NumPy — Введение
NumPy — это пакет Python. Это означает «Числовой Питон». Это библиотека, состоящая из объектов многомерного массива и набора процедур для обработки массива.
Numeric , предок NumPy, был разработан Джимом Хугуниным. Был также разработан еще один пакет Numarray, имеющий некоторые дополнительные функции. В 2005 году Трэвис Олифант создал пакет NumPy, включив функции Numarray в пакет Numeric. Есть много участников этого проекта с открытым исходным кодом.
Операции с использованием NumPy
Используя NumPy, разработчик может выполнять следующие операции:
-
Математические и логические операции над массивами.
-
Преобразования Фурье и процедуры для манипуляции с формой.
-
Операции, связанные с линейной алгеброй. NumPy имеет встроенные функции для линейной алгебры и генерации случайных чисел.
Математические и логические операции над массивами.
Преобразования Фурье и процедуры для манипуляции с формой.
Операции, связанные с линейной алгеброй. NumPy имеет встроенные функции для линейной алгебры и генерации случайных чисел.
NumPy — замена для MatLab
NumPy часто используется вместе с такими пакетами, как SciPy (Scientific Python) и Mat-plotlib (библиотека черчения). Эта комбинация широко используется в качестве замены MatLab, популярной платформы для технических вычислений. Тем не менее, Python альтернатива MatLab теперь рассматривается как более современный и полный язык программирования.
Это открытый исходный код, который является дополнительным преимуществом NumPy.
NumPy — Окружающая среда
Стандартный дистрибутив Python не поставляется в комплекте с модулем NumPy. Облегченной альтернативой является установка NumPy с помощью популярного установщика пакетов Python, pip .
pip install numpy
Лучший способ включить NumPy — это использовать устанавливаемый двоичный пакет, соответствующий вашей операционной системе. Эти двоичные файлы содержат полный стек SciPy (включая NumPy, SciPy, matplotlib, IPython, SymPy и пакеты носа вместе с ядром Python).
Windows
Anaconda (из https://www.continuum.io ) — это бесплатный дистрибутив Python для стека SciPy. Он также доступен для Linux и Mac.
Canopy ( https://www.enthought.com/products/canopy/ ) доступен как для бесплатного, так и для коммерческого распространения с полным стеком SciPy для Windows, Linux и Mac.
Python (x, y): это бесплатный дистрибутив Python со стеком SciPy и IDE Spyder для ОС Windows. (Загружается с https://www.python-xy.github.io/ )
Linux
Менеджеры пакетов соответствующих дистрибутивов Linux используются для установки одного или нескольких пакетов в стек SciPy.
Для Ubuntu
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipythonnotebook python-pandas python-sympy python-nose
Для Fedora
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy python-nose atlas-devel
Здание из источника
Core Python (2.6.x, 2.7.x и 3.2.x и далее) должен быть установлен с distutils и должен быть включен модуль zlib.
Компилятор GNU gcc (4.2 и выше) C должен быть доступен.
Чтобы установить NumPy, выполните следующую команду.
Python setup.py install
Чтобы проверить, правильно ли установлен модуль NumPy, попробуйте импортировать его из приглашения Python.
import numpy
Если он не установлен, появится следующее сообщение об ошибке.
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
import numpy
ImportError: No module named 'numpy'
В качестве альтернативы, пакет NumPy импортируется с использованием следующего синтаксиса —
import numpy as np
NumPy — объект Ndarray
Самый важный объект, определенный в NumPy, — это N-мерный тип массива, называемый ndarray . Описывает коллекцию предметов одного типа. К элементам в коллекции можно получить доступ, используя нулевой индекс.
Каждый элемент в ndarray занимает одинаковый размер блока в памяти. Каждый элемент в ndarray является объектом объекта типа данных (называемого dtype ).
Любой элемент, извлеченный из объекта ndarray (путем разрезания), представлен объектом Python одного из скалярных типов массива. На следующей диаграмме показана взаимосвязь между ndarray, объектом типа данных (dtype) и скалярным типом массива.
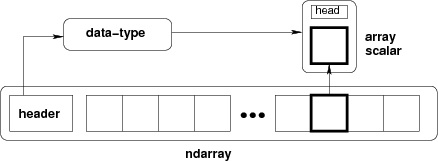
Экземпляр класса ndarray может быть создан с помощью различных процедур создания массива, описанных далее в руководстве. Основной ndarray создается с использованием функции массива в NumPy следующим образом:
numpy.array
Он создает ndarray из любого объекта, представляющего интерфейс массива, или из любого метода, который возвращает массив.
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
Приведенный выше конструктор принимает следующие параметры —
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
объект Любой объект, представляющий метод интерфейса массива, возвращает массив или любую (вложенную) последовательность. |
| 2 |
DTYPE Желаемый тип данных массива, необязательно |
| 3 |
копия Необязательный. По умолчанию (true) объект копируется |
| 4 |
порядок C (основной ряд) или F (основной столбец) или A (любой) (по умолчанию) |
| 5 |
subok По умолчанию возвращаемый массив принудительно становится массивом базового класса. Если это правда, подклассы прошли через |
| 6 |
ndmin Определяет минимальные размеры результирующего массива |
объект
Любой объект, представляющий метод интерфейса массива, возвращает массив или любую (вложенную) последовательность.
DTYPE
Желаемый тип данных массива, необязательно
копия
Необязательный. По умолчанию (true) объект копируется
порядок
C (основной ряд) или F (основной столбец) или A (любой) (по умолчанию)
subok
По умолчанию возвращаемый массив принудительно становится массивом базового класса. Если это правда, подклассы прошли через
ndmin
Определяет минимальные размеры результирующего массива
Посмотрите на следующие примеры, чтобы лучше понять.
Пример 1
import numpy as np a = np.array([1,2,3]) print a
Выход выглядит следующим образом —
[1, 2, 3]
Пример 2
# more than one dimensions import numpy as np a = np.array([[1, 2], [3, 4]]) print a
Выход выглядит следующим образом —
[[1, 2] [3, 4]]
Пример 3
# minimum dimensions import numpy as np a = np.array([1, 2, 3,4,5], ndmin = 2) print a
Выход выглядит следующим образом —
[[1, 2, 3, 4, 5]]
Пример 4
# dtype parameter import numpy as np a = np.array([1, 2, 3], dtype = complex) print a
Выход выглядит следующим образом —
[ 1.+0.j, 2.+0.j, 3.+0.j]
Объект ndarray состоит из непрерывного одномерного сегмента компьютерной памяти, объединенного со схемой индексации, которая отображает каждый элемент в определенном месте в блоке памяти. Блок памяти содержит элементы в главном порядке строки (стиль C) или главном порядке столбца (стиль FORTRAN или MatLab).
NumPy — типы данных
NumPy поддерживает гораздо большее разнообразие числовых типов, чем Python. В следующей таблице показаны различные скалярные типы данных, определенные в NumPy.
| Sr.No. | Типы данных и описание |
|---|---|
| 1 |
bool_ Логическое значение (True или False), хранящееся в байтах |
| 2 |
int_ Целочисленный тип по умолчанию (такой же, как C long; обычно либо int64, либо int32) |
| 3 |
ИНТЕРК Идентичен C int (обычно int32 или int64) |
| 4 |
INTP Целое число, используемое для индексации (так же, как C ssize_t; обычно либо int32, либо int64) |
| 5 |
int8 Байт (от -128 до 127) |
| 6 |
int16 Целое число (от -32768 до 32767) |
| 7 |
int32 Целое число (от -2147483648 до 2147483647) |
| 8 |
int64 Целое число (от -9223372036854775808 до 9223372036854775807) |
| 9 |
uint8 Целое число без знака (от 0 до 255) |
| 10 |
uint16 Целое число без знака (от 0 до 65535) |
| 11 |
uint32 Целое число без знака (от 0 до 4294967295) |
| 12 |
uint64 Целое число без знака (от 0 до 18446744073709551615) |
| 13 |
float_ Сокращение для float64 |
| 14 |
float16 Поплавок половинной точности: знаковый бит, 5-битная экспонента, 10-битная мантисса |
| 15 |
float32 Поплавок одинарной точности: знаковый бит, экспонента 8 бит, мантисса 23 бита |
| 16 |
float64 Поплавок двойной точности: знаковый бит, экспонента 11 бит, мантисса 52 бита |
| 17 |
сложный_ Сокращение для complex128 |
| 18 |
complex64 Комплексное число, представленное двумя 32-битными числами (действительные и мнимые компоненты) |
| 19 |
complex128 Комплексное число, представленное двумя 64-битными числами с плавающей точкой (действительная и мнимая компоненты) |
bool_
Логическое значение (True или False), хранящееся в байтах
int_
Целочисленный тип по умолчанию (такой же, как C long; обычно либо int64, либо int32)
ИНТЕРК
Идентичен C int (обычно int32 или int64)
INTP
Целое число, используемое для индексации (так же, как C ssize_t; обычно либо int32, либо int64)
int8
Байт (от -128 до 127)
int16
Целое число (от -32768 до 32767)
int32
Целое число (от -2147483648 до 2147483647)
int64
Целое число (от -9223372036854775808 до 9223372036854775807)
uint8
Целое число без знака (от 0 до 255)
uint16
Целое число без знака (от 0 до 65535)
uint32
Целое число без знака (от 0 до 4294967295)
uint64
Целое число без знака (от 0 до 18446744073709551615)
float_
Сокращение для float64
float16
Поплавок половинной точности: знаковый бит, 5-битная экспонента, 10-битная мантисса
float32
Поплавок одинарной точности: знаковый бит, экспонента 8 бит, мантисса 23 бита
float64
Поплавок двойной точности: знаковый бит, экспонента 11 бит, мантисса 52 бита
сложный_
Сокращение для complex128
complex64
Комплексное число, представленное двумя 32-битными числами (действительные и мнимые компоненты)
complex128
Комплексное число, представленное двумя 64-битными числами с плавающей точкой (действительная и мнимая компоненты)
Числовые типы NumPy являются экземплярами объектов типа d (типа данных), каждый из которых имеет уникальные характеристики. Типы доступны как np.bool_, np.float32 и т. Д.
Тип данных Объекты (dtype)
Объект типа данных описывает интерпретацию фиксированного блока памяти, соответствующего массиву, в зависимости от следующих аспектов:
-
Тип данных (целое число, объект с плавающей точкой или объект Python)
-
Размер данных
-
Порядок байтов (с прямым порядком байтов или с прямым порядком байтов)
-
В случае структурированного типа, имена полей, тип данных каждого поля и часть блока памяти заняты каждым полем.
-
Если тип данных является подмассивом, его форма и тип данных
Тип данных (целое число, объект с плавающей точкой или объект Python)
Размер данных
Порядок байтов (с прямым порядком байтов или с прямым порядком байтов)
В случае структурированного типа, имена полей, тип данных каждого поля и часть блока памяти заняты каждым полем.
Если тип данных является подмассивом, его форма и тип данных
Порядок байтов определяется префиксом «<» или «>» типа данных. «<» означает, что кодировка имеет младший порядок (наименее значимый хранится в наименьшем адресе). ‘>’ означает, что кодировка имеет порядковый номер (самый старший байт хранится в наименьшем адресе).
Объект dtype создается с использованием следующего синтаксиса —
numpy.dtype(object, align, copy)
Параметры —
-
Object — для преобразования в объект типа данных
-
Align — при значении true добавляет поле к полю, чтобы сделать его похожим на C-struct
-
Копировать — создает новую копию объекта dtype. Если false, результатом является ссылка на встроенный объект типа данных
Object — для преобразования в объект типа данных
Align — при значении true добавляет поле к полю, чтобы сделать его похожим на C-struct
Копировать — создает новую копию объекта dtype. Если false, результатом является ссылка на встроенный объект типа данных
Пример 1
# using array-scalar type import numpy as np dt = np.dtype(np.int32) print dt
Выход выглядит следующим образом —
int32
Пример 2
#int8, int16, int32, int64 can be replaced by equivalent string 'i1', 'i2','i4', etc. import numpy as np dt = np.dtype('i4') print dt
Выход выглядит следующим образом —
int32
Пример 3
# using endian notation import numpy as np dt = np.dtype('>i4') print dt
Выход выглядит следующим образом —
>i4
В следующих примерах показано использование структурированного типа данных. Здесь имя поля и соответствующий скалярный тип данных должны быть объявлены.
Пример 4
# first create structured data type import numpy as np dt = np.dtype([('age',np.int8)]) print dt
Выход выглядит следующим образом —
[('age', 'i1')]
Пример 5
# now apply it to ndarray object import numpy as np dt = np.dtype([('age',np.int8)]) a = np.array([(10,),(20,),(30,)], dtype = dt) print a
Выход выглядит следующим образом —
[(10,) (20,) (30,)]
Пример 6
# file name can be used to access content of age column import numpy as np dt = np.dtype([('age',np.int8)]) a = np.array([(10,),(20,),(30,)], dtype = dt) print a['age']
Выход выглядит следующим образом —
[10 20 30]
Пример 7
Следующие примеры определяют структурированный тип данных, называемый student, со строковым полем «name», целочисленным полем «age» и полем с плавающей точкой «marks». Этот dtype применяется к объекту ndarray.
import numpy as np student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')]) print student
Выход выглядит следующим образом —
[('name', 'S20'), ('age', 'i1'), ('marks', '<f4')])
Пример 8
import numpy as np student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')]) a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student) print a
Выход выглядит следующим образом —
[('abc', 21, 50.0), ('xyz', 18, 75.0)]
Каждый встроенный тип данных имеет код символа, который однозначно идентифицирует его.
-
‘b’ — логическое значение
-
‘i’ — (подписано) целое число
-
‘u’ — целое число без знака
-
‘f’ — с плавающей точкой
-
‘c’ — комплексная точка с плавающей точкой
-
‘m’ — timedelta
-
‘M’ — дата и время
-
‘O’ — (Python) объекты
-
‘S’, ‘a’ — (byte-) строка
-
‘U’ — Юникод
-
‘V’ — необработанные данные (недействительные)
‘b’ — логическое значение
‘i’ — (подписано) целое число
‘u’ — целое число без знака
‘f’ — с плавающей точкой
‘c’ — комплексная точка с плавающей точкой
‘m’ — timedelta
‘M’ — дата и время
‘O’ — (Python) объекты
‘S’, ‘a’ — (byte-) строка
‘U’ — Юникод
‘V’ — необработанные данные (недействительные)
NumPy — атрибуты массива
В этой главе мы обсудим различные атрибуты массива NumPy.
ndarray.shape
Этот атрибут массива возвращает кортеж, состоящий из измерений массива. Он также может быть использован для изменения размера массива.
Пример 1
import numpy as np a = np.array([[1,2,3],[4,5,6]]) print a.shape
Выход выглядит следующим образом —
(2, 3)
Пример 2
# this resizes the ndarray import numpy as np a = np.array([[1,2,3],[4,5,6]]) a.shape = (3,2) print a
Выход выглядит следующим образом —
[[1, 2] [3, 4] [5, 6]]
Пример 3
NumPy также предоставляет функцию изменения формы для изменения размера массива.
import numpy as np a = np.array([[1,2,3],[4,5,6]]) b = a.reshape(3,2) print b
Выход выглядит следующим образом —
[[1, 2] [3, 4] [5, 6]]
ndarray.ndim
Этот атрибут массива возвращает количество измерений массива.
Пример 1
# an array of evenly spaced numbers import numpy as np a = np.arange(24) print a
Выход выглядит следующим образом —
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
Пример 2
# this is one dimensional array import numpy as np a = np.arange(24) a.ndim # now reshape it b = a.reshape(2,4,3) print b # b is having three dimensions
Выход выглядит следующим образом —
[[[ 0, 1, 2] [ 3, 4, 5] [ 6, 7, 8] [ 9, 10, 11]] [[12, 13, 14] [15, 16, 17] [18, 19, 20] [21, 22, 23]]]
numpy.itemsize
Этот атрибут массива возвращает длину каждого элемента массива в байтах.
Пример 1
# dtype of array is int8 (1 byte) import numpy as np x = np.array([1,2,3,4,5], dtype = np.int8) print x.itemsize
Выход выглядит следующим образом —
1
Пример 2
# dtype of array is now float32 (4 bytes) import numpy as np x = np.array([1,2,3,4,5], dtype = np.float32) print x.itemsize
Выход выглядит следующим образом —
4
numpy.flags
Объект ndarray имеет следующие атрибуты. Его текущие значения возвращаются этой функцией.
| Sr.No. | Атрибут и описание |
|---|---|
| 1 |
C_CONTIGUOUS (C) Данные находятся в одном непрерывном сегменте в стиле C |
| 2 |
F_CONTIGUOUS (F) Данные находятся в одном непрерывном сегменте в стиле Фортрана. |
| 3 |
СОБСТВЕННЫЕ ДАННЫЕ (O) Массив владеет используемой памятью или занимает ее у другого объекта. |
| 4 |
ПИСЬМО (W) Область данных может быть записана в. Установка этого значения в False блокирует данные, делая их доступными только для чтения |
| 5 |
ВЫРАВНИЛ (A) Данные и все элементы выровнены соответствующим образом для оборудования |
| 6 |
UPDATEIFCOPY (U) Этот массив является копией некоторого другого массива. Когда этот массив освобожден, базовый массив будет обновлен с содержанием этого массива |
C_CONTIGUOUS (C)
Данные находятся в одном непрерывном сегменте в стиле C
F_CONTIGUOUS (F)
Данные находятся в одном непрерывном сегменте в стиле Фортрана.
СОБСТВЕННЫЕ ДАННЫЕ (O)
Массив владеет используемой памятью или занимает ее у другого объекта.
ПИСЬМО (W)
Область данных может быть записана в. Установка этого значения в False блокирует данные, делая их доступными только для чтения
ВЫРАВНИЛ (A)
Данные и все элементы выровнены соответствующим образом для оборудования
UPDATEIFCOPY (U)
Этот массив является копией некоторого другого массива. Когда этот массив освобожден, базовый массив будет обновлен с содержанием этого массива
пример
В следующем примере показаны текущие значения флагов.
import numpy as np x = np.array([1,2,3,4,5]) print x.flags
Выход выглядит следующим образом —
C_CONTIGUOUS : True F_CONTIGUOUS : True OWNDATA : True WRITEABLE : True ALIGNED : True UPDATEIFCOPY : False
NumPy — процедуры создания массива
Новый объект ndarray можно создать с помощью любой из следующих процедур создания массива или с помощью низкоуровневого конструктора ndarray.
numpy.empty
Создает неинициализированный массив заданной формы и dtype. Он использует следующий конструктор —
numpy.empty(shape, dtype = float, order = 'C')
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
форма Форма пустого массива в int или кортеж int |
| 2 |
DTYPE Желаемый тип выходных данных. Необязательный |
| 3 |
порядок ‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN |
форма
Форма пустого массива в int или кортеж int
DTYPE
Желаемый тип выходных данных. Необязательный
порядок
‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN
пример
Следующий код показывает пример пустого массива.
import numpy as np x = np.empty([3,2], dtype = int) print x
Выход выглядит следующим образом —
[[22649312 1701344351] [1818321759 1885959276] [16779776 156368896]]
Примечание . Элементы в массиве показывают случайные значения, поскольку они не инициализированы.
numpy.zeros
Возвращает новый массив указанного размера, заполненный нулями.
numpy.zeros(shape, dtype = float, order = 'C')
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
форма Форма пустого массива в int или последовательность int |
| 2 |
DTYPE Желаемый тип выходных данных. Необязательный |
| 3 |
порядок ‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN |
форма
Форма пустого массива в int или последовательность int
DTYPE
Желаемый тип выходных данных. Необязательный
порядок
‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN
Пример 1
# array of five zeros. Default dtype is float import numpy as np x = np.zeros(5) print x
Выход выглядит следующим образом —
[ 0. 0. 0. 0. 0.]
Пример 2
import numpy as np x = np.zeros((5,), dtype = np.int) print x
Теперь результат будет следующим:
[0 0 0 0 0]
Пример 3
# custom type import numpy as np x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')]) print x
Он должен произвести следующий вывод —
[[(0,0)(0,0)] [(0,0)(0,0)]]
numpy.ones
Возвращает новый массив указанного размера и типа, заполненный единицами.
numpy.ones(shape, dtype = None, order = 'C')
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
форма Форма пустого массива в int или кортеж int |
| 2 |
DTYPE Желаемый тип выходных данных. Необязательный |
| 3 |
порядок ‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN |
форма
Форма пустого массива в int или кортеж int
DTYPE
Желаемый тип выходных данных. Необязательный
порядок
‘C’ для массива мажорных строк в стиле C, ‘F’ для массива мажорных столбцов в стиле FORTRAN
Пример 1
# array of five ones. Default dtype is float import numpy as np x = np.ones(5) print x
Выход выглядит следующим образом —
[ 1. 1. 1. 1. 1.]
Пример 2
import numpy as np x = np.ones([2,2], dtype = int) print x
Теперь результат будет следующим:
[[1 1] [1 1]]
NumPy — массив из существующих данных
В этой главе мы обсудим, как создать массив из существующих данных.
numpy.asarray
Эта функция похожа на numpy.array за исключением того, что она имеет меньше параметров. Эта процедура полезна для преобразования последовательности Python в ndarray.
numpy.asarray(a, dtype = None, order = None)
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Входные данные в любой форме, такие как список, список кортежей, кортежей, кортежей кортежей или кортежей списков |
| 2 |
DTYPE По умолчанию тип данных входных данных применяется к результирующему ndarray |
| 3 |
порядок C (основной ряд) или F (основной столбец). C по умолчанию |
Входные данные в любой форме, такие как список, список кортежей, кортежей, кортежей кортежей или кортежей списков
DTYPE
По умолчанию тип данных входных данных применяется к результирующему ndarray
порядок
C (основной ряд) или F (основной столбец). C по умолчанию
Следующие примеры показывают, как вы можете использовать функцию asarray .
Пример 1
# convert list to ndarray import numpy as np x = [1,2,3] a = np.asarray(x) print a
Его вывод будет следующим:
[1 2 3]
Пример 2
# dtype is set import numpy as np x = [1,2,3] a = np.asarray(x, dtype = float) print a
Теперь результат будет следующим:
[ 1. 2. 3.]
Пример 3
# ndarray from tuple import numpy as np x = (1,2,3) a = np.asarray(x) print a
Его вывод будет —
[1 2 3]
Пример 4
# ndarray from list of tuples import numpy as np x = [(1,2,3),(4,5)] a = np.asarray(x) print a
Здесь результат будет следующим:
[(1, 2, 3) (4, 5)]
numpy.frombuffer
Эта функция интерпретирует буфер как одномерный массив. Любой объект, который предоставляет интерфейс буфера, используется в качестве параметра для возврата ndarray .
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
буфер Любой объект, который предоставляет интерфейс буфера |
| 2 |
DTYPE Тип данных возвращается ndarray. По умолчанию плавать |
| 3 |
подсчитывать Количество элементов для чтения, по умолчанию -1 означает все данные |
| 4 |
смещение Начальная позиция для чтения. По умолчанию 0 |
буфер
Любой объект, который предоставляет интерфейс буфера
DTYPE
Тип данных возвращается ndarray. По умолчанию плавать
подсчитывать
Количество элементов для чтения, по умолчанию -1 означает все данные
смещение
Начальная позиция для чтения. По умолчанию 0
пример
Следующие примеры демонстрируют использование функции frombuffer .
import numpy as np s = 'Hello World' a = np.frombuffer(s, dtype = 'S1') print a
Вот его вывод —
['H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd']
numpy.fromiter
Эта функция создает объект ndarray из любого повторяемого объекта. Эта функция возвращает новый одномерный массив.
numpy.fromiter(iterable, dtype, count = -1)
Здесь конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
итерируемый Любой повторяемый объект |
| 2 |
DTYPE Тип данных результирующего массива |
| 3 |
подсчитывать Количество элементов для чтения из итератора. По умолчанию -1, что означает все данные для чтения |
итерируемый
Любой повторяемый объект
DTYPE
Тип данных результирующего массива
подсчитывать
Количество элементов для чтения из итератора. По умолчанию -1, что означает все данные для чтения
В следующих примерах показано, как использовать встроенную функцию range () для возврата объекта списка. Итератор этого списка используется для формирования объекта ndarray .
Пример 1
# create list object using range function import numpy as np list = range(5) print list
Его вывод выглядит следующим образом —
[0, 1, 2, 3, 4]
Пример 2
# obtain iterator object from list import numpy as np list = range(5) it = iter(list) # use iterator to create ndarray x = np.fromiter(it, dtype = float) print x
Теперь результат будет следующим:
[0. 1. 2. 3. 4.]
NumPy — массив из числовых диапазонов
В этой главе мы увидим, как создать массив из числовых диапазонов.
numpy.arange
Эта функция возвращает объект ndarray, содержащий равномерно распределенные значения в заданном диапазоне. Формат функции следующий:
numpy.arange(start, stop, step, dtype)
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Начните Начало интервала. Если опущено, по умолчанию 0 |
| 2 |
стоп Конец интервала (не включая это число) |
| 3 |
шаг Интервал между значениями, по умолчанию 1 |
| 4 |
DTYPE Тип данных результирующего ndarray. Если не указан, используется тип данных ввода |
Начните
Начало интервала. Если опущено, по умолчанию 0
стоп
Конец интервала (не включая это число)
шаг
Интервал между значениями, по умолчанию 1
DTYPE
Тип данных результирующего ndarray. Если не указан, используется тип данных ввода
Следующие примеры показывают, как вы можете использовать эту функцию.
Пример 1
import numpy as np x = np.arange(5) print x
Его вывод будет следующим:
[0 1 2 3 4]
Пример 2
import numpy as np # dtype set x = np.arange(5, dtype = float) print x
Здесь результат будет —
[0. 1. 2. 3. 4.]
Пример 3
# start and stop parameters set import numpy as np x = np.arange(10,20,2) print x
Его вывод выглядит следующим образом —
[10 12 14 16 18]
numpy.linspace
Эта функция похожа на функцию arange () . В этой функции вместо размера шага указывается количество равномерно распределенных значений между интервалами. Использование этой функции заключается в следующем —
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
Конструктор принимает следующие параметры.
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Начните Начальное значение последовательности |
| 2 |
стоп Конечное значение последовательности, включенное в последовательность, если конечная точка установлена в true |
| 3 |
Num Количество равномерно распределенных выборок, которые будут сгенерированы. По умолчанию 50 |
| 4 |
конечная точка Истинно по умолчанию, следовательно, значение стопа включено в последовательность. Если ложь, она не включена |
| 5 |
retstep Если true, возвращает образцы и шаг между последовательными числами |
| 6 |
DTYPE Тип данных вывода ndarray |
Начните
Начальное значение последовательности
стоп
Конечное значение последовательности, включенное в последовательность, если конечная точка установлена в true
Num
Количество равномерно распределенных выборок, которые будут сгенерированы. По умолчанию 50
конечная точка
Истинно по умолчанию, следовательно, значение стопа включено в последовательность. Если ложь, она не включена
retstep
Если true, возвращает образцы и шаг между последовательными числами
DTYPE
Тип данных вывода ndarray
Следующие примеры демонстрируют использование функции linspace .
Пример 1
import numpy as np x = np.linspace(10,20,5) print x
Его вывод будет —
[10. 12.5 15. 17.5 20.]
Пример 2
# endpoint set to false import numpy as np x = np.linspace(10,20, 5, endpoint = False) print x
Выход будет —
[10. 12. 14. 16. 18.]
Пример 3
# find retstep value import numpy as np x = np.linspace(1,2,5, retstep = True) print x # retstep here is 0.25
Теперь результат будет —
(array([ 1. , 1.25, 1.5 , 1.75, 2. ]), 0.25)
numpy.logspace
Эта функция возвращает объект ndarray, который содержит числа, равномерно распределенные в лог-масштабе. Начальные и конечные конечные точки шкалы — это индексы базы, обычно 10.
numpy.logspace(start, stop, num, endpoint, base, dtype)
Следующие параметры определяют вывод функции logspace .
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Начните Начальная точка последовательности — базовый старт |
| 2 |
стоп Конечное значение последовательности — базовый стоп |
| 3 |
Num Количество значений между диапазоном. По умолчанию 50 |
| 4 |
конечная точка Если true, стоп — это последнее значение в диапазоне |
| 5 |
база База пространства журнала, по умолчанию 10 |
| 6 |
DTYPE Тип данных выходного массива. Если не указан, это зависит от других входных аргументов |
Начните
Начальная точка последовательности — базовый старт
стоп
Конечное значение последовательности — базовый стоп
Num
Количество значений между диапазоном. По умолчанию 50
конечная точка
Если true, стоп — это последнее значение в диапазоне
база
База пространства журнала, по умолчанию 10
DTYPE
Тип данных выходного массива. Если не указан, это зависит от других входных аргументов
Следующие примеры помогут вам понять функцию logspace .
Пример 1
import numpy as np # default base is 10 a = np.logspace(1.0, 2.0, num = 10) print a
Его вывод будет следующим:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402 35.93813664 46.41588834 59.94842503 77.42636827 100. ]
Пример 2
# set base of log space to 2 import numpy as np a = np.logspace(1,10,num = 10, base = 2) print a
Теперь результат будет —
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
NumPy — индексирование и нарезка
Содержимое объекта ndarray может быть доступно и изменено путем индексации или нарезки, как и встроенные в Python контейнерные объекты.
Как упоминалось ранее, элементы в объекте ndarray следуют за индексом, начинающимся с нуля. Доступны три типа методов индексации — доступ к полям, базовое разделение и расширенное индексирование .
Базовая нарезка является расширением базовой концепции Python нарезки до n измерений. Объект среза Python создается путем предоставления параметров start, stop и step встроенной функции среза . Этот объект слайса передается в массив для извлечения части массива.
Пример 1
import numpy as np a = np.arange(10) s = slice(2,7,2) print a[s]
Его вывод выглядит следующим образом —
[2 4 6]
В приведенном выше примере объект ndarray подготавливается функцией arange () . Затем определяется объект среза со значениями start, stop и step 2, 7 и 2 соответственно. Когда этот объект слайса передается ndarray, часть его, начиная с индекса 2 до 7 с шагом 2, разрезается.
Тот же результат можно получить, передав параметры среза, разделенные двоеточием: (start: stop: step), непосредственно объекту ndarray .
Пример 2
import numpy as np a = np.arange(10) b = a[2:7:2] print b
Здесь мы получим тот же результат —
[2 4 6]
Если указан только один параметр, будет возвращен один элемент, соответствующий индексу. Если перед ним вставлен знак:, будут извлечены все элементы этого индекса. Если используются два параметра (с: между ними), элементы между двумя индексами (не включая стоп-индекс) с первым шагом по умолчанию нарезаются.
Пример 3
# slice single item import numpy as np a = np.arange(10) b = a[5] print b
Его вывод выглядит следующим образом —
5
Пример 4
# slice items starting from index import numpy as np a = np.arange(10) print a[2:]
Теперь результат будет —
[2 3 4 5 6 7 8 9]
Пример 5
# slice items between indexes import numpy as np a = np.arange(10) print a[2:5]
Здесь результат будет —
[2 3 4]
Вышеприведенное описание относится и к многомерному ndarray .
Пример 6
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print a # slice items starting from index print 'Now we will slice the array from the index a[1:]' print a[1:]
Выход выглядит следующим образом —
[[1 2 3] [3 4 5] [4 5 6]] Now we will slice the array from the index a[1:] [[3 4 5] [4 5 6]]
Срез также может включать многоточие (…), чтобы сделать кортеж выделения той же длины, что и размерность массива. Если многоточие используется в позиции строки, он вернет ndarray, состоящий из элементов в строках.
Пример 7
# array to begin with import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print 'Our array is:' print a print '\n' # this returns array of items in the second column print 'The items in the second column are:' print a[...,1] print '\n' # Now we will slice all items from the second row print 'The items in the second row are:' print a[1,...] print '\n' # Now we will slice all items from column 1 onwards print 'The items column 1 onwards are:' print a[...,1:]
Результат этой программы следующий:
Our array is: [[1 2 3] [3 4 5] [4 5 6]] The items in the second column are: [2 4 5] The items in the second row are: [3 4 5] The items column 1 onwards are: [[2 3] [4 5] [5 6]]
NumPy — расширенное индексирование
Можно сделать выбор из ndarray, который представляет собой последовательность, не являющуюся кортежем, ndarray-объект целочисленного или логического типа данных или кортеж, в котором хотя бы один элемент является объектом последовательности. Расширенная индексация всегда возвращает копию данных. В отличие от этого, нарезка представляет только представление.
Существует два типа расширенной индексации — Integer и Boolean .
Целочисленная индексация
Этот механизм помогает в выборе любого произвольного элемента в массиве на основе его N-мерного индекса. Каждый целочисленный массив представляет количество индексов в этом измерении. Когда индекс состоит из столько целочисленных массивов, сколько размеров целевого ndarray, он становится простым.
В следующем примере выбран один элемент указанного столбца из каждой строки объекта ndarray. Следовательно, индекс строки содержит все номера строк, а индекс столбца указывает элемент, который должен быть выбран.
Пример 1
import numpy as np x = np.array([[1, 2], [3, 4], [5, 6]]) y = x[[0,1,2], [0,1,0]] print y
Его вывод будет следующим:
[1 4 5]
Выбор включает в себя элементы в (0,0), (1,1) и (2,0) из первого массива.
В следующем примере выбираются элементы, расположенные по углам массива 4X3. Индексами выбора строк являются [0, 0] и [3,3], тогда как индексами столбцов являются [0,2] и [0,2].
Пример 2
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' rows = np.array([[0,0],[3,3]]) cols = np.array([[0,2],[0,2]]) y = x[rows,cols] print 'The corner elements of this array are:' print y
Результат этой программы следующий:
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] The corner elements of this array are: [[ 0 2] [ 9 11]]
Результирующий выбор представляет собой объект ndarray, содержащий угловые элементы.
Расширенное и базовое индексирование можно объединить с помощью одного фрагмента (:) или многоточия (…) с индексным массивом. В следующем примере используется слайс для строки и расширенный индекс для столбца. Результат одинаков, когда срез используется для обоих. Но расширенный индекс приводит к копированию и может иметь разную структуру памяти.
Пример 3
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' # slicing z = x[1:4,1:3] print 'After slicing, our array becomes:' print z print '\n' # using advanced index for column y = x[1:4,[1,2]] print 'Slicing using advanced index for column:' print y
Результат этой программы будет следующим:
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] After slicing, our array becomes: [[ 4 5] [ 7 8] [10 11]] Slicing using advanced index for column: [[ 4 5] [ 7 8] [10 11]]
Индексирование логических массивов
Этот тип расширенного индексирования используется, когда результирующий объект должен быть результатом булевых операций, таких как операторы сравнения.
Пример 1
В этом примере элементы больше 5 возвращаются в результате логического индексирования.
import numpy as np x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) print 'Our array is:' print x print '\n' # Now we will print the items greater than 5 print 'The items greater than 5 are:' print x[x > 5]
Результатом этой программы будет —
Our array is: [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] The items greater than 5 are: [ 6 7 8 9 10 11]
Пример 2
В этом примере элементы NaN (не число) опускаются с помощью ~ (оператор дополнения).
import numpy as np a = np.array([np.nan, 1,2,np.nan,3,4,5]) print a[~np.isnan(a)]
Его вывод будет —
[ 1. 2. 3. 4. 5.]
Пример 3
В следующем примере показано, как отфильтровать не сложные элементы из массива.
import numpy as np a = np.array([1, 2+6j, 5, 3.5+5j]) print a[np.iscomplex(a)]
Здесь вывод выглядит следующим образом —
[2.0+6.j 3.5+5.j]
NumPy — вещание
Термин широковещание относится к способности NumPy обрабатывать массивы различных форм во время арифметических операций. Арифметические операции над массивами обычно выполняются с соответствующими элементами. Если два массива имеют одинаковую форму, то эти операции выполняются плавно.
Пример 1
import numpy as np a = np.array([1,2,3,4]) b = np.array([10,20,30,40]) c = a * b print c
Его вывод выглядит следующим образом —
[10 40 90 160]
Если размеры двух массивов различны, операции элемент-элемент невозможны. Тем не менее, в NumPy все еще возможны операции с массивами не похожих форм из-за возможности вещания. Меньший массив передается по размеру большего массива, чтобы они имели совместимые формы.
Вещание возможно при соблюдении следующих правил:
-
Массив с меньшим значением ndim, чем другой, в начале имеет «1».
-
Размер в каждом измерении выходной формы является максимальным из входных размеров в этом измерении.
-
Входные данные могут использоваться в вычислениях, если его размер в определенном измерении соответствует выходному размеру или его значение точно равно 1.
-
Если вход имеет размерность измерения 1, первая запись данных в этом измерении используется для всех вычислений в этом измерении.
Массив с меньшим значением ndim, чем другой, в начале имеет «1».
Размер в каждом измерении выходной формы является максимальным из входных размеров в этом измерении.
Входные данные могут использоваться в вычислениях, если его размер в определенном измерении соответствует выходному размеру или его значение точно равно 1.
Если вход имеет размерность измерения 1, первая запись данных в этом измерении используется для всех вычислений в этом измерении.
Набор массивов считается транслируемым, если приведенные выше правила дают действительный результат, и одно из следующего верно:
-
Массивы имеют точно такую же форму.
-
Массивы имеют одинаковое количество измерений, а длина каждого измерения равна общей длине или 1.
-
Массив, имеющий слишком мало измерений, может иметь свою форму с добавлением размера длины 1, так что указанное выше свойство имеет значение true.
Массивы имеют точно такую же форму.
Массивы имеют одинаковое количество измерений, а длина каждого измерения равна общей длине или 1.
Массив, имеющий слишком мало измерений, может иметь свою форму с добавлением размера длины 1, так что указанное выше свойство имеет значение true.
Следующая программа показывает пример вещания.
Пример 2
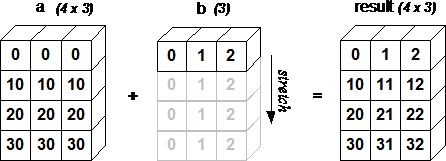
import numpy as np a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]]) b = np.array([1.0,2.0,3.0]) print 'First array:' print a print '\n' print 'Second array:' print b print '\n' print 'First Array + Second Array' print a + b
Результат этой программы будет следующим:
First array: [[ 0. 0. 0.] [ 10. 10. 10.] [ 20. 20. 20.] [ 30. 30. 30.]] Second array: [ 1. 2. 3.] First Array + Second Array [[ 1. 2. 3.] [ 11. 12. 13.] [ 21. 22. 23.] [ 31. 32. 33.]]
На следующем рисунке показано, как массив b транслируется, чтобы стать совместимым с a .
NumPy — перебор массива
Пакет NumPy содержит объект итератора numpy.nditer . Это эффективный многомерный объект-итератор, с помощью которого можно выполнять итерации по массиву. Каждый элемент массива посещается с использованием стандартного интерфейса итератора Python.
Давайте создадим массив 3X4 с помощью функции arange () и проведем итерацию по нему с помощью nditer .
Пример 1
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Modified array is:' for x in np.nditer(a): print x,
Результат этой программы следующий:
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: 0 5 10 15 20 25 30 35 40 45 50 55
Пример 2
Порядок итерации выбирается так, чтобы соответствовать макету памяти массива без учета конкретного порядка. Это можно увидеть, выполнив итерацию по транспонированному массиву.
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Transpose of the original array is:' b = a.T print b print '\n' print 'Modified array is:' for x in np.nditer(b): print x,
Вывод вышеуказанной программы следующий:
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Transpose of the original array is: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] Modified array is: 0 5 10 15 20 25 30 35 40 45 50 55
Порядок итерации
Если одни и те же элементы хранятся в порядке F-стиля, итератор выбирает более эффективный способ перебора массива.
Пример 1
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Transpose of the original array is:' b = a.T print b print '\n' print 'Sorted in C-style order:' c = b.copy(order='C') print c for x in np.nditer(c): print x, print '\n' print 'Sorted in F-style order:' c = b.copy(order='F') print c for x in np.nditer(c): print x,
Его вывод будет следующим:
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Transpose of the original array is: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] Sorted in C-style order: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] 0 20 40 5 25 45 10 30 50 15 35 55 Sorted in F-style order: [[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]] 0 5 10 15 20 25 30 35 40 45 50 55
Пример 2
Можно заставить объект nditer использовать определенный порядок, явно упомянув его.
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Sorted in C-style order:' for x in np.nditer(a, order = 'C'): print x, print '\n' print 'Sorted in F-style order:' for x in np.nditer(a, order = 'F'): print x,
Его вывод будет —
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Sorted in C-style order: 0 5 10 15 20 25 30 35 40 45 50 55 Sorted in F-style order: 0 20 40 5 25 45 10 30 50 15 35 55
Изменение значений массива
У объекта nditer есть еще один необязательный параметр, называемый op_flags . Его значение по умолчанию только для чтения, но может быть установлено в режим чтения-записи или только для записи. Это позволит изменять элементы массива с помощью этого итератора.
пример
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' for x in np.nditer(a, op_flags = ['readwrite']): x[...] = 2*x print 'Modified array is:' print a
Его вывод выглядит следующим образом —
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: [[ 0 10 20 30] [ 40 50 60 70] [ 80 90 100 110]]
Внешний цикл
Конструктор класса nditer имеет параметр flags , который может принимать следующие значения:
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
c_index Индекс C_order можно отслеживать |
| 2 |
f_index Индекс Fortran_order отслеживается |
| 3 |
многоиндексных Тип индексов с одним на итерацию можно отслеживать |
| 4 |
external_loop Вызывает значения, заданные как одномерные массивы с несколькими значениями вместо нульмерного массива |
c_index
Индекс C_order можно отслеживать
f_index
Индекс Fortran_order отслеживается
многоиндексных
Тип индексов с одним на итерацию можно отслеживать
external_loop
Вызывает значения, заданные как одномерные массивы с несколькими значениями вместо нульмерного массива
пример
В следующем примере итератор пересекает одномерные массивы, соответствующие каждому столбцу.
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'Original array is:' print a print '\n' print 'Modified array is:' for x in np.nditer(a, flags = ['external_loop'], order = 'F'): print x,
Выход выглядит следующим образом —
Original array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Modified array is: [ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55]
Вещательная итерация
Если два массива являются широковещательными , объединенный объект nditer может выполнять их итерацию одновременно. Предполагая, что массив a имеет размерность 3X4, и существует другой массив b размера 1X4, используется итератор следующего типа (массив b транслируется до размера a ).
пример
import numpy as np a = np.arange(0,60,5) a = a.reshape(3,4) print 'First array is:' print a print '\n' print 'Second array is:' b = np.array([1, 2, 3, 4], dtype = int) print b print '\n' print 'Modified array is:' for x,y in np.nditer([a,b]): print "%d:%d" % (x,y),
Его вывод будет следующим:
First array is: [[ 0 5 10 15] [20 25 30 35] [40 45 50 55]] Second array is: [1 2 3 4] Modified array is: 0:1 5:2 10:3 15:4 20:1 25:2 30:3 35:4 40:1 45:2 50:3 55:4
NumPy — Манипуляции с массивами
В пакете NumPy доступно несколько подпрограмм для манипулирования элементами в объекте ndarray. Они могут быть классифицированы на следующие типы —
Изменение формы
| Sr.No. | Форма и описание |
|---|---|
| 1 | перекроить
Придает массиву новую форму без изменения его данных |
| 2 | плоский
1-D итератор по массиву |
| 3 | расплющить
Возвращает копию массива, свернутого в одно измерение |
| 4 | запутывать
Возвращает непрерывный плоский массив |
Придает массиву новую форму без изменения его данных
1-D итератор по массиву
Возвращает копию массива, свернутого в одно измерение
Возвращает непрерывный плоский массив
Транспонировать операции
| Sr.No. | Операция и описание |
|---|---|
| 1 | транспонировать
Переставляет размеры массива |
| 2 | ndarray.T
То же, что self.transpose () |
| 3 | поперечный
Откатывает указанную ось назад |
| 4 | swapaxes
Меняет местами две оси массива |
Переставляет размеры массива
То же, что self.transpose ()
Откатывает указанную ось назад
Меняет местами две оси массива
Изменение размеров
| Sr.No. | Размер и описание |
|---|---|
| 1 | широковещательный
Создает объект, который имитирует вещание |
| 2 | broadcast_to
Трансляция массива в новую форму |
| 3 | expand_dims
Расширяет форму массива |
| 4 | выжимать
Удаляет одномерные записи из формы массива |
Создает объект, который имитирует вещание
Трансляция массива в новую форму
Расширяет форму массива
Удаляет одномерные записи из формы массива
Объединение массивов
| Sr.No. | Массив и описание |
|---|---|
| 1 | сцеплять
Объединяет последовательность массивов вдоль существующей оси |
| 2 | стек
Объединяет последовательность массивов вдоль новой оси |
| 3 | hstack
Составляет массивы в последовательности по горизонтали (по столбцам) |
| 4 | vstack
Устанавливает массивы в последовательности вертикально (по рядам) |
Объединяет последовательность массивов вдоль существующей оси
Объединяет последовательность массивов вдоль новой оси
Составляет массивы в последовательности по горизонтали (по столбцам)
Устанавливает массивы в последовательности вертикально (по рядам)
Расщепление массивов
| Sr.No. | Массив и описание |
|---|---|
| 1 | Трещина
Разбивает массив на несколько подмассивов |
| 2 | hsplit
Разбивает массив на несколько под-массивов по горизонтали (по столбцам) |
| 3 | vsplit
Разбивает массив на несколько подмассивов по вертикали (по строкам) |
Разбивает массив на несколько подмассивов
Разбивает массив на несколько под-массивов по горизонтали (по столбцам)
Разбивает массив на несколько подмассивов по вертикали (по строкам)
Добавление / удаление элементов
| Sr.No. | Элемент и описание |
|---|---|
| 1 | изменить размер
Возвращает новый массив с указанной формой |
| 2 | присоединять
Добавляет значения в конец массива |
| 3 | вставить
Вставляет значения вдоль заданной оси перед указанными индексами |
| 4 | удалять
Возвращает новый массив с удаленными вложенными массивами по оси |
| 5 | уникальный
Находит уникальные элементы массива |
Возвращает новый массив с указанной формой
Добавляет значения в конец массива
Вставляет значения вдоль заданной оси перед указанными индексами
Возвращает новый массив с удаленными вложенными массивами по оси
Находит уникальные элементы массива
NumPy — бинарные операторы
Ниже приведены функции для побитовых операций, доступные в пакете NumPy.
| Sr.No. | Операция и описание |
|---|---|
| 1 | bitwise_and
Вычисляет побитовое И операцию элементов массива |
| 2 | bitwise_or
Вычисляет побитовое ИЛИ операцию элементов массива |
| 3 | инвертировать
Вычисляет поразрядно НЕ |
| 4 | Сдвиг влево
Смещает биты двоичного представления влево |
| 5 | right_shift
Смещает биты двоичного представления вправо |
Вычисляет побитовое И операцию элементов массива
Вычисляет побитовое ИЛИ операцию элементов массива
Вычисляет поразрядно НЕ
Смещает биты двоичного представления влево
Смещает биты двоичного представления вправо
NumPy — Строковые функции
Следующие функции используются для выполнения векторизованных строковых операций для массивов dtype numpy.string_ или numpy.unicode_. Они основаны на стандартных строковых функциях встроенной библиотеки Python.
| Sr.No. | Описание функции |
|---|---|
| 1 | добавлять()
Возвращает поэлементную конкатенацию строк для двух массивов str или Unicode |
| 2 | многократно ()
Возвращает строку с множественной конкатенацией, поэлементно |
| 3 | центр()
Возвращает копию данной строки с элементами по центру в строке указанной длины |
| 4 | прописные буквы ()
Возвращает копию строки только с первым заглавным символом |
| 5 | заглавие()
Возвращает поэлементную заглавную версию строки или Unicode. |
| 6 | ниже ()
Возвращает массив с элементами, преобразованными в нижний регистр |
| 7 | Верхняя ()
Возвращает массив с элементами, преобразованными в верхний регистр |
| 8 | Трещина()
Возвращает список слов в строке, используя разделитель |
| 9 | splitlines ()
Возвращает список строк в элементе, ломающихся на границах строк |
| 10 | полоса ()
Возвращает копию с удаленными начальными и последними символами |
| 11 | присоединиться()
Возвращает строку, которая является объединением строк в последовательности |
| 12 | заменить ()
Возвращает копию строки со всеми вхождениями подстроки, замененной новой строкой |
| 13 | декодировать ()
Вызывает str.decode поэлементно |
| 14 | кодировать ()
Вызывает str.encode поэлементно |
Возвращает поэлементную конкатенацию строк для двух массивов str или Unicode
Возвращает строку с множественной конкатенацией, поэлементно
Возвращает копию данной строки с элементами по центру в строке указанной длины
Возвращает копию строки только с первым заглавным символом
Возвращает поэлементную заглавную версию строки или Unicode.
Возвращает массив с элементами, преобразованными в нижний регистр
Возвращает массив с элементами, преобразованными в верхний регистр
Возвращает список слов в строке, используя разделитель
Возвращает список строк в элементе, ломающихся на границах строк
Возвращает копию с удаленными начальными и последними символами
Возвращает строку, которая является объединением строк в последовательности
Возвращает копию строки со всеми вхождениями подстроки, замененной новой строкой
Вызывает str.decode поэлементно
Вызывает str.encode поэлементно
Эти функции определены в классе символьных массивов (numpy.char). Более старый пакет Numarray содержал класс chararray. Вышеуказанные функции в классе numpy.char полезны при выполнении векторизованных строковых операций.
NumPy — математические функции
Вполне понятно, что NumPy содержит большое количество различных математических операций. NumPy предоставляет стандартные тригонометрические функции, функции для арифметических операций, обработки комплексных чисел и т. Д.
Тригонометрические функции
NumPy имеет стандартные тригонометрические функции, которые возвращают тригонометрические отношения для данного угла в радианах.
пример
import numpy as np a = np.array([0,30,45,60,90]) print 'Sine of different angles:' # Convert to radians by multiplying with pi/180 print np.sin(a*np.pi/180) print '\n' print 'Cosine values for angles in array:' print np.cos(a*np.pi/180) print '\n' print 'Tangent values for given angles:' print np.tan(a*np.pi/180)
Вот его вывод —
Sine of different angles: [ 0. 0.5 0.70710678 0.8660254 1. ] Cosine values for angles in array: [ 1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01 6.12323400e-17] Tangent values for given angles: [ 0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00 1.63312394e+16]
Функции arcsin, arcos и arctan возвращают тригонометрическую обратную величину sin, cos и tan заданного угла. Результат этих функций может быть проверен функцией numpy.degrees () путем преобразования радиан в градусы.
пример
import numpy as np a = np.array([0,30,45,60,90]) print 'Array containing sine values:' sin = np.sin(a*np.pi/180) print sin print '\n' print 'Compute sine inverse of angles. Returned values are in radians.' inv = np.arcsin(sin) print inv print '\n' print 'Check result by converting to degrees:' print np.degrees(inv) print '\n' print 'arccos and arctan functions behave similarly:' cos = np.cos(a*np.pi/180) print cos print '\n' print 'Inverse of cos:' inv = np.arccos(cos) print inv print '\n' print 'In degrees:' print np.degrees(inv) print '\n' print 'Tan function:' tan = np.tan(a*np.pi/180) print tan print '\n' print 'Inverse of tan:' inv = np.arctan(tan) print inv print '\n' print 'In degrees:' print np.degrees(inv)
Его вывод выглядит следующим образом —
Array containing sine values: [ 0. 0.5 0.70710678 0.8660254 1. ] Compute sine inverse of angles. Returned values are in radians. [ 0. 0.52359878 0.78539816 1.04719755 1.57079633] Check result by converting to degrees: [ 0. 30. 45. 60. 90.] arccos and arctan functions behave similarly: [ 1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01 6.12323400e-17] Inverse of cos: [ 0. 0.52359878 0.78539816 1.04719755 1.57079633] In degrees: [ 0. 30. 45. 60. 90.] Tan function: [ 0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00 1.63312394e+16] Inverse of tan: [ 0. 0.52359878 0.78539816 1.04719755 1.57079633] In degrees: [ 0. 30. 45. 60. 90.]
Функции для округления
numpy.around ()
Это функция, которая возвращает значение, округленное до желаемой точности. Функция принимает следующие параметры.
numpy.around(a,decimals)
Куда,
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Входные данные |
| 2 |
десятичные Количество десятичных знаков, округляемых до. По умолчанию 0. Если отрицательное, целое число округляется до позиции слева от десятичной точки |
Входные данные
десятичные
Количество десятичных знаков, округляемых до. По умолчанию 0. Если отрицательное, целое число округляется до позиции слева от десятичной точки
пример
import numpy as np a = np.array([1.0,5.55, 123, 0.567, 25.532]) print 'Original array:' print a print '\n' print 'After rounding:' print np.around(a) print np.around(a, decimals = 1) print np.around(a, decimals = -1)
Он производит следующий вывод —
Original array: [ 1. 5.55 123. 0.567 25.532] After rounding: [ 1. 6. 123. 1. 26. ] [ 1. 5.6 123. 0.6 25.5] [ 0. 10. 120. 0. 30. ]
numpy.floor ()
Эта функция возвращает наибольшее целое число, не превышающее входной параметр. Пол скаляра x является наибольшим целым числом i , так что i <= x . Обратите внимание, что в Python пол всегда округляется от 0.
пример
import numpy as np a = np.array([-1.7, 1.5, -0.2, 0.6, 10]) print 'The given array:' print a print '\n' print 'The modified array:' print np.floor(a)
Он производит следующий вывод —
The given array: [ -1.7 1.5 -0.2 0.6 10. ] The modified array: [ -2. 1. -1. 0. 10.]
numpy.ceil ()
Функция ceil () возвращает верхний предел входного значения, т. Е. Ceil скаляра x — это наименьшее целое число i , такое что i> = x.
пример
import numpy as np a = np.array([-1.7, 1.5, -0.2, 0.6, 10]) print 'The given array:' print a print '\n' print 'The modified array:' print np.ceil(a)
Это даст следующий результат —
The given array: [ -1.7 1.5 -0.2 0.6 10. ] The modified array: [ -1. 2. -0. 1. 10.]
NumPy — Арифметические операции
Входные массивы для выполнения арифметических операций, таких как add (), subtract (), multiply () и split (), должны иметь одинаковую форму или соответствовать правилам вещания массива.
пример
import numpy as np a = np.arange(9, dtype = np.float_).reshape(3,3) print 'First array:' print a print '\n' print 'Second array:' b = np.array([10,10,10]) print b print '\n' print 'Add the two arrays:' print np.add(a,b) print '\n' print 'Subtract the two arrays:' print np.subtract(a,b) print '\n' print 'Multiply the two arrays:' print np.multiply(a,b) print '\n' print 'Divide the two arrays:' print np.divide(a,b)
Это даст следующий результат —
First array: [[ 0. 1. 2.] [ 3. 4. 5.] [ 6. 7. 8.]] Second array: [10 10 10] Add the two arrays: [[ 10. 11. 12.] [ 13. 14. 15.] [ 16. 17. 18.]] Subtract the two arrays: [[-10. -9. -8.] [ -7. -6. -5.] [ -4. -3. -2.]] Multiply the two arrays: [[ 0. 10. 20.] [ 30. 40. 50.] [ 60. 70. 80.]] Divide the two arrays: [[ 0. 0.1 0.2] [ 0.3 0.4 0.5] [ 0.6 0.7 0.8]]
Давайте теперь обсудим некоторые другие важные арифметические функции, доступные в NumPy.
numpy.reciprocal ()
Эта функция возвращает обратную аргумент, поэлементно. Для элементов с абсолютными значениями больше 1 результат всегда равен 0 из-за способа, которым Python обрабатывает целочисленное деление. Для целого числа 0 выдается предупреждение о переполнении.
пример
import numpy as np a = np.array([0.25, 1.33, 1, 0, 100]) print 'Our array is:' print a print '\n' print 'After applying reciprocal function:' print np.reciprocal(a) print '\n' b = np.array([100], dtype = int) print 'The second array is:' print b print '\n' print 'After applying reciprocal function:' print np.reciprocal(b)
Это даст следующий результат —
Our array is: [ 0.25 1.33 1. 0. 100. ] After applying reciprocal function: main.py:9: RuntimeWarning: divide by zero encountered in reciprocal print np.reciprocal(a) [ 4. 0.7518797 1. inf 0.01 ] The second array is: [100] After applying reciprocal function: [0]
numpy.power ()
Эта функция обрабатывает элементы в первом входном массиве как базовые и возвращает их в степени соответствующего элемента во втором входном массиве.
import numpy as np a = np.array([10,100,1000]) print 'Our array is:' print a print '\n' print 'Applying power function:' print np.power(a,2) print '\n' print 'Second array:' b = np.array([1,2,3]) print b print '\n' print 'Applying power function again:' print np.power(a,b)
Это даст следующий результат —
Our array is: [ 10 100 1000] Applying power function: [ 100 10000 1000000] Second array: [1 2 3] Applying power function again: [ 10 10000 1000000000]
numpy.mod ()
Эта функция возвращает остаток от деления соответствующих элементов во входном массиве. Функция numpy.remainder () также выдает тот же результат.
import numpy as np a = np.array([10,20,30]) b = np.array([3,5,7]) print 'First array:' print a print '\n' print 'Second array:' print b print '\n' print 'Applying mod() function:' print np.mod(a,b) print '\n' print 'Applying remainder() function:' print np.remainder(a,b)
Это даст следующий результат —
First array: [10 20 30] Second array: [3 5 7] Applying mod() function: [1 0 2] Applying remainder() function: [1 0 2]
Следующие функции используются для выполнения операций над массивом с комплексными числами.
-
numpy.real () — возвращает действительную часть аргумента сложного типа данных.
-
numpy.imag () — возвращает мнимую часть аргумента сложного типа данных.
-
numpy.conj () — возвращает комплексное сопряжение, полученное путем изменения знака мнимой части.
-
numpy.angle () — возвращает угол сложного аргумента. Функция имеет параметр степени. Если это правда, угол в градусах возвращается, в противном случае угол в радианах.
numpy.real () — возвращает действительную часть аргумента сложного типа данных.
numpy.imag () — возвращает мнимую часть аргумента сложного типа данных.
numpy.conj () — возвращает комплексное сопряжение, полученное путем изменения знака мнимой части.
numpy.angle () — возвращает угол сложного аргумента. Функция имеет параметр степени. Если это правда, угол в градусах возвращается, в противном случае угол в радианах.
import numpy as np a = np.array([-5.6j, 0.2j, 11. , 1+1j]) print 'Our array is:' print a print '\n' print 'Applying real() function:' print np.real(a) print '\n' print 'Applying imag() function:' print np.imag(a) print '\n' print 'Applying conj() function:' print np.conj(a) print '\n' print 'Applying angle() function:' print np.angle(a) print '\n' print 'Applying angle() function again (result in degrees)' print np.angle(a, deg = True)
Это даст следующий результат —
Our array is: [ 0.-5.6j 0.+0.2j 11.+0.j 1.+1.j ] Applying real() function: [ 0. 0. 11. 1.] Applying imag() function: [-5.6 0.2 0. 1. ] Applying conj() function: [ 0.+5.6j 0.-0.2j 11.-0.j 1.-1.j ] Applying angle() function: [-1.57079633 1.57079633 0. 0.78539816] Applying angle() function again (result in degrees) [-90. 90. 0. 45.]
NumPy — Статистические функции
NumPy имеет довольно много полезных статистических функций для нахождения минимального, максимального, процентильного стандартного отклонения и дисперсии и т. Д. Из заданных элементов в массиве. Функции объясняются следующим образом:
numpy.amin () и numpy.amax ()
Эти функции возвращают минимум и максимум из элементов данного массива вдоль указанной оси.
пример
import numpy as np a = np.array([[3,7,5],[8,4,3],[2,4,9]]) print 'Our array is:' print a print '\n' print 'Applying amin() function:' print np.amin(a,1) print '\n' print 'Applying amin() function again:' print np.amin(a,0) print '\n' print 'Applying amax() function:' print np.amax(a) print '\n' print 'Applying amax() function again:' print np.amax(a, axis = 0)
Это даст следующий результат —
Our array is: [[3 7 5] [8 4 3] [2 4 9]] Applying amin() function: [3 3 2] Applying amin() function again: [2 4 3] Applying amax() function: 9 Applying amax() function again: [8 7 9]
numpy.ptp ()
Функция numpy.ptp () возвращает диапазон (максимум-минимум) значений вдоль оси.
import numpy as np a = np.array([[3,7,5],[8,4,3],[2,4,9]]) print 'Our array is:' print a print '\n' print 'Applying ptp() function:' print np.ptp(a) print '\n' print 'Applying ptp() function along axis 1:' print np.ptp(a, axis = 1) print '\n' print 'Applying ptp() function along axis 0:' print np.ptp(a, axis = 0)
Это даст следующий результат —
Our array is: [[3 7 5] [8 4 3] [2 4 9]] Applying ptp() function: 7 Applying ptp() function along axis 1: [4 5 7] Applying ptp() function along axis 0: [6 3 6]
numpy.percentile ()
Процентиль (или процентиль) — это показатель, используемый в статистике, показывающий значение, ниже которого падает определенный процент наблюдений в группе наблюдений. Функция numpy.percentile () принимает следующие аргументы.
numpy.percentile(a, q, axis)
Куда,
| Sr.No. | Аргумент и описание |
|---|---|
| 1 |
Входной массив |
| 2 |
Q Процент для вычисления должен быть между 0-100 |
| 3 |
ось Ось, по которой рассчитывается процентиль |
Входной массив
Q
Процент для вычисления должен быть между 0-100
ось
Ось, по которой рассчитывается процентиль
пример
import numpy as np a = np.array([[30,40,70],[80,20,10],[50,90,60]]) print 'Our array is:' print a print '\n' print 'Applying percentile() function:' print np.percentile(a,50) print '\n' print 'Applying percentile() function along axis 1:' print np.percentile(a,50, axis = 1) print '\n' print 'Applying percentile() function along axis 0:' print np.percentile(a,50, axis = 0)
Это даст следующий результат —
Our array is: [[30 40 70] [80 20 10] [50 90 60]] Applying percentile() function: 50.0 Applying percentile() function along axis 1: [ 40. 20. 60.] Applying percentile() function along axis 0: [ 50. 40. 60.]
numpy.median ()
Медиана определяется как значение, отделяющее верхнюю половину выборки данных от нижней. Функция numpy.median () используется, как показано в следующей программе.
пример
import numpy as np a = np.array([[30,65,70],[80,95,10],[50,90,60]]) print 'Our array is:' print a print '\n' print 'Applying median() function:' print np.median(a) print '\n' print 'Applying median() function along axis 0:' print np.median(a, axis = 0) print '\n' print 'Applying median() function along axis 1:' print np.median(a, axis = 1)
Это даст следующий результат —
Our array is: [[30 65 70] [80 95 10] [50 90 60]] Applying median() function: 65.0 Applying median() function along axis 0: [ 50. 90. 60.] Applying median() function along axis 1: [ 65. 80. 60.]
numpy.mean ()
Среднее арифметическое — это сумма элементов вдоль оси, деленная на количество элементов. Функция numpy.mean () возвращает среднее арифметическое значений элементов в массиве. Если ось упоминается, она рассчитывается вдоль нее.
пример
import numpy as np a = np.array([[1,2,3],[3,4,5],[4,5,6]]) print 'Our array is:' print a print '\n' print 'Applying mean() function:' print np.mean(a) print '\n' print 'Applying mean() function along axis 0:' print np.mean(a, axis = 0) print '\n' print 'Applying mean() function along axis 1:' print np.mean(a, axis = 1)
Это даст следующий результат —
Our array is: [[1 2 3] [3 4 5] [4 5 6]] Applying mean() function: 3.66666666667 Applying mean() function along axis 0: [ 2.66666667 3.66666667 4.66666667] Applying mean() function along axis 1: [ 2. 4. 5.]
numpy.average ()
Средневзвешенное значение — это среднее значение, полученное в результате умножения каждого компонента на коэффициент, отражающий его важность. Функция numpy.average () вычисляет средневзвешенное значение элементов в массиве в соответствии с их весом, заданным в другом массиве. Функция может иметь параметр оси. Если ось не указана, массив выравнивается.
С учетом массива [1,2,3,4] и соответствующих весов [4,3,2,1] средневзвешенное значение рассчитывается путем сложения произведения соответствующих элементов и деления суммы на сумму весов.
Средневзвешенное значение = (1 * 4 + 2 * 3 + 3 * 2 + 4 * 1) / (4 + 3 + 2 + 1)
пример
import numpy as np a = np.array([1,2,3,4]) print 'Our array is:' print a print '\n' print 'Applying average() function:' print np.average(a) print '\n' # this is same as mean when weight is not specified wts = np.array([4,3,2,1]) print 'Applying average() function again:' print np.average(a,weights = wts) print '\n' # Returns the sum of weights, if the returned parameter is set to True. print 'Sum of weights' print np.average([1,2,3, 4],weights = [4,3,2,1], returned = True)
Это даст следующий результат —
Our array is: [1 2 3 4] Applying average() function: 2.5 Applying average() function again: 2.0 Sum of weights (2.0, 10.0)
В многомерном массиве можно указать ось для вычисления.
пример
import numpy as np a = np.arange(6).reshape(3,2) print 'Our array is:' print a print '\n' print 'Modified array:' wt = np.array([3,5]) print np.average(a, axis = 1, weights = wt) print '\n' print 'Modified array:' print np.average(a, axis = 1, weights = wt, returned = True)
Это даст следующий результат —
Our array is: [[0 1] [2 3] [4 5]] Modified array: [ 0.625 2.625 4.625] Modified array: (array([ 0.625, 2.625, 4.625]), array([ 8., 8., 8.]))
Стандартное отклонение
Стандартное отклонение — это квадратный корень из среднего квадрата отклонений от среднего. Формула для стандартного отклонения выглядит следующим образом:
std = sqrt(mean(abs(x - x.mean())**2))
Если массив [1, 2, 3, 4], то его среднее значение равно 2,5. Следовательно, квадратичные отклонения составляют [2,25, 0,25, 0,25, 2,25], а квадратный корень из его среднего значения делится на 4, т. Е. Sqrt (5/4) составляет 1.1180339887498949.
пример
import numpy as np print np.std([1,2,3,4])
Это даст следующий результат —
1.1180339887498949
отклонение
Дисперсия — это среднее квадратов отклонений, т. Е. Среднее (abs (x — x.mean ()) ** 2) . Другими словами, стандартное отклонение является квадратным корнем дисперсии.
пример
import numpy as np print np.var([1,2,3,4])
Это даст следующий результат —
1.25
NumPy — функции сортировки, поиска и подсчета
В NumPy доступны различные функции, связанные с сортировкой. Эти функции сортировки реализуют различные алгоритмы сортировки, каждый из которых характеризуется скоростью выполнения, наихудшей производительностью, требуемым рабочим пространством и стабильностью алгоритмов. Следующая таблица показывает сравнение трех алгоритмов сортировки.
| Добрый | скорость | худший случай | рабочая среда | стабильный |
|---|---|---|---|---|
| «Быстрой сортировки» | 1 | O (N ^ 2) | 0 | нет |
| ‘Сортировка слиянием’ | 2 | О (п * журнала (п)) | ~ П / 2 | да |
| «Пирамидальная сортировка» | 3 | О (п * журнала (п)) | 0 | нет |
numpy.sort ()
Функция sort () возвращает отсортированную копию входного массива. Имеет следующие параметры —
numpy.sort(a, axis, kind, order)
Куда,
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
Массив для сортировки |
| 2 |
ось Ось, по которой должен быть отсортирован массив. Если нет, массив выравнивается, сортируется по последней оси |
| 3 |
Добрый По умолчанию это быстрая сортировка |
| 4 |
порядок Если массив содержит поля, порядок сортировки полей |
Массив для сортировки
ось
Ось, по которой должен быть отсортирован массив. Если нет, массив выравнивается, сортируется по последней оси
Добрый
По умолчанию это быстрая сортировка
порядок
Если массив содержит поля, порядок сортировки полей
пример
import numpy as np a = np.array([[3,7],[9,1]]) print 'Our array is:' print a print '\n' print 'Applying sort() function:' print np.sort(a) print '\n' print 'Sort along axis 0:' print np.sort(a, axis = 0) print '\n' # Order parameter in sort function dt = np.dtype([('name', 'S10'),('age', int)]) a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt) print 'Our array is:' print a print '\n' print 'Order by name:' print np.sort(a, order = 'name')
Это даст следующий результат —
Our array is:
[[3 7]
[9 1]]
Applying sort() function:
[[3 7]
[1 9]]
Sort along axis 0:
[[3 1]
[9 7]]
Our array is:
[('raju', 21) ('anil', 25) ('ravi', 17) ('amar', 27)]
Order by name:
[('amar', 27) ('anil', 25) ('raju', 21) ('ravi', 17)]
numpy.argsort ()
Функция numpy.argsort () выполняет косвенную сортировку входного массива вдоль заданной оси и использует указанный вид сортировки для возврата массива индексов данных. Этот массив индексов используется для построения отсортированного массива.
пример
import numpy as np x = np.array([3, 1, 2]) print 'Our array is:' print x print '\n' print 'Applying argsort() to x:' y = np.argsort(x) print y print '\n' print 'Reconstruct original array in sorted order:' print x[y] print '\n' print 'Reconstruct the original array using loop:' for i in y: print x[i],
Это даст следующий результат —
Our array is: [3 1 2] Applying argsort() to x: [1 2 0] Reconstruct original array in sorted order: [1 2 3] Reconstruct the original array using loop: 1 2 3
numpy.lexsort ()
Функция выполняет косвенную сортировку с использованием последовательности клавиш. Ключи можно увидеть в виде столбца в электронной таблице. Функция возвращает массив индексов, по которому можно получить отсортированные данные. Обратите внимание, что последний ключ является первичным ключом сортировки.
пример
import numpy as np nm = ('raju','anil','ravi','amar') dv = ('f.y.', 's.y.', 's.y.', 'f.y.') ind = np.lexsort((dv,nm)) print 'Applying lexsort() function:' print ind print '\n' print 'Use this index to get sorted data:' print [nm[i] + ", " + dv[i] for i in ind]
Это даст следующий результат —
Applying lexsort() function: [3 1 0 2] Use this index to get sorted data: ['amar, f.y.', 'anil, s.y.', 'raju, f.y.', 'ravi, s.y.']
Модуль NumPy имеет ряд функций для поиска внутри массива. Доступны функции для нахождения максимума, минимума, а также элементы, удовлетворяющие заданному условию.
numpy.argmax () и numpy.argmin ()
Эти две функции возвращают индексы максимального и минимального элементов соответственно вдоль заданной оси.
пример
import numpy as np a = np.array([[30,40,70],[80,20,10],[50,90,60]]) print 'Our array is:' print a print '\n' print 'Applying argmax() function:' print np.argmax(a) print '\n' print 'Index of maximum number in flattened array' print a.flatten() print '\n' print 'Array containing indices of maximum along axis 0:' maxindex = np.argmax(a, axis = 0) print maxindex print '\n' print 'Array containing indices of maximum along axis 1:' maxindex = np.argmax(a, axis = 1) print maxindex print '\n' print 'Applying argmin() function:' minindex = np.argmin(a) print minindex print '\n' print 'Flattened array:' print a.flatten()[minindex] print '\n' print 'Flattened array along axis 0:' minindex = np.argmin(a, axis = 0) print minindex print '\n' print 'Flattened array along axis 1:' minindex = np.argmin(a, axis = 1) print minindex
Это даст следующий результат —
Our array is: [[30 40 70] [80 20 10] [50 90 60]] Applying argmax() function: 7 Index of maximum number in flattened array [30 40 70 80 20 10 50 90 60] Array containing indices of maximum along axis 0: [1 2 0] Array containing indices of maximum along axis 1: [2 0 1] Applying argmin() function: 5 Flattened array: 10 Flattened array along axis 0: [0 1 1] Flattened array along axis 1: [0 2 0]
numpy.nonzero ()
Функция numpy.nonzero () возвращает индексы ненулевых элементов во входном массиве.
пример
import numpy as np a = np.array([[30,40,0],[0,20,10],[50,0,60]]) print 'Our array is:' print a print '\n' print 'Applying nonzero() function:' print np.nonzero (a)
Это даст следующий результат —
Our array is: [[30 40 0] [ 0 20 10] [50 0 60]] Applying nonzero() function: (array([0, 0, 1, 1, 2, 2]), array([0, 1, 1, 2, 0, 2]))
numpy.where ()
Функция where () возвращает индексы элементов во входном массиве, где заданное условие выполняется.
пример
import numpy as np x = np.arange(9.).reshape(3, 3) print 'Our array is:' print x print 'Indices of elements > 3' y = np.where(x > 3) print y print 'Use these indices to get elements satisfying the condition' print x[y]
Это даст следующий результат —
Our array is: [[ 0. 1. 2.] [ 3. 4. 5.] [ 6. 7. 8.]] Indices of elements > 3 (array([1, 1, 2, 2, 2]), array([1, 2, 0, 1, 2])) Use these indices to get elements satisfying the condition [ 4. 5. 6. 7. 8.]
numpy.extract ()
Функция extract () возвращает элементы, удовлетворяющие любому условию.
import numpy as np x = np.arange(9.).reshape(3, 3) print 'Our array is:' print x # define a condition condition = np.mod(x,2) == 0 print 'Element-wise value of condition' print condition print 'Extract elements using condition' print np.extract(condition, x)
Это даст следующий результат —
Our array is: [[ 0. 1. 2.] [ 3. 4. 5.] [ 6. 7. 8.]] Element-wise value of condition [[ True False True] [False True False] [ True False True]] Extract elements using condition [ 0. 2. 4. 6. 8.]
NumPy — перестановка байтов
Мы видели, что данные, хранящиеся в памяти компьютера, зависят от того, какую архитектуру использует процессор. Это может быть порядок с прямым порядком байтов (наименее значимый хранится в наименьшем адресе) или порядок с прямым порядком байтов (старший значащий байт в наименьшем адресе)
numpy.ndarray.byteswap ()
Функция numpy.ndarray.byteswap () переключает между двумя представлениями: bigendian и little-endian.
import numpy as np a = np.array([1, 256, 8755], dtype = np.int16) print 'Our array is:' print a print 'Representation of data in memory in hexadecimal form:' print map(hex,a) # byteswap() function swaps in place by passing True parameter print 'Applying byteswap() function:' print a.byteswap(True) print 'In hexadecimal form:' print map(hex,a) # We can see the bytes being swapped
Это даст следующий результат —
Our array is: [1 256 8755] Representation of data in memory in hexadecimal form: ['0x1', '0x100', '0x2233'] Applying byteswap() function: [256 1 13090] In hexadecimal form: ['0x100', '0x1', '0x3322']
NumPy — копии и просмотры
При выполнении функций некоторые из них возвращают копию входного массива, а некоторые возвращают представление. Когда содержимое физически хранится в другом месте, оно называется Копировать . С другой стороны, если предоставляется другое представление того же содержимого памяти, мы называем его представлением .
Нет копии
Простые назначения не делают копию объекта массива. Вместо этого он использует тот же id () исходного массива для доступа к нему. Id () возвращает универсальный идентификатор объекта Python, аналогичный указателю в C.
Кроме того, любые изменения в одном отражаются в другом. Например, изменение формы одного также изменит форму другого.
пример
import numpy as np a = np.arange(6) print 'Our array is:' print a print 'Applying id() function:' print id(a) print 'a is assigned to b:' b = a print b print 'b has same id():' print id(b) print 'Change shape of b:' b.shape = 3,2 print b print 'Shape of a also gets changed:' print a
Это даст следующий результат —
Our array is: [0 1 2 3 4 5] Applying id() function: 139747815479536 a is assigned to b: [0 1 2 3 4 5] b has same id(): 139747815479536 Change shape of b: [[0 1] [2 3] [4 5]] Shape of a also gets changed: [[0 1] [2 3] [4 5]]
Просмотр или мелкая копия
NumPy имеет метод ndarray.view (), который представляет собой новый объект массива, который просматривает те же данные исходного массива. В отличие от предыдущего случая, изменение размеров нового массива не меняет размеры оригинала.
пример
import numpy as np # To begin with, a is 3X2 array a = np.arange(6).reshape(3,2) print 'Array a:' print a print 'Create view of a:' b = a.view() print b print 'id() for both the arrays are different:' print 'id() of a:' print id(a) print 'id() of b:' print id(b) # Change the shape of b. It does not change the shape of a b.shape = 2,3 print 'Shape of b:' print b print 'Shape of a:' print a
Это даст следующий результат —
Array a: [[0 1] [2 3] [4 5]] Create view of a: [[0 1] [2 3] [4 5]] id() for both the arrays are different: id() of a: 140424307227264 id() of b: 140424151696288 Shape of b: [[0 1 2] [3 4 5]] Shape of a: [[0 1] [2 3] [4 5]]
Срез массива создает вид.
пример
import numpy as np a = np.array([[10,10], [2,3], [4,5]]) print 'Our array is:' print a print 'Create a slice:' s = a[:, :2] print s
Это даст следующий результат —
Our array is: [[10 10] [ 2 3] [ 4 5]] Create a slice: [[10 10] [ 2 3] [ 4 5]]
Deep Copy
Функция ndarray.copy () создает глубокую копию. Это полная копия массива и его данных, которая не разделяется с исходным массивом.
пример
import numpy as np a = np.array([[10,10], [2,3], [4,5]]) print 'Array a is:' print a print 'Create a deep copy of a:' b = a.copy() print 'Array b is:' print b #b does not share any memory of a print 'Can we write b is a' print b is a print 'Change the contents of b:' b[0,0] = 100 print 'Modified array b:' print b print 'a remains unchanged:' print a
Это даст следующий результат —
Array a is: [[10 10] [ 2 3] [ 4 5]] Create a deep copy of a: Array b is: [[10 10] [ 2 3] [ 4 5]] Can we write b is a False Change the contents of b: Modified array b: [[100 10] [ 2 3] [ 4 5]] a remains unchanged: [[10 10] [ 2 3] [ 4 5]]
NumPy — матричная библиотека
Пакет NumPy содержит библиотеку Matrix numpy.matlib . Этот модуль имеет функции, которые возвращают матрицы вместо ndarray объектов.
matlib.empty ()
Функция matlib.empty () возвращает новую матрицу без инициализации записей. Функция принимает следующие параметры.
numpy.matlib.empty(shape, dtype, order)
Куда,
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
форма int или кортеж int, определяющий форму новой матрицы |
| 2 |
DTYPE Необязательный. Тип данных вывода |
| 3 |
порядок C или F |
форма
int или кортеж int, определяющий форму новой матрицы
DTYPE
Необязательный. Тип данных вывода
порядок
C или F
пример
import numpy.matlib import numpy as np print np.matlib.empty((2,2)) # filled with random data
Это даст следующий результат —
[[ 2.12199579e-314, 4.24399158e-314] [ 4.24399158e-314, 2.12199579e-314]]
numpy.matlib.zeros ()
Эта функция возвращает матрицу, заполненную нулями.
import numpy.matlib import numpy as np print np.matlib.zeros((2,2))
Это даст следующий результат —
[[ 0. 0.] [ 0. 0.]]
numpy.matlib.ones ()
Эта функция возвращает матрицу, заполненную 1 с.
import numpy.matlib import numpy as np print np.matlib.ones((2,2))
Это даст следующий результат —
[[ 1. 1.] [ 1. 1.]]
numpy.matlib.eye ()
Эта функция возвращает матрицу с 1 вдоль диагональных элементов и нулями в других местах. Функция принимает следующие параметры.
numpy.matlib.eye(n, M,k, dtype)
Куда,
| Sr.No. | Параметр и описание |
|---|---|
| 1 |
N Количество строк в результирующей матрице |
| 2 |
M Количество столбцов, по умолчанию n |
| 3 |
К Индекс диагонали |
| 4 |
DTYPE Тип данных вывода |
N
Количество строк в результирующей матрице
M
Количество столбцов, по умолчанию n
К
Индекс диагонали
DTYPE
Тип данных вывода
пример
import numpy.matlib import numpy as np print np.matlib.eye(n = 3, M = 4, k = 0, dtype = float)
Это даст следующий результат —
[[ 1. 0. 0. 0.] [ 0. 1. 0. 0.] [ 0. 0. 1. 0.]]
numpy.matlib.identity ()
Функция numpy.matlib.identity () возвращает матрицу идентификаторов заданного размера. Тождественная матрица — это квадратная матрица со всеми диагональными элементами, равными 1.
import numpy.matlib import numpy as np print np.matlib.identity(5, dtype = float)
Это даст следующий результат —
[[ 1. 0. 0. 0. 0.] [ 0. 1. 0. 0. 0.] [ 0. 0. 1. 0. 0.] [ 0. 0. 0. 1. 0.] [ 0. 0. 0. 0. 1.]]
numpy.matlib.rand ()
Функция numpy.matlib.rand () возвращает матрицу заданного размера, заполненную случайными значениями.
пример
import numpy.matlib import numpy as np print np.matlib.rand(3,3)
Это даст следующий результат —
[[ 0.82674464 0.57206837 0.15497519] [ 0.33857374 0.35742401 0.90895076] [ 0.03968467 0.13962089 0.39665201]]
Обратите внимание, что матрица всегда двумерна, тогда как ndarray — это n-мерный массив. Оба объекта являются взаимно конвертируемыми.
пример
import numpy.matlib import numpy as np i = np.matrix('1,2;3,4') print i
Это даст следующий результат —
[[1 2] [3 4]]
пример
import numpy.matlib import numpy as np j = np.asarray(i) print j
Это даст следующий результат —
[[1 2] [3 4]]
пример
import numpy.matlib import numpy as np k = np.asmatrix (j) print k
Это даст следующий результат —
[[1 2] [3 4]]
NumPy — линейная алгебра
Пакет NumPy содержит модуль numpy.linalg, который обеспечивает все функции, необходимые для линейной алгебры. Некоторые важные функции этого модуля описаны в следующей таблице.
| Sr.No. | Описание функции |
|---|---|
| 1 | точка
Точечный продукт двух массивов |
| 2 | VDOT
Точечное произведение двух векторов |
| 3 | внутренний
Внутреннее произведение двух массивов |
| 4 | matmul
Матричное произведение двух массивов |
| 5 | определитель
Вычисляет определитель массива |
| 6 | решать
Решает линейное матричное уравнение |
| 7 | фактура
Находит мультипликативную обратную матрицу |
Точечный продукт двух массивов
Точечное произведение двух векторов
Внутреннее произведение двух массивов
Матричное произведение двух массивов
Вычисляет определитель массива
Решает линейное матричное уравнение
Находит мультипликативную обратную матрицу
NumPy — Matplotlib
Matplotlib — это библиотека черчения для Python. Он используется вместе с NumPy для предоставления среды, которая является эффективной альтернативой с открытым исходным кодом для MatLab. Его также можно использовать с графическими инструментами, такими как PyQt и wxPython.
Модуль Matplotlib был впервые написан Джоном Д. Хантером. С 2012 года Michael Droettboom является основным разработчиком. В настоящее время Matplotlib ver. 1.5.1 является стабильной доступной версией. Пакет доступен в бинарном выпуске, а также в форме исходного кода на сайте www.matplotlib.org .
Обычно пакет импортируется в скрипт Python путем добавления следующего оператора:
from matplotlib import pyplot as plt
Здесь pyplot () — самая важная функция в библиотеке matplotlib, которая используется для построения 2D-данных. Следующий скрипт строит уравнение y = 2x + 5
пример
import numpy as np from matplotlib import pyplot as plt x = np.arange(1,11) y = 2 * x + 5 plt.title("Matplotlib demo") plt.xlabel("x axis caption") plt.ylabel("y axis caption") plt.plot(x,y) plt.show()
Объект ndarray x создается из функции np.arange () в качестве значений на оси x . Соответствующие значения на оси y сохраняются в другом ndarray-объекте y . Эти значения выводятся с использованием функции plot () подмодуля pyplot пакета matplotlib.
Графическое представление отображается функцией show () .
Приведенный выше код должен выдать следующий результат:
Вместо линейного графика значения можно отображать дискретно, добавив строку формата в функцию plot () . Можно использовать следующие символы форматирования.
| Sr.No. | Характер и описание |
|---|---|
| 1 |
‘-‘ Стиль сплошной линии |
| 2 |
‘-‘ Стиль пунктирной линии |
| 3 |
‘-‘. Стиль штрих-пунктирной линии |
| 4 |
‘:’ Стиль пунктирной линии |
| 5 |
» Маркер точки |
| 6 |
» Пиксельный маркер |
| 7 |
«о» Маркер круга |
| 8 |
‘v’ Маркер треугольника вниз |
| 9 |
‘^’ Маркер треугольника |
| 10 |
‘<‘ Маркер треугольника |
| 11 |
‘>’ Треугольник_правильный маркер |
| 12 |
‘1’ Tri_down маркер |
| 13 |
‘2’ Маркер Tri_up |
| 14 |
‘3’ Маркер Tri_left |
| 15 |
‘4’ Tri_right маркер |
| 16 |
‘s’ Квадратный маркер |
| 17 |
‘п’ Пентагон |
| 18 |
‘*’ Звездный маркер |
| 19 |
‘час’ Hexagon1 маркер |
| 20 |
‘ЧАС’ Hexagon2 маркер |
| 21 |
‘+’ Плюс маркер |
| 22 |
‘Икс’ Маркер X |
| 23 |
‘D’ Алмазный маркер |
| 24 |
‘d’ Тонкий алмаз |
| 25 |
‘|’ Vline маркер |
| 26 |
‘_’ Хлайн маркер |
‘-‘
Стиль сплошной линии
‘-‘
Стиль пунктирной линии
‘-‘.
Стиль штрих-пунктирной линии
‘:’
Стиль пунктирной линии
»
Маркер точки
»
Пиксельный маркер
«о»
Маркер круга
‘v’
Маркер треугольника вниз
‘^’
Маркер треугольника
‘<‘
Маркер треугольника
‘>’
Треугольник_правильный маркер
‘1’
Tri_down маркер
‘2’
Маркер Tri_up
‘3’
Маркер Tri_left
‘4’
Tri_right маркер
‘s’
Квадратный маркер
‘п’
Пентагон
‘*’
Звездный маркер
‘час’
Hexagon1 маркер
‘ЧАС’
Hexagon2 маркер
‘+’
Плюс маркер
‘Икс’
Маркер X
‘D’
Алмазный маркер
‘d’
Тонкий алмаз
‘|’
Vline маркер
‘_’
Хлайн маркер
Следующие цветовые сокращения также определены.
| символ | цвет |
|---|---|
| «Б» | синий |
| ‘г’ | зеленый |
| ‘р’ | красный |
| «С» | Cyan |
| «М» | фуксин |
| «У» | желтый |
| «К» | черный |
| «Ш» | белый |
Чтобы отобразить круги, представляющие точки, вместо линии в приведенном выше примере используйте «ob» в качестве строки формата в plot ().
пример
import numpy as np from matplotlib import pyplot as plt x = np.arange(1,11) y = 2 * x + 5 plt.title("Matplotlib demo") plt.xlabel("x axis caption") plt.ylabel("y axis caption") plt.plot(x,y,"ob") plt.show()
Приведенный выше код должен выдать следующий результат:
Участок синусоидальной волны
Следующий скрипт создает график синусоидальной волны с помощью matplotlib.
пример
import numpy as np import matplotlib.pyplot as plt # Compute the x and y coordinates for points on a sine curve x = np.arange(0, 3 * np.pi, 0.1) y = np.sin(x) plt.title("sine wave form") # Plot the points using matplotlib plt.plot(x, y) plt.show()
подзаговор ()
Функция subplot () позволяет вам изображать разные вещи на одном рисунке. В следующем сценарии изображены значения синуса и косинуса .
пример
import numpy as np import matplotlib.pyplot as plt # Compute the x and y coordinates for points on sine and cosine curves x = np.arange(0, 3 * np.pi, 0.1) y_sin = np.sin(x) y_cos = np.cos(x) # Set up a subplot grid that has height 2 and width 1, # and set the first such subplot as active. plt.subplot(2, 1, 1) # Make the first plot plt.plot(x, y_sin) plt.title('Sine') # Set the second subplot as active, and make the second plot. plt.subplot(2, 1, 2) plt.plot(x, y_cos) plt.title('Cosine') # Show the figure. plt.show()
Приведенный выше код должен выдать следующий результат:
бар()
Подмодуль pyplot предоставляет функцию bar () для генерации гистограмм. В следующем примере создается гистограмма из двух наборов массивов x и y .
пример
from matplotlib import pyplot as plt x = [5,8,10] y = [12,16,6] x2 = [6,9,11] y2 = [6,15,7] plt.bar(x, y, align = 'center') plt.bar(x2, y2, color = 'g', align = 'center') plt.title('Bar graph') plt.ylabel('Y axis') plt.xlabel('X axis') plt.show()
Этот код должен произвести следующий вывод —
NumPy — гистограмма с использованием Matplotlib
NumPy имеет функцию numpy.histogram (), которая представляет собой графическое представление распределения частот данных. Прямоугольники одинакового размера по горизонтали, соответствующие интервалу класса, называемому bin, и переменной высоте, соответствующей частоте.
numpy.histogram ()
Функция numpy.histogram () принимает входной массив и bin как два параметра. Последовательные элементы в массиве бинов действуют как границы каждого бина.
import numpy as np a = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) np.histogram(a,bins = [0,20,40,60,80,100]) hist,bins = np.histogram(a,bins = [0,20,40,60,80,100]) print hist print bins
Это даст следующий результат —
[3 4 5 2 1] [0 20 40 60 80 100]
PLT ()
Matplotlib может преобразовать это числовое представление гистограммы в график. Функция plt () подмодуля pyplot принимает массив, содержащий данные и массив bin, в качестве параметров и преобразует их в гистограмму.
from matplotlib import pyplot as plt import numpy as np a = np.array([22,87,5,43,56,73,55,54,11,20,51,5,79,31,27]) plt.hist(a, bins = [0,20,40,60,80,100]) plt.title("histogram") plt.show()
Он должен произвести следующий вывод —
I / O с NumPy
Объекты ndarray могут быть сохранены и загружены из файлов на диске. Доступные функции ввода / вывода:
-
Функции load () и save () обрабатывают / numPy двоичные файлы (с расширением npy )
-
Функции loadtxt () и savetxt () обрабатывают обычные текстовые файлы
Функции load () и save () обрабатывают / numPy двоичные файлы (с расширением npy )
Функции loadtxt () и savetxt () обрабатывают обычные текстовые файлы
NumPy представляет простой формат файла для объектов ndarray. В этом файле .npy хранятся данные, форма, тип d и другая информация, необходимая для восстановления ndarray в файле диска, чтобы массив был правильно извлечен, даже если файл находится на другом компьютере с другой архитектурой.
numpy.save ()
Файл numpy.save () хранит входной массив в файле на диске с расширением npy .
import numpy as np a = np.array([1,2,3,4,5]) np.save('outfile',a)
Чтобы восстановить массив из outfile.npy , используйте функцию load () .
import numpy as np b = np.load('outfile.npy') print b
Это даст следующий результат —
array([1, 2, 3, 4, 5])
Функции save () и load () принимают дополнительный логический параметр allow_pickles . Pickle в Python используется для сериализации и десериализации объектов перед сохранением или чтением из файла на диске.
savetxt ()
Хранение и извлечение данных массива в простом текстовом формате выполняется с помощью функций savetxt () и loadtxt () .
пример
import numpy as np a = np.array([1,2,3,4,5]) np.savetxt('out.txt',a) b = np.loadtxt('out.txt') print b
Это даст следующий результат —
[ 1. 2. 3. 4. 5.]
Функции savetxt () и loadtxt () принимают дополнительные необязательные параметры, такие как заголовок, нижний колонтитул и разделитель.