Apache Flink — платформа больших данных
Прогресс данных за последние 10 лет был огромным; это породило термин «большие данные». Не существует фиксированного размера данных, который вы можете назвать большими данными; любые данные, которые ваша традиционная система (RDBMS) не может обработать, — это большие данные. Эти Большие Данные могут быть в структурированном, полуструктурированном или неструктурированном формате. Первоначально в данных было три измерения — объем, скорость, разнообразие. Размеры теперь вышли за пределы только трех. Теперь мы добавили другие Vs — Veracity, Validity, Vulnerability, Value, Variable и т. Д.
Большие данные привели к появлению множества инструментов и платформ, которые помогают в хранении и обработке данных. Существует несколько популярных сред больших данных, таких как Hadoop, Spark, Hive, Pig, Storm и Zookeeper. Это также дало возможность создавать продукты Next Gen в нескольких областях, таких как здравоохранение, финансы, розничная торговля, электронная коммерция и многое другое.
Будь то MNC или стартап, каждый использует большие данные для их хранения, обработки и принятия более разумных решений.
Apache Flink — пакетная обработка в режиме реального времени
С точки зрения больших данных, существует два типа обработки:
- Пакетная обработка
- Обработка в реальном времени
Обработка, основанная на данных, собранных во времени, называется пакетной обработкой. Например, менеджер банка хочет обработать данные за последний месяц (собранные за определенное время), чтобы узнать количество чеков, которые были отменены за последний 1 месяц.
Обработка, основанная на непосредственных данных для мгновенного результата, называется обработкой в реальном времени. Например, менеджер банка получает предупреждение о мошенничестве сразу после совершения мошеннической операции (мгновенный результат).
В приведенной ниже таблице перечислены различия между пакетной обработкой и обработкой в реальном времени.
| Пакетная обработка | Обработка в реальном времени |
|---|---|
|
Статические файлы |
Потоки событий |
|
Периодически обрабатывается в минутах, часах, днях и т. Д. |
Обработано сразу наносекунд |
|
Прошлые данные на диске |
В памяти |
|
Пример — Генерация счета |
Пример — оповещение о транзакции через банкомат |
Статические файлы
Потоки событий
Периодически обрабатывается в минутах, часах, днях и т. Д.
Обработано сразу
наносекунд
Прошлые данные на диске
В памяти
Пример — Генерация счета
Пример — оповещение о транзакции через банкомат
В наши дни обработка в реальном времени широко используется в каждой организации. Варианты использования, такие как обнаружение мошенничества, оповещения в реальном времени в сфере здравоохранения и оповещения о сетевых атаках, требуют обработки мгновенных данных в режиме реального времени; задержка в несколько миллисекунд может оказать огромное влияние.
Идеальным инструментом для таких случаев использования в реальном времени был бы тот, который может вводить данные как поток, а не как пакет. Apache Flink — это инструмент для обработки в реальном времени.
Apache Flink — Введение
Apache Flink — это среда обработки в реальном времени, которая может обрабатывать потоковые данные. Это среда обработки потоков с открытым исходным кодом для высокопроизводительных, масштабируемых и точных приложений реального времени. Он имеет истинную потоковую модель и не принимает входные данные в виде пакетов или микропакетов.
Apache Flink был основан компанией Data Artisans и теперь разрабатывается под лицензией Apache от Apache Flink Community. В этом сообществе более 479 участников и 15500 + коммитов.
Экосистема на Apache Flink
На приведенной ниже диаграмме показаны различные уровни экосистемы Apache Flink —
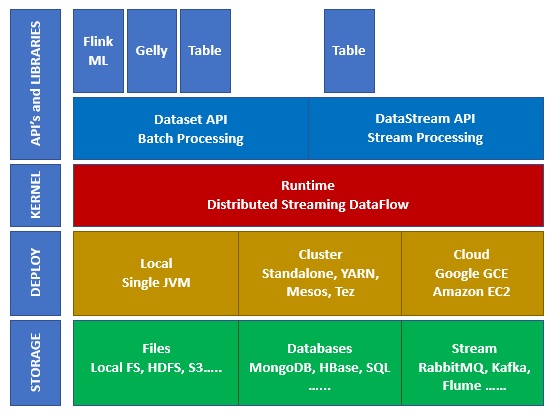
Место хранения
Apache Flink имеет несколько опций, откуда он может читать / записывать данные. Ниже приведен основной список хранения —
- HDFS (распределенная файловая система Hadoop)
- Локальная файловая система
- S3
- СУБД (MySQL, Oracle, MS SQL и т. Д.)
- MongoDB
- HBase
- Апач Кафка
- Apache Flume
развертывание
Вы можете развернуть Apache Fink в локальном режиме, режиме кластера или в облаке. Кластерный режим может быть автономным, YARN, MESOS.
В облаке Flink может быть развернут на AWS или GCP.
ядро
Это уровень времени выполнения, который обеспечивает распределенную обработку, отказоустойчивость, надежность, возможность итеративной обработки и многое другое.
API и библиотеки
Это верхний слой и самый важный слой Apache Flink. Он имеет Dataset API, который заботится о пакетной обработке, и Datastream API, который заботится о потоковой обработке. Есть и другие библиотеки, такие как Flink ML (для машинного обучения), Gelly (для обработки графиков), таблицы для SQL. Этот уровень предоставляет разнообразные возможности Apache Flink.
Apache Flink — Архитектура
Apache Flink работает над архитектурой Kappa. Архитектура Kappa имеет один процессор — поток, который обрабатывает весь ввод как поток, а механизм потоковой передачи обрабатывает данные в режиме реального времени. Пакетные данные в архитектуре каппа — это особый случай потоковой передачи.
Следующая диаграмма показывает архитектуру Apache Flink .
Ключевой идеей в архитектуре Kappa является обработка как пакетных данных, так и данных в реальном времени с помощью единого механизма обработки потоков.
Большая часть инфраструктуры больших данных работает на архитектуре Lambda, которая имеет отдельные процессоры для пакетных и потоковых данных. В архитектуре Lambda у вас есть отдельные кодовые базы для пакетного и потокового просмотра. Для запроса и получения результата необходимо объединить кодовые базы. Нелегко поддерживать отдельные кодовые базы / представления и объединять их, но архитектура Kappa решает эту проблему, поскольку имеет только одно представление — в режиме реального времени, поэтому объединение кодовой базы не требуется.
Это не означает, что архитектура Kappa заменяет архитектуру Lambda, она полностью зависит от варианта использования и приложения, которое решает, какая архитектура предпочтительнее.
На следующей диаграмме показана архитектура выполнения заданий Apache Flink.
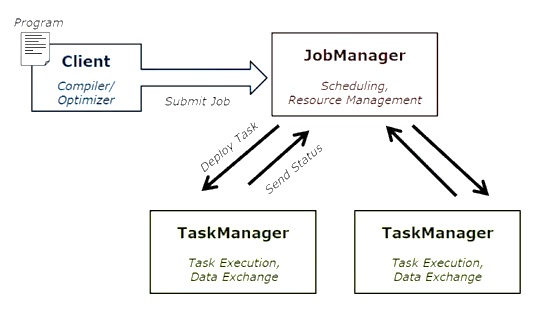
программа
Это кусок кода, который вы запускаете на кластере Flink.
клиент
Он отвечает за сбор кода (программы) и построение графика потока данных задания, а затем передает его в JobManager. Он также извлекает результаты работы.
JobManager
После получения графика потока данных задания от клиента он отвечает за создание графика выполнения. Он назначает задание для TaskManager в кластере и контролирует выполнение задания.
Диспетчер задач
Он отвечает за выполнение всех задач, которые были назначены JobManager. Все TaskManager запускают задачи в отдельных слотах с указанным параллелизмом. Он отвечает за отправку статуса задач в JobManager.
Особенности Apache Flink
Особенности Apache Flink следующие —
-
Он имеет потоковый процессор, который может запускать как пакетные, так и потоковые программы.
-
Он может обрабатывать данные с молниеносной скоростью.
-
API доступны на Java, Scala и Python.
-
Предоставляет API-интерфейсы для всех распространенных операций, которые очень просты в использовании для программистов.
-
Обрабатывает данные с низкой задержкой (наносекунды) и высокой пропускной способностью.
-
Его отказоустойчивый. Если происходит сбой узла, приложения или оборудования, это не влияет на кластер.
-
Может легко интегрироваться с Apache Hadoop, Apache MapReduce, Apache Spark, HBase и другими инструментами для работы с большими данными.
-
Управление в памяти может быть настроено для лучшего вычисления.
-
Он хорошо масштабируется и может масштабироваться до тысяч узлов в кластере.
-
Оконное управление очень гибкое в Apache Flink.
-
Предоставляет библиотеки обработки графиков, машинного обучения, обработки сложных событий.
Он имеет потоковый процессор, который может запускать как пакетные, так и потоковые программы.
Он может обрабатывать данные с молниеносной скоростью.
API доступны на Java, Scala и Python.
Предоставляет API-интерфейсы для всех распространенных операций, которые очень просты в использовании для программистов.
Обрабатывает данные с низкой задержкой (наносекунды) и высокой пропускной способностью.
Его отказоустойчивый. Если происходит сбой узла, приложения или оборудования, это не влияет на кластер.
Может легко интегрироваться с Apache Hadoop, Apache MapReduce, Apache Spark, HBase и другими инструментами для работы с большими данными.
Управление в памяти может быть настроено для лучшего вычисления.
Он хорошо масштабируется и может масштабироваться до тысяч узлов в кластере.
Оконное управление очень гибкое в Apache Flink.
Предоставляет библиотеки обработки графиков, машинного обучения, обработки сложных событий.
Apache Flink — системные требования
Ниже приведены системные требования для загрузки и работы на Apache Flink.
Рекомендуемая операционная система
- Microsoft Windows 10
- Ubuntu 16.04 LTS
- Apple macOS 10.13 / High Sierra
Требование к памяти
- Память — минимум 4 ГБ, рекомендуется 8 ГБ
- Место для хранения — 30 ГБ
Примечание. Java 8 должна быть доступна с уже установленными переменными среды.
Apache Flink — Настройка / Установка
Перед началом установки / установки Apache Flink давайте проверим, установлена ли в нашей системе Java 8.
Java — версия
Теперь мы продолжим загрузку Apache Flink.
wget http://mirrors.estointernet.in/apache/flink/flink-1.7.1/flink-1.7.1-bin-scala_2.11.tgz
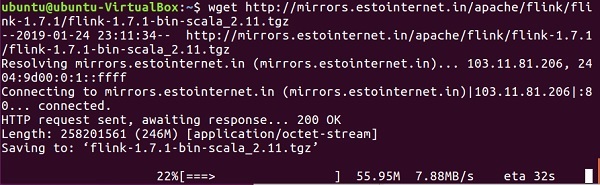
Теперь распакуйте файл tar.
tar -xzf flink-1.7.1-bin-scala_2.11.tgz

Перейдите в домашний каталог Флинка.
cd flink-1.7.1/
Запустите кластер Flink.
./bin/start-cluster.sh
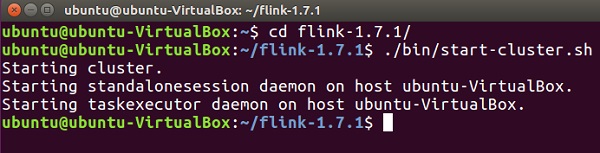
Откройте браузер Mozilla и перейдите по указанному ниже URL-адресу, откроется веб-панель Flink.
HTTP: // локальный: 8081
Так выглядит пользовательский интерфейс Apache Flink Dashboard.
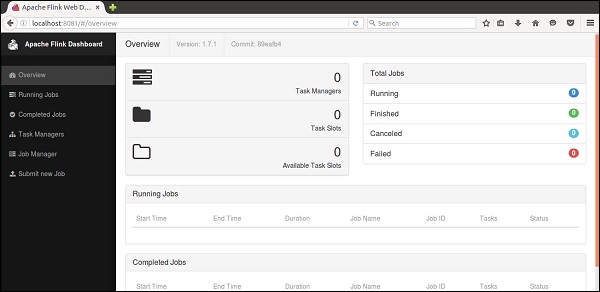
Теперь кластер Flink запущен и работает.
Apache Flink — Концепции API
Flink имеет богатый набор API-интерфейсов, с помощью которых разработчики могут выполнять преобразования как пакетных данных, так и данных в реальном времени. Разнообразные преобразования включают в себя отображение, фильтрацию, сортировку, объединение, группирование и агрегирование. Эти преобразования Apache Flink выполняются для распределенных данных. Давайте обсудим различные API, предлагаемые Apache Flink.
API набора данных
API набора данных в Apache Flink используется для выполнения пакетных операций с данными за период. Этот API может использоваться в Java, Scala и Python. Он может применять различные виды преобразований к наборам данных, такие как фильтрация, отображение, агрегирование, объединение и группировка.
Наборы данных создаются из таких источников, как локальные файлы, или путем чтения файла из определенного источника, и данные результатов могут быть записаны в различные приемники, такие как распределенные файлы или терминал командной строки. Этот API поддерживается языками программирования Java и Scala.
Вот программа Wordcount API Dataset —
public class WordCountProg { public static void main(String[] args) throws Exception { final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSet<String> text = env.fromElements( "Hello", "My Dataset API Flink Program"); DataSet<Tuple2<String, Integer>> wordCounts = text .flatMap(new LineSplitter()) .groupBy(0) .sum(1); wordCounts.print(); } public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) { for (String word : line.split(" ")) { out.collect(new Tuple2<String, Integer>(word, 1)); } } } }
DataStream API
Этот API используется для обработки данных в непрерывном потоке. Вы можете выполнять различные операции, такие как фильтрация, отображение, управление окнами, агрегация данных потока. В этом потоке данных есть различные источники, такие как очереди сообщений, файлы, потоки сокетов, и данные результатов могут быть записаны в различные приемники, такие как терминал командной строки. Оба языка программирования Java и Scala поддерживают этот API.
Вот потоковая программа Wordcount API DataStream, где у вас есть непрерывный поток подсчетов слов, и данные группируются во втором окне.
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; public class WindowWordCountProg { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<Tuple2<String, Integer>> dataStream = env .socketTextStream("localhost", 9999) .flatMap(new Splitter()) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1); dataStream.print(); env.execute("Streaming WordCount Example"); } public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word: sentence.split(" ")) { out.collect(new Tuple2<String, Integer>(word, 1)); } } } }
Apache Flink — Табличные API и SQL
Table API — это реляционный API с языком выражений, подобным SQL. Этот API может выполнять как пакетную, так и потоковую обработку. Он может быть встроен в API Java и Scala Dataset и Datastream. Вы можете создавать таблицы из существующих наборов данных и потоков данных или из внешних источников данных. С помощью этого реляционного API вы можете выполнять такие операции, как объединение, агрегирование, выбор и фильтрация. Независимо от того, является ли ввод пакетным или потоковым, семантика запроса остается неизменной.
Вот пример программы Table API —
// for batch programs use ExecutionEnvironment instead of StreamExecutionEnvironment val env = StreamExecutionEnvironment.getExecutionEnvironment // create a TableEnvironment val tableEnv = TableEnvironment.getTableEnvironment(env) // register a Table tableEnv.registerTable("table1", ...) // or tableEnv.registerTableSource("table2", ...) // or tableEnv.registerExternalCatalog("extCat", ...) // register an output Table tableEnv.registerTableSink("outputTable", ...); // create a Table from a Table API query val tapiResult = tableEnv.scan("table1").select(...) // Create a Table from a SQL query val sqlResult = tableEnv.sqlQuery("SELECT ... FROM table2 ...") // emit a Table API result Table to a TableSink, same for SQL result tapiResult.insertInto("outputTable") // execute env.execute()
Apache Flink — Создание приложения Flink
В этой главе мы узнаем, как создать приложение Flink.
Откройте Eclipse IDE, нажмите «Новый проект» и выберите «Java Project».
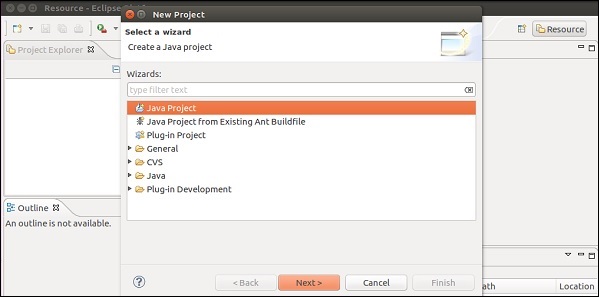
Дайте имя проекта и нажмите «Готово».
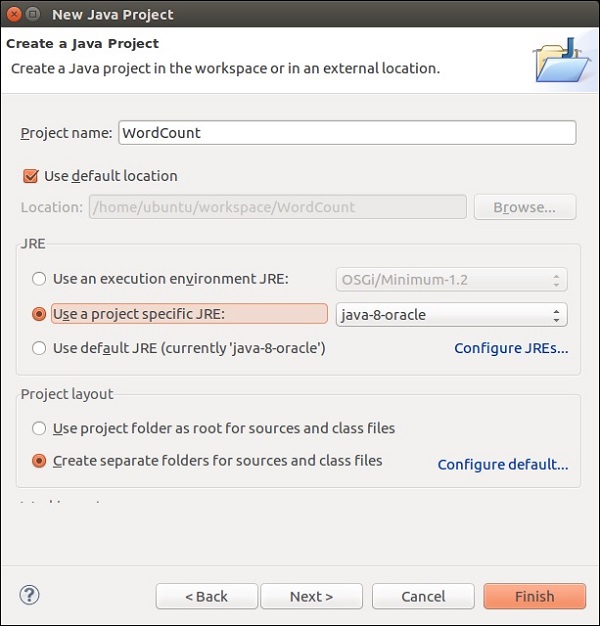
Теперь нажмите Finish, как показано на следующем скриншоте.
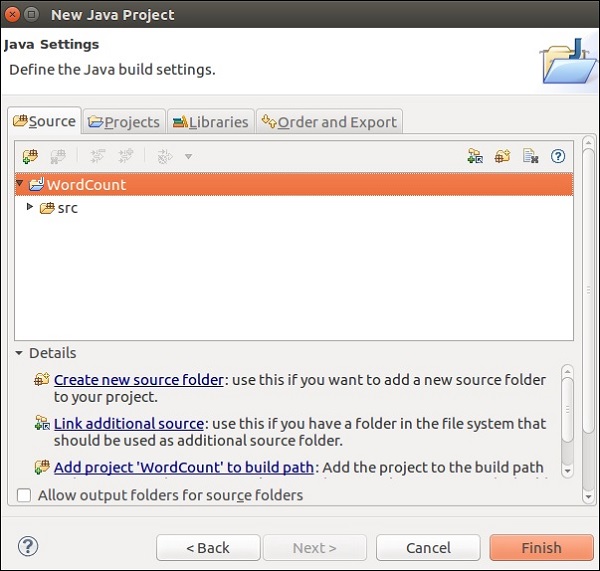
Теперь щелкните правой кнопкой мыши на src и перейдите в New >> Class.
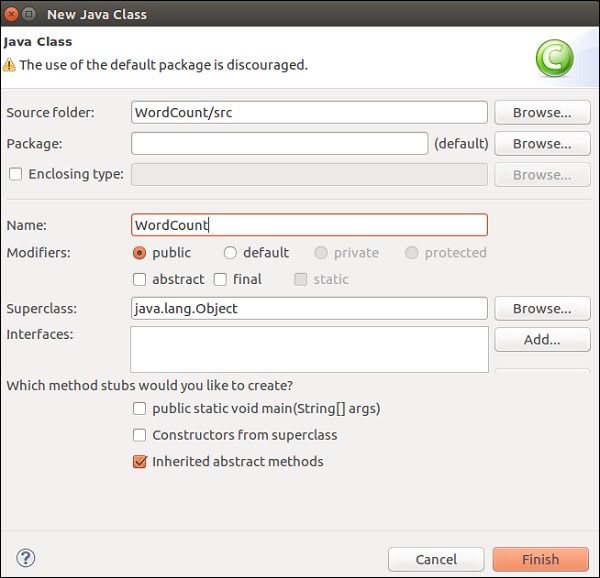
Дайте имя классу и нажмите «Готово».
Скопируйте и вставьте приведенный ниже код в редактор.
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.util.Collector; public class WordCount { // ************************************************************************* // PROGRAM // ************************************************************************* public static void main(String[] args) throws Exception { final ParameterTool params = ParameterTool.fromArgs(args); // set up the execution environment final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // make parameters available in the web interface env.getConfig().setGlobalJobParameters(params); // get input data DataSet<String> text = env.readTextFile(params.get("input")); DataSet<Tuple2<String, Integer>> counts = // split up the lines in pairs (2-tuples) containing: (word,1) text.flatMap(new Tokenizer()) // group by the tuple field "0" and sum up tuple field "1" .groupBy(0) .sum(1); // emit result if (params.has("output")) { counts.writeAsCsv(params.get("output"), "\n", " "); // execute program env.execute("WordCount Example"); } else { System.out.println("Printing result to stdout. Use --output to specify output path."); counts.print(); } } // ************************************************************************* // USER FUNCTIONS // ************************************************************************* public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> { public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // normalize and split the line String[] tokens = value.toLowerCase().split("\\W+"); // emit the pairs for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<>(token, 1)); } } } } }
Вы получите много ошибок в редакторе, потому что библиотеки Flink необходимо добавить в этот проект.
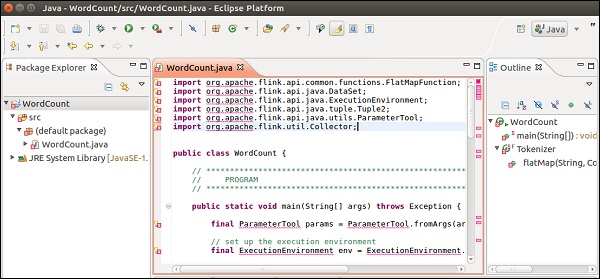
Щелкните правой кнопкой мыши по проекту >> Build Path >> Configure Build Path.
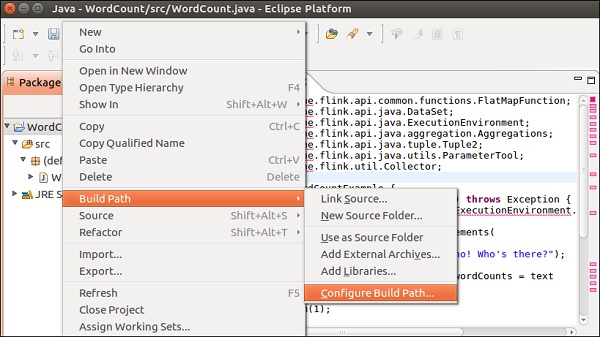
Выберите вкладку «Библиотеки» и нажмите «Добавить внешние файлы JAR».
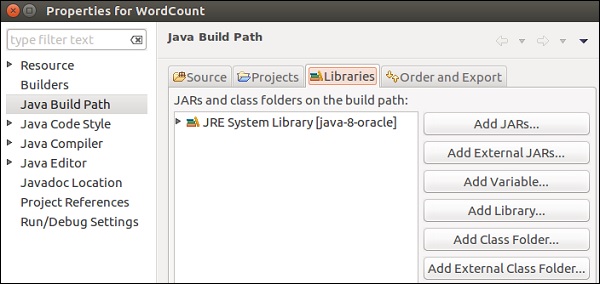
Перейдите в каталог lib Flink, выберите все 4 библиотеки и нажмите OK.
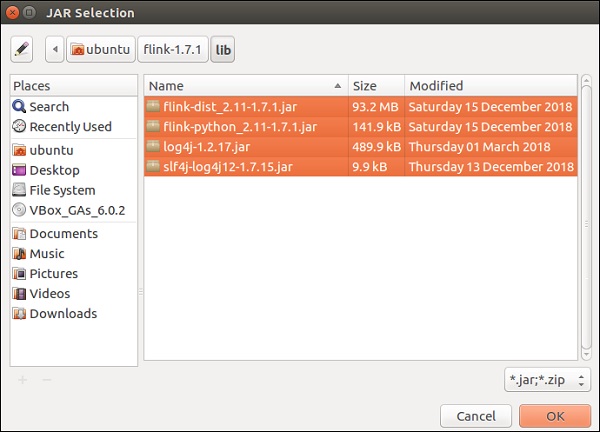
Перейдите на вкладку «Порядок и экспорт», выберите все библиотеки и нажмите «ОК».
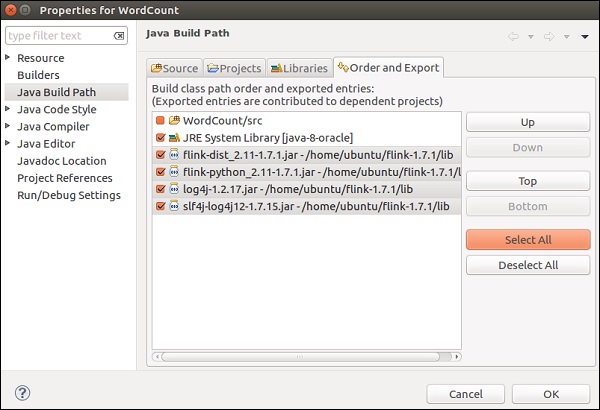
Вы увидите, что ошибок больше нет.
Теперь давайте экспортируем это приложение. Щелкните правой кнопкой мыши по проекту и выберите «Экспорт».
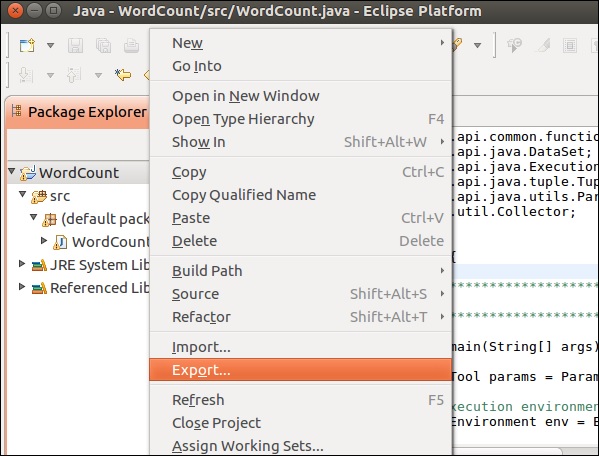
Выберите файл JAR и нажмите «Далее»
Укажите путь к месту назначения и нажмите «Далее».
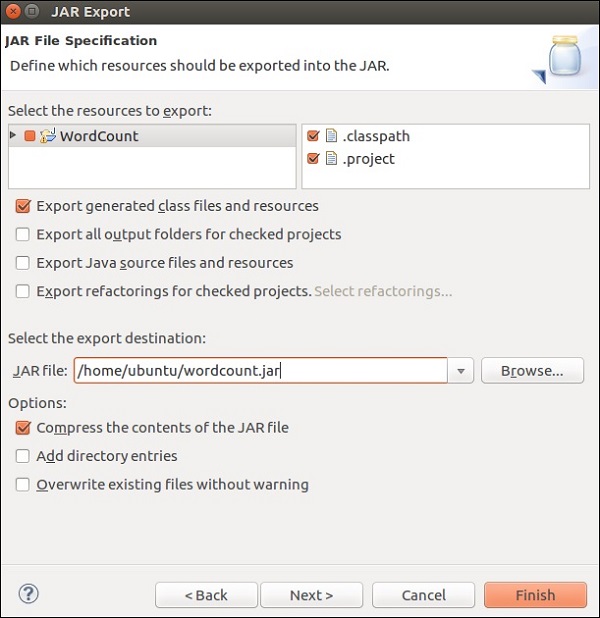
Нажмите на Далее>
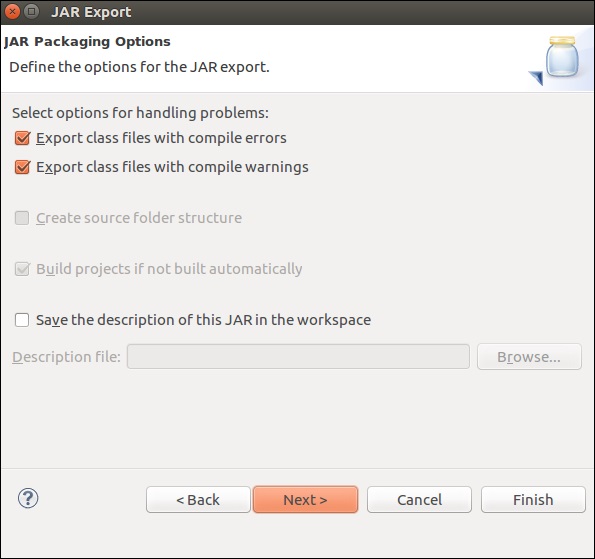
Нажмите «Обзор», выберите основной класс (WordCount) и нажмите «Готово».
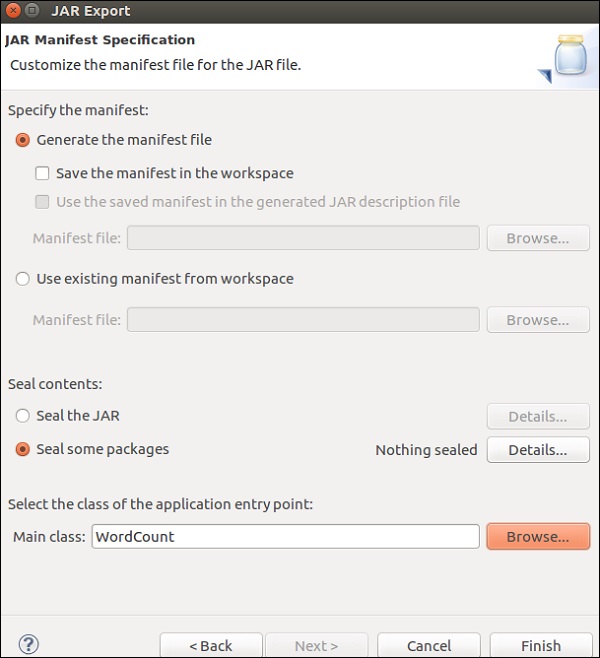
Примечание. Нажмите «ОК», если вы получили предупреждение.
Запустите приведенную ниже команду. В дальнейшем будет запущено приложение Flink, которое вы только что создали.
./bin/flink run /home/ubuntu/wordcount.jar --input README.txt --output /home/ubuntu/output

Apache Flink — Запуск программы Flink
В этой главе мы узнаем, как запустить программу Flink.
Давайте запустим пример подсчета слов Flink на кластере Flink.
Перейдите в домашний каталог Flink и запустите приведенную ниже команду в терминале.
bin/flink run examples/batch/WordCount.jar -input README.txt -output /home/ubuntu/flink-1.7.1/output.txt

Перейдите на панель инструментов Flink, вы сможете увидеть выполненную работу с ее деталями.
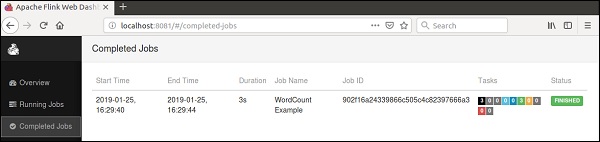
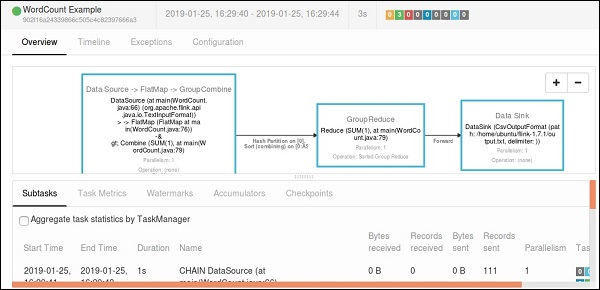
Если вы нажмете на Завершенные задания, вы получите подробный обзор работ.
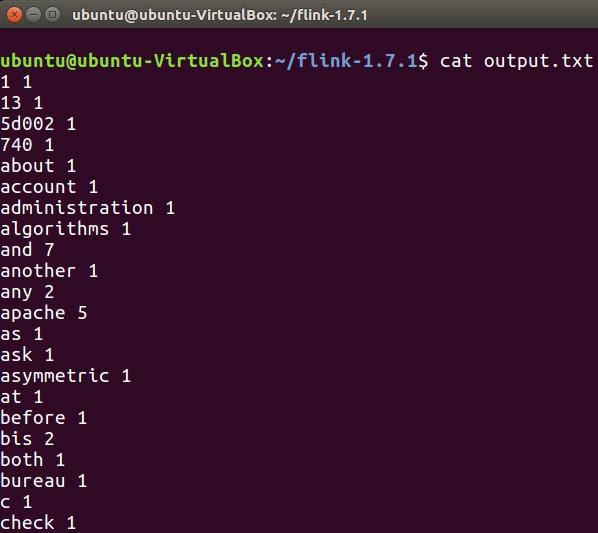
Чтобы проверить вывод программы wordcount, запустите приведенную ниже команду в терминале.
cat output.txt
Апач Флинк — Библиотеки
В этой главе мы узнаем о различных библиотеках Apache Flink.
Комплексная обработка событий (CEP)
FlinkCEP — это API в Apache Flink, который анализирует шаблоны событий при непрерывной потоковой передаче данных. Эти события близки к реальному времени, которые имеют высокую пропускную способность и низкую задержку. Этот API используется главным образом для данных датчика, которые поступают в режиме реального времени и очень сложны для обработки.
CEP анализирует структуру входного потока и очень скоро дает результат. Он имеет возможность предоставлять уведомления и оповещения в режиме реального времени в случае сложной схемы событий. FlinkCEP может подключаться к различным источникам входного сигнала и анализировать в них шаблоны.
Вот так выглядит пример архитектуры с CEP —
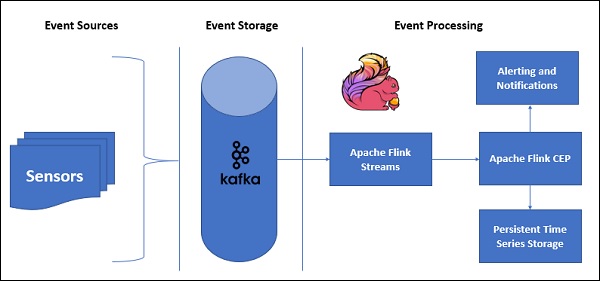
Данные датчиков будут поступать из разных источников, Kafka будет действовать как распределенная система обмена сообщениями, которая будет распределять потоки в Apache Flink, а FlinkCEP будет анализировать сложные шаблоны событий.
Вы можете писать программы в Apache Flink для обработки сложных событий с использованием Pattern API. Это позволяет вам определять шаблоны событий для обнаружения из данных непрерывного потока. Ниже приведены некоторые из наиболее часто используемых шаблонов CEP —
Начать
Он используется для определения начального состояния. Следующая программа показывает, как она определяется в программе Flink —
Pattern<Event, ?> next = start.next("next");
куда
Используется для определения условия фильтра в текущем состоянии.
patternState.where(new FilterFunction <Event>() {
@Override
public boolean filter(Event value) throws Exception {
}
});
следующий
Он используется для добавления нового состояния шаблона и соответствующего события, необходимого для передачи предыдущего шаблона.
Pattern<Event, ?> next = start.next("next");
С последующим
Он используется для добавления нового состояния шаблона, но здесь могут происходить другие события, ч / б два совпадающих события.
Pattern<Event, ?> followedBy = start.followedBy("next");
Gelly
API API Apache Flink — это Gelly. Gelly используется для анализа графиков в приложениях Flink с использованием набора методов и утилит. Вы можете анализировать огромные графики, используя Apache Flink API, распределенным образом с Gelly. Существуют и другие библиотеки графов, например Apache Giraph для той же цели, но поскольку Gelly используется поверх Apache Flink, он использует один API. Это очень полезно с точки зрения разработки и эксплуатации.
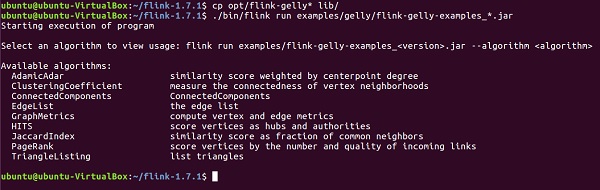
Давайте запустим пример, используя Apache Flink API — Gelly.
Во-первых, вам нужно скопировать 2 файла Gelly jar из каталога opt Apache Flink в его каталог lib. Затем запустите flink-gelly-examples jar.
cp opt/flink-gelly* lib/ ./bin/flink run examples/gelly/flink-gelly-examples_*.jar
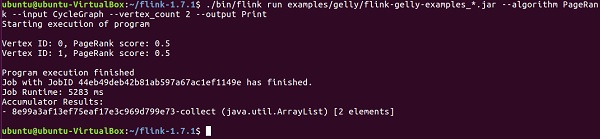
Давайте теперь запустим пример PageRank.
PageRank вычисляет оценку для каждой вершины, которая является суммой оценок PageRank, переданных по ребрам. Оценка каждой вершины делится поровну между ребрами. Вершины с высокими показателями связаны с другими вершинами с высокими показателями.
Результат содержит идентификатор вершины и счет PageRank.
usage: flink run examples/flink-gelly-examples_<version>.jar --algorithm PageRank [algorithm options] --input <input> [input options] --output <output> [output options] ./bin/flink run examples/gelly/flink-gelly-examples_*.jar --algorithm PageRank --input CycleGraph --vertex_count 2 --output Print
Apache Flink — Машинное обучение
Библиотека машинного обучения Apache Flink называется FlinkML. Поскольку за последние 5 лет использование машинного обучения экспоненциально росло, сообщество Flink решило добавить этот APO машинного обучения также в свою экосистему. Список участников и алгоритмов увеличивается в FlinkML. Этот API еще не является частью бинарного дистрибутива.
Вот пример линейной регрессии с использованием FlinkML —
// LabeledVector is a feature vector with a label (class or real value) val trainingData: DataSet[LabeledVector] = ... val testingData: DataSet[Vector] = ... // Alternatively, a Splitter is used to break up a DataSet into training and testing data. val dataSet: DataSet[LabeledVector] = ... val trainTestData: DataSet[TrainTestDataSet] = Splitter.trainTestSplit(dataSet) val trainingData: DataSet[LabeledVector] = trainTestData.training val testingData: DataSet[Vector] = trainTestData.testing.map(lv => lv.vector) val mlr = MultipleLinearRegression() .setStepsize(1.0) .setIterations(100) .setConvergenceThreshold(0.001) mlr.fit(trainingData) // The fitted model can now be used to make predictions val predictions: DataSet[LabeledVector] = mlr.predict(testingData)
Внутри flink-1.7.1 / examples / batch / path вы найдете файл KMeans.jar. Давайте запустим этот пример FlinkML.
Этот пример программы запускается с использованием точки по умолчанию и набора данных центроида.
./bin/flink run examples/batch/KMeans.jar --output Print

Apache Flink — варианты использования
В этой главе мы разберем несколько тестовых случаев в Apache Flink.
Апач Флинк — Bouygues Telecom
Bouygues Telecom — одна из крупнейших телекоммуникационных организаций Франции. У него более 11 миллионов мобильных абонентов и более 2,5 миллионов постоянных клиентов. Буиг впервые услышал об Apache Flink на встрече группы Hadoop в Париже. С тех пор они используют Flink для нескольких вариантов использования. Они обрабатывали миллиарды сообщений в день в режиме реального времени через Apache Flink.
Вот что Bouygues говорит об Apache Flink: «В итоге мы создали Flink, потому что система поддерживает истинную потоковую передачу — как на API, так и на уровне времени выполнения, что дает нам программируемость и низкую задержку, которые мы искали. Кроме того, мы смогли за короткое время настроить и запустить нашу систему с Flink по сравнению с другими решениями, в результате чего появилось больше доступных ресурсов для разработчиков для расширения бизнес-логики в системе ».
В Bouygues обслуживание клиентов является высшим приоритетом. Они анализируют данные в режиме реального времени, чтобы дать своим инженерам
-
Опыт клиентов в реальном времени через их сеть
-
Что происходит глобально в сети
-
Оценка сети и операции
Опыт клиентов в реальном времени через их сеть
Что происходит глобально в сети
Оценка сети и операции
Они создали систему под названием LUX (Logged User Experience), которая обрабатывала массивные данные журнала с сетевого оборудования с внутренней ссылкой на данные, чтобы дать индикаторы качества опыта, которые будут регистрировать их опыт клиентов, и создать тревожную функциональность для обнаружения любого сбоя в использовании данных в течение 60 секунд.
Чтобы достичь этого, им требовалась инфраструктура, которая может принимать массивные данные в режиме реального времени, проста в настройке и предоставляет богатый набор API для обработки потоковых данных. Apache Flink идеально подходил для Bouygues Telecom.
Апач Флинк — Алибаба
Alibaba — крупнейшая в мире компания, занимающаяся розничной торговлей через Интернет, с доходом в 394 млрд. Долл. США в 2015 году. Поиск Alibaba — это точка входа для всех клиентов, которая показывает все результаты поиска и дает соответствующие рекомендации.
Alibaba использует Apache Flink в своей поисковой системе, чтобы показывать результаты в режиме реального времени с максимальной точностью и релевантностью для каждого пользователя.
Alibaba искал рамки, которые были —
-
Очень гибкий в поддержании одной кодовой базы для всего процесса поисковой инфраструктуры.
-
Обеспечивает низкую задержку при изменении доступности продуктов на веб-сайте.
-
Последовательный и экономически эффективный.
Очень гибкий в поддержании одной кодовой базы для всего процесса поисковой инфраструктуры.
Обеспечивает низкую задержку при изменении доступности продуктов на веб-сайте.
Последовательный и экономически эффективный.
Apache Flink отвечает всем вышеперечисленным требованиям. Им нужна структура, которая имеет единый механизм обработки и может обрабатывать как пакетные, так и потоковые данные с одним и тем же механизмом, что и делает Apache Flink.
Они также используют Blink, разветвленную версию для Flink, чтобы удовлетворить некоторые уникальные требования для их поиска. Они также используют API таблиц Apache Flink с небольшими улучшениями для поиска.
Вот что Alibaba сказал по поводу Apache Flink: « Оглядываясь назад, это был, без сомнения, огромный год для Blink и Flink в Alibaba. Никто не думал, что мы добьемся такого большого прогресса в течение года, и мы очень благодарны всем люди, которые помогали нам в сообществе. Доказано, что Flink работает в очень больших масштабах. Мы как никогда полны решимости продолжать нашу работу с сообществом для продвижения Flink вперед! «
Апач Флинк — Флинк против Спарк против Хэдупа
Вот обширная таблица, в которой показано сравнение между тремя наиболее популярными средами для больших данных: Apache Flink, Apache Spark и Apache Hadoop.
| Apache Hadoop | Apache Spark | Апач флинк | |
|---|---|---|---|
|
Год происхождения |
2005 | 2009 | 2009 |
|
Место происхождения |
MapReduce (Google) Hadoop (Yahoo) | Калифорнийский университет, Беркли | Технический университет Берлина |
|
Механизм обработки данных |
партия | партия | Поток |
|
Скорость обработки |
Медленнее, чем Спарк и Флинк | 100 раз быстрее, чем Hadoop | Быстрее, чем искра |
|
Языки программирования |
Java, C, C ++, Ruby, Groovy, Perl, Python | Java, Scala, Python и R | Ява и Скала |
|
Модель программирования |
Уменьшение карты | Эластичные распределенные наборы данных (RDD) | Циклические потоки данных |
|
Обмен данными |
партия | партия | Конвейер и Пакет |
|
Управление памятью |
Основанный на диске | JVM Managed | Активно Управляемый |
|
Задержка |
Низкий | Средняя | Низкий |
|
пропускная способность |
Средняя | Высоко | Высоко |
|
оптимизация |
Руководство | Руководство | автоматическая |
|
API |
Низкий уровень | Высокий уровень | Высокий уровень |
|
Поддержка потоковой передачи |
Не Доступно | Spark Streaming | Flink Streaming |
|
Поддержка SQL |
Улей, Импала | SparkSQL | API таблиц и SQL |
|
Поддержка графиков |
Не Доступно | Graphx | Gelly |
|
Поддержка машинного обучения |
Не Доступно | SparkML | FlinkML |
Год происхождения
Место происхождения
Механизм обработки данных
Скорость обработки
Языки программирования
Модель программирования
Обмен данными
Управление памятью
Задержка
пропускная способность
оптимизация
API
Поддержка потоковой передачи
Поддержка SQL
Поддержка графиков
Поддержка машинного обучения
Apache Flink — Заключение
Сравнительная таблица, которую мы видели в предыдущей главе, в значительной степени завершает указатели. Apache Flink — наиболее подходящая среда для обработки и использования в реальном времени. Уникальная система с одним ядром позволяет обрабатывать как пакетные, так и потоковые данные с помощью различных API, таких как Dataset и DataStream.
Это не означает, что Hadoop и Spark выходят из игры, выбор наиболее подходящей среды больших данных всегда зависит и варьируется от варианта использования к варианту использования. Может быть несколько вариантов использования, в которых может быть подходящей комбинация Hadoop и Flink или Spark и Flink.
Тем не менее, Flink является лучшей платформой для обработки в реальном времени. Рост Apache Flink был удивительным, и число участников его сообщества растет день ото дня.
Счастливого мигания!