Люцен — Обзор
Lucene — это простая, но мощная библиотека поиска на основе Java. Его можно использовать в любом приложении, чтобы добавить в него возможность поиска. Lucene — это проект с открытым исходным кодом. Это масштабируемо. Эта высокопроизводительная библиотека используется для индексации и поиска практически любого текста. Библиотека Lucene предоставляет основные операции, необходимые для любого поискового приложения. Индексирование и поиск.
Как работает поисковое приложение?
Приложение поиска выполняет все или несколько из следующих операций:
| шаг | заглавие | Описание |
|---|---|---|
| 1 |
Получить сырье |
Первым шагом любого поискового приложения является сбор целевого содержимого, по которому должно выполняться поисковое приложение. |
| 2 |
Построить документ |
Следующим шагом является создание документа (ов) из необработанного содержимого, которое поисковое приложение может легко понять и интерпретировать. |
| 3 |
Проанализируйте документ |
Перед началом процесса индексации необходимо проанализировать, какая часть текста является кандидатом для индексации. Этот процесс — то, где документ проанализирован. |
| 4 |
Индексирование документа |
После того, как документы построены и проанализированы, следующим шагом является их индексация, чтобы этот документ можно было получить на основе определенных ключей, а не всего содержимого документа. Процесс индексирования аналогичен индексам в конце книги, где обычные слова показываются с номерами их страниц, так что эти слова можно быстро отслеживать вместо поиска по всей книге. |
| 5 |
Пользовательский интерфейс для поиска |
Когда база данных индексов готова, приложение может выполнить любой поиск. Чтобы упростить пользователю поиск, приложение должно предоставить пользователю среднее значение или пользовательский интерфейс, где пользователь может вводить текст и запускать процесс поиска. |
| 6 |
Построить запрос |
Как только пользователь отправляет запрос на поиск текста, приложение должно подготовить объект Query, используя этот текст, который можно использовать для запроса базы данных индекса для получения соответствующих сведений. |
| 7 |
Поисковый запрос |
Используя объект запроса, база данных индекса затем проверяется, чтобы получить соответствующую информацию и документы контента. |
| 8 |
Результаты рендеринга |
Как только результат получен, приложение должно решить, как показать результаты пользователю, используя пользовательский интерфейс. Сколько информации нужно показывать с первого взгляда и так далее. |
Получить сырье
Первым шагом любого поискового приложения является сбор целевого содержимого, по которому должно выполняться поисковое приложение.
Построить документ
Следующим шагом является создание документа (ов) из необработанного содержимого, которое поисковое приложение может легко понять и интерпретировать.
Проанализируйте документ
Перед началом процесса индексации необходимо проанализировать, какая часть текста является кандидатом для индексации. Этот процесс — то, где документ проанализирован.
Индексирование документа
После того, как документы построены и проанализированы, следующим шагом является их индексация, чтобы этот документ можно было получить на основе определенных ключей, а не всего содержимого документа. Процесс индексирования аналогичен индексам в конце книги, где обычные слова показываются с номерами их страниц, так что эти слова можно быстро отслеживать вместо поиска по всей книге.
Пользовательский интерфейс для поиска
Когда база данных индексов готова, приложение может выполнить любой поиск. Чтобы упростить пользователю поиск, приложение должно предоставить пользователю среднее значение или пользовательский интерфейс, где пользователь может вводить текст и запускать процесс поиска.
Построить запрос
Как только пользователь отправляет запрос на поиск текста, приложение должно подготовить объект Query, используя этот текст, который можно использовать для запроса базы данных индекса для получения соответствующих сведений.
Поисковый запрос
Используя объект запроса, база данных индекса затем проверяется, чтобы получить соответствующую информацию и документы контента.
Результаты рендеринга
Как только результат получен, приложение должно решить, как показать результаты пользователю, используя пользовательский интерфейс. Сколько информации нужно показывать с первого взгляда и так далее.
Помимо этих основных операций, поисковое приложение может также предоставить административный пользовательский интерфейс и помочь администраторам приложения контролировать уровень поиска на основе пользовательских профилей. Аналитика результатов поиска — еще один важный и продвинутый аспект любого поискового приложения.
Роль Lucene в поисковом приложении
Lucene играет роль в шагах со 2 по 7, упомянутых выше, и предоставляет классы для выполнения необходимых операций. В двух словах, Lucene является сердцем любого поискового приложения и обеспечивает жизненно важные операции, относящиеся к индексации и поиску. Получение содержимого и отображение результатов оставлено для обработки частью приложения.
В следующей главе мы выполним простое приложение поиска, используя библиотеку Lucene Search.
Lucene — Настройка среды
Из этого туториала вы узнаете, как подготовить среду разработки для начала работы с Spring Framework. В этом руководстве также будет рассказано, как настроить JDK, Tomcat и Eclipse на вашем компьютере перед установкой Spring Framework.
Шаг 1 — Настройка Java Development Kit (JDK)
Вы можете скачать последнюю версию SDK с сайта Oracle на Java: Java SE Downloads . Инструкции по установке JDK вы найдете в загруженных файлах; следуйте приведенным инструкциям для установки и настройки. Наконец, установите переменные среды PATH и JAVA_HOME, чтобы они ссылались на каталог, содержащий Java и javac, обычно это java_install_dir / bin и java_install_dir соответственно.
Если вы работаете в Windows и установили JDK в C: \ jdk1.6.0_15, вам придется поместить следующую строку в ваш файл C: \ autoexec.bat.
set PATH = C:\jdk1.6.0_15\bin;%PATH% set JAVA_HOME = C:\jdk1.6.0_15
Кроме того, в Windows NT / 2000 / XP вы также можете щелкнуть правой кнопкой мыши на « Мой компьютер» , выбрать « Свойства» , затем « Дополнительно» , затем « Переменные среды» . Затем вы обновите значение PATH и нажмете кнопку ОК .
В Unix (Solaris, Linux и т. Д.), Если SDK установлен в /usr/local/jdk1.6.0_15 и вы используете оболочку C, вы должны поместить следующее в свой файл .cshrc.
setenv PATH /usr/local/jdk1.6.0_15/bin:$PATH setenv JAVA_HOME /usr/local/jdk1.6.0_15
В качестве альтернативы, если вы используете интегрированную среду разработки (IDE), такую как Borland JBuilder, Eclipse, IntelliJ IDEA или Sun ONE Studio, скомпилируйте и запустите простую программу, чтобы подтвердить, что IDE знает, где вы установили Java, в противном случае выполните правильную настройку, как указано в документ IDE.
Шаг 2 — Настройка Eclipse IDE
Все примеры в этом руководстве написаны с использованием Eclipse IDE . Поэтому я хотел бы предложить, чтобы на вашем компьютере была установлена последняя версия Eclipse.
Чтобы установить Eclipse IDE, загрузите последние двоичные файлы Eclipse со страницы https://www.eclipse.org/downloads/ . После загрузки установки распакуйте бинарный дистрибутив в удобное место. Например, в C: \ eclipse для Windows или / usr / local / eclipse в Linux / Unix и, наконец, установите переменную PATH соответствующим образом.
Eclipse можно запустить, выполнив следующие команды на компьютере с Windows, или вы можете просто дважды щелкнуть по eclipse.exe
%C:\eclipse\eclipse.exe
Eclipse можно запустить, выполнив следующие команды на компьютере Unix (Solaris, Linux и т. Д.):
$/usr/local/eclipse/eclipse
После успешного запуска должен отобразиться следующий результат —
Шаг 3 — Настройка библиотек Lucene Framework
Если запуск прошел успешно, вы можете приступить к настройке вашей среды Lucene. Ниже приведены простые шаги для загрузки и установки фреймворка на вашем компьютере.
https://archive.apache.org/dist/lucene/java/3.6.2/
-
Выберите, хотите ли вы установить Lucene в Windows или Unix, а затем перейдите к следующему шагу, чтобы загрузить .zip-файл для windows и .tz-файл для Unix.
-
Загрузите подходящую версию двоичных файлов платформы Lucene с https://archive.apache.org/dist/lucene/java/ .
-
На момент написания этого руководства я скачал lucene-3.6.2.zip на свой компьютер с Windows, и когда вы разархивируете загруженный файл, он даст вам структуру каталогов внутри C: \ lucene-3.6.2, как показано ниже.
Выберите, хотите ли вы установить Lucene в Windows или Unix, а затем перейдите к следующему шагу, чтобы загрузить .zip-файл для windows и .tz-файл для Unix.
Загрузите подходящую версию двоичных файлов платформы Lucene с https://archive.apache.org/dist/lucene/java/ .
На момент написания этого руководства я скачал lucene-3.6.2.zip на свой компьютер с Windows, и когда вы разархивируете загруженный файл, он даст вам структуру каталогов внутри C: \ lucene-3.6.2, как показано ниже.
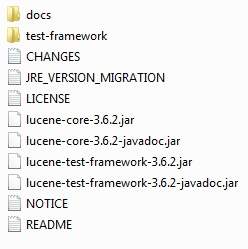
Вы найдете все библиотеки Lucene в каталоге C: \ lucene-3.6.2 . Убедитесь, что вы правильно установили переменную CLASSPATH в этом каталоге, иначе вы столкнетесь с проблемой при запуске приложения. Если вы используете Eclipse, то не обязательно устанавливать CLASSPATH, потому что все настройки будут выполнены через Eclipse.
Как только вы закончите с этим последним шагом, вы готовы приступить к первому примеру Lucene, который вы увидите в следующей главе.
Lucene — первое применение
В этой главе мы изучим фактическое программирование с помощью Lucene Framework. Прежде чем вы начнете писать свой первый пример с использованием инфраструктуры Lucene, вы должны убедиться, что вы правильно настроили свою среду Lucene, как объяснено в руководстве Lucene — Настройка среды . Рекомендуется иметь практические знания по Eclipse IDE.
Давайте теперь приступим к написанию простого Поискового приложения, которое напечатает количество найденных результатов поиска. Мы также увидим список индексов, созданных в ходе этого процесса.
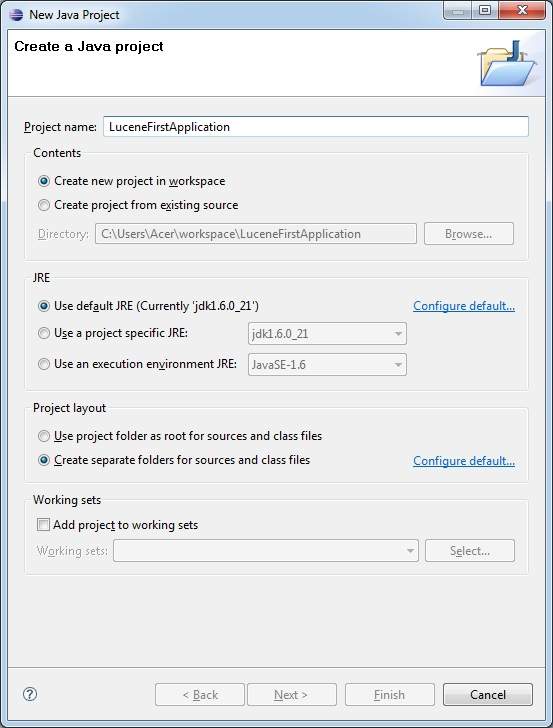
Шаг 1 — Создать проект Java
Первым шагом является создание простого Java-проекта с использованием Eclipse IDE. Выберите пункт « Файл»> «Создать» -> «Проект» и, наконец, выберите «Мастер Java-проектов» из списка. Теперь назовите ваш проект как LuceneFirstApplication, используя окно мастера следующим образом:
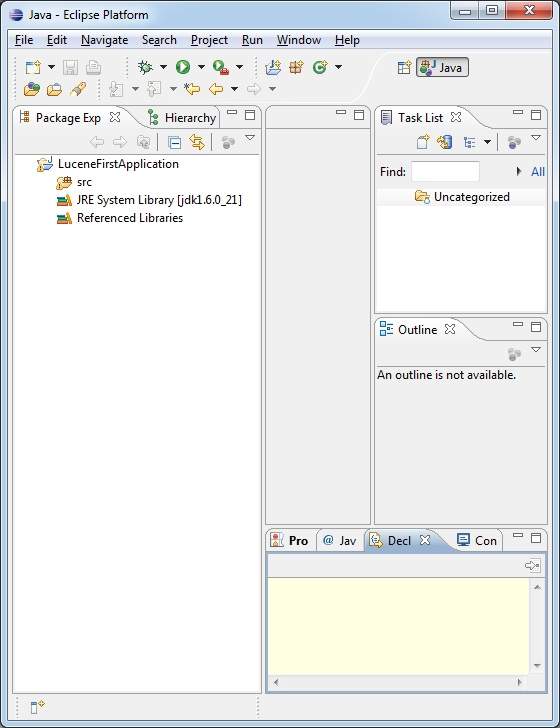
Как только ваш проект будет успешно создан, вы будете иметь следующий контент в Project Explorer —
Шаг 2 — Добавить необходимые библиотеки
Давайте теперь добавим базовую библиотеку Lucene в наш проект. Для этого щелкните правой кнопкой мыши имя вашего проекта LuceneFirstApplication и затем следуйте следующей опции, доступной в контекстном меню: « Путь сборки» -> «Настроить путь сборки» для отображения окна «Путь сборки Java» следующим образом —
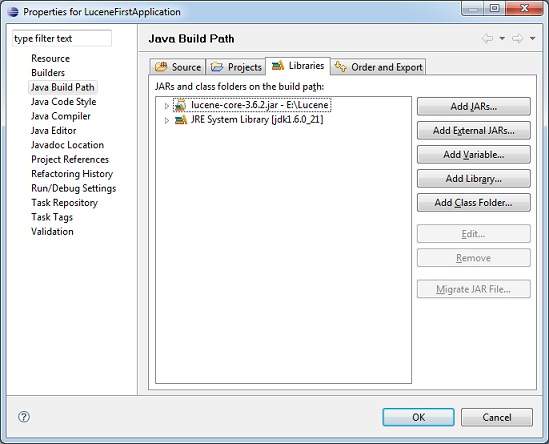
Теперь используйте кнопку « Добавить внешние JAR» , доступную на вкладке « Библиотеки », чтобы добавить следующий основной JAR из установочного каталога Lucene —
- Lucene-ядро-3.6.2
Шаг 3 — Создание исходных файлов
Теперь давайте создадим фактические исходные файлы в рамках проекта LuceneFirstApplication . Сначала нам нужно создать пакет с именем com.tutorialspoint.lucene. Для этого щелкните правой кнопкой мыши на src в разделе проводника пакетов и выберите опцию: New -> Package .
Далее мы создадим LuceneTester.java и другие java-классы в пакете com.tutorialspoint.lucene .
LuceneConstants.java
Этот класс используется для предоставления различных констант, которые будут использоваться в приложении-образце.
package com.tutorialspoint.lucene; public class LuceneConstants { public static final String CONTENTS = "contents"; public static final String FILE_NAME = "filename"; public static final String FILE_PATH = "filepath"; public static final int MAX_SEARCH = 10; }
TextFileFilter.java
Этот класс используется как фильтр файлов .txt .
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
Indexer.java
Этот класс используется для индексации необработанных данных, чтобы мы могли сделать их доступными для поиска с помощью библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException { //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException { writer.close(); } private Document getDocument(File file) throws IOException { Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(),Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(),Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException { System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException { //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); } }
Searcher.java
Этот класс используется для поиска в индексах, созданных индексатором, для поиска запрошенного содержимого.
package com.tutorialspoint.lucene; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException { Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException { query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException { return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException { indexSearcher.close(); } }
LuceneTester.java
Этот класс используется для проверки возможности индексации и поиска в библиотеке lucene.
package com.tutorialspoint.lucene; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void createIndex() throws IOException { indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); } private void search(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime)); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: " + doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } }
Шаг 4 — Создание каталога данных и индекса
Мы использовали 10 текстовых файлов от record1.txt до record10.txt, содержащих имена и другие сведения об учениках, и поместили их в каталог E: \ Lucene \ Data . Тестовые данные . Путь к каталогу индекса должен быть создан как E: \ Lucene \ Index . После запуска этой программы вы можете увидеть список индексных файлов, созданных в этой папке.
Шаг 5 — Запуск программы
Когда вы закончите с созданием источника, необработанных данных, каталога данных и каталога индекса, вы будете готовы к компиляции и запуску вашей программы. Для этого оставьте активную вкладку файла LuceneTester.Java активной и используйте либо опцию « Выполнить», доступную в Eclipse IDE, либо используйте Ctrl + F11 для компиляции и запуска приложения LuceneTester . Если приложение работает успешно, оно напечатает следующее сообщение в консоли Eclipse IDE —
Indexing E:\Lucene\Data\record1.txt Indexing E:\Lucene\Data\record10.txt Indexing E:\Lucene\Data\record2.txt Indexing E:\Lucene\Data\record3.txt Indexing E:\Lucene\Data\record4.txt Indexing E:\Lucene\Data\record5.txt Indexing E:\Lucene\Data\record6.txt Indexing E:\Lucene\Data\record7.txt Indexing E:\Lucene\Data\record8.txt Indexing E:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms 1 documents found. Time :0 File: E:\Lucene\Data\record4.txt
После того, как вы успешно запустите программу, у вас будет следующий контент в каталоге index —
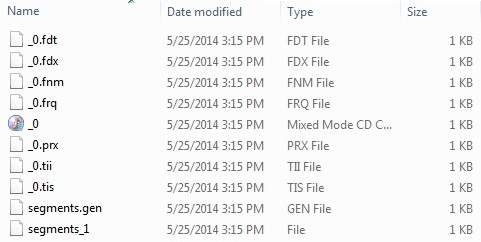
Lucene — Индексирование классов
Процесс индексирования является одной из основных функций, предоставляемых Lucene. Следующая диаграмма иллюстрирует процесс индексации и использование классов. IndexWriter является наиболее важным и ключевым компонентом процесса индексирования.
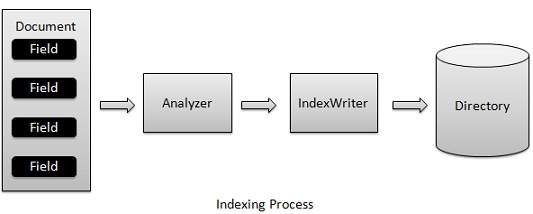
Мы добавляем Документ (ы), содержащий Поля (и), в IndexWriter, который анализирует Документ (ы) с помощью Анализатора, а затем создает / открывает / редактирует индексы по мере необходимости и сохраняет / обновляет их в Справочнике . IndexWriter используется для обновления или создания индексов. Он не используется для чтения индексов.
Индексирование классов
Ниже приведен список наиболее часто используемых классов в процессе индексирования.
| S.No. | Класс и описание |
|---|---|
| 1 | IndexWriter
Этот класс действует как основной компонент, который создает / обновляет индексы в процессе индексирования. |
| 2 | каталог
Этот класс представляет место хранения индексов. |
| 3 | анализатор
Этот класс отвечает за анализ документа и получение токенов / слов из текста, который нужно проиндексировать. Без анализа IndexWriter не может создать индекс. |
| 4 | Документ
Этот класс представляет собой виртуальный документ с полями, где поле — это объект, который может содержать содержимое физического документа, его метаданные и т. Д. Анализатор может понимать только Документ. |
| 5 | поле
Это самая низкая единица или начальная точка процесса индексации. Он представляет отношение пары «ключ-значение», в котором ключ используется для идентификации индексируемого значения. Предположим, что поле, используемое для представления содержимого документа, будет иметь ключ в качестве «содержимого», а значение может содержать часть или весь текст или числовое содержимое документа. Lucene может индексировать только текстовое или числовое содержимое. |
Этот класс действует как основной компонент, который создает / обновляет индексы в процессе индексирования.
Этот класс представляет место хранения индексов.
Этот класс отвечает за анализ документа и получение токенов / слов из текста, который нужно проиндексировать. Без анализа IndexWriter не может создать индекс.
Этот класс представляет собой виртуальный документ с полями, где поле — это объект, который может содержать содержимое физического документа, его метаданные и т. Д. Анализатор может понимать только Документ.
Это самая низкая единица или начальная точка процесса индексации. Он представляет отношение пары «ключ-значение», в котором ключ используется для идентификации индексируемого значения. Предположим, что поле, используемое для представления содержимого документа, будет иметь ключ в качестве «содержимого», а значение может содержать часть или весь текст или числовое содержимое документа. Lucene может индексировать только текстовое или числовое содержимое.
Lucene — Поиск классов
Процесс поиска снова является одной из основных функциональных возможностей, предоставляемых Lucene. Его поток похож на процесс индексации. Базовый поиск Lucene может быть выполнен с использованием следующих классов, которые также можно назвать базовыми классами для всех операций, связанных с поиском.
Поиск классов
Ниже приведен список наиболее часто используемых классов в процессе поиска.
| S.No. | Класс и описание |
|---|---|
| 1 | IndexSearcher
Этот класс действует как основной компонент, который читает / ищет индексы, созданные после процесса индексации. Требуется экземпляр каталога, указывающий на местоположение, содержащее индексы. |
| 2 | Срок
Этот класс является самой низкой единицей поиска. Это похоже на поле в процессе индексации. |
| 3 | запрос
Запрос является абстрактным классом, содержит различные служебные методы и является родителем всех типов запросов, которые Lucene использует в процессе поиска. |
| 4 | TermQuery
TermQuery является наиболее часто используемым объектом запросов и является основой многих сложных запросов, которые Lucene может использовать. |
| 5 | TopDocs
TopDocs указывает на первые N результатов поиска, которые соответствуют критериям поиска. Это простой контейнер указателей для указания на документы, которые являются результатом результатов поиска. |
Этот класс действует как основной компонент, который читает / ищет индексы, созданные после процесса индексации. Требуется экземпляр каталога, указывающий на местоположение, содержащее индексы.
Этот класс является самой низкой единицей поиска. Это похоже на поле в процессе индексации.
Запрос является абстрактным классом, содержит различные служебные методы и является родителем всех типов запросов, которые Lucene использует в процессе поиска.
TermQuery является наиболее часто используемым объектом запросов и является основой многих сложных запросов, которые Lucene может использовать.
TopDocs указывает на первые N результатов поиска, которые соответствуют критериям поиска. Это простой контейнер указателей для указания на документы, которые являются результатом результатов поиска.
Lucene — процесс индексации
Процесс индексирования является одной из основных функций, предоставляемых Lucene. Следующая диаграмма иллюстрирует процесс индексации и использование классов. IndexWriter является наиболее важным и ключевым компонентом процесса индексирования.
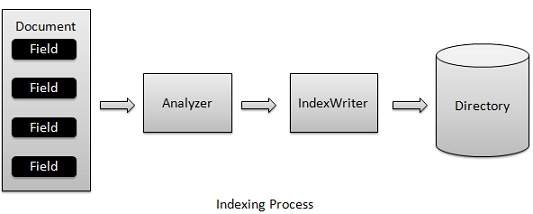
Мы добавляем Документ (ы), содержащий Поля (и), в IndexWriter, который анализирует Документ (ы) с помощью Анализатора, а затем создает / открывает / редактирует индексы по мере необходимости и сохраняет / обновляет их в Справочнике . IndexWriter используется для обновления или создания индексов. Он не используется для чтения индексов.
Теперь мы покажем вам пошаговый процесс, чтобы дать толчок к пониманию процесса индексации на базовом примере.
Создать документ
-
Создайте метод, чтобы получить документ Lucene из текстового файла.
-
Создайте различные типы полей, которые представляют собой пары «ключ-значение», содержащие ключи в качестве имен и значения в качестве содержимого для индексации.
-
Установить поле для анализа или нет. В нашем случае анализируется только содержимое, поскольку оно может содержать такие данные, как, am, are и т. Д., Которые не требуются в операциях поиска.
-
Добавьте вновь созданные поля в объект документа и верните его в метод вызывающей стороны.
Создайте метод, чтобы получить документ Lucene из текстового файла.
Создайте различные типы полей, которые представляют собой пары «ключ-значение», содержащие ключи в качестве имен и значения в качестве содержимого для индексации.
Установить поле для анализа или нет. В нашем случае анализируется только содержимое, поскольку оно может содержать такие данные, как, am, are и т. Д., Которые не требуются в операциях поиска.
Добавьте вновь созданные поля в объект документа и верните его в метод вызывающей стороны.
private Document getDocument(File file) throws IOException { Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; }
Создать IndexWriter
Класс IndexWriter действует как основной компонент, который создает / обновляет индексы в процессе индексирования. Выполните следующие шаги для создания IndexWriter —
Шаг 1 — Создать объект IndexWriter.
Шаг 2 — Создайте каталог Lucene, который должен указывать на место, где должны храниться индексы.
Шаг 3 — Инициализируйте объект IndexWriter, созданный с помощью каталога index, стандартного анализатора с информацией о версии и другими обязательными / дополнительными параметрами.
private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException { //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); }
Начать процесс индексации
Следующая программа показывает, как запустить процесс индексации:
private void indexFile(File file) throws IOException { System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); }
Пример приложения
Чтобы протестировать процесс индексации, нам нужно создать тест приложения Lucene.
| шаг | Описание |
|---|---|
| 1 |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс индексации. |
| 2 |
Создайте LuceneConstants.java, TextFileFilter.java и Indexer.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений. |
| 3 |
Создайте LuceneTester.java, как указано ниже. |
| 4 |
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями. |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс индексации.
Создайте LuceneConstants.java, TextFileFilter.java и Indexer.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений.
Создайте LuceneTester.java, как указано ниже.
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями.
LuceneConstants.java
Этот класс используется для предоставления различных констант, которые будут использоваться в приложении-образце.
package com.tutorialspoint.lucene; public class LuceneConstants { public static final String CONTENTS = "contents"; public static final String FILE_NAME = "filename"; public static final String FILE_PATH = "filepath"; public static final int MAX_SEARCH = 10; }
TextFileFilter.java
Этот класс используется как фильтр файлов .txt .
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
Indexer.java
Этот класс используется для индексации необработанных данных, чтобы мы могли сделать их доступными для поиска с помощью библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; import java.io.FileReader; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Indexer { private IndexWriter writer; public Indexer(String indexDirectoryPath) throws IOException { //this directory will contain the indexes Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); //create the indexer writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_36),true, IndexWriter.MaxFieldLength.UNLIMITED); } public void close() throws CorruptIndexException, IOException { writer.close(); } private Document getDocument(File file) throws IOException { Document document = new Document(); //index file contents Field contentField = new Field(LuceneConstants.CONTENTS, new FileReader(file)); //index file name Field fileNameField = new Field(LuceneConstants.FILE_NAME, file.getName(), Field.Store.YES,Field.Index.NOT_ANALYZED); //index file path Field filePathField = new Field(LuceneConstants.FILE_PATH, file.getCanonicalPath(), Field.Store.YES,Field.Index.NOT_ANALYZED); document.add(contentField); document.add(fileNameField); document.add(filePathField); return document; } private void indexFile(File file) throws IOException { System.out.println("Indexing "+file.getCanonicalPath()); Document document = getDocument(file); writer.addDocument(document); } public int createIndex(String dataDirPath, FileFilter filter) throws IOException { //get all files in the data directory File[] files = new File(dataDirPath).listFiles(); for (File file : files) { if(!file.isDirectory() && !file.isHidden() && file.exists() && file.canRead() && filter.accept(file) ){ indexFile(file); } } return writer.numDocs(); } }
LuceneTester.java
Этот класс используется для проверки возможности индексирования библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.IOException; public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.createIndex(); } catch (IOException e) { e.printStackTrace(); } } private void createIndex() throws IOException { indexer = new Indexer(indexDir); int numIndexed; long startTime = System.currentTimeMillis(); numIndexed = indexer.createIndex(dataDir, new TextFileFilter()); long endTime = System.currentTimeMillis(); indexer.close(); System.out.println(numIndexed+" File indexed, time taken: " +(endTime-startTime)+" ms"); } }
Создание каталога данных и индексов
Мы использовали 10 текстовых файлов от record1.txt до record10.txt, содержащих имена и другие сведения об учениках, и поместили их в каталог E: \ Lucene \ Data. Тестовые данные . Путь к каталогу индекса должен быть создан как E: \ Lucene \ Index . После запуска этой программы вы можете увидеть список индексных файлов, созданных в этой папке.
Запуск программы
Когда вы закончите с созданием источника, необработанных данных, каталога данных и каталога индекса, вы можете приступить к компиляции и запуску вашей программы. Для этого оставьте активную вкладку файла LuceneTester.Java активной и используйте либо опцию « Выполнить», доступную в Eclipse IDE, либо используйте Ctrl + F11 для компиляции и запуска приложения LuceneTester . Если ваше приложение работает успешно, оно напечатает следующее сообщение в консоли Eclipse IDE:
Indexing E:\Lucene\Data\record1.txt Indexing E:\Lucene\Data\record10.txt Indexing E:\Lucene\Data\record2.txt Indexing E:\Lucene\Data\record3.txt Indexing E:\Lucene\Data\record4.txt Indexing E:\Lucene\Data\record5.txt Indexing E:\Lucene\Data\record6.txt Indexing E:\Lucene\Data\record7.txt Indexing E:\Lucene\Data\record8.txt Indexing E:\Lucene\Data\record9.txt 10 File indexed, time taken: 109 ms
После того, как вы успешно запустите программу, у вас будет следующий контент в каталоге index —
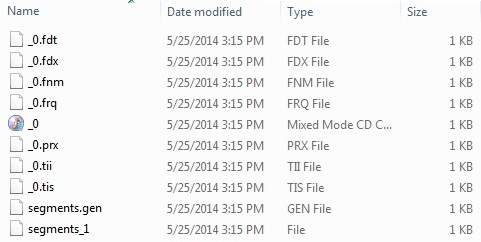
Lucene — индексирование операций
В этой главе мы обсудим четыре основные операции индексации. Эти операции полезны в разное время и используются в программном приложении для поиска.
Индексирование
Ниже приведен список часто используемых операций в процессе индексирования.
| S.No. | Операция и описание |
|---|---|
| 1 | Добавить документ
Эта операция используется на начальном этапе процесса индексирования для создания индексов для вновь доступного контента. |
| 2 | Обновить документ
Эта операция используется для обновления индексов для отражения изменений в обновленном содержимом. Это похоже на воссоздание индекса. |
| 3 | Удалить документ
Эта операция используется для обновления индексов, чтобы исключить документы, которые не требуется индексировать / искать. |
| 4 | Параметры поля
Параметры поля задают способ или управляют способами, которыми содержимое поля должно быть доступно для поиска. |
Эта операция используется на начальном этапе процесса индексирования для создания индексов для вновь доступного контента.
Эта операция используется для обновления индексов для отражения изменений в обновленном содержимом. Это похоже на воссоздание индекса.
Эта операция используется для обновления индексов, чтобы исключить документы, которые не требуется индексировать / искать.
Параметры поля задают способ или управляют способами, которыми содержимое поля должно быть доступно для поиска.
Lucene — поисковая операция
Процесс поиска является одной из основных функциональных возможностей, предоставляемых Lucene. Следующая диаграмма иллюстрирует процесс и его использование. IndexSearcher является одним из основных компонентов процесса поиска.
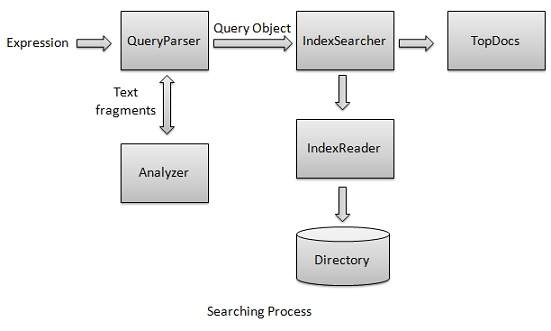
Сначала мы создаем каталог (и), содержащий индексы, а затем передаем его в IndexSearcher, который открывает каталог с помощью IndexReader . Затем мы создаем запрос с термином и выполняем поиск с использованием IndexSearcher , передавая запрос поисковику. IndexSearcher возвращает объект TopDocs, который содержит детали поиска вместе с идентификаторами документа, который является результатом операции поиска.
Теперь мы покажем вам пошаговый подход и поможем понять процесс индексации на простом примере.
Создать QueryParser
Класс QueryParser анализирует введенный пользователем ввод в запрос понятного формата Lucene. Выполните следующие шаги, чтобы создать QueryParser —
Шаг 1 — Создать объект QueryParser.
Шаг 2 — Инициализируйте объект QueryParser, созданный с помощью стандартного анализатора, имеющего информацию о версии и имя индекса, для которого должен выполняться этот запрос.
QueryParser queryParser; public Searcher(String indexDirectoryPath) throws IOException { queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); }
Создать IndexSearcher
Класс IndexSearcher выступает в качестве основного компонента, который индексирует поисковый индекс, созданный в процессе индексирования. Выполните следующие шаги для создания IndexSearcher —
Шаг 1 — Создать объект IndexSearcher.
Шаг 2 — Создайте каталог Lucene, который должен указывать на место, где должны храниться индексы.
Шаг 3 — Инициализируйте объект IndexSearcher, созданный с помощью каталога index.
IndexSearcher indexSearcher; public Searcher(String indexDirectoryPath) throws IOException { Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); }
Сделать поиск
Выполните следующие шаги, чтобы сделать поиск —
Шаг 1 — Создайте объект Query, анализируя поисковое выражение через QueryParser.
Шаг 2 — Выполните поиск, вызвав метод IndexSearcher.search ().
Query query; public TopDocs search( String searchQuery) throws IOException, ParseException { query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); }
Получить документ
Следующая программа показывает, как получить документ.
public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException { return indexSearcher.doc(scoreDoc.doc); }
Закрыть IndexSearcher
Следующая программа показывает, как закрыть IndexSearcher.
public void close() throws IOException { indexSearcher.close(); }
Пример приложения
Давайте создадим тестовое приложение Lucene для тестирования процесса поиска.
| шаг | Описание |
|---|---|
| 1 |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс поиска. |
| 2 |
Создайте LuceneConstants.java, TextFileFilter.java и Searcher.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений. |
| 3 |
Создайте LuceneTester.java, как указано ниже. |
| 4 |
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями. |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс поиска.
Создайте LuceneConstants.java, TextFileFilter.java и Searcher.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений.
Создайте LuceneTester.java, как указано ниже.
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями.
LuceneConstants.java
Этот класс используется для предоставления различных констант, которые будут использоваться в приложении-образце.
package com.tutorialspoint.lucene; public class LuceneConstants { public static final String CONTENTS = "contents"; public static final String FILE_NAME = "filename"; public static final String FILE_PATH = "filepath"; public static final int MAX_SEARCH = 10; }
TextFileFilter.java
Этот класс используется как фильтр файлов .txt .
package com.tutorialspoint.lucene; import java.io.File; import java.io.FileFilter; public class TextFileFilter implements FileFilter { @Override public boolean accept(File pathname) { return pathname.getName().toLowerCase().endsWith(".txt"); } }
Searcher.java
Этот класс используется для чтения индексов, созданных на необработанных данных, и поиска данных с использованием библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException { Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException { query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException { return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException { indexSearcher.close(); } }
LuceneTester.java
Этот класс используется для проверки возможности поиска библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.search("Mohan"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void search(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); TopDocs hits = searcher.search(searchQuery); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) +" ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } }
Создание каталога данных и индексов
Мы использовали 10 текстовых файлов с именем record1.txt для record10.txt, содержащих имена и другие сведения об учениках, и поместили их в каталог E: \ Lucene \ Data. Тестовые данные . Путь к каталогу индекса должен быть создан как E: \ Lucene \ Index. После запуска программы индексирования в главе Lucene — Процесс индексирования вы можете увидеть список индексных файлов, созданных в этой папке.
Запуск программы
Как только вы закончите с созданием источника, необработанных данных, каталога данных, каталога индекса и индексов, вы можете приступить к компиляции и запуску вашей программы. Для этого оставьте активную вкладку файла LuceneTester.Java активной и используйте либо опцию «Выполнить», доступную в Eclipse IDE, либо используйте Ctrl + F11 для компиляции и запуска приложения LuceneTesterapplication . Если ваше приложение работает успешно, оно напечатает следующее сообщение в консоли Eclipse IDE:
1 documents found. Time :29 ms File: E:\Lucene\Data\record4.txt
Lucene — Программирование запросов
Мы видели в предыдущей главе Lucene — Операция поиска , Lucene использует IndexSearcher для поиска и использует объект Query, созданный QueryParser в качестве входных данных. В этой главе мы собираемся обсудить различные типы объектов Query и различные способы их программного создания. Создание различных типов объектов Query дает контроль над типом поиска, который будет выполнен.
Рассмотрим случай расширенного поиска, предоставляемого многими приложениями, где пользователям предоставляется несколько вариантов ограничения результатов поиска. С помощью программирования запросов мы можем достичь того же самого очень легко.
Ниже приведен список типов запросов, которые мы обсудим в свое время.
| S.No. | Класс и описание |
|---|---|
| 1 | TermQuery
Этот класс действует как основной компонент, который создает / обновляет индексы в процессе индексирования. |
| 2 | TermRangeQuery
TermRangeQuery используется, когда нужно найти диапазон текстовых терминов. |
| 3 | PrefixQuery
PrefixQuery используется для сопоставления документов, индекс которых начинается с указанной строки. |
| 4 | BooleanQuery
BooleanQuery используется для поиска документов, которые являются результатом нескольких запросов с использованием операторов AND, OR или NOT . |
| 5 | PhraseQuery
Фразовый запрос используется для поиска документов, которые содержат определенную последовательность терминов. |
| 6 | WildCardQuery
WildcardQuery используется для поиска документов с использованием подстановочных знаков, таких как ‘*’ для любой последовательности символов? соответствие одному символу. |
| 7 | FuzzyQuery
FuzzyQuery используется для поиска документов с использованием нечеткой реализации, которая является приблизительным поиском, основанным на алгоритме расстояния редактирования. |
| 8 | MatchAllDocsQuery
MatchAllDocsQuery, как следует из названия, соответствует всем документам. |
Этот класс действует как основной компонент, который создает / обновляет индексы в процессе индексирования.
TermRangeQuery используется, когда нужно найти диапазон текстовых терминов.
PrefixQuery используется для сопоставления документов, индекс которых начинается с указанной строки.
BooleanQuery используется для поиска документов, которые являются результатом нескольких запросов с использованием операторов AND, OR или NOT .
Фразовый запрос используется для поиска документов, которые содержат определенную последовательность терминов.
WildcardQuery используется для поиска документов с использованием подстановочных знаков, таких как ‘*’ для любой последовательности символов? соответствие одному символу.
FuzzyQuery используется для поиска документов с использованием нечеткой реализации, которая является приблизительным поиском, основанным на алгоритме расстояния редактирования.
MatchAllDocsQuery, как следует из названия, соответствует всем документам.
Люцен — Анализ
В одной из наших предыдущих глав мы видели, что Lucene использует IndexWriter для анализа документов с использованием анализатора, а затем создает / открывает / редактирует индексы по мере необходимости. В этой главе мы собираемся обсудить различные типы объектов Analyzer и другие соответствующие объекты, которые используются в процессе анализа. Понимание процесса анализа и работы анализаторов поможет вам лучше понять, как Lucene индексирует документы.
Ниже приведен список объектов, которые мы обсудим в свое время.
| S.No. | Класс и описание |
|---|---|
| 1 | знак
Токен представляет текст или слово в документе с соответствующими деталями, такими как его метаданные (позиция, начальное смещение, конечное смещение, тип токена и приращение его позиции). |
| 2 | TokenStream
TokenStream является результатом процесса анализа и состоит из серии токенов. Это абстрактный класс. |
| 3 | анализатор
Это абстрактный базовый класс для каждого типа анализатора. |
| 4 | WhitespaceAnalyzer
Этот анализатор разбивает текст в документе на основе пробелов. |
| 5 | SimpleAnalyzer
Этот анализатор разбивает текст в документе на основе буквенных символов и помещает текст в нижний регистр. |
| 6 | StopAnalyzer
Этот анализатор работает так же, как SimpleAnalyzer и удаляет общие слова, такие как «a», «an», «the» и т. Д. |
| 7 | StandardAnalyzer
Это самый сложный анализатор, способный обрабатывать имена, адреса электронной почты и т. Д. Он записывает каждый токен в нижнем регистре и удаляет общие слова и знаки препинания, если таковые имеются. |
Токен представляет текст или слово в документе с соответствующими деталями, такими как его метаданные (позиция, начальное смещение, конечное смещение, тип токена и приращение его позиции).
TokenStream является результатом процесса анализа и состоит из серии токенов. Это абстрактный класс.
Это абстрактный базовый класс для каждого типа анализатора.
Этот анализатор разбивает текст в документе на основе пробелов.
Этот анализатор разбивает текст в документе на основе буквенных символов и помещает текст в нижний регистр.
Этот анализатор работает так же, как SimpleAnalyzer и удаляет общие слова, такие как «a», «an», «the» и т. Д.
Это самый сложный анализатор, способный обрабатывать имена, адреса электронной почты и т. Д. Он записывает каждый токен в нижнем регистре и удаляет общие слова и знаки препинания, если таковые имеются.
Люцен — сортировка
В этой главе мы рассмотрим порядок сортировки, в котором Lucene выдает результаты поиска по умолчанию или может изменяться по мере необходимости.
Сортировка по релевантности
Это режим сортировки по умолчанию, используемый Lucene. Lucene предоставляет результаты по наиболее значимому попаданию сверху.
private void sortUsingRelevance(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.RELEVANCE); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }
Сортировка по IndexOrder
Этот режим сортировки используется Lucene. Здесь первый проиндексированный документ отображается первым в результатах поиска.
private void sortUsingIndex(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.INDEXORDER); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); }
Пример приложения
Давайте создадим тестовое приложение Lucene для проверки процесса сортировки.
| шаг | Описание |
|---|---|
| 1 |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс поиска. |
| 2 |
Создайте LuceneConstants.java и Searcher.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений. |
| 3 |
Создайте LuceneTester.java, как указано ниже. |
| 4 |
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями. |
Создайте проект с именем LuceneFirstApplication в пакете com.tutorialspoint.lucene, как описано в главе « Lucene — First Application» . Вы также можете использовать проект, созданный в главе Lucene — First Application как таковой для этой главы, чтобы понять процесс поиска.
Создайте LuceneConstants.java и Searcher.java, как описано в главе « Lucene — Первое приложение» . Оставьте остальные файлы без изменений.
Создайте LuceneTester.java, как указано ниже.
Очистите и создайте приложение, чтобы убедиться, что бизнес-логика работает в соответствии с требованиями.
LuceneConstants.java
Этот класс используется для предоставления различных констант, которые будут использоваться в приложении-образце.
package com.tutorialspoint.lucene; public class LuceneConstants { public static final String CONTENTS = "contents"; public static final String FILE_NAME = "filename"; public static final String FILE_PATH = "filepath"; public static final int MAX_SEARCH = 10; }
Searcher.java
Этот класс используется для чтения индексов, созданных на необработанных данных, и поиска данных с использованием библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.File; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.Sort; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.util.Version; public class Searcher { IndexSearcher indexSearcher; QueryParser queryParser; Query query; public Searcher(String indexDirectoryPath) throws IOException { Directory indexDirectory = FSDirectory.open(new File(indexDirectoryPath)); indexSearcher = new IndexSearcher(indexDirectory); queryParser = new QueryParser(Version.LUCENE_36, LuceneConstants.CONTENTS, new StandardAnalyzer(Version.LUCENE_36)); } public TopDocs search( String searchQuery) throws IOException, ParseException { query = queryParser.parse(searchQuery); return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query) throws IOException, ParseException { return indexSearcher.search(query, LuceneConstants.MAX_SEARCH); } public TopDocs search(Query query,Sort sort) throws IOException, ParseException { return indexSearcher.search(query, LuceneConstants.MAX_SEARCH,sort); } public void setDefaultFieldSortScoring(boolean doTrackScores, boolean doMaxScores) { indexSearcher.setDefaultFieldSortScoring( doTrackScores,doMaxScores); } public Document getDocument(ScoreDoc scoreDoc) throws CorruptIndexException, IOException { return indexSearcher.doc(scoreDoc.doc); } public void close() throws IOException { indexSearcher.close(); } }
LuceneTester.java
Этот класс используется для проверки возможности поиска библиотеки Lucene.
package com.tutorialspoint.lucene; import java.io.IOException; import org.apache.lucene.document.Document; import org.apache.lucene.index.Term; import org.apache.lucene.queryParser.ParseException; import org.apache.lucene.search.FuzzyQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.Sort; import org.apache.lucene.search.TopDocs; public class LuceneTester { String indexDir = "E:\\Lucene\\Index"; String dataDir = "E:\\Lucene\\Data"; Indexer indexer; Searcher searcher; public static void main(String[] args) { LuceneTester tester; try { tester = new LuceneTester(); tester.sortUsingRelevance("cord3.txt"); tester.sortUsingIndex("cord3.txt"); } catch (IOException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } private void sortUsingRelevance(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.RELEVANCE); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } private void sortUsingIndex(String searchQuery) throws IOException, ParseException { searcher = new Searcher(indexDir); long startTime = System.currentTimeMillis(); //create a term to search file name Term term = new Term(LuceneConstants.FILE_NAME, searchQuery); //create the term query object Query query = new FuzzyQuery(term); searcher.setDefaultFieldSortScoring(true, false); //do the search TopDocs hits = searcher.search(query,Sort.INDEXORDER); long endTime = System.currentTimeMillis(); System.out.println(hits.totalHits + " documents found. Time :" + (endTime - startTime) + "ms"); for(ScoreDoc scoreDoc : hits.scoreDocs) { Document doc = searcher.getDocument(scoreDoc); System.out.print("Score: "+ scoreDoc.score + " "); System.out.println("File: "+ doc.get(LuceneConstants.FILE_PATH)); } searcher.close(); } }
Создание каталога данных и индексов
Мы использовали 10 текстовых файлов от record1.txt до record10.txt, содержащих имена и другие сведения об учениках, и поместили их в каталог E: \ Lucene \ Data. Тестовые данные . Путь к каталогу индекса должен быть создан как E: \ Lucene \ Index. После запуска программы индексирования в главе Lucene — Процесс индексирования вы можете увидеть список индексных файлов, созданных в этой папке.
Запуск программы
Как только вы закончите с созданием источника, необработанных данных, каталога данных, каталога индекса и индексов, вы можете скомпилировать и запустить вашу программу. Для этого сохраните активную вкладку файла LuceneTester.Java и используйте либо параметр «Выполнить», доступный в Eclipse IDE, либо используйте Ctrl + F11 для компиляции и запуска приложения LuceneTester . Если ваше приложение работает успешно, оно напечатает следующее сообщение в консоли Eclipse IDE: