Кубернетес — Обзор
Kubernetes в инструменте управления контейнерами с открытым исходным кодом, размещенном в Cloud Native Computing Foundation (CNCF). Это также известно как расширенная версия Borg, которая была разработана в Google для управления как долго выполняющимися процессами, так и пакетными заданиями, которые ранее обрабатывались отдельными системами.
Kubernetes поставляется с возможностью автоматизации развертывания, масштабирования приложения и операций с контейнерами приложений в кластерах. Он способен создавать контейнерную инфраструктуру.
Особенности Кубернетес
Ниже приведены некоторые из важных особенностей Kubernetes.
-
Продолжает разработку, интеграцию и развертывание
-
Контейнерная инфраструктура
-
Управление, ориентированное на приложения
-
Автоматически масштабируемая инфраструктура
-
Согласованность среды при разработке и производстве
-
Слабосвязанная инфраструктура, где каждый компонент может действовать как отдельный блок
-
Более высокая плотность использования ресурсов
-
Предсказуемая инфраструктура, которая будет создана
Продолжает разработку, интеграцию и развертывание
Контейнерная инфраструктура
Управление, ориентированное на приложения
Автоматически масштабируемая инфраструктура
Согласованность среды при разработке и производстве
Слабосвязанная инфраструктура, где каждый компонент может действовать как отдельный блок
Более высокая плотность использования ресурсов
Предсказуемая инфраструктура, которая будет создана
Одним из ключевых компонентов Kubernetes является то, что он может запускать приложения в кластерах физической и виртуальной машинной инфраструктуры. Он также имеет возможность запускать приложения в облаке. Это помогает в переходе от инфраструктуры, ориентированной на хост, к инфраструктуре, ориентированной на контейнеры.
Кубернетес — Архитектура
В этой главе мы обсудим основную архитектуру Kubernetes.
Кубернетес — кластерная архитектура
Как видно из следующей диаграммы, Kubernetes следует архитектуре клиент-сервер. При этом у нас есть master, установленный на одной машине, а узел на разных машинах Linux.
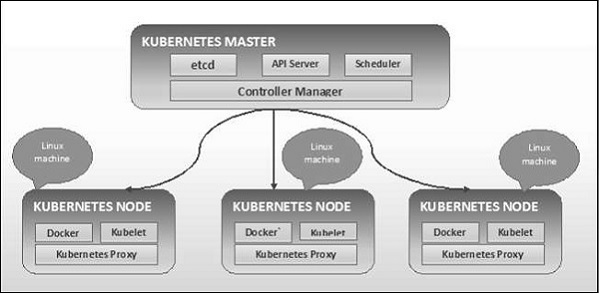
Ключевые компоненты мастера и узла определены в следующем разделе.
Kubernetes — основные компоненты машин
Ниже приведены компоненты Мастер машины Kubernetes.
etcd
Он хранит информацию о конфигурации, которая может использоваться каждым из узлов в кластере. Это хранилище значений ключей высокой доступности, которое может быть распределено по нескольким узлам. Он доступен только API-серверу Kubernetes, поскольку может содержать некоторую конфиденциальную информацию. Это распределенное ключевое значение Store, которое доступно всем.
API-сервер
Kubernetes — это сервер API, который обеспечивает все операции в кластере с использованием API. Сервер API реализует интерфейс, что означает, что различные инструменты и библиотеки могут легко взаимодействовать с ним. Kubeconfig — это пакет вместе с инструментами на стороне сервера, которые можно использовать для связи. Это выставляет API Kubernetes.
Диспетчер контроллеров
Этот компонент отвечает за большинство сборщиков, которые регулируют состояние кластера и выполняют задачу. В общем, его можно рассматривать как демон, который работает в бесконечном цикле и отвечает за сбор и отправку информации на сервер API. Он работает для получения общего состояния кластера, а затем вносит изменения, чтобы привести текущее состояние сервера в желаемое состояние. Ключевыми контроллерами являются контроллер репликации, контроллер конечной точки, контроллер пространства имен и контроллер учетной записи службы. Диспетчер контроллеров запускает контроллеры различного типа для обработки узлов, конечных точек и т. Д.
планировщик
Это один из ключевых компонентов мастера Kubernetes. Это услуга мастера, ответственная за распределение рабочей нагрузки. Он отвечает за отслеживание использования рабочей нагрузки на узлах кластера, а затем за размещение рабочей нагрузки, на которой доступны ресурсы, и за принятие рабочей нагрузки. Другими словами, это механизм, отвечающий за распределение модулей доступным узлам. Планировщик отвечает за использование рабочей нагрузки и выделение модуля новому узлу.
Kubernetes — Узел Компоненты
Ниже приведены ключевые компоненты сервера Node, которые необходимы для связи с мастером Kubernetes.
докер
Первым требованием каждого узла является Docker, который помогает запускать контейнеры инкапсулированных приложений в относительно изолированной, но облегченной операционной среде.
Кубеле Сервис
Это небольшая служба в каждом узле, отвечающая за передачу информации в службу уровня управления и обратно. Он взаимодействует с хранилищем etcd для чтения сведений о конфигурации и значений Wright. Это связывается с главным компонентом для получения команд и работы. Затем процесс kubelet берет на себя ответственность за поддержание рабочего состояния и сервера узла. Он управляет сетевыми правилами, переадресацией портов и т. Д.
Kubernetes Proxy Service
Это прокси-сервис, который работает на каждом узле и помогает сделать сервисы доступными для внешнего хоста. Он помогает пересылать запрос для исправления контейнеров и способен выполнять примитивную балансировку нагрузки. Это гарантирует, что сетевая среда предсказуема и доступна, и в то же время она также изолирована. Он управляет модулями на узлах, томами, секретами, проверкой работоспособности новых контейнеров и т. Д.
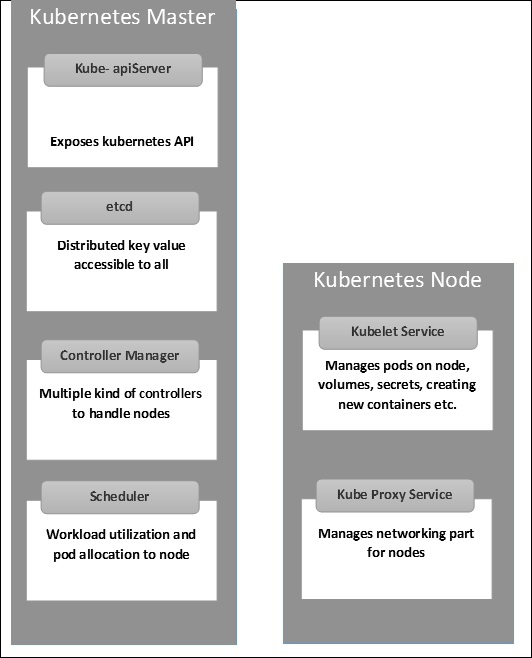
Kubernetes — структура хозяина и узла
Следующие иллюстрации показывают структуру Kubernetes Master и Node.
Kubernetes — Настройка
Важно настроить виртуальный центр обработки данных (vDC) перед настройкой Kubernetes. Это можно рассматривать как набор машин, где они могут общаться друг с другом через сеть. Для практического подхода вы можете настроить vDC на PROFITBRICKS, если у вас нет настроенной физической или облачной инфраструктуры.
После завершения настройки IaaS в любом облаке необходимо настроить мастер и узел .
Примечание . Настройка показана для компьютеров с Ubuntu. То же самое можно настроить и на других компьютерах с Linux.
Предпосылки
Установка Docker — Docker требуется на всех экземплярах Kubernetes. Ниже приведены инструкции по установке Docker.
Шаг 1 — Войдите в систему с учетной записью пользователя root.
Шаг 2 — Обновите информацию о пакете. Убедитесь, что пакет apt работает.
Шаг 3 — Запустите следующие команды.
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificates
Шаг 4 — Добавьте новый ключ GPG.
$ sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D $ echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main" | sudo tee /etc/apt/sources.list.d/docker.list
Шаг 5 — Обновите образ пакета API.
$ sudo apt-get update
После того как все вышеперечисленные задачи будут выполнены, вы можете начать с фактической установки механизма Docker. Однако перед этим вам необходимо убедиться, что версия ядра, которую вы используете, верна.
Установите Docker Engine
Выполните следующие команды для установки механизма Docker.
Шаг 1 — Войдите в систему.
Шаг 2 — Обновите индекс пакета.
$ sudo apt-get update
Шаг 3 — Установите Docker Engine, используя следующую команду.
$ sudo apt-get install docker-engine
Шаг 4 — Запустите демон Docker.
$ sudo apt-get install docker-engine
Шаг 5. Чтобы установить Docker, используйте следующую команду.
$ sudo docker run hello-world
Установите etcd 2.0
Это должно быть установлено на Kubernetes Master Machine. Чтобы установить его, выполните следующие команды.
$ curl -L https://github.com/coreos/etcd/releases/download/v2.0.0/etcd -v2.0.0-linux-amd64.tar.gz -o etcd-v2.0.0-linux-amd64.tar.gz ->1 $ tar xzvf etcd-v2.0.0-linux-amd64.tar.gz ------>2 $ cd etcd-v2.0.0-linux-amd64 ------------>3 $ mkdir /opt/bin ------------->4 $ cp etcd* /opt/bin ----------->5
В приведенном выше наборе команд —
- Сначала мы скачиваем etcd . Сохраните это с указанным именем.
- Затем мы должны распаковать tar-пакет.
- Мы делаем реж. внутри / opt с именем bin.
- Скопируйте извлеченный файл в целевое местоположение.
Теперь мы готовы строить Kubernetes. Нам нужно установить Kubernetes на все машины в кластере.
$ git clone https://github.com/GoogleCloudPlatform/kubernetes.git $ cd kubernetes $ make release
Приведенная выше команда создаст каталог _output в корне папки kubernetes. Далее мы можем извлечь каталог в любой каталог по нашему выбору / opt / bin и т. Д.
Затем следует сетевая часть, в которой нам нужно начать с настройки мастера и узла Kubernetes. Чтобы сделать это, мы сделаем запись в файле хоста, которую можно сделать на компьютере узла.
$ echo "<IP address of master machine> kube-master < IP address of Node Machine>" >> /etc/hosts
Ниже будет вывод вышеуказанной команды.
Теперь мы начнем с фактической конфигурации на Kubernetes Master.
Сначала мы начнем копировать все файлы конфигурации в их правильное расположение.
$ cp <Current dir. location>/kube-apiserver /opt/bin/ $ cp <Current dir. location>/kube-controller-manager /opt/bin/ $ cp <Current dir. location>/kube-kube-scheduler /opt/bin/ $ cp <Current dir. location>/kubecfg /opt/bin/ $ cp <Current dir. location>/kubectl /opt/bin/ $ cp <Current dir. location>/kubernetes /opt/bin/
Приведенная выше команда скопирует все файлы конфигурации в нужное место. Теперь вернемся к тому же каталогу, где мы создали папку Kubernetes.
$ cp kubernetes/cluster/ubuntu/init_conf/kube-apiserver.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-controller-manager.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-kube-scheduler.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-apiserver /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-controller-manager /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-kube-scheduler /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/
Следующим шагом является обновление скопированного файла конфигурации в / etc. реж.
Сконфигурируйте etcd на master с помощью следующей команды.
$ ETCD_OPTS = "-listen-client-urls = http://kube-master:4001"
Настроить куб-аписервер
Для этого нам нужно отредактировать файл / etc / default / kube-apiserver, который мы скопировали ранее.
$ KUBE_APISERVER_OPTS = "--address = 0.0.0.0 \ --port = 8080 \ --etcd_servers = <The path that is configured in ETCD_OPTS> \ --portal_net = 11.1.1.0/24 \ --allow_privileged = false \ --kubelet_port = < Port you want to configure> \ --v = 0"
Настройте диспетчер контроллеров куба
Нам нужно добавить следующий контент в / etc / default / kube-controller-manager .
$ KUBE_CONTROLLER_MANAGER_OPTS = "--address = 0.0.0.0 \ --master = 127.0.0.1:8080 \ --machines = kube-minion \ -----> #this is the kubernatics node --v = 0
Далее настройте планировщик куба в соответствующем файле.
$ KUBE_SCHEDULER_OPTS = "--address = 0.0.0.0 \ --master = 127.0.0.1:8080 \ --v = 0"
После того, как все вышеперечисленные задачи будут выполнены, мы сможем продолжить, подняв мастера Kubernetes. Для этого мы перезапустим Docker.
$ service docker restart
Конфигурация узла Kubernetes
Узел Kubernetes будет запускать две службы: kubelet и kube-proxy . Прежде чем двигаться дальше, нам нужно скопировать загруженные нами двоичные файлы в нужные им папки, где мы хотим настроить узел kubernetes.
Используйте тот же метод копирования файлов, который мы сделали для kubernetes master. Так как он будет запускать только kubelet и kube-proxy, мы настроим их.
$ cp <Path of the extracted file>/kubelet /opt/bin/ $ cp <Path of the extracted file>/kube-proxy /opt/bin/ $ cp <Path of the extracted file>/kubecfg /opt/bin/ $ cp <Path of the extracted file>/kubectl /opt/bin/ $ cp <Path of the extracted file>/kubernetes /opt/bin/
Теперь мы скопируем содержимое в соответствующий каталог.
$ cp kubernetes/cluster/ubuntu/init_conf/kubelet.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/init_conf/kube-proxy.conf /etc/init/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kubelet /etc/init.d/ $ cp kubernetes/cluster/ubuntu/initd_scripts/kube-proxy /etc/init.d/ $ cp kubernetes/cluster/ubuntu/default_scripts/kubelet /etc/default/ $ cp kubernetes/cluster/ubuntu/default_scripts/kube-proxy /etc/default/
Мы настроим файлы конфигурации kubelet и kube-proxy .
Мы настроим /etc/init/kubelet.conf .
$ KUBELET_OPTS = "--address = 0.0.0.0 \ --port = 10250 \ --hostname_override = kube-minion \ --etcd_servers = http://kube-master:4001 \ --enable_server = true --v = 0" /
Для kube-proxy мы настроим следующую команду.
$ KUBE_PROXY_OPTS = "--etcd_servers = http://kube-master:4001 \ --v = 0" /etc/init/kube-proxy.conf
Наконец, мы перезапустим сервис Docker.
$ service docker restart
Теперь мы закончили с настройкой. Вы можете проверить, выполнив следующие команды.
$ /opt/bin/kubectl get minions
Кубернетес — Изображения
Изображения Kubernetes (Docker) являются ключевыми строительными блоками контейнерной инфраструктуры. На данный момент мы поддерживаем только Kubernetes для поддержки образов Docker. Внутри каждого контейнера в модуле находится изображение Docker.
Когда мы настраиваем модуль, свойство изображения в файле конфигурации имеет тот же синтаксис, что и команда Docker. В файле конфигурации есть поле для определения имени изображения, которое мы планируем извлечь из реестра.
Ниже приведена общая структура конфигурации, которая извлекает образ из реестра Docker и развертывает его в контейнере Kubernetes.
apiVersion: v1
kind: pod
metadata:
name: Tesing_for_Image_pull -----------> 1
spec:
containers:
- name: neo4j-server ------------------------> 2
image: <Name of the Docker image>----------> 3
imagePullPolicy: Always ------------->4
command: ["echo", "SUCCESS"] ------------------->
В приведенном выше коде мы определили —
-
name: Tesing_for_Image_pull — это имя предназначено для идентификации и проверки имени контейнера, который будет создан после извлечения изображений из реестра Docker.
-
name: neo4j-server — это имя, данное контейнеру, который мы пытаемся создать. Вроде мы дали neo4j-сервер.
-
image: <имя образа Docker> — это имя изображения, которое мы пытаемся извлечь из Docker или внутреннего реестра изображений. Нам нужно определить полный путь к реестру вместе с именем образа, который мы пытаемся получить.
-
imagePullPolicy — Always — эта политика извлечения изображений определяет, что всякий раз, когда мы запускаем этот файл для создания контейнера, он снова вытягивает одно и то же имя.
-
команда: [«echo», «SUCCESS»] — при этом, когда мы создаем контейнер и если все идет хорошо, он будет отображать сообщение, когда мы получим доступ к контейнеру.
name: Tesing_for_Image_pull — это имя предназначено для идентификации и проверки имени контейнера, который будет создан после извлечения изображений из реестра Docker.
name: neo4j-server — это имя, данное контейнеру, который мы пытаемся создать. Вроде мы дали neo4j-сервер.
image: <имя образа Docker> — это имя изображения, которое мы пытаемся извлечь из Docker или внутреннего реестра изображений. Нам нужно определить полный путь к реестру вместе с именем образа, который мы пытаемся получить.
imagePullPolicy — Always — эта политика извлечения изображений определяет, что всякий раз, когда мы запускаем этот файл для создания контейнера, он снова вытягивает одно и то же имя.
команда: [«echo», «SUCCESS»] — при этом, когда мы создаем контейнер и если все идет хорошо, он будет отображать сообщение, когда мы получим доступ к контейнеру.
Чтобы вытащить изображение и создать контейнер, мы запустим следующую команду.
$ kubectl create –f Tesing_for_Image_pull
Как только мы получим журнал, мы получим вывод как успешный.
$ kubectl log Tesing_for_Image_pull
Приведенная выше команда выдаст вывод об успехе, или мы получим вывод как сбой.
Примечание. Рекомендуется попробовать все команды самостоятельно.
Кубернетес — Работа
Основной функцией задания является создание одного или нескольких модулей и отслеживание их успешности. Они гарантируют, что указанное количество модулей успешно завершено. Когда указанное количество успешных запусков модулей завершено, задание считается завершенным.
Создание работы
Используйте следующую команду, чтобы создать работу —
apiVersion: v1
kind: Job ------------------------> 1
metadata:
name: py
spec:
template:
metadata
name: py -------> 2
spec:
containers:
- name: py ------------------------> 3
image: python----------> 4
command: ["python", "SUCCESS"]
restartPocliy: Never --------> 5
В приведенном выше коде мы определили —
-
kind: Job → Мы определили вид как Job, который сообщит kubectl, что используемый файл yaml предназначен для создания модуля типа задания.
-
Имя: py → Это имя шаблона, который мы используем, и спецификация определяет шаблон.
-
name: py → мы дали имя как py под спецификацией контейнера, которая помогает идентифицировать Pod, который будет создан из него.
-
Image: python → изображение, которое мы собираемся вытащить, чтобы создать контейнер, который будет работать внутри контейнера.
-
restartPolicy: Never → Это условие перезапуска изображения задано как никогда, что означает, что если контейнер уничтожен или имеет значение false, он не будет перезапускаться сам.
kind: Job → Мы определили вид как Job, который сообщит kubectl, что используемый файл yaml предназначен для создания модуля типа задания.
Имя: py → Это имя шаблона, который мы используем, и спецификация определяет шаблон.
name: py → мы дали имя как py под спецификацией контейнера, которая помогает идентифицировать Pod, который будет создан из него.
Image: python → изображение, которое мы собираемся вытащить, чтобы создать контейнер, который будет работать внутри контейнера.
restartPolicy: Never → Это условие перезапуска изображения задано как никогда, что означает, что если контейнер уничтожен или имеет значение false, он не будет перезапускаться сам.
Мы создадим задание, используя следующую команду с yaml, которая сохраняется с именем py.yaml .
$ kubectl create –f py.yaml
Приведенная выше команда создаст задание. Если вы хотите проверить состояние задания, используйте следующую команду.
$ kubectl describe jobs/py
Приведенная выше команда создаст задание. Если вы хотите проверить состояние задания, используйте следующую команду.
Запланированная работа
Запланированная работа в Kubernetes использует Cronetes , которая берет работу Kubernetes и запускает их в кластере Kubernetes.
- Планирование работы будет запускать модуль в определенный момент времени.
- Для него создается пародийное задание, которое запускается автоматически.
Примечание . Функция запланированного задания поддерживается версией 1.4, и API betch / v2alpha 1 включается путем передачи –runtime-config = batch / v2alpha1 при запуске сервера API.
Мы будем использовать тот же yaml, который мы использовали для создания задания и сделать его запланированным.
apiVersion: v1
kind: Job
metadata:
name: py
spec:
schedule: h/30 * * * * ? -------------------> 1
template:
metadata
name: py
spec:
containers:
- name: py
image: python
args:
/bin/sh -------> 2
-c
ps –eaf ------------> 3
restartPocliy: OnFailure
В приведенном выше коде мы определили —
-
график работы: ч / 30 * * * *? → Чтобы запланировать выполнение задания каждые 30 минут.
-
/ bin / sh: это будет входить в контейнер с / bin / sh
-
ps –eaf → Запустит команду ps -eaf на компьютере и выведет список всех запущенных процессов внутри контейнера.
график работы: ч / 30 * * * *? → Чтобы запланировать выполнение задания каждые 30 минут.
/ bin / sh: это будет входить в контейнер с / bin / sh
ps –eaf → Запустит команду ps -eaf на компьютере и выведет список всех запущенных процессов внутри контейнера.
Эта концепция запланированного задания полезна, когда мы пытаемся создать и запустить набор задач в определенный момент времени, а затем завершить процесс.
Kubernetes — ярлыки и селекторы
Этикетки
Метки — это пары ключ-значение, которые прикрепляются к модулям, контроллеру репликации и службам. Они используются в качестве идентифицирующих атрибутов для таких объектов, как модули и контроллер репликации. Они могут быть добавлены к объекту во время создания и могут быть добавлены или изменены во время выполнения.
Селекторы
Ярлыки не обеспечивают уникальности. В целом можно сказать, что многие объекты могут иметь одинаковые метки. Селектор меток является основным примитивом группировки в Kubernetes. Они используются пользователями для выбора набора объектов.
Kubernetes API в настоящее время поддерживает два типа селекторов —
- Селекторы на основе равенства
- Набор на основе селекторов
Селекторы на основе равенства
Они позволяют фильтровать по ключу и значению. Соответствующие объекты должны удовлетворять всем указанным меткам.
Селекторы на основе множеств
Селекторы на основе набора позволяют фильтровать ключи в соответствии с набором значений.
apiVersion: v1
kind: Service
metadata:
name: sp-neo4j-standalone
spec:
ports:
- port: 7474
name: neo4j
type: NodePort
selector:
app: salesplatform ---------> 1
component: neo4j -----------> 2
В приведенном выше коде мы используем селектор меток как приложение: salesplatform и компонент как компонент: neo4j .
Как только мы запустим файл с помощью команды kubectl , он создаст службу с именем sp-neo4j-standalone, которая будет взаимодействовать через порт 7474. Тип ype — это NodePort с новым селектором меток в виде app: salesplatform и component: neo4j .
Кубернетес — Пространство имен
Пространство имен обеспечивает дополнительную квалификацию имени ресурса. Это полезно, когда несколько команд используют один и тот же кластер и существует вероятность конфликта имен. Это может быть как виртуальная стена между несколькими кластерами.
Функциональность пространства имен
Ниже приведены некоторые важные функции пространства имен в Kubernetes.
-
Пространства имен помогают взаимодействовать между модулями, используя одно и то же пространство имен.
-
Пространства имен — это виртуальные кластеры, которые могут располагаться поверх одного и того же физического кластера.
-
Они обеспечивают логическое разделение между командами и их средой.
Пространства имен помогают взаимодействовать между модулями, используя одно и то же пространство имен.
Пространства имен — это виртуальные кластеры, которые могут располагаться поверх одного и того же физического кластера.
Они обеспечивают логическое разделение между командами и их средой.
Создать пространство имен
Следующая команда используется для создания пространства имен.
apiVersion: v1 kind: Namespce metadata name: elk
Контролировать пространство имен
Следующая команда используется для управления пространством имен.
$ kubectl create –f namespace.yml ---------> 1 $ kubectl get namespace -----------------> 2 $ kubectl get namespace <Namespace name> ------->3 $ kubectl describe namespace <Namespace name> ---->4 $ kubectl delete namespace <Namespace name>
В приведенном выше коде,
- Мы используем команду для создания пространства имен.
- Это перечислит все доступное пространство имен.
- Это получит определенное пространство имен, имя которого указано в команде.
- Здесь будут описаны полные сведения об услуге.
- Это удалит определенное пространство имен, присутствующее в кластере.
Использование пространства имен в сервисе — пример
Ниже приведен пример файла примера использования пространства имен в сервисе.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
В приведенном выше коде мы используем то же пространство имен в метаданных службы с именем elk .
Кубернетес — Узел
Узел — это рабочая машина в кластере Kubernetes, которая также известна как миньон. Это рабочие единицы, которые могут быть физическими, виртуальными или облачными.
Каждый узел имеет всю необходимую конфигурацию, необходимую для запуска модуля, например прокси-службы и службы кублетов, а также Docker, который используется для запуска контейнеров Docker на модуле, созданном на узле.
Они не создаются Kubernetes, но они создаются внешне либо поставщиком облачных услуг, либо администратором кластера Kubernetes на физических или виртуальных машинах.
Ключевым компонентом Kubernetes для обработки нескольких узлов является диспетчер контроллеров, который запускает несколько видов контроллеров для управления узлами. Чтобы управлять узлами, Kubernetes создает объект типа узла, который будет проверять, что созданный объект является допустимым узлом.
Сервис с селектором
apiVersion: v1
kind: node
metadata:
name: < ip address of the node>
labels:
name: <lable name>
В формате JSON создается реальный объект, который выглядит следующим образом:
{
Kind: node
apiVersion: v1
"metadata":
{
"name": "10.01.1.10",
"labels"
{
"name": "cluster 1 node"
}
}
}
Контроллер узла
Они представляют собой набор служб, которые выполняются в мастере Kubernetes и постоянно отслеживают узел в кластере на основе metadata.name. Если все необходимые службы запущены, то узел проверяется, и вновь созданный модуль будет назначен этому узлу контроллером. Если он недействителен, мастер не назначит ему какой-либо модуль и будет ждать, пока он не станет действительным.
Мастер Kubernetes автоматически регистрирует узел, если флаг –register-node равен true.
–register-node = true
Однако, если администратор кластера хочет управлять им вручную, то это можно сделать, повернув плоскость —
–register-node = false
Кубернетес — Сервис
Служба может быть определена как логический набор модулей. Его можно определить как абстракцию в верхней части модуля, которая предоставляет один IP-адрес и имя DNS, по которым можно получить доступ к модулям. С Service очень легко управлять конфигурацией балансировки нагрузки. Это помогает очень легко масштабировать стручки.
Служба — это объект REST в Kubernetes, определение которого можно опубликовать в Kubernetes apiServer на мастере Kubernetes для создания нового экземпляра.
Сервис без селектора
apiVersion: v1 kind: Service metadata: name: Tutorial_point_service spec: ports: - port: 8080 targetPort: 31999
Приведенная выше конфигурация создаст сервис с именем Tutorial_point_service.
Файл конфигурации службы с помощью селектора
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: "My Application" -------------------> (Selector)
ports:
- port: 8080
targetPort: 31999
В этом примере у нас есть селектор; поэтому для передачи трафика нам нужно создать конечную точку вручную.
apiVersion: v1
kind: Endpoints
metadata:
name: Tutorial_point_service
subnets:
address:
"ip": "192.168.168.40" -------------------> (Selector)
ports:
- port: 8080
В приведенном выше коде мы создали конечную точку, которая будет направлять трафик к конечной точке, определенной как «192.168.168.40:8080».
Создание мультипортового сервиса
apiVersion: v1
kind: Service
metadata:
name: Tutorial_point_service
spec:
selector:
application: “My Application” -------------------> (Selector)
ClusterIP: 10.3.0.12
ports:
-name: http
protocol: TCP
port: 80
targetPort: 31999
-name:https
Protocol: TCP
Port: 443
targetPort: 31998
Типы услуг
ClusterIP — это помогает в ограничении службы в кластере. Он предоставляет сервис в пределах определенного кластера Kubernetes.
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: NodeportService
NodePort — он будет предоставлять сервис на статическом порту развернутого узла. Служба ClusterIP , к которой будет направляться служба NodePort , создается автоматически. Доступ к службе можно получить из-за пределов кластера, используя NodeIP: nodePort .
spec:
ports:
- port: 8080
nodePort: 31999
name: NodeportService
clusterIP: 10.20.30.40
Балансировщик нагрузки — использует балансировщик нагрузки облачных провайдеров. Службы NodePort и ClusterIP создаются автоматически, на которые будет направлять внешний балансировщик нагрузки.
Полный файл сервиса yaml с типом сервиса как Node Port. Попробуйте создать его самостоятельно.
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: env_name
Кубернетес — Под
Модуль — это набор контейнеров и его хранилище внутри узла кластера Kubernetes. Можно создать контейнер с несколькими контейнерами внутри. Например, хранение контейнера базы данных и контейнера данных в одном модуле.
Типы Стручка
Есть два типа стручков —
- Контейнер
- Мульти контейнер контейнер
Одноместный контейнерный контейнер
Их можно просто создать с помощью команды kubctl run, где у вас есть определенный образ в реестре Docker, который мы будем использовать при создании модуля.
$ kubectl run <name of pod> --image=<name of the image from registry>
Пример. Мы создадим модуль с изображением кота, который доступен в центре Docker.
$ kubectl run tomcat --image = tomcat:8.0
Это также можно сделать, создав файл yaml, а затем выполнив команду kubectl create .
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
После создания вышеуказанного файла yaml мы сохраняем файл с именем tomcat.yml и запускаем команду create для запуска документа.
$ kubectl create –f tomcat.yml
Это создаст стручок с именем кота. Мы можем использовать команду description вместе с kubectl для описания модуля.
Мульти контейнер контейнер
Множественные контейнеры создаются с использованием почты yaml с определением контейнеров.
apiVersion: v1
kind: Pod
metadata:
name: Tomcat
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
containerPort: 7500
imagePullPolicy: Always
-name: Database
Image: mongoDB
Ports:
containerPort: 7501
imagePullPolicy: Always
В приведенном выше коде мы создали один модуль с двумя контейнерами внутри, один для tomcat, а другой для MongoDB.
Kubernetes — контроллер репликации
Контроллер репликации является одной из ключевых функций Kubernetes, которая отвечает за управление жизненным циклом модуля. Он отвечает за то, чтобы убедиться, что указанное количество реплик pod запущено в любой момент времени. Он используется во время, когда нужно убедиться, что работает указанное количество модулей или хотя бы один модуль. Он может поднимать или опускать указанное количество стручков.
Рекомендуется использовать контроллер репликации для управления жизненным циклом модуля, а не создавать модуль снова и снова.
apiVersion: v1
kind: ReplicationController --------------------------> 1
metadata:
name: Tomcat-ReplicationController --------------------------> 2
spec:
replicas: 3 ------------------------> 3
template:
metadata:
name: Tomcat-ReplicationController
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat- -----------------------> 4
image: tomcat: 8.0
ports:
- containerPort: 7474 ------------------------> 5
Подробности настройки
-
Вид: ReplicationController → В приведенном выше коде мы определили тип контроллера репликации, который сообщает kubectl, что файл yaml будет использоваться для создания контроллера репликации.
-
name: Tomcat-ReplicationController → Это помогает определить имя, под которым будет создан контроллер репликации. Если мы запустим kubctl, получим rc <Tomcat-ReplicationController>, он покажет детали контроллера репликации.
-
replicas: 3 → Это помогает контроллеру репликации понять, что ему необходимо поддерживать три реплики модуля в любой момент времени в его жизненном цикле.
-
name: Tomcat → В разделе спецификаций мы определили имя как tomcat, которое сообщит контроллеру репликации, что контейнер, присутствующий внутри модулей, является tomcat.
-
containerPort: 7474 → Помогает убедиться, что все узлы в кластере, в котором контейнер запускает контейнер внутри модуля, будут доступны на одном и том же порту 7474.
Вид: ReplicationController → В приведенном выше коде мы определили тип контроллера репликации, который сообщает kubectl, что файл yaml будет использоваться для создания контроллера репликации.
name: Tomcat-ReplicationController → Это помогает определить имя, под которым будет создан контроллер репликации. Если мы запустим kubctl, получим rc <Tomcat-ReplicationController>, он покажет детали контроллера репликации.
replicas: 3 → Это помогает контроллеру репликации понять, что ему необходимо поддерживать три реплики модуля в любой момент времени в его жизненном цикле.
name: Tomcat → В разделе спецификаций мы определили имя как tomcat, которое сообщит контроллеру репликации, что контейнер, присутствующий внутри модулей, является tomcat.
containerPort: 7474 → Помогает убедиться, что все узлы в кластере, в котором контейнер запускает контейнер внутри модуля, будут доступны на одном и том же порту 7474.

Здесь служба Kubernetes работает как балансировщик нагрузки для трех реплик Tomcat.
Кубернетес — Реплика Наборы
Набор реплик гарантирует, сколько реплик модуля должно быть запущено. Это можно рассматривать как замену контроллера репликации. Основное различие между набором реплик и контроллером репликации состоит в том, что контроллер репликации поддерживает только селектор на основе равенства, тогда как набор реплик поддерживает селектор на основе набора.
apiVersion: extensions/v1beta1 --------------------->1
kind: ReplicaSet --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
selector:
matchLables:
tier: Backend ------------------> 3
matchExpression:
{ key: tier, operation: In, values: [Backend]} --------------> 4
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
labels:
app: App
component: neo4j
spec:
containers:
- name: Tomcat
image: tomcat: 8.0
ports:
- containerPort: 7474
Подробности настройки
-
apiVersion: extensions / v1beta1 → В приведенном выше коде версия API представляет собой расширенную бета-версию Kubernetes, которая поддерживает концепцию набора реплик.
-
kind: ReplicaSet → Мы определили тип как набор реплик, который помогает kubectl понять, что файл используется для создания набора реплик.
-
tier: Backend → Мы определили уровень метки как backend, который создает соответствующий селектор.
-
{key: tier, operation: In, values: [Backend]} → Это поможет matchExpression понять условие сопоставления, которое мы определили, и в операции, которая используется matchlabel для поиска деталей.
apiVersion: extensions / v1beta1 → В приведенном выше коде версия API представляет собой расширенную бета-версию Kubernetes, которая поддерживает концепцию набора реплик.
kind: ReplicaSet → Мы определили тип как набор реплик, который помогает kubectl понять, что файл используется для создания набора реплик.
tier: Backend → Мы определили уровень метки как backend, который создает соответствующий селектор.
{key: tier, operation: In, values: [Backend]} → Это поможет matchExpression понять условие сопоставления, которое мы определили, и в операции, которая используется matchlabel для поиска деталей.
Запустите указанный выше файл, используя kubectl, и создайте набор реплик сервера с предоставленным определением в файле yaml .

Кубернетес — Развертывания
Развертывания являются обновленной и более поздней версией контроллера репликации. Они управляют развертыванием наборов реплик, которые также являются обновленной версией контроллера репликации. Они имеют возможность обновлять набор реплик, а также могут выполнять откат к предыдущей версии.
Они предоставляют множество обновленных функций matchLabels и селекторов . У нас есть новый контроллер в мастере Kubernetes, который называется контроллером развертывания, что делает это возможным. У этого есть возможность изменить развертывание на полпути.
Изменение Развертывания
Обновление — пользователь может обновить текущее развертывание до его завершения. В этом случае существующее развертывание будет установлено и будет создано новое развертывание.
Удаление — пользователь может приостановить / отменить развертывание, удалив его до его завершения. Воссоздание того же развертывания возобновит его.
Откат — Мы можем откатить развертывание или развертывание в процессе. Пользователь может создать или обновить развертывание, используя DeploymentSpec.PodTemplateSpec = oldRC.PodTemplateSpec.
Стратегии развертывания
Стратегии развертывания помогают определить, каким образом новый RC должен заменить существующий RC.
Воссоздать — эта функция убьет все существующие RC, а затем вызовет новые. Это приводит к быстрому развертыванию, однако приводит к простою, когда старые модули не работают, а новые не работают.
Rolling Update — Эта функция постепенно разрушает старый RC и открывает новый. Это приводит к медленному развертыванию, однако развертывания не происходит. Во все времена в этом процессе доступно мало старых и мало новых.
Файл конфигурации развертывания выглядит следующим образом.
apiVersion: extensions/v1beta1 --------------------->1
kind: Deployment --------------------------> 2
metadata:
name: Tomcat-ReplicaSet
spec:
replicas: 3
template:
metadata:
lables:
app: Tomcat-ReplicaSet
tier: Backend
spec:
containers:
- name: Tomcatimage:
tomcat: 8.0
ports:
- containerPort: 7474
В приведенном выше коде единственное, что отличается от набора реплик, это то, что мы определили тип как развертывание.
Создать развертывание
$ kubectl create –f Deployment.yaml -–record deployment "Deployment" created Successfully.
Получить развертывание
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVILABLE AGE Deployment 3 3 3 3 20s
Проверьте состояние развертывания
$ kubectl rollout status deployment/Deployment
Обновление развертывания
$ kubectl set image deployment/Deployment tomcat=tomcat:6.0
Откат к предыдущему развертыванию
$ kubectl rollout undo deployment/Deployment –to-revision=2
Кубернетес — Тома
В Kubernetes том можно рассматривать как каталог, который доступен контейнерам в модуле. У нас есть разные типы томов в Kubernetes, и этот тип определяет, как создается том и его содержимое.
Концепция громкости присутствовала в докере, однако единственная проблема заключалась в том, что громкость была очень ограничена конкретной коробкой. Как только жизнь стручка закончилась, объем также был потерян.
С другой стороны, тома, которые создаются через Kubernetes, не ограничиваются каким-либо контейнером. Он поддерживает любые или все контейнеры, развернутые внутри капсулы Кубернетес. Ключевым преимуществом тома Kubernetes является то, что он поддерживает различные типы хранилищ, в которых модуль может использовать несколько из них одновременно.
Типы Кубернетес Объем
Вот список некоторых популярных томов Kubernetes —
-
emptyDir — это тип тома, который создается, когда Pod впервые назначается узлу. Он остается активным, пока Pod работает на этом узле. Том изначально пуст, и контейнеры в модуле могут читать и записывать файлы в томе emptyDir. После удаления Pod из узла данные в emptyDir удаляются.
-
hostPath — Этот тип тома монтирует файл или каталог из файловой системы узла узла в ваш модуль.
-
gcePersistentDisk — этот тип тома монтирует постоянный диск Google Compute Engine (GCE) в ваш модуль. Данные в gcePersistentDisk остаются нетронутыми, когда Pod удаляется из узла.
-
awsElasticBlockStore — этот тип тома монтирует хранилище эластичных блоков Amazon Web Services (AWS) в ваш модуль. Как и в случае с gcePersistentDisk , данные в хранилище awsElasticBlockStore остаются нетронутыми при удалении Pod из узла.
-
nfs — том nfs позволяет монтировать существующую NFS (сетевую файловую систему) в ваш модуль. Данные в томе NFS не удаляются при удалении Pod из узла. Объем только размонтирован.
-
iscsi — том iscsi позволяет монтировать существующий том iSCSI (SCSI через IP) в ваш модуль.
-
flocker — это диспетчер томов данных кластерного контейнера с открытым исходным кодом. Используется для управления объемами данных. Том Flocker позволяет монтировать набор данных Flocker в модуль. Если набор данных не существует во Flocker, то сначала необходимо создать его с помощью API Flocker.
-
glusterfs — Glusterfs — это сетевая файловая система с открытым исходным кодом. Том glusterfs позволяет монтировать том glusterfs в ваш модуль.
-
rbd — RBD означает блочное устройство Rados . Том rbd позволяет монтировать блочное устройство Rados в ваш модуль. Данные остаются сохраненными после того, как Pod удален из узла.
-
cephfs — том cephfs позволяет монтировать существующий том CephFS в ваш модуль. Данные остаются нетронутыми после удаления стручка из узла.
-
gitRepo — Том gitRepo монтирует пустой каталог и клонирует в него репозиторий git для использования вашим модулем.
-
секретный — секретный том используется для передачи конфиденциальной информации, такой как пароли, в стручки.
-
persistentVolumeClaim — том persistentVolumeClaim используется для монтирования PersistentVolume в модуль. PersistentVolumes — это способ для пользователей «требовать» надежного хранилища (такого как GCE PersistentDisk или том iSCSI), не зная деталей конкретной облачной среды.
-
downwardAPI — том downwardAPI используется для того, чтобы сделать нисходящие данные API доступными для приложений. Он монтирует каталог и записывает запрошенные данные в виде текстовых файлов.
-
azureDiskVolume — AzureDiskVolume используется для подключения диска данных Microsoft Azure к модулю .
emptyDir — это тип тома, который создается, когда Pod впервые назначается узлу. Он остается активным, пока Pod работает на этом узле. Том изначально пуст, и контейнеры в модуле могут читать и записывать файлы в томе emptyDir. После удаления Pod из узла данные в emptyDir удаляются.
hostPath — Этот тип тома монтирует файл или каталог из файловой системы узла узла в ваш модуль.
gcePersistentDisk — этот тип тома монтирует постоянный диск Google Compute Engine (GCE) в ваш модуль. Данные в gcePersistentDisk остаются нетронутыми, когда Pod удаляется из узла.
awsElasticBlockStore — этот тип тома монтирует хранилище эластичных блоков Amazon Web Services (AWS) в ваш модуль. Как и в случае с gcePersistentDisk , данные в хранилище awsElasticBlockStore остаются нетронутыми при удалении Pod из узла.
nfs — том nfs позволяет монтировать существующую NFS (сетевую файловую систему) в ваш модуль. Данные в томе NFS не удаляются при удалении Pod из узла. Объем только размонтирован.
iscsi — том iscsi позволяет монтировать существующий том iSCSI (SCSI через IP) в ваш модуль.
flocker — это диспетчер томов данных кластерного контейнера с открытым исходным кодом. Используется для управления объемами данных. Том Flocker позволяет монтировать набор данных Flocker в модуль. Если набор данных не существует во Flocker, то сначала необходимо создать его с помощью API Flocker.
glusterfs — Glusterfs — это сетевая файловая система с открытым исходным кодом. Том glusterfs позволяет монтировать том glusterfs в ваш модуль.
rbd — RBD означает блочное устройство Rados . Том rbd позволяет монтировать блочное устройство Rados в ваш модуль. Данные остаются сохраненными после того, как Pod удален из узла.
cephfs — том cephfs позволяет монтировать существующий том CephFS в ваш модуль. Данные остаются нетронутыми после удаления стручка из узла.
gitRepo — Том gitRepo монтирует пустой каталог и клонирует в него репозиторий git для использования вашим модулем.
секретный — секретный том используется для передачи конфиденциальной информации, такой как пароли, в стручки.
persistentVolumeClaim — том persistentVolumeClaim используется для монтирования PersistentVolume в модуль. PersistentVolumes — это способ для пользователей «требовать» надежного хранилища (такого как GCE PersistentDisk или том iSCSI), не зная деталей конкретной облачной среды.
downwardAPI — том downwardAPI используется для того, чтобы сделать нисходящие данные API доступными для приложений. Он монтирует каталог и записывает запрошенные данные в виде текстовых файлов.
azureDiskVolume — AzureDiskVolume используется для подключения диска данных Microsoft Azure к модулю .
Постоянный объем и Постоянное требование объема
Постоянный том (PV) — это часть сетевого хранилища, предоставленная администратором. Это ресурс в кластере, который не зависит от любого отдельного модуля, который использует PV.
Заявка о постоянном объеме (PVC) — Запрошенное Kubernetes хранилище для своих контейнеров известно как PVC. Пользователю не нужно знать основную подготовку. Заявки должны быть созданы в том же пространстве имен, в котором создается модуль.
Создание постоянного тома
kind: PersistentVolume ---------> 1
apiVersion: v1
metadata:
name: pv0001 ------------------> 2
labels:
type: local
spec:
capacity: -----------------------> 3
storage: 10Gi ----------------------> 4
accessModes:
- ReadWriteOnce -------------------> 5
hostPath:
path: "/tmp/data01" --------------------------> 6
В приведенном выше коде мы определили —
-
kind: PersistentVolume → Мы определили тип как PersistentVolume, который сообщает kubernetes, что используемый файл yaml предназначен для создания постоянного тома.
-
name: pv0001 → Имя создаваемого нами PersistentVolume.
-
Capacity: → Эта спецификация будет определять емкость PV, которую мы пытаемся создать.
-
storage: 10Gi → Это говорит базовой инфраструктуре, что мы пытаемся получить пространство 10Gi по указанному пути.
-
ReadWriteOnce → Указывает права доступа к тому, который мы создаем.
-
путь: «/ tmp / data01» → Это определение говорит машине, что мы пытаемся создать том по этому пути в базовой инфраструктуре.
kind: PersistentVolume → Мы определили тип как PersistentVolume, который сообщает kubernetes, что используемый файл yaml предназначен для создания постоянного тома.
name: pv0001 → Имя создаваемого нами PersistentVolume.
Capacity: → Эта спецификация будет определять емкость PV, которую мы пытаемся создать.
storage: 10Gi → Это говорит базовой инфраструктуре, что мы пытаемся получить пространство 10Gi по указанному пути.
ReadWriteOnce → Указывает права доступа к тому, который мы создаем.
путь: «/ tmp / data01» → Это определение говорит машине, что мы пытаемся создать том по этому пути в базовой инфраструктуре.
Создание PV
$ kubectl create –f local-01.yaml persistentvolume "pv0001" created
Проверка PV
$ kubectl get pv NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE pv0001 10Gi RWO Available 14s
Описание PV
$ kubectl describe pv pv0001
Создание постоянного тома
kind: PersistentVolumeClaim --------------> 1
apiVersion: v1
metadata:
name: myclaim-1 --------------------> 2
spec:
accessModes:
- ReadWriteOnce ------------------------> 3
resources:
requests:
storage: 3Gi ---------------------> 4
В приведенном выше коде мы определили —
-
kind: PersistentVolumeClaim → Указывает базовой инфраструктуре, что мы пытаемся получить заданный объем пространства.
-
name: myclaim-1 → Название претензии, которую мы пытаемся создать.
-
ReadWriteOnce → Определяет режим заявки, которую мы пытаемся создать.
-
хранилище: 3Gi → Это скажет kubernetes о количестве места, которое мы пытаемся получить.
kind: PersistentVolumeClaim → Указывает базовой инфраструктуре, что мы пытаемся получить заданный объем пространства.
name: myclaim-1 → Название претензии, которую мы пытаемся создать.
ReadWriteOnce → Определяет режим заявки, которую мы пытаемся создать.
хранилище: 3Gi → Это скажет kubernetes о количестве места, которое мы пытаемся получить.
Создание ПВХ
$ kubectl create –f myclaim-1 persistentvolumeclaim "myclaim-1" created
Получение деталей о ПВХ
$ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE myclaim-1 Bound pv0001 10Gi RWO 7s
Опишите ПВХ
$ kubectl describe pv pv0001
Использование PV и PVC с POD
kind: Pod
apiVersion: v1
metadata:
name: mypod
labels:
name: frontendhttp
spec:
containers:
- name: myfrontend
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts: ----------------------------> 1
- mountPath: "/usr/share/tomcat/html"
name: mypd
volumes: -----------------------> 2
- name: mypd
persistentVolumeClaim: ------------------------->3
claimName: myclaim-1
В приведенном выше коде мы определили —
-
volumeMounts: → Это путь в контейнере, на котором будет происходить монтаж.
-
Объем: → Это определение определяет определение объема, на которое мы будем претендовать.
-
persistentVolumeClaim: → При этом мы определяем имя тома, которое будем использовать в определенном модуле.
volumeMounts: → Это путь в контейнере, на котором будет происходить монтаж.
Объем: → Это определение определяет определение объема, на которое мы будем претендовать.
persistentVolumeClaim: → При этом мы определяем имя тома, которое будем использовать в определенном модуле.
Кубернетес — Секреты
Секреты могут быть определены как объекты Kubernetes, используемые для хранения конфиденциальных данных, таких как имя пользователя и пароли с шифрованием.
Существует множество способов создания секретов в Кубернетесе.
- Создание из текстовых файлов.
- Создание из файла yaml.
Создание из текстового файла
Чтобы создать секреты из текстового файла, такого как имя пользователя и пароль, сначала нам нужно сохранить их в текстовом файле и использовать следующую команду.
$ kubectl create secret generic tomcat-passwd –-from-file = ./username.txt –fromfile = ./. password.txt
Создание из файла Yaml
apiVersion: v1 kind: Secret metadata: name: tomcat-pass type: Opaque data: password: <User Password> username: <User Name>
Создание Секрета
$ kubectl create –f Secret.yaml secrets/tomcat-pass
Использование секретов
После того, как мы создали секреты, его можно использовать в модуле или контроллере репликации как —
- Переменная среды
- объем
В качестве переменной среды
Чтобы использовать секрет в качестве переменной окружения, мы будем использовать env в разделе spec файла pod yaml.
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: tomcat-pass
Как объем
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat:7.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"
Секретная конфигурация как переменная среды
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
spec:
nodeSelector:
resource-group:
containers:
- name: appname
image:
imagePullPolicy: Always
ports:
- containerPort: 3000
env: -----------------------------> 1
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: tomcat-secrets
В приведенном выше коде под определением env мы используем секреты в качестве переменной среды в контроллере репликации.
Секреты как громкость
apiVersion: v1
kind: pod
metadata:
name: appname
spec:
metadata:
name: appname
spec:
volumes:
- name: "secretstest"
secret:
secretName: tomcat-pass
containers:
- image: tomcat: 8.0
name: awebserver
volumeMounts:
- mountPath: "/tmp/mysec"
name: "secretstest"
Кубернетес — Сетевая политика
Сетевая политика определяет, как модули в одном и том же пространстве имен будут взаимодействовать друг с другом и конечной точкой сети. Это требует, чтобы расширения / v1beta1 / networkpolicies были включены в конфигурации времени выполнения на сервере API. Его ресурсы используют метки для выбора модулей и определения правил, разрешающих трафик для конкретного модуля в дополнение к тому, который определен в пространстве имен.
Во-первых, нам нужно настроить политику изоляции пространства имен. В основном, этот вид сетевых политик требуется для балансировщиков нагрузки.
kind: Namespace
apiVersion: v1
metadata:
annotations:
net.beta.kubernetes.io/network-policy: |
{
"ingress":
{
"isolation": "DefaultDeny"
}
}
$ kubectl annotate ns <namespace> "net.beta.kubernetes.io/network-policy =
{\"ingress\": {\"isolation\": \"DefaultDeny\"}}"
Как только пространство имен создано, нам нужно создать сетевую политику.
Сетевая политика Yaml
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: allow-frontend
namespace: myns
spec:
podSelector:
matchLabels:
role: backend
ingress:
- from:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
Кубернетес — API
Kubernetes API служит основой для декларативной схемы конфигурации системы. Инструмент командной строки Kubectl можно использовать для создания, обновления, удаления и получения объекта API. Kubernetes API выступает коммуникатором среди различных компонентов Kubernetes.
Добавление API в Kubernetes
Добавление нового API в Kubernetes добавит новые функции в Kubernetes, которые повысят функциональность Kubernetes. Однако наряду с этим также увеличатся стоимость и ремонтопригодность системы. Чтобы создать баланс между стоимостью и сложностью, для него есть несколько наборов.
Добавляемый API должен быть полезен для более чем 50% пользователей. Другого способа реализации функциональности в Кубернетесе нет. Исключительные обстоятельства обсуждаются на собрании сообщества Kubernetes, а затем добавляется API.
Изменения API
Чтобы расширить возможности Kubernetes, в систему постоянно вносятся изменения. Это сделано командой Kubernetes, чтобы добавить функциональность в Kubernetes, не удаляя и не влияя на существующую функциональность системы.
Чтобы продемонстрировать общий процесс, вот (гипотетический) пример —
-
Пользователь помещает объект Pod в / api / v7beta1 / …
-
JSON распаковывается в структуру v7beta1.Pod
-
Значения по умолчанию применяются к v7beta1.Pod
-
V7beta1.Pod преобразуется в структуру api.Pod
-
Api.Pod проверяется, и любые ошибки возвращаются пользователю
-
Api.Pod преобразуется в v6.Pod (потому что v6 является последней стабильной версией)
-
V6.Pod собирается в JSON и записывается в etcd
Пользователь помещает объект Pod в / api / v7beta1 / …
JSON распаковывается в структуру v7beta1.Pod
Значения по умолчанию применяются к v7beta1.Pod
V7beta1.Pod преобразуется в структуру api.Pod
Api.Pod проверяется, и любые ошибки возвращаются пользователю
Api.Pod преобразуется в v6.Pod (потому что v6 является последней стабильной версией)
V6.Pod собирается в JSON и записывается в etcd
Теперь, когда у нас есть объект Pod, пользователь может получить этот объект в любой поддерживаемой версии API. Например —
-
Пользователь ПОЛУЧАЕТ Pod из / api / v5 / …
-
JSON читается из etcd и распаковывается в структуру v6.Pod
-
Значения по умолчанию применяются к v6.Pod
-
V6.Pod преобразуется в структуру api.Pod
-
Api.Pod преобразуется в структуру v5.Pod
-
V5.Pod маршалируется в JSON и отправляется пользователю
Пользователь ПОЛУЧАЕТ Pod из / api / v5 / …
JSON читается из etcd и распаковывается в структуру v6.Pod
Значения по умолчанию применяются к v6.Pod
V6.Pod преобразуется в структуру api.Pod
Api.Pod преобразуется в структуру v5.Pod
V5.Pod маршалируется в JSON и отправляется пользователю
Смысл этого процесса заключается в том, что изменения API должны выполняться аккуратно и с обратной совместимостью.
Управление версиями API
Чтобы упростить поддержку нескольких структур, Kubernetes поддерживает несколько версий API, каждая с разными путями API, такими как / api / v1 или / apsi / extensions / v1beta1.
Стандарты управления версиями в Kubernetes определены в нескольких стандартах.
Альфа уровень
-
Эта версия содержит альфа (например, v1alpha1)
-
Эта версия может содержать ошибки; включенная версия может иметь ошибки
-
Поддержка ошибок может быть прекращена в любой момент времени.
-
Рекомендуется использовать только в краткосрочном тестировании, поскольку поддержка может присутствовать не всегда.
Эта версия содержит альфа (например, v1alpha1)
Эта версия может содержать ошибки; включенная версия может иметь ошибки
Поддержка ошибок может быть прекращена в любой момент времени.
Рекомендуется использовать только в краткосрочном тестировании, поскольку поддержка может присутствовать не всегда.
Бета уровень
-
Название версии содержит бета-версию (например, v2beta3)
-
Код полностью протестирован, и разрешенная версия должна быть стабильной.
-
Поддержка этой функции не будет прекращена; Там могут быть небольшие изменения.
-
Рекомендуется только для не критичного для бизнеса использования из-за возможных несовместимых изменений в последующих выпусках.
Название версии содержит бета-версию (например, v2beta3)
Код полностью протестирован, и разрешенная версия должна быть стабильной.
Поддержка этой функции не будет прекращена; Там могут быть небольшие изменения.
Рекомендуется только для не критичного для бизнеса использования из-за возможных несовместимых изменений в последующих выпусках.
Стабильный уровень
-
Имя версии vX, где X — целое число.
-
Стабильные версии функций появятся в выпущенном программном обеспечении для многих последующих версий.
Имя версии vX, где X — целое число.
Стабильные версии функций появятся в выпущенном программном обеспечении для многих последующих версий.
Кубернетес — Кубектл
Kubectl — это утилита командной строки для взаимодействия с API Kubernetes. Это интерфейс, который используется для связи и управления модулями в кластере Kubernetes.
Нужно настроить локальный kubectl для взаимодействия с кластером Kubernetes.
Настройка Kubectl
Загрузите исполняемый файл на локальную рабочую станцию с помощью команды curl.
В линуксе
$ curl -O https://storage.googleapis.com/kubernetesrelease/ release/v1.5.2/bin/linux/amd64/kubectl
На рабочей станции OS X
$ curl -O https://storage.googleapis.com/kubernetesrelease/ release/v1.5.2/bin/darwin/amd64/kubectl
После завершения загрузки переместите двоичные файлы в путь к системе.
$ chmod +x kubectl $ mv kubectl /usr/local/bin/kubectl
Конфигурирование Kubectl
Ниже приведены шаги для выполнения операции конфигурации.
$ kubectl config set-cluster default-cluster --server = https://${MASTER_HOST} --
certificate-authority = ${CA_CERT}
$ kubectl config set-credentials default-admin --certificateauthority = ${
CA_CERT} --client-key = ${ADMIN_KEY} --clientcertificate = ${
ADMIN_CERT}
$ kubectl config set-context default-system --cluster = default-cluster --
user = default-admin
$ kubectl config use-context default-system
-
Замените $ {MASTER_HOST} на адрес или имя главного узла, использованные в предыдущих шагах.
-
Замените $ {CA_CERT} абсолютным путем к ca.pem, созданному на предыдущих шагах.
-
Замените $ {ADMIN_KEY} абсолютным путем к admin-key.pem, созданному на предыдущих шагах.
-
Замените $ {ADMIN_CERT} абсолютным путем к admin.pem, созданному на предыдущих шагах.
Замените $ {MASTER_HOST} на адрес или имя главного узла, использованные в предыдущих шагах.
Замените $ {CA_CERT} абсолютным путем к ca.pem, созданному на предыдущих шагах.
Замените $ {ADMIN_KEY} абсолютным путем к admin-key.pem, созданному на предыдущих шагах.
Замените $ {ADMIN_CERT} абсолютным путем к admin.pem, созданному на предыдущих шагах.
Проверка настройки
Чтобы проверить, нормально ли работает kubectl , проверьте, правильно ли настроен клиент Kubernetes.
$ kubectl get nodes NAME LABELS STATUS Vipin.com Kubernetes.io/hostname = vipin.mishra.com Ready
Кубернетес — Kubectl Команды
Kubectl контролирует кластер Kubernetes. Это один из ключевых компонентов Kubernetes, который запускается на рабочей станции на любом компьютере после завершения установки. Он имеет возможность управлять узлами в кластере.
Команды Kubectl используются для взаимодействия и управления объектами Kubernetes и кластером. В этой главе мы обсудим несколько команд, используемых в Kubernetes через kubectl.
kubectl annotate — обновляет аннотацию на ресурсе.
$kubectl annotate [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N = VAL_N [--resource-version = version]
Например,
kubectl annotate pods tomcat description = 'my frontend'
api-версии kubectl — печатает поддерживаемые версии API в кластере.
$ kubectl api-version;
kubectl apply — имеет возможность конфигурировать ресурс по файлу или стандартному вводу.
$ kubectl apply –f <filename>
kubectl attach — это прикрепляет вещи к работающему контейнеру.
$ kubectl attach <pod> –c <container> $ kubectl attach 123456-7890 -c tomcat-conatiner
kubectl autoscale — используется для автоматического масштабирования таких модулей, как Развертывание, набор реплик, Контроллер репликации.
$ kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min = MINPODS] -- max = MAXPODS [--cpu-percent = CPU] [flags] $ kubectl autoscale deployment foo --min = 2 --max = 10
kubectl cluster-info — отображает информацию о кластере.
$ kubectl cluster-info
kubectl cluster-info dump — выводит соответствующую информацию о кластере для отладки и диагностики.
$ kubectl cluster-info dump $ kubectl cluster-info dump --output-directory = /path/to/cluster-state
kubectl config — изменяет файл kubeconfig.
$ kubectl config <SUBCOMMAD> $ kubectl config –-kubeconfig <String of File name>
kubectl config current-context — отображает текущий контекст.
$ kubectl config current-context #deploys the current context
kubectl config delete-cluster — удаляет указанный кластер из kubeconfig.
$ kubectl config delete-cluster <Cluster Name>
kubectl config delete-context — удаляет указанный контекст из kubeconfig.
$ kubectl config delete-context <Context Name>
kubectl config get-clusters — отображает кластер, определенный в kubeconfig.
$ kubectl config get-cluster $ kubectl config get-cluster <Cluser Name>
kubectl config get-contexts — описывает один или несколько контекстов.
$ kubectl config get-context <Context Name>
kubectl config set-cluster — Устанавливает запись кластера в Kubernetes.
$ kubectl config set-cluster NAME [--server = server] [--certificateauthority = path/to/certificate/authority] [--insecure-skip-tls-verify = true]
kubectl config set-context — устанавливает запись контекста в точке входа kubernetes.
$ kubectl config set-context NAME [--cluster = cluster_nickname] [-- user = user_nickname] [--namespace = namespace] $ kubectl config set-context prod –user = vipin-mishra
kubectl config set-credentials — Устанавливает запись пользователя в kubeconfig.
$ kubectl config set-credentials cluster-admin --username = vipin -- password = uXFGweU9l35qcif
kubectl config set — устанавливает индивидуальное значение в файле kubeconfig.
$ kubectl config set PROPERTY_NAME PROPERTY_VALUE
kubectl config unset — сбрасывает определенный компонент в kubectl.
$ kubectl config unset PROPERTY_NAME PROPERTY_VALUE
kubectl config use-context — устанавливает текущий контекст в файле kubectl.
$ kubectl config use-context <Context Name>
представление конфигурации kubectl
$ kubectl config view
$ kubectl config view –o jsonpath='{.users[?(@.name == "e2e")].user.password}'
kubectl cp — копирование файлов и каталогов в контейнеры и из них.
$ kubectl cp <Files from source> <Files to Destinatiion> $ kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container>
kubectl create — создать ресурс по имени файла или стандартному вводу. Для этого принимаются форматы JSON или YAML.
$ kubectl create –f <File Name> $ cat <file name> | kubectl create –f -
Таким же образом, мы можем создать несколько вещей, перечисленных в списке, используя команду create вместе с kubectl .
- развертывание
- Пространство имен
- квота
- секретный докер-реестр
- секрет
- секретный дженерик
- секретный тлс
- ServiceAccount
- сервисный кластер
- сервис балансировки нагрузки
- сервисный узел
kubectl delete — удаляет ресурсы по имени файла, стандартному имени, ресурсу и именам.
$ kubectl delete –f ([-f FILENAME] | TYPE [(NAME | -l label | --all)])
kubectl description — описывает любой конкретный ресурс в kubernetes. Показывает детали ресурса или группы ресурсов.
$ kubectl describe <type> <type name> $ kubectl describe pod tomcat
Слив kubectl — Это используется для слива узла в целях обслуживания. Он готовит узел к техническому обслуживанию. Это пометит узел как недоступный, так что ему не следует назначать новый контейнер, который будет создан.
$ kubectl drain tomcat –force
kubectl edit — используется для завершения ресурсов на сервере. Это позволяет напрямую редактировать ресурс, который можно получить с помощью инструмента командной строки.
$ kubectl edit <Resource/Name | File Name) Ex. $ kubectl edit rc/tomcat
kubectl exec — это помогает выполнить команду в контейнере.
$ kubectl exec POD <-c CONTAINER > -- COMMAND < args...> $ kubectl exec tomcat 123-5-456 date
kubectl expose — используется для представления объектов Kubernetes, таких как pod, контроллер репликации и служба, в качестве новой службы Kubernetes. Это имеет возможность выставить его через работающий контейнер или из файла yaml .
$ kubectl expose (-f FILENAME | TYPE NAME) [--port=port] [--protocol = TCP|UDP] [--target-port = number-or-name] [--name = name] [--external-ip = external-ip-ofservice] [--type = type] $ kubectl expose rc tomcat –-port=80 –target-port = 30000 $ kubectl expose –f tomcat.yaml –port = 80 –target-port =
kubectl get — эта команда способна извлекать данные в кластере о ресурсах Kubernetes.
$ kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columnsfile=...| go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...] (TYPE [NAME | -l label] | TYPE/NAME ...) [flags]
Например,
$ kubectl get pod <pod name> $ kubectl get service <Service name>
kubectl logs — они используются для получения журналов контейнера в модуле. Печать журналов может определять имя контейнера в модуле. Если POD имеет только один контейнер, нет необходимости определять его имя.
$ kubectl logs [-f] [-p] POD [-c CONTAINER] Example $ kubectl logs tomcat. $ kubectl logs –p –c tomcat.8
kubectl port-forward — они используются для переадресации одного или нескольких локальных портов на модули.
$ kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N] $ kubectl port-forward tomcat 3000 4000 $ kubectl port-forward tomcat 3000:5000
kubectl replace — возможность замены ресурса по имени файла или стандартному вводу .
$ kubectl replace -f FILENAME $ kubectl replace –f tomcat.yml $ cat tomcat.yml | kubectl replace –f -
kubectl roll-update — выполняет непрерывное обновление на контроллере репликации. Заменяет указанный контроллер репликации новым контроллером репликации, одновременно обновляя POD.
$ kubectl rolling-update OLD_CONTROLLER_NAME ([NEW_CONTROLLER_NAME] -- image = NEW_CONTAINER_IMAGE | -f NEW_CONTROLLER_SPEC) $ kubectl rolling-update frontend-v1 –f freontend-v2.yaml
Развертывание kubectl — оно способно управлять развертыванием развертывания.
$ Kubectl rollout <Sub Command> $ kubectl rollout undo deployment/tomcat
Помимо вышесказанного, мы можем выполнить несколько задач, используя развертывание, таких как —
- история развертывания
- пауза
- развертывание резюме
- статус развертывания
- отмена отмены
kubectl run — команда Run позволяет запускать образ в кластере Kubernetes.
$ kubectl run NAME --image = image [--env = "key = value"] [--port = port] [-- replicas = replicas] [--dry-run = bool] [--overrides = inline-json] [--command] -- [COMMAND] [args...] $ kubectl run tomcat --image = tomcat:7.0 $ kubectl run tomcat –-image = tomcat:7.0 –port = 5000
kubectl scale — масштабирует размер развертываний Kubernetes, ReplicaSet, Replication Controller или задания.
$ kubectl scale [--resource-version = version] [--current-replicas = count] -- replicas = COUNT (-f FILENAME | TYPE NAME ) $ kubectl scale –-replica = 3 rs/tomcat $ kubectl scale –replica = 3 tomcat.yaml
kubectl set image — обновляет изображение шаблона pod.
$ kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1 = CONTAINER_IMAGE_1 ... CONTAINER_NAME_N = CONTAINER_IMAGE_N $ kubectl set image deployment/tomcat busybox = busybox ngnix = ngnix:1.9.1 $ kubectl set image deployments, rc tomcat = tomcat6.0 --all
kubectl set resources — используется для установки содержимого ресурса. Обновляет ресурс / лимиты на объект с помощью шаблона pod.
$ kubectl set resources (-f FILENAME | TYPE NAME) ([--limits = LIMITS & -- requests = REQUESTS] $ kubectl set resources deployment tomcat -c = tomcat -- limits = cpu = 200m,memory = 512Mi
Верхний узел kubectl — отображает использование процессора / памяти / хранилища. Команда top позволяет увидеть потребление ресурсов для узлов.
$ kubectl top node [node Name]
Эту же команду можно использовать и с модулем.
Kubernetes — Создание приложения
Чтобы создать приложение для развертывания в Kubernetes, нам нужно сначала создать приложение в Docker. Это можно сделать двумя способами —
- Скачивая
- Из файла Docker
Скачивая
Существующий образ можно загрузить из центра Docker и сохранить в локальном реестре Docker.
Для этого выполните команду Docker pull .
$ docker pull --help Usage: docker pull [OPTIONS] NAME[:TAG|@DIGEST] Pull an image or a repository from the registry -a, --all-tags = false Download all tagged images in the repository --help = false Print usage
Ниже будет вывод вышеуказанного кода.

На скриншоте выше показан набор изображений, которые хранятся в нашем локальном реестре Docker.
Если мы хотим построить контейнер из образа, который состоит из приложения для тестирования, мы можем сделать это с помощью команды запуска Docker.
$ docker run –i –t unbunt /bin/bash
Из файла Docker
Чтобы создать приложение из файла Docker, нам нужно сначала создать файл Docker.
Ниже приведен пример файла Jenkins Docker.
FROM ubuntu:14.04
MAINTAINER vipinkumarmishra@virtusapolaris.com
ENV REFRESHED_AT 2017-01-15
RUN apt-get update -qq && apt-get install -qqy curl
RUN curl https://get.docker.io/gpg | apt-key add -
RUN echo deb http://get.docker.io/ubuntu docker main > /etc/apt/↩
sources.list.d/docker.list
RUN apt-get update -qq && apt-get install -qqy iptables ca-↩
certificates lxc openjdk-6-jdk git-core lxc-docker
ENV JENKINS_HOME /opt/jenkins/data
ENV JENKINS_MIRROR http://mirrors.jenkins-ci.org
RUN mkdir -p $JENKINS_HOME/plugins
RUN curl -sf -o /opt/jenkins/jenkins.war -L $JENKINS_MIRROR/war-↩
stable/latest/jenkins.war
RUN for plugin in chucknorris greenballs scm-api git-client git ↩
ws-cleanup ;\
do curl -sf -o $JENKINS_HOME/plugins/${plugin}.hpi \
-L $JENKINS_MIRROR/plugins/${plugin}/latest/${plugin}.hpi ↩
; done
ADD ./dockerjenkins.sh /usr/local/bin/dockerjenkins.sh
RUN chmod +x /usr/local/bin/dockerjenkins.sh
VOLUME /var/lib/docker
EXPOSE 8080
ENTRYPOINT [ "/usr/local/bin/dockerjenkins.sh" ]
После создания вышеуказанного файла сохраните его с именем Dockerfile и cd в пути к файлу. Затем выполните следующую команду.

$ sudo docker build -t jamtur01/Jenkins .
Как только изображение построено, мы можем проверить, работает ли оно нормально и может ли оно быть преобразовано в контейнер.
$ docker run –i –t jamtur01/Jenkins /bin/bash
Kubernetes — Развертывание приложений
Развертывание — это метод преобразования изображений в контейнеры и последующего размещения этих изображений в модулях в кластере Kubernetes. Это также помогает в настройке кластера приложений, который включает развертывание службы, модуля, контроллера репликации и набора реплик. Кластер можно настроить таким образом, чтобы приложения, развернутые на модуле, могли обмениваться данными друг с другом.
В этой настройке у нас может быть настройка балансировки нагрузки поверх одного приложения, перенаправляющего трафик на набор модулей, и позже они связываются с внутренними модулями. Связь между модулями происходит через сервисный объект, построенный в Кубернетесе.
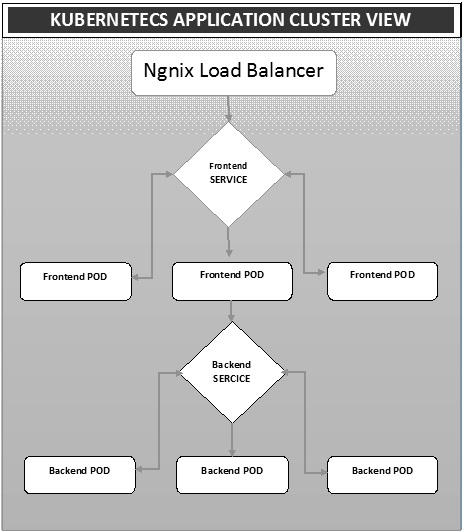
Namix Load Balancer Yaml File
apiVersion: v1
kind: Service
metadata:
name: oppv-dev-nginx
labels:
k8s-app: omni-ppv-api
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31999
name: omninginx
selector:
k8s-app: appname
component: nginx
env: dev
Контроллер репликации Ngnix Yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: appname
spec:
replicas: replica_count
template:
metadata:
name: appname
labels:
k8s-app: appname
component: nginx
env: env_name
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: BACKEND_HOST
value: oppv-env_name-node:3000
Интерфейсный сервис Yaml File
apiVersion: v1
kind: Service
metadata:
name: appname
labels:
k8s-app: appname
spec:
type: NodePort
ports:
- name: http
port: 3000
protocol: TCP
targetPort: 3000
selector:
k8s-app: appname
component: nodejs
env: dev
Файл Yaml контроллера репликации внешнего интерфейса
apiVersion: v1
kind: ReplicationController
metadata:
name: Frontend
spec:
replicas: 3
template:
metadata:
name: frontend
labels:
k8s-app: Frontend
component: nodejs
env: Dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 3000
resources:
requests:
memory: "request_mem"
cpu: "limit_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
env:
- name: ENV
valueFrom:
configMapKeyRef:
name: appname
key: config-env
Бэкэнд-сервис Yaml File
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
k8s-app: backend
spec:
type: NodePort
ports:
- name: http
port: 9010
protocol: TCP
targetPort: 9000
selector:
k8s-app: appname
component: play
env: dev
Файл Yaml контроллера резервного копирования
apiVersion: v1
kind: ReplicationController
metadata:
name: backend
spec:
replicas: 3
template:
metadata:
name: backend
labels:
k8s-app: beckend
component: play
env: dev
spec:
nodeSelector:
resource-group: oppv
containers:
- name: appname
image: IMAGE_TEMPLATE
imagePullPolicy: Always
ports:
- containerPort: 9000
command: [ "./docker-entrypoint.sh" ]
resources:
requests:
memory: "request_mem"
cpu: "request_cpu"
limits:
memory: "limit_mem"
cpu: "limit_cpu"
volumeMounts:
- name: config-volume
mountPath: /app/vipin/play/conf
volumes:
- name: config-volume
configMap:
name: appname
Кубернетес — автомасштабирование
Автоматическое масштабирование является одной из ключевых функций в кластере Kubernetes. Это особенность, в которой кластер способен увеличивать количество узлов при увеличении потребности в ответе на обслуживание и уменьшать количество узлов при уменьшении потребности. Эта функция автоматического масштабирования в настоящее время поддерживается в Google Cloud Engine (GCE) и Google Container Engine (GKE) и скоро начнет работать с AWS.
Чтобы настроить масштабируемую инфраструктуру в GCE, нам нужно сначала активировать проект GCE с включенными функциями облачного мониторинга Google, регистрации в облаке Google и включения стека-драйвера.
Сначала мы настроим кластер с несколькими работающими в нем узлами. После этого нам нужно установить следующую переменную окружения.
Переменная среды
export NUM_NODES = 2 export KUBE_AUTOSCALER_MIN_NODES = 2 export KUBE_AUTOSCALER_MAX_NODES = 5 export KUBE_ENABLE_CLUSTER_AUTOSCALER = true
После этого мы запустим кластер, запустив kube-up.sh . Это создаст кластер вместе с автоматическим скалярным дополнением кластера.
./cluster/kube-up.sh
При создании кластера мы можем проверить наш кластер, используя следующую команду kubectl.
$ kubectl get nodes NAME STATUS AGE kubernetes-master Ready,SchedulingDisabled 10m kubernetes-minion-group-de5q Ready 10m kubernetes-minion-group-yhdx Ready 8m
Теперь мы можем развернуть приложение в кластере, а затем включить горизонтальный модуль автоматического масштабирования. Это можно сделать с помощью следующей команды.
$ kubectl autoscale deployment <Application Name> --cpu-percent = 50 --min = 1 -- max = 10
Приведенная выше команда показывает, что мы будем поддерживать как минимум одну и максимум 10 копий POD по мере увеличения нагрузки на приложение.
Мы можем проверить состояние автоскалера, выполнив команду $ kubclt get hpa . Мы увеличим нагрузку на модули, используя следующую команду.
$ kubectl run -i --tty load-generator --image = busybox /bin/sh $ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
Мы можем проверить hpa , выполнив команду $ kubectl get hpa .
$ kubectl get hpa NAME REFERENCE TARGET CURRENT php-apache Deployment/php-apache/scale 50% 310% MINPODS MAXPODS AGE 1 20 2m $ kubectl get deployment php-apache NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE php-apache 7 7 7 3 4m
Мы можем проверить количество работающих модулей, используя следующую команду.
jsz@jsz-desk2:~/k8s-src$ kubectl get pods php-apache-2046965998-3ewo6 0/1 Pending 0 1m php-apache-2046965998-8m03k 1/1 Running 0 1m php-apache-2046965998-ddpgp 1/1 Running 0 5m php-apache-2046965998-lrik6 1/1 Running 0 1m php-apache-2046965998-nj465 0/1 Pending 0 1m php-apache-2046965998-tmwg1 1/1 Running 0 1m php-apache-2046965998-xkbw1 0/1 Pending 0 1m
И, наконец, мы можем получить статус узла.
$ kubectl get nodes NAME STATUS AGE kubernetes-master Ready,SchedulingDisabled 9m kubernetes-minion-group-6z5i Ready 43s kubernetes-minion-group-de5q Ready 9m kubernetes-minion-group-yhdx Ready 9m
Kubernetes — Настройка панели управления
Настройка информационной панели Kubernetes включает в себя несколько этапов с набором инструментов, необходимых для ее настройки.
- Докер (1.3+)
- идти (1,5+)
- nodejs (4.2.2+)
- нпм (1,3+)
- Ява (7+)
- глоток (3,9+)
- Кубернетес (1.1.2+)
Настройка панели инструментов
$ sudo apt-get update && sudo apt-get upgrade Installing Python $ sudo apt-get install python $ sudo apt-get install python3 Installing GCC $ sudo apt-get install gcc-4.8 g++-4.8 Installing make $ sudo apt-get install make Installing Java $ sudo apt-get install openjdk-7-jdk Installing Node.js $ wget https://nodejs.org/dist/v4.2.2/node-v4.2.2.tar.gz $ tar -xzf node-v4.2.2.tar.gz $ cd node-v4.2.2 $ ./configure $ make $ sudo make install Installing gulp $ npm install -g gulp $ npm install gulp
Проверка версий
Java Version $ java –version java version "1.7.0_91" OpenJDK Runtime Environment (IcedTea 2.6.3) (7u91-2.6.3-1~deb8u1+rpi1) OpenJDK Zero VM (build 24.91-b01, mixed mode) $ node –v V4.2.2 $ npn -v 2.14.7 $ gulp -v [09:51:28] CLI version 3.9.0 $ sudo gcc --version gcc (Raspbian 4.8.4-1) 4.8.4 Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Установка GO
$ git clone https://go.googlesource.com/go $ cd go $ git checkout go1.4.3 $ cd src Building GO $ ./all.bash $ vi /root/.bashrc In the .bashrc export GOROOT = $HOME/go export PATH = $PATH:$GOROOT/bin $ go version go version go1.4.3 linux/arm
Установка Kubernetes Dashboard
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard $ npm install -g bower
Запуск панели инструментов
$ git clone https://github.com/kubernetes/dashboard.git $ cd dashboard $ npm install -g bower $ gulp serve [11:19:12] Requiring external module babel-core/register [11:20:50] Using gulpfile ~/dashboard/gulpfile.babel.js [11:20:50] Starting 'package-backend-source'... [11:20:50] Starting 'kill-backend'... [11:20:50] Finished 'kill-backend' after 1.39 ms [11:20:50] Starting 'scripts'... [11:20:53] Starting 'styles'... [11:21:41] Finished 'scripts' after 50 s [11:21:42] Finished 'package-backend-source' after 52 s [11:21:42] Starting 'backend'... [11:21:43] Finished 'styles' after 49 s [11:21:43] Starting 'index'... [11:21:44] Finished 'index' after 1.43 s [11:21:44] Starting 'watch'... [11:21:45] Finished 'watch' after 1.41 s [11:23:27] Finished 'backend' after 1.73 min [11:23:27] Starting 'spawn-backend'... [11:23:27] Finished 'spawn-backend' after 88 ms [11:23:27] Starting 'serve'... 2016/02/01 11:23:27 Starting HTTP server on port 9091 2016/02/01 11:23:27 Creating API client for 2016/02/01 11:23:27 Creating Heapster REST client for http://localhost:8082 [11:23:27] Finished 'serve' after 312 ms [BS] [BrowserSync SPA] Running... [BS] Access URLs: -------------------------------------- Local: http://localhost:9090/ External: http://192.168.1.21:9090/ -------------------------------------- UI: http://localhost:3001 UI External: http://192.168.1.21:3001 -------------------------------------- [BS] Serving files from: /root/dashboard/.tmp/serve [BS] Serving files from: /root/dashboard/src/app/frontend [BS] Serving files from: /root/dashboard/src/app
Панель управления Kubernetes
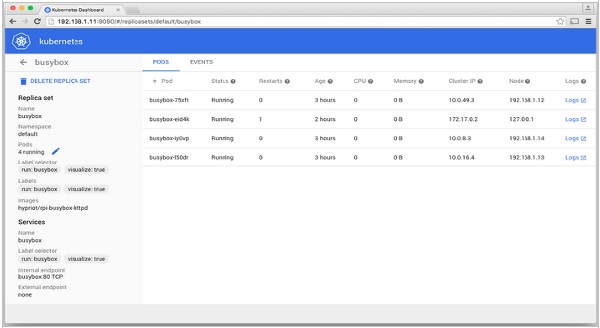
Кубернетес — Мониторинг
Мониторинг является одним из ключевых компонентов управления большими кластерами. Для этого у нас есть ряд инструментов.
Мониторинг с помощью Прометея
Это система мониторинга и оповещения. Он был построен в SoundCloud и был открыт в 2012 году. Он очень хорошо обрабатывает многомерные данные.
Прометей имеет несколько компонентов для участия в мониторинге —
-
Прометей — это основной компонент, который собирает и хранит данные.
-
Исследование узла Prometheus — получает матрицы уровня хоста и предоставляет их Prometheus.
-
Ranch-eye — это гакрокси и выставляет статистику cAdvisor Прометею.
-
Графана — Визуализация данных.
-
InfuxDB — база данных временных рядов, специально используемая для хранения данных из ранчо.
-
Prom-ranch-exporter — это простое приложение node.js, которое помогает запрашивать у сервера Rancher статус стека службы.
Прометей — это основной компонент, который собирает и хранит данные.
Исследование узла Prometheus — получает матрицы уровня хоста и предоставляет их Prometheus.
Ranch-eye — это гакрокси и выставляет статистику cAdvisor Прометею.
Графана — Визуализация данных.
InfuxDB — база данных временных рядов, специально используемая для хранения данных из ранчо.
Prom-ranch-exporter — это простое приложение node.js, которое помогает запрашивать у сервера Rancher статус стека службы.
Sematext Docker Agent
Это современный Docker-ориентированный агент метрик, событий и сбора журналов. Он работает как крошечный контейнер на каждом хосте Docker и собирает журналы, метрики и события для всех узлов кластера и контейнеров. Он обнаруживает все контейнеры (один модуль может содержать несколько контейнеров), включая контейнеры для основных служб Kubernetes, если основные службы развернуты в контейнерах Docker. После его развертывания все журналы и метрики сразу доступны из коробки.
Развертывание агентов на узлах
Kubernetes предоставляет DeamonSets, который обеспечивает добавление модулей в кластер.
Настройка агента SemaText Docker
Это настраивается с помощью переменных среды.
-
Получите бесплатный аккаунт на apps.sematext.com , если у вас его еще нет.
-
Создайте приложение SPM типа «Docker», чтобы получить маркер приложения SPM. SPM App будет хранить ваши показатели производительности Kubernetes и события.
-
Создайте приложение Logsene для получения токена приложения Logsene. Logsene App будет хранить ваши логи Kubernetes.
-
Измените значения LOGSENE_TOKEN и SPM_TOKEN в определении DaemonSet, как показано ниже.
-
Загрузите последний шаблон sematext-agent-daemonset.yml (простой текст) (также показан ниже).
-
Храните его где-нибудь на диске.
-
Замените заполнители SPM_TOKEN и LOGSENE_TOKEN на токены SPM и приложения Logsene.
Получите бесплатный аккаунт на apps.sematext.com , если у вас его еще нет.
Создайте приложение SPM типа «Docker», чтобы получить маркер приложения SPM. SPM App будет хранить ваши показатели производительности Kubernetes и события.
Создайте приложение Logsene для получения токена приложения Logsene. Logsene App будет хранить ваши логи Kubernetes.
Измените значения LOGSENE_TOKEN и SPM_TOKEN в определении DaemonSet, как показано ниже.
Загрузите последний шаблон sematext-agent-daemonset.yml (простой текст) (также показан ниже).
Храните его где-нибудь на диске.
Замените заполнители SPM_TOKEN и LOGSENE_TOKEN на токены SPM и приложения Logsene.
Создать объект DaemonSet
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: sematext-agent
spec:
template:
metadata:
labels:
app: sematext-agent
spec:
selector: {}
dnsPolicy: "ClusterFirst"
restartPolicy: "Always"
containers:
- name: sematext-agent
image: sematext/sematext-agent-docker:latest
imagePullPolicy: "Always"
env:
- name: SPM_TOKEN
value: "REPLACE THIS WITH YOUR SPM TOKEN"
- name: LOGSENE_TOKEN
value: "REPLACE THIS WITH YOUR LOGSENE TOKEN"
- name: KUBERNETES
value: "1"
volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock
- mountPath: /etc/localtime
name: localtime
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: localtime
hostPath:
path: /etc/localtime
Запуск агента доката Sematext с помощью kubectl
$ kubectl create -f sematext-agent-daemonset.yml daemonset "sematext-agent-daemonset" created
Kubernetes Log
Журналы контейнеров Kubernetes мало чем отличаются от журналов контейнеров Docker. Тем не менее, пользователи Kubernetes должны просматривать журналы для развернутых модулей. Следовательно, очень полезно иметь информацию, специфичную для Kubernetes, для поиска в журнале, например:
- Пространство имен Kubernetes
- Кубернетес под названием
- Кубернетес контейнер имя
- Название образа докера
- Кубернетес UID
Использование стека ELK и LogSpout
Стек ELK включает Elasticsearch, Logstash и Kibana. Для сбора и пересылки журналов на платформу ведения журнала мы будем использовать LogSpout (хотя есть и другие варианты, такие как FluentD).
В следующем коде показано, как настроить кластер ELK в Kubernetes и создать службу для ElasticSearch.
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elk
labels:
component: elasticsearch
spec:
type: LoadBalancer
selector:
component: elasticsearch
ports:
- name: http
port: 9200
protocol: TCP
- name: transport
port: 9300
protocol: TCP
Создание контроллера репликации
apiVersion: v1
kind: ReplicationController
metadata:
name: es
namespace: elk
labels:
component: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
component: elasticsearch
spec:
serviceAccount: elasticsearch
containers:
- name: es
securityContext:
capabilities:
add:
- IPC_LOCK
image: quay.io/pires/docker-elasticsearch-kubernetes:1.7.1-4
env:
- name: KUBERNETES_CA_CERTIFICATE_FILE
value: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "CLUSTER_NAME"
value: "myesdb"
- name: "DISCOVERY_SERVICE"
value: "elasticsearch"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: HTTP_ENABLE
value: "true"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
volumeMounts:
- mountPath: /data
name: storage
volumes:
- name: storage
emptyDir: {}
Кибана URL
Для Kibana мы предоставляем URL-адрес Elasticsearch в качестве переменной среды.
- name: KIBANA_ES_URL value: "http://elasticsearch.elk.svc.cluster.local:9200" - name: KUBERNETES_TRUST_CERT value: "true"
Пользовательский интерфейс Kibana будет доступен через контейнерный порт 5601 и соответствующую комбинацию хост / порт узла. Когда вы начнете, в Kibana не будет никаких данных (что ожидается, поскольку вы не выдвинули никаких данных).