Agile Data Science — Введение
Agile Data Science — это подход использования Data Science с гибкой методологией для разработки веб-приложений. Он фокусируется на результатах процесса обработки данных, пригодного для осуществления изменений в организации. Наука о данных включает создание приложений, которые описывают процесс исследования с помощью анализа, интерактивной визуализации, а также прикладного машинного обучения.
Основная цель гибкой науки о данных —
документируйте и проводите объяснительный анализ данных, чтобы найти и следовать критическому пути к привлекательному продукту.
Agile Data Science организована по следующему набору принципов:
Непрерывная итерация
Этот процесс включает в себя непрерывную итерацию с созданием таблиц, диаграмм, отчетов и прогнозов. Построение прогнозирующих моделей потребует много итераций разработки функций с извлечением и получением информации.
Промежуточный выход
Это список треков сгенерированных выходов. Говорят даже, что неудачные эксперименты также имеют выход. Отслеживание результатов каждой итерации поможет создать лучший результат на следующей итерации.
Эксперименты с прототипами
Эксперименты с прототипами включают в себя назначение задач и генерацию результатов в соответствии с экспериментами. В данной задаче мы должны выполнить итерацию, чтобы достичь понимания, и эти итерации лучше всего объяснить как эксперименты.
Интеграция данных
Жизненный цикл разработки программного обеспечения включает в себя различные фазы с данными, необходимыми для —
-
клиенты
-
разработчики и
-
бизнес
клиенты
разработчики и
бизнес
Интеграция данных открывает путь для улучшения перспектив и результатов.
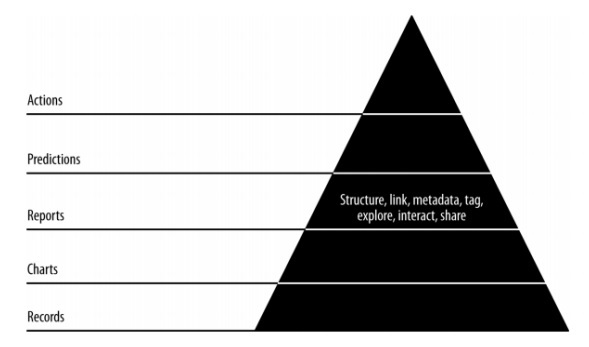
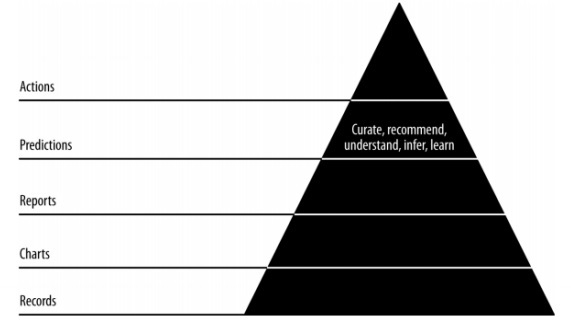
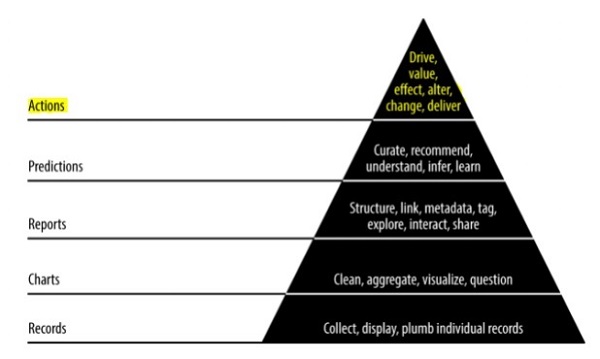
Значение данных пирамиды
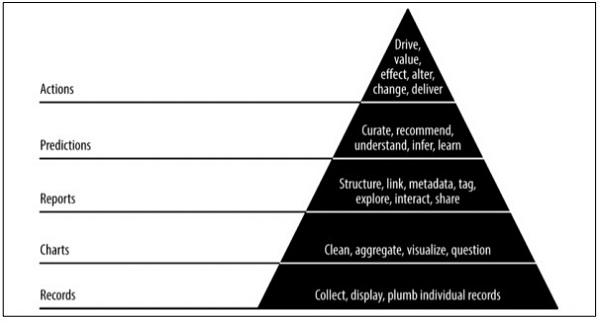
Приведенное выше значение пирамиды описывает уровни, необходимые для развития «гибкой науки о данных». Он начинается с сбора записей на основе требований и учета отдельных записей. Графики создаются после очистки и агрегирования данных. Агрегированные данные могут быть использованы для визуализации данных. Отчеты создаются с правильной структурой, метаданными и тегами данных. Второй слой пирамиды сверху включает прогнозный анализ. Слой прогнозирования — это место, где создается больше ценности, но оно помогает создавать хорошие прогнозы, ориентированные на проектирование объектов.
Самый верхний уровень включает действия, в которых ценность данных определяется эффективно. Лучшая иллюстрация этой реализации — «Искусственный интеллект».
Agile Data Science — Концепции методологии
В этой главе мы сосредоточимся на концепциях жизненного цикла разработки программного обеспечения, которые называются «гибкими». Методология разработки программного обеспечения Agile помогает создавать программное обеспечение с помощью пошаговых сессий за короткие итерации от 1 до 4 недель, чтобы разработка соответствовала изменяющимся бизнес-требованиям.
Существует 12 принципов, которые подробно описывают методологию Agile —
Удовлетворенность клиентов
Наивысший приоритет отдается клиентам, ориентирующимся на требования благодаря ранней и постоянной поставке ценного программного обеспечения
Приветствуя новые изменения
Изменения допустимы при разработке программного обеспечения. Agile процессы предназначены для работы, чтобы соответствовать конкурентным преимуществам клиента.
Доставка
Доставка рабочего программного обеспечения предоставляется клиентам в течение периода от одной до четырех недель.
сотрудничество
Бизнес-аналитики, качественные аналитики и разработчики должны работать вместе на протяжении всего жизненного цикла проекта.
мотивация
Проекты должны быть разработаны с кланом мотивированных людей. Это обеспечивает среду для поддержки отдельных членов команды.
Личный разговор
Личная беседа — это самый эффективный и эффективный метод отправки информации в команду разработчиков и внутри нее.
Измерение прогресса
Измерение прогресса — это ключ, который помогает определить прогресс в разработке проектов и программного обеспечения.
Поддержание постоянного темпа
Agile процесс фокусируется на устойчивом развитии. Бизнес, разработчики и пользователи должны иметь возможность поддерживать постоянный темп проекта.
мониторинг
Необходимо постоянно уделять внимание техническому совершенству и хорошему дизайну, чтобы улучшить гибкую функциональность.
Простота
В Agile процессах все просто и используются простые термины для измерения незавершенной работы.
Самоорганизованные условия
Гибкая команда должна быть самоорганизованной и независимой от лучшей архитектуры; требования и проекты возникают из самоорганизованных команд.
Обзор работы
Важно регулярно проверять работу, чтобы группа могла обдумать, как она продвигается. Своевременное рассмотрение модуля улучшит производительность.
Ежедневная стоянка
Под ежедневным выступлением понимается ежедневное статусное собрание членов команды. Он предоставляет обновления, связанные с разработкой программного обеспечения. Это также относится к устранению препятствий на пути развития проекта.
Ежедневная тренировка является обязательной практикой, независимо от того, как создается гибкая команда независимо от местоположения ее офиса.
Список особенностей ежедневного стенда следующий:
-
Продолжительность ежедневной встречи должна составлять примерно 15 минут. Он не должен распространяться на более длительный срок.
-
Стенд должен включать обсуждение обновления статуса.
-
Участники этой встречи обычно стоят с намерением закончить встречу быстро.
Продолжительность ежедневной встречи должна составлять примерно 15 минут. Он не должен распространяться на более длительный срок.
Стенд должен включать обсуждение обновления статуса.
Участники этой встречи обычно стоят с намерением закончить встречу быстро.
История пользователя
История обычно является требованием, которое сформулировано в нескольких предложениях на простом языке и должно быть завершено в течение итерации. Пользовательская история должна включать следующие характеристики —
-
Весь связанный код должен иметь соответствующие регистрации.
-
Модульные тесты для указанной итерации.
-
Все приемочные тесты должны быть определены.
-
Принятие от владельца продукта при определении истории.
Весь связанный код должен иметь соответствующие регистрации.
Модульные тесты для указанной итерации.
Все приемочные тесты должны быть определены.
Принятие от владельца продукта при определении истории.
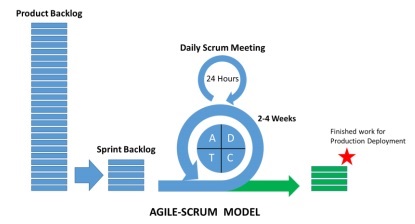
Что такое Scrum?
Скрам можно рассматривать как часть гибкой методологии. Это легкий процесс и включает в себя следующие функции —
-
Это структура процесса, которая включает в себя набор методов, которым необходимо следовать в последовательном порядке. Лучшая иллюстрация Scrum — следующие итерации или спринты.
-
Это «легкий» процесс, означающий, что процесс поддерживается как можно меньшим, чтобы максимизировать продуктивный выход в заданную продолжительность.
Это структура процесса, которая включает в себя набор методов, которым необходимо следовать в последовательном порядке. Лучшая иллюстрация Scrum — следующие итерации или спринты.
Это «легкий» процесс, означающий, что процесс поддерживается как можно меньшим, чтобы максимизировать продуктивный выход в заданную продолжительность.
Скрам-процесс известен своим отличительным процессом по сравнению с другими методологиями традиционного гибкого подхода. Он разделен на следующие три категории —
-
Роли
-
Артефакты
-
Коробки времени
Роли
Артефакты
Коробки времени
Роли определяют членов команды и их роли, включенные в процесс. Скрам Команда состоит из следующих трех ролей —
-
Скрам Мастер
-
Владелец продукта
-
команда
Скрам Мастер
Владелец продукта
команда
Артефакты Scrum предоставляют ключевую информацию, о которой должен знать каждый участник. Информация включает в себя информацию о продукте, запланированных мероприятиях и выполненных работах. Артефакты, определенные в рамках Scrum, следующие:
-
Резерв продукта
-
Спринт отставание
-
Диаграмма сгорания
-
инкремент
Резерв продукта
Спринт отставание
Диаграмма сгорания
инкремент
Временные рамки — это пользовательские истории, которые запланированы для каждой итерации. Эти пользовательские истории помогают в описании характеристик продукта, которые являются частью артефактов Scrum. Журнал ожидания продукта представляет собой список пользовательских историй. Эти пользовательские истории располагаются по приоритетам и направляются на встречи пользователей, чтобы решить, какой из них следует рассмотреть.
Почему Скрам Мастер?
Scrum Master взаимодействует с каждым членом команды. Давайте теперь посмотрим на взаимодействие Scrum Master с другими командами и ресурсами.
Владелец продукта
Scrum Master взаимодействует с владельцем продукта следующими способами —
-
Поиск методов, позволяющих добиться эффективного отставания пользовательских историй от продуктов и управления ими.
-
Помогая команде понять потребности в четких и кратких материалах, ожидающих решения.
-
Планирование продукта с учетом конкретной среды.
-
Обеспечение того, чтобы владелец продукта знал, как повысить стоимость продукта.
-
Содействие событиям Scrum по мере необходимости.
Поиск методов, позволяющих добиться эффективного отставания пользовательских историй от продуктов и управления ими.
Помогая команде понять потребности в четких и кратких материалах, ожидающих решения.
Планирование продукта с учетом конкретной среды.
Обеспечение того, чтобы владелец продукта знал, как повысить стоимость продукта.
Содействие событиям Scrum по мере необходимости.
Скрам Команда
Scrum Master взаимодействует с командой несколькими способами —
-
Тренировка организации в ее принятии Scrum.
-
Планирование внедрения Scrum для конкретной организации.
-
Помогая сотрудникам и заинтересованным сторонам понять требования и этапы разработки продукта.
-
Работа с Scrum Masters других команд для повышения эффективности применения Scrum указанной команды.
Тренировка организации в ее принятии Scrum.
Планирование внедрения Scrum для конкретной организации.
Помогая сотрудникам и заинтересованным сторонам понять требования и этапы разработки продукта.
Работа с Scrum Masters других команд для повышения эффективности применения Scrum указанной команды.
организация
Scrum Master взаимодействует с организацией несколькими способами. Некоторые из них упомянуты ниже —
-
Коучинг и команда Scrum взаимодействуют с самоорганизацией и включают в себя функцию перекрестной функциональности.
-
Тренировка организации и команд в таких областях, где Scrum еще не полностью принят или не принят.
Коучинг и команда Scrum взаимодействуют с самоорганизацией и включают в себя функцию перекрестной функциональности.
Тренировка организации и команд в таких областях, где Scrum еще не полностью принят или не принят.
Преимущества Scrum
Scrum помогает клиентам, членам команды и заинтересованным сторонам сотрудничать. Он включает в себя временные рамки и постоянную обратную связь от владельца продукта, гарантирующую, что продукт находится в рабочем состоянии. Скрам предоставляет преимущества для различных ролей проекта.
Покупатель
Спринты или итерации рассматриваются для более короткой продолжительности, а пользовательские истории разрабатываются в соответствии с приоритетом и учитываются при планировании спринта. Это гарантирует, что каждый спринт доставки, требования клиентов будут выполнены. Если нет, требования отмечаются и планируются и принимаются для спринта.
организация
Организация с помощью мастеров Scrum и Scrum может сосредоточиться на усилиях, необходимых для разработки пользовательских историй, тем самым уменьшая перегрузку работы и избегая переделок, если таковые имеются. Это также помогает поддерживать повышенную эффективность команды разработчиков и удовлетворенность клиентов. Этот подход также помогает в увеличении потенциала рынка.
Менеджеры по продукту
Главной обязанностью менеджеров по продуктам является поддержание качества продукта. С помощью Scrum Masters становится легко упростить работу, собрать быстрые ответы и принять изменения, если таковые имеются. Менеджеры по продукту также проверяют, соответствует ли проектированный продукт требованиям заказчика в каждом спринте.
Команда разработчиков
Благодаря ограниченному по времени характеру и сохранению спринтов в течение меньшего промежутка времени, команда разработчиков с энтузиазмом видит, что работа отражается и выполняется должным образом. Рабочий продукт увеличивает каждый уровень после каждой итерации, точнее мы можем назвать их «спринт». Пользовательские истории, разработанные для каждого спринта, становятся приоритетом клиента, добавляя больше ценности итерации.
Заключение
Scrum — это эффективная среда, в которой вы можете разрабатывать программное обеспечение для совместной работы. Он полностью разработан на гибких принципах. ScrumMaster всегда готов помочь и помочь команде Scrum. Он действует как личный тренер, который помогает вам придерживаться разработанного плана и выполнять все действия в соответствии с планом. Авторитет ScrumMaster никогда не должен выходить за рамки процесса. Он / она должен быть потенциально способен справиться с любой ситуацией.
Agile Data Science — процесс обработки данных
В этой главе мы поймем процесс науки о данных и терминологию, необходимую для понимания процесса.
«Наука о данных — это сочетание интерфейса данных, разработки алгоритмов и технологий для решения сложных аналитических задач».
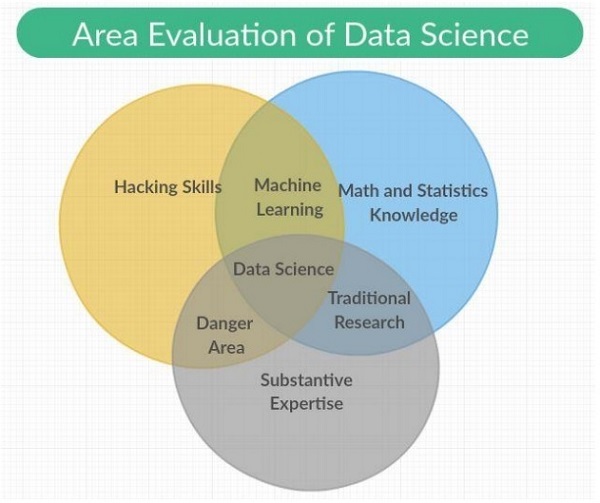
Наука о данных — это междисциплинарная область, охватывающая научные методы, процессы и системы с категориями, включенными в нее как «Машинное обучение, математика и статистика», с традиционными исследованиями. Это также включает в себя комбинацию навыков взлома с экспертизой. Наука о данных опирается на принципы математики, статистики, информатики и информатики, интеллектуального анализа данных и прогнозного анализа.
Различные роли, которые составляют часть команды по науке о данных, упомянуты ниже —
Клиенты
Клиенты — это люди, которые используют продукт. Их интерес определяет успех проекта, и их отзывы очень ценны в науке о данных.
Развитие бизнеса
Эта команда специалистов по науке данных подписывается на первых клиентов, либо из первых рук, либо путем создания целевых страниц и рекламных акций. Команда развития бизнеса поставляет стоимость продукта.
Менеджеры по продукту
Менеджеры по продуктам осознают важность создания лучшего продукта, который является ценным на рынке.
Дизайнеры взаимодействия
Они сосредоточены на взаимодействии между моделями данных, чтобы пользователи находили подходящую ценность.
Ученые данных
Исследователи данных исследуют и трансформируют данные новыми способами для создания и публикации новых функций. Эти ученые также объединяют данные из разных источников, чтобы создать новую ценность. Они играют важную роль в создании визуализаций с исследователями, инженерами и веб-разработчиками.
Исследователи
Как следует из названия, исследователи занимаются научной деятельностью. Они решают сложные проблемы, которые ученые не могут сделать. Эти проблемы включают в себя интенсивную направленность и время машинного обучения и модуль статистики.
Адаптация к изменениям
Все члены команды по науке о данных обязаны адаптироваться к новым изменениям и работать на основе требований. Несколько изменений должны быть сделаны для принятия гибкой методологии с наукой о данных, которые упомянуты следующим образом:
-
Выбор универсалов над специалистами.
-
Предпочтение маленьких команд над большими командами.
-
Использование высокоуровневых инструментов и платформ.
-
Непрерывное и повторное разделение промежуточных работ.
Выбор универсалов над специалистами.
Предпочтение маленьких команд над большими командами.
Использование высокоуровневых инструментов и платформ.
Непрерывное и повторное разделение промежуточных работ.
Заметка
В Agile Data Science Team небольшая команда универсалов использует высокоуровневые инструменты, которые масштабируются и уточняют данные с помощью итераций во все более высокие состояния ценности.
Рассмотрим следующие примеры, связанные с работой членов команды по науке о данных:
-
Дизайнеры поставляют CSS.
-
Веб-разработчики создают целые приложения, понимают пользовательский опыт и дизайн интерфейса.
-
Исследователи данных должны работать как над исследованиями, так и над созданием веб-сервисов, включая веб-приложения.
-
Исследователи работают в кодовой базе, которая показывает результаты, объясняющие промежуточные результаты.
-
Менеджеры по продуктам пытаются выявить и понять недостатки во всех смежных областях.
Дизайнеры поставляют CSS.
Веб-разработчики создают целые приложения, понимают пользовательский опыт и дизайн интерфейса.
Исследователи данных должны работать как над исследованиями, так и над созданием веб-сервисов, включая веб-приложения.
Исследователи работают в кодовой базе, которая показывает результаты, объясняющие промежуточные результаты.
Менеджеры по продуктам пытаются выявить и понять недостатки во всех смежных областях.
Гибкие инструменты и установка
В этой главе мы узнаем о различных инструментах Agile и их установке. Стек разработки гибкой методологии включает в себя следующий набор компонентов:
События
Событие — это событие, которое происходит или регистрируется вместе с его функциями и временными метками.
Событие может принимать различные формы, такие как серверы, датчики, финансовые транзакции или действия, которые наши пользователи выполняют в нашем приложении. В этом полном уроке мы будем использовать файлы JSON, которые облегчат обмен данными между различными инструментами и языками.
Коллекторы
Коллекционеры являются агрегаторами событий. Они систематически собирают события для хранения и агрегирования громоздких данных, ставя их в очередь для действий работников в реальном времени.
Распределенный документ
Эти документы включают многоузловую (несколько узлов), которая хранит документ в определенном формате. В этом уроке мы сосредоточимся на MongoDB.
Сервер веб-приложений
Сервер веб-приложений обеспечивает визуализацию данных в формате JSON через клиента с минимальными издержками. Это означает, что сервер веб-приложений помогает тестировать и развертывать проекты, созданные с помощью гибкой методологии.
Современный браузер
Это позволяет современному браузеру или приложению представлять данные как интерактивный инструмент для наших пользователей.
Местная экологическая обстановка
Для управления наборами данных мы сосредоточимся на среде Python Anaconda, которая включает в себя инструменты для управления Excel, CSV и многими другими файлами. После установки панель инструментов Anaconda будет показана ниже. Его также называют «Анаконда Навигатор» —

Навигатор включает «Jupyter Framework», который представляет собой систему ноутбука, которая помогает управлять наборами данных. Как только вы запустите фреймворк, он будет размещен в браузере, как указано ниже —

Agile Data Science — Обработка данных в Agile
В этой главе мы сосредоточимся на разнице между структурированными, полуструктурированными и неструктурированными данными.
Структурированные данные
Структурированные данные относятся к данным, хранящимся в формате SQL в таблице со строками и столбцами. Он включает в себя реляционный ключ, который отображается в предварительно разработанные поля. Структурированные данные используются в большем масштабе.
Структурированные данные представляют только 5-10% всех данных информатики.
Полуструктурированные данные
Полуструктурированные данные включают в себя данные, которые не находятся в реляционной базе данных. Они включают в себя некоторые из организационных свойств, которые облегчают анализ. Он включает в себя тот же процесс для хранения их в реляционной базе данных. Примерами полуструктурированной базы данных являются файлы CSV, документы XML и JSON. Базы данных NoSQL считаются полуструктурированными.
Неструктурированные данные
Неструктурированные данные представляют 80 процентов данных. Он часто включает в себя текстовый и мультимедийный контент. Лучшие примеры неструктурированных данных включают аудиофайлы, презентации и веб-страницы. Примерами неструктурированных данных, создаваемых машиной, являются спутниковые изображения, научные данные, фотографии и видео, данные радара и гидролокатора.
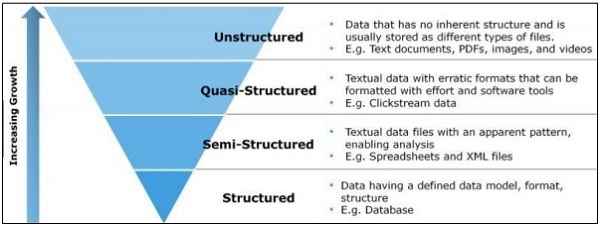
Вышеуказанная структура пирамиды специально фокусируется на объеме данных и соотношении, на котором они разбросаны.
Квази-структурированные данные отображаются как тип между неструктурированными и полуструктурированными данными. В этом руководстве мы сосредоточимся на полуструктурированных данных, которые полезны для гибкой методологии и исследований в области данных.
Полуструктурированные данные не имеют формальной модели данных, но имеют очевидную, самоописывающуюся структуру и структуру, которые вырабатываются в результате ее анализа.
Agile Data Science — SQL против NoSQL
Основное внимание в этом руководстве уделяется гибкой методологии с меньшим количеством шагов и внедрением более полезных инструментов. Чтобы понять это, важно знать разницу между базами данных SQL и NoSQL.
Большинство пользователей знакомы с базой данных SQL и хорошо разбираются в MySQL, Oracle или других базах данных SQL. За последние несколько лет база данных NoSQL получила широкое распространение для решения различных бизнес-задач и требований проекта.

В следующей таблице показана разница между базами данных SQL и NoSQL.
| SQL | NoSQL |
|---|---|
| Базы данных SQL в основном называются системой управления реляционными базами данных (RDBMS). | База данных NoSQL также называется документно-ориентированной базой данных. Это нереляционный и распределенный. |
| База данных на основе SQL включает в себя структуру таблицы со строками и столбцами. Коллекция таблиц и других структур схем называется база данных. | База данных NoSQL включает документы в качестве основной структуры, и включение документов называется сбором. |
| Базы данных SQL включают предопределенную схему. | Базы данных NoSQL содержат динамические данные и включают неструктурированные данные. |
| Базы данных SQL имеют вертикальное масштабирование. | Базы данных NoSQL масштабируются по горизонтали. |
| Базы данных SQL хорошо подходят для сложной среды запросов. | NoSQL не имеет стандартных интерфейсов для разработки сложных запросов. |
| Базы данных SQL невозможны для иерархического хранения данных. | Базы данных NoSQL лучше подходят для хранения иерархических данных. |
| Базы данных SQL лучше всего подходят для тяжелых транзакций в указанных приложениях. | Базы данных NoSQL по-прежнему не считаются сопоставимыми по высокой нагрузке для сложных транзакционных приложений. |
| Базы данных SQL обеспечивают отличную поддержку для своих поставщиков. | База данных NoSQL по-прежнему опирается на поддержку сообщества. Только несколько экспертов доступны для установки и развертывания для крупномасштабных развертываний NoSQL. |
| Базы данных SQL сосредоточены на свойствах ACID — атомарности, согласованности, изоляции и долговечности. | База данных NoSQL ориентирована на свойства CAP — согласованность, доступность и допуск раздела. |
| Базы данных SQL могут быть классифицированы как с открытым исходным кодом или с закрытым исходным кодом на основе поставщиков, которые выбрали их. | Базы данных NoSQL классифицируются в зависимости от типа хранилища. Базы данных NoSQL с открытым исходным кодом по умолчанию. |
Почему NoSQL для Agile?
Вышеупомянутое сравнение показывает, что база данных документов NoSQL полностью поддерживает гибкую разработку. Он не содержит схем и не полностью ориентирован на моделирование данных. Вместо этого NoSQL откладывает приложения и сервисы, и разработчики получают лучшее представление о том, как моделировать данные. NoSQL определяет модель данных как модель приложения.
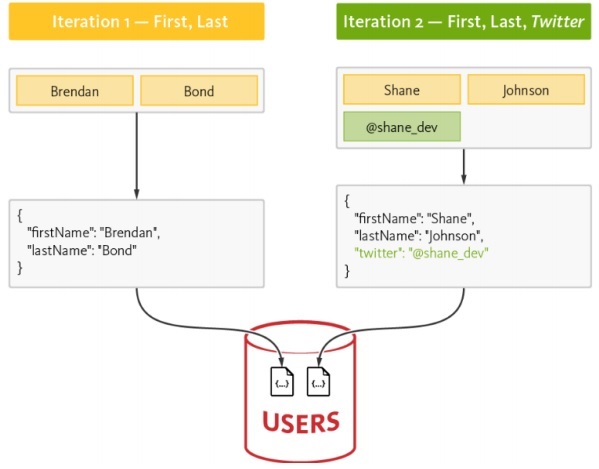
Установка MongoDB
В этом уроке мы сосредоточимся больше на примерах MongoDB, так как он считается лучшей «схемой NoSQL».
NoSQL и программирование потока данных
Бывают случаи, когда данные недоступны в реляционном формате, и нам нужно поддерживать их транзакции с помощью баз данных NoSQL.
В этой главе мы сосредоточимся на потоке данных NoSQL. Мы также узнаем, как это работает с сочетанием гибкой и науки о данных.
Одна из основных причин использования NoSQL в Agile — увеличение скорости в условиях рыночной конкуренции. Следующие причины показывают, как NoSQL лучше всего подходит для гибкой методологии программного обеспечения:
Меньше барьеров
Изменение модели, которая в настоящее время проходит через середину потока, имеет некоторые реальные затраты даже в случае быстрой разработки. С NoSQL пользователи работают с совокупными данными, а не тратят время на нормализацию данных. Суть в том, чтобы что-то сделать и работать с целью создания идеальных данных модели.
Увеличенная масштабируемость
Всякий раз, когда организация создает продукт, она уделяет больше внимания своей масштабируемости. NoSQL всегда известен своей масштабируемостью, но он работает лучше, когда он разработан с горизонтальной масштабируемостью.
Возможность использовать данные
NoSQL — это модель данных без схемы, которая позволяет пользователю легко использовать объемы данных, которые включают несколько параметров изменчивости и скорости. При рассмотрении выбора технологии, вы всегда должны учитывать тот, который использует данные в большем масштабе.
Поток данных NoSQL
Давайте рассмотрим следующий пример, в котором мы показали, как модель данных ориентирована на создание схемы RDBMS.
Ниже приведены различные требования схемы —
-
Идентификация пользователя должна быть указана.
-
Каждый пользователь должен обязательно иметь хотя бы один навык.
-
Детали опыта каждого пользователя должны быть сохранены должным образом.
Идентификация пользователя должна быть указана.
Каждый пользователь должен обязательно иметь хотя бы один навык.
Детали опыта каждого пользователя должны быть сохранены должным образом.
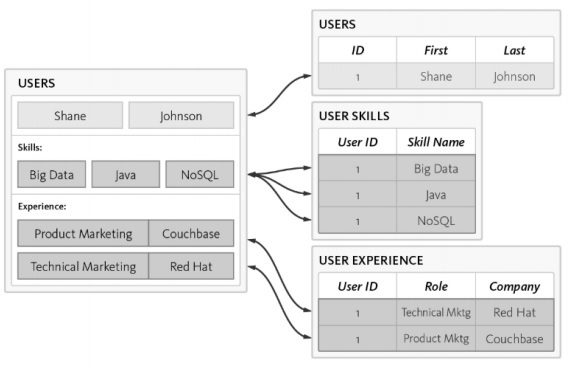
Пользовательская таблица нормализована с 3 отдельными таблицами —
-
пользователей
-
Навыки пользователя
-
Пользовательский опыт
пользователей
Навыки пользователя
Пользовательский опыт
Сложность возрастает при выполнении запросов к базе данных, а потребление времени отмечается с увеличением нормализации, что не подходит для Agile-методологии. Та же схема может быть разработана с базой данных NoSQL, как упомянуто ниже —
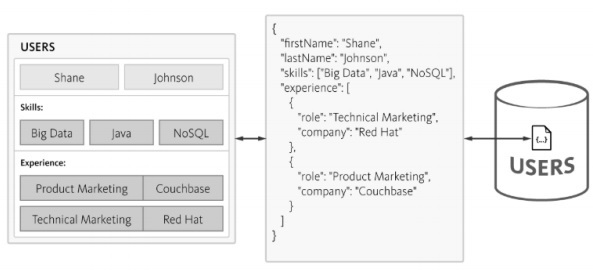
NoSQL поддерживает структуру в формате JSON, которая является легкой по структуре. С помощью JSON приложения могут хранить объекты с вложенными данными в виде отдельных документов.
Сбор и просмотр записей
В этой главе мы сосредоточимся на структуре JSON, которая является частью «гибкой методологии». MongoDB — это широко используемая структура данных NoSQL, которая легко собирает и отображает записи.
Шаг 1
Этот шаг включает в себя установление соединения с MongoDB для создания коллекции и указанной модели данных. Все, что вам нужно выполнить, это команда «mongod» для запуска соединения и команда mongo для подключения к указанному терминалу.
Шаг 2
Создайте новую базу данных для создания записей в формате JSON. На данный момент мы создаем фиктивную базу данных с именем «mydb».
>use mydb
switched to db mydb
>db
mydb
>show dbs
local 0.78125GB
test 0.23012GB
>db.user.insert({"name":"Agile Data Science"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
Шаг 3
Создание коллекции обязательно для получения списка записей. Эта функция полезна для исследований в области данных и результатов.
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>show collections
mycollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>db.agiledatascience.insert({"name" : "demoname"})
>show collections
mycol
mycollection
system.indexes
demoname
Agile Data Science — Визуализация данных
Визуализация данных играет очень важную роль в науке о данных. Мы можем рассматривать визуализацию данных как модуль науки о данных. Наука данных включает в себя нечто большее, чем построение прогностических моделей. Он включает в себя объяснение моделей и их использование для понимания данных и принятия решений. Визуализация данных является неотъемлемой частью представления данных наиболее убедительным образом.
С точки зрения науки о данных визуализация данных — это особенность, которая показывает изменения и тенденции.
Рассмотрим следующие рекомендации для эффективной визуализации данных —
-
Расположите данные по общему масштабу.
-
Использование баров более эффективно по сравнению кругов и квадратов.
-
Правильный цвет должен быть использован для точечных графиков.
-
Используйте круговую диаграмму, чтобы показать пропорции.
-
Визуализация солнечных лучей более эффективна для иерархических графиков.
Расположите данные по общему масштабу.
Использование баров более эффективно по сравнению кругов и квадратов.
Правильный цвет должен быть использован для точечных графиков.
Используйте круговую диаграмму, чтобы показать пропорции.
Визуализация солнечных лучей более эффективна для иерархических графиков.
Для Agile нужен простой язык сценариев для визуализации данных, а вместе с наукой о данных в сотрудничестве «Python» — это рекомендуемый язык для визуализации данных.
Пример 1
В следующем примере демонстрируется визуализация данных ВВП, рассчитанного в определенные годы. Matplotlib — лучшая библиотека для визуализации данных в Python. Установка этой библиотеки показана ниже —
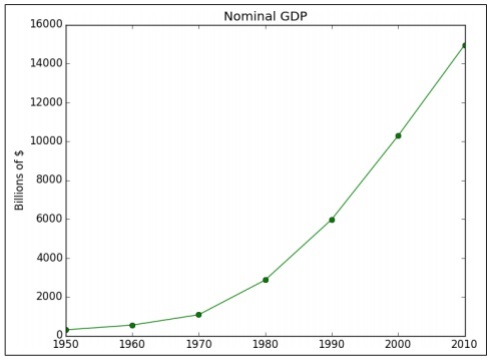
Рассмотрим следующий код, чтобы понять это —
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()
Выход
Приведенный выше код генерирует следующий вывод —
Существует множество способов настроить диаграммы с помощью меток осей, стилей линий и маркеров точек. Давайте сосредоточимся на следующем примере, который демонстрирует лучшую визуализацию данных. Эти результаты могут быть использованы для лучшего результата.
Пример 2
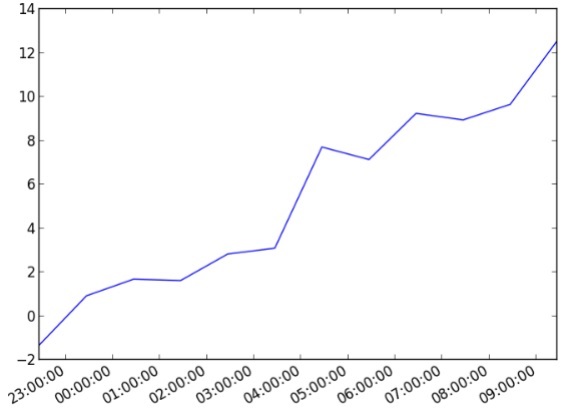
import datetime import random import matplotlib.pyplot as plt # make up some data x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)] y = [i+random.gauss(0,1) for i,_ in enumerate(x)] # plot plt.plot(x,y) # beautify the x-labels plt.gcf().autofmt_xdate() plt.show()
Выход
Приведенный выше код генерирует следующий вывод —
Agile Data Science — обогащение данных
Обогащение данных относится к ряду процессов, используемых для улучшения, уточнения и улучшения необработанных данных. Это относится к преобразованию полезных данных (необработанные данные в полезную информацию). Процесс обогащения данных фокусируется на превращении данных в ценный актив данных для современного бизнеса или предприятия.
Наиболее распространенный процесс обогащения данных включает в себя исправление орфографических или типографских ошибок в базе данных посредством использования специальных алгоритмов принятия решений. Инструменты обогащения данных добавляют полезную информацию в простые таблицы данных.
Рассмотрим следующий код для исправления орфографии слов —
import re
from collections import Counter
def words(text): return re.findall(r'\w+', text.lower())
WORDS = Counter(words(open('big.txt').read()))
def P(word, N=sum(WORDS.values())):
"Probabilities of words"
return WORDS[word] / N
def correction(word):
"Spelling correction of word"
return max(candidates(word), key=P)
def candidates(word):
"Generate possible spelling corrections for word."
return (known([word]) or known(edits1(word)) or known(edits2(word)) or [word])
def known(words):
"The subset of `words` that appear in the dictionary of WORDS."
return set(w for w in words if w in WORDS)
def edits1(word):
"All edits that are one edit away from `word`."
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R)>1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(word):
"All edits that are two edits away from `word`."
return (e2 for e1 in edits1(word) for e2 in edits1(e1))
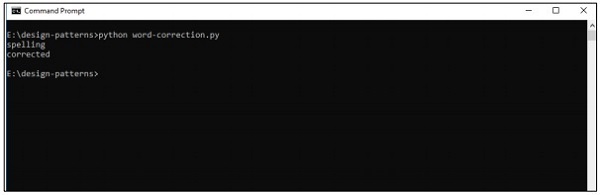
print(correction('speling'))
print(correction('korrectud'))
В этой программе мы сопоставим «big.txt», который включает исправленные слова. Слова совпадают со словами, включенными в текстовый файл, и выведите соответствующие результаты.
Выход
Приведенный выше код сгенерирует следующий вывод:
Agile Data Science — Работа с отчетами
В этой главе мы узнаем о создании отчетов, которые являются важным модулем гибкой методологии. Гибкие страницы диаграммы спринтов, созданные путем визуализации в полноценных отчетах. С отчетами диаграммы становятся интерактивными, статические страницы становятся динамическими и данные, связанные с сетью. Характеристики стадии отчета пирамиды значений данных приведены ниже —
Мы уделим больше внимания созданию CSV-файла, который можно использовать в качестве отчета для анализа данных и для подведения итогов. Хотя Agile фокусируется на меньшем количестве документации, создание отчетов, в которых упоминается прогресс в разработке продукта, всегда рассматривается.
import csv
#----------------------------------------------------------------------
def csv_writer(data, path):
"""
Write data to a CSV file path
"""
with open(path, "wb") as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for line in data:
writer.writerow(line)
#----------------------------------------------------------------------
if __name__ == "__main__":
data = ["first_name,last_name,city".split(","),
"Tyrese,Hirthe,Strackeport".split(","),
"Jules,Dicki,Lake Nickolasville".split(","),
"Dedric,Medhurst,Stiedemannberg".split(",")
]
path = "output.csv"
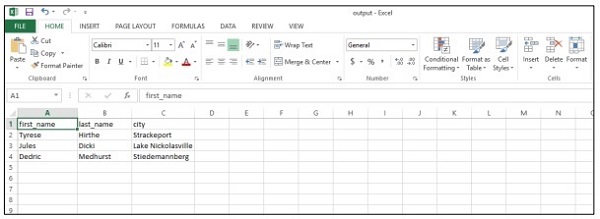
csv_writer(data, path)
Приведенный выше код поможет вам создать «CSV-файл», как показано ниже —
Давайте рассмотрим следующие преимущества отчетов csv (значения, разделенные запятыми):
- Это дружественный человек и легко редактировать вручную.
- Это просто реализовать и разобрать.
- CSV можно обрабатывать во всех приложениях.
- Это меньше и быстрее обрабатывать.
- CSV следует стандартному формату.
- Это обеспечивает простую схему для ученых данных.
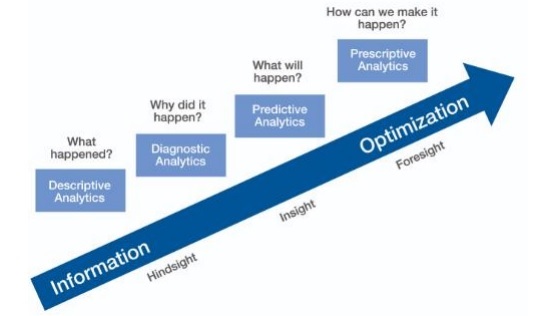
Agile Data Science — Роль Предсказаний
В этой главе мы узнаем о роли предсказаний в гибкой науке о данных. Интерактивные отчеты раскрывают различные аспекты данных. Предсказания формируют четвертый слой проворного спринта.
Делая прогнозы, мы всегда ссылаемся на прошлые данные и используем их как выводы для будущих итераций. В этом полном процессе мы переводим данные из пакетной обработки исторических данных в данные о будущем в реальном времени.
Роль прогнозов включает следующее:
-
Предсказания помогают в прогнозировании. Некоторые прогнозы основаны на статистическом выводе. Некоторые из прогнозов основаны на мнениях ученых мужей.
-
Статистический вывод связан с предсказаниями всех видов.
-
Иногда прогнозы точны, а иногда неточны.
Предсказания помогают в прогнозировании. Некоторые прогнозы основаны на статистическом выводе. Некоторые из прогнозов основаны на мнениях ученых мужей.
Статистический вывод связан с предсказаниями всех видов.
Иногда прогнозы точны, а иногда неточны.
Прогнозная аналитика
Прогнозная аналитика включает в себя различные статистические методы от прогнозирующего моделирования, машинного обучения и интеллектуального анализа данных, которые анализируют текущие и исторические факты для прогнозирования будущих и неизвестных событий.
Прогнозирующая аналитика требует данных обучения. Обучаемые данные включают в себя независимые и зависимые функции. Зависимые характеристики — это значения, которые пользователь пытается предсказать. Независимые функции — это функции, описывающие вещи, которые мы хотим предсказать на основе зависимых функций.
Изучение особенностей называется особенностью разработки; это важно для прогнозирования. Визуализация данных и анализ разведочных данных являются частями разработки функций; они составляют ядро гибкой науки о данных .
Делать прогнозы
Есть два способа делать прогнозы в гибкой науке о данных —
-
регрессия
-
классификация
регрессия
классификация
Построение регрессии или классификации полностью зависит от требований бизнеса и его анализа. Прогнозирование непрерывной переменной приводит к модели регрессии, а предсказание категориальных переменных приводит к модели классификации.
регрессия
Регрессия рассматривает примеры, которые содержат признаки и, таким образом, производят числовой вывод.
классификация
Классификация принимает входные данные и производит категориальную классификацию.
Примечание . Примерный набор данных, который определяет входные данные для статистического прогнозирования и позволяет машине учиться, называется «обучающими данными».
Извлечение функций с помощью PySpark
В этой главе мы узнаем о применении функций извлечения с помощью PySpark в Agile Data Science.
Обзор Spark
Apache Spark можно определить как среду быстрой обработки в реальном времени. Это делает вычисления для анализа данных в режиме реального времени. Apache Spark представлен как система потоковой обработки в режиме реального времени, а также может выполнять пакетную обработку. Apache Spark поддерживает интерактивные запросы и итерационные алгоритмы.
Spark написан на «языке программирования Scala».
PySpark можно рассматривать как комбинацию Python с Spark. PySpark предлагает оболочку PySpark, которая связывает Python API с ядром Spark и инициализирует контекст Spark. Большинство исследователей данных используют PySpark для отслеживания функций, как обсуждалось в предыдущей главе.
В этом примере мы сосредоточимся на преобразованиях, чтобы построить набор данных с именем count и сохранить его в определенном файле.
text_file = sc.textFile("hdfs://...")
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
Используя PySpark, пользователь может работать с RDD на языке программирования Python. Помогает в этом встроенная библиотека, которая охватывает основы документов и компонентов, управляемых данными.
Построение регрессионной модели
Логистическая регрессия относится к алгоритму машинного обучения, который используется для прогнозирования вероятности категориально зависимой переменной. В логистической регрессии зависимой переменной является двоичная переменная, которая состоит из данных, закодированных как 1 (логические значения true и false).
В этой главе мы сосредоточимся на разработке регрессионной модели в Python с использованием непрерывной переменной. Пример для модели линейной регрессии будет сфокусирован на исследовании данных из файла CSV.
Цель классификации — предсказать, будет ли клиент подписываться (1/0) на срочный депозит.
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
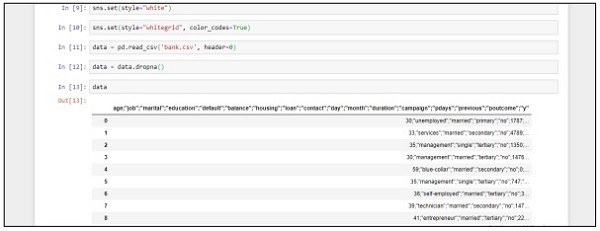
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))
Выполните следующие шаги для реализации вышеуказанного кода в Anaconda Navigator с «Блокнотом Jupyter» —
Шаг 1 — Запустите ноутбук Jupyter с помощью Anaconda Navigator.
Шаг 2 — Загрузите файл CSV, чтобы систематически получать выходные данные регрессионной модели.
Шаг 3 — Создайте новый файл и выполните вышеупомянутую строку кода, чтобы получить желаемый результат.
Развертывание системы прогнозирования
В этом примере мы узнаем, как создать и развернуть прогностическую модель, которая помогает в прогнозировании цен на жилье с использованием скрипта Python. Важная структура, используемая для развертывания прогностической системы, включает Anaconda и Jupyter Notebook.
Выполните следующие действия для развертывания системы прогнозирования —
Шаг 1 — Реализуйте следующий код для преобразования значений из CSV-файлов в связанные значения.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import mpl_toolkits
%matplotlib inline
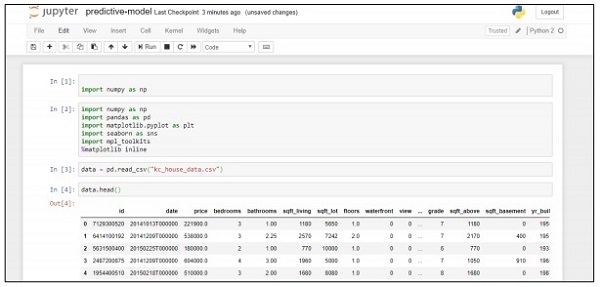
data = pd.read_csv("kc_house_data.csv")
data.head()
Приведенный выше код генерирует следующий вывод —
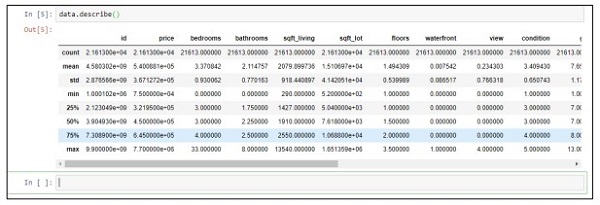
Шаг 2 — Выполните функцию description, чтобы получить типы данных, включенные в атрибуты файлов csv.
data.describe()
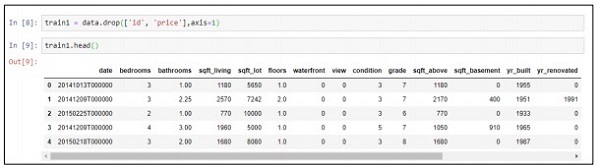
Шаг 3 — Мы можем отбросить связанные значения на основе развертывания прогнозной модели, которую мы создали.
train1 = data.drop(['id', 'price'],axis=1) train1.head()
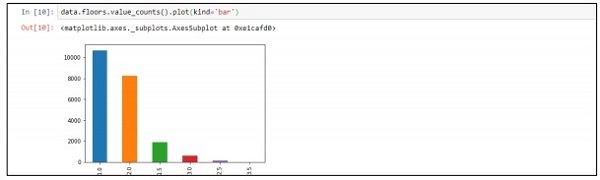
Шаг 4 — Вы можете визуализировать данные в соответствии с записями. Данные могут быть использованы для анализа данных науки и вывода технических документов.
data.floors.value_counts().plot(kind='bar')
Agile Data Science — SparkML
Библиотека машинного обучения, также называемая «SparkML» или «MLLib», состоит из общих алгоритмов обучения, включая классификацию, регрессию, кластеризацию и совместную фильтрацию.
Зачем изучать SparkML для Agile?
Spark становится де-факто платформой для построения алгоритмов и приложений машинного обучения. Разработчики работают над Spark для реализации машинных алгоритмов в масштабируемой и лаконичной форме в среде Spark. Мы изучим концепции машинного обучения, его утилиты и алгоритмы на этой основе. Agile всегда выбирает среду, которая обеспечивает короткие и быстрые результаты.
Алгоритмы ML
Алгоритмы ML включают в себя общие алгоритмы обучения, такие как классификация, регрессия, кластеризация и совместная фильтрация.
Характеристики
Он включает в себя извлечение признаков, преобразование, уменьшение размеров и выбор.
Трубопроводы
Конвейеры предоставляют инструменты для построения, оценки и настройки машинного обучения конвейеров.
Популярные алгоритмы
Ниже приведены несколько популярных алгоритмов —
-
Основная статистика
-
регрессия
-
классификация
-
Система рекомендаций
-
Кластеризация
-
Уменьшение размерности
-
Функция извлечения
-
оптимизация
Основная статистика
регрессия
классификация
Система рекомендаций
Кластеризация
Уменьшение размерности
Функция извлечения
оптимизация
Система рекомендаций
Система рекомендаций — это подкласс системы фильтрации информации, который ищет предсказания «рейтинга» и «предпочтения», которые пользователь предлагает для данного элемента.
Система рекомендаций включает в себя различные системы фильтрации, которые используются следующим образом:
Совместная фильтрация
Он включает в себя построение модели на основе прошлого поведения, а также аналогичных решений, принятых другими пользователями. Эта конкретная модель фильтрации используется для прогнозирования элементов, в которых заинтересован пользователь.
Контентная фильтрация
Она включает в себя фильтрацию отдельных характеристик элемента, чтобы рекомендовать и добавлять новые элементы с похожими свойствами.
В наших последующих главах мы сосредоточимся на использовании системы рекомендаций для решения конкретной проблемы и повышения эффективности прогнозирования с точки зрения гибкой методологии.
Исправление проблемы с предсказанием
В этой главе мы сосредоточимся на исправлении проблемы прогнозирования с помощью определенного сценария.
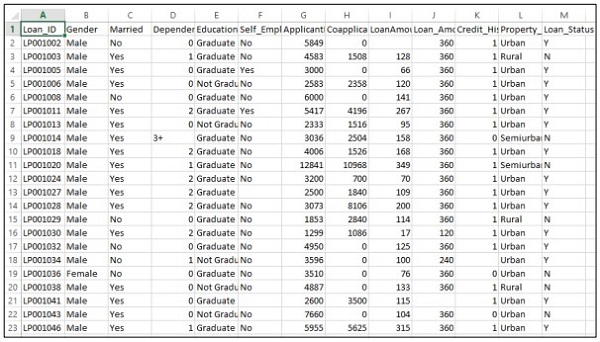
Учтите, что компания хочет автоматизировать данные о предоставлении кредита в соответствии с данными клиента, предоставленными через онлайн-заявку. Данные включают в себя имя клиента, пол, семейное положение, сумму кредита и другие обязательные данные.
Детали записываются в файл CSV, как показано ниже —
Выполните следующий код, чтобы оценить проблему прогнозирования —
import pandas as pd
from sklearn import ensemble
import numpy as np
from scipy.stats import mode
from sklearn import preprocessing,model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
#loading the dataset
data=pd.read_csv('train.csv',index_col='Loan_ID')
def num_missing(x):
return sum(x.isnull())
#imputing the the missing values from the data
data['Gender'].fillna(mode(list(data['Gender'])).mode[0], inplace=True)
data['Married'].fillna(mode(list(data['Married'])).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(list(data['Self_Employed'])).mode[0], inplace=True)
# print (data.apply(num_missing, axis=0))
# #imputing mean for the missing value
data['LoanAmount'].fillna(data['LoanAmount'].mean(), inplace=True)
mapping={'0':0,'1':1,'2':2,'3+':3}
data = data.replace({'Dependents':mapping})
data['Dependents'].fillna(data['Dependents'].mean(), inplace=True)
data['Loan_Amount_Term'].fillna(method='ffill',inplace=True)
data['Credit_History'].fillna(method='ffill',inplace=True)
print (data.apply(num_missing,axis=0))
#converting the cateogorical data to numbers using the label encoder
var_mod = ['Gender','Married','Education','Self_Employed','Property_Area','Loan_Status']
le = LabelEncoder()
for i in var_mod:
le.fit(list(data[i].values))
data[i] = le.transform(list(data[i]))
#Train test split
x=['Gender','Married','Education','Self_Employed','Property_Area','LoanAmount', 'Loan_Amount_Term','Credit_History','Dependents']
y=['Loan_Status']
print(data[x])
X_train,X_test,y_train,y_test=model_selection.train_test_split(data[x],data[y], test_size=0.2)
#
# #Random forest classifier
# clf=ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini',max_depth=3,max_features='auto',n_jobs=-1)
clf=ensemble.RandomForestClassifier(n_estimators=200,max_features=3,min_samples
_split=5,oob_score=True,n_jobs=-1,criterion='entropy')
clf.fit(X_train,y_train)
accuracy=clf.score(X_test,y_test)
print(accuracy)
Выход
Приведенный выше код генерирует следующий вывод.

Улучшение прогнозирования
В этой главе мы сосредоточимся на построении модели, которая помогает в прогнозировании успеваемости учащихся с помощью ряда атрибутов, включенных в него. Основное внимание уделяется отображению результатов отказов учащихся на экзамене.
Процесс
Целевое значение оценки — G3. Эти значения могут быть связаны и далее классифицированы как неудача и успех. Если значение G3 больше или равно 10, то студент сдает экзамен.
пример
Рассмотрим следующий пример, в котором выполняется код для прогнозирования производительности, если учащиеся —
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
main()
Выход
Приведенный выше код генерирует вывод, как показано ниже
Прогноз обрабатывается со ссылкой только на одну переменную. Со ссылкой на одну переменную, прогноз успеваемости студента, как показано ниже —
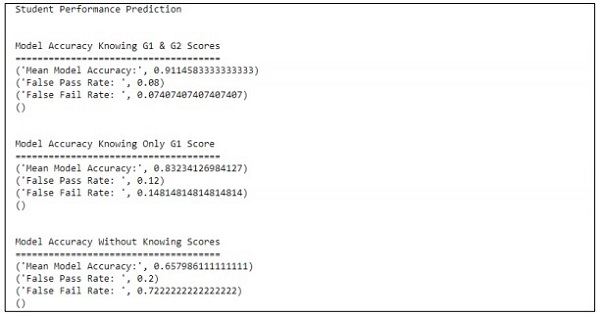
Создание лучшей сцены с гибкой и наукой о данных
Гибкая методология помогает организациям адаптироваться к изменениям, конкурировать на рынке и создавать высококачественные продукты. Наблюдается, что организации созревают с гибкой методологией, с возрастающим изменением требований со стороны клиентов. Компиляция и синхронизация данных с гибкими командами организации важна для объединения данных в соответствии с требуемым портфелем.
Создайте лучший план
Стандартизированная гибкая производительность зависит исключительно от плана. Упорядоченная схема данных повышает производительность, качество и оперативность прогресса организации. Уровень согласованности данных поддерживается с использованием исторических и реальных сценариев.
Рассмотрим следующую диаграмму, чтобы понять цикл эксперимента по науке о данных —
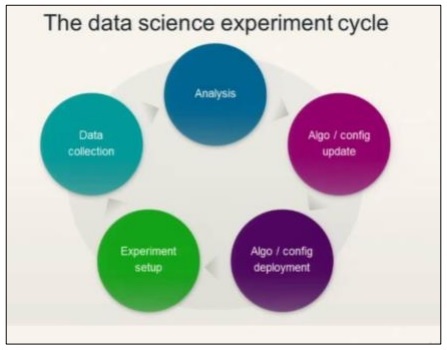
Наука о данных включает в себя анализ требований с последующим созданием алгоритмов на их основе. Как только алгоритмы разработаны вместе с настройкой среды, пользователь может создавать эксперименты и собирать данные для лучшего анализа.
Эта идеология вычисляет последний спринт agile, который называется «действия».
Действия включают в себя все обязательные задачи для последнего спринта или уровня гибкой методологии. Отслеживание этапов науки о данных (относительно жизненного цикла) можно поддерживать с помощью карточек историй в качестве элементов действий.
Прогнозный анализ и большие данные
Будущее планирования полностью заключается в настройке отчетов с данными, полученными в результате анализа. Это также будет включать манипуляции с анализом больших данных. С помощью больших данных можно анализировать отдельные фрагменты информации, эффективно разрезая и изменяя метрики организации. Анализ всегда считается лучшим решением.
Agile Data Science — Внедрение Agile
В процессе гибкой разработки используются различные методологии. Эти методологии могут также использоваться для исследования данных.
Блок-схема, приведенная ниже, показывает различные методологии —
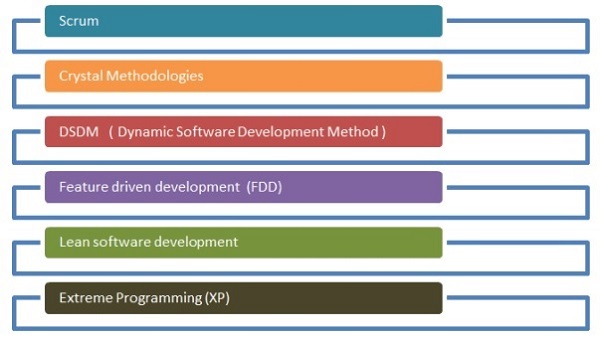
Scrum
С точки зрения разработки программного обеспечения, scrum означает управление работой с небольшой командой и управление конкретным проектом для выявления сильных и слабых сторон проекта.
Кристаллические методологии
Кристаллические методологии включают в себя инновационные методы управления и исполнения продукции. С помощью этого метода команды могут выполнять похожие задачи по-разному. Семья Кристаллов — одна из самых простых в применении методологий.
Метод динамической разработки программного обеспечения
Эта структура доставки в основном используется для реализации текущей системы знаний в методологии программного обеспечения.
Будущее развитие
В центре внимания этого жизненного цикла разработки находятся особенности, вовлеченные в проект. Он лучше всего подходит для моделирования объектов домена, разработки кода и функций для владельцев.
Lean Разработка программного обеспечения
Этот метод направлен на повышение скорости разработки программного обеспечения при низких затратах и фокусирует команду на предоставлении конкретной ценности для клиента.
Экстремальное программирование
Экстремальное программирование — это уникальная методология разработки программного обеспечения, которая направлена на повышение качества программного обеспечения. Это вступает в силу, когда заказчик не уверен в функциональности какого-либо проекта.
Гибкие методологии внедряются в поток данных науки, и это считается важной методологией программного обеспечения. Благодаря гибкой самоорганизации кросс-функциональные команды могут эффективно работать вместе. Как уже упоминалось, существует шесть основных категорий гибкой разработки, и каждая из них может быть связана с наукой о данных в соответствии с требованиями. Наука данных включает в себя итеративный процесс для статистического анализа. Agile помогает разбивать модули науки о данных и помогает эффективно обрабатывать итерации и спринты.
Процесс Agile Data Science — это удивительный способ понять, как и почему реализован модуль Data Science. Это решает проблемы творчески.