KDB + — Обзор
Это полная версия kdb + от систем kx, нацеленная в первую очередь на тех, кто изучает самостоятельно. KDB +, представленный в 2003 году, представляет собой новое поколение базы данных KDB, которая предназначена для сбора, анализа, сравнения и хранения данных.
Система kdb + содержит следующие два компонента:
-
KDB + — база данных (k база данных плюс)
-
Q — язык программирования для работы с kdb +
KDB + — база данных (k база данных плюс)
Q — язык программирования для работы с kdb +
И kdb +, и q написаны на языке программирования k (так же, как q, но менее читаемы).
Фон
Kdb + / q зародился как неясный академический язык, но с годами он постепенно улучшал удобство использования.
-
APL (1964, язык программирования)
-
A + (1988, модифицированный APL Артура Уитни)
-
K (1993, четкая версия A +, разработанная A. Whitney)
-
Kdb (1998, БД в колонке в памяти)
-
Kdb + / q (2003, язык q — более читаемая версия k)
APL (1964, язык программирования)
A + (1988, модифицированный APL Артура Уитни)
K (1993, четкая версия A +, разработанная A. Whitney)
Kdb (1998, БД в колонке в памяти)
Kdb + / q (2003, язык q — более читаемая версия k)
Почему и где использовать KDB +
Зачем? — Если вам нужно одно решение для данных в реальном времени с аналитикой, то вам следует рассмотреть kdb +. Kdb + хранит базу данных как обычные собственные файлы, поэтому у нее нет особых требований к аппаратному обеспечению и архитектуре хранения. Стоит отметить, что база данных — это просто набор файлов, поэтому ваша административная работа не составит труда.
Где использовать KDB + ? — Легко сосчитать, какие инвестиционные банки НЕ используют kdb +, поскольку большинство из них используют в настоящее время или планируют перейти с обычных баз данных на kdb +. Поскольку объем данных растет день ото дня, нам нужна система, которая может обрабатывать огромные объемы данных. KDB + выполняет это требование. KDB + не только хранит огромное количество данных, но и анализирует их в режиме реального времени.
Начиная
Имея такой большой опыт, давайте теперь изложим и узнаем, как настроить среду для KDB +. Начнем с того, как скачать и установить KDB +.
Загрузка и установка KDB +
Вы можете получить бесплатную 32-разрядную версию KDB + со всеми функциями 64-разрядной версии по адресу http://kx.com/software-download.php
Согласитесь с лицензионным соглашением, выберите операционную систему (доступно для всех основных операционных систем). Для операционной системы Windows последняя версия — 3.2. Загрузите последнюю версию. После того, как вы распакуете его, вы получите имя папки «windows», а внутри папки Windows вы получите еще одну папку «q» . Скопируйте всю папку q на ваш диск c: /.
Откройте терминал Run, введите место, где вы храните папку q ; это будет похоже на «c: /q/w32/q.exe». Как только вы нажмете Enter, вы получите новую консоль следующим образом —
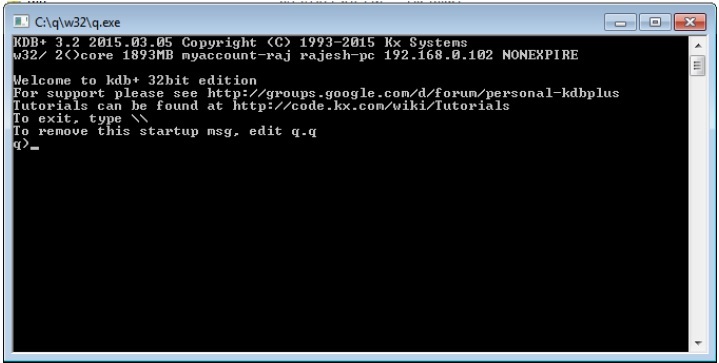
В первой строке вы видите номер версии 3.2 и дату выпуска 2015.03.05
Макет каталога
Пробная / бесплатная версия обычно устанавливается в каталогах,
Для Linux / Mac —
~/q / main q directory (under the user’s home) ~/q/l32 / location of linux 32-bit executable ~/q/m32 / Location of mac 32-bit executable
Для Windows —
c:/q / Main q directory c:/q/w32/ / Location of windows 32-bit executable
Файлы примеров —
После загрузки kdb + структура каталогов на платформе Windows будет выглядеть следующим образом:
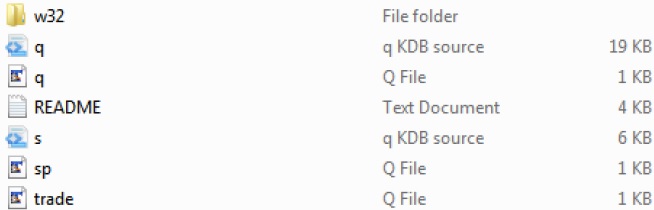
В приведенной выше структуре каталогов trade.q и sp.q являются примерами файлов, которые мы можем использовать в качестве ориентира.
KDB + — Архитектура
Kdb + — это высокопроизводительная база данных большого объема, изначально разработанная для обработки огромных объемов данных. Он полностью 64-битный, имеет встроенную многоядерную обработку и многопоточность. Та же архитектура используется для данных в реальном времени и исторических данных. База данных включает собственный мощный язык запросов q, поэтому аналитика может быть запущена непосредственно на данных.
kdb + tick — это архитектура, которая позволяет собирать, обрабатывать и запрашивать данные в реальном времени и исторические данные.
Kdb + / галочка Архитектура
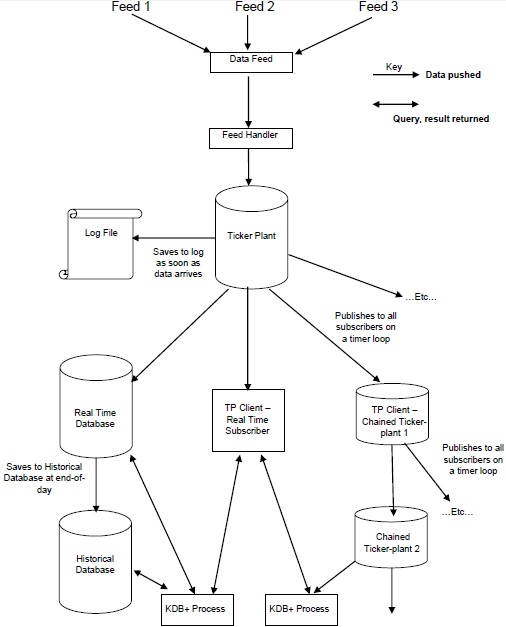
На следующем рисунке представлена обобщенная схема типичной архитектуры Kdb + / tick с последующим кратким объяснением различных компонентов и сквозного потока данных.
-
Каналы данных — это данные временных рядов, которые в основном предоставляются поставщиками каналов данных, такими как Reuters, Bloomberg или напрямую с бирж.
-
Чтобы получить соответствующие данные, данные из фида данных анализируются обработчиком фида .
-
После того, как данные обработаны обработчиком подачи, они отправляются на тиккерную станцию .
-
Чтобы восстановить данные после любого сбоя, тикер-завод сначала обновляет / сохраняет новые данные в файле журнала, а затем обновляет свои собственные таблицы.
-
После обновления внутренних таблиц и файлов журналов данные цикла времени непрерывно отправляются / публикуются в базу данных в режиме реального времени и всем подписчикам в цепочке, которые запрашивали данные.
-
В конце рабочего дня файл журнала удаляется, создается новый, а база данных в реальном времени сохраняется в исторической базе данных. Как только все данные сохранены в исторической базе данных, база данных в реальном времени очищает свои таблицы.
Каналы данных — это данные временных рядов, которые в основном предоставляются поставщиками каналов данных, такими как Reuters, Bloomberg или напрямую с бирж.
Чтобы получить соответствующие данные, данные из фида данных анализируются обработчиком фида .
После того, как данные обработаны обработчиком подачи, они отправляются на тиккерную станцию .
Чтобы восстановить данные после любого сбоя, тикер-завод сначала обновляет / сохраняет новые данные в файле журнала, а затем обновляет свои собственные таблицы.
После обновления внутренних таблиц и файлов журналов данные цикла времени непрерывно отправляются / публикуются в базу данных в режиме реального времени и всем подписчикам в цепочке, которые запрашивали данные.
В конце рабочего дня файл журнала удаляется, создается новый, а база данных в реальном времени сохраняется в исторической базе данных. Как только все данные сохранены в исторической базе данных, база данных в реальном времени очищает свои таблицы.
Компоненты архитектуры Kdb + Tick
Фиды данных
Каналы данных могут быть любыми рыночными или другими данными временных рядов. Рассматривайте каналы данных как необработанный ввод для обработчика каналов. Ленты могут быть получены непосредственно от биржи (потоковой передачи данных), от поставщиков новостей / данных, таких как Thomson-Reuters, Bloomberg или любых других внешних агентств.
Feed Handler
Обработчик каналов преобразует поток данных в формат, подходящий для записи в kdb +. Он подключен к каналу данных и извлекает и преобразует данные из формата, специфичного для канала, в сообщение Kdb +, которое публикуется в процессе установки тикера. Обычно обработчик подачи используется для выполнения следующих операций:
- Захват данных в соответствии с набором правил.
- Перевести (/ обогатить) эти данные из одного формата в другой.
- Поймай самые последние значения.
Тиккерный завод
Ticker Plant является важнейшим компонентом архитектуры KDB +. Это тикерная станция, с которой база данных в реальном времени или напрямую подписчики (клиенты) подключаются для доступа к финансовым данным. Он работает по механизму публикации и подписки . Как только вы получаете подписку (лицензию), определяется тиковая (обычная) публикация от издателя (тикерная установка). Он выполняет следующие операции —
-
Получает данные от обработчика каналов.
-
Сразу после того, как завод по производству тикеров получает данные, он сохраняет копию в виде файла журнала и обновляет ее, как только завод по производству тикеров получает любое обновление, чтобы в случае любого сбоя у нас не было потери данных.
-
Клиенты (подписчик в режиме реального времени) могут напрямую подписаться на тикер-завод.
-
В конце каждого рабочего дня, т. Е. Как только база данных в реальном времени получает последнее сообщение, она сохраняет все сегодняшние данные в исторической базе данных и передает их всем подписчикам, которые подписались на сегодняшние данные. Затем он сбрасывает все свои таблицы. Файл журнала также удаляется после сохранения данных в исторической базе данных или другом напрямую связанном подписчике с базой данных реального времени (rtdb).
-
В результате, тикерная фабрика, база данных в реальном времени и историческая база данных работают круглосуточно.
Получает данные от обработчика каналов.
Сразу после того, как завод по производству тикеров получает данные, он сохраняет копию в виде файла журнала и обновляет ее, как только завод по производству тикеров получает любое обновление, чтобы в случае любого сбоя у нас не было потери данных.
Клиенты (подписчик в режиме реального времени) могут напрямую подписаться на тикер-завод.
В конце каждого рабочего дня, т. Е. Как только база данных в реальном времени получает последнее сообщение, она сохраняет все сегодняшние данные в исторической базе данных и передает их всем подписчикам, которые подписались на сегодняшние данные. Затем он сбрасывает все свои таблицы. Файл журнала также удаляется после сохранения данных в исторической базе данных или другом напрямую связанном подписчике с базой данных реального времени (rtdb).
В результате, тикерная фабрика, база данных в реальном времени и историческая база данных работают круглосуточно.
Поскольку ticker-plant является приложением Kdb +, к его таблицам можно обращаться с помощью q, как и к любой другой базе данных Kdb +. Все клиенты Ticker-Plant должны иметь доступ к базе данных только в качестве подписчиков.
База данных в реальном времени
База данных в реальном времени (rdb) хранит сегодняшние данные. Это напрямую связано с тикером завода. Обычно он хранится в памяти в часы работы рынка (день) и записывается в историческую базу данных (hdb) в конце дня. Поскольку данные (данные rdb) хранятся в памяти, обработка выполняется чрезвычайно быстро.
Поскольку kdb + рекомендует иметь размер оперативной памяти, который в четыре или более раз превышает ожидаемый объем данных в день, запрос, выполняемый на rdb, очень быстрый и обеспечивает превосходную производительность. Поскольку база данных реального времени содержит только сегодняшние данные, столбец даты (параметр) не требуется.
Например, мы можем иметь запросы RDB, как,
select from trade where sym = `ibm OR select from trade where sym = `ibm, price > 100
Историческая база данных
Если нам нужно рассчитать оценки компании, нам нужно иметь ее исторические данные. Историческая база данных (hdb) содержит данные о транзакциях, совершенных в прошлом. Запись каждого нового дня будет добавлена в hdb в конце дня. Большие таблицы в hdb либо хранятся с разбивкой (каждый столбец хранится в своем собственном файле), либо они хранятся разделенными временными данными. Также некоторые очень большие базы данных могут быть дополнительно разделены с использованием par.txt (файл).
Эти стратегии хранения (распределенные, разделенные и т. Д.) Эффективны при поиске или доступе к данным из большой таблицы.
Историческая база данных также может использоваться для внутренней и внешней отчетности, т. Е. Для аналитики. Например, предположим, что мы хотим получить информацию о сделках компании IBM за определенный день из имени торговой (или любой) таблицы, нам нужно написать запрос следующим образом:
thisday: 2014.10.12 select from trade where date = thisday, sym =`ibm
Примечание. Мы напишем все такие запросы, как только получим обзор языка q .
Q Язык программирования
Kdb + поставляется со встроенным языком программирования, который известен как q . Он включает в себя расширенный набор стандартного SQL, который расширен для анализа временных рядов и предлагает много преимуществ по сравнению со стандартной версией. Любой, кто знаком с SQL, может выучить q за считанные дни и быстро написать свои собственные специальные запросы.
Запуск среды «q»
Чтобы начать использовать kdb +, вам нужно начать сеанс q . Есть три способа начать сеанс q —
-
Просто введите «c: /q/w32/q.exe» на своем терминале запуска.
-
Запустите командный терминал MS-DOS и введите q .
-
Скопируйте файл q.exe в «C: \ Windows \ System32» и на рабочем терминале просто введите «q».
Просто введите «c: /q/w32/q.exe» на своем терминале запуска.
Запустите командный терминал MS-DOS и введите q .
Скопируйте файл q.exe в «C: \ Windows \ System32» и на рабочем терминале просто введите «q».
Здесь мы предполагаем, что вы работаете на платформе Windows.
Типы данных
В следующей таблице приведен список поддерживаемых типов данных.
| название | пример | голец | Тип | Размер |
|---|---|---|---|---|
| логический | 1б | б | 1 | 1 |
| байт | 0xff | Икс | 4 | 1 |
| короткая | 23ч | час | 5 | 2 |
| ИНТ | 23i | я | 6 | 4 |
| долго | 23J | J | 7 | 8 |
| реальный | 2.3e | е | 8 | 4 |
| поплавок | 2.3f | е | 9 | 8 |
| голец | «А» | с | 10 | 1 |
| VARCHAR | `аб | s | 11 | * |
| месяц | 2003.03m | м | 13 | 4 |
| Дата | 2015.03.17T18: 01: 40,134 | Z | 15 | 8 |
| минут | 8:31 | U | 17 | 4 |
| второй | 8:31:53 | v | 18 | 4 |
| время | 18: 03: 18,521 | T | 19 | 4 |
| перечисление | `u $` b, где u: `a`b | * | 20 | 4 |
Формирование атома и списка
Атомы — это отдельные объекты, например, одно число, символ или символ. В приведенной выше таблице (разных типов данных) все поддерживаемые типы данных являются атомами. Список — это последовательность атомов или других типов, включая списки.
Передача атома любого типа в функцию монадического типа (т. Е. Функции с одним аргументом) вернет отрицательное значение, то есть –n , тогда как передача простого списка этих атомов в функцию типа вернет положительное значение n .
Пример 1 — Формирование атома и списка
/ Note that the comments begin with a slash “ / ” and cause the parser / to ignore everything up to the end of the line. x: `mohan / `mohan is a symbol, assigned to a variable x type x / let’s check the type of x -11h / -ve sign, because it’s single element. y: (`abc;`bca;`cab) / list of three symbols, y is the variable name. type y 11h / +ve sign, as it contain list of atoms (symbol). y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon y2: (`$”symbols may have interior blanks”) / string to symbol conversion y[0] / return `abc y 0 / same as y[0], also returns `abc y 0 2 / returns `abc`cab, same as does y[0 2] z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types, z 2 0 / returns (`a`b; `abc), z[2;0] / return `a. first element of z[2] x: “Hello World!” / list of character, a string x 4 0 / returns “oH” i.e. 4th and 0th(first) element
Q Language — Кастинг типов
Часто требуется изменить тип данных некоторых данных с одного типа на другой. Стандартная функция приведения — это двоичный оператор «$».
Три подхода используются для приведения из одного типа в другой (кроме строки) —
- Укажите желаемый тип данных по имени символа
- Укажите желаемый тип данных по его символу
- Укажите желаемый тип данных по его короткому значению.
Приведение целых чисел к плавающим
В следующем примере приведения целых чисел к плавающим, все три различных способа приведения эквивалентны —
q)a:9 18 27 q)$[`float;a] / Specify desired data type by its symbol name, 1 st way 9 18 27f q)$["f";a] / Specify desired data type by its character, 2 nd way 9 18 27f q)$[9h;a] / Specify desired data type by its short value, 3 rd way 9 18 27f
Проверьте, все ли три операции эквивалентны,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a]) 1b
Приведение строк в символы
Приведение строки к символам и наоборот работает немного по-другому. Давайте проверим это на примере —
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorld
Попытка привести строки к символам с использованием ключевых слов `symbol или 11h потерпит неудачу с ошибкой типа —
q)b "Hello" "World" "HelloWorld" q)`symbol$b 'type q)11h$b 'type
Приведение строк в не-символы
Преобразование строк в тип данных, отличный от символа, выполняется следующим образом:
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above
57 48 48i
q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900i
Таким образом, для приведения всей строки (списка символов) к одному атому типа данных x необходимо указать заглавную букву, представляющую тип данных x, в качестве первого аргумента оператора $ . Если вы укажете тип данных x любым другим способом, это приведет к тому, что приведение будет применено к каждому символу строки.
Q Language — временные данные
В языке q есть много разных способов представления и обработки временных данных, таких как время и дата.
Дата
Дата в kdb + внутренне сохраняется как целое число дней, так как наша справочная дата — 01 января 2000 года. Дата после этой даты внутренне сохраняется как положительное число, а дата до нее упоминается как отрицательное число.
По умолчанию дата записывается в формате «ГГГГ.ММ.ДД»
q)x:2015.01.22 / This is how we write 22nd Jan 2015 q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date 2015i q)x.year / Another way of extracting year 2015i q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date 22i q)x.dd / Another way of extracting day 22i
Арифметические и логические операции могут выполняться непосредственно по датам.
q)x+1 / Add one day 2015.01.23 q)x-7 / Subtract 7 days 2015.01.15
1 января 2000 года выпало на субботу. Поэтому любая суббота на протяжении всей истории или в будущем при делении на 7 даст остаток от 0, воскресенье дает 1, понедельник — 2.
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6
раз
Время хранится в виде целого числа миллисекунд с момента полуночи. Время записывается в формате ЧЧ: ММ: СС.МСС
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM q)tt1 03:30:00.000 q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time 3i q)tt1.hh 3i q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time 0i q)tt1.ss 0i
Как и в случае с датами, арифметика может быть выполнена непосредственно по времени.
DateTimes
Дата и время — это комбинация даты и времени, разделенных буквой «Т», как в стандартном формате ISO. Значение datetime хранит дробное число дней с полуночи 1 января 2000 года.
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012 q)type dt -15h q)dt 2012.12.20T04:54:59.000 9 q)`float$dt 4737.205
Основной дробный счетчик дней может быть получен путем приведения в плавающее положение.
Q Language — Списки
Списки являются основными строительными блоками языка q , поэтому очень важно хорошо понимать списки. Список — это просто упорядоченная коллекция атомов (атомных элементов) и других списков (группа из одного или нескольких атомов).
Типы Списка
Общий список заключает его элементы в соответствующие скобки и разделяет их точкой с запятой. Например —
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")
Если список состоит из атомов одного типа, он называется единым списком . Иначе, это известно как общий список (смешанный тип).
подсчитывать
Мы можем получить количество элементов в списке по его количеству.
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list q)count l1 / Calculating number of items in the list l1 4
Примеры простого списка
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"
** Примечание. Простой список символов называется строкой.
Список содержит атомы или списки. Чтобы создать единый список элементов , мы используем —
q)singleton:enlist 42 q)singleton ,42
Чтобы различить атом и эквивалентный синглтон , изучите знак их типа.
q)signum type 42 -1i q)signum type enlist 42 1i
Q Language — Индексирование
Список упорядочен слева направо по позиции его элементов. Смещение элемента от начала списка называется его индексом . Таким образом, первый элемент имеет индекс 0, второй элемент (если таковой имеется) имеет индекс 1 и т. Д. Список с номером n имеет индексную область от 0 до n – 1 .
Индексная нотация
Имея список L , элемент с индексом i доступен через L [i] . Получение элемента по его индексу называется индексацией элемента . Например,
q)L:(99;98.7e;`b;`abc;"z") q)L[0] 99 q)L[1] 98.7e q)L[4] "z
Индексированное назначение
Элементы в списке также могут быть назначены с помощью индексации элементов. Таким образом,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66
Списки из переменных
q)l1:(9;8;40;200) q)l2:(1 4 3; `abc`xyz) q)l:(l1;l2) / combining the two list l1 and l2 q)l 9 8 40 200 (1 4 3;`abc`xyz)
Присоединяющиеся списки
Самая распространенная операция в двух списках — это объединение их в большой список. Точнее, оператор соединения (,) добавляет свой правый операнд в конец левого операнда и возвращает результат. Он принимает атом в любом аргументе.
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6
гнездование
Сложность данных строится с использованием списков в качестве элементов списков.
глубина
Количество уровней вложенности для списка называется его глубиной. Атомы имеют глубину 0, а простые списки имеют глубину 1.
q)l1:(9;8;(99;88)) q)count l1 3
Вот список глубины 3 с двумя пунктами:
q)l5 9 (90;180;900 1800 2700 3600) q)count l5 2 q)count l5[1] 3
Индексирование по глубине
Можно индексировать непосредственно в элементы вложенного списка.
Повторное индексирование предметов
Извлечение элемента по одному индексу всегда приводит к получению самого верхнего элемента из вложенного списка.
q)L:(1;(100;200;(300;400;500;600))) q)L[0] 1 q)L[1] 100 200 300 400 500 600
Поскольку результат L [1] сам по себе является списком, мы можем извлечь его элементы, используя один индекс.
q)L[1][2] 300 400 500 600
Мы можем повторить одиночную индексацию еще раз, чтобы извлечь элемент из внутреннего вложенного списка.
q)L[1][2][0] 300
Вы можете прочитать это как,
Получить элемент по индексу 1 из L и извлечь из него элемент по индексу 2, а из него получить элемент по индексу 0.
Обозначение для индексации на глубине
Существует альтернативное обозначение для повторной индексации в составные части вложенного списка. Последний поиск также может быть записан как,
q)L[1;2;0] 300
Назначение через индекс также работает на глубине.
q)L[1;2;1]:900 q)L 1 (100;200;300 900 500 600)
Элидируемые индексы
Исключение индексов для общего списка
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"
Интерпретировать L [; 1;] как,
Получить все элементы во второй позиции каждого списка на верхнем уровне.
Интерпретировать L [;; 2] как,
Получить элементы в третьей позиции для каждого списка на втором уровне.
Q Language — Словари
Словари являются расширением списков, которые служат основой для создания таблиц. В математических терминах словарь создает
«Домен → диапазон»
или вообще (коротко) создает
«Ключ → значение»
отношения между элементами.
Словарь — это упорядоченная коллекция пар ключ-значение, которая примерно эквивалентна хеш-таблице. Словарь — это отображение, определяемое явной ассоциацией ввода-вывода между списком доменов и списком диапазонов посредством позиционного соответствия. При создании словаря используется примитив xkey (!)
ListOfDomain ! ListOfRange
Самый основной словарь отображает простой список в простой список.
| Вход (I) | Выход (O) |
|---|---|
| `Имя | `Джон |
| `Возраст | 36 |
| `Пол | «M» |
| Вес | 60,3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d q)d Name | `John Age | 36 Sex | "M" Weight | 60.3 q)count d / To get the number of rows in a dictionary. 4 q)key d / The function key returns the domain `Name`Age`Sex`Weight q)value d / The function value returns the range. `John 36 "M" 60.3 q)cols d / The function cols also returns the domain. `Name`Age`Sex`Weight
Уважать
Поиск значения словаря, соответствующего входному значению, называется поиском ввода.
q)d[`Name] / Accessing the value of domain `Name `John q)d[`Name`Sex] / extended item-wise to a simple list of keys `John "M"
Поиск с глаголом @
q)d1:`one`two`three!9 18 27 q)d1[`two] 18 q)d1@`two 18
Операции над словарями
Поправка и одобрение
Как и в случае списков, элементы словаря могут быть изменены с помощью индексированного присваивания.
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
Словари могут быть расширены с помощью назначения индекса.
q)d[`Height]:"182 Ft" q)d Name | `John Age | 35 Sex | "M" Weight | 60.3 Height | "182 Ft"
Обратный поиск с Find (?)
Оператор find (?) Используется для обратного просмотра путем сопоставления диапазона элементов с его элементом домена.
q)d2:`x`y`z!99 88 77 q)d2?77 `z
В случае, если элементы списка не являются уникальными, find возвращает первое сопоставление элементов из списка доменов.
Удаление записей
Чтобы удалить запись из словаря, используется функция delete (_) . Левый операнд (_) — это словарь, а правый операнд — это ключевое значение.
q)d2:`x`y`z!99 88 77 q)d2 _`z x| 99 y| 88
Пробел слева от _ требуется, если первый операнд является переменной.
q)`x`y _ d2 / Deleting multiple entries z| 77
Словари колонок
Словарные столбцы являются основой для создания таблиц. Рассмотрим следующий пример —
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27
Листать словарь
Чистый эффект от переворота словаря столбцов просто меняет порядок индексов. Это логически эквивалентно переносу строк и столбцов.
Переверните словарь столбца
Транспонирование словаря достигается применением унарного флип-оператора. Взгляните на следующий пример —
q)scores name | John Jenny Jonathan id | 9 18 27 q)flip scores name id --------------- John 9 Jenny 18 Jonathan 27
Перевернутый словарь перевернутых столбцов
Если вы транспонируете словарь дважды, вы получаете оригинальный словарь,
q)scores ~ flip flip scores 1b
Q Language — Таблица
Таблицы лежат в основе KDB +. Таблица представляет собой набор именованных столбцов, реализованных в виде словаря. q таблицы ориентированы на столбцы.
Создание таблиц
Таблицы создаются с использованием следующего синтаксиса —
q)trade:([]time:();sym:();price:();size:()) q)trade time sym price size -------------------
В приведенном выше примере мы не указали тип каждого столбца. Это будет установлено при первой вставке в таблицу.
Другой способ, мы можем указать тип столбца при инициализации —
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())
Или мы также можем определить непустые таблицы —
q)trade:([]sym:(`a`b);price:(1 2)) q)trade sym price ------------- a 1 b 2
Если в квадратных скобках нет столбцов, как в приведенных выше примерах, таблица не помечается .
Чтобы создать таблицу с ключами, мы вставляем столбец (столбцы) для ключа в квадратных скобках.
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$()) q)trade sym | time price size ----- | ---------------
Можно также определить типы столбцов, установив значения в нулевые списки различных типов —
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)
Получение информации о таблице
Давайте создадим торговый стол —
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow) q)cols trade / column names of a table `sym`mcap`ex q)trade.sym / Retrieves the value of column sym `ibm`msft`apple`samsung q)show meta trade / Get the meta data of a table trade. c | t f a ----- | ----- Sym | s Mcap | j ex | s
Первичные ключи и таблицы ключей
Таблица с ключами
Таблица с ключами — это словарь, который отображает каждую строку в таблице уникальных ключей на соответствующую строку в таблице значений. Давайте возьмем пример —
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eid
Теперь создайте простую таблицу с ключами, содержащую eid в качестве ключа,
q)valid: id ! val q)valid / table name valid, having key as eid eid | name id --- | --------------- 99 | John 9 198 | Jenny 18 297 | Jonathan 27
ForeignKeys
Внешний ключ определяет отображение из строк таблицы, в которой он определен, в строки таблицы с соответствующим первичным ключом .
Внешние ключи обеспечивают ссылочную целостность . Другими словами, попытка вставить значение внешнего ключа, которого нет в первичном ключе, потерпит неудачу.
Рассмотрим следующие примеры. В первом примере мы определим внешний ключ явно при инициализации. Во втором примере мы будем использовать отслеживание внешнего ключа, которое не предполагает каких-либо предварительных отношений между двумя таблицами.
Пример 1 — определение внешнего ключа при инициализации
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000) q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f) q)show meta tab c | t f a ------ | ---------- sym | s sector price | f q)show select from tab where sym.ex=`N sym price ---------------- APPLE 4.65382 APPLE 4.643817 APPLE 3.659978
Пример 2 — нет предопределенных отношений между таблицами
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000) tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)
Чтобы использовать отслеживание внешнего ключа, мы должны создать таблицу для ввода ключа в сектор.
q)show update mc:(sector([]symb:sym))[`MC] from tab sym price mc -------------------------- IBM 7.065297 1000 MSFT 4.812387 2000 MSFT 6.400545 2000 HSBC 3.704373 3000 HSBC 4.438651 3000
Общие обозначения для предопределенного внешнего ключа —
выберите ab из c, где a это внешний ключ (sym), b это a
поле в таблице первичного ключа (ind), c является
таблица внешнего ключа (торговля)
Манипулирующие столы
Давайте создадим одну торговую таблицу и проверим результат другого табличного выражения —
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365)) q)trade sym price size time ----------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842
Давайте теперь посмотрим на операторы, которые используются для манипулирования таблицами с использованием языка q .
Выбрать
Синтаксис для использования оператора Select следующий:
select [columns] [by columns] from table [where clause]
Давайте теперь возьмем пример, чтобы продемонстрировать, как использовать оператор Select —
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006
Вставить
Синтаксис для использования оператора вставки следующий:
`tablename insert (values) Insert[`tablename; values]
Давайте теперь возьмем пример, чтобы продемонстрировать, как использовать оператор вставки —
q)/ Insert expression example q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000) 5 6 q)trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 q)/Insert another value q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000] '] q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)] ,7 q)trade sym price size time ---------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000
удалять
Синтаксис для использования оператора Delete выглядит следующим образом:
delete columns from table delete from table where clause
Давайте теперь возьмем пример, чтобы продемонстрировать, как использовать оператор Delete —
q)/Delete expression example q)delete price from trade sym size time ------------------------------- msft 3162 02:32:17.036 msft 2917 01:44:56.936 hsbc 1492 00:25:23.210 samsung 1983 00:29:38.945 ibm 4006 07:24:26.842 hsbc 3020 09:30:17.004 apple 3012 09:15:00.000 samsung 3333 10:30:00.000 q)delete from trade where price > 3000 sym price size time ------------------------------------------- msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)delete from trade where price > 500 sym price size time ----------------------------------------- samsung 278.3498 1983 00:29:38.945 hsbc 302 3020 09:30:17.004 samsung 302 3333 10:30:00.000
Обновить
Синтаксис для использования оператора Update следующий:
update column: newValue from table where ….
Используйте следующий синтаксис, чтобы обновить формат / тип данных столбца, используя функцию приведения —
update column:newValue from `table where …
Давайте теперь возьмем пример, чтобы продемонстрировать, как использовать оператор Update —
q)/Update expression example q)update size:9000 from trade where price > 600 sym price size time ------------------------------------------ msft 743.8592 9000 02:32:17.036 msft 641.7307 9000 01:44:56.936 hsbc 838.2311 9000 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 9000 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 9000 09:15:00.000 samsung 302 3333 10:30:00.000 q)/Update the datatype of a column using the cast function q)meta trade c | t f a ----- | -------- sym | s price| f size | j time | t q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade `trade q)meta trade c | t f a ------ | -------- sym | s price | f size | f time | t
Q язык — глагол и наречия
Kdb + имеет существительные, глаголы и наречия. Все объекты данных и функции являются существительными . Глаголы улучшают читаемость, уменьшая количество квадратных скобок и скобок в выражениях. Наречия изменяют двоичные (2 аргумента) функции и глаголы для создания новых связанных глаголов. Функции, производимые наречиями, называются производными функциями или производными глаголами .
каждый
Каждое наречие, обозначаемое (`), изменяет двоичные функции и глаголы для применения к элементам списков вместо самих списков. Взгляните на следующий пример —
q)1, (2 3 5) / Join 1 2 3 5 q)1, '( 2 3 4) / Join each 1 2 1 3 1 4
Существует форма Each для монадических функций, которая использует ключевое слово «each». Например,
q)reverse ( 1 2 3; "abc") /Reverse a b c 1 2 3 q)each [reverse] (1 2 3; "abc") /Reverse-Each 3 2 1 c b a q)'[reverse] ( 1 2 3; "abc") 3 2 1 c b a
Каждый-левый и каждый-правый
Существует два варианта каждой из них для двоичных функций, которые называются Every-Left (\ 🙂 и Each-Right (/ :). В следующем примере объясняется, как их использовать.
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40
Q Language — Joins
В языке q у нас есть различные виды объединений, основанные на предоставленных входных таблицах и желаемых типах объединяемых таблиц. Объединение объединяет данные из двух таблиц. Помимо отслеживания внешнего ключа, есть еще четыре способа объединения таблиц:
- Простое соединение
- Asof присоединиться
- Левый присоединиться
- Союз присоединиться
Здесь, в этой главе, мы подробно обсудим каждое из этих объединений.
Простое соединение
Простое объединение — это самый простой тип объединения, выполняемый с запятой ‘,’. В этом случае две таблицы должны соответствовать типу , т. Е. Обе таблицы имеют одинаковое количество столбцов в одинаковом порядке и одинаковый ключ.
table1,:table2 / table1 is assigned the value of table2
Мы можем использовать объединение через запятую для таблиц одинаковой длины, чтобы соединять вбок. Здесь можно ввести одну из таблиц,
Table1, `Table2
Asof Регистрация (aj)
Это самое мощное соединение, которое используется для получения значения поля в одной таблице за время в другой таблице. Обычно он используется, чтобы получить преобладающую ставку и спросить во время каждой сделки.
Общий формат
aj[joinColumns;tbl1;tbl2]
Например,
aj[`sym`time;trade;quote]
пример
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6)) q)show aj[`a`b;tab1;tab2] a b d c ------------- 1 2 6 2 3 7 4 3 4 8 5 4 5 9 6
Левое соединение (lj)
Это особый случай aj, где второй аргумент является таблицей с ключами, а первый аргумент содержит столбцы ключа правого аргумента.
Общий формат
table1 lj Keyed-table
пример
q)/Left join- syntax table1 lj table2 or lj[table1;table2] q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6)) q)show lj[tab1;tab2] a b d c ------------- 1 2 6 2 3 7 4 3 4 8 5 4 5 9 6
Union Join (UJ)
Это позволяет создать объединение двух таблиц с различными схемами. Это в основном расширение простого соединения (,)
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9)) q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6)) q)show uj[tab1;tab2] a b d c ------------ 1 2 6 2 3 7 3 4 8 4 5 9 2 3 4 3 4 5 4 5 6
Если вы используете uj в таблицах с ключами, то первичные ключи должны совпадать.
Q Language — Функции
Типы функций
Функции можно классифицировать несколькими способами. Здесь мы классифицировали их на основе количества и типа аргумента, который они принимают, и типа результата. Функции могут быть,
-
Атомная — где аргументы являются атомными и дают атомные результаты
-
Агрегат — атом из списка
-
Uniform (список из списка) — Расширено понятие атома применительно к спискам. Количество списка аргументов равно количеству списка результатов.
-
Другое — если функция не из вышеуказанной категории.
Атомная — где аргументы являются атомными и дают атомные результаты
Агрегат — атом из списка
Uniform (список из списка) — Расширено понятие атома применительно к спискам. Количество списка аргументов равно количеству списка результатов.
Другое — если функция не из вышеуказанной категории.
Бинарные операции в математике называются двоичными функциями в q; например, «+». Точно так же унарные операции называются монадическими функциями ; например, «абс» или «пол».
Часто используемые функции
В программировании q часто используется довольно много функций. Здесь, в этом разделе, мы увидим использование некоторых популярных функций —
абс
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number 9.9
все
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value 0b
Макс (&), Мин (|) и Нет (!)
q) /And, Or, and Logical Negation q) 1b & 1b / And (Max) 1b q) 1b|0b / Or (Min) 1b q) not 1b /Logical Negate (Not) 0b
по возрастанию
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for grouped
средний
q)avg 3 4 5 6 7 / Return average of a list of numeric values 5f q)/Create on trade table q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)
от
q)/ by - Groups rows in a table at given sym q)select sum price by sym from trade / find total price for each sym sym | price ------ | -------- apple | 140.2165 ibm | 16.11385
смещ_по_столбцам
q)cols trade / Lists columns of a table `time`sym`price`size
подсчитывать
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9
порт
q)\p 9999 / assign port number q)/csv - This command allows queries in a browser to be exported to excel by prefixing the query, such as http://localhost:9999/.csv?select from trade where sym =`ibm
резать
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"
удалять
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97
отчетливый
q)/distinct - Returns the distinct element of a list q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number 1 2 3 4 5
завербоваться
q)/enlist - Creates one-item list. q)enlist 37 ,37 q)type 37 / -ve type value -7h q)type enlist 37 / +ve type value 7h
Заполнить (^)
q)/fill - used with nulls. There are three functions for processing null values. The dyadic function named fill replaces null values in the right argument with the atomic left argument. q)100 ^ 3 4 0N 0N -5 3 4 100 100 -5 q)`Hello^`jack`herry``john` `jack`herry`Hello`john`Hello
заливка
q)/fills - fills in nulls with the previous not null value. q)fills 1 0N 2 0N 0N 2 3 0N -5 0N 1 1 2 2 2 2 3 3 -5 -5
Первый
q)/first - returns the first atom of a list q)first 1 3 34 5 3 1
кувырок
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97
IASC
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list. q)iasc 5 4 0 3 4 9 2 3 1 4 0 5
Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list q)idesc 0 1 3 4 3 2 1 0
в
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents. q)(2 4) in 1 2 3 10b
вставить
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
ключ
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary. q)key 9 0 1 2 3 4 5 6 7 8 q)key `:c: `$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..
ниже
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`sym
Макс и Мин (т.е. | и &)
q)/Max and Min / a|b and a&b q)9|7 9 q)9&5 5
ноль
q)/null - return 1b if the atom is a null else 0b from the argument list q)null 1 3 3 0N 0001b
персик
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31
Предыдущая
q)/prev - returns the previous element i.e. pushes list forwards q)prev 0 1 3 4 5 7 0N 0 1 3 4 5
Случайный (?)
q)/random - syntax - n?list, gives random sequences of ints and floats q)9?5 0 0 4 0 3 2 2 0 1 q)3?9.9 0.2426823 1.674133 3.901671
сровнять с землей
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4
read0
q)/read0 - Read in a text file q)read0 `:c:/q/README.txt / gives the contents of *.txt file
READ1
q)/read1 - Read in a q data file q)read1 `:c:/q/t1 0xff016200630b000500000073796d0074696d6500707269636…
задний ход
q)/reverse - Reverse a list q)reverse 2 30 29 1 3 4 4 3 1 29 30 2 q)reverse "HelloWorld" "dlroWolleH"
задавать
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
SSR
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with] q)ssr["HelloWorld";"o";"O"] "HellOWOrld"
строка
q)/string - converts to string, converts all types to a string format. q)string (1 2 3; `abc;"XYZ";0b) (,"1";,"2";,"3") "abc" (,"X";,"Y";,"Z") ,"0"
С.В.
q)/sv - Scalar from vector, performs different tasks dependent on its arguments. It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters. q)24 60 60 sv 11 30 49 41449 / number of seconds elapsed in a day at 11:30:49
система
q)/system - allows a system command to be sent, q)system "dir *.py" " Volume in drive C is New Volume" " Volume Serial Number is 8CD2-05B2" "" " Directory of C:\\Users\\myaccount-raj" "" "09/14/2014 06:32 PM 22 hello1.py" " 1 File(s) 22 bytes"
таблицы
q)/tables - list all tables q)tables ` `s#`tab1`tab2`trade
сезам
q)/til - Enumerate q)til 5 0 1 2 3 4
отделка
q)/trim - Eliminate string spaces q)trim " John " "John"
против
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity q)"|" vs "20150204|msft|20.45" "20150204" "msft" "20.45"
xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36
xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
xcols
q)/xcols - Reorders the columns of a table, q)`size`price xcols trade size price time sym ----------------------------------------------------------- 36 72.05742 2009.06.18T06:04:42.919 apple 12 16.11385 2009.11.14T12:42:34.653 ibm 97 68.15909 2009.12.27T17:02:11.518 apple 99 48.35 2015.04.06T10:03:36.738 samsung 99 48.35 2015.04.06T10:03:47.540 samsung 99 48.35 2015.04.06T10:04:44.844 samsung
xdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12
Xgroup
q)/xgroup - Creates nested table q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40) 'length q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10) x | y ---- | ----------- 9 | 10 10 40 10 18 | 20 20 27 | ,30
xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99
Системные Команды
Системные команды управляют средой q . Они имеют следующую форму —
\cmd [p] where p may be optional
Некоторые из популярных системных команд были обсуждены ниже —
\ a [namespace] — Список таблиц в данном пространстве имен
q)/Tables in default namespace q)\a ,`trade q)\a .o / table in .o namespace. ,`TI
\ b — просмотр зависимостей
q)/ views/dependencies q)a:: x+y / global assingment q)b:: x+1 q)\b `s#`a`b
\ B — ожидающие представления / зависимости
q)/ Pending views/dependencies q)a::x+1 / a depends on x q)\B / the dependency is pending ' / the dependency is pending q)\B `s#`a`b q)\b `s#`a`b q)b 29 q)a 29 q)\B `symbol$()
\ cd — Сменить каталог
q)/change directory, \cd [name] q)\cd "C:\\Users\\myaccount-raj" q)\cd ../new-account q)\cd "C:\\Users\\new-account"
\ d — устанавливает текущее пространство имен
q)/ sets current namespace \d [namespace] q)\d /default namespace ' q)\d .o /change to .o q.o)\d `.o q.o)\d . / return to default q)key ` /lists namespaces other than .z `q`Q`h`j`o q)\d .john /change to non-existent namespace q.john)\d `.john q.john)\d . q)\d `.
\ l — загрузить файл или каталог из БД
q)/ Load file or directory, \l q)\l test2.q / loading test2.q which is stored in current path. ric | date ex openP closeP MCap ----------- | ------------------------------------------------- JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876 HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559 JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557 HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366 JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390 ric | date ex openP closeP MCap ---------- | ------------------------------------------------ INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375 RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201 SBIN | 2008.02.14 DOW 1.830857 9.006485 15465 INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143 SBIN | 2010.07.05 DOW 18.55637 10.54082 15873
\ p — номер порта
q)/ assign port number, \p q)\p 5001i q)\p 8888 q)\p 8888i
\\ — выход из консоли q
\\ - exit Exit form q.
Q Language — Встроенные функции
Язык программирования q имеет набор богатых и мощных встроенных функций. Встроенная функция может быть следующих типов:
-
Функция String — принимает строку в качестве входных данных и возвращает строку.
-
Агрегатная функция — принимает список в качестве входных данных и возвращает атом.
-
Унифицированная функция — берет список и возвращает список с тем же количеством.
-
Математическая функция — принимает числовой аргумент и возвращает числовой аргумент.
-
Разная функция — все функции, кроме указанных выше.
Функция String — принимает строку в качестве входных данных и возвращает строку.
Агрегатная функция — принимает список в качестве входных данных и возвращает атом.
Унифицированная функция — берет список и возвращает список с тем же количеством.
Математическая функция — принимает числовой аргумент и возвращает числовой аргумент.
Разная функция — все функции, кроме указанных выше.
Строковые функции
Like — сопоставление с образцом
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b q)"John" like "J??n" 1b q)"John My Name" like "J*" 1b
ltrim — удаляет ведущие пробелы
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks q)ltrim " Rick " "Rick "
rtrim — удаляет завершающие пробелы
q)/rtrim - takes string argument, returns the result of removing trailing blanks q)rtrim " Rick " " Rick"
ss — поиск строки
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source. q)"Life is beautiful" ss "i" 1 5 13
отделка — удаляет ведущие и задние пробелы
q)/trim - takes string argument, returns the result of removing leading & trailing blanks q)trim " John " "John"
Математические функции
acos — обратная кос
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi q)acos 1 0f q)acos -1 3.141593 q)acos 0 1.570796
кор — дает корреляцию
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments q)27 18 18 9 0 cor 27 36 45 54 63 -0.9707253
крест — декартово произведение
q)/cross - takes atoms or lists as arguments and returns their Cartesian product q)9 18 cross `x`y`z 9 `x 9 `y 9 `z 18 `x 18 `y 18 `z
дисперсия
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items q)var 45 0f q)var 9 18 27 36 101.25
wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument. q)1 2 3 4 wavg 200 300 400 500 400f
Агрегатные функции
все — и операция
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items. q)all 0b 0b q)all 9 18 27 36 1b q)all 10 20 30 1b
Любой — | операция
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items q)any 20 30 40 50 1b q)any 20012.02.12 2013.03.11 '20012.02.12
prd — арифметическое произведение
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product. q)prd `x`y`z! 10 20 30 6000 q)prd ((1 2; 3 4);(10 20; 30 40)) 10 40 90 160
Сумма — арифметическая сумма
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum. q)sum 2 3 4 5 6 20 q)sum (1 2; 4 5) 5 7
Унифицированные функции
Deltas — отличие от предыдущего пункта.
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor. q)deltas 2 3 5 7 9 2 1 2 2 2 q)deltas `x`y`z!9 18 27 x | 9 y | 9 z | 9
заполняет — заполняет нулевое значение
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls q)fills 1 0N 2 0N 4 1 1 2 2 4 q)fills `a`b`c`d! 10 0N 30 0N a | 10 b | 10 c | 30 d | 30
maxs — совокупный максимум
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items. q)maxs 1 2 4 3 9 13 2 1 2 4 4 9 13 13 q)maxs `a`b`c`d!9 18 0 36 a | 9 b | 18 c | 18 d | 36
Разные функции
Count — вернуть номер элемента
q)/count - returns the number of entities in its argument. q)count 10 30 30 3 q)count (til 9) 9 q)count ([]a:9 18 27;b:1.1 2.2 3.3) 3
Distinct — вернуть отдельные объекты
q)/distinct - monadic, returns the distinct entities in its argument q)distinct 1 2 3 4 2 3 4 5 6 9 1 2 3 4 5 6 9
За исключением — элемент не присутствует во втором аргументе.
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument q)1 2 3 4 3 1 except 1 2 3 4 3
fill — заполнить ноль первым аргументом
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target q)42^ 9 18 0N 27 0N 36 9 18 42 27 42 36 q)";"^"Life is Beautiful" "Life;is;Beautiful"
Q Language — Запросы
Запросы в q короче и проще и расширяют возможности sql. Основным выражением запроса является «выражение выбора», которое в своей простейшей форме извлекает вложенные таблицы, но также может создавать новые столбцы.
Общая форма выражения Select выглядит следующим образом:
Select columns by columns from table where conditions
** Примечание — по &, где фразы не являются обязательными, только «из выражения» является обязательным.
В общем, синтаксис будет —
select [a] [by b] from t [where c] update [a] [by b] from t [where c]
Синтаксис выражений q выглядит очень похоже на SQL, но выражения q просты и мощны. Эквивалентное выражение sql для приведенного выше выражения q будет выглядеть следующим образом:
select [b] [a] from t [where c] [group by b order by b] update t set [a] [where c]
Все предложения выполняются в столбцах и, следовательно, q может использовать порядок. Поскольку запросы Sql не основаны на порядке, они не могут воспользоваться этим преимуществом.
q реляционные запросы обычно намного меньше по размеру по сравнению с соответствующими им sql. Упорядоченные и функциональные запросы делают сложные вещи в SQL.
В исторической базе данных порядок предложения where очень важен, поскольку он влияет на производительность запроса. Переменная раздела (дата / месяц / день) всегда идет первой, за ней следует отсортированный и проиндексированный столбец (обычно столбец sym).
Например,
select from table where date in d, sym in s
намного быстрее чем,
select from table where sym in s, date in d
Основы Запросы
Давайте напишем скрипт запроса в блокноте (как показано ниже), сохраним (как * .q), а затем загрузим его.
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination
@[dst;`sym;:;sym];
n:1000000;
trade:([]sym:n?`sym;time:10:30:00.0+til
n;price:n?3.3e;size:n?9;ex:n?ex);
quote:([]sym:n?`sym;time:10:30:00.0+til
n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex);
{@[;`sym;`p#]`sym xasc x}each`trade`quote;
d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user
dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.
Запросы с ограничениями
* Обозначает запрос HDB
Выбрать все сделки IBM
select from trade where sym in `IBM
* Выберите все сделки IBM в определенный день
thisday: 2014.08.11 select from trade where date=thisday,sym=`IBM
Выбрать все сделки IBM с ценой> 100
select from trade where sym=`IBM, price > 100.0
Выберите все сделки IBM с ценой, меньшей или равной 100
select from trade where sym=`IBM,not price > 100.0
* Выберите все сделки IBM между 10.30 и 10.40, утром, в определенную дату
thisday: 2014.08.11 select from trade where date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000
Выбрать все сделки IBM в порядке возрастания цены
`price xasc select from trade where sym =`IBM
* Выберите все сделки IBM в порядке убывания цены за определенный промежуток времени
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBM
Сложная сортировка — сортировка по возрастанию в порядке возрастания, а затем сортировка результата по убыванию цены.
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5
Выбрать все сделки IBM или MSFT
select from trade where sym in `IBM`MSFT
* Рассчитать количество всех символов в порядке возрастания в течение определенного периода времени
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11
* Рассчитать количество всех символов в порядке убывания в течение определенного периода времени
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11
* Какова максимальная цена акций IBM за определенный период времени и когда это происходит впервые?
select time,ask from quote where date within 2014.08.07 2014.08.11, sym =`IBM, ask = exec first ask from select max ask from quote where sym =`IBM
Выберите последнюю цену для каждого сима в почасовых корзинах
select last price by hour:time.hh, sym from trade
Запросы с агрегациями
* Рассчитать vwap (средневзвешенная цена) всех символов
select vwap:size wavg price by sym from trade
* Подсчитать количество записей (в миллионах) за определенный месяц
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m
* HLOC — дневной максимум, минимум, открытие и закрытие для CSCO за определенный месяц
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO
* Ежедневный Vwap для CSCO в определенный месяц
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO
* Рассчитать среднечасовое значение, дисперсию и стандартное отклонение цены для AIG
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIG
Выберите диапазон цен в почасовых ведрах
select range:max[price] – min price by date,sym,hour:time.hh from trade
* Дневной спред (средняя ставка-спрос) для CSCO за определенный месяц
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO
* Ежедневные Торговые Значения для всех симов в определенном месяце
select dtv:sum size by date,sym from trade where date.month = 2014.08m
Извлечь 5 минут VWAP для CSCO
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO
* Извлечение 10 минутных баров для CSCO
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO
* Найдите время, когда цена превышает 100 базисных пунктов (100e-4) по сравнению с последней ценой CSCO на определенный день
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price
* Цена и объем за полный день для MSFT с интервалом в 1 минуту за последнюю дату в базе данных
select last price,last size by time.minute from trade where date = last date, sym = `MSFT
Q Language — межпроцессное взаимодействие
KDB + позволяет одному процессу связываться с другим процессом посредством межпроцессного взаимодействия. Процессы KDB + могут подключаться к любому другому KDB + на том же компьютере, в той же сети или даже удаленно. Нам просто нужно указать порт, и тогда клиенты смогут общаться с этим портом. Любой процесс q может взаимодействовать с любым другим процессом q, если он доступен в сети и ожидает подключения.
-
серверный процесс прослушивает соединения и обрабатывает любые запросы
-
клиентский процесс инициирует соединение и отправляет команды для выполнения
серверный процесс прослушивает соединения и обрабатывает любые запросы
клиентский процесс инициирует соединение и отправляет команды для выполнения
Клиент и сервер могут находиться на одной машине или на разных машинах. Процесс может быть как клиентом, так и сервером.
Общение может быть,
-
Синхронный (ожидание результата, который будет возвращен)
-
Асинхронный (без ожидания и без результата)
Синхронный (ожидание результата, который будет возвращен)
Асинхронный (без ожидания и без результата)
Инициализировать сервер
Сервер q инициализируется путем указания порта для прослушивания,
q –p 5001 / command line \p 5001 / session command
Ручка связи
Дескриптор связи — это символ, который начинается с «:» и имеет вид —
`:[server]:port-number
пример
`::5001 / server and client on same machine `:jack:5001 / server on machine jack `:192.168.0.156 / server on specific IP address `:www.myfx.com:5001 / server at www.myfx.com
Чтобы начать соединение, мы используем функцию «hopen», которая возвращает целочисленный дескриптор соединения. Этот дескриптор используется для всех последующих клиентских запросов. Например —
q)h:hopen `::5001 q)h"til 5" 0 1 2 3 4 q)hclose h
Синхронные и асинхронные сообщения
Как только у нас есть дескриптор, мы можем отправить сообщение синхронно или асинхронно.
Синхронное сообщение — после отправки сообщения оно ожидает и возвращает результат. Его формат выглядит следующим образом —
handle “message”
Асинхронное сообщение — после отправки сообщения немедленно приступите к обработке следующего оператора без необходимости ждать и возвращать результат. Его формат выглядит следующим образом —
neg[handle] “message”
Сообщения, которые требуют ответа, например, вызовы функций или операторы выбора, обычно используют синхронную форму; в то время как сообщения, которые не должны возвращать вывод, например, вставка обновлений в таблицу, будут асинхронными.
Q Language — Обработчик сообщений
Когда процесс q подключается к другому процессу q через межпроцессное взаимодействие, он обрабатывается обработчиками сообщений. Эти обработчики сообщений имеют поведение по умолчанию. Например, в случае синхронной обработки сообщений обработчик возвращает значение запроса. Синхронный обработчик в этом случае — .z.pg , который мы можем переопределить согласно требованию.
Процессы Kdb + имеют несколько предопределенных обработчиков сообщений. Обработчики сообщений важны для настройки базы данных. Некоторые из употреблений включают в себя —
-
Журнал — Журнал входящих сообщений (полезно в случае любой фатальной ошибки),
-
Безопасность — разрешить / запретить доступ к базе данных, вызовам определенных функций и т. Д. В зависимости от имени пользователя / IP-адреса. Помогает в предоставлении доступа только авторизованным подписчикам.
-
Обрабатывать подключения / отключения от других процессов.
Журнал — Журнал входящих сообщений (полезно в случае любой фатальной ошибки),
Безопасность — разрешить / запретить доступ к базе данных, вызовам определенных функций и т. Д. В зависимости от имени пользователя / IP-адреса. Помогает в предоставлении доступа только авторизованным подписчикам.
Обрабатывать подключения / отключения от других процессов.
Предопределенные обработчики сообщений
Некоторые из предопределенных обработчиков сообщений обсуждаются ниже.
.z.pg
Это синхронный обработчик сообщений (процесс get). Эта функция вызывается автоматически при получении сообщения синхронизации на экземпляре kdb +.
Параметр — это вызов строки / функции, который необходимо выполнить, т. Е. Переданное сообщение. По умолчанию это определяется следующим образом —
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle
.z.ps
Это асинхронный обработчик сообщений (набор процессов). Это эквивалентный обработчик для асинхронных сообщений. Параметр — это вызов строки / функции, который нужно выполнить. По умолчанию это определяется как,
.z.pg : {value x} / Can be overriden for a customized action.
Ниже приведен настраиваемый обработчик сообщений для асинхронных сообщений, в котором мы использовали защищенное выполнение.
.z.pg: {@[value; x; errhandler x]}
Здесь errhandler — это функция, используемая в случае непредвиденной ошибки.
.z.po []
Это обработчик открытого соединения (процесс-открытый). Он выполняется, когда удаленный процесс открывает соединение. Чтобы увидеть дескриптор, когда соединение с процессом открыто, мы можем определить .z.po как,
.z.po : {Show “Connection opened by” , string h: .z.h}
.z.pc []
Это обработчик закрытого соединения (process-close). Он вызывается, когда соединение закрыто. Мы можем создать наш собственный обработчик закрытия, который может сбросить глобальный дескриптор соединения на 0 и выполнить команду, чтобы таймер срабатывал (выполнялся) каждые 3 секунды (3000 миллисекунд).
.z.pc : { h::0; value “\\t 3000”}
Обработчик таймера (.z.ts) пытается заново открыть соединение. В случае успеха таймер выключается.
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }
.z.pi []
PI обозначает процесс ввода. Он вызывается для любого вида ввода. Он может использоваться для обработки ввода с консоли или удаленного ввода клиента. Используя .z.pi [], можно проверить ввод с консоли или заменить дисплей по умолчанию. Кроме того, он может быть использован для любых операций регистрации.
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9
.z.pw
Это обработчик соединения проверки (аутентификация пользователя). Он добавляет дополнительный обратный вызов при открытии соединения для сеанса KDB +. Он вызывается после проверок –u / -U и до .z.po (открытие порта).
.z.pw : {[user_id;passwd] 1b}
Входами являются ID пользователя (символ) и пароль (текст).
Q Language — Атрибуты
К спискам, словарям или столбцам таблицы могут быть применены атрибуты. Атрибуты накладывают определенные свойства в списке. Некоторые атрибуты могут исчезнуть при модификации.
Типы атрибутов
Сортировка (`s #)
`s # означает, что список отсортирован в порядке возрастания. Если список явно отсортирован по asc (или xasc), в списке автоматически будет установлен атрибут сортировки.
q)L1: asc 40 30 20 50 9 4 q)L1 `s#4 9 20 30 40 50
Список, который, как известно, сортируется, также может иметь атрибут, установленный явно. Q проверит, отсортирован ли список, а если нет, будет выдана ошибка s-fail .
q)L2:30 40 24 30 2 q)`s#L2 's-fail
Сортированный атрибут будет потерян при несортированном добавлении.
Расстались (`p #)
`p # означает, что список разделен и идентичные элементы хранятся непрерывно.
Диапазон — это тип int или temporal, имеющий базовое значение типа int, например, годы, месяцы, дни и т. Д. Вы также можете разделить символ, если он перечислен.
Применение атрибута parted создает индексный словарь, который отображает каждое уникальное выходное значение в позицию его первого вхождения. При разделении списка поиск выполняется намного быстрее, поскольку линейный поиск заменяется поиском по хеш-таблице.
q)L:`p# 99 88 77 1 2 3 q)L `p#99 88 77 1 2 3 q)L,:3 q)L 99 88 77 1 2 3 3
Примечание —
-
Атрибут parted не сохраняется под операцией в списке, даже если операция сохраняет разбиение.
-
Атрибут parted следует учитывать, когда число объектов достигает миллиарда, а большинство разделов имеют значительный размер, т. Е. Имеется значительное повторение.
Атрибут parted не сохраняется под операцией в списке, даже если операция сохраняет разбиение.
Атрибут parted следует учитывать, когда число объектов достигает миллиарда, а большинство разделов имеют значительный размер, т. Е. Имеется значительное повторение.
Сгруппированный (`g #)
`g # означает, что список сгруппирован. Создается и поддерживается внутренний словарь, который отображает каждый уникальный элемент на каждый из его индексов, что требует значительного места для хранения. Для списка длины L, содержащего u уникальных элементов размера s , это будет (L × 4) + (u × s) байтов.
Группировка может быть применена к списку, когда никакие другие предположения относительно его структуры не могут быть сделаны.
Атрибут может быть применен к любым типизированным спискам. Поддерживается при добавлении, но теряется при удалении.
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6 q)L `g#1 2 3 4 5 4 2 3 1 4 5 6 q)L,:9 q)L `g#1 2 3 4 5 4 2 3 1 4 5 6 9 q)L _:2 q)L 1 2 4 5 4 2 3 1 4 5 6 9
Уникальный (`#u)
Применение уникального атрибута (`u #) к списку означает, что элементы списка различны. Знание того, что элементы списка уникальны, значительно ускоряет различие и позволяет q выполнить некоторые сравнения на ранней стадии.
Когда список помечается как уникальный, для каждого элемента в списке создается внутренняя хеш-карта. Операции в списке должны сохранять уникальность, иначе атрибут будет утерян.
q)LU:`u#`MSFT`SAMSUNG`APPLE q)LU `u#`MSFT`SAMSUNG`APPLE q)LU,:`IBM /Uniqueness preserved q)LU `u#`MSFT`SAMSUNG`APPLE`IBM q)LU,:`SAMSUNG / Attribute lost q)LU `MSFT`SAMSUNG`APPLE`IBM`SAMSUNG
Примечание —
-
`u # сохраняется в конкатенациях, которые сохраняют уникальность. Он теряется при удалении и неуникальных конкатенациях.
-
Поиск по спискам `u # осуществляется через хеш-функцию.
`u # сохраняется в конкатенациях, которые сохраняют уникальность. Он теряется при удалении и неуникальных конкатенациях.
Поиск по спискам `u # осуществляется через хеш-функцию.
Удаление атрибутов
Атрибуты можно удалить, применив `#.
Применение атрибутов
Три формата для применения атрибутов:
-
L: `s # 14 2 3 3 9 / Указать при создании списка
-
@ [`.; `L; `s #] / Функциональное применение, т.е. к списку переменных L
/ в пространстве имен по умолчанию (то есть `.) применяются
/ отсортированный атрибут `s #
-
Обновление `s # time из` tab
/ Обновите таблицу (вкладку), чтобы применить
/ атрибут.
L: `s # 14 2 3 3 9 / Указать при создании списка
@ [`.; `L; `s #] / Функциональное применение, т.е. к списку переменных L
/ в пространстве имен по умолчанию (то есть `.) применяются
/ отсортированный атрибут `s #
Обновление `s # time из` tab
/ Обновите таблицу (вкладку), чтобы применить
/ атрибут.
Давайте применим вышеупомянутые три различных формата с примерами.
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).
Q Language — Функциональные запросы
Функциональные (динамические) запросы позволяют указывать имена столбцов в виде символов для типичных столбцов q-sql select / exec / delete. Это очень удобно, когда мы хотим динамически указывать имена столбцов.
Функциональные формы —
?[t;c;b;a] / for select ![t;c;b;a] / for update
где
-
т — таблица;
-
а — словарь агрегатов;
-
б за фраза; а также
-
с список ограничений.
т — таблица;
а — словарь агрегатов;
б за фраза; а также
с список ограничений.
Примечание —
-
Все q сущностей в a , b и c должны указываться по имени, что означает символы, содержащие имена сущностей.
-
Синтаксические формы select и update анализируются интерпретатором q в их эквивалентные функциональные формы, поэтому между этими двумя формами нет разницы в производительности.
Все q сущностей в a , b и c должны указываться по имени, что означает символы, содержащие имена сущностей.
Синтаксические формы select и update анализируются интерпретатором q в их эквивалентные функциональные формы, поэтому между этими двумя формами нет разницы в производительности.
Функциональный выбор
Следующий блок кода показывает, как использовать функциональный выбор —
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38
Пример 1
Начнем с самого простого случая, функциональная версия «select from t» будет выглядеть так:
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54
Пример 2
В следующем примере мы используем функцию enlist для создания синглетонов, чтобы гарантировать, что соответствующие объекты являются списками.
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54
Пример 3
q)groupby: enlist[`p] ! enlist `p q)selcols: enlist [`n]!enlist `n q)?[ `t;(); groupby;selcols] / select n by p from t p | n ----- | ------- 38 | msft 40 | ibm 45 | samsung 54 | apple
Функциональный Exec
Функциональная форма exec — это упрощенная форма выбора .
q)?[t;();();`n] / exec n from t (functional form of exec) `ibm`msft`samsung`apple q)?[t;();`n;`p] / exec p by n from t (functional exec) apple | 54 ibm | 40 msft | 38 samsung | 45
Функциональное обновление
Функциональная форма обновления полностью аналогична выбранной . В следующем примере enlist предназначен для создания синглетонов, чтобы входные объекты были списками.
q)c:enlist (>;`p;0) q)b: (enlist `n)!enlist `n q)a: (enlist `p) ! enlist (max;`p) q)![t;c;b;a] n p ------------- ibm 40 msft 38 samsung 45 apple 54
Функциональное удаление
Функциональное удаление — это упрощенная форма функционального обновления. Его синтаксис выглядит следующим образом —
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column names
Давайте теперь возьмем пример, чтобы показать, как работает функциональное удаление —
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54
Q Language — табличная арифметика
В этой главе мы научимся работать со словарями, а затем с таблицами. Начнем со словарей —
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d q)/ key of this dictionary (d) is given by q)key d `u`v`x`y`z q)/and the value by q)value d 9 18 27 36 45 q)/a specific value q)d`x 27 q)d[`x] 27 q)/values can be manipulated by using the arithmetic operator +-*% as, q)45 + d[`x`y] 72 81
Если нужно изменить значения словаря, то формулировка поправки может быть:
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75
Q Language — таблицы на диске
Данные на вашем жестком диске (также называемом исторической базой данных) могут быть сохранены в трех различных форматах — плоские файлы, разбитые таблицы и секционированные таблицы. Здесь мы узнаем, как использовать эти три формата для сохранения данных.
Плоский файл
Плоские файлы полностью загружаются в память, поэтому их размер (объем памяти) должен быть небольшим. Таблицы сохраняются на диске целиком в одном файле (поэтому размер имеет значение).
Функции, используемые для управления этими таблицами, устанавливаются / получают —
`:path_to_file/filename set tablename
Давайте рассмотрим пример, чтобы продемонстрировать, как это работает.
q)tables `. `s#`t`tab`tab1 q)`:c:/q/w32/tab1_test set tab1 `:c:/q/w32/tab1_test
В среде Windows плоские файлы сохраняются в расположении — C: \ q \ w32
Получите плоский файл с вашего диска (исторический дБ) и используйте команду get следующим образом:
q)tab2: get `:c:/q/w32/tab1_test q)tab2 sym | time price size --------- | ------------------------------- APPLE | 11:16:39.779 8.388858 12 MSFT | 11:16:39.779 19.59907 10 IBM | 11:16:39.779 37.5638 1 SAMSUNG | 11:16:39.779 61.37452 90 APPLE | 11:16:39.779 52.94808 73
Создается новая таблица tab2, содержимое которой хранится в файле tab1_test .
Таблицы с растяжкой
Если в таблице слишком много столбцов, мы храним такие таблицы в расширенном формате, т.е. сохраняем их на диске в каталоге. Внутри каталога каждый столбец сохраняется в отдельном файле под тем же именем, что и имя столбца. Каждый столбец сохраняется в виде списка соответствующего типа в двоичном файле kdb +.
Сохранение таблицы в расширенном формате очень полезно, когда нам приходится часто обращаться только к нескольким столбцам из множества столбцов. Каталог с развернутой таблицей содержит двоичный файл .d, который содержит порядок столбцов.
Подобно плоскому файлу, таблица может быть сохранена как развернутая с помощью команды set . Чтобы сохранить таблицу как развернутую, путь к файлу должен заканчиваться отрицательной реакцией —
`:path_to_filename/filename/ set tablename
Для чтения развернутой таблицы мы можем использовать функцию get —
tablename: get `:path_to_file/filename
Примечание. Чтобы таблица сохранялась как развернутая, она должна быть разблокирована и перечислена.
В среде Windows ваша файловая структура будет выглядеть следующим образом:
Разделенные таблицы
Секционированные таблицы предоставляют эффективные средства для управления огромными таблицами, содержащими значительные объемы данных. Разделенные таблицы — это расширенные таблицы, распределенные по нескольким разделам (каталогам).
Внутри каждого раздела таблица будет иметь свой собственный каталог со структурой развернутой таблицы. Таблицы могут быть разделены на день / месяц / год, чтобы обеспечить оптимизированный доступ к его контенту.
Чтобы получить содержимое секционированной таблицы, используйте следующий блок кода —
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0…. trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ….
Давайте попробуем получить содержимое торговой таблицы —
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 A
Примечание. Режим секционирования подходит для таблиц с миллионами записей в день (т. Е. Данные временных рядов).
Sym файл
Файл sym — это двоичный файл kdb +, содержащий список символов из всех таблиц с разделениями и секциями. Это можно прочитать с,
get `:sym
файл par.txt (необязательно)
Это файл конфигурации, используемый, когда разделы распределены по нескольким каталогам / дискам, и содержит пути к разделам диска.
Q Language — Функции обслуживания
.Q.en
.Q.en — это двоичная функция, которая помогает в развертывании таблицы путем перечисления символьного столбца. Это особенно полезно, когда мы имеем дело с историческими БД (splayed, таблицы разделов и т. Д.). —
.Q.en[`:directory;table]
где каталог — это домашний каталог базы данных истории, в которой находится файл sym, а таблица — это таблица для перечисления.
Ручное перечисление таблиц не требуется для сохранения их в виде таблиц с расширением, так как это будет сделано с помощью —
.Q.en[`:directory_where_symbol_file_stored]table_name
.Q.dpft
Функция .Q.dpft помогает в создании секционированных и сегментированных таблиц. Это расширенная форма .Q.en , поскольку она не только отображает таблицу, но и создает таблицу разделов.
В .Q.dpft используются четыре аргумента :
-
символьный дескриптор файла базы данных, в которой мы хотим создать раздел,
-
q значение данных, с которым мы собираемся разбить таблицу,
-
имя поля, с которым будет применен атрибут parted (`p #) (обычно` sym), и
-
имя таблицы.
символьный дескриптор файла базы данных, в которой мы хотим создать раздел,
q значение данных, с которым мы собираемся разбить таблицу,
имя поля, с которым будет применен атрибут parted (`p #) (обычно` sym), и
имя таблицы.
Давайте рассмотрим пример, чтобы увидеть, как это работает —
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25) q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab] `tab q)delete tab from ` 'type q)delete tab from `/ 'type q)delete tab from . 'type q)delete tab from `. `. q)tab 'tab
Мы удалили вкладку таблицы из памяти. Давайте теперь загрузим его из БД
q)\l c:/q/2014.08.24/ q)\a ,`tab q)tab sym time price ------------------------------- hsbc 07:38:13 15.64201 hsbc 07:21:05 5.387037 msft 06:16:58 11.88076 msft 08:09:26 12.30159 samsung 04:57:56 15.60838
.Q.chk
.Q.chk — это монадическая функция, единственным параметром которой является символьный дескриптор файла корневого каталога. Он создает пустые таблицы в разделе, где это необходимо, путем изучения каждого подкаталога раздела в корневом каталоге.
.Q.chk `:directory
где каталог — домашний каталог исторической базы данных.