Kdb + — это высокопроизводительная база данных большого объема, изначально разработанная для обработки огромных объемов данных. Он полностью 64-битный, имеет встроенную многоядерную обработку и многопоточность. Та же архитектура используется для данных в реальном времени и исторических данных. База данных включает собственный мощный язык запросов q, поэтому аналитика может быть запущена непосредственно на данных.
kdb + tick — это архитектура, которая позволяет собирать, обрабатывать и запрашивать данные в реальном времени и исторические данные.
Kdb + / галочка Архитектура
На следующем рисунке представлена обобщенная схема типичной архитектуры Kdb + / tick с последующим кратким объяснением различных компонентов и сквозного потока данных.
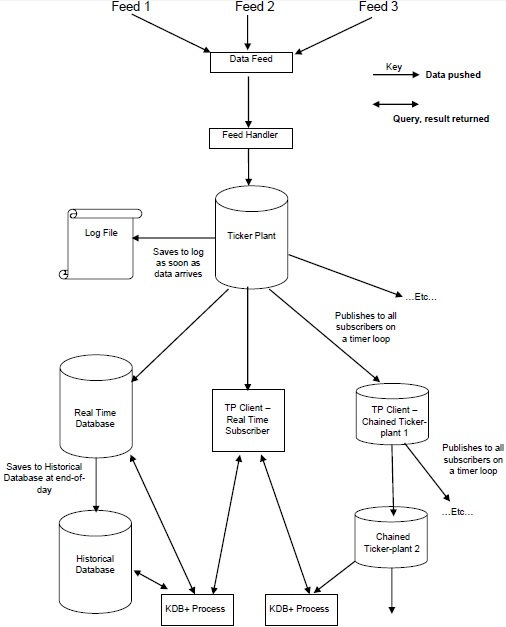
-
Каналы данных — это данные временных рядов, которые в основном предоставляются поставщиками каналов данных, такими как Reuters, Bloomberg или напрямую с бирж.
-
Чтобы получить соответствующие данные, данные из фида данных анализируются обработчиком фида .
-
После того, как данные обработаны обработчиком подачи, они отправляются на тиккерную станцию .
-
Чтобы восстановить данные после любого сбоя, тикер-завод сначала обновляет / сохраняет новые данные в файле журнала, а затем обновляет свои собственные таблицы.
-
После обновления внутренних таблиц и файлов журналов данные цикла времени непрерывно отправляются / публикуются в базу данных в режиме реального времени и всем подписчикам в цепочке, которые запрашивали данные.
-
В конце рабочего дня файл журнала удаляется, создается новый, а база данных в реальном времени сохраняется в исторической базе данных. Как только все данные сохранены в исторической базе данных, база данных в реальном времени очищает свои таблицы.
Каналы данных — это данные временных рядов, которые в основном предоставляются поставщиками каналов данных, такими как Reuters, Bloomberg или напрямую с бирж.
Чтобы получить соответствующие данные, данные из фида данных анализируются обработчиком фида .
После того, как данные обработаны обработчиком подачи, они отправляются на тиккерную станцию .
Чтобы восстановить данные после любого сбоя, тикер-завод сначала обновляет / сохраняет новые данные в файле журнала, а затем обновляет свои собственные таблицы.
После обновления внутренних таблиц и файлов журналов данные цикла времени непрерывно отправляются / публикуются в базу данных в режиме реального времени и всем подписчикам в цепочке, которые запрашивали данные.
В конце рабочего дня файл журнала удаляется, создается новый, а база данных в реальном времени сохраняется в исторической базе данных. Как только все данные сохранены в исторической базе данных, база данных в реальном времени очищает свои таблицы.
Компоненты архитектуры Kdb + Tick
Фиды данных
Каналы данных могут быть любыми рыночными или другими данными временных рядов. Рассматривайте каналы данных как необработанный ввод для обработчика каналов. Ленты могут быть получены непосредственно от биржи (потоковой передачи данных), от поставщиков новостей / данных, таких как Thomson-Reuters, Bloomberg или любых других внешних агентств.
Feed Handler
Обработчик каналов преобразует поток данных в формат, подходящий для записи в kdb +. Он подключен к каналу данных и извлекает и преобразует данные из формата, специфичного для канала, в сообщение Kdb +, которое публикуется в процессе установки тикера. Обычно обработчик подачи используется для выполнения следующих операций:
- Захват данных в соответствии с набором правил.
- Перевести (/ обогатить) эти данные из одного формата в другой.
- Поймай самые последние значения.
Тиккерный завод
Ticker Plant является важнейшим компонентом архитектуры KDB +. Это тикерная станция, с которой база данных в реальном времени или напрямую подписчики (клиенты) подключаются для доступа к финансовым данным. Он работает по механизму публикации и подписки . Как только вы получаете подписку (лицензию), определяется тиковая (обычная) публикация от издателя (тикерная установка). Он выполняет следующие операции —
-
Получает данные от обработчика каналов.
-
Сразу после того, как завод по производству тикеров получает данные, он сохраняет копию в виде файла журнала и обновляет ее, как только завод по производству тикеров получает любое обновление, чтобы в случае любого сбоя у нас не было потери данных.
-
Клиенты (подписчик в режиме реального времени) могут напрямую подписаться на тикер-завод.
-
В конце каждого рабочего дня, т. Е. Как только база данных в реальном времени получает последнее сообщение, она сохраняет все сегодняшние данные в исторической базе данных и передает их всем подписчикам, которые подписались на сегодняшние данные. Затем он сбрасывает все свои таблицы. Файл журнала также удаляется после сохранения данных в исторической базе данных или другом напрямую связанном подписчике с базой данных реального времени (rtdb).
-
В результате, тикерная фабрика, база данных в реальном времени и историческая база данных работают круглосуточно.
Получает данные от обработчика каналов.
Сразу после того, как завод по производству тикеров получает данные, он сохраняет копию в виде файла журнала и обновляет ее, как только завод по производству тикеров получает любое обновление, чтобы в случае любого сбоя у нас не было потери данных.
Клиенты (подписчик в режиме реального времени) могут напрямую подписаться на тикер-завод.
В конце каждого рабочего дня, т. Е. Как только база данных в реальном времени получает последнее сообщение, она сохраняет все сегодняшние данные в исторической базе данных и передает их всем подписчикам, которые подписались на сегодняшние данные. Затем он сбрасывает все свои таблицы. Файл журнала также удаляется после сохранения данных в исторической базе данных или другом напрямую связанном подписчике с базой данных реального времени (rtdb).
В результате, тикерная фабрика, база данных в реальном времени и историческая база данных работают круглосуточно.
Поскольку ticker-plant является приложением Kdb +, к его таблицам можно обращаться с помощью q, как и к любой другой базе данных Kdb +. Все клиенты Ticker-Plant должны иметь доступ к базе данных только в качестве подписчиков.
База данных в реальном времени
База данных в реальном времени (rdb) хранит сегодняшние данные. Это напрямую связано с тикером завода. Обычно он хранится в памяти в часы работы рынка (день) и записывается в историческую базу данных (hdb) в конце дня. Поскольку данные (данные rdb) хранятся в памяти, обработка выполняется чрезвычайно быстро.
Поскольку kdb + рекомендует иметь размер оперативной памяти, который в четыре или более раз превышает ожидаемый объем данных в день, запрос, выполняемый на rdb, очень быстрый и обеспечивает превосходную производительность. Поскольку база данных реального времени содержит только сегодняшние данные, столбец даты (параметр) не требуется.
Например, мы можем иметь запросы RDB, как,
select from trade where sym = `ibm OR select from trade where sym = `ibm, price > 100
Историческая база данных
Если нам нужно рассчитать оценки компании, нам нужно иметь ее исторические данные. Историческая база данных (hdb) содержит данные о транзакциях, совершенных в прошлом. Запись каждого нового дня будет добавлена в hdb в конце дня. Большие таблицы в hdb либо хранятся с разбивкой (каждый столбец хранится в своем собственном файле), либо они хранятся разделенными временными данными. Также некоторые очень большие базы данных могут быть дополнительно разделены с использованием par.txt (файл).
Эти стратегии хранения (распределенные, разделенные и т. Д.) Эффективны при поиске или доступе к данным из большой таблицы.
Историческая база данных также может использоваться для внутренней и внешней отчетности, т. Е. Для аналитики. Например, предположим, что мы хотим получить информацию о сделках компании IBM за определенный день из имени торговой (или любой) таблицы, нам нужно написать запрос следующим образом:
thisday: 2014.10.12 select from trade where date = thisday, sym =`ibm
Примечание. Мы напишем все такие запросы, как только получим обзор языка q .