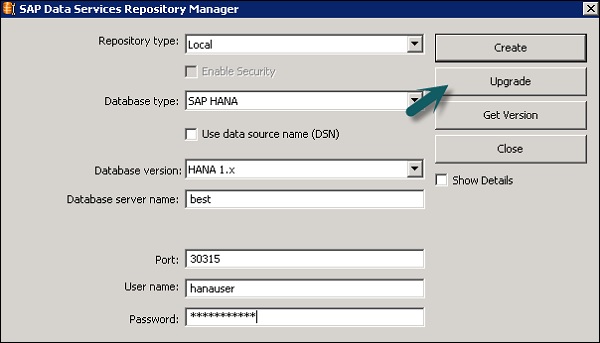
Вы увидите вывод, как показано на скриншоте ниже.

Консоль управления службами данных
Консоль управления службами данных (DSMC) используется для выполнения административных действий, таких как планирование заданий, создание отчетов о качестве в системе DS, проверка данных, документирование и т. Д.
Вы можете получить доступ к консоли управления службами данных следующими способами:
Вы можете получить доступ к Консоли управления службами данных, выбрав Пуск → Все программы → Службы данных → Консоль управления службами данных .
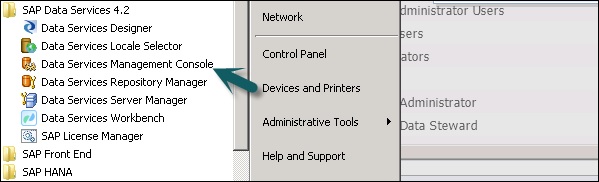
Вы также можете получить доступ к консоли управления службами данных через Designer, если вы уже вошли в систему.
Для доступа к консоли управления службами данных через домашнюю страницу Designer выполните следующие действия.

Чтобы получить доступ к консоли управления службами данных через Инструменты, выполните следующие действия:
Шаг 1. Перейдите в Инструменты → Консоль управления службами данных, как показано на следующем рисунке.
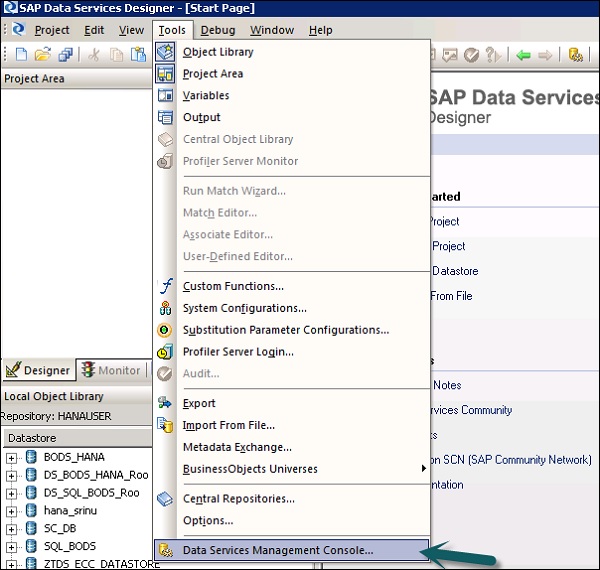
Шаг 2. После входа в консоль управления службами данных откроется главный экран, как показано на приведенном ниже снимке экрана. Вверху вы можете увидеть имя пользователя, под которым вы вошли в систему.
На домашней странице вы увидите следующие опции —
- администратор
- Авто Документация
- Проверка данных
- Анализ влияния и происхождения
- Операционная панель
- Отчеты о качестве данных
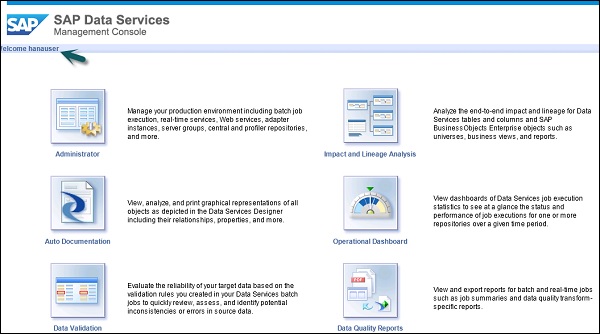
SAP BODS — модули DSMC
Ключевые функции каждого модуля Консоли управления службами данных описаны в этой главе.
Модуль администратора
Опция Администратор используется для управления —
- Пользователи и роли
- Чтобы добавить соединения для доступа к серверам и репозиториям
- Доступ к данным о работе, опубликованным для веб-сервисов
- Для планирования и мониторинга пакетных заданий
- Для проверки статуса сервера доступа и услуг в реальном времени.
После того, как вы нажмете вкладку « Администратор », вы увидите много ссылок на левой панели. Это — Статус, Пакет, Веб-сервисы, SAP-соединения, Группы серверов, Управление репозиториями профилировщика и История выполнения заданий.
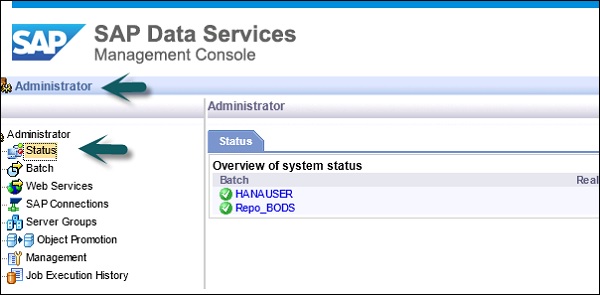
Вершины
Различные узлы находятся в модуле администратора, обсуждаются ниже.
Статус
Узел «Статус» используется для проверки состояния пакетных заданий и заданий в реальном времени, доступа к состоянию сервера, хранилищам адаптеров и профилировщика и другого состояния системы.
Нажмите Статус → Выбрать репозиторий.
На правой панели вы увидите вкладки следующих опций —
Состояние пакетного задания — используется для проверки состояния пакетного задания. Вы можете проверить информацию о задании, такую как Трассировка, Монитор, Ошибка и Монитор производительности, Время начала, Время окончания, Продолжительность и т. Д.
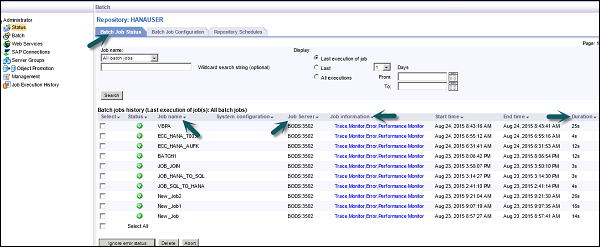
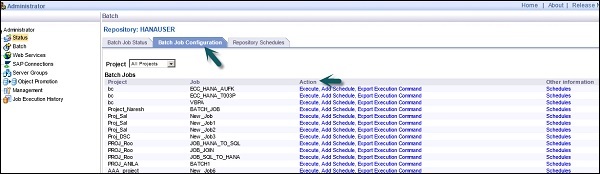
Конфигурация пакетных заданий — Конфигурация пакетных заданий используется для проверки расписания отдельных заданий, или вы можете добавить такие действия, как Выполнить, Добавить расписание, Экспортировать команду выполнения.
Расписания репозиториев — используется для просмотра и настройки расписаний для всех заданий в репозитории.
Пакетный узел
Под узлом Batch Job вы увидите те же опции, что и выше.
| Старший | Вариант и описание |
|---|---|
| 1 |
Пакетное задание Просмотрите статус последнего выполнения и подробную информацию о каждой работе. |
| 2 |
Конфигурация пакетного задания Настройте параметры выполнения и планирования для отдельных заданий. |
| 3 |
Графики репозитория Просмотр и настройка расписаний для всех заданий в хранилище. |
Пакетное задание
Просмотрите статус последнего выполнения и подробную информацию о каждой работе.
Конфигурация пакетного задания
Настройте параметры выполнения и планирования для отдельных заданий.
Графики репозитория
Просмотр и настройка расписаний для всех заданий в хранилище.
Узел веб-служб
Веб-службы используются для публикации заданий в реальном времени и пакетных заданий в качестве операции веб-службы и для проверки состояния этих операций. Это также используется для обеспечения безопасности заданий, опубликованных в виде веб-службы, и для просмотра файла WSDL .

SAP Connections
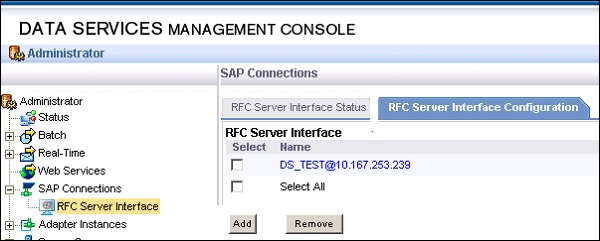
SAP Connections используется для проверки состояния или для настройки интерфейса сервера RFC в Консоли управления службами данных.
Чтобы проверить состояние интерфейса сервера RFC, перейдите на вкладку Состояние интерфейса сервера RFC. Чтобы добавить новый интерфейс сервера RFC, на вкладке конфигурации нажмите кнопку Добавить .
Когда откроется новое окно, введите сведения о конфигурации сервера RFC, нажмите « Применить» .
Группы серверов
Это используется для группировки всех серверов заданий, связанных с одним и тем же хранилищем, в одну группу серверов. Эта вкладка используется для балансировки нагрузки при выполнении заданий в службах данных.
Когда задание выполняется, оно проверяет соответствующий сервер задания и, если оно не работает, перемещает задание на другой сервер задания в той же группе. В основном используется в производстве для балансировки нагрузки.
Репозитории профилей
Когда вы подключаете репозиторий профилей к администратору, это позволяет вам расширить узел репозитория профилей. Вы можете перейти на страницу статуса Задачи профиля.
Узел управления
Чтобы использовать функцию вкладки «Администратор», необходимо добавить подключения к службам данных с помощью узла управления. Узел управления состоит из различных параметров конфигурации приложения администрирования.
История выполнения работ
Это используется для проверки истории выполнения задания или потока данных. Используя эту опцию, вы можете проверить историю выполнения одного пакетного задания или всех созданных вами пакетных заданий.
При выборе задания информация отображается в виде таблицы, которая состоит из имени репозитория, имени задания, времени начала, времени окончания, времени выполнения, состояния и т. Д.
SAP BODS — DS Designer Введение
Data Service Designer — это инструмент разработчика, который используется для создания объектов, состоящих из отображения данных, преобразования и логики. Он основан на графическом интерфейсе и работает дизайнером для Data Services.
Вы можете создавать различные объекты с помощью Data Services Designer, такие как проекты, задания, рабочие потоки, потоки данных, отображение, преобразования и т. Д.
Чтобы запустить Data Services Designer, выполните следующие действия.
Шаг 1 — Укажите Пуск → Все программы → SAP Data Services 4.2 → Дизайнер служб данных.

Шаг 2 — Выберите репозиторий и введите пароль для входа.
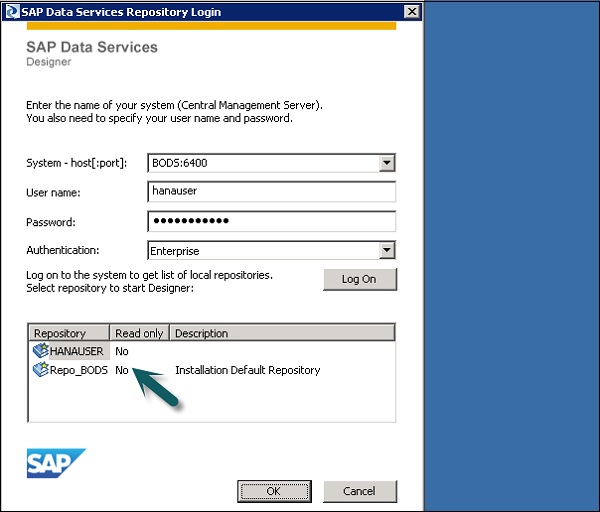
После того, как вы выберете репозиторий и войдете в Data Services Designer, появится домашний экран, как показано на рисунке ниже.

На левой панели у вас есть область проекта, в которой вы можете создать новый проект, задание, поток данных, рабочий процесс и т. Д. В области проекта имеется библиотека локальных объектов, которая состоит из всех объектов, созданных в службах данных.
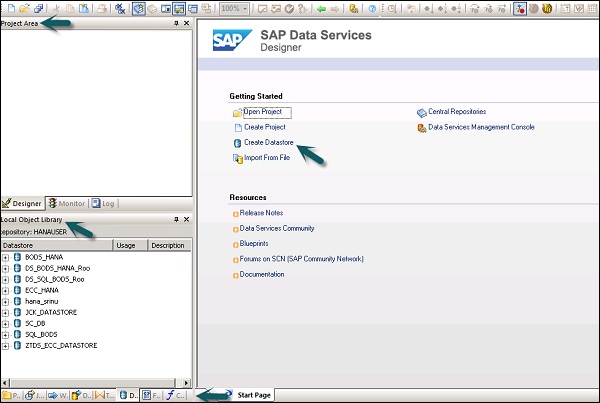
На нижней панели вы можете открыть существующие объекты, перейдя к определенным параметрам, таким как «Проект», «Работа», «Поток данных», «Рабочий поток» и т. Д. После выбора любого объекта на нижней панели он покажет вам все похожие объекты. созданный в репозитории под локальной библиотекой объектов.
На правой стороне у вас есть домашний экран, который можно использовать для —
- Создать проект
- Открытый проект
- Создать хранилище данных
- Создать хранилища
- Импорт из плоского файла
- Консоль управления службами данных
SAP BODS — ETL Flow в DS Designer
Для разработки потока ETL сначала необходимо создать хранилища данных для исходной и целевой системы. Следуйте инструкциям по созданию потока ETL —
Шаг 1 — Нажмите « Создать хранилище данных» .

Откроется новое окно.
Шаг 2 — Введите имя хранилища данных, тип хранилища данных и тип базы данных, как показано ниже. Вы можете выбрать другую базу данных в качестве исходной системы, как показано на скриншоте ниже.
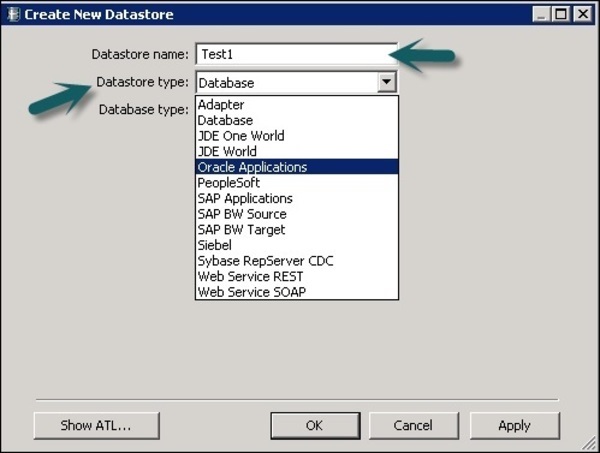
Шаг 3 — Чтобы использовать систему ECC в качестве источника данных, выберите Приложения SAP в качестве типа хранилища данных. Введите имя пользователя и пароль и на вкладке «Дополнительно» введите номер системы и номер клиента.
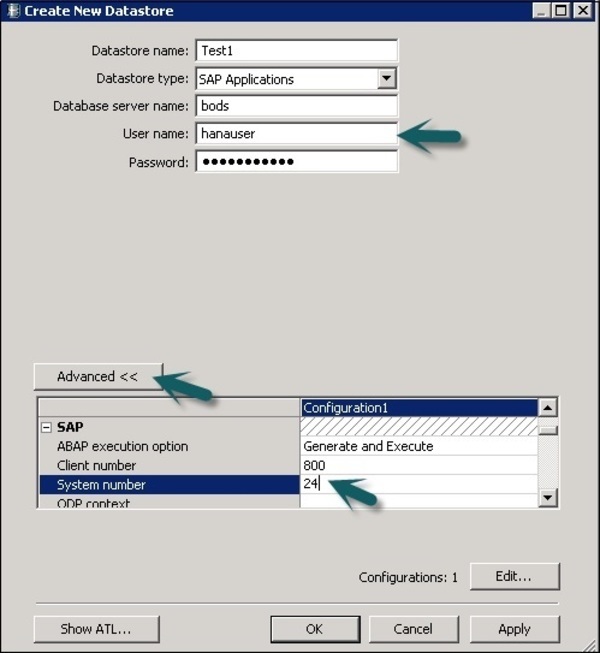
Шаг 4 — Нажмите OK, и хранилище данных будет добавлено в список библиотеки локальных объектов. Если вы развернете Datastore, он не покажет ни одной таблицы.
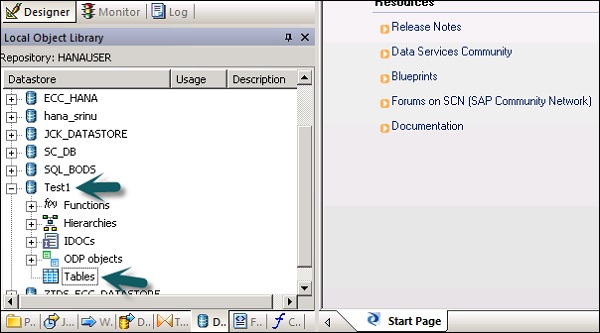
Шаг 5 — Чтобы извлечь любую таблицу из системы ECC для загрузки в целевую систему, щелкните правой кнопкой мыши Таблицы → Импорт по именам.
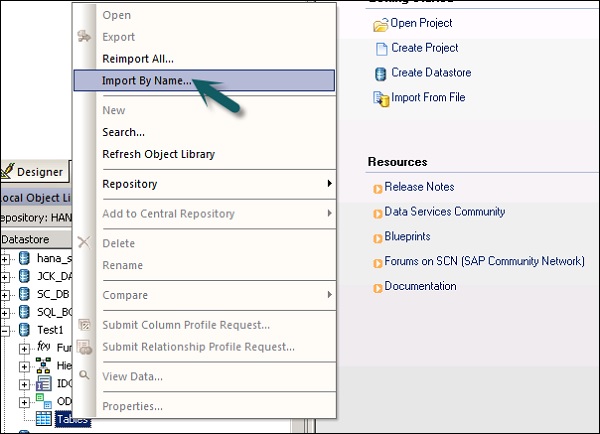
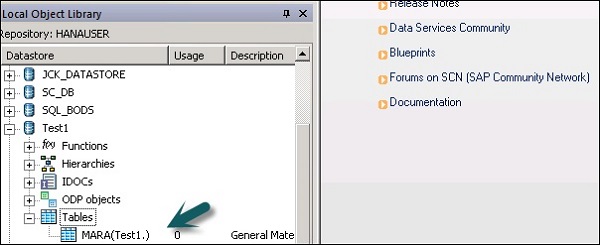
Шаг 6 — Введите имя таблицы и нажмите « Импорт» . Здесь используется таблица Mara, которая является таблицей по умолчанию в системе ECC.
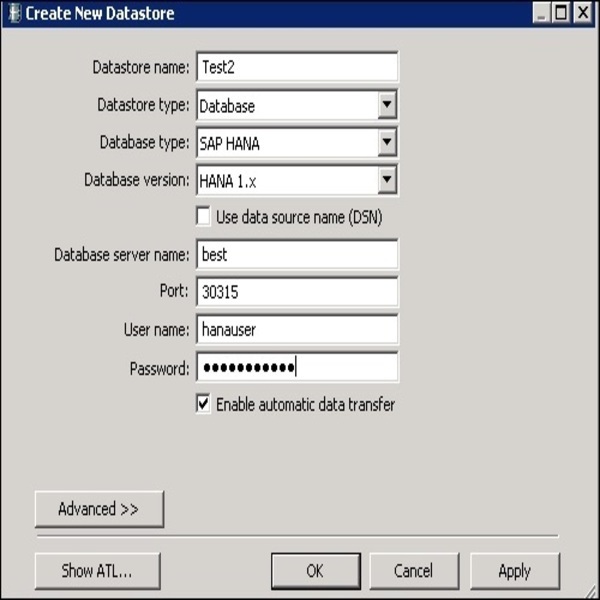
Шаг 7 — Аналогичным образом создайте хранилище данных для целевой системы. В этом примере HANA используется в качестве целевой системы.
Как только вы нажмете ОК, это хранилище данных будет добавлено в локальную библиотеку объектов, и внутри нее не будет таблицы.
Создать поток ETL
Чтобы создать поток ETL, создайте новый проект.
Шаг 1 — Выберите опцию « Создать проект» . Введите имя проекта и нажмите « Создать» . Он будет добавлен в область проекта.
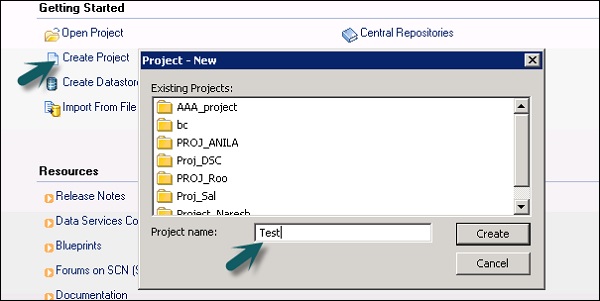
Шаг 2 — Щелкните правой кнопкой мыши на имени проекта и создайте новую пакетную работу / работу в реальном времени.

Шаг 3 — Введите название работы и нажмите Enter. Вы должны добавить рабочий поток и поток данных к этому. Выберите рабочий процесс и щелкните рабочую область, чтобы добавить к работе. Введите имя рабочего процесса и дважды щелкните его, чтобы добавить в область проекта.
Шаг 4 — Аналогичным образом выберите поток данных и перенесите его в область проекта. Введите имя потока данных и дважды щелкните, чтобы добавить его в новый проект.

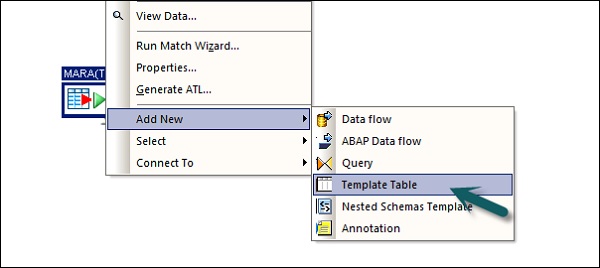
Шаг 5 — Теперь перетащите исходную таблицу под хранилище данных в рабочую область. Теперь вы можете перетащить целевую таблицу с аналогичным типом данных в рабочую область или создать новую таблицу шаблонов.
Чтобы создать новую таблицу шаблонов, щелкните правой кнопкой мыши исходную таблицу, добавив New → Template Table.
Шаг 6 — Введите имя таблицы и выберите хранилище данных из списка в качестве целевого хранилища данных. Имя владельца представляет имя схемы, где должна быть создана таблица.
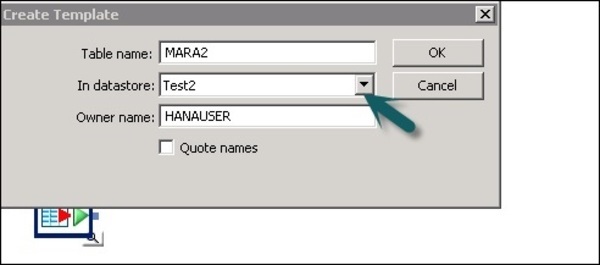
Таблица будет добавлена в рабочую область с этим именем таблицы.
Шаг 7 — Перетащите линию от исходной таблицы к целевой таблице. Нажмите на опцию Сохранить все вверху.
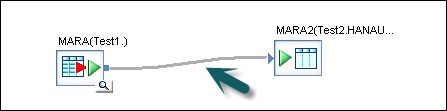
Теперь вы можете запланировать задание с помощью консоли управления службами данных или выполнить его вручную, щелкнув правой кнопкой мыши имя задания и выполнив.
SAP BODS — Обзор хранилища данных
Хранилища данных используются для настройки соединения между приложением и базой данных. Вы можете создать Datastore напрямую или с помощью адаптеров. Хранилище данных позволяет приложению / программному обеспечению считывать или записывать метаданные из приложения или базы данных и записывать в эту базу данных или приложение.
В Службах данных Business Objects вы можете подключаться к следующим системам, используя Datastore:
- Системы мэйнфреймов и базы данных
- Приложения и программное обеспечение с написанными пользователем адаптерами
- Приложения SAP, SAP BW, Oracle Apps, Siebel и др.
Службы данных SAP Business Objects предоставляют возможность подключения к интерфейсам мэйнфреймов с помощью Attunity Connector. Используя Attunity , подключите хранилище данных к приведенному ниже списку источников.
- DB2 UDB для OS / 390
- DB2 UDB для OS / 400
- IMS / DB
- VSAM
- Adabas
- Плоские файлы в OS / 390 и OS / 400
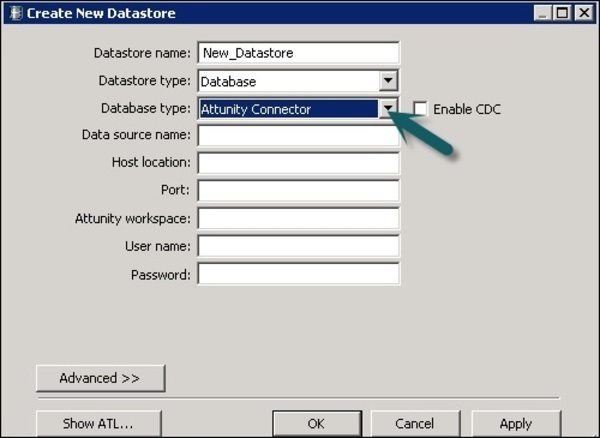
Используя разъем Attunity, вы можете подключиться к данным мэйнфрейма с помощью программного обеспечения. Это программное обеспечение необходимо установить вручную на мэйнфрейм-сервер и локальный сервер заданий клиента с использованием интерфейса ODBC.
Введите такие данные, как местоположение хоста, порт, рабочее пространство Attunity и т. Д.
Создать хранилище данных для базы данных
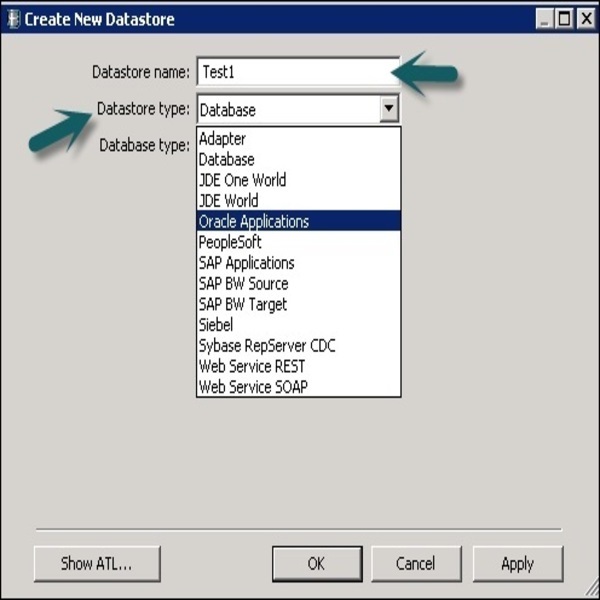
Чтобы создать хранилище данных для базы данных, выполните следующие действия.
Шаг 1 — Введите имя хранилища данных, тип хранилища данных и тип базы данных, как показано на рисунке ниже. Вы можете выбрать другую базу данных в качестве исходной системы, приведенной в списке.
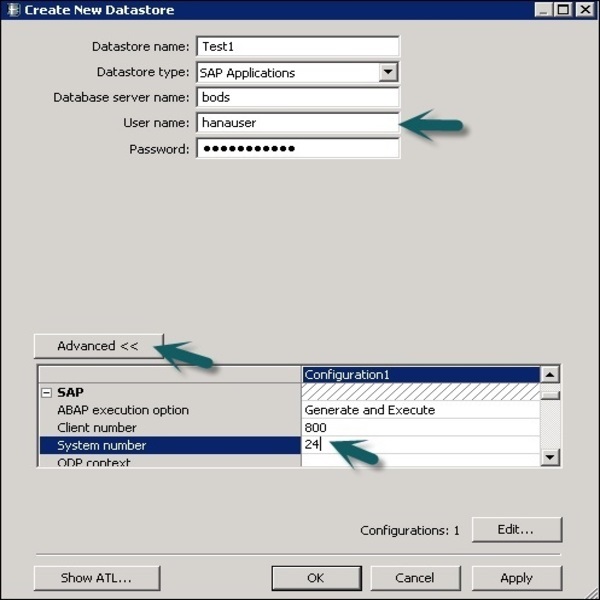
Шаг 2. Чтобы использовать систему ECC в качестве источника данных, выберите Приложения SAP в качестве типа хранилища данных. Введите имя пользователя и пароль. Перейдите на вкладку « Advance » и введите номер системы и номер клиента.
Шаг 3 — Нажмите OK, и хранилище данных будет добавлено в список библиотеки локальных объектов. Если развернуть хранилище данных, таблица для отображения отсутствует.
SAP BODS — Изменение хранилища данных
В этой главе мы узнаем, как редактировать или изменять хранилище данных. Чтобы изменить или отредактировать хранилище данных, выполните следующие действия.
Шаг 1 — Чтобы отредактировать хранилище данных, щелкните правой кнопкой мыши имя хранилища данных и нажмите Редактировать. Откроется редактор хранилища данных.
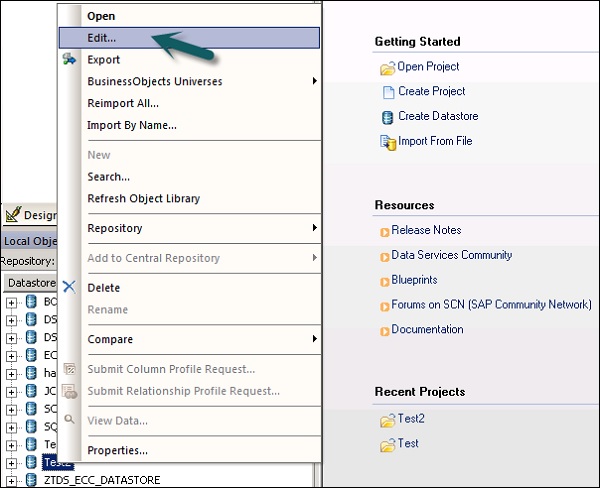
Вы можете редактировать информацию о соединении для текущей конфигурации хранилища данных.
Шаг 2 — Нажмите кнопку Advance , и вы сможете редактировать номер клиента, системный идентификатор и другие свойства.
Шаг 3 — Нажмите « Изменить», чтобы добавить, отредактировать и удалить конфигурации.
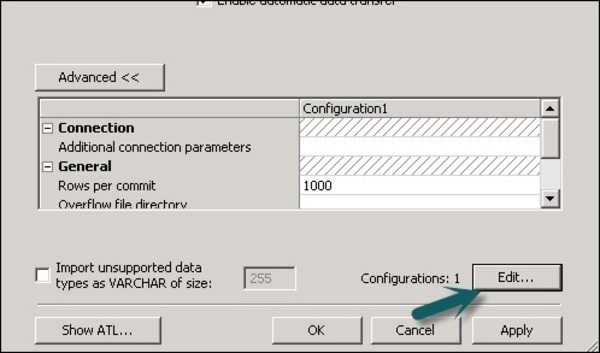
Шаг 4 — Нажмите OK, и изменения будут применены.
SAP BODS — хранилище данных памяти
Вы можете создать хранилище данных, используя память в качестве типа базы данных. Хранилища данных памяти используются для повышения производительности потоков данных в заданиях в реальном времени, поскольку они хранят данные в памяти для облегчения быстрого доступа и не требуют перехода к исходному источнику данных.
Хранилище данных памяти используется для хранения схем таблиц памяти в хранилище. Эти таблицы памяти получают данные из таблиц в реляционной базе данных или с использованием файлов иерархических данных, таких как сообщения XML и IDoc. Таблицы памяти остаются активными до тех пор, пока задание не будет выполнено, и данные в таблицах памяти не могут быть разделены между различными заданиями реального времени.
Создание хранилища данных памяти
Чтобы создать хранилище данных памяти, выполните следующие действия.
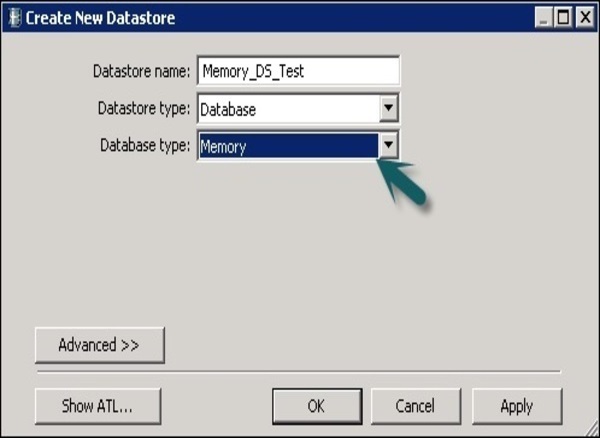
Шаг 1 — Нажмите «Создать хранилище данных» и введите имя хранилища данных «Memory_DS_TEST» . Таблицы памяти представлены обычными таблицами СУБД и могут быть идентифицированы с помощью соглашений об именах.
Шаг 2 — В Типе хранилища данных выберите База данных и в типе базы данных выберите Память . Нажмите ОК.
Шаг 3 — Теперь перейдите в Project → New → Project, как показано на скриншоте ниже.
Шаг 4 — Создайте новую работу, щелкнув правой кнопкой мыши. Добавьте рабочий поток и поток данных, как показано ниже.
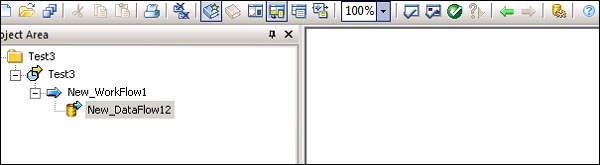
Шаг 5 — Выберите таблицу шаблонов и перетащите в рабочую область. Откроется окно «Создать таблицу».
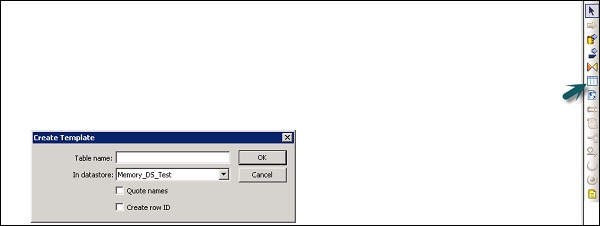
Шаг 6 — Введите имя таблицы и в Datastore выберите Memory Datastore. Если вам нужен сгенерированный системой идентификатор строки, установите флажок « Создать идентификатор строки» . Нажмите ОК.
Шаг 7 — Подключите эту таблицу памяти к потоку данных и нажмите Сохранить все вверху.
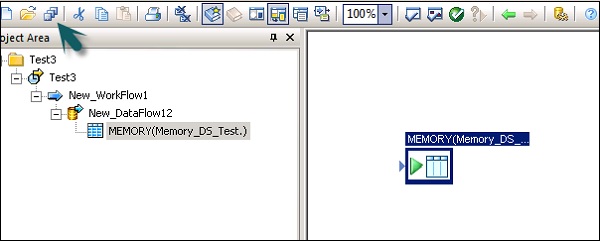
Таблица памяти как источник и цель
Чтобы использовать таблицу памяти в качестве цели —
Шаг 1 — Перейдите в локальную библиотеку объектов, щелкните вкладку «Хранилище данных». Разверните хранилище данных памяти → Разверните таблицы.
Шаг 2 — Выберите таблицу памяти, которую вы хотите использовать в качестве исходной или целевой таблицы, и перетащите ее в рабочий процесс. Подключите эту таблицу памяти к источнику или цели в потоке данных.
Шаг 3 — Нажмите кнопку Сохранить , чтобы сохранить работу.
SAP BODS — Связанное хранилище данных
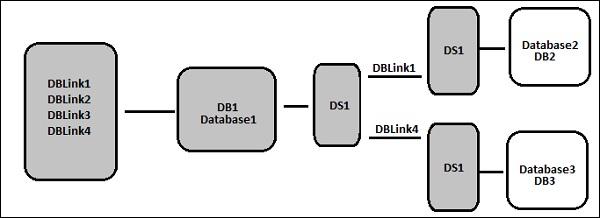
Существуют различные поставщики баз данных, которые предоставляют только односторонний путь связи из одной базы данных в другую. Эти пути известны как ссылки на базы данных. В SQL Server связанный сервер обеспечивает односторонний путь связи из одной базы данных в другую.
пример
Рассмотрим локальный сервер базы данных с именем «Product», хранящий ссылку на базу данных для доступа к информации на удаленном сервере базы данных под названием Customer . Теперь пользователи, которые подключены к удаленному серверу базы данных, Клиент не может использовать одну и ту же ссылку для доступа к данным на сервере базы данных Продукт. Пользователи, подключенные к «Заказчику», должны иметь отдельную ссылку в словаре данных сервера для доступа к данным на сервере базы данных Продукта.
Этот путь связи между двумя базами данных называется ссылкой на базу данных. Хранилища данных, которые создаются между этими связанными базами данных, называются связанными хранилищами данных.
Существует возможность подключения одного хранилища данных к другому хранилищу данных и импорта ссылки на внешнюю базу данных в качестве опции хранилища данных.
SAP BODS — хранилище данных адаптера
Адаптер Datastore позволяет импортировать метаданные приложения в репозиторий. Вы можете получить доступ к метаданным приложения и переместить пакетные данные и данные в реальном времени между различными приложениями и программным обеспечением.
Существует пакет разработки программного обеспечения для адаптеров — SDK, предоставляемый SAP, который можно использовать для разработки адаптированных адаптеров. Эти адаптеры отображаются в конструкторе служб данных в хранилище адаптеров.
Чтобы извлечь или загрузить данные с помощью адаптера, вы должны определить хотя бы одно хранилище данных для этой цели.
Адаптер Datastore — Определение
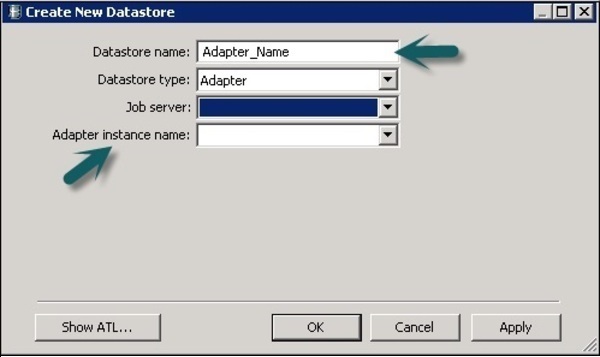
Чтобы определить Adaptive Datastore, выполните следующие шаги:
Шаг 1 — Нажмите Создать хранилище данных → Введите имя хранилища данных. Выберите тип хранилища данных в качестве адаптера. Выберите сервер заданий из списка и имя экземпляра адаптера и нажмите OK .
Для просмотра метаданных приложения
Щелкните правой кнопкой мыши на имени хранилища данных и нажмите Открыть . Откроется новое окно с метаданными источника. Нажмите на знак +, чтобы проверить объекты, и щелкните правой кнопкой мыши на объекте для импорта.
SAP BODS — форматы файлов
Формат файла определяется как набор свойств для представления структуры плоских файлов. Он определяет структуру метаданных. Формат файла используется для подключения к исходной и целевой базе данных, когда данные хранятся в файлах, а не в базе данных.
Формат файла используется для следующих функций —
- Создайте шаблон формата файла, чтобы определить структуру файла.
- Создайте конкретный исходный и целевой формат файла в потоке данных.
Следующий тип файлов может быть использован в качестве исходного или целевого файла с использованием формата файла —
- разграниченный
- SAP Transport
- Неструктурированный текст
- Неструктурированный двоичный
- Фиксированная ширина
Редактор формата файла
Редактор форматов файлов используется для установки свойств шаблонов форматов файлов и форматов исходного и целевого файлов.
В редакторе формата файла доступны следующие режимы:
-
Новый режим — позволяет создать новый шаблон формата файла.
-
Режим редактирования — позволяет редактировать существующий шаблон формата файла.
-
Исходный режим — позволяет редактировать формат файла определенного исходного файла.
-
Целевой режим — позволяет редактировать формат файла определенного целевого файла.
Новый режим — позволяет создать новый шаблон формата файла.
Режим редактирования — позволяет редактировать существующий шаблон формата файла.
Исходный режим — позволяет редактировать формат файла определенного исходного файла.
Целевой режим — позволяет редактировать формат файла определенного целевого файла.
Для редактора форматов файлов есть три рабочие области:
-
Свойства Значения — используется для редактирования значений свойств формата файла.
-
Атрибуты столбцов — используется для редактирования и определения столбцов или полей в файле.
-
Предварительный просмотр данных — используется для просмотра того, как настройки влияют на данные образца.
Свойства Значения — используется для редактирования значений свойств формата файла.
Атрибуты столбцов — используется для редактирования и определения столбцов или полей в файле.
Предварительный просмотр данных — используется для просмотра того, как настройки влияют на данные образца.
Создание формата файла
Чтобы создать формат файла, выполните следующие действия.
Шаг 1 — Перейдите в Local Object Library → Плоские файлы.
Шаг 2 — Щелкните правой кнопкой мыши по опции Плоские файлы → Создать.

Откроется новое окно редактора форматов файлов.
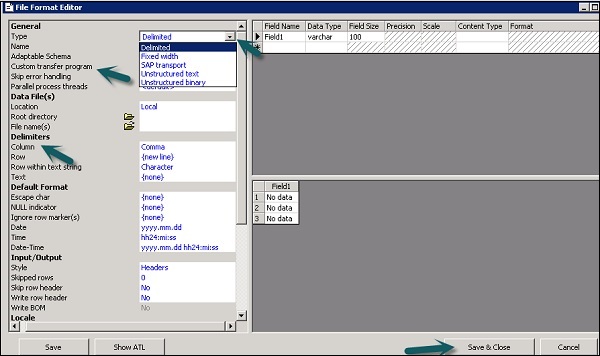
Шаг 3 — Выберите тип формата файла. Введите имя, которое описывает шаблон формата файла. Для файлов с разделителями и фиксированной шириной вы можете читать и загружать их с помощью Пользовательской программы передачи. Введите другие свойства, чтобы описать файлы, которые представляет этот шаблон.
Вы также можете указать структуру столбцов в рабочей области атрибутов столбцов для нескольких конкретных форматов файлов. Как только все свойства определены, нажмите кнопку Сохранить .
Редактирование формата файла
Чтобы отредактировать форматы файлов, выполните следующие действия.
Шаг 1 — В локальной библиотеке объектов перейдите на вкладку Формат .
Шаг 2 — Выберите формат файла, который вы хотите редактировать. Щелкните правой кнопкой мыши по опции « Изменить» .
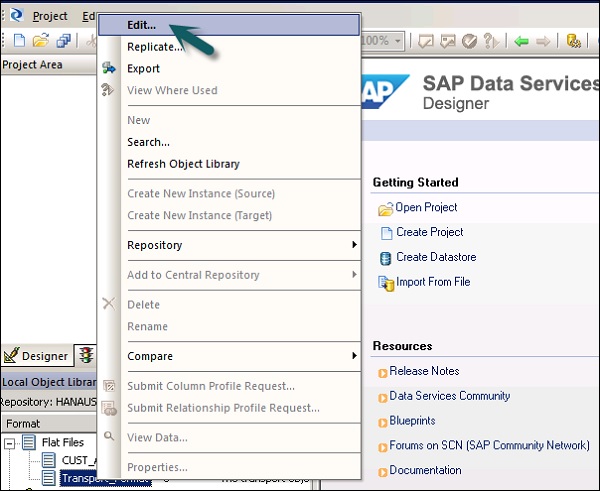
Внесите изменения в редактор форматов файлов и нажмите кнопку « Сохранить» .
SAP BODS — формат файла COBOL Copybook
Вы можете создать формат файла тетради COBOL, который замедляет создание только этого формата. Вы можете настроить источник позже, когда добавите формат в поток данных.
Вы можете создать формат файла и одновременно подключить его к файлу данных. Следуйте инструкциям ниже.
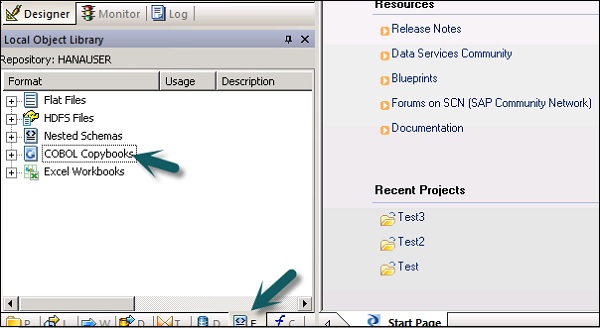
Шаг 1 — Перейдите в Локальную библиотеку объектов → Формат файла → Тетради COBOL.
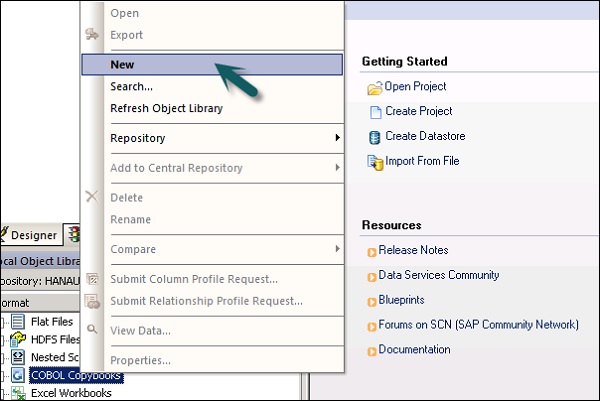
Шаг 2 — Щелкните правой кнопкой мыши по опции Новый .
Шаг 3 — Введите имя формата. Перейдите на вкладку «Формат» → выберите тетрадь COBOL для импорта. Расширение файла .cpy .
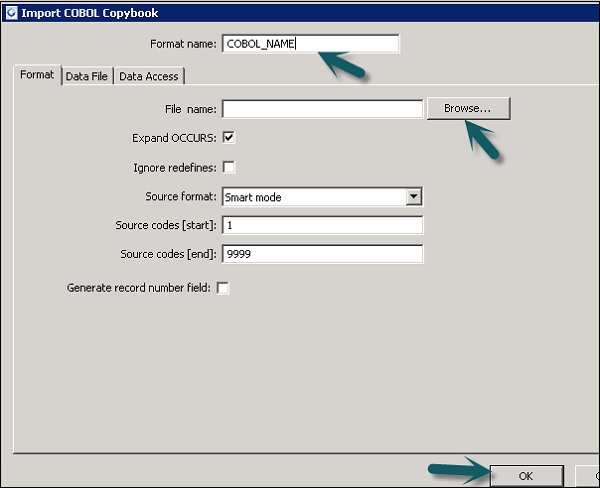
Шаг 4 — Нажмите ОК . Этот формат файла добавляется в локальную библиотеку объектов. Откроется диалоговое окно Имя схемы тетради COBOL. При необходимости переименуйте схему и нажмите ОК .
Извлечение данных из таблиц базы данных
Используя хранилища данных базы данных, вы можете извлекать данные из таблиц и функций в базе данных. Когда вы выполняете импорт данных для метаданных, Tool позволяет редактировать имена столбцов, типы данных, описание и т. Д.
Вы можете редактировать следующие объекты —
- Имя таблицы
- Название столбца
- Описание таблицы
- Описание столбца
- Тип данных столбца
- Тип содержимого столбца
- Атрибуты таблицы
- Основной ключ
- Имя владельца
Импорт метаданных
Чтобы импортировать метаданные, выполните следующие действия:
Шаг 1 — Перейдите в Local Object Library → перейдите в хранилище данных, которое вы хотите использовать.
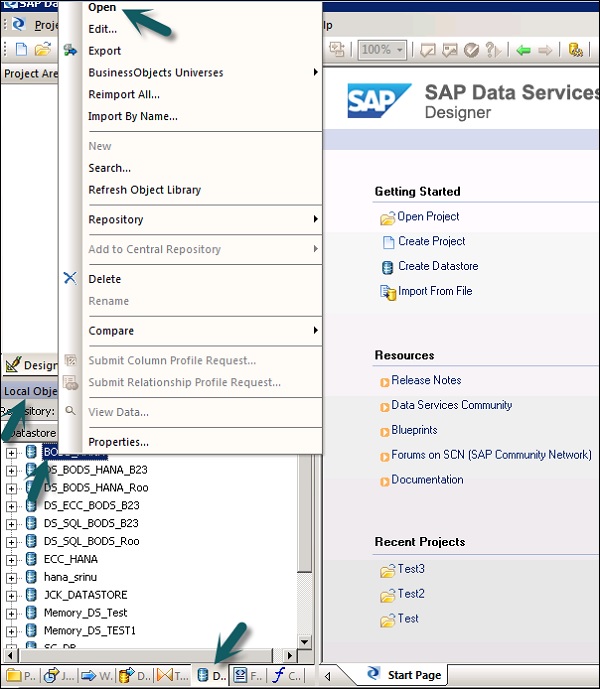
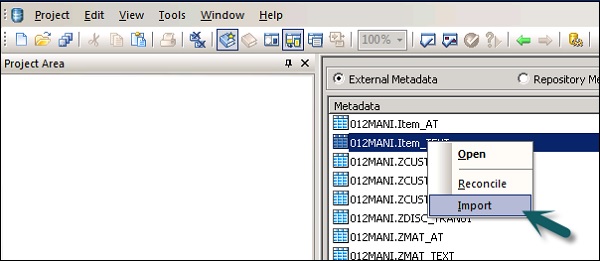
Шаг 2 — Щелкните правой кнопкой мыши на хранилище данных → Открыть.
В рабочей области будут отображены все элементы, доступные для импорта. Выберите элементы, для которых вы хотите импортировать метаданные.
В библиотеке объектов перейдите в хранилище данных, чтобы увидеть список импортированных объектов.
Извлечение данных из книги Excel
Вы можете использовать книгу Microsoft Excel в качестве источника данных, используя форматы файлов в службах данных. Книга Excel должна быть доступна в файловой системе Windows или файловой системе Unix.
| Sr.No. | Доступ и описание |
|---|---|
| 1 |
В библиотеке объектов перейдите на вкладку Форматы . Формальная форма рабочей книги Excel описывает структуру, определенную в рабочей книге Excel (обозначается расширением .xls). Шаблоны форматов для диапазонов данных Excel хранятся в библиотеке объектов. Шаблон используется для определения формата конкретного источника в потоке данных. Службы данных SAP получают доступ к рабочим книгам Excel только как к источникам (но не к целевым объектам). |
В библиотеке объектов перейдите на вкладку Форматы .
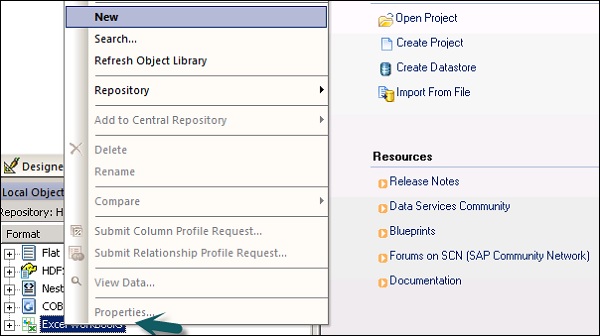
Формальная форма рабочей книги Excel описывает структуру, определенную в рабочей книге Excel (обозначается расширением .xls). Шаблоны форматов для диапазонов данных Excel хранятся в библиотеке объектов. Шаблон используется для определения формата конкретного источника в потоке данных. Службы данных SAP получают доступ к рабочим книгам Excel только как к источникам (но не к целевым объектам).
Нажмите правой кнопкой мыши на опцию New и выберите Excel Workbook, как показано на скриншоте ниже.
Извлечение данных из XML FILE DTD, XSD
Вы также можете импортировать формат файла схемы XML или DTD.
Шаг 1 — Перейдите в локальную библиотеку объектов → вкладка «Формат» → «Вложенная схема».
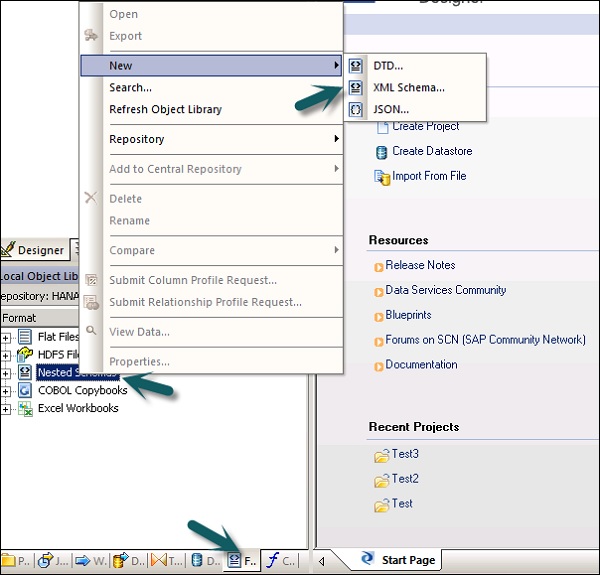
Шаг 2 — Укажите на Новый (Вы можете выбрать файл DTD или XML-схему или формат файла JSON). Введите имя формата файла и выберите файл, который вы хотите импортировать. Нажмите ОК.
Извлечение данных из тетрадей COBOL
Вы также можете импортировать формат файла в тетрадях COBOL. Перейдите в Локальную библиотеку объектов → Формат → Тетради COBOL.
SAP BODS — Введение в поток данных
Поток данных используется для извлечения, преобразования и загрузки данных из источника в целевую систему. Все преобразования, загрузка и форматирование происходит в потоке данных.
После определения потока данных в проекте его можно добавить в рабочий процесс или задание ETL. Поток данных может отправлять или получать объекты / информацию, используя параметры. Поток данных назван в формате DF_Name .

Пример потока данных
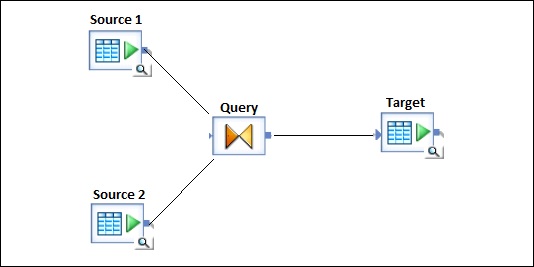
Предположим, что вы хотите загрузить таблицу фактов в систему DW с данными из двух таблиц в исходной системе.
Поток данных содержит следующие объекты —
- Таблица с двумя источниками
- Соединение между двумя таблицами и определено в преобразовании запроса
- Целевой стол
Существует три типа объектов, которые можно добавить в поток данных. Они —
- Источник
- цель
- Трансформации
Шаг 1 — Перейдите в Локальную библиотеку объектов и перетащите обе таблицы в рабочее пространство.
Шаг 2. Чтобы добавить преобразование запроса, перетащите курсор с правой панели инструментов.
Шаг 3 — Соедините обе таблицы и создайте целевую таблицу шаблонов, щелкнув правой кнопкой мыши поле Запрос → Добавить новый → Новая таблица шаблонов.
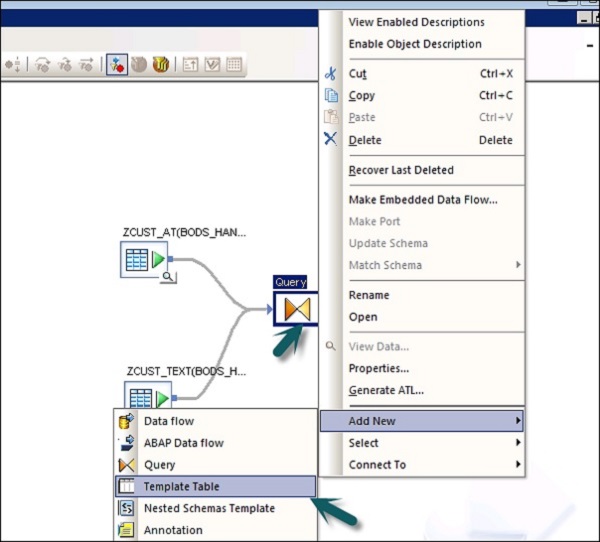
Шаг 4 — Введите имя целевой таблицы, имя хранилища данных и владельца (имя схемы), под которым должна быть создана таблица.
Шаг 5 — Перетащите целевой стол вперед и присоедините его к преобразованию запроса.
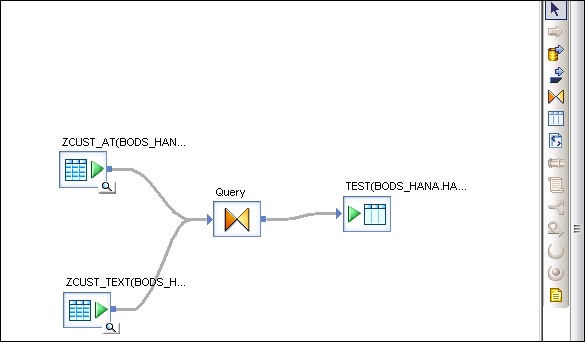
Передача параметров
Вы также можете передавать различные параметры в и из потока данных. При передаче параметра в поток данных объекты в потоке данных ссылаются на эти параметры. Используя параметры, вы можете передавать различные операции потоку данных.
Пример. Предположим, вы ввели параметр в таблицу с последним обновлением. Позволяет извлечь только те строки, которые были изменены с момента последнего обновления.
SAP BODS — Свойства изменения потока данных
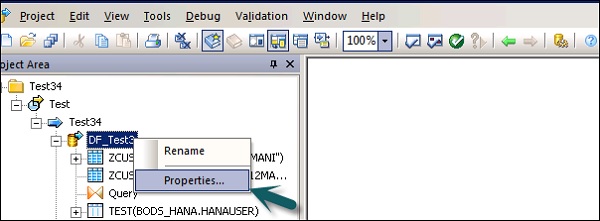
Вы можете изменить свойства потока данных, такие как «Выполнить один раз», тип кэша, ссылку на базу данных, параллелизм и т. Д.
Шаг 1 — Чтобы изменить свойства потока данных, щелкните правой кнопкой мыши Поток данных → Свойства
Вы можете установить различные свойства для потока данных. Свойства приведены ниже.
| Старший | Свойства и описание |
|---|---|
| 1 |
Выполнить только один раз Когда вы указываете, что поток данных должен выполняться только один раз, пакетное задание никогда не будет повторно выполнять этот поток данных после того, как поток данных завершится успешно, за исключением случаев, когда поток данных содержится в рабочем потоке, который является модулем восстановления, который повторно выполняет и не был успешно завершен в другом месте за пределами блока восстановления. Рекомендуется не отмечать поток данных как выполненный только один раз, если родительский рабочий поток является единицей восстановления. |
| 2 |
Используйте ссылки на базу данных Ссылки на базу данных — это пути связи между одним сервером базы данных и другим. Ссылки на базы данных позволяют локальным пользователям получать доступ к данным в удаленной базе данных, которая может находиться на локальном или удаленном компьютере с той же или другой базой данных. |
| 3 |
Степень параллелизма Степень параллелизма (DOP) — это свойство потока данных, которое определяет, сколько раз каждое преобразование в потоке данных реплицируется для обработки параллельного подмножества данных. |
| 4 |
Тип кеша Вы можете кэшировать данные для повышения производительности операций, таких как объединения, группы, сортировки, фильтрация, поиск и сравнение таблиц. Вы можете выбрать одно из следующих значений для параметра Тип кэша в окне Свойства потока данных —
|
Выполнить только один раз
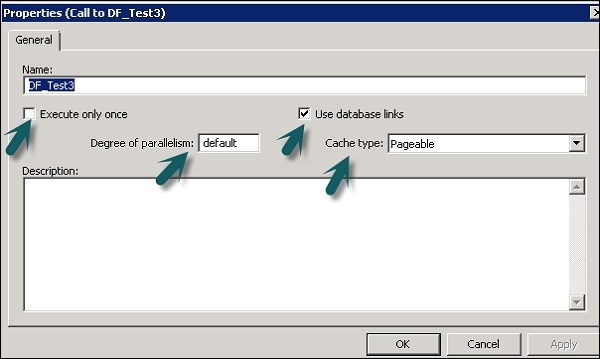
Когда вы указываете, что поток данных должен выполняться только один раз, пакетное задание никогда не будет повторно выполнять этот поток данных после того, как поток данных завершится успешно, за исключением случаев, когда поток данных содержится в рабочем потоке, который является модулем восстановления, который повторно выполняет и не был успешно завершен в другом месте за пределами блока восстановления. Рекомендуется не отмечать поток данных как выполненный только один раз, если родительский рабочий поток является единицей восстановления.
Используйте ссылки на базу данных
Ссылки на базу данных — это пути связи между одним сервером базы данных и другим. Ссылки на базы данных позволяют локальным пользователям получать доступ к данным в удаленной базе данных, которая может находиться на локальном или удаленном компьютере с той же или другой базой данных.
Степень параллелизма
Степень параллелизма (DOP) — это свойство потока данных, которое определяет, сколько раз каждое преобразование в потоке данных реплицируется для обработки параллельного подмножества данных.
Тип кеша
Вы можете кэшировать данные для повышения производительности операций, таких как объединения, группы, сортировки, фильтрация, поиск и сравнение таблиц. Вы можете выбрать одно из следующих значений для параметра Тип кэша в окне Свойства потока данных —
В памяти — выберите это значение, если поток данных обрабатывает небольшой объем данных, который может поместиться в доступной памяти.
Pageable — это значение по умолчанию.
Шаг 2 — Измените свойства, такие как Выполнить только один раз, Степень параллелизма и Типы кэша.
Исходные и целевые объекты
Поток данных может извлекать или загружать данные напрямую, используя следующие объекты:
-
Исходные объекты — Исходные объекты определяют источник, из которого извлекаются данные или вы читаете данные.
-
Целевые объекты — Target Objects определяет цель, в которую вы загружаете или записываете данные.
Исходные объекты — Исходные объекты определяют источник, из которого извлекаются данные или вы читаете данные.
Целевые объекты — Target Objects определяет цель, в которую вы загружаете или записываете данные.
Можно использовать следующий тип исходного объекта и использовать разные методы доступа для исходных объектов.
| Таблица | Файл в формате столбцов и строк, используемый в реляционных базах данных. | Прямой или через адаптер |
| Шаблон таблицы | Таблица шаблонов, которая была создана и сохранена в другом потоке данных (используется в разработке) | непосредственный |
| файл | Плоский файл с разделителями или фиксированной ширины | непосредственный |
| Документ | Файл с форматом приложения (не читается анализатором SQL или XML) | Через адаптер |
| XML-файл | Файл, отформатированный с помощью тегов XML | непосредственный |
| XML сообщение | Используется как источник работы в реальном времени | непосредственный |
Можно использовать следующие целевые объекты и применять другой метод доступа.
| Таблица | Файл в формате столбцов и строк, используемый в реляционных базах данных. | Прямой или через адаптер |
| Шаблон таблицы | Таблица, формат которой основан на выводе предыдущего преобразования (используется в разработке) | непосредственный |
| файл | Плоский файл с разделителями или фиксированной ширины | непосредственный |
| Документ | Файл с форматом приложения (не читается анализатором SQL или XML) | Через адаптер |
| XML-файл | Файл, отформатированный с помощью тегов XML | непосредственный |
| Файл шаблона XML | Файл XML, формат которого основан на предыдущем выводе преобразования (используется при разработке, главным образом для отладки потоков данных) | непосредственный |
SAP BODS — Введение в рабочий процесс
Рабочие процессы используются для определения процесса выполнения. Основная цель рабочего процесса — подготовиться к выполнению потоков данных и установить состояние системы после завершения выполнения потока данных.
Пакетные задания в проектах ETL аналогичны рабочим процессам, с той лишь разницей, что задание не имеет параметров.
Различные объекты могут быть добавлены в рабочий процесс. Они —
- Рабочий процесс
- Поток данных
- Сценарии
- Loops
- условия
- Попробуйте или поймать блоки
Вы также можете сделать вызов рабочего потока другим рабочим потоком, или рабочий поток может вызвать сам себя.
Примечание. В рабочем процессе шаги выполняются в последовательности слева направо.
Пример рабочего процесса
Предположим, есть таблица фактов, которую вы хотите обновить, и вы создали поток данных с преобразованием. Теперь, если вы хотите переместить данные из исходной системы, вы должны проверить последнюю модификацию таблицы фактов, чтобы извлечь только те строки, которые были добавлены после последнего обновления.
Для этого необходимо создать один сценарий, который определяет дату последнего обновления, а затем передать его в качестве входного параметра потоку данных.
Вы также должны проверить, активно или нет соединение данных с конкретной таблицей фактов. Если он не активен, вам нужно установить блок перехвата, который автоматически отправляет электронное письмо администратору, чтобы уведомить об этой проблеме.
SAP BODS — Создание рабочих процессов
Рабочие процессы могут быть созданы с использованием следующих методов —
- Библиотека объектов
- Палитра инструментов
Создание рабочего процесса с использованием библиотеки объектов
Чтобы создать рабочий процесс с использованием библиотеки объектов, выполните следующие действия.
Шаг 1 — Перейдите на вкладку «Библиотека объектов» → «Рабочий процесс».
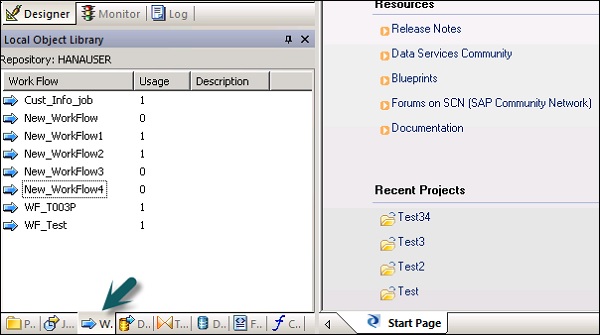
Шаг 2 — Щелкните правой кнопкой мыши по опции Новый .
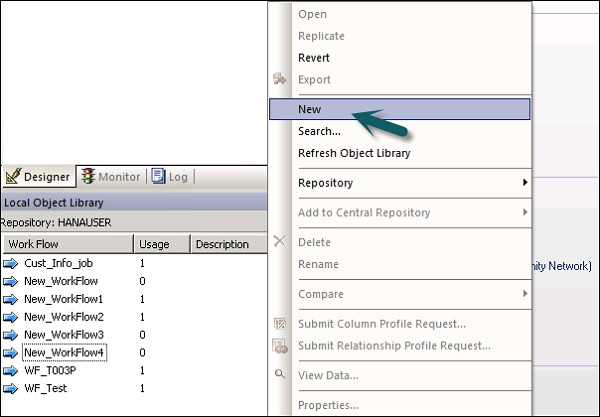
Шаг 3 — Введите имя рабочего процесса.
Создание рабочего процесса с использованием палитры инструментов
Чтобы создать рабочий процесс с использованием палитры инструментов, щелкните значок с правой стороны и перетащите рабочий процесс в рабочее пространство.
Вы также можете настроить выполнение рабочего процесса только один раз, перейдя в свойства рабочего процесса.
Conditionals
Вы также можете добавить условные выражения в рабочий процесс. Это позволяет вам реализовать логику If / Else / Then в рабочих процессах.
| Sr.No. | Условное и описание |
|---|---|
| 1 |
Если Булево выражение, которое оценивается как ИСТИНА или ЛОЖЬ. Вы можете использовать функции, переменные и стандартные операторы для построения выражения. |
| 2 |
затем Элементы рабочего потока для выполнения, если выражение If имеет значение TRUE. |
| 3 |
еще (Необязательно) Элементы рабочего потока для выполнения, если выражение If имеет значение FALSE. |
Если
Булево выражение, которое оценивается как ИСТИНА или ЛОЖЬ. Вы можете использовать функции, переменные и стандартные операторы для построения выражения.
затем
Элементы рабочего потока для выполнения, если выражение If имеет значение TRUE.
еще
(Необязательно) Элементы рабочего потока для выполнения, если выражение If имеет значение FALSE.
Чтобы определить условное
Шаг 1 — Перейдите в Рабочий процесс → Щелкните значок Условие на палитре инструментов с правой стороны.
![]()
Шаг 2 — Дважды щелкните имя Условного, чтобы открыть условный редактор If-Then – Else .
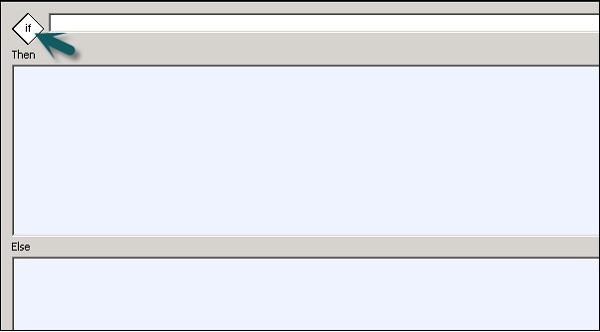
Шаг 3 — Введите логическое выражение, управляющее условием. Нажмите ОК.
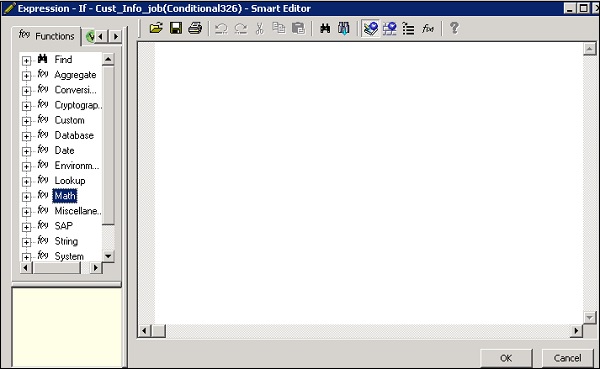
Шаг 4 — Перетащите поток данных, который вы хотите выполнить, в окно « Тогда и остальное» согласно выражению в условии IF.
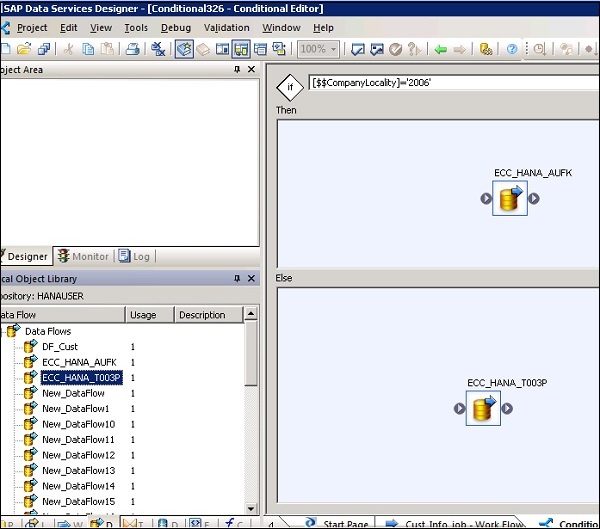
После выполнения условия вы можете отладить и проверить условие.
SAP BODS — типы преобразований
Преобразования используются для управления наборами данных в качестве входов и создания одного или нескольких выходов. Существуют различные преобразования, которые можно использовать в службах данных. Тип трансформации зависит от версии и приобретенного продукта.
Доступны следующие типы трансформаций —
Интеграция данных
Преобразования Data Integration используются для извлечения, преобразования и загрузки данных в систему DW. Это обеспечивает целостность данных и повышает производительность труда разработчиков.
- Data_Generator
- Обмен данными
- Дата вступления в силу
- Hierarchy_flattening
- Таблица сравнения, и т. Д.
Качество данных
Преобразования качества данных используются для улучшения качества данных. Вы можете применять синтаксический анализ, корректировать, стандартизировать, обогащать набор данных из исходной системы.
- ассоциированный
- Очистка данных
- DSF2 Walk Sequencer и т. Д.
Платформа
Платформа используется для перемещения набора данных. Используя это, вы можете генерировать, отображать и объединять строки из двух или более источников данных.
- случай
- сливаться
- Запрос и т. Д.
Обработка текстовых данных
Обработка текстовых данных позволяет обрабатывать большой объем текстовых данных.
SAP BODS — Добавление преобразования в поток данных
В этой главе вы увидите, как добавить Transform в поток данных.
Шаг 1 — Перейдите в Библиотеку объектов → вкладка «Преобразование».
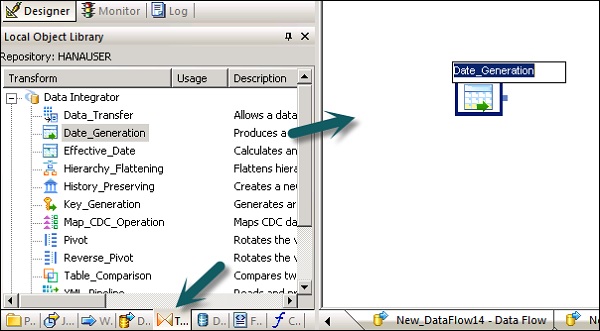
Шаг 2 — Выберите преобразование, которое вы хотите добавить в поток данных. Если вы добавите преобразование с возможностью выбора конфигурации, откроется приглашение.
Шаг 3 — Нарисуйте соединение потока данных, чтобы соединить источник с преобразованием.
Шаг 4 — Дважды щелкните имя Преобразования, чтобы открыть редактор преобразований.
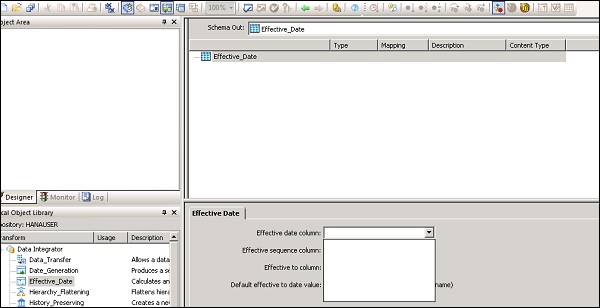
После завершения определения нажмите кнопку ОК, чтобы закрыть редактор.
SAP BODS — преобразование запросов
Это наиболее распространенное преобразование, используемое в службах данных, и вы можете выполнять следующие функции:
- Фильтрация данных из источников
- Объединение данных из нескольких источников
- Выполнять функции и преобразования данных
- Отображение столбцов из входных в выходные схемы
- Назначение первичных ключей
- Добавить новые столбцы, схемы и функции, приведенные к выходным схемам
Поскольку преобразование запроса является наиболее часто используемым преобразованием, для этого запроса предоставляется ярлык в палитре инструментов.
Чтобы добавить преобразование запроса, выполните следующие действия:
Шаг 1 — Щелкните палитру инструментов преобразования запросов. Щелкните в любом месте рабочего пространства потока данных. Подключите это к входам и выходам.

Если дважды щелкнуть значок преобразования запроса, откроется редактор запросов, который используется для выполнения операций запроса.
В преобразовании запроса присутствуют следующие области:
- Схема ввода
- Схема вывода
- параметры
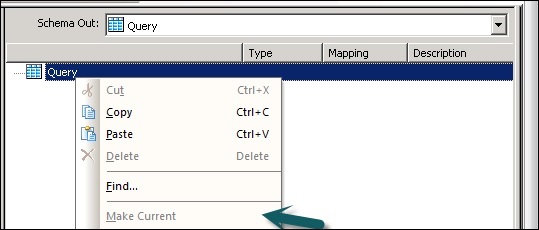
Схемы ввода и вывода содержат столбцы, вложенные схемы и функции. Schema In и Schema Out отображают текущую выбранную схему в преобразовании.
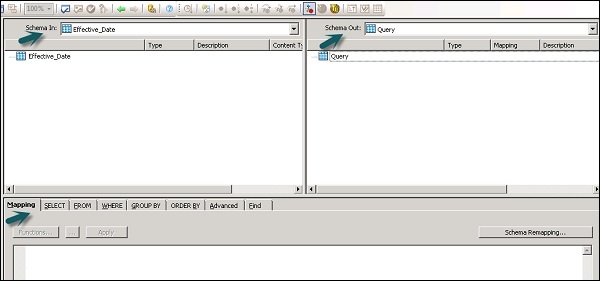
Чтобы изменить схему вывода, выберите схему в списке, щелкните правой кнопкой мыши и выберите «Сделать текущим».
Преобразование качества данных
Преобразования качества данных не могут быть напрямую связаны с восходящим преобразованием, которое содержит вложенные таблицы. Чтобы соединить эти преобразования, необходимо добавить преобразование запроса или преобразование конвейера XML между преобразованием из вложенной таблицы и преобразованием качества данных.
Как использовать преобразование качества данных?
Шаг 1 — Перейдите в Библиотеку объектов → вкладка «Преобразование»
Шаг 2. Разверните преобразование «Качество данных» и добавьте преобразование или конфигурацию преобразования, которую вы хотите добавить в поток данных.
Шаг 3 — Нарисуйте соединения потока данных. Дважды щелкните имя преобразования, откроется редактор преобразования. Во входной схеме выберите поля ввода, которые вы хотите отобразить.
Примечание. Для использования Associate Transform вы можете добавить пользовательские поля на вкладку ввода.
Преобразование обработки текстовых данных
Преобразование обработки текстовых данных позволяет извлекать конкретную информацию из большого объема текста. Вы можете искать факты и сущности, такие как клиенты, продукты и финансовые факты, специфичные для организации.
Это преобразование также проверяет отношения между сущностями и позволяет извлекать. Извлеченные данные с использованием обработки текстовых данных можно использовать в бизнес-аналитике, отчетности, запросах и аналитике.
Преобразование извлечения сущностей
В Data Services обработка текстовых данных осуществляется с помощью Entity Extraction, которая извлекает сущности и факты из неструктурированных данных.
Это включает анализ и обработку большого объема текстовых данных, поиск объектов, присвоение им соответствующего типа и представление метаданных в стандартном формате.
Преобразование Entity Extraction может извлекать информацию из любого текста, HTML, XML или определенного содержимого в двоичном формате (например, PDF) и генерировать структурированный вывод. Вы можете использовать вывод несколькими способами в зависимости от вашего рабочего процесса. Вы можете использовать его в качестве входных данных для другого преобразования или записи в несколько выходных источников, таких как таблица базы данных или плоский файл. Выход генерируется в кодировке UTF-16.
Entity Extract Transform можно использовать в следующих сценариях —
-
Поиск конкретной информации из большого объема текста.
-
Поиск структурированной информации из неструктурированного текста с существующей информацией для установления новых связей.
-
Отчетность и анализ качества продукции.
Поиск конкретной информации из большого объема текста.
Поиск структурированной информации из неструктурированного текста с существующей информацией для установления новых связей.
Отчетность и анализ качества продукции.
Различия между TDP и очисткой данных
Обработка текстовых данных используется для поиска соответствующей информации из неструктурированных текстовых данных. Однако очистка данных используется для стандартизации и очистки структурированных данных.
| параметры | Обработка текстовых данных | Очистка данных |
|---|---|---|
| Тип ввода | Неструктурированные данные | Структурированные данные |
| Размер входа | Более 5КБ | Менее чем 5 КБ |
| Область ввода | Широкий домен с множеством вариаций | Ограниченные вариации |
| Потенциальное использование | Потенциально значимая информация из неструктурированных данных | Качество данных для хранения в репозитории |
| Выход | Создание аннотаций в виде объектов, типов и т. Д. Ввод не изменяется | Создать стандартизированные поля, Ввод изменен |
SAP BODS — Обзор служб данных
Администрирование служб данных включает создание заданий в реальном времени и пакетных заданий, планирование заданий, встроенный поток данных, переменные и параметры, механизм восстановления, профилирование данных, настройку производительности и т. Д.
Работа в реальном времени
Вы можете создавать задания в реальном времени для обработки сообщений в реальном времени в конструкторе служб данных. Как пакетное задание, задание в реальном времени извлекает данные, преобразует и загружает их.
Каждое задание в реальном времени может извлекать данные из одного сообщения. Вы также можете извлечь данные из других источников, таких как таблицы или файлы.
Задания в реальном времени не выполняются с помощью триггеров в отличие от пакетных заданий. Они выполняются администраторами в режиме реального времени. Службы реального времени ждут сообщений от сервера доступа. Сервер доступа получает это сообщение и передает его службам реального времени, которые настроены на обработку типа сообщения. Службы реального времени выполняют сообщение, возвращают результат и продолжают обрабатывать сообщения, пока не получат инструкцию прекратить выполнение.
Real Time vs Batch Jobs
Преобразования, такие как ветви и логика управления, чаще используются в работе в реальном времени, что не относится к пакетным заданиям в конструкторе.
Задания в реальном времени не выполняются в ответ на расписание или внутренний триггер в отличие от пакетных заданий.
Создание рабочих мест в реальном времени
Задания в реальном времени могут быть созданы с использованием таких же объектов, как потоки данных, рабочие потоки, циклы, условные выражения, сценарии и т. Д.
Вы можете использовать следующие модели данных для создания рабочих мест в реальном времени —
- Модель единого потока данных
- Модель с несколькими потоками данных
Модель единого потока данных
Вы можете создать задание в реальном времени с одним потоком данных в его цикле обработки в реальном времени, которое включает в себя один источник сообщения и одну цель сообщения.
Создание работы в реальном времени с использованием единой модели данных —
Чтобы создать работу в реальном времени с использованием единой модели данных, выполните указанные шаги.
Шаг 1 — Перейдите в Дизайнер служб данных → Проект новый → Проект → Введите имя проекта
Шаг 2 — Щелкните правой кнопкой мыши пустое пространство в области проекта → Новая работа в реальном времени.

Рабочая область показывает две составляющие работы в реальном времени —
- RT_Process_begins
- Step_ends
Он показывает начало и конец работы в реальном времени.
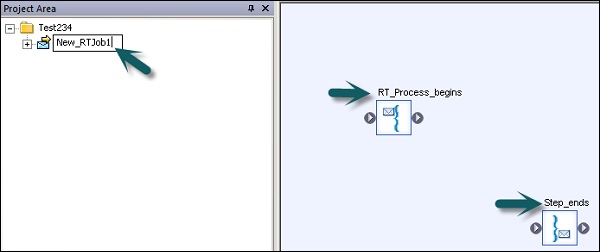
Шаг 3 — Чтобы создать задание в реальном времени с одним потоком данных, выберите поток данных из палитры инструментов на правой панели и перетащите его в рабочее пространство.
Щелкните внутри цикла, вы можете использовать один источник сообщения и одну цель сообщения в цикле обработки в реальном времени. Подключите начальную и конечную метки к потоку данных.
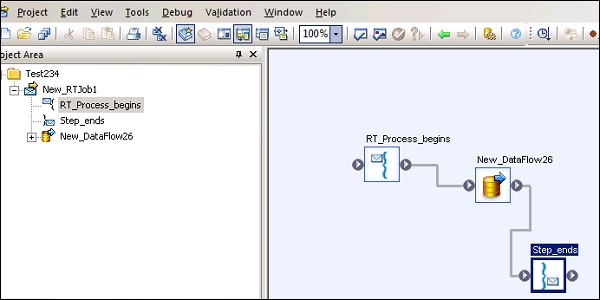
Шаг 4 — Добавьте необходимые объекты конфигурации в поток данных и сохраните задание.
Модель с несколькими потоками данных
Это позволяет создавать задания в реальном времени с несколькими потоками данных в цикле обработки в реальном времени. Также необходимо убедиться, что данные в каждой модели данных полностью обработаны, прежде чем они перейдут к следующему сообщению.
Тестирование в реальном времени
Вы можете проверить работу в реальном времени, передав образец сообщения в виде исходного сообщения из файла. Вы можете проверить, генерируют ли службы данных ожидаемое целевое сообщение.
Чтобы ваша работа дала ожидаемый результат, вы можете выполнить ее в режиме просмотра данных. Используя этот режим, вы можете захватывать выходные данные, чтобы убедиться, что ваша работа в реальном времени работает нормально.
Встроенные потоки данных
Встроенный поток данных известен как потоки данных, которые вызываются из другого потока данных в проекте. Внедренный поток данных может содержать несколько номеров источника и целей, но только один входной или выходной поток данных в основной поток данных.
Можно использовать следующие типы встроенных потоков данных:
-
Один вход — встроенный поток данных добавляется в конце потока данных.
-
Один выход — встроенный поток данных добавляется в начале потока данных.
-
Нет ввода или вывода — репликация существующего потока данных.
Один вход — встроенный поток данных добавляется в конце потока данных.
Один выход — встроенный поток данных добавляется в начале потока данных.
Нет ввода или вывода — репликация существующего потока данных.
Встроенный поток данных может использоваться для следующих целей —
-
Для упрощения отображения потока данных.
-
Если вы хотите сохранить логику потока и повторно использовать ее в других потоках данных.
-
Для отладки, при которой вы создаете разделы потока данных как встроенный поток данных и выполняете их отдельно.
Для упрощения отображения потока данных.
Если вы хотите сохранить логику потока и повторно использовать ее в других потоках данных.
Для отладки, при которой вы создаете разделы потока данных как встроенный поток данных и выполняете их отдельно.
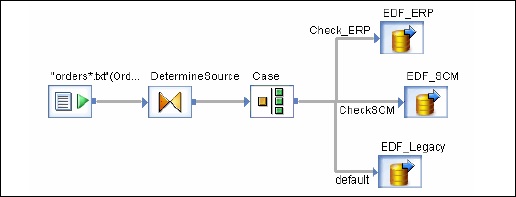
SAP BODS — Создание встроенного потока данных
Вы можете выбрать объект в существующем потоке данных. Существует два способа создания встроенного потока данных.
Опция 1
Щелкните правой кнопкой мыши по объекту и выберите, чтобы сделать его встроенным потоком данных.
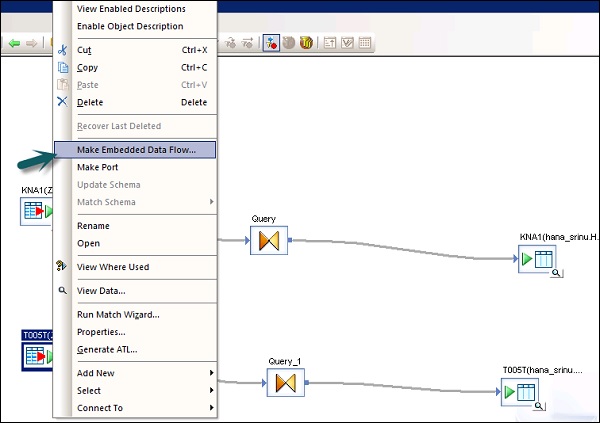
Вариант 2
Перетащите полный и проверенный поток данных из библиотеки объектов в открытый поток данных в рабочей области. Далее откройте созданный поток данных. Выберите объект, который вы хотите использовать в качестве порта ввода и вывода, и нажмите make port для этого объекта.
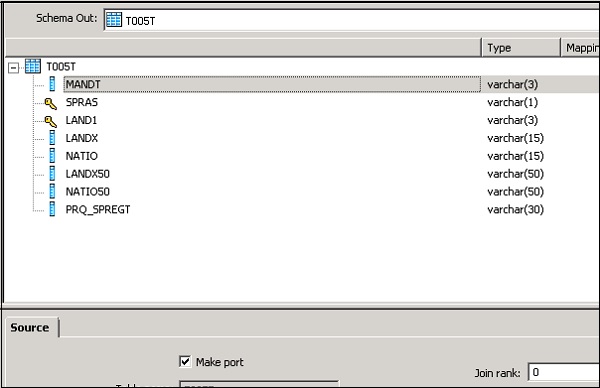
Службы данных добавляют этот объект в качестве точки подключения для встроенного потока данных.
Переменные и параметры
Вы можете использовать локальные и глобальные переменные с потоком данных и рабочим потоком, что обеспечивает большую гибкость при проектировании заданий.
Ключевые особенности —
-
Тип данных переменной может быть числом, целым числом, десятичным числом, датой или текстовой строкой, подобной символу.
-
Переменные могут использоваться в потоках данных и рабочих потоках как функция в предложении Where .
-
Локальные переменные в службах данных ограничены объектом, в котором они созданы.
-
Глобальные переменные ограничены заданиями, в которых они созданы. Используя глобальные переменные, вы можете изменить значения глобальных переменных по умолчанию во время выполнения.
-
Выражения, которые используются в рабочем процессе и потоке данных, называются параметрами .
-
Все переменные и параметры в рабочем потоке и потоках данных отображаются в окне переменных и параметров.
Тип данных переменной может быть числом, целым числом, десятичным числом, датой или текстовой строкой, подобной символу.
Переменные могут использоваться в потоках данных и рабочих потоках как функция в предложении Where .
Локальные переменные в службах данных ограничены объектом, в котором они созданы.
Глобальные переменные ограничены заданиями, в которых они созданы. Используя глобальные переменные, вы можете изменить значения глобальных переменных по умолчанию во время выполнения.
Выражения, которые используются в рабочем процессе и потоке данных, называются параметрами .
Все переменные и параметры в рабочем потоке и потоках данных отображаются в окне переменных и параметров.
Чтобы просмотреть переменные и параметры, выполните следующие действия:
Перейдите в Инструменты → Переменные.
Новое окно Переменные и параметры отображается. Он имеет две вкладки — Определения и Звонки.
Вкладка « Определения » позволяет создавать и просматривать переменные и параметры. Вы можете использовать локальные переменные и параметры на рабочем потоке и уровне потока данных. Глобальные переменные могут использоваться на уровне работы.
|
работа |
Локальные переменные Глобальные переменные |
Сценарий или условный в работе Любой объект в работе |
|
Рабочий процесс |
Локальные переменные параметры |
Этот рабочий поток или передается другим рабочим потокам или потокам данных с помощью параметра. Родительские объекты для передачи локальных переменных. Рабочие процессы могут также возвращать переменные или параметры родительским объектам. |
|
Поток данных |
параметры |
Предложение WHERE, сопоставление столбцов или функция в потоке данных. Поток данных. Потоки данных не могут возвращать выходные значения. |
работа
Локальные переменные
Глобальные переменные
Сценарий или условный в работе
Любой объект в работе
Рабочий процесс
Локальные переменные
параметры
Этот рабочий поток или передается другим рабочим потокам или потокам данных с помощью параметра.
Родительские объекты для передачи локальных переменных. Рабочие процессы могут также возвращать переменные или параметры родительским объектам.
Поток данных
параметры
Предложение WHERE, сопоставление столбцов или функция в потоке данных. Поток данных. Потоки данных не могут возвращать выходные значения.
На вкладке вызова вы можете увидеть имя параметра, определенного для всех объектов в определении родительского объекта.
Определение локальной переменной
Чтобы определить локальную переменную, откройте работу в реальном времени.
Шаг 1 — Перейдите в Инструменты → Переменные. Откроется новое окно переменных и параметров .
Шаг 2 — Перейдите в Переменную → Щелкните правой кнопкой мыши → Вставить
Это создаст новый параметр $ NewVariable0 .
Шаг 3 — Введите имя новой переменной. Выберите тип данных из списка.
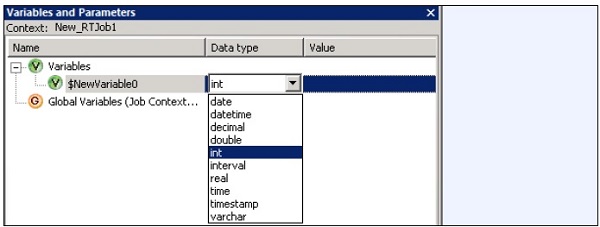
Как только это определено, закройте окно. Аналогичным образом вы можете определить параметры для потока данных и рабочего потока.
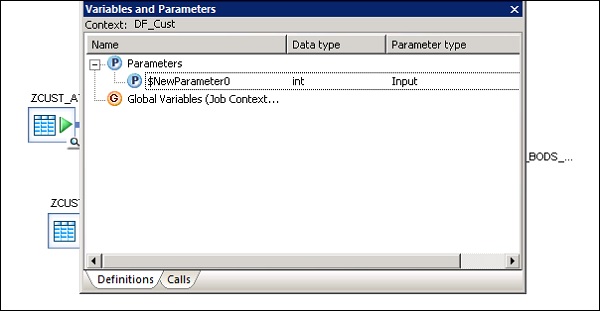
Механизм отладки и восстановления
Если ваша работа не выполняется успешно, вы должны исправить ошибку и перезапустить работу. В случае неудачных заданий существует вероятность того, что некоторые таблицы были загружены, изменены или частично загружены. Вам необходимо повторно выполнить задание, чтобы получить все данные и удалить дубликаты или отсутствующие данные.
Два метода, которые могут быть использованы для восстановления, следующие:
-
Автоматическое восстановление — позволяет запускать неудачные задания в режиме восстановления.
-
Восстановление вручную — это позволяет вам повторно запускать задания без частичного повторного запуска в прошлый раз.
Автоматическое восстановление — позволяет запускать неудачные задания в режиме восстановления.
Восстановление вручную — это позволяет вам повторно запускать задания без частичного повторного запуска в прошлый раз.
Чтобы запустить задание с включенной опцией восстановления в Designer
Шаг 1 — Щелкните правой кнопкой мыши на имени задания → Выполнить.
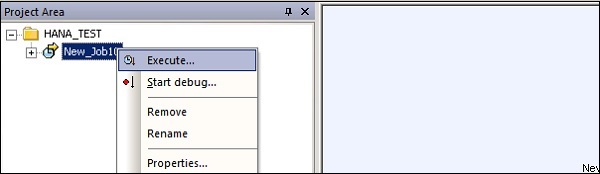
Шаг 2 — Сохранить все изменения и выполнить → Да.
Шаг 3 — Перейдите на вкладку Выполнение → Включить восстановление. Если этот флажок не установлен, Службы данных не восстановят задание, если оно не выполнится.

Чтобы запустить задание в режиме восстановления из Designer
Шаг 1 — Щелкните правой кнопкой мыши и выполните задание, как указано выше. Сохранить изменения.
Шаг 2 — Перейдите в Параметры выполнения. Вы должны убедиться, что установлен флажок Восстановить из последнего неудачного выполнения .
Примечание. Этот параметр отключен, если задание еще не выполнено. Это называется автоматическим восстановлением невыполненной работы.
Оценка данных и профилирование данных
Data Services Designer предоставляет функцию Data Profiling для обеспечения и улучшения качества и структуры исходных данных.
Data Profiler позволяет вам —
-
Найти аномалии в исходных данных, валидации и корректирующие действия и качество исходных данных.
-
Определите структуру и взаимосвязь исходных данных для лучшего выполнения заданий, рабочих потоков и потоков данных.
-
Найдите содержимое исходной и целевой систем, чтобы определить, что ваша работа возвращает ожидаемый результат.
Найти аномалии в исходных данных, валидации и корректирующие действия и качество исходных данных.
Определите структуру и взаимосвязь исходных данных для лучшего выполнения заданий, рабочих потоков и потоков данных.
Найдите содержимое исходной и целевой систем, чтобы определить, что ваша работа возвращает ожидаемый результат.
Data Profiler предоставляет следующую информацию о работе сервера Profiler —
Анализ столбца
-
Базовое профилирование — включает в себя информацию, такую как минимальное, максимальное, среднее и т. Д.
-
Подробное профилирование — включает в себя информацию, такую как различное количество, различный процент, медиана и т. Д.
Базовое профилирование — включает в себя информацию, такую как минимальное, максимальное, среднее и т. Д.
Подробное профилирование — включает в себя информацию, такую как различное количество, различный процент, медиана и т. Д.
Анализ отношений
-
Аномалии данных между двумя столбцами, для которых вы определяете отношения.
Аномалии данных между двумя столбцами, для которых вы определяете отношения.
Функция профилирования данных может использоваться для данных из следующих источников данных:
- SQL Server
- оракул
- DB2
- Соединитель Attunity
- Sybase IQ
- Teradata
Подключение к серверу Profiler
Для подключения к серверу профилей —
Шаг 1 — Перейдите в Инструменты → Профилировщик
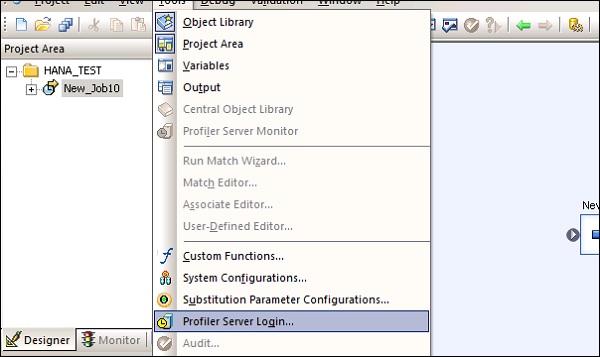
Шаг 2 — Введите данные, такие как Система, Имя пользователя, Пароль и Аутентификация.
Шаг 3 — Нажмите кнопку Вход в систему .
Когда вы подключены, отобразится список репозиториев профилировщика. Выберите репозиторий и нажмите « Подключиться» .
SAP BODS — методы настройки
Производительность задания ETL зависит от системы, в которой вы используете программное обеспечение Data Services, количества ходов и т. Д.
Существуют и другие факторы, влияющие на производительность в задаче ETL. Они —
-
База данных источника — База данных источника должна быть настроена для быстрого выполнения операторов выбора . Это можно сделать, увеличив размер ввода-вывода базы данных, увеличив размер разделяемого буфера для кэширования большего количества данных и не допуская параллельной обработки для небольших таблиц и т. Д.
-
Исходная операционная система — Исходная операционная система должна быть настроена на быстрое считывание данных с дисков. Установите протокол чтения вперед на 64 КБ.
-
Целевая база данных. Целевая база данных должна быть настроена для быстрого выполнения операций INSERT и UPDATE . Это может быть сделано с помощью —
- Отключение архивирования журнала.
- Отключение журнала повторов для всех таблиц.
- Максимизация размера общего буфера.
-
Целевая операционная система — Целевая операционная система должна быть настроена для быстрой записи данных на диски. Вы можете включить асинхронный ввод-вывод, чтобы сделать операции ввода / вывода максимально быстрыми.
-
Сеть — пропускной способности сети должно быть достаточно для передачи данных из источника в целевую систему.
-
База данных репозитория BODS. Для повышения производительности заданий BODS можно выполнить следующее:
-
Контролировать частоту дискретизации — если вы обрабатываете большой объем данных, заданных в задании ETL, отрегулируйте частоту дискретизации до более высокого значения, чтобы уменьшить количество вызовов ввода-вывода для файла журнала, тем самым повышая производительность.
-
Вы также можете исключить журналы служб данных из проверки на вирусы, если на сервере заданий настроена проверка на вирусы, так как это может привести к снижению производительности
-
-
ОС сервера заданий — в службах данных один поток данных в задании инициирует один процесс ‘al_engine’ , который инициирует четыре потока. Для максимальной производительности рассмотрим проект, который запускает один процесс al_engine на процессор одновременно. ОС сервера заданий должна быть настроена таким образом, чтобы все потоки распределялись по всем доступным процессорам.
База данных источника — База данных источника должна быть настроена для быстрого выполнения операторов выбора . Это можно сделать, увеличив размер ввода-вывода базы данных, увеличив размер разделяемого буфера для кэширования большего количества данных и не допуская параллельной обработки для небольших таблиц и т. Д.
Исходная операционная система — Исходная операционная система должна быть настроена на быстрое считывание данных с дисков. Установите протокол чтения вперед на 64 КБ.
Целевая база данных. Целевая база данных должна быть настроена для быстрого выполнения операций INSERT и UPDATE . Это может быть сделано с помощью —
Целевая операционная система — Целевая операционная система должна быть настроена для быстрой записи данных на диски. Вы можете включить асинхронный ввод-вывод, чтобы сделать операции ввода / вывода максимально быстрыми.
Сеть — пропускной способности сети должно быть достаточно для передачи данных из источника в целевую систему.
База данных репозитория BODS. Для повышения производительности заданий BODS можно выполнить следующее:
Контролировать частоту дискретизации — если вы обрабатываете большой объем данных, заданных в задании ETL, отрегулируйте частоту дискретизации до более высокого значения, чтобы уменьшить количество вызовов ввода-вывода для файла журнала, тем самым повышая производительность.
Вы также можете исключить журналы служб данных из проверки на вирусы, если на сервере заданий настроена проверка на вирусы, так как это может привести к снижению производительности
ОС сервера заданий — в службах данных один поток данных в задании инициирует один процесс ‘al_engine’ , который инициирует четыре потока. Для максимальной производительности рассмотрим проект, который запускает один процесс al_engine на процессор одновременно. ОС сервера заданий должна быть настроена таким образом, чтобы все потоки распределялись по всем доступным процессорам.
SAP BODS — центральный или локальный репозиторий
SAP BO Data Services поддерживают многопользовательскую разработку, где каждый пользователь может работать с приложением в своем локальном хранилище. Каждая группа использует центральный репозиторий для сохранения основной копии приложения и всех версий объектов в приложении.
Ключевые особенности —
-
В SAP Data Services вы можете создать центральное хранилище для хранения коллективной копии приложения. Он содержит всю информацию, которая также доступна в локальном хранилище. Тем не менее, он просто обеспечивает место для хранения информации об объекте. Чтобы внести какие-либо изменения, вам нужно работать в локальном хранилище.
-
Вы можете копировать объекты из центрального хранилища в локальное хранилище. Однако, если вам нужно внести какие-либо изменения, вам нужно проверить этот объект в центральном хранилище. Из-за этого другие пользователи не могут извлекать этот объект в центральном хранилище и, следовательно, они не могут вносить изменения в тот же объект.
-
После того, как вы внесете изменения в объект, вам необходимо зарегистрироваться на него. Это позволяет Data Services сохранять новый измененный объект в центральном хранилище.
-
Службы данных позволяют нескольким пользователям с локальными репозиториями одновременно подключаться к центральному репозиторию, но только один пользователь может извлекать и вносить изменения в конкретный объект.
-
Центральный репозиторий также поддерживает историю каждого объекта. Это позволяет вам вернуться к предыдущей версии объекта, если изменения не приводят к необходимости.
В SAP Data Services вы можете создать центральное хранилище для хранения коллективной копии приложения. Он содержит всю информацию, которая также доступна в локальном хранилище. Тем не менее, он просто обеспечивает место для хранения информации об объекте. Чтобы внести какие-либо изменения, вам нужно работать в локальном хранилище.
Вы можете копировать объекты из центрального хранилища в локальное хранилище. Однако, если вам нужно внести какие-либо изменения, вам нужно проверить этот объект в центральном хранилище. Из-за этого другие пользователи не могут извлекать этот объект в центральном хранилище и, следовательно, они не могут вносить изменения в тот же объект.
После того, как вы внесете изменения в объект, вам необходимо зарегистрироваться на него. Это позволяет Data Services сохранять новый измененный объект в центральном хранилище.
Службы данных позволяют нескольким пользователям с локальными репозиториями одновременно подключаться к центральному репозиторию, но только один пользователь может извлекать и вносить изменения в конкретный объект.
Центральный репозиторий также поддерживает историю каждого объекта. Это позволяет вам вернуться к предыдущей версии объекта, если изменения не приводят к необходимости.
Несколько пользователей
Службы данных SAP BO позволяют нескольким пользователям одновременно работать над одним приложением. Следующие термины должны рассматриваться в многопользовательской среде —
| Sr.No. | Многопользовательский и описание |
|---|---|
| 1 |
Объект высшего уровня Объект высшего уровня — это объект, который не зависит от какого-либо объекта в иерархии объектов. Например, если задание 1 состоит из рабочего потока 1 и потока данных 1, то задание 1 является объектом самого высокого уровня. |
| 2 |
Зависимые от объекта Зависимости объекта — это объекты, связанные с объектом самого высокого уровня в иерархии. Например, если задание 1 состоит из рабочего потока 1, который содержит поток данных 1, то и рабочий поток 1, и поток данных 1 являются зависимыми от задания 1. Кроме того, поток данных 1 зависит от рабочего потока 1. |
| 3 |
Версия объекта Версия объекта является экземпляром объекта. Каждый раз, когда вы добавляете или регистрируете объект в центральном хранилище, программное обеспечение создает новую версию объекта. Последняя версия объекта является последней или последней созданной версией. |
Объект высшего уровня
Объект высшего уровня — это объект, который не зависит от какого-либо объекта в иерархии объектов. Например, если задание 1 состоит из рабочего потока 1 и потока данных 1, то задание 1 является объектом самого высокого уровня.
Зависимые от объекта
Зависимости объекта — это объекты, связанные с объектом самого высокого уровня в иерархии. Например, если задание 1 состоит из рабочего потока 1, который содержит поток данных 1, то и рабочий поток 1, и поток данных 1 являются зависимыми от задания 1. Кроме того, поток данных 1 зависит от рабочего потока 1.
Версия объекта
Версия объекта является экземпляром объекта. Каждый раз, когда вы добавляете или регистрируете объект в центральном хранилище, программное обеспечение создает новую версию объекта. Последняя версия объекта является последней или последней созданной версией.
Чтобы обновить локальный репозиторий в многопользовательской среде, вы можете получить последнюю копию каждого объекта из центрального репозитория. Для редактирования объекта вы можете использовать опцию check out и check in.
SAP BODS — центральный репозиторий безопасности
Существуют различные параметры безопасности, которые можно применять в центральном хранилище для обеспечения его безопасности.
Различные параметры безопасности —
-
Аутентификация — это позволяет только аутентичным пользователям войти в центральный репозиторий.
-
Авторизация — это позволяет пользователю назначать разные уровни разрешений для каждого объекта.
-
Аудит — используется для ведения истории всех изменений, внесенных в объект. Вы можете проверить все предыдущие версии и вернуться к более старым версиям.
Аутентификация — это позволяет только аутентичным пользователям войти в центральный репозиторий.
Авторизация — это позволяет пользователю назначать разные уровни разрешений для каждого объекта.
Аудит — используется для ведения истории всех изменений, внесенных в объект. Вы можете проверить все предыдущие версии и вернуться к более старым версиям.
Создание небезопасного центрального репозитория
В многопользовательской среде разработки всегда целесообразно работать в режиме центрального репозитория.
Чтобы создать небезопасный центральный репозиторий, выполните следующие шаги:
Шаг 1 — Создайте базу данных, используя систему управления базами данных, которая будет действовать как центральное хранилище.
Шаг 2 — Перейти к менеджеру репозитория.
Шаг 3 — Выберите тип репозитория как Центральный. Введите данные базы данных, такие как имя пользователя и пароль, и нажмите « Создать» .
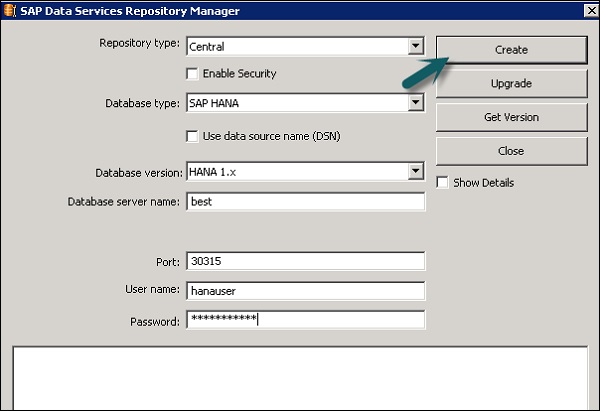
Шаг 4 — Чтобы определить соединение с центральным репозиторием, выберите Инструменты → Центральный репозиторий .
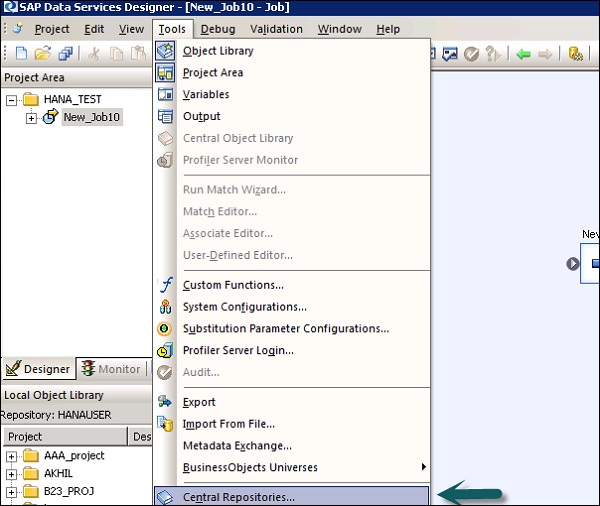
Шаг 5 — Выберите хранилище в подключении к Центральному хранилищу и щелкните значок « Добавить» .
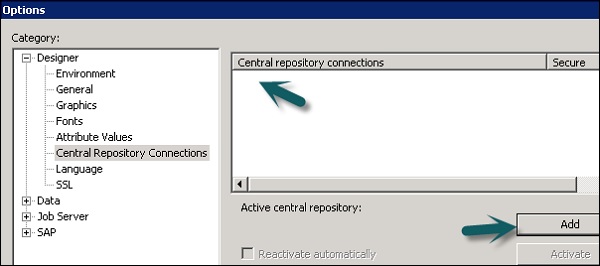
Шаг 6 — Введите пароль для центрального хранилища и нажмите кнопку « Активировать» .
Создание безопасного центрального репозитория
Чтобы создать безопасный центральный репозиторий, перейдите к Менеджеру репозитория. Выберите тип репозитория в качестве центрального. Установите флажок Включить защиту.
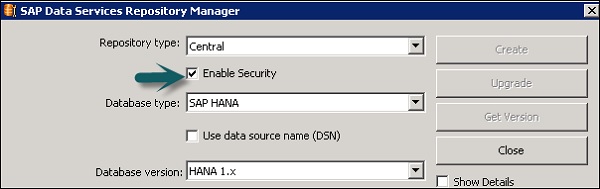
Создание многопользовательской среды
Для успешной разработки в многопользовательской среде целесообразно реализовать некоторые процессы, такие как регистрация и выписка.
Вы можете использовать следующие процессы в многопользовательской среде:
- фильтрация
- Проверка объектов
- Отмена проверить
- Проверка в объектах
- Маркировка объектов
Фильтрация применима, когда вы добавляете какие-либо объекты, регистрируетесь, извлекаете и помечаете объекты в центральном хранилище.
Миграция многопользовательских рабочих мест
В SAP Data Services миграция заданий может применяться на разных уровнях: уровне приложения, уровне репозитория, уровне обновления.
Вы не можете напрямую копировать содержимое одного центрального репозитория в другой центральный репозиторий; вам нужно использовать локальный репозиторий.
Первым шагом является получение последней версии всех объектов из центрального репозитория в локальный репозиторий. Активируйте центральное хранилище, в которое вы хотите скопировать содержимое. Добавьте все объекты, которые вы хотите скопировать из локального репозитория в центральный репозиторий.
Центральный репозиторий Миграция
Если вы обновляете версию SAP Data Services, вам также необходимо обновить версию репозитория.
При переносе центрального хранилища для обновления версии необходимо учитывать следующие моменты:
Сделайте резервную копию центрального хранилища всех таблиц и объектов.
Чтобы поддерживать версию объектов в службах данных, поддерживайте центральный репозиторий для каждой версии. Создайте новую централизованную историю с новой версией программного обеспечения Data Services и скопируйте все объекты в этот репозиторий.
Если вы устанавливаете новую версию Data Services, всегда рекомендуется, вам следует обновить ваш центральный репозиторий до новой версии объектов.
Обновите ваш локальный репозиторий до одной и той же версии, поскольку разные версии центрального и локального репозитория могут не работать одновременно.
Перед переносом центрального репозитория проверьте все объекты. Поскольку вы не обновляете центральный и локальный репозиторий одновременно, вам необходимо зарегистрировать все объекты. После того как ваш центральный репозиторий будет обновлен до более новой версии, вы не сможете регистрировать объекты из локального репозитория, который имеет более старую версию служб данных.