В этой главе мы изучим фактическое программирование с помощью Lucene Framework. Прежде чем вы начнете писать свой первый пример с использованием инфраструктуры Lucene, вы должны убедиться, что вы правильно настроили свою среду Lucene, как объяснено в руководстве Lucene — Настройка среды . Рекомендуется иметь практические знания по Eclipse IDE.
Давайте теперь приступим к написанию простого Поискового приложения, которое напечатает количество найденных результатов поиска. Мы также увидим список индексов, созданных в ходе этого процесса.
Шаг 1 — Создать проект Java
Первым шагом является создание простого Java-проекта с использованием Eclipse IDE. Выберите пункт « Файл»> «Создать» -> «Проект» и, наконец, выберите «Мастер Java-проектов» из списка. Теперь назовите ваш проект как LuceneFirstApplication, используя окно мастера следующим образом:
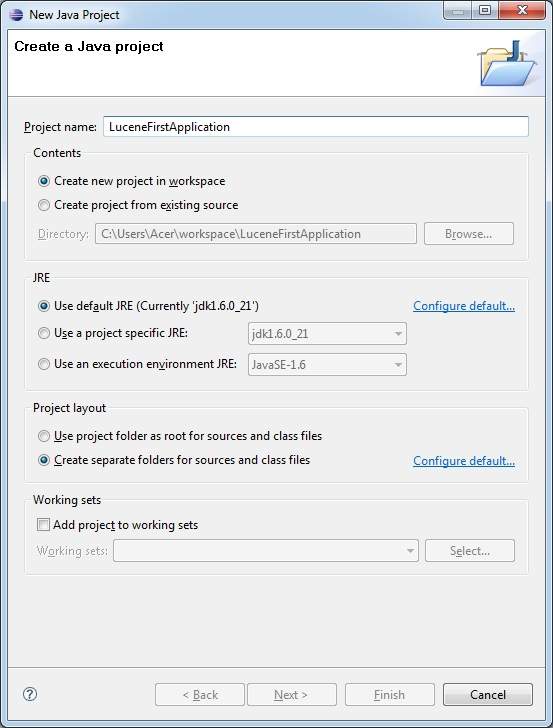
Как только ваш проект будет успешно создан, вы будете иметь следующий контент в Project Explorer —
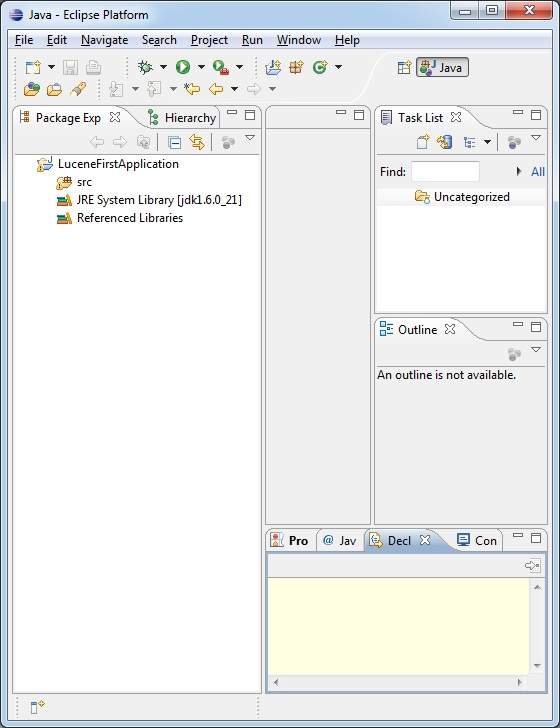
Шаг 2 — Добавить необходимые библиотеки
Давайте теперь добавим базовую библиотеку Lucene в наш проект. Для этого щелкните правой кнопкой мыши имя вашего проекта LuceneFirstApplication и затем следуйте следующей опции, доступной в контекстном меню: « Путь сборки» -> «Настроить путь сборки» для отображения окна «Путь сборки Java» следующим образом —
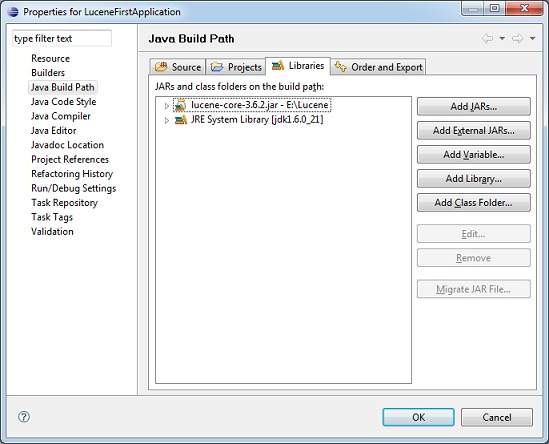
Теперь используйте кнопку « Добавить внешние JAR» , доступную на вкладке « Библиотеки », чтобы добавить следующий основной JAR из установочного каталога Lucene —
- Lucene-ядро-3.6.2
Шаг 3 — Создание исходных файлов
Теперь давайте создадим фактические исходные файлы в рамках проекта LuceneFirstApplication . Сначала нам нужно создать пакет с именем com.tutorialspoint.lucene. Для этого щелкните правой кнопкой мыши на src в разделе проводника пакетов и выберите опцию: New -> Package .
Далее мы создадим LuceneTester.java и другие java-классы в пакете com.tutorialspoint.lucene .
LuceneConstants.java
Этот класс используется для предоставления различных констант, которые будут использоваться в приложении-образце.
package com.tutorialspoint.lucene; public class LuceneConstants { public static final String CONTENTS = "contents"; public static final String FILE_NAME = "filename"; public static final String FILE_PATH = "filepath"; public static final int MAX_SEARCH = 10; }
TextFileFilter.java
Этот класс используется как фильтр файлов .txt .
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
Indexer.java
Этот класс используется для индексации необработанных данных, чтобы мы могли сделать их доступными для поиска с помощью библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException { //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException { writer.close(); } private Document getDocument(File file) throws IOException { Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException { System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException { //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); } }
Searcher.java
Этот класс используется для поиска в индексах, созданных индексатором, для поиска запрошенного содержимого.
package com.tutorialspoint.lucene; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException { Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException { query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException { return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException { indexSearcher.close(); } }
LuceneTester.java
Этот класс используется для проверки возможности индексации и поиска в библиотеке lucene.
package com.tutorialspoint.lucene; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void createIndex() throws IOException { indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); } private void search(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime)); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: " + doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } }
Шаг 4 — Создание каталога данных и индекса
Мы использовали 10 текстовых файлов от record1.txt до record10.txt, содержащих имена и другие сведения об учениках, и поместили их в каталог E: \ Lucene \ Data . Тестовые данные . Путь к каталогу индекса должен быть создан как E: \ Lucene \ Index . После запуска этой программы вы можете увидеть список индексных файлов, созданных в этой папке.
Шаг 5 — Запуск программы
Когда вы закончите с созданием источника, необработанных данных, каталога данных и каталога индекса, вы будете готовы к компиляции и запуску вашей программы. Для этого оставьте активную вкладку файла LuceneTester.Java активной и используйте либо опцию « Выполнить», доступную в Eclipse IDE, либо используйте Ctrl + F11 для компиляции и запуска приложения LuceneTester . Если приложение работает успешно, оно напечатает следующее сообщение в консоли Eclipse IDE —
Indexing E:\Lucene\Data\record1.txt Indexing E:\Lucene\Data\record10.txt Indexing E:\Lucene\Data\record2.txt Indexing E:\Lucene\Data\record3.txt Indexing E:\Lucene\Data\record4.txt Indexing E:\Lucene\Data\record5.txt Indexing E:\Lucene\Data\record6.txt Indexing E:\Lucene\Data\record7.txt Indexing E:\Lucene\Data\record8.txt Indexing E:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms 1 documents found. Time :0 File: E:\Lucene\Data\record4.txt
После того, как вы успешно запустите программу, у вас будет следующий контент в каталоге index —