KSDS известен как набор ключевых данных. Набор данных с последовательностью ключей (KSDS) является более сложным, чем ESDS и RRDS, но является более полезным и универсальным. Мы должны кодировать INDEXED внутри команды DEFINE CLUSTER для наборов данных KSDS. Кластер KSDS состоит из следующих двух компонентов:
-
Индекс. Компонент индекса в кластере KSDS содержит список значений ключей для записей в кластере с указателями на соответствующие записи в компоненте данных. Компонент индекса ссылается на физический адрес записи KSDS. Это связывает ключ каждой записи с относительным местоположением записи в наборе данных. Когда запись добавляется или удаляется, этот индекс обновляется соответствующим образом.
-
Данные — компонент данных кластера KSDS содержит фактические данные. Каждая запись в компоненте данных кластера KSDS содержит ключевое поле с одинаковым количеством символов и находится в одинаковой относительной позиции в каждой записи.
Индекс. Компонент индекса в кластере KSDS содержит список значений ключей для записей в кластере с указателями на соответствующие записи в компоненте данных. Компонент индекса ссылается на физический адрес записи KSDS. Это связывает ключ каждой записи с относительным местоположением записи в наборе данных. Когда запись добавляется или удаляется, этот индекс обновляется соответствующим образом.
Данные — компонент данных кластера KSDS содержит фактические данные. Каждая запись в компоненте данных кластера KSDS содержит ключевое поле с одинаковым количеством символов и находится в одинаковой относительной позиции в каждой записи.
Ниже приведены ключевые особенности KSDS —
-
Записи в наборе данных KSDS всегда сортируются по ключевому полю. Записи хранятся в порядке возрастания и сортировки по ключу.
-
Записи могут быть доступны последовательно и прямой доступ также возможен.
-
Записи идентифицируются с помощью ключа. Ключ каждой записи — это поле в предопределенной позиции в записи. Каждый ключ должен быть уникальным в наборе данных KSDS. Так что дублирование записей невозможно.
-
Когда новые записи вставляются, логический порядок записей зависит от последовательности сортировки ключевого поля.
-
Записи в наборе данных KSDS могут быть фиксированной длины или переменной длины.
-
KSDS можно использовать в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите файловую организацию как индексированную, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных KSDS.
Записи в наборе данных KSDS всегда сортируются по ключевому полю. Записи хранятся в порядке возрастания и сортировки по ключу.
Записи могут быть доступны последовательно и прямой доступ также возможен.
Записи идентифицируются с помощью ключа. Ключ каждой записи — это поле в предопределенной позиции в записи. Каждый ключ должен быть уникальным в наборе данных KSDS. Так что дублирование записей невозможно.
Когда новые записи вставляются, логический порядок записей зависит от последовательности сортировки ключевого поля.
Записи в наборе данных KSDS могут быть фиксированной длины или переменной длины.
KSDS можно использовать в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите файловую организацию как индексированную, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных KSDS.
Структура файла KSDS
Для поиска конкретной записи мы даем уникальное значение ключа. Значение ключа ищется в компоненте индекса. Как только ключ найден, извлекается соответствующий адрес памяти, который ссылается на компонент данных. Из адреса памяти мы можем получить фактические данные, которые хранятся в компоненте данных. Следующий пример показывает базовую структуру индекса и файла данных —
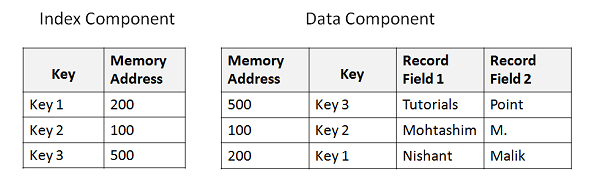
Определение кластера KSDS
Следующий синтаксис показывает, какие параметры мы можем использовать при создании кластера KSDS.
Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
DEFINE CLUSTER (NAME(ksds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - INDEXED - KEYS(length offset) - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(ksds-file-name.data)) - INDEX - (NAME(ksds-file-name.index))
пример
В следующем примере показано, как создать кластер KSDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) - INDEXED - KEYS(6 1) - RECSZ(80 80) - TRACKS(1,1) - CISZ(4096) - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.KSDSFILE.DATA)) - INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) - /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и создаст файл VSAM MY.VSAM.KSDSFILE.
Удаление кластера KSDS
Кластер KSDS удаляется с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает, какие параметры мы можем использовать при удалении кластера KSDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как удалить кластер KSDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.KSDSFILE CLUSTER /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит MY.VSAM.KSDSFILE VSAM Cluster.