В JasperReports для работы с текстами требуются специальные инструменты для обработки как символьных представлений, так и свойств форматирования текста. Любой текст можно рассматривать как последовательность символов с определенной структурой представления. Внешний вид текста состоит как из макета (и абзаца), так и из настроек шрифта. Но хотя в большинстве случаев текстовая разметка остается неизменной, настройки шрифта могут измениться при запуске отчета в разных локалях.
Мы знаем, что разные языки нуждаются в разных наборах символов для представления определенных символов. Поэтому работа с текстами означает работу со шрифтами. Однако подробное обсуждение того, как использовать шрифты в JasperReports, доступно в главе « Шрифты отчета» .
Одной из основных особенностей, касающихся текстового содержания в данном отчете, является возможность его интернационализации. Это означает, что мы можем запустить отчет в разных локализованных средах, используя разные языки и другие настройки локализации, без каких-либо жестко запрограммированных изменений. Кодировка символов является важной функцией, когда отчет предназначен для интернационализации.
Кодировка символов
Персонаж — это наименьшая единица письма, передающая значимую информацию. Это абстрактное понятие, персонаж не имеет визуального облика. «Прописная латинская буква A» отличается от «строчной латинской буквы a» и от «заглавной кириллицы A» и «заглавной греческой альфы».
Визуальное представление персонажа называется глифом . Определенный набор глифов называется шрифтом . «Прописные латинские буквы A», «Прописные кириллицы A» и «Прописные буквы греческого алфавита» могут иметь одинаковые глифы, но это разные символы. В то же время глифы для «заглавной латинской буквы A» могут выглядеть очень по-разному в Times New Roman, Gill Sans и Poetica канцелярском курсиве, но они по-прежнему представляют один и тот же символ.
Набор доступных символов называется репертуаром символов . Местоположение (индекс) данного символа в репертуаре называется его позицией кода или кодовой точкой. Метод численного представления кодовой точки в данном репертуаре называется кодировкой символов .
Кодировки обычно выражаются в октетах. Октет — это группа из восьми двоичных цифр, т. Е. Восьми единиц и нулей. Октет может выражать числовой диапазон от 0 до 255 или от 0x00 до 0xFF, чтобы использовать шестнадцатеричное представление.
Unicode
Юникод — это репертуар персонажей, который содержит большинство символов, используемых на языках мира. Он может вместить миллионы символов, и уже содержит сотни тысяч. Юникод делится на «плоскости» по 64К символов. В большинстве случаев используется только первый план, известный как базовый многоязычный план, или BMP.
UTF-8 является рекомендуемой кодировкой. Он использует переменное количество октетов для представления различных символов.
В файле JRXML атрибут кодировки указывается в заголовке. Он используется во время составления отчета для декодирования содержимого XML. Например, если отчет содержит только французские слова и такие символы, как ç, é, â, то достаточно кодировки ISO-8859-1 (aka Latin-1) —
<?xml version = "1.0" encoding = "ISO-8859-1"?>
Как видно выше, в идеале мы можем выбрать кодировку, подходящую для минимального набора символов, который может правильно представлять все символы в документе. Но в случае мультиязычных документов (т. Е. Документов, содержащих слова, написанные на нескольких языках), следует выбирать кодировку, адаптированную к минимальному набору символов, способную правильно представлять все символы в документе, даже если они принадлежат разным языкам. Одной из кодировок символов, способных обрабатывать многоязычные документы, является UTF-8 , используемый JasperReports в качестве значения кодировки по умолчанию.
Тексты обычно хранятся в файлах комплекта ресурсов, а не в документе во время интернационализации. Таким образом, бывают случаи, когда сам JRXML выглядит полностью ASCII-совместимым, но сгенерированные отчеты во время выполнения содержат тексты, которые невозможно прочитать с помощью ASCII. В результате для определенного типа форматов экспорта документов (таких как CSV, HTML, XHTML, XML и текст) необходимо знать кодировку для сгенерированного документа. Различные языки поддерживаются разными кодировками символов. Поэтому каждый раз нам нужно запускать отчет в локализованной среде. Далее, мы должны знать, какая кодировка символов наиболее подходит для сгенерированного языка документа. В этом случае свойство кодирования, определенное в самом файле JRXML, может быть более бесполезным.
Для решения такого рода проблем мы можем использовать свойство клиента экспорта, известное как net.sf.jasperreports.export.character.encoding . Это пользовательское свойство экспорта по умолчанию — UTF-8 и присутствует в JasperReports.
Это значение по умолчанию устанавливается в файле default.jasperreports.properties . Для более конкретных параметров во время экспорта также доступен параметр экспорта CHARACTER_ENCODING.
пример
Чтобы продемонстрировать использование поддержки юникода в Jasperreports, давайте напишем новый шаблон отчета (jasper_report_template.jrxml). Сохраните его в каталоге C: \ tools \ jasperreports-5.0.1 \ test . Здесь мы будем отображать текст на разных языках, используя символы Unicode (\ uXXXX). Любой символ, закодированный с помощью UTF-8, может быть представлен только с использованием его четырехзначного шестнадцатеричного кода. Например, греческая буква Γ может быть записана как \ u0393. Когда встречаются такие обозначения, механизм вызывает соответствующее представление символов в наборе символов, и будет распечатан только этот конкретный символ. Содержимое JRXML приведено ниже:
<?xml version = "1.0" encoding = "UTF-8"?> <jasperReport xmlns = "http://jasperreports.sourceforge.net/jasperreports" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://jasperreports.sourceforge.net/jasperreports http://jasperreports.sourceforge.net/xsd/jasperreport.xsd" name = "jasper_report_template" language = "groovy" pageWidth = "595" pageHeight = "842" columnWidth = "555" leftMargin = "20" rightMargin = "20" topMargin = "20" bottomMargin = "20"> <parameter name = "GreekText" class = "java.lang.String" isForPrompting = "false"> <defaultValueExpression><![CDATA["\u0394\u03B5\u03BD "+ "\u03BA\u03B1\u03C4\u03B1\u03BB\u03B1\u03B2\u03B1\u03AF"+ "\u03BD\u03C9 \u0395\u03BB\u03BB\u03B7\u03BD\u03B9\u03BA\u03AC"]]> </defaultValueExpression> </parameter> <parameter name = "CyrillicText" class = "java.lang.String" isForPrompting = "false"> <defaultValueExpression><![CDATA["\u042F \u043D\u0435 "+ "\u043C\u043E\u0433\u0443 \u043F\u043E\u043D\u044F\u0442\u044C "+ "\u0433\u0440\u0435\u0447\u0435\u0441\u043A\u0438\u0439"]]> </defaultValueExpression> </parameter> <parameter name = "ArabicText" class = "java.lang.String" isForPrompting = "false"> <defaultValueExpression><![CDATA["\u0627\u0646\u0646\u0649 \u0644\u0627 "+ "\u0627\u0641\u0647\u0645 \u0627\u0644\u0644\u063A\u0629 "+ "\u0627\u0644\u0639\u0631\u0628\u064A\u0629"]]> </defaultValueExpression> </parameter> <parameter name = "HebrewText" class = "java.lang.String" isForPrompting = "false"> <defaultValueExpression><![CDATA["\u05D0\u05E0\u05D9 \u05DC\u05D0 "+ "\u05DE\u05D1\u05D9\u05DF \u05E2\u05D1\u05E8\u05D9\u05EA"]]> </defaultValueExpression> </parameter> <title> <band height = "782"> <textField> <reportElement x = "0" y = "50" width = "200" height = "60"/> <textElement> <font fontName = "DejaVu Sans" size = "14"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{GreekText} + "\n" + $P{CyrillicText}]]> </textFieldExpression> </textField> <staticText> <reportElement x = "210" y = "50" width = "340" height = "60"/> <textElement/> <text> <![CDATA["GreekText and CyrillicText"]]> </text> </staticText> <textField> <reportElement x = "0" y = "120" width = "200" height = "60"/> <textElement> <font fontName = "DejaVu Sans" size = "14" isBold = "true"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{GreekText} + "\n" + $P{CyrillicText}]]> </textFieldExpression> </textField> <staticText> <reportElement x = "210" y = "120" width = "340" height = "60"/> <textElement/> <text><![CDATA["GreekText and CyrillicText"]]></text> </staticText> <textField> <reportElement x = "0" y = "190" width = "200" height = "60"/> <textElement> <font fontName = "DejaVu Sans" size = "14" isItalic = "true" isUnderline = "true"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{GreekText} + "\n" + $P{CyrillicText}]]> </textFieldExpression> </textField> <staticText> <reportElement x = "210" y = "190" width = "340" height = "60"/> <textElement/> <text><![CDATA["GreekText and CyrillicText"]]></text> </staticText> <textField> <reportElement x = "0" y = "260" width = "200" height = "60"/> <textElement> <font fontName = "DejaVu Sans" size = "14" isBold = "true" isItalic = "true" isUnderline = "true"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{GreekText} + "\n" + $P{CyrillicText}]]> </textFieldExpression> </textField> <staticText> <reportElement x = "210" y = "260" width = "340" height = "60"/> <textElement/> <text><![CDATA["GreekText and CyrillicText"]]></text> </staticText> <textField> <reportElement x = "0" y = "330" width = "200" height = "60"/> <textElement textAlignment = "Right"> <font fontName="DejaVu Sans" size = "22"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{ArabicText}]]> </textFieldExpression> </textField> <textField> <reportElement x = "210" y = "330" width = "340" height = "60"/> <textElement textAlignment = "Right"> <font fontName = "DejaVu Sans" size = "22"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{HebrewText}]]> </textFieldExpression> </textField> </band> </title> </jasperReport>
В приведенном выше файле мы видим наличие кодировки UTF-8. Также локализованные фрагменты текста Unicode хранятся в параметрах документа.
Код Java для заполнения и генерации отчета, как показано ниже. Давайте сохраним этот файл JasperUnicodeReportFill.java в каталоге C: \ tools \ jasperreports-5.0.1 \ test \ src \ com \ tutorialspoint.
package com.tutorialspoint; import net.sf.jasperreports.engine.JREmptyDataSource; import net.sf.jasperreports.engine.JRException; import net.sf.jasperreports.engine.JasperFillManager; public class JasperUnicodeReportFill { public static void main(String[] args) { String sourceFileName ="C://tools/jasperreports-5.0.1/test/" + "jasper_report_template.jasper"; try { JasperFillManager.fillReportToFile(sourceFileName, null, new JREmptyDataSource()); } catch (JRException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
Здесь мы используем экземпляр JREmptyDataSource при заполнении отчетов для имитации источника данных с одной записью в нем, но со всеми полями в этой единственной записи, равными NULL .
Генерация отчетов
Мы скомпилируем и выполним вышеуказанный файл, используя наш обычный процесс сборки ANT. Содержимое файла build.xml (сохраненного в каталоге C: \ tools \ jasperreports-5.0.1 \ test) приведено ниже.
Файл импорта — baseBuild.xml выбирается из главы « Настройка среды» и должен быть расположен в том же каталоге, что и build.xml.
<?xml version = "1.0" encoding = "UTF-8"?> <project name = "JasperReportTest" default = "viewFillReport" basedir = "."> <import file = "baseBuild.xml" /> <target name = "viewFillReport" depends = "compile,compilereportdesing,run" description = "Launches the report viewer to preview the report stored in the .JRprint file."> <java classname = "net.sf.jasperreports.view.JasperViewer" fork = "true"> <arg value = "-F${file.name}.JRprint" /> <classpath refid = "classpath" /> </java> </target> <target name = "compilereportdesing" description = "Compiles the JXML file and produces the .jasper file."> <taskdef name = "jrc" classname = "net.sf.jasperreports.ant.JRAntCompileTask"> <classpath refid = "classpath" /> </taskdef> <jrc destdir = "."> <src> <fileset dir = "."> <include name = "*.jrxml" /> </fileset> </src> <classpath refid = "classpath" /> </jrc> </target> </project>
Далее, давайте откроем окно командной строки и перейдем в каталог, где находится build.xml. Наконец, выполните команду ant -Dmain-class = com.tutorialspoint.JasperUnicodeReportFill (viewFullReport является целью по умолчанию) следующим образом:
C:\tools\jasperreports-5.0.1\test>ant -Dmain-class=com.tutorialspoint.JasperUnicodeReportFill Buildfile: C:\tools\jasperreports-5.0.1\test\build.xml clean-sample: [delete] Deleting directory C:\tools\jasperreports-5.0.1\test\classes [delete] Deleting: C:\tools\jasperreports-5.0.1\test\jasper_report_template.jasper [delete] Deleting: C:\tools\jasperreports-5.0.1\test\jasper_report_template.jrprint compile: [mkdir] Created dir: C:\tools\jasperreports-5.0.1\test\classes [javac] C:\tools\jasperreports-5.0.1\test\baseBuild.xml:28: warning: 'includeantruntime' was not set, defaulting t [javac] Compiling 1 source file to C:\tools\jasperreports-5.0.1\test\classes compilereportdesing: [jrc] Compiling 1 report design files. [jrc] log4j:WARN No appenders could be found for logger (net.sf.jasperreports.engine.xml.JRXmlDigesterFactory). [jrc] log4j:WARN Please initialize the log4j system properly. [jrc] log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. [jrc] File : C:\tools\jasperreports-5.0.1\test\jasper_report_template.jrxml ... OK. run: [echo] Runnin class : com.tutorialspoint.JasperUnicodeReportFill [java] log4j:WARN No appenders could be found for logger (net.sf.jasperreports.extensions.ExtensionsEnvironment). [java] log4j:WARN Please initialize the log4j system properly. viewFillReport: [java] log4j:WARN No appenders could be found for logger (net.sf.jasperreports.extensions.ExtensionsEnvironment). [java] log4j:WARN Please initialize the log4j system properly. BUILD SUCCESSFUL Total time: 4 minutes 1 second
В результате вышеупомянутой компиляции открывается окно JasperViewer, как показано на приведенном ниже экране —
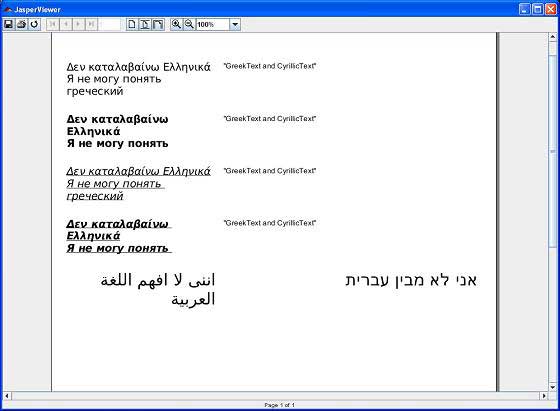
Здесь мы видим, что текст отображается на разных языках. Также мы видим, что языки сгруппированы на одной странице и также смешаны в один и тот же текстовый элемент.