VSAM — Обзор
Метод доступа к виртуальному хранилищу (VSAM) — это высокопроизводительный метод доступа и организация набора данных, который организует и поддерживает данные через структуру каталога. Он использует концепцию виртуального хранилища и может защищать наборы данных на разных уровнях, предоставляя пароли. VSAM можно использовать в программах на языке COBOL, таких как физические последовательные файлы. VSAM — это логические наборы данных для хранения записей. Файлы могут быть прочитаны последовательно и случайным образом в VSAM. Это улучшенный способ хранения данных, который преодолевает некоторые ограничения обычных файловых систем, таких как последовательные файлы.
Характеристики VSAM
Ниже приведены характеристики VSAM —
-
VSAM защищает данные от несанкционированного доступа с помощью паролей.
-
VSAM обеспечивает быстрый доступ к наборам данных.
-
VSAM имеет опции для оптимизации производительности.
-
VSAM позволяет совместно использовать наборы данных как в пакетной, так и в онлайн-среде.
-
VSAM более структурированы и организованы для хранения данных.
-
Свободное место автоматически используется в файлах VSAM.
VSAM защищает данные от несанкционированного доступа с помощью паролей.
VSAM обеспечивает быстрый доступ к наборам данных.
VSAM имеет опции для оптимизации производительности.
VSAM позволяет совместно использовать наборы данных как в пакетной, так и в онлайн-среде.
VSAM более структурированы и организованы для хранения данных.
Свободное место автоматически используется в файлах VSAM.
Ограничения VSAM
Единственным ограничением VSAM является то, что он не может быть сохранен на томе TAPE. Он всегда хранится в пространстве DASD. Для хранения данных требуется несколько цилиндров, что не является экономически эффективным.
VSAM — Компоненты
VSAM состоит из следующих компонентов —
- VSAM кластер
- Зона контроля
- Интервал управления
VSAM кластер
VSAM — это логические наборы данных для хранения записей, которые называются кластерами. Кластер является ассоциацией индекса, набора последовательностей и частей данных набора данных. Пространство, занимаемое кластером VSAM, разделено на смежные области, называемые контрольными интервалами. Мы обсудим контрольные интервалы позже в этом модуле.
В кластере VSAM есть два основных компонента:
-
Компонент индекса содержит часть индекса. Записи индекса присутствуют в компоненте индекса. Используя компонент индекса, VSAM может извлекать записи из компонента данных.
-
Компонент данных содержит часть данных. Фактические записи данных присутствуют в компоненте данных.
Компонент индекса содержит часть индекса. Записи индекса присутствуют в компоненте индекса. Используя компонент индекса, VSAM может извлекать записи из компонента данных.
Компонент данных содержит часть данных. Фактические записи данных присутствуют в компоненте данных.
Интервал управления
Интервалы управления (CI) в VSAM эквивалентны блокам для наборов данных не-VSAM. В методах, отличных от VSAM, единица данных определяется блоком. VSAM работает с логической областью данных, которая называется Интервалы управления.
Интервалы управления — это наименьшая единица передачи между диском и операционной системой. Всякий раз, когда запись извлекается непосредственно из хранилища, весь CI, содержащий эту запись, считывается в буфер ввода-вывода VSAM. Затем нужная запись переносится в рабочую область из буфера VSAM.
Интервал управления состоит из —
- Логические Отчеты
- Управляющие информационные поля
- Свободное место
Когда загружается набор данных VSAM, создаются контрольные интервалы. Размер контрольного интервала по умолчанию составляет 4 КБ, и он может увеличиваться до 32 КБ.
Анализ контрольного интервала
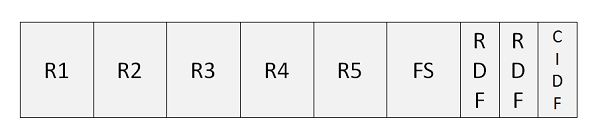
Ниже приводится описание терминов, используемых в вышеуказанной программе —
-
R1..R5 — Записи, которые хранятся в интервале управления.
-
FS — FS — это свободное место, которое можно использовать для дальнейшего расширения набора данных.
-
RDF — RDF известен как поля определения записи. RDF имеют длину 3 байта. Он описывает длину записей и сообщает, сколько смежных записей имеют одинаковую длину.
-
CIDF — CIDF известен как поля определения интервала управления. CIDF имеют длину 4 байта и содержат информацию об интервале управления.
R1..R5 — Записи, которые хранятся в интервале управления.
FS — FS — это свободное место, которое можно использовать для дальнейшего расширения набора данных.
RDF — RDF известен как поля определения записи. RDF имеют длину 3 байта. Он описывает длину записей и сообщает, сколько смежных записей имеют одинаковую длину.
CIDF — CIDF известен как поля определения интервала управления. CIDF имеют длину 4 байта и содержат информацию об интервале управления.
Зона контроля
Контрольная зона (CA) формируется путем объединения двух или более контрольных интервалов. Набор данных VSAM состоит из одной или нескольких областей управления. Размер VSAM всегда кратен его контрольной области. Файлы VSAM расширяются в единицах контрольных областей.
Ниже приведен пример области управления.

VSAM — кластер
Кластер VSAM определен в JCL . JCL использует утилиту IDCAMS для создания кластера. IDCAMS — это служебная программа, разработанная IBM, для служб доступа. Он используется в первую очередь для определения наборов данных VSAM.
Определение кластера
Следующий синтаксис показывает основные параметры, которые сгруппированы в Определить кластер, данные и индекс .
.DEFINE CLUSTER (NAME(vsam-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - [INDEXED / NONINDEXED / NUMBERED / LINEAR] - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [KEYS(length offset)] - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE] ) - DATA - (NAME(vsam-file-name.data)) - INDEX - (NAME(vsam-file-name.index)) - CATALOG(catalog-name[/password]))
Параметры на уровне CLUSTER применяются ко всему кластеру. Параметры на уровне DATA или INDEX применяются только к компоненту данных или индекса.
Мы обсудим каждый параметр подробно в следующей таблице —
| Sr.No | Параметры с описанием |
|---|---|
| 1 |
ОПРЕДЕЛИТЬ КЛАСТЕР Команда «Определить кластер» используется для определения кластера и определения атрибутов параметров для кластера и его компонентов. |
| 2 |
НАЗВАНИЕ NAME указывает имя файла VSAM, для которого мы определяем кластер. |
| 3 |
БЛОКИ Blocks указывает количество блоков, назначенных для кластера. |
| 4 |
ОБЪЕМЫ Тома указывает один или несколько томов, которые будут содержать кластер или компонент. |
| 5 |
INDEXED / NINDEXED / NUMBERED / LINEAR Этот параметр может принимать три значения INDEXED, NONINDEXED или NUMBERED в зависимости от типа набора данных, который мы создаем. Для файлов с последовательностью ключей (KSDS) используется опция INDEXED. Для файлов с последовательной записью (ESDS) используется опция NONINDEXED. Для файлов относительной записи (RRDS) требуется опция NUMBERED. Для файлов Linear (LDS) требуется опция LINEAR. Значением этого параметра по умолчанию является INDEXED. Мы обсудим больше о KSDS, ESDS, RRDS и LDS в следующих модулях. |
| 6 |
RECSZ Параметр «Размер записи» имеет два значения: «Средний» и «Максимальный размер записи». Среднее указывает среднюю длину логических записей в файле, а максимальное — длину записей. |
| 7 |
СВОБОДНОЕ МЕСТО Свободное пространство указывает процент свободного пространства, которое нужно зарезервировать для контрольных интервалов (CI) и областей управления (CA) компонента данных. Значение по умолчанию для этого параметра составляет ноль процентов. |
| 8 |
CISZ CISZ известен как размер контрольного интервала. Указывает размер контрольных интервалов. |
| 9 |
КЛЮЧИ Параметр Keys определяется только в файлах последовательности ключей (KSDS). Он определяет длину и смещение первичного ключа от первого столбца. Диапазон значений этого параметра составляет от 1 до 255 байтов. |
| 10 |
READPW Значение в параметре READPW указывает пароль уровня чтения. |
| 11 |
ДЛЯ / К Значение этого параметра указывает количество времени в днях и днях для сохранения файла. Значение по умолчанию для этого параметра — ноль дней. |
| 12 |
UPDATEPW Значение в параметре UPDATEPW указывает пароль уровня обновления. |
| 13 |
REUSE / NOREUSE Параметр REUSE позволяет определить кластеры, которые можно сбросить до пустого состояния, не удаляя и не переопределяя их. |
| 14 |
ДАННЫЕ — ИМЯ Часть DATA кластера содержит имя набора данных, которое содержит фактические данные файла. |
| 15 |
ИНДЕКС-NAME Часть INDEX кластера содержит первичный ключ и указатель памяти для соответствующей записи в части данных. Он определяется, когда используется кластер с последовательностью ключей. |
| 16 |
КАТАЛОГ Параметр catalog обозначает каталог, в котором будет определен файл. Мы поговорим о каталоге отдельно в следующих модулях. |
ОПРЕДЕЛИТЬ КЛАСТЕР
Команда «Определить кластер» используется для определения кластера и определения атрибутов параметров для кластера и его компонентов.
НАЗВАНИЕ
NAME указывает имя файла VSAM, для которого мы определяем кластер.
БЛОКИ
Blocks указывает количество блоков, назначенных для кластера.
ОБЪЕМЫ
Тома указывает один или несколько томов, которые будут содержать кластер или компонент.
INDEXED / NINDEXED / NUMBERED / LINEAR
Этот параметр может принимать три значения INDEXED, NONINDEXED или NUMBERED в зависимости от типа набора данных, который мы создаем. Для файлов с последовательностью ключей (KSDS) используется опция INDEXED. Для файлов с последовательной записью (ESDS) используется опция NONINDEXED. Для файлов относительной записи (RRDS) требуется опция NUMBERED. Для файлов Linear (LDS) требуется опция LINEAR. Значением этого параметра по умолчанию является INDEXED. Мы обсудим больше о KSDS, ESDS, RRDS и LDS в следующих модулях.
RECSZ
Параметр «Размер записи» имеет два значения: «Средний» и «Максимальный размер записи». Среднее указывает среднюю длину логических записей в файле, а максимальное — длину записей.
СВОБОДНОЕ МЕСТО
Свободное пространство указывает процент свободного пространства, которое нужно зарезервировать для контрольных интервалов (CI) и областей управления (CA) компонента данных. Значение по умолчанию для этого параметра составляет ноль процентов.
CISZ
CISZ известен как размер контрольного интервала. Указывает размер контрольных интервалов.
КЛЮЧИ
Параметр Keys определяется только в файлах последовательности ключей (KSDS). Он определяет длину и смещение первичного ключа от первого столбца. Диапазон значений этого параметра составляет от 1 до 255 байтов.
READPW
Значение в параметре READPW указывает пароль уровня чтения.
ДЛЯ / К
Значение этого параметра указывает количество времени в днях и днях для сохранения файла. Значение по умолчанию для этого параметра — ноль дней.
UPDATEPW
Значение в параметре UPDATEPW указывает пароль уровня обновления.
REUSE / NOREUSE
Параметр REUSE позволяет определить кластеры, которые можно сбросить до пустого состояния, не удаляя и не переопределяя их.
ДАННЫЕ — ИМЯ
Часть DATA кластера содержит имя набора данных, которое содержит фактические данные файла.
ИНДЕКС-NAME
Часть INDEX кластера содержит первичный ключ и указатель памяти для соответствующей записи в части данных. Он определяется, когда используется кластер с последовательностью ключей.
КАТАЛОГ
Параметр catalog обозначает каталог, в котором будет определен файл. Мы поговорим о каталоге отдельно в следующих модулях.
пример
Ниже приведен основной пример, показывающий, как определить кластер в JCL.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) - INDEXED - RECSZ(80 80) - TRACKS(1,1) - KEYS(5 0) - CISZ(4096) - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.KSDSFILE.DATA)) - INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и создаст файл VSAM MY.VSAM.KSDSFILE.
Удаление кластера
Чтобы удалить файл VSAM, необходимо удалить кластер VSAM с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом. Если набор данных VSAM не истек, он не будет удален. Для удаления таких типов наборов данных используйте опцию PURGE.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает параметры, которые мы можем использовать с оператором Delete. Мы обсудим каждый из них подробно в следующей таблице —
| Sr.No | Параметры с описанием |
|---|---|
| 1 |
ERASE / NOERASE Опция ERASE указана для переопределения атрибута ERASE, указанного для объекта в каталоге. Параметр NOERASE выбран по умолчанию. |
| 2 |
СИЛА / НОФОРС Опция FORCE указана для удаления пробела и USERCATALOG, даже если они не пусты. Параметр NOFORCE выбран по умолчанию. |
| 3 |
ОЧИСТКА / НОПУРЖ Параметр PURGE используется для удаления набора данных VSAM, если срок действия набора данных не истек. Параметр NOPURGE выбран по умолчанию. |
| 4 |
SCRATCH / NOSCRATCH Опция SCRATCH предназначена для удаления связанной записи для объекта из оглавления тома. Он в основном используется для наборов данных, не относящихся к vsam, таких как GDG. Параметр NOSCRATCH выбран по умолчанию. |
ERASE / NOERASE
Опция ERASE указана для переопределения атрибута ERASE, указанного для объекта в каталоге. Параметр NOERASE выбран по умолчанию.
СИЛА / НОФОРС
Опция FORCE указана для удаления пробела и USERCATALOG, даже если они не пусты. Параметр NOFORCE выбран по умолчанию.
ОЧИСТКА / НОПУРЖ
Параметр PURGE используется для удаления набора данных VSAM, если срок действия набора данных не истек. Параметр NOPURGE выбран по умолчанию.
SCRATCH / NOSCRATCH
Опция SCRATCH предназначена для удаления связанной записи для объекта из оглавления тома. Он в основном используется для наборов данных, не относящихся к vsam, таких как GDG. Параметр NOSCRATCH выбран по умолчанию.
пример
Ниже приведен основной пример, показывающий, как удалить кластер в JCL.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.KSDSFILE CLUSTER PURGE /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит файл VSAM MY.VSAM.KSDSFILE.
VSAM — ESDS
ESDS известен как набор данных с последовательным входом. Набор данных с последовательной записью ведет себя как последовательная организация файлов с некоторыми дополнительными функциями. Мы можем получить доступ к записям напрямую и в целях безопасности можем также использовать пароли. Мы должны кодировать NONINDEXED внутри команды DEFINE CLUSTER для наборов данных ESDS. Ниже приведены ключевые особенности ESDS —
-
Записи в кластере ESDS хранятся в том порядке, в котором они были вставлены в набор данных.
-
На записи ссылаются по физическому адресу, который известен как относительный байтовый адрес (RBA) . Предположим, если в наборе данных ESDS у нас есть 80-байтовые записи, RBA первой записи будет 0, RBA для второй записи будет 80, для третьей записи это будет 160 и так далее.
-
Записи могут быть последовательно доступны через RBA, который известен как адресный доступ.
-
Записи хранятся в том порядке, в котором они были вставлены. Новые записи вставляются в конце.
-
Удаление записей невозможно в наборе данных ESDS. Но они могут быть помечены как неактивные.
-
Записи в наборе данных ESDS могут иметь фиксированную длину или переменную длину.
-
ESDS не индексируется. Ключи отсутствуют в наборе данных ESDS, поэтому он может содержать повторяющиеся записи.
-
ESDS может использоваться в программах на языке COBOL, как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл ESDS для обработки внутри программы. В программе COBOL укажите организацию файлов как Последовательный и режим доступа как Последовательный с набором данных ESDS.
Записи в кластере ESDS хранятся в том порядке, в котором они были вставлены в набор данных.
На записи ссылаются по физическому адресу, который известен как относительный байтовый адрес (RBA) . Предположим, если в наборе данных ESDS у нас есть 80-байтовые записи, RBA первой записи будет 0, RBA для второй записи будет 80, для третьей записи это будет 160 и так далее.
Записи могут быть последовательно доступны через RBA, который известен как адресный доступ.
Записи хранятся в том порядке, в котором они были вставлены. Новые записи вставляются в конце.
Удаление записей невозможно в наборе данных ESDS. Но они могут быть помечены как неактивные.
Записи в наборе данных ESDS могут иметь фиксированную длину или переменную длину.
ESDS не индексируется. Ключи отсутствуют в наборе данных ESDS, поэтому он может содержать повторяющиеся записи.
ESDS может использоваться в программах на языке COBOL, как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл ESDS для обработки внутри программы. В программе COBOL укажите организацию файлов как Последовательный и режим доступа как Последовательный с набором данных ESDS.
Определение кластера ESDS
Следующий синтаксис показывает, какие параметры мы можем использовать при создании кластера ESDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
DEFINE CLUSTER (NAME(esds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - NONINDEXED - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(esds-file-name.data))
пример
В следующем примере показано, как создать кластер ESDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.ESDSFILE) - NONINDEXED - RECSZ(80 80) - TRACKS(1,1) - CISZ(4096) - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.ESDSFILE.DATA)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он создаст файл VS. MY.VSAM.ESDSFILE.
Удаление ESDS кластера
Кластер ESDS удаляется с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает, какие параметры мы можем использовать при удалении кластера ESDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как удалить кластер ESDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.ESDSFILE CLUSTER /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит MY.VSAM.ESDSFILE VSAM Cluster.
ВСАМ — КСДС
KSDS известен как набор ключевых данных. Набор данных с последовательностью ключей (KSDS) является более сложным, чем ESDS и RRDS, но является более полезным и универсальным. Мы должны кодировать INDEXED внутри команды DEFINE CLUSTER для наборов данных KSDS. Кластер KSDS состоит из следующих двух компонентов:
-
Индекс. Компонент индекса в кластере KSDS содержит список значений ключей для записей в кластере с указателями на соответствующие записи в компоненте данных. Компонент индекса ссылается на физический адрес записи KSDS. Это связывает ключ каждой записи с относительным местоположением записи в наборе данных. Когда запись добавляется или удаляется, этот индекс обновляется соответствующим образом.
-
Данные — компонент данных кластера KSDS содержит фактические данные. Каждая запись в компоненте данных кластера KSDS содержит ключевое поле с одинаковым количеством символов и находится в одинаковой относительной позиции в каждой записи.
Индекс. Компонент индекса в кластере KSDS содержит список значений ключей для записей в кластере с указателями на соответствующие записи в компоненте данных. Компонент индекса ссылается на физический адрес записи KSDS. Это связывает ключ каждой записи с относительным местоположением записи в наборе данных. Когда запись добавляется или удаляется, этот индекс обновляется соответствующим образом.
Данные — компонент данных кластера KSDS содержит фактические данные. Каждая запись в компоненте данных кластера KSDS содержит ключевое поле с одинаковым количеством символов и находится в одинаковой относительной позиции в каждой записи.
Ниже приведены ключевые особенности KSDS —
-
Записи в наборе данных KSDS всегда сортируются по ключевому полю. Записи хранятся в порядке возрастания и сортировки по ключу.
-
Записи могут быть доступны последовательно и прямой доступ также возможен.
-
Записи идентифицируются с помощью ключа. Ключ каждой записи — это поле в предопределенной позиции в записи. Каждый ключ должен быть уникальным в наборе данных KSDS. Так что дублирование записей невозможно.
-
Когда новые записи вставляются, логический порядок записей зависит от последовательности сортировки ключевого поля.
-
Записи в наборе данных KSDS могут быть фиксированной длины или переменной длины.
-
KSDS можно использовать в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите файловую организацию как индексированную, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных KSDS.
Записи в наборе данных KSDS всегда сортируются по ключевому полю. Записи хранятся в порядке возрастания и сортировки по ключу.
Записи могут быть доступны последовательно и прямой доступ также возможен.
Записи идентифицируются с помощью ключа. Ключ каждой записи — это поле в предопределенной позиции в записи. Каждый ключ должен быть уникальным в наборе данных KSDS. Так что дублирование записей невозможно.
Когда новые записи вставляются, логический порядок записей зависит от последовательности сортировки ключевого поля.
Записи в наборе данных KSDS могут быть фиксированной длины или переменной длины.
KSDS можно использовать в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите файловую организацию как индексированную, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных KSDS.
Структура файла KSDS
Для поиска конкретной записи мы даем уникальное значение ключа. Значение ключа ищется в компоненте индекса. Как только ключ найден, извлекается соответствующий адрес памяти, который ссылается на компонент данных. Из адреса памяти мы можем получить фактические данные, которые хранятся в компоненте данных. Следующий пример показывает базовую структуру индекса и файла данных —
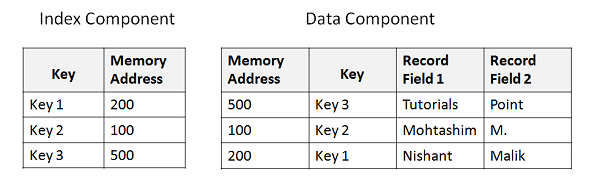
Определение кластера KSDS
Следующий синтаксис показывает, какие параметры мы можем использовать при создании кластера KSDS.
Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
DEFINE CLUSTER (NAME(ksds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - INDEXED - KEYS(length offset) - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(ksds-file-name.data)) - INDEX - (NAME(ksds-file-name.index))
пример
В следующем примере показано, как создать кластер KSDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) - INDEXED - KEYS(6 1) - RECSZ(80 80) - TRACKS(1,1) - CISZ(4096) - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.KSDSFILE.DATA)) - INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) - /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и создаст файл VSAM MY.VSAM.KSDSFILE.
Удаление кластера KSDS
Кластер KSDS удаляется с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает, какие параметры мы можем использовать при удалении кластера KSDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как удалить кластер KSDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.KSDSFILE CLUSTER /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит MY.VSAM.KSDSFILE VSAM Cluster.
VSAM — RRDS
RRDS известен как набор данных относительной записи. Кластер RRDS похож на кластер ESDS. Единственное отличие состоит в том, что записи RRDS доступны по относительному номеру записи (RRN) , мы должны кодировать NUMBERED внутри команды DEFINE CLUSTER. Ниже приведены ключевые особенности RRDS —
-
Набор данных относительной записи имеет записи, которые идентифицируются по номеру относительной записи (RRN) , который является порядковым номером относительно первой записи.
-
RRDS обеспечивает доступ к записям по номерам, таким как запись 1, запись 2 и т. Д. Это обеспечивает произвольный доступ и предполагает, что прикладная программа имеет способ получить нужные номера записей.
-
Доступ к записям в наборе данных RRDS можно получить последовательно, в относительном порядке номеров записей или напрямую, указав относительный номер записи требуемой записи.
-
Записи в наборе данных RRDS хранятся в слотах фиксированной длины. На каждую запись ссылается номер своего слота, номер может варьироваться от 1 до максимального количества записей в наборе данных.
-
Записи в RRDS могут быть записаны путем вставки новой записи в пустой слот.
-
Записи могут быть удалены из кластера RRDS, оставляя тем самым пустой слот.
-
Приложения, которые используют записи фиксированной длины или номер записи с контекстным значением, которые могут использовать наборы данных RRDS.
-
RRDS может использоваться в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите организацию файлов как RELATIVE, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных RRDS.
Набор данных относительной записи имеет записи, которые идентифицируются по номеру относительной записи (RRN) , который является порядковым номером относительно первой записи.
RRDS обеспечивает доступ к записям по номерам, таким как запись 1, запись 2 и т. Д. Это обеспечивает произвольный доступ и предполагает, что прикладная программа имеет способ получить нужные номера записей.
Доступ к записям в наборе данных RRDS можно получить последовательно, в относительном порядке номеров записей или напрямую, указав относительный номер записи требуемой записи.
Записи в наборе данных RRDS хранятся в слотах фиксированной длины. На каждую запись ссылается номер своего слота, номер может варьироваться от 1 до максимального количества записей в наборе данных.
Записи в RRDS могут быть записаны путем вставки новой записи в пустой слот.
Записи могут быть удалены из кластера RRDS, оставляя тем самым пустой слот.
Приложения, которые используют записи фиксированной длины или номер записи с контекстным значением, которые могут использовать наборы данных RRDS.
RRDS может использоваться в программах на языке COBOL , как и любой другой файл. Мы будем указывать имя файла в JCL, и мы можем использовать файл KSDS для обработки внутри программы. В программе COBOL укажите организацию файлов как RELATIVE, и вы можете использовать любой режим доступа (последовательный, случайный или динамический) с набором данных RRDS.
Структура файла RRDS
Пространство разделено на слоты фиксированной длины в файловой структуре RRDS. Слот может быть либо полностью свободным, либо полностью заполненным. Таким образом, новые записи могут быть добавлены в пустые слоты, а существующие записи могут быть удалены из слотов, которые заполнены. Мы можем получить доступ к любой записи напрямую, указав относительный номер записи. Следующий пример показывает базовую структуру файла данных —
Компонент данных
| Относительный номер записи | Поле записи 1 | Поле записи 2 |
|---|---|---|
| 1 | Руководство | точка |
| 2 | Mohtashim | М. |
| 3 | Nishant | Malik |
Определение кластера RRDS
Следующий синтаксис показывает, какие параметры мы можем использовать при создании кластера RRDS.
Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
DEFINE CLUSTER (NAME(rrds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - NUMBERED - RECSZ(average maximum) - [FREESPACE(CI-Percentage,CA-Percentage)] - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(rrds-file-name.data))
пример
В следующем примере показано, как создать кластер RRDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.RRDSFILE) - NUMBERED - RECSZ(80 80) - TRACKS(1,1) - REUSE - FREESPACE(3 3) ) - DATA (NAME(MY.VSAM.RRDSFILE.DATA)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он создаст файл VSAM MY.VSAM.RRDSFILE.
Удаление кластера RRDS
Кластер RRDS удаляется с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает, какие параметры мы можем использовать при удалении кластера RRDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как удалить кластер RRDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.RRDSFILE CLUSTER /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит MY.VSAM.RRDSFILE VSAM Cluster.
VSAM — LDS
LDS известен как линейный набор данных. Линейный набор данных является единственной формой набора данных потока байтов, которая используется в используемых в традиционных файлах операционной системы. Линейные наборы данных используются редко. Ниже приведены ключевые особенности LDS —
-
Наборы линейных данных не содержат RDF и CIDF, так как не содержат никакой управляющей информации, встроенной в его CI.
-
Данные, к которым можно обращаться в виде байтово-адресуемых строк в виртуальном хранилище в линейных наборах данных.
-
Линейные наборы данных имеют размер контрольного интервала 4 КБ.
-
LDS — это файл, не относящийся к vsam, с некоторыми средствами VSAM, такими как использование информации IDCAMS и VSAM в каталоге.
-
В настоящее время DB2 является крупнейшим пользователем линейных наборов данных.
-
IDCAMS используется для определения LDS, но доступ к нему осуществляется с помощью макроса Data-In-Virtual (DIV).
-
Линейный набор данных не имеет концепций записей. Все байты LDS являются байтами данных.
Наборы линейных данных не содержат RDF и CIDF, так как не содержат никакой управляющей информации, встроенной в его CI.
Данные, к которым можно обращаться в виде байтово-адресуемых строк в виртуальном хранилище в линейных наборах данных.
Линейные наборы данных имеют размер контрольного интервала 4 КБ.
LDS — это файл, не относящийся к vsam, с некоторыми средствами VSAM, такими как использование информации IDCAMS и VSAM в каталоге.
В настоящее время DB2 является крупнейшим пользователем линейных наборов данных.
IDCAMS используется для определения LDS, но доступ к нему осуществляется с помощью макроса Data-In-Virtual (DIV).
Линейный набор данных не имеет концепций записей. Все байты LDS являются байтами данных.
Определение кластера LDS
Следующий синтаксис показывает, какие параметры мы можем использовать при создании кластера LDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
DEFINE CLUSTER (NAME(lds-file-name) - BLOCKS(number) - VOLUMES(volume-serial) - LINEAR - CISZ(number) - [READPW(password)] - [FOR(days)|TO(date)] - [UPDATEPW(password)] - [REUSE / NOREUSE]) - DATA - (NAME(lds-file-name.data))
пример
В следующем примере показано, как создать кластер LDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE CLUSTER (NAME(MY.VSAM.LDSFILE) - LINEAR - TRACKS(1,1) - CISZ(4096) ) - DATA (NAME(MY.VSAM.LDSFILE.DATA)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он создаст файл VSAM MY.VSAM.LDSFILE.
Удаление LDS кластера
Кластер LDS удаляется с помощью утилиты IDCAMS. Команда DELETE удаляет запись кластера VSAM из каталога и при необходимости удаляет файл, освобождая тем самым пространство, занимаемое объектом.
DELETE data-set-name CLUSTER [ERASE / NOERASE] [FORCE / NOFORCE] [PURGE / NOPURGE] [SCRATCH / NOSCRATCH]
Выше синтаксис показывает, какие параметры мы можем использовать при удалении кластера LDS. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как удалить кластер LDS в JCL с помощью утилиты IDCAMS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEPNAME EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DELETE MY.VSAM.LDSFILE CLUSTER /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он удалит MY.VSAM.LDSFILE VSAM Cluster.
VSAM — Команды
Команды VSAM используются для выполнения определенных операций с наборами данных VSAM. Ниже приведены наиболее полезные команды VSAM.
- изменять
- репродукция
- Listcat
- исследовать
- проверить
изменять
Команда ALTER используется для изменения атрибутов файла VSAM. Мы можем изменить атрибуты файла VSAM, которые мы упомянули в определении кластера VSAM. Ниже приведен синтаксис для изменения атрибутов:
ALTER file-cluster-name [password] [ADDVOLUMES(volume-serial)] [BUFFERSPACE(size)] [EMPTY / NOEMPTY] [ERASE / NOERASE] [FREESPACE(CI-percentage CA-percentage)] [KEYS(length offset)] [NEWNAME(new-name)] [RECORDSIZE(average maximum)] [REMOVEVOLUMES(volume-serial)] [SCRATCH / NOSCRATCH] [TO(date) / FOR(days)] [UPGRADE / NOUPGRADE] [CATALOG(catalog-name [password]]
Выше синтаксис показывает, какие параметры мы можем изменить в существующем кластере VSAM. Описание параметров остается тем же, что указано в модуле VSAM — Cluster.
пример
В следующем примере показано, как использовать команду ALTER для увеличения свободного пространства, для добавления дополнительных томов и для Alter Keys —
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * ALTER MY.VSAM.KSDSFILE [ADDVOLUMES(2)] [FREESPACE(6 6)] [KEYS(10 2)] /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и это изменит свободное пространство, тома и ключи.
репродукция
Команда REPRO используется для загрузки данных в набор данных VSAM. Он также используется для копирования данных из одного набора данных VSAM в другой. Мы можем использовать эту команду для копирования данных из последовательного файла в файл VSAM. Утилита IDCAMS использует команду REPRO для загрузки наборов данных.
REPRO INFILE(in-ddname) OUTFILE(out-ddname)
В приведенном выше синтаксисе in-ddname — это имя DD для входного набора данных, в котором есть записи. Out-ddname — это имя DD для выходного набора данных, куда будут скопированы записи входных наборов данных.
пример
В следующем примере показано, как копировать записи из одного набора данных в другой набор данных VSAM.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //IN DD DSN = MY.VSAM.KSDSFILE,DISP = SHR //OUT DD DSN = MY.VSAM1.KSDSFILE,DISP = SHR //SYSPRINT DD SYSOUT = * //SYSIN DD * REPRO INFILE(IN) OUTFILE(OUT) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и скопировать все записи из MY.VSAM.KSDSFILE в файл VSAM MY.VSAM1.KSDSFILE.
Listcat
Команда LISTCAT используется для получения подробностей каталога набора данных VSAM. Команда Listcat предоставляет следующую информацию о наборах данных VSAM —
- Информация о СМС
- RLS Информация
- Объем информации
- Сфера информации
- Распределение информации
- Атрибуты набора данных
LISTCAT ENTRY(vsam-file-name) ALL
В приведенном выше синтаксисе vsam-file-name — это имя набора данных VSAM, для которого нам нужна вся информация. ВСЕ ключевое слово указано, чтобы получить все детали каталога.
пример
В следующем примере показано, как получить все данные с помощью команды Listcat для набора данных VSAM.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * LISTCAT ENTRY(MY.VSAM.KSDSFILE) ALL /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и отображать все подробности каталога о наборе данных MY.VSAM.KSDSFILE.
исследовать
Команда Examine используется для проверки структурной целостности кластера последовательностей ключей. Он проверяет компоненты индекса и данных и, если обнаружена какая-либо проблема, сообщения об ошибках отправляются в спул. Вы можете проверить любое из сообщений IDCxxxxx.
EXAMINE NAME(vsam-ksds-name) - INDEXTEST DATATEST - ERRORLIMIT(50)
В приведенном выше синтаксисе vsam-ksds-name — это имя набора данных VSAM, для которого нам нужно проверить часть индекса и данных кластера VSAM.
пример
В следующем примере показано, как проверить, синхронизированы ли часть индекса и данных набора данных KSDS.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * EXAMINE NAME(MY.VSAM.KSDSFILE) - INDEXTEST DATATEST - ERRORLIMIT(50) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он покажет все проблемы с набором данных VSAM в одном из сообщений IDCxxxxx в спуле.
проверить
Команда Verify используется для проверки и исправления файлов VSAM, которые не были закрыты должным образом после ошибки. Команда добавляет правильные записи End-Of-Data в файл.
VERIFY DS(vsam-file-name)
В приведенном выше синтаксисе vsam-file-name — это имя набора данных VSAM, для которого нам нужно проверить ошибки.
пример
В следующем примере показано, как проверить и исправить ошибки в наборе данных VSAM —
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * VERIFY DS(MY.VSAM.KSDSFILE) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и это исправит ошибки в наборе данных VSAM.
VSAM — альтернативный индекс
Альтернативный индекс — это дополнительный индекс, который создается для наборов данных KSDS / ESDS в дополнение к их первичному индексу. Альтернативный индекс обеспечивает доступ к записям с использованием более одного ключа. Ключ альтернативного индекса может быть неуникальным ключом, он может иметь дубликаты.
Создание альтернативного указателя
Следующие шаги используются для создания альтернативного индекса —
- Определить альтернативный индекс
- Определить путь
- Индекс здания
Определить альтернативный индекс
Альтернативный индекс определяется с помощью команды DEFINE AIX .
DEFINE AIX - (NAME(alternate-index-name) - RELATE(vsam-file-name) - CISZ(number) - FREESPACE(CI-Percentage,CA-Percentage) - KEYS(length offset) - NONUNIQUEKEY / UNIQUEKEY - UPGRADE / NOUPGRADE - RECORDSIZE(average maximum)) - DATA - (NAME(vsam-file-name.data)) - INDEX - (NAME(vsam-file-name.index))
Выше синтаксис показывает параметры, которые используются при определении альтернативного индекса. Мы уже обсуждали некоторые параметры в модуле определения кластера, и некоторые новые параметры используются при определении альтернативного индекса, который мы обсудим здесь —
| Sr.No | Параметры с описанием |
|---|---|
| 1 |
ОПРЕДЕЛИТЬ ЭКС Команда Define AIX используется для определения альтернативного индекса и определения атрибутов параметров для его компонентов. |
| 2 |
НАЗВАНИЕ NAME указывает имя альтернативного индекса. |
| 3 |
ОТНОСИТЬСЯ RELATE указывает имя кластера VSAM, для которого создается альтернативный индекс. |
| 4 |
NONUNIQUEKEY / UNIQUEKEY UNIQUEKEY указывает, что альтернативный индекс уникален, а NONUNIQUEKEY указывает, что дубликаты могут существовать. |
| 5 |
ОБНОВЛЕНИЕ / НОПГРАД UPGRADE указывает, что альтернативный индекс должен быть изменен, если базовый кластер изменен, а NOUPGRADE указывает, что альтернативные индексы должны быть оставлены в покое, если базовый кластер изменен. |
ОПРЕДЕЛИТЬ ЭКС
Команда Define AIX используется для определения альтернативного индекса и определения атрибутов параметров для его компонентов.
НАЗВАНИЕ
NAME указывает имя альтернативного индекса.
ОТНОСИТЬСЯ
RELATE указывает имя кластера VSAM, для которого создается альтернативный индекс.
NONUNIQUEKEY / UNIQUEKEY
UNIQUEKEY указывает, что альтернативный индекс уникален, а NONUNIQUEKEY указывает, что дубликаты могут существовать.
ОБНОВЛЕНИЕ / НОПГРАД
UPGRADE указывает, что альтернативный индекс должен быть изменен, если базовый кластер изменен, а NOUPGRADE указывает, что альтернативные индексы должны быть оставлены в покое, если базовый кластер изменен.
пример
Ниже приведен основной пример, показывающий, как определить альтернативный индекс в JCL.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE AIX (NAME(MY.VSAM.KSDSAIX) - RELATE(MY.VSAM.KSDSFILE) - CISZ(4096) - FREESPACE(20,20) - KEYS(20,7) - NONUNIQUEKEY - UPGRADE - RECORDSIZE(80,80)) - DATA(NAME(MY.VSAM.KSDSAIX.DATA)) - INDEX(NAME(MY.VSAM.KSDSAIX.INDEX)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0 и создать альтернативный индекс MY.VSAM.KSDSAIX.
Определить путь
Определить путь используется для связи альтернативного индекса с базовым кластером. При определении пути мы указываем имя пути и альтернативный индекс, с которым связан этот путь.
DEFINE PATH - NAME(alternate-index-path-name) - PATHENTRY(alternate-index-name))
Выше синтаксис имеет два параметра. NAME используется для указания имени пути альтернативного индекса, а PATHENTRY используется для указания имени альтернативного индекса.
пример
Ниже приведен основной пример определения пути в JCL.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * DEFINE PATH - NAME(MY.VSAM.KSDSAIX.PATH) - PATHENTRY(MY.VSAM.KSDSAIX)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он создаст путь между альтернативным индексом и базовым кластером.
Индекс здания
Команда BLDINDEX используется для создания альтернативного индекса. BLDINDEX считывает все записи в индексированном наборе данных VSAM (или базовом кластере) и извлекает данные, необходимые для создания альтернативного индекса.
BLDINDEX - INDATASET(vsam-cluster-name) - OUTDATASET(alternate-index-name))
Выше синтаксис имеет два параметра. INDATASET используется для указания имени кластера VSAM, а OUTDATASET используется для указания альтернативного имени индекса.
пример
Ниже приведен основной пример построения индекса в JCL.
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C //STEP1 EXEC PGM = IDCAMS //SYSPRINT DD SYSOUT = * //SYSIN DD * BLDINDEX - INDATASET(MY.VSAM.KSDSFILE) - OUTDATASET(MY.VSAM.KSDSAIX)) /*
Если вы выполните вышеупомянутый JCL на сервере мейнфреймов. Он должен выполняться с MAXCC = 0, и он будет строить индекс.
VSAM — Каталог
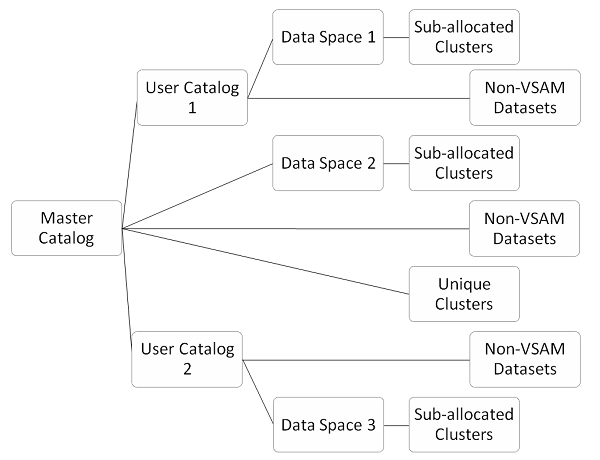
Каталог поддерживает единицу и объем, в котором находится набор данных. Каталог используется для поиска наборов данных. Наборы данных, отличные от VSAM, создают запись каталога с помощью параметра расположения в JCL. Наборы данных VSAM поддерживают свой собственный каталог в виде кластера KSDS. На следующем изображении вы можете увидеть тип каталогов VSAM —
Мастер Каталог
Главный каталог сам по себе является файлом, который отслеживает и управляет операциями VSAM. Это только один главный каталог в любой системе, который содержит записи о наборах системных данных и наборах данных VSAM. Наборы данных VSAM и Non-VSAM могут иметь запись в главном каталоге, но это не очень хорошая практика. Главный каталог создается в процессе создания системы и находится на системном томе. Главный каталог владеет всеми ресурсами VSAM в операционной системе. Все файлы, используемые в VSAM, контролируются главным каталогом. Мастер каталог отвечает за следующие операции —
- Авторизация пароля для файлов
- Повышение безопасности
- Доступ VSAM к файлам
- Управление пространством файла
- Расположение файла
- Свободное пространство доступно в файле
При изменении любого из указанных выше атрибутов файла они автоматически обновляются в главном каталоге. Главный каталог определяется с помощью программ IDCAMS.
Пользовательский каталог
Пользовательский каталог имеет ту же структуру и понятия, что и основной каталог. Он присутствует на следующем уровне иерархии после основного каталога. Пользовательский каталог не является обязательным в системе, но он используется для повышения безопасности системы VSAM. Главный каталог указывает на файлы VSAM, но если каталог пользователя присутствует, то главный каталог указывает на каталог пользователя. Пользовательских каталогов может быть много в соответствии с требованиями системы. В структуре VSAM, если основной каталог удален, это не повлияет на пользовательский каталог. Пользовательский каталог содержит записи о конкретных наборах данных приложения. Информация каталога пользователя хранится в мастер-каталоге.
Пространство данных
Пространство данных — это область устройства хранения с прямым доступом, выделенная исключительно для использования VSAM. Пространство данных должно быть создано до создания кластеров VSAM. Область, занимаемая пространством данных, записывается в оглавлении тома (VTOC), поэтому пространство не будет доступно для распределения для любого другого использования, будь то VSAM или не VSAM. У VTOC есть вход области, занятой пространством. VSAM создает пространство данных для хранения записей каталога пользователя. VSAM контролирует это пространство, отслеживает и поддерживает это пространство, необходимое для файлов VSAM.
Уникальные Кластеры
Уникальные кластеры состоят из отдельного пространства данных, которое полностью используется кластером, созданным в нем. Уникальные кластеры создаются из нераспределенного пространства в хранилище с прямым доступом.
Перераспределенные кластеры
Перераспределенный файл VSAM разделяет пространство VSAM с другими перераспределенными файлами. Он указывает, что файл должен быть размещен в пределах существующего пространства VSAM. Перераспределение используется для упрощения управления и контроля пространств VSAM.
Наборы данных не-VSAM
Наборы данных не-VSAM находятся как на ленте, так и в хранилище с прямым доступом. Наборы данных, отличные от VSAM, могут иметь записи как в основном каталоге, так и в пользовательских каталогах. Основная функция каталогизации наборов данных, отличных от VSAM, заключается в сохранении серийной информации о единицах и томах.
VSAM — Статус файла
При работе с наборами данных VSAM вы можете столкнуться с неожиданностями. Ниже приведены общие коды состояния файлов с их описанием, которые помогут вам решить проблемы.