С помощью Python мы можем очистить любой веб-сайт или отдельные элементы веб-страницы, но есть ли у вас какие-либо идеи, законно ли это или нет? Перед тем как соскобить любой веб-сайт, мы должны знать о законности веб-соскоба. В этой главе будут объяснены концепции, связанные с законностью веб-скребков.
Вступление
Как правило, если вы собираетесь использовать очищенные данные для личного использования, то проблем может не быть. Но если вы собираетесь публиковать эти данные, то перед тем, как сделать то же самое, вы должны сделать запрос на загрузку для владельца или провести некоторое предварительное исследование политик, а также данных, которые вы собираетесь очистить.
Требуется исследование до выскабливания
Если вы ориентируетесь на веб-сайт для сбора данных с него, нам необходимо понять его масштаб и структуру. Ниже приведены некоторые файлы, которые нам нужно проанализировать, прежде чем приступить к просмотру веб-страниц.
Анализ robots.txt
На самом деле большинство издателей позволяют программистам сканировать свои сайты в некоторой степени. В другом смысле, издатели хотят сканировать определенные части веб-сайтов. Чтобы определить это, веб-сайты должны установить некоторые правила, определяющие, какие части можно сканировать, а какие нет. Такие правила определены в файле с именем robots.txt .
robots.txt — это читаемый человеком файл, используемый для идентификации частей сайта, которые сканерам разрешено, а также не разрешено просматривать. Стандартного формата файла robots.txt не существует, и издатели веб-сайта могут вносить изменения в соответствии со своими потребностями. Мы можем проверить файл robots.txt для определенного веб-сайта, указав косую черту и robots.txt после URL этого веб-сайта. Например, если мы хотим проверить его на Google.com, нам нужно ввести https://www.google.com/robots.txt, и мы получим что-то следующее:
User-agent: * Disallow: /search Allow: /search/about Allow: /search/static Allow: /search/howsearchworks Disallow: /sdch Disallow: /groups Disallow: /index.html? Disallow: /? Allow: /?hl= Disallow: /?hl=*& Allow: /?hl=*&gws_rd=ssl$ and so on……..
Вот некоторые из наиболее распространенных правил, которые определены в файле robots.txt веб-сайта:
User-agent: BadCrawler Disallow: /
Приведенное выше правило означает, что файл robots.txt просит сканер с пользовательским агентом BadCrawler не сканировать их веб-сайт.
User-agent: * Crawl-delay: 5 Disallow: /trap
Приведенное выше правило означает, что файл robots.txt задерживает сканер на 5 секунд между запросами на загрузку для всех пользовательских агентов во избежание перегрузки сервера. Ссылка / trap попытается заблокировать вредоносные сканеры, которые переходят по запрещенным ссылкам. Существует еще много правил, которые могут быть определены издателем сайта в соответствии с их требованиями. Некоторые из них обсуждаются здесь —
Анализ файлов Sitemap
Что вы должны делать, если хотите сканировать веб-сайт для получения обновленной информации? Вы будете сканировать каждую веб-страницу для получения этой обновленной информации, но это увеличит трафик сервера этого конкретного веб-сайта. Вот почему веб-сайты предоставляют файлы карты сайта, которые помогают сканерам находить обновляемый контент без необходимости сканировать каждую веб-страницу. Стандарт Sitemap определен по адресу http://www.sitemaps.org/protocol.html .
Содержимое файла Sitemap
Ниже приведено содержимое файла карты сайта https://www.microsoft.com/robots.txt , обнаруженного в файле robot.txt.
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml Sitemap: https://www.microsoft.com/learning/sitemap.xml Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8 Sitemap: https://www.microsoft.com/store/collections.xml Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
Приведенный выше контент показывает, что карта сайта содержит список URL-адресов на веб-сайте и, кроме того, позволяет веб-мастеру указывать дополнительную информацию, такую как дата последнего обновления, изменение содержимого, важность URL-адреса по отношению к другим и т. Д., Относительно каждого URL-адреса.
Какой размер сайта?
Влияет ли размер веб-сайта, то есть количество веб-страниц веб-сайта, на способ сканирования? Конечно да. Потому что, если у нас будет меньше веб-страниц для сканирования, эффективность не будет серьезной проблемой, но предположим, что если на нашем веб-сайте есть миллионы веб-страниц, например, Microsoft.com, то последовательная загрузка каждой веб-страницы займет несколько месяцев и тогда эффективность будет серьезной проблемой.
Проверка размера сайта
Проверяя размер результатов поискового робота Google, мы можем оценить размер веб-сайта. Наш результат может быть отфильтрован по ключевому слову site во время поиска в Google. Например, оценка размера https://authoraditiagarwal.com/ приведена ниже —
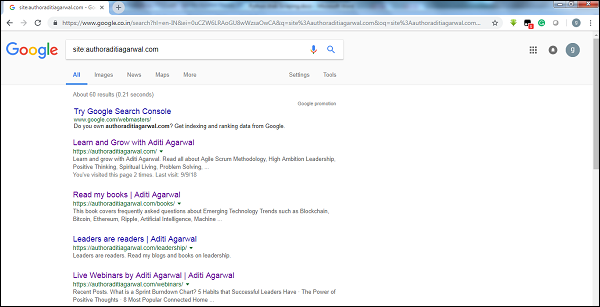
Вы можете увидеть около 60 результатов, которые означают, что это не большой веб-сайт, и сканирование не приведет к проблеме эффективности.
Какая технология используется сайтом?
Еще один важный вопрос: влияет ли технология, используемая веб-сайтом, на то, как мы сканируем? Да, это влияет. Но как мы можем проверить технологии, используемые веб-сайтом? Существует библиотека Python с именем buildwith, с помощью которой мы можем узнать о технологии, используемой веб-сайтом.
пример
В этом примере мы собираемся проверить технологию, используемую веб-сайтом https://authoraditiagarwal.com с помощью встроенной библиотеки Python . Но перед использованием этой библиотеки нам нужно установить ее следующим образом:
(base) D:\ProgramData>pip install builtwith Collecting builtwith Downloading https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0 2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz Requirement already satisfied: six in d:\programdata\lib\site-packages (from builtwith) (1.10.0) Building wheels for collected packages: builtwith Running setup.py bdist_wheel for builtwith ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b f926764a924873e0304f10b2524 Successfully built builtwith Installing collected packages: builtwith Successfully installed builtwith-1.3.3
Теперь, с помощью следующей простой строки кодов, мы можем проверить технологию, используемую конкретным сайтом —
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
Кто является владельцем сайта?
Владелец веб-сайта также имеет значение, потому что если известно, что владелец блокирует сканеры, сканеры должны соблюдать осторожность при отборе данных с веб-сайта. Есть протокол Whois, с помощью которого мы можем узнать о владельце сайта.
пример
В этом примере мы собираемся проверить владельца сайта скажем microsoft.com с помощью Whois. Но перед использованием этой библиотеки нам нужно установить ее следующим образом:
(base) D:\ProgramData>pip install python-whois Collecting python-whois Downloading https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8 5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB) 100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s Requirement already satisfied: future in d:\programdata\lib\site-packages (from python-whois) (0.16.0) Building wheels for collected packages: python-whois Running setup.py bdist_wheel for python-whois ... done Stored in directory: C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b 4dcc81ab212a3d5e52ab32dc531 Successfully built python-whois Installing collected packages: python-whois Successfully installed python-whois-0.7.0
Теперь, с помощью следующей простой строки кодов, мы можем проверить технологию, используемую конкретным сайтом —