Splunk — Обзор
Splunk — это программное обеспечение, которое обрабатывает и извлекает информацию из машинных данных и других форм больших данных. Эти машинные данные генерируются процессором, на котором работает веб-сервер, устройства IOT, журналы из мобильных приложений и т. Д. Нет необходимости предоставлять эти данные конечным пользователям и не имеет никакого делового значения. Тем не менее, они чрезвычайно важны для понимания, мониторинга и оптимизации производительности машин.
Splunk может читать эти неструктурированные, полуструктурированные или редко структурированные данные. После прочтения данных, он позволяет искать, отмечать, создавать отчеты и информационные панели по этим данным. С появлением больших данных Splunk теперь может принимать большие данные из различных источников, которые могут быть или не быть машинными данными, и выполнять аналитику больших данных.
Таким образом, благодаря простому инструменту для анализа журналов, Splunk прошел долгий путь, чтобы стать общим аналитическим инструментом для неструктурированных машинных данных и различных форм больших данных.
Категории продукта
Splunk доступен в трех различных категориях продуктов:
-
Splunk Enterprise — используется компаниями, которые имеют крупную ИТ-инфраструктуру и бизнес, ориентированный на ИТ. Это помогает в сборе и анализе данных с веб-сайтов, приложений, устройств и датчиков и т. Д.
-
Splunk Cloud — это облачная платформа с теми же функциями, что и в корпоративной версии. Его можно получить из самого Splunk или через облачную платформу AWS.
-
Splunk Light — позволяет искать, сообщать и оповещать обо всех данных журнала в режиме реального времени из одного места. Он имеет ограниченные функциональные возможности и функции по сравнению с двумя другими версиями.
Splunk Enterprise — используется компаниями, которые имеют крупную ИТ-инфраструктуру и бизнес, ориентированный на ИТ. Это помогает в сборе и анализе данных с веб-сайтов, приложений, устройств и датчиков и т. Д.
Splunk Cloud — это облачная платформа с теми же функциями, что и в корпоративной версии. Его можно получить из самого Splunk или через облачную платформу AWS.
Splunk Light — позволяет искать, сообщать и оповещать обо всех данных журнала в режиме реального времени из одного места. Он имеет ограниченные функциональные возможности и функции по сравнению с двумя другими версиями.
Особенности Splunk
В этом разделе мы обсудим важные особенности редакции предприятия —
Попадание данных
Splunk может принимать различные форматы данных, такие как JSON, XML и неструктурированные машинные данные, такие как веб-страницы и журналы приложений. Неструктурированные данные могут быть смоделированы в структуру данных по мере необходимости пользователем.
Индексирование данных
Полученные данные индексируются Splunk для ускорения поиска и запросов в различных условиях.
Поиск данных
Поиск в Splunk включает использование индексированных данных с целью создания метрик, прогнозирования будущих тенденций и определения закономерностей в данных.
Использование оповещений
Оповещения Splunk могут использоваться для запуска электронных писем или RSS-каналов, когда в анализируемых данных обнаруживаются определенные критерии.
Сводки
Splunk Dashboards могут отображать результаты поиска в виде диаграмм, отчетов и сводок и т. Д.
Модель данных
Индексированные данные могут быть смоделированы в один или несколько наборов данных на основе специальных знаний предметной области. Это облегчает навигацию для конечных пользователей, которые анализируют бизнес-кейсы без изучения технических особенностей языка обработки поиска, используемого Splunk.
Splunk — Окружающая среда
В этом руководстве мы стремимся установить корпоративную версию. Эта версия доступна для бесплатной оценки в течение 60 дней со всеми включенными функциями. Вы можете скачать установку, используя ссылку ниже, которая доступна для платформ Windows и Linux.
https://www.splunk.com/en_us/download/splunk-enterprise.html.
Версия для Linux
Версия для Linux загружается по ссылке для скачивания, приведенной выше. Мы выбираем тип пакета .deb, так как установка будет производиться на платформе Ubuntu.
Мы узнаем это с пошаговым подходом —
Шаг 1
Загрузите пакет .deb, как показано на скриншоте ниже.
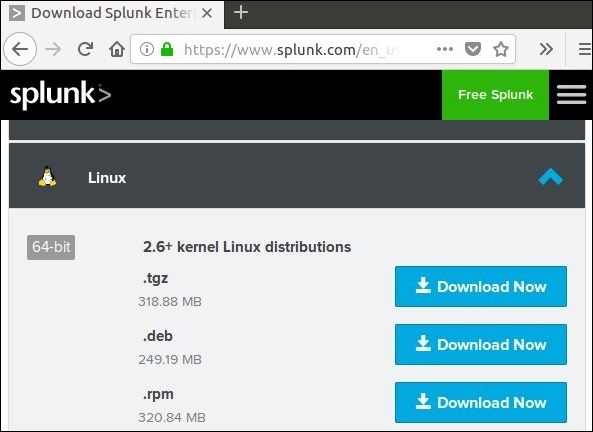
Шаг 2
Перейдите в каталог загрузки и установите Splunk, используя указанный выше загруженный пакет.
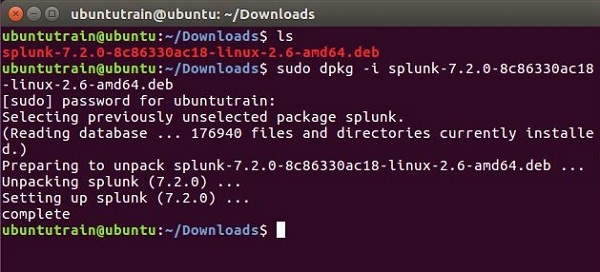
Шаг 3
Затем вы можете запустить Splunk, используя следующую команду с аргументом accept license. Он запросит у администратора имя пользователя и пароль, которые вы должны предоставить и запомнить.
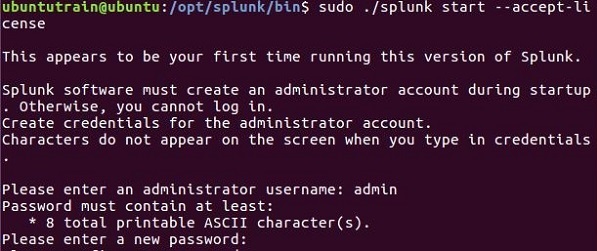
Шаг 4
Сервер Splunk запускается и указывает URL-адрес, по которому можно получить доступ к интерфейсу Splunk.
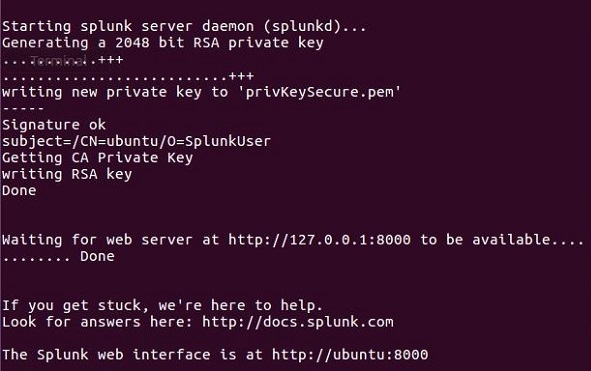
Шаг 5
Теперь вы можете получить доступ к URL-адресу Splunk и ввести идентификатор пользователя и пароль администратора, созданные на шаге 3.
Версия для Windows
Версия для Windows доступна как установщик MSI, как показано на рисунке ниже —
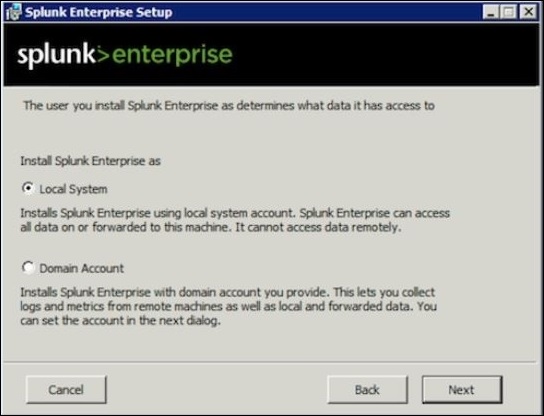
Двойной щелчок на установщике msi устанавливает версию Windows в прямом направлении. Два важных шага, где мы должны сделать правильный выбор для успешной установки, заключаются в следующем.
Шаг 1
Поскольку мы устанавливаем его в локальной системе, выберите вариант локальной системы, как указано ниже —
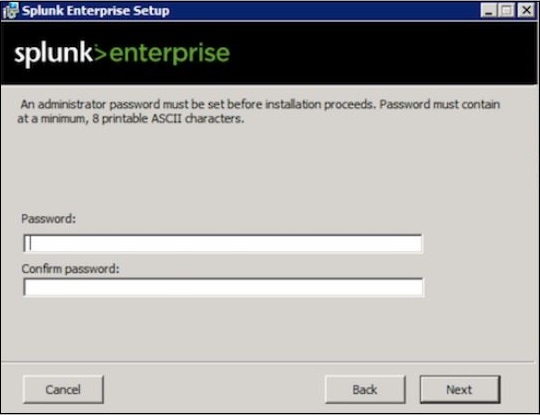
Шаг 2
Введите пароль администратора и запомните его, так как он будет использоваться в будущих конфигурациях.
Шаг 3
На последнем этапе мы видим, что Splunk успешно установлен и его можно запустить из веб-браузера.
Шаг 4
Затем откройте браузер и введите указанный URL-адрес, http: // localhost: 8000 , и войдите в Splunk, используя ID пользователя и пароль администратора.
Splunk — Интерфейс
Веб-интерфейс Splunk состоит из всех инструментов, необходимых для поиска, составления отчетов и анализа поступающих данных. Тот же веб-интерфейс предоставляет функции для администрирования пользователей и их ролей. Он также предоставляет ссылки для приема данных и встроенные приложения, доступные в Splunk.
На рисунке ниже показан начальный экран после входа в Splunk с учетными данными администратора.
Ссылка администратора
Раскрывающийся список Администратор дает возможность устанавливать и редактировать данные администратора. Мы можем сбросить идентификатор электронной почты администратора и пароль, используя приведенный ниже экран —
Кроме ссылки администратора, мы также можем перейти к опции настроек, где мы можем установить часовой пояс и домашнее приложение, в котором целевая страница будет открываться после вашего входа в систему. В настоящее время он открыт на домашней странице, как показано ниже —
Ссылка настроек
Это ссылка, которая показывает все основные функции, доступные в Splunk. Например, вы можете добавить файлы поиска и определения поиска, выбрав ссылку поиска.
Мы обсудим важные настройки этих ссылок в следующих главах.
Ссылка для поиска и отчетности
Ссылка для поиска и создания отчетов приводит нас к функциям, где мы можем найти наборы данных, доступные для поиска в отчетах и оповещениях, созданных для этих поисков. Это ясно показано на скриншоте ниже —
Splunk — попадание данных
Прием данных в Splunk происходит через функцию « Добавить данные», которая является частью приложения поиска и отчетности. После входа в систему на главном экране интерфейса Splunk отображается значок « Добавить данные», как показано ниже.
При нажатии на эту кнопку у нас появляется экран для выбора источника и формата данных, которые мы планируем передать в Splunk для анализа.
Сбор данных
Мы можем получить данные для анализа с официального сайта Splunk. Сохраните этот файл и разархивируйте его на свой локальный диск. При открытии папки вы можете найти три файла, которые имеют разные форматы. Это данные журнала, генерируемые некоторыми веб-приложениями. Мы также можем собрать другой набор данных, предоставленных Splunk, который доступен на официальной веб-странице Splunk.
Мы будем использовать данные из обоих этих наборов для понимания работы различных функций Splunk.
Загрузка данных
Затем мы выбираем файл secure.log из папки mailsv, который мы сохранили в нашей локальной системе, как упоминалось в предыдущем абзаце. После выбора файла мы переходим к следующему шагу, используя зеленую кнопку «Далее» в правом верхнем углу.
Выбор типа источника
Splunk имеет встроенную функцию для определения типа загружаемых данных. Это также дает пользователю возможность выбрать тип данных, отличный от выбранного Splunk. При нажатии на выпадающий тип источника мы видим различные типы данных, которые Splunk может принять и включить для поиска.
В текущем примере, приведенном ниже, мы выбираем тип источника по умолчанию.
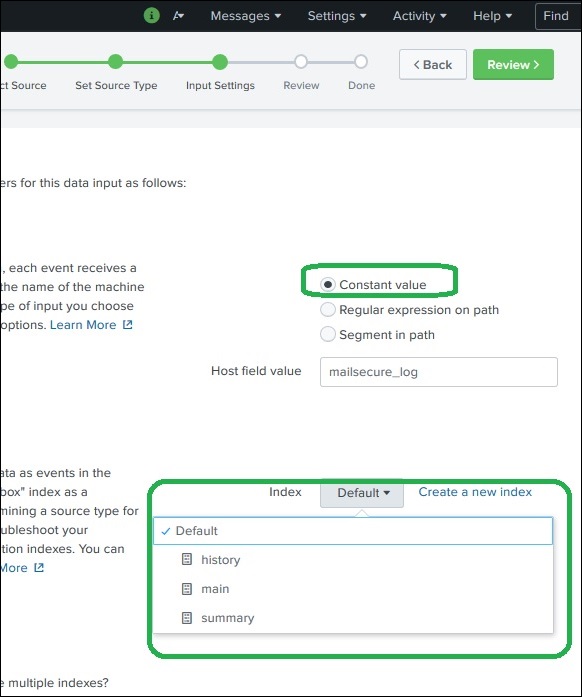
Настройки ввода
На этом этапе приема данных мы настраиваем имя хоста, с которого поступают данные. Ниже приведены варианты на выбор, для имени хоста —
Постоянное значение
Это полное имя хоста, где находятся исходные данные.
регулярное выражение на пути
Когда вы хотите извлечь имя хоста с помощью регулярного выражения. Затем введите регулярное выражение для хоста, который вы хотите извлечь, в поле Регулярное выражение.
сегмент в пути
Если вы хотите извлечь имя хоста из сегмента в пути вашего источника данных, введите номер сегмента в поле Номер сегмента. Например, если путь к источнику — / var / log / и вы хотите, чтобы третий сегмент (имя хост-сервера) был значением хоста, введите «3».
Далее мы выбираем тип индекса, который будет создан на входных данных для поиска. Мы выбираем стратегию индекса по умолчанию. Сводный индекс создает только сводку данных посредством агрегации и создает для них индекс, в то время как индекс истории предназначен для хранения истории поиска. Это ясно изображено на изображении ниже —
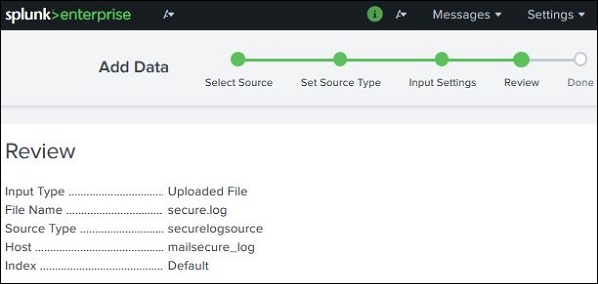
Настройки просмотра
После нажатия на следующую кнопку, мы видим сводку настроек, которые мы выбрали. Мы просматриваем его и выбираем Далее, чтобы завершить загрузку данных.
По окончании загрузки появляется следующий экран, который показывает успешное получение данных и дальнейшие возможные действия, которые мы можем предпринять с данными.
Splunk — Типы источников
Все входящие данные в Splunk сначала оцениваются встроенным блоком обработки данных и классифицируются по определенным типам и категориям данных. Например, если это журнал с веб-сервера apache, Splunk может распознать это и создать соответствующие поля из прочитанных данных.
Эта функция в Splunk называется обнаружением типов источников, и для этого используются встроенные типы источников, известные как «предварительно обученные» типы источников.
Это облегчает анализ, поскольку пользователю не нужно вручную классифицировать данные и назначать любые типы данных полям входящих данных.
Поддерживаемые типы источников
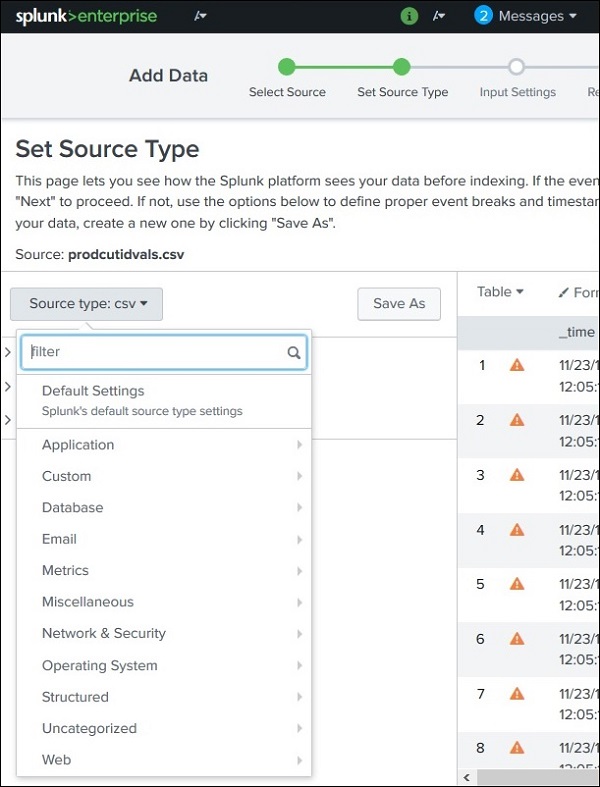
Поддерживаемые типы источников в Splunk можно увидеть, загрузив файл с помощью функции « Добавить данные», а затем выбрав раскрывающийся список «Тип источника». На изображении ниже мы загрузили файл CSV, а затем проверили все доступные параметры.
Подкатегория типа источника
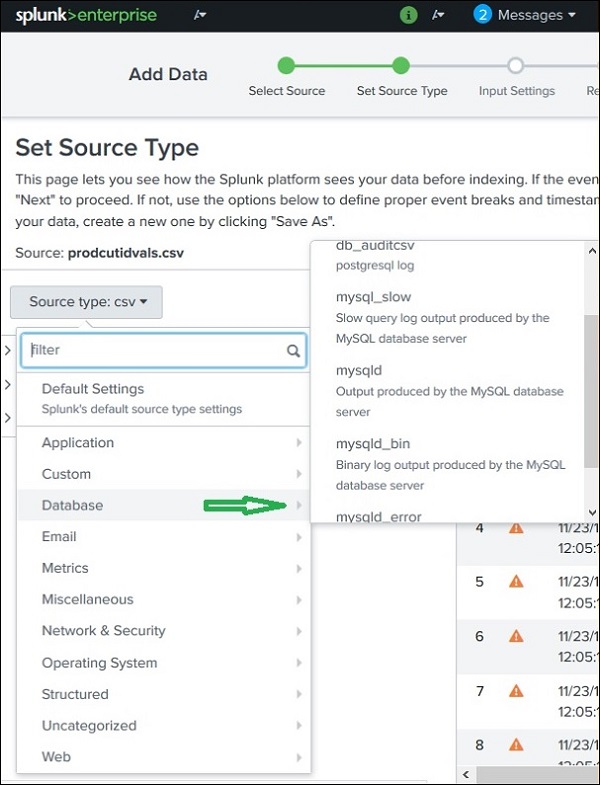
Даже в этих категориях мы можем дополнительно нажать, чтобы увидеть все поддерживаемые подкатегории. Поэтому, когда вы выбираете категорию базы данных, вы можете найти различные типы баз данных и их поддерживаемые файлы, которые Splunk может распознать.
Предварительно обученные типы источников
В приведенной ниже таблице перечислены некоторые важные предварительно обученные типы источников, которые распознает Splunk.
| Название типа источника | Природа |
|---|---|
| access_combined | Журналы веб-сервера HTTP в комбинированном формате NCSA (могут генерироваться Apache или другими веб-серверами) |
| access_combined_wcookie | Журналы веб-сервера http в комбинированном формате NCSA (могут быть сгенерированы apache или другими веб-серверами) с добавлением поля cookie в конце |
| apache_error | Стандартный журнал ошибок веб-сервера Apache |
| linux_messages_syslog | Стандартный системный журнал linux (/ var / log / messages на большинстве платформ) |
| log4j | Стандартный вывод Log4j, производимый любым сервером J2EE, использующим log4j |
| mysqld_error | Стандартный журнал ошибок MySQL |
Splunk — Базовый поиск
Splunk имеет надежную функцию поиска, которая позволяет вам искать весь набор данных, который принимается. Эта функция доступна через приложение под названием « Поиск и отчетность», которое можно увидеть на левой боковой панели после входа в веб-интерфейс.
При нажатии на приложение поиска и отчетности нам предоставляется окно поиска, где мы можем начать наш поиск по данным журнала, которые мы загрузили в предыдущей главе.
Мы вводим имя хоста в формате, как показано ниже, и нажимаем на значок поиска в правом верхнем углу. Это дает нам результат, выделяющий поисковый запрос.
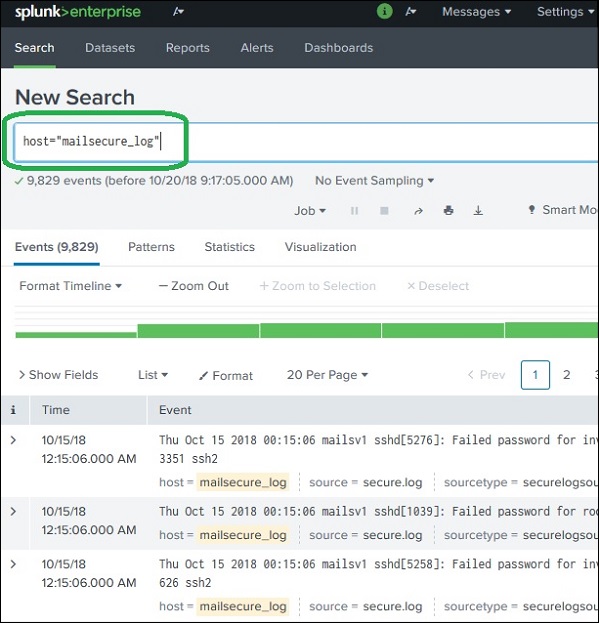
Объединение условий поиска
Мы можем объединить термины, используемые для поиска, написав их один за другим, но поместив строки поиска пользователя в двойные кавычки.
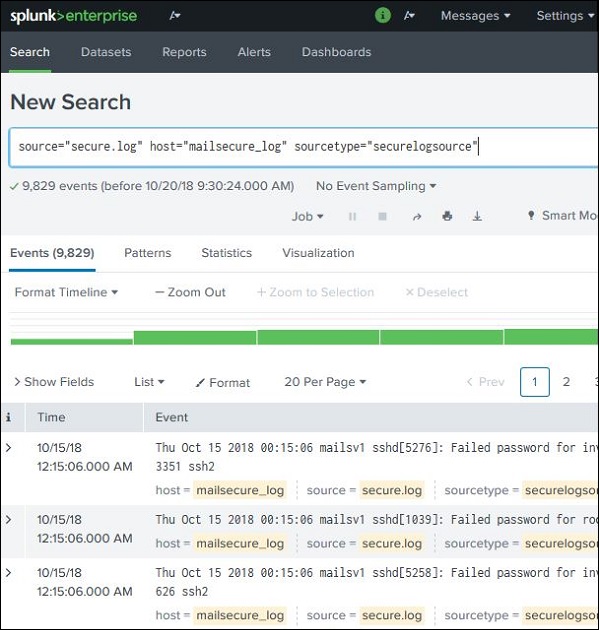
Использование Wild Card
Мы можем использовать подстановочные знаки в нашей опции поиска в сочетании с операторами И / ИЛИ . В приведенном ниже поиске мы получаем результат, в котором в файле журнала содержатся термины, содержащие сбой, сбой, сбой и т. Д., А также пароль в той же строке.
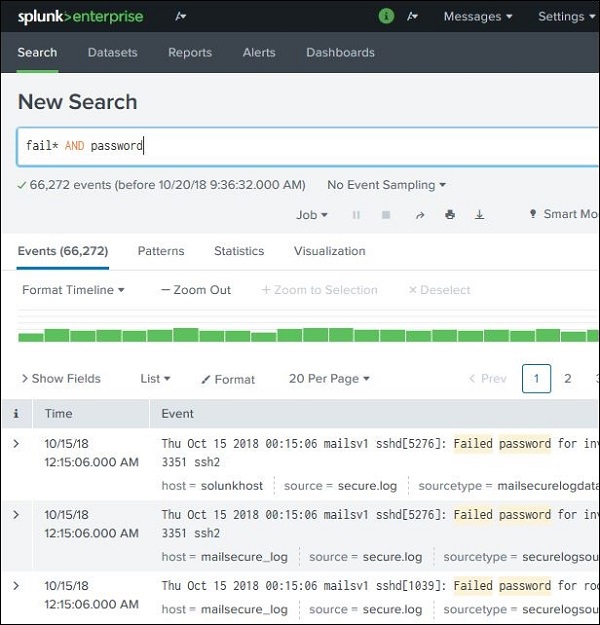
Уточнение результатов поиска
Мы можем дополнительно уточнить результаты поиска, выбрав строку и добавив ее в поиск. В приведенном ниже примере мы нажимаем на строку 3351 и выбираем опцию Добавить в поиск .
После добавления 3351 к поисковому запросу мы получаем следующий результат, который показывает только те строки из журнала, которые содержат 3351 в них. Также отметьте, как изменилась временная шкала результата поиска, поскольку мы уточнили поиск.
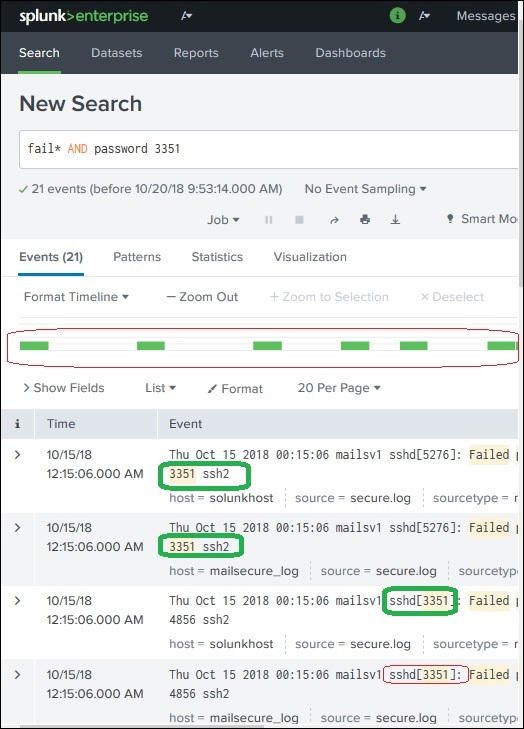
Splunk — поиск полей
Когда Splunk читает загруженные машинные данные, он интерпретирует данные и делит их на множество полей, которые представляют собой единый логический факт о всей записи данных.
Например, одна запись информации может содержать имя сервера, метку времени события, тип регистрируемого события, будь то попытка входа в систему или ответ http, и т. Д. Даже в случае неструктурированных данных Splunk пытается разделить поля на значение ключа. пары или разделить их на основе типов данных, которые они имеют, числовые и строковые и т. д.
Продолжая с данными, загруженными в предыдущей главе, мы можем увидеть поля из файла secure.log , щелкнув ссылку показать поля, которая откроет следующий экран. Мы можем заметить поля, созданные Splunk из этого файла журнала.
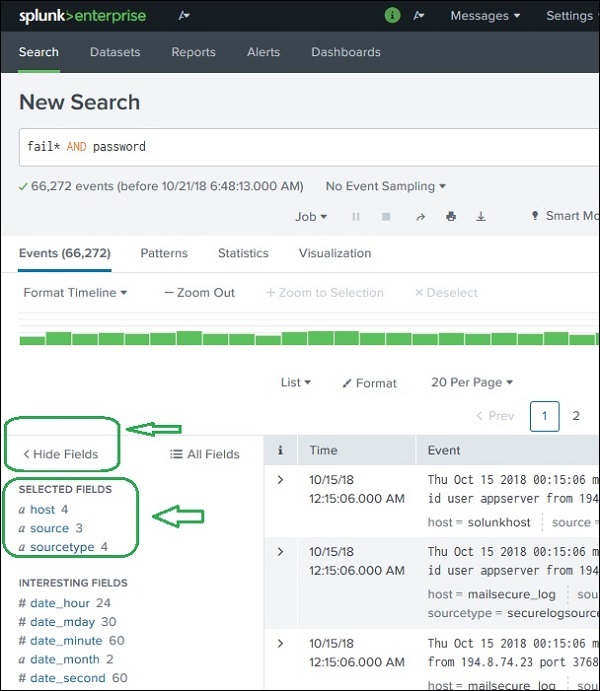
Выбор полей
Мы можем выбрать, какие поля отображать, выбрав или отменив выбор полей из списка всех полей. При нажатии на все поля открывается окно со списком всех полей. Некоторые из этих полей помечены галочками, показывая, что они уже выбраны. Мы можем использовать флажки, чтобы выбрать наши поля для отображения.
Помимо имени поля, оно отображает количество различных значений, которые имеют поля, тип данных и процент событий, в которых присутствует это поле.
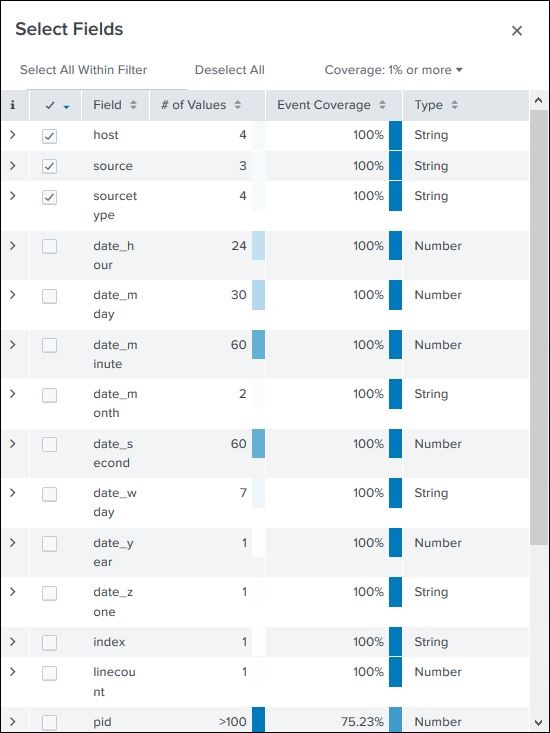
Сводка по полю
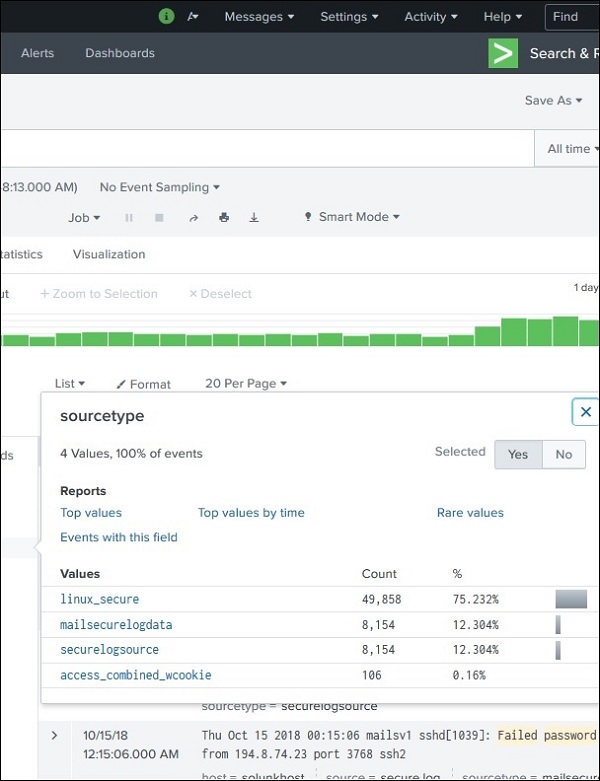
Очень подробные статистические данные для каждого выбранного поля становятся доступными, нажав на название поля. Он показывает все различные значения для поля, их количество и их проценты.
Использование полей в поиске
Имена полей также могут быть вставлены в поле поиска вместе с конкретными значениями для поиска. В приведенном ниже примере мы стремимся найти все записи на дату 15 октября для хоста с именем mailsecure_log . Мы получаем результат для этой конкретной даты.
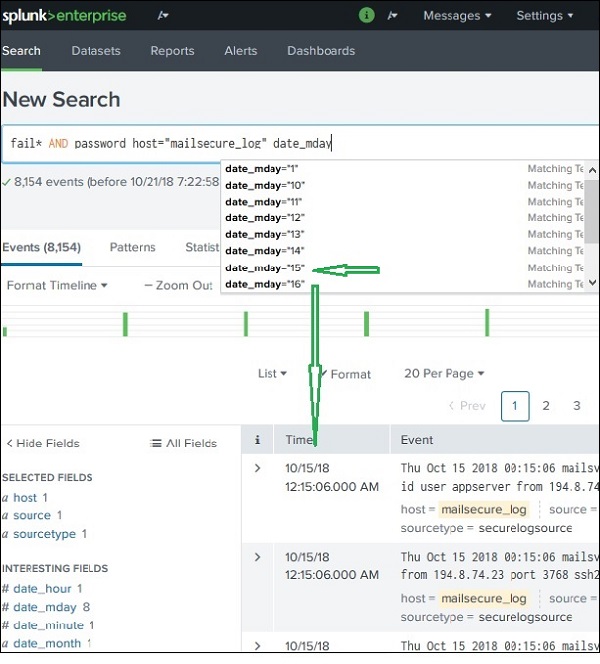
Splunk — поиск по временному диапазону
Веб-интерфейс Splunk отображает временную шкалу, которая указывает распределение событий за определенный промежуток времени. Существуют предварительно установленные интервалы времени, из которых вы можете выбрать определенный диапазон времени или настроить диапазон времени в соответствии со своими потребностями.
На приведенном ниже экране показаны различные предварительно установленные параметры шкалы времени. Выбор любой из этих опций приведет к получению данных только за тот конкретный период времени, который вы также можете проанализировать в дальнейшем с использованием доступных опций временной шкалы.
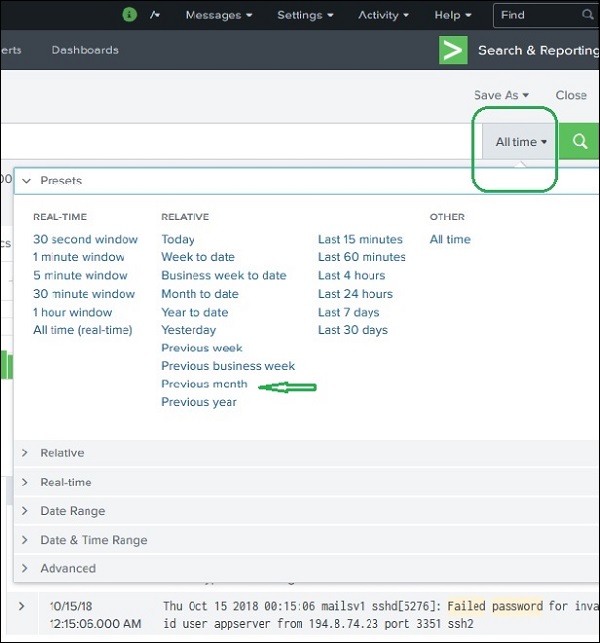
Например, выбор варианта предыдущего месяца дает нам результат только за предыдущий месяц, как вы можете видеть в разбросе графика временной шкалы ниже.
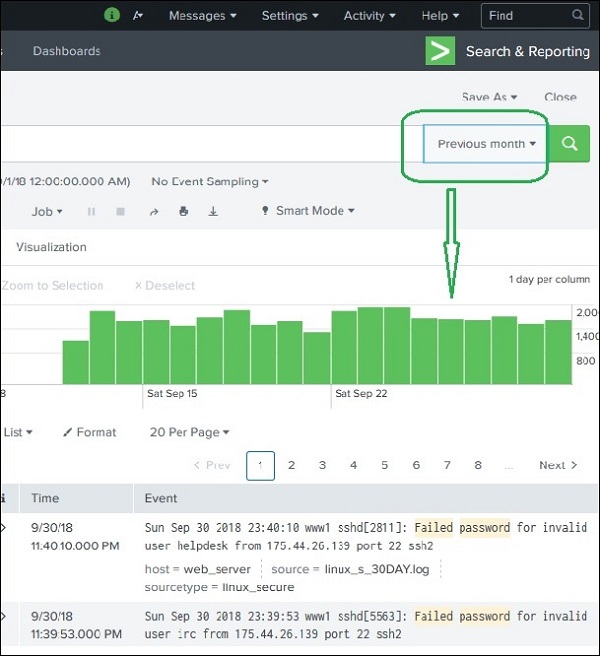
Выбор подмножества времени
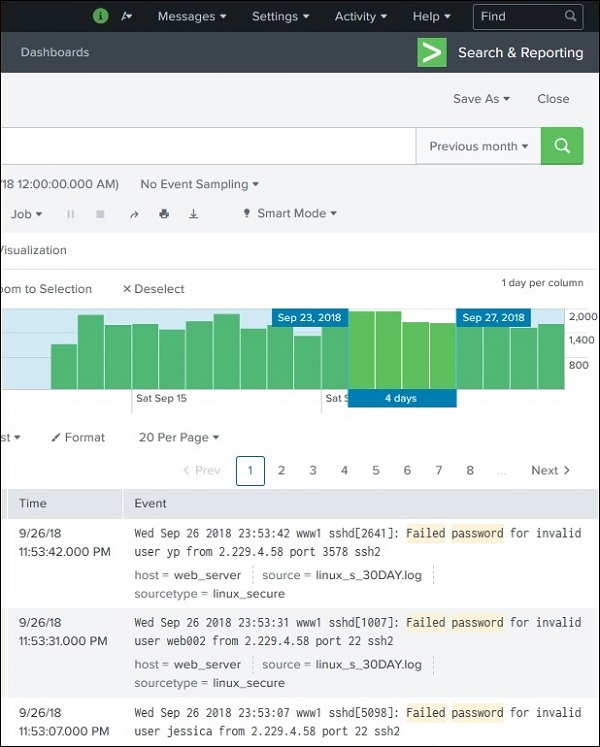
Щелкая и перетаскивая полосы на временной шкале, мы можем выбрать подмножество результата, который уже существует. Это не вызывает повторного выполнения запроса. Он только отфильтровывает записи из существующего набора результатов.
На рисунке ниже показан выбор подмножества из набора результатов —
Самый ранний и последний
Две команды, самую раннюю и самую позднюю, можно использовать в строке поиска, чтобы указать временной интервал, между которым вы фильтруете результаты. Это похоже на выбор временного подмножества, но оно осуществляется с помощью команд, а не с помощью щелчка по определенной строке временной шкалы. Таким образом, он обеспечивает более точный контроль над тем диапазоном данных, который вы можете выбрать для анализа.
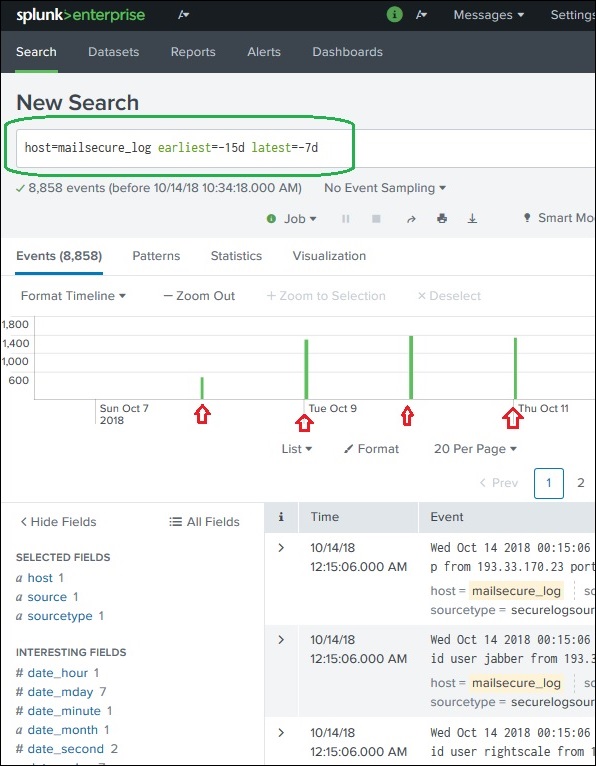
На изображении выше мы даем интервал времени от последних 7 дней до последних 15 дней. Итак, данные между этими двумя днями отображаются.
События рядом
Мы также можем найти ближайшие события определенного времени, указав, насколько близко мы хотим, чтобы события были отфильтрованы. У нас есть возможность выбора шкалы интервала, например: секунды, минуты, дни, недели и т. Д.
Splunk — общий доступ к экспорту
Когда вы запускаете поисковый запрос, результат сохраняется как задание на сервере Splunk. Хотя это задание было создано одним конкретным пользователем, оно может быть передано другим пользователям, чтобы они могли начать использовать этот набор результатов без необходимости повторного создания запроса для него. Результаты также могут быть экспортированы и сохранены в виде файлов, которые могут быть переданы пользователям, которые не используют Splunk.
Обмен результатами поиска
После успешного выполнения запроса мы можем увидеть небольшую стрелку вверх в центре справа на веб-странице. Нажатие на этот значок дает URL-адрес, по которому можно получить доступ к запросу и результату. Необходимо предоставить разрешение пользователям, которые будут использовать эту ссылку. Разрешение предоставляется через интерфейс администрирования Splunk.
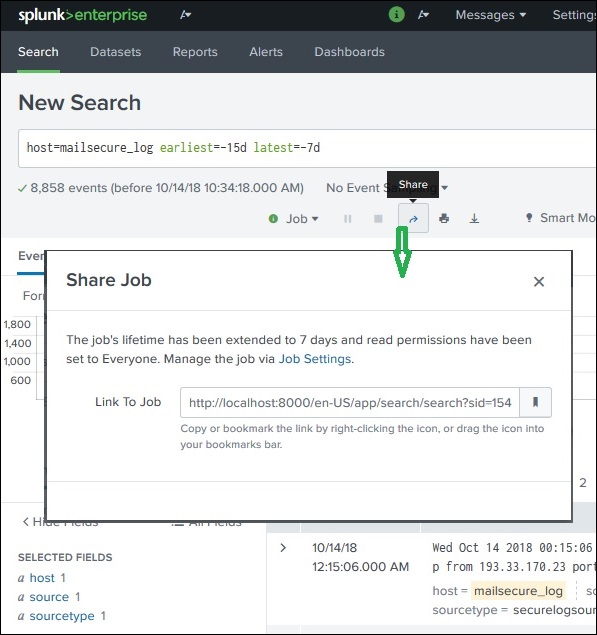
Нахождение сохраненных результатов
Задания, которые сохраняются для использования всеми пользователями с соответствующими разрешениями, можно найти, выполнив поиск ссылки на задания в меню действий в правой верхней части интерфейса Splunk. На изображении ниже мы нажимаем на выделенную ссылку с именем jobs, чтобы найти сохраненные вакансии.
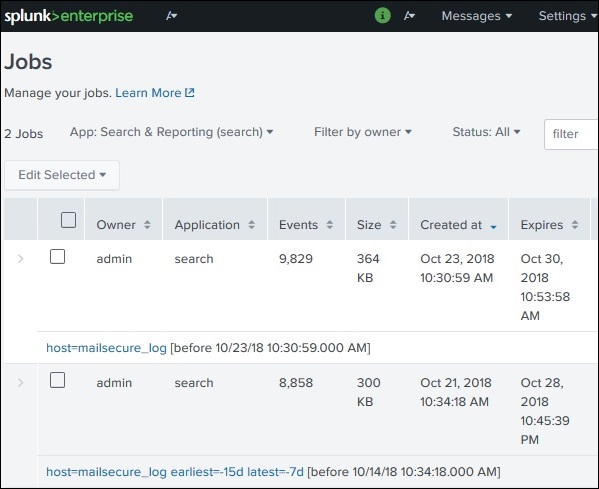
После нажатия на ссылку выше, мы получаем список всех сохраненных заданий, как показано ниже. Он, мы должны отметить, что есть дата окончания срока действия, где сохраненное задание будет автоматически удалено из Splunk. Вы можете настроить эту дату, выбрав задание и нажав «Изменить выбранное», а затем выбрав «Продлить срок действия».
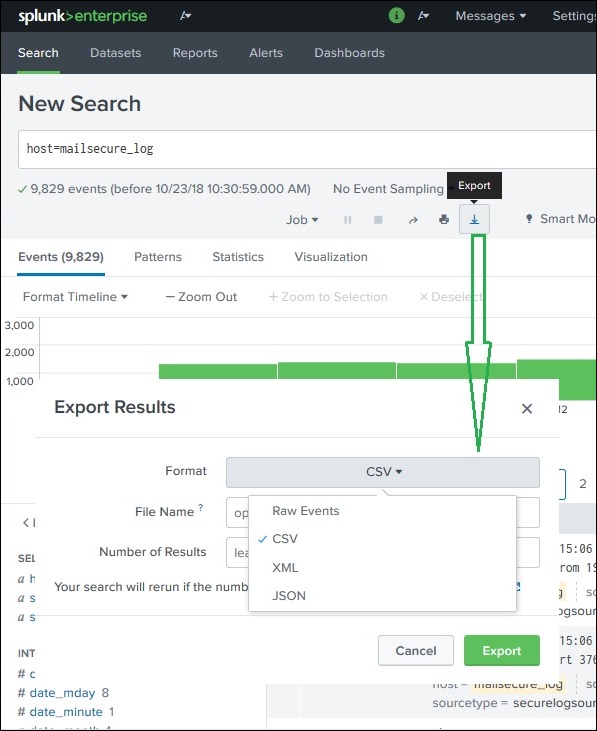
Экспорт результатов поиска
Мы также можем экспортировать результаты поиска в файл. Доступны три различных формата для экспорта: CSV, XML и JSON. При нажатии на кнопку «Экспорт» после выбора форматов файл загружается из локального браузера в локальную систему. Это объясняется на изображении ниже —
Splunk — Язык поиска
Язык обработки поиска Splunk (SPL) — это язык, содержащий множество команд, функций, аргументов и т. Д., Которые написаны для получения желаемых результатов из наборов данных. Например, когда вы получаете набор результатов для поискового запроса, вы можете дополнительно отфильтровать некоторые более конкретные условия из набора результатов. Для этого вам нужно добавить несколько дополнительных команд в существующую команду. Это достигается путем изучения использования SPL.
Компоненты SPL
SPL имеет следующие компоненты.
-
Условия поиска — это ключевые слова или фразы, которые вы ищете.
-
Команды — действие, которое вы хотите выполнить с результирующим набором, например, отформатировать результат или сосчитать их.
-
Функции — Какие расчеты вы собираетесь применить к результатам. Как сумма, средняя и т. Д.
-
Предложения — Как сгруппировать или переименовать поля в наборе результатов.
Условия поиска — это ключевые слова или фразы, которые вы ищете.
Команды — действие, которое вы хотите выполнить с результирующим набором, например, отформатировать результат или сосчитать их.
Функции — Какие расчеты вы собираетесь применить к результатам. Как сумма, средняя и т. Д.
Предложения — Как сгруппировать или переименовать поля в наборе результатов.
Давайте обсудим все компоненты с помощью изображений в следующем разделе —
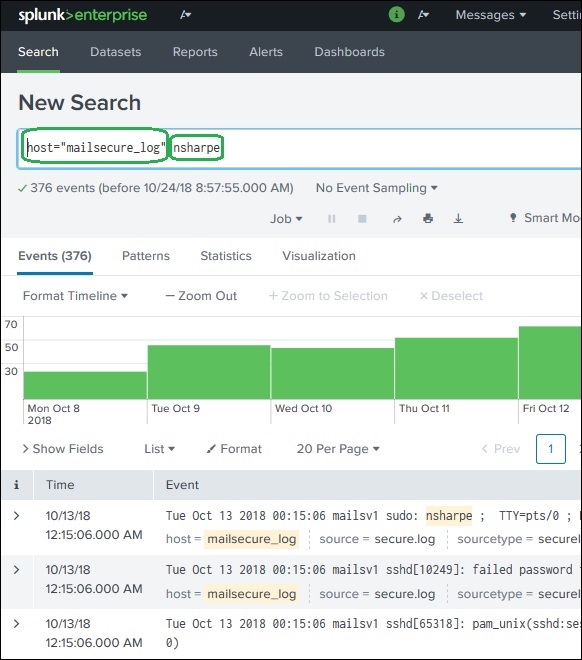
Условия поиска
Это термины, которые вы упоминаете в строке поиска, чтобы получить конкретные записи из набора данных, которые соответствуют критериям поиска. В приведенном ниже примере мы ищем записи, которые содержат два выделенных термина.
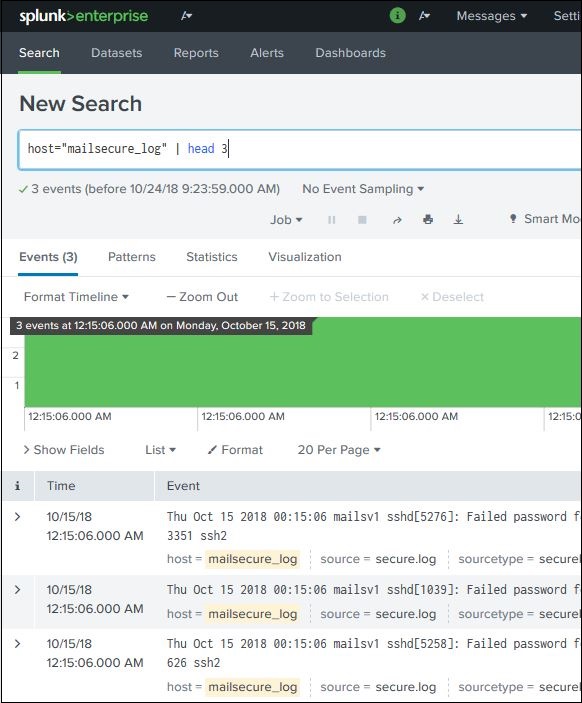
команды
Вы можете использовать множество встроенных команд, предоставляемых SPL, чтобы упростить процесс анализа данных в наборе результатов. В приведенном ниже примере мы используем команду head, чтобы отфильтровать только первые 3 результата из операции поиска.
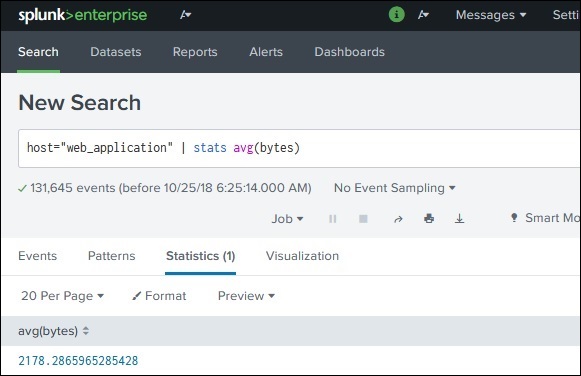
функции
Наряду с командами Splunk также предоставляет множество встроенных функций, которые могут принимать входные данные из анализируемого поля и выдавать выходные данные после применения вычислений к этому полю. В приведенном ниже примере мы используем функцию Stats avg (), которая вычисляет среднее значение числового поля, принимаемого в качестве входных данных.
Статьи
Когда мы хотим получить результаты, сгруппированные по какому-то конкретному полю, или мы хотим переименовать поле в выводе, мы используем предложение group by и предложение as соответственно. В приведенном ниже примере мы получаем средний размер байтов каждого файла, присутствующего в журнале web_application . Как видите, результат показывает имя каждого файла, а также средние байты для каждого файла.
Splunk уже включает функции оптимизации, анализирует и обрабатывает ваши поиски для максимальной эффективности. Эта эффективность достигается в основном за счет следующих двух целей оптимизации —
Ранняя фильтрация — эта оптимизация фильтрует результаты очень рано, так что объем обрабатываемых данных сокращается как можно раньше в процессе поиска. Этот ранний фильтр позволяет избежать ненужных поисков и вычислений для событий, которые не являются частью окончательных результатов поиска.
Параллельная обработка — встроенная оптимизация может изменить порядок обработки поиска, так чтобы как можно больше команд выполнялось параллельно на индексаторах перед отправкой результатов поиска в поисковую головку для окончательной обработки.
Splunk предоставил нам инструменты для анализа работы поисковой оптимизации. Эти инструменты помогают нам выяснить, как используются условия фильтра и какова последовательность этих шагов оптимизации. Это также дает нам стоимость различных шагов, связанных с поисковыми операциями.
Рассмотрим операцию поиска, чтобы найти события, содержащие слова: сбой, сбой или пароль. Когда мы помещаем этот поисковый запрос в поле поиска, встроенные оптимизаторы действуют автоматически, чтобы определить путь поиска. Мы можем проверить, сколько времени потребовалось для поиска определенного количества результатов поиска, и при необходимости можно продолжить проверку каждого шага оптимизации вместе с затратами, связанными с ним.
Мы следуем по пути Поиск → Работа → Проверить работу, чтобы получить эти данные, как показано ниже —
На следующем экране приведены подробности оптимизации, которая произошла для вышеуказанного запроса. Здесь нам нужно отметить количество событий и время, необходимое для возврата результата.
Мы также можем отключить встроенную оптимизацию и заметить разницу во времени, затраченном на результат поиска. Результат может или не может быть лучше, чем встроенный поиск. В случае, если это лучше, мы всегда можем выбрать этот вариант отключения оптимизации только для этого конкретного поиска.
На приведенной ниже диаграмме мы используем команду Без оптимизации, представленную как noop в поисковом запросе.
Следующий экран дает нам результат использования без оптимизации. Для данного запроса результаты приходят быстрее без использования встроенных оптимизаций.
Это команды в Splunk, которые используются для преобразования результата поиска в такие структуры данных, которые будут полезны для представления статистики и визуализации данных.
Ниже приведены некоторые примеры команд преобразования:
Подсветка — для выделения конкретных терминов в результате.
Диаграмма — для создания диаграммы из результатов поиска.
Статистика — для создания статистических сводок из результатов поиска.
Эта команда используется для выделения определенных терминов в наборе результатов поиска . Он используется путем предоставления поисковых терминов в качестве аргументов функции выделения. Несколько поисковых терминов поставляются через запятую.
В приведенном ниже примере мы ищем термины, сафари и масло в наборе результатов.
Команда диаграммы — это команда преобразования, которая возвращает ваши результаты в виде таблицы. Затем результаты можно использовать для отображения данных в виде диаграммы, такой как столбец, линия, площадь и т. Д. В приведенном ниже примере мы создаем горизонтальную гистограмму путем построения графика среднего размера байтов для каждого типа файла.
Команда Stats преобразует набор данных результатов поиска в различные статистические представления в зависимости от типов аргументов, которые мы предоставляем для этой команды.
В приведенном ниже примере мы используем команду stats с функцией count, которая затем группируется по другому полю. Здесь мы подсчитываем количество имен файлов, создаваемых в каждый день недели. Результат поиска строки выходят в виде таблицы из строк, созданных для каждого дня.
Отчеты Splunk — это результаты, сохраненные в результате действия поиска, которое может отображать статистику и визуализации событий. Отчеты можно запускать в любое время, и они получают свежие результаты при каждом запуске. Отчетами можно делиться с другими пользователями и добавлять на информационные панели. Более сложные отчеты могут позволить функции детализации просматривать основные события, которые создают окончательную статистику.
В этой главе мы увидим, как создавать и редактировать пример отчета.
Создание отчета — это простой процесс, в котором мы используем параметр « Сохранить как», чтобы сохранить результат операции поиска, выбрав параметр « Сохранить как» . На диаграмме ниже показана опция.
Нажав на опцию «Отчеты» в раскрывающемся списке, мы получим следующее окно, в котором запрашиваются дополнительные входные данные, такие как имя отчета, описание и выбор таймера. Если мы выбираем средство выбора времени, оно позволяет настраивать временной диапазон при запуске отчета. На диаграммах ниже показано, как мы заполняем необходимые данные, а затем нажимаем кнопку «Сохранить».
После нажатия кнопки «Сохранить», чтобы создать отчет на предыдущем шаге, мы получаем следующее окно с запросом о настройке отчета, как показано ниже. Здесь мы можем настроить разрешения, составить расписание отчета и т. Д. У нас также есть возможность перейти к следующему шагу и добавить отчет на панель мониторинга.
Если мы нажмем « Просмотр» на предыдущем шаге, мы увидим отчет. Мы также получаем параметры конфигурации после создания отчета.
Хотя мы можем редактировать разрешения, расписание и т. Д., Иногда нам нужно изменить исходную строку поиска. Это можно сделать, выбрав опцию « Открыть в поиске», как показано на рисунке выше. Это снова откроет исходную опцию поиска, которую мы можем отредактировать для нового поиска. Обратитесь к изображению ниже —
Панель инструментов используется для представления таблиц или диаграмм, которые имеют какое-то деловое значение. Это делается с помощью панелей. Панели на панели мониторинга содержат диаграмму или сводные данные в визуально привлекательной форме. Мы можем добавить несколько панелей и, следовательно, несколько отчетов и диаграмм на одну панель.
Мы продолжим поисковый запрос из предыдущей главы, который показывает количество файлов по дням недели.
Мы выбираем вкладку Визуализация, чтобы увидеть результат в виде круговой диаграммы. Чтобы поместить диаграмму на панель инструментов, мы можем выбрать опцию Сохранить как → Панель панели, как показано ниже.
На следующем экране будет запрошено заполнение информации о приборной панели и панели в ней. Мы заполняем экран деталями, как показано ниже.
При нажатии на кнопку «Сохранить» на следующем экране можно просмотреть панель инструментов. Выбрав для просмотра панель мониторинга, мы получим следующий вывод, где мы увидим панель мониторинга и параметры для редактирования, экспорта или удаления.
Мы можем добавить второй график на панель инструментов, добавив новую панель, содержащую график. Ниже приведена гистограмма и ее запрос, который мы собираемся добавить на панель инструментов выше.
Затем мы заполняем детали для второго графика и нажимаем Сохранить, как показано на рисунке ниже —
Наконец, мы получаем панель инструментов, которая содержит обе диаграммы на двух разных панелях. Как вы можете видеть на изображении ниже, мы можем отредактировать панель мониторинга, чтобы добавить больше панелей, и вы можете добавить больше элементов ввода: кнопки «Текст», «Радио» и «Раскрывающийся список», чтобы создать более сложные панели мониторинга.
Splunk может принимать различные типы источников данных и создавать таблицы, которые похожи на реляционные таблицы. Они называются набором табличных данных или просто таблицами . Они предоставляют простые способы анализа и фильтрации данных и поиска и т. Д. Эти наборы табличных данных также используются при создании сводного анализа, который мы изучим в этой главе.
Мы используем надстройку Splunk с именем Надстройка наборов данных Splunk для создания и управления наборами данных. Его можно загрузить с веб-сайта Splunk, https://splunkbase.splunk.com/app/3245/#/details. Его необходимо установить, следуя инструкциям, приведенным на вкладке сведений в этой ссылке. При успешной установке мы видим кнопку с именем Create New Table Dataset .
Затем мы нажимаем кнопку « Создать новый набор табличных данных» , и она дает нам возможность выбрать один из трех вариантов ниже.
Индексы и типы источников — выберите из существующего индекса или типа источника, которые уже добавлены в Splunk через приложение «Добавить данные».
Существующие наборы данных. Возможно, вы уже создали ранее некоторый набор данных, который хотите изменить, создав из него новый набор данных.
Поиск — напишите поисковый запрос, и результат может быть использован для создания нового набора данных.
В нашем примере мы выбираем индекс, который будет нашим источником набора данных, как показано на рисунке ниже —
При нажатии кнопки «ОК» на приведенном выше экране нам предоставляется возможность выбрать различные поля, которые мы хотим в итоге получить в наборе данных таблицы. Поле _time выбрано по умолчанию, и это поле нельзя удалить. Мы выбираем поля: байты, categoryID, clientIP и файлы .
При нажатии на кнопку «Готово» на приведенном выше экране мы получаем итоговую таблицу набора данных со всеми выбранными полями, как показано ниже. Здесь набор данных стал похож на реляционную таблицу. Мы сохраняем набор данных с помощью опции сохранить как, доступной в верхнем правом углу.
Мы используем вышеупомянутый набор данных для создания сводного отчета. Сводный отчет отражает агрегацию значений одного столбца по отношению к значениям в другом столбце. Другими словами, значения одного столбца превращаются в строки, а значения других столбцов превращаются в строки.
Чтобы достичь этого, сначала мы выбираем набор данных на вкладке набора данных, а затем выбираем опцию Визуализировать с помощью сводной диаграммы в столбце Действия для этого набора данных.
Далее мы выбираем соответствующие поля для создания сводной таблицы. Мы выбираем идентификатор категории в опции разделения столбцов, так как это поле, значения которого должны отображаться в разных столбцах отчета. Затем мы выбираем File в опции Split Rows, так как это поле, значения которого должны быть представлены в строках. Результат показывает количество значений каждой категории для каждого значения в поле файла.
Затем мы можем сохранить сводную таблицу как отчет или панель в существующей панели мониторинга для дальнейшего использования.
В результате поискового запроса мы иногда получаем значения, которые не могут четко передать значение поля. Например, мы можем получить поле, которое перечисляет значение идентификатора продукта в виде числового результата. Эти цифры не дадут нам никакого представления о том, что это за продукт. Но если мы перечислим название продукта вместе с идентификатором продукта, это даст нам хороший отчет, в котором мы поймем значение результата поиска.
Такое связывание значений одного поля с полем с тем же именем в другом наборе данных с использованием равных значений из обоих наборов данных называется процессом поиска. Преимущество заключается в том, что мы получаем связанные значения из двух разных наборов данных.
Чтобы успешно создать поле поиска в наборе данных, нам нужно выполнить следующие шаги:
Мы рассматриваем набор данных с хостом как web_application и смотрим на поле productid. Это поле просто число, но мы хотим, чтобы названия продуктов отражались в нашем наборе результатов запросов. Мы создаем поисковый файл со следующими деталями. Здесь мы сохранили имя первого поля как productid, которое совпадает с полем, которое мы собираемся использовать из набора данных.
Затем мы добавляем поисковый файл в среду Splunk с помощью экранов настроек, как показано ниже —
После выбора поисков у нас появляется экран для создания и настройки поиска. Мы выбираем файлы таблицы поиска, как показано ниже.
Мы просматриваем, чтобы выбрать файл productidvals.csv в качестве нашего файла поиска для загрузки, и выбираем поиск в качестве целевого приложения. Мы также сохраняем имя файла назначения.
При нажатии кнопки «Сохранить» файл сохраняется в хранилище Splunk в виде файла поиска.
Чтобы поисковый запрос мог искать значения из файла подстановки, который мы только что загрузили выше, нам нужно создать определение подстановки. Мы делаем это, снова перейдя в Настройки → Поиск → Определение поиска → Добавить новый .
Затем мы проверяем доступность добавленного определения поиска, перейдя в « Настройки» → «Поиск» → «Определение поиска» .
Далее нам нужно выбрать поле поиска для нашего поискового запроса. Это сделано, перейдя в Новый поиск → Все поля . Затем установите флажок для продукта, который автоматически добавит поле productdescription из файла поиска.
Теперь мы используем поле «Уточняющий запрос» в поисковом запросе, как показано ниже. Визуализация показывает результат с полем productdescription вместо productid.
Планирование — это процесс настройки триггера для автоматического запуска отчета без вмешательства пользователя. Ниже приведены примеры использования отчета:
Запуская один и тот же отчет с разными интервалами: ежемесячно, еженедельно или ежедневно, мы можем получить результаты за этот конкретный период.
Повышена производительность панели мониторинга, поскольку отчеты завершают работу в фоновом режиме до того, как панель открывается пользователями.
Отправка отчетов автоматически по электронной почте после его завершения.
Расписание создается путем редактирования функции расписания отчета. Мы переходим к опции Edit Schedule на кнопке Edit, как показано на рисунке ниже.
Нажав кнопку «Изменить расписание», мы получим следующий экран, в котором изложены все параметры для создания расписания.
В приведенном ниже примере мы берем все параметры по умолчанию, и отчет планируется запускать каждую неделю в понедельник в 6 часов утра.
Ниже приведены важные особенности планирования —
Диапазон времени — указывает диапазон времени, из которого отчет должен извлекать данные. Это может длиться 15 минут, последние 4 часа или последняя неделя и т. Д.
Приоритет расписания — если одновременно запланировано более одного отчета, это определит приоритет конкретного отчета.
Окно расписаний. Если имеется несколько расписаний отчетов с одинаковым приоритетом, мы можем выбрать временное окно, которое поможет отчету запускаться в любое время в течение этого окна. Если это 5 минут, то отчет будет запущен в течение 5 минут от запланированного времени. Это помогает повысить производительность запланированных отчетов за счет расширения их времени выполнения.
Действия по расписанию предполагают выполнение некоторых шагов после запуска отчета. Например, вы можете отправить электронное письмо с указанием статуса выполнения отчета или запустить другой скрипт. Такие действия можно выполнить, установив параметр, нажав кнопку « Добавить действия» , как показано ниже —
Оповещения Splunk — это действия, которые запускаются при выполнении определенного критерия, определенного пользователем. Целью оповещений может быть регистрация действия, отправка электронного письма или вывод результата в поисковый файл и т. Д.
Вы создаете оповещение, запустив поисковый запрос и сохранив его результат в виде оповещения. На снимке экрана ниже мы берем поиск по дневному количеству файлов и сохраняем результат как предупреждение, выбрав опцию Сохранить как .
На следующем снимке экрана мы настраиваем свойства оповещения. На рисунке ниже показан экран конфигурации —
Цель и выбор каждого из этих вариантов объясняется ниже —
Заголовок — это название оповещения.
Описание — это подробное описание того, что делает предупреждение.
Разрешение — его значение определяет, кто может получить доступ, запустить или изменить предупреждение. Если объявлено как частное, все разрешения имеют только создатель оповещения. Чтобы быть доступными для других, этот параметр должен быть изменен на Общий в приложении . В этом случае каждый имеет доступ для чтения, но только опытный пользователь имеет доступ к редактированию для предупреждения.
Тип оповещения — Запланированное оповещение запускается с заранее заданным интервалом, время выполнения которого определяется днем и временем, выбранными из раскрывающихся списков. Но другая опция оповещения в режиме реального времени заставляет поиск работать непрерывно в фоновом режиме. Всякий раз, когда условие выполняется, действие предупреждения выполняется.
Условие запуска. Условие запуска проверяет критерии, указанные в триггере, и устанавливает изменение только при соблюдении критериев оповещения. Вы можете определить количество результатов или количество источников или количество хостов в результатах поиска, чтобы активировать предупреждение. Если он установлен на один раз, он будет выполняться только один раз, когда будет выполнено условие результата, но если для него установлено значение « Для каждого результата», он будет выполняться для каждой строки в наборе результатов, где выполняется условие триггера.
Действия триггера — Действия триггера могут дать желаемый результат или отправить электронное письмо, когда условие триггера выполнено. На рисунке ниже показаны некоторые важные триггерные действия, доступные в Splunk.
Управление знаниями Splunk — это поддержка объектов знаний для реализации Splunk Enterprise.
Ниже приведены основные особенности управления знаниями —
Убедитесь, что объекты знаний используются и используются соответствующими группами людей в организации.
Нормализуйте данные событий, применяя соглашения об именах объектов знаний и удаляя дубликаты или устаревшие объекты.
Наблюдать за стратегиями улучшения поиска и сводной производительности (ускорение отчетов, ускорение модели данных, сводная индексация, поиск в пакетном режиме).
Построить модели данных для пользователей Pivot.
Это объект Splunk для получения конкретной информации о ваших данных. Когда вы создаете объект знаний, вы можете сохранить его в тайне или поделиться им с другими пользователями. Примеры объекта знаний: сохраненные поиски, теги, извлечение полей, поиск и т. Д.
При использовании программного обеспечения Splunk объекты знаний создаются и сохраняются. Но они могут содержать дублирующую информацию или могут эффективно не использоваться всей предполагаемой аудиторией. Для решения таких проблем нам необходимо управлять этими объектами. Это делается путем их правильной классификации и последующего использования надлежащего управления разрешениями для их обработки. Ниже приводится использование и классификация различных объектов знаний —
Поля и извлечение полей — это первый уровень знаний программного обеспечения Splunk. Поля, автоматически извлекаемые из программного обеспечения Splunk из данных ИТ, помогают придать смысл необработанным данным. Извлеченные вручную поля расширяются и улучшаются на этом уровне смысла.
Используйте типы событий и транзакции для группировки интересных наборов похожих событий. Типы событий группируют наборы событий, обнаруженных при поиске. Транзакции — это коллекции концептуально связанных событий, охватывающих время.
Поиск и действия рабочего процесса — это категории объектов знаний, которые расширяют полезность ваших данных различными способами. Поиск полей позволяет добавлять поля к вашим данным из внешних источников данных, таких как статические таблицы (файлы CSV) или команды на основе Python. Действия рабочего процесса обеспечивают взаимодействие между полями в ваших данных и другими приложениями или веб-ресурсами, такими как поиск WHOIS в поле, содержащем IP-адрес.
Теги и псевдонимы используются для управления и нормализации наборов полевой информации. Вы можете использовать теги и псевдонимы для группировки наборов связанных значений полей и для предоставления извлеченных тегов полей, которые отражают различные аспекты их идентичности. Например, вы можете сгруппировать события из множества хостов в определенном месте (например, в здании или городе) вместе, назначив один и тот же тег каждому хосту.
Если у вас есть два разных источника, использующих разные имена полей для ссылки на одни и те же данные, то вы можете нормализовать свои данные, используя псевдонимы (например, путем подстановки псевдонима к ipaddress).
Модели данных являются представлениями одного или нескольких наборов данных и управляют инструментом Pivot, позволяя пользователям Pivot быстро создавать полезные таблицы, сложные визуализации и надежные отчеты без необходимости взаимодействия с языком поиска программного обеспечения Splunk. Модели данных разрабатываются менеджерами знаний, которые полностью понимают формат и семантику своих проиндексированных данных. Типичная модель данных использует другие типы объектов знаний.
Мы обсудим некоторые примеры этих объектов знаний в следующих главах.
Подпоиск — это особый случай регулярного поиска, когда результатом вторичного или внутреннего запроса является входная информация для первичного или внешнего запроса. Это похоже на концепцию подзапроса в случае языка SQL. В Splunk первичный запрос должен возвращать один результат, который может быть введен во внешний или вторичный запрос.
Когда поиск содержит подпоиск, подпоиск запускается первым. Подиски должны быть заключены в квадратные скобки при первичном поиске.
Рассмотрим случай поиска файла из веб-журнала, который имеет максимальный размер в байтах. Но это может меняться каждый день. Тогда мы хотим найти только те события, где размер файла равен максимальному размеру, а это воскресенье.
Сначала мы создаем подпоиск, чтобы найти максимальный размер файла. Мы используем функцию Stat max с полем с именем bytes в качестве аргумента. Это определяет максимальный размер файла за период времени, в течение которого выполняется поисковый запрос.
На изображении ниже показаны результаты поиска и результаты этого поиска.
Затем мы добавляем запрос подзапроса к первичному или внешнему запросу, помещая подзапрос в квадратные скобки. Также к поисковому запросу добавляется условие поиска.
Как мы видим, результат содержит только события, размер файла которых равен максимальному размеру файла, найденному с учетом всех событий, а днем события является воскресенье.
Макросы поиска — это многократно используемые блоки языка обработки поиска (SPL), которые можно вставить в другие поисковые запросы. Они используются, когда вы хотите использовать одну и ту же логику поиска для разных частей или значений в наборе данных динамически. Они могут принимать аргументы динамически, и результат поиска будет обновляться в соответствии с новыми значениями.
Чтобы создать макрос поиска, перейдем в настройки → Расширенный поиск → Поиск макросов → Добавить новый . Это поднимает экран ниже, где мы начинаем создавать макрос.
Мы хотим показать различную статистику о размере файла из журнала web_applications . Статистика о максимальном, минимальном и среднем значении размера файла с использованием поля байтов в журнале. Результат должен отображать эту статистику для каждого файла, указанного в журнале.
Таким образом, тип статистики носит динамический характер. Имя функции stats будет передано в качестве аргумента в макрос.
Далее мы определяем макрос, устанавливая различные свойства, как показано на экране ниже. Имя макроса содержит (1), что указывает на наличие одного аргумента, передаваемого в макрос, когда он используется в строке поиска. fun — это аргумент, который будет передан макросу во время выполнения поискового запроса.
Чтобы использовать макрос, мы делаем его частью строки поиска. При передаче разных значений аргумента мы видим разные результаты, как и ожидалось.
Попробуйте найти средний размер в байтах файлов. Мы передаем avg в качестве аргумента и получаем результат, как показано ниже. Макрос был сохранен под `sign как часть поискового запроса.
Точно так же, если мы хотим максимальный размер файла для каждого из файлов, присутствующих в журнале, то мы используем max в качестве аргумента. Результат как показано ниже.
В поиске Splunk мы можем создавать собственные события из набора данных на основе определенных критериев. Например, мы ищем только те события, которые имеют http-код состояния 200. Теперь это событие можно сохранить как тип события с именем, определенным пользователем как status200, и использовать это имя как часть будущих поисков.
Короче говоря, тип события представляет собой поиск, который возвращает определенный тип события или полезную коллекцию событий. Каждое событие, которое может быть возвращено поиском, получает связь с этим типом события.
Существует два способа создать тип события после того, как мы определили критерии поиска. Один из них — запустить поиск, а затем сохранить его как тип события. Другой способ — добавить новый тип события на вкладке настроек . Мы увидим оба способа его создания в этом разделе.
Рассмотрим поиск событий, которые имеют критерий успешного значения статуса http 200 и тип события, запускаемый в среду. После выполнения поискового запроса мы можем выбрать опцию Сохранить как, чтобы сохранить запрос как тип события.
На следующем экране будет предложено указать имя типа события, выбрать необязательный тег, а затем выбрать цвет, которым события будут выделены. Параметр priority решает, какой тип события будет отображаться первым, если два или более типа событий соответствуют одному и тому же событию.
Наконец, мы можем увидеть, что тип события был создан, перейдя к параметру Настройки → Типы событий .
Другой вариант создания нового типа события — использовать параметр « Настройки» → «Типы событий», как показано ниже, где мы можем добавить новый тип события:
При нажатии на кнопку « Новый тип события» мы получаем следующий экран для добавления того же запроса, что и в предыдущем разделе.
Чтобы просмотреть событие, которое мы только что создали выше, мы можем написать поисковый запрос ниже в поле поиска, и мы можем увидеть итоговые события вместе с цветом, который мы выбрали для типа события.
Мы можем использовать тип события вместе с другими запросами. Здесь мы указываем некоторые частичные критерии из Типа события, и результат представляет собой смесь событий, которая показывает цветные и неокрашенные события в результате.
Splunk имеет отличные возможности визуализации, которые показывают различные графики. Эти диаграммы создаются на основе результатов поискового запроса, где для получения числовых результатов используются соответствующие функции.
Например, если мы посмотрим на средний размер файла в байтах из набора данных с именем web_applications, мы можем увидеть результат на вкладке статистики, как показано ниже —
Чтобы создать базовую диаграмму, сначала убедитесь, что данные видны на вкладке статистики, как показано выше. Затем мы нажимаем на вкладку Визуализация, чтобы получить соответствующий график. Приведенные выше данные создают круговую диаграмму по умолчанию, как показано ниже.
Мы можем изменить тип диаграммы, выбрав другую опцию диаграммы из названия диаграммы. Нажав на один из этих параметров, вы получите диаграмму для этого типа графика.
Диаграммы также могут быть отформатированы с помощью параметра Формат. Эта опция позволяет установить значения для осей, установить легенды или показать значения данных на графике. В приведенном ниже примере мы выбрали горизонтальную диаграмму и выбрали параметр для отображения значений данных в качестве параметра «Формат».
Много раз, мы должны поместить один график поверх другого, чтобы сравнить или увидеть тренд двух графиков. Splunk поддерживает эту функцию с помощью функции наложения диаграммы, доступной на вкладке визуализации. Чтобы создать такую диаграмму, нам нужно сначала создать диаграмму с двумя переменными, а затем добавить третью переменную, которая может создать оверлейную диаграмму.
Продолжая примеры из предыдущей главы, мы выясняем размер байтов файлов в разные дни недели, а затем добавляем средний размер байтов для этих дней. На рисунке ниже показана диаграмма, показывающая размер в байтах в зависимости от среднего размера файлов в разные дни недели.
Далее, мы собираемся добавить статистическую функцию, называемую стандартным отклонением, к вышеуказанному поисковому запросу. Это принесет дополнительную переменную, необходимую для создания наложения диаграммы. На изображении ниже показана статистика результата запроса, который будет использоваться при визуализации.
Чтобы создать наложение диаграммы, следуем Визуализация → Формат → Наложение диаграммы.
Это вызывает всплывающее окно, где нам нужно выбрать поле, которое будет наложенным графиком. В этом случае мы выбираем stdev (байты) в качестве поля, как показано на рисунке ниже. Мы также можем заполнить другие значения: заголовок, масштаб и их интервалы, минимальные значения, максимальные значения и т. Д. Для нашего примера мы выбираем значения по умолчанию после выбора поля для параметра наложения.
После выбора вышеуказанных опций мы можем закрыть всплывающее окно наложения графика и увидеть окончательный график, как показано ниже —
Спарклайн — это небольшое представление некоторой статистической информации без отображения осей. Обычно это выглядит как линия с выпуклостями, чтобы показать, как изменилось определенное количество за период времени. Splunk имеет встроенную функцию для создания спарклайнов из событий, которые он ищет. Это часть функции создания графика.
Нам нужно выбрать поле и формулу поиска, которая будет использоваться при создании спарклайна. На рисунке ниже показаны значения среднего размера в байтах некоторых файлов на хосте web_application.
Чтобы создать Sparklines из приведенной выше статистики, мы добавляем функцию Sparkline в поисковый запрос, как показано на рисунке ниже. Табличное представление вышеупомянутой статистики теперь начинает отображать спарклайны для среднего байтового размера этих файлов. Здесь мы взяли All Time в качестве периода времени для расчета изменения среднего размера файлов в байтах. Если мы изменим этот период времени, то природа графиков изменится.
Если мы изменим период времени для приведенного выше графика с Все время на Последние 30 дней, мы увидим, что спарклайны будут немного отличаться, как показано ниже. Здесь нужно отметить, как мало имен файлов исчезли из списка, поскольку эти файлы не были доступны в тот период времени.
Индексирование — это механизм, позволяющий ускорить процесс поиска, присваивая числовые адреса фрагменту данных, в котором выполняется поиск. Индексирование Splunk аналогично концепции индексации в базах данных. Установка Splunk создает три индекса по умолчанию следующим образом.
main — это индекс по умолчанию в Splunk, где хранятся все обработанные данные.
Внутренний — в этом индексе хранятся внутренние журналы и показатели обработки Splunk.
аудит — этот индекс содержит события, связанные с монитором изменений файловой системы, аудитом и всей историей пользователей.
Индексаторы Splunk создают и поддерживают индексы. Когда вы добавляете данные в Splunk, индексатор обрабатывает их и сохраняет их в назначенном индексе (по умолчанию, в основном индексе или в том, который вы идентифицируете).
Мы можем взглянуть на существующие индексы, перейдя в Настройки → Индексы после входа в Splunk. На изображении ниже показана опция.
При дальнейшем нажатии на индексы, мы можем увидеть список индексов, которые Splunk поддерживает для данных, которые уже захвачены в Splunk. На рисунке ниже показан такой список.
Мы можем создать новый индекс с желаемым размером по данным, которые хранятся в Splunk. Дополнительные данные, которые поступают, могут использовать этот недавно созданный индекс, но улучшенную функциональность поиска. Шаги для создания индекса: Настройки → Индексы → Новый индекс . Появится экран ниже, где мы упоминаем имя индекса и распределение памяти и т. Д.
После создания указанного выше индекса мы можем настроить события, которые будут проиндексированы этим конкретным индексом. Мы выбираем тип события. Используйте путь Настройки → Ввод данных → Файлы и каталоги . Затем мы выбираем конкретный файл событий, который мы хотим прикрепить к вновь созданному событию. Как вы можете видеть на картинке ниже, мы присвоили этому индексу индекс index_web_app.
Много раз нам нужно будет сделать некоторые вычисления для полей, которые уже доступны в событиях Splunk. Мы также хотим сохранить результат этих вычислений в качестве нового поля, которое впоследствии будет использоваться при различных поисках. Это стало возможным благодаря использованию концепции вычисляемых полей в поиске Splunk.
Простейший пример — показать первые три символа дня недели вместо полного названия дня. Нам нужно применить определенную функцию Splunk для достижения этой манипуляции с полем и сохранить новый результат под новым именем поля.
В файле журнала Web_application есть два поля с именами bytes и date_wday. Значение в поле байтов — это количество байтов. Мы хотим отобразить это значение как ГБ. Для этого потребуется разделить поле на 1024, чтобы получить значение в ГБ. Нам нужно применить этот расчет к полю байтов.
Аналогично, date_wday отображает полное название дня недели. Но нам нужно отобразить только первые три символа.
Существующие значения в этих двух полях показаны на рисунке ниже —
Для создания вычисляемого поля мы используем функцию eval. Эта функция сохраняет результат расчета в новом поле. Мы собираемся применить следующие два расчета —
Мы добавляем новые поля, созданные выше, в список полей, которые мы отображаем как часть результатов поиска. Для этого мы выбираем « Все поля» и ставим галочку напротив названия этих новых полей, как показано на рисунке ниже.
После выбора полей выше, мы можем увидеть вычисленные поля в результатах поиска, как показано ниже. Поисковый запрос отображает рассчитанные поля, как показано ниже —
Теги используются для назначения имен конкретным полям и комбинациям значений. Эти поля могут относиться к типу события, хосту, источнику или типу источника и т. Д. Вы также можете использовать тег для группировки набора значений полей, чтобы их можно было искать с помощью одной команды. Например, вы можете пометить все различные файлы, сгенерированные в понедельник, тегом с именем mon_files.
Чтобы найти пару поле-значение, которую мы собираемся пометить, нам нужно развернуть события и найти поле, которое необходимо рассмотреть. На рисунке ниже показано, как мы можем расширить событие, чтобы увидеть поля —
Мы можем создать теги, добавив значение тега к паре поле-значение, используя опцию Edit Tags, как показано ниже. Мы выбираем поле под столбцом Действия.
На следующем экране предлагается определить тег. Для поля Status мы выбираем значение состояния 503 или 505 и назначаем тег с именем server_error, как показано ниже. Мы должны сделать это одно за другим, выбрав два события, каждое с событиями со значениями состояния 503 и 505. На рисунке ниже показан метод для значения состояния как 503. Мы должны повторить те же шаги для события со значением состояния, как 505.
После того, как теги созданы, мы можем искать события, содержащие тег, просто написав имя тега в строке поиска. На изображении ниже мы видим все события, которые имеют статус: 503 или 505.
Приложение Splunk — это расширение функциональности Splunk, которое имеет собственный встроенный контекст пользовательского интерфейса для удовлетворения конкретных потребностей. Приложения Splunk состоят из различных объектов знаний Splunk (поиска, тегов, типов событий, сохраненных поисков и т. Д.). Сами приложения могут использовать или использовать другие приложения или надстройки. Splunk может запускать любое количество приложений одновременно.
Когда вы входите в Splunk, вы попадаете в приложение, которое обычно представляет собой приложение Splunk Search . Таким образом, почти каждый раз, когда вы находитесь внутри интерфейса Splunk, вы используете приложение.
Мы можем перечислить доступные приложения в Splunk, используя пункт Приложения → Управление приложениями . При переходе по этой опции открывается следующий экран, в котором перечислены существующие приложения, доступные в интерфейсе Splunk.
Ниже приведены важные значения, связанные с приложениями Splunk.
Имя — это имя приложения, уникальное для каждого приложения.
Имя папки Это имя, которое будет использоваться для каталога в $ SPLUNK_HOME / etc / apps /. Название папки не может содержать символ «точка» (.).
Версия — это строка версии приложения. Видимый Указывает, должно ли приложение быть видимым в Splunk Web. Приложения, содержащие пользовательский интерфейс, должны быть видны.
Совместное использование — это уровень разрешений (чтение или запись), предоставляемых различным пользователям Splunk для этого конкретного приложения.
Статус — Статус: это текущий статус доступности приложения. Это может быть включено или отключено для использования.
Правильная настройка разрешений для использования приложения имеет важное значение. Мы можем ограничить использование приложения одним пользователем или несколькими пользователями, включая всех пользователей. Приведенный ниже экран, который появляется после нажатия на ссылку разрешений в приведенном выше, используется для изменения доступа к различным ролям.
По умолчанию флажки «Чтение и запись» доступны для всех. Но мы можем изменить это, перейдя к каждой роли и выбрав соответствующее разрешение для этой конкретной роли.
Существует широкий спектр потребностей, для которых используются функции поиска Splunk. Итак, появился рынок Splunk App, в котором представлены различные приложения, созданные отдельными лицами и организациями. Они доступны как в бесплатной, так и в платной версиях. Мы можем просматривать эти приложения, выбрав « Приложения» → «Управление приложениями» → «Просмотреть другие приложения» . Поднимается экран ниже.
Как видите, появляется имя приложения вместе с кратким описанием функциональности приложения. Это поможет вам решить, какое приложение использовать. Также обратите внимание на то, как приложения классифицируются в левой панели, чтобы помочь быстрее выбрать тип приложения.
Удаление данных из Splunk возможно с помощью команды delete . Сначала мы создаем условие поиска для извлечения событий, которые мы хотим пометить для удаления. Как только условие поиска будет приемлемым, мы добавим предложение delete в конец команды, чтобы удалить эти события из Splunk. После удаления даже пользователь с правами администратора не может просматривать эти данные в Splunk.
Удаление данных необратимо. Если вы по-прежнему хотите, чтобы удаленные данные возвращались в Splunk, у вас должна быть оригинальная копия исходных данных, которую можно использовать для повторной индексации данных в Splunk. Это будет процесс, похожий на создание нового индекса.
Любой пользователь, включая администратора, не имеет доступа к удалению данных по умолчанию. По умолчанию только роль can_delete может удалять события. Итак, мы создаем нового пользователя, назначаем эту роль и затем выполняем вход с учетными данными этого нового пользователя, чтобы выполнить операцию удаления. На изображении ниже показано, как мы создаем нового пользователя с ролью «can_delete». Мы попадаем на этот экран, следуя пути Настройки → Контроль доступа → Пользователи → Новый пользователь .
Затем мы выходим из интерфейса Splunk и снова входим в систему с этим вновь созданным пользователем.
Сначала нам нужно определить список событий, которые мы хотим удалить. Это делается с помощью обычного поискового запроса, определяющего условие фильтра. В приведенном ниже примере мы выбираем поиск событий из хоста web_application, значение поля http статуса которого равно 505. Наша цель — удалить только тот набор данных, который содержит эти значения, для удаления из результата поиска. На рисунке ниже показан этот набор выбранных данных.
Далее мы используем команду удаления, чтобы удалить выбранные выше данные из набора результатов. Это включает в себя просто добавление слова удаления после «|» в конце поискового запроса, как показано ниже —
После выполнения поискового запроса выше, мы можем увидеть следующий экран, где эти события были удалены.
Вы также можете дополнительно выполнить поисковый запрос, чтобы убедиться, что эти события не возвращаются в наборе результатов.
Диаграммы, созданные в Splunk, имеют множество функций для их настройки в соответствии с потребностями пользователя. Эти настройки помогают полностью отобразить данные или изменить интервал, для которого рассчитываются данные. После первоначального создания диаграммы мы углубимся в функции настройки.
Давайте рассмотрим приведенный ниже поисковый запрос для получения статистики различных измерений размера байтов файлов по дням недели. Мы выбираем столбчатую диаграмму для отображения графика и видим значения по умолчанию в значениях оси X и оси Y.
Мы можем настроить оси, отображаемые на графике, выбрав « Формат» → «Ось X» . Здесь мы редактируем заголовок диаграммы. Мы также изменим параметр «Поворот метки», чтобы выбрать наклонную метку, чтобы она лучше вписывалась в диаграмму. После их редактирования на графике можно увидеть результаты, выделенные зелеными полями ниже.
Легенды диаграммы также можно настроить с помощью параметра Формат → Легенда . Мы редактируем опцию Legend Position, чтобы отметить ее сверху. Мы также редактируем опцию «Обрезание легенды», чтобы при необходимости урезать конец легенды. В приведенной ниже корзине показаны легенды, отображаемые в верхней части с цветами и значениями.
Splunk Enterprise отслеживает и индексирует файл или каталог по мере появления новых данных. Вы также можете указать подключенный или общий каталог, включая сетевые файловые системы, если Splunk Enterprise может читать из каталога. Если указанный каталог содержит подкаталоги, процесс монитора рекурсивно проверяет их на наличие новых файлов, пока каталоги могут быть прочитаны.
Вы можете включить или исключить чтение файлов или каталогов с помощью белых и черных списков.
Если вы отключите или удалите вход монитора, Splunk Enterprise не прекращает индексирование файлов: ссылки на входы. Это только перестает проверять эти файлы снова.
Вы указываете путь к файлу или каталогу, и процессор монитора использует все новые данные, записанные в этот файл или каталог. Таким образом вы можете отслеживать журналы приложений в реальном времени, например журналы веб-доступа, приложения Java 2 Platform или .NET и т. Д.
Используя веб-интерфейс Splunk, мы можем добавлять файлы или каталоги для мониторинга. Мы идем в Splunk Home → Добавить данные → Монитор, как показано на рисунке ниже —
При нажатии кнопки «Монитор» открывается список типов файлов и каталогов, которые можно использовать для мониторинга файлов. Далее мы выбираем файл, который хотим отслеживать.
Далее мы выбираем значения по умолчанию, так как Splunk может анализировать файл и автоматически настраивать параметры мониторинга.
После последнего шага мы видим следующий результат, который фиксирует события из файла для мониторинга.
Если какое-либо значение в событии изменяется, то приведенный выше результат обновляется, чтобы показать последний результат.
Команда sort сортирует все результаты по указанным полям. Пропущенные поля обрабатываются как имеющие наименьшее или наибольшее возможное значение этого поля, если порядок по убыванию или возрастанию соответственно. Если первым аргументом команды сортировки является число, то возвращается не более того количества результатов по порядку. Если номер не указан, используется ограничение по умолчанию 10000. Если указано число 0, возвращаются все результаты.
Мы можем назначить конкретный тип данных для искомых полей. Существующий тип данных в наборе данных Splunk может отличаться от типа данных, который мы вводим в поисковый запрос. В приведенном ниже примере мы сортируем поле состояния как числовое в порядке возрастания. Кроме того, поле с именем url ищется как строка, а отрицательный знак указывает на сортировку по убыванию.
Мы также можем указать количество результатов, которые будут отсортированы, а не весь результат поиска. Приведенный ниже результат поиска показывает сортировку только 50 событий со статусом по возрастанию и URL-адресом по убыванию.
Мы можем переключать результат всего поискового запроса, используя предложение reverse. Полезно использовать существующий запрос, не изменяя и не отменяя результат сортировки по мере необходимости.
Много раз мы заинтересованы в поиске наиболее распространенных значений, доступных в поле. Верхняя команда в Splunk помогает нам достичь этого. Это также помогает найти количество и процентную частоту, с которой значения встречаются в событиях.
В простейшей форме мы просто получаем количество и процент такого количества по сравнению с общим числом событий. В приведенном ниже примере мы находим 8 самых популярных значений продукта.
Далее, мы можем также включить другое поле как часть предложения by этой верхней команды, чтобы отобразить результат field1 для каждого набора field2. В приведенном ниже поиске мы находим три лучших продукта для каждого имени файла. Обратите внимание, как имена файлов повторяются 3 раза, показывая разные продукты для этого файла.
Мы также можем решить отображать определенные столбцы, используя дополнительные параметры, доступные в Splunk с командой Top. В приведенной ниже команде мы отключаем показ опции процента и отображаем только верхний идентификатор продукта по имени файла.
Команда stats используется для вычисления сводной статистики по результатам поиска или событиям, извлеченным из индекса. Команда stats работает с результатами поиска в целом и возвращает только те поля, которые вы указали.
Каждый раз, когда вы вызываете команду stats, вы можете использовать одну или несколько функций. Однако вы можете использовать только одно предложение BY. Если команда stats используется без предложения BY, возвращается только одна строка, которая является агрегацией по всему входящему набору результатов. Если используется предложение BY, возвращается одна строка для каждого отдельного значения, указанного в предложении BY.
Ниже мы видим примеры некоторых часто используемых команд stats.
Мы можем найти среднее значение числового поля с помощью функции avg () . Эта функция принимает имя поля в качестве ввода. Без предложения BY он выдаст одну запись, которая показывает среднее значение поля для всех событий. Но с предложением by это даст несколько строк в зависимости от того, как поле сгруппировано по дополнительному новому полю.
В приведенном ниже примере мы находим средний размер в байтах файлов, сгруппированных по различным кодам состояния http, связанным с событиями, связанными с этими файлами.
Команда stats может использоваться для отображения диапазона значений числового поля с помощью функции range . Мы продолжаем предыдущий пример, но вместо усреднения мы теперь используем вместе функции max (), min () и range в команде stats, чтобы мы могли увидеть, как был рассчитан диапазон, взяв разницу между значениями max и мин столбцы.
Статистически сфокусированные значения, такие как среднее значение и дисперсия полей, также рассчитываются аналогичным образом, как указано выше, с использованием соответствующих функций с командой stats. В приведенном ниже примере мы используем функции mean () и var () для достижения этой цели. Мы продолжаем использовать те же поля, что и в предыдущих примерах. Результат показывает среднее значение и дисперсию значений поля с именем bytes в строках, организованных по значениям http-статуса событий.