Кросс-таблицы (кросс-табулирования) — это отчеты, содержащие таблицы, в которых данные располагаются по строкам и столбцам в табличной форме. Объект кросс-таблицы используется для вставки отчета кросс-таблицы в основной отчет. Кросс-таблицы могут использоваться с любым уровнем данных (номинальным, порядковым, интервальным или относительным) и обычно отображать обобщенные данные, содержащиеся в переменных отчета, в форме динамической таблицы. Переменные используются для отображения агрегированных данных, таких как суммы, числа, средние значения.
Crosstab Properties
Элемент JRXML <crosstab> используется для вставки кросс-таблицы в отчет.
атрибут
Ниже приведен список атрибутов элемента < crosstab > —
-
isRepeatColumnHeaders — указывает, следует ли перепечатывать заголовки столбцов после разрыва страницы. Значением по умолчанию является true .
-
isRepeatRowHeaders — указывает, следует ли перепечатывать заголовки строк после разрыва столбца кросс-таблицы. Значением по умолчанию является true .
-
columnBreakOffset — Когда происходит разрыв столбца, указывает количество вертикального пространства, измеренное в пикселях, перед тем, как последующий фрагмент кросс-таблицы будет размещен ниже предыдущего на той же странице. Значение по умолчанию 10.
-
runDirection — указывает, должны ли данные кросс- таблицы заполняться слева направо (LTR) или справа налево (RTL). Значением по умолчанию является LTR.
-
ignoreWidth — указывает, будет ли кросс- таблица расширяться за пределы начального предела ширины кросс- таблицы , и не будет ли разрывов столбцов. В противном случае он остановит рендеринг столбцов в пределах ширины кросс-таблицы и продолжит работу с оставшимися столбцами только после того, как все строки начнут рендеринг. Значением по умолчанию является false .
isRepeatColumnHeaders — указывает, следует ли перепечатывать заголовки столбцов после разрыва страницы. Значением по умолчанию является true .
isRepeatRowHeaders — указывает, следует ли перепечатывать заголовки строк после разрыва столбца кросс-таблицы. Значением по умолчанию является true .
columnBreakOffset — Когда происходит разрыв столбца, указывает количество вертикального пространства, измеренное в пикселях, перед тем, как последующий фрагмент кросс-таблицы будет размещен ниже предыдущего на той же странице. Значение по умолчанию 10.
runDirection — указывает, должны ли данные кросс- таблицы заполняться слева направо (LTR) или справа налево (RTL). Значением по умолчанию является LTR.
ignoreWidth — указывает, будет ли кросс- таблица расширяться за пределы начального предела ширины кросс- таблицы , и не будет ли разрывов столбцов. В противном случае он остановит рендеринг столбцов в пределах ширины кросс-таблицы и продолжит работу с оставшимися столбцами только после того, как все строки начнут рендеринг. Значением по умолчанию является false .
Подэлементы
Элемент <crosstab> имеет следующие подэлементы —
-
<reportElement> — этот элемент определяет положение, ширину и высоту кросс-таблицы внутри ее вложения. Атрибуты для этого элемента включают все стандартные атрибуты <reportElement>.
-
<crosstabParameter> — этот элемент используется для доступа к переменным и параметрам отчета из кросс-таблицы. Атрибуты для этого элемента включают —
-
name — определяет имя параметра
-
класс — указывает класс параметров.
-
-
<parametersMapExpression> — Этот элемент используется для передачи переменной отчета или параметра, содержащего экземпляр java.util.Map , в качестве набора параметров для кросс-таблицы. Этот элемент не содержит атрибутов.
-
<crosstabDataset> — этот элемент определяет набор данных, который будет использоваться для заполнения кросс-таблицы (подробное объяснение см. в следующем разделе). Атрибуты для этого элемента включают —
-
isDataPreSorted — указывает, предварительно ли отсортированы данные в наборе данных. Значением по умолчанию является false .
-
-
<crosstabHeaderCell> — этот элемент определяет содержимое области, найденной в верхнем левом углу кросс-таблицы, где встречаются заголовки столбцов и строки. Размер этой ячейки вычисляется автоматически на основе определенной ширины и высоты строки и столбца.
-
<rowGroup> — этот элемент определяет группу, используемую для разделения данных на строки. Атрибуты для этого элемента включают —
-
name — определяет имя группы строк.
-
ширина — это определяет ширину группы строк.
-
headerPosition — определяет позицию содержимого заголовка (Top, Middle, Bottom, Stretch).
-
totalPosition — определяет позицию всего столбца (Start, End, None).
Этот элемент содержит следующие подэлементы —
-
<Ковш>
-
<crosstabRowHeader>
-
<crosstabTotalRowHeader>
-
-
<columnGroup> — этот элемент определяет группу, используемую для разделения данных на столбцы. Атрибуты для этого элемента включают —
-
name — определяет имя группы столбцов.
-
высота — определяет высоту заголовка группы столбцов.
-
headerPosition — определяет позицию содержимого заголовка ( Right, Left, Center, Stretch ).
-
totalPosition — определяет позицию всего столбца ( Start, End, None ).
Этот элемент содержит следующие подэлементы —
-
<Ковш>
-
<crosstabColumnHeader>
-
<crosstabTotalColumnHeader>
-
-
<measure> — этот элемент определяет вычисление, которое будет выполняться по строкам и столбцам. Атрибуты для этого элемента включают —
-
имя — это определяет имя меры.
-
класс — указывает класс меры.
-
вычисление — указывает, какое вычисление должно выполняться между значениями ячейки кросс-таблицы. Его значения могут быть любыми из следующих: Ничего, Счетчик, DistinctCount, Сумма, Среднее, Минимальное, Максимальное, Стандартное отклонение, Дисперсия и Первое . Значением по умолчанию является Ничто .
-
-
<crosstabCell> — этот элемент определяет способ размещения данных в ячейках без заголовка. Атрибуты для этого элемента включают —
-
columnTotalGroup — указывает группу, используемую для расчета общего количества столбцов.
-
высота — это определяет высоту ячейки.
-
rowTotalGroup — указывает группу, используемую для вычисления итоговой суммы строки.
-
ширина — это определяет ширину ячейки.
-
-
<whenNoDataCell> — этот элемент определяет, что отображать в пустой ячейке кросс-таблицы. Этот элемент не содержит атрибутов.
<reportElement> — этот элемент определяет положение, ширину и высоту кросс-таблицы внутри ее вложения. Атрибуты для этого элемента включают все стандартные атрибуты <reportElement>.
<crosstabParameter> — этот элемент используется для доступа к переменным и параметрам отчета из кросс-таблицы. Атрибуты для этого элемента включают —
name — определяет имя параметра
класс — указывает класс параметров.
<parametersMapExpression> — Этот элемент используется для передачи переменной отчета или параметра, содержащего экземпляр java.util.Map , в качестве набора параметров для кросс-таблицы. Этот элемент не содержит атрибутов.
<crosstabDataset> — этот элемент определяет набор данных, который будет использоваться для заполнения кросс-таблицы (подробное объяснение см. в следующем разделе). Атрибуты для этого элемента включают —
isDataPreSorted — указывает, предварительно ли отсортированы данные в наборе данных. Значением по умолчанию является false .
<crosstabHeaderCell> — этот элемент определяет содержимое области, найденной в верхнем левом углу кросс-таблицы, где встречаются заголовки столбцов и строки. Размер этой ячейки вычисляется автоматически на основе определенной ширины и высоты строки и столбца.
<rowGroup> — этот элемент определяет группу, используемую для разделения данных на строки. Атрибуты для этого элемента включают —
name — определяет имя группы строк.
ширина — это определяет ширину группы строк.
headerPosition — определяет позицию содержимого заголовка (Top, Middle, Bottom, Stretch).
totalPosition — определяет позицию всего столбца (Start, End, None).
Этот элемент содержит следующие подэлементы —
<Ковш>
<crosstabRowHeader>
<crosstabTotalRowHeader>
<columnGroup> — этот элемент определяет группу, используемую для разделения данных на столбцы. Атрибуты для этого элемента включают —
name — определяет имя группы столбцов.
высота — определяет высоту заголовка группы столбцов.
headerPosition — определяет позицию содержимого заголовка ( Right, Left, Center, Stretch ).
totalPosition — определяет позицию всего столбца ( Start, End, None ).
Этот элемент содержит следующие подэлементы —
<Ковш>
<crosstabColumnHeader>
<crosstabTotalColumnHeader>
<measure> — этот элемент определяет вычисление, которое будет выполняться по строкам и столбцам. Атрибуты для этого элемента включают —
имя — это определяет имя меры.
класс — указывает класс меры.
вычисление — указывает, какое вычисление должно выполняться между значениями ячейки кросс-таблицы. Его значения могут быть любыми из следующих: Ничего, Счетчик, DistinctCount, Сумма, Среднее, Минимальное, Максимальное, Стандартное отклонение, Дисперсия и Первое . Значением по умолчанию является Ничто .
<crosstabCell> — этот элемент определяет способ размещения данных в ячейках без заголовка. Атрибуты для этого элемента включают —
columnTotalGroup — указывает группу, используемую для расчета общего количества столбцов.
высота — это определяет высоту ячейки.
rowTotalGroup — указывает группу, используемую для вычисления итоговой суммы строки.
ширина — это определяет ширину ячейки.
<whenNoDataCell> — этот элемент определяет, что отображать в пустой ячейке кросс-таблицы. Этот элемент не содержит атрибутов.
Группировка данных в кросс-таблице
Механизм расчета кросс-таблицы агрегирует данные, просматривая связанные записи набора данных. Чтобы собрать данные, сначала нужно сгруппировать их. В кросс-таблице строки и столбцы основаны на определенных элементах группы, называемых сегментами . Определение корзины должно содержать —
-
bucketExpression — выражение, которое будет оценено для получения элементов группы данных.
-
comptorExpression — Необходим в том случае, если естественное упорядочение значений не является лучшим выбором.
-
orderByExpression — указывает значение, используемое для сортировки данных.
bucketExpression — выражение, которое будет оценено для получения элементов группы данных.
comptorExpression — Необходим в том случае, если естественное упорядочение значений не является лучшим выбором.
orderByExpression — указывает значение, используемое для сортировки данных.
Группы строк и столбцов (определенные выше) в кросс-таблице полагаются на сегменты .
Встроенные переменные кросс-таблицы
Ниже приведен список текущих значений меры и итогов разных уровней, соответствующих ячейке, можно получить через переменные, названные в соответствии со следующей схемой:
-
Текущее значение вычисления меры сохраняется в переменной, имя которой совпадает с именем меры.
-
<Measure> _ <Column Group> _ALL — Это дает итоговое значение для всех записей в группе столбцов из той же строки.
-
<Measure> _ <Row Group> _ALL — это итоговое значение для всех записей в группе строк из одного столбца.
-
<Measure> _ <Row Group> _ <Column Group> _ALL — Это дает объединенную сумму, соответствующую всем записям в группах строк и столбцов.
Текущее значение вычисления меры сохраняется в переменной, имя которой совпадает с именем меры.
<Measure> _ <Column Group> _ALL — Это дает итоговое значение для всех записей в группе столбцов из той же строки.
<Measure> _ <Row Group> _ALL — это итоговое значение для всех записей в группе строк из одного столбца.
<Measure> _ <Row Group> _ <Column Group> _ALL — Это дает объединенную сумму, соответствующую всем записям в группах строк и столбцов.
пример
Чтобы продемонстрировать кросс-таблицы, напишем новый шаблон отчета (jasper_report_template.jrxml). Здесь мы добавим кросс-таблицу в сводный раздел. Сохраните его в каталоге C: \ tools \ jasperreports-5.0.1 \ test . Содержимое файла приведено ниже.
<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE jasperReport PUBLIC "//JasperReports//DTD Report Design//EN" "http://jasperreports.sourceforge.net/dtds/jasperreport.dtd"> <jasperReport xmlns = "http://jasperreports.sourceforge.net/jasperreports" xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation = "http://jasperreports.sourceforge.net/jasperreports http://jasperreports.sourceforge.net/xsd/jasperreport.xsd" name = "jasper_report_template" language = "groovy" pageWidth = "595" pageHeight = "842" columnWidth = "555" leftMargin = "20" rightMargin = "20" topMargin = "20" bottomMargin = "20"> <parameter name = "ReportTitle" class = "java.lang.String"/> <parameter name = "Author" class = "java.lang.String"/> <field name = "name" class = "java.lang.String"/> <field name = "country" class = "java.lang.String"/> <title> <band height = "70"> <line> <reportElement x = "0" y = "0" width = "515" height = "1"/> </line> <textField isBlankWhenNull = "true" bookmarkLevel = "1"> <reportElement x = "0" y = "10" width = "515" height = "30"/> <textElement textAlignment = "Center"> <font size = "22"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{ReportTitle}]]> </textFieldExpression> <anchorNameExpression> <![CDATA["Title"]]> </anchorNameExpression> </textField> <textField isBlankWhenNull = "true"> <reportElement x = "0" y = "40" width = "515" height = "20"/> <textElement textAlignment = "Center"> <font size = "10"/> </textElement> <textFieldExpression class = "java.lang.String"> <![CDATA[$P{Author}]]> </textFieldExpression> </textField> </band> </title> <summary> <band height = "60"> <crosstab> <reportElement width = "782" y = "0" x = "0" height = "60"/> <rowGroup name = "nameGroup" width = "100"> <bucket> <bucketExpression class = "java.lang.String"> <![CDATA[$F{name}]]> </bucketExpression> </bucket> <crosstabRowHeader> <cellContents> <box border = "Thin" borderColor = "black"/> <textField> <reportElement width = "100" y = "0" x = "0" height = "20"/> <textElement textAlignment = "Right" verticalAlignment = "Middle"/> <textFieldExpression> <![CDATA[$V{nameGroup}]]> </textFieldExpression> </textField> </cellContents> </crosstabRowHeader> </rowGroup> <columnGroup name = "countryGroup" height = "20"> <bucket> <bucketExpression class = "java.lang.String"> $F{country} </bucketExpression> </bucket> <crosstabColumnHeader> <cellContents> <box border = "Thin" borderColor = "black"/> <textField isStretchWithOverflow = "true"> <reportElement width = "60" y = "0" x = "0" height = "20"/> <textElement verticalAlignment = "Bottom"/> <textFieldExpression> <![CDATA[$V{countryGroup}]]> </textFieldExpression> </textField> </cellContents> </crosstabColumnHeader> </columnGroup> <measure name = "tailNumCount" class = "java.lang.Integer" calculation = "Count"> <measureExpression>$F{country}</measureExpression> </measure> <crosstabCell height = "20" width = "60"> <cellContents backcolor = "#FFFFFF"> <box borderColor = "black" border = "Thin"/> <textField> <reportElement x = "5" y = "0" width = "55" height = "20"/> <textElement textAlignment = "Left" verticalAlignment = "Bottom"/> <textFieldExpression class = "java.lang.Integer"> $V{tailNumCount} </textFieldExpression> </textField> </cellContents> </crosstabCell> </crosstab> </band> </summary> </jasperReport>
Детали вышеупомянутого файла следующие:
-
Кросс-таблица определяется элементом <crosstab>.
-
Элемент <rowGroup> определяет группу для разделения данных на строки. Здесь каждая строка будет отображать данные для другого имени.
-
Элементы <bucket> и <bucketExpression> определяют, какое выражение отчета использовать в качестве разделителя группы для <rowGroup>. Здесь мы использовали поле имени в качестве разделителя, чтобы разделить строки по имени.
-
Элемент <crosstabRowHeader> определяет выражение, которое будет использоваться в качестве заголовка строки. Он содержит единственный подэлемент, а именно <cellContents>, который действует как внутренняя полоса внутри кросс-таблицы. Вместо определения имени переменной для текстового поля внутри <crosstabRowHeader>, мы присвоили имя <rowGroup> (через его атрибут name), поэтому оно создает неявную переменную. Элемент <crosstabRowHeader> определяет содержимое ячейки заголовка для всей строки. Он принимает один элемент <cellContents> как единственный подэлемент.
-
Элемент <columnGroup> и его подэлементы аналогичны элементу <rowGroup>, за исключением того, что он влияет на столбцы, а не на строки.
-
Элемент <measure> определяет вычисление для строк и столбцов. Атрибут вычисления имеет значение Count .
-
Элемент <crosstabCell> определяет способ размещения данных в ячейках без заголовка. Этот элемент также содержит единственный элемент <crosstabCell> в качестве единственного подэлемента.
Кросс-таблица определяется элементом <crosstab>.
Элемент <rowGroup> определяет группу для разделения данных на строки. Здесь каждая строка будет отображать данные для другого имени.
Элементы <bucket> и <bucketExpression> определяют, какое выражение отчета использовать в качестве разделителя группы для <rowGroup>. Здесь мы использовали поле имени в качестве разделителя, чтобы разделить строки по имени.
Элемент <crosstabRowHeader> определяет выражение, которое будет использоваться в качестве заголовка строки. Он содержит единственный подэлемент, а именно <cellContents>, который действует как внутренняя полоса внутри кросс-таблицы. Вместо определения имени переменной для текстового поля внутри <crosstabRowHeader>, мы присвоили имя <rowGroup> (через его атрибут name), поэтому оно создает неявную переменную. Элемент <crosstabRowHeader> определяет содержимое ячейки заголовка для всей строки. Он принимает один элемент <cellContents> как единственный подэлемент.
Элемент <columnGroup> и его подэлементы аналогичны элементу <rowGroup>, за исключением того, что он влияет на столбцы, а не на строки.
Элемент <measure> определяет вычисление для строк и столбцов. Атрибут вычисления имеет значение Count .
Элемент <crosstabCell> определяет способ размещения данных в ячейках без заголовка. Этот элемент также содержит единственный элемент <crosstabCell> в качестве единственного подэлемента.
Java-коды для заполнения отчетов остаются без изменений. Содержимое файла C: \ tools \ jasperreports-5.0.1 \ test \ src \ com \ tutorialspoint \ JasperReportFill.java указано ниже —
package com.tutorialspoint;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import net.sf.jasperreports.engine.JRException;
import net.sf.jasperreports.engine.JasperFillManager;
import net.sf.jasperreports.engine.data.JRBeanCollectionDataSource;
public class JasperReportFill {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
String sourceFileName =
"C://tools/jasperreports-5.0.1/test/jasper_report_template.jasper";
DataBeanList DataBeanList = new DataBeanList();
ArrayList<DataBean> dataList = DataBeanList.getDataBeanList();
JRBeanCollectionDataSource beanColDataSource =
new JRBeanCollectionDataSource(dataList);
Map parameters = new HashMap();
/**
* Passing ReportTitle and Author as parameters
*/
parameters.put("ReportTitle", "List of Contacts");
parameters.put("Author", "Prepared By Manisha");
try {
JasperFillManager.fillReportToFile(
sourceFileName, parameters, beanColDataSource);
} catch (JRException e) {
e.printStackTrace();
}
}
}
Содержимое файла POJO C: \ tools \ jasperreports-5.0.1 \ test \ src \ com \ tutorialspoint \ DataBean.java :
package com.tutorialspoint;
public class DataBean {
private String name;
private String country;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
}
Содержимое файла C: \ tools \ jasperreports-5.0.1 \ test \ src \ com \ tutorialspoint \ DataBeanList.java выглядит следующим образом:
package com.tutorialspoint;
import java.util.ArrayList;
public class DataBeanList {
public ArrayList<DataBean> getDataBeanList() {
ArrayList<DataBean> dataBeanList = new ArrayList<DataBean>();
dataBeanList.add(produce("Manisha", "India"));
dataBeanList.add(produce("Dennis Ritchie", "USA"));
dataBeanList.add(produce("V.Anand", "India"));
dataBeanList.add(produce("Shrinath", "California"));
return dataBeanList;
}
/**
* This method returns a DataBean object,
* with name and country set in it.
*/
private DataBean produce(String name, String country) {
DataBean dataBean = new DataBean();
dataBean.setName(name);
dataBean.setCountry(country);
return dataBean;
}
}
Генерация отчетов
Далее, давайте скомпилируем и выполним вышеуказанные файлы, используя наш обычный процесс сборки ANT. Содержимое файла build.xml (сохраненного в каталоге C: \ tools \ jasperreports-5.0.1 \ test) приведено ниже.
Файл импорта — baseBuild.xml взят из главы « Настройка среды» и должен быть расположен в том же каталоге, что и build.xml.
<?xml version = "1.0" encoding = "UTF-8"?>
<project name = "JasperReportTest" default = "viewFillReport" basedir = ".">
<import file = "baseBuild.xml" />
<target name = "viewFillReport" depends = "compile,compilereportdesing,run"
description = "Launches the report viewer to preview the
report stored in the .JRprint file.">
<java classname = "net.sf.jasperreports.view.JasperViewer" fork = "true">
<arg value = "-F${file.name}.JRprint" />
<classpath refid = "classpath" />
</java>
</target>
<target name = "compilereportdesing" description = "Compiles the JXML file and
produces the .jasper file.">
<taskdef name = "jrc" classname = "net.sf.jasperreports.ant.JRAntCompileTask">
<classpath refid = "classpath" />
</taskdef>
<jrc destdir = ".">
<src>
<fileset dir = ".">
<include name = "*.jrxml" />
</fileset>
</src>
<classpath refid = "classpath" />
</jrc>
</target>
</project>
Далее, давайте откроем окно командной строки и перейдем в каталог, где находится build.xml. Наконец, выполните команду ant -Dmain-class = com.tutorialspoint.JasperReportFill (viewFullReport является целью по умолчанию) следующим образом:
C:\tools\jasperreports-5.0.1\test>ant -Dmain-class=com.tutorialspoint.JasperReportFill
Buildfile: C:\tools\jasperreports-5.0.1\test\build.xml
clean-sample:
[delete] Deleting directory C:\tools\jasperreports-5.0.1\test\classes
[delete] Deleting: C:\tools\jasperreports-5.0.1\test\jasper_report_template.jasper
compile:
[mkdir] Created dir: C:\tools\jasperreports-5.0.1\test\classes
[javac] C:\tools\jasperreports-5.0.1\test\baseBuild.xml:28:
warning: 'includeantruntime' was not set, defaulting to
[javac] Compiling 3 source files to C:\tools\jasperreports-5.0.1\test\classes
compilereportdesing:
[jrc] Compiling 1 report design files.
[jrc] log4j:WARN No appenders could be found for logger
(net.sf.jasperreports.engine.xml.JRXmlDigesterFactory).
[jrc] log4j:WARN Please initialize the log4j system properly.
[jrc] log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig
for more info.
[jrc] File : C:\tools\jasperreports-5.0.1\test\jasper_report_template.jrxml ... OK.
run:
[echo] Runnin class : com.tutorialspoint.JasperReportFill
[java] log4j:WARN No appenders could be found for logger
(net.sf.jasperreports.extensions.ExtensionsEnvironment).
[java] log4j:WARN Please initialize the log4j system properly.
viewFillReport:
[java] log4j:WARN No appenders could be found for logger (
net.sf.jasperreports.extensions.ExtensionsEnvironment).
[java] log4j:WARN Please initialize the log4j system properly.
BUILD SUCCESSFUL
Total time: 20 minutes 53 seconds
В результате вышеупомянутой компиляции открывается окно JasperViewer, как показано на приведенном ниже экране —
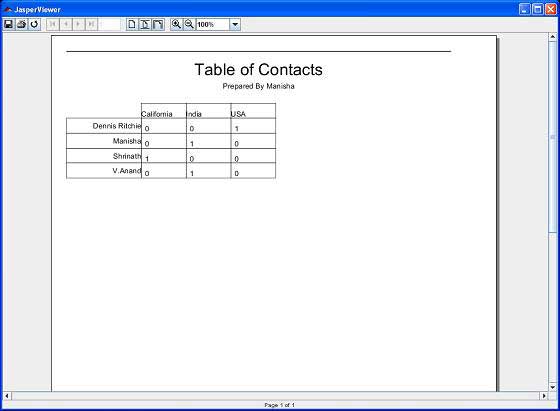
Здесь мы видим, что каждая страна и название сведены в таблицу.