Apache Kafka — Введение
В больших данных используется огромный объем данных. Что касается данных, у нас есть две основные проблемы. Первая задача состоит в том, как собрать большой объем данных, а вторая задача — проанализировать собранные данные. Чтобы преодолеть эти трудности, вам нужна система обмена сообщениями.
Кафка предназначена для распределенных высокопроизводительных систем. Кафка имеет тенденцию работать очень хорошо как замена более традиционному брокеру сообщений. По сравнению с другими системами обмена сообщениями, Kafka имеет лучшую пропускную способность, встроенное разбиение, репликацию и собственную отказоустойчивость, что делает его подходящим для крупномасштабных приложений обработки сообщений.
Что такое система обмена сообщениями?
Система обмена сообщениями отвечает за передачу данных из одного приложения в другое, поэтому приложения могут сосредоточиться на данных, но не беспокоиться о том, как их обмениваться. Распределенный обмен сообщениями основан на концепции надежной очереди сообщений. Сообщения помещаются в очередь асинхронно между клиентскими приложениями и системой обмена сообщениями. Доступны два типа шаблонов обмена сообщениями: один — «точка-точка», а другой — система обмена сообщениями «публикация-подписка». Большинство шаблонов сообщений следуют pub-sub .
Система обмена сообщениями точка-точка
В системе точка-точка сообщения сохраняются в очереди. Один или несколько потребителей могут потреблять сообщения в очереди, но конкретное сообщение может потреблять максимум один потребитель. Как только потребитель прочитает сообщение в очереди, оно исчезнет из этой очереди. Типичным примером этой системы является система обработки заказов, где каждый заказ обрабатывается одним обработчиком заказов, но несколько процессоров заказов могут работать одновременно. Следующая диаграмма изображает структуру.
Публикация-подписка Система сообщений
В системе публикации-подписки сообщения сохраняются в теме. В отличие от двухточечной системы, потребители могут подписаться на одну или несколько тем и использовать все сообщения в этой теме. В системе «Публикация-подписка» производители сообщений называются издателями, а потребители сообщений — подписчиками. Примером из реальной жизни является Dish TV, который публикует различные каналы, такие как спортивные состязания, фильмы, музыка и т. Д., И любой может подписаться на свой собственный набор каналов и получать их, когда доступны их подписанные каналы.
Что такое Кафка?
Apache Kafka — это распределенная система обмена сообщениями «публикация-подписка» и надежная очередь, которая может обрабатывать большой объем данных и позволяет передавать сообщения из одной конечной точки в другую. Кафка подходит как для автономного, так и для онлайн-рассылки сообщений. Сообщения Kafka сохраняются на диске и реплицируются в кластере для предотвращения потери данных. Kafka построен поверх службы синхронизации ZooKeeper. Он очень хорошо интегрируется с Apache Storm и Spark для анализа потоковых данных в реальном времени.
Выгоды
Ниже приведены некоторые преимущества Кафки —
-
Надежность — Кафка распределяется, разбивается, тиражируется и отказоустойчива.
-
Масштабируемость — система обмена сообщениями Kafka легко масштабируется без простоев.
-
Долговечность — Kafka использует
распределенный журнал фиксации,
который означает, что сообщения сохраняются на диске настолько быстро, насколько это возможно, а значит, и долговечны -
Производительность — Кафка обладает высокой пропускной способностью для публикации и подписки сообщений. Он поддерживает стабильную производительность даже при хранении многих ТБ сообщений.
Надежность — Кафка распределяется, разбивается, тиражируется и отказоустойчива.
Масштабируемость — система обмена сообщениями Kafka легко масштабируется без простоев.
Долговечность — Kafka использует распределенный журнал фиксации,
который означает, что сообщения сохраняются на диске настолько быстро, насколько это возможно, а значит, и долговечны
Производительность — Кафка обладает высокой пропускной способностью для публикации и подписки сообщений. Он поддерживает стабильную производительность даже при хранении многих ТБ сообщений.
Kafka очень быстр и гарантирует нулевое время простоя и нулевую потерю данных.
Случаи применения
Кафку можно использовать во многих случаях использования. Некоторые из них перечислены ниже —
-
Метрики — Кафка часто используется для оперативного мониторинга данных. Это включает в себя агрегирование статистики из распределенных приложений для получения централизованных потоков оперативных данных.
-
Решение для агрегации журналов — Kafka может использоваться в рамках всей организации для сбора журналов от нескольких служб и предоставления их в стандартном формате нескольким потребителям.
-
Потоковая обработка — популярные платформы, такие как Storm и Spark Streaming, считывают данные из темы, обрабатывают их и записывают обработанные данные в новую тему, где они становятся доступными для пользователей и приложений. Высокая прочность Kafka также очень полезна в контексте потоковой обработки.
Метрики — Кафка часто используется для оперативного мониторинга данных. Это включает в себя агрегирование статистики из распределенных приложений для получения централизованных потоков оперативных данных.
Решение для агрегации журналов — Kafka может использоваться в рамках всей организации для сбора журналов от нескольких служб и предоставления их в стандартном формате нескольким потребителям.
Потоковая обработка — популярные платформы, такие как Storm и Spark Streaming, считывают данные из темы, обрабатывают их и записывают обработанные данные в новую тему, где они становятся доступными для пользователей и приложений. Высокая прочность Kafka также очень полезна в контексте потоковой обработки.
Нужно для кафки
Kafka — это унифицированная платформа для обработки всех потоков данных в реальном времени. Kafka поддерживает доставку сообщений с низкой задержкой и дает гарантию отказоустойчивости при наличии отказов машины. Он способен обрабатывать большое количество разнообразных потребителей. Кафка очень быстрая, выполняет 2 миллиона операций записи в секунду. Кафка сохраняет все данные на диск, что, по сути, означает, что все записи идут в кеш страниц ОС (ОЗУ). Это позволяет очень эффективно передавать данные из кэша страниц в сетевой сокет.
Апач Кафка — Основы
Прежде чем углубляться в Kafka, вы должны знать основные термины, такие как темы, брокеры, производители и потребители. Следующая диаграмма иллюстрирует основные термины, а таблица подробно описывает компоненты диаграммы.
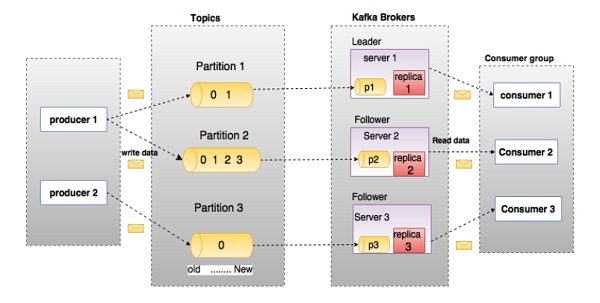
На приведенной выше диаграмме тема настроена на три раздела. Раздел 1 имеет два коэффициента смещения 0 и 1. Раздел 2 имеет четыре коэффициента смещения 0, 1, 2 и 3. Раздел 3 имеет один коэффициент смещения 0. Идентификатор реплики совпадает с идентификатором сервера, на котором она размещена.
Предположим, если коэффициент репликации для темы установлен на 3, то Kafka создаст 3 одинаковые реплики каждого раздела и поместит их в кластер, чтобы сделать доступными для всех своих операций. Чтобы сбалансировать нагрузку в кластере, каждый брокер хранит один или несколько таких разделов. Несколько производителей и потребителей могут публиковать и получать сообщения одновременно.
| S.No | Компоненты и описание |
|---|---|
| 1 |
темы Поток сообщений, относящихся к определенной категории, называется темой. Данные хранятся в темах. Темы разбиты на разделы. Для каждой темы Кафка хранит минимум один раздел. Каждый такой раздел содержит сообщения в неизменной упорядоченной последовательности. Раздел реализован как набор файлов сегментов одинакового размера. |
| 2 |
раздел Темы могут иметь много разделов, поэтому он может обрабатывать произвольный объем данных. |
| 3 |
Смещение раздела Каждое секционированное сообщение имеет уникальный идентификатор последовательности, называемый |
| 4 |
Реплики раздела Реплики — это не что иное, как |
| 5 |
Брокеры
|
| 6 |
Кафка кластер Kafka с несколькими брокерами называется кластером Kafka. Кластер Kafka может быть расширен без простоев. Эти кластеры используются для управления сохранением и репликацией данных сообщений. |
| 7 |
Производители Производители — это издатели сообщений на одну или несколько тем Кафки. Производители отправляют данные брокерам Kafka. Каждый раз, когда производитель публикует сообщение для брокера, он просто добавляет сообщение в последний файл сегмента. На самом деле, сообщение будет добавлено в раздел. Производитель также может отправлять сообщения в раздел по своему выбору. |
| 8 |
Потребители Потребители читают данные от брокеров. Потребители подписываются на одну или несколько тем и используют опубликованные сообщения, извлекая данные у брокеров. |
| 9 |
лидер |
| 10 |
толкатель Узел, который следует инструкциям лидера, называется последователем. Если лидер терпит неудачу, один из последователей автоматически становится новым лидером. Последователь действует как обычный потребитель, извлекает сообщения и обновляет свое собственное хранилище данных. |
темы
Поток сообщений, относящихся к определенной категории, называется темой. Данные хранятся в темах.
Темы разбиты на разделы. Для каждой темы Кафка хранит минимум один раздел. Каждый такой раздел содержит сообщения в неизменной упорядоченной последовательности. Раздел реализован как набор файлов сегментов одинакового размера.
раздел
Темы могут иметь много разделов, поэтому он может обрабатывать произвольный объем данных.
Смещение раздела
Каждое секционированное сообщение имеет уникальный идентификатор последовательности, называемый смещением
.
Реплики раздела
Реплики — это не что иное, как резервные копии
раздела. Реплики никогда не читают и не записывают данные. Они используются для предотвращения потери данных.
Брокеры
Брокеры — это простая система, отвечающая за поддержание опубликованных данных. Каждый брокер может иметь ноль или более разделов на тему. Предположим, если в теме N разделов и N брокеров, у каждого брокера будет один раздел.
Предположим, что если в теме N разделов и более N брокеров (n + m), у первого N брокера будет один раздел, а у следующего M-брокера не будет никакого раздела для этой конкретной темы.
Предположим, что если в теме есть N разделов и меньше, чем N брокеров (нм), каждый брокер будет иметь один или несколько разделов, разделяющих их. Этот сценарий не рекомендуется из-за неравного распределения нагрузки среди брокера.
Кафка кластер
Kafka с несколькими брокерами называется кластером Kafka. Кластер Kafka может быть расширен без простоев. Эти кластеры используются для управления сохранением и репликацией данных сообщений.
Производители
Производители — это издатели сообщений на одну или несколько тем Кафки. Производители отправляют данные брокерам Kafka. Каждый раз, когда производитель публикует сообщение для брокера, он просто добавляет сообщение в последний файл сегмента. На самом деле, сообщение будет добавлено в раздел. Производитель также может отправлять сообщения в раздел по своему выбору.
Потребители
Потребители читают данные от брокеров. Потребители подписываются на одну или несколько тем и используют опубликованные сообщения, извлекая данные у брокеров.
лидер
Лидер
— это узел, отвечающий за все операции чтения и записи для данного раздела. Каждый раздел имеет один сервер, выступающий в качестве лидера.
толкатель
Узел, который следует инструкциям лидера, называется последователем. Если лидер терпит неудачу, один из последователей автоматически становится новым лидером. Последователь действует как обычный потребитель, извлекает сообщения и обновляет свое собственное хранилище данных.
Apache Kafka — кластерная архитектура
Посмотрите на следующую иллюстрацию. На ней показана кластерная диаграмма Кафки.
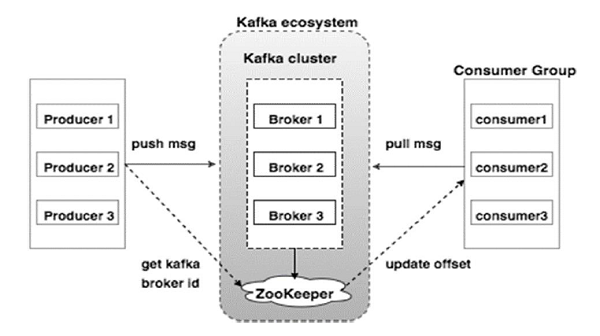
В следующей таблице описан каждый из компонентов, показанных на приведенной выше схеме.
| S.No | Компоненты и описание |
|---|---|
| 1 |
Маклер Кластер Kafka обычно состоит из нескольких брокеров для поддержания баланса нагрузки. Брокеры Kafka не имеют статуса, поэтому они используют ZooKeeper для поддержания своего кластерного состояния. Один экземпляр брокера Kafka может обрабатывать сотни тысяч операций чтения и записи в секунду, а каждый брокер может обрабатывать ТБ сообщений без влияния на производительность. Выбор лидера брокера Kafka может быть сделан ZooKeeper. |
| 2 |
Работник зоопарка ZooKeeper используется для управления и координации брокера Kafka. Сервис ZooKeeper в основном используется для уведомления производителя и потребителя о наличии любого нового брокера в системе Kafka или сбое брокера в системе Kafka. В соответствии с уведомлением, полученным Zookeeper относительно присутствия или отказа брокера, производитель и потребитель принимают решение и начинают согласовывать свою задачу с каким-либо другим брокером. |
| 3 |
Производители Производители передают данные брокерам. Когда запускается новый брокер, все производители ищут его и автоматически отправляют сообщение этому новому брокеру. Производитель Kafka не ждет подтверждений от брокера и отправляет сообщения так быстро, как может обработать брокер. |
| 4 |
Потребители Поскольку брокеры Kafka не имеют состояния, это означает, что потребитель должен поддерживать количество сообщений, использованных с помощью смещения раздела. Если потребитель подтверждает конкретное смещение сообщения, это означает, что потребитель использовал все предыдущие сообщения. Потребитель отправляет брокеру асинхронный запрос на получение, чтобы подготовить буфер байтов к использованию. Потребители могут перемотать или перейти к любой точке раздела, просто указав значение смещения. Значение смещения потребителя сообщается ZooKeeper. |
Маклер
Кластер Kafka обычно состоит из нескольких брокеров для поддержания баланса нагрузки. Брокеры Kafka не имеют статуса, поэтому они используют ZooKeeper для поддержания своего кластерного состояния. Один экземпляр брокера Kafka может обрабатывать сотни тысяч операций чтения и записи в секунду, а каждый брокер может обрабатывать ТБ сообщений без влияния на производительность. Выбор лидера брокера Kafka может быть сделан ZooKeeper.
Работник зоопарка
ZooKeeper используется для управления и координации брокера Kafka. Сервис ZooKeeper в основном используется для уведомления производителя и потребителя о наличии любого нового брокера в системе Kafka или сбое брокера в системе Kafka. В соответствии с уведомлением, полученным Zookeeper относительно присутствия или отказа брокера, производитель и потребитель принимают решение и начинают согласовывать свою задачу с каким-либо другим брокером.
Производители
Производители передают данные брокерам. Когда запускается новый брокер, все производители ищут его и автоматически отправляют сообщение этому новому брокеру. Производитель Kafka не ждет подтверждений от брокера и отправляет сообщения так быстро, как может обработать брокер.
Потребители
Поскольку брокеры Kafka не имеют состояния, это означает, что потребитель должен поддерживать количество сообщений, использованных с помощью смещения раздела. Если потребитель подтверждает конкретное смещение сообщения, это означает, что потребитель использовал все предыдущие сообщения. Потребитель отправляет брокеру асинхронный запрос на получение, чтобы подготовить буфер байтов к использованию. Потребители могут перемотать или перейти к любой точке раздела, просто указав значение смещения. Значение смещения потребителя сообщается ZooKeeper.
Apache Kafka — WorkFlow
На данный момент мы обсудили основные понятия Кафки. Давайте теперь пролить свет на рабочий процесс Кафки.
Kafka — это просто набор тем, разделенных на один или несколько разделов. Раздел Кафки — это линейно упорядоченная последовательность сообщений, где каждое сообщение идентифицируется по их индексу (называемому смещением). Все данные в кластере Кафки являются несвязным объединением разделов. Входящие сообщения записываются в конце раздела, а сообщения последовательно читаются потребителями. Долговечность обеспечивается репликацией сообщений различным брокерам.
Kafka обеспечивает быструю, надежную, устойчивую, отказоустойчивую и безотказную работу системы обмена сообщениями на основе pub-sub и очереди. В обоих случаях производители просто отправляют сообщение в тему, а потребитель может выбрать любой тип системы обмена сообщениями в зависимости от своих потребностей. Давайте рассмотрим шаги в следующем разделе, чтобы понять, как потребитель может выбрать систему обмена сообщениями по своему выбору.
Рабочий процесс обмена сообщениями Pub-Sub
Ниже приведен пошаговый рабочий процесс сообщений Pub-Sub.
-
Производители отправляют сообщения в тему на регулярной основе.
-
Брокер Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы. Это гарантирует, что сообщения в равной степени разделены между разделами. Если производитель отправляет два сообщения и имеется два раздела, Kafka сохранит одно сообщение в первом разделе и второе сообщение во втором разделе.
-
Потребитель подписывается на определенную тему.
-
Как только потребитель подписывается на тему, Kafka предоставит потребителю текущее смещение темы, а также сохранит смещение в ансамбле Zookeeper.
-
Потребитель будет регулярно запрашивать у Кафки новые сообщения (например, 100 мс).
-
Как только Кафка получает сообщения от производителей, она отправляет эти сообщения потребителям.
-
Потребитель получит сообщение и обработает его.
-
Как только сообщения обработаны, потребитель отправит подтверждение брокеру Kafka.
-
Как только Кафка получает подтверждение, он меняет смещение на новое значение и обновляет его в Zookeeper. Поскольку в Zookeeper поддерживаются смещения, потребитель может правильно прочитать следующее сообщение даже во время нарушения правил работы сервера.
-
Этот вышеописанный поток будет повторяться до тех пор, пока потребитель не остановит запрос.
-
Потребитель имеет возможность в любое время перемотать / перейти к нужному смещению темы и прочитать все последующие сообщения.
Производители отправляют сообщения в тему на регулярной основе.
Брокер Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы. Это гарантирует, что сообщения в равной степени разделены между разделами. Если производитель отправляет два сообщения и имеется два раздела, Kafka сохранит одно сообщение в первом разделе и второе сообщение во втором разделе.
Потребитель подписывается на определенную тему.
Как только потребитель подписывается на тему, Kafka предоставит потребителю текущее смещение темы, а также сохранит смещение в ансамбле Zookeeper.
Потребитель будет регулярно запрашивать у Кафки новые сообщения (например, 100 мс).
Как только Кафка получает сообщения от производителей, она отправляет эти сообщения потребителям.
Потребитель получит сообщение и обработает его.
Как только сообщения обработаны, потребитель отправит подтверждение брокеру Kafka.
Как только Кафка получает подтверждение, он меняет смещение на новое значение и обновляет его в Zookeeper. Поскольку в Zookeeper поддерживаются смещения, потребитель может правильно прочитать следующее сообщение даже во время нарушения правил работы сервера.
Этот вышеописанный поток будет повторяться до тех пор, пока потребитель не остановит запрос.
Потребитель имеет возможность в любое время перемотать / перейти к нужному смещению темы и прочитать все последующие сообщения.
Рабочий процесс очереди сообщений / группы потребителей
В системе обмена сообщениями в очереди вместо одного потребителя группа потребителей с одинаковым идентификатором группы
будет подписываться на тему. Проще говоря, потребители, подписывающиеся на тему с одинаковым идентификатором группы
, рассматриваются как единая группа, и сообщения распределяются между ними. Давайте проверим фактический рабочий процесс этой системы.
-
Производители регулярно отправляют сообщения в тему.
-
Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы, аналогично предыдущему сценарию.
-
Отдельный потребитель подписывается на конкретную тему, предположим, что
Тема-01
сидентификатором
группы в
качествеГруппы-1
. -
Kafka взаимодействует с потребителем так же, как и Pub-Sub Messaging, пока новый потребитель не подпишется на ту же тему,
Topic-01
с тем жеидентификатором
группы,
что иGroup-1
. -
По прибытии нового потребителя Kafka переключает свою работу в режим совместного использования и обменивается данными между двумя потребителями. Это совместное использование будет продолжаться до тех пор, пока число потребителей не достигнет количества разделов, настроенных для этой конкретной темы.
-
Как только число потребителей превысит количество разделов, новый потребитель не получит никаких дальнейших сообщений, пока один из существующих потребителей не откажется от подписки. Этот сценарий возникает потому, что каждому потребителю в Kafka будет назначен как минимум один раздел, и как только все разделы будут назначены существующим потребителям, новым потребителям придется ждать.
-
Эта функция также называется
Consumer Group
. Таким же образом, Kafka предоставит лучшее из обеих систем очень простым и эффективным способом.
Производители регулярно отправляют сообщения в тему.
Kafka хранит все сообщения в разделах, настроенных для этой конкретной темы, аналогично предыдущему сценарию.
Отдельный потребитель подписывается на конкретную тему, предположим, что Тема-01
с идентификатором
группы в
качестве Группы-1
.
Kafka взаимодействует с потребителем так же, как и Pub-Sub Messaging, пока новый потребитель не подпишется на ту же тему, Topic-01
с тем же идентификатором
группы,
что и Group-1
.
По прибытии нового потребителя Kafka переключает свою работу в режим совместного использования и обменивается данными между двумя потребителями. Это совместное использование будет продолжаться до тех пор, пока число потребителей не достигнет количества разделов, настроенных для этой конкретной темы.
Как только число потребителей превысит количество разделов, новый потребитель не получит никаких дальнейших сообщений, пока один из существующих потребителей не откажется от подписки. Этот сценарий возникает потому, что каждому потребителю в Kafka будет назначен как минимум один раздел, и как только все разделы будут назначены существующим потребителям, новым потребителям придется ждать.
Эта функция также называется Consumer Group
. Таким же образом, Kafka предоставит лучшее из обеих систем очень простым и эффективным способом.
Роль ZooKeeper
Важнейшей зависимостью Apache Kafka является Apache Zookeeper, который является сервисом распределенной конфигурации и синхронизации. Zookeeper служит координационным интерфейсом между брокерами Kafka и потребителями. Серверы Kafka обмениваются информацией через кластер Zookeeper. Kafka хранит основные метаданные в Zookeeper, такие как информация о темах, брокерах, смещениях потребителей (средства чтения очереди) и так далее.
Поскольку вся критическая информация хранится в Zookeeper, и он обычно реплицирует эти данные по всему ансамблю, сбой Kafka broker / Zookeeper не влияет на состояние кластера Kafka. Кафка восстановит состояние, как только Zookeeper перезапустится. Это дает нулевое время простоя для Кафки. Выбор лидера между брокером Kafka также осуществляется с помощью Zookeeper в случае отказа лидера.
Чтобы узнать больше о Zookeeper, пожалуйста, обратитесь к Zookeeper
Давайте продолжим, как установить Java, ZooKeeper и Kafka на вашем компьютере в следующей главе.
Apache Kafka — этапы установки
Ниже приведены шаги для установки Java на вашем компьютере.
Шаг 1 — Проверка установки Java
Надеемся, что вы уже установили Java на своем компьютере прямо сейчас, поэтому вы просто подтвердите это с помощью следующей команды.
$ java -version
Если Java успешно установлен на вашем компьютере, вы можете увидеть версию установленной Java.
Шаг 1.1 — Скачать JDK
Если Java не загружена, загрузите последнюю версию JDK, перейдя по следующей ссылке и загрузите последнюю версию.
http://www.oracle.com/technetwork/java/javase/downloads/index.html
Теперь последняя версия — JDK 8u 60, а файл — «jdk-8u60-linux-x64.tar.gz». Пожалуйста, загрузите файл на свой компьютер.
Шаг 1.2 — Извлечение файлов
Обычно загружаемые файлы хранятся в папке загрузок, проверяют ее и извлекают настройку tar, используя следующие команды.
$ cd /go/to/download/path $ tar -zxf jdk-8u60-linux-x64.gz
Шаг 1.3 — Перейдите в опционный каталог
Чтобы сделать Java доступным для всех пользователей, переместите извлеченный контент Java в
папку usr / local / java
/.
$ su password: (type password of root user) $ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/
Шаг 1.4 — Установить путь
Чтобы установить переменные path и JAVA_HOME, добавьте следующие команды в файл ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60 export PATH=$PATH:$JAVA_HOME/bin
Теперь примените все изменения в текущей работающей системе.
$ source ~/.bashrc
Шаг 1.5 — Альтернативы Java
Используйте следующую команду для изменения Альтернативы Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100
Шаг 1.6. Теперь проверьте Java с помощью команды проверки (java -version), описанной в шаге 1.
Шаг 2 — Установка ZooKeeper Framework
Шаг 2.1 — Скачать ZooKeeper
Чтобы установить ZooKeeper Framework на свой компьютер, перейдите по следующей ссылке и загрузите последнюю версию ZooKeeper.
http://zookeeper.apache.org/releases.html
На данный момент последняя версия ZooKeeper — 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Шаг 2.2 — Извлечение файла tar
Извлеките файл tar, используя следующую команду
$ cd opt/ $ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6 $ mkdir data
Шаг 2.3 — Создание файла конфигурации
Откройте файл конфигурации с именем conf / zoo.cfg
с помощью команды vi «conf / zoo.cfg» и всех следующих параметров, чтобы установить в качестве отправной точки.
$ vi conf/zoo.cfg tickTime=2000 dataDir=/path/to/zookeeper/data clientPort=2181 initLimit=5 syncLimit=2
После того, как файл конфигурации был успешно сохранен и снова возвращен в терминал, вы можете запустить сервер zookeeper.
Шаг 2.4 — Запустите ZooKeeper Server
$ bin/zkServer.sh start
После выполнения этой команды вы получите ответ, как показано ниже —
$ JMX enabled by default $ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTED
Шаг 2.5 — Запустите CLI
$ bin/zkCli.sh
После ввода вышеуказанной команды вы будете подключены к серверу zookeeper и получите ответ ниже.
Connecting to localhost:2181 ................ ................ ................ Welcome to ZooKeeper! ................ ................ WATCHER:: WatchedEvent state:SyncConnected type: None path:null [zk: localhost:2181(CONNECTED) 0]
Шаг 2.6 — остановка сервера Zookeeper
После подключения сервера и выполнения всех операций вы можете остановить сервер zookeeper с помощью следующей команды —
$ bin/zkServer.sh stop
Теперь вы успешно установили Java и ZooKeeper на свой компьютер. Давайте посмотрим шаги для установки Apache Kafka.
Шаг 3 — Установка Apache Kafka
Давайте продолжим со следующих шагов, чтобы установить Kafka на ваш компьютер.
Шаг 3.1 — Скачать Кафку
Чтобы установить Kafka на свой компьютер, нажмите на ссылку ниже —
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgz
Теперь последняя версия, т.е. — kafka_2.11_0.9.0.0.tgz, будет загружена на ваш компьютер.
Шаг 3.2 — Извлечение файла tar
Извлеките файл tar, используя следующую команду —
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz $ cd kafka_2.11.0.9.0.0
Теперь вы загрузили последнюю версию Kafka на свой компьютер.
Шаг 3.3 — Запустить сервер
Вы можете запустить сервер, дав следующую команду —
$ bin/kafka-server-start.sh config/server.properties
После запуска сервера вы увидите ответ ниже на вашем экране —
$ bin/kafka-server-start.sh config/server.properties [2016-01-02 15:37:30,410] INFO KafkaConfig values: request.timeout.ms = 30000 log.roll.hours = 168 inter.broker.protocol.version = 0.9.0.X log.preallocate = false security.inter.broker.protocol = PLAINTEXT ……………………………………………. …………………………………………….
Шаг 4 — остановите сервер
После выполнения всех операций вы можете остановить сервер, используя следующую команду —
$ bin/kafka-server-stop.sh config/server.properties
Теперь, когда мы уже обсудили установку Kafka, мы можем узнать, как выполнять основные операции с Kafka, в следующей главе.
Apache Kafka — Основные операции
Сначала давайте приступим к реализации конфигурации с одним узлом и одним посредником,
а затем перенесем нашу настройку на конфигурацию с одним узлом и несколькими посредниками.
Надеюсь, вы уже установили Java, ZooKeeper и Kafka на свою машину. Прежде чем перейти к настройке Kafka Cluster, сначала вам нужно запустить ZooKeeper, потому что Kafka Cluster использует ZooKeeper.
Запустить ZooKeeper
Откройте новый терминал и введите следующую команду —
bin/zookeeper-server-start.sh config/zookeeper.properties
Чтобы запустить Kafka Broker, введите следующую команду —
bin/kafka-server-start.sh config/server.properties
После запуска Kafka Broker введите команду jps
на терминале ZooKeeper, и вы увидите следующий ответ:
821 QuorumPeerMain 928 Kafka 931 Jps
Теперь вы можете увидеть два демона, запущенных на терминале, где QuorumPeerMain — это демон ZooKeeper, а другой — демон Kafka.
Конфигурация с одним узлом и одним брокером
В этой конфигурации у вас есть один экземпляр ZooKeeper и идентификатор брокера. Ниже приведены шаги для его настройки.
Создание раздела Kafka — Kafka предоставляет утилиту командной строки с именем kafka-topics.sh
для создания разделов на сервере. Откройте новый терминал и введите приведенный ниже пример.
Синтаксис
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic-name
пример
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Hello-Kafka
Мы только что создали тему под названием Hello-Kafka
с одним разделом и одним фактором реплики. Созданный выше вывод будет похож на следующий вывод —
Вывод — Создана тема Hello-Kafka
После создания темы вы можете получить уведомление в окне терминала брокера Kafka и журнал для созданной темы, указанный в «/ tmp / kafka-logs /» в файле config / server.properties.
Список тем
Чтобы получить список тем на сервере Kafka, вы можете использовать следующую команду —
Синтаксис
bin/kafka-topics.sh --list --zookeeper localhost:2181
Выход
Hello-Kafka
Так как мы создали тему, она перечислит только Hello-Kafka
. Предположим, если вы создадите более одной темы, вы получите названия тем в выводе.
Начать продюсер для отправки сообщений
Синтаксис
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
Из приведенного выше синтаксиса для клиента командной строки производителя требуются два основных параметра:
Broker-list — список брокеров, которым мы хотим отправлять сообщения. В этом случае у нас есть только один брокер. Файл Config / server.properties содержит идентификатор порта посредника, поскольку мы знаем, что наш посредник прослушивает порт 9092, поэтому вы можете указать его напрямую.
Название темы. Вот пример названия темы.
пример
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
Производитель будет ждать ввода от stdin и публикует данные в кластере Kafka. По умолчанию каждая новая строка публикуется как новое сообщение, а свойства производителя по умолчанию указываются в файле config /
provider.properties. Теперь вы можете набрать несколько строк сообщений в терминале, как показано ниже.
Выход
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka[2016-01-16 13:50:45,931] WARN property topic is not valid (kafka.utils.Verifia-bleProperties) Hello My first message
My second message
Начать приемник для получения сообщений
Как и для производителя, свойства потребителя по умолчанию указаны в файле config / consumer.proper-ties
. Откройте новый терминал и введите приведенный ниже синтаксис для использования сообщений.
Синтаксис
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name --from-beginning
пример
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka --from-beginning
Выход
Hello My first message My second message
Наконец, вы можете вводить сообщения из терминала производителя и видеть, что они появляются в терминале потребителя. На данный момент у вас есть очень хорошее понимание кластера с одним узлом с одним брокером. Давайте теперь перейдем к конфигурации с несколькими брокерами.
Конфигурация с одним узлом и несколькими брокерами
Прежде чем перейти к настройке кластера с несколькими брокерами, сначала запустите сервер ZooKeeper.
Создайте несколько брокеров Kafka — у нас есть один экземпляр брокера Kafka уже в con-fig / server.properties. Теперь нам нужно несколько экземпляров брокера, поэтому скопируйте существующий файл server.prop-erties в два новых файла конфигурации и переименуйте его в server-one.properties и server-two.prop -ties. Затем отредактируйте оба новых файла и назначьте следующие изменения:
конфиг / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=1 # The port the socket server listens on port=9093 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-1
конфиг / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=2 # The port the socket server listens on port=9094 # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs-2
Запуск нескольких брокеров. После внесения всех изменений на трех серверах откройте три новых терминала, чтобы запустить каждого брокера по одному.
Broker1 bin/kafka-server-start.sh config/server.properties Broker2 bin/kafka-server-start.sh config/server-one.properties Broker3 bin/kafka-server-start.sh config/server-two.properties
Теперь у нас работают три разных брокера. Попробуйте сами проверить все демоны, набрав jps на терминале ZooKeeper, и вы увидите ответ.
Создание темы
Давайте назначим значение коэффициента репликации как три для этой темы, потому что у нас работают три разных брокера. Если у вас есть два брокера, то назначенное значение реплики будет равно двум.
Синтаксис
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic topic-name
пример
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 -partitions 1 --topic Multibrokerapplication
Выход
created topic “Multibrokerapplication”
Команда Describe
используется для проверки, какой посредник прослушивает текущую созданную тему, как показано ниже —
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation
Выход
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic Multibrokerappli-cation Topic:Multibrokerapplication PartitionCount:1 ReplicationFactor:3 Configs: Topic:Multibrokerapplication Partition:0 Leader:0 Replicas:0,2,1 Isr:0,2,1
Исходя из вышеприведенного вывода, мы можем заключить, что в первой строке дается сводка по всем разделам, показывая название темы, количество разделов и коэффициент репликации, который мы уже выбрали. Во второй строке каждый узел будет лидером для случайно выбранной части разделов.
В нашем случае мы видим, что наш первый брокер (с broker.id 0) является лидером. Тогда Реплики: 0,2,1 означает, что все брокеры копируют тему, наконец, Isr
— это набор синхронных
реплик. Ну, это подмножество реплик, которые в настоящее время живы и захвачены лидером.
Начать продюсер для отправки сообщений
Эта процедура остается такой же, как в настройке одного брокера.
пример
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
Выход
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication [2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties) This is single node-multi broker demo This is the second message
Начать приемник для получения сообщений
Эта процедура остается такой же, как показано в настройке одного брокера.
пример
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion --from-beginning
Выход
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Multibrokerapplica-tion —from-beginning This is single node-multi broker demo This is the second message
Основные тематические операции
В этой главе мы обсудим различные основные темы операций.
Изменение темы
Как вы уже поняли, как создать тему в Kafka Cluster. Теперь давайте изменим созданную тему, используя следующую команду
Синтаксис
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name --parti-tions count
пример
We have already created a topic “Hello-Kafka” with single partition count and one replica factor. Now using “alter” command we have changed the partition count. bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic Hello-kafka --parti-tions 2
Выход
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected Adding partitions succeeded!
Удаление темы
Чтобы удалить тему, вы можете использовать следующий синтаксис.
Синтаксис
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_name
пример
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafka
Выход
> Topic Hello-kafka marked for deletion
Примечание. Это не окажет влияния, если для delete.topic.enable не задано значение true.
Apache Kafka — простой пример для продюсера
Давайте создадим приложение для публикации и использования сообщений с помощью клиента Java. Клиент производителя Kafka состоит из следующих API.
KafkaProducer API
Давайте разберемся с наиболее важным набором API производителей Kafka в этом разделе. Центральная часть API KafkaProducer —
класс KafkaProducer
. Класс KafkaProducer предоставляет возможность подключить брокер Kafka в своем конструкторе с помощью следующих методов.
-
Класс KafkaProducer предоставляет метод send для асинхронной отправки сообщений в тему. Подпись send () выглядит следующим образом
Класс KafkaProducer предоставляет метод send для асинхронной отправки сообщений в тему. Подпись send () выглядит следующим образом
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1) , callback);
-
ProducerRecord — производитель управляет буфером записей, ожидающих отправки.
-
Обратный вызов — предоставленный пользователем обратный вызов для выполнения, когда запись была подтверждена сервером (ноль означает отсутствие обратного вызова).
ProducerRecord — производитель управляет буфером записей, ожидающих отправки.
Обратный вызов — предоставленный пользователем обратный вызов для выполнения, когда запись была подтверждена сервером (ноль означает отсутствие обратного вызова).
-
Класс KafkaProducer предоставляет метод сброса, обеспечивающий фактическое завершение всех ранее отправленных сообщений. Синтаксис метода очистки следующий:
Класс KafkaProducer предоставляет метод сброса, обеспечивающий фактическое завершение всех ранее отправленных сообщений. Синтаксис метода очистки следующий:
public void flush()
-
Класс KafkaProducer предоставляет метод partitionFor, который помогает в получении метаданных раздела для данной темы. Это может быть использовано для пользовательского разбиения. Суть этого метода заключается в следующем —
Класс KafkaProducer предоставляет метод partitionFor, который помогает в получении метаданных раздела для данной темы. Это может быть использовано для пользовательского разбиения. Суть этого метода заключается в следующем —
public Map metrics()
Возвращает карту внутренних метрик, поддерживаемых производителем.
-
public void close () — класс KafkaProducer предоставляет блоки методов close, пока все ранее отправленные запросы не будут выполнены.
public void close () — класс KafkaProducer предоставляет блоки методов close, пока все ранее отправленные запросы не будут выполнены.
API продюсера
Центральной частью API производителя является класс Producer
. Класс Producer предоставляет возможность подключить брокер Kafka в своем конструкторе следующими методами.
Класс продюсера
Класс продюсера предоставляет метод send для отправки сообщений в одну или несколько тем с использованием следующих подписей.
public void send(KeyedMessaget<k,v> message) - sends the data to a single topic,par-titioned by key using either sync or async producer. public void send(List<KeyedMessage<k,v>>messages) - sends data to multiple topics. Properties prop = new Properties(); prop.put(producer.type,”async”) ProducerConfig config = new ProducerConfig(prop);
Существует два типа производителей — Sync и Async .
Та же конфигурация API применима и к производителю Sync
. Разница между ними заключается в том, что производитель синхронизации отправляет сообщения напрямую, но отправляет сообщения в фоновом режиме. Асинхронный производитель предпочтителен, когда вы хотите более высокую пропускную способность. В предыдущих выпусках, таких как 0.8, у асинхронного производителя нет обратного вызова для send () для регистрации обработчиков ошибок. Это доступно только в текущей версии 0.9.
public void close ()
Класс Producer предоставляет метод close для закрытия соединений пула производителей со всеми брокерами Kafka.
Настройки конфигурации
Основные параметры конфигурации API производителя приведены в следующей таблице для лучшего понимания —
| S.No | Настройки конфигурации и описание |
|---|---|
| 1 |
ID клиента определяет приложение производителя |
| 2 |
producer.type синхронизация или асинхронность |
| 3 |
ACKs Конфигурация acks контролирует критерии по запросам производителя. |
| 4 |
повторы Если запрос производителя не удался, автоматически повторите попытку с указанным значением. |
| 5 |
bootstrap.servers загрузочный список брокеров. |
| 6 |
linger.ms если вы хотите уменьшить количество запросов, вы можете установить для linger.ms нечто большее, чем какое-либо значение. |
| 7 |
key.serializer Ключ для интерфейса сериализатора. |
| 8 |
value.serializer значение для интерфейса сериализатора. |
| 9 |
размер партии Размер буфера. |
| 10 |
buffer.memory контролирует общий объем памяти, доступной производителю для буферизации. |
ID клиента
определяет приложение производителя
producer.type
синхронизация или асинхронность
ACKs
Конфигурация acks контролирует критерии по запросам производителя.
повторы
Если запрос производителя не удался, автоматически повторите попытку с указанным значением.
bootstrap.servers
загрузочный список брокеров.
linger.ms
если вы хотите уменьшить количество запросов, вы можете установить для linger.ms нечто большее, чем какое-либо значение.
key.serializer
Ключ для интерфейса сериализатора.
value.serializer
значение для интерфейса сериализатора.
размер партии
Размер буфера.
buffer.memory
контролирует общий объем памяти, доступной производителю для буферизации.
ProducerRecord API
ProducerRecord — это пара ключ / значение, отправляемая в кластер Kafka. Конструктор классаProducerRecord для создания записи с парами разделов, ключей и значений с использованием следующей подписи.
public ProducerRecord (string topic, int partition, k key, v value)
-
Тема — определенное пользователем название темы, которое будет добавлено в запись.
-
Раздел — количество разделов
-
Ключ — ключ, который будет включен в запись.
- Значение — запись содержимого
Тема — определенное пользователем название темы, которое будет добавлено в запись.
Раздел — количество разделов
Ключ — ключ, который будет включен в запись.
public ProducerRecord (string topic, k key, v value)
Конструктор класса ProducerRecord используется для создания записи с ключом, парами значений и без разделения.
-
Тема — Создать тему для назначения записи.
-
Ключ — ключ для записи.
-
Значение — запись содержимого.
Тема — Создать тему для назначения записи.
Ключ — ключ для записи.
Значение — запись содержимого.
public ProducerRecord (string topic, v value)
Класс ProducerRecord создает запись без раздела и ключа.
-
Тема — создать тему.
-
Значение — запись содержимого.
Тема — создать тему.
Значение — запись содержимого.
Методы класса ProducerRecord перечислены в следующей таблице:
| S.No | Методы класса и описание |
|---|---|
| 1 |
публичная строковая тема () Тема будет добавлена в запись. |
| 2 |
открытый ключ K () Ключ, который будет включен в запись. Если такой клавиши нет, значение null будет возвращено здесь. |
| 3 |
общедоступное значение V () Записать содержимое. |
| 4 |
раздел () Количество разделов для записи |
публичная строковая тема ()
Тема будет добавлена в запись.
открытый ключ K ()
Ключ, который будет включен в запись. Если такой клавиши нет, значение null будет возвращено здесь.
общедоступное значение V ()
Записать содержимое.
раздел ()
Количество разделов для записи
Приложение SimpleProducer
Перед созданием приложения сначала запустите ZooKeeper и Kafka broker, затем создайте свою собственную тему в Kafka broker, используя команду create topic. После этого создайте класс Java с именем Sim-pleProducer.java
и введите следующую кодировку.
//import util.properties packages import java.util.Properties; //import simple producer packages import org.apache.kafka.clients.producer.Producer; //import KafkaProducer packages import org.apache.kafka.clients.producer.KafkaProducer; //import ProducerRecord packages import org.apache.kafka.clients.producer.ProducerRecord; //Create java class named “SimpleProducer” public class SimpleProducer { public static void main(String[] args) throws Exception{ // Check arguments length value if(args.length == 0){ System.out.println("Enter topic name”); return; } //Assign topicName to string variable String topicName = args[0].toString(); // create instance for properties to access producer configs Properties props = new Properties(); //Assign localhost id props.put("bootstrap.servers", “localhost:9092"); //Set acknowledgements for producer requests. props.put("acks", “all"); //If the request fails, the producer can automatically retry, props.put("retries", 0); //Specify buffer size in config props.put("batch.size", 16384); //Reduce the no of requests less than 0 props.put("linger.ms", 1); //The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); Producer<String, String> producer = new KafkaProducer <String, String>(props); for(int i = 0; i < 10; i++) producer.send(new ProducerRecord<String, String>(topicName, Integer.toString(i), Integer.toString(i))); System.out.println(“Message sent successfully”); producer.close(); } }
Компиляция — приложение может быть скомпилировано с помощью следующей команды.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
Выполнение — приложение может быть выполнено с помощью следующей команды.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>
Выход
Message sent successfully To check the above output open new terminal and type Consumer CLI command to receive messages. >> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning 1 2 3 4 5 6 7 8 9 10
Простой потребительский пример
На данный момент мы создали производителя для отправки сообщений в кластер Kafka. Теперь давайте создадим потребителя для потребления сообщений из кластера Kafka. API KafkaConsumer используется для приема сообщений из кластера Kafka. Конструктор класса KafkaConsumer определен ниже.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)
configs — вернуть карту пользовательских конфигов.
Класс KafkaConsumer имеет следующие важные методы, которые перечислены в таблице ниже.
| S.No | Метод и описание |
|---|---|
| 1 |
public java.util.Set назначение <TopicPar-tition> () Получить набор разделов, назначенных в настоящее время потребителем. |
| 2 |
подписка на открытую строку () Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. |
| 3 |
public void sub-scribe (темы java.util.List <java.lang.String>, слушатель ConsumerRe-balanceListener) Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. |
| 4 |
публичный аннулировать подписку () Отписаться на темы из данного списка разделов. |
| 5 |
публичный подпункт void (темы java.util.List <java.lang.String>) Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. Если данный список тем пуст, он обрабатывается так же, как и отмена подписки (). |
| 6 |
открытый подписок void (шаблон java.util.regex.Pattern, слушатель ConsumerRebalanceLis-tener) Шаблон аргумента относится к шаблону подписки в формате регулярного выражения, а аргумент слушателя получает уведомления от шаблона подписки. |
| 7 |
public void as-sign (разделы java.util.List <TopicPartition>) Вручную назначьте список разделов клиенту. |
| 8 |
опрос() Получить данные для тем или разделов, указанных с помощью одного из API подписки / назначения. Это вернет ошибку, если темы не подписаны перед опросом данных. |
| 9 |
public void commitSync () Смещение коммитов, возвращаемое при последнем опросе () для всех подписанных списков тем и разделов. Та же операция применяется к commitAsyn (). |
| 10 |
public void seek (раздел TopicPartition, длинное смещение) Получить текущее значение смещения, которое потребитель будет использовать в следующем методе poll (). |
| 11 |
общедоступное резюме () Возобновить приостановленные разделы. |
| 12 |
public void wakeup () Пробуждение потребителя. |
public java.util.Set назначение <TopicPar-tition> ()
Получить набор разделов, назначенных в настоящее время потребителем.
подписка на открытую строку ()
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы.
public void sub-scribe (темы java.util.List <java.lang.String>, слушатель ConsumerRe-balanceListener)
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы.
публичный аннулировать подписку ()
Отписаться на темы из данного списка разделов.
публичный подпункт void (темы java.util.List <java.lang.String>)
Подпишитесь на данный список тем, чтобы получить динамически подписанные разделы. Если данный список тем пуст, он обрабатывается так же, как и отмена подписки ().
открытый подписок void (шаблон java.util.regex.Pattern, слушатель ConsumerRebalanceLis-tener)
Шаблон аргумента относится к шаблону подписки в формате регулярного выражения, а аргумент слушателя получает уведомления от шаблона подписки.
public void as-sign (разделы java.util.List <TopicPartition>)
Вручную назначьте список разделов клиенту.
опрос()
Получить данные для тем или разделов, указанных с помощью одного из API подписки / назначения. Это вернет ошибку, если темы не подписаны перед опросом данных.
public void commitSync ()
Смещение коммитов, возвращаемое при последнем опросе () для всех подписанных списков тем и разделов. Та же операция применяется к commitAsyn ().
public void seek (раздел TopicPartition, длинное смещение)
Получить текущее значение смещения, которое потребитель будет использовать в следующем методе poll ().
общедоступное резюме ()
Возобновить приостановленные разделы.
public void wakeup ()
Пробуждение потребителя.
ConsumerRecord API
API ConsumerRecord используется для получения записей из кластера Kafka. Этот API состоит из имени темы, номера раздела, из которого принимается запись, и смещения, которое указывает на запись в разделе Kafka. Класс ConsumerRecord используется для создания записи потребителя с определенным именем темы, количеством разделов и парами <ключ, значение>. Имеет следующую подпись.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
-
Тема — Название темы для записи потребителя, полученной из кластера Kafka.
-
Раздел — Раздел по теме.
-
Ключ — ключ записи, если ключа не существует, возвращается ноль.
-
Значение — запись содержимого.
Тема — Название темы для записи потребителя, полученной из кластера Kafka.
Раздел — Раздел по теме.
Ключ — ключ записи, если ключа не существует, возвращается ноль.
Значение — запись содержимого.
ConsumerRecords API
ConsumerRecords API действует как контейнер для ConsumerRecord. Этот API используется для хранения списка ConsumerRecord для каждого раздела для определенной темы. Его конструктор определен ниже.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List <Consumer-Record>K,V>>> records)
-
TopicPartition — возвращает карту разделов для определенной темы.
-
Записи — возврат списка ConsumerRecord.
TopicPartition — возвращает карту разделов для определенной темы.
Записи — возврат списка ConsumerRecord.
В классе ConsumerRecords определены следующие методы.
| S.No | Методы и описание |
|---|---|
| 1 |
public int count () Количество записей по всем темам. |
| 2 |
публичный набор разделов () Набор разделов с данными в этом наборе записей (если данные не были возвращены, то набор пуст). |
| 3 |
публичный итератор итератор () Итератор позволяет циклически проходить через коллекцию, получать или перемещать элементы. |
| 4 |
Публичный список записей () Получить список записей для данного раздела. |
public int count ()
Количество записей по всем темам.
публичный набор разделов ()
Набор разделов с данными в этом наборе записей (если данные не были возвращены, то набор пуст).
публичный итератор итератор ()
Итератор позволяет циклически проходить через коллекцию, получать или перемещать элементы.
Публичный список записей ()
Получить список записей для данного раздела.
Настройки конфигурации
Параметры конфигурации основных параметров конфигурации API клиента-клиента перечислены ниже:
| S.No | Настройки и описание |
|---|---|
| 1 |
bootstrap.servers Начальный список брокеров. |
| 2 |
group.id Назначает отдельного потребителя в группу. |
| 3 |
enable.auto.commit Включите автоматическую фиксацию для смещений, если значение истинно, иначе не зафиксировано. |
| 4 |
auto.commit.interval.ms Верните, как часто обновленные смещения записываются в ZooKeeper. |
| 5 |
session.timeout.ms Указывает, сколько миллисекунд Кафка будет ждать, пока ZooKeeper ответит на запрос (чтение или запись), прежде чем отказаться от и продолжать потреблять сообщения. |
bootstrap.servers
Начальный список брокеров.
group.id
Назначает отдельного потребителя в группу.
enable.auto.commit
Включите автоматическую фиксацию для смещений, если значение истинно, иначе не зафиксировано.
auto.commit.interval.ms
Верните, как часто обновленные смещения записываются в ZooKeeper.
session.timeout.ms
Указывает, сколько миллисекунд Кафка будет ждать, пока ZooKeeper ответит на запрос (чтение или запись), прежде чем отказаться от и продолжать потреблять сообщения.
Приложение SimpleConsumer
Шаги приложения производителя остаются неизменными. Сначала запустите брокера ZooKeeper и Kafka. Затем создайте приложение SimpleConsumer
с помощью класса Java с именем SimpleCon-sumer.java
и введите следующий код.
import java.util.Properties; import java.util.Arrays; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.ConsumerRecord; public class SimpleConsumer { public static void main(String[] args) throws Exception { if(args.length == 0){ System.out.println("Enter topic name"); return; } //Kafka consumer configuration settings String topicName = args[0].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer <String, String>(props); //Kafka Consumer subscribes list of topics here. consumer.subscribe(Arrays.asList(topicName)) //print the topic name System.out.println("Subscribed to topic " + topicName); int i = 0; while (true) { ConsumerRecords<String, String> records = con-sumer.poll(100); for (ConsumerRecord<String, String> record : records) // print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); } } }
Компиляция — приложение может быть скомпилировано с помощью следующей команды.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.java
Выполнение — приложение может быть выполнено с помощью следующей команды
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>
Вход — откройте CLI производителя и отправьте несколько сообщений в тему. Вы можете указать smple input как «Hello Consumer».
Вывод — следующим будет вывод.
Subscribed to topic Hello-Kafka offset = 3, key = null, value = Hello Consumer
Apache Kafka — пример группы потребителей
Потребительская группа — это многопоточное или многопользовательское потребление по темам Kafka.
Потребительская группа
-
Потребители могут присоединиться к группе, используя тот же
group.id.
-
Максимальный параллелизм группы заключается в том, что количество потребителей в группе ← нет разделов.
-
Kafka назначает разделы темы потребителю в группе, так что каждый раздел потребляется ровно одним потребителем в группе.
-
Кафка гарантирует, что сообщение будет прочитано только одним потребителем в группе.
-
Потребители могут видеть сообщение в том порядке, в котором они были сохранены в журнале.
Потребители могут присоединиться к группе, используя тот же group.id.
Максимальный параллелизм группы заключается в том, что количество потребителей в группе ← нет разделов.
Kafka назначает разделы темы потребителю в группе, так что каждый раздел потребляется ровно одним потребителем в группе.
Кафка гарантирует, что сообщение будет прочитано только одним потребителем в группе.
Потребители могут видеть сообщение в том порядке, в котором они были сохранены в журнале.
Перебалансировка потребителя
Добавление большего количества процессов / потоков приведет к перебалансировке Kafka. Если какой-либо потребитель или брокер не может отправить пульс ZooKeeper, его можно перенастроить через кластер Kafka. Во время этого перебалансирования Kafka назначит доступные разделы доступным потокам, возможно, переместив раздел в другой процесс.
import java.util.Properties; import java.util.Arrays; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.ConsumerRecord; public class ConsumerGroup { public static void main(String[] args) throws Exception { if(args.length < 2){ System.out.println("Usage: consumer <topic> <groupname>"); return; } String topic = args[0].toString(); String group = args[1].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", group); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArraySerializer"); props.put("value.deserializer", "org.apache.kafka.common.serializa-tion.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(topic)); System.out.println("Subscribed to topic " + topic); int i = 0; while (true) { ConsumerRecords<String, String> records = con-sumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); } } }
компиляция
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.java
выполнение
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group >>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":. ConsumerGroup <topic-name> my-group
Здесь мы создали пример группы названий my-group
с двумя потребителями. Точно так же вы можете создать свою группу и количество потребителей в группе.
вход
Откройте CLI производителя и отправьте несколько сообщений вроде —
Test consumer group 01 Test consumer group 02
Вывод первого процесса
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 01
Вывод второго процесса
Subscribed to topic Hello-kafka offset = 3, key = null, value = Test consumer group 02
Теперь, надеюсь, вы бы поняли SimpleConsumer и ConsumeGroup, используя демонстрационную версию клиента Java. Теперь у вас есть представление о том, как отправлять и получать сообщения с помощью клиента Java. Давайте продолжим интеграцию Kafka с технологиями больших данных в следующей главе.
Apache Kafka — интеграция со штормом
В этой главе мы узнаем, как интегрировать Kafka с Apache Storm.
О Шторме
Первоначально Storm был создан Натаном Марцем и командой BackType. За короткое время Apache Storm стал стандартом для распределенной системы обработки в реальном времени, которая позволяет обрабатывать огромный объем данных. Storm работает очень быстро, и тест показал, что он обрабатывает более миллиона кортежей в секунду на узел. Apache Storm работает непрерывно, потребляя данные из настроенных источников (Spouts) и передает данные по конвейеру обработки (Bolts). Комбинированные, носики и болты составляют топологию.
Интеграция со Storm
Kafka и Storm естественным образом дополняют друг друга, а их мощное сотрудничество позволяет осуществлять потоковую аналитику в реальном времени для быстро перемещающихся больших данных. Интеграция Kafka и Storm облегчает разработчикам прием и публикацию потоков данных из топологий Storm.
Концептуальный поток
Носик является источником потоков. Например, носик может читать кортежи из темы Кафки и выдавать их в виде потока. Болт потребляет входные потоки, обрабатывает и, возможно, испускает новые потоки. Болты могут делать что угодно, от запуска функций, фильтрации кортежей, выполнения потоковых агрегаций, потоковых объединений, общения с базами данных и многого другого. Каждый узел в топологии Storm выполняется параллельно. Топология работает бесконечно, пока вы не прекратите ее. Storm автоматически переназначит все неудачные задачи. Кроме того, Storm гарантирует, что не произойдет потери данных, даже если машины выйдут из строя и сообщения будут отброшены.
Давайте подробно рассмотрим API интеграции Kafka-Storm. Существует три основных класса для интеграции Kafka с Storm. Они заключаются в следующем —
BrokerHosts — ZkHosts & StaticHosts
BrokerHosts — это интерфейс, а ZkHosts и StaticHosts — две его основные реализации. ZkHosts используется для динамического отслеживания брокеров Kafka, сохраняя детали в ZooKeeper, в то время как StaticHosts используется для ручной / статической настройки брокеров Kafka и его данных. ZkHosts — это простой и быстрый способ доступа к брокеру Kafka.
Подпись ZkHosts выглядит следующим образом —
public ZkHosts(String brokerZkStr, String brokerZkPath) public ZkHosts(String brokerZkStr)
Где brokerZkStr — это хост ZooKeeper, а brokerZkPath — путь ZooKeeper для поддержки сведений о брокере Kafka.
KafkaConfig API
Этот API используется для определения параметров конфигурации для кластера Kafka. Подпись Кафки Кон-Фига определяется следующим образом
public KafkaConfig(BrokerHosts hosts, string topic)
Хосты — BrokerHosts могут быть ZkHosts / StaticHosts.
Тема — название темы.
Хосты — BrokerHosts могут быть ZkHosts / StaticHosts.
Тема — название темы.
SpoutConfig API
Spoutconfig — это расширение KafkaConfig, которое поддерживает дополнительную информацию ZooKeeper.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)
-
Hosts — BrokerHosts может быть любой реализацией интерфейса BrokerHosts.
-
Тема — название темы.
-
zkRoot — корневой путь ZooKeeper.
-
id — носик хранит состояние смещений, которые он потребляет в Zookeeper. Идентификатор должен однозначно идентифицировать ваш носик.
Hosts — BrokerHosts может быть любой реализацией интерфейса BrokerHosts.
Тема — название темы.
zkRoot — корневой путь ZooKeeper.
id — носик хранит состояние смещений, которые он потребляет в Zookeeper. Идентификатор должен однозначно идентифицировать ваш носик.
SchemeAsMultiScheme
SchemeAsMultiScheme — это интерфейс, который определяет, как преобразованный ByteBuffer из Kafka превращается в штормовый кортеж. Он является производным от MultiScheme и принимает реализацию класса Scheme. Существует множество реализаций класса Scheme, и одной из таких реализаций является StringScheme, которая анализирует байт как простую строку. Он также контролирует наименование вашего поля вывода. Подпись определяется следующим образом.
public SchemeAsMultiScheme(Scheme scheme)
-
Схема — байтовый буфер, потребляемый от кафки.
Схема — байтовый буфер, потребляемый от кафки.
KafkaSpout API
KafkaSpout — это наша реализация spout, которая будет интегрироваться с Storm. Он извлекает сообщения из темы kafka и отправляет их в экосистему Storm в виде кортежей. KafkaSpout получает информацию о конфигурации от SpoutConfig.
Ниже приведен пример кода для создания простого носика Кафки.
// ZooKeeper connection string BrokerHosts hosts = new ZkHosts(zkConnString); //Creating SpoutConfig Object SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, "/" + topicName UUID.randomUUID().toString()); //convert the ByteBuffer to String. spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); //Assign SpoutConfig to KafkaSpout. KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
Создание болта
Bolt — это компонент, который принимает кортежи в качестве входных данных, обрабатывает кортежи и создает новые кортежи в качестве выходных данных. Болты будут реализовывать интерфейс IRichBolt. В этой программе для выполнения операций используются два класса болтов WordSplitter-Bolt и WordCounterBolt.
Интерфейс IRichBolt имеет следующие методы —
-
Подготовить — Предоставляет болту среду для выполнения. Исполнители запустят этот метод для инициализации носика.
-
Выполнить — обработать один кортеж ввода.
-
Очистка — вызывается, когда затвор собирается отключиться.
-
DeclareOutputFields — Объявляет схему вывода кортежа.
Подготовить — Предоставляет болту среду для выполнения. Исполнители запустят этот метод для инициализации носика.
Выполнить — обработать один кортеж ввода.
Очистка — вызывается, когда затвор собирается отключиться.
DeclareOutputFields — Объявляет схему вывода кортежа.
Давайте создадим SplitBolt.java, который реализует логику для разделения предложения на слова, и CountBolt.java, который реализует логику для разделения уникальных слов и подсчета его появления.
SplitBolt.java
import java.util.Map; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.task.OutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.IRichBolt; import backtype.storm.task.TopologyContext; public class SplitBolt implements IRichBolt { private OutputCollector collector; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } @Override public void execute(Tuple input) { String sentence = input.getString(0); String[] words = sentence.split(" "); for(String word: words) { word = word.trim(); if(!word.isEmpty()) { word = word.toLowerCase(); collector.emit(new Values(word)); } } collector.ack(input); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } @Override public void cleanup() {} @Override public Map<String, Object> getComponentConfiguration() { return null; } }
CountBolt.java
import java.util.Map; import java.util.HashMap; import backtype.storm.tuple.Tuple; import backtype.storm.task.OutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.IRichBolt; import backtype.storm.task.TopologyContext; public class CountBolt implements IRichBolt{ Map<String, Integer> counters; private OutputCollector collector; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.counters = new HashMap<String, Integer>(); this.collector = collector; } @Override public void execute(Tuple input) { String str = input.getString(0); if(!counters.containsKey(str)){ counters.put(str, 1); }else { Integer c = counters.get(str) +1; counters.put(str, c); } collector.ack(input); } @Override public void cleanup() { for(Map.Entry<String, Integer> entry:counters.entrySet()){ System.out.println(entry.getKey()+" : " + entry.getValue()); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } @Override public Map<String, Object> getComponentConfiguration() { return null; } }
Отправка в топологию
Топология Storm — это в основном структура Thrift. Класс TopologyBuilder предоставляет простые и легкие методы для создания сложных топологий. Класс TopologyBuilder имеет методы для установки spout (setSpout) и для установки болта (setBolt). Наконец, TopologyBuilder имеет createTopology для создания топологии. Методы shuffleGrouping и fieldsGrouping помогают установить группировку потока для носика и болтов.
Локальный кластер. В целях разработки мы можем создать локальный кластер, используя объект LocalCluster,
а затем передать топологию, используя метод submitTopology
класса LocalCluster
.
KafkaStormSample.java
import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import java.util.ArrayList; import java.util.List; import java.util.UUID; import backtype.storm.spout.SchemeAsMultiScheme; import storm.kafka.trident.GlobalPartitionInformation; import storm.kafka.ZkHosts; import storm.kafka.Broker; import storm.kafka.StaticHosts; import storm.kafka.BrokerHosts; import storm.kafka.SpoutConfig; import storm.kafka.KafkaConfig; import storm.kafka.KafkaSpout; import storm.kafka.StringScheme; public class KafkaStormSample { public static void main(String[] args) throws Exception{ Config config = new Config(); config.setDebug(true); config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1); String zkConnString = "localhost:2181"; String topic = "my-first-topic"; BrokerHosts hosts = new ZkHosts(zkConnString); SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic, UUID.randomUUID().toString()); kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4; kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4; kafkaSpoutConfig.forceFromStart = true; kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig)); builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout"); builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter"); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("KafkaStormSample", config, builder.create-Topology()); Thread.sleep(10000); cluster.shutdown(); } }
Перед тем как приступить к компиляции, для интеграции Kakfa-Storm требуется куратор клиентской библиотеки ZooKeeper. Куратор версии 2.9.1 поддерживает Apache Storm версии 0.9.5 (которую мы используем в этом руководстве). Загрузите указанные ниже jar-файлы и поместите их в путь к классу java.
- Куратор-клиент-2.9.1.jar
- Куратор-каркасного 2.9.1.jar
После включения файлов зависимостей, скомпилируйте программу с помощью следующей команды:
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.java
выполнение
Запустите Kafka Producer CLI (объяснено в предыдущей главе), создайте новую тему под названием my-first-topic
и предоставьте несколько примеров сообщений, как показано ниже —
hello kafka storm spark test message another test message
Теперь запустите приложение, используя следующую команду —
java -cp «/path/to/Kafka/apache-storm-0.9.5/lib/*» :. KafkaStormSample
Пример вывода этого приложения указан ниже —
storm : 1 test : 2 spark : 1 another : 1 kafka : 1 hello : 1 message : 2
Apache Kafka — интеграция с искрой
В этой главе мы поговорим о том, как интегрировать Apache Kafka с Spark Streaming API.
О Спарк
Spark Streaming API обеспечивает масштабируемую высокопроизводительную отказоустойчивую обработку потоков потоков данных. Данные могут поступать из многих источников, таких как Kafka, Flume, Twitter и т. Д., И могут обрабатываться с использованием сложных алгоритмов, таких как высокоуровневые функции, такие как map, Reduce, Join и Window. Наконец, обработанные данные можно отправить в файловые системы, базы данных и живые панели мониторинга. Эластичные распределенные наборы данных (RDD) — это фундаментальная структура данных Spark. Это неизменяемая распределенная коллекция объектов. Каждый набор данных в RDD разделен на логические разделы, которые могут быть вычислены на разных узлах кластера.
Интеграция с Spark
Kafka — это потенциальная платформа обмена сообщениями и интеграции для потоковой передачи Spark. Kafka выступает в качестве центрального узла для потоков данных в реальном времени и обрабатывается с использованием сложных алгоритмов в Spark Streaming. После обработки данных Spark Streaming может публиковать результаты в еще одной теме Kafka или хранить в HDFS, базах данных или информационных панелях. Следующая диаграмма изображает концептуальный поток.
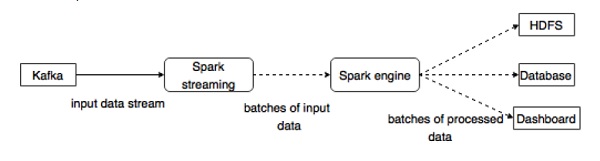
Теперь давайте подробно рассмотрим API Kafka-Spark.
SparkConf API
Он представляет конфигурацию для приложения Spark. Используется для установки различных параметров Spark в виде пар ключ-значение.
Класс SparkConf
имеет следующие методы —
-
set (строковый ключ, строковое значение) — установить переменную конфигурации.
-
удалить (строковый ключ) — удалить ключ из конфигурации.
-
setAppName (string name) — установить имя приложения для вашего приложения.
-
get (string key) — получить ключ
set (строковый ключ, строковое значение) — установить переменную конфигурации.
удалить (строковый ключ) — удалить ключ из конфигурации.
setAppName (string name) — установить имя приложения для вашего приложения.
get (string key) — получить ключ
StreamingContext API
Это основная точка входа для функциональности Spark. SparkContext представляет соединение с кластером Spark и может использоваться для создания RDD, аккумуляторов и широковещательных переменных в кластере. Подпись определяется так, как показано ниже.
public StreamingContext(String master, String appName, Duration batchDuration, String sparkHome, scala.collection.Seq<String> jars, scala.collection.Map<String,String> environment)
-
master — кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
-
appName — имя вашей работы, отображаемое в веб-интерфейсе кластера.
-
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
master — кластерный URL для подключения (например, mesos: // host: port, spark: // host: port, local [4]).
appName — имя вашей работы, отображаемое в веб-интерфейсе кластера.
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
public StreamingContext(SparkConf conf, Duration batchDuration)
Создайте StreamingContext, предоставив конфигурацию, необходимую для нового SparkContext.
-
conf — параметры искры
-
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
conf — параметры искры
batchDuration — интервал времени, в течение которого потоковые данные будут разделены на пакеты
API KafkaUtils
API KafkaUtils используется для подключения кластера Kafka к потоковой передаче Spark. Этот API имеет подпись createStream
существенного метода, определенную как ниже.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream( StreamingContext ssc, String zkQuorum, String groupId, scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)
Показанный выше метод используется для создания входного потока, который извлекает сообщения от Kafka Brokers.
-
ssc — объект StreamingContext.
-
zkQuorum — Кворум Зоопарка .
-
groupId — идентификатор группы для этого потребителя.
-
themes — вернуть карту тем для потребления.
-
storageLevel — уровень хранилища, используемый для хранения полученных объектов.
ssc — объект StreamingContext.
zkQuorum — Кворум Зоопарка .
groupId — идентификатор группы для этого потребителя.
themes — вернуть карту тем для потребления.
storageLevel — уровень хранилища, используемый для хранения полученных объектов.
В API KafkaUtils есть еще один метод createDirectStream, который используется для создания входного потока, который напрямую извлекает сообщения из брокеров Kafka без использования какого-либо получателя. Этот поток может гарантировать, что каждое сообщение от Kafka будет включено в преобразования ровно один раз.
Пример приложения сделан в Scala. Чтобы скомпилировать приложение, пожалуйста, скачайте и установите sbt
, инструмент сборки scala (похож на maven). Основной код приложения представлен ниже.
import java.util.HashMap import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord} import org.apache.spark.SparkConf import org.apache.spark.streaming._ import org.apache.spark.streaming.kafka._ object KafkaWordCount { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>") System.exit(1) } val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)) .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2) wordCounts.print() ssc.start() ssc.awaitTermination() } }
Сценарий сборки
Интеграция искра-кафка зависит от банки с искрой, потоковой искрой и искрой Kafka. Создайте новый файл build.sbt
и укажите детали приложения и его зависимость. Sbt
загрузит необходимый jar при компиляции и упаковке приложения.
name := "Spark Kafka Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0" libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"
Компиляция / Упаковка
Выполните следующую команду, чтобы скомпилировать и упаковать файл jar приложения. Нам нужно отправить файл jar в консоль spark для запуска приложения.
sbt package
Отправка в Spark
Запустите интерфейс командной строки Kafka Producer (описанный в предыдущей главе), создайте новую тему под названием my-first-topic
и предоставьте несколько примеров сообщений, как показано ниже.
Another spark test message
Выполните следующую команду, чтобы отправить приложение в консоль spark.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming -kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark -kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>
Пример вывода этого приложения показан ниже.
spark console messages .. (Test,1) (spark,1) (another,1) (message,1) spark console message ..
Приложение в реальном времени (Twitter)
Давайте проанализируем приложение в реальном времени, чтобы получить последние твиттеры и их хэштеги. Ранее мы видели интеграцию Storm и Spark с Kafka. В обоих сценариях мы создали Kafka Producer (используя cli) для отправки сообщения в экосистему Kafka. Затем интеграция шторма и искры считывает сообщения с помощью потребителя Kafka и вводит их в экосистему шторма и искры соответственно. Итак, практически нам нужно создать Kafka Producer, который должен —
- Прочитайте каналы Twitter, используя «Twitter Streaming API»,
- Обрабатывать каналы,
- Извлеките хэштеги и
- Отправь это Кафке.
Как только Кафка
получает хеш-теги
, интеграция Storm / Spark получает информацию и отправляет ее в экосистему Storm / Spark.
API потоковой передачи Twitter
«Twitter Streaming API» доступен на любом языке программирования. «Twitter4j» — это неофициальная библиотека Java с открытым исходным кодом, которая предоставляет модуль на основе Java для быстрого доступа к «API потоковой передачи Twitter». «Twitter4j» предоставляет основанную на слушателе структуру для доступа к твитам. Чтобы получить доступ к «API потоковой передачи Twitter», нам нужно войти в учетную запись разработчика Twitter и получить следующие данные аутентификации OAuth .
- Customerkey
- CustomerSecret
- маркер доступа
- AccessTookenSecret
После создания учетной записи разработчика загрузите файлы jar «twitter4j» и поместите их в путь к классу java.
Полный код производителя Твиттера Kafka (KafkaTwitterProducer.java) приведен ниже —
import java.util.Arrays; import java.util.Properties; import java.util.concurrent.LinkedBlockingQueue; import twitter4j.*; import twitter4j.conf.*; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; public class KafkaTwitterProducer { public static void main(String[] args) throws Exception { LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000); if(args.length < 5){ System.out.println( "Usage: KafkaTwitterProducer <twitter-consumer-key> <twitter-consumer-secret> <twitter-access-token> <twitter-access-token-secret> <topic-name> <twitter-search-keywords>"); return; } String consumerKey = args[0].toString(); String consumerSecret = args[1].toString(); String accessToken = args[2].toString(); String accessTokenSecret = args[3].toString(); String topicName = args[4].toString(); String[] arguments = args.clone(); String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length); ConfigurationBuilder cb = new ConfigurationBuilder(); cb.setDebugEnabled(true) .setOAuthConsumerKey(consumerKey) .setOAuthConsumerSecret(consumerSecret) .setOAuthAccessToken(accessToken) .setOAuthAccessTokenSecret(accessTokenSecret); TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance(); StatusListener listener = new StatusListener() { @Override public void onStatus(Status status) { queue.offer(status); // System.out.println("@" + status.getUser().getScreenName() + " - " + status.getText()); // System.out.println("@" + status.getUser().getScreen-Name()); /*for(URLEntity urle : status.getURLEntities()) { System.out.println(urle.getDisplayURL()); }*/ /*for(HashtagEntity hashtage : status.getHashtagEntities()) { System.out.println(hashtage.getText()); }*/ } @Override public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) { // System.out.println("Got a status deletion notice id:" + statusDeletionNotice.getStatusId()); } @Override public void onTrackLimitationNotice(int numberOfLimitedStatuses) { // System.out.println("Got track limitation notice:" + num-berOfLimitedStatuses); } @Override public void onScrubGeo(long userId, long upToStatusId) { // System.out.println("Got scrub_geo event userId:" + userId + "upToStatusId:" + upToStatusId); } @Override public void onStallWarning(StallWarning warning) { // System.out.println("Got stall warning:" + warning); } @Override public void onException(Exception ex) { ex.printStackTrace(); } }; twitterStream.addListener(listener); FilterQuery query = new FilterQuery().track(keyWords); twitterStream.filter(query); Thread.sleep(5000); //Add Kafka producer config settings Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("acks", "all"); props.put("retries", 0); props.put("batch.size", 16384); props.put("linger.ms", 1); props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serializa-tion.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); int i = 0; int j = 0; while(i < 10) { Status ret = queue.poll(); if (ret == null) { Thread.sleep(100); i++; }else { for(HashtagEntity hashtage : ret.getHashtagEntities()) { System.out.println("Hashtag: " + hashtage.getText()); producer.send(new ProducerRecord<String, String>( top-icName, Integer.toString(j++), hashtage.getText())); } } } producer.close(); Thread.sleep(5000); twitterStream.shutdown(); } }
компиляция
Скомпилируйте приложение с помощью следующей команды —
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.java
выполнение
Откройте две консоли. Запустите выше скомпилированное приложение, как показано ниже, в одной консоли.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”: . KafkaTwitterProducer <twitter-consumer-key> <twitter-consumer-secret> <twitter-access-token> <twitter-ac-cess-token-secret> my-first-topic food
Запустите любое из приложений Spark / Storm, описанных в предыдущей главе, в другом окне. Главное, на что следует обратить внимание, это то, что используемая тема должна быть одинаковой в обоих случаях. Здесь мы использовали «my-first-topic» в качестве названия темы.
Выход
Выходные данные этого приложения будут зависеть от ключевых слов и текущего канала Twitter. Пример выходных данных указан ниже (штормовая интеграция).
. . . food : 1 foodie : 2 burger : 1 . . .
Apache Kafka — Инструменты
Kafka Tool упакован в «org.apache.kafka.tools. *. Инструменты подразделяются на системные инструменты и инструменты репликации.
Системные инструменты
Системные инструменты могут быть запущены из командной строки с помощью скрипта класса run. Синтаксис выглядит следующим образом —
bin/kafka-run-class.sh package.class - - options
Некоторые из системных инструментов упомянуты ниже —
-
Kafka Migration Tool — этот инструмент используется для миграции брокера с одной версии на другую.
-
Mirror Maker — этот инструмент используется для обеспечения зеркалирования одного кластера Kafka другому.
-
Consumer Offset Checker — Этот инструмент отображает Consumer Group, Topic, Partition, Off-set, logSize, Owner для указанного набора тем и Consumer Group.
Kafka Migration Tool — этот инструмент используется для миграции брокера с одной версии на другую.
Mirror Maker — этот инструмент используется для обеспечения зеркалирования одного кластера Kafka другому.
Consumer Offset Checker — Этот инструмент отображает Consumer Group, Topic, Partition, Off-set, logSize, Owner для указанного набора тем и Consumer Group.
Инструмент репликации
Репликация Kafka — это инструмент проектирования высокого уровня. Целью добавления инструмента репликации является повышение надежности и доступности. Некоторые из инструментов репликации упомянуты ниже —
-
Инструмент создания тем — создает тему с количеством разделов по умолчанию, коэффициентом репликации и использует схему по умолчанию Kafka для назначения реплики.
-
Инструмент для создания списка тем — этот инструмент выводит информацию для заданного списка тем. Если в командной строке не указано ни одной темы, инструмент запрашивает у Zookeeper все темы и выводит информацию о них. Поля, которые отображает инструмент, — это название темы, раздел, лидер, реплики, isr.
-
Add Partition Tool — Создание темы, необходимо указать количество разделов для темы. Позже для темы может понадобиться больше разделов, когда объем темы увеличится. Этот инструмент помогает добавить больше разделов для определенной темы, а также позволяет вручную назначать реплики добавленным разделам.
Инструмент создания тем — создает тему с количеством разделов по умолчанию, коэффициентом репликации и использует схему по умолчанию Kafka для назначения реплики.
Инструмент для создания списка тем — этот инструмент выводит информацию для заданного списка тем. Если в командной строке не указано ни одной темы, инструмент запрашивает у Zookeeper все темы и выводит информацию о них. Поля, которые отображает инструмент, — это название темы, раздел, лидер, реплики, isr.
Add Partition Tool — Создание темы, необходимо указать количество разделов для темы. Позже для темы может понадобиться больше разделов, когда объем темы увеличится. Этот инструмент помогает добавить больше разделов для определенной темы, а также позволяет вручную назначать реплики добавленным разделам.
Apache Kafka — Приложения
Kafka поддерживает многие из лучших на сегодняшний день промышленных приложений. В этой главе мы дадим очень краткий обзор некоторых наиболее заметных применений Kafka.
щебет
Twitter — это онлайн-сервис социальных сетей, который предоставляет платформу для отправки и получения пользовательских твитов. Зарегистрированные пользователи могут читать и публиковать твиты, но незарегистрированные пользователи могут читать только твиты. Twitter использует Storm-Kafka как часть своей инфраструктуры потоковой обработки.
Apache Kafka используется в LinkedIn для данных потока операций и рабочих показателей. Система обмена сообщениями Kafka помогает LinkedIn в различных продуктах, таких как LinkedIn Newsfeed, LinkedIn Today, для потребления онлайн-сообщений и в дополнение к автономным аналитическим системам, таким как Hadoop. Высокая прочность Kafka также является одним из ключевых факторов, связанных с LinkedIn.
Netflix
Netflix — американский многонациональный поставщик потокового мультимедиа по запросу. Netflix использует Kafka для мониторинга в реальном времени и обработки событий.
Mozilla
Mozilla — это сообщество свободного программного обеспечения, созданное в 1998 году членами Netscape. Кафка вскоре заменит часть текущей производственной системы Mozilla для сбора данных о производительности и использовании из браузера конечного пользователя для таких проектов, как телеметрия, тестовый пилот и т. Д.
оракул
Oracle обеспечивает собственное подключение к Kafka из своего продукта Enterprise Service Bus под названием OSB (Oracle Service Bus), который позволяет разработчикам использовать встроенные посреднические возможности OSB для реализации поэтапных конвейеров данных.